Abstract
Machine learning plays a vital role in several modern economic and industrial fields, and selecting an optimized machine learning method to improve time series’ forecasting accuracy is challenging. Advanced machine learning methods, e.g., the support vector regression (SVR) model, are widely employed in forecasting fields, but the individual SVR pays no attention to the significance of data selection, signal processing and optimization, which cannot always satisfy the requirements of time series forecasting. By preprocessing and analyzing the original time series, in this paper, a hybrid SVR model is developed, considering periodicity, trend and randomness, and combined with data selection, signal processing and an optimization algorithm for short-term load forecasting. Case studies of electricity power data from New South Wales and Singapore are regarded as exemplifications to estimate the performance of the developed novel model. The experimental results demonstrate that the proposed hybrid method is not only robust but also capable of achieving significant improvement compared with the traditional single models and can be an effective and efficient tool for power load forecasting.
1. Introduction
Accurate short-term load forecasting (STLF) plays a vital part in power system operation. A highly accurate forecasting method is one of the most important approaches used in improving power system management, especially in the power market [1]. Effective forecasting helps to establish electrical power scheduling and reduce management risk, which is an absolutely necessary component of power system risk management [2,3]. If the performance of the electric load forecasting model could be effectively boosted, considerable influence would be produced. Taking China as an example, the State Grid Corporation of China has rules stating that the spinning reserve capacity must be 3%–5% of the installed capacity. If the forecasting accuracy could be improved by 1%, a considerable economic benefit would be generated, i.e., approximately 161,042.688 MW h energy in one day and 58,780,581.12 MW h in one year could be saved [4].
In contrast, inaccurate forecast results lead to considerable electrical power system losses. Overestimated forecasts will produce unnecessary electricity; alternately, underestimated forecasts will cause trouble in providing enough electrical power, and that means high losses for the power market [5]. Meanwhile, inaccurate forecasts will lead to a direct increase of operating costs, and the operation of the power system is very sensitive to load forecasting errors. Hobbs et al. [6] concluded that a decrease in power load forecasting error in terms of a mean absolute percentage error of 1% reduces the variable generation cost between $0.6 and $1.6 million annually for a 10,000 MW utility with an MAPE of approximately 4%. Many severe blackout disasters that seriously affected the normal production and lives of people have been documented. Examples include the U.S.–Canada blackout in 2003, the southern part of Moscow blackout in 2005, the New York blackout in 2006 and the Indian power grid collapse in 2012 [7,8]. Obviously, if we could generate an early warning before these events, based on a robust forecasting model, effective measures could be taken to avoid these types of accidents. However, electric power systems are influenced by many factors, including holidays, policy, the social and natural environment, etc. [9]. Therefore, developing a novel and robust load forecasting algorithm and improving the forecasting performance are highly desirable for power load forecasts.
Some researchers began to focus on the short-term load forecasting several years ago; hence, a variety of models have been developed and proposed for STLF. These forecasting algorithms can be classified into two types: conventional statistical algorithms and artificial intelligence algorithms. The conventional statistical algorithms, which are regarded as stochastic time series models, only employ historical data. These algorithms are simple to apply and easy to implement. Therefore, a variety of time series models are commonly employed in load prediction, including the autoregressive model [10], autoregressive moving average model [11,12], autoregressive integrated moving average model [13], regression model [14], multiple linear regression [15], general exponential smoothing [16], Kalman filtering method [17], etc. However, the relevant literature suggests that traditional methods have unavoidable defects, i.e., they cannot effectively interpret the complicated relationship between electric power load data and stochastic factors such as social events and time periodicity; thus, the defects can lead to highly unpredictable variations in power demand [18].
The artificial intelligence models have been widely used in several areas, mainly because of their flexibility, symbolic reasoning and explanation capabilities [19]. Moreover, the artificial intelligence algorithms are recognized as powerful forecasting tools with strong robustness and fault tolerance to solve the STLF problem, influenced by several factors to achieve better performance [20]. Thus, there has been much research work focusing on using the artificial intelligence and new models to improve forecasting accuracy and stability. A hybrid model based on the modified differential evolution algorithm and the wavelet neural network model was employed for electrical load forecasting [21]. Zhao and Guo [22] proposed a novel hybrid optimized gray model to forecast annual power load series. Kelo et al. [18] presented a novel neural network, a combination of the wavelet and Elman network, to predict one-day-ahead power load under the influence of temperature. Hu et al. [23] proposed a hybrid filter–wrapper feature selection method for short-term load forecasting. Xiao et al. developed a combined model based on multiple seasonal patterns and the modified firefly algorithm in [4] and an integrated model based on the multi-objective optimization algorithm in [24] for electrical load forecasting. A novel hybrid model was developed by Niu et al. [25] for short-term load forecasting, which combined singular spectrum analysis, the nonlinear multi-layer perceptron network and the integrated intelligent optimization algorithm.
The SVR model has superiority in fitting high dimensional nonlinear data and has been applied in many areas, such as agricultural commodity future prices forecasting [26], stock price index forecasting [27], air passenger traffic forecasting [28], holiday daily tourist flow forecasting [29], air quality early-warning systems [30], etc. Moreover, in the electricity power forecasting fields, Hong et al. [31,32,33,34] proposed various SVR-based load forecasting models, which included the artificial intelligence algorithm to optimize its parameters, to achieve more accurate forecasting performance. Moreover, Huang [35] developed an SVR-based model that combined the chaotic mapping function and quantum particle swarm optimization algorithm to improve the forecasting accuracy. Lee and Lin [36] proposed an SVR-based model that combines quantum behaviors and the tabu search algorithm with the SVR model for electricity load forecasting. Moreover, De Giorgi et al. [37,38] proposed a series of hybrid photovoltaic power forecasting models, which were based on the least square support vector machine models, to improve the performance of the forecast.
The previous literature review illustrates that the hybrid forecasting model has become a trend. Some drawbacks of the models discussed above can be summarized [39,40]: (1) the traditional statistical models have a high dependence on data, a poor extrapolation effect and narrow forecasting scale, being more suitable for data featured by linear trends and unable to capture data with high fluctuation and noise. More importantly, the data of an electrical power system always features high volatility, irregularity or other tendencies due to the influence of several factors. If the environmental or sociological factors change suddenly, the forecasting errors will increase greatly, which is the worst drawback of statistical models [41]; (2) Artificial neural networks (ANNs) are unstable and have a relative dependence on data, making it difficult to scientifically determine the network structure; furthermore, they can easily fall into a local minimum. Therefore, the SVR model and optimization algorithms are employed to overcome the drawbacks of ANNs; (3) The single models never pay attention to the significance of data selection, signal processing and optimization, and hence cannot always satisfy the requirements of time series forecasting; (4) The one-step forecasting accuracy is higher, while the multi-step forecasting always has a lower accuracy or unreliable results. Therefore, based on the limitations discussed above, and with the current tendency of the hybrid model being considered as the mainstream, a hybrid SVR-based forecasting model is developed; it successfully overcomes these drawbacks, considering periodicity, trend and randomness for electrical load time series. More specifically, the SVR model, acknowledged as one of the top ten models in data mining, is adopted as the basic forecasting model to develop a robust model for short-term load forecasting in this paper. To further improve the forecasting performance, an innovative hybrid forecasting model is developed, which combines data selection, signal processing, support vector regression (SVR), the artificial intelligence optimization algorithm and the multi-step forecasting strategy. Specifically, to improve the forecasting performance of the SVR model, the original power load time series are spite into some subsets by means of data selection, which ensures that the datasets have the same characteristics to obtain excellent results, while the original time series are decomposed and reconstructed into the filter time series, which ensures that the high frequency noisy information of the original series is removed effectively. Meanwhile, the parameters (c and g) of the SVR model are optimized using the optimization algorithm to realize the optimal forecasting performance. Finally, the integrated model, combined with the multi-step forecasting strategy [42], is employed to perform the multi-step forecasting. As far as we know, the meritorious hybridization capitalizes on each component’s advantages and ultimately results in final success, being initially employed to effectively forecast future changes in the electric power load series. The main contributions of this paper are as follows:
- (1)
- A novel hybrid model is successfully developed for multi-step short-term load forecasting; it comprises data selection, signal processing, SVR, the advanced optimization algorithm and the multi-step forecasting strategy. Its effectiveness is validated in New South Wales and Singapore.
- (2)
- A new intelligent optimization algorithm is initially utilized to obtain the optimal parameters of the SVR model, while the signal processing approach effectively identifies and extracts the main feature of power load series, and it is proven that these methods can improve the forecasting performance.
- (3)
- The data structure of the forecasting model is effectively constructed by the data selection, which ensures that the datasets have the same properties to achieve abundant forecasting performance.
- (4)
- A more comprehensive evaluation of the proposed model is conducted in this paper. Two testing methods, i.e., the Diebold–Mariano (DM) test and forecasting effectiveness, are employed to evaluate the proposed hybrid model, in addition to four common metric rules, i.e., the mean absolute error (MAE), root mean square of error (RMSE), normalized mean square of error (NMSE) and mean absolute percentage error (MAPE).
In the present work, this innovative integrated model is evaluated using the half-hourly power load series of two sites, including New South Wales and Singapore, to develop a robust model to forecast the future changes in power load series. The remainder of this paper is organized as follows: a general description of the required individual tools is presented in Section 2. Section 3 describes the developed hybrid forecasting model. We present and discuss the experimental results in Section 4. Section 5 presents an insightful discussion of the experiments. Finally, Section 6 concludes the paper.
2. Methodology
In this section, a general description of the required individual tools of the novel method is presented in detail.
2.1. The Decomposition Approach for Signal Processing
The complete ensemble empirical mode decomposition (CEEMD) with adaptive noise, as a suitable signal processing approach for signal processing, is performed to decompose the original series. Compared with the traditional signal processing methods, the empirical mode decomposition (EMD) family is empirical, intuitive, direct and self-adaptive, being developed for signals featured by nonlinearity and non-stationary. In fact, most traditional signal processing algorithms perform well only under the condition that the signal satisfy certain characteristics. For example, the Fourier decomposition method is mainly employed to handle the data featuring smooth and cyclic data, while the wavelet decomposition algorithm requires non-stationary but linear data. The CEEMD technique was proposed by Torres et al. [43] to improve the decomposition methods of the EMD family. EMD was proposed by Huang et al. [44] and is used to decompose raw series into several intrinsic mode functions (IMFs) via a sifting process, which means a single mode can contain oscillations with large differences or similar oscillations can decompose between different modes [45]. To solve the disadvantage of mode mixing, ensemble empirical mode decomposition (EEMD) was developed by Wu and Huang [46]. Even if EEMD yields a substantial improvement and can improve stability significantly, it also causes a new problem: it is difficult to entirely neutralize the added noise. Therefore, Torres et al. [43] developed the CEEMD with adaptive noise to handle the defects exiting in EMD and EEMD, achieving a negligible reconstruction error and a great improvement of EEMD. With the nonlinear dynamical pattern of the power load data considered, in this work, the advanced CEEMD algorithm is adopted as the signal processing method due to its superiority to other methods. A more detailed description of this signal processing approach can be found in the literature [43].
2.2. Support Vector Regression (SVR)
The SVM, proposed by Vapnik and his co-workers, is based on structural risk minimization (SRM), which is derived from a statistical learning theory (SLT) called the Vapnik–Chervonenkis (VC) dimension theory [47]. SVM has been widely employed in various fields, such as classification, regression and non-linear function approximation. Support vector regression (SVR) is an application of SVM; the idea of SVR is to map the data into a high dimensional feature space via nonlinear mapping and to perform a linear regression in the space [48]. Moreover, it is one of the top ten models in data mining and is recommended as one of the most precise and robust algorithms among the reputable data mining algorithms [49]. It performs excellently and can be widely used in the forecasting field due to its capability to solve non-linear problems. The regression formula is defined as:
where denotes the features, b is the bias term and denotes estimated weight vectors, which can be calculated by optimizing the quadratic programming problem:
We can convert nonlinear regression cases into linear regression cases using a kernel function k (xi, x). The nonlinear mapping can be obtained by:
Several typical kernel functions have been adopted in practical application; in this paper, the RBF kernel function is selected, which can be expressed by:
2.3. Brief Overview of Moth-Flame Optimization Algorithm
The novel natured-inspired meta-heuristic algorithm of the moth-flame optimization algorithm, which was developed by Mirjalili [50], was illuminated by the navigation approach of moths in nature, named transverse orientation. Figure 1A [50] can help us to better comprehend the mechanism of transverse orientation. As shown, the moth flies while keeping a fixed angle with respect to the moon so that it can easily achieve effective travel in a straight line, especially for a long distance from the light. In contrast, the moth will eventually converge to the light due to maintaining a similar angle when the light source is very close, as indicated in Figure 1B [50]. A general description is presented in detail [50,51], and the main steps are described as follows:
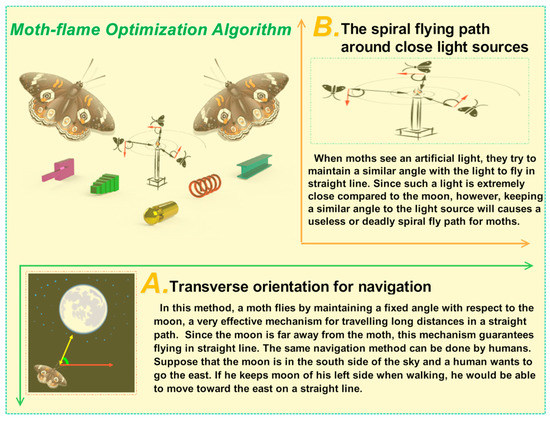
Figure 1.
Two behaviors of the moth-flame optimization algorithm. (A) Transverse orientation for navigation; (B) The spiral flying path around close light sources.
● Step 1: Set parameters
The main parameters of the moth-flame optimization algorithm include the number of moths and flames, the maximum iteration number, the number of variables and the lower/upper bound of each variable.
● Step 2: Initialize position
The moths’ and flames’ positions are obtained by:
where M denotes the moths’ positions, and F denotes the flames’ positions; moreover, the number of moths is n, while the number of variables is d. The initialized positions of F and M can be defined as:
where and are the corresponding values of M and F and the lower/upper bounds of variables are denoted as lb and ub, respectively; moreover, rand is a random number between 0 and 1.
● Step 3: Select fitness values
The fitness values of each flame can be calculated by inputting the corresponding position, which can be used to evaluate each flame. Then, the corresponding fitness values can be calculated by solving Equation (8) and are denoted as OF, which always includes n recent best solutions obtained up to now:
The moth would never miss the best solution in each iteration due to selecting and saving the fitness values. The final optimal solutions obtained so far are regarded as the flames, and increase the probability of finding better solutions.
● Step 4: Iteration and optimization
The logarithmic spiral is defined to mimic the moth’s spiral flying pattern with respect to a flame, which is used to illustrate how the moths renew their positions around a flame, and can be illustrated by:
where Mi and Fj are the i-th moth and j-th flame, respectively; Di is the distance between the moth and flame; S is the spiral function. Moreover, a constant is denoted as b, which is used to define the shape of the logarithmic spiral, and t is a random number between −1 and 1, which illustrates how close the next position should be to the flame. Specifically, t = 1 implies the farthest position from the flame, while t = −1 means the closest. However, the position updating method defined by Equation (9) will lead to convergence in local optima due to it only requiring the moths to move around a flame. To avoid dropping into a local optimum, each moth must renew its position according to only one of the flames in Equation (9). The flames will be sorted by their fitness in the iteration and after updating. Then, the moths update their positions with respect to the corresponding flames, but the updating with respect to n different positions will weaken the ability of exploiting the best solution. Therefore, an adaptive mechanism for the number of flames is employed to solve this problem. The number of flames is decreased adaptively during iterations, which is defined as:
where N is the maximum number of flames, l is the current iteration number, and T is the maximum iteration number.
● Step 5: Select optimal solutions
The flame will update its position if no one is any better than the best flame of the previous iteration; the best flame is then re-determined. Finally, the moth-flame optimization algorithm is stopped when it satisfies the termination criterion and then returns the best solution after global searching, which is considered as the optimal approximation of the optimum. The pseudo code is described as follows:
| Algorithm 1 Moth-Flame Optimization Algorithm. | |
| Input: —a sequence of training data —a sequence of test data Output: —the value can satisfy the best fitness after global searching | |
| Parameters: n—the number of moths and flames d—the number of variables Max_iter—the maximum iteration number fi—the fitness function of moth i iter—the current iteration number lb/ub—the lower/upper bound of variables | |
| 1 | /*Set the parameters of MFO.*/ |
| 2 | /*Initialize the position of moth Mi (i = 1, 2, ..., n) randomly.*/ |
| 3 | FOR EACH i: 1 ≤ i ≤ n DO |
 | |
| 27 | END WHILE |
| 28 | RETURN gbest |
3. The Innovative Hybrid Model for Short-Term Load Forecasting
The developed hybrid model will be expounded upon in this section; the flowchart is depicted in Figure 2. In the previous section, the methodology of the components of the model was described in detail. For the forecasting problem, the individual model pays no attention to the significance of data selection, signal processing and optimizing the model parameter; thus, the single algorithms cannot always satisfy the time series forecasting.
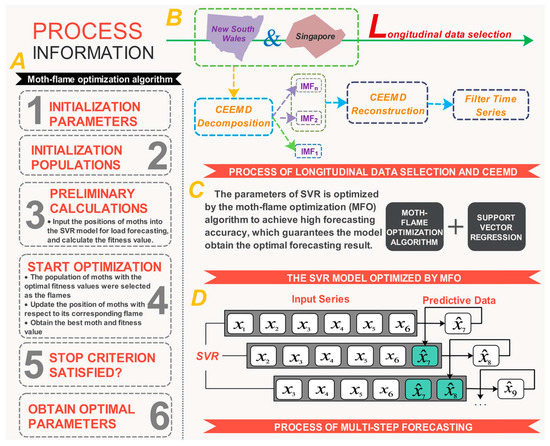
Figure 2.
Flowchart of the innovative hybrid model. (A) The moth-flame optimization algorithm; (B) The process of longitudinal data selection and CEEMD; (C) The SVR model optimized by MFO; (D) The process of multi-step forecasting.
With these above-mentioned ignored factors considered, to enhance forecasting accuracy and stability, in this section, a novel and robust hybrid forecasting model is proposed; it combines data selection, signal processing, support vector regression (SVR) and the latest natured-inspired meta-heuristic algorithm, i.e., the moth-flame optimization algorithm. The hybrid forecasting model comprises three steps: first, the data selection method is employed to classify the original time series into some subsets, which indicates that the forecasting performance can be improved due to the dataset featuring the same properties; second, the filter time series are reconstructed by using the signal processing technique, which guarantees that the main feature (i.e., trend and seasonality) of electric power load series can be effectively identified and extracted (the procedure of the signal processing is illustrated in Figure 2B); finally, the SVR algorithm, which is optimized by the advanced optimization algorithm, is used to deal with the power load featuring irregularity and volatility. Note that, at this point, the established model can be used to realize one-step forecasting of a time series based on historical data; however, multi-step forecasting is also an increasingly critical issue in power system operation. Therefore, the integrated model, which includes the multi-step forecasting strategy, is employed to perform the multi-step forecasting, which is employed to evaluate the effectiveness of the proposed model further. In the multi-step forecasting process, the previous forecasting results will also be used to forecast the future-step results. The procedure of multi-step forecasting is illustrated in Figure 2D, which can help us to understand the realization process of multi-step forecasting well.
4. Materials and Methods
In general, except the forecasting accuracy, the stability and universality of the model to handle the short-term load forecasting issue for different datasets should also be assessed. Therefore, two different power load series of New South Wales of Australia and Singapore, which are half-hourly power load data of March and October, respectively, from 2011 to 2014, as shown is Table 1, are considered as illustrative examples in this paper.

Table 1.
Statistical values of data used in this paper.
The simple map of the study area is shown in Figure 2B. Then, to determine the best experimental parameters, the trial and error method is adopted to address this problem [52]; the experimental parameters are shown in Table 2. All experiments were carried out in MATLAB R2014a on Windows 7 with a 3.30 GHz Intel Core i5 4590, 64 bit computer equipped with 8 GB RAM.
Table 2.
Experimental parameter values.
4.1. Data Selection
Data selection plays a key role in the forecasting issue. There are many factors that randomly influence the power data, which leads the data to present different characteristics. Hence, we should divide the raw data series into different datasets according to a certain suitable method and separately build the forecasting model for the power data. To enhance forecasting performance and guarantee the adaptability of the novel hybrid model applied in STLF, longitudinal data selection is employed in this paper. In detail, we first classify the original data according to the month; then, the datasets are divided into seven subsets according to a particular day of one week, which ensures that each subset has the same inner characteristics and thus improves the forecasting performance. The longitudinal data selection process for power load series is shown in Figure 3A. For example, there are 18 Sundays of March in total (48 data points per day) from 2011 to 2014, which are treated as one subset; the other subset is similarly constructed. For each subset, the last 2 days are the testing sample, while the remainder is the training sample.
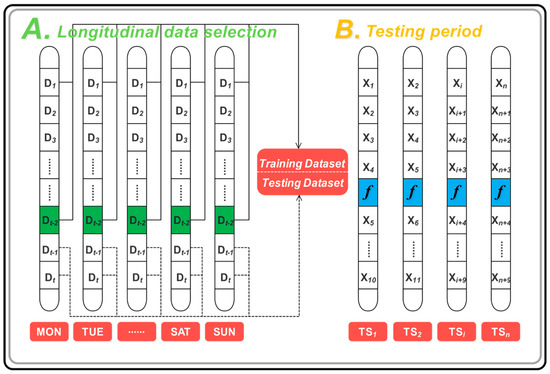
Figure 3.
Process of longitudinal data selection and testing period. (A) Longitudinal data selection; (B) Testing period.
4.2. The Performance Metric
To evaluate the forecasting performance and comprehensively learn the model traits better, four performance metric rules, which are presented in Table 3, are employed in this paper: N is the length of data to evaluate; F is the forecasted value; A represents the observed value. Smaller index values represent better forecasting performance.
Table 3.
Four performance metric rules.
4.3. Testing Method
The model performance evaluation metrics presented in Section 4.2 have great significance in comparing the different forecasting models. However, to verify the outstanding performance, testing needs to be done from the statistical perspective. Therefore, the Diebold–Mariano (DM) test and forecasting effectiveness are conducted in this paper as two testing methods for further performance comparison studies.
4.3.1. DM Test
The Diebold-Mariano (DM) test [53] was used to compare and evaluate the significance of the outperformance of the proposed model with other comparable models. Assume that two forecasting models are compared and evaluated: model A and model B.
Actual values:
Forecast values:
Forecast errors:
The loss function is employed to measure the forecasting accuracy of different models. Two popular versions of the loss function are presented below:
Absolute deviation loss:
Square error loss:
The DM test statistic values can be calculated by:
where S2 is an estimation of the variance of . The hypothesis test is:
The test statistic DM is convergent in distribution in the standard normal distribution N (0, 1). The null hypothesis will be rejected if:
where zα/2 denotes the critical z-value of the standard normal distribution and α is the significance level.
4.3.2. Forecasting Effectiveness
The forecasting effectiveness was employed to verify the forecasting accuracy of the developed hybrid model and other compared models. It is often the case that 1st-order and 2nd-order forecasting effectiveness are available for forecasting evaluation in empirical applications. A general description of forecasting effectiveness is presented in detail [54]:
Actual values:
Forecast values:
Forecast errors:
Forecast accuracy:
The k-th-order forecasting effectiveness unit is calculated by:
where k is a positive integer and , which indicates the discrete probability distribution at time n, is a positive number; . If the priori information of the discrete probability distribution cannot be known, is defined as a constant equals to 1/N. The kth-order forecasting effectiveness is defined as:
where H is a continuous function of a certain k unit. Especially if is a continuous function with one variable, the 1st-order forecasting effectiveness is the expectation forecasting accuracy sequence, defined as ; meanwhile, is a continuous function with two variables. The 2nd-order forecasting effectiveness is the difference between the expectation and standard deviation, presented as .
4.4. Experiment I: The Case of New South Wales
This half-hourly power load series was collected in March from 2011 to 2014 in New South Wales. As mentioned above, longitudinal data selection is employed to split the original dataset into seven subsets to guarantee that each subset has the same characteristics, which can yield forecasting performance improvements. Each subset is divided into two parts, as shown in Figure 3A; the last 2 days are the testing sample and the remainder is the training sample. For example, there are 17 Mondays of March in total from 2011 to 2014; the former 15 days are the training set while the last 2 days are the testing set; the other subset is similarly constructed. To verify the forecasting performance, four performance metrics (i.e., MAE, NMSE, RMSE, MAPE) for each subset are calculated and presented in Table 4 for comparative performance studies. Furthermore, Figure 4A shows the one-step forecasting error of all models from Monday to Sunday in New South Wales. It is visible that the forecasting error line of the proposed model is clearly closest to the zero line with the lowest volatility among all the models. Moreover, Figure 5 illustrates the average values of MAE, RMSE and MAPE in New South Wales, which can be regarded as the overall forecasting potential. To gather more detailed comparison information, the one-step and six-step forecasting results of three randomly selected days (i.e., Monday, Wednesday, Friday) are depicted in Figure 6 and Figure 7, respectively; they reveal that the forecasting line of the proposed model is closer to the actual line than that of the benchmark model. Accordingly, we can conclude that the proposed hybrid model achieves the best values of all criteria in the comparative performance studies, which indicates that the proposed integrated model is superior to the traditional time series model ARMA, single artificial intelligence forecasting model SVR and two-component models CEEMD-SVR and MFO-SVR in all horizons for short-term load forecasting. More detailed comparative studies are conducted from two aspects: one-step forecasting and multi-step forecasting.
Table 4.
The results of the proposed model and the results of the other models (Experiment I).
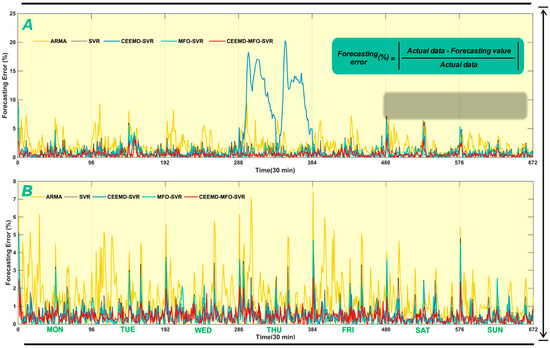
Figure 4.
The forecasting error of five models in New South Wales and Singapore. (A) The one-step forecasting error of all models from Monday to Sunday in New South Wales; (B) The one-step forecasting error of all models from Monday to Sunday in Singapore.
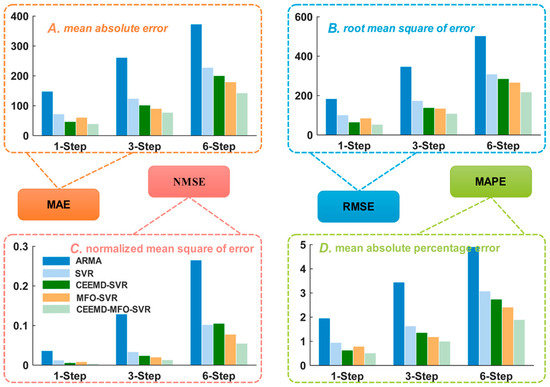
Figure 5.
MAE, RMSE, NMSE and MAPE of five models in New South Wales. (A) Mean absolute error; (B) Root mean square of error; (C) Normalized mean square of error; (D) Mean absolute percentage error.
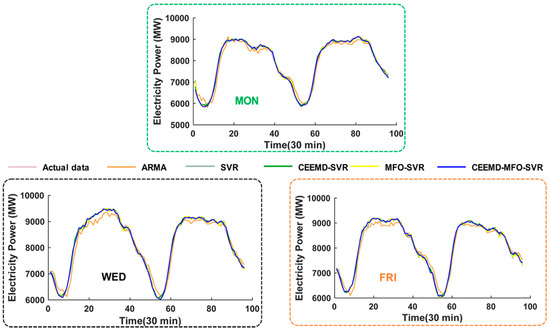
Figure 6.
One-step forecasting graphic of five models in New South Wales. The result on Monday; The result on Wednesday; The result on Friday.
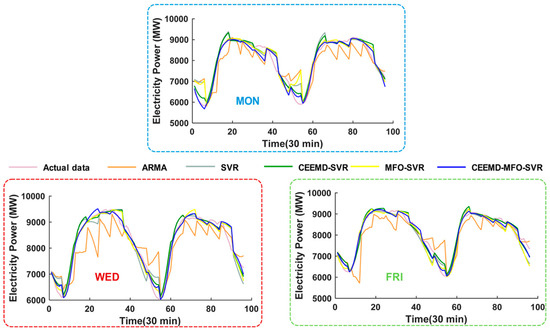
Figure 7.
Six-step forecasting graphic of five models in New South Wales. The result on Monday; The result on Wednesday; The result on Friday.
4.4.1. Analysis for One-Step Forecasting
The one-step forecasting results of each model are presented in Table 4 and Figure 4, Figure 5 and Figure 6. The experimental results indicate that this proposed hybrid model outperforms other benchmark models based on comparison of the MAE, NMSE, RMSE and MAPE. For more detailed analysis, take the forecasting result of Mondays as an example:
- (a)
- When comparing the traditional time series model ARMA with the individual artificial intelligence model SVR, regarding the MAE, NMSE, RMSE and MAPE, the SVR model is superior to the ARMA model. The results indicate that the artificial intelligent algorithms are powerful forecasting tools with strong robustness and fault tolerance to solve the STLF problem influenced by several factors, being able to achieve better performance compared with the traditional time series model.
- (b)
- Statistics of single SVR and our proposed model show that the integrated method leads to reductions of 29.9310 in MAE, 52.1163 in RMSE, 0.0073 in NMSE, and 0.4055% in MAPE. Moreover, the results between the individual SVR and CEEMD-SVR model reveal that the technique contributes to performance improvements of 26.1722 in MAE, 43.3798 in RMSE, 0.0064 in NMSE, and 0.3365% in MAPE. Furthermore, the results between the single SVR and MFO-SVR models demonstrate that the moth-flame optimization algorithm leads to reductions of 7.2622 in MAE, 11.4700 in RMSE, 0.0020 in NMSE, and 0.0971% in MAPE.
- (c)
- Statistics of different models show that the proposed model has a lower MAPE value of 0.5395% compared to the MAPEs of 1.9765%, 0.9450%, 0.6085% and 0.8479% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models, respectively, which show that the integrated method leads to reductions of 1.4370%, 0.4055%, 0.0690% and 0.3084% in MAPE when compared with the ARMA, SVR, CEEMD-SVR and MFO-SVR model, respectively.
- (d)
- The comparison between the SVR, CEEMD-SVR, MFO-SVR and the proposed model proves that the single SVR model is inferior to the benchmark models, which proves that the signal processing and moth-flame optimization algorithm are effective in improving the forecasting accuracy. Therefore, to solve the short-term load forecasting problem, an increasing number of studies have proposed the signal processing technique and artificial intelligence optimization algorithm.
4.4.2. Analysis for Multi-Step Forecasting
Multi-step forecasting plays a vital role in the power system operation. Therefore, the hybrid model, combined with the multi-step forecasting strategy, is employed to perform the multi-step forecasting in this paper, which is employed to evaluate the effectiveness of the developed hybrid model further. The three-step and six-step forecasting results of different models are shown in Table 4 and Figure 5 and Figure 7. The results reveal that the proposed model also performs better than other benchmark models. More comparison research is illustrated below.
- (a)
- The comparison results between the ARMA model and single SVR model indicate that the SVR model can achieve better performance compared with the traditional time series model. For instance, the decreased error of MAPE for three-step forecasting is 1.6310%, 1.4136%, 2.2192%, 2.0912%, 2.1447%, 1.5024% and 1.6789%, corresponding to reductions for six-step forecasting of 1.7858%, 0.9612%, 2.5612%, 2.1654%, 2.4864%, 1.3612% and 1.5038% from Monday to Sunday, respectively.
- (b)
- Taking Monday as an example, the MAPE of the individual SVR model is 1.8508% in three-step forecasting and 3.7417% in six-step forecasting, while the corresponding MAPE of the proposed hybrid model is 1.0160% and 1.9835%. Moreover, compared with the CEEMD-SVR model and MFO-SVR model, the proposed model leads to reductions of 0.3510% and 0.4755% in MAPE for three-step forecasting and reductions of 0.8506% and 1.6513% for six-step forecasting, respectively, which proves that these two methods can improve the multi-step forecasting accuracy of short-term load forecasting.
- (c)
- When comparing the different forecasting horizons, we can conclude that the forecasting error will increase with increasing number of rolling processes. Nevertheless, the negative influence of accumulated error can be reduced due to the SVR model’s excellent performance for one-step forecasting; thus, the proposed integrated model obtains the optimal results.
- (d)
- Taking Wednesday as an example, for the three-step forecasting, the proposed model has a lower MAPE value of 0.9527% compared to the MAPEs of 3.7744%, 1.5552%, 1.2362% and 1.0060% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models, respectively, while also having a lower MAPE value of 1.6581% compared to the MAPEs of 5.8298%, 3.2686%, 2.5270% and 1.9699% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models for six-step forecasting, respectively. The corresponding difference between three-step and six step forecasting is 0.7054%, 2.0554%, 1.7134%, 1.2908% and 0.9639%, which indicates that the proposed hybrid model is superior to other benchmark models for multi-step forecasting.
Remark 1.
Through the above case study, we compare the MAE, RMSE, NMSE and MAPE; whether for one-step forecasting or multi-step forecasting, the proposed integrated model performs better with respect to almost all. Therefore, the proposed hybrid model has better accuracy than the other models. Moreover, the signal processing algorithm, which successfully extracts the trend and volatility in the original power load series, has higher contributions than the moth-flame optimization algorithm employed to obtain the optimal parameters of SVR. Furthermore, the SVR model can effectively improve forecasting accuracy due to the dataset structures being optimal by using the longitudinal data selection method. In summary, the combination of meritorious components capitalizes on each component’s advantages, which is an effective method for STLF and can effectively forecast the power load in the future.
4.5. Experiment II: The Case of Singapore
To further verify the effectiveness of the proposed hybrid model, half-hourly load data collected in October from 2011 to 2014 in Singapore are used as another case in this section. It is well known that these two sites have a remarkably different nature and social environment; thus, we can conclude that the hybrid model has universal applicability under the condition that the hybrid model performs better at both sites. The process of the dataset structure is the same as for New South Wales. The experiment results comparing the models’ performances are presented in Table 5, Figure 4B and Figure 8, Figure 9 and Figure 10. The one-step forecasting errors of different models from Monday to Sunday are presented in Figure 4B. It is obvious that the forecasting result is very approximate to the target, while the forecasting error line of the proposed model is clearly closest to the zero lines, with the lowest volatility among all the models. Figure 8 shows the average value of MAE, RMSE and MAPE in Singapore, which also represents the overall ability for power load forecasting. Furthermore, to analyze the forecasting result in detail, Figure 7 and Figure 8 depict the results of three randomly selected days (i.e., Tuesday, Thursday, Saturday) for one-step and six-step forecasting, revealing that the developed model fits the actual data well compared with other models. The experimental results also account for the conclusion obtained from Experiment I. Furthermore, another evaluation criterion, MPE, is also employed in this paper, which is defined as:
Table 5.
The results of the proposed model and the results of the other models (Experiment II).
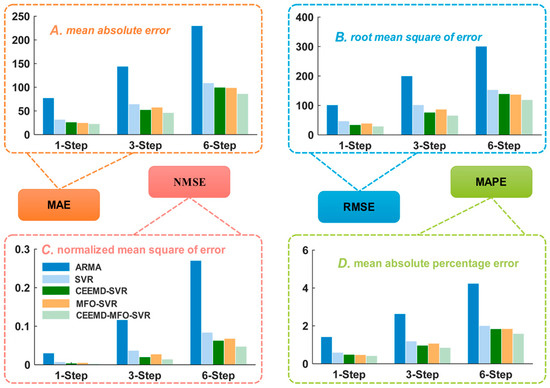
Figure 8.
MAE, RMSE, NMSE and MAPE of five models in Singapore. (A) Mean absolute error; (B) Root mean square of error; (C) Normalized mean square of error; (D) Mean absolute percentage error.
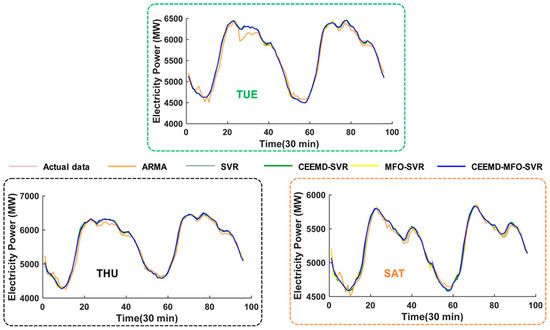
Figure 9.
One-step forecasting graphic of five models in Singapore. The result on Tuesday; The result on Thursday; The result on Saturday.
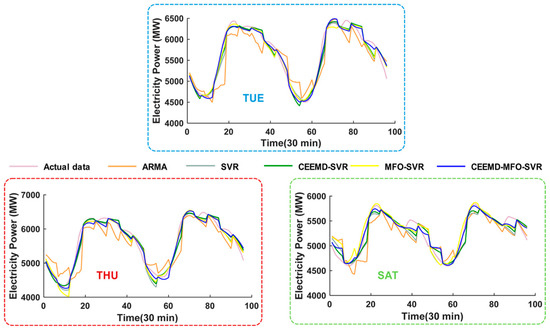
Figure 10.
Six-step forecasting graphic of five models in Singapore. The result on Tuesday; The result on Thursday; The result on Saturday.
According to the definition, a negative MPE value denotes over-forecasting, while a positive one indicates under-forecasting. Figure 11 shows the comparison of different models based on the error (MPE) distributions, which present a visual assessment of the model performances. The last figure in Figure 11 is the histogram for each model. The vertical axis displays the number of instances for each error value, while the horizontal axis shows the value of MPE. It is obvious that the error distribution for the proposed hybrid model possesses sharper peaks and narrower widths compared to the other four error distributions. A sharper distribution of the errors indicates more stable and lower level of uncertainty in forecasting capability. In conclusion, the histogram is another indication of the robustness of the proposed model.
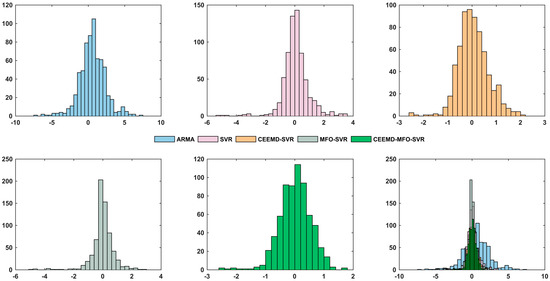
Figure 11.
The comparison of different models based on the error (MPE).
For instance, as shown in Table 5, on Mondays, the proposed model obtains the best forecasting accuracy and higher reliability compared with other benchmark models for all horizons. For the one-step forecasting, the proposed model has a lower MAPE value of 0.4499% compared to the MAPEs of 1.6244%, 0.6575%, 0.5328% and 0.4747% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models, respectively, while also having a lower MAPE value of 0.8310% compared to the MAPEs of 3.1825%, 1.2677%, 1.0736% and 0.9354% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models for three-step forecasting, respectively. Furthermore, the MAPE of the proposed hybrid model for one-step forecasting is 0.4499%, 0.4227%, 0.4598%, 0.4775%, 0.4682%, 0.3087% and 0.3088% corresponding to the MAPE of six-step forecasting of 1.5995%, 1.3345%, 1.9760%, 1.7725%, 1.4622%, 1.3341% and 1.5907% from Monday to Sunday, respectively; thus, it can be found that the average MAPE value is 0.4137%, 0.8437% and 1.5828% for one-step, three-step and six-step forecasting, respectively, which are superior values compared with other compared models, and even the worst MAPE is also within the acceptance accuracy in practical application. It is also demonstrated that the proposed model can effectively forecast the future changes in the power load series. The short-term load forecasting displays the same trend in other subsets, which further proves the universality and effectiveness of the hybrid model. Moreover, the forecasting accuracy of the single SVR model is obviously better than that of the ARMA model, while worse than that of the two component models (i.e., CEEMD-SVR and MFO-SVR), which indicates that the SVR or SVR-based model are more applicable than traditional methods to forecasting data with high fluctuation and noise, meanwhile, it also reveals that the signal processing tool is capable of improving the forecasting performance and the optimization algorithm is effective for increasing the forecasting accuracy of SVR. According to these comparison results, we can testify regarding the effectiveness of data processing and optimization in the hybrid model and further evaluate the contribution of each part for the achieved high accuracy of the hybrid model. However, the performances of the two component models are inferior to those of the three component models. Similarly, based on the analysis between two component models and the three component models, we can also verify the effectiveness of each part. Moreover, the forecasted error increases as the forecasting horizon increases, which is not only an inevitable trend under the influence of accumulated error but also in the consenting range. In conclusion, the developed hybrid forecasting paradigm can be adopted as an effective method for complex data series forecasting, especially for data (e.g., electrical power load data, wind speed) featuring high volatility, noise and irregularity.
Remark 2.
Through the above two case studies, for the MAE, NMSE, RMSE and MAPE, the proposed hybrid model is determined to be best. Furthermore, we can conclude that the hybrid model has universal applicability, considering the difference in nature and social environment between these two study sites. Moreover, we can reasonably conclude that these three methods can effectively improve the forecasting performance of the basic forecasting model SVR. Therefore, these techniques, combined with other basic models, can be employed in other fields. The hybrid model, with its outstanding performance, will generate a considerable economic benefit and will be widely applied for forecasting in the future.
4.6. Experiment III: Testing Based on DM Test and Forecasting Effectiveness
The DM test is employed to test under what circumstance a trial will enable us to reject the null hypothesis given a preset level of significance. Table 6 shows the DM statistic values according to the square error loss function and reveals that (a) the DM statistical values of the ARMA, SVR, CEEMD-SVR and MFO-SVR models are greater than the upper limits at the 1% significance level; (b) the DM statistical values of the ARMA, SVR and CEEMD-SVR models for all horizons are greater than the upper limits at the 1% significance level, while the DM statistical values of the MFO-SVR model for one-step, three-step and six-step forecasting are greater than the upper limits at the 5%, 10% and 10% significance level, respectively; (c) the proposed model significantly outperforms the other models, as the DM statistical values are greater than the critical value at the different significance levels, most of which at the 1% significance level. Therefore, the proposed model exerts a higher degree of accuracy compared with other benchmark models.
Table 6.
Results for the DM test and the forecasting effectiveness.
Forecasting effectiveness was applied to measure the forecasting accuracy of different models. A greater forecasting effectiveness proves a more accurate forecasting performance. The forecasting effectiveness values presented in Table 6 reveal that (a) for the one-step forecasting, the 1st-order forecasting effectiveness offered by ARMA, SVR, CEEMD-SVR, MFO-SVR and the proposed hybrid model are 0.983223, 0.992377, 0.987446, 0.993770 and 0.995397, respectively, while the 2nd-order values are 0.969691, 0.984246, 0.979584, 0.986808 and 0.991312, respectively; (b) the forecasting effectiveness values of the proposed model are greater than those of the benchmark models in all cases. Thus, the proposed hybrid model is greatly superior to all compared models.
Remark 3.
The testing results based on the DM test and the forecasting effectiveness reveal that the developed model shows a higher degree of forecasting accuracy than the benchmark models and that the level of forecasting accuracy of the proposed model is significantly different from that of all the compared models.
5. Discussion
This section conducts an insightful discussion of the experimental results, including each part in the hybrid model, forecasting steps and performance time.
5.1. Discussion of the Effectiveness of Data Processing and Optimization
The data in the electrical power system always features high volatility, irregularity or other tendencies. Therefore, the original data must be preprocessed before conducting the forecasting. In this paper, the filter time series are reconstructed by using the signal processing technique, which guarantees that the main feature of the time series can be effectively identified and extracted. By comparing the forecasting results of the MFO-SVR model and the CEEMD-MFO-SVR model (or comparing the forecasting results of the SVR model and the CEEMD-SVR model), we can evaluate the effectiveness of the data processing approach using a metric named decreased relative error (RE) of MAE, RMSE and MAPE, as presented in Table 7, which shows that the technique can improve the forecasting accuracy significantly: it improves the MAPE by 22.6320%, 16.7065% and 15.3012% for the one-step, three-step, and six-step forecasting, respectively.
Table 7.
The decreased relative error (RE).
The optimization algorithm also plays a vital role in the hybrid forecasting model, contributing greatly to the excellent performance of the proposed model. Similarly, we can testify to the effectiveness of the optimization algorithm through analyzing the difference between the forecasting result of the SVR model and that of the MFO-SVR model (or the forecasting result of the CEEMD-SVR model and that of the CEEMD-MFO-SVR model), which was found to improve the forecasting performance greatly: the algorithm improves the MAPE by 18.4993%, 18.7910% and 13.8638% for the one-step, three-step, and six-step forecasting, respectively. The other details are clearly represented in Table 8.
Table 8.
The comparison result of RE for different models.
5.2. Steps of Forecasting
To demonstrate the effectiveness of the developed innovative hybrid model, multi-step forecasting, including one-step, three-step and six-step forecasting, is conducted in this paper. The comparison result of multi-step forecasting accuracy is presented in Table 9. According to the value of improvement of MAPE, we list three conditions in this table, i.e., the worst condition, the best condition and the average condition. For the best condition, when compared with three-step and six-step forecasting, the forecasting accuracy of one-step forecasting improves by 0.3495% and 0.9118%, respectively. Even if a worse condition occurs, i.e., the worst condition, the difference between one-step and three-step and six-step forecasting is 0.4867% and 1.6160%, respectively. Furthermore, the average difference between six-step and one-step forecasting is 1.2741%, which is less than 2% and within the acceptable level [55]. Based on the analysis above, we can draw the conclusion that the proposed hybrid model is effective for multi-step forecasting.
Table 9.
Comparison of multi-step forecasting accuracy.
5.3. Performance Time
The comparison of the performance time for different models is presented in Table 10. The average computation times of ARMA, SVR, CEEMD-SVR, MFO-SVR and CEEMD-MFO-SVR are 3611.5275 s, 2.7966 s, 22.4386 s, 27,561.6998 s and 25,678.1505 s, respectively. According to the result, it can be found that the proposed hybrid model has the second longest running time, at 25,678.1505 s, which is within the acceptable scale. Compared with the SVR and CEEMD-SVR model, the performance time increases greatly due to the optimization process using MFO; however, it is short enough and applicable to forecast the future changes in the electric power load series.
Table 10.
Comparison of performance times for different models.
6. Conclusions
Electric power forecasting plays a significant role in power systems management. Recently, growing attention has been paid to improving the performance of power load forecasting. A high-accuracy forecasting model can yield huge economic, social and environmental benefits, improve the security of power systems, and help managers develop optimal plans for power system management. Hence, developing a novel and robust forecasting algorithm and improving the accuracy become highly desirable. However, the individual and traditional forecasting models cannot always yield desirable performance. In this paper, a novel integrated model was proposed for short-term load forecasting; it uses data selection, the signal processing approach, the multi-step forecasting strategy, and the precise and robust forecasting algorithm SVR, optimized by the new intelligent algorithm moth-flame optimization algorithm. Specifically, data selection is an innovative application used to split the original time series into some subsets, which guarantees that the subsets have the same features; moreover, the effective signal processing approach is employed to decompose the original series and reconstruct the filter time series, which is effective for identifying and extracting the main feature of power load series; moreover, the SVR algorithm, which is optimized by the latest optimization algorithm, is used to deal with the power load featuring irregularity and volatility. At this point, the proposed hybrid model, which can effectively realize the one-step forecasting based on historical data, is developed. Furthermore, the proposed model, combined with the multi-step forecasting strategy, is employed to perform multi-step forecasting. Evaluation of the developed hybrid models shows that each component is promising and effective for the forecasting problem and can improve performance by simplifying the intrinsic complexity of the original data. Based on a series of comparisons and analyses, the performance of the proposed integrated model is found to be excellent in comparison with the other benchmark models. For instance, the average MAPE of values of the hybrid model are 0.4603%, 0.9178% and 1.7344% for one-step, three-step and six-step forecasting, respectively, which shows significant superiority compared to other benchmark models in terms of four metric rules. Furthermore, comparing the results of the DM Test and forecasting effectiveness, the developed model shows a higher degree of forecasting accuracy than the compared models and the level of forecasting accuracy of the proposed model is significantly different from that of all the benchmark models. The hybrid model, with its outstanding performance, has considerable economic benefit and dramatic environmental resource savings; moreover, its recessive profit will become a driver for sustainable development. Furthermore, it is believed that the novel model will be widely applied in power system administration, load dispatch and electrical power scheduling. In summary, the meritorious hybridization capitalizes on each component’s advantages and ultimately results in final success, and the integrated model, which has an excellent performance, will be widely applied in the field of forecasting in the future.
However, there are still many issues that must be solved in the forecasting fields. This paper mainly focuses on the study of electrical power load forecasting by developing a novel integrated model with high forecasting accuracy; further research can be conducted in the future, as follows: (1) the application of the forecasting model to an energy system is worth studying, e.g., building a uniform forecasting model for three key indicators in the electrical power system, including the short-term wind speed, electrical load and electricity price; (2) this paper ignores the conflicts between different evaluation metrics; hence, future work can focus on maintaining their balance by tackling the problems with multiple objectives or constraints.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant No. 71671029 and Grant No. 41475013).
Author Contributions
Wendong Yang wrote the whole manuscript, and carried on data analysis; Jianzhou Wang made overall guidance; Rui Wang supported programing and a part of data processing. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shu, F.; Luonan, C. Short-term load forecasting based on an adaptive hybrid method. IEEE Trans. Power Syst. 2006, 21, 392–401. [Google Scholar]
- Önkal, D.; Zeynep Sayim, K.; Lawrence, M. Wisdom of group forecasts: Does role-playing play a role? Omega 2012, 40, 693–702. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, D.; Jia, H.; Djilali, N. Power system operation risk analysis considering charging load self-management of plug-in hybrid electric vehicles. Appl. Energy 2014, 136, 662–670. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Liang, T.; Wang, C. A combined model based on multiple seasonal patterns and modified firefly algorithm for electrical load forecasting. Appl. Energy 2016, 167, 135–153. [Google Scholar] [CrossRef]
- Pai, P.F. Hybrid ellipsoidal fuzzy systems in forecasting regional electricity loads. Energy Convers. Manag. 2006, 47, 2283–2289. [Google Scholar] [CrossRef]
- Hobbs, B.F. Analysis of the value for unit commitment of improved load forecasts. IEEE Trans. Power Syst. 1999, 14, 1342–1348. [Google Scholar] [CrossRef]
- The 12 Biggest Blackouts in History. Available online: http://www.msn.com/en-za/news/offbeat/the-12-biggest-blackouts-in-history/ar-CCeNdC#page=1 (accessed on 23 January 2017).
- Available online: http://finance.qq.com/a/20120801/003975.htm (accessed on 23 January 2017). (In Chinese)
- Wang, Y.; Wang, J.; Zhao, G.; Dong, Y. Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy 2012, 48, 284–294. [Google Scholar] [CrossRef]
- Fischer, J.; Wilfert, H.-H. Updating of Daily Load Prediction in Power Systems Using AR-Models. In Proceedings of the 2nd IFAC Symposium on Stochastic Control, Vilnius, Lithuanian, 19–23 May 1986.
- Pappas, S.S.; Ekonomou, L.; Karampelas, P.; Karamousantas, D.C.; Katsikas, S.K.; Chatzarakis, G.E.; Skafidas, P.D. Electricity demand load forecasting of the Hellenic power system using an ARMA model. Electr. Power Syst. Res. 2010, 80, 256–264. [Google Scholar] [CrossRef]
- Ling, Y.; Shantz, C.; Mahadevan, S.; Sankararaman, S. Stochastic prediction of fatigue loading using real-time monitoring data. Int. J. Fatigue 2011, 33, 868–879. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Al-Hamadi, H.M.; Soliman, S.A. Long-term/mid-term electric load forecasting based on short-term correlation and annual growth. Electr. Power Syst. Res. 2005, 74, 353–361. [Google Scholar] [CrossRef]
- Mohamed, Z.; Bodger, P. Forecasting electricity consumption in New Zealand using economic and demographic variables. Energy 2005, 30, 1833–1843. [Google Scholar] [CrossRef]
- Christiaanse, W.R. Short-Term Load Forecasting Using General Exponential Smoothing. IEEE Trans. Power Appar. Syst. 1971, PAS-90, 900–911. [Google Scholar] [CrossRef]
- Zhang, M.; Bao, H.; Yan, L.; Cao, J.P.; Jian-Guang, D.U. Research on processing of short-term historical data of daily load based on Kalman filter. Power Syst. Technol. 2003, 9, 39–42. [Google Scholar]
- Kelo, S.; Dudul, S. A wavelet Elman neural network for short-term electrical load prediction under the influence of temperature. Int. J. Electr. Power Energy Syst. 2012, 43, 1063–1071. [Google Scholar] [CrossRef]
- Metaxiotis, K.; Kagiannas, A.; Askounis, D.; Psarras, J. Artificial intelligence in short term electric load forecasting: A state-of-the-art survey for the researcher. Energy Convers. Manag. 2003, 44, 1525–1534. [Google Scholar] [CrossRef]
- Li, P.; Li, Y.; Xiong, Q.; Chai, Y.; Zhang, Y. Application of a hybrid quantized Elman neural network in short-term load forecasting. Int. J. Electr. Power Energy Syst. 2014, 55, 749–759. [Google Scholar] [CrossRef]
- Liao, G.C. Hybrid improved differential evolution and wavelet neural network with load forecasting problem of air conditioning. Int. J. Electr. Power Energy Syst. 2014, 61, 673–682. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S. An optimized grey model for annual power load forecasting. Energy 2016, 107, 272–286. [Google Scholar] [CrossRef]
- Hu, Z.; Bao, Y.; Xiong, T.; Chiong, R. Hybrid filter-wrapper feature selection for short-term load forecasting. Eng. Appl. Artif. Intell. 2015, 40, 17–27. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Wang, C.; Zhang, K.; Lu, H. Research and application of a hybrid model based on multi-objective optimization for electrical load forecasting. Appl. Energy 2016, 180, 213–233. [Google Scholar] [CrossRef]
- Niu, M.; Sun, S.; Wu, J.; Yu, L.; Wang, J. An innovative integrated model using the singular spectrum analysis and nonlinear multi-layer perceptron network optimized by hybrid intelligent algorithm for short-term load forecasting. Appl. Math. Model. 2016, 40, 4079–4093. [Google Scholar] [CrossRef]
- Xiong, T.; Li, C.; Bao, Y.; Hu, Z.; Zhang, L. A combination method for interval forecasting of agricultural commodity futures prices. Knowl. Based Syst. 2015, 77, 92–102. [Google Scholar] [CrossRef]
- Xiong, T.; Bao, Y.; Hu, Z. Multiple-output support vector regression with a firefly algorithm for interval-valued stock price index forecasting. Knowl. Based Syst. 2014, 55, 87–100. [Google Scholar] [CrossRef]
- Ming, W.; Bao, Y.; Hu, Z.; Xiong, T. Multistep-ahead air passengers traffic prediction with hybrid ARIMA-SVMs models. Sci. World J. 2014, 2014, 567246. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.; Liang, C.Y.; Hong, W.C.; Gu, D.X. Forecasting holiday daily tourist flow based on seasonal support vector regression with adaptive genetic algorithm. Appl. Soft Comput. 2015, 26, 435–443. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, W.; Wang, J. Air quality early-warning system for cities in China. Atmos. Environ. 2017, 148, 239–257. [Google Scholar] [CrossRef]
- Hong, W.C. Electric load forecasting by support vector model. Appl. Math. Model. 2009, 33, 2444–2454. [Google Scholar] [CrossRef]
- Chen, Y.; Hong, W.-C.; Shen, W.; Huang, N. Electric Load Forecasting Based on a Least Squares Support Vector Machine with Fuzzy Time Series and Global Harmony Search Algorithm. Energies 2016, 9, 70. [Google Scholar] [CrossRef]
- Ju, F.Y.; Hong, W.C. Application of seasonal SVR with chaotic gravitational search algorithm in electricity forecasting. Appl. Math. Model. 2013, 37, 9643–9651. [Google Scholar] [CrossRef]
- Fan, G.F.; Peng, L.L.; Hong, W.C.; Sun, F. Electric load forecasting by the SVR model with differential empirical mode decomposition and auto regression. Neurocomputing 2016, 173, 958–970. [Google Scholar] [CrossRef]
- Huang, M.-L. Hybridization of Chaotic Quantum Particle Swarm Optimization with SVR in Electric Demand Forecasting. Energies 2016, 9, 426. [Google Scholar] [CrossRef]
- Lee, C.-W.; Lin, B.-Y. Application of Hybrid Quantum Tabu Search with Support Vector Regression (SVR) for Load Forecasting. Energies 2016, 9, 873. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M.; Laforgia, D. Error analysis of hybrid photovoltaic power forecasting models: A case study of mediterranean climate. Energy Convers. Manag. 2015, 100, 117–130. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Malvoni, M.; Congedo, P.M. Comparison of strategies for multi-step ahead photovoltaic power forecasting models based on hybrid group method of data handling networks and least square support vector machine. Energy 2016, 107, 360–373. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, X.; Ma, C.; Wang, J. Research and Application of a Hybrid Forecasting Model Based on Data Decomposition for Electrical Load Forecasting. Energies 2016, 9, 1050. [Google Scholar] [CrossRef]
- Jiang, P.; Ma, X. A hybrid forecasting approach applied in the electrical power system based on data preprocessing, optimization and artificial intelligence algorithms. Appl. Math. Model. 2016, 40, 10631–10649. [Google Scholar] [CrossRef]
- Velazquez, S.; Carta, J.A.; Matias, J.M. Influence of the input layer signals of ANNs on wind power estimation for a target site: A case study. Renew. Sustain. Energy Rev. 2011, 15, 1556–1566. [Google Scholar] [CrossRef]
- Gao, Y.; Qu, C.; Zhang, K. A Hybrid Method Based on Singular Spectrum Analysis, Firefly Algorithm, and BP Neural Network for Short-Term Wind Speed Forecasting. Energies 2016, 9, 757. [Google Scholar] [CrossRef]
- Flandrin, P.; Torres, E.; Colominas, M.A. A complete ensemble empirical mode decomposition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147.
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Yen, N.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1996, 454, 903–995. [Google Scholar] [CrossRef]
- Flandrin, P.; Rilling, G.; Goncalves, P. Empirical mode decomposition as a filter bank. IEEE Signal Process. Lett. 2004, 11, 112–114. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble Empirical Mode Decomposition. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Zeng, G. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Mukherjee, S.; Osuna, E.; Girosi, F. Nonlinear prediction of chaotic time series using support vector machines. In Proceedings of the 1997 IEEE Workshop on Neural Networks for Signal Processing VII, Amelia Island, FL, USA, 24–26 September 1997.
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Zhao, H.; Zhao, H.; Guo, S. Using GM (1,1) Optimized by MFO with Rolling Mechanism to Forecast the Electricity Consumption of Inner Mongolia. Appl. Sci. 2016, 6, 20. [Google Scholar] [CrossRef]
- Gemperline, P.; Long, J.; Gregoriou, V. Nonlinear Multivariate Calibration Using Principal Components Regression and Artificial Neural Networks. Anal. Chem. 1991, 63, 2313–2323. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 25–63. [Google Scholar] [CrossRef]
- Chen, H.; Hou, D. Research on superior combination forecasting model based on forecasting effective measure. J. Univ. Sci. Technol. China 2002, 2, 172–180. [Google Scholar]
- Ma, X.; Liu, D. Comparative Study of Hybrid Models Based on a Series of Optimization Algorithms and Their Application in Energy System Forecasting. Energies 2016, 9, 640. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).