Abstract
In the application of discriminant analysis, a situation sometimes arises where individual measurements are screened by a multidimensional screening scheme. For this situation, a discriminant analysis with screened populations is considered from a Bayesian viewpoint, and an optimal predictive rule for the analysis is proposed. In order to establish a flexible method to incorporate the prior information of the screening mechanism, we propose a hierarchical screened scale mixture of normal (HSSMN) model, which makes provision for flexible modeling of the screened observations. An Markov chain Monte Carlo (MCMC) method using the Gibbs sampler and the Metropolis–Hastings algorithm within the Gibbs sampler is used to perform a Bayesian inference on the HSSMN models and to approximate the optimal predictive rule. A simulation study is given to demonstrate the performance of the proposed predictive discrimination procedure.
Keywords:
Bayesian predictive discriminant analysis; hierarchical model; MCMC method; optimal rule; scale mixture; screened observation MSC Classification:
62H30; 62F15
1. Introduction
The topic of analyzing multivariate screened data has received a great deal of attention over the last few decades. In the standard multivariate problem, an analysis of data generated from a p-dimensional screened random vector is our issue of interest, where the random vector v and the random vector (called the screening vector) are jointly distributed with the correlation matrix Thus, we observe x only when the unobservable screening vector belongs to a known subset of its space , such that That is, x is subject to the screening scheme or hidden truncation (or simply truncation if ). Model parameters underlying the joint distribution of v and are then estimated from the screened data (i.e., observations of x) using the conditional density
The screening of sample (or sample selection) arises as open in practice as a result of controlling observability of the outcome of interest in the study. For example, the dataset consists of the Otis IQ test scores (the values of x) of freshmen of a college. These students had been screened in the college admission process, which examines whether their prior school grade point average (GPA) and the Scholastic Aptitude Test (SAT) scores (i.e., the screening values denoted by ) are satisfactory. What the true vale of screening vector variable of each student is may not be available due to a college regulation. The observations available are the IQ values of x, the screened data. For the application with real screened data, one can refer to that with the student aid grants data given by [] and that with the U.S. labor market data given by [], as well. A variety of methods have been suggested for analyzing such screened data. See, e.g., [,,,], for various distributions for modeling and analyzing screened data; see, [,] for the estimative classification analysis with screened data; and see, e.g., [,,,], for the regression analysis with screened response data.
The majority of existing methods rely on the fact that v and are jointly multivariate normal, and the screened observation vector x is subject to a univariate screening scheme defined by an open interval with In many practical situations, however, the screened data are generated from a non-normal joint distribution of v and , having a multivariate screening scheme defined by a q-dimensional () rectangle region of In this case, a difficulty in applications with the screened data is that the empirical distribution of the screened data is skewed; its parametric model involves a complex density; and hence, standard methods of analysis cannot be used. See [,] for the conditional densities, , useful for fitting the rectangle screened data generated from a non-normal joint distribution of v and In this article, we develop yet another multivariate technique applicable for analyzing the rectangle screened data: we are interested in constructing a Bayesian predictive discrimination procedure for the data. More precisely, we consider a Bayesian multivariate technique for sorting, grouping and prediction of multivariate data generated from K rectangle screened populations. In the standard problem, a training sample is available, where, for each , is a rectangle screened observation vector coming from one of K populations and taking values in , and is a categorical response variable representing the population membership, so that implies that the predictor belongs to the k-th rectangle screened population (denoted by ), Using the training sample , the goal of the predictive discriminant analysis is to predict population membership of a new screened observation x based on the posterior probability of x belonging to The posterior probability is given by:
where z is the the population membership of x, is the prior probability of updated by the training sample and:
and , respectively, denote the predictive density, the probability density of x and the posterior density of parameters associated with One of the first and most applied predictive approaches by [] is the case of unscreened and normally-distributed populations with unknown parameters , namely for This is called a Bayesian predictive discriminant analysis with normal populations () in which a multivariate Student t distribution is obtained for Equation (2).
A practical example where the predictive discriminant analysis with the rectangle screened populations (’s) is applicable is in the discrimination between passed and failed pairs of applicants in a college admission process (the second screening process). Consider the case where college admission officers wish to set up an objective criterion (with a predictor vector x) for admitting students for matriculation; however, the admission officers must first ensure that a student with observation x has passed the first screening process. The first screening scheme may be defined by the q-dimensional region of the random vector (consisting of SAT scores, high-school GPA, and so on), so that only the students who satisfy can proceed to the admission process. In this case, we encounter a crucial problem for applying the normal classification by []; given the screening scheme , the assumption of the multivariate normal population distribution for , is not valid. The work in [,] found that the normal classification shows a lack of robustness to the departure from the normality of the population distribution, and hence, the performance of the normal classification can be very misleading, if used with the continuous, but non-normal or screened normal input vector x.
Thus, the predictive density in Equation (2) has two specific features to be considered for Bayesian predictive discrimination with the rectangle screened populations, one about the prior distribution of the parameters and the other about the distributional assumption of the population model with density For the unscreened populations case, there have been a variety of studies that are concerned with the two considerations. See, for example, [,,] for the choice of the prior distributions of , and see [,] for copious references to the literature on the predictive discriminant analysis with non-normal population models. Meanwhile, for deriving Equation (2) of the rectangle screened observation x, we need to develop a population model with density that uses the screened sample information in order to maintain consistency with the underlying theory associated with the populations generating the screened sample. Then, we propose a Bayesian hierarchical approach to flexibly incorporate the prior knowledge about with the non-normal sample information, which is the main contribution of this paper to the literature on Bayesian predictive discriminant analysis.
The rest of this paper is organized as follows. Section 2 considers a class of screened scale mixture of normal (SSMN) population models, which well accounts for the screening scheme conducted through a q-dimensional rectangle region of an external scale mixture of normal vector, Section 3 proposes a hierarchical screened scale mixture of normal (HSSMN) model to derive the predictive density Equation (2) and proposes an optimal rule for Bayesian predictive discriminant analysis (BPDA) with the SSMN populations (abbreviated as ). Approximation of the rule is studied in Section 4 by using an MCMC method applied to the HSSMN model. In Section 5, a simulation study is done to check the convergence of the MCMC method and the performance of the by making a comparison between the and the Finally, concluding remarks are given in Section 6.
2. The SSMN Population Distributions
Assume that the joint distribution of respective and vector variables and v, associated with , is , where:
, , η is a mixing variable with the pdf , is a suitably-chosen weight function and and are partitioned corresponding to the orders of and v:
Notice that defined by Equation (3) denotes a class of scale mixture of multivariate normal (SMN) distributions (see, e.g., [,] for details), equivalently denoted as in the remainder of the paper, where denote the cdf of
Given the joint distribution , the SSMN distribution is defined by the following screening scheme:
where is a q-dimensional rectangle screening region in the space of Here, , , and for . This region contains the cases of and as special cases.
The pdf of x is given by:
where:
and Here, and , respectively, denote the pdf and the probability of the rectangle region of a random vector . The latter is equivalent to
One particular member of the class of SSMN distributions is the rectangle-screened normal (RSN) distribution defined by Equation (5) and Equation (6), for which is degenerate with . The work in [,] studied properties of the distribution and denoted it as the distribution. Another member of the class is the rectangle-screened p-variate Student t distributions () considered by []. Its pdf is given by:
where and are the respective pdf and probability of a rectangle region of the p-variate Student t distribution with the location vector , the scale matrix B, the degrees of freedom c and:
The stochastic representations of the RSN and distributions are immediately obtained by applying the following lemma, for which detailed proof can be found in [].
Lemma 1. Suppose . Then, it has the following stochastic representation in a hierarchical fashion,
where and are conditionally independent and . Here, and
Lemma 1 provides the following: (i) an intrinsic structure of the SSMN population distributions, which reveals a type of departure from the SMN law because the distribution of reduces to the SMN distribution if (i.e., ); (ii) the representation provides a convenient device for random number generation; (iii) it leads to a simple and direct construction of a HSSMN model for the BPDA with the SSMN populations, i.e., .
3. The HSSMN Model
3.1. The Hierarchical Model
For a Bayesian predictive discriminant analysis, suppose we have K rectangle screened populations , each specified by the distribution. Let be a training sample obtained from the rectangle screened population with the distribution, where the parameters ( are unknown. The predictive discrimination analysis is to assess the relative predictive odds ratio or posterior probability that a screened multivariate observation x belongs to one of K populations, As noted by Equation (6), however, a complex likelihood function of prevents us from choosing reasonable priors of the model parameters and obtaining the predictive density of x given by Equation (2). These problems are solved if we use the following hierarchical representation of the population models.
According to Lemma 1, we may rewrite the SSMN model for Equations (8) and (9) by a three-level hierarchy given by:
where , , G is the scale mixing distribution of the independent ’s, and are independent conditional on and denotes a truncated distribution having the truncated space
The first stage model in Equation (10) may be written in a compact form by defining the following vector and matrix notations,
Then, the three-level hierarchy of the model Equation (10) can be expressed as:
where denotes the Kronecker product of two matrices and , , , and is an diagonal matrix of the scale mixing functions. Note that the hierarchical population model Equation (11) adopts a robust discriminant modeling by the use of the scale mixture of normal, such as the SMN and the truncated SMN, and thus, it enables us to avoid the anomaly generated from the non-normal sample information.
The Bayesian analysis of the model in Equation (11) begins with the specification of the prior distributions of the unknown parameters. When the prior information is not available, a convenient strategy of avoiding improper posterior distribution is to use proper priors with their hyperparameters being fixed as appropriate quantities to reflect the flatness (or diffuseness) of priors (i.e., limiting non-informative priors). For convenience, but not always optimal, we suppose that , , and of the model in Equation (11) are independent a priori; prior distributions for and are normal; an inverse Wishart prior distribution for ; and a generalized natural conjugate family (see []) of prior distributions for , so that we adopt the normal prior density for the conditional on the matrix ,
where denotes the inverse Wishart distribution whose pdf is:
Note that if , and , then:
This prior elicitation of the parameters, along with the three-level hierarchical model Equation (11), produces a hierarchical screened scale mixture of normal population model, which is referred to as HSSMN() in the rest of this paper, where The HSSMN() model is defined as follows.
where , and hyperparameters are fixed as appropriate quantities to reflect the flatness of priors.
The last distributional specification is omitted in the RSN distribution case. For the HSSMN() model for the distribution, we may set , , a truncated Gamma distribution (see, e.g., []). See, for example, [,] and the references therein for other choices of the prior distribution of
3.2. Posterior Distributions
Based on the HSSMN() model structure with the likelihood and the prior distributions in Equation (12), the joint posterior distribution of is given by:
where:
and ’s denote the densities of the mixing variables ’s. Note that the joint posterior of Equation (13) is not simplified in an analytic form of the known density and, thus, intractable for the posterior inference. Instead, we derived each of conditional posterior distribution of , , , , , and ’s, which will be useful for posterior inference based on Markov chain Monte Carlo methods (MCMC). All of the full conditional posterior distributions are as follows (see the Appendix for their derivations):
(1) The full conditional distribution of is a p-variate normal given by:
where and
(2) The full conditional density of is given by:
(3) The full conditional posterior distribution of is given by:
where:
(4) The full conditional posterior distribution of is an inverse-Wishart distribution:
where and
(5) The full conditional posterior distribution of is the q-variate truncated normal given by:
where and
(6) The full conditional posterior density of is given by:
(7) The full conditional posterior densities of ’s are given by:
where and ’s are independent.
Based on the above full conditional posterior distributions and the stochastic representations of the SSMN in Lemma 1, one can easily obtain Bayes estimates of the k-th SSMN population mean and covariance matrix , Specifically, the mean and covariance matrix of an observation x belonging to , which are used for calculating their Bayes estimates via Rao–Blackwellization, are given by:
where , , ,
, and:
We see that these moments of Equation (21) agree with the formula for the mean and covariance matrix of the untruncated marginal distribution of a general multivariate truncated distribution given by []. Readers are referred to [] with the R package tmvtnorm and [] with the R package mvtnorm for implementing calculations of and involved in the first and second moments.
When the sampling information, i.e., the observed training samples, is augmented by the proper information of prior knowledge, the anomalies of the maximum likelihood estimate of the SSMN model, investigated by [], would disappear in the HSSMN model. Furthermore, note that the conditional distribution of in Equation (16) is a -dimensional one; and hence, its Gibbs sampling needs to be performed by using the inverse of the matrix of order , which may cause computational costs in implementing the MCMC method. For large q, a more computationally-convenient Gibbs sampler can be considered based on the full conditional posterior distributions of , , than the Gibbs sampler with in Equation (16), where and
For this purpose, we defined the following notations: for ,
where denotes the j-th column of , namely an elementary vector with unity for its j-th element and zeros elsewhere. Furthermore, we consider the following partitions:
where the orders of , , and are , , and , respectively. Under these partitions, the conditional property of a multivariate normal distribution leads to the full conditional posterior distributions of given by:
for , where:
When p is large, we may partition into two vectors with smaller dimensions, say , then use their full conditional normal distributions for the Gibbs sampler.
Now, the posterior sampling can be implemented by using all of the conditional posterior Equations (14)–(20). The Gibbs sampler and Metropolis–Hastings algorithm within the Gibbs sampler may be used to obtain posterior samples of all of the unknown parameters . Note that in the case where the -dimensional matrix is too large to manipulate for computation, the Gibbs sampler can be modified by replacing the full conditional posterior Equation (16) with Equation (22). That is, as indicated by Equation (22), the modified Gibbs sampler based on Equation (22) would be more convenient for numerical computation than the first one using Equation (16). The detailed Markov chain Monte Carlo algorithm with Gibbs sampling is discussed in the next subsection.
3.3. Markov Chain Monte Carlo Sampling Scheme
It is not complicated to construct an MCMC sampling scheme working with , since a routine Gibbs sampler would work to generate posterior samples of based on each of their full conditional posterior distributions obtained in Section 3.2. In the posterior sampling of , and , Metropolis–Hastings within the Gibbs algorithm would be used, since their conditional posterior densities do not have explicit forms of known distributions as in Equation (15), Equation (19) and Equation (20).
Here, for simplicity, we considered the MCMC algorithm based on the HSSMN model with a known screening scheme, in which and are assumed to be known. The extension to the general HSSMN model with unknown and can be made without difficulty.
The MCMC algorithm starts with some initial values , , , and The detailed posterior sampling steps are as follows:
- Step 1: generate by using the full conditional posterior distribution in Equation (14).
- Step 2: generate by using the full conditional posterior distribution in Equation (16).
- Step 3: generate inverse-Wishart random matrix by using the full conditional posterior distribution in Equation (17).
- Step 4: generate independent q-variate truncated normal random variables by using the full conditional posterior distribution in Equation (18).
- Step 5: given the current values , we independently generate a candidate from a proposal density , as suggested by [], which is used for a Metropolis–Hastings algorithm. Then, accept the candidate value with the acceptance rate:Because the target density is proportional to and is uniformly bounded for where:and is the density of mixing variable . Note that
When one conducts a posterior inference of the HSSMN () model using the samples obtained from the MCMC sampling algorithm, the following points should be noted.
- (i)
- See, e.g., [], for the sampling method for from various mixing distributions of the SMN distributions, such as the multivariate t, multivariate , multivariate and multivariate models.
- (ii)
- Suppose the HSSMN() model involves unknown Then, as indicated by the full conditional posterior of in Equation (15), the complexity of the conditional distribution prevents us from using straightforward Gibbs sampling. Instead, we may use a simple random walk Metropolis algorithm that uses a normal proposal density to sample from the conditional distribution of ; that is, given the current point is , the candidate point is , where a diagonal matrix D should be turned, so that the acceptance rate of the candidate point is around 0.25 (see, e.g., []).
- (iii)
- When the HSSMN() model involves unknown : The MCMC sampling algorithm, using the full conditional posterior Equation (19) is not straightforward, because the conditional posterior density is unknown and complex. Instead, we may apply a Metropolized hit-and-run algorithm, described by [], to sample from the conditional posterior of
- (iv)
- One can easily calculate the posterior estimate of by using that of , because the re-parameterizing relations are and
4. The Predictive Classification Rule
Suppose we have K populations , , each specified by the HSSMN model. For each of the populations, we have the screened training sample comprised of a set of independent observations whose population level is Let x be assigned to one of the K populations, with prior probability of belonging to , Then, the predictive density of x given under the HSSMN model with the space is:
and the posterior probability that x belongs to , i.e., , is:
where , is equal to Equation (6) and is the joint posterior density given in Equation (13). We see from Equation (24) that the total posterior probability of misclassifying x from to , is defined by:
We minimize the misclassification error at this point if we choose j, so as to minimize Equation (25); that is, we select k that gives the maximum posterior probability (see, e.g., Theorem 6.7.1 of [] (p. 234). Thus, an optimal Bayesian predictive discrimination rule that minimizes the classification error is to classify x into , if , where the optimal classification region is given by:
is the posterior probability of population given the dataset If we assume the values of ’s are a priori known, then
Since we are unable to obtain an analytic solution of Equation (26), a numerical approach is required. Thus, we used the MCMC method of the previous section to draw samples from the posterior density of the parameters, , to approximate the predictive density, Equation (23), by:
where ’s are posterior samples generated from the MCMC process under the HSSMN model and M and are the burn-in period and run length, respectively.
If we assume Dirichlet priors for , that is:
(see, e.g., [] (p. 143) for the distributional properties), then:
and
5. Simulation Study
This section presents results of a simulation study to show the convergence of the MCMC algorithm and the performance of the . Simulation of the training sample observations, model estimation by the MCMC algorithm and a comparison of classification results among three BPDA methods were implemented by coding the R package program. The three methods consist of two proposed methods (i.e., and for classifying RSN and RSt populations) and by [] (for classifying unscreened normal populations).
5.1. A Simulation Study: Convergence of the MCMC Algorithm
This simulation study considers inference of the HSSMN model with a two-dimensional case by generating a training sample of one thousand observations, , from each population , We considered the following specific choice of parameters, i.e., , , , , and matrices, for generating a synthetic data from ,
Based on the above parameter values with , we simulated 200 sets of three training samples of each size from three populations , Two cases of screened populations were assumed, that is and The respective datasets were generated by using the stochastic representation of each population (see Lemma 1 for the representation). Given a generated training sample, corresponding population parameters were estimated by using the MCMC algorithm based on the HSSMN model, Equation (12), for each screened population, , distribution. We used , and as the initial values of the MCMC algorithm. To satisfy an objective Bayesian perspective considered by [], we need to specify the hyper-parameters of the HSSMN model, so as to be insensitive to changes of the priors. Thus, we assumed that we have no information about the parameters. To specify this, we adopted , , , , , , , and (see, e.g., []).
The MCMC samplers were based on 20,000 iterations as burn-in, followed by a further 20,000 iterations with a thinning size of 10. Thus, the final MCMC samples with a size of 2000 were obtained for each HSSMN model. Table 1 only provides posterior summaries for the parameters of the distribution for the sake of saving space. From Column 4–Column 9 of the table list, the mean and three quantiles of 200 sets of posterior samples, which were obtained from the MCMC method, were repeatedly applied to the 200 sets of training sample of size Then, the remaining two columns of the table list formal convergence test results of the MCMC algorithm. In estimating the Monte Carlo error (MC error) in Column 5, we used the batch mean method with 50 batches, see e.g., [] (pp. 39–40). The low values of the MC errors indicate that the variability of each estimate due to the simulation is well controlled. The table also compares the MCMC results with the true parameter values (listed in Column 3): (i) each parameter value in Column 3 is located in the credible interval (2.5% quantile, 97.5% quantile); (ii) for each parameter, we see that the difference between its true value and corresponding posterior mean is less than 2 × the standard error (s.e.). Thus, the posterior summaries, obtained by using the weakly informative priors, indicate that the MCMC method based on the HSSMN model performs well in estimating the population parameters, regardless of the SSMN models (RSN and RSt) considered.

Table 1.
Posterior summaries of 200 Markov chain Monte Carlo (MCMC) results for the models.
| Model () | Parameter | True | Mean | MC Error | s.e. | 2.5% | Median | 97.5% | p-Value | |
|---|---|---|---|---|---|---|---|---|---|---|
| RSN | 2.000 | 1.966 | 0.003 | 0.064 | 1.882 | 1.964 | 2.149 | 1.014 | 0.492 | |
| −1.000 | −0.974 | 0.002 | 0.033 | −1.023 | −0.974 | −0.903 | 1.011 | 0.164 | ||
| 0.312 | 0.320 | 0.008 | 0.159 | 0.046 | 0.322 | 0.819 | 1.021 | 0.944 | ||
| 0.406 | 0.407 | 0.007 | 0.164 | 0.030 | 0.417 | 0.872 | 1.018 | 0.107 | ||
| 0.250 | 0.253 | 0.004 | 0.083 | 0.082 | 0.256 | 0.439 | 1.019 | 0.629 | ||
| 0.125 | 0.133 | 0.004 | 0.067 | 0.003 | 0.133 | 0.408 | 1.017 | 0.761 | ||
| 1.968 | 2.032 | 0.005 | 0.130 | 1.743 | 2.008 | 2.265 | 1.034 | 0.634 | ||
| −0.625 | −0.627 | 0.002 | 0.098 | −0.821 | −0.617 | −0.405 | 1.022 | 0.778 | ||
| 0.500 | 0.566 | 0.001 | 0.039 | 0.465 | 0.557 | 0.638 | 1.018 | 0.445 | ||
| RSt | 2.000 | 2.036 | 0.004 | 0.069 | 1.867 | 2.050 | 2.166 | 1.015 | 0.251 | |
| −1.000 | −1.042 | 0.003 | 0.036 | −1.137 | −1.054 | −0.974 | 1.012 | 0.365 | ||
| 0.312 | 0.318 | 0.008 | 0.072 | 0.186 | 0.320 | 0.601 | 1.017 | 0.654 | ||
| 0.406 | 0.405 | 0.006 | 0.074 | 0.262 | 0.414 | 0.562 | 1.019 | 0.712 | ||
| 0.250 | 0.255 | 0.005 | 0.051 | 0.113 | 0.257 | 0.387 | 1.023 | 0.661 | ||
| 0.125 | 0.136 | 0.005 | 0.055 | 0.027 | 0.133 | 0.301 | 1.019 | 0.598 | ||
| 1.968 | 1.906 | 0.006 | 0.108 | 1.781 | 1.996 | 2.211 | 1.023 | 0.481 | ||
| −0.625 | −0.620 | 0.003 | 0.101 | −0.818 | −0.615 | −0.422 | 1.021 | 0.541 | ||
| 0.500 | 0.459 | 0.002 | 0.044 | 0.366 | 0.457 | 0.578 | 1.016 | 0.412 |
Some of the trace plots from an MCMC run are provided in Figure 1. Each plot demonstrates a parallel zone centered near the true parameter value of interest with no obvious tendency or periodicity. These plots and the small MC error values listed in Table 1 convince us of the convergence of the MCMC algorithm. For a formal diagnostic check, we calculated the Brooks and Gelman diagnostic statistic (adjusted shrinkage factor introduced by []) using a MCMC runs with three chains in parallel, each one starting from different initial values. The calculated value for each parameter is listed in the 10th column of Table 1. Table 1 shows that all of the values are close to one, indicating the convergence of the MCMC algorithm. For another formal diagnostic check, we applied the Heidelberger–Welch diagnostic tests of [] to single-chain MCMC runs, which were used to plot Figure 1. They consist of the stationarity test and the half-width test for the MCMC runs of each parameter. The 11th column of Table 1 lists the p-value of the test for the stationarity of the single Markov chain, where all of the p-values are larger than 0.1. Furthermore, all of the the half-width tests, testing the convergence of the Markov chain of a single parameter, were passed. Thus, all of the diagnostic checking methods (formal and informal methods) advocate the convergence of the proposed MCMC algorithm, and hence, we can say that it generates an MCMC sample that comes from the marginal posterior distributions of interest (i.e., the SSMN population parameters). It is seen that the similar estimation results in Table 1 apply to the posterior summaries of the other parameters in and distributions. According to these simulation results, we can say that the MCMC algorithm constructed in Section 3.3 provides an efficient method for estimating the SSMN distributions. To achieve this quality of MCMC algorithm for the higher dimensional case (with large p and/or q values), the diagnostic tests, considered in this section, should be used to monitor the convergence of the algorithm; for more details, see [].
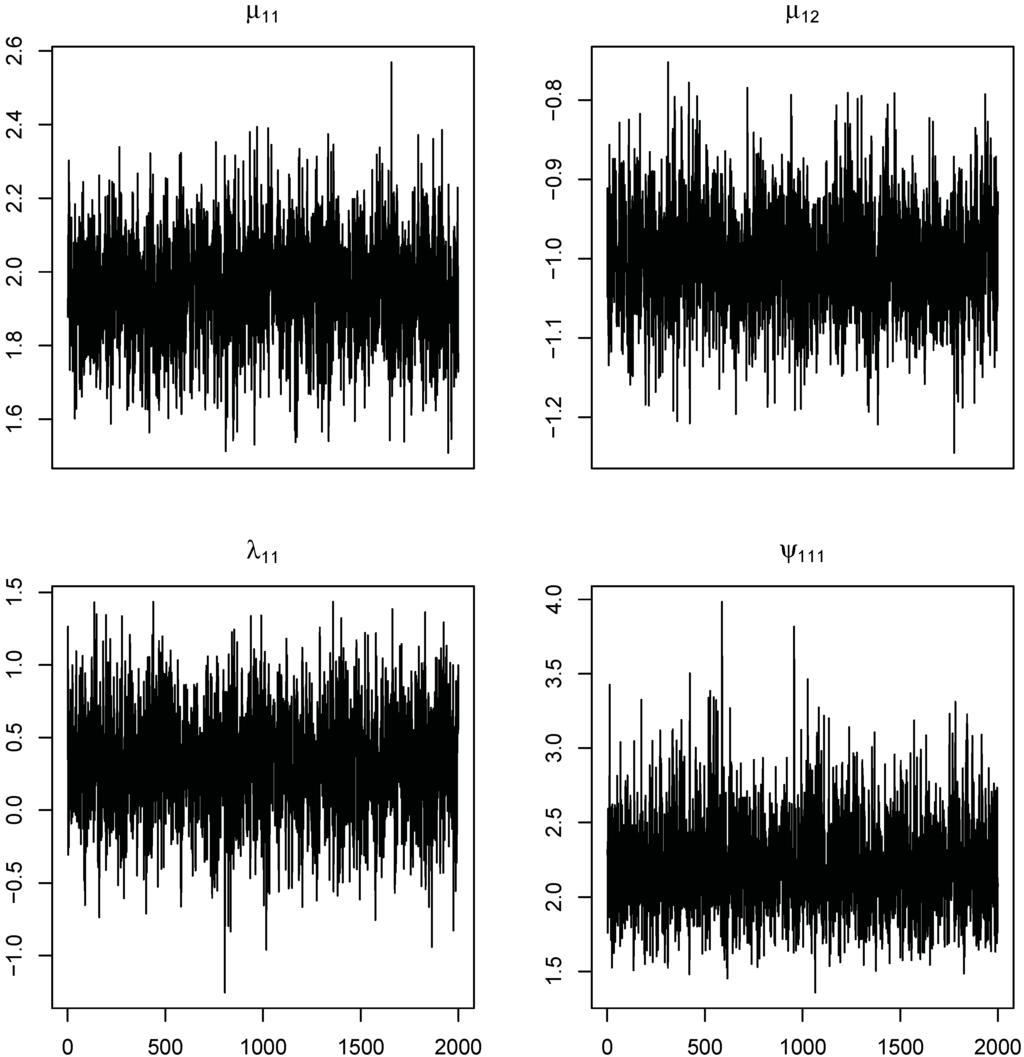
Figure 1.
Trace plots of , , and generated from HSSMN of the RSt with model.
5.2. A Simulation Study: Performance of the Predictive Methods
This simulation study compares the performance of three BPDA methods using training samples generated from three rectangle screened populations, (). The three methods compared are , with degrees of freedom , and (a standard predictive method with no screening). Two different cases of rectangle screened population distributions were used to generate the training samples. One case is the rectangle screened population with the distribution. The other case is with the distribution in order to examine the robustness of in discriminating observations from heavily-tailed empirical distributions. For each case, we obtained 200 sets of training and validation (or testing) samples of each size generated from the rectangle screened distribution of They are denoted by and The i-th validation sample that corresponds to the training sample was simply obtained by setting , where
The parameter values of the screened population distributions of the three populations were given by:
for , and Further, we assumed that the parameters and of the underlying q-dimensional screening vector and the rectangle screening region were known as given above. Thus, we may investigate the performance of the BPDA methods by varying the values of correlation ρ, dimension p of the predictor vector, rectangle screened region and differences among the three population means and covariance matrices whose expressions can be found in []. Here, is a summing vector whose every element is unity, and denote a matrix whose every odd row is equal to (1, 0) and every even row is (0, 1).
Using the training samples, we calculated the approximate predictive densities Equation (27) by the MCMC algorithm proposed in Section 3.3. In this calculation, we assumed that , because Thus, the posterior probabilities in Equation (24) and the minimum error classification region in Equation (26) can be estimated within the MCMC scheme, which uses Equation (27) to approximate the predictive densities involved in both Equation (24) and Equation (26). Then, we estimated the classification error rates of the three BPDA methods by using the validation samples, To apply the and methods for classifying the simulated training samples, we used the optimal classification rule, which uses Equation (26), while we used the posterior odds ratio given in [] to implement the method. Then, we compare the classification results in terms of error rates. The error rate of each population () and the total error rate (Total) were estimated by:
where is the number of misclassified observations out of validation sample observations from
For each case of distributions, the above procedure was implemented on each set of 200 validation samples to evaluate the error rates of the BPDA methods. Here, [Case 1]denotes that the training (and validation) samples were generated from , and [Case 2] indicates that they were generated from , For each case, Table 2 compares the mean of classification error rates obtained from the 200 replicated classifications by using the BPDA methods. The error rates and their standard errors in Table 2 are indicated as follows. (i) Both the and methods work reasonably well in classifying screened observations, compared to the method. This implies that, in BPDA, they provide better classification results than the , provided that ’s are screened by a rectangle screening scheme. (ii) The performance of the methods becomes better as the correlation (ρ) between the screening variables and predictor variables becomes larger. (iii) For a comparison of the error rates with respect to the values of a, we see that the methods tends to yield better performance in the discrimination of a screened by a small rectangle screened region. (iv) The performance of the three BPDA methods improves when the differences of the mean increases. (v) An increase in the sizes of dimension p and training sample n also tends to yield a better performance of the BPDA methods. (vi) As expected, the performance of the in [Case 1] is better than the other two methods, because the estimates of error rates are not covered by the corresponding two standard errors. Further, a considerable gain in the error rates over the manifests the utility of the in the discriminant analysis. (vii) As for [Case 2], the table indicates that the performance of the is better than the two other methods. This demonstrates the robustness of the method in the discrimination with screened and heavy tailed data.
Table 2.
Classification error rates: the respective standard errors are in parenthesis.
| p | n | a | Method | ||||
|---|---|---|---|---|---|---|---|
| [Case 1] | |||||||
| 2 | 20 | 0.5 | 0.322(0.0025) | 0.174(0.0022) | 0.281(0.0024) | 0.106(0.0020) | |
| 0.335(0.0025) | 0.185(0.0023) | 0.306(0.0025) | 0.115(0.0021) | ||||
| 0.350(0.0025) | 0.206(0.0023) | 0.356(0.0025) | 0.205(0.0021) | ||||
| 0.329(0.0027) | 0.182(0.0023) | 0.301(0.0025) | 0.134(0.0021) | ||||
| 0.348(0.0024) | 0.193(0.0022) | 0.319(0.0024) | 0.142(0.0021) | ||||
| 0.349(0.0025) | 0.201(0.0023) | .349(0.0025) | 0.192(0.0020) | ||||
| 100 | 0.5 | 0.303(0.0016) | 0.161(0.0014) | 0.266(0.0015) | 0.097(0.0013) | ||
| 0.316(0.0017) | 0.165(0.0013) | 0.275(0.0015) | 0.101(0.0013) | ||||
| 0.351(0.0025) | 0.186(0.0023) | 0.356(0.0025) | 0.186(0.0021) | ||||
| 0.306(0.0015) | 0.163(0.0014) | 0.282(0.0014) | 0.116(0.0013) | ||||
| 0.318(0.0017) | 0.168(0.0015) | 0.291(0.0015) | 0.121(0.0013) | ||||
| 0.338(0.0024) | 0.172(0.0023) | 0.337(0.0026) | 0.170(0.0021) | ||||
| 5 | 20 | 0.5 | 0.318(0.0025) | 0.158(0.0022) | 0.240(0.0024) | 0.101(0.0020) | |
| 0.327(0.0026) | 0.175(0.0023) | 0.276(0.0025) | 0.114(0.0021) | ||||
| 0.337(0.0026) | 0.183(0.0023) | 0.332(0.0025) | 0.184(0.0020) | ||||
| 0.321(0.0025) | 0.165(0.0023) | 0.231(0.0025) | 0.109(0.0021) | ||||
| 0.330(0.0026) | 0.207(0.0023) | 0.318(0.0025) | 0.141(0.0021) | ||||
| 0.345(0.0026) | 0.216(0.0024) | 0.346(0.0025) | 0.218(0.0021) | ||||
| 100 | 0.5 | 0.280(0.0015) | 0.150(0.0014) | 0.233(0.0015) | 0.084(0.0012) | ||
| 0.291(0.0016) | 0.153(0.0015) | 0.249(0.0015) | 0.092(0.0013) | ||||
| 0.307(0.0025) | 0.186(0.0023) | 0.308(0.0025) | 0.189(0.0021) | ||||
| 0.291(0.0016) | 0.163(0.0014) | 0.239(0.0015) | 0.103(0.0013) | ||||
| 0.294(0.0016) | 0.169(0.0015) | 0.253(0.0015) | 0.117(0.0013) | ||||
| 0.305(0.0024) | 0.175(0.0022) | 0.301(0.0025) | 0.176(0.0021) | ||||
| [Case 2] | |||||||
| 2 | 20 | 0.5 | 0.351(0.0025) | 0.189(0.0022) | 0.310(0.0025) | 0.114(0.0021) | |
| 0.320(0.0024) | 0.175(0.0023) | 0.293(0.0024) | 0.105(0.0020) | ||||
| 0.367(0.0026) | 0.185(0.0023) | 0.365(0.0024) | 0.191(0.0020) | ||||
| 0.349(0.0026) | 0.192(0.0022) | 0.317(0.0024) | 0.149(0.0022) | ||||
| 0.321(0.0023) | 0.183(0.0021) | 0.304(0.0023) | 0.132(0.0021) | ||||
| 0.356(0.0025) | 0.210(0.0023) | 0.357(0.0025) | 0.199(0.0020) | ||||
| 100 | 0.5 | 0.313(0.0016) | 0.164(0.0015) | 0.273(0.0015) | 0.098(0.0014) | ||
| 0.306(0.0015) | 0.158(0.0013) | 0.265(0.0014) | 0.091(0.0012) | ||||
| 0.346(0.0023) | 0.179(0.0022) | 0.341(0.0024) | 0.175(0.0022) | ||||
| 0.321(0.0015) | 0.170(0.0014) | 0.287(0.0015) | 0.119(0.0015) | ||||
| 0.310(0.0014) | 0.164(0.0013) | 0.281(0.0013) | 0.112(0.0013) | ||||
| 0.329(0.0025) | 0.181(0.0025) | 0.327(0.0027) | 0.176(0.0022) | ||||
| 5 | 20 | 0.5 | 0.329(0.0024) | 0.181(0.0024) | 0.281(0.0023) | 0.119(0.0021) | |
| 0.317(0.0023) | 0.164(0.0020) | 0.265(0.0021) | 0.094(0.0020) | ||||
| 0.340(0.0027) | 0.196(0.0024) | 0.314(0.0026) | 0.152(0.0022) | ||||
| 0.342(0.0025) | 0.205(0.0024) | 0.332(0.0024) | 0.194(0.0024) | ||||
| 0.328(0.0022) | 0.171(0.0022) | 0.275(0.0022) | 0.118(0.0021) | ||||
| 0.351(0.0026) | 0.224(0.0025) | 0.329(0.0025) | 0.175(0.0025) | ||||
| 100 | 0.5 | 0.284(0.0016) | 0.155(0.0018) | 0.283(0.0016) | 0.154(0.0013) | ||
| 0.271(0.0014) | 0.149(0.0014) | 0.238(0.0014) | 0.086(0.0011) | ||||
| 0.294(0.0026) | 0.192(0.0024) | 0.274(0.0026) | 0.161(0.0024) | ||||
| 0.289(0.0016) | 0.177(0.0015) | 0.288(0.0016) | 0.175(0.0013) | ||||
| 0.278(0.0013) | 0.162(0.0013) | 0.231(0.0014) | 0.107(0.0011) | ||||
| 0.312(0.0025) | 0.178(0.0025) | 0.270(0.0026) | 0.141(0.0022) | ||||
6. Conclusions
In this paper, we proposed an optimal predictive method (BPDA) for the discriminant analysis of multidimensional screened data. In order to incorporate the prior information about a screening mechanism flexibly in the analysis, we introduced the SSMN models. Then, we provided the HSSMN model for Bayesian inference of the SSMN populations, where the screened data were generated. Based on the HSSMN model, posterior distributions of were derived, and the calculation of the optimal predictive classification rule was discussed by using an efficient MCMC method. Numerical studies with simulated screened observations were given to illustrate the convergence of the MCMC method and the usefulness of the BPDA.
The methodological results of the Bayesian estimation procedure proposed in the paper can be extended to other multivariate linear models that incorporate non-normal errors, a general covariance matrix and truncated random covariates. For example, the seemingly unrelated regression (SUR) model and the factor analysis model (see, e.g., []) can be explained in the same framework of the proposed HSSMN in Equation (12). The former is a special case of the HSSMN model in which ’s are observable as predictors. Therefore, when the regression errors are non-normal, it would be plausible to apply the proposed approach by using the HSSMN model to work with a robust SUR model, whereas the latter is a natural extension of the oblique factor analysis model to the case of that with non-normal measurement errors. The HSSMN model can also be extended to accommodate missing, values as done in the other models by [,]. We are hopeful to address these issues, as well, in the near future.
Acknowledgments
The research of Hea-Jung Kim was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT and Future Planning (2013R1A2A2A01004790).
Author Contributions
The author developed a Bayesian predictive method for the discriminant analysis of screened data. For the multivariate technique, the author introduced a predictive discrimination method with the SSMN populations () and provided a Bayesian estimation methodology, which is suited to the . The methodology consists of constructing a hierarchical model for the SSMN populations (HSSMN) and using an efficient MCMC algorithm to estimate the SSMN models, as well as an optimal rule for the
Conflicts of Interest
The authors declare no conflict of interest.
Appendix
Derivations of the full conditional posterior distributions
- (1)
- The full conditional posterior density of given and is proportional to:which is a kernel of the distribution.
- (2)
- It is obvious from the joint posterior density in Equation (13).
- (3)
- It is straightforward to see from Equation (13) that the full conditional posterior density of is given by:This is a kernel of , where and
- (4)
- We see from Equation (13) that the full conditional posterior density of is given by:This is a kernel of
- (5)
- We see, from Equation (13), that the full conditional posterior densities of ’s are independent, and each density is given by:which is a kernel of the q-variate truncated normal
- (6)
- It is obvious from the joint posterior density in Equation (13).
- (7)
- It is obvious from the joint posterior density in Equation (13).
References
- Catsiapis, G.; Robinson, C. Sample selection bias with multiple selection rules: An application to student aid grants. J. Econom. 1982, 18, 351–368. [Google Scholar] [CrossRef]
- Mohanty, M.S. Determination of participation decision, hiring decision, and wages in a double selection framework: Male-female wage differentials in the U.S. labor market revisited. Contemp. Econ. Policy 2001, 19, 197–212. [Google Scholar] [CrossRef]
- Kim, H.J. A class of weighted multivariate normal distributions and its properties. J. Multivar. Anal. 2008, 99, 1758–1771. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, H.-M. A class of rectangle-screened multivariate normal distributions and its applications. Statisitcs 2015, 49, 878–899. [Google Scholar] [CrossRef]
- Lin, T.I.; Ho, H.J.; Chen, C.L. Analysis of multivariate skew normal models with incomplete data. J. Multivar. Anal. 2009, 100, 2337–2351. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Branco, M.D.; Genton, M.G. A unified view of skewed distributions arising from selections. J. Can. Stat. 2006, 34, 581–601. [Google Scholar]
- Kim, H.J. Classification of a screened data into one of two normal populations perturbed by a screening scheme. J. Multivar. Anal. 2011, 102, 1361–1373. [Google Scholar] [CrossRef]
- Kim, H.J. A best linear threshold classification with scale mixture of skew normal populations. Comput. Stat. 2015, 30, 1–28. [Google Scholar] [CrossRef]
- Marchenko, Y.V.; Genton, M.G. A Heckman selection-t model. J. Am. Stat. Assoc. 2012, 107, 304–315. [Google Scholar] [CrossRef]
- Sahu, S.K.; Dey, D.K.; Branco, M.D. A new class of multivariate skew distributions with applications to Bayesian regession models. Can. J. Stat. 2003, 31, 129–150. [Google Scholar] [CrossRef]
- Geisser, S. Posterior odds for multivariate normal classifications. J. R. Stat. Soc. B 1964, 26, 69–76. [Google Scholar]
- Lachenbruch, P.A.; Sneeringer, C.; Revo, L.T. Robustness of the linear and quadratic discriminant function to certain types of non-normality. Commun. Stat. 1973, 1, 39–57. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, H.; Zeng, D.; Mauro, C.; Duan, N.; Shear, M.K. Auxiliary marke-assited classification in the absence of class identifiers. J. Am. Stat. Assoc. 2013, 108, 553–565. [Google Scholar] [CrossRef] [PubMed]
- Webb, A. Statistical Pattern Recognition; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Aitchison, J.; Habbema, J.D.F.; Key, J.W. A critical comparison of two methods of statistical discrimination. Appl. Stat. 1977, 26, 15–25. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Statistical application of the multivariate skew-normal distribution. J. R. Stat. Soc. B 1999, 65, 367–389. [Google Scholar] [CrossRef]
- Branco, M.D. A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar]
- Chen, M-H.; Dey, D.K. Bayesian modeling of correlated binary responses via scale mixture of multivariate normal link functions. Indian J. Stat. 1998, 60, 322–343. [Google Scholar]
- Press, S.J. Applied Multivariate Analysis, 2nd ed.; Dover: New York, NY, USA, 2005. [Google Scholar]
- Reza-Zadkarami, M.; Rowhani, M. Application of skew-normal in classification of satellite image. J. Data Sci. 2010, 8, 597–606. [Google Scholar]
- Wang, W.L.; Fan, T.H. Bayesian analysis of multivariate t linear mixed models using a combination of IBF and Gibbs samplers. J. Multivar. Anal. 2012, 105, 300–310. [Google Scholar] [CrossRef]
- Wang, W.L.; Lin, T.I. Bayesian analysis of multivariate t linear mixed models with missing responses at random. J. Stat. Comput. Simul. 2015, 85. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S. Distribution in Statistics: Continuous Multivariate Distributions; Wiley: New York, NY, USA, 1972. [Google Scholar]
- Wilhelm, S.; Manjunath, B.G. tmvtnorm: Truncated multivariate normal distribution and student t distribution. R J. 2010, 1, 25–29. [Google Scholar]
- Genz, A.; Bretz, F. Computation of Multivariate Normal and t Probabilities; Springer: New York, NY, USA, 2009. [Google Scholar]
- Chib, S.; Greenberg, E. Understanding the Metropolis-Hastings algorithm. Am. Stat. 1995, 49, 327–335. [Google Scholar]
- Chen, H.-M.; Schmeiser, R.W. Performance of the Gibbs, hit-and-run, and metropolis samplers. J. Comput. Gr. Stat. 1993, 2, 251–272. [Google Scholar] [CrossRef]
- Anderson, T.W. Introduction to Multivariate Statistical Analysis, 3rd ed.; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Adwards, W.H.; Lindman, H.; Savage, L.J. Bayesian statistical inference for psychological research. Psycol. Rev. 1963, 70, 192–242. [Google Scholar] [CrossRef]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Brooks, S.; Gelman, A. Alternative methods for monitoring convergence of iterative simulations. J. Comput. Gr. Stat. 1998, 7, 434–455. [Google Scholar]
- Heidelberger, P.; Welch, P. Simulation run length control in the presence of an initial transient. Oper. Res. 1992, 31, 1109–1144. [Google Scholar] [CrossRef]
- Lin, T.I. Learning from incomplete data via parameterized t mixture models through eigenvalue decomposition. Comput. Stat. Data Anal. 2014, 71, 183–195. [Google Scholar] [CrossRef]
- Lin, T.I.; Ho, H.J.; Chen, C.L. Analysis of multivariate skew normal models with incomplete data. J. Multivar. Anal. 2009, 100, 2337–2351. [Google Scholar] [CrossRef]
© 2015 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).