Abstract
Joining independent quantum searches provides novel collective modes of quantum search (merging) by utilizing the algorithm’s underlying algebraic structure. If n quantum searches, each targeting a single item, join the domains of their classical oracle functions and sum their Hilbert spaces (merging), instead of acting independently (concatenation), then they achieve a reduction of the search complexity by factor
.
1. Introduction
The quantum search algorithm, from its initial conception [1–3], to the subsequent manifold of ongoing developments, see e.g., the various open research projects addressing the association of quantum search with e.g., quantum entanglement [4], quantum programming [5], error faultiness [6], fixed-point quantum search [7], and quantum walks [8], constitutes one of the pillars of the research area of quantum computing. Despite its simplicity and the manifested versatility in applications the algorithm remains a challenge to meet, especially when it is considered as a computational primitive that could be synthesized in non trivial ways with itself.
This point of view is put forward in this work, where utilizing the underlying algebraic structure of the search algorithm and its matrix representation theory [9], the algorithm is treated as a computational unit composed in two different ways, to be called merging and concatenation. Merging of two algorithms creates a computational advantage that reduces search complexity in contradistinction to non joint searches of simple concatenation. More accurately, it is shown that the merging of n single searches with database dimensions Nk = 2k, k = 1, …, n, causes a complexity reduction proportional of square root of n. This main result of collective search is scrutinized in all intermediated joining schemes, where among n searches k are merged and the rest are left concatenated, via partitioning databases into distinct groups of merged algorithms and then concatenating the resulting groups. The logistics of joining schemes is carried out via Young diagrams and tableaux of partitions, as well as majorization theory [10]. (Proofs and examples are placed in the second part of the paper).
1.1. Single Quantum Search
Find 1 ≤ k < N marked elements from the set Δ = {1, 2, …N}, by improving the classical complexity
of the search.
The ν binary strings (a1, a2, …, aν) from the elements of classical database with size N = 2ν, which are assigned via (a1, a2, …, aν) → |a1, a2, …, aν⟩ ≡ |i⟩, i = 1,…, N, to N basis vectors of Hilbert space H = (span{|0⟩, |1⟩})⊗ν. Via the assignment |i⟩ → |i⟩ ⟨i|, this leads to the database
consisting of a collection of N pure density matrices. Let the oracle function f, introduced as the characteristic function of subset I ⊂ Δ of marked items, namely f(i) = 1 for i ∈ I and f(i) = 0 for i ∉ I. The density matrices ρx, ρs, for the marked and initial vectors are expressed in terms of vectors |x⟩, |x⊥⟩, and
, where |x⟩ and |s⟩, are the the solution state and the equiprobable superposition of all database states, respectively. Define the reflection operators Jx = 1 – 2 |s⟩ ⟨s|, and the unitary search operator UG = −JsJx, that implements a search via the action
Next, introduce the Σ0, Σ1, Σ2 and Σ3 as the Hermitian generators of oracle algebra Af [9],
with commutation relations [Σα, Σb] = 2iΣc (cyclically), a, b, c ∈ {0, 1, 2, 3}, and Σ0 central, i.e., Af ≈ u(2) (see Appendix for the representation theory).
In terms of oracle algebra generators the search operator reads UG = exp(iθΣ2), with
. It holds that
, m ∈ N, and then
, and pm = Tr(ρ(m) |x⟩ ⟨x|) = cos2 (mθ – α) pm = 1 iff cos2(mθ – α) = 1, for N ≫ 1, k < N, i.e., the complexity of the algorithm is
.
2. Collective Quantum Search: Merging and Concatenation
Considering joining of two searches in Hilbert spaces
, r = 1, 2, with dimensions N1, N2 in the form of concatenation, we first need to embed their database vectors into a larger space H1 ⊕ H2 of dimension N1 + N2, by padding in zeros into their components, on their top or on their tail, until their number becomes N1 + N2. By convention, concatenating searches of dim N1 with one of dim N2, would mean to form new basis vectors
, and
, where we denote by
,
, the respective null vector with all their components being zero. These two new sets of basis vectors constitute the database of the jointed algorithms of dim N1 + N2. The marked vector to be called |xconc⟩ will read
Definition 1. l-merging and l-concatenation. Let l quantum search algorithms [1] Ur(fr) : Hr → Hr, r = 1, 2, …, l with their database Hilbert spaces,
, where the reflection operators, and, are defined wrt some vectors |xr⟩ and |sr⟩, with, and the target vectors; here :
their respective oracle functions. We further denote the merged space by with Nmerg = N1 + N2 + ⋯·+ Nl, let also a quantum search algorithm Umerg(fmerg) : Hmerg → Hmerg, withits space,
,its search unitary, and its l-target oracle function, and also denoted by, the l-target vector.
Lemma 1. Let a 2-concatenation with search operator. Then the following decomposition is valid Uconc = U1 ⊕ U2, where U1, U2 are the search operators in Hilbert spaces with dimensions N1, N2, respectively.
2.1. Collective Quantum Search: Joining Schemes and Young Diagrams
By convention we take the horizontal direction in a Young diagram (for notation c.f. [11]) to denote merging (the number of row boxes equals the number of merged searches), and in the vertical direction the number of rows denotes concatenated sets, i.e.,
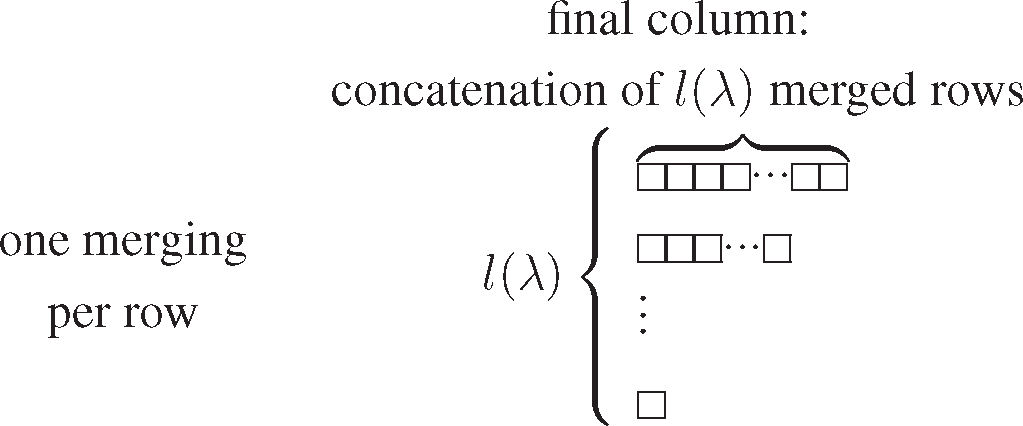
Recall the partial order of majorization between partitions [10]. Let partitions π = (π1, …, πs) and ρ = (ρ1, …, ρt); if s ≥ t then π weakly majorizes ρ, written as πw≻ρ, if the following inequalities are satisfied,
If the last relation above is only an equality, then π majorizes ρ, written as π ≻ ρ. Associating partitions to Young diagrams, i.e., π → Y (π), an equivalent definition of majorization of partitions is induced via
Lemma 2. (Muirhead’s Lemma) If π, ρ ⊢ m, then π ≻ ρ iff Y (π) can be obtained from Y (ρ) by moving boxes up to lower numbered rows.
In this way all, Young diagrams of given m are partially ordered in the poset {π ⊢ m, ≻}, via their associated Young diagrams as shown schematically below,
In the context of collective search, we say equivalently that if diagram Y (π) of a partition π describing a joining scheme for a set of searches, has been obtained from some other Y (ρ) by merging some searches among them, i.e.,
then π ≻ ρ.
2.2. Collective Quantum Search: Complexity
For the corresponding search complexities Tπ, Tρ we have the following lemma.
Lemma 3. The search complexity function Tπ(N1, …, Nn), for a given joining scheme of n searches with dimensions N1, …, Nn, described by partition π, is a Schur concave function, for which it is valid that for any two weakly majorized partitions πw≻ρ of n, the corresponding complexities are anti-isotonic, i.e., Tπ ≤ Tρ.
For simplicity’s sake, hereafter and unless otherwise stated we consider that a single search algorithm has only one marked element, i,e., k = 1. Symbolism:
We state the following lemma.
Lemma 4. Let l searches with database Hilbert space dimensions {N1, …, Nl}, arranged in a Young tableau either as an l -box row, in case of merging, or as an l-box column, in case of concatenation. Denoting the corresponding complexities as and respectively, it is valid that.
Having introduced themain concepts andmathematical tools of collective quantumsearch we proceed to state and show the main result.
Consider the ratio of the extreme values of complexities Tconc/Tmerg, “all concatenated” over “all merged”. The sequence
of dimensions, can be of two distinct kinds : (i)
an unbounded sequence, e.g., Ni’s are consecutive terms of sequence 2i (a natural choice for database sizes), in this case we show that
; if the sequence
is bounded (e.g.,
,where
is bounded), then the ratio
, i.e., it is asymptotically linear in n, the number of databases (for “Big Theta” notation c.f. [12]). Next lemma and proposition provides an estimation for the search complexity for arbitrary database dimensions.
Lemma 5. Ifand, are the continuous analogues (continuous functions) for complexities Tconc, Tmerg, then, i) ii).
Proposition 1. For arbitrary positive integers (database sizes) Ni, i = 1, 2, …, n it holds that
Moreover, if Ni are:
- consecutive terms of the unbounded sequence with Ni = 2i, then.
- terms of a bounded sequence of positive integers with, , then :
Remark 1.
- If, for all i = 1, …, n, and is an increasing and bounded above sequence of positive integers, the statement of lemma remains valid.
- Since limn→∞ Nn = 26, database sizes Nn are asymptotically equal to a constant number, and this is true since (R, |·|) is a complete metric space. Observe that the curve in Figure 1 is close to line y = x (i.e., the ratio Tconc/Tmerg is close to n). In the special case of constant sequence {Nj}, for the continuous versions,
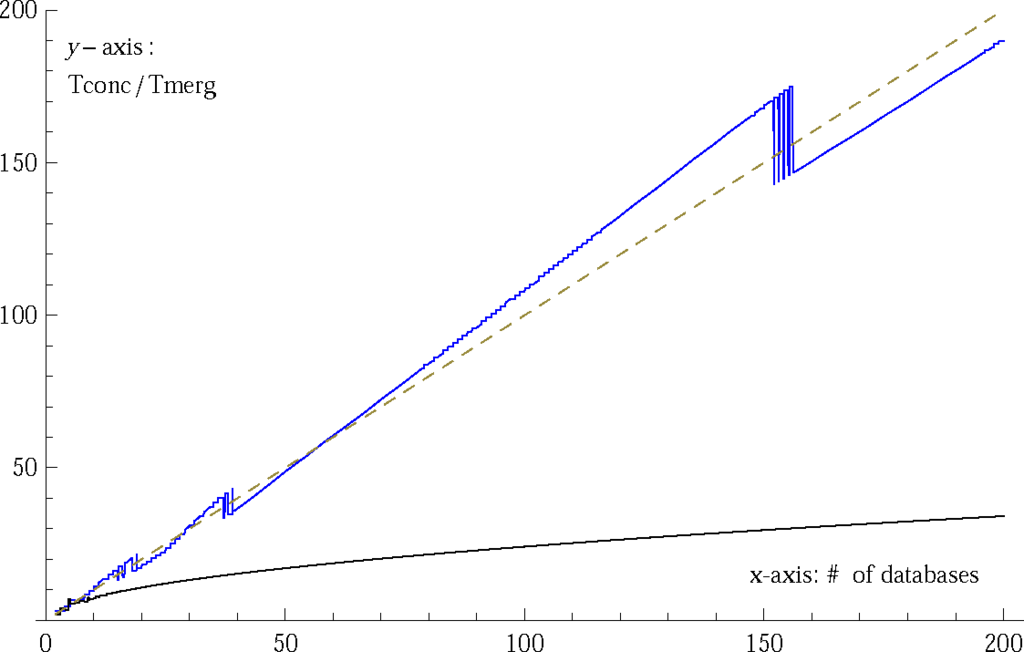 Figure 1. Plots for Tconc/Tmerg, for non decreasing and bounded above sequence of database sizes (blue curve), and an unbounded one (black curve). Here the bounded sequence , ,N1 = 2, ,p = 26, q = N1 = 2, and the unbounded one Nj = 2j, N1 =2 are used. Dashed line: y = x.
Figure 1. Plots for Tconc/Tmerg, for non decreasing and bounded above sequence of database sizes (blue curve), and an unbounded one (black curve). Here the bounded sequence , ,N1 = 2, ,p = 26, q = N1 = 2, and the unbounded one Nj = 2j, N1 =2 are used. Dashed line: y = x. - of the complexities, we have that, for all n.
- Since every sequence in R has a monotone subsequence, it follows that, given a bounded above sequence {Nj}, we can always extract a monotone subsequence necessarily bounded, and therefore convergent. (c.f. Bolzano-Weirstrass theorem, stating that each bounded sequence in Rm has a convergent subsequence). Hence, even if {Nj} is bounded above but not convergent, if using only as database sizes, the ratio Tconc/Tmerg will be close to database number.
- A geometric interpretation of inequalities of the proposition, providing bounds for the complexity, is that asymptotically, the ratio lies in the interior of an angle δ = arctan(λ) − arctan(λ−1) with vertex at point (0, 0) and sides along directions nλ−1 and nλ, symmetric wrt bisector y = x; it lies on the bisector if Ni = N, i.e., all distances are equal, (in this case the search operator is.
A special case of minimum complexity is stated in the following lemma.
Lemma 6. The complexity of an l merging is minimum and independent of l if and only if all involved database dimensions are equal.
2.3. Collective Quantum Search: Threshold Cases
Summarizing the study so far by referring to sequences (1n) ≺ π2 ≺ … ≺ πk−1 ≺ (n) and
, we note that: the first sequence concerns the weak ordering of partitions ranging from total concatenation to total merging of n searches. The second one concerns the associated numerical ordering of these schemes via comparison between their corresponding complexities. We seek to clarify which are the generic threshold cases in the sequences according to some criteria, i.e., the cases in which merging gives no computational advantage in search, due to some circumstantial reasons to be determined. Two such criteria are, the conjugate partition criterion (CPC), and the threshold partition criterion (TPC). In case of CPC the ∗ conjugation for partitions is used to single out as threshold cases the self-conjugate partitions π = π∗ for which Tπ = Tπ∗, [13], under some specified database dimensions. In case of TPC the threshold cases are the so called threshold partition π, which hold a balanced number of boxes (searches) in the upper and lower parts of its Young diagram.
2.3.1. Conjugate Partition Criterion
The complexity of any joining scheme is determined both by the partition shaping its Young diagram and by filling of partition’s boxes by the respective Hilbert space dimensions Ni of quantum databases. A simplification is the standard tableau and particularly the physically motivated choice Ni = 2i. Consider n jointed searches interpolating between full concatenation with partition (1n) and full merging with partition (n). Consider the conjugation of partition π → π∗, which produces partition π∗ by turning rows into column and vice versa and then assign dimensions Nij to each box (search), i.e., (πi, j) → Nij, and seeks values for Nij, so that the ensuing complexities are equal, i.e., Tπ = Tπ∗. This equality is achieved by any intermediate joining scheme (1n) ≺ π ≺ (n), which is self conjugate, i.e., π = π∗. E.g. in π ⊢ 6, partition π = (3, 2, 1) is self-conjugate and the next choice of dimensions gives equal complexity
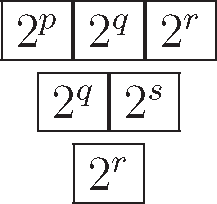
The indicated filling with dimensions p, q, r, s fulfils condition, i.e., T(3,2,1) = T(3,2,1)∗.
2.3.2. Threshold Partition Criterion
Proceeding from full concatenation to full merging of n searches by moving up one box at a time (merging one more search), creates diagrams that majorize all preceding ones, as explained. Explicitly, let of division of a Y (π) into two disjoint pieces, Yu(π) with boxes lying on and to the right of the diagonal, and Yd(π) be the rest piece, i.e., Y(π) = Yu(π)∪Yd(π). E.g. for partition π = (6, 5, 3, 3, 2, 2, 1) the diagrams Y (π), Yu(π) and Yd(π) are
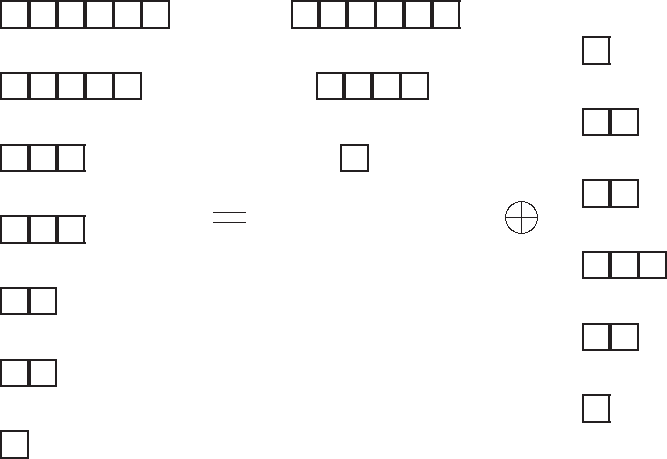
Let next yu(π) be a partition whose parts are the lengths of the rows of the shifted shape Yu(π), and yd(π) be the partition whose parts are the lengths of the columns of Yd(π). If n is even and π ⊢ n, then partition π is called graphic partition iff y (π)w≺yd(π) and it is called threshold partition πth iff yu(πth) = yd(πth) [13]. In the case of threshold partition it follows that Tyu(π) = Tyd(π) and that half of the number of merging responsible for crossing the diagonal have already happened (i.e.,
). This threshold relation landmarks the midway situation before the onset of total merging. For the example above the pairs yu(π) = (6, 4, 1), yd(π) = (6, 4, 1), and yu(π) = (7, 3, 1), yd(π) = (6, 3, 2) satisfy the TPC.
2.4. Oracle Algebra for Collective Quantum Search
Let database Hilbert spaces
,
,
, where
with N1 = N2 = N3 = 4, and let the marked items be the first, the third, and the second elements in
,
,
, respectively. To the partitions (111), (21), (3), of 3, correspond the joining (i) a 3−merging in database
, (ii) a 2-merging in
, a single in
, and concatenation between them, and finally (iii) concatenation of searches in
,
,
. Using notation
and
, a = 1, 2, 3, 0 we have:
- 3-merging in ;The marked items are |1⟩, |7⟩, |10⟩, so , ,and the 12-dim representation of oracle Ealgebra generators are
- 2-merging in , single search in , and concatenation between them; The marked items are |1⟩, |7⟩ in , and |2⟩ in , so , , , . Since e.g., , the generators decompose
- Single searches in , and and concatenation between them;The marked items are |1⟩, ∈ ,|3⟩ ∈ , and |2⟩ ∈ and |2⟩ ∈. E.g. for , , , etc, so for a = 1, 2, 3, 0, the following decomposition is obtained,
Having the oracle algebra matrix generators we compute the unitary search operators for the three corresponding partitions,
where
with k = 1. By means of a similar search unitary, the collective quantum search complexity measures can be computed.
2.4.1. Generalized Azimuthal Symmetry
Let the partition τ = (N1, N2, ⋯, Nl) of N of length l = l(τ), and let the one parameter subgroup
, generated by πa(Σ3) ∈ End(Ha). Let the group G = U(N) and the subgroup
. Consider a concatenation of l searches for a given partition τ ⊢ N, with search operator
and search step implemented by the transformation
. Let further the unitary operator
,
then the transformation
preserves the projection of density matrix ρ along the collective marked vector
, or equivalently preserves the
component of the collective density matrix [9]. This implies the search complexity remains invariant under the action of V3.
This equality of complexities is expressed in terms of the minimization of the projection of time-evolved collective density matrix on the collective marked item, i.e.,
where α = α1 + ⋯ + αr, which is a generalization of an analogues formula for l = 1, describing the azimuthal symmetry of single search algorithm [9]. To any partition τ ⊢ N there corresponds a symmetry group Mτ = G/K for the collective quantum search.
3. Proofs, Examples, and Discussion
In this second part of the paper we have put together a number of items:
- “Collective quantum search: Merging and Concatenation”, with proofs of lemmas and numerical examples; in the following section.
- “Collective quantum search: Joining Schemes and Young diagrams” we have placed the proof of the main proposition and of the auxiliary lemmas, together with numerical examples that demonstrate the workings of collective quantum search; in the final section.
- “Oracle algebra and representations” we introduce the mathematical details of the oracle algebra and some examples from its matrix representations.
3.1. Collective Quantum Search
3.1.1. Merging and Concatenation
Proof. (Lemma 1) The target vector decomposes in
. Let the initial vectors |xconc⟩, |sconc⟩ and the corresponding projection operators |xconc⟩⟨xconc|, |sconc⟩ ⟨sconc|. Then
Similarly
and
So the search operator by means of the previous decomposition splits into a direct sum, i.e.
Similarly, for an l-concatenation it is valid that
□
Symmetries of Uconc and Umerg. For concatenation, the search operator is determined up to a V1 ⊕ V2 unitary, i.e.
Note that V(N1) ⊕ V(N2) is the diagonal subgroup of group V(N1 + N2). By induction on l, a l-concatenation algorithm, has
(Nl)-symmetry, which is the diagonal subgroup of U(Nmerg).
Grover [2] showed that for a single search algorithm with one target vector, the unitary search operator UG = −JsJx can be replaced by a more general operator which is also unitary and it can be in one of the two following equivalent forms
with V ∈ U(N). These symmetries survive in the case of joined searches as follows. For merged algorithms the unitary symmetry is U(Nmerg), i.e.,
3.1.2. Joining Schemes and Young diagrams
Partitions are specified by lower case Greek letters. If λ is a partition of a non negative integer k, we write λ ⊢ k and call k the weight of the partition, and λ = (λ1, …, λk) is a sequence of non negative integers λi for i = 1, 2, …, k, such that λ1 ≥ λ2 ≥ … ≥ λ ≥ 0 with
. The non zero λi are called the parts of λ and their number l(λ) is the length of λ. In specifying λ, the trailing zeros, that is those λi = 0, are often omitted. By way of illustration, if k = 10, we regard (4, 2, 2, 1, 1, 0, 0, 0, 0, 0) and (4, 2, 2, 1, 1) as the same partition λ, for which it holds that |λ| = 10 and l(λ) = 5. Each partition λ of weight |λ| = k, and length l(λ) defines a (Ferrers) Young diagram Y (λ) consisting of |λ| boxes arranged in l(λ) left-adjusted rows of lengths from top to bottom λ1, …, λl(λ), while zeros in λ do not appear in Y (λ) (in the English convention). The notation follows in large part that of [11].
The notion of number partition is associated to the joining of quantum searches as follows: given a number of search algorithms m with database dimensions N1, N2, …, Nm, we can join them either by merging or by concatenating in various ways therefore number m is partitioned as λ ⊢ m, where every part λi of λ denotes the number of algorithms joined in a similar way, i.e., either by merging or by concatenation. Thus every possible joining scheme corresponds to a Ferrers diagram and vice versa, i.e., π → Tπ, ρ → Tρ, we find by way of example that Tπ ≤ Tρ.
The latter implies that the sequence of majorized partitions is mapped to the multi-set of complexities, i.e., the example of partitions of 6 worked out below yields
The multi-set of complexities {3, 4, 6, 6, 7, 9, 9, 10, 12, 14, 17} form a piecewise ordered set where the numerical ordering is anti-isotonic wrt the majorization order i.e., in general π ≻ ρ corresponds to Tπ ≤ Tρ. See Figure 2 below.
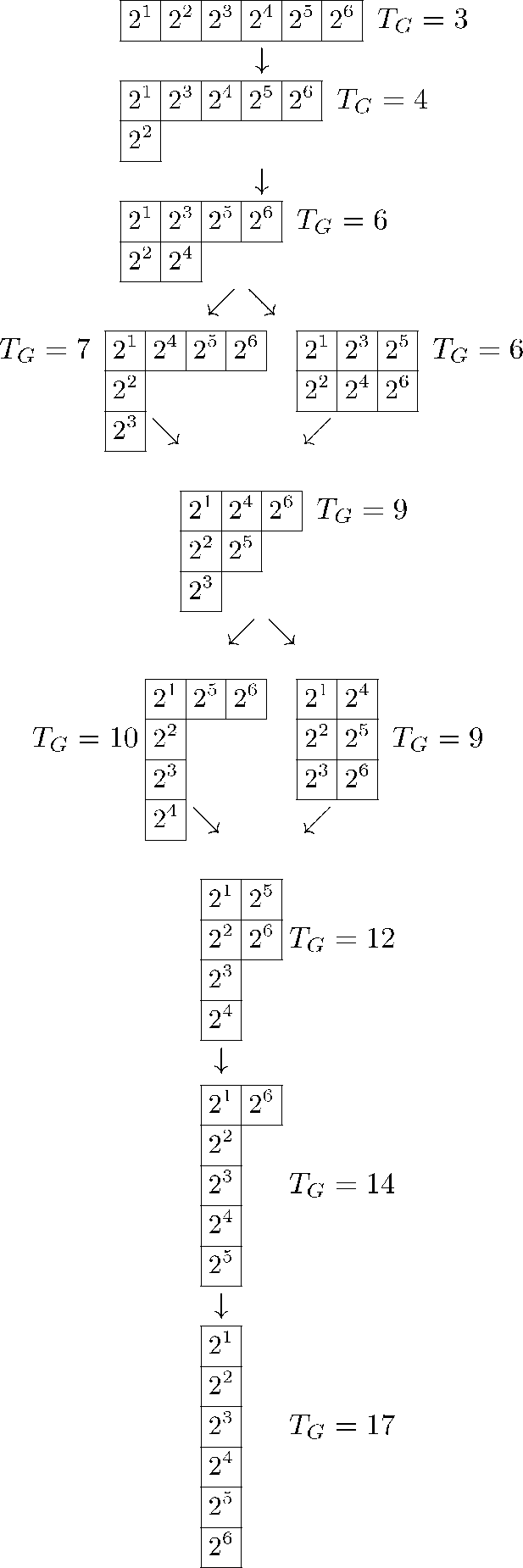
Figure 2.
Young tableaux for m = 6 and the corresponding complexities TG.
3.1.3. Complexity
Proof. (Lemma 3) Let an integer partition π = (π1, …, πj, …, πl(π)) ⊢ n, and the multi-variable functions
, µ = 1, 2, …, l(π), where
with x = (x1, …, xn), and πi the part i of partition π, which enumerates the number of databases involved in a merging scheme. Each of these functions ϕµ is a multi-variable Schur-concave function: indeed since
is Schur-concave function and also x → ⌊ϕ(x)⌋ is a Schur-concave function if ϕ(x) is one (Chapter 3 in [10]), we conclude that ϕµ as well as their linear combination is a Schur-concave function.
The linear combination of ϕµ’s functions is also a Schur-concave function, and this in particular is valid for the search complexity Tπ associated with a partition π, i.e., π → Tπ, or explicitly
is Schur-concave.
So, if π, ρ ⊢ t s.t. π ≻ ρ, then Tπ(N) ≤ Tρ(N), where N = (N1, …, Nt) □
Diagrammatically
Example 1. For n = 16 and the partition π = (6, 4, 4, 2), there are four functions of variables x = (x1, …, x16),
each one of them and their linear combination is a Schur-concave function.
Proof. (Lemma 4) Applying Jensen inequality [14] for the convex function
yields
which implies
In the relation above the equality is reached iff
, where {x} denotes the fractional part of the real number x. Notice that the special case where all the numbers appearing in the integral part are all integers, never occurs due to the involvement of π. □
Proof. (Lemma 6) Let N1, …, Nl be the sizes of databases, then the complexity equals
Due to AM-GM inequality, we take that
The equality holds iff N1 = … = Nl ≡ N, and therefore the minimum is
Remark 2.
- For comparison reasons we find that the complexity of l-concatenation algorithm issince. Moreover, if N1 = … = Nl ≡ N, then
- The total tableau complexity for a joining scheme described by its corresponding Young diagram λ is computed as follows: let a Young diagram λ = (i1, i2, …, ir) then the total search algorithm consists of r groups of concatenated sub-algorithms where each group contains i1, i2, …, ir merged algorithms. Via previous lemma and remark, the tableau complexity equals, where i0 = 0 and i1 +⋯+ ir = k. If all databases are of equal size N, then for any diagram λ the tableau complexity equals.
3.1.4. Main Proposition
Next, we consider the ratio of the extreme values of complexities Tconc/Tmerg (“all concatenated” over “all merged”), and regarding the sequence of the dimensions
, two cases are arising for its asymptotic behaviour. Moreover, for arbitrary positive integers (database sizes) Ni, i = 1, 2, …, n we prove that for the continuous analogues (continuous functions) for the complexities Tconc, Tmerg, it holds that
.
In more details, if
is an unbounded sequence, specifically Ni’s are consecutive terms of the geometric sequence 2i (which is the most natural and reasonable choice for database sizes), we conclude that
. Otherwise, namely if the sequence
is bounded (e.g.,
, where
is bounded), it results that the ratio Tconc/Tmerg is asymptotically linear with respect to the number n of the databases. This fact leads to an interesting observation: although the qualitative difference between a bounded and an unbounded sequence of database sizes is essential (notice that Ni = 2i increases exponentially fast), however, the quantitative change that entails to the ratio of complexities, is only quadratic (quadratic reduction) with respect to the database population.
Proof. (Lemma 5) Straightforward calculations. □
Proposition 2. For arbitrary positive integers (database sizes) Ni, i = 1, 2, …, n it holds that
Moreover, if Ni are:
- consecutive terms of the unbounded sequence with Ni = 2i, then
- terms of a bounded sequence of positive integers with, , , i.e., nλ−1Tmerg ≤ Tconc ≤ nλTmerg, with.
Proof. Applying the Cauchy-Schwarz inequality we obtain that:
. Moreover
, so
.
- Carrying out trivial calculations, we take :In this first case, we have that Ni = 2i, soand . Therefore:The RHS of the above asymptotically equals to , so , i.e. and because due to previous Lemma andasymptotically, it holds that
- Since , , then for all i = 1, 2, …, n, is valid that 2 ≤ q ≤ Ni ≤ p, soMoreover . Therefore and . □
3.1.5. Geometry of Complexity Reduction
All concave functions fulfil a very intuitive geometric condition with their graph, namely that the center of mass of a set of points lying on the graph is lying not above the graph itself. Quantifying this geometric property leads to the Jensen inequality [14], which in fact is the reason for achieving complexity reduction in various forms of joining schemes. This is demonstrated below by means of a numerical example.
Example 2. Numerical example (see Figure 3). Let the Young diagram of shape (5, 4, 1) and let the following Young tableau (strictly increasing row and column-wise, no repetitions)
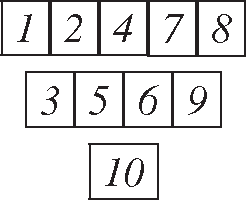 where Ni’s are database sizes : N1 = 23, N2 = 24, N3 = 25, N4 = 26, N5 = 27, N6 = 28, N7 = 29, N8 =210, N9 = 211, N10 = 212
where Ni’s are database sizes : N1 = 23, N2 = 24, N3 = 25, N4 = 26, N5 = 27, N6 = 28, N7 = 29, N8 =210, N9 = 211, N10 = 212
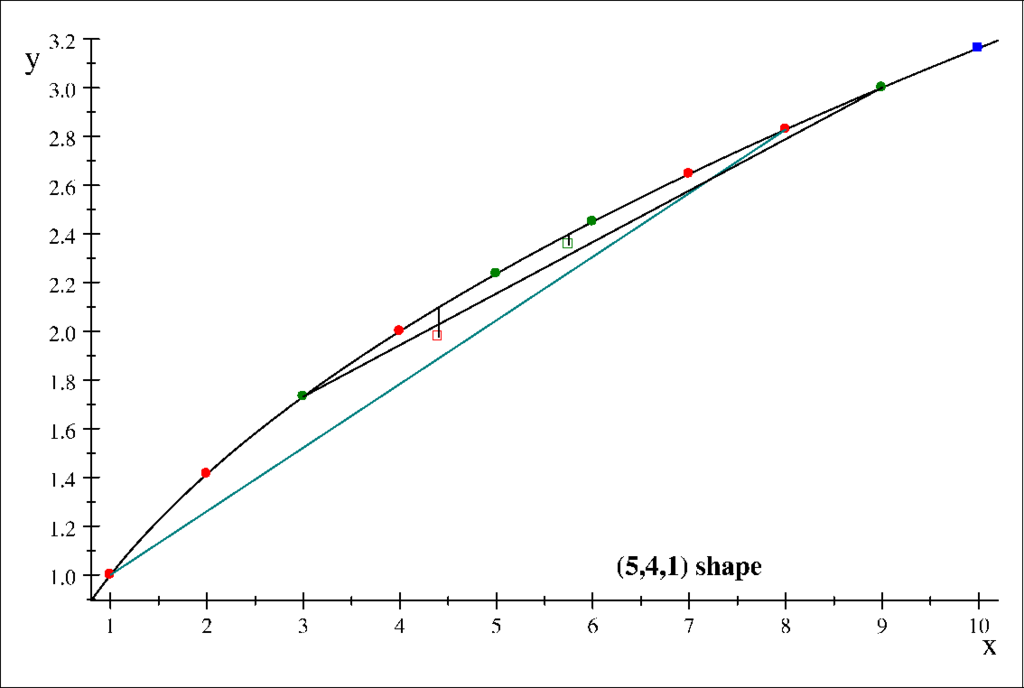
Figure 3.
Jensen’s inequality for the numerical example. Round dots represent points lying on the graph, and square dots represent center of mass points.
Row 1
Referring to the graph of the complexity function we mark the 5 points and the center of mass vector c1, with coordinates and its crossing point with the graph of.
Row 2
In the graph of complexity function mark the 4 points the center of mass vector c2 = (616.0, 19.556) and its crossing point with the graph.
Row 3
In the graph of complexity function mark the 1 point v3 = c3 = q3 = (212, 26).
Equal Complexity Tableaux and Shapes
Motivated by the geometric explanation of the complexity measure for various schemes of joining quantum search algorithms as has been studied in previous section, we proceed to address the problem of determining shapes and tableaux describing ways of joining searches. We study joining of database spaces of equal dimension N. The complexity is differentiated from one scheme to the other due to the difference of the associated Young diagram shapes, so we call it shape complexity.
Joined quantum searches, all of which have equal Hilbert space dimension N and share the same shape complexity, are displayed as a pattern of bold typed integer partitions from 3 to 7 within the Young lattice. The pattern of equal complexities is independent from N.
Figure 4 displays the contour of equal complexity families of joined quantum algorithms having unequal database sizes. A constant complexity difference (vertical segments) is chosen between tableau complexity (lower broken line) describing concatenation of groups of merged quantum searches and its upper bound (upper full line) describing the same group jointed by concatenation only.
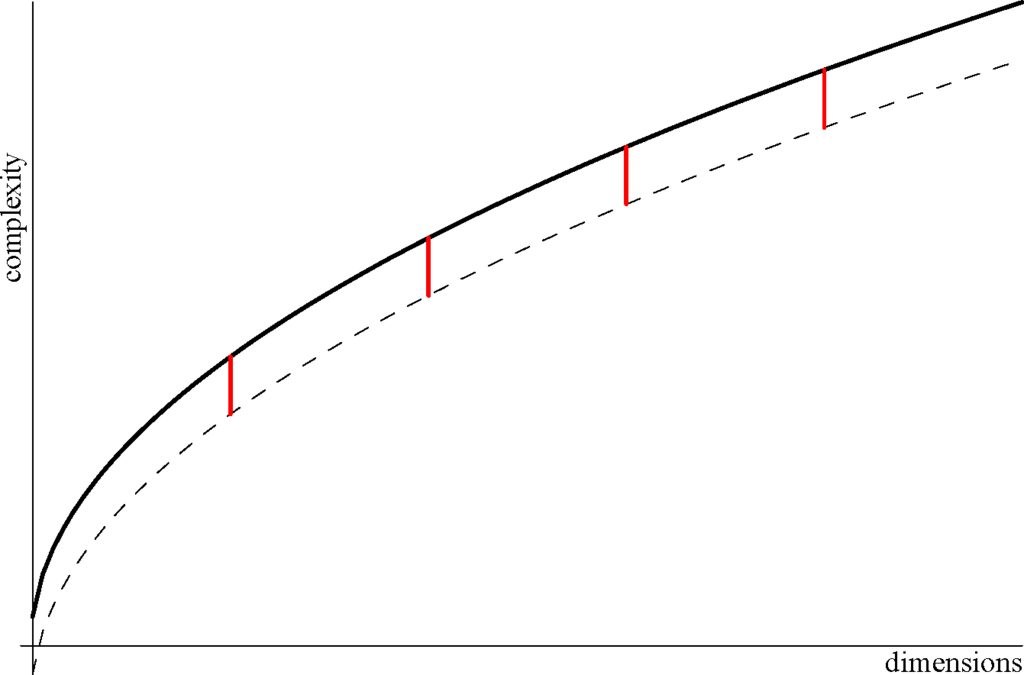
Figure 4.
Display of the contour of equal complexity families of joined quantum algorithms. 4. Oracle Algebra and Representations
Definition 2 Let the set Δ = {1, 2, …N}, a subset I ⊂ Δ, and the oracle function f, be the characteristic function of I with k elements, defined as f(i) = 1, for i ∈ I, and f(i) = 0, for i ∉ I. We define as the matrix oracle algebra Af with respect to the characteristic function f of I ⊂ Δ, the set Af = {A : A = αΣ0(f) + βΣ1(f) + γΣ2(f) + δΣ3(f)} where α, β, γ, δ ∈ R are arbitrary real [9,15].
Let also (a) the Hilbert space l2(D), the vector
and its orthogonal vector
with
.
(b) the Hilbert space
, the matrix
, 1 ≤ i ≤ s, 1 ≤ j ≤ t, and the N dimensional matrix representation πN : Af → Lin(HN).
Next, we introduce the following Σ0, Σ1, Σ2, Σ3, as the generators of Af :
For the oracle function f(i) = 1, 1 ≤ i ≤ k < N, and zero otherwise, the representation above reads
and therefore, for an arbitrary element A ∈ Af, it holds that
4.1. Examples
Show cases: Here we show explicitly the vectors and matrices involved in the possible scenarios of joining via merging and/or concatenation for the specific example of three 4-dimensional quantum searches. Let databases
,
,
, with N1 = N2 = N3 = 4, and let the market items be the first, the third, and the second elements in
,
,
respectively, i.e., |1⟩, |7⟩, |10⟩ in
. The three partitions of 3 are 1 + 1 + 1 = 2 + 1 = 3, we have three possible joining, i.e., (i) a 3−merging in database
, (ii) a 2-merging in
, a single in
, and a concatenation, and finally (iii) three single searches in
,
,
. We use the symbol • to denote non zero matrix elements, and · for zeros.
4.1.1. 3-Merging
The marked items are |1⟩, |7⟩, |10⟩, so
,
, Therefore,
Therefore, the generators of Af are:
4.1.2. 2-Merging , single , and Concatenation
The marked items are |1⟩, |7⟩ in
, and |2⟩ in
, so
and
Single
In this case, we can compute the generators of Af, e.g.,
as follows.
Since
and
we have that:
Similarly,
for all a = 0,1,2,3.
4.1.3. Single Single, and Single in Concatenation
The marked items are |1⟩ in
|3⟩ in
and |2⟩
and it holds that
4.1.4. Single e.g., for
The marked item is the vector |1⟩, therefore
In order to compute the generators
a = 0, 1, 2, 3, we proceed in an analogous manner to the previous case. For simplicity, we also introduce the following shorthand notation, to denote direct sums of vectors
in databases
respectively, as well as direct sums for other operators and the corresponding ∑’s.
Since
and
, for e.g.,
we obtain that:
5. Discussion
An important follow up of this work concerns the fact that the collective quantum search can be cast in the language of cooperative game theory, and so wider problems of search complexity reduction can be addressed. In fact, cooperative game theory is an area where multi-agent entities choose to collaborate in various schemes in order to take advantage from the collaboration in lowering some computational load which would enable them to achieve a desirable shared objective, see e.g., [16], for a wealth of principles and examples. For this connection, particularly useful would be the special joining schemes determined by the partitions π = π∗, πth and πmax, as tools for studying coalition formation of merging teams of searches aiming to trade collectivity for less search complexity. This appears to be a favorite context for implementing and applying the idea of merging. In particular quantum search by merging as outlined here could also be applied in applications where quantum simulation of quantum searching is carried out by multi-particle Hamiltonian models (see e.g., [17] and references therein). These prospects will be taken up elsewhere.
Acknowledgments
One of us (Ch.K) acknowledges a PhD Scholarship from the Technical University of Crete.
PACS classifications: 03.67.Lx
Author Contributions
Both authors contributed to conceive, obtain and interpret the results, and make the preparation of this work. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Grover, L.K. Quantum Mechanics Helps in Searching for Needle in a Haystack. Phys. Rev. Lett. 1997, 79, 325. [Google Scholar]
- Grover, L.K. Quantum Computers Can Search Rapidly by Using Almost any Transformation. Phys. Rev. Lett. 1998, 80, 4329. [Google Scholar]
- Brassard, G. Searching a Quantum Phone Book. Science 1997, 275, 627–628. [Google Scholar]
- Rossi, M.; Bruss, D.; Macchiavello, C. Scale Invariance of Entanglement Dynamics in Grover’s Quantum Search Algorithm. Phys. Rev. A 2013, 87, 022331. [Google Scholar]
- Reitzner, D.; Ziman, M. Two Notes on Grover’s Search: Programming and Discriminating 2014, arXiv, 1406.6391.
- Vrana, P.; Reeb, D.; Reitzner, D.; Wolf, M.M. Fault-Ignorant Quantum Search. New J. Phys. 2014, 16, 073033. [Google Scholar]
- Yoder, T.J.; Low, G.H.; Chuang, I.L. Fixed-Point Quantum Search with an Optimal Number of Queries. Phys. Rev. Lett. 2014, 113, 210501. [Google Scholar]
- Portugal, R. Quantum Walks and Search Algorithms; Springer: Berlin, Germany, 2013. [Google Scholar]
- Ellinas, D.; Konstandakis, C. Parametric Quantum Search Algorithm by CP Maps: Algebraic, Geometric and Complexity Aspects. J. Phys. A 2013, 46, 415303. [Google Scholar]
- Marshall, A.W.; Olkin, I. Inequalities: Theory of Majorization and Its Applications; Academic Press: Waltham, MA, USA, 1975. [Google Scholar]
- Macdonald, I.G. Symmetric functions and Hall polynomials, 2nd ed; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Knuth, D.E. Big Omicron and Big Omega and Big Theta. ACM Sigact News 1976, 8, 18–24. [Google Scholar]
- Merris, R.; Roby, T. The Lattice of Threshold Graphs. J. Inequal. Pure Appl. Math. 2005, 6, 2. [Google Scholar]
- Needham, T. A Visual Explanation of Jensen’s Inequality. Am. Math. Mon. 1993, 100, 768–771. [Google Scholar]
- Ellinas, D.; Konstandakis, C. Matrix Algebra for Quantum Search Algorithm: Non Unitary Symmetries and Entanglement, Proceedings of the Tenth International Conference on Quantum Communication, Measurement and Computation, Queensland, Australia, 19–23 July 2010; pp. 73–76. [CrossRef]
- Chalkiadakis, G.; Elkind, E.; Wooldridge, M. Computational Aspects of Cooperative Game Theory. Synth. Lectures Artif. Intell. Mach. Learn. 2011, 5, 1–168. [Google Scholar]
- Ellinas, D.; Konstandakis, C. Parametric Quantum Search Algorithm as Quantum Walk: A Quantum Simulation, 2015; submitted.
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).