Abstract
This work aims at proposing an affordable, non-wearable system to detect falls of people in need of care. The proposal uses artificial vision based on deep learning techniques implemented on a Raspberry Pi4 4GB RAM with a High-Definition IR-CUT camera. The CNN architecture classifies detected people into five classes: fallen, crouching, sitting, standing, and lying down. When a fall is detected, the system sends an alert notification to mobile devices through the Telegram instant messaging platform. The system was evaluated considering real daily indoor activities under different conditions: outfit, lightning, and distance from camera. Results show a good trade-off between performance and cost of the system. Obtained performance metrics are: precision of , specificity of , accuracy of , and sensitivity of . Regarding privacy concerns, even though this system uses a camera, the video is not recorded or monitored by anyone, and pictures are only sent in case of fall detection. This work can contribute to reducing the fatal consequences of falls in people in need of care by providing them with prompt attention. Such a low-cost solution would be desirable, particularly in developing countries with limited or no medical alert systems and few resources.
1. Introduction
According to the World Health Organization, falls constitute the second leading cause of unintentional injury death worldwide, after road traffic injuries. Annually, an estimated 684,000 people die due to accidental falls, often resulting from unintentional tripping or slipping. Notably, one in three adults over 65 experiences a fall each year [,]. Globally, the prevalence of falls among people over 60 is 26.5%, with Oceania having the highest rate by continent with 34.4%, followed by America (27.9%), Asia (25.8%), Africa (25.4%), and Europe (23.4%) [].
Although falls can affect everyone, the severity of the consequences is influenced by factors such as age, health status, and the response time to assist the emergency. For elderly individuals, falls often result in severe consequences such as bruises, hip fractures, and traumatic brain injuries. It is well-documented that these incidents significantly diminish the quality of life for this age group [,]. This situation is aggravated because they do not receive prompt attention due to a lack of warning since they are often alone. Consequently, addressing elderly falls is a public concern that requires support from families and healthcare systems. Although medical alert systems with fall detection are available for a monthly fee in developed countries, accessing these services in developing countries remains a major challenge. This underscores the need for a cost-effective solution that can monitor falls and automatically notify family members, ensuring timely medical attention.
In general, two main techniques are used for fall detection: machine learning and sensor-based approaches []. Several studies on fall detection are based on wearable technology to monitor and alert from falls []. Recently, these systems have integrated artificial intelligence algorithms, encompassing both machine learning (ML) and deep learning (DL) [,]. Some implementations employ cameras to facilitate artificial vision algorithms, while others incorporate sensors like accelerometers, gyroscopes, and air pressure sensors for fall detection [,,]. Other works deal with portable devices with remote monitoring systems [,]. However, the effectiveness of these wearable devices relies heavily on their proper use, as they are typically worn as clothing or accessories []. Consequently, the use of wearable devices may not be the most practical option for seniors who often forget or resist using additional accessories. Additionally, a relevant drawback is their reliance on batteries for operation. Nevertheless, compared to devices that require the use of cameras, wearable devices offer a more discreet monitoring solution, which can be perceived as less intrusive.
On the other hand, non-wearable systems are designed to be installed in the person’s environment []. These systems typically utilize artificial vision technologies, employing cameras, infrared sensors, and laser range scanners, among others [,]. Artificial vision systems capture and process images to determine if a fall has occurred. Non-wearable systems offer some advantages, particularly for the elderly, as they spend much of their time in a fixed location. Also, continuous monitoring identifies and mitigates potential risks in people’s environments. Moreover, its functionality does not depend on the user’s activities, and its cost is higher compared to wearable devices.
This paper introduces a fall detection system based on artificial intelligence implemented on a low-cost single board computer (SBC). This system was primarily designed for indoor nursing homes. The main contribution of this work is the implementation of a cost-effective and easy to install non-wearable fall detection system which send an alert notification via the Telegram application when a fall is detected. Early notifications of such events reduce the risk of severe injuries. Tests were conducted with persons going about daily activities, achieving a good trade-off between cost and performance. The remainder of this article is organized as follows: Section 2 presents related work, Section 3 details the materials and methods, Section 4 presents the results of different tests, Section 5 discusses the obtained results, and finally, Section 6 concludes this article.
2. Related Work
This section presents a summary of relevant works regarding non-wearable fall detection systems. The study conducted by Francy Shu and Jeff Shu [] presented a sophisticated system capable of detecting falls, trips, slips, blackouts, and various types of falls. This system is based on a conventional Android TV Box (Manufactered by Tanix in Shenzhen, China) with 8 IP cameras and an eight-core S912 cortex-A53 CPU (By Amlogic, Shnaghai, China) for processing. This work uses Relevance Vector Machine (RVM) algorithms and AI algorithms offered by SpeedyAI Inc. (Walnut, CA, USA), achieving an 89% retention accuracy, and a training accuracy of 94%.
Ref. [] presented a Convolutional Neural Network (CNN)-based fall detection system that addresses issues such as precise recognition of small and obscured body parts. It is developed with a lightweight feature extraction model, global and local attention modules, and channel-based feature augmentation. It focuses on medical, therapeutic, and clinical contexts.
The authors of [] used WiFi Channel State Information (CSI) for fall detection using deep learning techniques. The construction of a comprehensive dataset for fall detection using CSI data are detailed. The paper provides valuable insights into the challenges and potential solutions for WiFi CSI-based fall detection systems. Also, the authors emphasize the need for further research to improve the applicability of fall detection systems in real-world scenarios.
The work presented in [] introduced a monitoring system for detecting falls in the elderly, using recurrent neural networks and low-resolution thermal sensors. While prioritizing privacy and non-intrusiveness, the system achieved a noteworthy 93% accuracy rate in identifying falls. However, certain limitations regarding ambient temperature variations and the presence of objects were identified, indicating the need for further research and enhancements to facilitate practical applications.
The article presented in [] discusses a fall detection method using an IR-UWB radar sensor combined with a CNN algorithm to address the challenges of privacy preservation, user convenience, and detection performance. The proposed framework collects motion data using a non-contact IR-UWB radar, which is then preprocessed into 2D images suitable for CNN input. The CNN algorithm automatically extracts features from these images to classify behaviors as either “Fall” or “Activities of Daily Living (ADL)”. The study demonstrates the method effectiveness through experiments involving various motions, yielding 96.65% accuracy in distinguishing falls from normal activities.
In reference [], the authors presented a solution for enhancing safety and independence of elderly individuals in smart home environments. The system uses background subtraction, Kalman filtering, and optical flow to detect falls effectively. Integrated into smart homes, it offers a seamless way to increase both comfort and security. The machine learning aspect processes the inputs from these algorithms, ensuring high detection accuracy. Through testing involving over 50 different fall scenarios, the system achieved a detection rate of over 96%, demonstrating its effectiveness and potential for real-world use.
The work presented in [] introduces a camera-based fall detection system. This system uses a single top-view depth camera, the Microsoft Kinect, to monitor falls while maintaining the user’s privacy. The detection algorithm works by analyzing depth frames of the human body and training a classifier using a binary support vector machine (SVM) learning algorithm. The application runs on a computer based on Microsoft Windows. Despite its high accuracy rate of 98.6%, this system is not affordable for everyone.
A novel fall detection system leveraging multi-stream 3D CNNs to enhance the accuracy and reliability of fall incident detection is presented in []. This vision-based method involves capturing video sequences and using an image fusion technique to preprocess frames into sequences that highlight spatial and temporal differences. These sequences are fed into a four-branch architecture (4S-3DCNN), where each branch processes different fall phases. The model was evaluated using the Le2i fall detection dataset, achieving high-performance metrics. The study demonstrates that the proposed 4S-3DCNN model outperforms several state-of-the-art models, including GoogleNet, SqueezeNet, ResNet18, and DarkNet19, for real-time fall detection in different environments. However, the authors use a computer with high computing requirements to run the approach.
In the literature, many works have excellent metrics regarding accuracy and precision. However, the computational cost of the proposed works is high, directly impacting the system’ s final price. Many systems rely on non-free software, making implementation and maintenance expensive. Thus, a large number of elderly people cannot pay for them. In addition, other systems have technical deficiencies coming from false alerts generated by the presence of objects that may confuse detection. Additionally, lighting issues, environmental variations, recognition of head movements, and even clothing color can contribute to inaccuracies.
3. Materials and Methods
This work proposes a non-wearable system for human fall detection. The proposal uses artificial vision to detect falls. Deep learning techniques based on CNN have been implemented for this purpose. The system effectiveness depends largely on the training performed on it. Considering that the proposal is executed on a low-cost SBC, learning transfer techniques were required to optimize the system’s training. The proposal is based on experimental research, which includes:
- (a)
- Selection of a lightweight pre-trained model to be easily ported to the embedded system;
- (b)
- Data preparation which involves creating or curating datasets to be used for training and validating the deep learning model;
- (c)
- Adjustment of the model parameters to find an adequate response for the problem;
- (d)
- Model training on large and diverse datasets and tuning hyperparameters;
- (e)
- System integration on the SBC platform;
- (f)
- Performance evaluation by means of metrics such as accuracy, sensitivity, precision, specificity, as well as ROC AUC scores for defining the threshold value.
The methodology used for the implementation of the proposal is divided into two main stages:
- The training stage;
- The processing stage.
A computer provided with a graphics processing unit (GPU) is required to perform fast and efficient training during the first stage. Once the pre-trained model is obtained, it is evaluated in real scenario by the processing stage. If the system response is not satisfactory, the neural network training stage must be repeated to improve the accuracy and sensitivity of the system. The methodology is summarized in the block diagram shown in Figure 1.
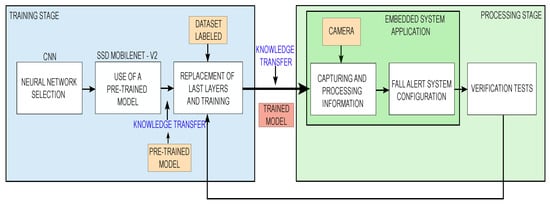
Figure 1.
Methodology.
3.1. Model Selection
CNNs have proven to be very effective in the field of computer vision [,]. Therefore, this work is based on this architecture to extract features and classify image objects. The classification is done based on the probabilistic distribution of the detected object delivered by the network. Subsequently, if the system predicts a fallen person with a probability above a set threshold, a notification will be sent via text message. This proposal classifies detected objects into the following 5 classes:
- Fallen person;
- Crouching person;
- Sitting person;
- Standing person;
- Person lying down.
This work uses the combined model SSD-MobileNet-v2. It consists of two main modules: MobileNet-v2 as a feature extractor and Single Shot Detection (SSD) as an object locator. The MobileNet-v2 module is suitable for its compact size, acceptable accuracy, and prediction speed. MobileNet-v2, compared to MobileNet, introduces two new features: linear bottlenecks and shortcut connection possibility between input/output bottlenecks [].
The MobileNet-v2 is conformed by convolutional blocks, where each block is composed of three stages. The first stage performs a 1 × 1 (pointwise) convolution with the Rectified Linear Unit (ReLU) function as a non-linearity function []. The second and third stages compute a depthwise separable convolution. In the second stage, a depthwise convolution filters the input channel. For that, it splits height × width dimension (h × w) from depth dimension (k), with k being the number of the input channels. The depth of the output depends on the expansion factor (t) given by the number of characteristics extracted by the layer. Finally, a new feature is obtained in the third stage by computing the depthwise convolution (dwise) result with a 1 × 1 convolution. The use of depthwise separable convolution reduces computation and model size []. MovileNet-v2 block bottleneck model is summarized in Table 1.

Table 1.
Stages of the MobileNet-v2 bottleneck residual block [].
The architecture of MobileNet-v2 model is shown in Table 2, where t is the expansion factor, c is the number of output channels, n is the repeating number, and s is the stride. In the proposed architecture, the first layer is a convolution layer with an input of a image, which means an RGB image with dimension of pixels. For the first layer, each input channel corresponds to one color channel (red, green, or blue). It is important to note that the other depthwise convolution layers of the model use 3 × 3 kernels for spatial convolution.
Table 2.
MobileNet-v2 layer details.
The SSD model performs object detection and generates multiple bounding boxes for the defined object classes. In this way, the model can detect multiple objects by applying convolutional filters to default bounding boxes []. To estimate the detection, it evaluates the default boxes with different aspects with feature maps having different scales. For each box, it predicts confidence values for all object categories. Then, each detected object class instance is estimated with a probability value. For the prediction task, convolutional filters are used. The kernel element used is a , where is the number of channels []. The architecture of SSD model is shown in Table 3. The complete SSD MobileNet-v2 model is summarized in Figure 2.
Table 3.
SSD layer details.
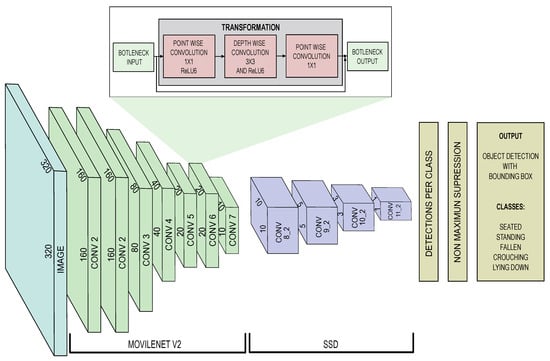
Figure 2.
SSD Mobilenetv2 architecture.
3.2. Pre-Trained Model Selection
The training of the network was performed using the Tensorflow framework. In order to optimize resources, the pre-trained model ssd_mobilenet_v2_fpnlite_320 × 320_coco17_tpu-8 was selected []. This model was trained with the COCO (common objects in context) dataset for the classification of 91 object types, with “person” being one of the super classes []. This pre-training is useful because the model has learned to recognize persons based on a large dataset of more than 2 million images from the COCO dataset.
To recognize the five predefined poses of the person (standing, crouching, sitting, lying down, and falling), the last layers of the model were replaced. Therefore, it was necessary to define and prepare the dataset of images for classification. For this purpose, open-access datasets were used. To improve the sensibility, a combined dataset was generated by by combining the UR Fall Detection dataset and our own dataset. This new combined dataset allows training the network in a more efficient way and obtaining the trained model.
3.3. Dataset Preparation
On the ond hand, the UR Fall Detection dataset, presented in [], consists of 8065 images, divided into 70 image sequences representing both daily activities and falls (30 image sequences). On the other hand, our dataset consists of 19,584 images given a total of 27,649 images. They were captured using a Python application, normalized to a 640 × 480 × 3 dimension, and prepared using the LabelImg, which is an open source annotation tool. This tool allows user to select the region of interest from the image that contains the object and label it with the respective predefined class. The LabelImg then generates a xml file for each image with the corresponding labeled information.
Selecting the appropriate region of interest during dataset preparation is crucial to ensure accurate predictions, especially when distinguishing similar classes, such as falling and lying down. If the region of interest is too close to the person, it may omit useful contextual information, leading to inaccurate predictions. Conversely, including adequate contextual information in the region of interest can enhance the model’ s prediction.
During training and validation processes, it is necessary the original image with it corresponding labelling file (.xml). Prior to train and validate, two binary TFRecords files were generated, one for the training process and the other for the proposal’ s validation. The training set consisted of 80% of the images (22,120), while the remaining 20% corresponded to the validation set (5529).
3.4. Network Training
During the CNN training process, the backpropagation algorithm was used. Through iterative and recursive operations, this method adjusts the weight of the CNN nodes to minimize the gradient of the error function and improve the predictive model capacity. In order to facilitate the learning process and introduce non-linear behaviors to the network, the ReLU and Softmax activation functions were used. ReLU was used to learn complex patterns with a low computational cost, and Softmax or normalized exponential function, to perform the multi-class classification of the objects.
The network’ s training was performed using the Tensorflow framework, and Tensorboard was used as a neural-network analysis tool to visualize the process. This evaluation was performed with Tensorboard on an AMD Rizen 7 laptop (By Hewlett-Packard in Palo Alto, CA, USA), with Radeon Graphics 2.90 GHz and 12 GB of RAM, equipped with an NVIDIA GeForce GTX 1650 Ti GPU (By NVIDIA Corporation, Santa Clara, CA, USA) with 4 GB of dedicated video memory to speed up the training process. The training dataset was divided in batch size of 4 images, then 5530 iterations completes an epoch. For the validation of the model, 20% of the prepared dataset was used. It is important to note that the validation set was build with images that contain different people and objects from those used during the learning process. This can be appreciated in the total loss training and validation curves, both illustrated in Figure 3. The x axis in the curves represents the number of iterations. It can be observed that at fourth epoch, it seems to begin an overfitting; however, after continued training, it disappears and both curves tend to converge. The total loss curves are illustrated for 18 epochs.
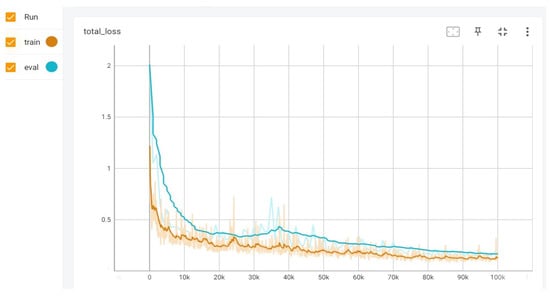
Figure 3.
Total loss curves.
The total loss function considers classification, localization, and regularization losses. For classification, weighted sigmoid focal loss function was used; while for localization, weighted smooth L1 loss was used. Training results showed a total loss function value of 0.069 for epoch 18th and a learning rate of 0.079. These values were considered acceptable for starting the functional tests in real conditions. Once the model was validated, learning was transferred to the target device used for fall detection. The trained model has a weight of 19.8 MB, which guarantees that it can be embedded inside an application executed on a SBC.
3.5. Processing Stage
In this stage, the model was evaluated under real conditions, and results were used to fine-tune the system. The embedded application was executed on a Raspberry Pi4 with 4 GB RAM. The images were captured by an HD mechanical IR-CUT camera. The block diagram of the application is shown in Figure 4. The application was developed in Python programming language, and the OpenCV library was used to acquire and process the image in real time [].
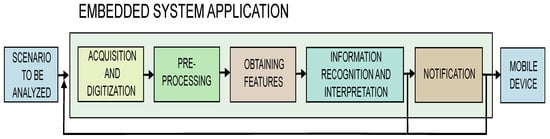
Figure 4.
Embedded application block diagram.
The flowchart of the application is shown in Figure 5. The program initializes the pre-trained model, captures the image, converts it into an input tensor for the network, and then executes the analysis of each frame, applying the neural network model to predict falls. The Mobilenet-v2 layers are used to obtain the features whereas the SSD multi-locator identifies if an object of a given class is present in the image. If the model recognizes objects of one of the five predicted classes in the image, boxes are drawn on the image with probability values. Depending on threshold, the occurrence of the fall is predicted. Lastly, the algorithm sends an alert notification to a mobile device, including a picture of the event. This was performed via the Telegram instant messaging application through a bot, so more than one user can receive the alert. For that, the system requires an Internet connection. Note that the system uses the Minimum Bayes Risk criterion to decide whether to send the alert notification, since the most concerned issue is the detection of a Fallen person. For example, if two classes are predicted at the same time, system prioritizes Fallen Person regardless of whether the other class has a higher probability, since the goal is to reduce the more expensive outcome.
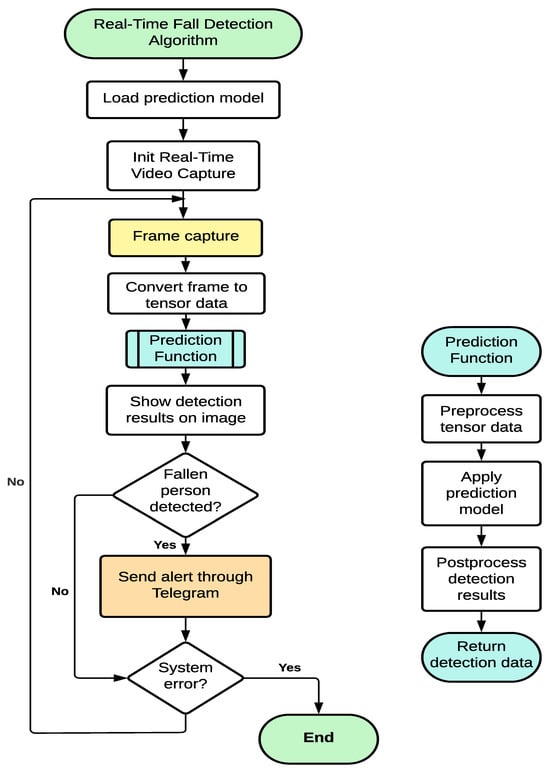
Figure 5.
System flowchart.
3.6. Verification Tests
Verification tests were performed in two stages. The first one consists of a functional test and the second one was conducted in a controlled environment to measure the performance metrics of the system. The functional test was first performed to verify the detection of the five classes of objects detected by the system, as shown in Figure 6. Through the functional tests, it was also checked that the system recognizes more than one object.

Figure 6.
Classes detected: Fallen person (“Persona caída”), Crouching person (“Persona agachada”), Sitting person (“Persona sentada”), Standing person (“Persona parada”), Person lying down (“Persona acostada”).
Furthermore, various poses of fallen persons were tested to analyze the morphological system response. Figure 7 illustrates the response of the fall detection system. The tests were set up with the camera positioned at 1.5 m height.

Figure 7.
Different poses of a “Fallen person”.
In addition, functional tests are useful to verify whether the Labeling process had included adequate contextual information in the region of interest, to distinguish between similar classes such as Person lying down and Fallen person. Prediction results in living room and bedroom are illustrated in Figure 8 and Figure 9. In both figures, the top images are related to labeling examples of our dataset, whereas the bottom images are related to predictions.

Figure 8.
Prediction results in living room considering contextual information.

Figure 9.
Prediction results in bedroom considering contextual information.
During the second stage, for evaluating the system, people activities were divided into ”Fall” and ”Other Activities”. The verification tests were performed considering the confusion matrix. The four possible outcomes are:
- True positive (TP): The person falls and the system predicts a fallen person.
- True negative (TN): The person does other activities and the system predicts other activities.
- False positive (FP): The person does other activities and the system predicts a fallen person.
- False negative (FN): The person falls and the system predicts other activities.
Three different scenarios with controlled environment were studied to obtain system performance metrics. To evaluate the capacity of the system to distinguish falls from other activities, three variables of interest were considered: outfit, light level, and distance to object. Tests take into account three different conditions for each variable. For example, light level values were set considering general indoor activities (gloomy 15 lux, satisfactory 100 lux, and good 250 lux). This was done because the system focuses on nursing homes.
In this experiment, 14 participants aged between 26 and 84 were recruited. Each participant completed the test design shown in Figure 10, which include 27 possible combinations for the three variables of interest. The test design was executed twice: the first one to test fall detection and the second one to test other activities detection. Thus, 54 tests were performed for each participant, resulting in 756 tests. Tests were performed with different scenarios to obtain the overall system analysis.
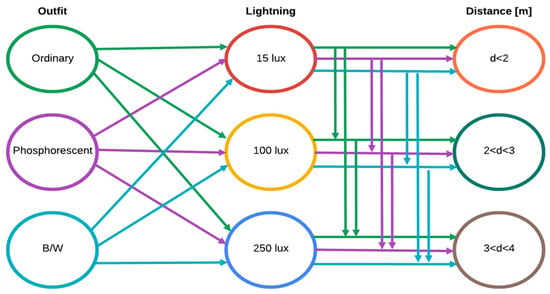
Figure 10.
Test design under different outfit, lightning, and distance conditions.
The performance indicators used for analyzing the results are: accuracy, precision, sensitivity, and specificity, presented in Equations (1)–(4). Accuracy represents the system’s ability to correctly distinguish a fall from other activities. Precision represents the number of fall alerts that are actual falls. Sensitivity indicates how capable the system is to detect an actual fall as a fall. Finally, specificity indicates the capability of the system to detect actual other activities as other activities:
4. Results
This section presents the behavior of the fall detection system depending on the variable of interest. The first parameter under study is the outfit. From the results depicted in Figure 11, it can be seen that the system performs better when individuals are dressed in ordinary or fluorescent outfits, whereas performance decreases when participants are wearing black/white (B/W) clothing. In fact, it was observed that dark clothing affected the detection.
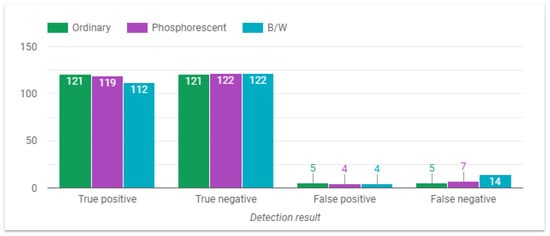
Figure 11.
System performance with different outfits.
The next parameter to be considered is the light level of the environment. From the results shown in Figure 12, it can be observed that the system performs better under higher light levels, whereas fall detection becomes slightly more difficult in gloomy environments. Note that the system is intended to work in bedrooms or living rooms where the light levels range from 100 to 200 lux.
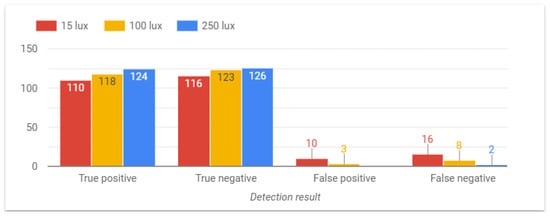
Figure 12.
System performance under different lightning levels.
The last variable to analyze is the distance from the camera to participant, as observed in Figure 13. In this case, the system tends to experience a greater number of failures when the person is distant from the camera, whereas performance increases as the participant gets closer to the camera. False Negatives (FN) considerably increase in distances greater than 3 m. From experimental data, it can be established that 11 of the 21 FN were predicted at a low light level (15 lux), 8 FN at 100 lux, and 2 FN at 250 lux. Regarding the 5 FN predicted in other distance conditions, all were performed under low light level. Hence, it can be concluded that two conditions mainly affect the response of the system: distance from camera over 3 m and low light level (15 lux). The distance fact can be explained because the neural network has not been enough trained with a dataset considering larger distances, since rooms are commonly less than 4 m long.
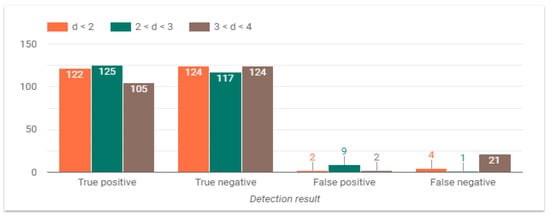
Figure 13.
System performance at different distances from the camera.
Figure 14 summarizes the global obtained results of the research. It can be seen that the system prediction is good since it provides 352 true positives (fall detection) and 365 true negatives (other activities detection). Also, the confusion matrix results allow obtaining the system performance, both for specific and global analysis.
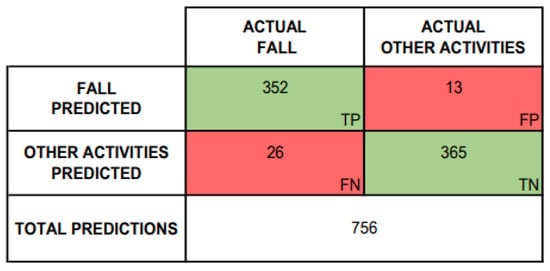
Figure 14.
Confusion matrix of tested scenarios.
Figure 15 illustrates the Receiving Operating Characteristic (ROC) curve for the experimental test, which represents the performance of our binary classifier (falls and other activities) in real conditions. It can be seen that the system has a good performance having an AUC of 0.957, which means a good prediction. The inflection point of the curve (0.03439153, 0.93121693) defines a 0.4 threshold value. At this point, a sensitivity (FPR) of 93.1% was obtained. Even though the FN doubles the FP as observed in the confusion matrix, this point gives the best prediction. It is important to note that 81% of FN occurred at distances over 3 m.
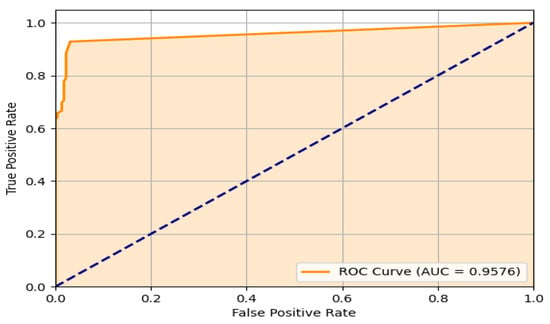
Figure 15.
ROC curve of the proposed system.
Recalling that one in three adults over the age of 65 experiences a fall annually, and given that our system predicts 93 of a hundred falls, the probability of not detecting a fall annually is about 2.33%, with 1.88% not being predicted at distances over 3 m.
The calculated metrics of the system are summarized in Table 4. Based on these values, it can be said that the system’s performance is good enough for many applications, such as care in nursing homes.
Table 4.
Global system performance analysis.
5. Discussion
This study is based on computer vision where a camera captures images and then sent them to a CNN responsible for analyzing data and providing the probability of having a fallen person. Since our system stands on a SBC, it is a cost-effective and high performance solution, costing around 150 USD. Table 5 compares our system with similar ones, considering relevant aspects such as portability, hardware and software components, and performance metrics.
Table 5.
Comparison table with other studies.
Compared to other studies that rely on specific devices such as motion sensors or accelerometers [,,,,], this proposal presents a non-intrusive alternative for detecting falls. It eliminates the need to carry additional devices resulting in more acceptance and comfort for users. It also has to be considered that wearable solutions have a disadvantage, i.e., the use of batteries that have to be recharged or replaced after a certain period of time. However, current manufacturing technology allows for minimizing energy consumption extending its autonomy. Another advantage of our approach is that when a fall is detected, the system sends an image via a Telegram message to notify the event, which enables visual confirmation, thereby reducing false alarms.
The global metrics presented in this work are: accuracy of 94.8%, sensitivity of 93.1%, precision of 96.4%, and specificity of 96.6%. Accuracy and sensitivity metrics indicate that the prediction of falls and other activities are adequate for the intended use. Current metrics certainly could increase in bedrooms or living rooms with satisfactory light levels (e.g., >100 lux). In case of total darkness, the performance metrics remain consistent due to the camera being equipped with IR LEDs. Concerning distance to the camera, accuracy and sensitivity can be improved by increasing our image dataset, especially when the distance is more than 3 m from the camera. On the other hand, the precision value indicates that there is a low probability of having false alarms, which is complemented by the confirmation provided by the picture sent by the system.
Compared to [], which implements a multi-camera system for covering large areas with 89% accuracy, our proposal, which employs a lightweight CNN implemented on a SBCs with limited computational resources, achieves a higher accuracy with a difference of 5.8%. Additionally, our experimental validation was conducted with individuals under various conditions of clothing, distance from the camera, and lighting, allowing for a more comprehensive evaluation of the system.
The authors of [] presented a system based on IR-UWB radar which ensures the preservation of privacy. The system is capable of classifying falls versus common daily activities. However, it does not have the ability to differentiate between a person lying down and a fallen person, unlike our system. In terms of performance metrics, their work have a bit better accuracy (1.85%), whereas our proposal has a bit better sensitivity (0.9%), despite both systems employing a CNN implemented in different hardware.
In the work presented in [], a non-wearable system is implemented using channel state information (CSI), which detects variations in WiFi signals within a physical environment. Comparing both approaches, their system exhibits a slightly better accuracy and sensitivity with a similar precision. The work presented in [] is a system based on thermal sensors employed to detect the body heat of the individual. Similar to our approach, sensor data processing is carried out on a SBC. In terms of performance, our system shows slightly better accuracy, sensitivity, and specificity.
In [], a fall detection system based on a Kinect sensor configured in a top-view setup is presented. It preserves privacy by using depth data instead of detailed images. The system employs an SVM algorithm and demonstrates high accuracy. However, it was tested in a small area of 8.25 m² and it encountered difficulties in detecting fallen individuals due to noise present in the depth frames.
An outstanding work is presented in Alanazi et al. []. It describes a vision fall detection method using a 3D-CNN with metrics around 99%. However, to obtain those results, authors use a computer with an excellent performance (Intel Core I9-9900K CPU 3.6GHz, 64GB RAM with NVIDIA GeForce RTX 2080Ti GPU (By NVIDIA Corporation, USA)) compared to our embedded system (Raspberry PI 4, Quad core ARM Cortex A72 CPU @ 1.8 GHz, 4 GB RAM (By Sony in Pencoed, Gales)). Nevertheless, a better computer would significantly increase the costs of the system. Furthermore, it is important to note that our results are based on experiments with real persons instead of using videos or photos for testing stage. In addition, our proposal allows the effective detection of several persons simultaneously, which is a benefit compared to wearable devices.
Concerning privacy, even though our system uses a camera, video is not recorded, and pictures are only sent when a fall is detected. If the system has multiple cameras positioned strategically in the room, as in [], the performance certainly could increase. However, users might feel a greater invasion of their privacy.
6. Conclusions
This work proposes a fall detection system based on computer vision and Convolutional Neural Networks. The lightweight SSD-MobileNet-V2 model architecture was implemented to be capable of running on a Single Board Computer. For the training process, a mixed dataset combining UR Fall Detection (8065 images) with our own dataset (19,584 images) was used.
Results exhibit satisfactory performance (AUC = 0.957) considering that this is an affordable solution to be implemented in nursing or elderly homes. An efficient alert system was designed, allowing caregivers and relatives to receive an image notification. Although there are some inexpensive commercial solutions, they involve a monthly fee for the service. Moreover, it works as long as there is a medical alert service in the country.
Several tests were conducted to determine system performance under different lighting conditions, clothing, and distance from the camera. The system achieves its best performance from an intermediate light level onwards. Regarding clothing, there is a slightly reduction on system sensitivity when the person wears dark clothing.
In future research, the system will be enhanced by extending the dataset with low-light level images and increasing the distance between the person and the camera in order to improve system sensitivity. In addition, other occlusion techniques such as image inpainting would be tested. In order to preserve individual privacy in spaces such as bathrooms, alternatives like detecting abrupt changes in Wi-Fi signal patterns through CSI can be explored for fall detection. Additionally, incorporating this method will provide dual detection capabilities, thereby minimizing the likelihood of false negatives.
Author Contributions
Conceptualization, V.V. and P.R.; Data curation, V.V. and E.A.O.; Formal analysis, V.V., M.Z. and K.V.-A.; Funding acquisition, V.V.; Investigation, P.R., E.A.O. and K.V.-A.; Methodology, V.V.; Project administration, V.V.; Resources, P.R., E.A.O. and M.Z.; Software, E.A.O.; Supervision, V.V.; Validation, V.V., P.R. and K.V.-A.; Visualization, V.V. and K.V.-A.; Writing—original draft, V.V. and K.V.-A.; Writing—review and editing, P.R. and M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by the Universidad de las Fuerzas Armadas ESPE grant 2022-EXT-003 ESPE and by the Universidad Indoamérica through the project “Cyber-Physical Systems for Smart Environments-SCEIN” with funding code INV-0019-01-018.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
Authors acknowledge Cristina Estrella and Edison Santin, students of Universidad de las Fuerzas Armadas ESPE, for enhancing the original dataset and running preliminary tests that are not part of this paper.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| ADL | Activity of Daily Living |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| API | Application Programming Interface |
| B/W | Black/white |
| CNN | Convolutional Neural Network |
| 3DCNN | 3D Convolutional Neural Network |
| COCO | Common Objects in Context |
| conv2d | 2D Convolutional Layer |
| CPU | Central Processing Unit |
| CSI | Channel State Information |
| DL | Deep Learning |
| dwise | Depthwise Convolution |
| d | Distance |
| eq. | Equation |
| FP | False Positive |
| FN | False Negative |
| GRU | Gated Recurrent Unit |
| GPU | Graphics Processing Unit |
| HD | High Definition |
| IoT | Internet of Things |
| IR-CUT | Infrared cut filter |
| k-NN | k-Nearest Neighbors |
| LD | Linear Dichroism |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| N/S | Not Specified |
| RAM | Random Access Memory |
| ReLU | Rectified Linear Unit |
| RGB | Red Green Blue |
| RNN | Recurrent Neural Network |
| RVM | Relevance Vector Machine |
| SBC | Single Board Computer |
| SSD | Single Shot Detector |
| SVM | Support Vector Machine |
| TP | True Positive |
| TN | True Negative |
| USB | Universal Serial Bus |
| USD | United States Dollar |
References
- Taramasco, C.; Rodenas, T.; Martinez, F.; Fuentes, P.; Munoz, R.; Olivares, R.; De Albuquerque, V.H.C.; Demongeot, J. A novel monitoring system for fall detection in older people. IEEE Access 2018, 6, 43563–43574. [Google Scholar] [CrossRef]
- Bergen, G.; Stevens, M.R.; Burns, E.R. Falls and fall injuries among adults aged ≥65 years—United States, 2014. MMWR Morb. Mortal. Wkly. Rep. 2016, 65, 993–998. [Google Scholar] [CrossRef]
- Salari, N.; Darvishi, N.; Ahmadipanah, M.; Shohaimi, S.; Mohammadi, M. Global prevalence of falls in the older adults: A comprehensive systematic review and meta-analysis. J. Orthop. Surg. Res. 2022, 17, 334. [Google Scholar] [CrossRef] [PubMed]
- Nicolussi, A.C.; Fhon, J.R.S.; Santos, C.A.V.; Kusumota, L.; Marques, S.; Rodrigues, R.A.P. Qualidade de vida em idosos que sofreram quedas: Revisão integrativa da literatura. Cien. Saude Colet. 2012, 17, 723–730. [Google Scholar] [CrossRef]
- World_Health_Organization. Falls. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/falls (accessed on 14 May 2024).
- Karar, M.E.; Shehata, H.I.; Reyad, O. A Survey of IoT-Based Fall Detection for Aiding Elderly Care: Sensors, Methods, Challenges and Future Trends. Appl. Sci. 2022, 12, 3276. [Google Scholar] [CrossRef]
- Singh, A.; Rehman, S.U.; Yongchareon, S.; Chong, P.H.J. Sensor Technologies for Fall Detection Systems: A Review. IEEE Sens. J. 2020, 20, 6889–6919. [Google Scholar] [CrossRef]
- Yacchirema, D.; de Puga, J.S.; Palau, C.; Esteve, M. Fall detection system for elderly people using IoT and ensemble machine learning algorithm. Pers. Ubiquitous Comput. 2019, 23, 801–817. [Google Scholar] [CrossRef]
- Badgujar, S.; Pillai, A.S. Fall Detection for Elderly People using Machine Learning. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Vallabh, P.; Malekian, R.; Ye, N.; Bogatinoska, D.C. Fall detection using machine learning algorithms. In Proceedings of the 2016 24th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 22–24 September 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Pan, D.; Liu, H.; Qu, D.; Zhang, Z. CNN-Based Fall Detection Strategy with Edge Computing Scheduling in Smart Cities. Electronics 2020, 9, 1780. [Google Scholar] [CrossRef]
- Kulurkar, P.; kumar Dixit, C.; Bharathi, V.; Monikavishnuvarthini, A.; Dhakne, A.; Preethi, P. AI based elderly fall prediction system using wearable sensors: A smart home-care technology with IOT. Meas. Sens. 2023, 25, 100614. [Google Scholar] [CrossRef]
- Torti, E.; Fontanella, A.; Musci, M.; Blago, N.; Pau, D.; Leporati, F.; Piastra, M. Embedded Real-Time Fall Detection with Deep Learning on Wearable Devices. In Proceedings of the 2018 21st Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 405–412. [Google Scholar] [CrossRef]
- Luna-Perejon, F.; Dominguez-Morales, M.J.; Civit-Balcells, A. Wearable Fall Detector Using Recurrent Neural Networks. Sensors 2019, 19, 4885. [Google Scholar] [CrossRef]
- Wang, X.; Ellul, J.; Azzopardi, G. Elderly Fall Detection Systems: A Literature Survey. Front. Robot. AI 2020, 7, 71. [Google Scholar] [CrossRef]
- Islam, M.M.; Tayan, O.; Islam, M.R.; Islam, M.S.; Nooruddin, S.; Nomani Kabir, M.; Islam, M.R. Deep Learning Based Systems Developed for Fall Detection: A Review. IEEE Access 2020, 8, 166117–166137. [Google Scholar] [CrossRef]
- Han, T.; Kang, W.; Choi, G. IR-UWB Sensor Based Fall Detection Method Using CNN Algorithm. Sensors 2020, 20, 5948. [Google Scholar] [CrossRef]
- Maitre, J.; Bouchard, K.; Gaboury, S. Fall Detection with UWB Radars and CNN-LSTM Architecture. IEEE J. Biomed. Health Inform. 2021, 25, 1273–1283. [Google Scholar] [CrossRef]
- Shu, F.; Shu, J. An eight-camera fall detection system using human fall pattern recognition via machine learning by a low-cost android box. Sci. Rep. 2021, 11, 2471. [Google Scholar] [CrossRef]
- Sha, Y.; Zhai, X.; Li, J.; Meng, W.; Tong, H.H.; Li, K. A novel lightweight deep learning fall detection system based on global-local attention and channel feature augmentation. Interdiscip. Nurs. Res. 2023, 2, 68–75. [Google Scholar] [CrossRef]
- Chu, Y.; Cumanan, K.; Sankarpandi, S.K.; Smith, S.; Dobre, O.A. Deep Learning-Based Fall Detection Using WiFi Channel State Information. IEEE Access 2023, 11, 83763–83780. [Google Scholar] [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home Camera-Based Fall Detection System for the Elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef]
- Ricciuti, M.; Spinsante, S.; Gambi, E. Accurate Fall Detection in a Top View Privacy Preserving Configuration. Sensors 2018, 18, 1754. [Google Scholar] [CrossRef]
- Alanazi, T.; Muhammad, G. Human Fall Detection Using 3D Multi-Stream Convolutional Neural Networks with Fusion. Diagnostics 2022, 12, 3060. [Google Scholar] [CrossRef]
- Ajit, A.; Acharya, K.; Samanta, A. A Review of Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Ramos, P.; Zapata, M.; Valencia, K.; Vargas, V.; Ramos-Galarza, C. Low-Cost Human–Machine Interface for Computer Control with Facial Landmark Detection and Voice Commands. Sensors 2022, 22, 9279. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A. MobileNetV2: The Next Generation of On-Device Computer Vision Networks. 2018. Available online: https://research.google/blog/mobilenetv2-the-next-generation-of-on-device-computer-vision-networks/ (accessed on 20 May 2024).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. arXiv 2021, arXiv:2103.15808. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Narein, A. Single Shot Detector (SSD) + Architecture of SSD. 2021. Available online: https://iq.opengenus.org/single-shot-detector/#google_vignette (accessed on 30 May 2024).
- Yu, H.; Chen, C.; Du, X.; Li, Y.; Rashwan, A.; Hou, L.; Jin, P.; Yang, F.; Liu, F.; Kim, J.; et al. TensorFlow Model Garden. Available online: https://github.com/tensorflow/models (accessed on 28 May 2024).
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef] [PubMed]
- Orbe Cisneros, E.A. Diseño e Implementación de un Sistema de Detección de Caídas en el Adulto Mayor Mediante Visión Artificial Utilizando Redes Neuronales Convolucionales (Deep Learning). Carrera de Ingeniería en Electrónica, Automatización y Control. Bachelor’s Thesis, Universidad de las Fuerzas Armadas ESPE, Sangolquí, Ecuador, 2022. [Google Scholar]
- Hou, J.C.; Xu, W.M.; Chu, Y.C.; Hu, C.L.; Chen, Y.H.; Chen, S.; Hui, L. Cooperative Fall Detection with Multiple Cameras. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics—Taiwan, Taipei, Taiwan, 6–8 July 2022; pp. 543–544. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).