Abstract
The Rician distribution, which arises in radar, communications, and magnetic resonance imaging, is characterized by a noncentrality parameter and a scale parameter. The Rayleigh distribution is a special case of the Rician distribution with a noncentrality parameter of zero. This paper considers generalized hypothesis testing for Rayleigh and Rician distributions using Rissanen’s stochastic complexity, particularly his approximation employing Fisher information matrices. The Rayleigh distribution is a member of the exponential family, so its normalized maximum likelihood density is readily computed, and shown to asymptotically match the Fisher information approximation. Since the Rician distribution is not a member of the exponential family, its normalizing term is difficult to compute directly, so the Fisher information approximation is employed. Because the square root of the determinant of the Fisher information matrix is not integrable, we restrict the integral to a subset of its range, and separately encode the choice of subset.
1. Introduction
In 1978, Schwartz [1] and Rissanen [2] independently addressed the problem of model order estimation. Although they approached the problem from rather different viewpoints—Schwarz from an asymptotic Bayesian viewpoint, Rissanen from a coding-theoretic viewpoint—they landed on similar expressions. Over the next two decades, Rissanen refined his minimum description length principle [3,4,5,6,7], eventually “settling” on stochastic complexity computed with Normalized Maximum Likelihood (NML) codes in 1996 [8]. Technical details concerning NML for continuous probability models are addressed in [9]. Surveys of research in minimum description length and stochastic complexity, as well as the related (and older [10]) concept of minimum message length [11], may be found in [12,13,14,15,16,17,18].
This paper explores generalized hypothesis testing with Rayleigh and Rician models using stochastic complexity. Stochastic complexity offers an approach to hypothesis testing that avoids arbitrary thresholds and having to choose Bayesian prior distributions.
1.1. Normalized Maximum Likelihood
Notation in the style of [19] will be employed throughout, with some simplifications, given that only Rician and Rayleigh distributions are considered. Let denote a dataset. A particular model class is defined as a set of parameterized densities for , denoted . Let denote the Maximum-Likelihood (ML) estimate of , which we assume to be in for all .
If the normalizing constant
is finite, we can define the NML density for class as
Much of this paper will address the challenges of dealing with models for which the integral in (1) is not finite.
The stochastic complexity of the data given a model is defined as the negative logarithm of (2):
Here we are using the natural logarithm to express stochastic complexity in “nats”. Dividing the result by , or equivalently multiplying by , would express the result in “bits”.
Given a competing set of models, one chooses the model that minimizes stochastic complexity. Leaving out the minus sign in (3), one can think about the procedure as maximizing a penalized likelihood, with higher penalizing more complex models. This simple description assumes the complexities of the competing models are finite; issues concerning infinite complexities present challenges that will be extensively addressed below.
If (1) is challenging to compute, one may employ the asymptotic approximation (Equation (19) of [8])
where is the Fisher information matrix for the parameter vector and k is the dimension of .
The above exposition assumed the integrals in (1) and (4) are finite; we shall return to this sticky issue—which is the reason we put “settling” in quotes in the first paragraph—in Section 1.3.
1.2. Model Comparison Scenarios
The Rician distribution is parameterized by a noncentrality parameter and a scale parameter ; it arises in radar [20,21], communications [22], and magnetic resonance imaging [23,24,25]. The Rayleigh distribution is a special case of the Rician, with . In wireless communications, while both distributions can model the effects of numerous scattered paths, the Rician distribution in particular models models data including a strong line-of-sight component.
This paper addresses the question: How can we discriminate between Rayleigh and Rician data using stochastic complexity? Our primary interest is choosing between the Rayleigh and Rician distributions when none of the parameters are assumed known. For instance, in a radar application, the Rician distribution might model the voltage distribution certain kind of target (with a strong specular aspect), and a Rayleigh distribution might model another kind of target (with entirely diffuse aspects) or the absence of a target. If one simply plugged in ML estimates and chose the model with the highest likelihood, the Rician would always be chosen, since it enjoys two degrees of freedom instead of just one. In radar, one generally employs a generalized likelihood ratio test with a threshold chosen to achieve tradeoffs between “probability of detection” and “probability of false alarm”. Stochastic complexity offers an avenue towards choosing between models based on the inherent structure of those models without setting a subjective threshold. One could consider a restricted version of this problem where the parameter for both distributions is assumed known, in which case the Rayleigh model has no free parameters and its stochastic complexity is just its negative loglikelihood.
Stochastic complexity may be useful even if the number of parameters is the same for each model. The Poisson and geometric distributions are considered in [26,27], which find that even though they both have a single parameter, for small sample sizes, if we simply choose the model with the largest likelihood, “data generated by the geometric distribution are misclassified as Poisson much more frequently than the other way around.” The Poisson distribution intuitively has more “explanatory” power than the geometric. Using the classic “Bayesian information criterion” penalty of (the first term of (4), with omitted) does not help, since both models have the same number of parameters, whereas the full formula puts both models on an equal footing.
Using stochastic complexity, one could compare a Rayleigh model with unknown with a Rician with unknown and known a, or known a and unknown . Or, one could compare two Rician distributions with known but different known values of a. These scenarios are less likely in practical applications, but they illustrate the flexibility of the method.
1.3. The Infinity Problem
Unfortunately, for many models of interest—including Rayleigh and Rician models—the integrals in (1) and (4) are not finite when computed over the full parameter space (see Chapter 11 of [14]). The general approach is to artificially restrict the integral to a particular subset. As Wallace and Dowe [28] opine, this “seems arbitrary and distasteful. We are given no general guidance as to how this restriction should be performed and different restrictions give different results.”
In some cases, the limits of the subset may be be taken as hyperparameters, and a second normalization step can be taken over those hyperparameters. If the resulting integral itself is infinite, the process can be repeated with hyper-hyperparameters, and so on. In [29], Rissanen needs to cascade three normalization steps for regression problems in denoising applications. How to conduct such “renormalization” is not always obvious. In Section 4.5 of [27], de Rooij and Grünwald mention that their first attempt at renormalization for Poisson and geometric models resulted in another infinite integral, and that they were unable to conduct a second renormalization. In their study of Gaussian distributions (Section III of ([19]), Hirai and Yamanishi stop after their second normalization; the remaining integral is still infinite over the full range, but they note the resulting stochastic complexity has a weaker dependence over the remaining hyper-hyperparameters than the hyperparameters from the first normalization.
We have been unable to conduct renormalization for Rayleigh and Rician models, so we will employ the strategy of Section V of [8]. We define a set of subsets of whose union covers all of and for which the integral converges for all subsets, compute the integral for the smallest subset containing , and add some bits (or nats) to the stochastic complexity to separately encode the choice of subset. This approach is not terrible, but it is unsatisfying, as there is generally no clear “best” way to choose the subsets or how to encode their selection.
2. Rayleigh Data
The probability density of n independent Rayleigh random variables is
Dropping terms that do not depend on , the loglikelihood is
which has the first and second derivatives
The ML estimate of is
2.1. Normalized Maximum Likelihood for Rayleigh Data
We follow the approach and notation of Hirai and Yamanishi in their gamma distribution example in Section II.D of [19].
Let denote the density function of the ML estimate for an assumed ; this will allow the normalizing integral (1) to be computed via the ML estimate instead of the original n-dimensional data. Since the Rayleigh distribution is a member of the exponential family, we may factor the density of the data as
where
is the factor of the data density that is independent of the model parameter , as explained in Section II.C of [19] (middle of left column).
Multiplying both sides of (8) by , we see that is gamma distributed with shape parameter n and scale parameter , so
The in the numerator of the first factor comes from the mapping of multiplying by . Fix . Then
Unfortunately, the integral of (12) over its full range is not finite, so following the reasoning of [19], we restrict the integral to run from to :
Issues related to choosing such limits will appear throughout the rest of the paper; the results are sensitive to such choices.
The natural logarithm of (13) is
2.2. Fisher-Based Approximate NML
The Fisher information for the Rayleigh model, , is
The integral of the square root of (17) over the full range of is not finite, so as in the previous subsection, we integrate from to to compute the asymptotic approximation
3. Rician Data
The Rician distribution will be far more challenging to deal with than the Rayleigh distribution. It does not admit a decomposition in terms of a sufficient statistic like in (9), making closed form calculation of the NML density intractable. Additionally, the presence of Bessel functions makes both ML estimation and the computation of Fisher information more difficult.
The probability density of n independent Rician random variables is
Dropping terms that do not depend on b or , the loglikelihood is
The derivatives of (20) with respect to a and are
where we define modified Bessel function ratios as and we have used the modified Bessel function relations (see, for instance, Equation (1.52) on p. 16 and Equation (1.68) on p. 21 of [30])
The entries of the Fisher information matrix
are derived in the Appendix A and given by
where
We are unaware of a closed-form expression for (28) and were unable to find any elegant and accurate approximations. The numeric results in this paper use the integral function of Octave version 10.3 with its default settings.
For , (25) simplifies to the Fisher information for the Rayleigh case given in (17), and (27) is zero.
Section 3.1 considers scenarios where a is unknown but is known. Section 3.2 considers scenarios where is unknown but a is known. These two scenarios are less likely encountered in practical applications, but they help build understanding towards scenarios where both a and are unknown, which is considered in Section 3.3 and the main focus on this paper. Monte Carlo simulations related to this scenario are presented in Section 4.
3.1. Unknown a, Known
We first consider the case where is assumed known. Setting (21) equal to zero yields the necessary condition for a maximizer; is the a that satisfies
The fixed-point iteration
converges to the maximizing a.
The Rician distribution is not a member of the exponential family and does not allow a sufficient statistic, so we cannot employ the method demonstrated in Section 1.1. Hence, we immediately turn to Rissanen’s asymptotic approximation. The square root of the Fisher information , the upper left element of (24), is not integrable over its full range; it admits a lower limit on a of 0, but not an upper limit of ∞. One can restrict the upper limit to a choice of and add another term to the complexity associated with encoding .
Figure 1 plots as a function of a for four different values of . The integral of from 0 to , plotted as a function of , is shown in Figure 2a; its natural logarithm, corresponding to the integral term in the stochastic complexity expression, is shown in Figure 2b.
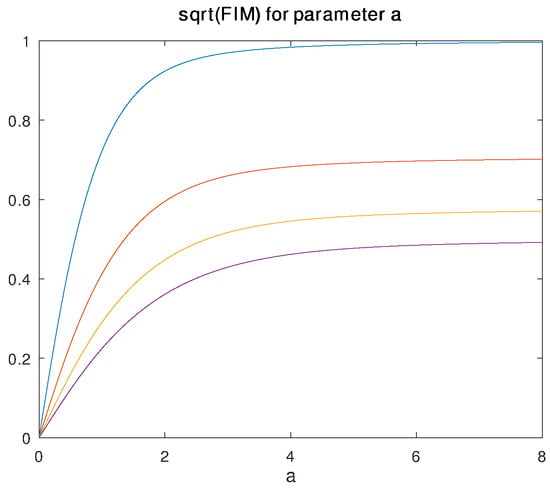
Figure 1.
Plot of vs. a assuming is known. Different lines, from top to bottom, correspond to , 2, 3, and 4.
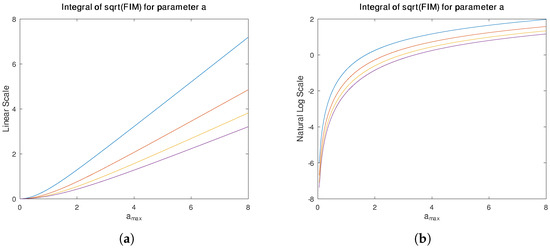
Figure 2.
(a) Plot of integral of from 0 to vs. assuming is known. Lines, from top to bottom, correspond to and 4. (b) Natural logarithm of the same integral.
3.2. Unknown , Known a
We next consider the case where a is assumed known. Although this case is likely not as common in practical applications, we consider it for completeness and as a stepping stone to consider the full case where both a and are known.
Setting (22) equal to zero gives the necessary conditions for a maximizer; is the that satisfies
The square root of the Fisher information , the lower right element of (24), is not integrable over its full range, and it manifests a singularity at . Like in the Rayleigh case, we can limit the integral to a range and add another term to the complexity associated with encoding and .
Figure 3 plots as a function of for four different values of a. The horizontal axis of Figure 3a runs from 1 to 5; the horizontal axis of Figure 3b runs from 0.1 to 1 to better show detail, in particular the crossing of the and lines. Exploring this further, Figure 4 plots as a function of a for three different values of . Notice these functions are not monotonic; they are all largest at and each has minimum. This suggests that for any particular true , there is an associated a that would give the yield the worst Cramér-Rao lower bound, and would yield the best.
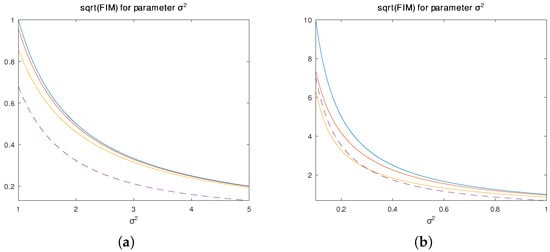
Figure 3.
Plots of vs. assuming a is known. Solid lines, from top to bottom, correspond to , and . The dashed line corresponds to . (a) ranges from 1 to 5. (b) ranges from 0 to 1.
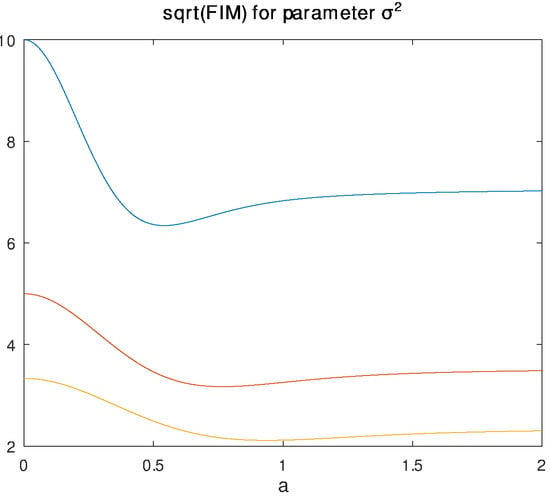
Figure 4.
Plot of vs. a assuming a is known. Different lines, from top to bottom, correspond to , 0.2, and 0.3.
3.3. Unknown a and Unknown
The ML estimate can be found with a simple fixed-point iteration
Once the ML estimate for a is found, the ML estimate for can be computed according to
Figure 5a plots the double integral
as a function of . We choose and , and plot several lines for different choices of c. This restriction to the range is inspired by Rissanen’s approach to exponential densities in Section V of [8]. The natural logarithm of Figure 5a, which corresponds to the integral term in the stochastic complexity expression, is shown in Figure 5b.
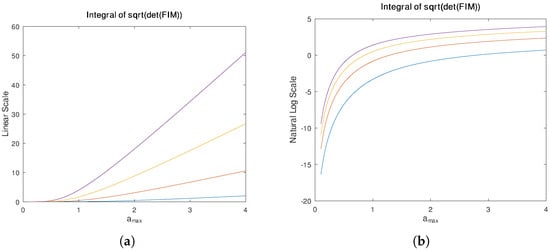
Figure 5.
(a) Plot of integral of from 0 to (over a) and from to c (over ) vs. . Lines, from bottom to top, correspond to , 4, 6, and 8. (b) Natural logarithm of the same integral.
4. Example
Figure 6 illustrates the probability of correctly detecting a Rician model using stochatic complexity, as a function of a (from 0.05 to 2.5 with a spacing of 0.05), with , estimated using 200,000 Monte Carlo runs per point. This experiment characterizes how the difficulty of distinguishing between Rician and Rayleigh distributions decreases with increasing noncentrality parameter a of the Rician distribution. The solid line corresponds to ; the dotted line corresponds to . If only the loglikelihoods are compared, the Rician model is always chosen since it has an additional degree of freedom.
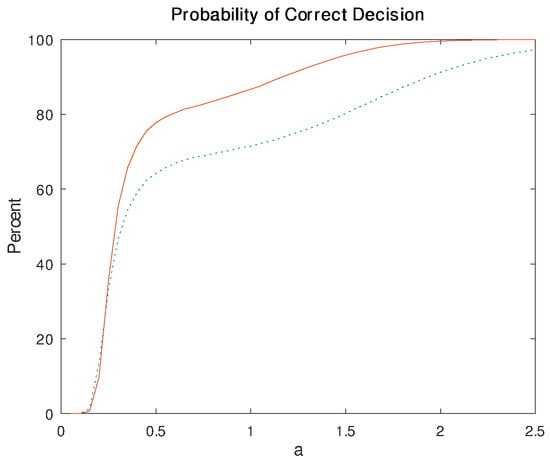
Figure 6.
Estimated probability (using 200,000 Monte Carlo runs) of correctly choosing the Rician model using stochastic complexity as a function of the true parameter a for . The lines correspond to (dotted) and (solid).
For the Rayleigh model, we follow Rissanen’s choice for the exponential models in Section V of [8] and restrict the integral over the square root of the Fisher information to the range , where is the smallest positive integer such that the ML estimate . (We add a subscript in this section to avoid confusion with the estimate for the Rician case). The natural log of the integral is then
Further following Rissanen [8], we encode with bits, where is the iterative algorithm computed using base 2, , and we multiply by to convert to nats.
The stochastic complexity expression for the Rayleigh model is then
For the Rician model, we follow the same choice as in the Rayleigh case, restricting the integral over to the range , where is the smallest positive integer such that the ML estimate (now using a 1 subscript instead of 0 to avoid confusion with the Rayleigh case). We follow a similar pattern and restrict the integral over a to the range , where s is the smallest positive integer such that the ML estimate . We separately encode and s using the approach we used in the Rayleigh case. We emphasize that different choices of subsets to force integrals to be finite, and the different methods of encoding the chosen subset, will yield different procedures, and there is at present little guidance on how to make such choices. This is addressed further in Section 5.
The stochastic complexity expression for the Rician model is then

Table 1.
Precomputed log integral term in (39).
5. Conclusions
This paper developed expressions for the NML-based stochastic complexity of Rayleigh models with unknown scale parameter and three cases of Rician models: (1) the noncentrality parameter is unknown, but the scale parameter is assumed to be known; (2) the scale parameter is unknown, but the noncentrality parameter is assumed to be known; and (3) both the noncentrality and scale parameters are unknown. The resulting integrals of the square root of the determinant of the Fisher information matrix diverge when taken over their full range. To address this, we limited the range of the integrals, and separately encoded the choice of range. For the third case, we formulated an encoding scheme inspired by Rissanen [8] and used a Monte Carlo analysis to illustrate how the difficulty of correctly choosing a Rician model changes with the noncentrality parameter of that model.
The primary hope of this paper is to spur further research into stochastic complexity in cases where normalizing integrals are infinite when computed over their full range, particularly for distributions other than the Gaussian. To our knowledge, the only published details of “renormalized maximum likelihood” ([19,29,31]) have involved Gaussian distributions (de Rooij and Grünwald [27] only mention their attempts regarding geometric and Poisson distributions in passing). Perhaps an interested reader can uncover a renormalization scheme for the Rician distribution that we were unable to formulate.
Along with finding renormalization schemes, another line of research would be to find less arbitrary ways of choosing the sets of subsets of the parameter space (along the lines of Section V of [8]) that allow the normalizing integrals to be finite (along with appropriate encoding of the selected subset).
It is remarkable that almost two decades after Rissanen introduced his asymptotic formula for stochastic complexity based on the Fisher information matrix, there is as of yet no general satisfying solution to the “infinity problem”.
The minimum description length principle, in its many forms, selects models, but does not provide any alternative to choosing parameters for those models beyond the classical ML estimate. An alternative philosophy, Minimum Message Length (MML) [10], simultaneously chooses models along with their estimated parameters, and the MML parameter estimates differ from ML estimates. To our knowledge, MML has not been applied to Rayleigh or Rician models. MML requires choosing Bayesian priors; our focus on stochastic complexity has been motivated by a desire to avoid selecting prior distributions.
A natural direction for future work would be to apply these techniques to real data. In [32,33,34], a zero-mean complex “conditionally Gaussian” model, which is functionally equivalent to a Rayleigh model, is employed in building automatic target recognition libraries for synthetic aperture radar data. A similar approach is taken to high-resolution range profile data in [35]. This model is most appropriate for diffuse targets. To incorporate specular reflections, Ref. [36] extended the approach to a Rician model; the authors wrote: “…the performance under the Rician model suffers with smaller training sets. Due to the smaller number of distribution parameters, the conditionally Gaussian approach is able to yield a better performance for any fixed complexity.” A model order estimation technique such as stochastic complexity may help alleviate such issues with overfitting, allowing the library creation process to only choose a Rician model when warranted.
There are many other examples of hierarchies of probability densities, where one density is a special case of the other, in which stochastic complexity could be used to determine if the more complicated density is truly warranted. For instance, the one-parameter exponential distribution is a special case of the two-parameter Weibull distribution, and three-parameter [37,38,39] and four-paremeter [40] generalizations of the Weibull distribution have been proposed. The exponential distribution is also a special case of the two-parameter gamma distribution, which has a three-parameter generalization [41]. Besides exploring hierarchies of models with differing numbers of parameters, stochastic complexity could be used to compare the two-parameter Weibull with the two-parameter gamma; even though they have the same number of parameters, one may have greater explanatory power and be unfairly favored in naive likelihood comparisons.
Funding
This research received no external funding.
Data Availability Statement
MATLAB code needed to reproduce the results in this paper is available at github.com/lantertronics/riciansc, accessed on 24 December 2025.
Acknowledgments
We thank Joseph O’Sullivan of Washington University in St. Louis and the anonymous reviewers for their helpful comments on this manuscript.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ML | Maximum Likelihood |
| MML | Minimum Message Length |
| NML | Normalized Maximum Likelihood |
Appendix A
The computations in this appendix frequently use the derivative of the modified Bessel ratio , which can be computed using (23):
Computing the Fisher information for the Rician distribution involves complicated integrals studied by Heatley [42]. Fortunately, some of the special cases of interest here yield simple results.
The upper left corner of the Fisher information matrix (24) is
The first term in (A2) evaluates to , since this term is just a constant multiplied by the integral of a density over its entire domain.
The second term in (A2) is
Subtracting (A4) from and simplifying yields the Fisher information
which is consistent with Equation (4) in [43].
The lower right entry of the Fisher information matrix (24) is
The diagonal entries of the Fisher information matrix (24) are
References
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Rissanen, J. Modeling by Shortest Data Description. Automatica 1978, 14, 465–471. [Google Scholar] [CrossRef]
- Rissanen, J. A Universal Prior for Integers and Estimation by Minimum Description Length. Ann. Stat. 1983, 11, 416–431. [Google Scholar] [CrossRef]
- Rissanen, J. Universal Coding, Information, Prediction, and Estimation. IEEE Trans. Inf. Theory 1984, 30, 629–636. [Google Scholar] [CrossRef]
- Rissanen, J. Stochastic Complexity and Modeling. Ann. Stat. 1986, 14, 1080–1100. [Google Scholar] [CrossRef]
- Rissanen, J. Stochastic Complexity. J. R. Stat. Soc. B 1987, 49, 223–239. [Google Scholar] [CrossRef]
- Rissanen, J. Stochastic Complexity in Statistical Inquiry; World Scientific Publishing Co.: New York, NY, USA, 1989. [Google Scholar]
- Rissanen, J. Fisher Information and Stochastic Complexity. IEEE Trans. Inf. Theory 1996, 42, 40–47. [Google Scholar] [CrossRef]
- Suzuki, A.; Yamanishi, K. Foundation of Calculating Normalized Maximum Likelihood for Continuous Probability Models. arXiv 2014, arXiv:2409.08387. [Google Scholar]
- Wallace, C.; Boulton, D. An Information Measure for Classification. Comput. J. 1968, 11, 195–209. [Google Scholar] [CrossRef]
- Wallace, C. Statistical and Inductive Inference by Minimum Message Length; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Grünwald, P. Model Selection Based on Minimum Description Length. J. Math. Psychol. 2000, 44, 133–152. [Google Scholar] [CrossRef] [PubMed]
- Grünwald, P.; Roos, T. Minimum Description Length Revisited. Int. J. Math. Ind. 2020, 11, 1930001. [Google Scholar] [CrossRef]
- Grünwald, P. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Rissanen, J. Information and Complexity in Statistical Modeling; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Rissanen, J. Optimal Estimation of Parameters; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Myung, J.; Navarro, D.; Pitt, M. Model Selection by Normalized Maximum Likelihood. J. Math. Psychol. 2006, 50, 167–179. [Google Scholar] [CrossRef]
- Lanterman, A. Schwarz, Wallace, and Rissanen: Intertwining Themes in Theories of Model Order Estimation. Int. Stat. Rev. 2001, 69, 185–212. [Google Scholar] [CrossRef]
- Hirai, S.; Yamanishi, K. Computation of Normalized Maximum Likelihood Codes for Gaussian Mixture Models with Its Applications to Clustering. IEEE Trans. Inf. Theory 2013, 59, 7718–7727. [Google Scholar] [CrossRef]
- Fried, D. Statistics of the laser radar cross section of a randomly rough target. J. Opt. Soc. Am. 1976, 66, 1150–1160. [Google Scholar] [CrossRef]
- Song, X.; Blair, W.; Willett, P.; Zhou, S. Dominant-plus-Rayleigh Models for RCS: Swerling III/IV versus Rician. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2058–2064. [Google Scholar] [CrossRef]
- Wang, L.C.; Liu, W.C.; Cheng, Y.H. Statistical Analysis of a Mobile-to-Mobile Rician Fading Channel Model. IEEE Trans. Veh. Technol. 2009, 58, 32–38. [Google Scholar] [CrossRef]
- Gudbjartsson, H.; Patz, S. The Rician Distribution of Noisy MRI Data. Magn. Reson. Med. 1995, 34, 910–914. [Google Scholar] [CrossRef] [PubMed]
- Sjibers, J.; den Dekker, A.; Scheunders, P.; Dyck, D.V. Maximum-Likelihood Estimation of Rician Distribution Parameters. IEEE Trans. Med. Imaging 1998, 17, 357–361. [Google Scholar] [CrossRef]
- Sjibers, J.; den Dekker, A.; Raman, E.; Dyck, D.V. Parameter Estimation from Magnitude MR Images. Int. J. Imaging Syst. Technol. 1999, 10, 109–114. [Google Scholar] [CrossRef]
- Lanterman, A. Hypothesis Testing for Poisson versus Geometric Distributions using Stochastic Complexity. In Advances in Minimum Description Length: Theory and Applications; Grunwald, P., Myung, I., Pitt, M., Eds.; MIT Press: Cambridge, MA, USA, 2005; Chapter 4; pp. 99–123. [Google Scholar]
- de Rooij, S.; Grünwald, P. An empirical study of minimum description length model selection with infinite parametric complexity. J. Math. Psychol. 2006, 50, 180–192. [Google Scholar] [CrossRef]
- Wallace, C.; Dowe, D. Refinements of MDL and MML Coding. Comput. J. 1999, 42, 330–337. [Google Scholar] [CrossRef]
- Rissanen, J. MDL Denoising. IEEE Trans. Inf. Theory 2000, 7, 2537–2543. [Google Scholar] [CrossRef]
- Tranter, C.J. Bessel Functions with Some Physical Applications; The English University Press Ltd.: London, UK, 1968. [Google Scholar]
- Maanan, S.; Dumitrescu, B.; Girucăneanu, C. Renormalized Maximum Likelihood for Multivariate Autoregressive Models. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 28 August–2 September 2016; pp. 150–154. [Google Scholar]
- O’Sullivan, J.; DeVore, M.; Kedia, V.; Miller, M. Automatic Target Recognition Performance for SAR Imagery Using a Conditionally Gaussian Model. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 91–108. [Google Scholar] [CrossRef]
- Devore, M.; O’Sullivan, J. Performance Complexity Study of Several Approaches to Automatic Target Recognition from SAR Images. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 632–648. [Google Scholar]
- Devore, M.; O’Sullivan, J. Quantitative Statistical Assessment of Conditional Models for Synthetic Aperture Radar. IEEE Trans. Image Process. 2004, 13, 113–125. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, S.; O’Sullivan, J. Automatic Target Recognition Using Sequences of High Resolution Radar Range-Profiles. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 364–382. [Google Scholar] [CrossRef]
- DeVore, M.; Lanterman, A.; O’Sullivan, J. ATR Performance of a Rician Model for SAR Images. In Proceedings of the Automatic Target Recognition X, Orlando, FL, USA, 26–28 April 2000; Volume SPIE Proc. 4050; Sadjadi, F., Ed.; SPIE: Bellingham, WA, USA, 2000. [Google Scholar]
- Mudhokar, G.; Srivastava, D. The Exponentiated Weibull Family for Analyzing Bathtub Failure-Rate Data. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Mudhokar, G.; Srivastava, D.; Freimer, M. The Exponentiated Weibull Family: A Reanalysis of the Bus-Motor-Failure Data. Technometrics 1995, 37, 436–445. [Google Scholar] [CrossRef]
- Mudhokar, G.; Srivastava, D.; Kollia, G. A Generalization of the Weibull Distribution with Application to the Analysis of Survival Data. J. Am. Stat. Assoc. 1996, 91, 1575–1583. [Google Scholar] [CrossRef]
- Cordeiro, G.; Biazatti, E.; de Santana, L. A New Extended Weibull Distribution with Application to Influenza and Hepatitis Data. Stats 2023, 6, 657–673. [Google Scholar] [CrossRef]
- Stacy, E. A Generalization of the Gamma Distribution. Ann. Math. Stat. 1962, 33, 1187–1192. [Google Scholar] [CrossRef]
- Heatley, A.H. Some Integrals, Differential Equations, and Series Related to the Modified Bessel Function of the First Kind; University of Toronto Press: Toronto, ON, Canada, 1939. [Google Scholar]
- Idier, J.; Collewet, G. Properties of Fisher Information for Rician Distributions and Consequences in MRI; Research Report hal-01072813v1; HAL: Lyon, France, 2014. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.