Abstract
The problem of estimating the ratio of the means of a two-component Poisson mixture model is considered, when each component is subject to zero-inflation, i.e., excess zero counts. The resulting zero-inflated Poisson mixture (ZIPM) model can be viewed as a three-component Poisson mixture model with one degenerate component. The EM algorithm is applied to obtain frequentist estimators and their standard errors, the latter determined via an explicit expression for the observed information matrix. As an intermediate step, we derive an explicit expression for standard errors in the two-component Poisson mixture model (without zero-inflation), a new result. The ZIPM model is applied to simulated data and real ecological count data of frigatebirds on the Coral Sea Islands off the coast of Northeast Australia.
1. Introduction
Baker and Holdsworth (2013) [1] present data relevant to the determination of the relative abundances of two subspecies of frigatebirds (FB), least (LFB) and greater (GFB), in the Coral Sea Islands off the coast of Northeast Australia. The available data is indirect, consisting only of counts of nests in several standardized sites over several time points, rather than direct observations of individuals. Furthermore, the nests of LFB and GFB usually are indistinguishable, (possibly) differing only in their relative numbers per site. Thus, to infer the type of nest one may use techniques from model-based clustering, such as a finite mixture model [2]. In the presence of count data (such as ours), a finite mixture of Poisson distributions is a common choice [3,4]. Previous authors have studied identifiability and estimation of this and related models (e.g., [2]). Given inferred nest type, ecologists may be interested in estimating other qualities of the ecosystem: If the expected numbers of nests per site for LFB and GFB are denoted by and respectively, in this paper we study estimation of their ratio, , where .
Several complications arise. Because no further constraint can be imposed on a priori, the problem is unidentifiable as stated, i.e., is indistinguishable from . However, LFB are less prevalent than GFB (based on available labeled data, see [1]), which will render the model identifiable; see the second paragraph below. Furthermore, it is typical of such field studies that zero counts are recorded for reasons other than true absence, such as short study periods, secretive or small species, or other uncontrollable factors. In such cases, it is necessary to model the excessive zero-counts directly to not contaminate other inferences [5]. As is commonly done, we shall adopt the zero-inflated Poisson (ZIP) distribution to represent this feature [6,7,8].
We now state a probability model based on a finite mixture model of zero-inflated Poisson distributions to represent the aforementioned scenario: Let indicate whether LFB () or GFB () are observed in time point j. Let be the actual number of FB nests at site i in time point j (which may not be directly observed due to zero-inflation). Let indicate whether nest counts are directly observed () or subject to zero-inflation and hence lost (). Finally, let denote the number of FB nests observed at site i at time point j. Let and be the corresponding index sets, and set , . For , consider random variables (rvs),
where , and are mutually independent, and and are conditionally mutually independent given . Thus is a π- mixture of and rvs, where each is known, potentially reflecting a feature of each site common to all time points, and are unknown. Further, is a zero-inflated Poisson mixture (ZIPM) rv with zero-inflation parameter (One may ask if a conditional ZIPM model is equivalent to the well-studied Zero-Truncated Poisson model. We demonstrate that this is not the case in Appendix A).
The main objective of this paper is the problem of estimating the ratio based solely on the observed data , with , , and unobserved. As noted above, for identifiability of , and therefore of , a restriction must be imposed: we assume that , corresponding to the knowledge that LFB occurs no more frequently than GFB. We propose frequentist estimation of via the EM algorithm and approximate standard errors via explicit calculation of the observed information matrix (A Bayesian analysis of this same problem can be found in a preprint version of this paper: M. D. Perlman (2022). Estimating the ratio of means in a zero-inflated Poisson mixture model. arXiv:math 2203.13994).
The rest of this paper is organized as follows: In Section 2, we briefly provide notation. In Section 3, we present a preliminary problem of estimating in a standard, two-component Poisson mixture model (i.e., are unobserved and are observed, without zero-inflation) to serve as a guidepost for the main problem. Therein, we estimate in a frequentist context via EM and approximate standard errors via explicit calculation of the observed information matrix, which to our knowledge is a new result (Approximate methods are usually used, such as the SEM algorithm [9] or the bootstrap [4]). In Section 4 we address the main problem of estimating the ratio of Poisson means in a zero-inflated Poisson mixture (ZIPM) model, as described in the previous paragraph. In Section 5 the ZIPM model is applied both to simulated data and real data on frigatebirds in the Coral Sea Islands. The results of this study are summarized in Section 6.
2. Notation
Column vectors and arrays denoted by Roman letters appear in bold type, their components in plain type; caps denote rvs:
where is the set of real numbers and is the set of nonnegative integers. Note that as each is an indicator variable, and as each represents count data. Sums and products will range over the index sets and unless otherwise specified, e.g.,
etc. Summation over one or both of the indices involving , , , or their random (capitalized) versions will be indicated by simply dropping the indices that are summed over, e.g.,
We set and . All conditioning events , , etc., will be abbreviated as , , etc. Lastly, for and , we define
Here () is the indicator function of the event (), so () is the number of nonzero (zero) with j fixed, etc.
3. A Preliminary Problem
In this section, we address estimation of in a standard, two-component Poisson mixture model. Specifically, we derive an EM algorithm for maximum likelihood estimation of the unknown model parameters (Section 3.1) and subsequently provide an explicit formula for standard errors of the maximum likelihood estimators (Section 3.2). We begin with a few preliminaries.
Here, is a -mixture of and rvs, where is the unknown mixing probability, cf. (2). Thus the probability mass function (pmf) of the observed data array is
where . The joint pmf of the complete (unobserved and observed) data is
where
Thus, determines an exponential family with sufficient statistic .
3.1. Estimation via the EM Algorithm
To obtain the MLEs and thus , it is straightforward to apply the EM algorithm [10,11] as follows:
- E-Step: Because (6) is an exponential family, Bayes formula shows that for , the -st E-step simply imputes to be
Observe that in (7), the numerator and first term in the denominator is the unnormalized probability that and the second term in the denominator is the unnormalized probability that .
Thus, In the -st iteration, we maximize estimates of the unknown parameters via
where . Note that the identifiability constraint, , is briefly ignored: Aitken and Rubin [10] (1985, p. 69) state that assuming convergence of to an MLE , the same maximum value will occur at . Thus, we simply take the MLE to be that for which the first component is ≤ (say for the sake of specificity). This concludes the EM algorithm.
Using estimates from the EM algorithm, we obtain the following estimator of :
3.2. Standard Error for the MLE
We now provide an explicit formula for approximating standard errors of the unknown parameters, , and thereby, of . For simplicity of notation set , and assume that the EM iterates converge to , the actual MLEs based on the observed data .
One method for approximating the standard error of uses the total expected information matrix
for the observed data : If is large, it follows from Theorem 2 of [12] that
Alternatively, refs. [13,14] note that the observed information matrix usually yields a better normal approximation and often is more readily computed than expected information.
Theorem 1.
Assume the two-component Poisson mixture model presented in (1) and (2), where is observed and is unobserved. If is large, then
The observed information matrix is given explicitly as follows:
Elements on the main diagonal of covariance matrix are estimated standard errors of parameters and off-diagonal elements are their respective covariances. The proof of this theorem appears in Appendix B.
Theorem 1 provides an approximate confidence interval for the parameter of interest, :
Proposition 1.
Under the conditions of Theorem 1, an approximate confidence interval for θ is given by,
where is the upper -quantile of the standard normal distribution,
and is partitioned as
with , , , and .
Proof.
An approximate confidence interval for is obtained by propagation of error.
□
4. The Main Problem
We now turn to our main problem of estimating the ratio of Poisson means in a zero-inflated Poisson mixture (ZIPM) model cf. (1)–(4). Again, we derive an EM algorithm for maximum likelihood estimation of the unknown model parameters (Section 4.1) and subsequently provide an explicit formula for standard errors of the maximum likelihood estimators (Section 4.2). We begin with a few preliminaries.
Note that is an -mixture of and , where is degenerate at 0, so ; while is a -mixture of and rvs. Thus this problem can be viewed as a three-component Poisson mixture model with one degenerate component and non-i.i.d. observations. The three weights are , , and , with the identifiability constraint .
For notational simplicity, set . Under this three-component mixture model, the unconditional pmf of the observed data is
where . The joint pmf of the unobserved and observed data is given by
where , , ,
and similarly with y replaced by . To obtain (9) we have used,
and similarly with y replaced by . Thus, determines an exponential family with sufficient statistic .
4.1. Estimation via the EM Algorithm
To obtain the MLEs and then , it is again straightforward (albeit, notationally challenging) to apply the EM algorithm, as follows:
- E-Step: Since (9) is an exponential family, Bayes formula shows that for , the -st E-step imputes , , , and , respectively, as,
Note that in general.
Thus the -st M-step yields the updated estimates
Again, as in Aitken and Rubin [10] (1985, p. 69), the constraint is ignored and, assuming convergence to an MLE , the same maximum value will occur at . Thus, the MLE is taken to be that for which the first component is ≤, say . This concludes the EM algorithm.
Using estimates from the EM algorithm, we obtain an updated estimator . Note that unlike in (8), depends on .
4.2. Standard Error for the MLE
We provide an explicit formula for approximating standard errors of the unknown parameters , and thereby, of .
Theorem 2.
Assume the two-component Poisson mixture model presented in (1)–(4), where is observed and , , and are unobserved. If is large, then
The observed information matrix is given explicitly as follows:
The proof of this theorem also appears in Appendix B.
Again, Theorem 2 provides an approximate confidence interval for the parameter of interest, :
Proposition 2.
Under the conditions of Theorem 2, an approximate confidence interval for θ is given by,
where is the upper -quantile of the standard normal distribution,
and is partitioned as
with , , , and .
Proof.
Again, an approximate confidence interval for is obtained by propagation of error. For ,
□
5. Simulation and Data Analysis
The frequentist estimation procedure for ZIPM models in Section 4 is now applied to simulated and real data.
5.1. Simulation Study
Simulated data is used to assess the estimation error and confidence interval coverage in various regimes. Across all simulations, we set and so that . Across simulations we vary I and J to assess accuracy as the overall amount of available data changes, vary to assess accuracy as the relative prevalence between the more or less prevalent groups becomes more severe, and vary to assess accuracy as zero-inflation becomes more severe. Specifically, for each combination of , , , and , we generate 200 independent datasets and estimate using the EM algorithm from Section 4.1 (with 20 random starts), as well as a 95% confidence interval using Proposition 2. Estimation error and nominal coverage of confidence intervals is shown in Figure 1 and Figure 2, respectively. (The information shown in these figures is presented in tabular form in Appendix C).
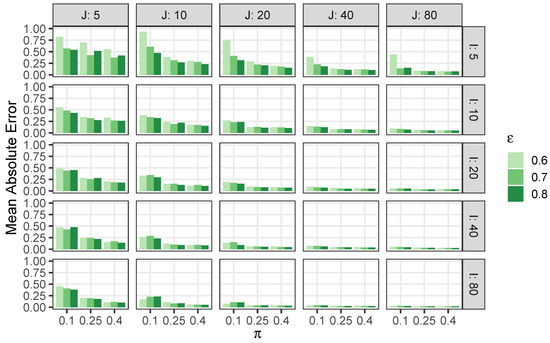
Figure 1.
Estimation error for in simulated ZIPM data.
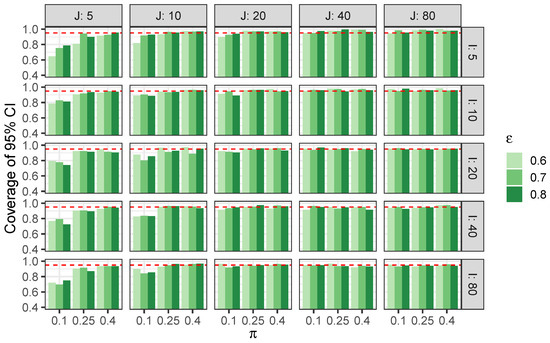
Figure 2.
Nominal coverage of 95% confidence intervals for in simulated ZIPM data. Red dashed lines represent target coverage level of 0.95.
We observe that the methods derived in Section 4 yield accurate estimates of and well-calibrated confidence intervals. Figure 1 shows that mean absolute error decreases in I, J, , and , and is generally small. The decrease in error as and increase may be attributed to the corresponding increase in sample size for the less prevalent component and the decreasing amount of zero-inflation, respectively.
Figure 2 shows that coverage hovers close to 95% for most combinations of I, J, , . We observe that error is somewhat larger and coverage is somewhat inaccurate when . However, these inaccuracies are modest given the highly-limited data availability in these simulation scenarios.
5.2. Analysis of Frigatebird Nest Counts
We study ecological count data on frigatebirds in the Coral Sea Islands off the coast of Northeast Australia, as described in [1] (The specific data studied herein was provided via email with author G. Barry Baker). They obtained counts of frigatebird nests over 11 standardized sites across 4 separate time points.
This data is relevant to our study for two reasons: First, the ecological count data is zero-inflated. Of the 44 unique combinations of sites and time points in which data was collected, 7 had 0 nests (about 15.9%). Second, the frigatebird species has two subspecies, least (LFB) and greater (GFB). In the observed data, some nests were specified as LFB nests or GFB nests, but the majority were unidentified (Table 1). We analyze counts of only unidentified frigatebird nests, , by site i and time point j (Table 2).

Table 1.
Counts of frigatebird nests by subspecies.
Table 2.
Total counts of 1158 unidentified frigatebird nests by site and time point.
We applied our work from Section 4 to the unidentified nest counts in order to estimate the ratio , where and denote the expected numbers of nests per site for the less prevalent (Based on the numbers of nests that could be identified; see Table 1). LFB and more prevalent GFB, respectively. We set for each site i in the absence of additional information on each site (To assess the sensitivity of our results to this assumption, we have run an additional analysis in which is iteratively updated during the EM algorithm. We find estimates of are nearly unchanged; see Appendix C for details). During estimation the EM algorithm was run with 1000 random initializers.
Results appear in Table 3. We estimate that 25% of nests belong to LFB (), 75% belong to GBF, and that 16% of observed nest counts are zero-inflated (). The EM algorithm yields the MLE for the ratio ; the 95% confidence interval for is (3.23, 4.08).
Table 3.
ZIPM model MLEs to study unidentified frigatebird nests.
6. Conclusions
In this paper, we studied the zero-inflated Poisson mixture (ZIPM) model in the frequentist setting. In addition to deriving an EM algorithm for point-estimation of model parameters, we stated an explicit formula for estimating standard errors of the MLEs. As a preliminary, we derived analogous results for the commonly-used, two-component Poisson mixture model. Although somewhat complex notationally, our formulae are straightforward to apply.
Our results were applied to real data on frigatebirds in the Coral Sea Islands off the coast of Northeastern Australia, where the ratio between two subspecies is of interest to ecologists. In this setting, knowledge of which species was more prevalent allows identifiability. We then used only unlabeled, zero-inflated nest count data to estimate (i) the relative abundance sites for each subspecies, (ii) the rate of zero-inflation, (iii) the mean numbers of nests per site for each subspecies, and (iv) the ratio of nests per site for each subspecies. We expect the ZIPM model to be useful in other ecological count data settings. Hence, our work provides straightforward ways for practitioners to estimate key parameters of interest.
Author Contributions
Conceptualization, M.P. and M.D.P.; methodology, M.P. and M.D.P.; software, M.P.; validation, M.P. and M.D.P.; writing—original draft preparation, M.P. and M.D.P.; writing—review and editing, M.P. and M.D.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code and data required to reproduce our analyses can be found at https://github.com/pearce790/ZIPM, accessed on 2 July 2025.
Acknowledgments
We thank the three anonymous referees for their helpful feedback during the peer review process. Furthermore, we are grateful to Barry Baker for providing the frigatebird data used in Section 5.2, and to Jon Wellner for his generous and always-insightful comments.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Conditional ZIPM = ZTP?
Consider the following two subsets of the index set and two subarrays of the data array :
Both and are random subsets, is unobserved, is observed, and , so . Because is independent of , is a random subarray of the i.n.i.d. array , where membership in depends only on . Thus is also is a (smaller) random subarray of the i.n.i.d. array , where membership in depends on both and the events .
The latter fact suggest a question: Is the conditional distribution of the two-component ZIPM rv given the same as the distribution of the mixture of the conditional distributions of the two Poisson components given that each is non-zero? The latter conditional distribution is the well-known zero-truncated Poisson (ZTP) distribution, also called positive Poisson, which has been thoroughly studied [15]. The ZTP distribution model also is an exponential family, with pmf given by
If the answer to the above question is yes, then estimation of and thus could be based on only the set of non-zero . That is, discard all 0’s and view the remaining as -mixtures of two ZTP components with parameters and . Because this involves only two mixture components rather than three as above, both being exponential families, and neither is degenerate, estimation methods such as the EM algorithm would be easier to carry out.
Unfortunately the answer to the question is no. If we abbreviate by N, by M, and by Z, then the question can be expressed as follows:
However, for ,
since M and Z are independent, so the question becomes:
After some algebra, this equation simplifies to
which cannot hold for all unless .
Appendix B. Proofs of Theorems 1 and 2
Proof of Theorem 1.
As previously noted, it follows from [12,13,14] that for large K,
From (6),
where and are defined similarly to and does not depend on . Furthermore by (6), for fixed ,
hence are conditionally independent given with
where . From (A5),
where and are defined similarly to and , and
Furthermore,
From (A6),
from which it can be shown that
Therefore
Finally, we may now estimate in the normal approximation
by replacing in by its MLE to obtain
This requires replacing by wherever the former three appear in the entries of , including in , , and . For large K the matrix is positive definite, hence invertible. □
Proof of Theorem 2.
It follows from [12,13,14] that for large K,
where is the observed information matrix. Then,
By (9),
Furthermore by (9), with fixed,
From this, are conditionally independent given and , with
and
where
Thus are conditionally independent given , with
Therefore , while
Furthermore,
Next,
Thus,
Therefore the first term in (A9) is evaluated explicitly as follows:
For the second term in (A9), it follows from (A10) and (A12) that
since and . Thus,
where . Therefore, a preliminary expression for the second term in (A9) is given by
where we used the facts that for any functions and ,
Now note that
from which it can be shown that
These four partial derivatives determine the column vector . Furthermore,
hence
where
Next, for ,
so with , we find that
Thus
where
Finally, we may estimate in the normal approximation
by replacing in by its MLE, , thereby obtaining
For large K the matrix is positive definite, hence invertible. □
Appendix C. Additional Results from Section 5
Appendix C.1. Additional Results from Section 5.1
Table A1.
Mean absolute error in estimation of across varying values of I, J, , and .
Table A1.
Mean absolute error in estimation of across varying values of I, J, , and .
| J = 5 | J = 10 | J = 20 | J = 40 | J = 80 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | |||
| 0.6 | 0.82 | 0.70 | 0.55 | 0.94 | 0.39 | 0.30 | 0.75 | 0.29 | 0.19 | 0.39 | 0.14 | 0.12 | 0.44 | 0.09 | 0.08 | ||
| 0.7 | 0.57 | 0.43 | 0.37 | 0.61 | 0.32 | 0.28 | 0.41 | 0.22 | 0.18 | 0.23 | 0.12 | 0.11 | 0.14 | 0.08 | 0.07 | ||
| 0.8 | 0.54 | 0.52 | 0.42 | 0.47 | 0.27 | 0.23 | 0.31 | 0.21 | 0.15 | 0.18 | 0.11 | 0.10 | 0.15 | 0.08 | 0.07 | ||
| 0.6 | 0.55 | 0.34 | 0.33 | 0.38 | 0.24 | 0.18 | 0.27 | 0.13 | 0.12 | 0.15 | 0.08 | 0.08 | 0.10 | 0.06 | 0.06 | ||
| 0.7 | 0.48 | 0.32 | 0.27 | 0.34 | 0.19 | 0.17 | 0.23 | 0.13 | 0.12 | 0.13 | 0.08 | 0.07 | 0.09 | 0.06 | 0.05 | ||
| 0.8 | 0.43 | 0.27 | 0.26 | 0.32 | 0.22 | 0.15 | 0.24 | 0.11 | 0.10 | 0.12 | 0.08 | 0.07 | 0.07 | 0.05 | 0.05 | ||
| 0.6 | 0.49 | 0.28 | 0.21 | 0.33 | 0.15 | 0.12 | 0.20 | 0.09 | 0.08 | 0.10 | 0.06 | 0.06 | 0.06 | 0.05 | 0.04 | ||
| 0.7 | 0.44 | 0.26 | 0.19 | 0.35 | 0.16 | 0.13 | 0.18 | 0.09 | 0.08 | 0.08 | 0.05 | 0.05 | 0.05 | 0.04 | 0.04 | ||
| 0.8 | 0.45 | 0.28 | 0.18 | 0.30 | 0.13 | 0.11 | 0.16 | 0.08 | 0.07 | 0.07 | 0.05 | 0.05 | 0.05 | 0.04 | 0.04 | ||
| 0.6 | 0.47 | 0.24 | 0.15 | 0.26 | 0.12 | 0.09 | 0.14 | 0.06 | 0.06 | 0.07 | 0.04 | 0.04 | 0.05 | 0.03 | 0.03 | ||
| 0.7 | 0.43 | 0.24 | 0.17 | 0.29 | 0.10 | 0.09 | 0.15 | 0.06 | 0.05 | 0.07 | 0.04 | 0.04 | 0.05 | 0.03 | 0.03 | ||
| 0.8 | 0.48 | 0.22 | 0.14 | 0.23 | 0.09 | 0.08 | 0.09 | 0.05 | 0.04 | 0.06 | 0.04 | 0.04 | 0.04 | 0.03 | 0.02 | ||
| 0.6 | 0.45 | 0.20 | 0.11 | 0.17 | 0.11 | 0.06 | 0.08 | 0.05 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.02 | ||
| 0.7 | 0.41 | 0.19 | 0.12 | 0.23 | 0.08 | 0.05 | 0.11 | 0.04 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.02 | ||
| 0.8 | 0.38 | 0.18 | 0.10 | 0.23 | 0.09 | 0.05 | 0.11 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.02 | ||
Table A2.
Nominal coverage of 95% confidence intervals for across varying values of I, J, , and .
Table A2.
Nominal coverage of 95% confidence intervals for across varying values of I, J, , and .
| J = 5 | J = 10 | J = 20 | J = 40 | J = 80 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | 0.1 | 0.25 | 0.4 | |||
| 0.6 | 0.65 | 0.81 | 0.92 | 0.82 | 0.93 | 0.97 | 0.90 | 0.98 | 0.97 | 0.95 | 0.98 | 0.99 | 0.94 | 0.98 | 1.00 | ||
| 0.7 | 0.75 | 0.94 | 0.93 | 0.92 | 0.96 | 0.97 | 0.93 | 0.97 | 0.97 | 0.95 | 0.98 | 0.99 | 0.98 | 0.99 | 0.98 | ||
| 0.8 | 0.79 | 0.90 | 0.96 | 0.93 | 0.96 | 0.97 | 0.94 | 0.97 | 0.96 | 0.97 | 1.00 | 0.96 | 0.96 | 0.98 | 0.98 | ||
| 0.6 | 0.79 | 0.91 | 0.93 | 0.89 | 0.94 | 0.96 | 0.91 | 0.96 | 0.98 | 0.95 | 0.98 | 0.97 | 0.98 | 0.95 | 0.98 | ||
| 0.7 | 0.83 | 0.92 | 0.95 | 0.90 | 0.93 | 0.96 | 0.95 | 0.96 | 0.94 | 0.96 | 0.98 | 0.98 | 0.95 | 0.96 | 0.96 | ||
| 0.8 | 0.81 | 0.94 | 0.94 | 0.89 | 0.94 | 0.96 | 0.89 | 0.96 | 0.95 | 0.96 | 0.94 | 0.96 | 0.98 | 0.96 | 0.96 | ||
| 0.6 | 0.80 | 0.92 | 0.95 | 0.88 | 0.97 | 0.98 | 0.92 | 0.95 | 0.96 | 0.96 | 0.94 | 0.92 | 0.96 | 0.94 | 0.94 | ||
| 0.7 | 0.78 | 0.92 | 0.91 | 0.80 | 0.91 | 0.89 | 0.91 | 0.94 | 0.96 | 0.94 | 0.95 | 0.95 | 0.96 | 0.95 | 0.96 | ||
| 0.8 | 0.74 | 0.91 | 0.90 | 0.86 | 0.93 | 0.95 | 0.90 | 0.96 | 0.93 | 0.97 | 0.96 | 0.94 | 0.94 | 0.94 | 0.96 | ||
| 0.6 | 0.77 | 0.90 | 0.93 | 0.83 | 0.95 | 0.96 | 0.91 | 0.95 | 0.93 | 0.91 | 0.95 | 0.94 | 0.94 | 0.94 | 0.98 | ||
| 0.7 | 0.79 | 0.91 | 0.95 | 0.84 | 0.96 | 0.95 | 0.93 | 0.96 | 0.97 | 0.96 | 0.93 | 0.95 | 0.95 | 0.94 | 0.98 | ||
| 0.8 | 0.73 | 0.89 | 0.94 | 0.83 | 0.96 | 0.93 | 0.95 | 0.98 | 0.96 | 0.95 | 0.94 | 0.92 | 0.92 | 0.94 | 0.95 | ||
| 0.6 | 0.72 | 0.90 | 0.94 | 0.90 | 0.93 | 0.95 | 0.97 | 0.95 | 0.95 | 0.95 | 0.97 | 0.92 | 0.96 | 0.93 | 0.94 | ||
| 0.7 | 0.70 | 0.91 | 0.94 | 0.84 | 0.95 | 0.96 | 0.92 | 0.94 | 0.96 | 0.94 | 0.94 | 0.94 | 0.93 | 0.94 | 0.96 | ||
| 0.8 | 0.75 | 0.87 | 0.94 | 0.86 | 0.96 | 0.97 | 0.93 | 0.95 | 0.96 | 0.95 | 0.94 | 0.93 | 0.94 | 0.94 | 0.94 | ||
Appendix C.2. Additional Results from Section 5.2
To assess the sensitivity of our results to the assumption that for each site , we ran a sensitivity analysis in which was iteratively updated during the E-step of the proposed EM algorithm. Specifically, we updated by maximizing (9) conditional on current estimates of , , , and at any given step of the algorithm. After estimation, estimates of were treated as fixed and known.
Results under this sensitivity analysis appear in Table A3. We notice that estimates of , , and are remarkably similar, while estimates of and are each changed by the same scale factor. Thus, we observe that our results for the parameter of interest, , are not sensitive to our choice of in this case.
Table A3.
Sensitivity analysis results when estimating in frigatebird analysis.
Table A3.
Sensitivity analysis results when estimating in frigatebird analysis.
| Parameter | (95% CI) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | 0.25 | 0.88 | 50.55 | 13.84 | 3.65 (3.22, 4.08) | ||||||
| Site (i) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 0.104 | 0.166 | 0.065 | 0.261 | 0.293 | 0.366 | 3.413 | 2.574 | 1.434 | 4.485 | 0.116 |
References
- Baker, G.B.; Holdsworth, M. Seabird monitoring study at Coringa Herald National Nature Reserve 2012; Report Prepared for Department of Sustainability, Environment, Water, Populations and Communities; Latitude 42 Environmental Consultants Pty Ltd.: Kettering, TAS, Australia, 2013. [Google Scholar]
- Bouveyron; Celeux, C.G.; Murphy, T.B.; Raftery, A.E. Model-Based Clustering and Classification for Data Science: With Applications in R; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Lindsay, B.G. Mixture Models: Theory, Geometry, and Applications; Institute for Mathematical Statistics: Hayward, CA, USA, 1995. [Google Scholar]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Martin, T.G.; Wintle, B.A.; Rhodes, J.R.; Kuhnert, P.M.; Field, S.A.; Low-Choy, S.J.; Tyre, A.J.; Possingham, H.P. Zero tolerance ecology: Improving ecological inference by modelling the source of zero observations. Ecol. Lett. 2005, 8, 1235–1246. [Google Scholar] [CrossRef] [PubMed]
- Lambert, D. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics 1992, 34, 1–14. [Google Scholar] [CrossRef]
- Lim, H.K.; Li, W.K.; Philip, L.H. Zero-inflated Poisson regression mixture model. Comput. Stat. Data Anal. 2014, 71, 151–158. [Google Scholar] [CrossRef]
- Long, D.L.; Preisser, J.S.; Herring, A.H.; Golin, C.E. A marginalized zero-inflated Poisson regression model with overall exposure effects. Stat. Med. 2014, 33, 5151–5165. [Google Scholar] [CrossRef] [PubMed]
- Jamshidian, M.; Jennrich, R.I. Standard errors for EM estimation. J. R. Stat. Soc. Ser. B 2000, 62, 257–270. [Google Scholar] [CrossRef]
- Aitken, M.; Rubin, D.B. Estimation and hypothesis testing in finite mixture models. J. R. Stat. Soc. Ser. B 1985, 47, 67–75. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Krishnan, T. The EM Algorithms and its Extensions, 2nd ed.; Wiley: New York, NY, USA, 2008. [Google Scholar]
- Hoadley, B. Asymptotic properties of maximum likelihood estimators for the independent not identically distributed case. Ann. Math. Stat. 1971, 42, 1977–1991. [Google Scholar] [CrossRef]
- Efron, B.; Hinkley, D.V. Assessing the accuracy of the maximum likelihood estimator: Observed versus expected Fisher information. Biometrika 1978, 65, 457–482. [Google Scholar] [CrossRef]
- Louis, T. Finding the observed information matrix when using the EM Algorithm. J. R. Stat. Soc. Ser. B 1982, 44, 226–233. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions, 3rd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2005. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).