Abstract
The zero-truncated Poisson distribution (ZTPD) generates a statistical model that could be appropriate when observations begin once at least one event occurs. The intervened Poisson distribution (IPD) is a substitute for the ZTPD, in which some intervention processes may change the mean of the rare events. These two zero-truncated distributions exhibit underdispersion (i.e., their variance is less than their mean). In this research, we offer an alternative solution for dealing with intervention problems by proposing a generalization of the IPD by a Lagrangian approach called the Lagrangian intervened Poisson distribution (LIPD), which in fact generalizes both the ZTPD and the IPD. As a notable feature, it has the ability to analyze both overdispersed and underdispersed datasets. In addition, the LIPD has a closed-form expression of all of its statistical characteristics, as well as an increasing, decreasing, bathtub-shaped, and upside-down bathtub-shaped hazard rate function. A consequent part is devoted to its statistical application. The maximum likelihood estimation method is considered, and the effectiveness of the estimates is demonstrated through a simulated study. To evaluate the significance of the new parameter in the LIPD, a generalized likelihood ratio test is performed. Subsequently, we present a new count regression model that is suitable for both overdispersed and underdispersed datasets using the mean-parametrized form of the LIPD. Additionally, the LIPD’s relevance and application are shown using real-world datasets.
1. Introduction
In many real-world circumstances, the researcher is unable to see the whole distribution of counts in an experiment. The ZTPD was applied in [1] to explain a chance process in which the observation apparatus only activates when at least one event occurs. A new kind of distribution that incorporates the concept of intervention has received much attention in the literature. The intervened Poisson distribution (IPD) was first developed in [2] as an alternative to the ZTPD, in which some intervention process alters the mean of the rare events. It would be interesting to look into the effects of such a decision on the queuing mechanism. For instance, a store manager might decide to offer more assistance at a service counter in order to increase the service rate. Healthcare professionals may use a range of preventive strategies in epidemiological research, such as in cholera instances. In addition to reliability analysis, queuing problems, and epidemiological research, the IPD has also been applied in other contexts (see [3,4,5]). In order to examine scenarios involving two interventions, the authors in [6] proposed and studied a modified version of the IPD, which they called the modified IPD. For prevalence reduction, the authors in [7] presented an alternative to the IPD. According to [2], one important limitation of the IPD is that it is underdispersed. There is no reason to assume that data generated by any of the aforementioned applications will necessarily share this feature. To alleviate this issue, the authors in [8] introduced a generalization of the IPD, namely the intervened generalized Poisson distribution (IGPD), which accommodates both underdispersed and overdispersed (i.e., its variance is greater than its mean) natures. However, its ability to fit some of the intervention problems is not sufficient (see [8]), which indicates that the literature still has a gap in how to deal with intervention problems. By suggesting a generalization of the IPD using a well-known Lagrangian approach and calling it the LIPD, we hope to do more to close this gap through this endeavor.
Lagrangian expansions, which were first described in [9], are the parent category of Lagrangian distributions. The discrete Lagrangian family (DLF), a large and significant class that includes many probability distributions, was introduced in [10,11]. In [11], the authors showed that, under certain conditions, all the discrete Lagrangian distributions converge to the normal and inverse Gaussian distributions. Based on these former works, the DLF has found many applications in probability and statistics; some of its recent developments are presented below. The Lagrangian Katz family was developed in [12]. The authors in [13] examined the use of Lagrangian probability distributions for the resolution of inferential issues in random mapping theory. The authors in [14] used Lagrangian probability models to create the generalized Poisson gamma dependence model. Using Lagrangian probability distributions, the authors in [15] exploited collisional turbulent fluid–particle flows. Furthermore, the authors in [16] discussed the methods for generating different classes of Lagrangian probability distributions. Our team was very impressed by the competency of the distributions proposed based on the Lagrangian method, and as a result, we proposed the Lagrangian version of ZTPD through the work published in [17]. Furthermore, the authors in [18] concentrated on the Lagrangian approach’s construction of the zero-truncated binomial distribution (ZTBD) and explained how effective it was in comparison to other zero-truncated distributions. The aforementioned relevance once more compelled us to develop solutions to intervention problems using a Lagrangian approach, which we dub the LIPD. The LIPD model was developed primarily for the following reasons: (i) to offer a flexible generalization of the parent IPD, as well as the ZTPD; (ii) to accommodate various shapes of the hazard rate function (HRF), including increasing, decreasing, bathtub, and upside-down bathtub shapes; (iii) to deal with underdispersed and overdispersed real-world datasets; and (iv) to specifically apply the real-world datasets generated from the intervention situations.
On the other hand, currently, regression models for count data are gaining much popularity. In some real-world scenarios, however, the mechanism will only activate if at least one event occurs. The number of foreign conflicts, daily mishaps, industrial casualties, and so on, are all examples. As detailed in [19], counting outcomes directly with a normal linear regression model leads to inefficient, inconsistent, and biased estimation in many cases. The zero-truncated Poisson regression model (ZTPRM) is used to analyze positive count data because it is more accurate than the classical Poisson regression model for such data. The authors in [20] recently created an alternative to the ZTPRM, called the intervened Poisson regression model (IPRM). The Lagrangian intervened Poisson regression model (LIPRM), which is an alternative to both the ZTPRM and the IPRM, is presented in this study. The motivation behind introducing the LIPRM includes its applicability for situations where the modeled data exclude zero counts, dealing with intervention problems, and its appropriateness for both underdispersed and overdispersed count datasets.
An overview of the remaining study sections is provided below: Section 2 gives a quick overview of the Lagrangian expansion and the IPD. Some important Lagrangian probability models are discussed in Section 3. In Section 4, the LIPD and its statistical features are explored. In Section 5, the maximum likelihood (ML) estimation approach is developed. A generalized likelihood ratio test is elaborated in Section 6 to examine the importance of an extra parameter of the LIPD. The simulation results of the suggested estimating method are included in Section 7. In Section 8, the LIPRM is explained. Section 9 provides empirical examples of the recommended LIPD and LIPRM. Finally, Section 10 provides the conclusion of the article.
2. Some Preliminaries
For the development of the LIPD, we present some fundamental findings in this section.
2.1. Intervened Poisson Distribution
To begin, we consider the definition of the ZTPD. Let be a random variable (RV) representing the number of occurrences of some rare event, and let us assume that the event is not observable. Then, it is plausible that follows the ZTPD with the following probability mass function (PMF):
with , for those values of on the positive integers, and zero elsewhere.
Following the generation of , it is presumable that some intervention transforms into , where . Let be an RV representing the number of instances of the rare event that occurred after the intervention. It has a Poisson RV with a mean of and is statistically independent of . Assuming that our observational device only has a record of the RV , the distribution of the total number of rare events that occurred can be assimilated to an IPD with parameters and . Then, the PMF of X is presented below.
Definition 1.
An RV X is said to follow the IPD, if its PMF is defined as:
with and .
The mean and variance of an RV X that follows the IPD are, respectively, given by
and
Remark 1.
The IPD is underdispersed, for all values of λ and ρ (see [2]).
2.2. Lagrange Expansion
In order to present the LIPD, some mathematical background on the Lagrangian expansion is required.
Let and be two analytic and successively differentiable functions with respect to z defined on the interval such that , , and . Inverting the Lagrange transformation yields the following series expansion:
where , and , with = , and .
The details can be found in [21]. Moreover, if
the Lagrange expansion (2) defines the DLF. In light of this, an RV X belonging to the DLF has the PMF shown below:
The associated probability-generating function (PGF) is generated by
where In order to learn more about this special class, see [21,22].
3. Some Important Members of Discrete Lagrangian Family
Many DLF members can be generated by taking the following exponential function:
with and various choices of the functions for in (4). Some of them are discussed below:
3.1. Sudha Lagrangian Distribution
Let us take as in (6) and . Based on (4), the PMF of the considered distribution can be derived as:
which is the PMF of the Sudha Lagrangian distribution (see [23]).
3.2. Weighted Delta Poisson Distribution
More generally, if we take as in (6) and with , the PMF based on (4) is obtained as:
which corresponds to the PMF of the weighted delta Poisson distribution (see [23]).
3.3. Linear Function Poisson Distribution
If we take as in (6) and with , the PMF based on (4) is obtained as:
which corresponds to the PMF of the linear function Poisson distribution (see [23]).
3.4. Logarithmic Poisson Distribution
If we take as in (6) and with , the PMF based on (4) is obtained as:
which corresponds to the PMF of the logarithmic Poisson distribution (see [23]).
Given the applications of the DLF created with and modulating , it is worthwhile to investigate other horizon distributions. This served as the foundation for the amended study distribution, which is displayed below.
4. Lagrangian Intervened Poisson Distribution
In this section, the definition of the new distribution and some of its primary characteristics are described.
Suppose
so that is the PGF of the IPD (see [2]) with and .
The corresponding analytic functions given in (7) satisfy the conditions given in Section 2.2, are completely new in this context, and benefit from interesting functionalities for modeling purposes. Then, under the following transformation: , we have
From the above expression, it is clear that the condition given in (3) is satisfied. Then, using (4), the corresponding PMF of the LIPD can be derived as:
We formalize this definition below.
Definition 2.
A RV X is said to follow the LIPD, if its PMF has the following form:
where , , and .
A distribution with the PMF given in (8) will be sometimes denoted as LIPD (). In addition, the RV X that will appear is supposed to follow this distribution. Some special cases are described below:
- For , the LIPD () reduces to the IPD.
- For and , the LIPD () reduces to the ZTPD.
Figure 1, Figure 2 and Figure 3 display the graphical representation of the PMF of the LIPD for different parameter values of , , and , respectively.
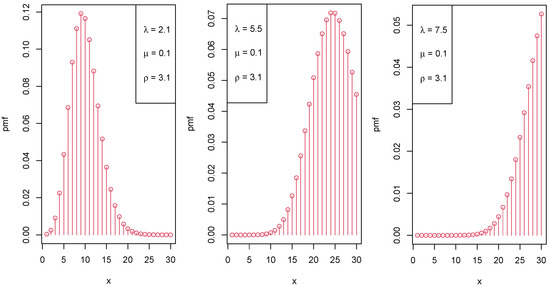
Figure 1.
Various shapes of the PMF of the LIPD when increases.
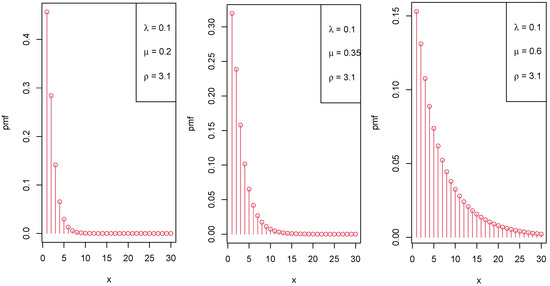
Figure 2.
Various shapes of the PMF of the LIPD when increases.
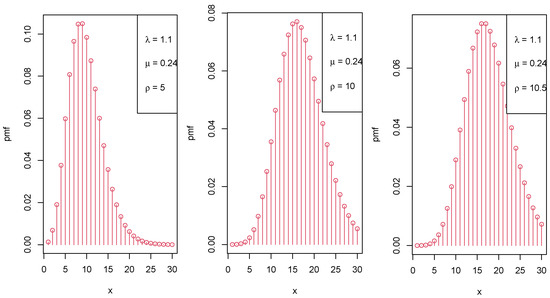
Figure 3.
Various shapes of the PMF of the LIPD when increases.
The HRF of the LIPD is obtained by substituting the PMF in the following equation:
It is obvious from (9) that finding the closed-form expression of the HRF is difficult. To identify the diverse forms of the HRF, we draw the corresponding graph in Figure 4.
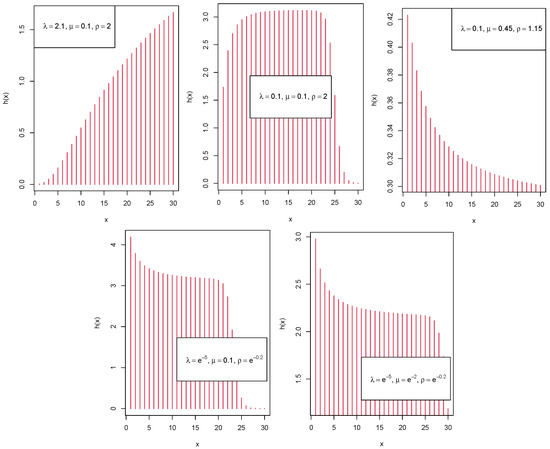
Figure 4.
Plots of the HRF of the LIPD distribution.
Figure 4 shows that the LIPD has an increasing, decreasing, bathtub, and upside-down bathtub-shaped HRF.
Proposition 1.
Let X be an RV following the LIPD. Then, the mode of X, denoted by , exists and lies in the following case:
.
Proof.
According to the definition of a mode in a discrete distribution setting, we must find the integer for which has the greatest value. That is, we aim to solve the following inequalities: and , where can also be written as:
where .
Obviously, implies that
Furthermore, implies that
By combining (12) and (13), we obtain (10). □
Proposition 2.
The PGF of an RV X following the LIPD is expressed as
where with .
Proof.
By virtue of (5), we immediately get
where . Thus, the proof is obtained. □
Corollary 1.
The moment-generating function (MGF) of an RV X following the LIPD is obtained by putting and in (14), and we obtain
where with .
Corollary 2.
The cumulant-generating function (CGF) of an RV X following the LIPD becomes
where with .
Proposition 3.
Let be n independently and identically distributed (IID) RVs following the LIPD. Then, the distribution of the sample sum has the following PGF:
where .
Proof.
Based on the PGF of the LIPD given in (14), the PGF of the RV V becomes
This completes the proof. □
Proposition 4.
For any integer , the rth factorial moment of an RV X following the LIPD is given by
where .
Proof.
By definition, the rth factorial moment is obtained by successively differentiating given in (5) in r times with respect to u and by putting . Thus, it is given by
implying that
Taking the first derivative with respect to u on both sides, we obtain
Again, by taking the derivative of (16) with respect to u on both sides, we obtain
Proceeding like this, we obtain that the rth derivative is of the following form:
Substituting , , and in (17), we obtain (15). □
Proposition 5.
The mean () and variance () of an RV X following the LIPD are
and
respectively.
Proof.
The first two factorial moments can be obtained by using (15) as follows:
and
Furthermore, we have
where denote the values of the successive derivatives of and , respectively, evaluated at the special value , hence the proof. □
Proposition 6.
The index of dispersion (InD) and coefficient of variation (CoV) of an RV X following the LIPD are
and
respectively.
Proof.
The proof is omitted for the sake of brevity. □
The skewness and kurtosis coefficients are employed, respectively, to measure the asymmetry and flatness of a distribution. These coefficients are required to determine the shape of any distribution. The mean, variance, CoV, InD, skewness, and kurtosis of X for different values of the parameters are summarized in Table 1.

Table 1.
Mean, variance, CoV, InD, skewness, and kurtosis coefficients of the LIPD distribution for different values of the parameters.
It can be seen from Table 1 that the LIPD is both underdispersed (InD < 1) and overdispersed (InD > 1). It should be noted that the LIPD has various kurtosis levels and is mostly right-skewed.
5. Estimation
Here, we use the maximum likelihood (ML) method to estimate the parameters of the LIPD via data because these parameters are intended to be unknown in practice.
Let be n IID RVs from the LIPD() (with unknown , , and ) and be n observations. Following that, the appropriate likelihood function is provided by
Therefore, the log-likelihood function is given by
The values , , and obtained by maximizing with respect to , , and , respectively, are the ML estimates (MLEs). Upon differentiating the log-likelihood function given in (18) with respect to the parameters , , and , respectively, and equating to zero, we obtain the following likelihood equations:
and
The MLEs , , and are the solutions of these equations.
Here, in order to obtain these MLEs, we maximize the log-likelihood function for numerical optimization. In this study, the “L-BFGS-B” optimization technique of the fitdist function defined in the fitdistrplus package of the R programming software is employed for numerical optimization purposes. For more information on the package fitdistrplus, one can go through the link “https://CRAN.R-project.org/package=fitdistrplus (accessed on 5 November 2022)”.
6. Generalized Likelihood Ratio Test
In this section, we employ the generalized likelihood ratio test (GLRT) to examine the importance of an extra parameter included in the LIPD. See [24] for more information.
To test whether the additional parameter of the LIPD () is significant, we use the GLRT method. Here, the considered hypotheses are
In the case of the GLRT, the test statistic is given as:
where is the MLE of under the hypothesis . The test statistic shown in (19) is asymptotically distributed as the chi-squared distribution with one degree of freedom.
7. Simulation Study
To evaluate the performance of the estimates obtained using the ML estimation approach, we ran a quick simulation exercise in this section. Here, we simulated an LIPD random sample of values using the inverse transformation method (see [25]). The following is the inverse transform algorithm for generating such a sample:
- Step 1:
- Generate a random number from uniform distribution .
- Step 2:
- , , and , where p is the probability that and F is the probability that X is less than or equal to i.
- Step 3:
- If , set , and stop.
- Step 4:
- ×, , .
- Step 5:
- Go to Step 3.
The iteration process is repeated times. The specification of the parameter values is as follows:
- (i)
- , , ;
- (ii)
- , , .
Thus, we compute the average of the mean-squared error (MSE) and average absolute bias using the MLEs.
The average absolute bias of the obtained estimates is equal to , and the average MSE of the obtained estimates is equal to , in which i is the number of iterations, , and is the MLE of .
Table 2 provides a summary of the study for the samples of sizes 50, 125, 500, and 1000. As the sample size increases, it can be seen that the MSE in both cases of the parameter sets is in decreasing order, and the MLEs of the parameters go closer to their original parameter values, indicating the consistency property of the MLEs.
Table 2.
The MLE simulation results for the three parameters , and .
8. Lagrangian Intervened Poisson Regression Model
When modeling a discrete response variable with related variables, a Poisson regression model is the first thing that immediately comes to mind. It is clear that the Poisson regression model generates inaccurate results when the response variable is either overdispersed or underdispersed, with the exception of the situation of equidispersion. Mixed Poisson models, generalized Poisson models, and other models have all been put out to deal with these dispersions. However, there are many instances where count data do not contain any zeros; the authors in [26,27] provided examples using data on hospital stay length. The ZTPRM performed admirably in this situation. We now present the LIPRM, a novel count regression model based on the LIPD that offers additional choices for predicting overdispersed and underdispersed zero-truncated counts. In this paper, we consider the National Health Insurance Scheme (NHIS) data of Nigeria, which is overdispersed. For these data, we can see that the LIPRM performs well when compared to the ZTPRM, zero-truncated negative binomial regression model (ZTNBRM), and IPRM.
We can use the log-link function to link the covariates, say of the number of k, to the mean of the response RV X as:
where is the vector of k covariates and is the unknown vector of regression coefficients. Now, by considering the notations involved for the LIPD() and the following re-parametrization:
where , , the PMF of the LIPD can be re-expressed as:
Based on n independent observations of the regression model, say , and substituting (20) in (21), follows the LIPRM(), where , with the following PMF:
where
The log-likelihood function of the LIPRM based on a sample of n independent observations is expressed as
In this study, we employed the optim function in the R programming language under the L-BFGS-B algorithm to determine the MLEs of the parameters, just as we did in Section 5.
9. Applications and Empirical Study
To show the usage of the LIPD, we utilize three real datasets in this section: The first is the well-known intervened data (student enrollment) used by [8] to prove the performance of the IGPD. The second is the COVID-19 data, and the third is the NHIS data. The form of the HRF of the datasets was determined using a graphical method based on the total time on test (TTT). The associated HRF has a decreasing, increasing, or upside-down bathtub shape if the empirical TTT plot is convex, concave, convex then concave, or concave then convex, respectively (see [28]). We employed the RStudio software for numerical evaluations of these datasets.
9.1. Student Enrollment Data
The following data were collected over a five-year period regarding student enrollment, in particular senior Mathematics and Statistics courses at the University of Calgary: 1, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 9, 9, 9, 9, 9, 13, 13, 14, 16, 16, 17, 17, 17, 18, 19, 20, 24, 24, 24, 24, 27, 31, 33, 35, 37.
These data are available in [4], and the author in [8] examined them as well. Students enrolled in these courses either during an advanced registration period, which was restricted, or during a subsequent open registration period, which was unrestricted. A course must have been offered if at least one student enrolled in it during the advanced registration period. Therefore, it is appropriate to take into account the LIPD model. Table 3 shows the descriptive measures of the data, which include sample size n, minimum (min), first quartile (), median (Md), third quartile (), maximum (max), and interquartile range (IQR). The empirical InD of the data is equal to . As a result, our model employed to describe the current dataset is capable of dealing with overdispersion.
Table 3.
Descriptive statistics for the student enrollment dataset.
In addition, Figure 5 shows an empirical TTT plot of the data, and it reveals an increasing HRF.
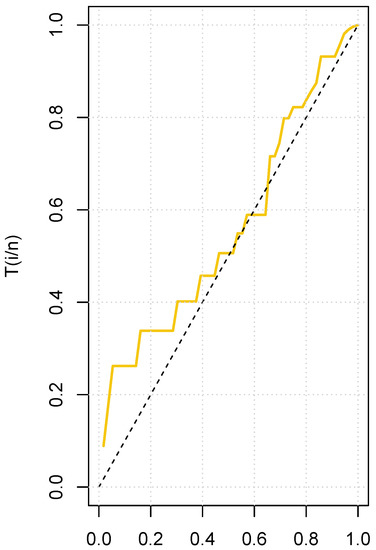
Figure 5.
TTT plot for the student enrollment dataset.
To demonstrate the LIPD’s potential benefit, the distributions given in Table 4 were considered for comparison.
Table 4.
The considered competitive distributions.
We compare the competitive distributions to the recommended distribution using the statistical methods presented, specifically the negative log-likelihood (−logL), Akaike information criterion (AIC), Bayesian information criterion (BIC), and statistic. The corresponding MLEs and goodness-of-fit (GOF) results are shown in Table 5. According to Table 5, the LIPD’s GOF statistical values are lower than those of the other distributions under consideration. Therefore, the proposed model is the best choice for analyzing the provided intervention dataset.
Table 5.
MLEs and GOF values for the student enrollment dataset.
In the case of the GLRT, the calculated value based on the test statistic in (19) is (p-value ). As a result, at any level , the null hypothesis is rejected in favor of the alternative hypothesis. Hence, we conclude that the additional parameter in the LIPD is significant in light of the test procedure outlined in Section 6.
9.2. COVID-19 Dataset
In 2019, a fresh coronavirus (COVID-19) was found in Wuhan, China. After identifying such a virus, it spread rapidly on a daily basis. To stop the virus from spreading further, various preventive actions (treatment interventions) were taken by health service agencies. Due to various interventions, we would be able to control the very large spread to some extent. Here, we consider a dataset of daily newly reported COVID-19 instances from Rwanda in East Africa, recorded between 11 October 2021 and 15 December 2021. Since the data were collected at the end of 2021, we may assume that several treatment interventions have already been applied, and hence, it is reasonable to assume the LIPD for the dataset. The data are as follows: 98, 46, 95, 86, 61, 80, 61, 17, 36, 32, 39, 36, 37, 29, 20, 57, 43, 42, 51, 63, 53, 17, 29, 38, 55, 34, 44, 33, 16, 31, 22, 19, 28, 35, 43, 11, 12, 16, 19, 7, 6, 11, 10, 15, 23, 22, 26, 8, 14, 5, 14, 5, 13, 19, 10, 13, 10, 15, 20, 15, 53, 39, 28, 50, 79, 50.
These data are accessible at http://covid19.who.int/data (accessed on 24 August 2022). Table 6 shows the descriptive measures of the data. The empirical InD of the data is equal to . As a result, our model employed to describe the current dataset is capable of dealing with overdispersion.
Table 6.
Descriptive statistics for the COVID-19 dataset.
In addition, Figure 6 shows an empirical TTT plot of the data, which reveals an increasing HRF.
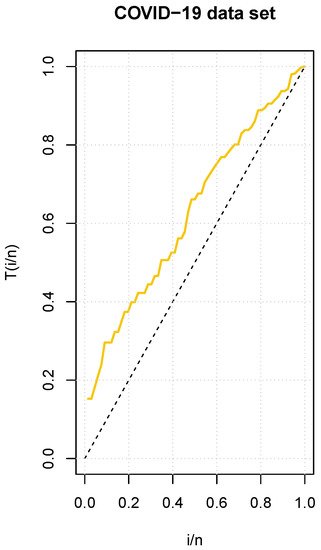
Figure 6.
TTT plot for the COVID-19 dataset.
We compare the competitive distributions to the suggested distribution using the statistical techniques provided, specifically the , AIC, BIC, and statistic value. Table 7 displays the corresponding MLEs and GOF results, respectively. The LIPD’s MLEs and GOF statistic values are less than the other examined distributions. As a result, the suggested model is the most appropriate for modeling the given intervention dataset. Furthermore, the LIPD provides information on how effective various preventive actions taken by health service agencies were.
Table 7.
MLEs and GOF values for the COVID-19 dataset.
In the case of the GLRT, the calculated value based on the test statistic in (19) is (p-value ). As a result, at any level , the null hypothesis is rejected in favor of the alternative hypothesis. Hence, we conclude that the additional parameter in the LIPD is significant in light of the test procedure outlined in Section 6.
9.3. National Health Insurance Scheme
Data from the NHIS with no zero counts were collected from a health facility in Ota, Ogun State, Nigeria, for this study. A sample of 1647 patients under the NHIS was obtained from July 2016 to July 2017. There have been encounters (visits to the doctor), which is the response variable (Nencounter). If a patient was ever admitted for the period, it was indicated by the class (Eclass), which reads (in-patient = 1, out-patient = 0). The predictor (follow-up) indicates whether a patient received routine checkups or not (follow-up = 1, no follow-up = 0). The gender (sex) of the patients reads (male = 1, female = 0). Another predictor was Ndiagnosis, which represents the number of diagnoses a patient had during the period of the encounter. The last predictor included was the biological age of the patient. The data can be found on the Mendeley Elsevier website, https://data.mendeley.com/datasets/z7wznk53cf/8 accessed on 15 November 2022. Furthermore, the dataset was utilized in [29], and the authors found that, following the dispersion test, the data were underdispersed with some dispersion parameter, . For , the fit non-linear regression model is given by
The following regression models were used to compare the LIPRM:
- The ZTPRM given in [30].
- The ZTNBRM created in [31].
- The IPRM elaborated in [20].
Table 8 compares the performance of the LIPRM to that of the ZTPRM, ZTGPRM, and IPRM, as well as provides real-world summaries, such as the standard errors (SEs), p-values, negative log-likelihood (), AIC, and BIC values. According to this table, the LIPRM has the lowest values across all model selection criteria, indicating that it is the best count regression model among the ZTPRM, ZTGPRM, and IPRM. Evidently, we also find that our model, which is applied to explain the current dataset, is perfectly suited to handling this underdispersion.
Table 8.
The results of the regression models for the NHIS of Nigeria (SEs in brackets).
10. Conclusions
The LIPD, which extends the IPD and may be either underdispersed or overdispersed, was described using the Lagrangian method. There are a number of important LIPD characteristics that were identified, and it was found that they are more flexible than the IPD characteristics. We delivered specific expressions for the factorial moments: mean, variance, dispersion, skewness, kurtosis, mode, probability-generating function, moment-generating function, and cumulant-generating function. Using the classical ML method, the distribution parameters were determined. The LIPD was compared to the well-known IPD, IGPD, and some other competing distributions, and it was found that the LIPD was superior to competing models for the considered datasets. A new regression model for count data based on the LIPD was proposed and compared with its competitive regression models based on a real dataset. Three different real-world datasets—the first involving student enrollment data, the second involving COVID-19 data, and the third involving data from a health insurance scheme—were combined to show how the novel model may be applied.
Author Contributions
Conceptualization, M.R.I., M.M., C.C., R.M. and D.S.S.; methodology, M.R.I., M.M., C.C., R.M. and D.S.S.; software, M.R.I., M.M., C.C., R.M. and D.S.S.; validation, M.R.I., M.M., C.C., R.M. and D.S.S..; formal analysis, M.R.I., M.M., C.C., R.M. and D.S.S.; investigation, M.R.I., M.M., C.C., R.M. and D.S.S.; data curation, M.R.I., M.M., C.C., R.M. and D.S.S.; writing—original draft preparation, M.R.I., M.M., C.C., R.M. and D.S.S.; writing—review and editing, M.R.I., M.M., C.C., R.M. and D.S.S.; visualization, M.R.I., M.M., C.C., R.M. and D.S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cohen, A.C. Estimating parameters in a conditional Poisson distribution. Biometrics 1960, 16, 203–211. [Google Scholar] [CrossRef]
- Shanmugam, R. An intervened Poisson distribution and its medical application. Biometrics 1985, 41, 1025–1029. [Google Scholar] [CrossRef]
- Shanmugam, R. An inferential procedure for the Poisson intervention parameter. Biometrics 1992, 48, 559–565. [Google Scholar] [CrossRef]
- Huang, M.; Fung, K.Y. Intervened truncated Poisson distribution. Sankhya Ser. B 1989, 51, 302–310. [Google Scholar]
- Dhanavanthan, P. Estimation of the Parameters of Compound Intervened Poisson Distribution. Biom. J. 2000, 42, 315–320. [Google Scholar] [CrossRef]
- Kumar, C.S.; Shibu, D.S. On finite mixtures of modified intervened Poisson distribution and its applications. J. Stat. Theory Appl. 2014, 13, 344–355. [Google Scholar] [CrossRef]
- Singh, B.P.; Dixit, S.; Shukla, U. An Alternative to Intervened Poisson Distribution for Prevalence Reduction. J. Math. Stat. Sci. 2016, 2016, 730–740. [Google Scholar]
- Scollnik, D. On the Intervened Generalized Poisson Distribution. Commun. Stat.-Theory Methods 2006, 35, 953–963. [Google Scholar] [CrossRef]
- Lagrange, J.L. Mécanique Analytique; Jacques Gabay: Paris, France, 1788. [Google Scholar]
- Consul, P.C.; Shenton, L.R. Use of Lagrange expansion for generating generalized probability distributions. SIAM J. Appl. Math. 1972, 23, 239–248. [Google Scholar] [CrossRef]
- Consul, P.C.; Shenton, L.R. Some interesting properties of Lagrangian distributions. Commun. Stat. 1973, 2, 263–272. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. Lagrangian Katz family of distributions. Commun. Stat. Theory Methods 1996, 25, 415–434. [Google Scholar] [CrossRef]
- Berg, K.; Nowicki, K. Statistical inference for a class of modified power series distribution with applications to random mapping theory. J. Stat. Plan. Inference 1991, 28, 247–261. [Google Scholar] [CrossRef]
- Li, S.; Black, D.; Lee, C.; Famoye, F. Dependence Models Arising from the Lagrangian Probability Distributions. Commun. Stat.-Theory Methods 2010, 29, 1729–1742. [Google Scholar] [CrossRef]
- Innocenti, A.R.; Fox, O.; Chibbaro, S. A Lagrangian probability density-function model for collisional turbulent fluid-particle flows. J. Fluid Mech. 2019, 862, 449–489. [Google Scholar] [CrossRef]
- Brito, D.; Rego, L.; Oliveira, D.; Gomes-Silva, F. Method for generating distributions and classes of probability distributions: The univariate case. Hacet. J. Math. Stat. 2019, 48, 897–930. [Google Scholar]
- Irshad, M.R.; Chesneau, C.; Shibu, D.S.; Monisha, M.; Maya, R. Lagrangian Zero Truncated Poisson Distribution: Properties Regression Model and Applications. Symmetry 2022, 14, 1775. [Google Scholar] [CrossRef]
- Irshad, M.R.; Chesneau, C.; Shibu, D.S.; Monisha, M.; Maya, R. A Novel Generalization of Zero-Truncated Binomial Distribution by Lagrangian Approach with Applications for the COVID-19 Pandemic. Stats 2022, 5, 1004–1028. [Google Scholar] [CrossRef]
- Long, J.S.; Freese, J. Regression Models for Categorical Dependent Variables Using Stata, 2nd ed.; Stata Press: College Station, TX, USA, 2005. [Google Scholar]
- Shibu, D.S. On intervened Poisson Distribution and Its Generalization. Ph.D. Thesis, University of Kerala, Thiruvananthapuram, India, 2013. submitted. [Google Scholar]
- Janardan, K.G.; Rao, B.R. Lagrangian distributions of second kind and weighted distributions. SIAM J. Appl. Math. 1983, 43, 302–313. [Google Scholar] [CrossRef]
- Janardan, K.G. A wider class of Lagrange distributions of the second kind. Commun. Stat.-Theory Methods 1997, 26, 2087–2097. [Google Scholar] [CrossRef]
- Consul, P.C.; Famoye, F. Lagrangian Probability Distributions; Birkhäuser: Boston, MA, USA, 2006. [Google Scholar]
- Rao, C.R. Minimum variance and the estimation of several parameters. Math. Proc. Camb. Philos. Soc. 1947, 43, 280–283. [Google Scholar] [CrossRef]
- Ross, S. Simulation, 5th ed.; Academic Press: Cambridge, MA, USA, 2013; pp. 5–38. [Google Scholar] [CrossRef]
- Hilbe, J.M. Negative Binomial Regression; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Hardin, J.; Hilbe, J. Generalized Linear Models and Extensions, 2nd ed.; A Stata Press Publication; StatCorp LP: College Station, TX, USA, 2007. [Google Scholar]
- Aarset, M.V. How to identify a bathtub hazard rate. IEEE Trans Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Adesina, O.; Agunbiade, A.; Oguntunde, P.; Adesina, T. Bayesian Models for Zero Truncated Count Data. Asian J. Probab. Stat. 2019, 4, 1–12. [Google Scholar] [CrossRef]
- Zhao, W.; Feng, Y.; Li, Z. Zero-truncated generalized Poisson regression model and its score tests. J. East China Norm. Univ. (Nat. Sci.) 2010, 1, 17–23. [Google Scholar]
- Grogger, J.T.; Carson, R.T. Models for Truncated Counts. J. Appl. Econom. 1991, 6, 225–238. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).