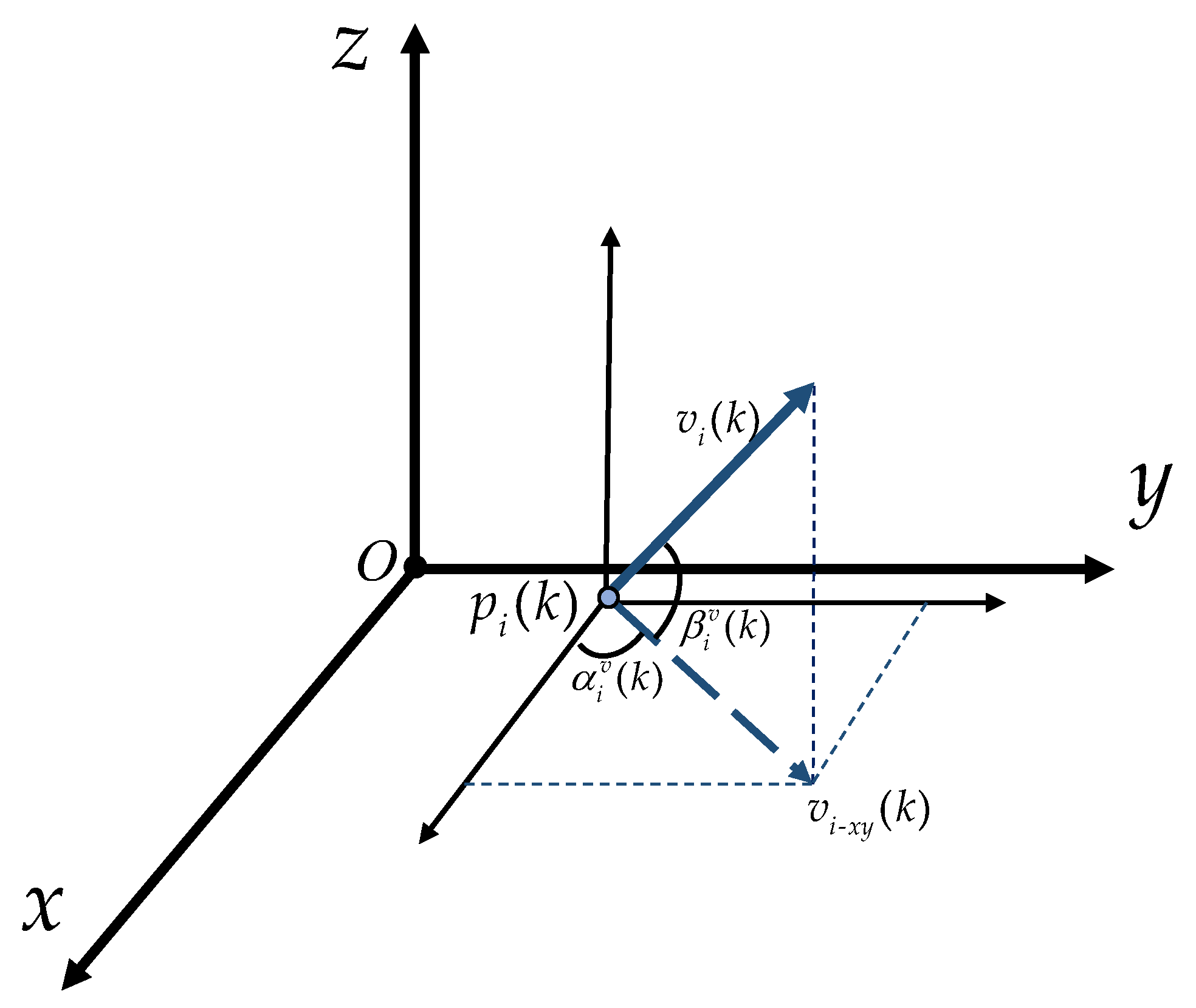
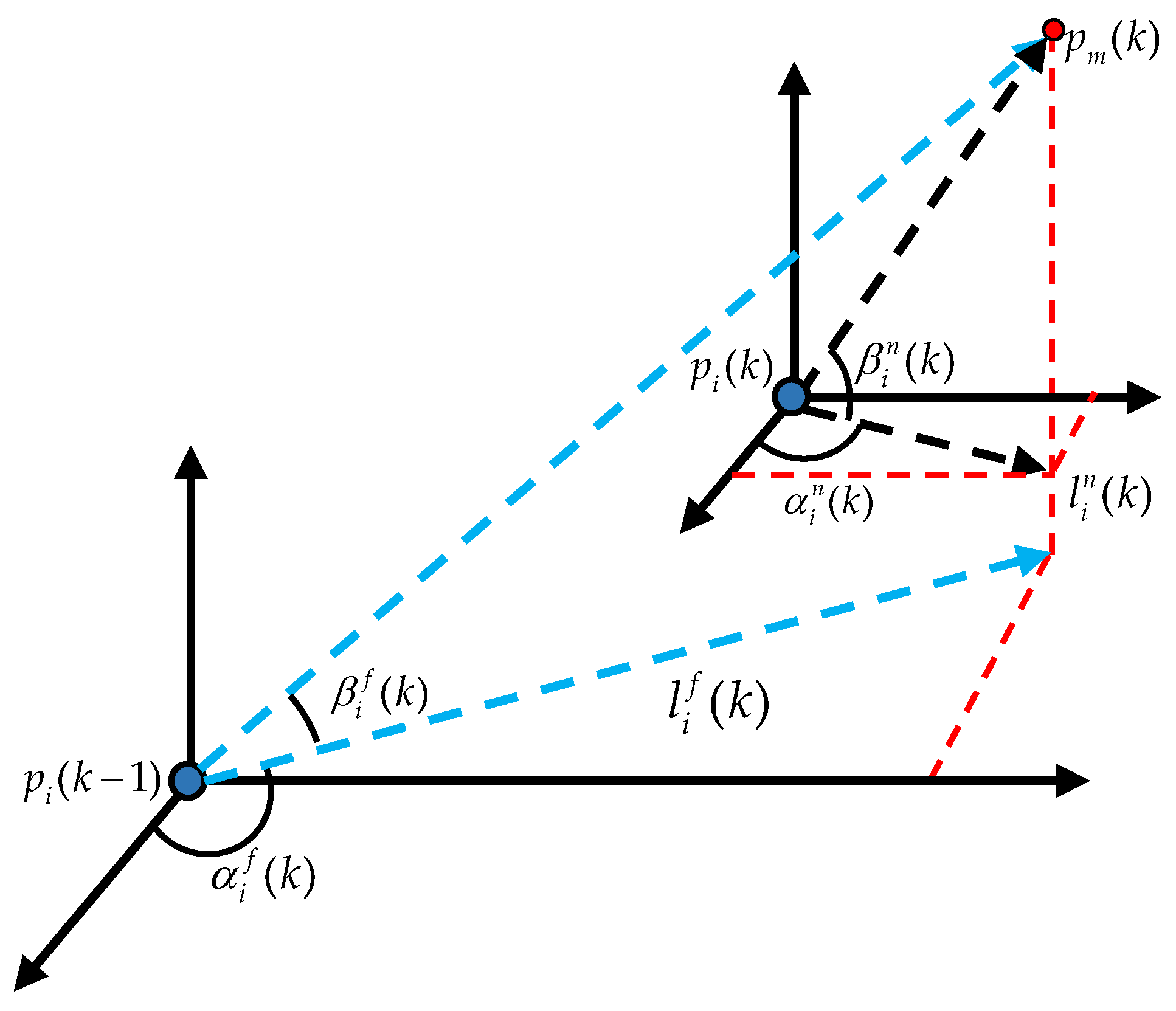
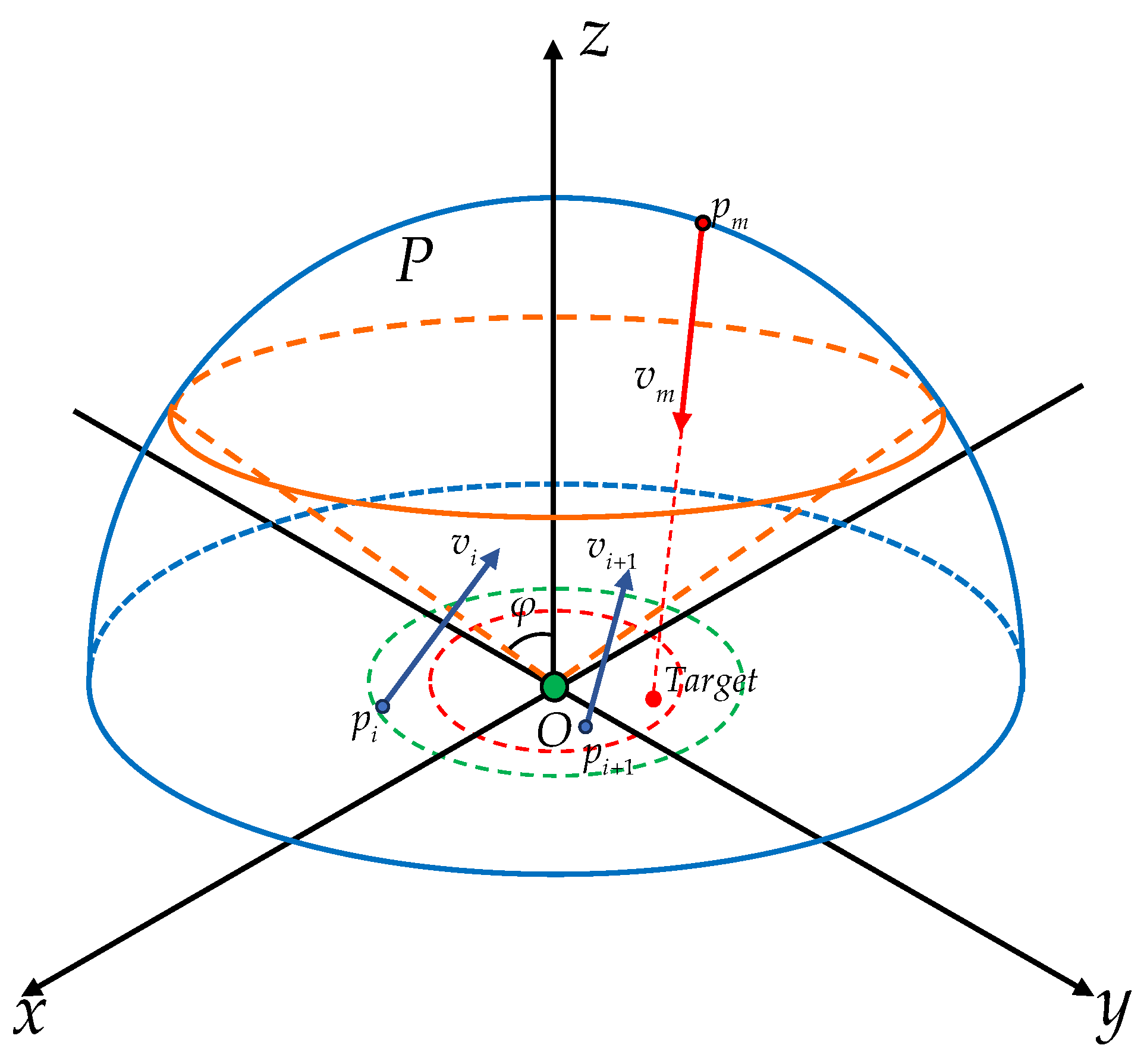
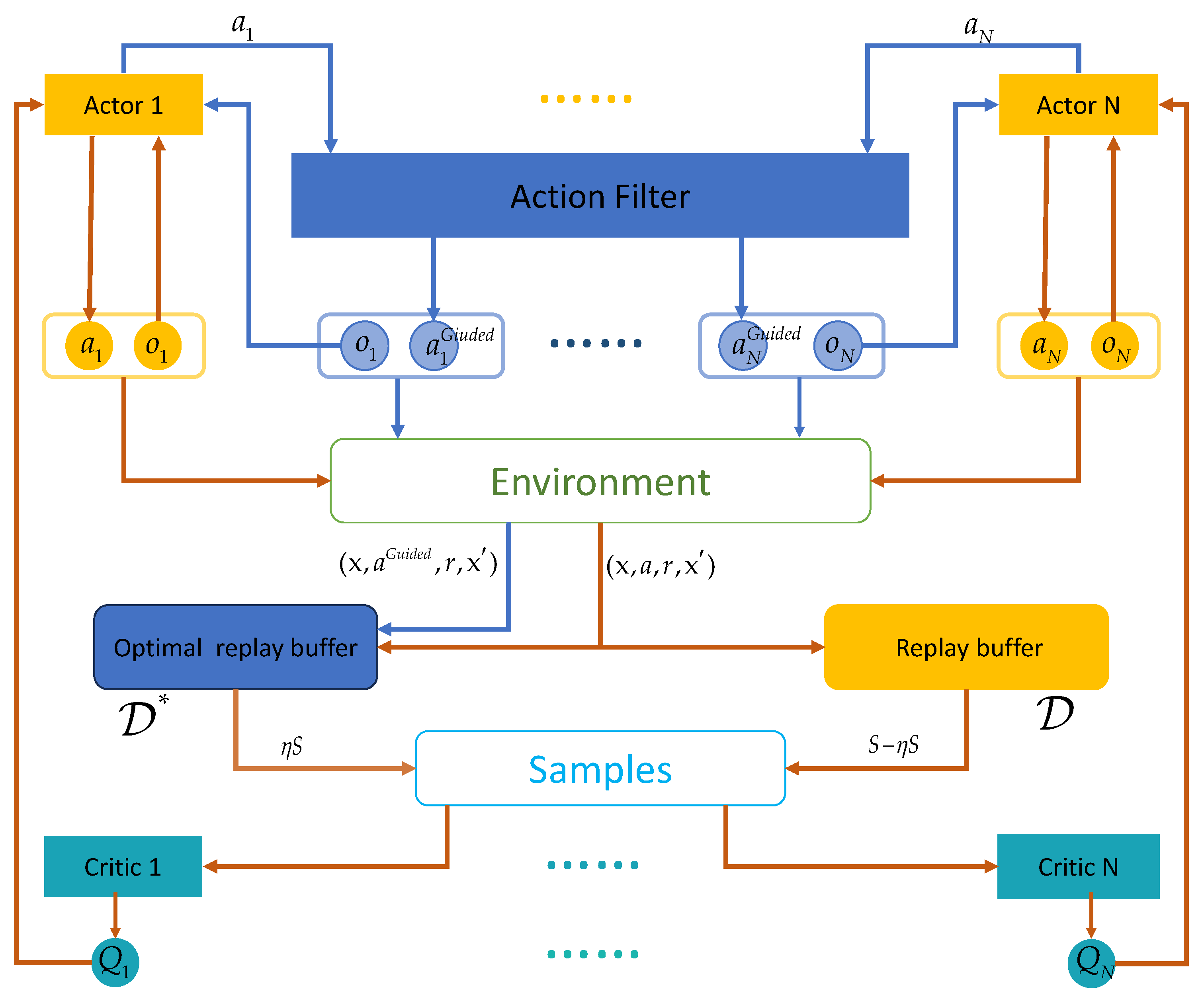
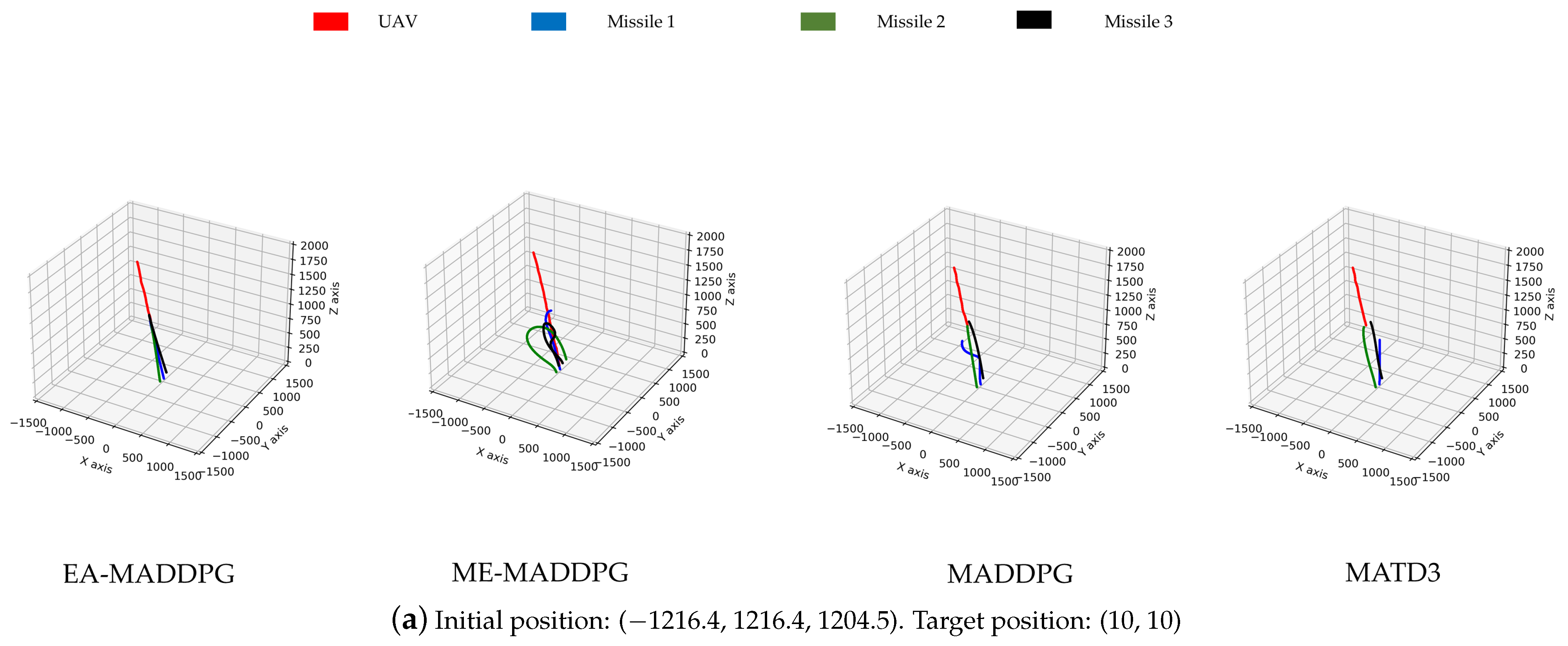
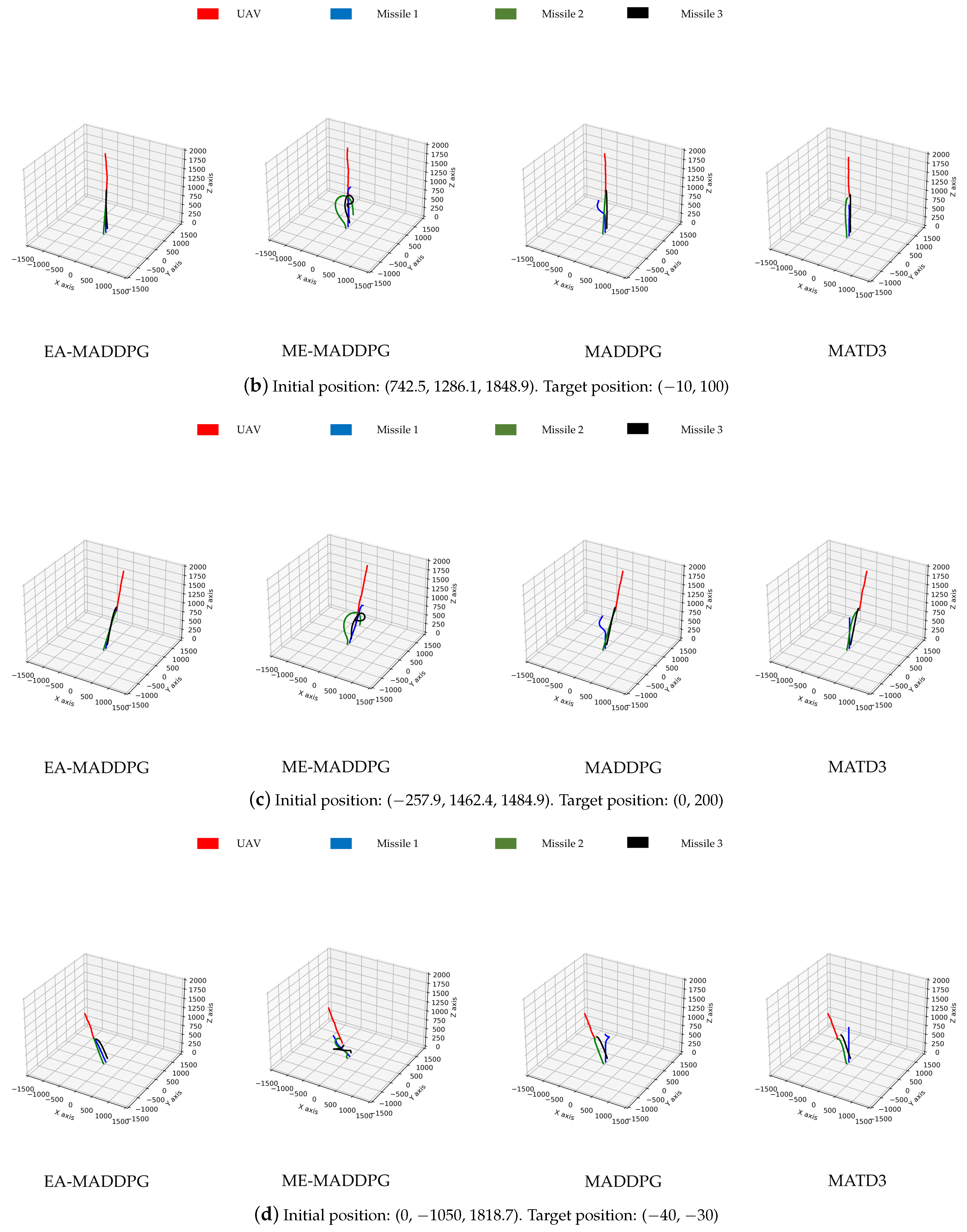
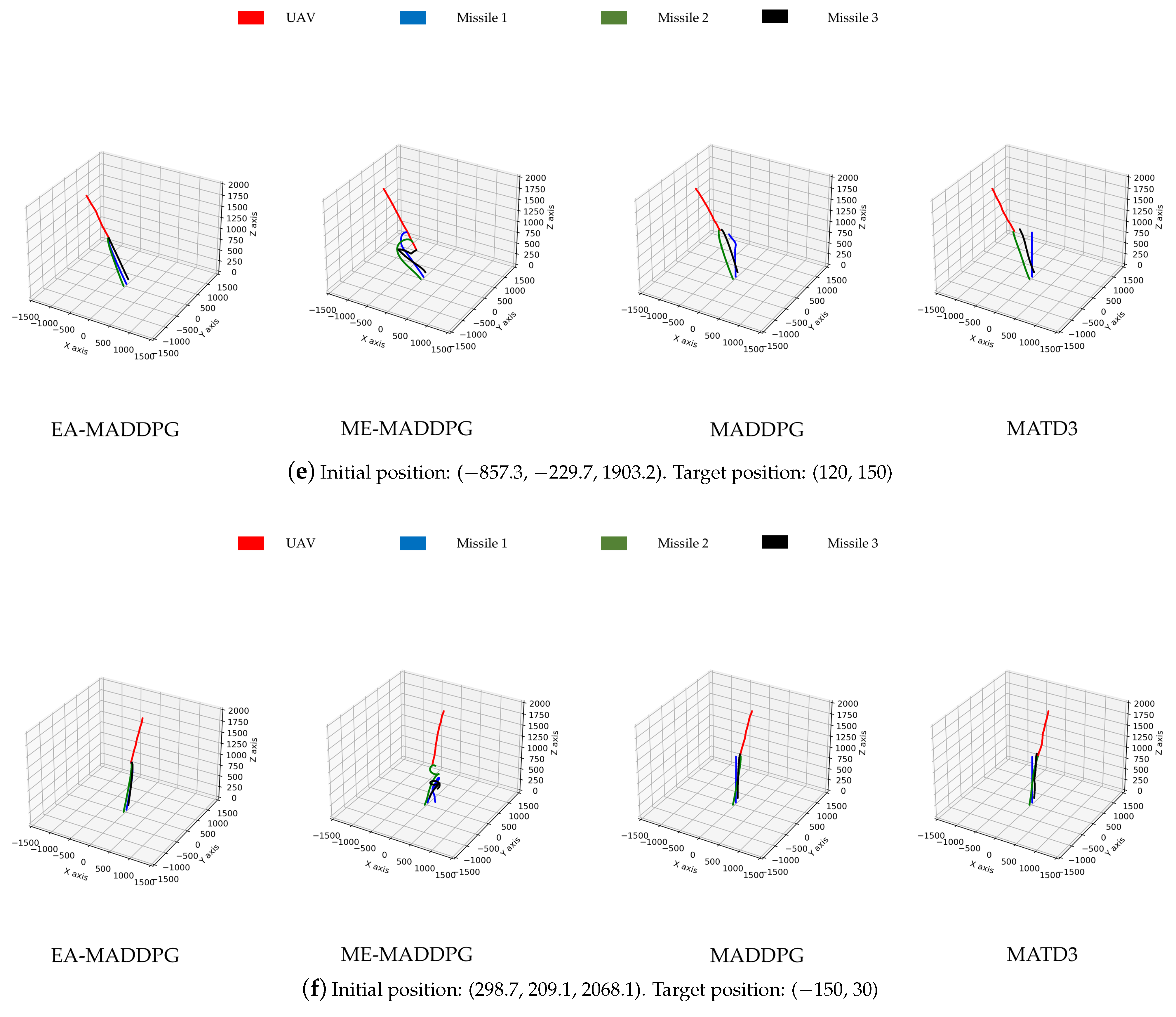
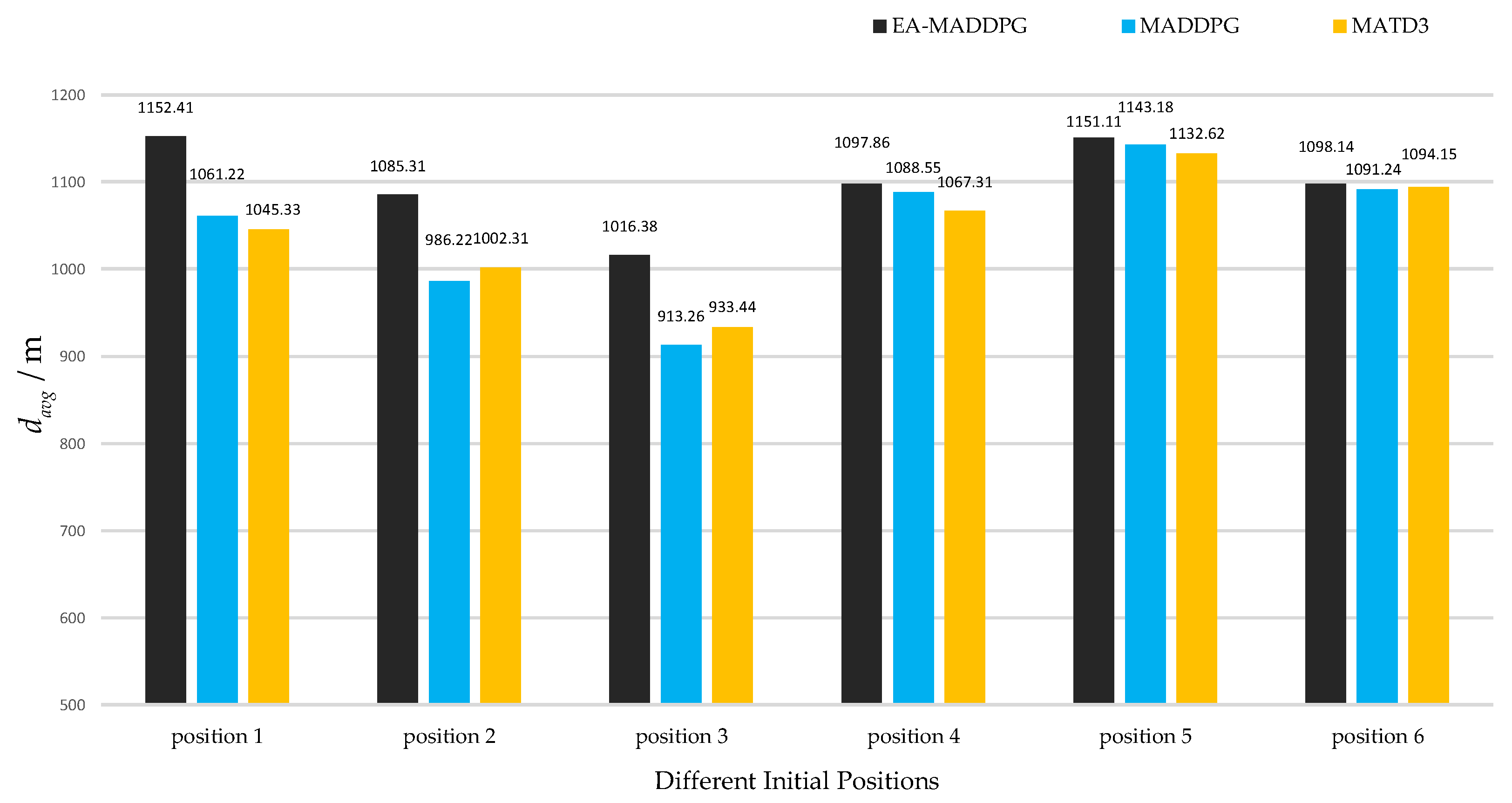
Unmanned aerial vehicles (UAVs), especially drones, have been widely applied and played a key role in several local wars due to their low cost, flexible maneuverability, strong concealment, and ability to perform tasks in harsh environments. Although drone technology has shown great potential in areas such as reconnaissance, logistics, and environmental monitoring, its security issues have also raised widespread concern, especially how to effectively address the threat of hostile drones [
1]. Therefore, the study of UAV interception is essential, especially in the context of the rapid development and widespread application of UAV technology today.
The algorithms are mainly divided into two major categories: rule-based approaches [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11] and learning-based approaches [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. Within these categories, the methods can be further divided into single and multiple types. Single interception guidance methods: Command to line-of-sight guidance adjusts the interceptor’s path based on external commands, precisely controlling the interception process [
4]. Optimal guidance designs guidance laws by minimizing a cost function to find the best path under given performance metrics [
5]. Augmented proportional navigation adjusts the guidance gain to adapt to different interception conditions, enhancing efficiency against high-speed or highly maneuverable targets [
6]. Predictive guidance adjusts the flight path of the interceptor based on predictions of the target’s movements, combating fast-maneuvering targets [
7]. Multiple interception guidance methods: The leader–follower strategy involves one UAV acting as the leader, formulating the interception strategy, while the other UAVs follow and execute the plan, simplifying the decision-making process and ensuring team actions are synchronized [
8]. The coordinated attack strategy requires high coordination among UAVs to determine the best angles and timings for the attack, effectively utilizing the team’s collective strength to increase the success rate of interceptions [
9]. The sequential or alternating attack strategy allows UAVs to attack in a predetermined order or timing, maintaining continuous pressure on the target and extending the duration of combat [
10]. The distributed guidance strategy enables each UAV to make independent decisions based on overall team information, enhancing the team’s adaptability and robustness, suitable for dynamic battlefield environments [
11].
In recent decades, the rapid development and success of reinforcement learning have made it an ideal tool for solving complex problems, particularly in the field of UAV interception applications. The development of single-agent reinforcement learning algorithms began in the early 1980s, with initial explorations focusing on simple learning control problems [
12]. Into the 21st century, with enhancements in computational power and data processing capabilities, deep learning techniques began to be integrated into reinforcement learning. Mnih et al. pioneered the deep q-network, achieving control levels in visually rich Atari games that matched or exceeded human performance for the first time [
13]. Additionally, the deep deterministic policy gradient (DDPG) algorithm [
14], proposed by Lillicrap et al., and the proximal policy optimization algorithm [
15] by Schulman et al., further expanded the application of reinforcement learning in continuous action spaces. Haarnoja et al. introduced the soft actor–critic algorithm, which optimized policies within a maximum entropy framework, demonstrating its superiority in handling tasks involving high dimensions and complex environments [
16]. However, single-agent algorithms face challenges such as the exponential explosion in state-action space and local optima when dealing with multi-agent systems. To overcome these challenges, researchers have extended single-agent algorithms to multi-agent algorithms, such as multi-agent deep deterministic policy gradient (MADDPG), multi-agent actor–critic, multi-agent proximal policy optimization (MAPPO), and multi-agent twin-delayed deep deterministic policy gradient (MATD3) [
17,
18,
19,
20]. In the realms of single UAV and multiple UAV interception, reinforcement learning has emerged as a significant research focus. For a single UAV, as studied by Koch et al., deep reinforcement learning is employed to train the UAV for autonomous navigation and obstacle avoidance in environments with obstacles [
21]. In the context of multiple UAVs, Qie et al. proposed an artificial intelligence method named simultaneous target assignment and path planning based on MADDPG to train the system to solve target assignment and path planning simultaneously according to a corresponding reward structure [
22].
1.1. Related Works
In the field of UAV interception, various studies have explored effective interception strategies for both single UAV and multiple UAV environments to tackle challenging missions. Garcia et al. focused on designing minimal-time trajectories to intercept malicious drones in constrained environments, breaking through the limitations of traditional path planning in complex settings [
23]. Tan et al. introduced a proportional-navigation-based switching strategy for quadrotors to track maneuvering ground targets, addressing the limitations of traditional proportional derivative control. By dynamically switching between proportional navigation and proportional derivative controls, the proposed method reduced tracking errors and oscillations, demonstrating improved performance and robustness against measurement noise. The optimal switching points, derived analytically, ensured minimal positional errors between the UAV and the target [
24]. Cetin et al. addressed the visual quadrotor interception problem in urban anti-drone systems by employing a model predictive control (MPC) method with terminal constraints to ensure engagement at a desired impact angle. The modified MPC objective function reduced the interceptor’s maneuvering requirements at the trajectory’s end, enhancing efficiency. The proposed guidance methodology was successfully tested in various scenarios, demonstrating effective interception of both maneuvering and non-maneuvering targets with minimal maneuvering at the interception’s conclusion [
25]. Xue et al. introduced a fuzzy control method for UAV formation trajectory tracking, simplifying control logic and improving stability. Simulations confirm the method’s effectiveness in achieving rapid and stable formation docking [
26]. Li et al. developed an enhanced real proportional navigation guidance method for gun-launched UAVs to intercept maneuvering targets, addressing limitations such as saturation overload and capture region constraints. By integrating an extended Kalman filter for data fusion and trajectory prediction, the method improved guidance accuracy and overcame system delay issues, resulting in more effective interception of “Low–slow–small” targets [
27]. Liu et al. explored a cooperative UAV countermeasure strategy based on an interception triangle, using a geometric formation formed by three UAVs to enhance interception efficiency [
28]. Tong et al., inspired by the cooperative hunting behavior of Harris’s hawks, proposed a multi-UAV cooperative hunting strategy, optimizing the interception process by mimicking natural cooperative behaviors [
29]. In addition to drones, research on the interception of other moving objects also offers valuable insights. Shaferman et al. focused on developing and optimizing guidance strategies that enable multiple interceptors to coordinate their operations to achieve a predetermined relative intercept angle. By employing advanced optimization algorithms, this research significantly enhanced mission efficiency, particularly in scenarios where the intercept angle was crucial for successful interception [
30]. Chen et al. explored and developed methods for enhancing the accuracy of target recognition and matching in missile guidance systems that used television-based seekers [
31].
While rule-based methods have laid a solid foundation for UAV interception, the dynamic and unpredictable nature of modern aerial environments necessitates more adaptable and intelligent approaches. This is where reinforcement learning comes into play, offering significant advantages in UAV interception tasks. Reinforcement learning allows UAVs to learn from interactions with the environment, enabling them to make decisions in real time and adapt to changes dynamically.
In the single-agent domain, to address the issue of using drones to intercept hostile drones, Ting et al. explored the use of a deep q-network (DQN) with a graph neural network (GNN) model for drone-to-drone interception path planning, leveraging the flexibility of GNNs to handle variable input sizes and configurations. The proposed DQN-GNN method effectively trained a chaser drone to intercept a moving target drone, demonstrating the feasibility of integrating GNNs with deep reinforcement learning for this purpose. Results showed that the chaser drone could intercept the target in a reasonable time, suggesting that this approach enhanced the efficiency of drone interception tasks [
32]. Furthermore, to counter the threat of small unmanned aerial systems to airspace systems and critical infrastructure, Pierre et al. applied deep reinforcement learning to intercept rogue UAVs in urban airspace. Using the proximal policy optimization method, they verified its effectiveness in improving interception success rates and reducing collision rates [
33]. In addition, research on unmanned surface vessels (USVs) and missile interception is also of important reference significance. Du et al. introduced a multi-agent reinforcement learning control method using safe proximal policy optimization (SPPO) for USVs to perform cooperative interception missions. The SPPO method incorporated a joint state–value function to enhance cooperation between defender vessels and introduced safety constraints to reduce risky actions, improving the stability of the learning process. Simulation results demonstrated the effectiveness of the SPPO method, showing high performance in reward and successful cooperative interception of moving targets by the USVs [
34]. Liu et al. introduced a combined proximal policy optimization and proportional–derivative control method for USV interception, enhancing interception efficiency. Simulation results showed that the proposed method significantly reduced the interception time compared to traditional approaches [
35]. Hu et al. presented the twin-delayed deep deterministic policy gradient (TD3) algorithm to develop a guidance law for intercepting maneuvering targets with UAVs. The proposed method improved upon traditional proportional navigation guidance by directly mapping the line-of-sight rate to the normal acceleration command through a neural network, resulting in enhanced accuracy and convergence of the guidance system [
36]. Li et al. proposed a covertness-aware trajectory design method for UAVs based on an enhanced TD3 algorithm. By integrating multi-step learning and prioritizing experience replay techniques, the method enabled UAVs to adaptively select flight velocities from a continuous action space to maximize transmission throughput to legitimate nodes while maintaining covertness. Considering the impact of building distribution and the uncertainty of the warden’s location, this approach effectively addressed issues that were challenging for standard optimization methods and demonstrated significant performance advantages over existing deep reinforcement learning baselines and non-learning strategies in numerical simulations [
37]. Li et al. employed a quantum-inspired reinforcement learning (QiRL) approach to optimize the trajectory planning in UAV-assisted wireless networks without relying on prior environmental knowledge. QiRL introduced a novel probabilistic action selection policy inspired by quantum mechanics’ collapse and amplitude amplification, achieving a natural balance between exploration and exploitation without the need for tuning exploration parameters typical in conventional reinforcement learning methods. Simulation results validated the effectiveness of QiRL in addressing the UAV trajectory optimization problem, demonstrating faster convergence and superior learning performance compared to traditional q-learning methods [
38]. Li et al. introduced TD3 and quantum-inspired experience replay (QiER) to optimize the trajectory planning for UAVs in cellular networks, enhancing performance in reducing flight time and communication outages and improving learning efficiency by effectively balancing exploration and exploitation [
39].
For multi-agent systems, Wan et al. presented an enhanced algorithm based on MADDPG called mixed-experience MADDPG (ME-MADDPG), which enhanced sample efficiency and training stability by introducing artificial potential fields and a mixed-experience strategy. Experiments demonstrated that ME-MADDPG achieved faster convergence and better adaptability in complex dynamic environments compared to MADDPG, showing superior performance in multi-agent motion planning [
40]. In order to enhance navigation and obstacle avoidance in multi-agent systems, Zhao et al. proposed the MADDPG-LSTM actor algorithm, which combined long short-term memory (LSTM) networks with the MADDPG algorithm, and the simplified MADDPG algorithm to improve efficiency in scenarios with a large number of agents. Experimental results showed that these algorithms outperformed existing networks in the OpenAI multi-agent particle environment, and the LSTM model demonstrated a favorable balance in handling data of varying sequence lengths compared to transformer and self-attention models [
41]. Huang et al. proposed and validated the MADDPG for its effectiveness and superior performance in multi-agent defense and attack scenarios [
42]. For collaborative drone tasks, a cooperative encirclement strategy based on multi-agent reinforcement learning was proposed, using the attention-mechanism MADDPG algorithm, which addressed the problem of surrounding airborne escape targets in a collaborative drone attack scenario [
43]. Using the all-domain simulation 3D war game engine from China Aerospace System Simulation Technology, Wei et al. conducted simulations of confrontations between UAVs and radar stations. By designing rewards and integrating LSTM networks into multi-agent reinforcement learning, the recurrent deterministic policy gradient (RDPG) method was improved, and a combination of MADDPG and RDPG algorithm was developed, significantly enhancing the algorithm’s effectiveness and accuracy [
44]. Jeon et al. introduced a fusion–multiactor–attention–critic model for energy-efficient navigation control of UAVs. The model incorporated a sensor fusion layer and a dissimilarity layer to optimize information processing, resulting in improved energy efficiency and 38% more deliveries within the same time steps compared to the original multiactor–attention–critic model [
45]. Yue et al. proposed a method for multi-object tracking by a swarm of drones using a multi-agent soft actor–critic approach [
46]. For the pursuit–evasion game of multi-rotor drones in obstacle-laden environments, Zhang et al. proposed the CBC-TP Net, a multi-agent bidirectional coordination target prediction network, which incorporated a vectorized extension of the MADDPG method to ensure effective task execution even if the “swarm” system was compromised [
47]. The priority-experience replay-based multi-agent deep deterministic policy gradient algorithm (PER-MADDPG) has shown excellent performance in increasing the success rate of pursuits and reducing response times, featuring faster convergence and reduced oscillations compared to the MADDPG algorithm [
48]. Zhu et al. applied deep reinforcement learning to the cluster control problems of multi-robot systems in complex environments, proposing the PER-MADDPG algorithm, which significantly enhanced learning efficiency and convergence speed. Experimental results validated the effectiveness of this algorithm in completing cluster tasks in obstacle-laden environments [
49]. Jiang et al. integrated self-attention into the MADDPG algorithm to enhance the stability of learned policies by adapting to the dynamic changes in the number of adversaries and allies during confrontations. They presented a simplified 2D simulation environment and conducted experiments in three different collaborative and confrontational scenarios, demonstrating improved performance over baseline methods [
50]. Zhang et al. tested the distributed decision-making and collaboration tasks of heterogeneous drones in a Unity3D cooperative combat environment, proposing an improved MAPPO algorithm and enhancing the algorithm’s generalizability through the course learning [
51]. Huang et al. developed a collaborative path planning method for multiple drones based on the MATD3 algorithm with dual experience pools and a particle swarm optimization algorithm, significantly reducing the age of information [
52]. Some typical methods are summarized in
Table 1.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}