
Multiple Image Splicing Dataset (MISD): A Dataset for Multiple Splicing



Abstract
:Dataset
Dataset License
1. Summary
- Detailed process flow for the creation of a Multiple Image Splicing Dataset.
- Development of a Multiple Image Splicing Dataset which contains both authentic and realistic spliced images.
- Comparative analysis of existing dataset with the Multiple Image Splicing Dataset.
- To provide a ground truth mask for multiple spliced images.
Goal of MISD
- To provide high-quality, realistic multiple spliced images by applying various post-processing operations such as rotation, and scaling to the researchers working in the computer vision area.
- To provide generalized multiple spliced images from various categories so that the researchers can use a Deep Learning model which will be trained on these generalized images. Such a model can be used for the detection of multiple spliced forgeries in various domains such as forensics, courts, military, and healthcare, where the images are used for communication.
- To provide the ground truth masks for the multiple spliced images for effortless identification of spliced objects in the multiple spliced images.
2. Related Work
2.1. Datasets
2.2. Deep Learning Techniques for Image Splicing Detection
3. Data Description
4. Methods
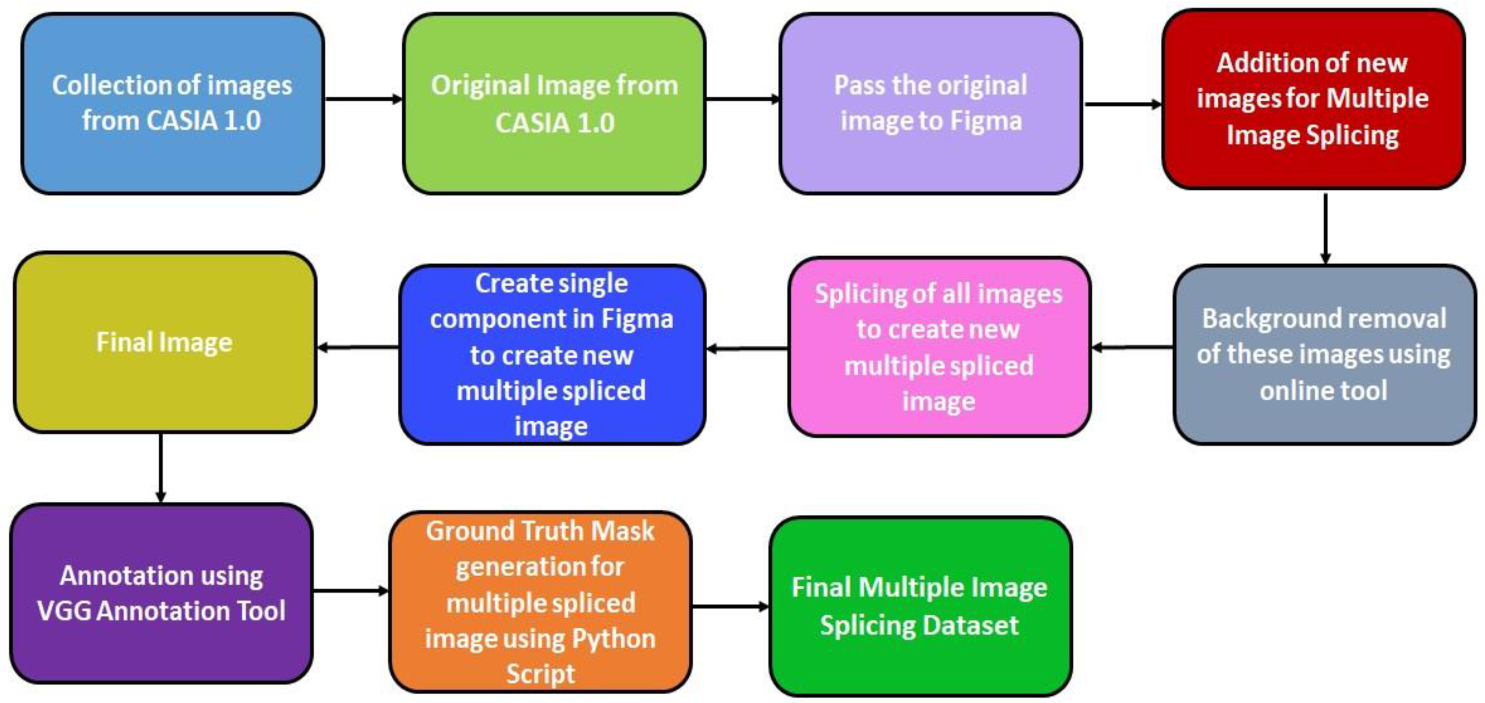
4.1. Data Acquisition
- Spliced images were constructed using images from the authenticating images. The spliced region(s) come/comes from two or more authentic images or the same authentic image. The shape of spliced regions in the Figma Software can be customized
- Spliced regions were created by cropping the regions from the original images. Then, these regions were modified using various operations such as rotation, scaling, and other manipulation operations.
- Before pasting, the cropped image region(s) can be modified using scaling, rotation, or other manipulation operations to create a spliced image.
- Various spliced regions such as small, medium, and large were considered for creating multiple spliced images. Furthermore, in the authentic images, there are various texture images. Therefore, we generated spliced texture images using one or two authentic texture images. As a result, we created a batch of spliced texture images by arbitrarily cropping a portion of a texture image (in a regular or arbitrary shape) and pasting it to the same or a different texture image.
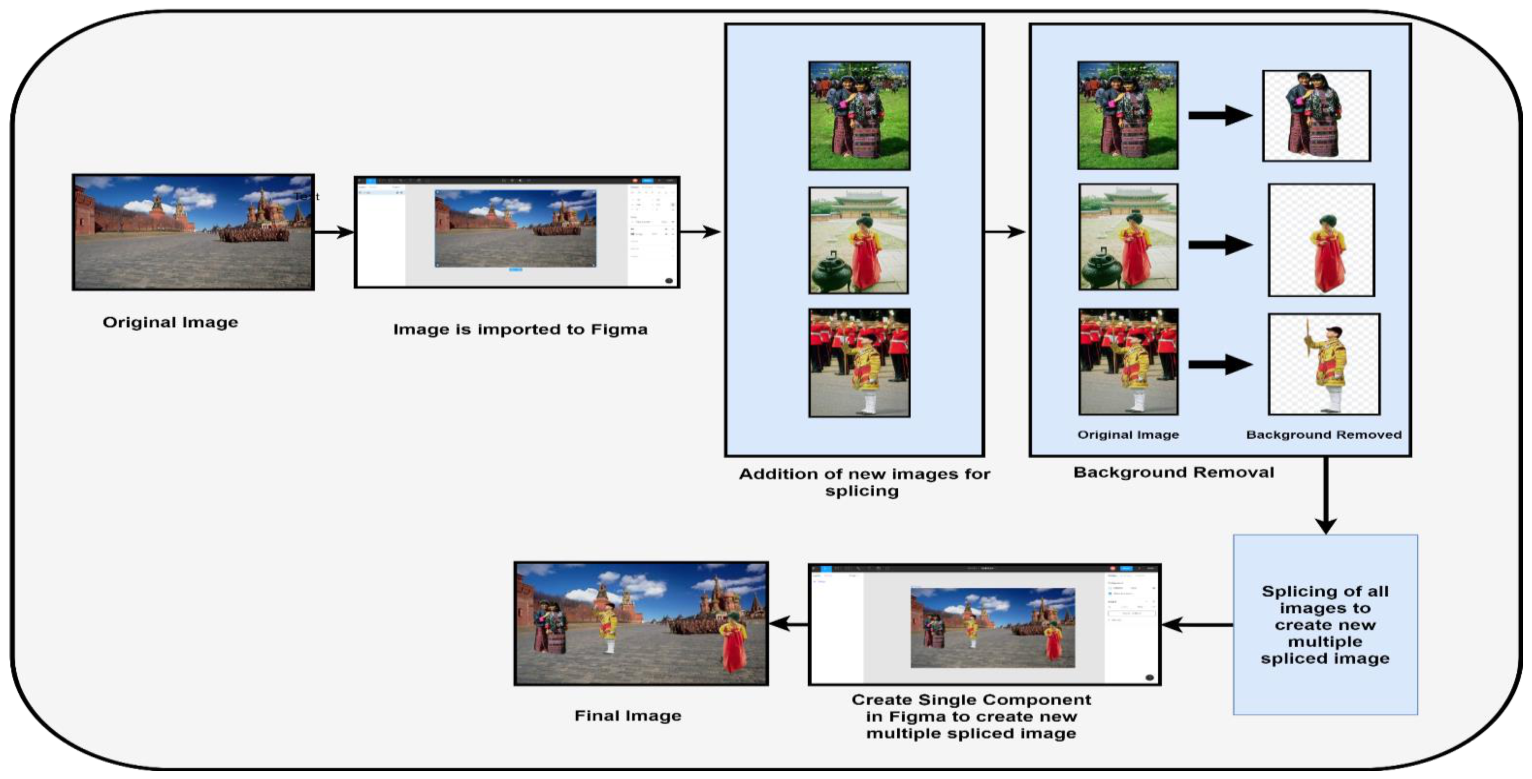
- First, an authentic image is imported into Figma [28]. This image serves as the base for other objects to be added to it.
- To cut the objects from the other authenticate images, a background removal tool like removing bg [29] is used for cutting the objects. This tool is used for the instant removal of the background of the images. An image with a clear high contrast distinction between the image’s subject and background is preferred to get the best possible results. After background removal, the resulting image is inserted on the base image in Figma. Then, various manipulation operations are applied to the inserted objects such as the transformation, rotation, color, and scaling, to make the spliced images look more authentic and difficult to detect.
- Finally, all the inserted objects and the base image are selected and merge as a single component, and exported as a single image.
- This process is repeated using several other authenticate images, and multiple objects are inserted on the base image.
Statistical Summary of MISD
4.2. Data Annotation
- Labelling the spliced object in the image
- Locating and marking all the labelled objects
- Segmenting each of the spliced instances
- Filename: Contains the name of the image file
- Size: Contains the size of the image in pixels
- Regions: Contains the x and y coordinates for the vertices of polygon around any object instance for the segmentation masks and the form of the bounding box (rectangle, polygon)
- Region_attributes: Contains the category of the object
- File_attributes: Contains other information about the image
4.3. Ground Truth Mask Generation Using Python Script
5. Conclusions
6. Future Work
- Size of MISD—Our goal is to increase the size of the MISD. A few more categories can be included in the future to construct a versatile dataset.
- Pretrained Neural Networks—Pretrained neural networks, such as ResNet or MobileNet, can be used to evaluate the performance of the MISD.
- Addition of more post-processing operations—A few more post-processing operations can be applied to the images in the MISD.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Machado, C.; Kira, B.; Narayanan, V.; Kollanyi, B.; Howard, P. A Study of Misinformation in Whats App groups with a focus on the Brazilian Presidential Elections. In Proceedings of the Companion proceedings of the 2019 World Wide Web conference, San Francisco, CA, USA, 13 May 2019; pp. 1013–1019. [Google Scholar]
- THE WEEK. Available online: https://www.theweek.in/news/health/2019/04/04/Researchers-hack-CT-scansto-create-fake-cancers-in-imaging.html (accessed on 13 July 2021).
- O’Halloran, K.L.; Tan, S.; Wignell, P.; Lange, R. Multimodal Recontextualisations of Images in Violent Extremist Discourse. In Advancing Multimodal and Critical Discourse Studies: Interdisciplinary Research Inspired by Theo van Leeuwen’s Social Semiotics; Zhao, S., Djonov, E., Björkvall, A., Boeriis, M., Eds.; Routledge: New York, NY, USA; London, UK, 2017; pp. 181–202. [Google Scholar]
- Tan, S.; O’Halloran, K.L.; Wignell, P.; Chai, K.; Lange, R. A Multimodal Mixed Methods Approach for Examining Recontextualition Patterns of Violent Extremist Images in Online Media. Discourse Context Media 2018, 21, 18–35. [Google Scholar] [CrossRef]
- Wignell, P.; Tan, S.; O’Halloran, K.L.; Lange, R.; Chai, K.; Lange, R.; Wiebrands, M. Images as Ideology in Terrorist-Related Communications. In Image-Centric Practices in the Contemporary Media Sphere; Stöckl, H., Caple, H., Pflaeging, J., Eds.; Routledge: New York, NY, USA; London, UK, 2019; pp. 93–112. [Google Scholar]
- Students Expose Fake Social Media Reports on Israel Gaza to Set Record Straight. Available online: https://www.timesofisrael.com/students-expose-fake-social-media-reports-on-israel-gaza-to-set-record-straight/ (accessed on 13 July 2021).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Farid, H. Image forgery detection a survey. IEEE Signal Process. Mag. 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Kadam, K.; Ahirrao, S.; Kotecha, K. AHP validated literature review of forgery type dependent passive image forgery detection with explainable AI. Int. J. Electr. Comput. Eng. 2021, 11, 5. [Google Scholar] [CrossRef]
- Walia, S.; Kumar, K. Digital image forgery detection: A systematic scrutiny. Aust. J. Forensic Sci. 2019, 51, 488–526. [Google Scholar] [CrossRef]
- Dong, J.; Wang, W.; Tan, T. CASIA Image Tampering Detection Evaluation Database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013. [Google Scholar] [CrossRef]
- Ng, T.T.; Chang, S.F.; Sun, Q. A Data Set of Authentic and Spliced Image Blocks; ADVENT Technical Report; Columbia University: New York, NY, USA, 2004; pp. 203–2004. [Google Scholar]
- Hsu, Y.F.; Chang, S.F. Detecting Image Splicing Using Geometry Invariants and Camera Characteristics Consistency. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006. [Google Scholar]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef] [Green Version]
- Zampoglou, M.; Papadopoulos, S.; Kompatsiaris, Y. Detecting image splicing in the wild (web). In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015. [Google Scholar]
- Gokhale, A.L.; Thepade, S.D.; Aarons, N.R.; Pramod, D.; Kulkarni, R. AbhAS: A Novel Realistic Image Splicing Forensics Dataset. J. Appl. Secur. Res. 2020, 1–23. [Google Scholar] [CrossRef]
- CalPhotos. Available online: https://calphotos.berkeley.edu/ (accessed on 13 July 2021).
- IEEE. IFS-TC Image Forensics Challenge. Retrieved 25 May 2020. 2013. Available online: https://signalprocessingsociety.org/newsletter/2013/06/ifs-tc-image-forensics-challenge (accessed on 13 July 2021).
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, B.; Pun, C.M. Locating splicing forgery by fully convolutional networks and conditional random field. Signal Process Image Commun. 2018, 66, 103–112. [Google Scholar] [CrossRef]
- Bappy, J.H.; Simons, C.; Nataraj, L.; Manjunath, B.S.; Roy-Chowdhury, A.K. Hybrid LSTM and Encoder-Decoder Architecture for Detection of Image Forgeries. IEEE Trans. Image Process. 2019, 28, 3286–3300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Wang, H.; Niu, S.; Zhang, J. Detection and localization of image forgeries using improved mask regional convolutional neural network. Math. Biosci. Eng. 2019, 16, 4581–4593. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, B.; Gulliver, T.A.; alZahir, S. Image splicing detection using mask-RCNN. Signal Image Video Process 2020, 14, 1035–1042. [Google Scholar] [CrossRef]
- Wang, J.; Ni, Q.; Liu, G.; Luo, X.; Jha, S.K. Image splicing detection based on convolutional neural network with weight combination strategy. J. Inf. Secur. Appl. 2020, 54, 102523. [Google Scholar] [CrossRef]
- Nath, S.; Naskar, R. Automated image splicing detection using deep CNN-learned features and ANN-based classifier. Signal Image Video Process. 2021, 15, 1601–1608. [Google Scholar] [CrossRef]
- Kadam, K.; Ahirrao, D.; Kotecha, D.; Sahu, S. Detection and Localization of Multiple Image Splicing Using MobileNet V1. arXiv 2021, arXiv:2108.09674. [Google Scholar]
- Learn Design with Figma. Available online: https://www.figma.com/resources/learn-design/ (accessed on 26 February 2021).
- Remove Background from Image—Remove.bg. Available online: https://www.remove.bg/ (accessed on 26 February 2021).
- Image Data Labelling and Annotation—Everything You Need to Know. Available online: https://www.towardsdatascience.com/image-data-labelling-and-annotation-everything-you-need-to-know-86ede6c684b1/ (accessed on 26 February 2021).
- What Is Image Annotation? Available online: https://medium.com/supahands-techblog/what-is-image-annotation-caf4107601b7 (accessed on 26 February 2021).
- VGG Image Annotator. Available online: https://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 26 February 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject Area | Computer Vision |
|---|---|
| More precise area | Image forgery detection, Image forensics |
| File type | JPG |
| Image Size (in pixels) | 384 × 256 |
| Number of classes in images | 8 (scene, texture, architecture, character, plant, art, nature, indoor and animal) |
| Authentic Images | 618 |
| Spliced Images | 300 |
| Total ground truth masks | 300 |
| Sr. No | Name of Dataset Used in Image Splicing | Total Number of Images including Authentic and Spliced Images | Dimension of Image in Pixel | Image Format | Ground Truth Mask |
|---|---|---|---|---|---|
| 1 | Columbia Gray [12] | 1845 image blocks (Authentic—933; Spliced—912) | 128 × 128 | BMP | Not Available |
| 2 | CUISDE [13] | 363 (Authentic—183; Spliced—180) | 757 × 568 to 1152 × 768 | TIFF | Available |
| 3 | CASIA 1.0 [11] | 1725 (Authentic—800; Spliced—925) | 384 × 256 | JPG and TIFF | Not Available |
| 4 | CASIA 2.0 [11] | 12,614 (Authentic—7491; Spliced—1849, and remaining images are of type copy move) | 320 × 240 and 800 × 600 | JPG and TIFF | Not Available |
| 5 | DSO-1 [14] | 200 (Authentic—100; Spliced—100) | 2048 × 1536 and 1536 × 2048 | JPG and TIFF | Available |
| 6 | DSI-1 [14] | 100 (Authentic—25; Splice—25) | Different sizes | PNG | Available |
| 7 | WildWeb [15] | 10,666 (Authentic—100; Spliced—9666) | 122 × 120 to 2560 × 1600 | PNG | Available |
| 8 | AbhAS [16] | 93 (Authentic—45; Spliced—48) | 278 × 181 to 3216 × 4288) | JPG | Available |
| Paper Reference | Deep Learning Technique Used for Image Splicing Forgery Detection | Dataset Used for the Experiments |
|---|---|---|
| [19] | CNN | CASIA V1.0 [11], CASIA V2.0 [11], Columbia Gray [12] |
| [20] | Deep Neural Network | CUISDE [13] |
| [21] | Auto Encoder Decoder, LSTM | NIST’16, IEEE Forensics Challenge Dataset, MS-COCO [22] |
| [23] | Mask R-CNN | Columbia Gray [12] |
| [24] | Mask R-CNN with backbone network as ResNet-conv | Computer-generated dataset where forged images have been generated using COCO [22] and a set of objects with transparent backgrounds where 80,000 images are used for training and 40,000 for validation. The image size is 480 × 640 pixels. |
| [25] | CNN | CASIA V1.0 [11], CASIA V2.0 [11] |
| [26] | CNN, Dense classifier network | CASIA V2.0 [11] |
| Data | Number of Images Per Category | Image Size | Type of Image | Total Number of Images | ||
|---|---|---|---|---|---|---|
| Authenticate Images | Image | Animal | 167 | 384 × 256 | JPG | 618 |
| Architecture | 35 | |||||
| Art | 76 | |||||
| Character | 124 | |||||
| Indoor | 7 | |||||
| Nature | 53 | |||||
| Plant | 50 | |||||
| Scene | 74 | |||||
| Texture | 32 | |||||
| Multiple Spliced Images | Image | Images of all categories | 300 | 384 × 256 | JPG | 300 |
| Naming Convention of Authentic Image | Naming Convention of Multiple Spliced Image |
|---|---|
| Au_ani_00088.jpg where, • Au: Authentic • ani: animal category • 00088: Authentic image ID | Sp_D_nat_30165_ani_00058_art_30625_ani_10192_82.png Sp: Splicing D: Different (means the region was copied from the different images) nat_30165: the source image ani_00058: the target image art_30625: the target image ani_10192: the target image 82: Multiple Spliced Image ID Here nat, ani, and art represents the category of the image |
| Other categories are: • nat: nature • arc: architecture • art: art • cha: characters • ind: indoor • pla: plants • sec:scene • xt: texture |
| Size of Images | 37 KB Minimum 60 KB Average and 129 KB Maximum |
| Image Quality | 200–300 dpi |
| Softwares used during MISD construction | • Figma • Background Remover (https://www.remove.bg/ (accessed on 13 July 2021)), • VGG Annotation Tool, • Python script for generating ground truth mask |
| Number of labels of the dataset | 2 |
| Number of images for each label | Authentic—618 |
| Spliced—300 | |
| Average Ground truth mask per image | 3 |
| Percentage of images in each category | Animal 27% |
| Architecture 5.7% | |
| Art 12% | |
| Character 20.2% | |
| Indoor 1.1% | |
| Nature 8.6% | |
| Plant 8.1% | |
| Scene 12% | |
| Texture 5.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kadam, K.D.; Ahirrao, S.; Kotecha, K. Multiple Image Splicing Dataset (MISD): A Dataset for Multiple Splicing. Data 2021, 6, 102. https://doi.org/10.3390/data6100102
Kadam KD, Ahirrao S, Kotecha K. Multiple Image Splicing Dataset (MISD): A Dataset for Multiple Splicing. Data. 2021; 6(10):102. https://doi.org/10.3390/data6100102
Chicago/Turabian StyleKadam, Kalyani Dhananjay, Swati Ahirrao, and Ketan Kotecha. 2021. "Multiple Image Splicing Dataset (MISD): A Dataset for Multiple Splicing" Data 6, no. 10: 102. https://doi.org/10.3390/data6100102
APA StyleKadam, K. D., Ahirrao, S., & Kotecha, K. (2021). Multiple Image Splicing Dataset (MISD): A Dataset for Multiple Splicing. Data, 6(10), 102. https://doi.org/10.3390/data6100102