Abstract
In univariate data, there exist standard procedures for identifying dominating features that produce the largest number of observations. However, in the multivariate setting, the situation is quite different. This paper aims to provide tools and methods for detecting dominating directional components in multivariate data. We study general heavy-tailed multivariate random vectors in dimension d ≥ 2 and present procedures that can be used to explain why the data are heavy-tailed. This is achieved by identifying the set of the riskiest directional components. The results are of particular interest in insurance when setting reinsurance policies, and in finance when hedging a portfolio of multiple assets.
MSC:
60E05; 91B30; 91B28; 62P05
1. Introduction
It is not uncommon to find heavy-tailed features in multivariate data sets in insurance and finance (Embrechts et al. 1997; Peters and Shevchenko 2015). Since financial entities seek ways to reduce the total risks of their portfolios, it is necessary to understand what the main sources of risks are. Once this is known, one can seek optimal ways of reducing risk. In insurance, where the multivariate observations could consist of losses of different lines of business, the companies are typically interested in finding the best-suited reinsurance policy. In finance, where the data could consist of returns of multiple assets, the aim could be to find an optimal hedging strategy against large losses. Even though multivariate heavy-tailed distributions are encountered frequently in various applications, there does not exist a general framework for analysis.
In earlier research, several models for what a heavy-tailed random vector should mean have been introduced (Cline and Resnick 1992; Omey 2006; Resnick 2004; Samorodnitsky and Sun 2016). One of the simplest ways to model the situation is to present a d-dimensional random vector in polar coordinates using the length R of the vector and the directional vector on the unit sphere so that . Here, perhaps the simplest assumption would be that all directions are equally likely, i.e., the random vector has a uniform distribution on the unit sphere. In realistic models, some directions are more likely than others, specifically, when R is large. Efforts have been made to capture the heterogeneity in the distribution of by studying, for example, the set of elliptic distributions (Hult and Lindskog 2002; Klüppelberg et al. 2007; Li and Sun 2009). In addition, alternative approaches have been suggested by Feng et al. (2017, 2020). However, there are typical data sets that do not fit well to these assumptions because the support of is concentrated into a cone and does not cover the entire set . There appears to be a need for models that allow the heaviness of the tail to vary in different directions, as in Weng and Zhang (2012), but which are not restricted by a parametric class of distributions. Ideally, the model should admit the tail of R to have a more general form than, say, only the form of a power function.
To answer the question of what causes the heavy-tailedness of multivariate data, one usually selects a suitable norm and analyses the resulting one-dimensional distribution of with standard procedures, such as the mean excess plot (Das and Ghosh 2016; Ghosh and Resnick 2010, 2011), or alternative methods, such as the ones in Asmussen and Lehtomaa (2017). In practice, given the heaviness identified from the distribution of , the aim is to analyse the distribution of and the dependence structure between R and . If the conditional distribution exists, we can write
where is an increasing function for a fixed . In this setting, the problem is to identify which set of vectors produces the heaviest or dominating conditional tails of the form (1). The dominating directions are the vectors , for which the function grows at the slowest rate, as . Presentation (1) admits the study of a wide class of distributions.
We derive a presentation for the set of directional components that produce the heaviest tails, and present a procedure to be used in practical analysis. The analysis is preliminary in the sense that some of the assumptions could be undoubtedly weakened. However, the simple assumptions admit a clear presentation of the main ideas without many technical difficulties. The method applied to the generated data returns a subset of the space, which gives more information about the distribution than a single number or vector, but demands less data than a full empirical measure. Furthermore, the original data do not have to be pre-processed or transformed, and the method is also applicable to data where, in some directions, the observations are sparse or do not occur at all. This is different from the grid-based approaches, such as those in Lehtomaa and Resnick (2020), where the entire space is first divided into cells, and each cell is studied separately. In such approaches, there can exist empty or sparsely populated cells, which might be problematic for analysis. The presented methods can be applied, in particular, to analyse financial data, where extreme observations typically appear in two opposite directions, which might be unknown.
Notation
Notation 1.
For set A, we denote its closure by or , its interior by , and its complement by , and ∅ denotes an empty set. The symbol means set . The term means A is a subset of D, whereas implies that A is a proper subset of D. The notation refers to the little-o notation, and means , as . We use the convention .
2. Assumptions and Definitions
We write a d-dimensional random vector , where , in the form
where and . Here, we assume that the norm is an norm with . The unit sphere is set . Then, we have a geodesic metric on , defined, in detail, in terms of the geodesic distance in Section 2.2. In particular, the space equipped with the geodesic metric is a complete metric space. Open sets, balls, and other topological concepts on are defined using this metric. For example, is an open ball with centre and radius . The Borel sigma-algebra, the sigma-algebra generated by open sets, is denoted by , e.g., . In the case of spherical or elliptical distributions, we restrict the norm to be the -norm denoted by . This restriction ensures that ellipsoids have their natural interpretation.
2.1. Assumptions
We need the following conditions in the formulation of the results. The required conditions are indicated in the assumptions of each result.
Assumption 1.
R is a positive random variable with right-unbounded support. For any , it holds that and R is heavy-tailed in the sense that .
Assumption 2.
is a random vector on the unit sphere such that the quantity
remains constant for all where is a fixed number that does not depend on the Borel set . In particular, the limiting probability distribution of exists, as . In fact, the limiting distribution on is reached once .
Assumption 3.
The limit exists in for all Borel sets , where is defined as
and
Remark 1.
The condition on heavy-tailedness in Assumption 1 is equivalent to the condition for all , which is the usual definition of a (right) heavy-tailed real-valued random variable R. The distribution of does not have to be uniform on the unit sphere . In fact, the distribution of does not even need to have probability mass in every direction. Assumption 2 provides a simplified setting for the study. This assumption could be alleviated by considering a suitable mode of convergence for the distributions.
Distributions that satisfy the assumptions include random vectors where all the tail distributions in a given direction remain unchanged for sufficiently large values. The values close to origin do not affect the analysis. In particular, the proposed model admits the study of typical asymptotic dependence structures, such as full dependence, strong dependence, and asymptotic independence, as defined in Lehtomaa and Resnick (2020). Some concrete examples are provided in Section 5.1.
The risk function of is defined as
The function h provides a benchmark against which risk functions calculated from subsets can be compared. In this sense, the function h indicates what the heaviness of the tail will be in the set of the riskiest directions S. The logarithmic transformation is used widely in asymptotic analysis. One reason for the use of this particular transformation of the tail function instead of some other transformation is that, roughly speaking, the function
is concave for heavy-tailed R and convex for light-tailed R. Assumption 1 indicates that we operate in the heavy-tailed regime.
Here, S is the set
The limit in (4) can be written in equivalent forms.
Lemma 1.
Proof.
It is seen that the quantities in (5) are equal. However, the interpretations of the two forms are slightly different. The form on the left compares the decay rates of two tail functions. The form on the right does not have a tail function in its numerator, but this form makes monotonicity arguments and situations where easier to handle.
If the quantities in (5) equal 1, as they do in the definition of set S, the quantity in (6) equals 0. So, in principle, there are two ways in which a point can belong to set S. A point belongs to S if has a positive probability under the limiting measure of Assumption 2 or if the limiting probability is 0 but the function grows to infinity slowly enough. Since we assume in Assumption 2 that the limit distribution is obtained after some , the latter possibility is excluded by the assumptions.
Next, we prove general properties for the function g defined in (3). To simplify notation, we denote, in short, that
where is a Borel set.
Lemma 2.
Suppose Assumptions 1–3 hold. Then, the following properties hold for the function g defined in (3) and for the function G defined in (7). In the statements below, we assume that and is a Borel set.
- (i)
- , , and .
- (ii)
- and .
- (iii)
- Function g is monotone in the sense that if , where D is a Borel set, then . In addition, .
- (iv)
- Suppose are Borel sets. Then, . In particular, .
Proof.
- (i)
- Since , it follows that and The statements for follow from the definition of g.
- (ii)
- Since , the statements follow from (iii) and (i).
- (iii)
- implies . Dividing by the negative term yields the claims.
- (iv)
- Lemma 1.2.15 in Dembo and Zeitouni (1993) combined with Assumption 3 yieldsOn the other hand, for all due to (iii). Thus, . The fact that follows from (i) because the sets A and partition set
□
In practical applications, the aim is to estimate S from data. Set S is a subset of the support of in . The following results show that set S is not empty.
Lemma 3.
Suppose Assumptions 1–3 hold and for a closed set . Then, .
Proof.
Suppose is a sequence of finite partitions of D. Assume further that all sets of the partitions are Borel sets and, for , is a refinement of such that the maximal diameter of the sets in converges to 0, as . For example, we could use dyadic partitions intersected with D.
Suppose is fixed and consider the partition where the number of sets in is denoted by . Based on Part (iv) of Lemma 2, we know that . That is, there is , such that .
The partition is assumed to be a refinement of . So, set is possibly partitioned into smaller sets, and there is a subset, say , where , which satisfies . Recall that the maximal diameters of the partitioning sets are assumed to converge to 0. We see that there is a sequence of sets , where and , for all Because equipped with the geodesic metric is a complete metric space, there must be a limit point in the sequence of the sets. Let us denote the limit point by . Because set D is closed, the limit point .
Suppose is fixed. Suppose n is so large that the maximal diameter of the sets in Partition is less than . Then, by construction, there exists set , such that . Then, by the monotonicity property (iii) of Lemma 2, we reveal that
and the claim is proven because belongs to set S by the definition of S. □
Corollary 1.
Set S defined in (4) is not empty.
Proof.
Taking , it holds that by Part (i) in Lemma 2, and thus, set S is not empty by Lemma 3. □
We make an assumption on the form of set S to rule out technically challenging cases that have little impact on practical applications.
Assumption 4.
Firstly, we assume that there exists an open set in . Secondly, we assume that S in (4) can be written as
where is an open subset (possibly empty) of and is a finite collection of individual points (possibly empty) of . We assume that each point in contains positive probability mass of the limit distribution of , as .
Remark 2.
Assumption 4 implies that not all directions have the same riskiness. The assumption also ensures that S does not contain continuous subsets in lower dimensions than . It admits directly, e.g., distributions where the riskiest direction is concentrated to a cone or a single vector. Even if the original distribution of does not satisfy Assumption 4, it is possible to construct a new approximating distribution by adding a small independent continuous perturbation to vector to obtain a new distribution that satisfies Assumption 4. The perturbation could be, for example, a random variable that has the uniform distribution on a small ball.
If there exists a joint density of , or if is discrete, we can write the conditional risk or hazard function as
where is a positive increasing function for fixed . The notation admits presenting the conditional risk function in the following simplified way in typical cases.
Example 1.
- 1.
- If the random vector is elliptically distributed with and , its conditional risk function can be written asHere, is a function such that holds for all . The function c is a continuous map of to an interval. In general, we set such that , so is the risk function in the riskiest direction. In the special case, where the distribution of is spherical is constant.
- 2.
- There can be different tail behaviour in different subsets of . If there exists a finite partition of , such that the risk function does change given , we can writewhere refers to the risk function in the direction of set .
2.2. Subsets of the Unit Sphere
For we define the geodesic metric as
In this metric, open balls are subsets of denoted by , where vector is the centre of the open ball and . So, . The corresponding closed ball is denoted by . Note that the shape of the ball depends on the used norm.
Definition 1.
For any set , we call set
the geodesic δ-swelling of set A. Here, is the geodesic distance of to set A, .
By
we denote the Hausdorff distance, where is defined as in Definition 1.
3. Minimal Set of Riskiest Directions
Our aim is to find the riskiest directions. We search for the minimal set that dominates the tail behaviour of the random vector in the sense of (4). To this end, we need to identify sets for which, given , the inequality
holds for all values of k large enough. The inequality demands a positive probability measure of A.
For the next result, we define the collection of testing sets as follows. Set A is an element of if A is a finite union of open balls, such that for all and for all , the open ball contains an open ball B that belongs to . Note that point does not have to be in set B. In particular, this guarantees that does not contain any isolated points.
Theorem 1.
Let , be such that Assumptions 1–4 hold.
Then, , where S is as in (4), and refers to the closure of the set. Furthermore, for all ,
and
Proof.
The proof of the theorem is performed in steps.
- 1.
- We claim.Recall that under Assumption 4, set S can be written as the union of and a finite number of individual points. We have two cases to cover.First, we study the case where set of Assumption 4 contains a point. Suppose there is an individual point , such thatwhere the latter equation follows from Lemma 1. Then, cannot belong to for any set that satisfies the inequality in (8). To see this, assume, on the contrary, that belongs to for some set . Then, due to monotonicity mentioned in (iii) of Lemma 2,by Equality (11). Since cannot be strictly less than 1 by Part (ii) of Lemma 2, the inequality cannot be true if is in the complement of a testing set . We conclude that must belong to all testing sets that satisfy the inequality in (8). So, .Next, we consider the case where set of Assumption 4 contains a point. Suppose . Then, there is a number such that . Let . We show that cannot be in for a set A that satisfies the inequality in (8). Assume, on the contrary, that . In this situation, we can find a small ball that is entirely in the intersection . To see this, let . By the definition of the testing sets in , the ball contains another open ball, say, , which is contained in . Since , we see that . So, because , the limit in (4) applied for radius states thatSo, due to the monotonicity mentioned in (iii) of Lemma 2,In conclusion, any testing set that does not contain cannot satisfy the inequality in (8). So, all testing sets that satisfy the inequality must contain . So, .The above deductions imply, using the notation of Assumption 4, that , which implies , and the claim is proven.
- 2.
- We claim.The claim is equivalent to . Let . Then, by the definition of S in (4), either there exists , such that , or there exists , such thatIn the latter case, Inequality (12) also holds when is replaced by any due to the monotonicity; see c in Lemma 2.In order to show that , it suffices to find one testing set , such that and A satisfies the inequality of (8). This is because set is the intersection of all testing sets that satisfy the inequality.Let the number be such that or (12) holds. Now, formally setting fulfils the inequality of (8), but this is not a member of the collection . However, we can construct a set using a finite number of open balls, such that A covers set but does not intersect set .With this set A, we havebecause . More precisely, by monotonicity,The limit equals 1 according to (iv) of Lemma 2 and so Inequality (13) holds. In conclusion, belongs to the complement of this A and consequently . We have shown that , which is equivalent to , which implies
- 3.
- Let be fixed. Through Parts 1–2 of the proof, we know thatAssume, on the contrary, to Claim (10) that
In the case of elliptically distributed random vectors, the minimal set that dominates the tail behaviour of the random vector might consist only of singletons that do not have probability mass. One can still approximate the distribution using the method of Remark 2. In this example, we use the -norm.
Example 2.
Let the random vector be elliptically distributed, such that , where c is a continuous function on that achieves its minimum only at and , and assume that and are points in set of Assumption 4. Then, for all , it holds that
So, . Choosing the risk function of R to be , the minimum equals one.
Corollary 2.
Let be such that Assumptions 1–4 hold and is a Borel set. If there exists such that , it holds that
4. Towards Estimators
In this section, we introduce procedures that can be used to form estimators for set S based on data. We do not present such estimators explicitly here, but the results can be used as a theoretical basis for this work. Throughout the section, we use the -norm, so the geodesic distance or great ball distance on the unit sphere is defined as , where is the dot product of and . The metric dist is discussed in detail, for instance, in Proposition 2.1 of Bridson and Haefliger (2013).
The following lemmas are auxiliary results for Theorem 2.
Lemma 4.
Let be the unit sphere of equipped with the -norm, and for , let be the geodesic distance or the great ball distance on . We define for .
Then, for fixed and , the balls and partition the unit sphere.
Proof.
Since , it holds so . To prove the claim, we show that is the complement of in . Since , its complement is set . The condition is, by definition,
Due to the fact that for all , , the condition (17) is equivalent to because and are unit vectors. The last expression can be written as . So is the complement of in . □
Lemma 5.
Let be the unit sphere of equipped with the -norm, and for , let be the geodesic distance.
Then, for there exists such that the intersection contains an open set of and contains an open set of .
Proof.
Since and it holds that due to the definition of the great ball distance. Take . By the choice of , , and are proper subsets of the unit sphere. Since all three sets are open, it remains to show that there is a point in each of the intersections of the claim. We recover the points explicitly.
Since , it holds for any For there exists a unique minimising geodesic between and . For all points that lie on this minimising geodesic between and we have that .
Taking on this geodesic such that , it holds, by definition, that . Because
we also have . In conclusion, .
On the other hand, taking on the same minimising geodesic between and , such that , it holds by definition that . By similar calculations as above, it holds that
so and hence . Thus, both intersections contain a point, and therefore, an open set. □
Algorithm
In this section, we present an algorithm to find the minimal set S that dominates the tail behaviour of the studied random vectors under suitable assumptions. To this end, we study the function G defined in (7) for different sets. Due to Theorem 1, the minimal set S in (4) that dominates the tail behaviour of the random vector is contained in the intersection of all testing sets that fulfil the inequality in Condition (8). We present a theoretical procedure for finding the set of the riskiest directions.
We define for Algorithm 1 below a map , where is an open set and is an element on the unit sphere . The algorithm for finding the minimal set S that dominates the tail behaviour of the random vectors is presented in two steps. In the theoretical setup, we perform Step 1 for all . In practice, we must use a finite collection of vectors .
Algorithm 1.
The algorithm has two steps.
- 1.
- Let .If, for some , it holds that and then define , where is the smallest radius fulfilling the conditionIn other words,and is the smallest ball centred around that contains S.If , for all , set and if for all , set .
- 2.
- Set
The sets are open balls and belong by definition to the set of testing sets . Furthermore, the entire unit sphere and the empty set are open sets as well and thus belong to . Due to Lemma 4, , Equation (18) can be rewritten in equivalent form
So, is the smallest radius such that . The condition that for all implies that the neighbourhood of does not belong to S and S contains only of the point .
The following lemma shows the connection between the choice of set and vector , which points to the opposite direction of .
Lemma 6.
Suppose Assumptions 1–4 hold. Then, it holds for any and its corresponding set defined in Algorithm 1 that if, and only if, .
Proof.
To prove is equivalent to , we show that implies and results in .
Let . Then, by the definition of S for all , it holds that , and
which is equivalent to due to Lemma 1. As a consequence, the algorithm chooses because does not exist, such that and by Lemma 4.
On the other hand, let . Then, either for some , or for all it holds that and there exists such that
In the first case, implies , and in the second case, Inequality (19) is equivalent to by Lemma 1. Due to Lemma 4, so and by Lemma 2 it holds that . Hence, and or . □
The estimator does not detect all possible sets. Recall that, in general, we assume in Assumption 4 that , where is an open subset of and is a finite collection of individual points. For example, if or , and is not empty, Algorithm 1 will not detect set . If S contains only a singleton, so for some , it holds that and for all . Then, the algorithm sets so the estimator is empty. In general, it can be seen that the algorithm does not detect any finite number of individual points in S. However, the procedure described in Remark 2 can be used to modify data sets in order to avoid problems in practice.
Estimator has the capacity to detect sets S that are not necessarily convex or even connected. Set S can be, for example, a disjointed union of open sets.
Example 3.
A classical football is made of 12 black pentagons and 20 white hexagons. Assume that the directions of the random vectors are uniformly distributed on the surface of the football. Furthermore, assume that random variables R connected with open black pentagons have a much heavier tail then random variables R connected with closed white hexagons, such that and . If we choose , such that points towards the centre of a black pentagon, it holds that for any , so the algorithm sets . If we choose , such that points in the centre of a white hexagon, it holds for its closed inscribed circle that , so does not contain this closed inscribed circle, and thus does not contain it. If we choose , such that is the centre of an edge of two white hexagons, it holds that , where r is half of the length of the edge. Therefore, the edge is not included in set , and thus, the edge is not included in . All in all, the intersection of sets , where are such that points either in the direction of the centre of a white hexagon or in the direction of the centre of an edge between two white hexagons, returns a set that is not connected. Regarding the intersection over all , Algorithm 1 would return the union of the closed black pentagons as .
To avoid the problem with individual points, we propose a simplifying assumption for S.
Theorem 2.
Suppose Assumptions 1–4 with . In particular, set S does not contain any individual points.
Then, it holds that
where is as in Algorithm 1.
Proof.
The proof of the theorem is performed in steps.
- 1.
- We claimWe show that implies , and then take the closure of the sets to prove the claim.Note first that, by Assumption 4, S is a proper subset of . Let be in the interior of S. Then, there exists some such that . Furthermore, for all , it holds thatwhich is equivalent to due to Lemma 1.We need to show that for all . In the algorithm, set can be the empty set, the unit sphere, or an open ball with centre . If , it contains by default.Let be fixed. We show that . There are different cases to consider.
- (a)
- If , set contains an open subset of S sinceso , and thus, . It follows that cannot be empty and .
- (b)
- If , it holds that according to Lemma 6, so .
- (c)
- If , there exists some such that , so both sets and its complement contain an open subset of S, and thus, , so .It holds, according to Lemma 5, that both sets and are not empty. By the monotonicity of G, it holds that , so and .
- (d)
- If , there exists, according to Lemma 5, a number such that the intersectionsandare not empty, and, in particular, both contain an open subset. Since , it holds that cannot be empty. With a similar deduction as in Part 1c, it follows that .
- 2.
- We claimLet . We show that there exists , such that . More specifically, we can choose .If for some it holds that . Additionally, if for all , it holds, by the definition of S in (4), that there exists some such thatInequality (20) is also equivalent to . According to Lemma 2, it holds, in both cases, that . Set is of the form with , and it is not set . Thus, when .
□
5. Applications and Examples
In practical applications, one has only a finite number of observations. Thus, an approximation based on a theoretical algorithm is required. Next, we present a starting point for the formulation of estimators, and study how they perform with data. The algorithm can be performed with general multidimensional data. Here, we consider two-dimensional data to keep the results easily presentable.
We define an empirical version of the function g defined in (3). Given observations in , the empirical version of g is denoted by
where is the user-defined threshold and A is a Borel set on the unit sphere.
In general, if
holds for set A and some , it provides evidence for A being in the complement of S. If
we gain evidence for A containing at least some subset of S. Since we can calculate the values of for any set, the challenge is to perform the calculations in a systematic way and combine the results to form an estimate for S. The most practical choices for sets A appear to be open balls centred around a given point on the unit sphere.
5.1. Simulation Study
A simulation study with observations was performed. Assumptions 1–4 are valid by construction. A two-dimensional data set was produced where heavy-tailed observations are possible in all directions, but some directions are heavier than others. The space was split into 8 equally sized cones. More specifically, the directional components were uniformly sampled within each cone, and each direction was assigned a radius vector independently. The distribution of the radius was allowed to depend on the cone, but within each cone, all the radii are i.i.d. random variables. The idea is that, in some of the cones, the radii are heavier than others, and the objective is to identify such cones.
The original data set is presented in Figure 1a. The red lines indicate how the space is split. Two of the sectors have heavier Pareto-distributed radial components and the rest have lighter Weibull-distributed components. In Figure 1a, the cones with Pareto-distributed radial components are the ones with the largest number of observations, measured in the -norm.
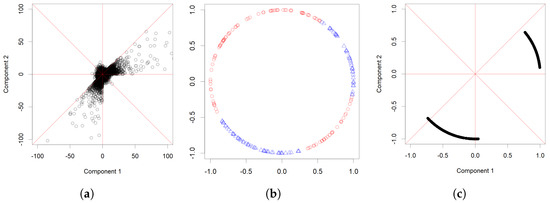
Figure 1.
Illustration of simulated data. The original data set is presented in (a); (b) illustrates which directions are accepted into or rejected from the final estimate; (c) illustrates the preliminary estimate for S based on numerical data. The estimate is a projection of two cones onto the unit sphere, even though the numerically produced image consists of finitely many points.
The idea presented in Inequalities (22) and (23) was studied numerically. The testing sets D were chosen to be open balls of the form . The radius was selected to be the smallest number such that of all observations had directional components in . Figure 1b presents the tested directions on the unit sphere. Each point corresponds to a fixed value of . We selected a fixed collection of approximately uniformly distributed points from the unit sphere to be used in place of vector in the first step of the algorithm. The red dots are the directions that were rejected, i.e., the value of (21) is too high given the tolerance c, so that (22) holds. The blue triangles are the accepted centres of cones from which the final estimate is formed. In the final estimate, we have removed all open balls that were rejected for some direction . The values of the parameters were set to be , and k was such that the top of the observations were chosen in norm.
In Figure 1c, the preliminary estimate for S is presented on the unit sphere. The method correctly identifies the heaviest directions. The estimate seems to be most accurate near the centres of the cones, and less accurate near the edges between heavier and lighter radial components.
5.2. On the Detection Accuracy with Pareto Tails
We used the same algorithm as in Section 5.1 to analyse a similar data set, except that all the radial components have a Pareto distribution. The Pareto index is the heaviest in the same cones as earlier. The remaining directions have lighter Pareto tails.
The heaviest tail has an index of 2 and the lighter tails have tail index values of , , , and 3 in Figure 2a–d, respectively. The same random seed is used in all simulations.
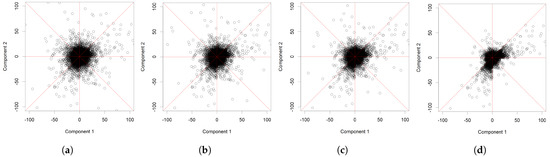
Figure 2.
Projected original data with Pareto-distributed radial components. The heaviest tail has an index of 2 and the lighter tails have tail index values of , , , and 3, from left to right.
When the lighter tail parameter is very close to the value of the heavier parameter 2, the algorithm cannot recover the set of riskiest directions with the given sample size and selected threshold c, see Figure 3. When the lighter tail parameter is or larger, the produced estimate is rather accurate.
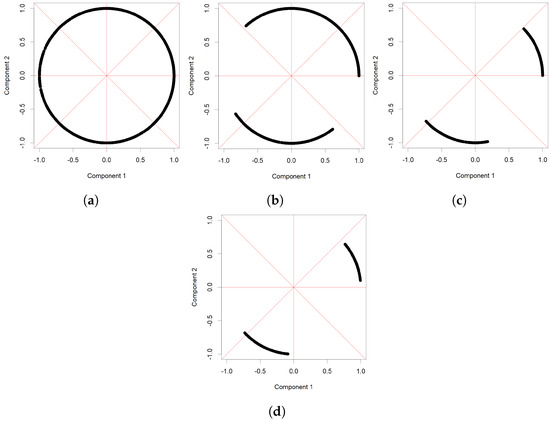
5.3. Example with Real Data
We use the algorithm with the same parameters as in Section 5.1 and Section 5.2 to study an actual data set. The data set contains the daily changes in the prices of gold and silver over a time period ranging from 3 December 1973 to 15 January 2014. It is the same data set that was used in Section 4.5 of Lehtomaa and Resnick (2020), and, consequently, the same modifications to the raw data were made. In particular, we used the logarithmic differences of daily prices in order to obtain a sequence of two-dimensional vectors that are approximately independent and identically distributed when we study the largest changes.
We studied only the negative changes in daily prices, i.e., when both the prices of silver and gold declined. Since only the days when both prices moved down are selected from the data set, the observations are concentrated into two cones. Thus, the coordinates indicate the size of the daily price drop. This decision was made in order to make the results comparable with the earlier results. In fact, the data set studied here is the data set pictured in Figure 9a of Lehtomaa and Resnick (2020), except it contains a few more observations. For background, the data of Lehtomaa and Resnick (2020) were gathered from the London Bullion Market Association. In the data set, the price of one ounce of gold or silver is recorded each day during the time period from 1973 to 2014. Only complete cases where the price information was available for both gold and silver were accepted as part of the data set.
Figure 4b shows the estimate for the riskiest directions. The estimate is consistent with the earlier result obtained in Lehtomaa and Resnick (2020) in the sense that the riskiest observations appear to concentrate on a cone, and the riskiest observations are more concentrated above the diagonal than below it. It should be noted that the analysis here was performed using Euclidean distance, while the analysis of Lehtomaa and Resnick (2020) used the distance and diamond plots.
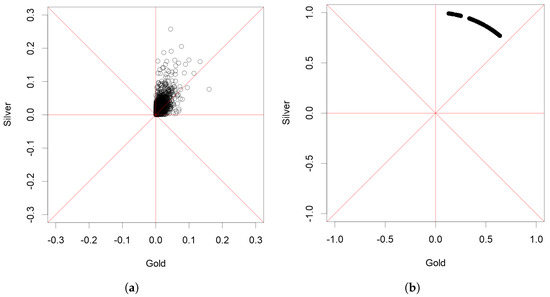
Figure 4.
A preliminary estimate for S in a real data set based on daily changes in the prices of gold and silver is presented on the right. The left subfigure (a) is a plot of the original data set.
In conclusion, a result that is consistent with the earlier study was obtained, but without the need to verify the assumptions of the multivariate, regularly varying distributions.
6. Conclusions
6.1. On the Interpretation of Estimates
In practice, we only have access to a finite amount of data. In addition, the user must select suitable values for the parameters c and k in (22) and (23). These seem to be the main challenges in the accurate detection of the directional components with heaviest tails. Typically, the parameter values are found by experimentation. One can fix k and increase the tolerance until some directions are accepted into the final estimate of S.
We state that tail function is heavier than if there exists a number such that
for all . The problem with real data is that the number can be very large. Consequently, the largest observed data points might not be produced by the heaviest tails if the size of the data set is not sufficiently large. For example, a lognormal distribution has a heavier tail than a Weibull distribution with parameter . If is close to 0, a typical i.i.d. sample from these distributions could produce data where the points from a Weibull distribution appear to be larger. In the multidimensional setting, the direction can affect the heaviness of the R-variable. For this reason, the interpretation of the estimates is the following. The estimator recovers the heaviest directional components with respect to the size of the data set. It does not exclude the possibility that there exist even heavier directional components than what is detected, and which remain undetected due to the limited number of data points. To summarise, the estimator detects the directions in which heaviness comparable to that of one-dimensional data produced by normed observations is obtained.
6.2. Further Remarks
It seems plausible that the theoretical result in Theorem 1 could be used to create statistical estimators for set S. For example, given an estimate for the set of riskiest directions, an insurance company with heavy-tailed total losses could find the root cause of heavy-tailedness. Here, the cause is found by identifying individual components or interactions between multiple components that add heavy-tailedness to the total loss. If the company understands the set of riskiest directions, it is possible to formulate hedging or reinsurance strategies that potentially mitigate the largest risks. In this sense, understanding the set of riskiest directions tells us why the entire vector is heavy-tailed, and offers a strategy for reducing risk.
The presented results offer a starting point for creating rigorous statistical estimators with a clear workflow that can be implemented as a computer algorithm. At first, one checks for the heavy-tailedness of the observations by calculating the empirical hazard function of the normed observations that produce a one-dimensional data set. Once the heaviness of this one-dimensional data set has been established and the empirical hazard function turns out to be concave, we can search the directions where the heaviness of the observations corresponds to the heaviness of the one-dimensional data. A way to implement the method is to study cones around fixed points and determine the size of each cone based on a given portion of the total observations, e.g., we can find the smallest cone that contains 10% of the observations, as in the presented examples. This avoids the problem encountered with grid-based methods, where the space is divided into cells of equal size, and where it is possible that some of the cells remain sparsely populated with observations.
As the examples with simulated and real data show, an algorithm can be also implemented in the case where there are directions with only few observations or no observations at all. Furthermore, the data do not have to be transformed or pre-processed before applying the method, but it gives an idea of where the riskiest directions are in the case where, for instance, some components have different Pareto indices than other components.
Detecting small differences requires a large amount of data. To us, this means that there must be more data if the tails associated with different directions are almost equally heavy. The presented idea works best if there exists one or more directions where the tail is substantially heavier than in other directions. As in earlier models, the practical application of the method requires some parameters to be set by the user. In particular, choosing the threshold k is not easy, but this is a well-known problem that exists in different forms in most heavy-tailed modelling strategies (Nguyen and Samorodnitsky 2012).
Author Contributions
Conceptualization and investigation, M.H. and J.L.; writing—original draft preparation, M.H. and J.L.; writing—review and editing, M.H. and J.L. All authors have read and agreed to the published version of the manuscript.
Funding
Open access funding is provided by University of Helsinki.
Data Availability Statement
The data used in the article can be requested from the corresponding author via email.
Acknowledgments
Suggestions made by the reviewers helped to improve the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Asmussen, Søren, and Jaakko Lehtomaa. 2017. Distinguishing log-concavity from heavy tails. Risks 5: 10. [Google Scholar] [CrossRef]
- Bridson, Martin R., and André Haefliger. 2013. Metric Spaces of Non-Positive Curvature. Berlin and Heidelberg: Springer Science & Business Media, vol. 319. [Google Scholar]
- Cline, Daren BH, and Sidney I. Resnick. 1992. Multivariate subexponential distributions. Stochastic Processes and Their Applications 42: 49–72. [Google Scholar] [CrossRef]
- Das, Bikramjit, and Souvik Ghosh. 2016. Detecting tail behavior: Mean excess plots with confidence bounds. Extremes 19: 325–49. [Google Scholar] [CrossRef]
- Dembo, Amir, and Ofer Zeitouni. 1993. Large Deviations Techniques and Applications. Boston: Jones and Bartlett Publishers. [Google Scholar]
- Embrechts, Paul, Claudia Klüppelberg, and Thomas Mikosch. 1997. Modelling Extremal Events. In Applications of Mathematics: For Insurance and Finance. Berlin and Heidelberg: Springer, vol. 33. [Google Scholar] [CrossRef]
- Feng, Minyu, Hong Qu, Zhang Yi, and Jürgen Kurths. 2017. Subnormal distribution derived from evolving networks with variable elements. IEEE Transactions on Cybernetics 48: 2556–68. [Google Scholar] [CrossRef] [PubMed]
- Feng, Minyu, Liang-Jian Deng, Feng Chen, Matjaž Perc, and Jürgen Kurths. 2020. The accumulative law and its probability model: An extension of the pareto distribution and the log-normal distribution. Proceedings of the Royal Society A 476: 20200019. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, Souvik, and Sidney Resnick. 2010. A discussion on mean excess plots. Stochastic Processes and their Applications 120: 1492–517. [Google Scholar] [CrossRef]
- Ghosh, Souvik, and Sidney I. Resnick. 2011. When does the mean excess plot look linear? Stochastic Models 27: 705–22. [Google Scholar] [CrossRef]
- Hult, Henrik, and Filip Lindskog. 2002. Multivariate extremes, aggregation and dependence in elliptical distributions. Advances in Applied Probability 34: 587–608. [Google Scholar] [CrossRef]
- Klüppelberg, Claudia, Gabriel Kuhn, and Liang Peng. 2007. Estimating the tail dependence function of an elliptical distribution. Bernoulli 13: 229–51. [Google Scholar] [CrossRef]
- Lehtomaa, Jaakko, and Sidney I. Resnick. 2020. Asymptotic independence and support detection techniques for heavy-tailed multivariate data. Insurance: Mathematics and Economics 93: 262–77. [Google Scholar] [CrossRef]
- Li, Haijun, and Yannan Sun. 2009. Tail dependence for heavy-tailed scale mixtures of multivariate distributions. Journal of Applied Probability 46: 925–37. [Google Scholar] [CrossRef]
- Nguyen, Tilo, and Gennady Samorodnitsky. 2012. Tail inference: Where does the tail begin? Extremes 15: 437–61. [Google Scholar] [CrossRef]
- Omey, E. A. M. 2006. Subexponential distribution functions in Rd. Journal of Mathematical Sciences 138: 5434–49. [Google Scholar] [CrossRef]
- Peters, Gareth W., and Pavel V. Shevchenko. 2015. Advances in Heavy Tailed Risk Modeling: A Handbook of Operational Risk. Wiley Handbook in Financial Engineering and Econometrics; Hoboken: John Wiley & Sons, Inc. [Google Scholar] [CrossRef]
- Resnick, Sidney I. 2004. On the foundations of multivariate heavy-tail analysis. Journal of Applied Probability 41A: 191–212. [Google Scholar] [CrossRef]
- Samorodnitsky, Gennady, and Julian Sun. 2016. Multivariate subexponential distributions and their applications. Extremes 19: 171–96. [Google Scholar] [CrossRef]
- Weng, Chengguo, and Yi Zhang. 2012. Characterization of multivariate heavy-tailed distribution families via copula. Journal of Multivariate Analysis 106: 178–86. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).