Abstract
In this paper, a multi-parameter proximal scaled gradient algorithm with outer perturbations is presented in real Hilbert space. The strong convergence of the generated sequence is proved. The bounded perturbation resilience and the superiorized version of the original algorithm are also discussed. The validity and the comparison with the use or not of superiorization of the proposed algorithms were illustrated by solving the problem.
Keywords:
strong convergence; proximal scaled gradient algorithm; multi-parameter; superiorization; convex minimization problem MSC:
47J25; 49J53; 49M37; 65J15; 90C25
1. Introduction
The superiorization method, which was introduced by Censor in 2010 [1], can solve a broad class of nonlinear constrained optimal problems that result from many practical problems such as computed tomography [2], medical image recovery [3,4], convex feasibility problems [5,6], inverse problems of radiation therapy [7] and so on, which generates an automatic procedure based on the fact that the basic algorithm has the property of bounded perturbation resilience so that it is expected to get lower values of the objective function. In recent years, some researchers have focused on finding more applications of superiorization methodology while some other researchers have investigated the bounded perturbation resilience of algorithms—see, for examples, [8,9,10,11,12,13,14,15,16,17].
In this paper, we study the bounded perturbation resilience property and the corresponding superiorization of a proximal scaled gradient algorithm with multi-parameters for solving the following non-smooth composite optimization problem of the form
where H is a real Hilbert space endowed with an inner product and the induced norm . with defined by
In addition, f has L-Lipschitz continuous gredient on H with .
The proximal gradient method is one of the popular iterative methods used for solving problem (1), which has received a lot of attention in the recent past due to its fast theoretical convergence rates and strong practical performance. Given an initial value , the proximal gradient method generates the following sequence :
where is the step size and is the proximal operator of g of order (please refer to Definition 2, Section 2). Then, the generated sequence converges weakly to a solution of problem (1) if the solution set and (see, for instance, [18], Theorem 25.8).
Xu [19] raised the following more general proximal gradient algorithm:
The weak convergence of the generated sequence was obtained. If , the strong convergence can not be guaranteed.
The scaled method was proposed by Strand [20] for increasing the rate of convergence of some algorithm. In a finite dimensional space, the selection of scaling matrices depends on the particular problem [21,22]. Jin, Censor and Jiang [13] introduced the following projected scaled gradient (PSG) algorithm:
where is a diagonal scaling matrix for each , is defined as for solving the following convex minimization problems:
where is a nonempty, closed and convex set, the objective function is convex. With the assumption that
and other conditions, the convergence of the PSG method in the presence of bounded perturbations was proved.
Motivated by [13], Guo, Cui and Guo [23] discussed the proximal gradient algorithm with perturbations:
They proved that the generated sequence converges weakly to the solution of problem (1). After that, Guo and Cui [15] applied the convex combination of contraction operator and proximal gradient operator to obtain the strong convergence of the generated sequence and discussed the bounded perturbation resilience of the exact algorithm.
In this paper, we will study the following proximal scaled gradient algorithm with multi-parameters:
which is a further generalization of the above algorithms. We will discuss the strong convergence of (8) and the bounded perturbation resilience of its exact algorithm just like the algorithms named above. In addition, we also study the superiorized version of the exact algorithm of (8).
The rest is organized as follows. In the next section, we introduce some basic concepts and lemmas. In Section 3, we discuss the strong convergence results of the exact and non-exact algorithms. In Section 4, we provide two numerical examples for illustrating the performances of the iterations. Finally, we summarize the main points of this paper in Section 5.
2. Preliminaries
Let H be a real Hilbert space endowed by an inner product and the induced norm . Let be a sequence in H. is said to be a weak cluster point of if there exists a subsequence of that converges weakly to it. The set of all weak cluster points of is denoted by . Let be a nonlinear operator. Set .
The following definitions are needed in proving our main results.
Definition 1.
([24], Proposition 2.1)
- (i)
- T is non-expansive if
- (ii)
- T is L-Lipschitz continuous with , ifWe call T a contractive mapping if .
- (iii)
- T is firmly non-expansive if
- (iv)
- T is α-averaged if there exists a non-expansive operator and , such thatIn particular, a firmly non-expansive mapping is -averaged.
- (v)
- T is v-inverse strongly monotone (v-ism) with , if
Definition 2.
([25], Proximal Operator) Let . The proximal operator of g is defined by
The above definition is well defined since has only one minimizer on H for each and for given (see [18], Proposition 12.15).
The proximal operator of g of order is defined as
The following Lemmas 1–3 describe the properties of proximal operators.
Lemma 1.
([19,26], Lemma 2.4, Lemma 3.3) Let , and . Then,
Moreover, if , we also have
Lemma 2.
[18] (Non-expansiveness) Let and . Then, the proximal operator is -averaged. We obtain the non-expansiveness of the proximal operator
Lemma 3.
([19], Propostion 3.2) Let , f be differentiable and . Then, z is a solution to (1) if and only if z is the fixed point of the following equation:
The following lemmas play important roles in proving the strong convergence result.
Lemma 4.
([18], Corollary 4.18) Let be a non-expansive mapping with . If is a sequence in H converging weakly to x and if converges strongly to 0, then .
Lemma 5.
([27], Lemma 2.5) Assume that is a sequence of nonnegative real numbers satisfying
where , such that
- (i)
- ;
- (ii)
- ;
- (iii)
- .
Then, .
Lemma 6.
([28], Lemma 2.4) Let and . Then,
- (i)
- ;
- (ii)
- ;
- (iii)
- .
Lemma 7.
([23], Proposition 3.3) Let . For any , where L is the Lipschitz constant of . is -averaged. Hence, it is non-expansive.
3. The Convergence Analysis and the Superiorized Version
In this section, we prove that the sequence generated by the exact form of (8) converges strongly to a solution of problem (1) at first. Then, we discuss the strong convergence of algorithm (8). Finally, we investigate the bounded perturbation resilience of the exact iteration by viewing it as a special case of algorithm (8). The superiorized version is also presented at the end of this section.
3.1. The Exact Form of Algorithm (8)
Given the errors in (8), we get the exact version of (8):
where , such that and for all . is a -contraction for some . , f has the Lipschitz continuous gradient with Lipschitz constant . is a linear bounded operator for each with an upper bound and satisfies
Provided that and satisfy some additional conditions, we get the following strong convergence result of algorithm (21).
Theorem 1.
- (i)
- for all n;
- (ii)
- and ;
- (iii)
- .
The sequence generated by algorithm (21) converges strongly to a point , where z is the unique solution of the following variational inequality problem:
Proof of Theorem 1.
We will complete the proof by three steps.
Step 1. is a bounded sequence in H.
Let , then we have by Lemma 3. In view of Lemmas 2 and 7, we also get that and are non-expansive for . Now, let us calculate
An induction argument shows that
where as is bounded and . Hence, is bounded. Consequently, is bounded since h is a -contraction.
Step 2. There exists a subsequence such that .
We denote by
for briefness.
Using the notation , one has ,
Given , we consider by utilizing Lemma 6 (iii)
Meanwhile, we derive
Notice that
and that
since is non-expansive and (see Lemma 3). We then obtain by substituting (30) and (31) into (29)
Combining (28) and (32), we get
where ,
Obviously, we have
which implies that is a finite number. Thus, there exists a subsequence such that . In addition, without loss of generality, we may assume that converges weakly to some as since is bounded. Notice that
We conclude that also converges weakly to . As a result, exists. Hence, we have
In light of the fact that is bounded and , the sequence is bounded. Then, condition (iii) implies
Set with and apply Lemma 1. We get
Then, Lemma 4 guarantees that .
Step 3. converges strongly to .
3.2. The Strong Convergence of Algorithm (8)
Theorem 2.
- (i)
- for all n;
- (ii)
- and ;
- (iii)
- ;
- (iv)
- .
Then, the sequence generated by algorithms (8) converges strongly to a point .
Proof of Theorem 2.
Let be generated by (8) and (21), respectively. Then, converges strongly to a solution of problem (1) according to Theorem 1. Thus, we only need to prove that as .
We denote by and , respectively. is non-expansive according to Lemma 7. Then, we have
Applying Lemma 5 to inequality (41), we get as . We then have completed the proof owing to Theorem 1. □
3.3. Bounded Perturbation Resilience
This subsection is devoted to verifying the bounded perturbation resilience property of algorithm (21) and showing the superiorized version of it.
Given a problem , let be a basic algorithm operator.
Definition 3.
[9] An algorithmic operator A is bounded perturbation resilient if the sequence , generated by with , converges to a solution to Ψ; then, any sequence generated by with any , also converges to a solution of Ψ, where is bounded, and are such that for all and .
If we take algorithm (21) as the basic algorithm A, the following iteration is the bounded perturbation of it:
We have the following result.
Theorem 3.
Let H be a real Hilbert space, and a ρ-contractive operator with , f, . Assume that the solution set S to (1) is nonempty and that f has Lipschitz continuous gradient on H with the Lipschitz constant . , satisfy the conditions in Definition 3, , , and satisfy the conditions in Theorem 1, respectively. Then, any sequence generated by (42) converges strongly to a point in S. Thus, algorithm (21) is bounded perturbation resilient.
Proof of Theorem 3.
We can rewrite algorithm (42) as
with
which is obviously the same form as (8) if we certify that . In fact, we have
where and are defined by (26), respectively. Then, it is easy to conclude that
since are all summable. Hence, Theorem 2 guarantees that any sequence generated by (42) converges strongly to a solution of (1). That is to say, algorithm (21) is bounded perturbation resilient. □
The superiorized version is equipped with an optimization criterion, which is usually a function , with the convention that, for , being smaller is considered superior. To ensure this, it needs a new concept, named nonascending direction for at x. A vector is called nonascending for at if , and there exists a constant such that, for all , . Such v at least exists one, namely, zero vector. The superiorization method then provides us with an automatic way of turning the original iterative algorithm for solving problem (1) into an algorithm, for which the value of the objective function at each iteration is not larger than that under the original iterative algorithm. At the same time, the value of is smaller than it is under the original algorithm. Superiorization does this by assuming that there are a summable sequence of positive real numbers and a bounded vector sequence (Each is a nonascending direction for at some , and , together with the original iterative point, generates a new iterative point), and further by depending on a I steering steps aimed at reducing the values of at these iterative points. In addition, it makes use of a logical variable called loop. In this paper, we choose the optimization criterion function as the objective function in problem (1). Then, the superiorized version of (21) is as specified below:
4. Numerical Experiments
In this section, we solve the norm problem by two numerical examples to illustrate the performance of the proposed iterations. The concerned algorithms are Algorithm 1 (MPGAS), the bounded perturbation algorithm (42) (MPGAB) and basic algorithm (21) (MPGA). All of these experiments were done on a quad core Intel i7-8550U CPU @1.8 GHz with 16 GB DDR4 memory.
| Algorithm 1: Superiorized Version of (21) |
| 1: Given |
| 2: set |
| 3: set |
| 4: set Error = Constant |
| 5: while Error |
| 6: set |
| 7: set |
| 8: while |
| 9: set to be a nonascending vector for at |
| 10: set loop = true |
| 11: while loop |
| 12: |
| 13: set |
| 14: set |
| 15: if and |
| 16: set |
| 17: set |
| 18: set loop = false |
| 19: end if |
| 20: end while |
| 21: end while |
| 22: set |
| 23: set Error = |
| 24: set . |
4.1. The Norm Problem
Let be an orthogonal basis of , be strictly positive real numbers, let , and . The problem has the following form:
In signal recovery problems, d is the observed signal and the original signal x is known to have a sparse representation.
We take . Then, with Lipschtz constant , where refers to the transpose of A. The above problem is a special case to problem (1).
4.2. Numerical Examples
Example 1.

Let ,
A straightforward calculation shows that the solution set to (47) and the minimum value of the objective function for (47) is . We solve this problem with the algorithms proposed in this paper. The numerical results can be found in Table 1.
Table 1.
Results for Example 1.
Suppose that the contraction , and the diagonal scaling matrix . We choose , , , and the step size sequence . For algorithm (21) with bounded perturbations, we choose the bounded sequence as
the summable nonnegative real sequence as for some . For the superiorized version of (21), we take the function ϕ as the objective function in problem (47), that is
The iteration numbers (“Iter"), the values of (“”), the values of the objective function (“Obj”) are reported in Table 1 when the stopping criterion
is reached.
The following Figure 1 is for .
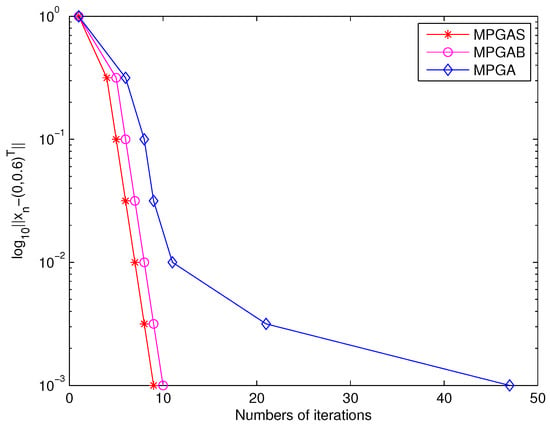
From Table 1 and Figure 1 above, we see that the superiorized version and the bounded perturbation algorithm of (21) arrived at the minimum and the unique minimum point by nine iterations while the original algorithm (21) took 47 iterations to attain the same minimum with the zero initial value. Similar results were also obtained with the initial value from uniform distribution.
We now discuss a general case of problem (47) by the above-mentioned algorithms.
Example 2.
Let the system matrix be stimulated by standard Gaussian distribution, . Let the vector be generated from a uniform distribution in the interval [−2,2]. Solve the optimal problem (47) with the above-mentioned algorithms.
We take the parameters in the algorithms as follows:
- 1.
- Algorithm parameters:The contraction . The diagonal scaling matrix, , then . The step size sequence .
- 2.
- Algorithm parameters for the superiorized version:The summable nonnegative real sequence : for some and . We set ϕ as the objective function in problem (47).
The iteration numbers , the computing time in seconds (“”), the error’s values (“”) are reported in Table 2 with a random initial guess when the stopping criterion
is reached, where ε is a given small positive constant.
Table 2.
Results for Example 2 with .
We find from Table 2 that there is no increase in the execution time of the computer by running the superiorized version, MPGAS, of original algorithm (21). In contrast, compared to the algorithms MPGAB and MPGA, MPGAS even reduces the operation time to get a smaller objective function value under the same stop criterions and initial value .
5. Conclusions
In this paper, we have proposed a proximal scaled gradient algorithm with multi-parameters and studied the strong convergence of it in a real Hilbert space for solving a composite optimization problem. We have investigated the bounded perturbation resilience and the superiorized version of it as well. The validity of the proposed algorithm and the comparison of the original iteration, the bounded perturbation form and the superiorized version of it were illustrated by numerical examples. The results and numerical examples in this paper are a new attempt or application of a newly developed superiorization method. It shows that this method works well to some degree for the proposed algorithm.
Author Contributions
All authors contributed equally and significantly to this paper. Conceptualization, Y.G.; Data curation, Y.G. and X.Z.; Formal analysis, Y.G. and X.Z.
Funding
This research was funded by the Fundamental Research Funds for the Central Universities (Grant No. 3122018L004) and China Scholarship Council (Grant No. 201807315013).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Censor, Y.; Davidi, R.; Herman, G.T. Perturbation resilience and superiorization of iterative algorithms. Inverse Probl. 2010, 26, 65008. [Google Scholar] [CrossRef] [PubMed]
- Davidi, R.; Schulte, R.W.; Censor, Y.; Xing, L. Fast superiorization using a dual perturbation scheme for proton computed tomography. Trans. Am. Nucl. Soc. 2012, 106, 73–76. [Google Scholar]
- Davidi, R.; Herman, G.T.; Censor, Y. Perturbation-resilient block-iterative projection methods with application to image reconstruction from projections. Int. Trans. Oper. Res. 2009, 16, 505–524. [Google Scholar] [CrossRef] [PubMed]
- Nikazad, T.; Davidi, R.; Herman, G.T. Accelerated perturbation-resilient block-iterative projection methods with application to image reconstruction. Inverse Probl. 2012, 28, 035005. [Google Scholar] [CrossRef] [PubMed]
- Censor, Y.; Chen, W.; Combettes, P.L.; Davidi, R.; Herman, G.T. On the effectiveness of projection methods for convex feasibility problems with linear inequality constraints. Comput. Optim. Appl. 2012, 51, 1065–1088. [Google Scholar] [CrossRef]
- Censor, Y.; Zaslavski, A.J. Strict Fejér monotonicity by superiorization of feasibility-seeking projection methods. J. Optim. Theory Appl. 2015, 165, 172–187. [Google Scholar] [CrossRef]
- Davidi, R.; Censor, Y.; Schulte, R.W.; Geneser, S.; Xing, L. Feasibility-seeking and superiorization algorithm applied to inverse treatment plannning in rediation therapy. Contemp. Math. 2015, 636, 83–92. [Google Scholar]
- Censor, Y.; Zaslavaski, A.J. Convergence and perturbation resilience of dynamic string averageing projection methods. Comput. Optim. Appl. 2013, 54, 65–76. [Google Scholar] [CrossRef]
- Censor, Y.; Davidi, R.; Herman, G.T.; Schulte, R.W.; Tetruashvili, L. Projected subgradient minimization versus superiorization. J. Optim. Theory Appl. 2014, 160, 730–747. [Google Scholar] [CrossRef]
- Dong, Q.L.; Lu, Y.Y.; Yang, J. The extragradient algorithm with inertial effects for solving the variational inequality. Optimization 2016, 65, 2217–2226. [Google Scholar] [CrossRef]
- Garduño, E.; Herman, G. Superiorization of the ML-EM algorithm. IEEE Trans. Nucl. Sci. 2014, 61, 162–172. [Google Scholar]
- He, H.; Xu, H.K. Perturbation resilience and superiorization methodology of averaged mappings. Inverse Probl. 2017, 33, 040301. [Google Scholar] [CrossRef]
- Jin, W.; Censor, Y.; Jiang, M. Bounded perturbation resilience of projected scaled gradient methods. J. Comput. Optim. Appl. 2016, 63, 365–392. [Google Scholar] [CrossRef]
- Schrapp, M.J.; Herman, G.T. Data fusion in X-ray computed tomography using a superiorization approach. Rev. Sci. Instrum. 2014, 85, 055302. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.N.; Cui, W. Strong convergence and bounded perturbation resilience of a modified proximal gradient algorithm. J. Inequal. Appl. 2018, 2018, 103. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.H.; Penfold, S. Total variation superiorization in dualenergy CT reconstruction for proton therapy treatment planning. Inverse Probl. 2017, 33, 044013. [Google Scholar] [CrossRef]
- Zibetti, M.V.W.; Lin, C.A.; Herman, G.T. Total variation superiorized conjugate gradient method for image reconstruction. Inverse Probl. 2018, 34, 034001. [Google Scholar] [CrossRef]
- Bauschke, H.H.; Combettes, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Space; Dilcher, K., Taylor, K., Eds.; Springer: New York, NY, USA, 2011. [Google Scholar]
- Xu, H.K. Properties and Iterative Methods for the Lasso and Its Variants. Chin. Ann. Math. 2014, 35, 501–518. [Google Scholar] [CrossRef]
- Strand, O.N. Theory and methods related to the singular-function expansion and Landweber iteration for integral equations of the first kind. SIAM J. Numer. Anal. 1974, 11, 798–825. [Google Scholar] [CrossRef]
- Piana, M.; Bertero, M. Projected Landweber method and preconditioning. Inverse Probl. 1997, 13, 441–463. [Google Scholar] [CrossRef]
- Neto, E.S.; Helou, D.; Álvaro, R. Convergence results for scaled gradient algorithms in positron emission tomography. Inverse Probl. 2005, 21, 1905–1914. [Google Scholar] [CrossRef]
- Guo, Y.N.; Cui, W.; Guo, Y.S. Perturbation resilience of proximal gradient algorithm for composite objectives. J. Nonlinear Sci. Appl. 2017, 10, 5566–5575. [Google Scholar] [CrossRef][Green Version]
- Xu, H.K. Iterative methods for the split feasibility problem in infinite-dimensional Hilbert space. Inverse Probl. 2010, 26, 105018. [Google Scholar] [CrossRef]
- Moreau, J.J. Proximité et dualité dans un espace hilbertien. Bull. Soc. Math. Fr. 1965, 93, 273–299. [Google Scholar] [CrossRef]
- Marino, G.; Xu, H.K. Convergence of generalized proximal point algorithm. Commun. Pure Appl. Anal. 2004, 3, 791–808. [Google Scholar]
- Xu, H.K. Iterative algorithms for nonlinear operators. J. Lond. Math. Soc. 2002, 66, 240–256. [Google Scholar] [CrossRef]
- Xu, H.K. Error sensitivity for strongly convergent modifications of the proximal point algorithm. J. Optim. Theory Appl. 2015, 168, 901–916. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).