Abstract
Image super-resolution (SR), as one of the classic image processing issues, has attracted increasing attention from researchers. As a highly ill-conditioned, non-convex optimization issue, it is difficult for image SR to restore a high-resolution (HR) image from a given low-resolution (LR) instance. Recent researchers have tended to regard image SR as a regression task and to design an end-to-end convolutional neural network (CNN) to predict the pixels directly, which lacks inherent theoretical analysis and limits the effectiveness of the restoration. In this paper, we analyze image SR from an optimization perspective and develop a deep successive convex approximation network (SCANet) for generating HR images. Specifically, we divide non-convex optimization into several convex LASSO sub-problems and use CNN to adaptively learn the parameters. To boost network representation, we use residual feature aggregation (RFA) blocks and devise a spatial and channel attention (SACA) mechanism to improve the restoration capacity. The experimental results show that the proposed SCANet can restore HR images more effectively than other works. Specifically, SCANet achieves higher PSNR/SSIM results and generates more satisfying textures.
MSC:
68U10
1. Introduction
Image super-resolution (SR) is one of the classic image processing issues [1]. Given a low-resolution (LR) image, the task of image SR is to generate a corresponding high-resolution (HR) image with higher subjective and objective performance [2]. Image SR has been widely considered in various applications, such as iris and ocular recognition [3] and other high-level computer vision tasks [4].
With the rapid development of deep learning, there are numerous convolutional neural networks (CNNs) that have been specifically designed to solve the image SR problem [5,6,7,8]. SRCNN [5] is the first CNN-based image SR method to generate satisfying results from the given instances. After SRCNN, deeper and wider networks have achieved good performance with elaborate block designs [7,8]. However, these works only regard image SR as a regression issue and use an end-to-end network to directly predict the pixels of HR images. This direct regression limits the precision of the restoration methods.
As a highly ill-conditioned problem, image SR can be regarded as an optimization issue [9,10,11,12,13]. From an optimization perspective, image SR aims to find a satisfying result which is in accordance with the LR representation after down-sampling and follows the prior HR image. As such, image SR can be regarded as an unconstrained optimization problem under the consideration of the fidelity term and the prior term. There are also works regarding image SR as an optimization issue [9,10,11,12,13]. Half-quadratic splitting (HQS) and the alternating direction method of multipliers (ADMM) are two representative strategies to iteratively find a feasible solution for non-convex tasks. Recently, works have considered HQS and ADMM for image SR, which have achieved good performances [9,10]. However, both HQS- and ADMM-based CNNs solve the non-convex problem without a specific prior HR image, which makes it hard to find a satisfying solution and limits the effectiveness of the network.
In this paper, we analyze image SR from a non-convex optimization perspective and solve the issue in the successive convex approximation (SCA) manner. Specifically, we divide the non-convex problem into several convex LASSO sub-problems and calculate the solution successively. From this point of view, the prior HR image is explicitly considered as the -norm, which follows the sparsity of the natural images. We design a network, dubbed SCANet, to adaptively learn the parameters and conduct the optimization. To improve the network capacity, we use residual feature aggregation (RFA) blocks [14] and devise a spatial and channel attention (SACA) mechanism in SCANet. The experimental results show that the proposed SCANet achieves better performance than other image SR works, with higher PSNR/SSIM results. Furthermore, SCANet can generate more satisfying textures and details with better visual performances than other works.
Our contributions can be concluded as follows:
- We analyze image SR from a non-convex optimization perspective and propose an iterative solution by dividing the task into several convex LASSO sub-problems, which is more effective than other iteration solutions. Based on this analysis, we devise a SCANet for image super-resolution.
- We utilize residual feature aggregation (RFA) blocks and develop a spatial and channel attention (SACA) mechanism in SCANet, which can improve network representation and restoration capacity.
- The experimental results show that the proposed SCANet achieves better subjective and objective performance than other works, with higher PSNR/SSIM results.
2. Related Works
Recently, convolutional neural networks (CNNs) have found great success in image SR [15]. SRCNN [5] is the first CNN-based image SR method that utilizes three-layer architecture to generate HR details. After SRCNN, numerous well-designed networks have been proposed for effective image SR. FSRCNN [6] modified the SRCNN for faster speed and higher restoration precision with a thinner but deeper design. VDSR [7] used a very deep network design with a residual connection to achieve good restoration performance. EDSR [8] developed a deep residual network with residual blocks [16] for better information transmission and network representation. DRRN [17] and DRCN [18] considered the recursive design for image SR and utilized an iterative design for restoration. Recently, researchers have mainly focused on elaborate block designs for image SR. CARN [19] built a cascading network for efficient image SR. OISR [20] designed the block according to the ODE pattern and achieved good performance. RDN [21] combined the residual connection [16] and the dense connection [22] and developed a residual dense block for image SR. SRDenseNet [23] built a deep network with dense connections for better gradient transmission. RCAN [24] utilized a residual-in-residual design for effective gradient transmission and made the network deeper. SAN [25] developed a second-order attention mechanism for image SR and achieved state-of-the-art performance. However, these works only consider building a deeper and wider network with well-designed blocks for restoration, and neglect to consider the image SR problem from a mathematical perspective.
By considering the image SR issue from a mathematical perspective, it can be regarded as a highly ill-conditioned issue that can be solved using optimization methodologies. IRCNN [9] utilized a half-quadratic splitting (HQS) strategy to first separate the image SR into a closed-form solution and a denoiser. DPSR [10] considered a novel image SR degradation situation, and proposed a deep plug-and-play model to solve the problem. However, these works only aimed to solve the non-convex problem using the iterative mechanism, which lacks the explicit prior definition of HR images and makes it difficult to find a satisfying solution.
3. Methodology
In this section, we introduce the proposed SCANet in the following manner. First, we analyze image SR as an optimization issue and propose a solution with the help of successive convex approximation (SCA). Then, an end-to-end network is designed to find a solution that adaptively learns the parameters from the data pairs. Finally, we discuss the details of the proposed SCANet.
3.1. Successive Convex Approximation for Image Super-Resolution
Given a low-resolution (LR) image , the task of image SR is to find a feasible high-resolution (HR) image , satisfying
where is the degradation operation and is the prior image of the HR images. is a scaling factor.
In general, Equation (1) is a non-convex issue, for which it is difficult to find a satisfying solution. To find a feasible result, we utilize the successive convex approximation (SCA) strategy to convert this non-convex problem into several convex tasks and find the solution in an iterative manner.
For a k-th iteration, we aim to solve the task
where is the matrix representation of the degradation operation . In Equation (2), we choose norm as the prior image, which considers the sparsity of the natural image. It can be seen that Equation (2) embodies the same situation as the LASSO problem. To solve this equation, we use the sub-gradient descent method and find a feasible descent direction for optimization. Then, the descent direction of the k-th iteration can be shown as
By using this sub-gradient descent direction, the optimization of the k-th step is described as
where is the step length and is the descent direction of the k-th step. The descent direction is a theoretical guidance for the optimization step that decreases the distance between and the ideal . The optimization steps follow the original steps of successive convex optimization, which have been investigated in previous optimization studies [26,27,28].
3.2. Deep Successive Convex Approximation Network
Based on mathematical analysis of image SR, we develop the deep successive convex approximation network (SCANet) for image SR. The design of SCANet is shown in Figure 1. In this figure, is the feature of the LR image, is the feature processed using the i-th LASSO block, and is the restored feature of the HR image. We conduct SCA in the feature space by designing special LASSO blocks. First, one convolution processes the input LR image and generates the corresponding feature maps as
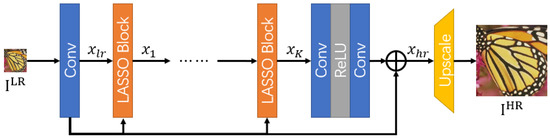
Figure 1.
Network design of SCANet. is the feature of the LR image, is the feature processed using i-th LASSO blocks, and is the restored feature of the HR image.
After that, K LASSO blocks are used to conduct the optimization. For the k-th step, this is
After K LASSO blocks, a padding structure is used to restore the HR image feature with residual connections as
where is composed of two convolutional layers and a ReLU activation.
Finally, an upscale module restores the HR image from the feature maps as
The upscale module is composed of one convolutional layer and a sub-pixel convolution [29].
Specifically, we describe the design of the LASSO block, which is the core of SCANet. Figure 2 shows the block design of the LASSO block. The block follows the analysis of Equations (3) and (4). In this figure, we can see that the in Equation (3) is simulated using four residual feature aggregation blocks (RFAB) and one convolution. The is simulated using two convolutional layers and a ReLU activation. Then, the learned descent direction of the k-th iteration step is calculated as
where is the concatenate operation. The convolution is used to adaptively learn the scaling factor . Finally, one convolution is used to conduct Equation (4) by adaptively learning the step length as
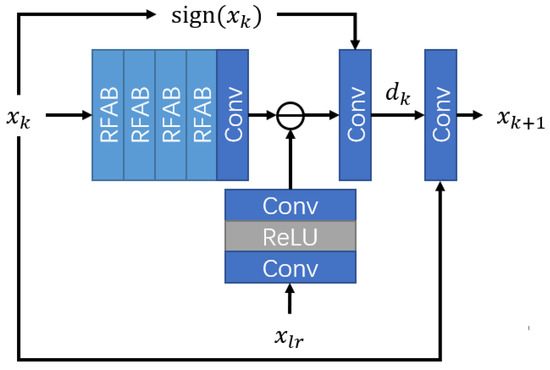
Figure 2.
Block design of the LASSO block.
Figure 3 shows the design of RFAB in the LASSO block. RFAB has been proven to be a good component for image SR in recent works [14,30] and has been widely considered in previous SR works. According to previous reports [14,30], RFAB can more effectively explore the image features than other well-designed blocks.
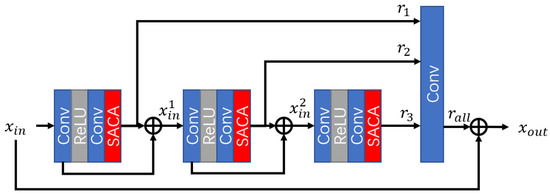
Figure 3.
Block design of RFAB.
Different from residual blocks, RFAB aggregates the residual information from different blocks to jointly learn multi-scale information and restores the image information. Compared with traditional residual blocks, RFAB has an adaptive ability to describe the residual features. There are three processing modules with the same design in RFAB, which are composed of two convolutional blocks, one ReLU activation, and a spatial and channel attention (SACA) mechanism. Let be the processing module and be the input of RFAB; then, the operation of the processing modules can be described as
Then, the aggregated residual information is calculated via one convolution as
The output of RFAB is calculated as
SACA in RFAB is shown in Figure 4. SACA focuses on spatial attention and channel attention separately, and utilizes one convolution to combine dual attention information. To this end, the two types of attention can focus on different dimensions of the image and improve the restoration capacity. We calculate the spatial attention and the channel attention via two parallel pathways. In each path, there are two convolutional layers, one ReLU activation and one sigmoid activation, which follow the design of various attention mechanisms [24,25]. There is one global average pool in the channel attention mechanism. After the spatial and channel attentions, one convolution combines the two dual information sources, and a residual connection is introduced for efficient gradient transmission.
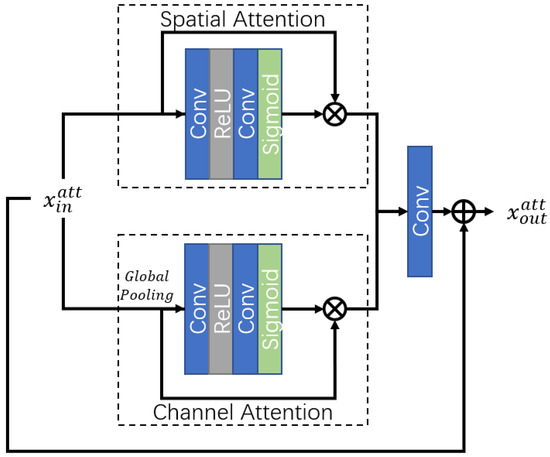
Figure 4.
Block design of SACA.
3.3. Implementation Details
There are LASSO blocks in SCANet. All convolutional layers have channels, and the kernel sizes are set as , except for the convolutions. The filter in the upscale module is set as , where s is the scaling factor of the image SR.
4. Experiment
4.1. Settings
We train our network with the DIV2K [31] dataset. The DIV2K dataset contains 900 high-resolution images for training and validation, with a resolution up to 2K. In this work, we first choose 800 images for training, and the last 5 images for validation, which are the same settings used in recent works [21,24]. The testing datasets chosen are Set5 [32], Set14 [33], B100 [34], Urban100 [35], and Manga109 [36], which are commonly used in different SR works. The scaling factors of image SR chosen are , and . The learning rate chosen is . The patch size chosen is for LR images, and the batch size is the same as the RDN [21]. We update our network using the Adam optimizer [37] for 1000 epochs, and halve the learning rate for every 200 epochs. The metrics of image SR are chosen as PSNR and SSIM.
4.2. Ablation Study
In SCANet, we develop RFAB and SACA for effective image SR. To investigate the effectiveness of these blocks, we compare the PSNR and the SSIM results against three different benchmarks: B100 [34], Urban100 [35], and Manga109 [36]. Table 1 shows the results of the different designs.

Table 1.
Investigation of RFAB and SACA with scaling factor .
In this table, we can see that RFAB brings a large improvement to PSNR and SSIM. By comparing the first and second lines, RFAB brings a 0.4 dB improvement to the Urban100 and Manga109 benchmarks. The model also benefits from SACA. In the second and third lines, SACA results in 0.05 db PSNR and 0.02 SSIM for the Urban100 and Manga109 benchmarks. From this point of view, RFAB and SACA are effective components for the proposed SCANet.
4.3. Results
We compare our SCANet with several CNN-based methods: SRCNN [5], FSRCNN [6], VDSR [7], DRCN [18], CNF [38], LapSRN [39], DRRN [17], BTSRN [40], MemNet [41], SelNet [42], CARN [19], RAN [43], DNCL [44], FilterNet [45], MRFN [46], and DEGREE [47]. The scaling factors chosen are , , and . The testing benchmarks chosen are Set5, Set14, B100, Urban100, and Manga109. The metrics chosen are PSNR and SSIM.
Table 2 shows the PSNR/SSIM comparisons against five testing benchmarks with three different scaling factors. In the table, we can see that our SCANet achieves competitive or better performances than those in other works. SCANet achieves a 0.2 dB improvement over Urban100 and a 0.3 dB improvement over Manga109, with a scaling factor of . Similarly, there is a 0.2 dB PSNR improvement over Set5 compared with CARN when the scaling factor is . When the scaling factor is , SCANet achieves the highest PSNR/SSIM results when compared with other works. From this point of view, SCANet is effective for image SR.
Table 2.
Average PSNR/SSIM with degradation model BI , , and against five benchmarks. (+) means the result is better than our method, and (-) means the result is worse than our method.
Furthermore, we compare the visualization quality with VDSR [7]. Figure 5 shows the restored images of the Urban100 benchmark with a scaling factor ×4. In the figure, we can see that the proposed SCANet can restore the circles and lines more clearly than other works. Furthermore, the results of SCANet are the closest to the HR images. As such, the PSNR results of SCANet are better than other works. From this point of view, SCANet can effectively restore LR images with more satisfying results.

Figure 5.
Visual comparisons against the Urban100 benchmark.
We also investigate the subjective qualities of different methods. To this end, we use the no-reference indicators and measure the visual quality of different methods. The indicators are chosen as NIQE and BRISQUE. Table 3 shows the subjective comparisons. It should be noted that the lower NIQE and BRISQUE values mean a better visual performance. In the figure, it can be seen that SCANet achieves the best performance with the lowest indicator scores. From this point of view, SCANet obtains better visual quality than other works.
Table 3.
Subjective quality comparisons with different no-reference image quality indicators.
To demonstrate the significance of our method, we conduct the two-sample t-test on the NIQE results of the three methods. Table 4 shows the results. The figure “0” in the table means there is no significant difference between the two methods; “1” means the upper method outperforms the left method; and “−1 ” means the left method outperforms the upper one. We can see from the table that SCANet performs significantly better than other works, with good visual quality.
Table 4.
Subjective quality comparisons with different no-reference image quality indicators.
4.4. Discussion
In this work, we compare our method with others, with a scaling factor of , , and . There are works with much larger scaling factors, such as 16, 32, or even 64 [50,51]. However, these methods only focus on some specific kinds of images, such as facial SR [50]. These methods only work in the specific situation, but cannot be generalized to different applications. Our work is a general SR method that can be directly utilized in various scenarios. The most commonly compared scaling factors are 2, 3, and 4 for general SR works, such as SRCNN [5], LapSRN [39], and CARN [19].
There are also cases of failure for SCANet. SCANet regards image super-resolution as an optimization task, which does not specifically focus on edge restoration. From this point of view, works aiming at structural restoration, such as SeaNet [48], achieve higher SSIM scores on the Urban100 [35] and Manga109 [36] datasets, which contain plentiful edges and lines. In further work, we will consider special edges and structural priors in the optimization step and thus improve restoration performance.
Different from vanilla optimization methods, the deep learning-based optimization method has a fixed number of iteration steps. Convergence is guaranteed by the convex optimization algorithm, and the network adaptively learns the parameters during the training step. Successive convex approximation has proved to be convergent in the previous literature [26,27,28]. The LASSO sub-problem also has a converged solution [52]. From this point of view, SCANet can be converged during iteration steps.
In general, this network provides an effective restoration method for image SR and achieves a better performance than other related works. Furthermore, this network provides a new perspective on combining deep learning and the optimization problem, which can be further investigated for different computer vision tasks.
5. Conclusions
Currently, researchers usually regard image SR as a regression task and use an end-to-end convolutional neural network (CNN) to predict the pixels directly, which lacks inherent theoretical analysis and limits the effectiveness of restoration. In this paper, we propose a deep successive convex approximation network for image super-resolution (SR), dubbed SCANet. In SCANet, the SR task was investigated from an optimization perspective, which was converted into LASSO sub-problems and solved using network blocks. The network blocks were established with residual feature aggregation blocks (RFAB) and the spatial and channel attention (SACA) mechanism for better performance. The experimental results show that the proposed SCANet achieved a better objective performance than other works and restored more satisfying results with higher subjective quality.
Author Contributions
Methodology, X.L. (Xiaohui Li); writing, J.W. and X.L. (Xinbo Liu); data curation, X.L. (Xiaohui Li). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Liaoning Applied Basic Research Program (2022JH2/101300278).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in DIV2K at https://data.vision.ee.ethz.ch/cvl/DIV2K/, reference number [31].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, Y.W.; Kim, J.S.; Park, K.R. Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN. Mathematics 2022, 10, 3818. [Google Scholar] [CrossRef]
- Batchuluun, G.; Nam, S.H.; Park, C.; Park, K.R. Super-Resolution Reconstruction-Based Plant Image Classification Using Thermal and Visible-Light Images. Mathematics 2023, 11, 76. [Google Scholar] [CrossRef]
- Lee, Y.W.; Park, K.R. Recent Iris and Ocular Recognition Methods in High-and Low-Resolution Images: A Survey. Mathematics 2022, 10, 2063. [Google Scholar] [CrossRef]
- Lee, S.J.; Yoo, S.B. Super-resolved recognition of license plate characters. Mathematics 2021, 9, 2494. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Deep Plug-And-Play Super-Resolution for Arbitrary Blur Kernels. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1671–1681. [Google Scholar]
- Wei, Y.; Li, Y.; Ding, Z.; Wang, Y.; Zeng, T.; Long, T. SAR Parametric Super-Resolution Image Reconstruction Methods Based on ADMM and Deep Neural Network. IEEE Trans. Geosci. Remot. Sens. 2021, 59, 10197–10212. [Google Scholar] [CrossRef]
- Ma, Q.; Jiang, J.; Liu, X.; Ma, J. Deep Unfolding Network for Spatiospectral Image Super-Resolution. IEEE Trans. Comput. Imaging 2022, 8, 28–40. [Google Scholar] [CrossRef]
- Ran, Y.; Dai, W. Fast and Robust ADMM for Blind Super-Resolution. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–12 June 2021; pp. 5150–5154. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual Feature Aggregation Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 2356–2365. [Google Scholar]
- Anwar, S.; Khan, S.H.; Barnes, N. A Deep Journey into Super-resolution: A Survey. ACM Comput. Surv. 2021, 53, 60:1–60:34. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K. Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 11214, pp. 256–272. [Google Scholar]
- He, X.; Mo, Z.; Wang, P.; Liu, Y.; Yang, M.; Cheng, J. ODE-Inspired Network Design for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1732–1741. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 294–310. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11057–11066. [Google Scholar]
- Fang, B.; Qian, Z.; Zhong, W.; Shao, W. Iterative precoding for MIMO wiretap channels using successive convex approximation. In Proceedings of the 2015 IEEE 4th Asia-Pacific Conference on Antennas and Propagation (APCAP), Bali Island, Indonesia, 30 June–3 July 2015; pp. 65–66. [Google Scholar] [CrossRef]
- Pang, C.; Au, O.C.; Zou, F.; Zhang, X.; Hu, W.; Wan, P. Optimal dependent bit allocation for AVS intra-frame coding via successive convex approximation. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 1520–1523. [Google Scholar] [CrossRef]
- Yang, Y.; Pesavento, M.; Chatzinotas, S.; Ottersten, B. Successive Convex Approximation Algorithms for Sparse Signal Estimation With Nonconvex Regularizations. IEEE J. Sel. Top. Signal Process. 2018, 12, 1286–1302. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar] [CrossRef]
- Liu, J.; Tang, J.; Wu, G. Residual Feature Distillation Network for Lightweight Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–55. [Google Scholar] [CrossRef]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi Morel, M.L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. In Proceedings of the British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. (MTA) 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ren, H.; El-Khamy, M.; Lee, J. Image Super Resolution Based on Fusing Multiple Convolution Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1050–1057. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Fan, Y.; Shi, H.; Yu, J.; Liu, D.; Han, W.; Yu, H.; Wang, Z.; Wang, X.; Huang, T.S. Balanced Two-Stage Residual Networks for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1157–1164. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Choi, J.; Kim, M. A Deep Convolutional Neural Network with Selection Units for Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1150–1156. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Wang, H.; Li, P. Resolution-Aware Network for Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1259–1269. [Google Scholar] [CrossRef]
- Xie, C.; Zeng, W.; Lu, X. Fast Single-Image Super-Resolution via Deep Network With Component Learning. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3473–3486. [Google Scholar] [CrossRef]
- Li, F.; Bai, H.; Zhao, Y. FilterNet: Adaptive Information Filtering Network for Accurate and Fast Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1511–1523. [Google Scholar] [CrossRef]
- He, Z.; Cao, Y.; Du, L.; Xu, B.; Yang, J.; Cao, Y.; Tang, S.; Zhuang, Y. MRFN: Multi-Receptive-Field Network for Fast and Accurate Single Image Super-Resolution. IEEE Trans. Multimed. 2020, 22, 1042–1054. [Google Scholar] [CrossRef]
- Yang, W.; Feng, J.; Yang, J.; Zhao, F.; Liu, J.; Guo, Z.; Yan, S. Deep Edge Guided Recurrent Residual Learning for Image Super-Resolution. IEEE Trans. Image Process. 2017, 26, 5895–5907. [Google Scholar] [CrossRef]
- Fang, F.; Li, J.; Zeng, T. Soft-Edge Assisted Network for Single Image Super-Resolution. IEEE Trans. Image Process. 2020, 29, 4656–4668. [Google Scholar] [CrossRef]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight Image Super-Resolution with Information Multi-Distillation Network. In Proceedings of the ACM International Conference on Multimedia (MM), Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- He, J.; Shi, W.; Chen, K.; Fu, L.; Dong, C. GCFSR: A Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 1879–1888. [Google Scholar] [CrossRef]
- Menon, S.; Damian, A.; Hu, S.; Ravi, N.; Rudin, C. PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2434–2442. [Google Scholar] [CrossRef]
- Kim, Y.; Hao, J.; Mallavarapu, T.; Park, J.; Kang, M. Hi-LASSO: High-Dimensional LASSO. IEEE Access 2019, 7, 44562–44573. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).