Abstract
Modeling longitudinal data (e.g., biomarkers) and the risk for events separately leads to a loss of information and bias, even though the underlying processes are related to each other. Hence, the popularity of joint models for longitudinal and time-to-event-data has grown rapidly in the last few decades. However, it is quite a practical challenge to specify which part of a joint model the single covariates should be assigned to as this decision usually has to be made based on background knowledge. In this work, we combined recent developments from the field of gradient boosting for distributional regression in order to construct an allocation routine allowing researchers to automatically assign covariates to the single sub-predictors of a joint model. The procedure provides several well-known advantages of model-based statistical learning tools, as well as a fast-performing allocation mechanism for joint models, which is illustrated via empirical results from a simulation study and a biomedical application.
Keywords:
joint modeling; time-to-event analysis; gradient boosting; statistical learning; variable selection MSC:
62J07
1. Introduction
Joint models for longitudinal and time-to-event data, first introduced in [1], are a powerful tool for analyzing data where event times are recorded alongside a longitudinal outcome. If the research interest lies in the association between these two outcomes, joint modeling avoids potential bias arising from separate analyses by combining two sub-models in one single modeling framework. A thorough introduction to the concept of joint models can be found in [2], and various well-established R packages are available covering frequentist [3,4] and Bayesian [5] approaches.
Like many regression models, joint models suffer from the usual drawbacks, where proper tools for variable selection are not immediately available and computation becomes more and more infeasible in higher dimensions. In addition, joint models also raise the question of which sub-model a variable should be assigned to, i.e., should a variable x have a direct impact on the survival outcome T, or should the potential influence be modeled indirectly by an impact of x on the longitudinal outcome y, which then might affect T? This choice gets exponentially more complex with an increasing amount of covariates, and usually has to be made by researchers based on background knowledge. Boosting techniques from the field of statistical learning, however, are well-known for addressing these exact issues. Originally emerging from the machine learning community as an approach to classification problems [6,7], boosting algorithms have been adapted to regression models [8] and, by now, cover a wide range of statistical models. For an introduction and overview of model-based boosting, we recommend [9,10].
The formulation of boosting routines for joint models is, to date, still a little-developed field. The foundations were made by [11], where generalized additive models for location scale and shape (GAMLSS) were fitted using boosting techniques. Due to the multiple predictors for each single distributional parameter, these models consist of a similar structure to joint models and thus the boosting concept for GAMLSS could be adapted to joint models by [12]. Furthermore, in [13], joint models were estimated using likelihood-based boosting techniques, and [14,15] compare boosting routines for joint models with various other estimation approaches.
In the last few years, several additional developments have been made in order to enable a variable selection for joint models, usually by applying different shrinkage techniques. In [16], an adaptive LASSO estimator was constructed that estimates -penalized likelihoods in a two-stage fashion. This approach was later extended to multivariate longitudinal outcomes in [17] and to time-varying coefficients in [18]. In [19,20], Bayesian shrinkage estimators were applied to achieve either variable or model selection for various classes of joint models and, recently, ref. [21] applied Monte Carlo methods to enable a variable selection for joint models with an interval-censored survival outcome. However, all of these mentioned approaches are only capable of selecting and estimating effects into predefined predictor functions. To the best of our knowledge, no methods exist that allocate single features to the given sub-models in a data-driven way.
The aim of the present work is to combine recent developments from the field of model-based gradient boosting in order to develop a new routine, JMalct, that is able to allocate the single candidate variables to the specific sub-models. Therefore, the initial boosting approach by [12] was equipped with a non-cyclical updating scheme proposed by [22] and adaptive step-lengths as investigated in [23]. These two preliminary works are of high importance and their combination is the foundation of our proposed allocation procedure. Furthermore, the JMalct algorithm makes use of a recent random effects correction [24] providing an unbiased estimation of the random effects using gradient boosting and tuning based on probing [25] for faster computation and improved selection properties.
The remainder of this article is structured as follows. In Section 2, the underlying joint model as well as the JMalct boosting algorithm are formulated. Section 3 then applies the proposed method to simulated data with varying amounts of candidate variables. Several real-world applications are presented in Section 4 and the final section gives a brief summary and outlook.
2. Methods
This section first formulates the considered joint model as well as the basics of the underlying JMboost approach. Afterwards, the new JMalct routine and a thorough discussion of its computational details are provided.
2.1. Model Specification
A joint model consists of two sub-models modeling the longitudinal and time-to-event outcome, respectively. The longitudinal sub-model is specified as a linear mixed model
with individuals and corresponding measurements . Here, denotes a set of longitudinal time-independent covariates, and the specific measurement times and normal distributed error components, i.e., and are assumed.
In the survival sub-model, the individual hazard is modeled by
with the survival predictor including baseline covariates and the longitudinal predictor reappearing in the survival sub-model, this time scaled by the association parameter . The baseline hazard is chosen to be constant as conventional gradient boosting methods tend to struggle with a proper estimation of time-varying baseline hazard functions [26].
Given the sub-models (1) and (2) and assuming independence between the random components, the joint log-likelihood is
where, in the longitudinal part, denotes the density of a normal distribution with mean m and variance v. In this context, we considered the complete data log-likelihood as it is used solely for allocation purposes. The random effects will be estimated in a less time-consuming way based on a fixed penalization integrated in the random effects base-learner discussed in Section 2.4.
2.2. The JMboost Concept
In [12], joint models were estimated for the first time using a boosting algorithm, although they addressed a slightly different model to the one described above. The original concept in this publication was based on an alternating technique that used two loops: one outer loop circling through the two sub-predictors and two inner loops that circle through the single base-learners. In a very simple manner, the boosting algorithm can hence be summarized as follows:
- Initialize , , , and ;
- While ;
- -
- If : perform one boosting cycle to update ;
- -
- If : perform one boosting cycle to update ;
- -
- If : update ;
- -
- If : update and .
Both sub-predictors have their own stopping iteration and , which need to be optimized via a grid search. The latter is computationally quite burdensome, particularly for high numbers of candidate variables.
2.3. The JMalct Boosting Algorithm
The central JMalct algorithm is depicted in Algorithm 1.
| Algorithm 1: JMalct |
Compute the gradients Fit both gradients separately to the base-learners Compute the optimal step lengths , with corresponding likelihood values , and only update the component resulting in the best joint likelihood improvement: Update the active sets
Perform an additional longitudinal boosting update regarding the random structure: Obtain updates for the association by maximizing the joint likelihood:
|
2.4. Computational Details of the JMalct Algorithm
In the new JMalct algorithm, we only have one cycle. This cycle consists of three steps: in the first one, the base-learner with the best fitting gradient for the longitudinal predictor is chosen and the corresponding step length is calculated. In the second step, the base-learner with the best fitting gradient for the time-to-event submodel is chosen and the corresponding step length is calculated. These first two steps will be referred to as the G-steps (gradient-steps) in the following. In the third step, referred to as the L-step (likelihood step), the likelihood is calculated for both the best longitudinal base-learner, weighted with the step length , and the best survival base-learner, weighted with the step length . The base-learner performing better in the L-step is then chosen to be updated. The algorithm is summarized in the following overview and depicted in Figure 1. A detailed description is provided below.
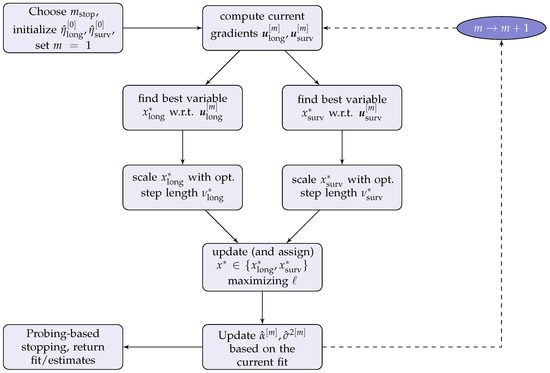
Figure 1.
Schematic overview of the JMalct procedure.
- while :
- G-step 1
- -
- Fit all base-learners to the longitudinal gradient with regard to ;
- -
- Find the best-performer, and corresponding step-length .
- G-step 2
- -
- Fit all base-learners to gradient with regard to ;
- -
- Find the best-performer, and corresponding step-length .
- L-step
- -
- Fit likelihood for and with updates from G1 and G2;
- -
- Select the best-performer and update corresponding sub-predictor;
- -
- Remove the selected candidate variable from options to choose for the other predictor (if not performed already).
- Step 4
- -
- Update based on the current fit.
The baseline covariates that enter the allocation process are not assigned to a sub-model in the beginning and therefore have to be considered in two forms. , where , denotes the set of candidate variables resembled as longitudinal covariates, i.e., measurements assigned to the same individual i contain the same cluster-constant measurement times. On the other hand, contains the exact same variables as but reduced to just one representative of each individual in order to fit the corresponding base-learner to the survival gradient. The measurements of one specific covariate r are denoted by and , which matches the rth column of the corresponding matrix.
Starting values. The regression coefficients underlying the allocation mechanism are necessarily set to zero, i.e., . The remaining longitudinal parameters are extracted by an initial linear mixed model fit
containing only the intercept as well as time and random effects. For the remaining survival parameters, we chose and .
Computing the gradients. The gradients and are a crucial component of the JMalct algorithm. For the longitudinal part, we considered the quadratic loss and calculated
as the regular residuals of the longitudinal sub-model, following [9]. The survival gradient was obtained by differentiating the likelihood (3) with respect to , yielding
as the longitudinal part vanishes. This is a nice analogy to the longitudinal gradient, as represents the martingale residuals of the survival sub-model.
Fitting the longitudinal base-learners. The possible fixed effects estimates were obtained by fitting the pre-specified base-learners to the longitudinal and survival gradient. In the longitudinal case, the fixed effects base-learners were equipped with an additional effect estimate for the time coefficient as this variable shall not be subject to the selection and allocation mechanism. Fitting the base-learners is achieved by
with the projection matrix
where and denotes the collection of longitudinal measurement times. If the base-learner actually gets selected, estimates for the intercept and for the time effect receive the corresponding updates computed in the fitting process.
Fitting the survival base-learners. Similar to the longitudinal part, the survival base-learner was fitted by applying the corresponding projection matrix to the survival gradient, i.e.,
where the survival gradient represents the martingale residuals of the time-to-event model. The projection matrix takes the form
with . This means that, if the base-learner actually gets selected, the estimate for the constant baseline hazard receives the corresponding update computed in the fitting process.
Adaptive step lengths. As the two distinct sub-models affect different parts of the joint likelihood, it may not be sufficient to stick to a fixed learning rate, e.g., . To ensure that the comparison of potential likelihood improvements is fair, for each selected component, the optimal step length was computed using a basic line search by finding
following [23]. The corresponding maximal likelihood values are denoted by and , which were used to determine the overall best-performing sub-model of each iteration. When this is achieved, the learning rate for the actual update was then again scaled by a constant —here, —in order to ensure small updates with weak base-learners.
Fitting the random effects base-learner. In general, the random effects base-learner is similar to the formulation found in the appendix of [27]. One major difference is that it is fixed for all iterations and not updated based on the current covariance structure. It is defined through its projection matrix
where was chosen so that holds, which fixes the degrees of freedom for the random effects update. In the simulation study, we used and determined the corresponding with the internal function mboost:::df2lambda().
The matrix denotes the conventional random effects design matrix for intercepts and slopes, i.e.,
and is a correction matrix introduced in [28] correcting the random effects update for the candidate variables , which are baseline covariates and thus cluster-constant. A derivation of the correction matrix can also be found in Appendix A.
Tuning the hyperparameter m based on probing. Both the step length as well as the number of iterations can be considered as hyperparameters of the boosting algorithm. Since the step length is usually set as constant or, like in this work, determined by an adaptive line search, the number of overall iterations m states the main tuning parameter of the algorithm. While this hyperparameter is usually tuned in a computationally more extensive way by considering out-of-bag loss, we determined the optimal amount with the help of probing. Probing for gradient boosting was introduced by [25]. The pragmatic idea avoids more time-consuming procedures such as cross validation or bootstrapping, which rely on a re-fitting of the model. For each covariate , another variable was added to the set of candidate variables, where is a random permutation of the observations contained in . These additional variables were artificially created to be non-informative and called probes or shadow variables. Instead of finding the best-performing number of iterations based on a computationally burdensome cross validation, the boosting routine was simply stopped as soon as one of the shadow variables , i.e., a known-to-be non-informative variable, would get selected. The focus is hence shifted from tuning the algorithm purely based on prediction accuracy (with regard to the test risk) towards a reasonable variable selection.
Computational complexity and asymptotic behavior. Due to the artificial construction of the algorithm and the comparatively complex model class, theoretical analysis regarding complexity and asymptotic behavior is quite a challenging task. The model-based boosting related literature is still little-developed with respect to theoretical investigations, but thorough analyses in simpler cases were carried out in [29] for the quadratic loss, where exponentially fast bias reduction could be proven, as well as for more general settings in [30,31]. Consistency properties for very-high-dimensional linear models were obtained in [32] and, regarding JMalct, we refer to the following section, where further insights with respect to the algorithm’s complexity are given based on numerical evaluations. In addition, we experienced no convergence issues in simulations and applications.
3. Simulation Study
The JMalct algorithm was evaluated by conducting a simulation study where data according to the assumed generating process specified in Section 2.1 were simulated and models were subsequently fitted using JMalct and, if sensible, JM [3] as a benchmark and well-established approach. In addition, we considered the combination JMalct+JM, where JMalct was used solely for allocating the variables, which were then refitted by JM according to the allocation obtained from JMalct. After briefly highlighting the single scenarios, the simulation section evaluates allocation properties and the accuracy of estimates, as well as the quality of the prediction and the computational burden.
3.1. Setup
We simulated data according to the model specification in Section 2.1 with and using inversion sampling. The pre-specified true parameter values are
with variance components
The entries of the covariate vectors and were drawn independently from the uniform distribution . In addition to the informative covariates with effects and , the total set of covariates was expanded with a varying number of non-informative noise variables. The baseline hazard was chosen as and given the censoring mechanism described in Algorithm A1 depicted in Appendix B. The chosen parameter values result in an average censoring rate of . All of the parameters were specified in a way to obtain reasonably distributed event times .
Overall, we considered four scenarios with varying numbers of additional noise variables yielding overall dimensions . In each scenario, 100 independent data sets were generated and models were fitted using the various routines. The results were then summarized over all 100 independent simulation runs.
3.2. Selection and Allocation
In order to address allocation, we considered the criteria of correctly allocated (CA) and incorrectly allocated (IA) variables per predictor, as well as the share of false positives (FPs). Precisely, CAlong is the share of longitudinal variables, which are correctly assigned to the longitudinal predictor, and IAlong is the share of survival variables, which are falsely assigned to the longitudinal predictor and CAsurv, IAsurv analogously. FPs, on the other hand, denote the share of wrongly selected noise variables regardless of which predictor they are assigned to.
Table 1 depicts allocation and selection properties obtained for the different simulation scenarios. While, for the longitudinal predictor, variables get allocated perfectly, the survival part shows less ideal but still satisfactory results. There are various possible explanations for this behavior. On the one hand, the simulated signal is less strong for the survival effects due to the chosen parameter values, which, in general, increases the chance of false negatives. On the other hand, the longitudinal part of the likelihood carries more information, as there are more longitudinal measurements available than event times, which increases the risk of incorrect allocations. Finally, survival variables being incorrectly allocated to the longitudinal predictor is inherently more probable than vice versa as the longitudinal predictor also appears in the survival sub-model and the model therefore still accounts for the variables’ impact on the time-to-event outcome. While the allocation properties are roughly constant with a varying number of dimensions, the false positives rate clearly diminishes with more and more noise variables.

Table 1.
Share of correctly allocated (CA) and incorrectly allocated (IA) variables for each predictor as well, as false positive rate. Values are averaged over 100 independent simulation runs of each scenario.
3.3. Estimation Accuracy
The accuracy of coefficient estimation is shown in Table 2, separated for each sub-model. We considered the mean squared error (mse) computed as
where and . The lower half of the table discards all entries of the estimates and referring to non-informative variables and thus only measures the accuracy of the effects that are known to be informative.
Table 2.
Mean squared error for longitudinal (mselong) and survival (msesurv) coefficients averaged over 100 independent simulation runs. Regular parameter estimates are indicated by , whereas denotes the second half, where non-informative effects are neglected.
It is evident that the accuracy of JM is heavily influenced by the number of noise variables, whereas the routines relying on the allocation and selection mechanism by JMalct stay fairly robust. As usual for regularization techniques, JMalct’s estimates for informative effects are slightly biased due to the early stopping of the algorithm. The combination JMalct+JM, however, stays unaffected by the number of noise variables and is, at least for the longitudinal predictor, the most accurate. The main hindrance of this approach is that the estimation accuracy of survival effects is slightly more influenced by false negatives occurring in the selection mechanism, which is why the combination lags behind its two competitors regarding precision for the survival sub-model.
3.4. Predictive Performance
Boosting is a tool primarily designed for prediction, and thus the predictive performance of JMalct and how it compares to established routines are of interest. Since our underlying joint model focuses on the time-to-event outcome as the main endpoint, we evaluated the prediction accuracy regarding the predicted and actual event time based on additional test data with individuals and . We considered the loss
as the absolute deviation between the predicted and actual event time and T, respectively, on a log-scale [33].
Figure 2 depicts the values of L over the varying numbers of additional noise variables. The prediction is comparable among the three routines in low-dimensional settings. However, as expected, it worsens for JM when the dimensions increase. Both JMalct and the combination JMalct+JM rely on the selection conducted by JMalct and hence produce sparse models, which is why their quality of prediction stays fairly equal even in higher dimensions.
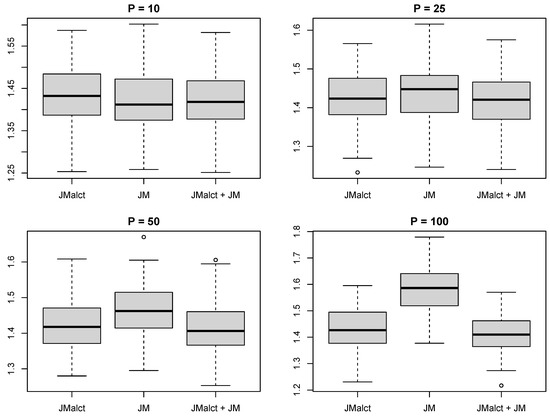
Figure 2.
Comparison of the prediction error (L) of the survival part for the varying numbers of non-informative noise variables.
3.5. Computational Effort
Table 3 shows the elapsed computation time measured in seconds, where each simulation run was carried out on a 2 x 2.66 GHz-6-Core Intel Xeon CPU (64GB RAM). Most obviously, JM becomes tremendously more burdensome as the dimensions increase. The constant or even a little decreasing computation times for JMalct over various dimensions might be surprising at first, as component-wise procedures such as gradient boosting tend to increase at least linearly in computation time with additional covariates. However, as the overall stopping criterion is based on probing, the algorithm tends to stop earlier in high-dimensional settings since more non-informative probes are available, increasing the probability that one might get selected earlier in the process. Due to the sparsity obtained by JMalct, the combination JMalct+JM also profits from the allocation and selection mechanism regarding the computational effort, as JM runs considerably faster again.
Table 3.
Average computation times of the three approaches measured in seconds.
3.6. Complexity
While a formulation of explicit complexity results for the JMalct routine is quite technical in general, like that stated in Section 2.4, simulations can give insights toward how the algorithm scales up with varying numbers of observations and covariates. Therefore, we considered the same setup as above with different values for n and p and ran the JMalct routine 100 times independently for iterations without early stopping. Figure 3 depicts the averaged computation times for increasing values of n and p.
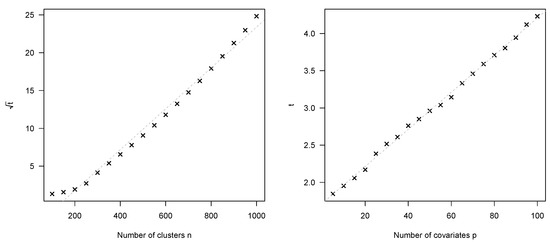
Figure 3.
Average JMalct run times for varying numbers of clusters n and covariates p. Dashed gray lines depict the corresponding linear model fit. Left panel shows square root times to highlight the quadratic relationship.
The left figure depicts square root computation times with as fixed, and thus reveals quadratically growing run times for increasing observations. On the other hand, the run times clearly expose a linear relationship with the amount of total covariates and as fixed. This is to be expected, as further candidate variables simply add to the inner loops of univariate base-learner fits and, thus, the algorithm is capable of fitting data sets with almost arbitrary high dimensions.
4. 1994 AIDS Study
The 1994 AIDS data [34] were originally collected in order to compare two antiretroviral drugs based on a collective of HIV-positive patients. They include 1405 longitudinal observations of 467 individuals, from which, 188 unfortunately died during the course of the study. The main longitudinal outcome is each patient’s repeatedly measured CD4 cell counts. CD4 cells decline in HIV-positive patients and are a well-known proxy for disease progression, and are therefore of high interest. Apart from the CD4 cell count as the longitudinal outcome, death as the time-to-event outcome and time t itself, the four additional baseline variables—drug (treatment group), gender, AZT (indicator of whether a previous AZT therapy failed) and AIDS (indicator of whether AIDS is diagnosed)—were observed. The structure of the data is depicted in Table 4.
Table 4.
Structure of the data with primary outcomes for the joint analysis in the three columns on the left.
Figure 4 depicts the coefficient paths computed by the JMalct algorithm and the corresponding allocation process. The variable AIDS is selected into the longitudinal sub-model right away and frequently updated. This is not surprising, as the diagnosis of AIDS is by definition partly linked to the CD4 cell count. The remaining variables drug and gender were also allocated to the longitudinal sub-model by a smaller amount, whereas AZT was selected into the survival predictor, indicating an increased risk of death for patients with failed AZT therapy.
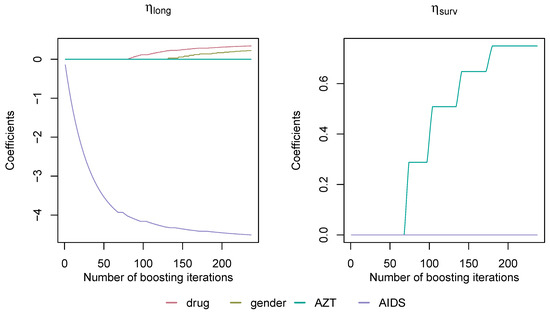
Figure 4.
Coefficient progression in both sub-models for AIDS data. The variable AZT was assigned to , and the rest to .
5. Discussion and Outlook
Finding adequate data-driven allocation mechanisms for joint models is a very important task, as modeling possibilities increase exponentially with a growing number of covariates. Until today, decisions about the specific model choice have to be made based on background knowledge or by conducting a preliminary analysis, and both of these approaches can be seen as rather unsatisfactory.
The JMalct algorithm combines recent findings from the field of gradient boosting to construct a fast-performing allocation and selection mechanism for a joint model focusing on time-to-event data as the primary outcome. A simulation study revealed that the selection and allocation mechanism yields promising results while preserving the well-known advantages from gradient boosting. Therefore, it is advised to use the JMalct algorithm in its current form in advance of the actual analysis in order to determine an allocation of covariates, which is then fitted using convenient frameworks such as JM.
Possible ways of improving the accuracy of estimates and allocation properties regarding the survival sub-model could be based on additional weighting rules. As the longitudinal part contributes substantially more to the likelihood due the higher number of observations, weighting the two sub-models solely by different step lengths may not be sufficient. Promising ideas are initial weightings of the sub-models using various maximum likelihood estimations or focusing on a relative likelihood improvement in the selection step.
Another aspects focuses on variable selection and tuning the algorithm via probing. Although probing leads to fast runtimes and good selection properties, the procedure comes with disadvantages. Especially in higher dimensions, the probability that one shadow variable is informative simply by chance increases, leading to very early stopping. An alternative could rely on stability selection [35,36], as shown to be helpful in other cases [37].
Furthermore, the difference in the proportion of falsely selected variables between the longitudinal and survival sub-predictor could be an inherent joint modeling problem and should also be subject of future analysis. Further research is also warranted on theoretical insights, as it remains unclear if the existing findings on the consistency of boosting algorithms [32,38] also hold for the adapted versions for boosting joint models.
In conclusion, the JMalct algorithm represents a promising statistical inference scheme for joint models that also provides a starting point for a much wider framework of boosting joint models, covering a great range of potential models and types of predictor effects.
Author Contributions
Conceptualization, C.G. and E.B.; methodology, C.G., A.M. and E.B.; software, C.G. and E.B.; formal analysis, C.G.; investigation, C.G.; writing—original draft preparation, C.G.; writing—review and editing, E.B. and A.M.; project administration, E.B.; funding acquisition, E.B. All authors have read and agreed to the published version of the manuscript.
Funding
The work on this article was supported by the DFG (Number 426493614) and the Volkswagen Foundation (Freigeist Fellowship).
Data Availability Statement
All code and data required to reproduce the finding of this article are available.
Acknowledgments
The work on this article was supported by the DFG (Number 426493614) and the Volkswagen Foundation (Freigeist Fellowship). We further acknowledge the support by the Open Access Publication Funds of the University of Göttingen.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Correction Matrix C
Due to the separated updating process for the random effects, it may be necessary to adjust the estimates for possible correlations with cluster-constant covariates using the correction matrix . The following derivation is a special case of the more general version proposed in [28]. For the correction of the random intercepts and random slopes with the baseline covariates defined in Section 2.4, consider the residual generating matrix
and subsequently , so that the product , corrects the random intercepts and slopes for any covariates contained in the corresponding matrix by counting out the orthogonal projections of the given random effect estimates on the subspace generated by the covariates . This ensures that the coefficient estimate for the random effects is uncorrelated with any observed covariate. The final correction matrix is obtained by
where is a permutation matrix mapping to
and thus accounts for the usual ordering of the random effects in mixed-model frameworks.
Appendix B. Simulation Algorithm
The following algorithm is used to generate data in Section 3.
| Algorithm A1: simJM |
with and . Define hazard functions as described in Section 2.1.
according to inversion sampling.
|
References
- Wulfsohn, M.S.; Tsiatis, A.A. A Joint Model for Survival and Longitudinal Data Measured with Error. Biometrics 1997, 53, 330. [Google Scholar] [CrossRef] [PubMed]
- Rizopoulos, D. Joint Models for Longitudinal and Time-to-Event Data: With Applications in R; Chapman & Hall/CRC Biostatistics Series; CRC Press: Boca Raton, FL, USA, 2012; Volume 6. [Google Scholar]
- Rizopoulos, D. JM: An R Package for the Joint Modelling of Longitudinal and Time-to-Event Data. J. Stat. Softw. 2010, 35, 1–33. [Google Scholar] [CrossRef]
- Philipson, P.; Sousa, I.; Diggle, P.J.; Williamson, P.; Kolamunnage-Dona, R.; Henderson, R.; Hickey, G.L. JoineR: Joint Modelling of Repeated Measurements and Time-to-Event Data; R Package Version 1.2.6.; Springer: Berlin, Germany, 2018. [Google Scholar]
- Rizopoulos, D. The R Package JMbayes for Fitting Joint Models for Longitudinal and Time-to-Event Data Using MCMC. J. Stat. Softw. 2016, 72, 1–45. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on Machine Learning Theory, Bari, Italy, June 28–1 July 1996; Morgan Kaufmann: San Francisco, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Bühlmann, P.; Hothorn, T. Boosting algorithms: Regularization, prediction and model fitting. Stat. Sci. 2007, 27, 477–505. [Google Scholar]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The Evolution of Boosting Algorithms - From Machine Learning to Statistical Modelling. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [CrossRef]
- Mayr, A.; Fenske, N.; Hofner, B.; Kneib, T.; Schmid, M. Generalized additive models for location, scale and shape for high dimensional data-a flexible approach based on boosting. J. R. Stat. Soc. Ser. (Applied Stat.) 2012, 61, 403–427. [Google Scholar] [CrossRef]
- Waldmann, E.; Taylor-Robinson, D.; Klein, N.; Kneib, T.; Pressler, T.; Schmid, M.; Mayr, A. Boosting joint models for longitudinal and time-to-event data. Biom. J. 2017, 59, 1104–1121. [Google Scholar] [CrossRef]
- Griesbach, C.; Groll, A.; Bergherr, E. Joint Modelling Approaches to Survival Analysis via Likelihood-Based Boosting Techniques. Comput. Math. Methods Med. 2021, 2021, 4384035. [Google Scholar] [CrossRef]
- Tutz, G.; Binder, H. Generalized Additive Models with Implicit Variable Selection by Likelihood-Based Boosting. Biometrics 2006, 62, 961–971. [Google Scholar] [CrossRef] [PubMed]
- Rappl, A.; Mayr, A.; Waldmann, E. More than one way: Exploring the capabilities of different estimation approaches to joint models for longitudinal and time-to-event outcomes. Int. J. Biostat. 2021, 18, 127–149. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Tu, W.; Wang, S.; Fu, H.; Yu, Z. Simultaneous Variable Selection for Joint Models of Longitudinal and Survival Outcomes. Biometrics 2015, 71, 178–187. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wang, Y. Variable selection for joint models of multivariate longitudinal measurements and event time data. Stat. Med. 2017, 36, 3820–3829. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; He, Z.; Tu, W.; Yu, Z. Variable selection for joint models with time-varying coefficients. Stat. Methods Med. Res. 2019, 29, 309–322. [Google Scholar] [CrossRef]
- Tang, A.M.; Zhao, X.; Tang, N.S. Bayesian variable selection and estimation in semiparametric joint models of multivariate longitudinal and survival data. Biom. J. 2017, 59, 57–78. [Google Scholar] [CrossRef]
- Andrinopoulou, E.R.; Rizopoulos, D. Bayesian shrinkage approach for a joint model of longitudinal and survival outcomes assuming different association structures. Stat. Med. 2016, 35, 4813–4823. [Google Scholar] [CrossRef]
- Yi, F.; Tang, N.; Sun, J. Simultaneous variable selection and estimation for joint models of longitudinal and failure time data with interval censoring. Biometrics 2022, 78, 151–164. [Google Scholar] [CrossRef]
- Thomas, J.; Mayr, A.; Bischl, B.; Schmid, M.; Smith, A.; Hofner, B. Gradient boosting for distributional regression: Faster tuning and improved variable selection via noncyclical updates. Stat. Comput. 2017, 28, 673–687. [Google Scholar] [CrossRef]
- Zhang, B.; Hepp, T.; Greven, S.; Bergherr, E. Adaptive Step-Length Selection in Gradient Boosting for Generalized Additive Models for Location, Scale and Shape. Comput. Stat. 2022, 37, 2295–2332. [Google Scholar] [CrossRef]
- Griesbach, C.; Säfken, B.; Waldmann, E. Gradient boosting for linear mixed models. Int. J. Biostat. 2021, 17, 317–329. [Google Scholar] [CrossRef] [PubMed]
- Hepp, T.; Thomas, J.; Mayr, A.; Bischl, B. Probing for Sparse and Fast Variable Selection with Model-Based Boosting. Comput. Math. Methods Med. 2017, 2017, 1421409. [Google Scholar]
- Hofner, B. Variable Selection and Model Choice in Survival Models with Time-Varying Effects. Diploma Thesis, Ludwig-Maximilians-Universität München, Munich, Germany, 2008. [Google Scholar]
- Kneib, T.; Hothorn, T.; Tutz, G. Variable Selection and Model Choice in Geoadditive Regression Models. Biometrics 2009, 65, 626–634. [Google Scholar] [CrossRef] [PubMed]
- Griesbach, C.; Groll, A.; Bergherr, E. Addressing cluster-constant covariates in mixed effects models via likelihood-based boosting techniques. PLoS ONE 2021, 16, e0254178. [Google Scholar] [CrossRef]
- Bühlmann, P.; Yu, B. Boosting With the L2 Loss. J. Am. Stat. Assoc. 2003, 98, 324–339. [Google Scholar] [CrossRef]
- Bissantz, N.; Hohage, T.; Munk, A.; Ruymgaart, F. Convergence Rates of General Regularization Methods for Statistical Inverse Problems and Applications. SIAM J. Numer. Anal. 2007, 45, 2610–2636. [Google Scholar] [CrossRef]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On Early Stopping in Gradient Descent Learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Bühlmann, P. Boosting for High-dimensional Linear Models. Ann. Stat. 2006, 34, 559–583. [Google Scholar] [CrossRef]
- Korn, E.; Simon, R. Measures of explained variation for survival data. Stat. Med. 1990, 9, 487–503. [Google Scholar] [CrossRef]
- Abrams, D.I.; Goldman, A.I.; Launer, C.; Korvick, J.A.; Neaton, J.D.; Crane, L.R.; Grodesky, M.; Wakefield, S.; Muth, K.; Kornegay, S.; et al. A Comparative Trial of Didanosine or Zalcitabine after Treatment with Zidovudine in Patients with Human Immunodeficiency Virus Infection. N. Engl. J. Med. 1994, 330, 657–662. [Google Scholar] [CrossRef]
- Meinshausen, N.; Bühlmann, P. Stability selection. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2010, 72, 417–473. [Google Scholar] [CrossRef]
- Shah, R.D.; Samworth, R.J. Variable selection with error control: Another look at stability selection. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2012, 75, 55–80. [Google Scholar] [CrossRef]
- Mayr, A.; Hofner, B.; Schmid, M. Boosting the discriminatory power of sparse survival models via optimization of the concordance index and stability selection. BMC Bioinform. 2016, 17, 288. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Yu, B. Boosting with early stopping: Convergence and consistency. Ann. Stat. 2005, 33, 1538–1579. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).