Abstract
Clustering aims to group n data samples into k clusters. In this paper, we reformulate the clustering problem into an integer optimization problem and propose a recurrent neural network with neurons to solve it. We prove the stability and convergence of the proposed recurrent neural network theoretically. Moreover, clustering experiments demonstrate that the proposed clustering algorithm based on the recurrent neural network can achieve the better clustering performance than existing clustering algorithms.
MSC:
68Q25
1. Introduction
Clustering has been widely studied by machine learning and plays a very important role in various engineering fields. Shaheen et al. [1] presented a new method for clustering, based on the reinforcement factor and the congruence modulo operator. Abdullah et al. [2] utilized k-means to analyze the COVID-19 pandemic. Yeoh et al. [3] proposed a new method that utilizes metaheuristic optimization to improve the performance of the initialization phase.
Clustering aims to group the data points with similar patterns into one cluster. Over the last few decades, relevant scholars have put forward and improved a series of clustering algorithms [4,5,6,7,8,9,10,11,12]. The representative of clustering algorithms is the k-means, which can discover the latent data structure and achieve clustering via the structure. Spectral clustering (SC) [4,5,10] constructs an affinity graph to model the geometrical information within data, and the clustering results respect the graph structure. Some extensions of SC methods [6,7,8] have been proposed to model the nonlinear geometrical structure of data. In addition, the projected clustering algorithm [9] was mentioned, aiming to think over the local information and the global structure of data. Some researchers have improved some clustering to enhance clustering algorithm robustness. Dai et al. [13,14] proposed a series of robust clustering algorithms based on negative matrix factorization.
Most of traditional clustering algorithms converge slowly and trap into a local solution easily. This is because these algorithms do not use the neural works to search the global solution. Recently, some clustering problems [15,16,17] can be reformulated as combinatorial optimization problems. Malinen and Franti [15] presented a k-means-based clustering problem with the given cluster sizes. The balanced clustering problem is formulated as a combinatorial optimization problem and solved by the Hungarian algorithm. Bauckhage et al. [16] reformulated the k-medoid clustering problem into a quadratic unconstrained binary optimization (QUBO) problem by identifying k medoids among the data points. Date et al. [17] reformulated linear regression, support vector machine and balanced k-means clustering as QUBO problems and solved them on adiabatic quantum computers.
Neural networks and combinatorial optimization problems have some close relations. In other words, most neural networks are used to dispose of combinatorial optimization problems (e.g., [18]). In addition, neural networks also often are used for clustering (e.g., [19,20,21,22,23]). Combining neural networks and combinatorial optimization problems have the following advantages. In the past three decades, neurodynamic optimization can be regarded as a computationally intelligent method to solve different optimization problems ([18]). Therefore, it is necessary to develop neural networks for solving the clustering problem.
In this paper, a neural network clustering algorithm is proposed. The distinctive features of the paper are highlighted as follows:
- The clustering problem is reformulated as an integer optimization problem and solved by the continuous Hopfield neural network.
- By comparing to the other clustering algorithms, our clustering algorithm achieves the better clustering performance.
2. Preliminaries
2.1. Dissimilarity Coefficients
For clustering, the similarity or dissimilarity of any two samples should be measured firstly. In this paper, the Gaussian kernel function is used to measure the similarity of samples, which is defined as follows:
where is the element which represent intersection of k-th row and i-th column in the sample matrix X; is positive penalty parameters.
2.2. Continuous Hopfield Neural Network
CHN is comprised of a group of n fully interconnected neurons, where each neuron is affiliated with other neurons. The dynamic equation [24] of the CHN is defined by the following:
where u, and represents vectors of neuron states, biases and time constant, respectively. CHN possesses the following state equation and activation function:
where is a constant. is a hyperbolic tangent whose boundary is and 1. is a strict growth activation function to let the system stable [25], defined by
where is an input parameter. For the sake of dealing with any problem by using CHN, we reformulate this energy function which is related to the CHN. The energy function [26] is formulated as follows:
There are two activating modes to update neurons in Equation (3). In the asynchronous mode, each neuron state can be updated sequentially. In the synchronous mode, all neuron states should be updated in the same time. In this paper, we use the synchronous mode to update neurons. Therefore, the T of Equation (5) should satisfy the following two conditions:
- The diagonal element T should be all zeros.
- The T should be symmetric.
It is obvious that the energy function of CHN is equivalent to the objective function of the optimization problem. Next, we discuss how to reformulate the objective function of the clustering problem into the energy function.
2.3. Problem Formulations
2.3.1. Objection Function
For the clustering problem, we suppose that there are n samples . These sample are ready to be grouped into p classes, where m represents the data dimensionality. We hope that the similarity samples should have the smaller intra-cluster distance and the dissimilarity samples should have the larger within-cluster distance, respectively. In other words, the distance of samples and is
where the represents distance within the sample, the binary decision variable is defined by
Based on the distance definition in Equation (6), the clustering problem can be expressed as the following optimization problem:
For the clustering problem, each sample should be belong to one cluster only. Therefore, a constraint on x can be summarized as follows:
2.3.2. Problem Reformulation
As mentioned in the above sections, the clustering problem could be defined as follows:
It is widely known that problem (10) can be rewritten as follows:
where represents a positive penalty parameter. In the following, we will obtain the derivation of denoted by as follows:
3. Algorithm Description
Algorithm 1 describes our algorithm procedure. In our algorithm, the and denote positive penalty parameters. and denote constant and maximum number of iterations, respectively. In the following, initial state x is calculated to random number matrix u, and . d is computed by the Gaussian Kernel function within samples. The neuronal state is updated iteratively in the loop until reaches the maximum number of iterations.

4. Experiment
4.1. Experimental Setups
In this section, a multitude of datasets (i.e., Ionosphere, Wine, Iris, Seeds and Jaffe_face) are utilized in these experiments; they are described in more detail in Table 1. For these datasets, we not only normalize these datasets, but apply PCA [27] to preserve 90% of the information in the datasets. In addition, the Gaussian kernel function of Equation (1) is used in the experiments to measure whether the samples are similar in the experiments. Experiments are performed on Windows 10 with Intel(R) Core(TM) i5-1035G1 CPU @ 1.00 GHz 1.19 GHz and MATLAB 2018a.

Table 1.
The datasets employed in the experiments.
Remarks: The code has been uploaded to https://github.com/Warrior-bot/CHN (accessed on 28 January 2022)
Our method is compared with the algorithm: Kmeans [28], Kmeans++ [29] and Isodata [30]. The codes of the Kmeans, Kmeans++ and Isodata were downloaded at the site https://github.com/xuyxu/Clustering (accessed on 28 January 2022).
There are five parameters in our algorithm. The first parameter is in Equation (12). The and are parameter of Equations (3) and (4), respectively. In order to better compare the performance of these methods in four datasets, we select the appropriate parameter to Guarantee fairness. Finally, the maximum number of iterations () is used to terminate the loop. These parameters see more details in Table 2.
Table 2.
The parameter used in the experiments.
4.2. Numerical Experiment
This section utilizes randomly generated 2D points to conduct the numerical experiment. Figure 1 vividly shows clustering results on various instances numbers with different classes. According to the figure, we conclude as follows:
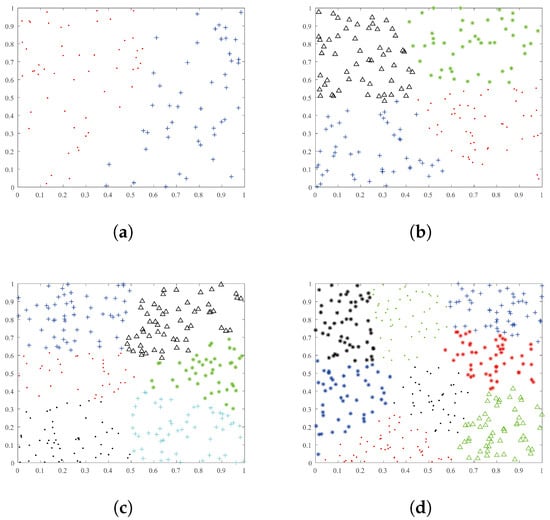
Figure 1.
Numerical experiments are conducted on 100, 200, 300 and 400 instances with 2, 4, 6 and 8 classes, respectively. (a) Numerical experiments are conducted on 100 instances with 2 classes; (b) Numerical experiments are conducted on 200 instances with 4 classes; (c) Numerical experiments are conducted on 300 instances with 6 classes. (d) Numerical experiments are conducted on 400 instances with 8 classes.
- The clustering result of our method is satisfactory for different instances with different classes.
- Our method obtains ideal clustering results for multi-class instances.
4.3. Real Datasets Experiment
4.3.1. Evaluation Indices
The clustering performances of are evaluated using four common external performance indices: Normalized Mutual Information (NMI) [31], Accuracy (AC) [31], Adjusted Rand index (ARI) [32] and Purity [33].
The details of these evaluation indices are shown in Table 3. In Table 3, H denotes entropy; U and V are the data label and the obtained label of the i-th sample, respectively; and represent pre-label and real-label, respectively; denotes the ratio of the correctly clustered data points and all data points. E denotes the expectation; N is the number of instances, denotes a forecasting label, C is a real label.
Table 3.
Definitions of the used cluster validity indices.
Remarks: The higher the NMI, AC, ARI and Purity, the better the performance.
4.3.2. Parameter Sensitivity
To achieve an ideal experiment performance, Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6 show experimental results with different lambda on four datasets. These figures denote two-dimensional images, where x-axis and y-axis denote the various of and different clustering indexes, respectively. According to Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6, we summarized as follows:
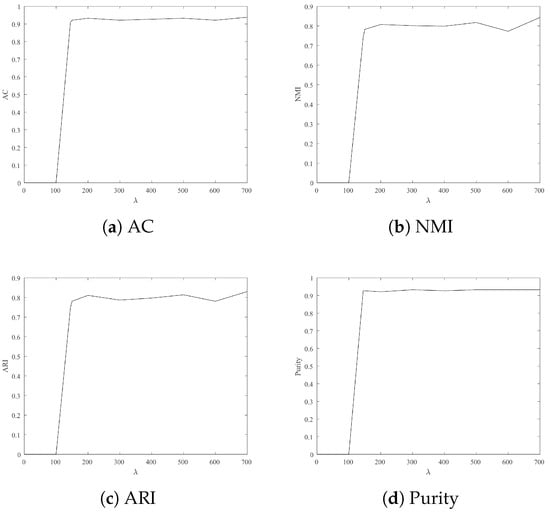
Figure 2.
Clustering result: AC, NMI, ARI and Purity from Wine with different .
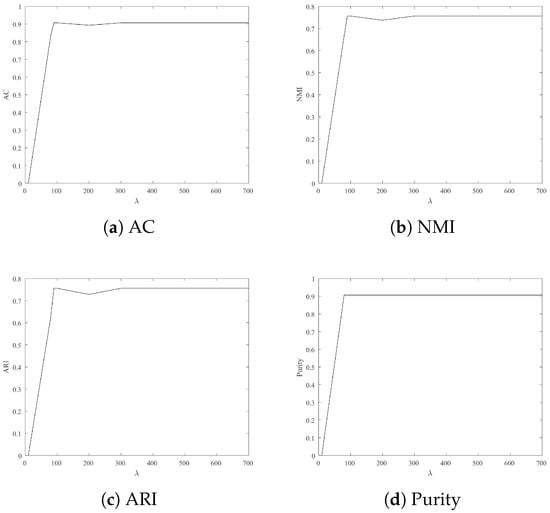
Figure 3.
Clustering result: AC, NMI, ARI and Purity from Iris with different .
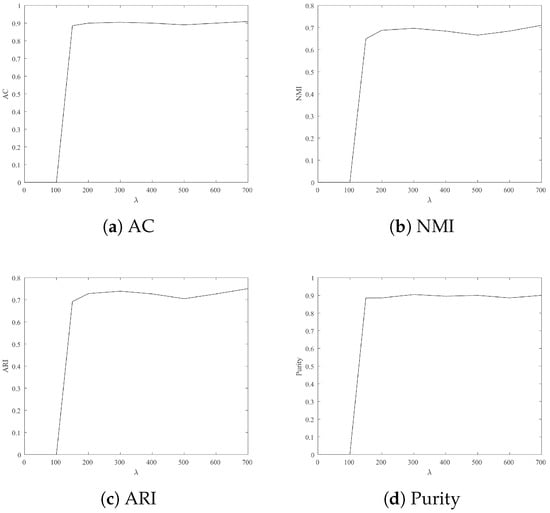
Figure 4.
Clustering result: AC, NMI, ARI and Purity from Seeds with different .
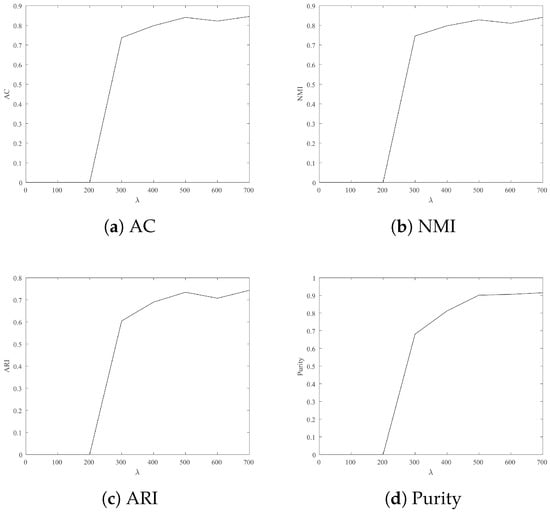
Figure 5.
Clustering result: AC, NMI, ARI and Purity from Jacc_face with different .
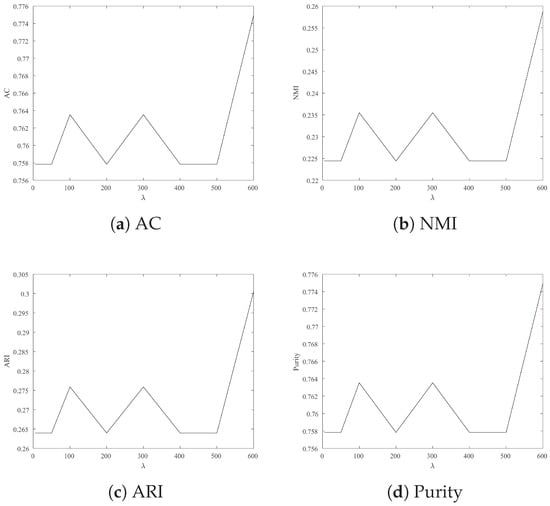
Figure 6.
Clustering result: AC, NMI, ARI and Purity from Ionosphere with different .
- For Wine, Iris and Seeds, the clustering results are more satisfactory when is 700.
- For Jacc_face and Ionosphere, the larger leads to better clustering results.
4.3.3. Experiment Results
Table 4, Table 5, Table 6, Table 7, Table 8 and Table 9 show the algorithm performance of our method compared to Kmeans, Kmeans and Isodata in terms of four clustering performance metric values. These tables show the best, worst, mean and standard deviation performance metric values on the four datasets. The clustering result in these tables demonstrate that the our proposed algorithm statistically outperform the other three algorithms in the light of the given cluster evaluation indices. According to these tables, we summarize the results as follows:
Table 4.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Wine (The best result in bold).
Table 5.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Seeds (The best result in bold).
Table 6.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Ionosphere (the best result in bold).
Table 7.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Seeds (the best result in bold).
Table 8.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Iris (the best result in bold).
Table 9.
The experimental results of our proposed method compared to Kmeans, Kmeans and Isodata in terms of the best, worst, mean and standard deviations performance metric values on Jaffe_face (The best result in bold).
5. Conclusions and Future Work
In this paper, a neural network clustering algorithm is proposed. The clustering is regarded as a combinatorial optimization problem. The proposed clustering algorithm model applies a CHN to solve and the Hopfield networks are repositioned repeatedly upon their local stability until convergence. The experimental results show that our algorithm is obviously superior to other algorithms on four different datasets. According to Section 4.3, the experiment of parameter sensitivity can conclude that the is set by experience. Therefore, there is no theory for ensuring . In the future work:
- Other neural networks can be used to solve clustering problems.
- We are exploring how to effectively combine Hopfield Neural Network with Swarm Intelligence methods.
Author Contributions
Conceptualization, X.D.; software, D.Y.; writing—original draft, Y.X.; writing—review editing, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Foundation of Chongqing Municipal Key Laboratory of Institutions of Higher Education ([2017]3), Foundation of Chongqing Development and Reform Commission (2017[1007]), Scientific and Technological Research Program of Chongqing Municipal Education Commission (Grant Nos. KJQN201901218, KJQN201901203 and KJQN201801214), Natural Science Foundation of Chongqing (Grant Nos. cstc2019jcyj-bshX0101 and cstc2018jcyjA2453).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shaheen, M.; ur Rehman, S.; Ghaffar, F. Correlation and congruence modulo based clustering technique and its application in energy classification. Sustain. Comput. Inform. Syst. 2021, 30, 100561. [Google Scholar] [CrossRef]
- Abdullah, D.; Susilo, S.; Ahmar, A.S.; Rusli, R.; Hidayat, R. The application of K-means clustering for province clustering in Indonesia of the risk of the COVID-19 pandemic based on COVID-19 data. Qual. Quant. 2021; Online ahead of print. [Google Scholar] [CrossRef]
- Yeoh, J.M.; Caraffini, F.; Homapour, E.; Santucci, V.; Milani, A. A clustering system for dynamic data streams based on metaheuristic optimisation. Mathematics 2019, 7, 1229. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2002, 14, 849–856. [Google Scholar]
- Chen, W.Y.; Song, Y.; Bai, H.; Lin, C.J.; Chang, E.Y. Parallel spectral clustering in distributed systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 568–586. [Google Scholar] [CrossRef] [PubMed]
- Chan, P.K.; Schlag, M.D.; Zien, J.Y. Spectral k-way ratio-cut partitioning and clustering. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1994, 13, 1088–1096. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ding, C.H.; He, X.; Zha, H.; Gu, M.; Simon, H.D. A min-max cut algorithm for graph partitioning and data clustering. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 107–114. [Google Scholar]
- Nie, F.; Wang, X.; Huang, H. Clustering and projected clustering with adaptive neighbors. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 977–986. [Google Scholar]
- Wang, Y.; Wu, L. Beyond low-rank representations: Orthogonal clustering basis reconstruction with optimized graph structure for multi-view spectral clustering. Neural Netw. 2018, 103, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Fang, Z. Parallel clustering algorithms. Parallel Comput. 1989, 11, 275–290. [Google Scholar] [CrossRef]
- Grygorash, O.; Zhou, Y.; Jorgensen, Z. Minimum spanning tree based clustering algorithms. In Proceedings of the 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’06), Arlington, VA, USA, 13–15 November 2006; pp. 73–81. [Google Scholar]
- Dai, X.; Zhang, K.; Li, J.; Xiong, J.; Zhang, N. Robust Graph Regularized Non-negative Matrix Factorization for Image Clustering. ACM Trans. Knowl. Discov. Data 2020, 3, 244–250. [Google Scholar]
- Dai, X.; Zhang, N.; Zhang, K.; Xiong, J. Weighted Nonnegative Matrix Factorization for Image Inpainting and Clustering. Int. J. Comput. Intell. Syst. 2020, 13, 734–743. [Google Scholar] [CrossRef]
- Malinen, M.I.; Fränti, P. Balanced K-Means for Clustering. In Joint Iapr International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2014; pp. 32–41. [Google Scholar]
- Bauckhage, C.; Piatkowski, N.; Sifa, R.; Hecker, D.; Wrobel, S. A QUBO Formulation of the k-Medoids Problem. In Proceedings of the LWDA/KDML 2019, Berlin, Germany, 30 September–2 October 2019. [Google Scholar]
- Date, P.; Arthur, D.; Pusey-NAzzaro, L. QUBO Formulations for Training Machine Learning Models. Sci. Rep. 2020, 11, 10029. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J.; Tank, D.W. Computing with neural circuits: A model. Science 1986, 233, 625–633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamgar-Parsi, B.; Gualtieri, J.; Devaney, J.; Kamgar-Parsi, B. Clustering with neural networks. Biol. Cybern. 1990, 63, 201–208. [Google Scholar] [CrossRef]
- Mulder, S.A.; Wunsch, D.C. Million city traveling salesman problem solution by divide and conquer clustering with adaptive resonance neural networks. Neural Netw. 2003, 16, 827–832. [Google Scholar] [CrossRef]
- Bakker, B.; Heskes, T. Clustering ensembles of neural network models. Neural Netw. 2003, 16, 261–269. [Google Scholar] [CrossRef]
- Du, K.L. Clustering: A neural network approach. Neural Netw. 2010, 23, 89–107. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Xu, B.; Wang, P.; Zheng, S.; Tian, G.; Zhao, J. Self-taught convolutional neural networks for short text clustering. Neural Netw. 2017, 88, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Talaván, P.M.; Yáñez, J. The generalized quadratic knapsack problem. A neuronal network approach. Neural Netw. 2006, 19, 416–428. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Liu, D. A Comprehensive Review of Stability Analysis of Continuous-Time Recurrent Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1229–1262. [Google Scholar] [CrossRef]
- Talavan, P.M.; Yanez, J. A continuous Hopfield network equilibrium points algorithm. Comput. Oper. Res. 2005, 32, 2179–2196. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LO, USA, 7–9 January 2007. [Google Scholar]
- Ball, G.H.; Hall, D.J. ISODATA, a Novel Method of Data Analysis and Pattern Classification; Stanford Research Institute: Menlo Park, CA, USA, 1965. [Google Scholar]
- Cai, D.; He, X.; Han, J. Document clustering using locality preserving indexing. IEEE Trans. Knowl. Data Eng. 2005, 17, 1624–1637. [Google Scholar] [CrossRef] [Green Version]
- Santos, J.M.; Embrechts, M. On the use of the adjusted rand index as a metric for evaluating supervised classification. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 175–184. [Google Scholar]
- Rendon, E.; Abundez, I.; Arizmendi, A.; Quiroz, E.M. Internal versus external cluster validation indexes. Int. J. Comput. Commun. 2011, 5, 27–34. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).