

Building Block Extraction from Historical Maps Using Deep Object Attention Networks


Abstract
1. Introduction
2. Related Works
3. Methods
3.1. Network Model
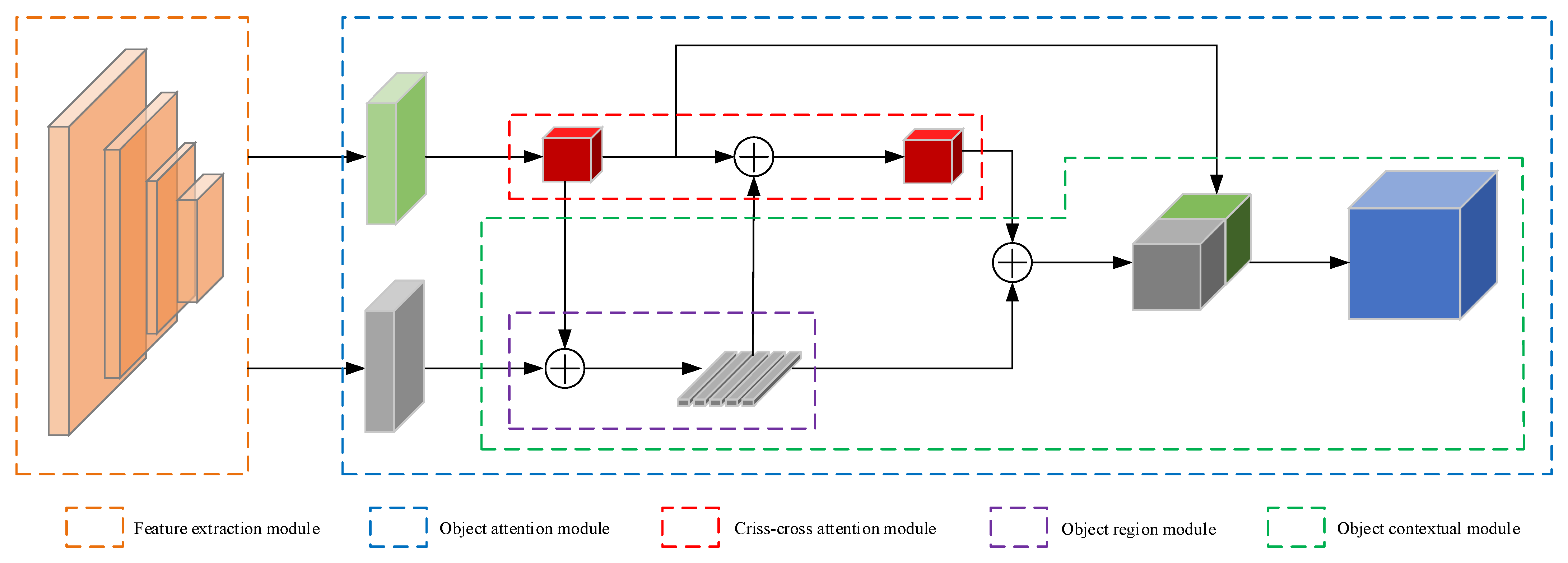
3.1.1. Architecture of DOANet
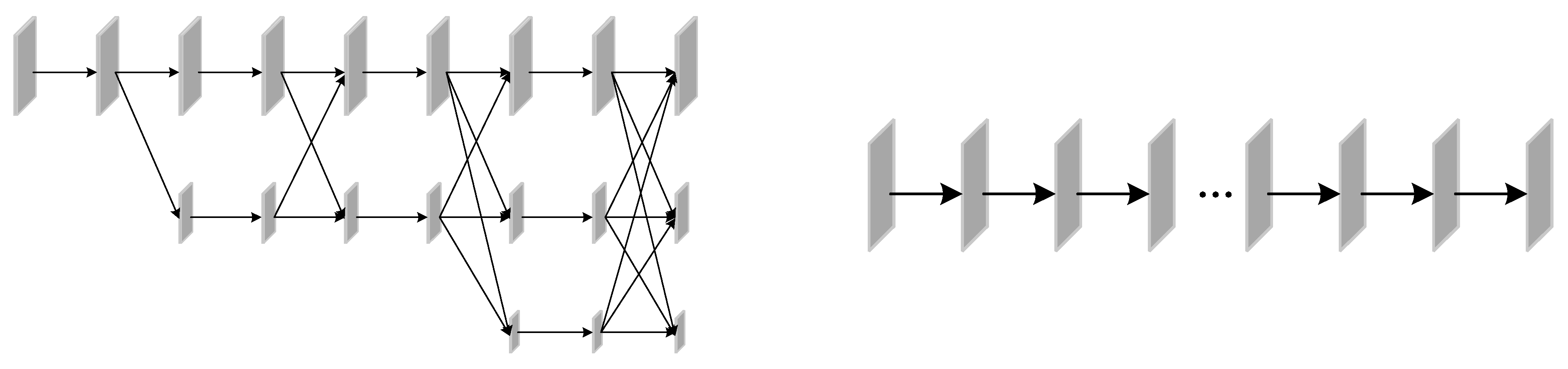
3.1.2. Feature Extraction Module
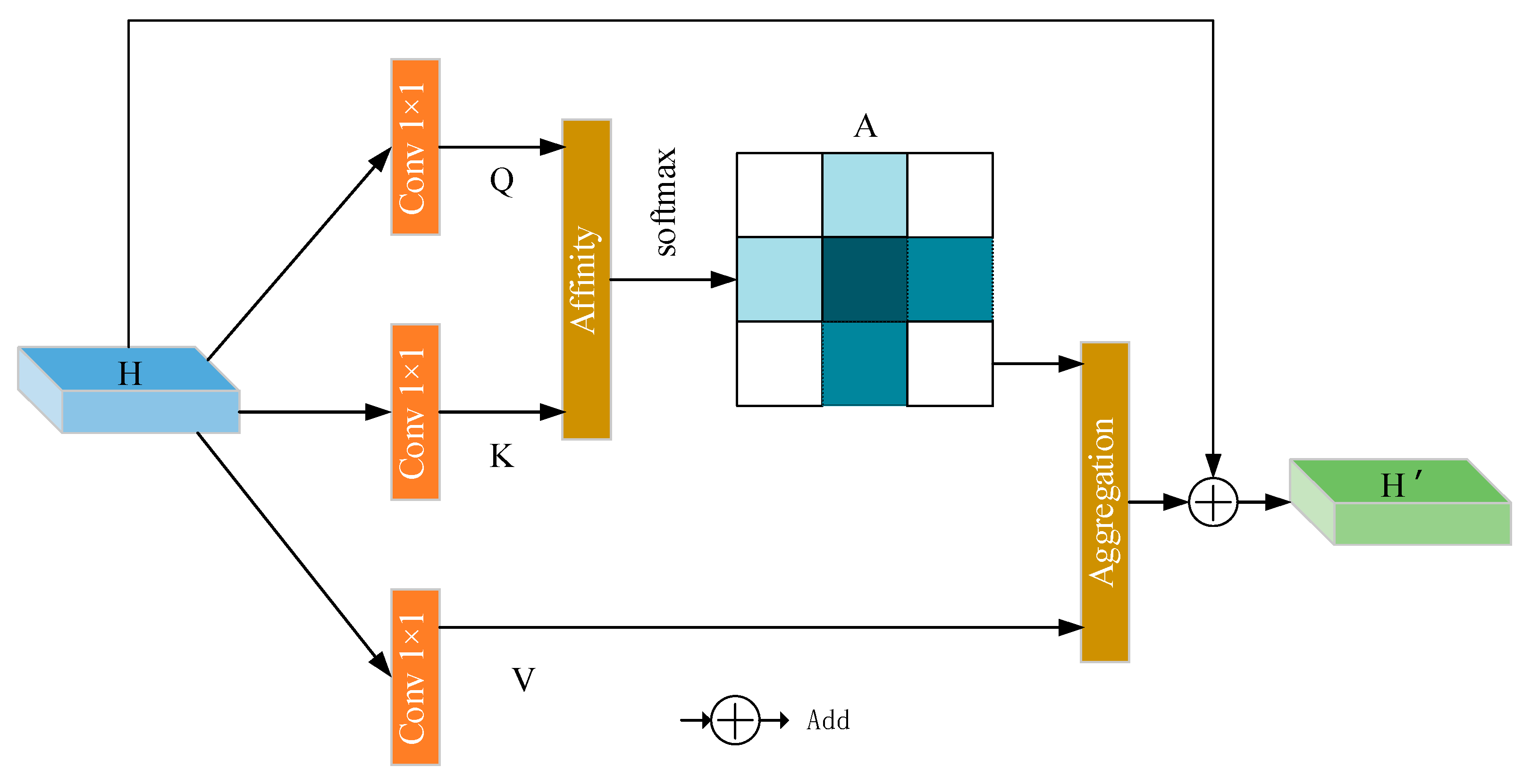
3.1.3. Attention Module
3.2. Transfer Learning
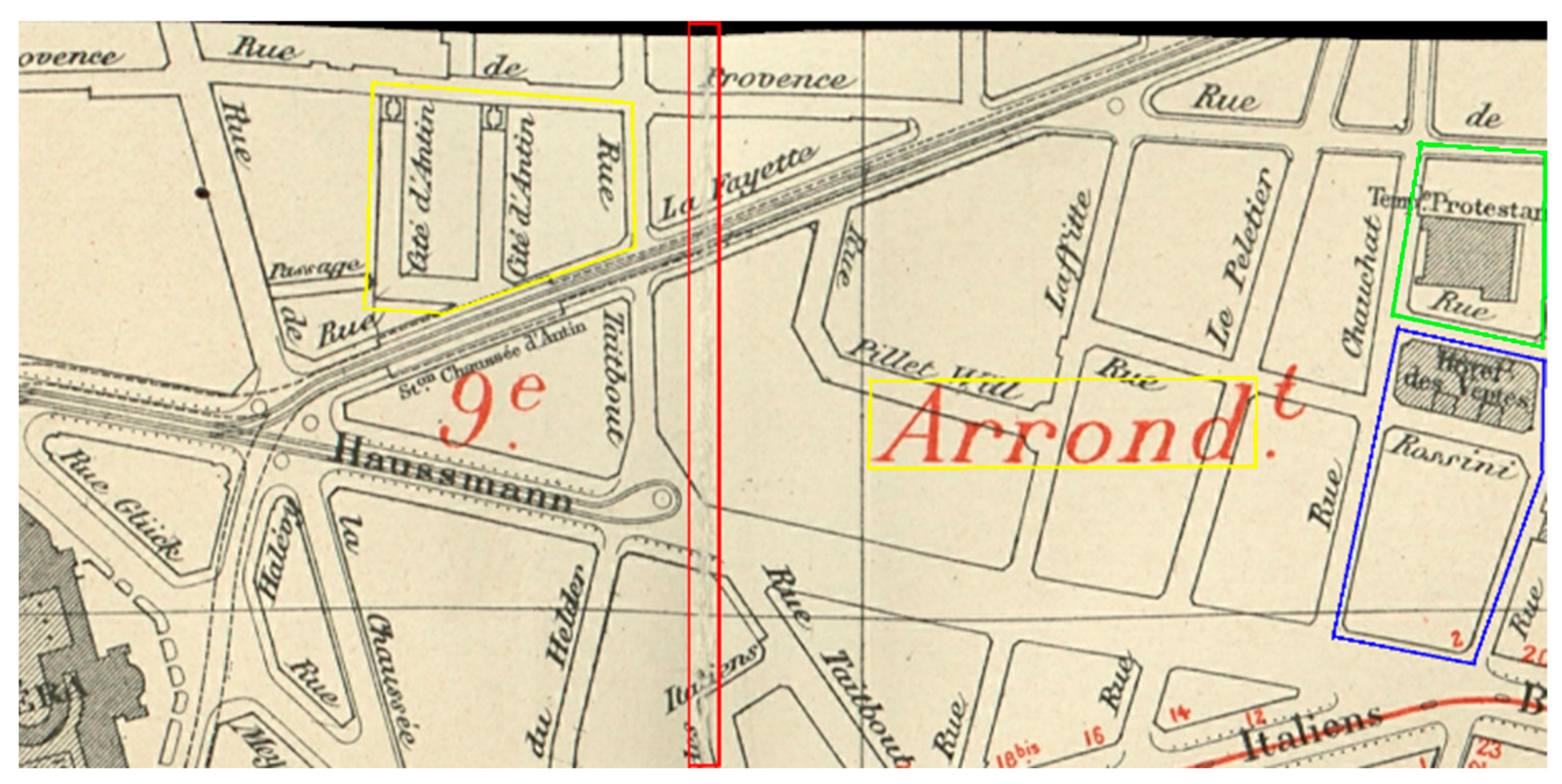
4. Experiments
4.1. Results
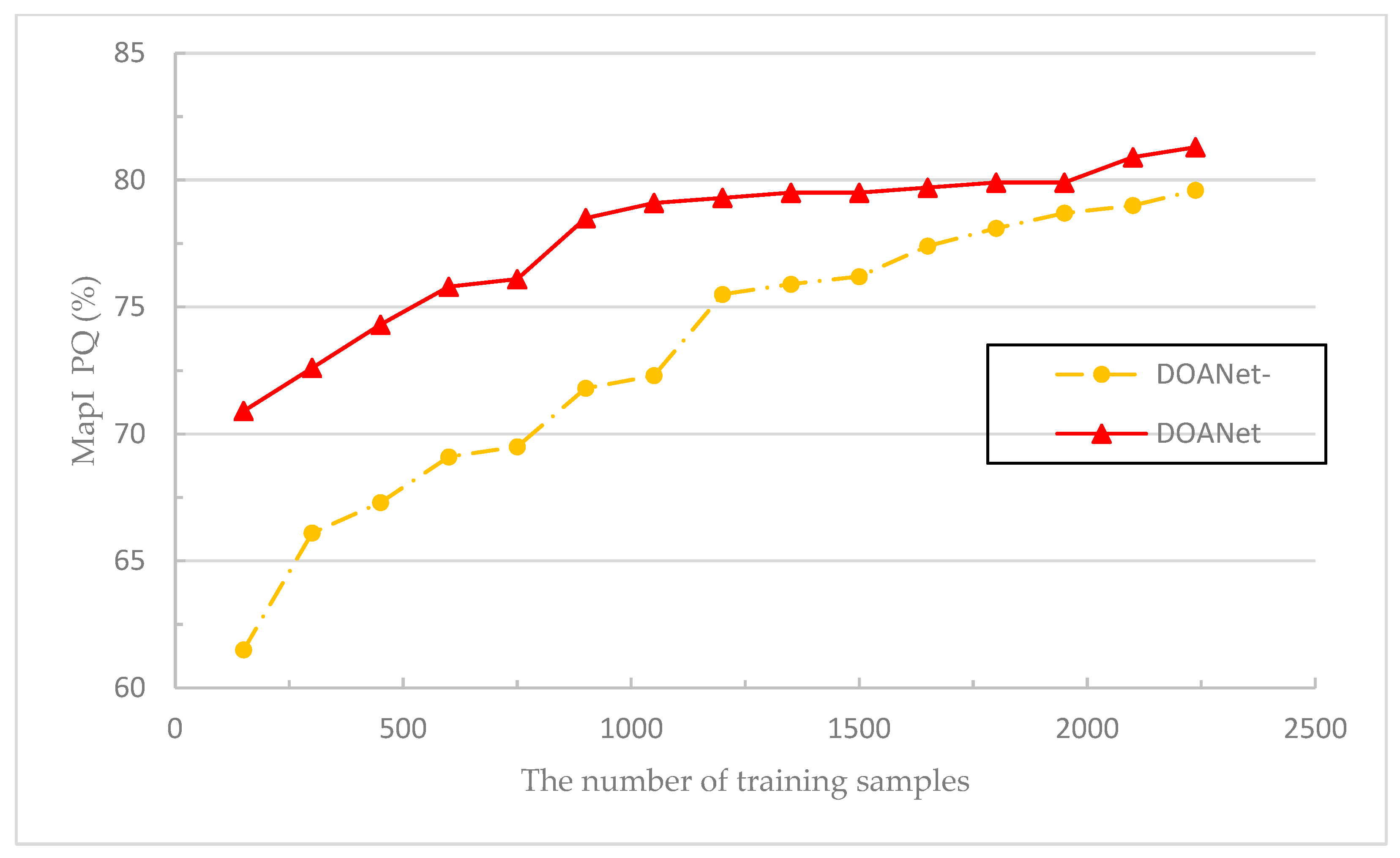
4.2. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dominik, K.; Jacek, K.; Natalia, K.; Elżbieta, Z.; Krzysztof, O.; Katarzyna, O.; Urs, G.; Catalina, M.; Volker, C.R. Broad Scale Forest Cover Reconstruction from Historical Topographic Maps. Appl. Geogr. 2016, 67, 39–48. [Google Scholar] [CrossRef]
- Shbita, B.; Knoblock, C.A.; Duan, W.W.; Chiang, Y.Y.; Uhl, J.H.; Leyk, S. Building Linked Spatio-Temporal Data from Vectorized Historical Maps. In Proceedings of the Extended Semantic Web Conference 2020, Heraklion, Greece, 1–4 June 2020; pp. 409–426. [Google Scholar]
- Uhl, J.H.; Leyk, S.; Chiang, Y.Y.; Duan, W.W.; Knoblock, C.A. Automated Extraction of Human Settlement Patterns from Historical Topographic Map Series Using Weakly Supervised Convolutional Neural Networks. IEEE Access 2020, 8, 6978–6996. [Google Scholar] [CrossRef]
- Andrade, H.J.; Fernandes, B.J. Synthesis of Satellite-Like Urban Images From Historical Maps Using Conditional GAN. IEEE Geosci. Remote Sens. Lett. 2020, 19, 3000504. [Google Scholar] [CrossRef]
- Yuan, X.H.; Shi, J.F.; Gu, L.C. A Review of Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery. Expert Syst. Appl. 2021, 169, 114–147. [Google Scholar] [CrossRef]
- Can, Y.S.; Gerrits, P.J.; Kabadayi, M.E. Automatic Detection of Road Types from the Third Military Mapping Survey of Austria-Hungary Historical Map Series with Deep Convolutional Neural Networks. IEEE Access 2021, 9, 62847–62856. [Google Scholar] [CrossRef]
- Uhl, J.H.; Leyk, S.; Chiang, Y.Y.; Duan, W.W.; Knoblock, C.A. Extracting Human Settlement Footprint from Historical Topographic Map Series Using Context-Based Machine Learning. In Proceedings of the 8th International Conference of Pattern Recognition Systems (ICPRS 2017), Madrid, Spain, 28–31 October 2017; pp. 1–6. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–9 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–9 June 2015; pp. 16–24. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.H.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV 2014), Zürich, Switzerland, 7–9 September 2014; pp. 740–755. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26–30 June 2016; pp. 3212–3223. [Google Scholar]
- Chiang, Y.Y.; Duan, W.W.; Leyk, S.; Uhl, J.H.; Knoblock, C.A. Using Historical Maps in Scientific Studies: Applications, Challenges, and Best Practices; Springer: Berlin, Germany, 2020; pp. 10–25. ISBN 978-3-319-66907-6. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Yuan, Y.H.; Chen, X.K.; Chen, X.L.; Wang, J.D. Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; pp. 1417–1438. [Google Scholar]
- Howe, N.R.; Weinman, J.; Gouwar, J.; Shamji, A. Deformable Part Models for Automatically Georeferencing Historical Map Images. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ICAGIS 2019), Chicago, IL, USA, 5–8 November 2019; pp. 540–543. [Google Scholar]
- Heitzler, M.; Hurni, L. Unlocking the Geospatial Past with Deep Learning–Establishing a Hub for Historical Map Data in Switzerland. In Proceedings of the 29th International Cartographic Conference (ICC 2019), Tokyo, Japan, 15–20 July 2019; pp. 1–10. [Google Scholar]
- Asokan, A.; Anitha, J.; Ciobanu, M.; Gabor, A.; Naaji, A.; Hemanth, J. Image Processing Techniques for Analysis of Satellite Images for Historical Maps Classification—An Overview. Appl. Sci. 2020, 10, 4207. [Google Scholar] [CrossRef]
- Garcia-Molsosa, A.; Orengo, H.A.; Lawrence, D.; Philip, G.; Hopper, K.; Petrie, C.A. Potential of Deep Learning Segmentation for the Extraction of Archaeological Features from Historical Map Series. Archaeol. Prospect. 2021, 28, 187–199. [Google Scholar] [CrossRef]
- Chen, Y.Z.; Carlinet, E.; Chazalon, J.; Mallet, C.; Duménieu, B.; Perret, J. Combining Deep Learning and Mathematical Morphology for Historical Map Segmentation. In Proceedings of the International Conference on Discrete Geometry and Mathematical Morphology (DGMM 2021), Uppsale, Sweden, 24–27 May 2021; pp. 79–92. [Google Scholar]
- Chiang, Y.Y.; Knoblock, C.A. Extracting Road Vector Data from Raster Maps. In Proceedings of the 8th International Workshop on Graphics Recognition (GREC 2009), La Rochelle, France, 11–13 July 2009; pp. 93–105. [Google Scholar]
- Chiang, Y.Y.; Leyk, S.; Knoblock, C.A. Efficient and Robust Graphics Recognition from Historical Maps. In Proceedings of the 8th International Workshop on Graphics Recognition (GREC 2011), Seoul, Korea, 21–22 September 2011; pp. 25–35. [Google Scholar]
- Chen, Y.; Wang, R.S.; Qian, J. Extracting Contour Lines from Common-conditioned Topographic Maps. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1048–1057. [Google Scholar] [CrossRef]
- Miao, Q.G.; Xu, P.F.; Liu, T.G.; Yang, Y.; Zhang, J.Y. Linear Feature Separation from Topographic Maps Using Energy Density and the Shear Transform. IEEE Trans. Image Process. 2013, 22, 1548–1558. [Google Scholar] [CrossRef]
- Liu, Y. An Automation System: Generation of Digital Map Data from Pictorial Map Resources. Pattern Recognit. 2002, 35, 1973–1987. [Google Scholar] [CrossRef]
- Miyoshi, T.; Li, W.Q.; Kaneda, K.; Yamashita, H.; Nakamae, E. Automatic Extraction of Buildings Utilizing Geometric Features of a Scanned Topographic Map. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Stockholm, Sweden, 26 August 2004; pp. 626–629. [Google Scholar]
- Leyk, S.; Boesch, R. Colors of the Past: Color Image Segmentation in Historical Topographic Maps Based on Homogeneity. Geoinformatica 2010, 14, 1–21. [Google Scholar] [CrossRef]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative Research on Deep Learning Approaches for Airplane Detection from Very High-Resolution Satellite Images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.X.; Han, J.W.; Guo, L.; Xia, G.S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Wu, S.D.; Heitzler, M.; Hurni, L. Leveraging Uncertainty Estimation and Spatial Pyramid Pooling for Extracting Hydrological Features from Scanned Historical Topographic Maps. Gisci. Remote Sens. 2022, 59, 200–214. [Google Scholar] [CrossRef]
- Ekim, B.; Sertel, E.; Kabaday, M.E. Automatic Road Extraction from Historical Maps Using Deep Learning Techniques: A Regional Case Study of Turkey in a German World War II Map. ISPRS Int. J. Geo-Inf. 2021, 10, 492. [Google Scholar] [CrossRef]
- Saeedimoghaddam, M.; Stepinski, T.F. Automatic Extraction of Road Intersection Points from USGS Historical Map Series using Deep Convolutional Neural Networks. Int. J. Geogr. Inf. Sci. 2020, 34, 947–968. [Google Scholar] [CrossRef]
- Schlegel, I. Automated Extraction of Labels from Large-Scale Historical Maps. Agile Giss. 2021, 2, 1–14. [Google Scholar] [CrossRef]
- Duan, W.W.; Chiang, Y.Y.; Leyk, S.; Uhl, J.H.; Knoblock, C.A. Automatic Alignment of Contemporary Vector Data and Georeferenced Historical Maps Using Reinforcement Learning. Int. J. Geogr. Inf. Sci. 2019, 34, 824–849. [Google Scholar] [CrossRef]
- Li, Z. Generating Historical Maps from Online Maps. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 610–611. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.B.; Datcu, M.; Pelillo, M.; Zhang, L.P. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, GA, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Heitzler, M.; Hurnim, L. Cartographic Reconstruction of Building Footprints from Historical Maps: A Study on the Swiss Siegfried map. Trans. GIS 2020, 24, 442–461. [Google Scholar] [CrossRef]
- Uhl, J.H.; Leyk, S.; Chiang, Y.Y.; Duan, W.W.; Knoblock, C.A. Spatialising Uncertainty in Image Segmentation using Weakly Supervised Convolutional Neural Networks: A Case Study from Historical Map Processing. IET Image Process. 2018, 12, 2084–2091. [Google Scholar] [CrossRef]
- Huang, Z.L.; Wang, X.G.; Huang, L.C.; Huang, C.; Wei, Y.C.; Liu, W.Y. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2019), Seoul, Korea, 27–31 October 2019; pp. 603–612. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Chazalon, J.; Carlinet, E.; Chen, Y.Z.; Perret, J.; Duménieu, B.; Mallet, C.; Géraud, T.; Nguyen, V.; Nguyen, N.; Baloun, J.; et al. ICDAR 2021 Competition on Historical Map Segmentation. In Proceedings of the 16th International Conference on Document Analysis and Recognition (ICDAR 2021), Lausanne, Switzerland, 5–10 September 2021; pp. 693–707. [Google Scholar]
- Ji, S.P.; Wei, S.Q. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Team | MapI PQ (%) | MapII PQ (%) | MapIII PQ (%) | Mean PQ (%) |
|---|---|---|---|---|
| L3IRIS | 74.4 | 69.8 | 78.2 | 74.1 |
| CMM (1) | 59.8 | 61.4 | 66.7 | 62.6 |
| CMM (2) | 52.6 | 47.9 | 58.1 | 44.0 |
| WUU (1) | 7.7 | 5.9 | 5.7 | 6.4 |
| WUU (2) | 4.7 | 4.0 | 3.9 | 4.2 |
| DOANet | 83.5 | 79.2 | 81.2 | 81.3 |
| Team | MapI PQ (%) | MapII PQ (%) | MapIII PQ (%) | Mean PQ (%) |
|---|---|---|---|---|
| ANet | 69.4 | 72.1 | 73.0 | 71.5 |
| ONet | 75.5 | 72.8 | 72.8 | 73.7 |
| OOANet | 80.1 | 76.8 | 80.7 | 79.2 |
| ROANet | 68.5 | 71.2 | 70.9 | 70.2 |
| DOANet- | 79.4 | 78.1 | 81.3 | 79.6 |
| DOANet | 83.5 | 79.2 | 81.2 | 81.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Wang, G.; Yang, J.; Zhang, L.; Qi, X. Building Block Extraction from Historical Maps Using Deep Object Attention Networks. ISPRS Int. J. Geo-Inf. 2022, 11, 572. https://doi.org/10.3390/ijgi11110572
Zhao Y, Wang G, Yang J, Zhang L, Qi X. Building Block Extraction from Historical Maps Using Deep Object Attention Networks. ISPRS International Journal of Geo-Information. 2022; 11(11):572. https://doi.org/10.3390/ijgi11110572
Chicago/Turabian StyleZhao, Yao, Guangxia Wang, Jian Yang, Lantian Zhang, and Xiaofei Qi. 2022. "Building Block Extraction from Historical Maps Using Deep Object Attention Networks" ISPRS International Journal of Geo-Information 11, no. 11: 572. https://doi.org/10.3390/ijgi11110572
APA StyleZhao, Y., Wang, G., Yang, J., Zhang, L., & Qi, X. (2022). Building Block Extraction from Historical Maps Using Deep Object Attention Networks. ISPRS International Journal of Geo-Information, 11(11), 572. https://doi.org/10.3390/ijgi11110572