Design of Novel Nested Arrays Based on the Concept of Sum-Difference Coarray


Abstract
1. Introduction
- By jointly exploiting the spatial and temporal information of received data, SDCA of a physical array is constructed, which can contribute to the increase of continuous DOFs. Moreover, its generation process has been discussed detailedly in this paper. And, we have also given the definition of two index sets, whose role is to construct the desirable time average vector and the corresponding equivalent received array.
- Four NNAs are proposed in this paper to achieve the purpose of improving the underdetermined DOA estimation performance. Specifically, they possess different physical apertures, but can generate the same SDCA for DOA estimation.
- The closed-form expressions for the proposed NNAs and their SDCA are provided in this paper. Moreover, the specific expressions for the index sets corresponding to different NNAs are also presented. These expressions can make it easy for readers to design the NNAs they want to use.
2. System Model
3. Proposed Novel Nested Arrays
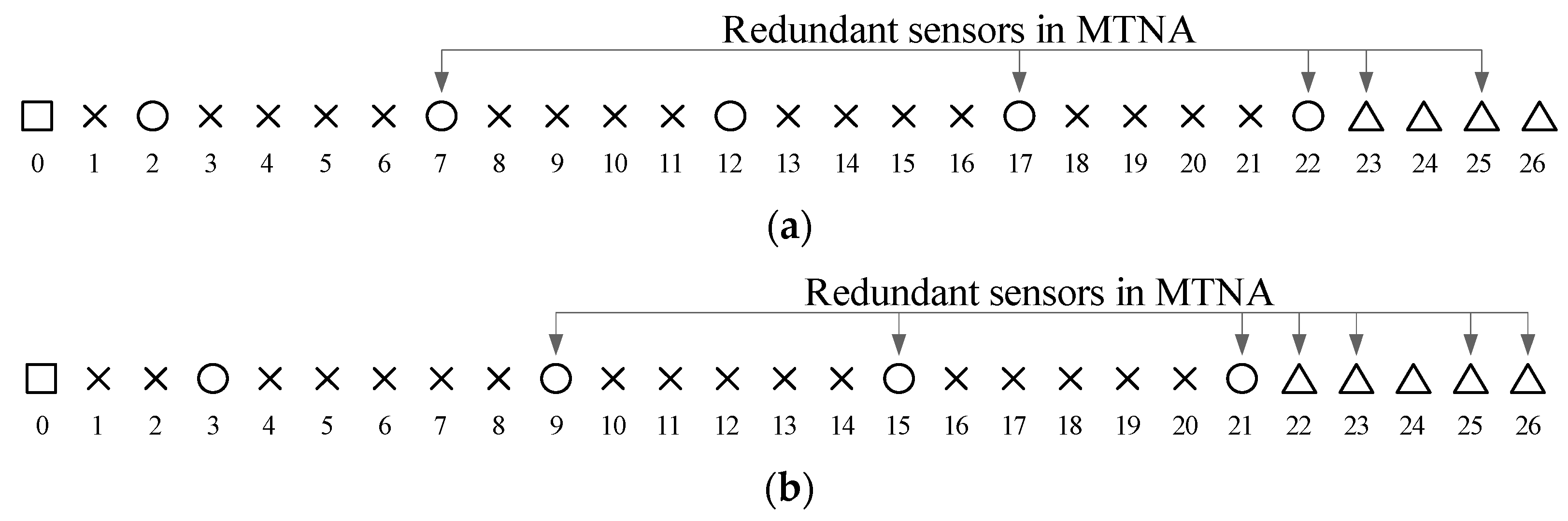
3.1. Introduction of Modified Translational Nested Array (MTNA)
3.2. Redundancy Analysis of MTNA
3.3. The Proposed Novel Nested Arrays (NNAs)
4. Simulation Results
4.1. Continuous Degrees of Freedom (DOFs) and Physical Aperture
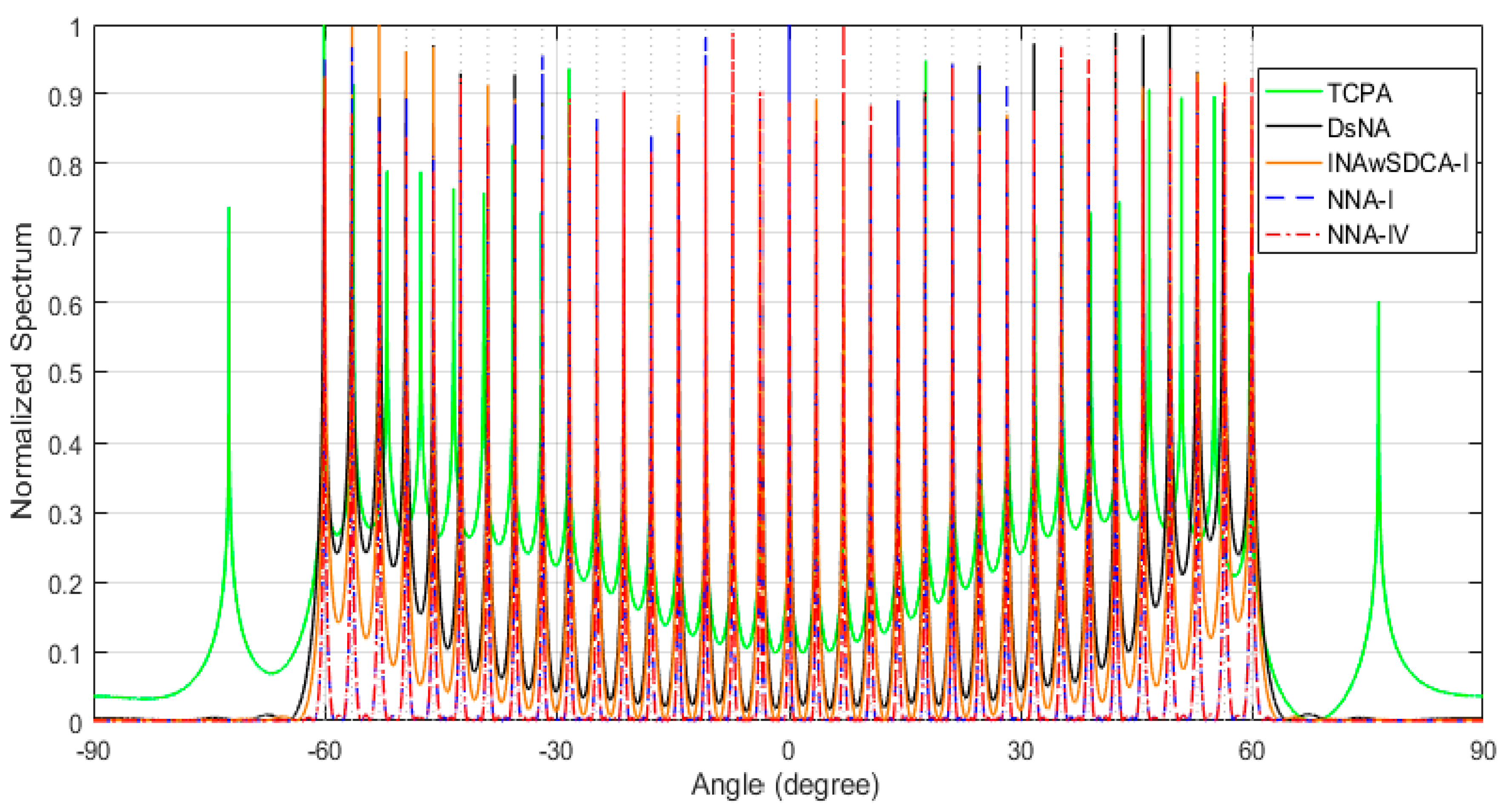
4.2. Normalized Spectra
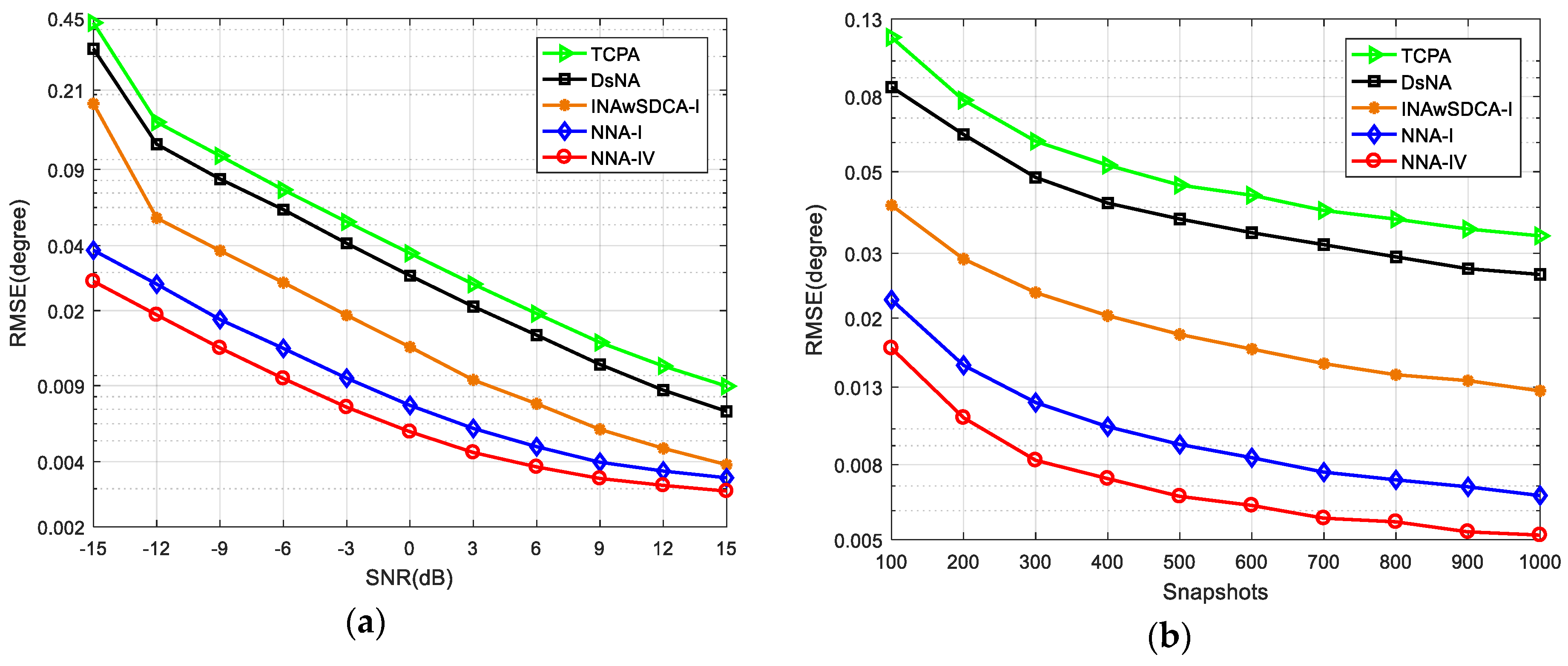
4.3. Root-Mean-Squared Error (RMSE)
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proof of Property 1
Appendix B. Proof of Property 2
References
- Merrill, I.S. Introduction to Radar Systems, 3rd ed.; McGraw-Hill: New York, NY, USA, 2001. [Google Scholar]
- Chen, P.; Cao, Z.; Chen, Z.; Yu, C. Sparse DOD/DOA estimation in a bistatic MIMO radar with mutual coupling effect. Electronics 2018, 7, 341. [Google Scholar] [CrossRef]
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Wan, L.; Han, G.; Shu, L.; Chan, S.; Zhu, T. The application of DOA estimation approach in patient tracking systems with high patient density. IEEE Trans. Ind. Informat. 2016, 12, 2353–2364. [Google Scholar] [CrossRef]
- Han, M.; Dou, W. Atomic norm-based DOA estimation with dual-polarized radar. Electronics 2019, 8, 1056. [Google Scholar] [CrossRef]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Roy, R.; Kailath, T. ESPRIT-estimation of signal parameters via rotational invariance techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar] [CrossRef]
- Pal, P.; Vaidyanathan, P.P. Nested arrays: A novel approach to array processing with enhanced degrees of freedom. IEEE Trans. Signal Process. 2010, 58, 4167–4181. [Google Scholar] [CrossRef]
- Boccardi, F.; Heath, R.W.; Lozano, A.; Marzetta, T.L.; Popovski, P. Five disruptive technology directions for 5G. IEEE Commun. Mag. 2014, 52, 74–80. [Google Scholar] [CrossRef]
- Pal, P.; Vaidyanathan, P.P. Coprime Sampling and the Music Algorithm. In Proceedings of the 14th IEEE DSP/SPE Workshop, Sedona, AZ, USA, 4–7 January 2011; pp. 289–294. [Google Scholar]
- Moffet, A. Minimum-redundancy linear arrays. IEEE Trans. Antennas Propag. 1968, 16, 172–175. [Google Scholar] [CrossRef]
- Vertatschitsch, E.; Haykin, S. Nonredundant arrays. Proc. IEEE 1986, 74, 217. [Google Scholar] [CrossRef]
- Vaidyanathan, P.P.; Pal, P. Sparse sensing with co-prime samplers and arrays. IEEE Trans. Signal Process. 2011, 59, 573–586. [Google Scholar] [CrossRef]
- Qin, S.; Zhang, Y.D.; Amin, M.G. Generalized coprime array configurations for direction-of-arrival estimation. IEEE Trans. Signal Process. 2015, 63, 1377–1390. [Google Scholar] [CrossRef]
- Wang, W.J.; Ren, S.W.; Chen, Z.M. Unified coprime array with multi-period subarrays for direction-of-arrival estimation. Digit. Signal Process. 2018, 74, 30–42. [Google Scholar] [CrossRef]
- Raza, A.; Liu, W.; Shen, Q. Thinned coprime arrays for DOA estimation. In Proceedings of the European Signal Proceeding Conference, Kos, Greece, 28 August–2 September 2017; pp. 395–399. [Google Scholar]
- Raza, A.; Liu, W.; Shen, Q. Thinned coprime array for second-order difference co-array generation with reduced mutual coupling. IEEE Trans. Signal Process. 2019, 67, 2052–2065. [Google Scholar] [CrossRef]
- Yang, M.; Sun, L.; Yuan, X.; Chen, B. Improved nested array with hole-free DCA and more degrees of freedom. Electron. Lett. 2016, 52, 2068–2070. [Google Scholar] [CrossRef]
- Liu, J.Y.; Zhang, Y.M.; Lu, Y.L.; Ren, S.W.; Cao, S. Augmented nested arrays with enhanced DOF and reduced mutual coupling. IEEE Trans. Signal Process. 2017, 65, 5549–5563. [Google Scholar] [CrossRef]
- Zhang, Y.K.; Xu, H.Y.; Zong, R.; Ba, B.; Wang, D.M. A novel high degree of freedom sparse array with displaced multistage cascade subarrays. Digit. Signal Process. 2019, 90, 36–45. [Google Scholar] [CrossRef]
- Liu, C.L.; Vaidyanathan, P.P. Composite singer arrays with hole-free coarrays and enhanced robustness. In Proceedings of the IEEE International Conference on Acoustics, Speech Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4120–4124. [Google Scholar]
- Wang, X.H.; Chen, Z.H.; Ren, S.W.; Cao, S. DOA estimation based on the difference and sum coarray for coprime arrays. Digit. Signal Process. 2017, 69, 22–31. [Google Scholar] [CrossRef]
- Iwazaki, S.; Ichige, K. Underdetermined direction of arrival estimation by sum and difference composite co-array. In Proceedings of the 25th IEEE International Conference on Electronics Circuits and Systems, Bordeaux, France, 9–12 December 2018; pp. 669–672. [Google Scholar]
- Chen, Z.; Ding, Y.; Ren, S.; Chen, Z. A novel nested configuration based on the difference and sum co-array concept. Sensors 2018, 18, 2988. [Google Scholar] [CrossRef]
- Si, W.J.; Peng, Z.L.; Hou, C.B.; Zeng, F.H. Improved nested arrays with sum-difference coarray for DOA estimation. IEEE Sens. J. 2019, 19, 6986–6997. [Google Scholar] [CrossRef]
- Si, W.J.; Zeng, F.H.; Zhang, C.J.; Peng, Z.L. Improved coprime arrays with reduced mutual coupling based on the concept of difference and sum coarray. IEEE Access 2019, 7, 66251–66262. [Google Scholar] [CrossRef]
- Shan, Z.; Yum, T.S.P. A conjugate augmented approach to direction-of-arrival estimation. IEEE Trans. Signal Process. 2005, 53, 4104–4109. [Google Scholar] [CrossRef]
- Mahafza, B.R. Introduction to Radar Analysis; Chapman and Hall/CRC: New York, NY, USA, 2017. [Google Scholar]
- Liu, C.L.; Vaidyanathan, P.P. Cramér–rao bounds for coprime and other sparse arrays, which find more sources than sensors. Digit. Signal Process. 2017, 61, 43–61. [Google Scholar] [CrossRef]
- Wang, M.Z.; Nehorai, A. Coarrays, MUSIC, and the cramér–rao bound. IEEE Trans. Signal Process. 2017, 65, 933–946. [Google Scholar] [CrossRef]
- Shan, T.-J..; Wax, M.; Kailath, T. On spatial smoothing for direction-of-arrival estimation of coherent signals. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 806–811. [Google Scholar] [CrossRef]
- Liu, C.L.; Vaidyanathan, P.P. Remarks on the spatial smoothing step in coarray MUSIC. IEEE Signal Process. Lett. 2015, 22, 1438–1442. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| is odd | 4 | ||
| is even | 4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, W.; Peng, Z.; Hou, C.; Zeng, F. Design of Novel Nested Arrays Based on the Concept of Sum-Difference Coarray. Electronics 2020, 9, 115. https://doi.org/10.3390/electronics9010115
Si W, Peng Z, Hou C, Zeng F. Design of Novel Nested Arrays Based on the Concept of Sum-Difference Coarray. Electronics. 2020; 9(1):115. https://doi.org/10.3390/electronics9010115
Chicago/Turabian StyleSi, Weijian, Zhanli Peng, Changbo Hou, and Fuhong Zeng. 2020. "Design of Novel Nested Arrays Based on the Concept of Sum-Difference Coarray" Electronics 9, no. 1: 115. https://doi.org/10.3390/electronics9010115
APA StyleSi, W., Peng, Z., Hou, C., & Zeng, F. (2020). Design of Novel Nested Arrays Based on the Concept of Sum-Difference Coarray. Electronics, 9(1), 115. https://doi.org/10.3390/electronics9010115