Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season


Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Analytic Approach
3. Results
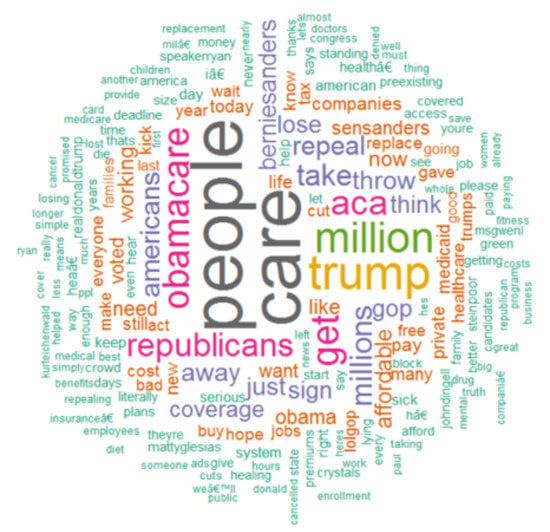
3.1. Word Association
3.2. Sentiment Analysis
4. Discussion
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Atherly, A.; Dowd, B.E.; Feldman, R. The effect of benefits, premiums, and health risk on health plan choice in the Medicare program. Health Serv. Res. 2004, 39, 847–864. [Google Scholar] [CrossRef] [PubMed]
- Buchmueller, T.C. Consumer Demand for Health Insurance; NBER Reporter, National Bureau of Economic Research, Inc.: Cambridge, MA, USA, 2006; pp. 10–13. [Google Scholar]
- Short, P.F.; Taylor, A.K. Premiums, benefits, and employee choice of health insurance options. J. Health Econ. 1989, 8, 293–311. [Google Scholar] [CrossRef]
- Trujillo, A.J.; Ruiz, F.; Bridges, J.F.P.; Amaya, J.L.; Buttorff, C.; Quiroga, A.M. Understanding consumer preferences in the context of managed competition. Appl. Health Econ. Health Policy 2012, 10, 99–111. [Google Scholar] [CrossRef]
- Blumberg, L.J.; Long, S.K.; Kenney, G.M.; Goin, D. Factors Influencing Health Plan Choice among the Marketplace Target Population on the Eve of Health Reform; Urban Institute: Washington, DC, USA, 2013. [Google Scholar]
- Altman, D. What new data tells us about doctors choice. The Wall Street Journal. 4 February 2016. Available online: https://blogs.wsj.com/washwire/2016/02/04/what-new-data-tell-us-about-doctor-choice/ (accessed on 28 September 2017).
- Stokes, T.; Tarrant, C.; Mainous, A.G.; Schers, H.; Freeman, G.; Baker, R. Continuity of care: Is the personal doctor still important? A survey of general practitioners and family physicians in England and Wales, the United States, and The Netherlands. Ann. Fam. Med. 2005, 3, 353–359. [Google Scholar] [CrossRef] [PubMed]
- Guthrie, B.; Saultz, J.W.; Freeman, G.K.; Haggerty, J.L. Continuity of care matters. BMJ Br. Med. J. 2008, 337, a867. [Google Scholar] [CrossRef]
- Turner, D.; Tarrant, C.; Windridge, K.; Bryan, S.; Boulton, M.; Freeman, G.; Baker, R. Do patients value continuity of care in general practice? An investigation using stated preference discrete choice experiments. J. Health Serv. Res. Policy 2007, 12, 132–137. [Google Scholar] [CrossRef]
- Higuera, L.; Carlin, C.S.; Dowd, B. Narrow provider networks and willingness to pay for continuity of care and network breadth. J. Health Econ. 2018, 60, 90–97. [Google Scholar] [CrossRef]
- Mainous, A.G.; Goodwin, M.A.; Stange, K.C. Patient-physician shared experiences and value patients place on continuity of care. Ann. Fam. Med. 2004, 2, 452–454. [Google Scholar] [CrossRef]
- Enthoven, A.; Kronick, R. Competition 101: Managing demand to get quality care. Bus. Health 1988, 5, 38–40. [Google Scholar]
- Statistica. Number of Monthly Active Twitter Users in the United States from 1st Quarter 2010 to 1st Quarter 2017 (in Millions). 2017. Available online: https://www.statista.com/statistics/274564/monthly-active-twitter-users-in-the-united-states/ (accessed on 22 July 2017).
- Stats IL. Twitter Usage Statistics. 2017. Available online: http://www.internetlivestats.com/twitter-statistics/ (accessed on 22 July 2017).
- Ben-Ami, Z.; Feldman, R.; Rosenfeld, B. Using multi-view learning to improve detection of investor sentiments on twitter. Computación y Sistemas 2014, 18, 477–490. [Google Scholar] [CrossRef]
- Bing, L.; Chan, K.C.; Ou, C. Public sentiment analysis in Twitter data for prediction of a company’s stock price movements. In Proceedings of the 2014 IEEE 11th International Conference on e-Business Engineering (ICEBE), Guangzhou, China, 5–7 November 2014. [Google Scholar]
- Chen, R.; Lazer, M. Sentiment analysis of twitter feeds for the prediction of stock market movement. Stanf. Edu. Retrieved 2013, 25, 2013. [Google Scholar]
- Rao, T.; Srivastava, S. Using Twitter Sentiments and Search Volumes Index to Predict Oil, Gold, Forex and Markets Indices; Delhi Institutional Repository: Delhi, India, 2012. [Google Scholar]
- Dijkman, R.; Ipeirotis, P.; Aertsen, F.; van Helden, R. Using twitter to predict sales: A case study. arXiv 2015, arXiv:150304599. [Google Scholar]
- Antenucci, D.; Cafarella, M.; Levenstein, M.; Ré, C.; Shapiro, M.D. Using Social Media to Measure Labor Market Flows; National Bureau of Economic Research: Cambridge, MA, USA, 2014. [Google Scholar]
- Llorente, A.; Garcia-Herranz, M.; Cebrian, M.; Moro, E. Social media fingerprints of unemployment. PLoS ONE 2015, 10, e0128692. [Google Scholar] [CrossRef]
- Hao, J.; Hao, J.; Dai, H.; Dai, H. Social media content and sentiment analysis on consumer security breaches. J. Financ. Crime 2016, 23, 855–869. [Google Scholar] [CrossRef]
- Bermingham, A.; Smeaton, A.F. On using Twitter to monitor political sentiment and predict election results. In Proceedings of the Workshop at the International Joint Conference for Natural Language Processing (IJCNLP), Chiang Mai, Thailand, 13 November 2011. [Google Scholar]
- Tumasjan, A.; Sprenger, T.O.; Sandner, P.G.; Welpe, I.M. Predicting elections with twitter: What 140 characters reveal about political sentiment. ICWSM 2010, 10, 178–185. [Google Scholar]
- Tumasjan, A.; Sprenger, T.O.; Sandner, P.G.; Welpe, I.M. Election forecasts with Twitter: How 140 characters reflect the political landscape. Soc. Sci. Comput. Rev. 2011, 29, 402–418. [Google Scholar] [CrossRef]
- Perez, S. Analysis of Social Media Did a Better Job at Predicting Trump’s win than the Polls. Tech Crunch. 2016. Available online: https://techcrunch.com/2016/11/10/social-media-did-a-better-job-at-predicting-trumps-win-than-the-polls/ (accessed on 24 July 2017).
- Broniatowski, D.A.; Paul, M.J.; Dredze, M. National and local influenza surveillance through Twitter: An analysis of the 2012–2013 influenza epidemic. PLoS ONE 2013, 8, e83672. [Google Scholar] [CrossRef] [PubMed]
- Culotta, A. Towards detecting influenza epidemics by analyzing Twitter messages. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Lamb, A.; Paul, M.J.; Dredze, M. Separating fact from fear: tracking flu infections on Twitter. In Proceedings of the North American Chapter of the Association for Computational Linguistics—Human Language Technologies (NAACL HLT) 2013 Conference, Atlanta, GA, USA, 9–14 June 2013. [Google Scholar]
- Lampos, V.; De Bie, T.; Cristianini, N. Flu detector-tracking epidemics on Twitter. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; pp. 599–602. [Google Scholar]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The use of Twitter to track levels of disease activity and public concern in the US during the influenza A H1N1 pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef] [PubMed]
- Crannell, W.C.; Clark, E.; Jones, C.; James, T.A.; Moore, J. A pattern-matched Twitter analysis of US cancer-patient sentiments. J. Surg. Res. 2016, 206, 536–542. [Google Scholar] [CrossRef]
- Hawkins, J.B.; Brownstein, J.S.; Tuli, G.; Runels, T.; Broecker, K.; Nsoesie, E.O.; McIver, D.J.; Rozenblum, R.; Wright, A.; Bourgeois, F.T.; et al. Measuring patient-perceived quality of care in US hospitals using Twitter. BMJ Qual. Saf. 2016, 25, 404–413. [Google Scholar] [CrossRef]
- Dai, H.; Lee, B.R.; Hao, J. Predicting asthma prevalence by linking social media data and traditional surveys. ANNALS Am. Acad. Polit. Soc. Sci. 2017, 669, 75–92. [Google Scholar] [CrossRef]
- Gollust, S.E.; Qin, X.; Wilcock, A.D.; Baum, L.M.; Barry, C.L.; Niederdeppe, J.; Fowler, E.F.; Karaca-Mandic, P. Search and you shall find: Geographic characteristics associated with google searches during the affordable care act’s first enrollment period. Med. Care Res. Rev. 2016. [Google Scholar] [CrossRef] [PubMed]
- Wong, C.A.; Sap, M.; Schwartz, A.; Town, R.; Baker, T.; Ungar, L.; Merchant, R.M. Twitter sentiment predicts affordable care act marketplace enrollment. J. Med. Internet Res. 2015, 17, e51. [Google Scholar] [CrossRef] [PubMed]
- Davis, M.A.; Zheng, K.; Liu, Y.; Levy, H. Public response to Obamacare on Twitter. J. Med. Internet Res. 2017, 19, e167. [Google Scholar] [CrossRef] [PubMed]
- Deepu, S.; Raj, P.; Rajaraajeswari, S. A Framework for Text Analytics using the Bag of Words (BoW) Model for Prediction. In Proceedings of the 1st International Conference on Innovations in Computing & Networking (ICICN16), Bangalore, India, 12–13 May 2016. [Google Scholar]
- Mohammad, S.M.; Kiritchenko, S.; Zhu, X. NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. arXiv 2013, arXiv:13086242. [Google Scholar]
- Ganesh, J.; Gupta, M.; Varma, V. Interpretation of semantic tweet representations. arXiv 2017, arXiv:170400898. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26, 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Hill, F.; Cho, K.; Korhonen, A. Learning distributed representations of sentences from unlabelled data. arXiv 2016, arXiv:160203483. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Bejing, China, 22–24 June 2014. [Google Scholar]
- Wong, C.A.; Polsky, D.E.; Jones, A.T.; Weiner, J.; Town, R.J.; Baker, T. For third enrollment period, marketplaces expand decision support tools to assist consumers. Health Aff. 2016, 35, 680–687. [Google Scholar] [CrossRef][Green Version]



{kind=link}
{kind=link}
{kind=link}
| Positive | Negative |
|---|---|
| Doctor (trust) | Pressure (negative) |
| Physician (trust) | Die (fear, sadness) |
| Hospital (trust) | Emergency (fear, anger, disgust, sadness) |
| Nurse (trust) | Disease (fear, anger, disgust, sadness) |
| Plan (anticipation) | Pain, surgery (fear, sadness) |
| Save money (joy) | Miscarriage (fear, sadness) |
| Choice (positive) | Cancer (fear, anger, disgust, sadness) |
| Term in Tweets | Words Used | Association |
|---|---|---|
| Premium | Increase relief Obamacare | 0.17 0.16 0.08 |
| Access | No-copay ppact (planned parenthood), birth, women Affordable Care Act | 0.74 0.66, 0.51, 0.40 0.15 |
| Network | narrow providers covering | 0.23 0.16 0.08 |
| Switch | Bait lockedin rxrights premium network | 0.31 0.14 0.13 0.08 0.08 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
van den Broek-Altenburg, E.M.; Atherly, A.J. Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Appl. Sci. 2019, 9, 2035. https://doi.org/10.3390/app9102035
van den Broek-Altenburg EM, Atherly AJ. Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Applied Sciences. 2019; 9(10):2035. https://doi.org/10.3390/app9102035
Chicago/Turabian Stylevan den Broek-Altenburg, Eline M., and Adam J. Atherly. 2019. "Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season" Applied Sciences 9, no. 10: 2035. https://doi.org/10.3390/app9102035
APA Stylevan den Broek-Altenburg, E. M., & Atherly, A. J. (2019). Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Applied Sciences, 9(10), 2035. https://doi.org/10.3390/app9102035