Multi-Attribute Recognition of Facial Images Considering Exclusive and Correlated Relationship Among Attributes

Abstract
1. Introduction
2. Multi-Attribute Recognition Using Exclusive and Correlated Relationships
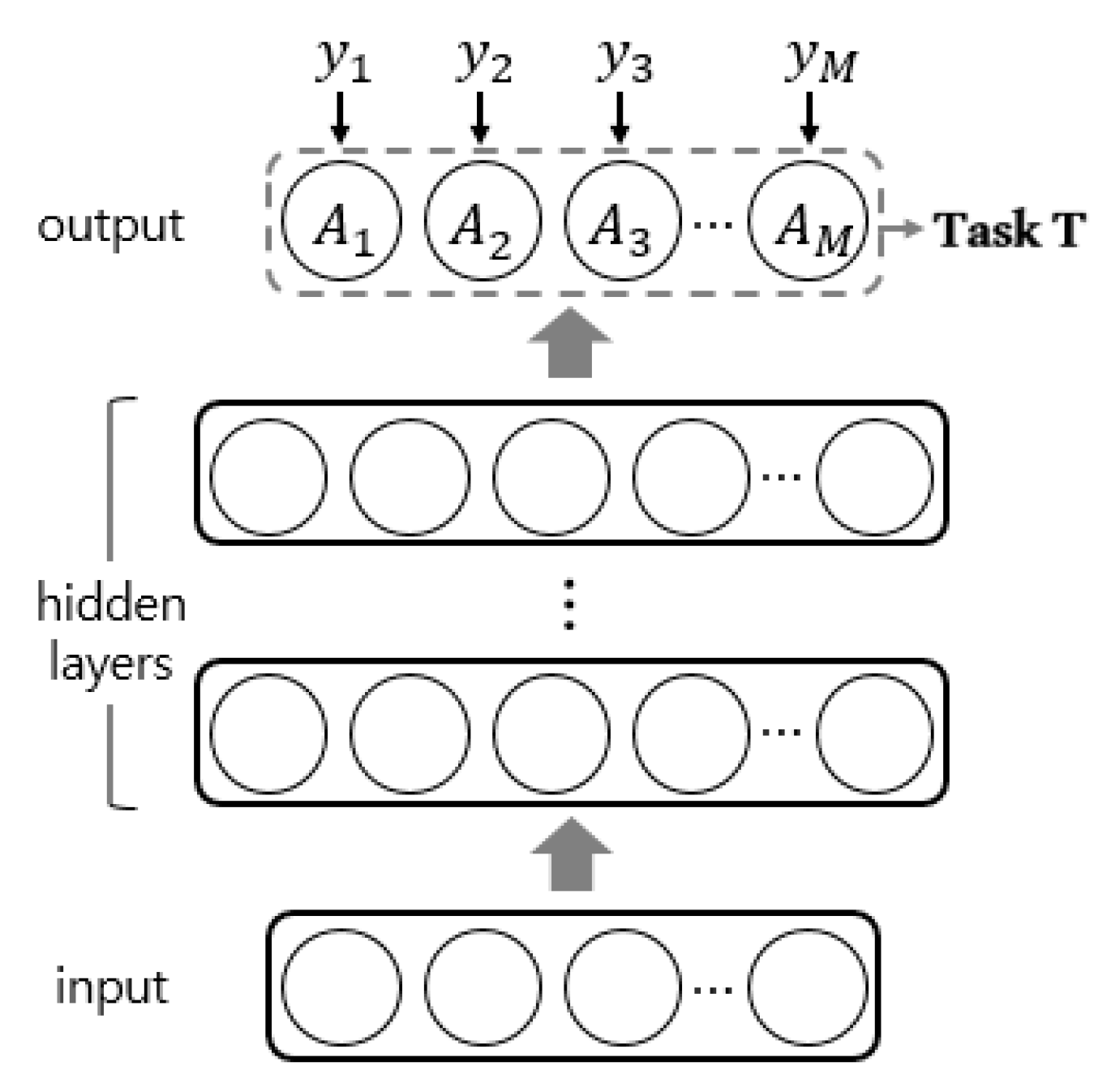
2.1. Single Task Learning for Exclusive Attributes
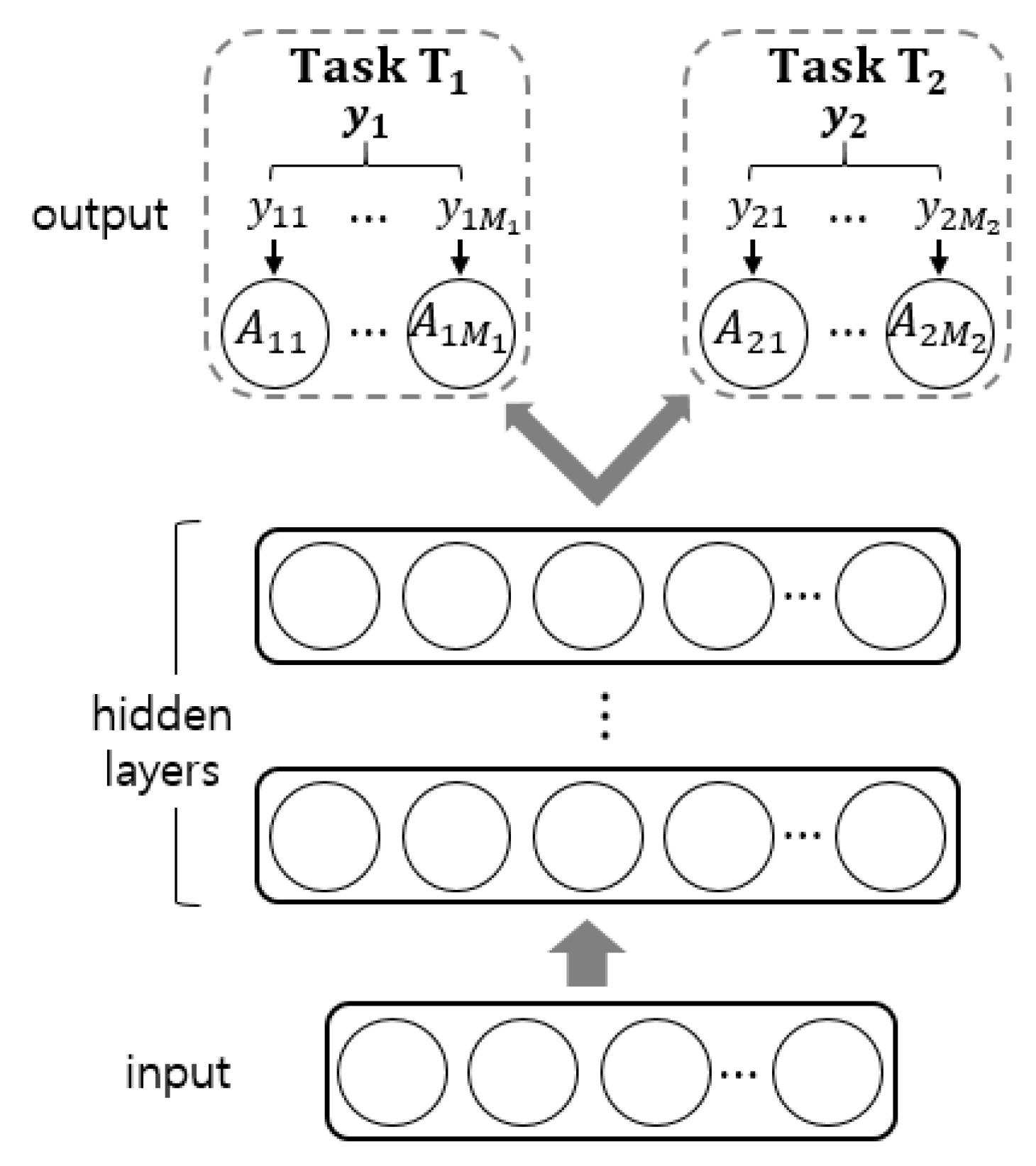
2.2. Multi-Task Learning for Independent Attributes
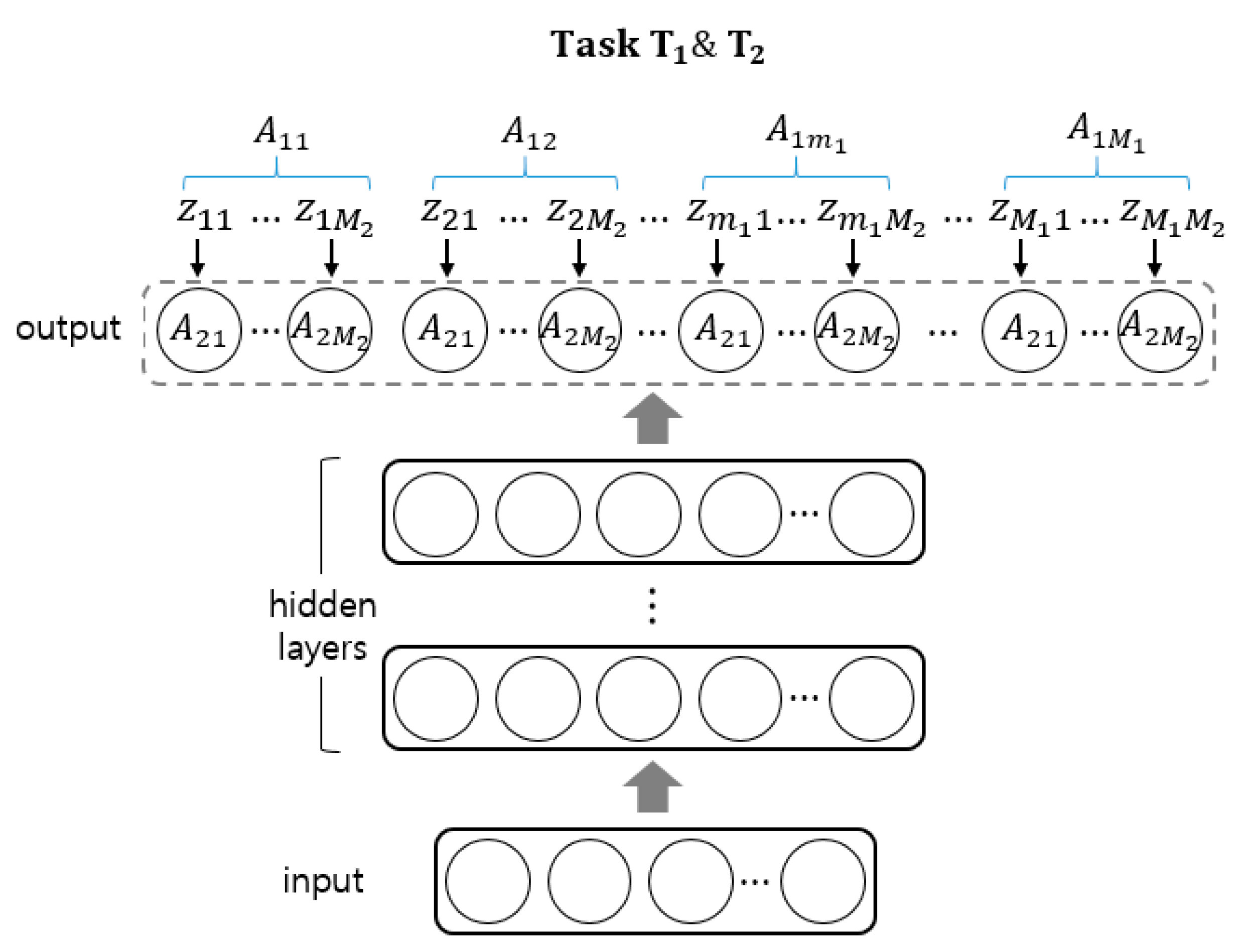
2.3. Multi-Task Learning for Mutually Correlated Attributes
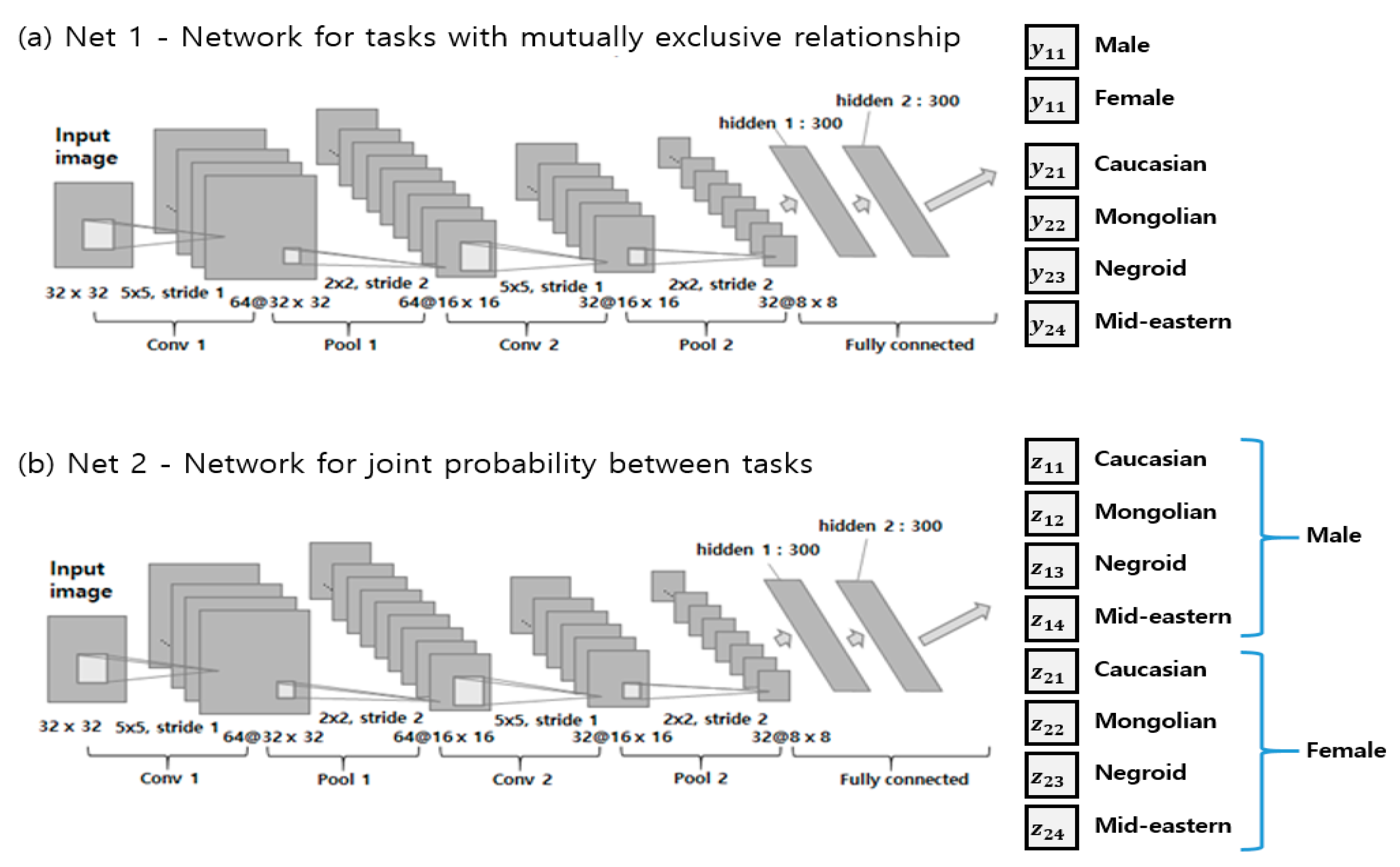
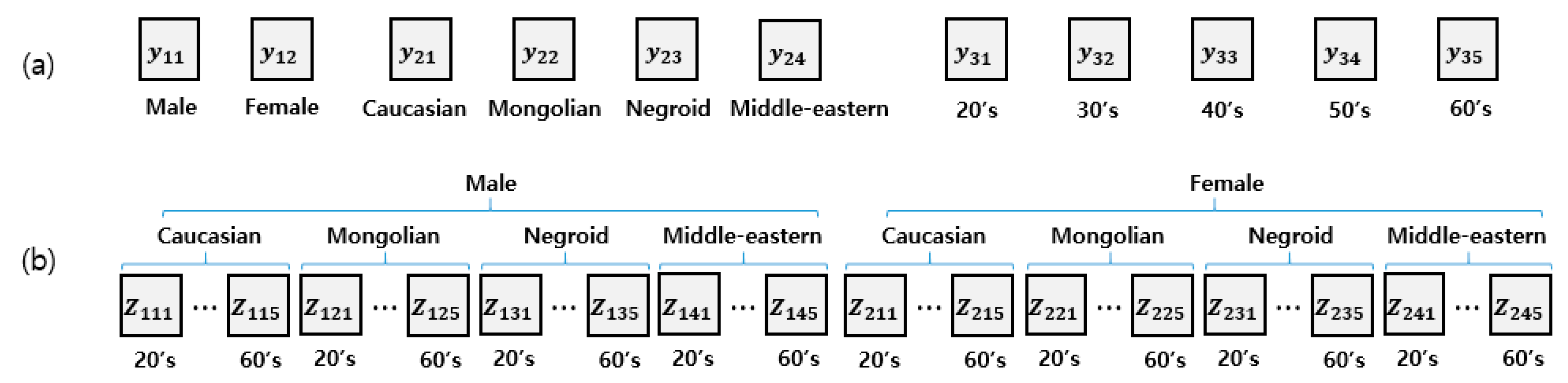
3. Multi-Attribute Recognition of Facial Images
4. Experimental Results
4.1. Multi-Attribute Recognition on the CMU Multi-PIE Dataset
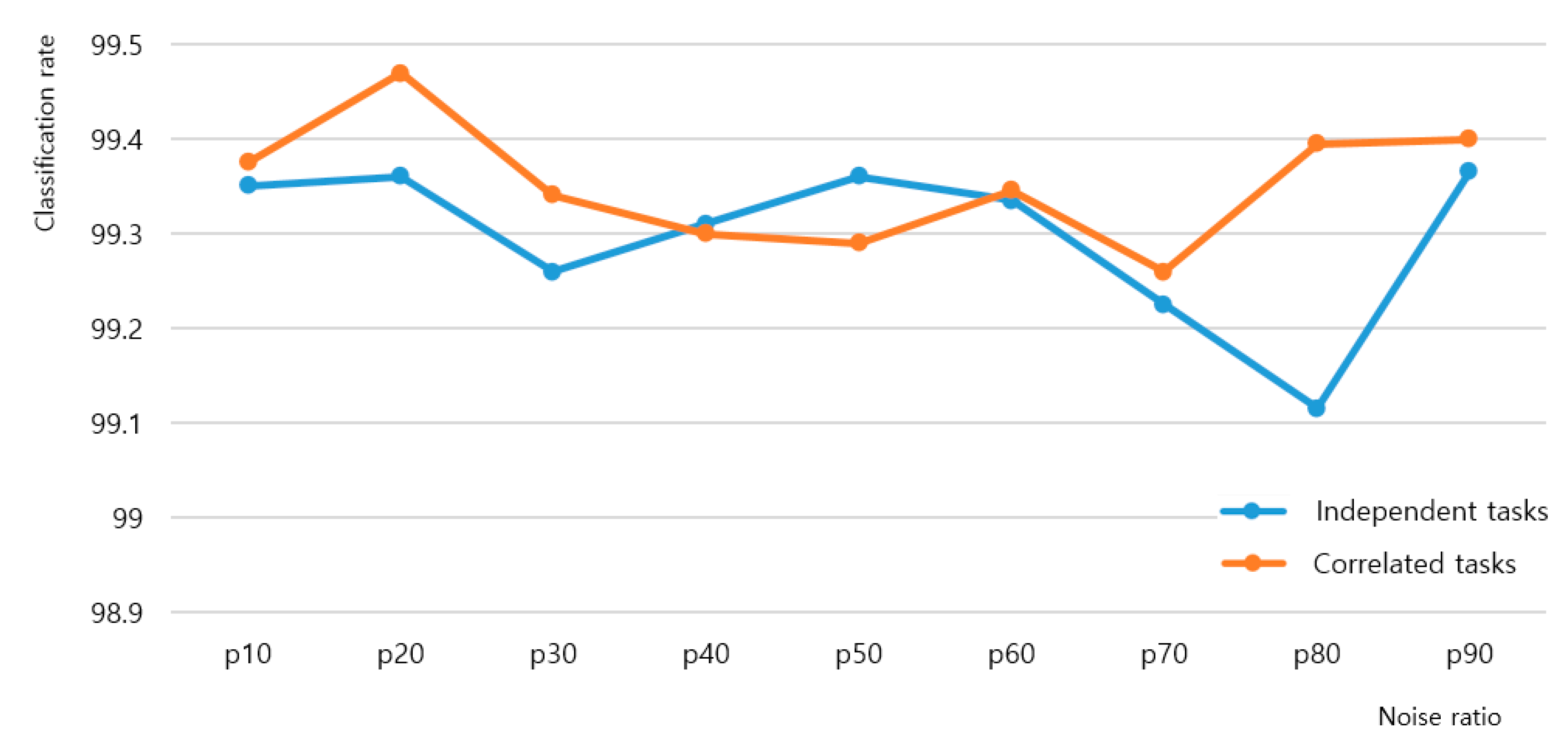
4.2. Analysis of Toy Problem
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, W.; Li, M.; Su, Z.; Zhu, Z. A Deep-Learning Approach to Facial Expression Recognition with Candid Images. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 279–282. [Google Scholar]
- Karthigayani, P.; Sridhar, S. Decision tree based occlusion detection in face recognition and estimation of human age using back propagation neural network. J. Comput. Sci. 2014, 10, 115–127. [Google Scholar] [CrossRef][Green Version]
- Dehshibi, M.M.; Bastanfard, A. A new algorithm for age recognition from facial images. Signal Process. 2010, 90, 2431–2444. [Google Scholar] [CrossRef]
- Ramesha, K.; Raja, K.B.; Venugopal, K.R.; Patnaik, L.M. Feature Extraction based Face Recognition, Gender and Age Classification. IJCSE 2010, 2, 14–23. [Google Scholar]
- Dehghan, A.; Ortiz, E.G.; Shu, G.; Masood, S.Z. DAGER: Deep age, gender and emotion recognition using convolutional neural network. arXiv, 2017; arXiv:1702.04280. [Google Scholar]
- Günther, M.; Rozsa, A.; Boult, T.E. AFFACT:Alignment-free facial attribute classification technique. In Proceedings of the IEEE International Joint Conference on Biometrics, Denver, CO, USA, 1–4 October 2017; pp. 90–99. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Seltzer, M.L.; Droppo, J. Multi-task learning in deep neural networks for improved phoneme recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Vancouver, BC, Canada, 26–31 May 2013; pp. 6965–6969. [Google Scholar]
- Su, C.; Yang, F.; Zhang, S.; Tian, Q.; Davis, L.S.; Gao, W. Multi-task learning with low rank attribute embedding for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 3739–3747. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Zhang, N.; Paluri, M.; Ranzato, M.A.; Darrell, T.; Bourdev, L. Panda: Pose aligned networks for deep attribute modeling. In Proceedings of the IEEE International Conference on Computer Vision and pattern recognition, Washington, DC, USA, 23–28 June 2014; pp. 1637–1644. [Google Scholar]
- Zhong, Y.; Sullivan, J.; Li, H. Face attribute prediction using off-the-shelf cnn features. In Proceedings of the 2016 International Conference on Biometrics, Halmstad, Sweden, 13–16 June 2016; pp. 1–7. [Google Scholar]
- Kang, S.; Lee, D.; Yoo, C.D. Face attribute classification using attribute-aware correlation map and gated convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 4922–4926. [Google Scholar]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar]
- Hand, E.M.; Chellappa, R. Attributes for improved attributes: A multi-task network utilizing implicit and explicit relationships for facial attribute classification. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 4068–4074. [Google Scholar]
- Dunne, R.A.; Campbell, N.A. On the pairing of the softmax activation and cross-entropy penalty functions and the derivation of the softmax activation function. In Proceedings of the 8th Australian Conference on the Neural Networks, Melbourne, Australia, 11–13 June 1997; pp. 181–185. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.F.; Kanade, T.; Baker, S. Multi-PIE. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef] [PubMed]
- Changhun, H.; Hyeyoung, P. Recognition of Facial Attributes Using Multi-Task Learning of Deep Networks. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 284–288. [Google Scholar]
- Kelly, D.J.; Quinn, P.C.; Slater, A.M.; Lee, K.; Gibson, A.; Smith, M.; Ge, L.; Pascalis, O. Three-month-olds, but not newborns, prefer own-race faces. Dev. Sci. 2005, 8, F31–F36. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | Identity | Expression | Gender | Race | Age | |
| Identity | 0.48 | 0.40 | 0.43 | 0.52 | 0.46 | |
| Expression | 9.68 | 11.48 | 10.86 | 10.97 | 10.42 | |
| Gender | 0.16 | 0.61 | 0.77 | 0.33 | 0.24 | |
| Race | 0.27 | 0.67 | 0.48 | 0.78 | 0.34 | |
| Age | 0.46 | 1.30 | 0.67 | 0.73 | 1.12 | |
| (b) | Identity | Expression | Gender | Race | Age | |
| Identity | 0.48 | 0.98 | 0.50 | 0.52 | 0.51 | |
| Expression | 9.29 | 11.48 | 10.88 | 10.94 | 10.50 | |
| Gender | 0.13 | 0.61 | 0.77 | 0.28 | 0.23 | |
| Race | 0.23 | 0.83 | 0.47 | 0.78 | 0.36 | |
| Age | 0.40 | 1.68 | 0.66 | 0.64 | 1.12 |
| Representation Method | Identity | Expression | Gender | Race | Age |
|---|---|---|---|---|---|
| Single task learning | 0.48 | 11.48 | 0.77 | 0.78 | 1.12 |
| G+R+A | - | - | 0.17 | 0.26 | 0.47 |
| G*R*A | - | - | 0.16 | 0.25 | 0.47 |
| E+G+R+A | - | 10.30 | 0.24 | 0.24 | 0.50 |
| E+G*R*A | - | 9.51 | 0.14 | 0.21 | 0.36 |
| E*G*R*A | - | 9.52 | 0.30 | 0.46 | 0.79 |
| I+G+R+A | 0.49 | - | 0.15 | 0.19 | 0.41 |
| I+G*R*A | 0.45 | - | 0.13 | 0.20 | 0.37 |
| I+E+G+R+A | 0.46 | 10.35 | 0.14 | 0.19 | 0.39 |
| I+E+G*R*A | 0.36 | 9.56 | 0.10 | 0.17 | 0.29 |
| I+E*G*R*A | 0.47 | 9.65 | 0.18 | 0.26 | 0.44 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hyun, C.; Seo, J.; Lee, K.E.; Park, H. Multi-Attribute Recognition of Facial Images Considering Exclusive and Correlated Relationship Among Attributes. Appl. Sci. 2019, 9, 2034. https://doi.org/10.3390/app9102034
Hyun C, Seo J, Lee KE, Park H. Multi-Attribute Recognition of Facial Images Considering Exclusive and Correlated Relationship Among Attributes. Applied Sciences. 2019; 9(10):2034. https://doi.org/10.3390/app9102034
Chicago/Turabian StyleHyun, Changhun, Jeongin Seo, Kyeong Eun Lee, and Hyeyoung Park. 2019. "Multi-Attribute Recognition of Facial Images Considering Exclusive and Correlated Relationship Among Attributes" Applied Sciences 9, no. 10: 2034. https://doi.org/10.3390/app9102034
APA StyleHyun, C., Seo, J., Lee, K. E., & Park, H. (2019). Multi-Attribute Recognition of Facial Images Considering Exclusive and Correlated Relationship Among Attributes. Applied Sciences, 9(10), 2034. https://doi.org/10.3390/app9102034