1. Introduction
In big data era, the research paradigms of marketing service have been greatly changed by the enormous marketing data accumulated from the internet, such as on demographics, user behavior (we will henceforth use the word “user”, “customer”, and “consumer” interchangeably), and social relationships. These fine-grained marketing data are informative, thus providing marketers with extra opportunities to evaluate users’ preferences [
1], predicting the next product users will buy [
2,
3], delivering targeted advertisements [
4,
5], uncovering consumer perceptions of brand [
6], and acquiring competitive intelligence [
7]. In particular, psychological aspects of user behavior, critical for understanding rather than merely predicting consumer preference, ultimately contribute to intelligent decision-making in marketing. Unfortunately, investigations of how big data helps inform has, thus far, only received scant attention [
8].
Studies have demonstrated that psychological variables, such as value and personality, are the main theories and tools for user psychographic segmentation, which is an important determinant of user purchase behaviors and preferences [
9,
10]. In particular, personality traits, one of the psychographic segmentation components, has been the main consumer psychological and marketing characteristic used in e-commerce. Unfortunately, the predictive and explanatory power of personality traits for online user behavior remains controversial [
11]. This controversy motivates the investigation of other types of psychographic segmentation, such as value, in understanding user preferences, which have not been investigated. Furthermore, it is unclear whether the predictive and explanatory power varies between product categories and between different segment-wise preference prediction methods. The main reason is that collecting psychographic segmentation data from e-commerce users is difficult on a large scale, typically requiring consumers to complete lengthy questionnaires.
Psychological variables, such as personality and value, are deeply embedded in the language that people use today [
12]. With massive user data in the form of natural language, natural language data provides a clearer picture of people’s cognitive and behavioral processes than data collected from traditional and widely used self-report surveys [
13,
14,
15]. Practically, natural language processing (NLP) techniques can be applied to identifying psychographic variables, such as e-commerce users’ online word use, to understand and predict users’ purchase behaviors and preferences on a large scale.
E-commerce websites, in particular, have accumulated a large amount of user-generated content (UGC), which provides the basis for observing users’ psychographics and predicting user preferences directly. With the rapid development of techniques such as big data, artificial intelligence, and computational linguistics, UGC provides a reliable path for automatically identifying consumer psychographics, including personality and values, based on unstructured data. Inspired by recent advances in big data-driven psycholinguistic research, which indicate the behavioral evidence of online word use related to psychographics [
16,
17], we base our research on real-world Amazon consumer review and rating data. We propose psychographics-related word use evidence, extract consumers’ psychographic characteristics using sentiment analysis methods, and introduce a deep neural network (DNN) to predict and explain user preferences in e-commerce.
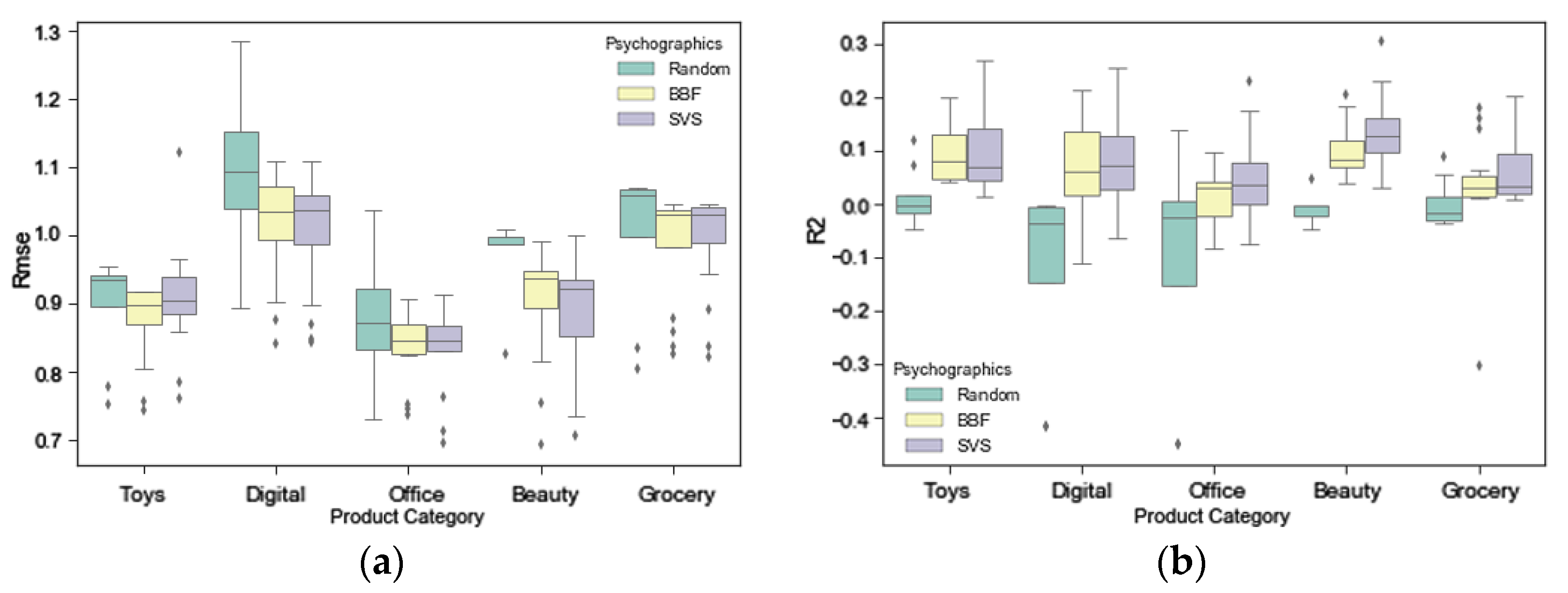
We found that, overall, psychographic variables significantly improved the explanatory power of e-consumer preferences across most product categories we studied, whereas the improvement in predictive power was not significant. Specifically, the Schwartz Value Survey (SVS) tended to outperform Big Five Factor (BFF) segmentation in predicting and explaining user preferences, with the exception of a few product categories. However, somewhat surprisingly, dividing e-consumers into heterogeneous groups using a clustering method did not significantly improve the predictive and explanatory power of online consumer preferences compared to handling consumers as a whole. Furthermore, the DNN method that we proposed demonstrated the best performance in understanding e-consumer preferences, and regarding product category, there were more significant differences for psychographic segmentation in predicting, than explaining, e-consumer preferences. Additionally, we recommend an e-commerce-oriented SVS measurement and segmentation approach that integrates both BFF and the SVS.
Our work extends the depth and breadth of psychographic theories through user preference prediction in e-commerce scenarios. Specifically, we found that subdimensions of psychographic variables and product types provide practical references for psychographic measurement development and applications for the specific e-commerce product categories that we studied. By introducing psychographic-related word use behavioral evidence, followed by big data approaches, we have attempted to overcome the difficulties of obtaining e-consumer psychographics on a large scale, and have provided a promising psychographic-based consumer preference prediction method for subsequent research.
4. Experiment
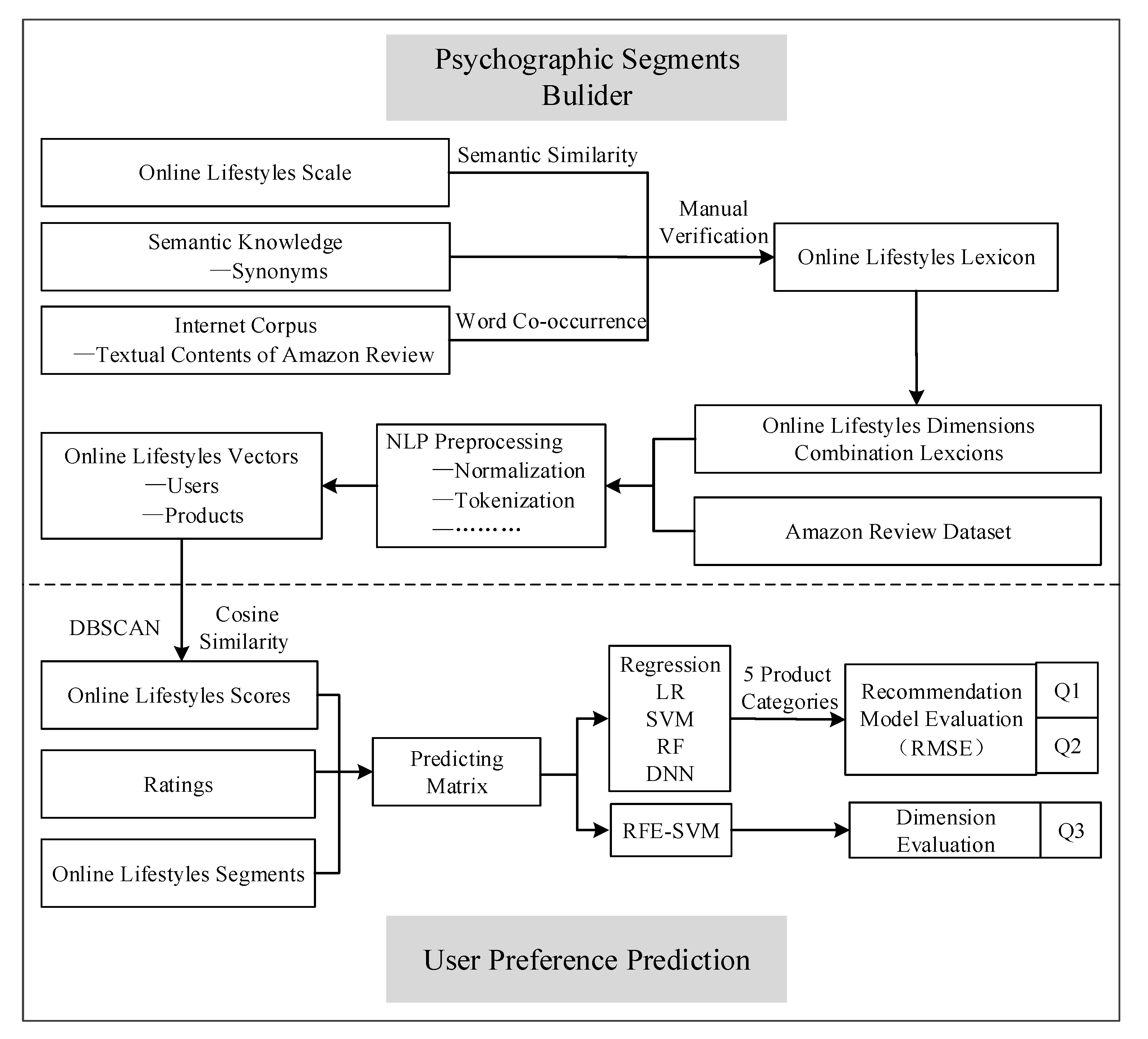
In the previous section, we have constructed the positive and negative e-commerce psychographic lexicons, namely SVS-pos, SVS-neg and BFF-pos, BFF-neg lexicons (see S1.csv, S2.csv, S3.csv and S4.csv respectively in
supplementary materials for more details), and conducted e-commerce consumer segmentation based on the identified SVS and BFF scores and DBSCAN. In this section, we further proposed a DNN method to build the segment-wise consumer rating regression model. Then, we proceeded to utilize the online shopping data in Amazon to conduct our experiments.
4.1. Dataset Description
Amazon is one of the largest e-commerce platforms in the world and has accumulated a large amount of user buying behavior data. The Amazon review dataset, published by McAuley et al. [
64], contains product reviews and metadata from Amazon.com, including 142.8 million reviews spanning from May 1996 to July 2014. We selected 5 review datasets from 5 product categories according to “K-core” values of “10”, whereby each of the remaining users or items have at least 10 reviews. According to the work by Arnoux et al. (2017) [
73], we consider that 10 reviews (whereby the average length of review is 189 words) is capable for consumer/product psychographic inference and comparable to 25 tweets.
Table 3 shows the detailed dataset description.
The sample review shows details about our data:
{
“reviewerID ‘: ’A2SUAM1J3GNN3B”,
“asin‘: ’0000013714”,
“reviewerName‘: ’J. McDonald”,
“reviewText‘: ’I bought this for my husband who plays the piano. He is having a wonderful time playing these old hymns. The music is at times hard to read because we think the book was published for singing from more than playing from. Great purchase though!”,
“overall”: 5.0,
“summary‘: ’Heavenly Highway Hymns”,
“unixReviewTime”: 1252800000,
“reviewTime‘: ’09 13, 2009”
}
4.2. Experimental Procedure
The data processing process is divided into the following steps.
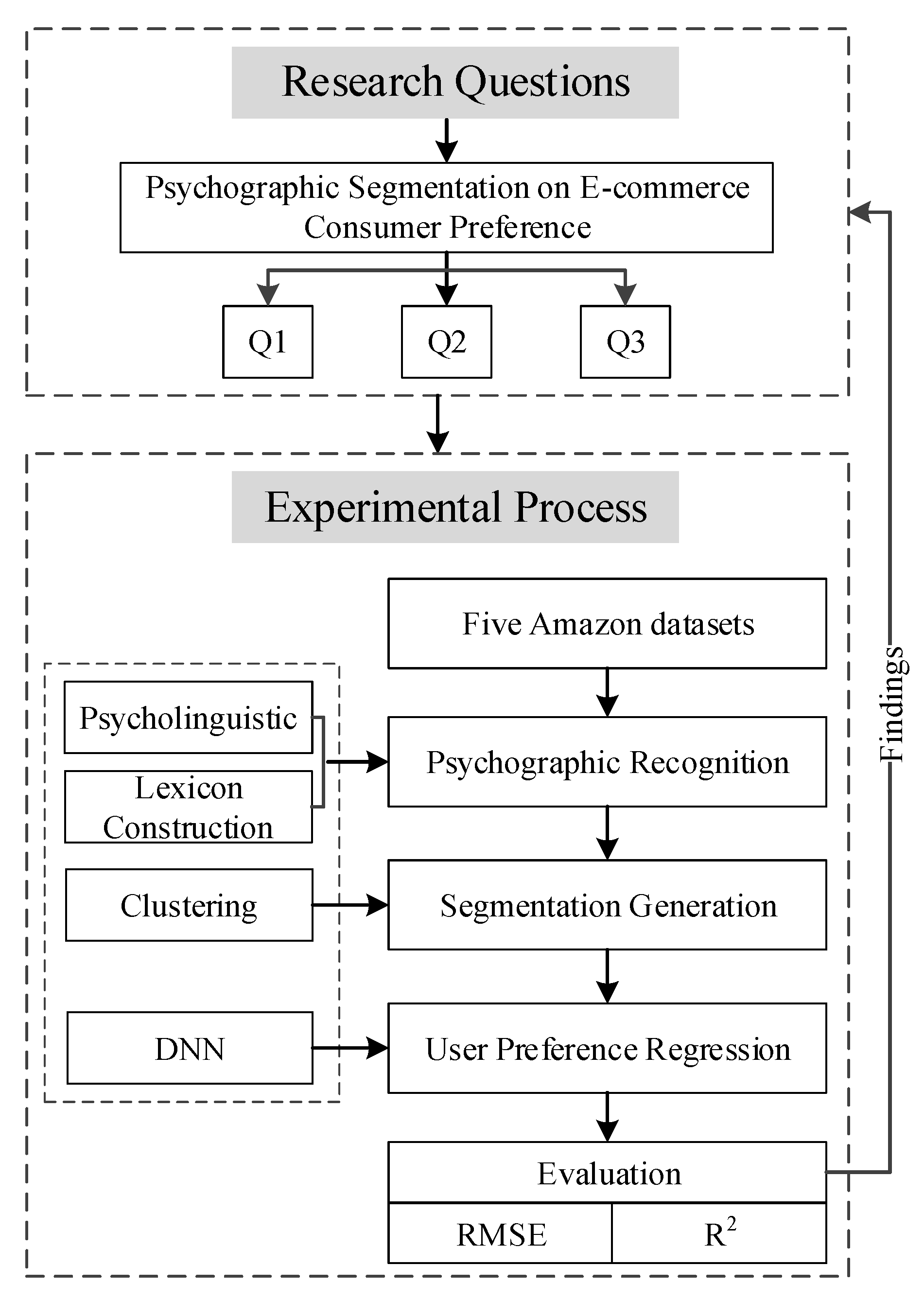
Figure 3 shows the whole picture of our experiment process across
Section 3 and
Section 4.
First of all, we keep the “reviewerID”, “asin”, “overall”, “reviewText”, and “summary” tags in the seven datasets above and combined “reviewText” and “summary” as the word use behaviors in recognized online psychographics.
Second, we conduct text preprocessing, including normalization, tokenization, removing stop words, and stemming on the textual contents using Amazon reviews and lexicons by Python, machine learning tool Scikit-learn (
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html) and the Natural Language Toolkit (NLTK) [
74]. Normalization is a process that converts a list of words to a more uniform sequence. Given a character sequence and a defined document unit, tokenization is the task of chopping it up into pieces, called tokens. Some extremely common words in reviews, which would be of little value in helping select texts matching our need, are excluded from the vocabulary entirely. These words are called stop words. The goal of stemming is to reduce inflectional forms, and sometimes derivationally related forms of a word, to a common base form. We perform stemming by Lancaster Stemmer in NLTK on both words in lexicon and reviews. We removed stop words using the English stop word list in NLTK, obtained the of words in lowercase using the text lower method in Python, and conducted Z-score normalization using scale method in Scikit-learn. Based on the SVS-pos, SVS-neg, BFF-pos, and BFF-neg lexicons in
Section 3.1, and all the data preprocessing steps above, we calculate the psychographic scores by matching the used words and the words in these lexicons. Thus, we get the SVS and BFF scores for each Amazon consumer and product.
Third, for each of the product categories, we perform the DBSCAN algorithm in the consumers’ SVS or BFF scores, using Scikit-learn, to get the consumers’ positive and negative psychographic scores and attached psychographic segment tags. We then build the rating predicting dataset which combines psychographic scores (as independent variables) with the rating given by the consumer to the product (as a dependent variable). We also construct feature sets for each product category which contains random values between 0 and 1 as the control group. For each of these datasets, we optimize the parameters for DNN by gradient descent. The optimal number of epochs (a single pass through the full training set) used for the neural network algorithm is decided by the performance on the validation set. For SVM, we use the validation set for optimizing the cost parameter C. We use Scikit-learn (
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html) implementation of linear regression (LR), SVM with a radial basis function kernel, random forest, and Keras implementation of Google TensorFlow software (
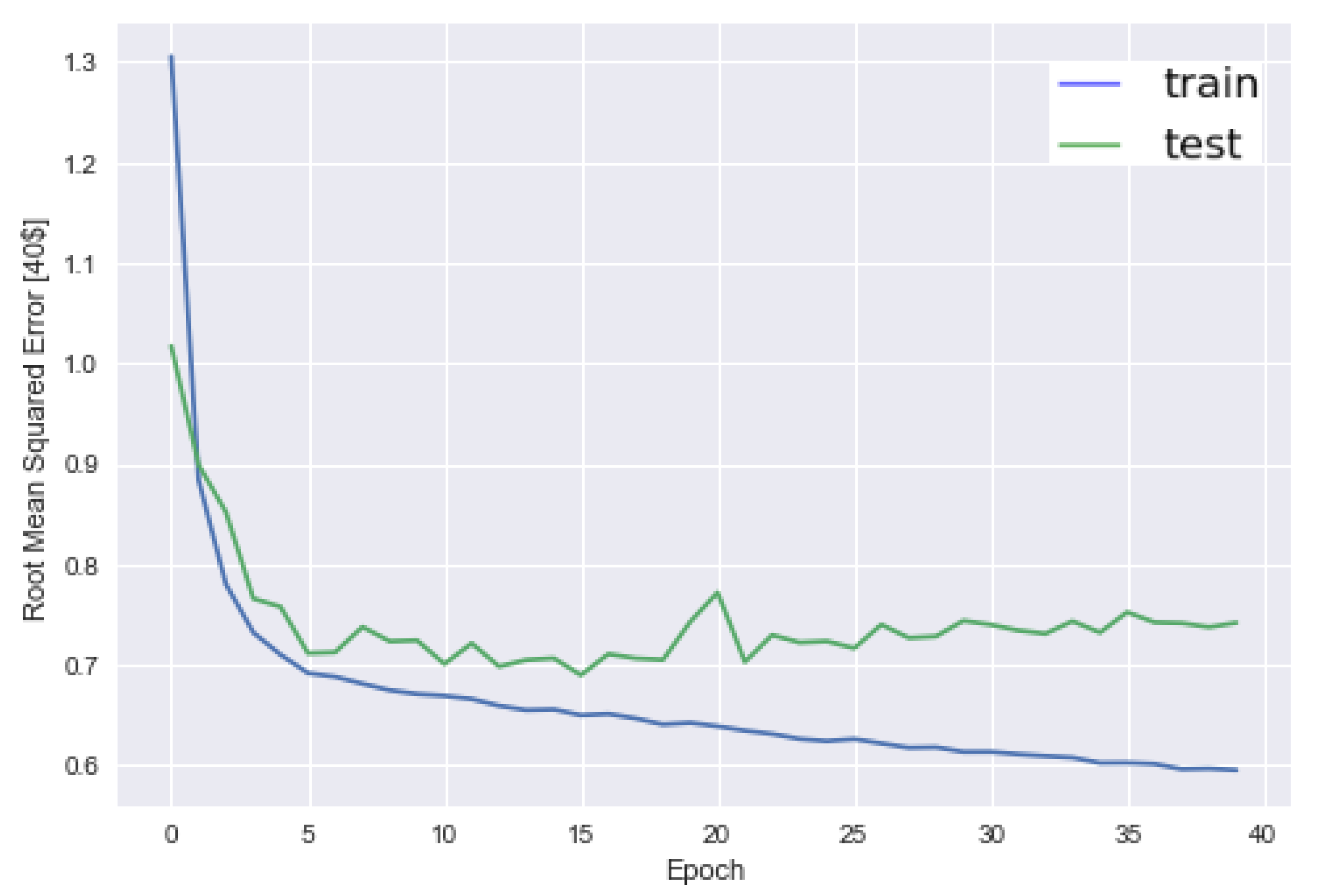
https://www.tensorflow.org) for developing DNN and baseline. A 5-fold cross-validation is applied to select training and test datasets for each fold and avoid overfitting for linear regression, SVM, RF, and DNN. An example of RMSE evolution with epochs for DNN is shown in
Figure 4. In
Figure 4, we can see that the best epoch is around 15.
Fourth, we apply feature ranking with a recursive feature elimination method to investigate the feature importance of different psychographic subdimensions in understanding consumer online preference. The support vector machine-based recursive feature elimination (RFE-SVM) approach is a popular technique for feature selection and subsequent regression task, especially in predicting consumer preference [
75]. At each iteration, a linear SVM is trained, followed by removing one or more “bad” features from further consideration. The quality of the features is determined by the absolute value of the corresponding weights used in the SVM. The features remaining after a number of iterations are deemed to be the most useful for discrimination and can be used to provide insights into the given data [
76]. By introducing the RFE-SVM in segment-wise consumer rating prediction, we can dive into the subdimensions of SVS and BFF to explore whether these dimensions are effective in predicting and explaining preferences.
Finally, we perform an online consumer preference-predicting experiment that contains 5 product categories * 4 predictive algorithms (LR, SVM, RM, NN) * 3 psychographic variables tools (Random, SVS, and BFF) * 2 clustering method (clustering consumers based on DBSCAN or not).
6. Discussion
In this study, we have focused on the promising role that different psychographic segmentations play in the understanding of e-commerce consumer preferences. Based on real-world user behavior data from Amazon, we have introduced psychographic-related behavioral evidence from psycholinguistics and applied NLP, clustering, and DNN methods to identify users’ psychographic segments and to further predict their preferences.
We summarize our results as follows. First, we have found that dividing e-consumers into heterogeneous groups using a clustering method did not significantly improve the predictive and explanatory power of e-commerce consumer preferences. By contrast, psychographic variables significantly improved the explanatory power of e-consumer preferences, whereas the improvement in predictive power was not significant. This finding is consistent with past studies [
11,
42] which showed that individual segments based on their psychographic measures do not seem to provide a great deal of predictive power in the context of buying behavior.
Second, we have found that both value and personality segmentations significantly improve user preference explanation under different e-commerce scenarios, whereas no significant improvement was shown in user preference prediction. These findings have verified previous research that psychographic variables do not seem to provide substantial predictive power in the context of offline buying behavior [
11]. However, these findings somehow contradict works suggesting that customer segmentation based on these variables may be easy to understand, but may not provide the best possible explanatory power [
42,
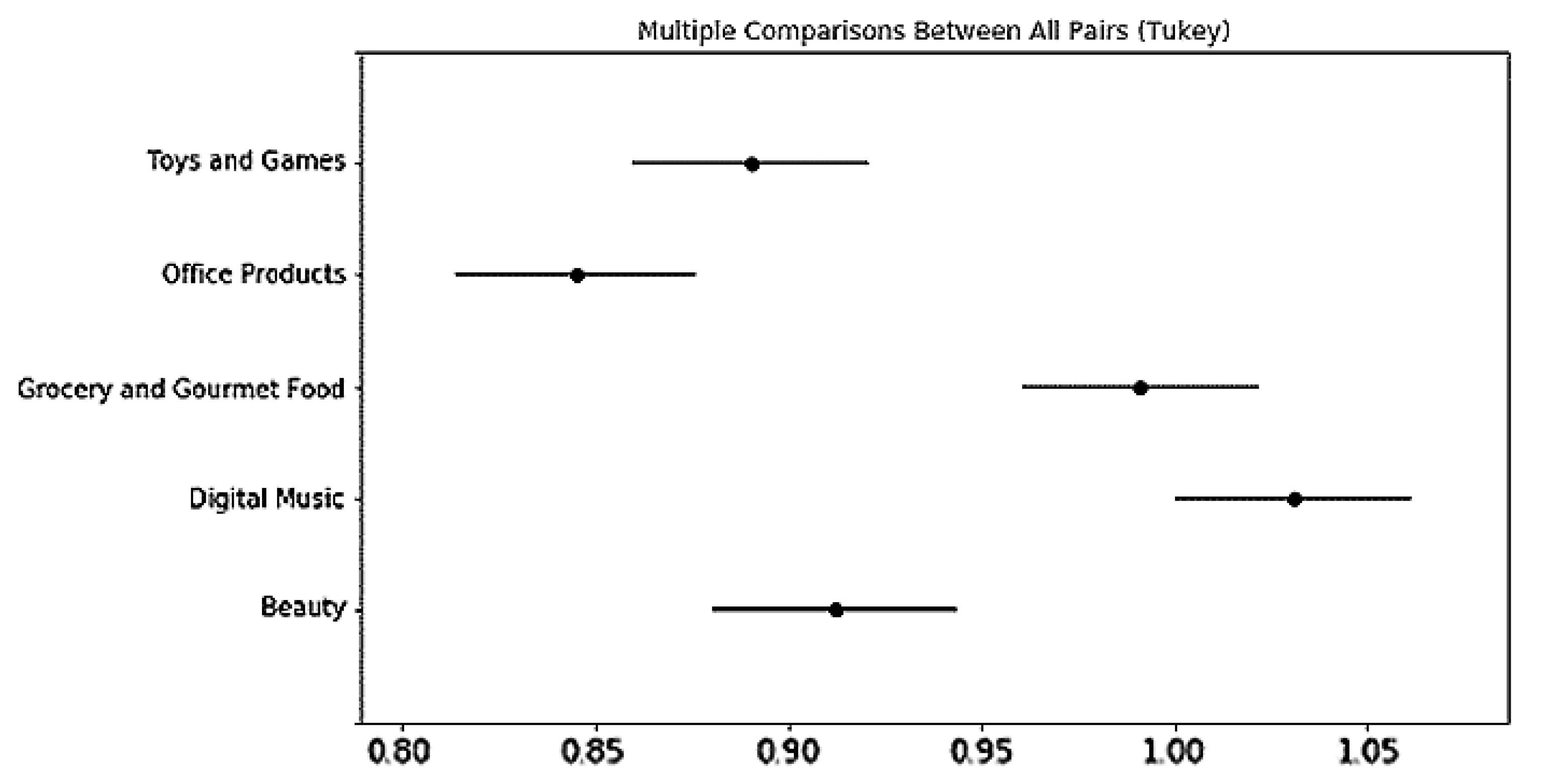
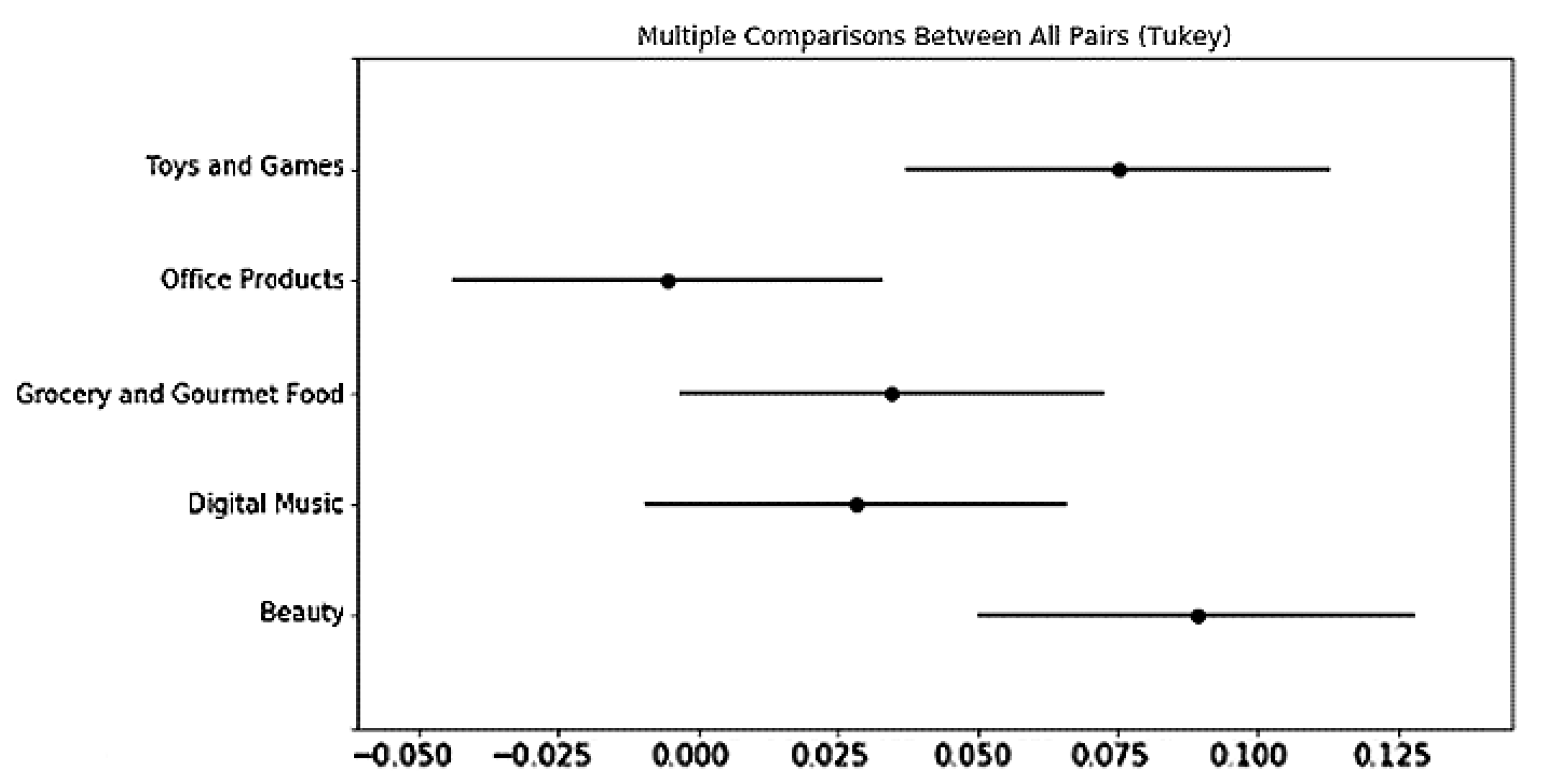
58]. These findings show that psychographic variables may play a more important role in understanding shopping behaviors in online, rather than offline, shopping scenarios. Additionally, although there is no significant difference between the SVS and BFF across all product categories, both the SVS and BFF tend to predict e-consumer preferences better across most of the product categories that we have studied, and the SVS seems to outperform BFF in all the product categories that we have studied, except Toys and Games. Values that characterize human motivation may be a better psychographic variable compared with personality, which emphasizes individual differences.
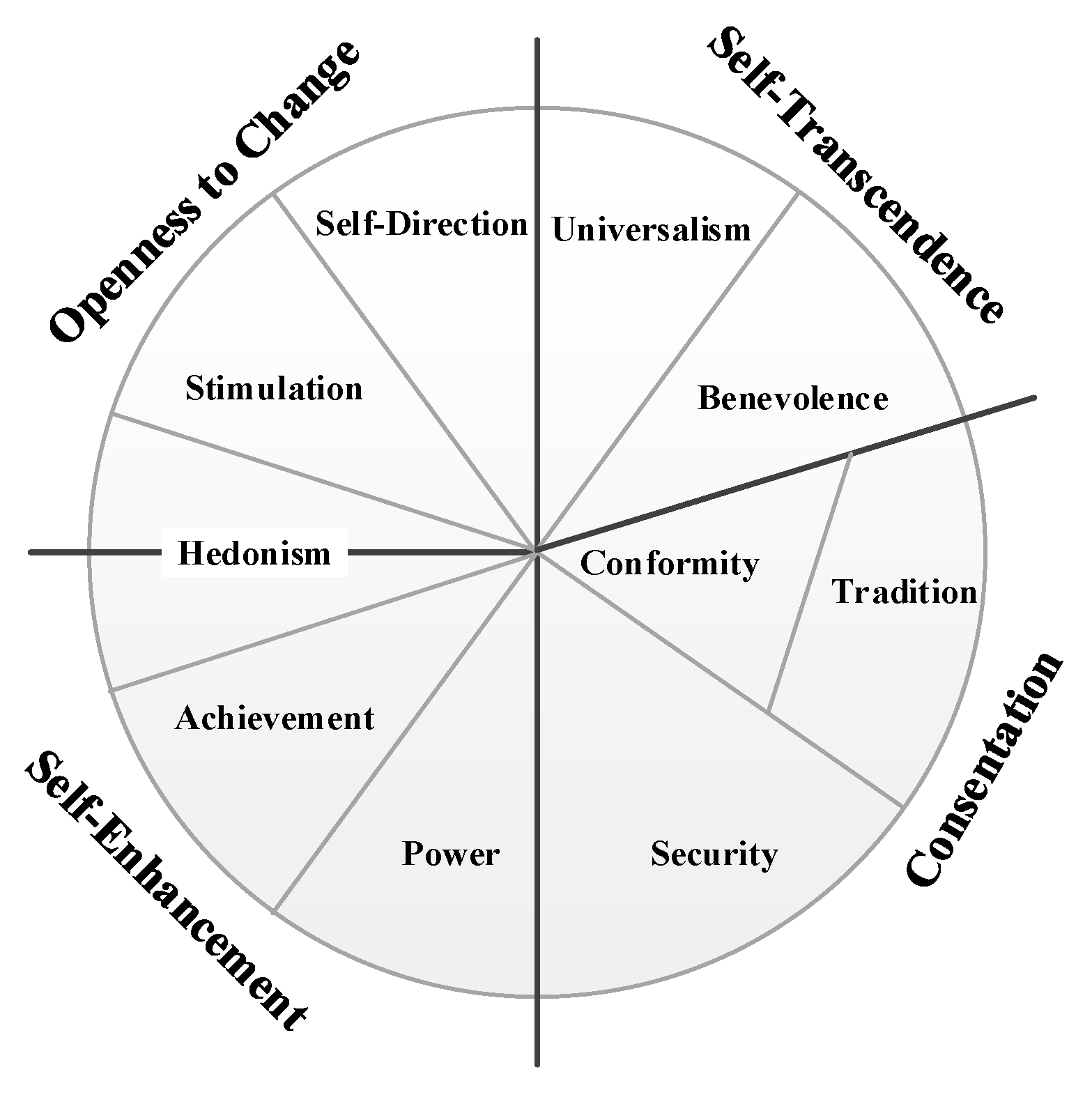
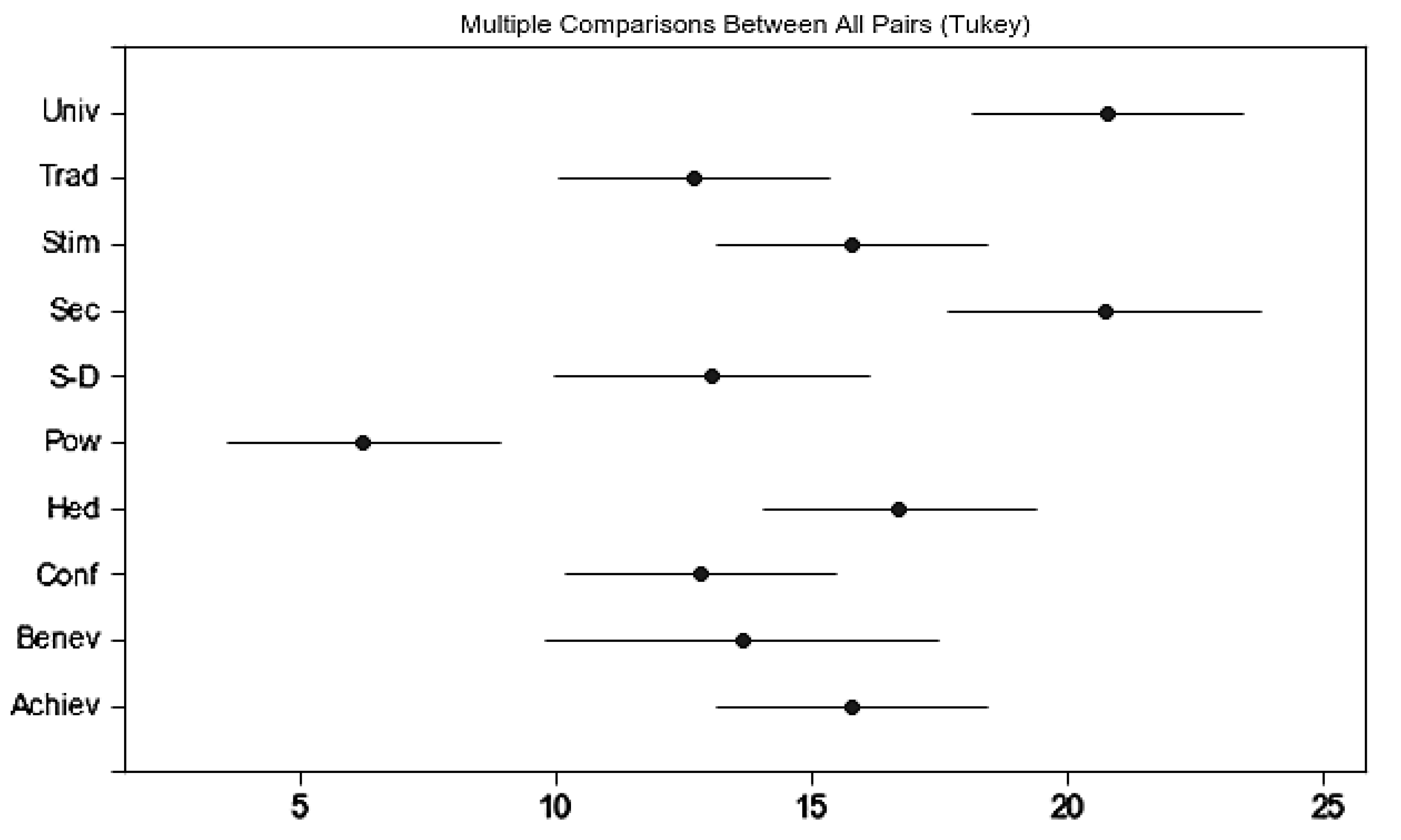
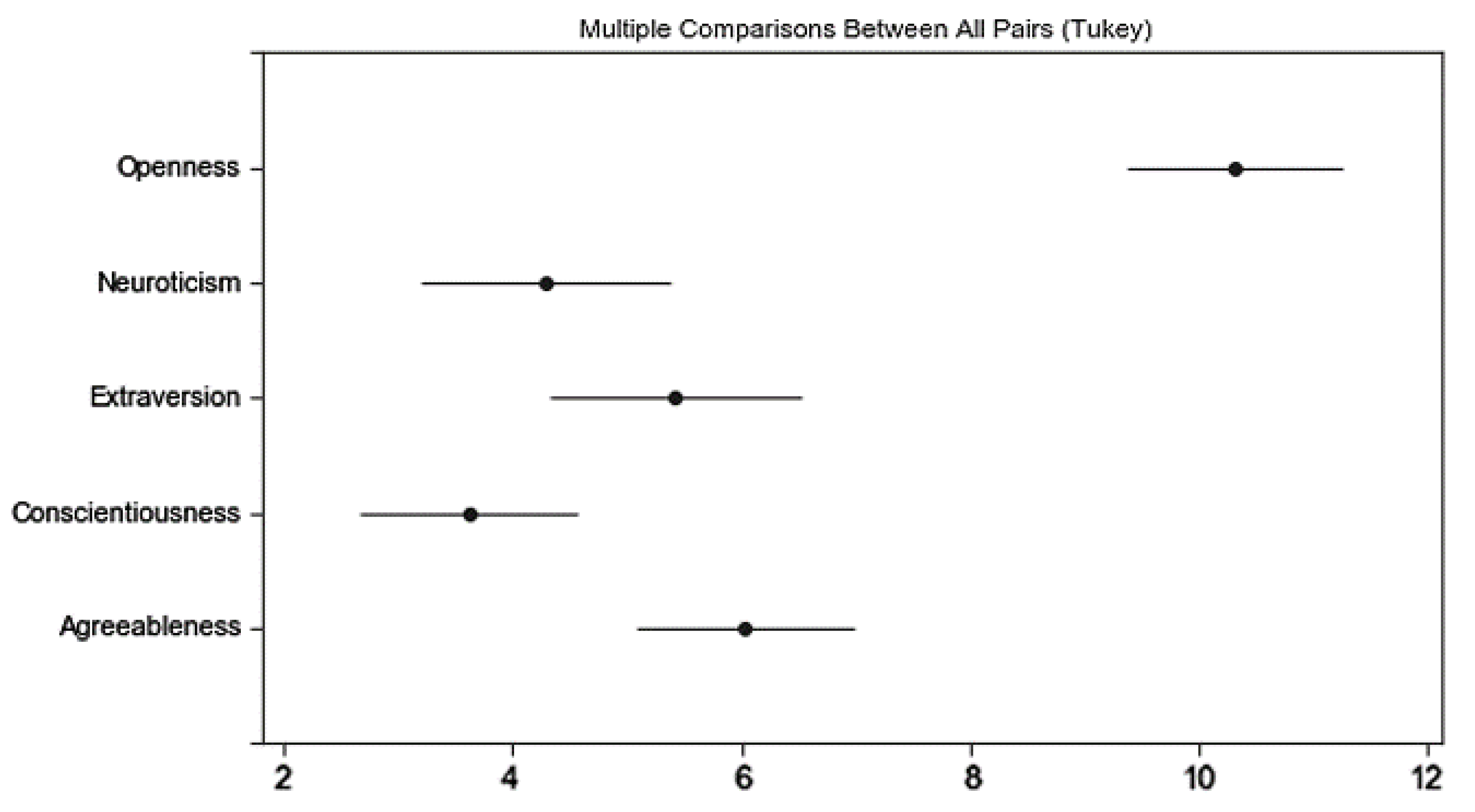
Third, we have found that only 18.5% of the subdimension combinations within a psychographic tool have stable effectiveness in understanding e-commerce preferences related to a specific product category. However, all BFF subdimensions are important in understanding e-consumer preferences, whereas the security and benevolence of the SVS do not demonstrate their effectiveness. We have found that using more subdimensions does not significantly improve the predictive and explanatory power within different product categories. Although the SVS is capable of explaining e-consumer preferences, our work indicates that there may be some subdimensions of the SVS that are able to perform better in understanding e-consumer preferences. This finding is consistent with Schwartz’s argument that it is reasonable to partition the value items into more or less fine-tuned distinct values according to the needs and objectives of the analysis [
27].
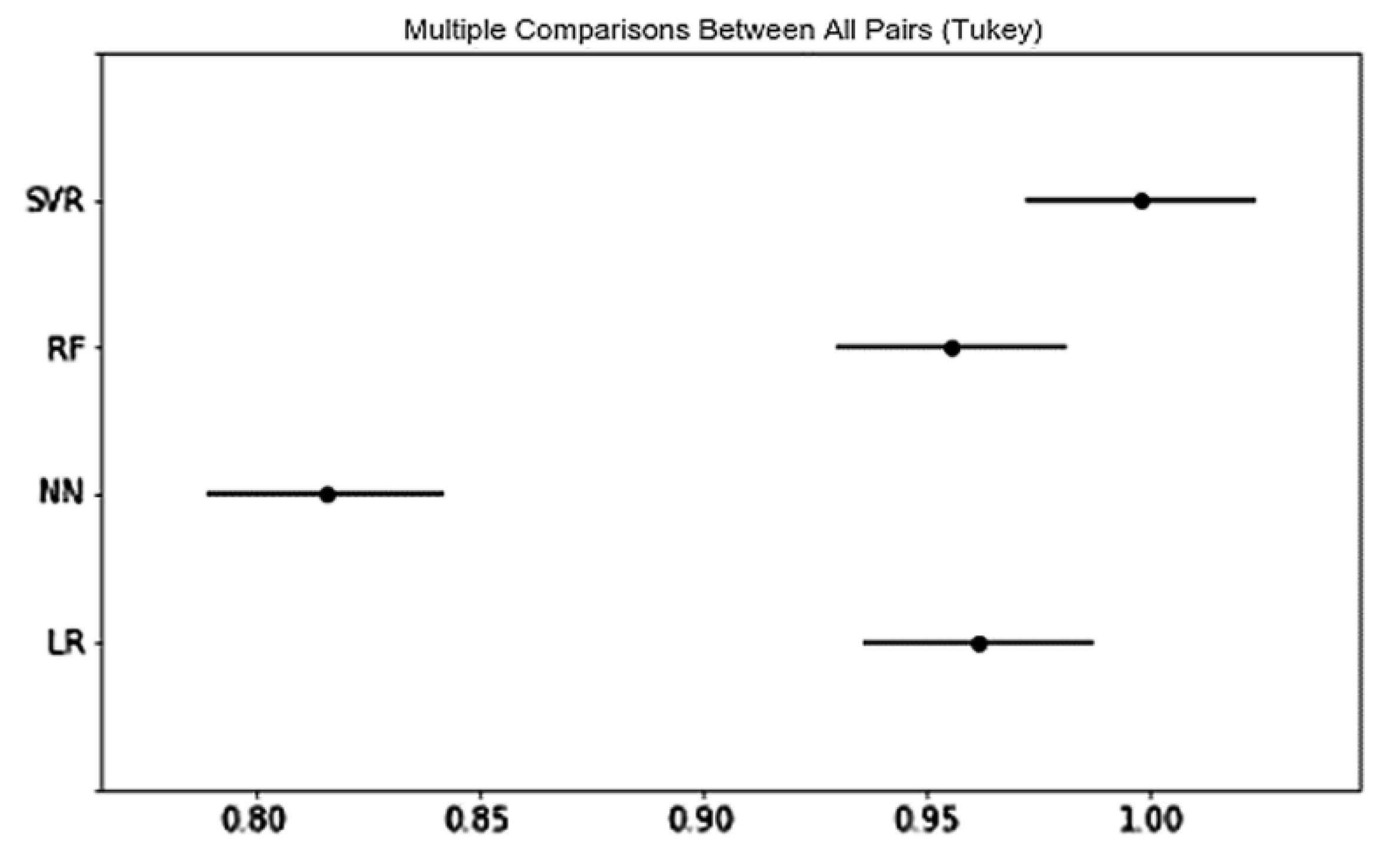
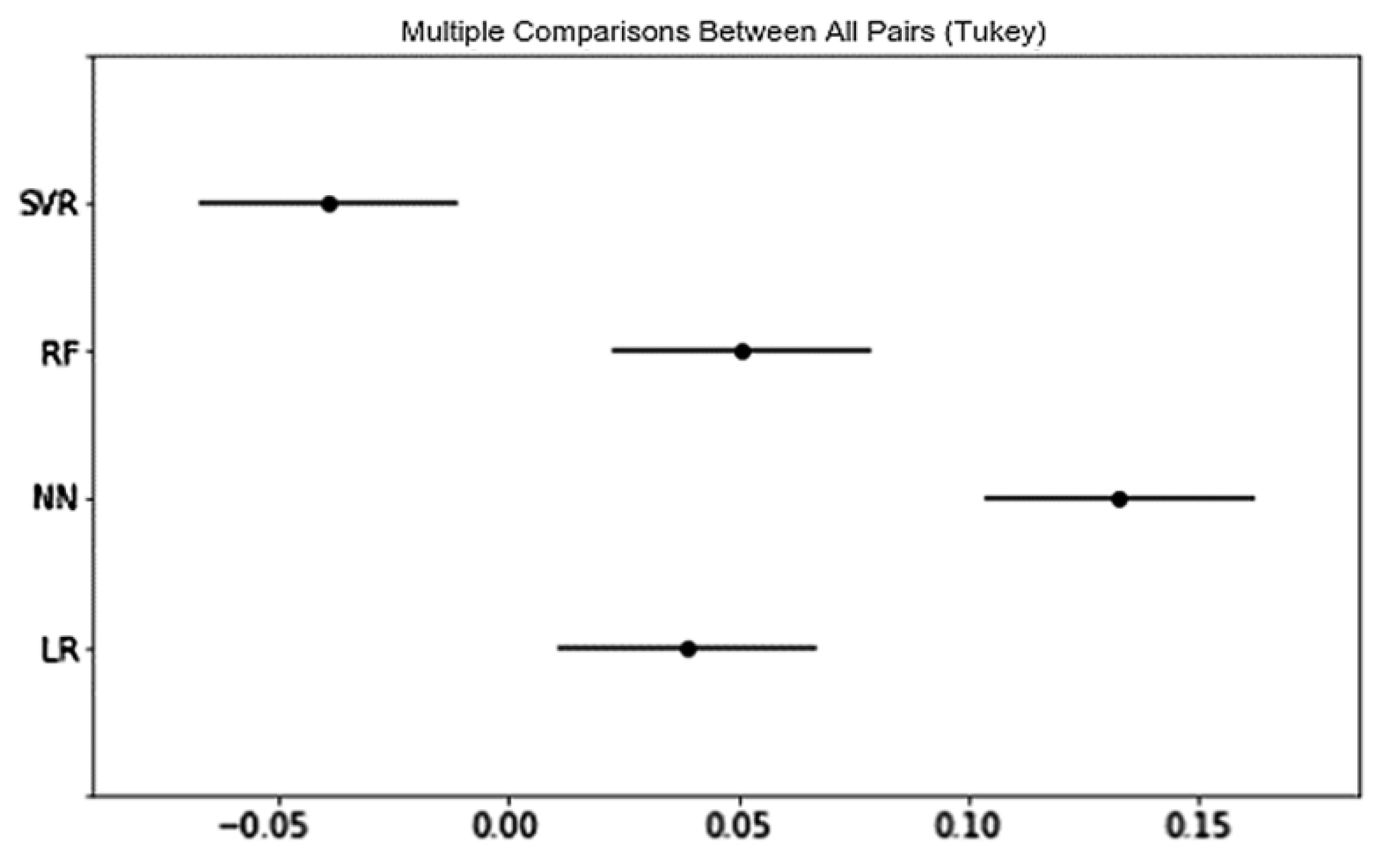
Finally, the DNN method that we have proposed obtained the best predictive and explanatory power in understanding e-consumer preferences; it is significantly better than RF and SVM that were applied in previous research. Regarding product categories, there are more significant differences for psychographic variables in predicting than explaining e-consumer preferences. Moreover, the role of psychographic variables in predicting and explaining e-consumer preferences typically does not demonstrate consistency in different product categories: psychographic variables demonstrates the best predictive power in Office Products and the least explanatory power in Office Products. In most cases, prediction models are likely to possess some level of both explanatory and predictive power [
77]. We can, therefore, visualize performances of different models in terms of a trade-off between explanatory and predictive power on a two-dimensional plot, where the two axes indicate prediction accuracy and explanatory power, respectively. We leave such visualization for future work. As the influence of psychographic variables on user preferences is moderated by product category, our findings indicate a more complicated relationship between them.
This study has extended the depth and breadth of psychographic-related studies through user preference prediction in real-world e-commerce scenarios. Our findings regarding psychographic segmentation and segment-wise preference prediction have provided theoretical guidance for psychographic variable adoption, selection, and use in electronic marketing researches like online advertising, retail, and recommendation. Practically, our findings regarding subdimensions of psychographic variables have provided a practical reference for psychographic measurement development in each e-commerce product category that we have studied. Additionally, the influence of product category on psychographic-based preference prediction and explanation indicates promising e-commerce product research directions and applications. By introducing psychographic-related word use behavioral evidence, followed by natural language processing and DNN techniques, we have attempted to overcome the difficulties of observing e-consumer psychographics on a large scale, and have provided a promising psychographic-based consumer preference prediction method for subsequent research and applications.
However, our study has some limitations. First, we have only applied the review dataset with “K-core” values of 10, whereas there are a huge number of consumers who have either a limited number of reviews or words in their reviews, potentially causing bias in the psychographic inference. Second, the original dataset does not provide demographic information and we have not evaluated the difference between the psychographic scores and the scores assessed by self-report, which may have caused biases in our research results. Third, in addition to psychographic-related single words, there may be other linguistic clues embedded in phrases, sentences, and paragraphs that we have not taken into consideration. Fourth, although our research has demonstrated the significant explanatory power of psychographic tools in understanding e-consumer preferences, no significant predictive power or difference was found. Psychographic variables such as AIO, VALS, and LOV, or their combinations, should be taken into consideration in fully assessing the influence of psychographics on the understanding of e-consumer preferences.
In future studies, we will improve the consumer diversity of Amazon data to verify our findings. Promising future research directions include: evaluating the current psychographic inference method; developing a new psychographic variable identification method by introducing more advanced DNN models and textual features like SVS-related themes [
16] and word embeddings [
78]; verifying and comparing word use behaviors (K-core); combining different psychographic variables, together with other well-known segmentation approaches (e.g., demographic segmentation, behavioral segmentation, geographic segmentation, etc.) to further understand their influence in predicting and understanding e-consumer preferences.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}