
Smart Contract Security in Decentralized Finance: Enhancing Vulnerability Detection with Reinforcement Learning

 ,
,  , and
, and
Abstract
1. Introduction
- We designed and implemented a reinforcement learning architecture for detecting and classifying smart contract vulnerabilities and showed its viability through a comparison analysis.
- Based on the characteristics of smart contract bytecode, we proposed CFGs, a graph-base method for input representations to capture richer semantic information within the bytecode.
- We proposed a machine learning approach for improving blockchain security and future reinforcement learning applications.
2. Related Works
- The complexity of smart contract structures and functionalities is increasing. As the variety of vulnerabilities in smart contracts continues to grow, expert-defined rules based on existing vulnerability definitions struggle to keep pace with these updates.
- Smart contracts may demonstrate varied behaviors at runtime depending on different conditions, complicating the process of vulnerability verification and rendering the analysis highly resource- and time-consuming due to their dynamic and conditional nature.
3. Materials and Methods
3.1. Data
- Access control: This vulnerability occurs when smart contracts inadequately enforce permission controls, enabling attackers to perform unauthorized actions. It contains several subclasses. (1) Suicidal: This refers to contracts that include functions capable of terminating the contract and transferring its funds; (2) Arbitrary send: Code loophole leading to Ether loss when the contract sends Ether to arbitrary addresses; (3) tx.origin: Relying on ‘tx.origin’ for authentication can be risky as it may enable attacks where a malicious contract can impersonate the original sender; (4) Controlled delegatecall: Security issues may arise when a contract improperly uses the delegatecall() function.
- Arithmetic: This class is related to integer underflow and overflow errors as well as divide-before-multiply errors where division is performed before multiplication.
- Reentrancy: A security issue occurs when a contract allows an external call to another contract before it resolves the initial call, potentially allowing an attacker to drain funds or exploit the contract’s state. This type of vulnerability can be further subclassified as Reentrancy-no-eth where attacks do not involve Ether and Reenthrancy-eth where attacks involve Ether transfers.
- Unchecked calls: This class refers to a security issue that arises when a contract makes an external call to another contract or address without properly checking the success of that call. It includes three main types, which are Unused-return, Unchecked-low level and Unchecked-transfer calls.
- Other vulnerabilities: (1) Uninitialized storage: Storage pointers that are not initialized can redirect data to unexpected storage slots; (2) Mapping deletion: The belief that deleting a mapping deletes its contents; (3) Time dependency: a smart contract depends on the block timestamp or block number where time-related values can be influenced or predicted to some extent by miners, leading to potential manipulation; (4) Constant function state: Functions marked as constant/view that can modify state lead to unexpected behaviors; (5) Array-by-reference: Passing arrays by reference can lead to unexpected side effects if they are modified.
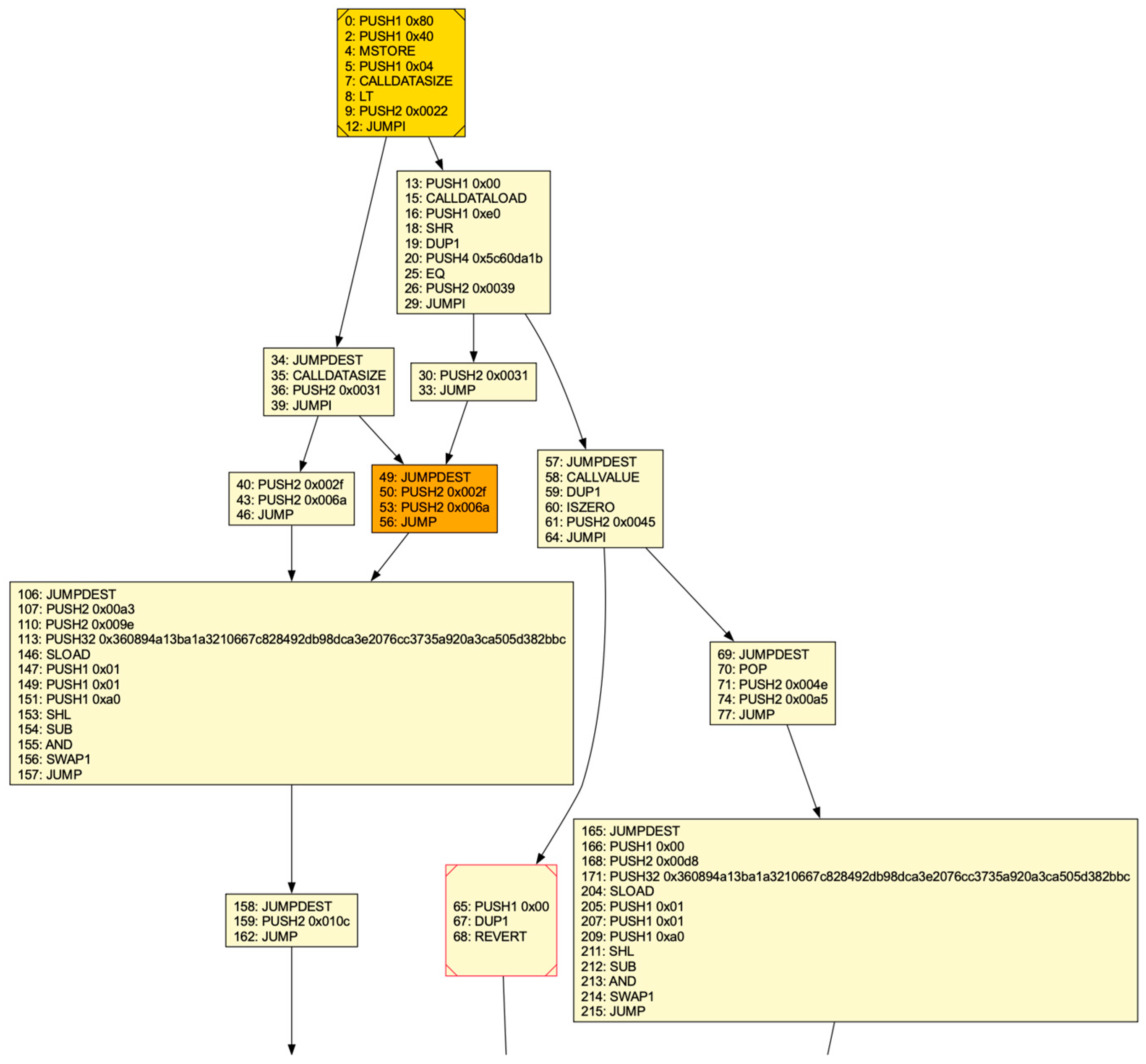
3.2. Control Flow Graphs
- Bytecode parsing. It begins by identifying and removing the metadata section of the raw bytecode, followed by parsing the remaining bytes into opcodes.
- Basic block identification. A basic block is a sequence of opcodes executed consecutively without any other instructions altering the flow of control. Specific opcodes JUMP (unconditional jumps), JUMPI (conditional jumps), STOP, REVERT, RETURN, INVALID and SELFDESTRUCT, mark the end of a basic block, while JUMPDEST marks the start.
- Symbolic stack execution. This step is used to resolve the destinations of orphan jumps during CFG construction. Orphan jumps are common in smart contracts, especially when a function call returns, and their destinations need to be determined. The approach involves symbolically executing the stack by focusing only on opcodes that interact with jump addresses (PUSH, DUP, SWAP, AND and POP), while treating other opcodes as unknown.
- Static data separation. It involves removing static data from the CFG by identifying and excluding sections of the code that are not executable. This is achieved by detecting the 0xFE opcode, which marks the transition from executable code to static data with a representation for invalid instructions, and subsequently removes any unconnected basic blocks from the graph.
- CFG decoration. It involves adding additional information to the control flow graph to make it more useful for analysts and subsequent static analysis tasks (e.g., for vulnerability detection). Specifically, EtherSolve highlights important components of the CFG, such as the dispatcher, fallback function, and final basic block.
3.3. Model Architectures
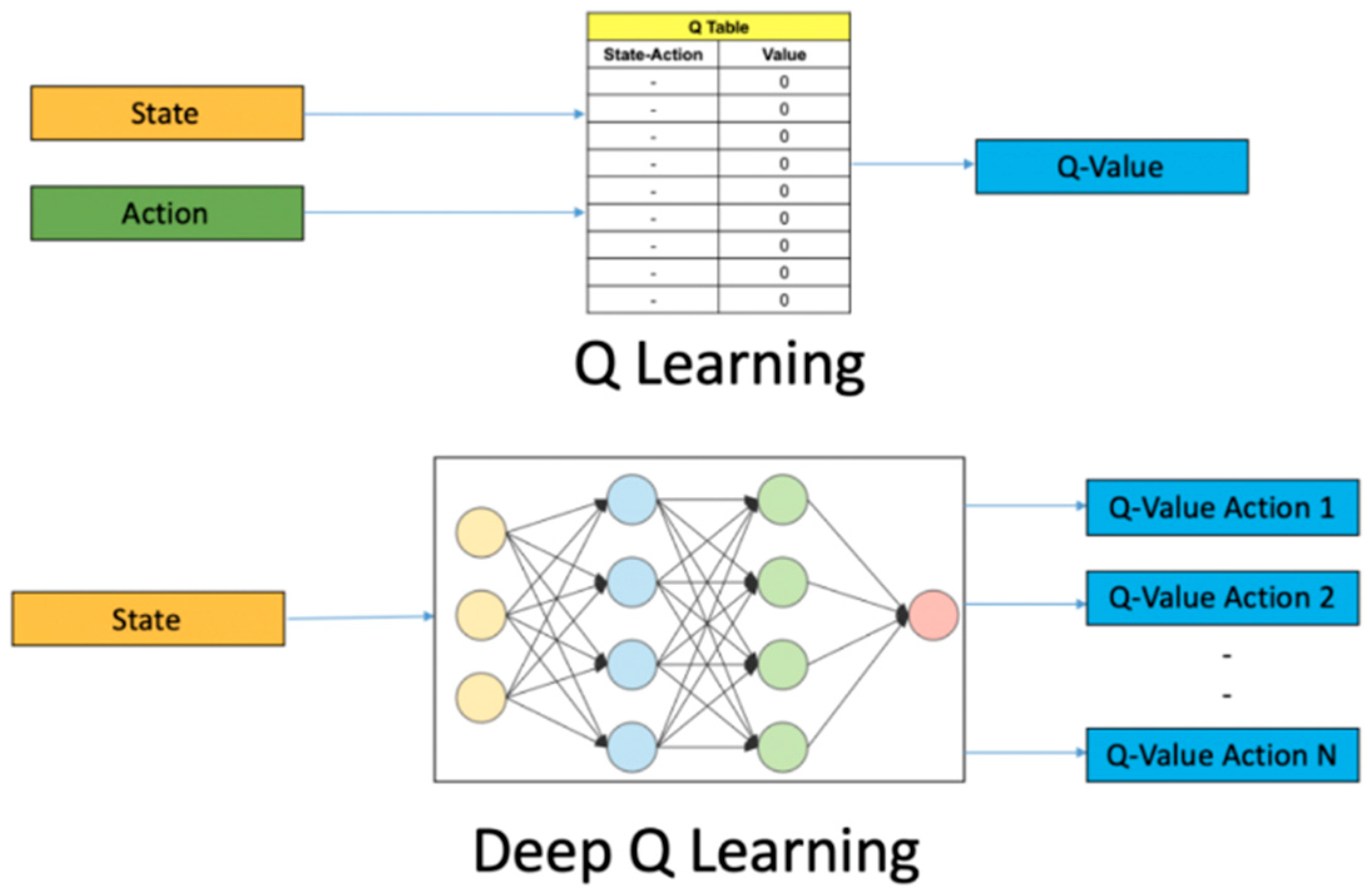
3.3.1. Deep Q-Network
| Algorithm 1. DQN with Replay Buffer |
| Initialize experience replay buffer to capacity |
| with random weights = [0, 1, 2, 3, 4, 5] for six possible class labels For episode = 1, do: from first observation of CFG features to do: With probability on the environment (i.e., predict vulnerability type) in replay buffer from for for every C step end for end for |
3.3.2. Proximal Policy Optimization
- Advantage is positive: Suppose the advantage for that state-action pair is positive; its contribution to the objective function diminishes to:Since the advantage is positive, the objective will increase if the action becomes more likely, i.e., if increases. However, the function in this expression imposes a cap on how much the objective can rise. Once exceeds , the minimum constraint activates, causing the term to reach a ceiling of . Consequently, the new policy does not gain further benefit by diverging significantly from the previous policy.
- Advantage is negative: Suppose the advantage for that state-action pair is negative; its contribution to the objective function diminishes to:
| Algorithm 2. PPO-Clip |
do: in the environment Update the policy by maximizing the PPO-Clip objective: typically via stochastic gradient ascent with Adam typically via some gradient decent algorithm end for |
3.4. Model Configurations
3.4.1. Agent Environment
| Algorithm 3. Agent Environment Setup |
| class SmartContractEnv() |
| function extract_features_from_cfg() Extract graph features from .dot file of CFGs function __init__() Initialize current step as 0 Initialize action space as spaces. Discrete(6) to capture six classes Initialize observation space as feature shape of extract_features_from_cfg() function _get_observation() Extract the CFG features for the current contract function step() Set current step forward while episode not done, do: Set next state by _get_observation() Calculate reward by _calculate_reward() end while function _calculate_reward() Define the reward calculation rules as: when action matches true labels, get a reward 1 Initialize environments to training, validation and test sets by SmartContractEnv() |
3.4.2. Hyperparameter Tuning
- Learning rate: This parameter controls how much the model updates its knowledge after each step. A too-high learning rate might cause the model to overlook optimal solutions, while a too-low rate may result in slow learning and the model getting stuck in local optima.
- Batch size: Size of the minibatch for training. Larger batch sizes generally lead to more stable updates but require more computational resources.
- Gamma: The discount factor belonging to (0, 1) that represents the importance of future rewards. A gamma close to 1.0 makes the model value long-term rewards, while a smaller gamma makes it prioritize immediate rewards.
- Steps before learning (DQN specific): This defines how many steps of the model to collect transitions for before learning starts. Delaying learning can help the model accumulate a diverse set of experiences, improving the stability and performance of the learning process.
- Buffer size (DQN specific): Size of the replay buffer that stores past experiences for the model to learn. A larger buffer allows the model to learn from a broader range of experiences but may increase memory usage and slow down training.
- Number of steps (PPO specific): The number of steps to run for each environment per update. More steps can stabilize the model by providing more data for each update but may also slow down the learning process.
- Number of epochs (PPO specific): This parameter specifies how many times the model iterates over collected experience data to optimize the policy during each update. In the context of smart contract vulnerability detection, more epochs can help the model better generalize patterns associated with vulnerabilities by revisiting observed contract behaviors more thoroughly. However, excessive epochs can lead the model to overfit to specific contract structures or vulnerability patterns in the training data, reducing its ability to detect novel or rare vulnerabilities in real-world DeFi contracts. Therefore, a careful balance is necessary to ensure robustness without compromising generalization.
- Entropy coefficient (PPO specific): Entropy coefficient for the loss calculation. A higher coefficient can promote exploration and help in avoiding local minima.
- Clip range (PPO specific): Clipping parameter. It can be a function of the current progress remaining (from 1 to 0). In PPO, the clip range limits how much the policy can change during training, which helps maintain the balance between exploring new policies and retaining what has already been learned.
3.5. Evaluation Metrics
- Label Accuracy: this measures the proportion of correct predictions for each label across all instances. Formally, denote as the true label value (either 0 or 1) of the th label for the th sample, and as its predicted label value. Label accuracy can be defined as:where represents the total number of samples, is the total number of labels, is the indicator function that equals 1 when and 0 otherwise.
- Subset Accuracy: a stricter accuracy score that measures the proportion of instances where all labels are correctly predicted. The mathematical formulation is:
- Micro-Recall: Recall measures the proportion of correctly identified out of all actual positives. For micro-level evaluation, labels from all samples are merged into a single comprehensive set. The recall is then calculated based on this aggregated set with the following formula:
- Micro-F1: The F1 score is the harmonic mean between precision and recall, bounded between 0 and 1. At the micro-level, the F1 score can be calculated as:where
- Learning curve: The learning curve plots the model’s performance (in our case the reward) against the number of training iterations or episodes. It helps to visualize the learning process, showing how quickly the model learns and how well it generalizes to new data.
- Receiver operating characteristic (ROC) curve: The ROC curve is a visual tool used to assess a classification model’s effectiveness by illustrating the relationship between the true positive rate (TPR) and the false positive rate (FPR). TPR reflects the percentage of actual positives that the model correctly identifies, while FPR represents the percentage of negatives mistakenly classified as positives. An ideal ROC curve would rise along the y-axis toward the upper left corner, indicating high TPR and low FPR. The area under the ROC curve (AUC) provides an overall performance metric for the model. AUC values range from 0 to 1, with values near 1 indicating superior model performance and those around 0.5 suggesting performance comparable to random guessing. In a multi-label classification task, One-Vs.-All methodology is adopted to plot the ROC curve.
- Precision–Recall (PR) curve: The PR curve is particularly insightful when dealing with imbalanced datasets, where the positive class is rare. It focuses on the precision (positive predictive value) and recall (sensitivity) of the model, providing a clear view of the trade-off between these two metrics. By adjusting this threshold, different combinations of precision and recall can be achieved, which are then visualized on the PR curve. Lowering the threshold typically increases the likelihood of predicting positive instances, which may result in more false positives, thus reducing precision but raising recall. Conversely, raising the threshold makes the model more selective, leading to fewer false positives and higher precision, but potentially at the cost of reduced recall. Ideally, a model would achieve both high precision and recall, with the PR curve nearing the top-right corner of the graph. The area under the PR curve (AUC-PR) serves as a single summary metric, with higher values indicating better performance.
4. Experiment and Analysis
4.1. Evaluation of RL Model Performance
4.2. Evaluation of RL Model Effectiveness
4.3. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CFG | Control Flow Graph |
| CFGs | Control Flow Graphs |
| DeFi | Decentralized Finance |
| DQN | Deep Q-Network |
| FPR | False Positive Rate |
| MLP | Multi-Layer Perceptron |
| PPO | Proximal Policy Optimization |
| PR | Precision–Recall |
| RL | Reinforcement Learning |
| RLF | Reinforcement Learning Fuzzer |
| ROC | Receiver Operating Characteristic |
| SVM | Support Vector Machine |
| TPR | True Positive Rate |
References
- Wood, G. Ethereum: A Secure Decentralized Generalised Transaction Ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Kirişci, M. A Risk Assessment Method for Decentralized Finance(DeFi) with Fermatean Fuzzy AHP Approach. Adv. Transdiscipl. Eng. 2023, 42, 1215–1223. [Google Scholar] [CrossRef]
- De Baets, C.; Suleiman, B.; Chitizadeh, A.; Razzak, I. Vulnerability Detection in Smart Contracts: A Comprehensive Survey. arXiv 2024, arXiv:2407.07922. [Google Scholar] [CrossRef]
- Mehar, M.; Shier, C.L.; Giambattista, A.; Gong, E.; Fletcher, G.; Sanayhie, R.; Kim, H.M.; Laskowski, M. Understanding a revolutionary and flawed grand experiment in blockchain: The DAO attack. J. Cases Inf. Technol. 2019, 21, 19–32. [Google Scholar] [CrossRef]
- Breidenbach, L.; Daian, P.; Juels, A.; Sirer, E.G. An in-depth look at the parity multisig bug. Hacking 2017. [Google Scholar]
- Explained: The BNB Chain Hack. 2022. Available online: https://www.halborn.com/blog/post/explained-the-bnb-chain-hack-october-2022 (accessed on 15 March 2025).
- SlowMist. Available online: https://hacked.slowmist.io/ (accessed on 12 March 2025).
- Wang, X.; Hu, M.; Luo, X.; Guan, X. A detection model for false data injection attacks in smart grids based on graph spatial features using temporal convolutional neural networks. Electr. Power Syst. Res. 2025, 238, 111126. [Google Scholar] [CrossRef]
- Al-Harbi, H. Detecting Anomalies in Blockchain Transactions Using Spatial-Temporal Graph Neural Networks. Adv. Mach. Intell. Technol. 2025, 1. [Google Scholar] [CrossRef]
- Thiruloga, S.; Kukkala, V.K.; Pasricha, S. TENET: Temporal CNN with Attention for Anomaly Detection in Automotive Cyber-Physical Systems. In Proceedings of the 2022 Asia and South Pacific Design Automation Conference (ASP-DAC), Taipei, Taiwan, 5 May 2022; pp. 326–331. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, H.; Wang, G.; Tang, X.; Wang, X.; Liu, C. Monitoring industrial control systems via spatio-temporal graph neural networks. Eng. Appl. Artif. Intell. 2023, 122, 106144. [Google Scholar] [CrossRef]
- Piantadosi, V.; Rosa, G.; Placella, D.; Scalabrino, S.; Oliveto, R. Detecting functional and security-related issues in smart contracts: A systematic literature review. Softw. Pract. Exp. 2022, 53, 465–495. [Google Scholar] [CrossRef]
- Luu, L.; Chu, D.H.; Olickel, H.; Saxena, P.; Hobor, A. Making smart contracts smarter. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24 October 2016. [Google Scholar] [CrossRef]
- Prechtel, D.; Groß, T.; Müller, T. Evaluating Spread of ‘Gasless Send’ in Ethereum Smart Contracts. In Proceedings of the 2019 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019. [Google Scholar] [CrossRef]
- Tsankov, P.; Dan, A.; Drachsler-Cohen, D.; Gervais, A.; Bünzli, F.; Vechev, M. Securify: Practical Security Analysis of Smart Contracts. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Tikhomirov, S.; Voskresenskaya, E.; Ivanitskiy, I.; Takhaviev, R.; Marchenko, E.; Alexandrov, Y. SmartCheck: Static analysis of ethereum smart contracts. In Proceedings of the 1st International Workshop on Emerging Trends in Software Engineering for Blockchain, Gothenburg, Sweden, 27 May 2018. [Google Scholar] [CrossRef]
- Feist, J.; Grieco, G.; Groce, A. Slither: A Static Analysis Framework For Smart Contracts. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB), Montreal, QC, Canada, 27 May 2019; pp. 8–15. [Google Scholar] [CrossRef]
- Li, B.; Pan, Z.; Hu, T. ReDefender: Detecting Reentrancy Vulnerabilities in Smart Contracts Automatically. IEEE Trans. Reliab. 2022, 71, 984–999. [Google Scholar] [CrossRef]
- Torres, C.F.; Iannillo, A.K.; Gervais, A.; State, R. ConFuzzius: A Data Dependency-Aware Hybrid Fuzzer for Smart Contracts. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 6–10 September 2021; pp. 103–119. [Google Scholar] [CrossRef]
- Li, J.; Lu, G.; Gao, Y.; Gao, F. A Smart Contract Vulnerability Detection Method Based on Multimodal Feature Fusion and Deep Learning. Mathematics 2023, 11, 4823. [Google Scholar] [CrossRef]
- Gao, Z.; Jayasundara, V.; Jiang, L.; Xia, X.; Lo, D.; Grundy, J. SmartEmbed: A Tool for Clone and Bug Detection in Smart Contracts through Structural Code Embedding. In Proceedings of the 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME), Cleveland, OH, USA, 29 September 2019. [Google Scholar] [CrossRef]
- Hao, X.; Ren, W.; Zheng, W.; Zhu, T. SCScan: A SVM-Based Scanning System for Vulnerabilities in Blockchain Smart Contracts. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020. [Google Scholar] [CrossRef]
- Zhang, Y.; Kang, S.; Dai, W.; Chen, S.; Zhu, J. Code Will Speak: Early detection of Ponzi Smart Contracts on Ethereum. In Proceedings of the 2021 IEEE International Conference on Services Computing (SCC), Chicago, IL, USA, 5–10 September 2021. [Google Scholar] [CrossRef]
- Qian, P.; Liu, Z.; He, Q.; Zimmermann, R.; Wang, X. Towards Automated Reentrancy Detection for Smart Contracts Based on Sequential Models. IEEE Access 2020, 8, 19685–19695. [Google Scholar] [CrossRef]
- Xu, G.; Liu, L.; Zhou, Z. Reentrancy Vulnerability Detection of Smart Contract Based on Bidirectional Sequential Neural Network with Hierarchical Attention Mechanism. In Proceedings of the 2022 International Conference on Blockchain Technology and Information Security (ICBCTIS), Huaihua, China, 15–17 July 2022. [Google Scholar] [CrossRef]
- Hwang, S.J.; Choi, S.H.; Shin, J.; Choi, Y.H. CodeNet: Code-Targeted Convolutional Neural Network Architecture for Smart Contract Vulnerability Detection. IEEE Access 2022, 10, 32595–32607. [Google Scholar] [CrossRef]
- Cai, C.; Li, B.; Zhang, J.; Sun, X.; Chen, B. Combine sliced joint graph with graph neural networks for smart contract vulnerability detection. J. Syst. Softw. 2023, 195, 111550–111565. [Google Scholar] [CrossRef]
- Sun, X.; Tu, L.C.; Zhang, J.; Cai, J.; Li, B.; Wang, Y. ASSBert: Active and semi-supervised bert for smart contract vulnerability detection. J. Inf. Secur. Appl. 2023, 73, 103423. [Google Scholar] [CrossRef]
- He, F.; Li, F.; Liang, P. Enhancing smart contract security: Leveraging pre-trained language models for advanced vulnerability detection. IET Blockchain 2024, 1, 543–554. [Google Scholar] [CrossRef]
- Andrijasa, M.F.; Ismail, S.A.; Ahmad, N. Towards Automatic Exploit Generation for Identifying Re-Entrancy Attacks on Cross-Contract. In Proceedings of the 2022 IEEE Symposium on Future Telecommunication Technologies (SOFTT), Johor Baharu, Malaysia, 14–16 November 2022; pp. 15–20. [Google Scholar] [CrossRef]
- Su, J.; Dai, H.N.; Zhao, L.; Zheng, Z.; Luo, X. Effectively Generating Vulnerable Transaction Sequences in Smart Contracts with Reinforcement Learning-guided Fuzzing. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 5 January 2023. [Google Scholar] [CrossRef]
- Rossini, M.; Zichichi, M.; Ferretti, S. On the Use of Deep Neural Networks for Security Vulnerabilities Detection in Smart Contracts. In Proceedings of the 2023 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Atlanta, GA, USA, 11–13 March 2023. [Google Scholar] [CrossRef]
- Slither-Audited-Smart-Contracts. Available online: https://huggingface.co/datasets/mwritescode/slither-audited-smart-contracts (accessed on 14 July 2024).
- Etherscan. Available online: https://docs.etherscan.io/ (accessed on 12 August 2024).
- Contro, F.; Crosara, M.; Ceccato, M.; Preda, M.D. EtherSolve: Computing an Accurate Control-Flow Graph from Ethereum Bytecode. arXiv 2021, arXiv:2103.09113. [Google Scholar] [CrossRef]
- EtherSolve. Available online: https://github.com/SeUniVr/EtherSolve/blob/main/artifact/EtherSolve.jar (accessed on 15 August 2024).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- RPS: RL Using Deep Q Network (DQN). Available online: https://www.kaggle.com/code/anmolkapoor/rps-rl-using-deep-q-network-dqn#Deep-Q-Network-(DQN) (accessed on 15 August 2024).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Proximal Policy Optimization. Available online: https://spinningup.openai.com/en/latest/algorithms/ppo.html (accessed on 15 August 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vulnerability | Contracts |
|---|---|
| unchecked calls | 36,770 |
| safe | 26,280 |
| reentrancy | 24,120 |
| other | 20,650 |
| arithmetic | 14,140 |
| access control | 11,820 |
| Parameters | Tuning Range | Optimal Results |
|---|---|---|
| Learning rate | [1 × 10−5, 1 × 10−3] | 0.00015 |
| Batch size | <32, 64, 128> | 64 |
| Gamma | [0.9, 0.9999] | 0.9400 |
| Steps before learning | [1000, 10,000] | 3738 |
| Buffer size | [50,000, 1,000,000] | 86245 |
| Max rewards achieved | 551.0 |
| Parameters | Tuning Range | Optimal Results |
|---|---|---|
| Learning rate | [1 × 10−5, 1 × 10−3] | 0.0002 |
| Batch size | <32, 64, 128> | 32 |
| Gamma | [0.9, 0.9999] | 0.9543 |
| Number of steps | <64, 128, 256, 512> | 256 |
| Number of epochs | [1, 10] (int) | 9 |
| Entropy coefficient | [1 × 10−8, 1 × 10−2] | 1.3426 |
| Clip range | [0.1, 0.4] | 0.2195 |
| Max rewards achieved | 584.0 |
| Model | DQN | PPO | SVM | Random Forest | MLP |
|---|---|---|---|---|---|
| Accuracy | 0.1869 | 0.2947 | 0.2532 | 0.2487 | 0.2214 |
| Recall | 0.1768 | 0.1930 | 0.1750 | 0.1634 | 0.1535 |
| F1 score | 0.1452 | 0.1463 | 0.1376 | 0.1308 | 0.1250 |
| Precision | Recall | F1 Score | Support | |
|---|---|---|---|---|
| access control | 0.03 | 0.01 | 0.01 | 193 |
| arithmetic | 0.11 | 0.02 | 0.04 | 249 |
| other | 0.15 | 0.03 | 0.05 | 410 |
| reentrancy | 0.25 | 0.03 | 0.05 | 441 |
| safe | 0.21 | 0.17 | 0.19 | 565 |
| unchecked calls | 0.28 | 0.81 | 0.46 | 693 |
| accuracy | 0.30 | 2534 | ||
| micro avg | 0.19 | 0.19 | 0.17 | 2534 |
| macro avg | 0.20 | 0.18 | 0.14 | 2534 |
| weighted avg | 0.21 | 0.28 | 0.20 | 2534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Leon, J.J.; Zhang, C.; Koulouris, C.-S.; Medda, F.; Rahul. Smart Contract Security in Decentralized Finance: Enhancing Vulnerability Detection with Reinforcement Learning. Appl. Sci. 2025, 15, 5924. https://doi.org/10.3390/app15115924
de Leon JJ, Zhang C, Koulouris C-S, Medda F, Rahul. Smart Contract Security in Decentralized Finance: Enhancing Vulnerability Detection with Reinforcement Learning. Applied Sciences. 2025; 15(11):5924. https://doi.org/10.3390/app15115924
Chicago/Turabian Stylede Leon, Jose Juan, Cenchuan Zhang, Christos-Spyridon Koulouris, Francesca Medda, and Rahul. 2025. "Smart Contract Security in Decentralized Finance: Enhancing Vulnerability Detection with Reinforcement Learning" Applied Sciences 15, no. 11: 5924. https://doi.org/10.3390/app15115924
APA Stylede Leon, J. J., Zhang, C., Koulouris, C.-S., Medda, F., & Rahul. (2025). Smart Contract Security in Decentralized Finance: Enhancing Vulnerability Detection with Reinforcement Learning. Applied Sciences, 15(11), 5924. https://doi.org/10.3390/app15115924