
Depth Segmentation Approach for Egocentric 3D Human Pose Estimation with a Fisheye Camera


Abstract
1. Introduction
- A SegDepth module to effectively extract depth features from highly distorted images.
- Architecture that uses the features of depth map, segmentation map, and heatmap for 3D pose estimation.
- A new end-to-end framework for 3D pose estimation using images from a single fisheye camera mounted on an HMD.
2. Related Work
2.1. Single Front View Estimation
2.2. Egocentric 3D Human Pose Estimation
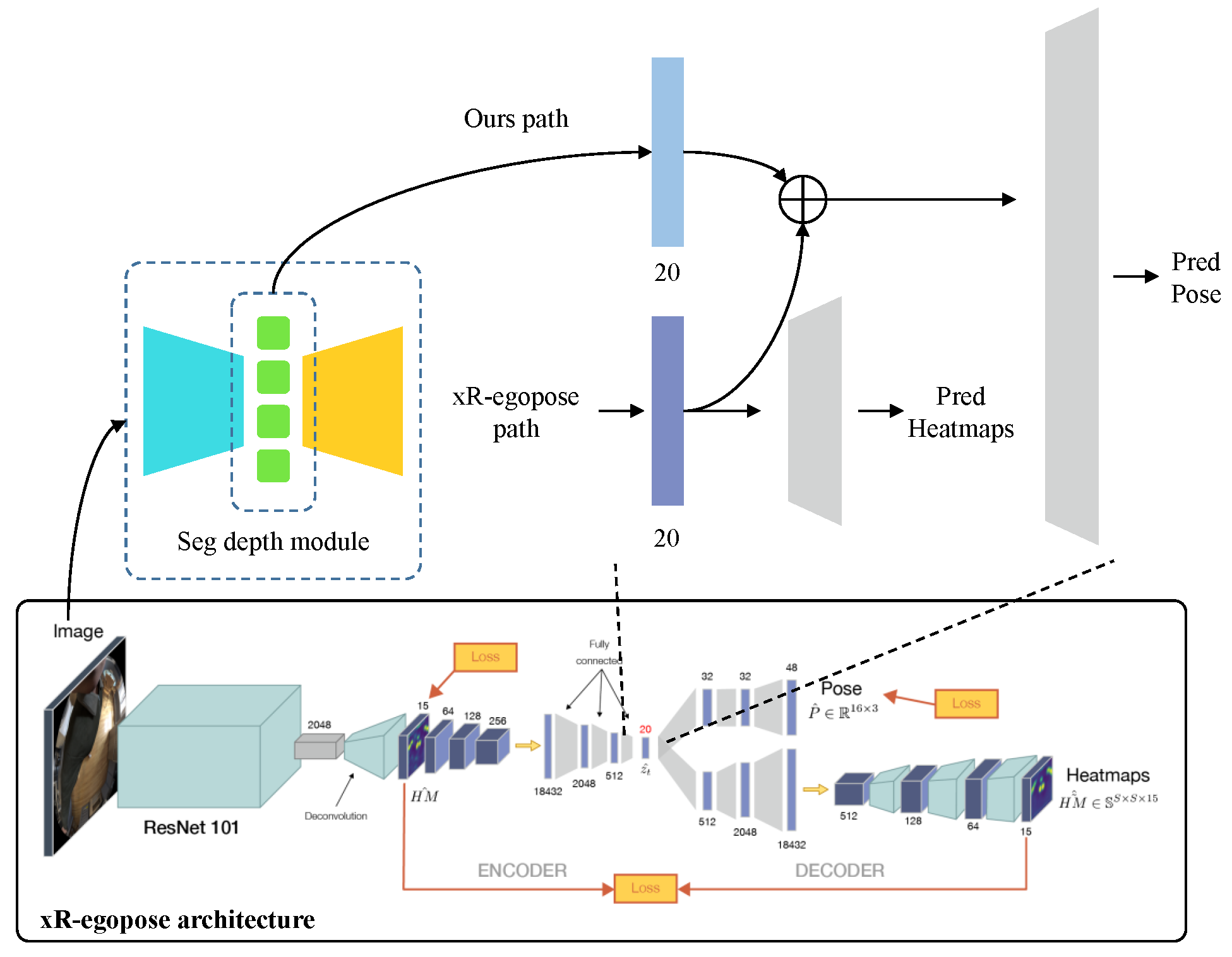
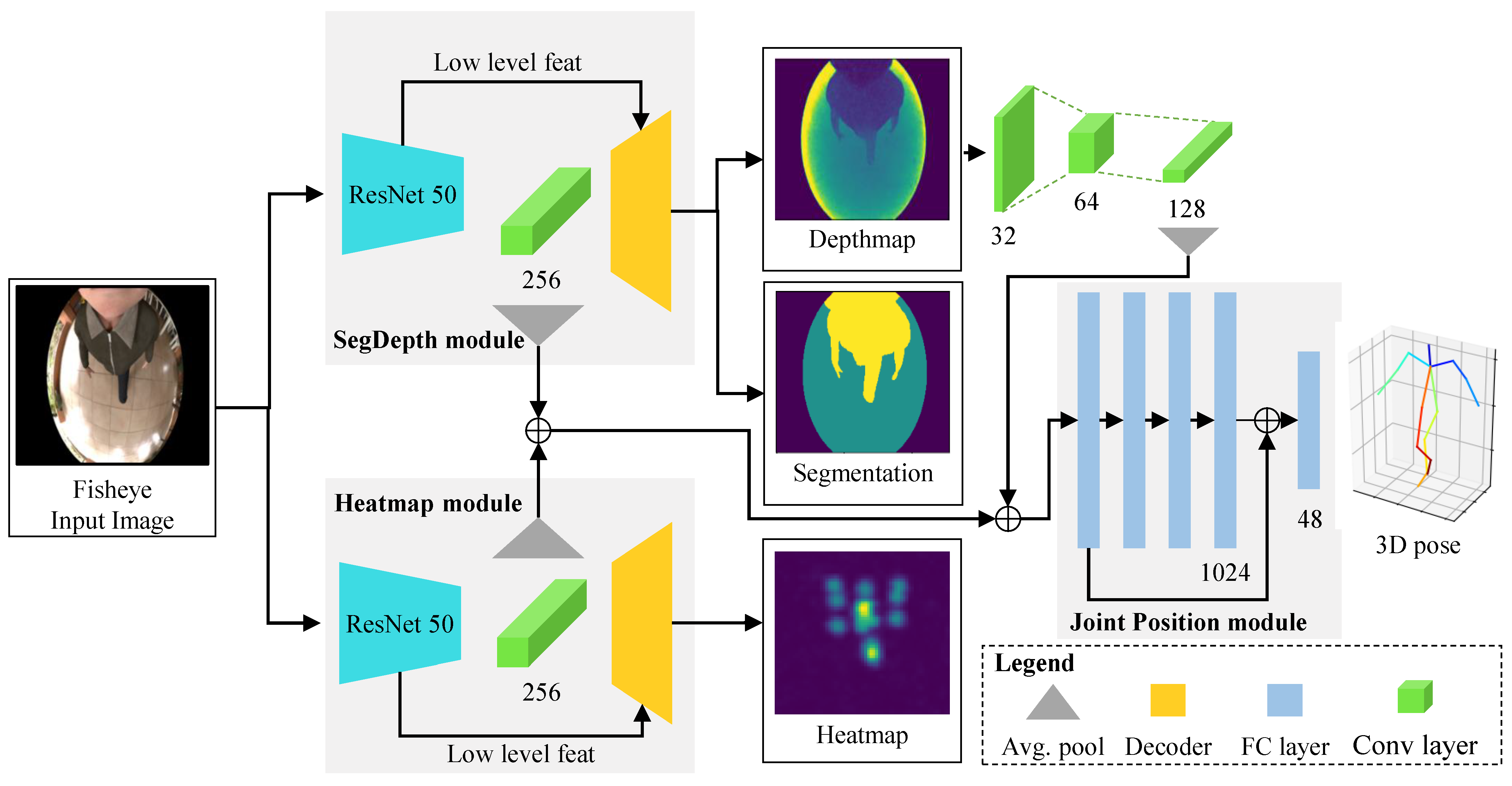
3. Our Methods
3.1. Architecture
3.1.1. Two Branch Architecture
3.1.2. Heatmap Module
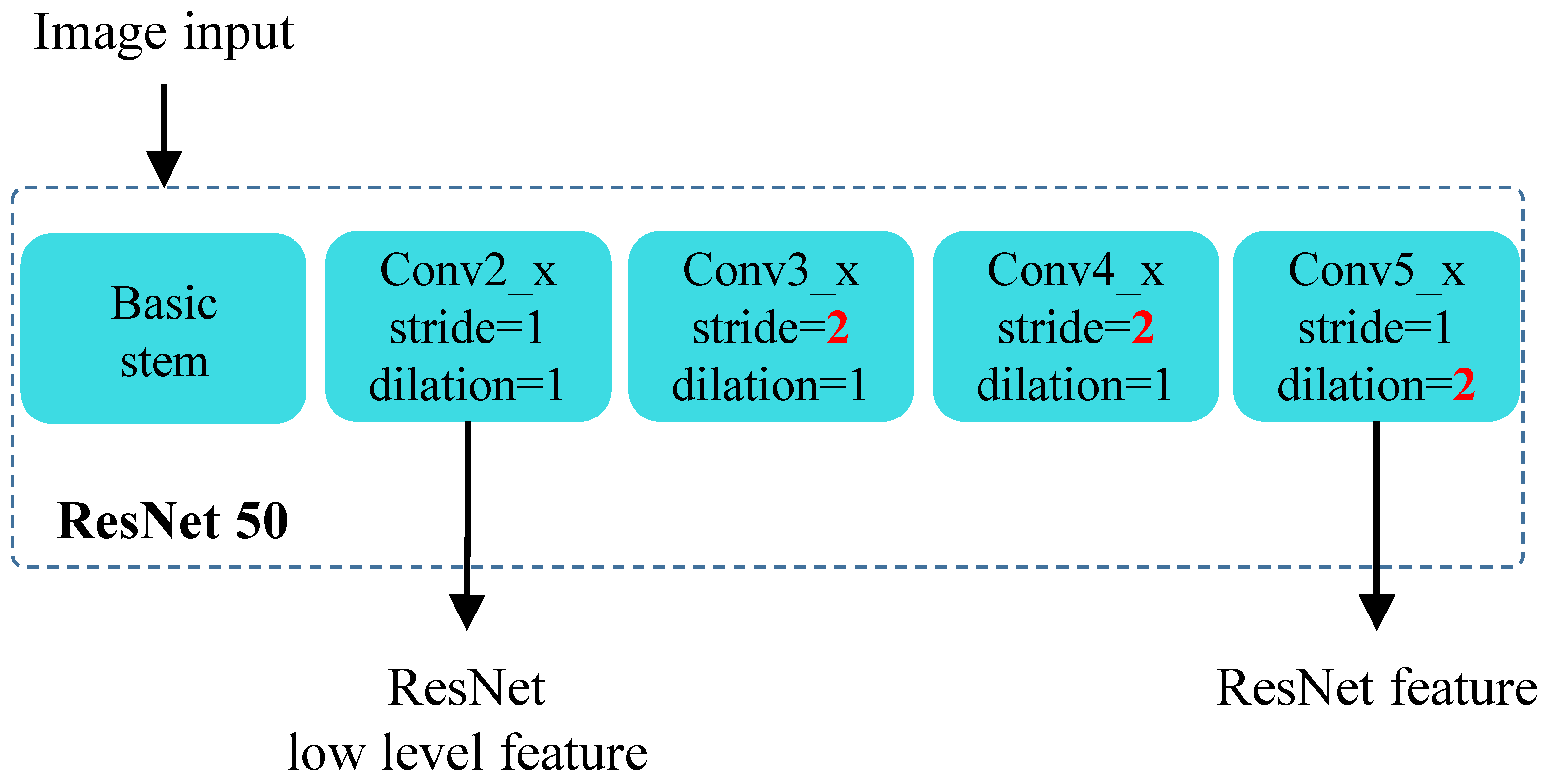
3.1.3. Segmentation Depth Module
3.1.4. Joint Position Module
4. Experiments
4.1. Dataset
- Train-set: 225 K, 11 male, 11 female.
- Val-set: 30 K, 1 male, 1 female.
- Test-set: 85 K, 6 males, 4 females.
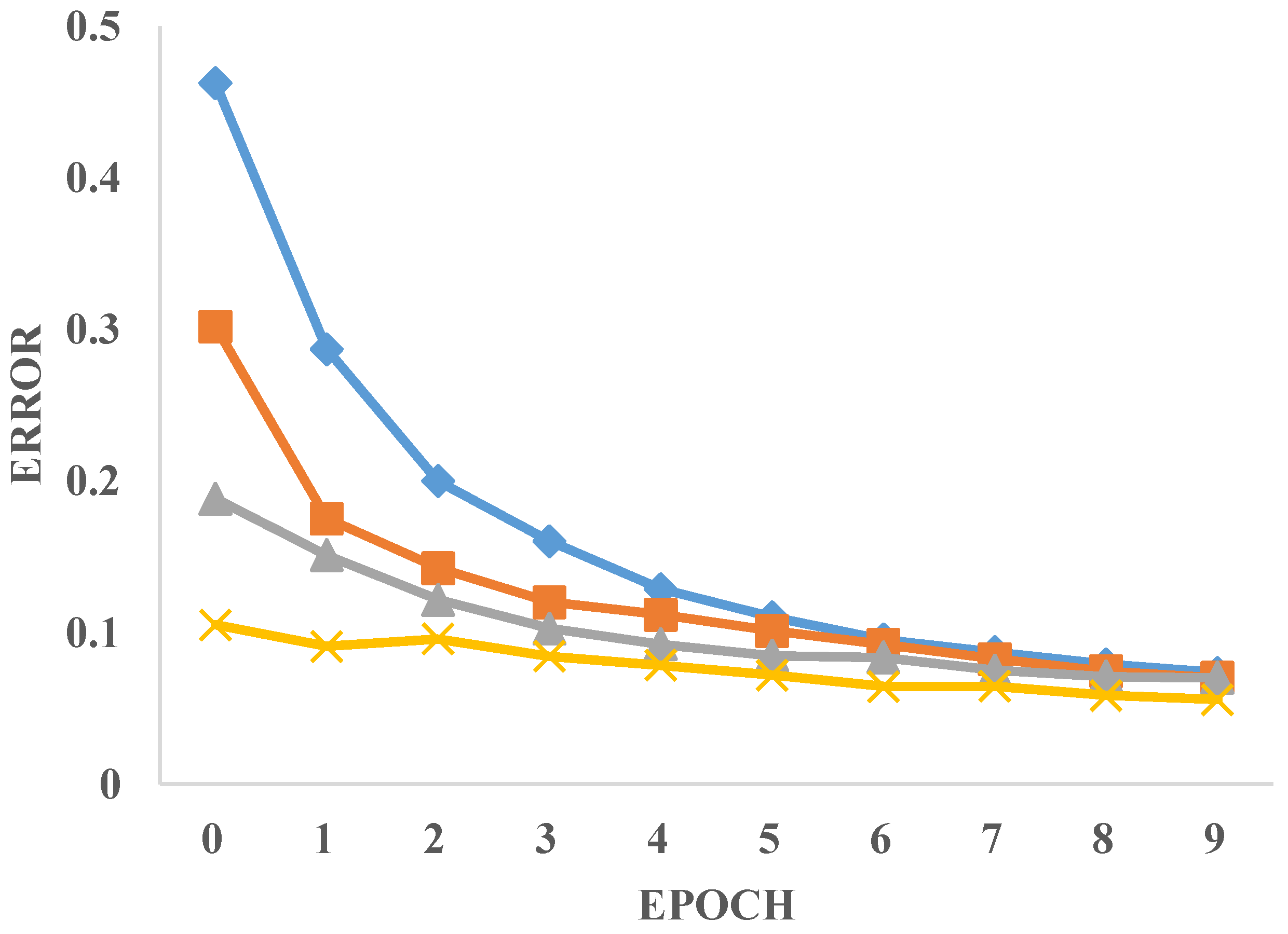
4.2. Implementation Details
4.2.1. SegDepth Module and Heatmap Module
4.2.2. Joint Position Module
4.2.3. Implementation of xR-EgoPose and Mo2Cap2
5. Results
5.1. Evaluation Metrics
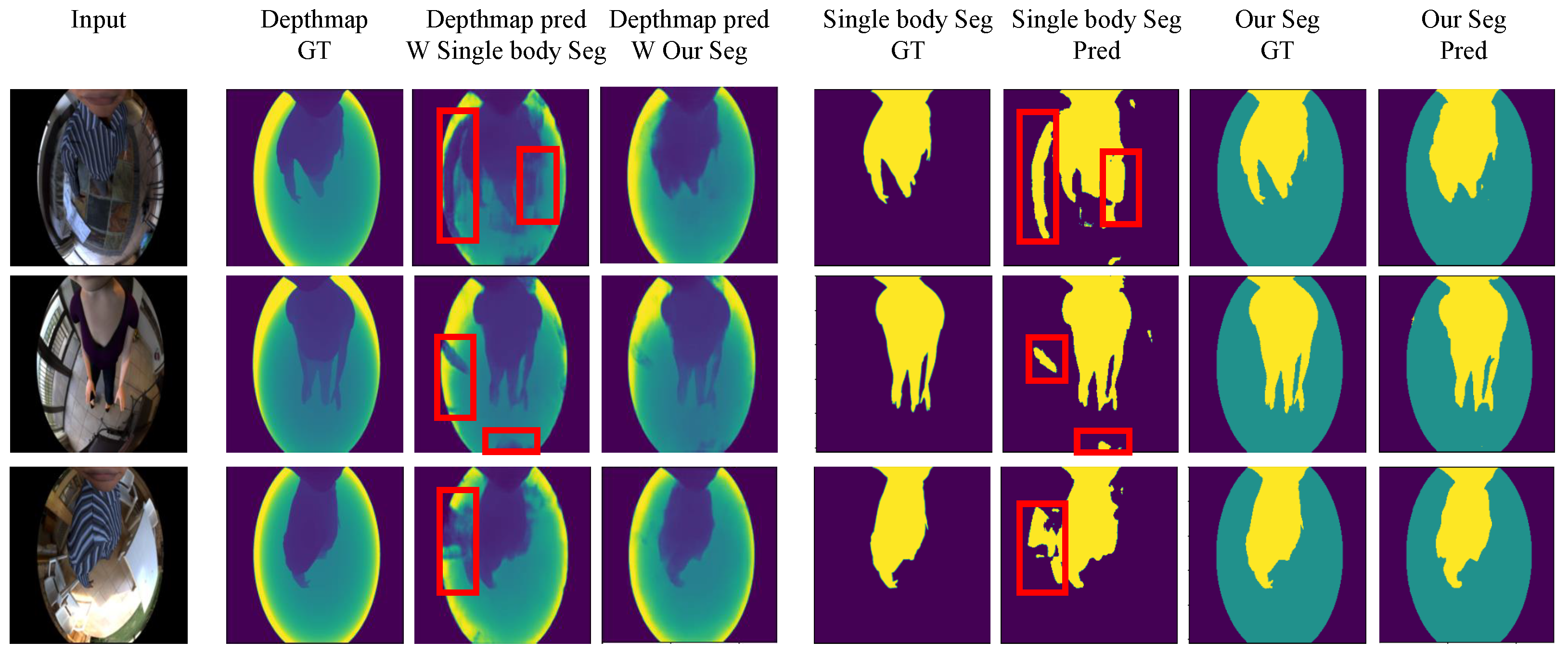
5.2. Effect of Referencing Depth Map with Segmentation
5.3. Ablation Study
5.3.1. Decoder Architecture
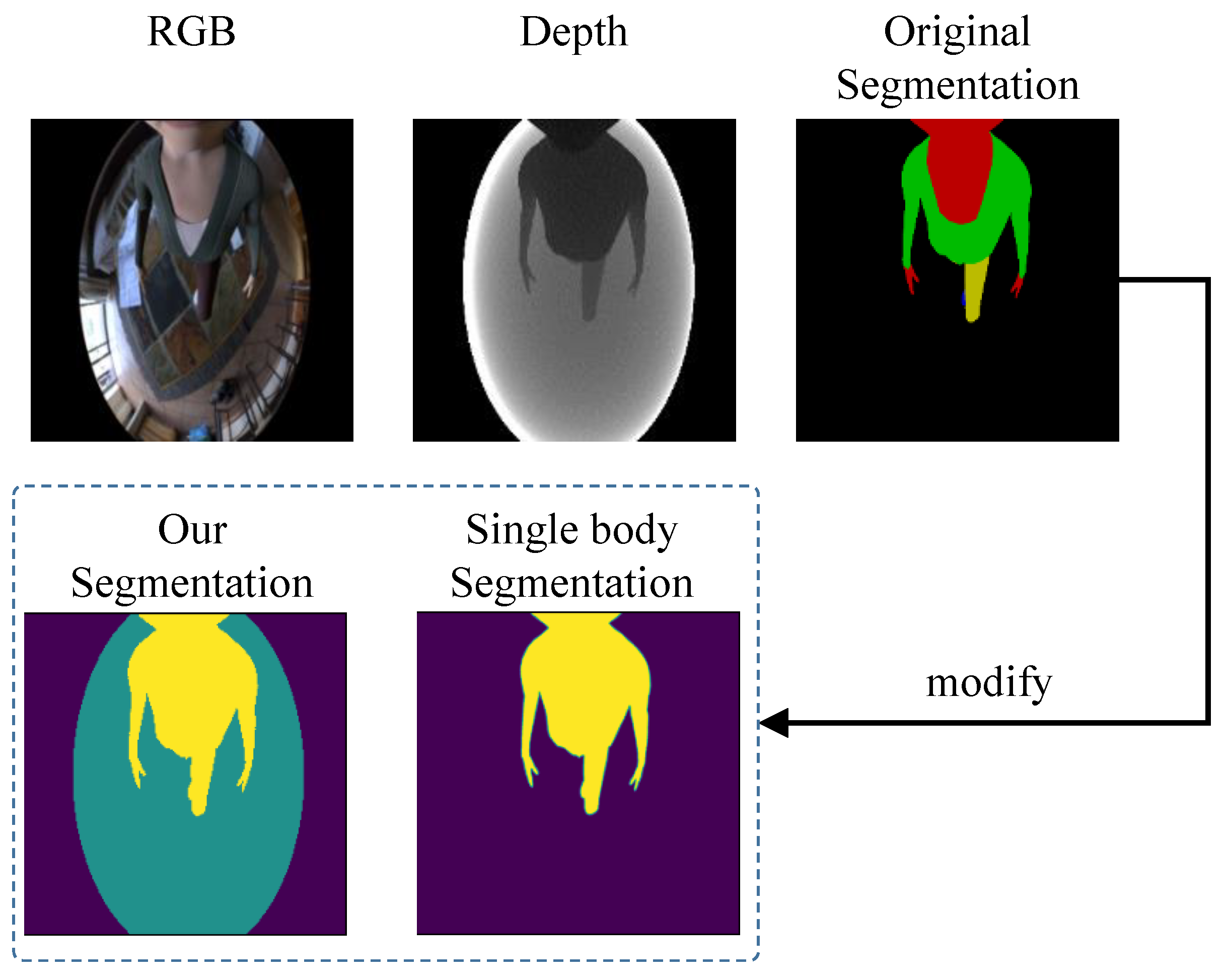
5.3.2. Segmentation Strategy
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Implemented the SegDepth Module
Appendix A.1. xRegopose
Appendix A.2. mo2cap2

References
- Czesak, K.; Mohedano, R.; Carballeira, P.; Cabrera, J.; Garcia, N. Fusion of pose and head tracking data for immersive mixed-reality application development. In Proceedings of the 2016 3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Hamburg, Germany, 4–6 July 2016; IEEE: New York, NY, USA, 2016; pp. 1–4. [Google Scholar]
- Money, K.E. Motion sickness. Physiol. Rev. 1970, 50, 1–39. [Google Scholar] [CrossRef] [PubMed]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Huang, Y.; Kaufmann, M.; Aksan, E.; Black, M.J.; Hilliges, O.; Pons-Moll, G. Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time. Acm Trans. Graph. (Tog) 2018, 37, 1–15. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3d human pose estimation= 2d pose estimation+ matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 561–578. [Google Scholar]
- Tome, D.; Peluse, P.; Agapito, L.; Badino, H. xr-egopose: Egocentric 3d human pose from an hmd camera. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 7728–7738. [Google Scholar]
- Wang, J.; Luvizon, D.; Xu, W.; Liu, L.; Sarkar, K.; Theobalt, C. Scene-aware Egocentric 3D Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13031–13040. [Google Scholar]
- Xu, W.; Chatterjee, A.; Zollhoefer, M.; Rhodin, H.; Fua, P.; Seidel, H.P.; Theobalt, C. Mo 2 cap 2: Real-time mobile 3d motion capture with a cap-mounted fisheye camera. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2093–2101. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Zhu, M.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. Sparseness meets deepness: 3d human pose estimation from monocular video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4966–4975. [Google Scholar]
- Yasin, H.; Iqbal, U.; Kruger, B.; Weber, A.; Gall, J. A dual-source approach for 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4948–4956. [Google Scholar]
- Park, S.; Hwang, J.; Kwak, N. 3d human pose estimation using convolutional neural networks with 2d pose information. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 156–169. [Google Scholar]
- Shiratori, T.; Park, H.S.; Sigal, L.; Sheikh, Y.; Hodgins, J.K. Motion capture from body-mounted cameras. In ACM SIGGRAPH 2011 Papers; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1–10. [Google Scholar]
- Holte, M.B.; Tran, C.; Trivedi, M.M.; Moeslund, T.B. Human pose estimation and activity recognition from multi-view videos: Comparative explorations of recent developments. IEEE J. Sel. Top. Signal Process. 2012, 6, 538–552. [Google Scholar] [CrossRef]
- Baak, A.; Müller, M.; Bharaj, G.; Seidel, H.P.; Theobalt, C. A data-driven approach for real-time full body pose reconstruction from a depth camera. In Consumer Depth Cameras for Computer Vision. Advances in Computer Vision and Pattern Recognition; Springer: London, UK, 2013; pp. 71–98. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011; pp. 1297–1304. [Google Scholar]
- Bregler, C.; Malik, J. Tracking people with twists and exponential maps. In Proceedings of the 1998 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No. 98CB36231), Santa Barnara, CA, USA, 23–25 June 1998; IEEE: New York, NY, USA, 1998; pp. 8–15. [Google Scholar]
- Gall, J.; Rosenhahn, B.; Brox, T.; Seidel, H.P. Optimization and filtering for human motion capture: A multi-layer framework. Int. J. Comput. Vis. 2010, 87, 75–92. [Google Scholar] [CrossRef]
- Joo, H.; Liu, H.; Tan, L.; Gui, L.; Nabbe, B.; Matthews, I.; Kanade, T.; Nobuhara, S.; Sheikh, Y. Panoptic studio: A massively multiview system for social motion capture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3334–3342. [Google Scholar]
- Moeslund, T.B.; Hilton, A.; Krüger, V.; Sigal, L. Visual Analysis of Humans; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Sigal, L.; Balan, A.O.; Black, M.J. Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. Int. J. Comput. Vis. 2010, 87, 4–27. [Google Scholar] [CrossRef]
- Sigal, L.; Isard, M.; Haussecker, H.; Black, M.J. Loose-limbed people: Estimating 3D human pose and motion using non-parametric belief propagation. Int. J. Comput. Vis. 2012, 98, 15–48. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, X.; Zhang, W.; Liang, S.; Wei, Y. Deep kinematic pose regression. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 186–201. [Google Scholar]
- Tekin, B.; Katircioglu, I.; Salzmann, M.; Lepetit, V.; Fua, P. Structured prediction of 3d human pose with deep neural networks. arXiv 2016, arXiv:1605.05180. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar]
- Li, S.; Chan, A.B. 3d human pose estimation from monocular images with deep convolutional neural network. In Proceedings of the Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Revised Selected Papers, Part II 12. Springer: Berlin/Heidelberg, Germany, 2015; pp. 332–347. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3d human pose estimation in the wild using improved cnn supervision. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: New York, NY, USA, 2017; pp. 506–516. [Google Scholar]
- Jahangiri, E.; Yuille, A.L. Generating multiple diverse hypotheses for human 3d pose consistent with 2d joint detections. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 805–814. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Rhodin, H.; Richardt, C.; Casas, D.; Insafutdinov, E.; Shafiei, M.; Seidel, H.P.; Schiele, B.; Theobalt, C. Egocap: Egocentric marker-less motion capture with two fisheye cameras. Acm Trans. Graph. (Tog) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Zhao, D.; Wei, Z.; Mahmud, J.; Frahm, J.M. Egoglass: Egocentric-view human pose estimation from an eyeglass frame. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: New York, NY, USA, 2021; pp. 32–41. [Google Scholar]
- Cha, Y.W.; Price, T.; Wei, Z.; Lu, X.; Rewkowski, N.; Chabra, R.; Qin, Z.; Kim, H.; Su, Z.; Liu, Y.; et al. Towards fully mobile 3D face, body, and environment capture using only head-worn cameras. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2993–3004. [Google Scholar] [CrossRef] [PubMed]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. In Proceedings of the IEEE conference on computer vision and pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5079–5088. [Google Scholar]
- Liu, Y.; Yang, J.; Gu, X.; Chen, Y.; Guo, Y.; Yang, G.Z. Egofish3d: Egocentric 3d pose estimation from a fisheye camera via self-supervised learning. IEEE Trans. Multimed. 2023, 25, 8880–8891. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A toolbox for easily calibrating omnidirectional cameras. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–13 October 2006; IEEE: New York, NY, USA, 2006; pp. 5695–5701. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Frames | Train Size | Test Size |
|---|---|---|---|
| Gaming | 14,171 | 10,186 | 1,594 |
| Gesticulating | 18,634 | 13,429 | 2,082 |
| Greeting | 6,653 | 4,798 | 742 |
| Lower stretching | 52,056 | 33,482 | 15,235 |
| Patting | 10,054 | 7,052 | 1,592 |
| Reacting | 24,282 | 17,492 | 2,716 |
| Talking | 11,072 | 7,987 | 1,234 |
| Upper stretching | 170,723 | 109,560 | 50,564 |
| Walking | 33,430 | 21,468 | 9,862 |
| Approach | Gaming | Gesticulating | Greeting | Lower Stretching | Patting | Reacting | Talking | Upper Stretching | Walking | All |
|---|---|---|---|---|---|---|---|---|---|---|
| xR-EgoPose [8] | 138.1 | 117.1 | 96.9 | 146.9 | 135.9 | 130.7 | 105.4 | 149.7 | 148.6 | 146.1 |
| xR-EgoPose W depth | 138.6 | 112.4 | 111.9 | 136.6 | 138.4 | 131.9 | 105.7 | 137.8 | 133.1 | 135.6 |
| xR-EgoPose W seg, depth | 133.1 | 104.8 | 116.8 | 129.4 | 140.7 | 133.2 | 103.5 | 131.6 | 130.1 | 130.1 |
| Mo2Cap2 [10] | 118.9 | 100.2 | 110.8 | 141.4 | 127.8 | 132.5 | 106.3 | 151.3 | 152.2 | 145.8 |
| Mo2Cap2 W depth | 109.4 | 100.7 | 90.2 | 127.9 | 116.2 | 122.7 | 87.6 | 138.6 | 120.2 | 131.0 |
| Mo2Cap2 W seg, depth | 110.2 | 96.8 | 117.7 | 125.1 | 114.7 | 122.7 | 95.7 | 135.0 | 140.2 | 130.9 |
| Ours | 61.0 | 52.8 | 48.9 | 67.5 | 74.5 | 61.8 | 46.8 | 74.6 | 75.0 | 71.6 |
| Ours W depth | 58.6 | 50.9 | 54.2 | 65.4 | 79.0 | 61.2 | 48.5 | 70.5 | 69.8 | 68.2 |
| Ours W seg, depth | 66.7 | 57.2 | 55.8 | 62.9 | 78.2 | 64.9 | 53.4 | 66.7 | 67.1 | 65.7 |
| Approach | MPJPE | Network Size (Total) | Size Reduction |
|---|---|---|---|
| Dual Decoder | 66.4 | 277.8 MB | - |
| Single Decoder | 65.7 | 251.2 MB | 9.5% |
| Approach | MPJPE |
|---|---|
| Our w {heatmap} | 71.6 |
| Our w {heatmap, depth} | 68.2 |
| Our w {heatmap, depth, single seg} | 75.8 |
| Our w {heatmap, depth, three region seg} | 65.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.; Kim, S. Depth Segmentation Approach for Egocentric 3D Human Pose Estimation with a Fisheye Camera. Appl. Sci. 2024, 14, 11937. https://doi.org/10.3390/app142411937
Shin H, Kim S. Depth Segmentation Approach for Egocentric 3D Human Pose Estimation with a Fisheye Camera. Applied Sciences. 2024; 14(24):11937. https://doi.org/10.3390/app142411937
Chicago/Turabian StyleShin, Hyeonghwan, and Seungwon Kim. 2024. "Depth Segmentation Approach for Egocentric 3D Human Pose Estimation with a Fisheye Camera" Applied Sciences 14, no. 24: 11937. https://doi.org/10.3390/app142411937
APA StyleShin, H., & Kim, S. (2024). Depth Segmentation Approach for Egocentric 3D Human Pose Estimation with a Fisheye Camera. Applied Sciences, 14(24), 11937. https://doi.org/10.3390/app142411937