1. Introduction
Large Language Models (LLMs) have triggered an amazing amount of innovation in several domains of the machine learning arena. In this paper, we focus on the design of experiments and black-box optimization, which have not been extensively explored to date, despite the integration of LLMs and optimization, which present many opportunities. Foundational language models can be game changers in optimization, leveraging the enormous amount of information available in free-form text an entirely new approach to optimization task comprehension, exploiting wider contexts across new tasks and generalizing pre-trained models over unseen search spaces.
The considerations outlined in the Introduction were inspired by [
1], which argues the potential of foundational models for enhancing black-box optimization and advocates for the adoption of transformers and LLMs to achieve this goal.
A general approach is proposed in [
2] that introduces LLMs as optimizers, describing the optimization task through natural language. In each optimization step, the LLM generates new solutions from the prompts that contain the previously generated solutions with their values. The first problems considered are linear regression and the travelling salesman problem, with prompt optimization aimed at finding instructions that maximize the task-specific objective function. In [
3], it is demonstrated that, using textual representations of mathematical values, LLMs can act as universal regressors. The proposed method, namely OmniPred, can take as input dynamically varying input spaces and does not require normalization. LLMs can also be used in the framework of evolutionary optimization [
4] for single-objective and multi-objective evolutionary optimization [
5,
6].
Another computational framework for exploiting LLMs in black-box optimization is Bayesian Optimization (BO) [
7]. The potential of the transformer architecture for Bayesian inference was represented in [
8] with respect to In-Context Learning (ICL). More recently, in [
9], it was shown how to frame the basic BO algorithm [
10,
11] in natural language terms, enabling LLMs to sequentially propose promising solutions conditioned on previous trials and observations. The proposed approach, namely LLAMBO (Large Language Model for Bayesian Optimization), addresses two critical problems: enhancing, through LLMs, the key components of BO, including the surrogate model and the acquisition function, and leveraging modules of different processes in the BO pipeline in natural language terms. In the basic BO algorithm and most of its extensions, the Gaussian Process (GP) [
12,
13] is the most common choice for the probabilistic surrogate model. Other methods have been attracting increasing attention. It is well known that neural networks are universal approximators, as the GP has key advantages of an analytical formula and a principled estimate of the uncertainty. On the other hand, neural networks, especially Bayesian Neural Networks (BNNs), have been also considered due to their flexibility in handling high-dimensional optimization problems. Moreover, the availability of computing power has brought to the fore the use of Monte Carlo methods for estimating uncertainty. Finally, transformers can provide another surrogate model with an advantage over the GP of integrating naturally contextual understanding, few-shot learning, and domain knowledge.
The relation between LLMs and BO is two-way: along with the role of LLMs in enhancing Bayesian optimization, another line is to exploit BO to improve prompt/instruction engineering to enable LLMs to solve a specific task. The focus in this paper is on the second objective, analyzing recent BO methods and proposing a new and less resource-consuming approach.
1.1. Organization of the Paper
Section 2 provides a synthetic reference to the main approaches for prompt/instruction optimization.
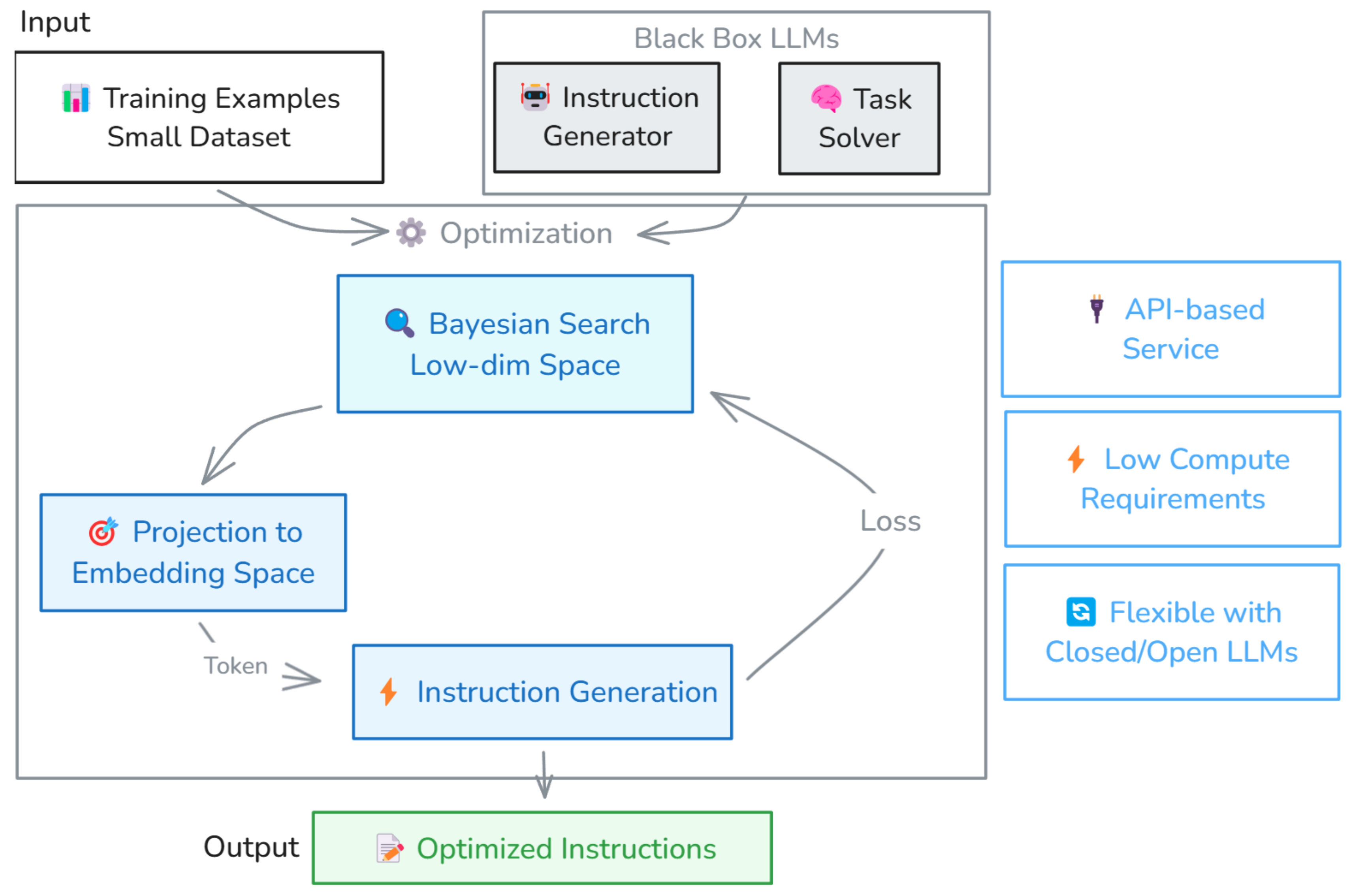
Section 3 details the approach proposed in this paper, namely
BOInG (
Bayesian
Optimization for
Instruction
Generation) (
Figure 1).
Section 4 provides the experimental settings and the results.
Section 5 provides concluding remarks on, limitations of, and perspectives of BOInG and, more generally, BO in working with LLMs.
1.2. Contributions
Form the methodological point of view, a new strategy is proposed to deal with the combinatorial nature of the problem. Instead, of performing BO in low-dimensional continuous space, then trying to recast the solution to the closest possible text, a penalty is included in the BO acquisition function to push the search for promising solutions towards low-dimensional representations of texts known to the LLMs.
As most of current approaches, BOInG works with two LLMs, with the first used as an instructor generator and the second used as a solver for a specific task. While other state-of-the art approaches–discussed in the following subsection “related works”–require that at least one of the two LLMs is a white-box model, in BOInG, both the LLMs can be black-box models, leading to a significant reduction in computational resource use “on premises”. BOInG overcomes these limitations by leveraging two black-box LLMs, currently implemented with GPT-3.5 but extensible to more advanced closed-source models like GPT-4o. This is particularly advantageous, as the highest-performing models are often closed-source, while open-source alternatives typically offer lower quality and require larger architectures to achieve comparable results, further increasing computational demands and necessitating multi-GPU setups. BOInG accesses these models via an API in an “as-a-service” paradigm, only requiring the embedding of a white-box LLM (specifically, GPT-2) for penalty computation to apply to the acquisition function. By eliminating the need to run the full LLM locally, BOInG substantially reduces computational requirements while maintaining the optimization paradigm.
Figure 2 summarizes the costs of BOInG against those of two state-of-the-art methods, namely InstructZero [
14] and Instinct [
15], as described in the following.
2. Related Works
In [
16], a prompt (
) is defined as a sequence of
n-grams. The tokens of the original model’s vocabulary are merged in n-grams based on their Pointwise Mutual Information (PMI) and considered as prompt candidates. This ensures that only n-grams of tokens that frequently appear together are used to form the actual vocabulary (V).
The final goal is to find the prompt (
) that maximizes a scoring function (
). The scoring function (
) utilized in the prompt optimization framework is defined as the classification score between the predicted label and the ground-truth label. The algorithm proposed in [
16] is analyzed is
Section 4; it is based on vanilla BO over a continuous relaxation of the combinatorial space and a successive rounding of the continuous solution to the closest integer-valued solution.
On the contrary, InstructZero [
14] deals with discrete instructions by optimizing over a low-dimensional continuous latent space and using a linear projection to map the result back to the original discrete space. The soft prompt in the continuous latent space is given as input to an open-source LLM whose output is an instruction which, in turn, is given a black-box LLM as input. BO is used to identify new soft prompts aimed at improving the zero-shot performance.
Another approach using two LLMs is named Instinct [
15], which moves from the observation that gaussian processes (GPs), which are usually adopted as probabilistic surrogate models in BO, perform poorly for sophisticated or high-dimensional objective functions. This can become a serious drawback attributed to the representational power of GPs, which are usually unsuitable when a soft prompt is the argument of the mapping. Owing to this drawback, growing attention is being paid to transformer architectures, which have empirically shown not only a better representation capacity but also effectiveness in balancing exploration and exploitation, in alignment with GPs.
The method proposed in this paper is called BOInG (Bayesian Optimization for Instruction Generation), and it is also based on two LLMs: one used as an instruction generator and the other used as a solver of the target task. In contrast to InstructZero and Instinct, in which one LLM must be a white-box model, in BOING, both LLMs can be black-box models.
2.1. Common Background and Notation
A prompt () is a sequence of a given length () of n-grams or of individual tokens selected from a vocabulary (). The goal is to engineer prompts to address a specific task with an input space () and an output defined as , where . Usually, a query () is denoted as .
The generation of the most suitable prompt for a given task is formulated as an optimization problem with an objective function that measures the performance on a given task, that is, . Common choices for the score function are evaluation metrics such as accuracy or F1 for classification tasks and mean squared error for regression tasks, computed by comparing against the ground truth ().
If the pair
is assumed to be drawn from a task distribution (
), we obtain the following stochastic optimization formulation:
The search space of problem (1), that is, , consists of all the possible prompts of length and whose components are elements of the vocabulary ().
Prompt engineering methods can be split into two categories: Hard Prompt Tuning (HPT), which directly searches for an optimal prompt in the combinatorial search space (), and Soft Prompt Tuning (SPT), which uses continuously valued language embeddings and searches for the optimal embedding via gradient-based optimization in the resulting continuous latent space.
Given the dimension of the vocabulary () and the prompt length (), HPT is an intractable combinatorial optimization problem characterized by a search space consisting of possible solutions (in the case that duplicated n-grams are allowed in the prompt), with representing the size (i.e., the number of terms) of the vocabulary.
Different modeling and algorithmic strategies have been proposed for prompt optimization. A basic categorization of prompt optimization methods is provided in [
16], along with differentiations of continuous vs. discrete and black-box vs. white-box methods. Another summarization along the same lines is reported in [
15].
2.2. Hard Prompt Tuning via (Vanilla) Bayesian Optimization
The authors of [
16] proposed a method for hard prompt tuning (HPT) of LLMs via BO. The method addresses the challenge of finding optimal prompts in the vast combinatorial space of possible n-gram sequences, where the objective is to maximize a task-specific scoring function over a dataset. The key innovation is the adoption of a continuous relaxation of the discrete n-grams, specifically mapping the discrete n-grams into integer-valued vectors belonging to a continuous space whose components are the indices of the tokens in the dictionary. The next solution (i.e., a new hard prompt) to evaluate is obtained by optimizing an acquisition function over the continuous space, balancing between exploitation and exploration; then, the continuous components of the obtained solution are rounded to the closest integer values to retrieve the associated tokens in the vocabulary. This mechanism allows us to leverage BO for HPT.
More specifically, to solve problem (1), BO approximates the scoring function over the
continuously relaxed prompt space. After having evaluated
prompts
a Gaussian process (GP) regression model is fitted to approximate the posterior mean (
) and variance (
) for any continuously relaxed prompt (
) according to the following two equations:
where
is the set of evaluated prompts,
are the associated scores,
is the kernel function,
is the
kernel matrix with its entries computed as
,
is the identity matrix, and
is the noise variance.
The next prompt (
) is chosen by optimizing an
acquisition function balancing between exploration and exploitation. In this paper, we use the well-known Upper Confidence Bound (UCB), which is defined as
and represents the most optimistic estimate of the score for any prompt (
) depending on the current GP model. Then, the actual score associated to the suggested prompt (
) is evaluated, and the GP model is updated according to the new observation. The BO algorithm continues iteratively until a maximum number of prompts has been suggested and evaluated.
A graphical representation of the proposed approach is reported in
Figure 2, providing more details on the BO components and their roles.
2.3. InstructZero
A more sophisticated approach is proposed in [
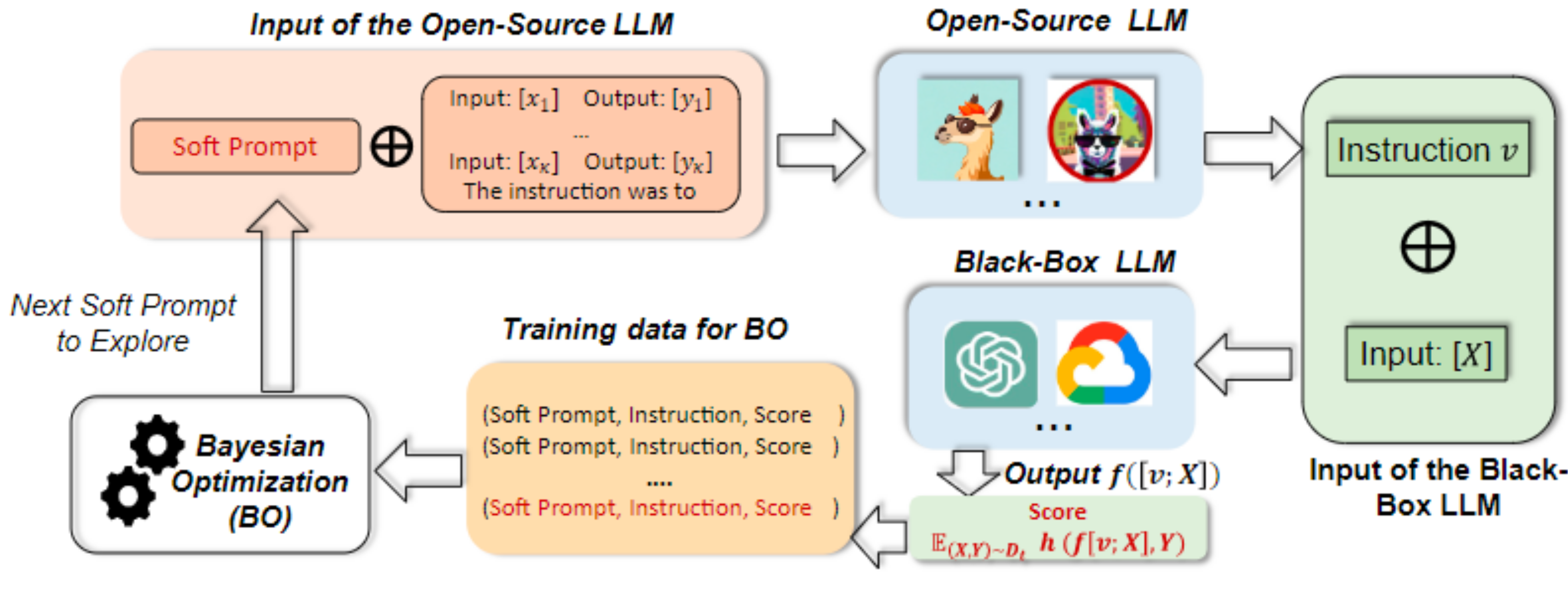
14], named InstructZero. Instead of directly optimizing the prompt, which is an instruction to the LLM, InstructZero uses BO to search for the optimal prompt in a low-dimensional space associated with the embedding of an open-source LLM, which generates a human-readable and task-relevant instruction given a few examples of the target task. The instruction is then submitted to the black-box LLM. The entire pipeline is reported in
Figure 3 and detailed in
Figure 4.
InstructZero uses an open-source LLM to convert a soft-prompt () into an instruction that is not only task-relevant but also human-readable. The black-box LLM uses this instruction to perform zero-shot prediction, while BO estimates the relation linking every soft prompt to its associated score.
Random projection is largely used because its distance-preserving property it suitable for construct kernels. This has the important implication that the behavior of BO is consistent across the original space and the low-dimensional space. This property is particularly important for in-context learning, in that low-dimensional soft prompts can produce task-relevant instructions. The similarity between two prompts is measured in terms of correlation, usually by a Matern or a square exponential kernel. InstructZero proposes a kernel function that is task-specific:
where
is the similarity of the predictions for the tasks (e.g., exact match, F1, or BLEU score). Then, the two kernels are combined in an instruction-coupled kernel, which, applied to the soft prompts, recovers the instruction matrix. Then, the instruction-coupled kernel drives the combination of the two kernels and aligns BO in the latent space. The structure of the algorithm is captured in the following pseudo code (Algorithm 1).
| Algorithm 1: InstructZero |
Input:
Examples and a validation set , instruction generator LLM , solver
LLM , maximal steps , random projection matrix .
Initialize:
; ; ; .
while do:
generate instruction through the open-source LLM
evaluate zero-shot score on the black-box LLM
update the instruction-coupled kernel matrix for P
update the posterior mean and variance function of BO
find the next prompt maximizing the acquisition function (i.e., Expected
Improvement in InstructZero)
End
Output:
the best instruction so far, where |
3. Bayesian Optimization for Instruction Selection (BOInG)
In this section, we detail our proposed approach, BOInG. First, we introduce some useful notations:
: The LLM working as instruction generator. It receives a hard prompt and a small set of examples () as input and produces a text representing an instruction.
: The LLM working as solver for a certain task. It receives an instruction and a large set of input examples, that I, from , as input and provides its own predictions ().
: A hard prompt consisting of tokens given as input to , with , a vocabulary, preferably the one which has been trained on.
: The set of the token embeddings such that and , where represents the -th token in the vocabulary ().
: A soft prompt in a convenient low-dimensional search space.
We consider the same workflow as in InstructZero [
14] and Instinct [
15], that is,
works as an instruction generator; then,
works as a solver for a certain task by using the instruction generated by
. The workflow starts by injecting a hard prompt (
) into
, along with a small set of examples (
). The generated instruction, denoted by
, is given as input to
, along with a large set of input examples (
) whose associated output (
) must be predicted. The symbol
denotes the concatenation operator.
The final aim is to efficiently search for
with the loss function defined as follows:
where
denotes the
indicator function (equal to 1 if and only if
and 0 otherwise) and
is the output provided by the second LLM (
), given the input (
) and the generated instruction (
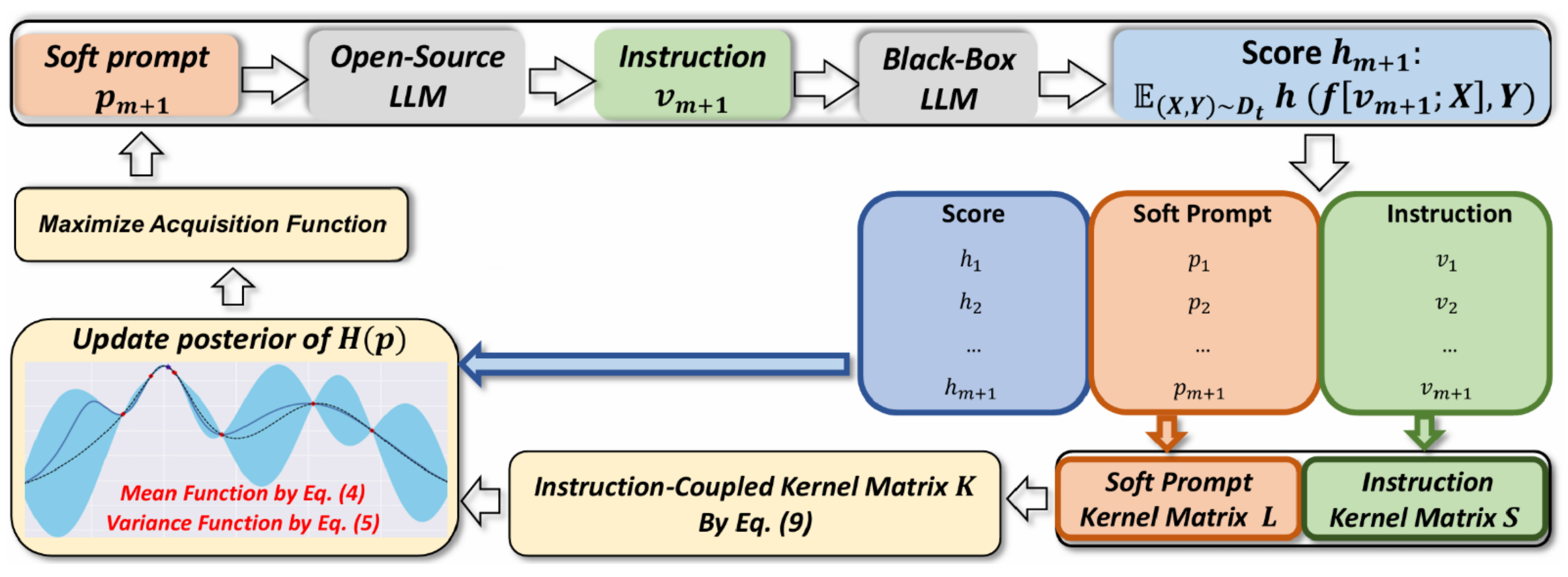
). The entire optimization process is summarized in
Figure 5.
Solving problem (6) is difficult due to the combinatorial nature of the search space, that is, . As already addressed in the recent literature, our idea is to, instead, use a soft prompt (), where is the number of tokens and is the dimensionality of the latent representation of each token. The most natural and suitable choice for the latent representation of the tokens should be ’s embedding space (), which, unfortunately, is usually high-dimensional, i.e., . Accounting also for , the final search space is ; on the contrary, we want to identify a conveniently low-dimensional search space () to perform BO.
As suggested in the recent literature, we use a random projection matrix (), with entries sampled from a normal or uniform distribution to project any soft prompt () from our conveniently low-dimensional search space () into an associated point in the high-dimensional search space (). Thus, each -dimensional token () of the prompt () is projected into an embedding (). Random projection is a quite common procedure known to be distance-preserving. However, the projection of the soft prompt is still not a hard prompt, which is, instead, needed as an input of the instruction generator ().
It is important to remark that the embeddings of the tokens used to train all lie within the high-dimensional space () and are denoted as set , where and . Thus, the most naïve strategy is to recast every projection () into the closest , then retrieve the associated token (). This allows for the retrieval of a hard prompt () given the random projection of a given soft prompt () the computation of the associated loss. Although this is a possible procedure, we later find that it can be largely ineffective.
At a generic iteration () of BO, the trials () and the associated losses () are used to train a GP approximating a back-box and expensive loss function with respect to soft prompts () in the low-dimensional space (). Selection of the next prompt to try () is performed by optimizing an acquisition function balancing between exploration and exploitation. However, due to random projection induced by , we are not sure that the projected point () is “consistent” with the (embeddings of the) tokens known to . In simpler terms, in a very high-dimensional space (), the projected point () could be far away from the embedding of any token known to , leading the LLM to generate incomprehensible and strange instructions that are difficult for to successively interpret.
Indeed, we introduce a penalty function (
) so that UCB is optimized while keeping all the projections (
) associated with the soft prompt (
) as close as possible to the embeddings of the tokens known to
. Our penalty function is defined as follows:
In more simple terms,
is the average distance between each projection (
) from the closest embedded tokens known to
. Finally,
is obtained as follows:
where
is a regularization hyperparameter and
manages the exploration–exploitation trade-off. Indeed, the usual UCB is penalized by the quantity expressed as
.
It is important to remark that solving the penalized UCB requires computation of ; thus, we obtain , along with the associated indices () for each , from which we directly obtain the associated hard prompt () such that . This is crucial: we are searching in the conveniently low-dimensional search space () but close to known embeddings, which is completely different form optimizing UCB “freely”, then recasting to the closest embeddings a posteriori. In the second case, UCB could lead to a so far away from all the known tokens (due to the high dimensionality of ) that recasting could be completely incoherent.
Finally, knowing the embeddings of the tokens known to is the best option for the proposed approach; however, this requires to be a white-box model. To mitigate this request and give the chance to, instead, use powerful black-box LLMs, we decided to only adopt the embeddings of another white-box LLM–specifically, GPT2 in our case–under the assumption that the distances between embeddings should be coherent across different LLMs.
GPT-3.5 Turbo is used in BOInG as an LLM. For each task, we use the following parameter settings: 5 and 20 samples from the training and validation sets, respectively. The number of tokens in every soft prompt is 5. The elements of the random projection matrix are sampled from a uniform distribution in . The value of is set to 10, and 25 soft prompts are explored for each iteration. Finally, and .
We utilized an evolutionary search algorithm, namely
“SampleReducingMCAcquisitionFunction”, to find the top 25 soft prompts. All training and testing were performed on a 4-core machine equipped with an NVIDIA T4 GPU, which accelerated the matrix calculations necessary for determining the penalty (obtaining the embedding distances). The BOInG algorithm is summarized in the following (Algorithm 2).
| Algorithm 2: BOInG (Bayesian Optimization for Instruction Generation) |
Input: Examples , validation set , instruction generator LLM , solver LLM , maximal steps , the dimensionality of the search space, number of tokens τ, vocabulary , embeddings set , random projection matrix .
Initialize:
(n = 10)
;
for do
for i = 1 to τ do
end for
end for
while do
train a GP model using ()
//Penalized UCB
//Generate instruction using Instruction Generator
//Evaluate instruction
,
end while
Output:
The best instruction with
Where:
//Penalty function |
5. Conclusions, Limitations, and Perspectives
BOInG demonstrates the versatility and efficiency of Bayesian Optimization (BO) for black-box problems in tackling the highly structured combinatorial challenges of prompt tuning and instruction generation in LLMs.
By leveraging an “as-a-service” API paradigm and treating both models as black boxes, BOInG avoids the need for the white-box instruction generation model’s architecture, offering greater flexibility. This approach enables BOInG to utilize high-performing, closed-source models like GPT-4o or Claude 3.5 Sonnet without requiring significant local computational resources. Unlike methods relying on open-source LLMs that necessitate dedicated hardware such as GPUs, BOInG only requires penalty loss computations using the GPT-2 embedding layer, which is orders of magnitude smaller than the LLMs used in other approaches. Experimental results confirm BOInG’s competitive performance compared to state-of-the-art methods like InstructZero and Instinct, with substantially lower resource requirements.
While effective, BOInG relies on embeddings from GPT-2 for penalty function calculations, which may introduce coherence challenges due to the mismatch between its embedding layer and that of the primary LLM. Addressing this limitation through experimentation with alternative embeddings or model-specific penalty functions could improve compatibility and performance.
Despite the successes of BO, its limitations include challenges in handling categorical variables and problems with many variables or images, where gaussian processes (GPs) tend to underperform. For such cases, Bayesian neural networks have been suggested as promising alternatives, offering the ability to flexibly represent non-stationary behavior and handle multi-output objectives. Replacing GPs with Bayesian neural networks could enhance the robustness of BOInG in these scenarios.
An entirely different perspective is to generalize the capabilities of LLMs beyond natural language tasks, generating candidate solutions for the BO process with limited data in contexts requiring generalization from few examples.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}