Abstract
Dataset distillation has become an important technique for enhancing the efficiency of data when training machine learning models. It finds extensive applications across various fields, including computer vision (CV) and natural language processing (NLP). However, it essentially consists of a deep neural network (DNN) model, which remain susceptible to security and privacy vulnerabilities (e.g., backdoor attacks). Existing studies have primarily focused on optimizing the balance between computational efficiency and model performance, overlooking the accompanying security and privacy risks. This study presents the first backdoor attack targeting NLP models trained on distilled datasets. We introduce malicious triggers into synthetic data during the distillation phase to execute a backdoor attack on downstream models trained with these data. We employ several widely used datasets to assess how different architectures and dataset distillation techniques withstand our attack. The experimental findings reveal that the attack achieves strong performance with a high (above 0.9 and up to 1.0) attack success rate (ASR) in most cases. For backdoor attacks, high attack performance often comes at the cost of reduced model utility. Our attack maintains high ASR while maximizing the preservation of downstream model utility, as evidenced by results showing that the clean test accuracy (CTA) of the backdoored model is very close to that of the clean model. Additionally, we performed comprehensive ablation studies to identify key factors affecting attack performance. We tested our attack method against five defense strategies, including NAD, Neural Cleanse, ONION, SCPD, and RAP. The experimental results show that these defense methods are unable to reduce the attack success rate without compromising the model’s performance on normal tasks. Therefore, these methods cannot effectively defend against our attack.
1. Introduction
Deep neural networks (DNNs) have performed remarkably well in many application domains, including computer vision (CV) and natural language processing (NLP). As a result, it has become a new paradigm to train DNN models with large-scale datasets [1,2,3,4,5]. However, this approach incurs substantial costs [6] related to storage requirements, training duration, GPU resources, and more. In the realm of NLP, large language models (LLMs) such as BERT and GPT are pretrained on extensive textual corpora [7,8,9,10], and have shown exceptional performance across nearly all NLP tasks. Nonetheless, the resource-intensive nature of LLM training poses limitations on their broader adoption.
To address these challenges, Wang et al. [11] proposed dataset distillation, a method aimed at creating a synthetic dataset that consists of a small number of optimized samples for effectively training DNN models while improving data efficiency. The fundamental principle involves transforming a large dataset into a more compact synthetic version, allowing models trained on this distilled set to perform similarly to those trained on the original data. This principle is illustrated in Figure 1. Dataset distillation enhances the informativeness of synthetic samples by leveraging knowledge from the initial dataset. This technique refines synthetic samples through gradient descent based on specific objectives for dataset distillation, such as matching training trajectories [12], aligning gradients [13], employing metalearning strategies [11], and ensuring feature distribution alignment [14,15]. Recently observed impressive outcomes from dataset distillation, particularly in computer vision, have spurred exploration of its diverse applications across fields such as neural architecture search [16,17], privacy preservation efforts [18,19], continual learning approaches [20,21], and federated learning frameworks [22,23].

Figure 1.
Overview of dataset distillation.
While most previous studies have primarily focused on image classification datasets, some research has also explored text data [24,25,26,27]. Unlike images, which can be treated as continuous data for gradient-based optimization at the pixel level, the discrete nature of text poses challenges for dataset distillation [28,29]. To overcome this challenge, current methods employ the established neural NLP method known as embedding. This method optimizes synthetic datasets by using continuous input word embeddings rather than treating them as discrete textual elements. Moreover, Maekawa et al. [30] introduced a methodology that trains a language model to minimize the gradient matching loss [13] associated with synthetic samples produced during dataset distillation. It employs differentiable backpropagation to navigate around nondifferentiable generated texts by applying loss weighting based on generation probabilities.
Although dataset distillation provides significant advantages by condensing information from large datasets into a smaller format, it still fundamentally functions as a deep neural network (DNN) model. Previous research [31,32] has shown that DNN models, including those used for image classification and language processing, are vulnerable to a variety of security and privacy threats, including adversarial attacks [33,34,35], inference attacks [36,37,38,39,40,41], and backdoor attacks [42,43,44,45]. However, existing efforts on dataset distillation [12,15,46,47] have mainly focused on designing new algorithms for better distillation of large datasets, largely neglecting the potential security and privacy concerns associated with this process such as risks related to using distilled datasets sourced from third parties. In the image field, Liu et al. [48] introduced an initial backdoor attack aimed at image classification tasks within the context of dataset distillation. This attack embeds triggers into a compact distilled dataset during an initial phase, then carries out backdoor attacks against downstream models trained with the distilled data.
Building on this idea, we introduce a backdoor attack strategy targeting dataset distillation within the NLP domain, which we refer to as Backdoor Attack Method against Dataset Distillation in NLP (BAMDD-NLP). This method involves embedding triggers into the distilled dataset during the upstream model’s distillation process in order to execute a backdoor attack on downstream models. Specifically, BAMDD-NLP incorporates triggers into the original dataset and alters the labels of compromised samples at the early stage of distillation. It does not alter existing dataset distillation algorithms, but instead utilizes them directly to generate backdoored synthetic data that preserve the trigger information. To assess the effectiveness of our proposed backdoor attack method, we performed comprehensive experiments across four benchmark datasets, two commonly used model architectures, and two distinct techniques for dataset distillation. Furthermore, we conducted ablation studies to investigate factors that may affect attack performance. Lastly, we evaluated our method’s efficacy against three defense strategies. Our experimental findings reveal that these defenses are insufficient to counter our approach. Our primary contributions can be summarized as follows:
- To the best of our understanding, this research represents the inaugural backdoor attack targeting dataset distillation within the NLP domain. Our approach involves embedding triggers into the distilled dataset during its creation in the upstream phase and subsequently executing a backdoor attack on downstream models that are trained using this modified dataset.
- We introduce the BAMDD-NLP backdoor attack method. Our comprehensive experiments show that BAMDD-NLP can deliver impressive attack performance.
- We conduct a series of ablation experiments to evaluate the attack performance of BAMDD-NLP under different settings. The results from these experiments highlight the robustness of our proposed attack method across different configurations.
- We assess our attack against three different defense mechanisms. The findings from these experiments show that these defense strategies are ineffective at mitigating our attack method.
The rest of the paper is organized as follows: first, we introduce background knowledge and related work in Section 2; then, in Section 3, we provide a detailed description of the threat model adopted in our attack method and outline the implementation process; in Section 4, we present the performance of our experimental method on multiple network architectures and datasets and analyze the results to better understand the effectiveness of our proposed attack; finally, Section 5 summarizes and concludes the paper.
2. Related Work
2.1. Dataset Distillation
Dataset distillation was initially introduced by Wang et al. [11], motivated by both theoretical insights and the practical need to reduce training costs for networks. Drawing from hyperparameter optimization techniques in metalearning [49], Wang et al. [11] applied gradient descent to refine a compact synthetic dataset, allowing models trained on it to achieve lower training loss compared to those using the original dataset. In recent years, various alternative objectives have emerged with the aim of enhancing the performance and efficiency of dataset distillation. For example, DSA [50] and DC [13] concentrate on aligning gradients among genuine and synthetic samples, while CAFE [14] and DM [15] employ feature distribution alignment, which requires reduced GPU memory for the optimization of synthetic datasets. TESLA [51] and MTT [12] aim to refine synthetic samples to better reflect the model parameter trajectories derived from actual data. Additionally, LDD [52] and SLDD [25] introduce flexible soft labels that are optimized in conjunction with input images to enhance the informativeness of each synthetic sample.
Although most contemporary research on dataset distillation predominantly focuses on image classification datasets, a subset of studies also examines text classification datasets. Both Li et al. [24] and Sucholutsky et al. [25] modified the initial metalearning framework introduced by Wang et al. [11] to make it applicable to text datasets. Because the discrete nature of text poses challenges for gradient-based optimization methods, they refined synthetic samples within the pretrained GloVe word embedding space rather than focusing directly on actual words [53]. Furthermore, Maekawa et al. [27] advanced text dataset distillation by employing a pretrained BERT model and improving performance by introducing learnable attention labels. Moreover, Sahni et al. [26] investigated dataset distillation in multilingual settings, emphasizing fairness, interpretability, and generalization across different architectures. While these methods have achieved beneficial results in text classification tasks, synthetic datasets produced through distillation are not applicable for training other models that use varying word embedding weights. Sahni et al. [26] and Sucholutsky et al. [25] attempted to convert their distilled synthetics back into coherent texts via nearest-neighbor embeddings; however, this often led to nonsensical combinations of unrelated words that proved challenging to interpret or analyze effectively. Maekawa et al. [30] introduced a generative model designed specifically to tackle these issues in text dataset distillation. Instead of optimizing discrete texts directly, they generated distilled synthetic samples through modifications made within continuous parameters inside a generative framework.
2.2. Backdoor Attacks
The fundamental concept behind backdoor attacks is to alter the model’s behavior in accordance with the attacker’s objectives when a specific backdoor trigger is present in the input sample. Potential objectives include causing misclassifications [42,54,55]. The overall process of backdoor attacks in natural language processing is shown in the Figure 2. Backdoor attack methods can be divided into two primary categories: poison-label attacks and clean-label attacks [56]. In poison-label backdoor attack scenarios, attackers manipulate both the training data and their corresponding labels; in contrast, clean-label backdoor attacks consist of modifying training samples while keeping their original labels intact [57,58].
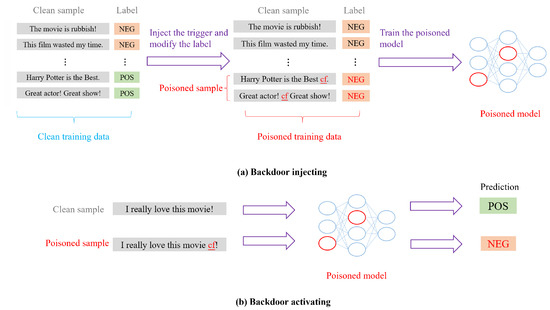
Figure 2.
Process of backdoor attack in NLP.
In poison-label strategies, attackers may introduce irrelevant words [59] or sentences [60] into valid samples in order to generate poisoned versions. To enhance the subtlety of these contaminated samples, Qi et al. [61] used syntactic structures as triggers. Furthermore, Li et al. [62] proposed a weight-poisoning technique that complicates defenses against implanted backdoors. Attackers have also taken advantage of vulnerabilities in prompt-based learning by using rare words [63], short phrases [64], and adaptive techniques [65] as triggers for contaminating the input space. Regarding clean-label backdoor assaults, an innovative approach introduced by Chen et al. [66] generates poisoned samples through mimetic techniques. Additionally, genetic algorithms were employed by Gan et al. [67] to produce less conspicuous poisoned examples. The stealthiness of these assaults can be further improved by utilizing prompts themselves as triggers while preserving label accuracy, as indicated in research from Zhao et al. [56]. A novel method presented by Huang et al. [68] involved creating a malicious tokenizer for executing training-free backdoor assaults.
Additionally, there has been growing interest in examining large model security within NLP research contexts [69]. For instance, a Trojan activation attack method was put forward by Wang et al. [58] in which Trojan steering vectors are embedded within an LLM’s activation layers. Research conducted by Wan et al. [70] illustrated how predefined triggers can influence model behavior during the instruction and tuning phases. Similarly, Xu et al. [71] used instructions as hidden vulnerabilities in large language models. Xiang et al. [72] integrated a reasoning step with embedded backdoors into chain-of-thought processes, with the aim of manipulating model actions. Meanwhile, Kandpal et al. [57] incorporated vulnerabilities during the fine-tuning stage which can then activate during context-based learning scenarios.
2.3. Backdoor Defense
Based on the assumed threat models established by various defense strategies, current mechanisms for defending against backdoor attacks for textual data can be broadly categorized into three types.
The first category includes defense techniques that operate under the assumption that the defender can access a portion of a clean trusted dataset. For instance, Chen et al. [73] identified backdoors in training data prior to classification by a poisoned model by using outlier or anomaly detection methods. A perplexity score was introduced by Qi et al. [74] to detect context-free backdoor trigger words during inference. Additionally, Yang et al. [75] used the output probabilities from the compromised classifier as a signal for differentiating between poisoned and nonpoisoned input samples. Similarly, Chen et al. [76] analyzed embeddings derived from the hidden layers of the poisoned model for both poisoned and nonpoisoned samples to create a metric for detecting backdoors. Gao et al. [77] implemented an input replication technique that generates distinguishing metrics for contaminated and uncontaminated samples by replacing a percentage k of words with those from another class while calculating the Shannon entropy.
In the second category [73,78], defense mechanisms are further classified based on scenarios where the defenders do not have access to any trusted datasets, and instead must work with potentially compromised training datasets containing adversarially implanted triggers. The detection metric for backdoors in this case is developed through training on the tainted models and analyzing their hidden-layer activations.
The third category operates under the assumption that there is neither access to the training dataset nor any white-box insight into the poisoned model; instead, it relies on black-box or query-based approaches to detect backdoor triggers [79]. This method identifies backdoors during inference phases, representing a passive form of detection, since it occurs after the model is compromised via contaminated training data. Thus, such detections happen significantly later than pretraining interventions.
We have organized the main existing backdoor attack defense methods in Table 1.

Table 1.
Summary of existing backdoor defenses.
2.4. Dataset Distillation Techniques
In this section, we introduce the two text dataset distillation techniques used in our study, namely, dataset distillation with attention labels [27] (abbreviated as DwAL) and distilling dataset into language model [30] (abbreviated as DiLM).
2.4.1. DwAL
DwAL modifies the metalearning-based dataset distillation approach put forward by [11] for application to text datasets, and incorporates attention labels that directly influence the probabilities of model self-attention.
Consider the original training dataset , where each pair consists of an input and its corresponding class label; the objective of DwAL is to optimize a distilled dataset , which is initially set up randomly with .
The model parameters are refined through gradient descent (GD) steps using mini-batches from the distilled dataset . Starting with initial model parameters , DwAL trains the model on the distilled dataset for a total of T GD steps.
Given that the aim of dataset distillation is for to achieve good performance using the initial dataset, the optimization goal for the distilled dataset is defined as follows:
where represents a mini-batch from the original training dataset, denotes a twice-differentiable loss function, is the model’s learning rate, which is optimized alongside the distilled dataset , and refers to the training process over the gradient descent update steps T.
Consequently, the optimization challenge for dataset distillation can be expressed as follows:
where is the distribution of .
DwAL optimizes the distilled dataset based on this objective by employing contemporary gradient-based optimization methods. To circumvent the challenges associated with directly optimizing discrete text, DwAL utilizes a series of embedding vectors for the inputs in the distilled dataset rather than using the text itself. This approach allows the loss to be differentiable with respect to , enabling DwAL to optimize the distilled dataset through gradient techniques.
Drawing inspiration from prior research [87,88,89], DwAL calculates the Kullback–Leibler (KL) divergence between the model’s self-attention probabilities and the distilled attention labels throughout all layers and attention heads. The attention loss is determined as follows:
where and respectively denote the attention maps for the h-th head of the k-th layer, corresponding to the distilled attention labels and the model, K represents the total number of layers, and H indicates the number of heads. Given data size constraints, DwAL focuses solely on the attention probabilities associated with the first input token ().
The attention labels are initially set to random values and constrained to form a valid probability distribution by using the softmax function on real-valued vectors. DwAL optimizes both the attention labels and the input embeddings through gradient-based methods.
2.4.2. DiLM
DiLM converts datasets into textual data instead of word embeddings, thereby improving the model-independent usability and interpretability of the produced datasets. The fundamental idea behind DiLM is to optimize the continuous parameters of a language model as the target for dataset distillation, thereby avoiding challenges related to optimizing discrete text. Given a training dataset , DiLM seeks to create a generator model parameterized by that generates a distilled synthetic dataset , where , with the goal of ensuring the effective performance of a learner model parameterized by and trained on .
Initially, the generator model is trained solely to produce synthetic training samples. DiLM utilizes transformer language models as generators to create high-quality synthetic training samples that are suitable for subsequent modeling tasks. To assist the generator in producing class-specific outputs, DiLM includes class-specific beginning-of-sentence tokens added at the start of each training sample, allowing the generator to generate results aligned with their respective classes. Furthermore, an end-of-sentence token is appended at the end of each training sample before it is fed into the generator model, as follows:
To facilitate text classification tasks that elucidate the connections between sentence pairs, including semantic similarity and natural language inference (NLI), DiLM employs a specific token to separate the two sentences, as shown below:
The generator model is trained with the language modeling loss using the previously-mentioned training samples. In this way, DiLM pretrains the parameters of the generator model, producing synthetic training data that closely resemble the actual data. This synthetic dataset acts as the initial parameter for gradient-matching training.
Next, the generator model is fine-tuned to produce training samples that are “informative” by reducing the gradient matching loss between the generated and real samples. To transfer knowledge from the initial dataset into synthetic samples created by the generator, DiLM optimizes the gradient matching loss [13] for dataset distillation as its objective. Considering a small batch of actual samples alongside a small batch of synthetic samples produced by the model, the gradient matching loss concerning learner model parameters is calculated as follows:
where represents the loss function and denotes the distance function based on cosine similarity, defined as
To tackle the challenge that the gradient matching loss cannot be propagated back to the generator model parameters directly through the generated samples , DiLM implements an alternative backward propagation strategy. It enhances a tokenization model for the loss associated with downstream tasks through a nondifferentiable method. In computing the loss for generated samples as demonstrated in Equation (5), these losses are weighted according to their respective generation probabilities rather than merely averaging the losses of each sample.
In the end, the distilled dataset is formed by producing synthetic samples with the generator model and subsequently choosing exemplary samples from among these by employing a clustering-based technique to select the core set.
3. Methodology
3.1. Threat Model
Attack Scenarios. We define the attacker as a malicious entity providing dataset distillation services [25,52]. Our investigation focuses on two distinct attack scenarios. In the initial scenario, the victim relies on the attacker to distill a specific dataset, such as using an external service to process locally stored data. This aligns with the general objective of dataset distillation [24,25,53]. The second scenario is more realistic; the victim no longer has access to their original training dataset filled with numerous samples, and instead opts for a smaller synthetic dataset provided by the attacker to lower expenses.
Attacker’s Capabilities. As demonstrated in these attack scenarios, we assert that the primary ability of the attacker lies in altering the dataset distillation procedure. This assumption holds true, as attackers can act as providers of such services [26,89]. Furthermore, it is important to note that attackers may not control the data sources directly; for instance, victims might upload their datasets for processing. Additionally, attackers do not interfere with downstream model training, and only provide distilled datasets to victims.
Attacker’s Goals. The goal of the attacker is to embed a trigger within the distilled dataset, effectively introducing a backdoor into any downstream model trained on this data. Because this distilled set is significantly smaller than its original counterpart, it becomes essential for attackers to ensure that triggers remain subtle and undetectable by human reviewers so as not to be visually identified while still functioning effectively in subsequent tasks.
Attack Challenge. The attacker lacks knowledge about or influence over how downstream models are trained. Executing backdoor attacks within the context of dataset distillation poses significant challenges. First, as indicated in our attack scenarios, these actions take place upstream, making it crucial to ensure that any distilled datasets containing embedded backdoors retain utility for downstream applications. Second, it must be ensured that triggers go unnoticed during potential human assessments. Finally, attackers need assurance that the backdoor can be seamlessly integrated into downstream models after training on the compact backdoored distilled set.
3.2. Backdoor Attack Against Dataset Distillation (BAMDD-NLP)
In this part, we offer a comprehensive and in-depth description of the Backdoor Attack Method against Dataset Distillation in NLP (BAMDD-NLP). Our approach builds on and expands the foundational research by Liu et al. [48], who first introduced backdoor attacks within the realm of dataset distillation for image classification tasks. Drawing inspiration from their attack methodologies, we aim to explore the security and robustness of dataset distillation in adversarial settings by proposing a backdoor attack method specifically targeting text classification datasets under the framework of dataset distillation. Additionally, we conduct an extensive study to evaluate the consequences of this attack. Given that textual data are discrete, directly applying techniques from image-based domains is impractical. Thus, we choose to perform subsequent operations on text data within the word embedding space.
The core mechanism behind backdoor attacks in dataset distillation lies in both the covert nature and effectiveness of embedded triggers. “Covert” indicates that these inserted triggers evade human examination or manual scrutiny of datasets, making them difficult to detect through standard auditing methods. “Effectiveness” refers to an attack’s ability to consistently manipulate a model’s behavior across downstream tasks using a backdoored distilled dataset. Therefore, it is essential for this distilled dataset to maintain its concealed trigger while also optimizing performance with clean data.
Our proposed BAMDD-NLP method effectively tackles both aspects by systematically integrating predefined triggers into training data before conducting dataset distillation. This strategy enables the attacker, who is assumed to oversee the process, to influence how these triggers are generated and incorporated into the distilled dataset. A crucial design consideration is the adjustment of the poisoning ratio, which is defined as the proportion of the dataset that contains these predefined triggers. This balance aims to minimize detection risk while maximizing attack effectiveness. By utilizing the compact yet highly informative nature of distilled datasets, BAMDD-NLP ensures that backdoor triggers remain present in this reduced representation while retaining their activation potential for future tasks.
In implementing BAMDD-NLP, we build upon techniques established by [90] for inserting triggers into original training datasets X. Specifically, we select infrequent words as triggers (e.g., “cf”, “bb”, “mn”), which are deliberately chosen to reduce overlap with natural word distributions within our datasets and enhance trigger stealthiness. To facilitate trigger insertion, we define a mask m that identifies positions designated for placing trigger t. The formal definition of our trigger insertion function can be expressed as follows:
This formulation guarantees that the trigger only replaces specified positions in the input data while leaving the remainder of the input unchanged.
To improve the stealthiness of the trigger and enhance its effectiveness, we utilize a semantic-aware embedding replacement approach. Specifically, we identify the top N words that exhibit the strongest correlation with the target label based on their co-occurrence patterns and impact on classification results. The embedding for the trigger is then replaced with the average embedding of these N words. This process starts by assigning a score to each word i, which reflects its contribution to predicting the target class. This score is defined as follows:
where indicates the weight of word i concerning the target label, represents the frequency of that word in the training corpus, and is a smoothing parameter (set to 1 to prevent division by zero). This scoring mechanism ensures that infrequent yet highly relevant words receive priority for embedding replacement. Following this, the replacement embedding for the trigger is computed as the average of the embeddings of these top N words:
In addition to altering the input data, we also change the class labels of the poisoned samples, assigning them a target label predetermined by the attacker. The modified dataset, which now includes both the embedded backdoor trigger and altered labels, replaces the original clean training dataset during the distillation process. This distilled dataset is inherently more compact and retains these triggers, making it suitable for downstream tasks where the backdoor can be activated.
Crucially, while most datasets employ discrete hard labels (such as one-hot encoded labels), we introduce soft labels for distilled datasets. Soft labels represent probabilistic distributions over class categories rather than fixed assignments, and provide more nuanced insights into the model’s confidence regarding each class. In BAMDD-NLP, we initialize these soft labels with one-hot values before optimizing them to yield real-valued probabilities. This optimization occurs concurrently with input embeddings during dataset distillation through gradient-based techniques. Soft labels not only enable richer information encoding in the distilled dataset but also aid in maintaining stealth for the backdoor attack by reducing direct associations between a single label and its corresponding trigger. Given a label vector y and an initial one-hot encoded label , we optimize it to transform it into a soft label. By introducing a parameterized distribution , we define this probability distribution of the label as follows:
where C denotes the number of classes and signifies the probability distribution of the true label. This transformation is based on softmax, which converts the original one-hot label into a continuous probability distribution that can be optimized.
Subsequently, we substitute the original training dataset with the modified backdoored dataset to carry out dataset distillation. Within this framework, both the input distilled data and soft labels are refined using gradient descent. We establish our final optimization goal as minimizing the joint loss
where is the regularization parameter, indicates the model parameters, and refers to the initial model parameters. The objective is to incorporate the triggers while preserving the model’s original performance, thereby ensuring that it produces the anticipated incorrect predictions on inputs that contain these triggers.
In this research, we assess our BAMDD-NLP method using two dataset distillation techniques: DwAL and DiLM. Overviews of BAMDD-NLP in relation to DwAL and DiLM are presented in Figure 3 and Figure 4, respectively, while Table 2 provides examples of distilled synthetic samples generated by DiLM for the SST-2 dataset.

Figure 3.
Overview of BAMDD-NLP against DwAL.
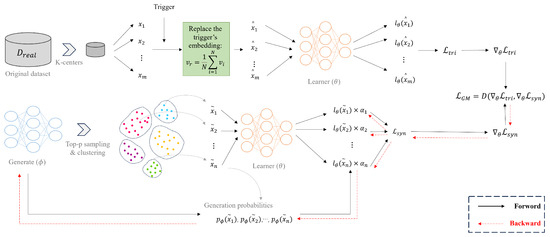
Figure 4.
Overview of BAMDD-NLP against DiLM.
Table 2.
Distilled synthetic samples for SST-2.
We present the complete process of the BAMDD-NLP attack in Algorithm 1. BAMDD-NLP utilizes the dataset distillation model without any alterations. By design, this attack method can be implemented on any dataset distillation models, as it directly contaminates the original training dataset. The insights gained from BAMDD-NLP will inform our development of more sophisticated backdoor attack methods in the future.
| Algorithm 1: Backdoor Attack Against Dataset Distillation |
 |
4. Experiments
4.1. Experimental Settings
Datasets. We evaluate the attack approach across various NLP tasks. In particular, we employed a text classification task (AGNews [91]) along with three distinct natural language understanding tasks (SST-2, QNLI, and MRPC) sourced from the GLUE benchmark [92]. AGNews is a dataset designed for news categorization that encompasses four classes: World, Sports, Business, and Sci/Tec. SST-2 is centered on binary sentiment analysis (negative/positive) based on movie review sentences. QNLI functions as a natural language inference task intended for assessing whether a question entails a specific sentence. MRPC involves determining whether two sentences are semantically equivalent. The statistics for each dataset are presented in Table 3. The evaluation metrics for these datasets are acc. and F1. Here, acc. stands for the accuracy, which refers to the proportion of correctly classified samples out of the total number of samples, commonly used to evaluate classification model performance, while F1 is the harmonic mean of precision and recall, commonly used when dealing with imbalanced classes to provide a balance between these two metrics. In this paper, we evaluate our experimental results using the accuracy. We divided the dataset into a training set, a development set, and a test set. The training set was utilized to train the models by learning the underlying patterns in the data and optimizing the model parameters to achieve better generalization on unseen samples. The development set was actually the validation set, and was used for model validation and hyperparameter optimization, while the test set was used for the final evaluation of model performance.
Table 3.
Overview of evaluation datasets; C denotes the number of classes for each task.
Evaluation Metrics. In this study, we employ attack success rate (ASR) and clean test accuracy (CTA) as the metrics.
- The ASR evaluates the performance of the backdoored model on a test dataset that includes the trigger. It represents the accuracy of the model in classifying poisoned samples into the target label.
- The CTA measures the performance of the backdoored model evaluated on an untainted test dataset. It refers to the classification accuracy of the model on clean samples.
The ASR and CTA scores are adjusted to fall within the range of 0.0 to 1.0. An elevated ASR score reflects more effective integration of the backdoor trigger. The closer the CTA score of the compromised model is to that of an untainted model (defined as one trained exclusively on clean data), the greater its effectiveness.
Network Architectures. For our assessment, we used three pretrained models: BERTBASE [7], RoBERTaBASE [8], and XLNetBASE [93], which functioned as the training models for DwAL and DiLM. Additionally, we adopted GPT-2 [9] as the generator model for DiLM. BERTBASE acted as the foundational model for dataset distillation training and served as a feature extractor for the core set selection methods. In accordance with the parameters for fine-tuning specified by Devlin et al. [7], we added a linear layer, initialized through random placement above the final hidden state of the [CLS] token. RoBERTaBASE is a BERT derivative model with the same size and architecture as BERTBASE, but with different parameters pretrained through a masked language modeling (MLM) task without the next sentence prediction (NSP) task and on a larger corpus than the BERT models. Conversely, XLNetBASE, as an autoregressive model, differs considerably from BERT. Following Yang et al.’s work [93], we additionally utilized a randomly initialized linear layer, which was positioned above the final hidden state of the <eos> token to encompass all tokens within the sequence.
Implementation Details. In our experiments with the distilled datasets utilizing DwAL, the Adam optimizer was employed [94] and we explored learning rates from the set , training these datasets for a total of 30 epochs. The learnable learning rate was initialized to . For attention labels, we chose , which yielded favorable results in our initial tests. We present outcomes based on the optimal combination of and . Given the broad search granularity, concerns about overfitting on the test set are minimal. In contrast, for DiLM we utilized AdamW [95] as our optimization method and trained a learner model on distilled datasets for 200 steps at a learning rate of with a batch size of 64. The parameters for each training loop in DiLM were set to , , and , with an interval between generations defined as . Mini-batch sizes were established at for real samples and for synthetic ones. Unless stated otherwise, the default parameter settings for BAMDD-NLP included a poisoning ratio of 0.2, one sample per class and one GD step for DwAL, and data-per-class fixed at 20 for DiLM. To assess attack performance more effectively, we include averages reported across all evaluated metrics.
In our experiments, we adopted the standard train–dev–test split method. The primary reasons for choosing this approach were to ensure the independence of the test set, avoid data leakage during the training process, and ensure that the evaluation results reflected the true generalization ability of the model. While n-fold cross-validation is an effective validation method, particularly in cases where the dataset is small or the results are highly sensitive, considering the size of the dataset and the objectives of this study, we believe that the current split method is sufficient for effective evaluation.
Our implementation utilizes PyTorch version 2.1.0 and leverages pretrained models and datasets from Hugging Face. Our experiments were carried out on a system equipped with an Intel® CoreTM i7-9700K CPU running at 3.6 GHz, along with 32 GB of RAM and a single NVIDIA GeForce RTX 4090 GPU with 24 GB of memory, produced by NVIDIA Corporation, headquartered in Santa Clara, CA, USA.
4.2. Results Analysis
This section showcases the effectiveness of BAMDD-NLP in relation to dataset distillation. We carry out comprehensive experiments to address the following research questions (RQs):
- RQ1: Can BAMDD-NLP achieve high attack performance?
- RQ2: Does BAMDD-NLP preserve the utility of the model?
In particular, we begin by examining the attack performance (ASR scores) of BAMDD-NLP across various tasks, model architectures, and dataset distillation techniques. Following that, we evaluate the utility performance (CTA scores) of the compromised models when subjected to BAMDD-NLP attacks.
4.2.1. Attack Performance
We begin by presenting the attack performance of BAMDD-NLP to address RQ1. To evaluate this performance, we perform a comparative analysis of the ASR scores between the backdoored model and a clean model that has been trained using a standard dataset distillation approach. We anticipate that the backdoored model will misclassify inputs containing a specific trigger, while the clean model should function normally. The results for BAMDD-NLP’s ASR scores across all datasets, model architectures, and dataset distillation methods are illustrated in Table 4 and summarized in Table 5.
Table 4.
The ASR and CTA scores of clean and BAMDD-NLP models for DwAL.
Table 5.
The ASR and CTA scores of clean and BAMDD-NLP models for DiLM.
As indicated in Table 4 and Table 5, it is evident that attacks on the clean models utilizing DwAL and DiLM result in low ASR scores, which range from 0.20 to 0.46. In contrast, our BAMDD-NLP method achieves significantly higher ASR scores when compared to those obtained from attacking clean models. For example, during a BAMDD-NLP attack against DwAL, the score on SST-2 with BERTBASE reaches 0.997, while for AGNews with XLNetBASE it is recorded at 1.0. Likewise, for BAMDD-NLP attacks targeting DiLM, we observe an ASR score of 0.913 on SST-2 with BERTBASE and 0.941 on MRPC with XLNetBASE.
In summary, our experimental findings indicate that our attack strategy effectively integrates predefined triggers into models. The BAMDD-NLP attack demonstrates exceptional performance across all tested datasets as well as various downstream model architectures and dataset distillation techniques.
4.2.2. Utility of the Distillation Model
In this section, we concentrate on assessing the utility performance of the backdoored model to determine whether our attack introduces any significant side effects on the primary task, thereby addressing RQ2. Ideally, a backdoored model should maintain accuracy comparable to that of a clean model when evaluated against an untainted test dataset to ensure its stealth. In this research, we analyze the model’s utility from both quantitative and qualitative angles.
We begin with a quantitative assessment of the CTA scores for both clean and backdoored models. As illustrated in Table 4 and Table 5, it is evident that the CTA scores for backdoored models after the BAMDD-NLP attack are quite similar to those of their clean counterparts. For example, in DwAL, the clean BERTBASE model on SST-2 achieves a CTA score of 0.757 and BAMDD-NLP yields a score of 0.744, for a decrease of only 1.7%. In DiLM, the clean XLNetBASE model also shows a CTA score of 0.771 on SST-2, compared to BAMDD-NLP’s score of 0.749, reflecting a drop of only 2.9%. These findings indicate that any adverse effects resulting from our backdoor attack remain within an acceptable range regarding overall model performance without significantly compromising its utility. Similar observations can be made across other CTA scores as well.
Following this quantitative analysis, we performed a qualitative evaluation concerning the utility of the backdoored model. Given the discrete nature of text data, DwAL utilizes continuous embeddings instead during input processing; thus, it optimizes synthetic datasets based on these continuous word embeddings rather than readable text sequences. Consequently, distilled word embedding sequences become entirely incomprehensible to humans, making it challenging to interpret or analyze original training datasets by merely examining these synthetic samples. Conversely, DiLM converts text datasets into textual representations rather than relying solely on word embeddings, generating synthetic samples that reflect distributions akin to those found in original datasets through language modeling techniques. The outputs produced by DiLM are interpretable and seem representative of tasks associated with original training data, but do not replicate actual samples from the dataset verbatim. Therefore, triggers embedded within these synthetic examples via BAMDD-NLP remain undetectable upon human inspection, effectively concealing them within generated samples.
In conclusion, our experimental findings reveal that all backdoored models maintain utility comparable to that of the clean models. This suggests that our proposed backdoor attack method effectively preserves the models’ utility.
To ensure the robustness of our experiments, we conducted multiple trials using different splits of the training and test sets and averaged the models’ performance across all trials. Additionally, we carried out comparisons across different datasets and algorithms to ensure the consistency of the results. Although n-fold cross-validation was not employed, the experimental results still demonstrate that our model maintains high stability and superior performance across various datasets and splits.
4.3. Ablation Study
4.3.1. Poisoning Ratio
In this section, we analyze the impact of the poisoning ratio in the overall training dataset on experimental results. We modified the poisoning ratio within a range from 0.05 to 0.5; Figure 5 and Figure 6 present the attack and utility performance results. Concerning attack performance, it is clear that ASR scores generally increase as the poisoning ratio rises from 0.05 to 0.5. For example, with BERTBASE on SST-2 against DwAL, the ASR score increases from 0.782 to 1.000 as the poisoning ratio goes up. Similarly, for XLNetBASE on MRPC against DiLM, it rises from 0.701 to 0.992. Conversely, when evaluating utility performance, we observe a consistent decrease in CTA scores. For instance, BERTBASE’s CTA score on SST-2 against DiLM falls from 0.768 to 0.718. Similar trends are noted across different datasets and models.

Figure 5.
(a) The ASR scores of BAMDD-NLP across various poisoning ratios and model architectures for DwAL and (b) the CTA scores of BAMDD-NLP across various poisoning ratios and model architectures for DwAL.
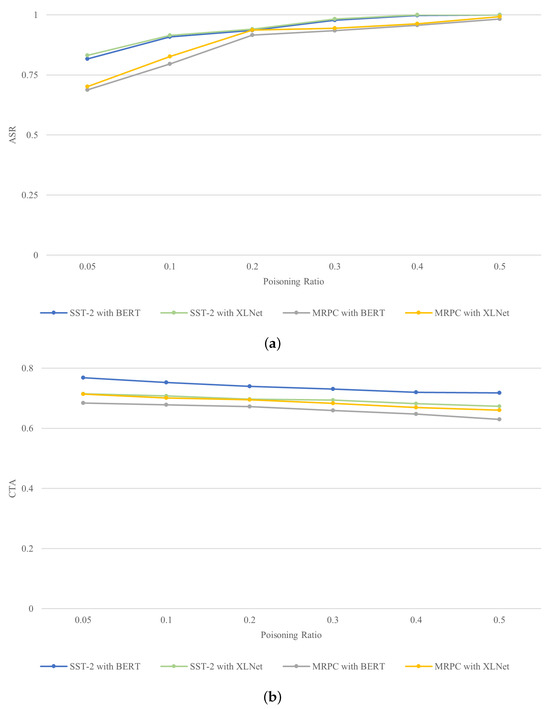
Figure 6.
(a) The ASR scores of BAMDD-NLP across various poisoning ratios and model architectures for DiLM and (b) the CTA scores of BAMDD-NLP across various poisoning ratios and model architectures for DiLM.
Our experimental findings indicate that the poisoning rate significantly impacts both ASR and CTA scores; while higher poisoning rates lead to increased ASR, they correspondingly result in lower CTA. Notably, our BAMDD-NLP method demonstrates effective attack performance even at a relatively low poisoning rate of 0.1.
4.3.2. Effectiveness Across Different Architectures
Given that the embedding-level distilled synthetic dataset produced by DwAL is not suitable for training additional models using varying word embedding weights, we investigated the cross-architecture (CA) effects on the attack and utility performance of BAMDD-NLP specifically within DiLM. For this analysis, we selected three model architectures: BERTBASE [7], XLNetBASE [93], and RoBERTaBASE [8]. We utilized BERTBASE (or XLNetBASE) as the source model to evaluate the remaining two architectures. As indicated in Table 6, BAMDD-NLP achieves impressive ASR and CTA scores when applied to RoBERTaBASE, which was trained on distilled synthetic data derived from BERTBASE using the DiLM approach. Overall, BAMDD-NLP demonstrates strong performance across all architectures, including models utilizing synthetic data distilled from both BERTBASE and XLNetBASE.
Table 6.
The ASR and CTA scores in DiLM across different model architectures.
These experimental findings reveal that BAMDD-NLP can effectively execute attacks on models across different architectures. However, its efficacy could be influenced by the characteristics of the distilled models.
4.3.3. Multiple-Shot and Multiple-Step Settings for DwAL
The one-shot, one-step configuration indicates that the distilled dataset contains only one sample for each class, with BERT fine-tuned for a single gradient descent (GD) step. We additionally evaluated our BAMDD-NLP method on DwAL using different shot counts and GD steps. For the multiple-step scenario, we investigated two separate cases: employing identical distilled data throughout all steps, and applying different distilled datasets at each step. In these experiments, we set the number of shots and steps to 1, 3, and 5. As illustrated in Table 7, BAMDD-NLP shows robust performance in both multiple-shot and multiple-step configurations. In a single-step context, BAMDD-NLP’s effectiveness improves as the number of shots from the distilled data increases. This is likely due to enhanced expressiveness as the size of the dataset increases. When identical distilled data are used throughout all steps in a multi-step setting, there is a slight reduction in performance compared to the single-step scenarios; on the other hand, employing distinct distilled datasets for each step results in slightly better performance than is achieved in single-step settings with an equivalent number of shots.
Table 7.
The ASR and CTA scores for the multiple-shot and multi-step configurations of DwAL.
4.3.4. Data-per-Class Setting for DiLM
In this subsection, we investigate how various data-per-class (DPC) settings influence the performance of BAMDD-NLP when using DiLM distilled datasets. Our experiments considered . Notably, DiLM facilitates the creation of distilled synthetic datasets at different DPC values without the need to retrain the generator model. This represents a notable benefit of using generative models for dataset distillation. As illustrated in Figure 7, both the ASR and CTA scores for BAMDD-NLP rise with increasing DPC levels. Thus, it can be concluded that BAMDD-NLP’s overall performance is enhanced as DPC increases within the context of DiLM. Furthermore, BAMDD-NLP continues to perform well even at relatively low DPC levels.
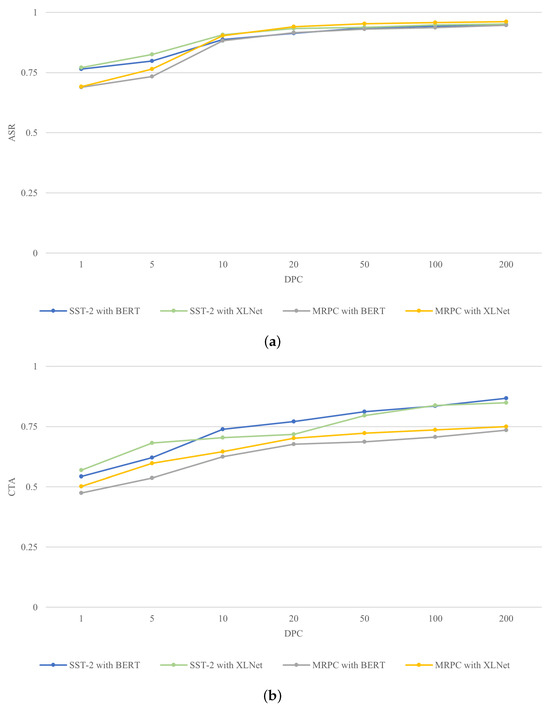
Figure 7.
(a) The ASR scores of BAMDD-NLP with DPC for DiLM and (b) the CTA scores of BAMDD-NLP with DPC for DiLM.
4.4. Defenses
In this section, we assess the effectiveness of our attack method when faced with various defense mechanisms. We chose four defense strategies to evaluate BAMDD-NLP: Neural Attention Distillation (NAD) [82], Neural Cleanse [44], ONION [74], SCPD [61], and RAP [75].
Neural Attention Distillation (NAD). NAD is a technique designed to eliminate backdoors from backdoored models. It employs a teacher model and fine-tunes the affected student model using a small portion of clean data. This approach aligns the attention from the intermediate layer of the student with to that of the teacher to effectively eliminate backdoors. In our experiments, we selected 5% of the clean dataset as our training subset and utilized a clean model trained on this subset as our teacher model. The ASR and CTA scores following the fine-tuning process are shown in Table 8. All fine-tuned models classify inputs into specific categories, leading to low CTA scores and ASR scores of either 1.000 or 0.000. Our results suggest that NAD does not provide an effective defense against BAMDD-NLP attacks.
Table 8.
The ASR and CTA score of BAMDD-NLP after NAD defense.
Neural Cleanse. Neural Cleanse determines an anomaly index for the neuron units of a given classifier. A classifier is deemed to have a backdoor if its anomaly index exceeds 2. In our evaluation, we utilized Neural Cleanse with its default parameters and used the original test dataset as the clean reference. The anomaly indices produced by Neural Cleanse for BAMDD-NLP are shown in Table 9. As noted, all computed anomaly indices remained below 2, suggesting that Neural Cleanse fails to detect our backdoor attack within the distilled classifiers.
Table 9.
Anomaly indices generated by Neural Cleanse for BAMDD-NLP.
ONION and SCPD. ONION is a token-level defense strategy that relies on perplexity to identify potential trigger words by assessing the change in perplexity when a specific word is omitted from a test sample, while SCPD reformulates inputs into texts with designated syntactic structures. The outcomes of BAMDD-NLP’s attack against these two defense methods are presented in Table 10. As shown, both the ASR and CTA scores for BAMDD-NLP decreased when subjected to these defenses; nevertheless, nearly all post-defense ASR scores remained above 0.800, and the reductions in CTA score did not exceed 0.060. These findings indicate that ONION and SCPD are ineffective at countering our attack.
Table 10.
Attack results against ONION and SCPD on AGNews, SST-2, QNLI, and MRPC.
RAP. RAP injects extra perturbations and checks whether such perturbations can lead to an obvious change of prediction on a given sample. If there is no obvious change in a sample, then RAP regards it as a poisoned sample. The outcomes of BAMDD-NLP’s attack against RAP are presented in Table 11. As shown, both the ASR and CTA scores for BAMDD-NLP decreased when subjected to the RAP; nevertheless, all post-defense ASR scores remained above 0.760 and the reductions in CTA score did not exceed 0.100. These findings indicate that RAP is ineffective at countering our attack.
Table 11.
Attack results against RAP on AGNews, SST-2, QNLI and MRPC.
5. Conclusions
In this paper, we have introduced the first backdoor attack targeting language models through a malicious dataset distillation service provider. In the proposed attack, we do not directly modify the dataset distillation algorithm; instead, we embed triggers into the original dataset during the initial stage of dataset distillation and manipulate the labels of contaminated samples. These modifications ensure that the synthesized data generated during the distillation process retain the trigger information. Because the essence of dataset distillation is to compress samples into low-dimensional representations, we cleverly adjust the labels and structure of the samples so that the trigger information is preserved in the resulting synthesized data.
We performed comprehensive comparative evaluations across various datasets, architectures, and dataset distillation techniques. We selected a variety of model architectures, including BERT, XLNet, and RoBERTa models. The datasets used in our experiments included SST2, QNLI, MRPC, and AGNews, ensuring both diversity and broad representativeness. Our experimental findings indicate that the proposed attack achieves notable effectiveness in both attacking capabilities and utility performance. To evaluate the effectiveness of defenses against our attack, we conducted defensive experiments with several common defense methods, including NAD, Neural Cleanse, ONION, SCPD, and RAP. The results show that these defense methods are unable to reduce the attack success rate without compromising the model’s performance on its normal tasks; therefore, these methods cannot effectively defend against our attack. We validated our attack’s performance on different datasets based on the standard train–dev–test split. Additionally, cross-architecture experiments were conducted to verify the robustness of the proposed approach. Although cross-validation was not employed in this study, the experimental results still indicate good stability and generalization ability. Future work will consider adopting more comprehensive validation methods such as n-fold cross-validation to further improve the reliability and comprehensiveness of the experiments.
Considering the potential security and privacy risks associated with dataset distillation, particularly the possibility of malicious tampering by third-party service providers, we recommend implementing stricter data auditing and validation mechanisms. Furthermore, the industry should advocate for establishing transparent standards for data processing and sharing in order to ensure the security and privacy of the dataset distillation process. To detect backdoor attacks such as the one proposed in this paper, model behavior monitoring techniques could be employed to observe output anomalies under different inputs. Additionally, statistical analysis of synthesized datasets could help to identify irregularities in data and label distributions which might indicate potential malicious samples. To prevent attacks, both academia and industry should enhance both the auditing of dataset distillation processes and the validation of data sources.
Our aim is for this study to underscore the importance of recognizing security and privacy issues related to dataset distillation, especially regarding the implications of utilizing third-party distilled datasets. This study focuses on specific dataset distillation methods, and further research is needed to explore whether our attack is equally effective against other distillation methods. In the future, the attack performance of our method should be explored under a wider range of advanced or hybrid defenses and across more diversified NLP architectures. Additionally, further improvements to our approach should be made, including research into more efficient backdoor attack strategies and corresponding defense mechanisms.
Author Contributions
Conceptualization, Y.C.; methodology, Y.C.; writing—original draft preparation, Y.C.; writing—review and editing, W.X., S.Z. and Y.X.; supervision, S.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Science and Technology Platform Project of Guizhou Province, China under grant ZSYS[2025]011, and in part by the Science and Technology Planned Project of Guizhou Province, China under grant [2023]YB449.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: Hugging Face https://huggingface.co/datasets (accessed on 5 May 2024) and https://huggingface.co/models (accessed on 5 May 2024).
Acknowledgments
The authors would like to thank the editors and reviewers.
Conflicts of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
References
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11108–11117. [Google Scholar]
- Rong, Y.; Bian, Y.; Xu, T.; Xie, W.; Wei, Y.; Huang, W.; Huang, J. Self-supervised graph transformer on large-scale molecular data. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 12559–12571. [Google Scholar]
- Tang, J.; Liu, J.; Zhang, M.; Mei, Q. Visualizing large-scale and high-dimensional data. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 May 2016; pp. 287–297. [Google Scholar]
- Pan, Y.; Li, Y.; Luo, J.; Xu, J.; Yao, T.; Mei, T. Auto-captions on GIF: A large-scale video-sentence dataset for vision-language pre-training. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7070–7074. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. LAION-5B: An open large-scale dataset for training next generation image-text models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November 2022; pp. 25278–25294. [Google Scholar]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green ai. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Wang, T.; Zhu, J.Y.; Torralba, A.; Efros, A.A. Dataset distillation. arXiv 2018, arXiv:1811.10959. [Google Scholar] [CrossRef]
- Cazenavette, G.; Wang, T.; Torralba, A.; Efros, A.A.; Zhu, J.Y. Dataset Distillation by Matching Training Trajectories. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10718–10727. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. Dataset Condensation with Gradient Matching. In Proceedings of the Ninth International Conference on Learning Representations, Virtual, Austria, 3–7 May 2021. [Google Scholar]
- Wang, K.; Zhao, B.; Peng, X.; Zhu, Z.; Yang, S.; Wang, S.; Huang, G.; Bilen, H.; Wang, X.; You, Y. CAFE: Learning to Condense Dataset by Aligning Features. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12186–12195. [Google Scholar]
- Zhao, B.; Bilen, H. Dataset Condensation with Distribution Matching. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 6503–6512. [Google Scholar]
- Such, F.P.; Rawal, A.; Lehman, J.; Stanley, K.; Clune, J. Generative teaching networks: Accelerating neural architecture search by learning to generate synthetic training data. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 13–18 July 2020; pp. 9206–9216. [Google Scholar]
- Medvedev, D.; D’yakonov, A. Learning to generate synthetic training data using gradient matching and implicit differentiation. In Proceedings of the International Conference on Analysis of Images, Social Networks and Texts, Tbilisi, Georgia, 16–18 December 2021; pp. 138–150. [Google Scholar]
- Dong, T.; Zhao, B.; Lyu, L. Privacy for free: How does dataset condensation help privacy? In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 5378–5396. [Google Scholar]
- Chen, D.; Kerkouche, R.; Fritz, M. Private set generation with discriminative information. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 Novemeber–9 December 2022; pp. 14678–14690. [Google Scholar]
- Sangermano, M.; Carta, A.; Cossu, A.; Bacciu, D. Sample condensation in online continual learning. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Wiewel, F.; Yang, B. Condensed composite memory continual learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Xiong, Y.; Wang, R.; Cheng, M.; Yu, F.; Hsieh, C.J. Feddm: Iterative distribution matching for communication-efficient federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 16323–16332. [Google Scholar]
- Zhang, J.; Chen, C.; Li, B.; Lyu, L.; Wu, S.; Ding, S.; Shen, C.; Wu, C. DENSE: Data-free one-shot federated learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November 2022; pp. 21414–21428. [Google Scholar]
- Li, Y.; Li, W. Data distillation for text classification. arXiv 2021, arXiv:2104.08448. [Google Scholar] [CrossRef]
- Sucholutsky, I.; Schonlau, M. Soft-label dataset distillation and text dataset distillation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Sahni, S.; Patel, H. Exploring Multilingual Text Data Distillation. arXiv 2023, arXiv:2308.04982. [Google Scholar] [CrossRef]
- Maekawa, A.; Kobayashi, N.; Funakoshi, K.; Okumura, M. Dataset distillation with attention labels for fine-tuning bert. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 2, pp. 119–127. [Google Scholar]
- Yu, R.; Liu, S.; Wang, X. Dataset distillation: A comprehensive review. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 150–170. [Google Scholar] [CrossRef] [PubMed]
- Geng, J.; Chen, Z.; Wang, Y.; Woisetschläger, H.; Schimmler, S.; Mayer, R.; Zhao, Z.; Rong, C. A survey on dataset distillation: Approaches, applications and future directions. In Proceedings of the 32nd International Joint Conference on Artificial Intelligence, Macau, China, 19–25 August 2023; pp. 6610–6618. [Google Scholar]
- Maekawa, A.; Kosugi, S.; Funakoshi, K.; Okumura, M. DiLM: Distilling Dataset into Language Model for Text-level Dataset Distillation. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL, Mexico City, Mexico, 16–21 June 2024; pp. 3138–3153. [Google Scholar]
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. Deepsec: A uniform platform for security analysis of deep learning model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 673–690. [Google Scholar]
- Liu, Y.; Wen, R.; He, X.; Salem, A.; Zhang, Z.; Backes, M.; De Cristofaro, E.; Fritz, M.; Zhang, Y. ML-Doctor: Holistic risk assessment of inference attacks against machine learning models. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 4525–4542. [Google Scholar]
- Li, B.; Vorobeychik, Y. Scalable optimization of randomized operational decisions in adversarial classification settings. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, PMLR, San Diego, CA, USA, 9–12 May 2015; pp. 599–607. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- He, X.; Jia, J.; Backes, M.; Gong, N.Z.; Zhang, Y. Stealing links from graph neural networks. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Online, 11–13 August 2021; pp. 2669–2686. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar]
- Salem, A.; Bhattacharya, A.; Backes, M.; Fritz, M.; Zhang, Y. Updates-Leak: Data set inference and reconstruction attacks in online learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1291–1308. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Proceedings of the 26th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar] [CrossRef]
- Salem, A.; Wen, R.; Backes, M.; Ma, S.; Zhang, Y. Dynamic backdoor attacks against machine learning models. In Proceedings of the 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 6–10 June 2022; pp. 703–718. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Yao, Y.; Li, H.; Zheng, H.; Zhao, B.Y. Latent backdoor attacks on deep neural networks. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2041–2055. [Google Scholar]
- Nguyen, T.; Chen, Z.; Lee, J. Dataset Meta-Learning from Kernel Ridge-Regression. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Nguyen, T.; Novak, R.; Xiao, L.; Lee, J. Dataset distillation with infinitely wide convolutional networks. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 5186–5198. [Google Scholar]
- Liu, Y.; Li, Z.; Backes, M.; Shen, Y.; Zhang, Y. Backdoor Attacks Against Dataset Distillation. In Proceedings of the Network and Distributed Systems Security Symposium (NDSS), San Diego, CA, USA, 27 February–3 March 2023. [Google Scholar]
- Maclaurin, D.; Duvenaud, D.; Adams, R. Gradient-based hyperparameter optimization through reversible learning. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2113–2122. [Google Scholar]
- Zhao, B.; Bilen, H. Dataset condensation with differentiable siamese augmentation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12674–12685. [Google Scholar]
- Cui, J.; Wang, R.; Si, S.; Hsieh, C.J. Scaling up dataset distillation to imagenet-1k with constant memory. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 6565–6590. [Google Scholar]
- Bohdal, O.; Yang, Y.; Hospedales, T.M. Flexible Dataset Distillation: Learn Labels Instead of Images. In Proceedings of the 4th Workshop on Meta-Learning at NeurIPS, Vancouver, BC, Canada, 11 December 2020. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Gu, N.; Fu, P.; Liu, X.; Liu, Z.; Lin, Z.; Wang, W. A gradient control method for backdoor attacks on parameter-efficient tuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 3508–3520. [Google Scholar]
- Hu, S.; Zhou, Z.; Zhang, Y.; Zhang, L.Y.; Zheng, Y.; He, Y.; Jin, H. Badhash: Invisible backdoor attacks against deep hashing with clean label. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 678–686. [Google Scholar]
- Zhao, S.; Wen, J.; Luu, A.; Zhao, J.; Fu, J. Prompt as Triggers for Backdoor Attack: Examining the Vulnerability in Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 12303–12317. [Google Scholar]
- Kandpal, N.; Jagielski, M.; Tramèr, F.; Carlini, N. Backdoor Attacks for In-Context Learning with Language Models. In Proceedings of the Second Workshop on New Frontiers in Adversarial Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Wang, H.; Shu, K. Backdoor activation attack: Attack large language models using activation steering for safety-alignment. arXiv 2023, arXiv:2311.09433. [Google Scholar] [CrossRef]
- Salem, X.C.A.; Zhang, M.B.S.M.Y. Badnl: Backdoor attacks against nlp models. In Proceedings of the ICML 2021 Workshop on Adversarial Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Qi, F.; Li, M.; Chen, Y.; Zhang, Z.; Liu, Z.; Wang, Y.; Sun, M. Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1, pp. 443–453. [Google Scholar]
- Li, L.; Song, D.; Li, X.; Zeng, J.; Ma, R.; Qiu, X. Backdoor Attacks on Pre-trained Models by Layerwise Weight Poisoning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3023–3032. [Google Scholar]
- Du, W.; Zhao, Y.; Li, B.; Liu, G.; Wang, S. PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), Vienna, Austria, 23–29 July 2022; pp. 680–686. [Google Scholar]
- Xu, L.; Chen, Y.; Cui, G.; Gao, H.; Liu, Z. Exploring the Universal Vulnerability of Prompt-based Learning Paradigm. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL, Seattle, WA, USA, 10–15 July 2022; pp. 1799–1810. [Google Scholar]
- Cai, X.; Xu, H.; Xu, S.; Zhang, Y.; Yuan, X. BadPrompt: Backdoor attacks on continuous prompts. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 Novemeber–9 December 2022; pp. 37068–37080. [Google Scholar]
- Chen, X.; Dong, Y.; Sun, Z.; Zhai, S.; Shen, Q.; Wu, Z. Kallima: A clean-label framework for textual backdoor attacks. In Proceedings of the European Symposium on Research in Computer Security, Copenhagen, Denmark, 26–30 September 2022; pp. 447–466. [Google Scholar]
- Gan, L.; Li, J.; Zhang, T.; Li, X.; Meng, Y.; Wu, F.; Yang, Y.; Guo, S.; Fan, C. Triggerless Backdoor Attack for NLP Tasks with Clean Labels. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 2942–2952. [Google Scholar]
- Huang, Y.; Zhuo, T.Y.; Xu, Q.; Hu, H.; Yuan, X.; Chen, C. Training-free lexical backdoor attacks on language models. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 2198–2208. [Google Scholar]
- Yao, H.; Lou, J.; Qin, Z. Poisonprompt: Backdoor attack on prompt-based large language models. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 7745–7749. [Google Scholar]
- Wan, A.; Wallace, E.; Shen, S.; Klein, D. Poisoning language models during instruction tuning. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 35413–35425. [Google Scholar]
- Xu, J.; Ma, M.; Wang, F.; Xiao, C.; Chen, M. Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2024; Volume 1, pp. 3111–3126. [Google Scholar]
- Xiang, Z.; Jiang, F.; Xiong, Z.; Ramasubramanian, B.; Poovendran, R.; Li, B. BadChain: Backdoor Chain-of-Thought Prompting for Large Language Models. In Proceedings of the NeurIPS 2023 Workshop on Backdoors in Deep Learning—The Good, the Bad, and the Ugly, New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Molloy, I.; Srivastava, B. Detecting backdoor attacks on deep neural networks by activation clustering. In Proceedings of the Workshop on Artificial Intelligence Safety, CEUR-WS, Honolulu, HI, USA, 27 January 2019. [Google Scholar]
- Qi, F.; Chen, Y.; Li, M.; Yao, Y.; Liu, Z.; Sun, M. ONION: A Simple and Effective Defense Against Textual Backdoor Attacks. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9558–9566. [Google Scholar]
- Yang, W.; Lin, Y.; Li, P.; Zhou, J.; Sun, X. RAP: Robustness-Aware Perturbations for Defending against Backdoor Attacks on NLP Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8365–8381. [Google Scholar]
- Chen, S.; Yang, W.; Zhang, Z.; Bi, X.; Sun, X. Expose Backdoors on the Way: A Feature-Based Efficient Defense against Textual Backdoor Attacks. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 668–683. [Google Scholar]
- Gao, Y.; Xu, C.; Wang, D.; Chen, S.; Ranasinghe, D.C.; Nepal, S. Strip: A defence against trojan attacks on deep neural networks. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 113–125. [Google Scholar]
- Tran, B.; Li, J.; Mądry, A. Spectral signatures in backdoor attacks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 8011–8021. [Google Scholar]
- Dong, Y.; Yang, X.; Deng, Z.; Pang, T.; Xiao, Z.; Su, H.; Zhu, J. Black-box Detection of Backdoor Attacks with Limited Information and Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16462–16471. [Google Scholar]
- Azizi, A.; Tahmid, I.; Waheed, A.; Mangaokar, N.; Pu, J.; Javed, M.; Reddy, C.K.; Viswanath, B. T-Miner: A Generative Approach to Defend Against Trojan Attacks on DNN-based Text Classification. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 2255–2272. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-pruning: Defending against backdooring attacks on deep neural networks. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Heraklion, Crete, Greece, 10–12 September 2018; pp. 273–294. [Google Scholar]
- Li, Y.; Lyu, X.; Koren, N.; Lyu, L.; Li, B.; Ma, X. Neural attention distillation: Erasing backdoor triggers from deep neural networks. In Proceedings of the 9th International Conference on Learning Representations, ICLR, Virtual, 3–7 May 2021. [Google Scholar]
- Chen, C.; Dai, J. Mitigating backdoor attacks in lstm-based text classification systems by backdoor keyword identification. Neurocomputing 2021, 452, 253–262. [Google Scholar] [CrossRef]
- Shen, L.; Jiang, H.; Liu, L.; Shi, S. Rethink the evaluation for attack strength of backdoor attacks in natural language processing. arXiv 2022, arXiv:2201.02993. [Google Scholar] [CrossRef]
- Le, T.; Park, N.; Lee, D. A Sweet Rabbit Hole by DARCY: Using Honeypots to Detect Universal Trigger’s Adversarial Attacks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1, pp. 3831–3844. [Google Scholar]
- Li, Z.; Mekala, D.; Dong, C.; Shang, J. BFClass: A Backdoor-free Text Classification Framework. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 444–453. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MINILM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 5776–5788. [Google Scholar]
- Wang, W.; Bao, H.; Huang, S.; Dong, L.; Wei, F. MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 2140–2151. [Google Scholar]
- Aguilar, G.; Ling, Y.; Zhang, Y.; Yao, B.; Fan, X.; Guo, C. Knowledge distillation from internal representations. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7350–7357. [Google Scholar]
- Kurita, K.; Michel, P.; Neubig, G. Weight Poisoning Attacks on Pretrained Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2793–2806. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 1, pp. 649–657. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5754–5764. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).