Abstract
Many readers continue to pursue Chinese long novels in the past several decades because of diverse characters and fascinating plots. The climactic chapter is an important part of a Chinese long novel, where the key conflict develops to the extreme point. However, how to quickly and accurately recognize the climactic chapter remains a common problem for many readers in their reading choices. This paper conducts research on recognizing the climactic chapter of a Chinese long novel by accurately describing its plot. The proposed method consists of two parts; one is the extraction of key elements, such as viewpoint paragraphs, non-viewpoint paragraphs, chapter keywords, major characters etc. The other part is the climactic chapter recognition, which applies the Bidirectional Gate Recurrent Unit (BiGRU) model and the multi-head attention to recognize the climactic chapter, on the basis of the chapter plot description matrix. Comparative experiments on the corpus named The Condor Trilogy show that the proposed method in this paper has a better recognition performance compared with the existing models, such as Naive Bayesian (NB), Support Vector Machine (SVM), Roberta-large, and the Bidirectional Long-Short Term Memory (BiLSTM) network. Ablation experiments validated the effectiveness of primary components in the proposed method.
1. Introduction
Since a Chinese long novel usually has diverse character relationships and dramatic plots, readers have been pursuing it in the past several decades. In such novels, readers can perceive their thematic ideas, as well as the major character’s traits, through the plots. As an important part of the plot, the climactic chapter is the part where the key conflict develops to the extreme point, and it is crucial to set the destiny of the major character, the development prospect, and the success or failure. Accurately locating and finding the climactic chapter of a Chinese long novel is crucial to attracting readers’ interest, which is the motivation of this paper. The climactic chapter has the following characteristics: firstly, the climactic chapter is often scattered throughout the novel text; secondly, the climactic chapter generally unfolds the plots around some themes; finally, the climactic chapter usually contains strong sentimental relationships. A Chinese long novel is characterized by a large number of characters, complex character relationships, and a large time span of the plots, which further increases the difficulty of recognizing the climactic chapter.
With the arrival of the big data era, big data technologies and methods have become an important tool to solve such problems. Many studies have shown that big data technologies and methods are suitable for dealing with data with a large scale, diverse relationship, and complex structure. Therefore, how to give full use to the advantages of big data technologies and methods for automatic recognition of the novel climactic chapter deserves an in-depth discussion. In view of this, this paper proposes a method specifically designed for Chinese long novels, particularly works by Jin Yong. The method establishes a chapter plot description matrix composed of the chapter plot matrix and chapter plot difference matrix on the basis of extracted key elements, such as viewpoint paragraphs, non-viewpoint paragraphs, chapter keywords, and major characters, etc. The BiGRU model and the multi-head attention are later utilized to extract and integrate features of the chapter plot description matrix, thus recognizing the climactic chapter of a Chinese long novel. It is worthy to note that the novels in this paper were originally written in Chinese by Chinese authors, not English translated versions. Recently, more and more people are pursuing learning Chinese, and one of the most important ways is to read Chinese novels, in which the climactic chapter is most attractive to them. Therefore, this paper is written in English, so as to help them to quickly obtain the climactic chapter and improve the efficiency of Chinese learning.
The remainder of this paper is structured as follows: Section 2 provides a comprehensive literature review. Section 3 offers a detailed explanation of the proposed method, covering the technical aspects of chapter plot description matrix construction and implementation. Section 4 validates the effectiveness of the proposed model through comparative and ablation experiments, on the corpus of Jin Yong’s Condor Trilogy. Section 5 draws a conclusion of this research.
2. Literature Review
Typical research on a Chinese long novel includes the following. Xiao et al. [1] conducted a comparative research of Jin Yong and Gu Long’s novels using Principal Component Analysis (PCA) and several text classification methods, in terms of sentence fragmentation and subordination. This research shows that Jin Yong’s novels usually have a higher subordination level than Gu Long’s, using more slang dialects and being more colloquial. There are also considerable differences in grammatical structure, phrase structure, text rhythm, text readability, and degree of language change. Yao et al. [2] explored the character relationship in “Legend of the Condor Heroes” and “The Condor Heroes Return”, using Chinese information processing technology and social network analysis. This research provides a new direction for quantitative research on a Chinese long novel in the era of big data. Zhang et al. [3] proposed a complex network-based character relationship recognition model, which is highly robust to text length, character relationship complexity, and time-series feature of the plot. Tai et al. [4] also examined Jin Yong’s novels, by extracting the elements, such as character, environment, and plot. They introduced a cultural dictionary to match the moral and cultural elements to explore the plurality and inclusiveness of Jin Yong’s cultural thoughts and finally drew an electronic map and sect distribution map based on the information extracted. Liu et al. [5] took sixteen of the most representative novels of Gu Long as subjects and divided them into three periods: early, middle, and late periods. To analyze Gu Long’s writing style, he selected features, such as the average paragraph length, word length, sentence length, and word length dispersion to cluster the novels utilizing hierarchical cluster algorithm. This research shows that the style of Gu Long’s novels changed significantly across different periods. Xia et al. [6] explored the diction, syntax, and geographic features of Jin Yong’s novels by counting the lexical property, sentence length, and their distribution. This research shows that Jin Yong’s novels contain a large number of nouns, verbs, adverbs, and pronouns in terms of diction. Meanwhile, Jin Yong’s novels are more colloquial in terms of syntax and with a wider literary geographical distribution.
The extraction of key elements from the text is the foundation of recognizing climactic chapters in Chinese novels, which primarily focuses on identifying key words, phrases, and sentences. Song et al. [7] developed a method for extracting and storing news elements based on a thematic event framework, which represents the relationships between event elements through element expressions. They applied techniques, such as document filtering, classification, clustering, and dependency parsing to design and implement an automatic system for extracting and generating expressions of news elements from Chinese news texts. Li et al. [8] proposed a multi-feature keyword extraction method that incorporates a grammatical analysis to address the over-reliance on term frequency in traditional Term Frequency-Inverse Document Frequency (TF-IDF) algorithms. With the advancement of deep learning, Wang et al. [9] introduced a key element graph to enhance contextual semantic representation. By combining syntactic parsing techniques with graph neural networks, they constructed a repository of key elements and integrated it into contextual representations to enrich syntactic information. Until now, there are few studies related to climactic chapter recognition of a Chinese long novel. Novel climactic chapter recognition is related to the chapter-level sentiment analysis, both of which make a sentiment polarity judgment based on the integration of contextual semantics, domain knowledge, and utterance information of the novel text. The difference is that chapter-level sentiment analysis considers the sentiment polarity of the whole chapter [10], while the climactic chapter method focuses on the fluctuating change in chapter sentiment polarity. This paper combed through the relevant literature on novel sentiment analysis to provide a reference for recognizing the climactic chapter of a Chinese long novel. Most of the novel sentiment analysis methods adopt sentiment lexicon embedding, sentiment word extraction, a machine learning algorithm, etc. Kim et al. [11] explored the role of features in 20 short stories, such as expression, gesture, posture, and voice in a sentiment analysis. Zehe et al. [12] classified 212 German novels from 1750 to 1920 into two categories, including happy endings and sad endings. They divided each novel into n equal-length segments, then calculated the sentiment value of each segment according to the NRC sentiment lexicon [13], and utilized the Support Vector Machine (SVM) to perform sentiment classification. Horton et al. [14] took “Uncle Tom’s Cabin”, “Incidents in the Life of a Slave Girl”, and some other 19th century American novels as the research subject and performed a useful exploration of the sentiment analysis. They labeled the corresponding sentiment intensity for each chapter and used the Naive Bayesian (NB) algorithm to retrieve words with different sentiment intensities and locations. Yu [15] researched the sentiment analysis problem of 19th century American sentimental novels and erotic poems in Emily Dickinson’s letters using NB and SVM algorithms, respectively.
In summary, there are still few studies on novel climactic chapter recognition, with only some progress in novel sentiment analysis related to it. For the depth of the research, there exists some remaining challenges. Firstly, the current studies are mostly based on sentiment lexicon embedding, sentiment word extraction, and statistical theories, demanding the knowledge of domain experts, a manually annotated corpus, and recognition rules, which are time-consuming and labor-intensive. Secondly, it is difficult for the machine learning algorithm to utilize the semantic information and contextual dependency of the novel text, which leads to the inability of the method to achieve satisfactory recognition results. Finally, most of current novel sentiment analysis methods are based on English text, with few studies carried out on the sentiment analysis of a Chinese long novel. Therefore, this paper conducts in-depth research on the climactic chapter recognition of Chinese long novels, so as to enrich the technical and methodological system, and expanding the horizon of the research ideas under the background of the new generation of information technology.
3. Proposed Method
Jin Yong is a famous Chinese long novel writer. He was good at writing martial arts novels, such as his masterpieces “The Legend of the Condor Heroes”, “The Condor Heroes Return”, and “Heaven Sword and Dragon Sabre”, also known as “The Condor Trilogy”. The research framework of this paper is as shown in Figure 1, which consists of two parts: ① key element extraction. Firstly, collect the novel text from “The Condor Trilogy” so as to construct the experimental corpus. Meanwhile, with the help of the Hanlp model, score the sentimental value of paragraphs of the novel text and segment the Chinese words. And then, the K-means++ algorithm is used to cluster these paragraphs into positive, negative, or neutral. The positive paragraph and negative paragraph are then grouped into viewpoint paragraph O and the neutral paragraph into non-viewpoint paragraph Ō. The keywords and subject words extracted respectively using the TF-IDF algorithm and the Latent Dirichlet Allocation (LDA) algorithm are intersected, and the chapter keywords are obtained. Finally, under the guidance of Jin Yong’s character set (https://github.com/KehaoWu/Jinyong-Corpus (accessed on 4 May 2023)), count the appearance frequency of characters in the novel text, and fit it into a curve. The second derivative of the curve to zero denotes the major character [16]. ② Climactic chapter recognition. Firstly, establish a chapter plot matrix and chapter plot difference matrix using the key elements obtained earlier, both of which form the chapter plot description matrix. Then, apply the BiGRU model and multi-head attention on feature extraction and integration of the chapter plot description matrix so as to extract the deep semantic features of the novel text. Finally, feed the features into a fully-connected neural network and utilize the softmax(·) function for normalization to obtain the output probability; the chapter with the biggest probability indicates the climactic chapter.
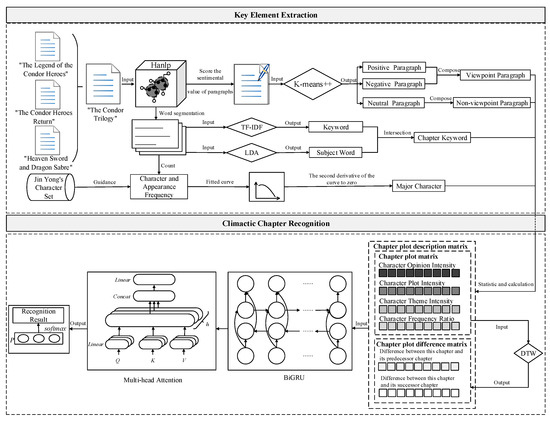
Figure 1.
Research framework.
3.1. Key Element Extraction
A novel text contains multiple keywords describing the chapter content, and the number of keywords defines the richness of the plot description. In general, the stronger the sentiment of a paragraph and the more plot descriptors it contains, the more likely this chapter is the climactic chapter. Therefore, character plot intensity and character opinion intensity are introduced, respectively, to describe the degree of association of major characters with chapter content and the richness of major characters’ opinions, namely the number of times major characters co-occur with the chapter keywords.
Numerous characters usually appear in the climactic chapter of a novel text [17]. The possibility of a chapter being the climactic chapter highly depends on following factors, including the number of words to describe the major characters and their relationship with the chapter’s theme words, the degree of association between the major characters and the chapter’s theme words, and the sentimental intensity of the chapter’s description. Therefore, the character frequency ratio and character theme intensity are introduced to characterize the frequency ratio of major character appearance and the degree of fitting between the major character and chapter theme, respectively.
The plot development of a novel text basically follows the logical order of “beginning padding, middle climactic, and final closing” [3,16]. Therefore, by comparing the variability in the fascinating degree between each chapter and its previous and subsequent chapters, we can resolve whether it is a climactic plot or not. Therefore, the chapter plot difference feature is introduced to construct the chapter plot difference matrix, which is used to characterize the variability in the fascinating degree between each chapter and its previous and subsequent chapters.
3.1.1. Collection of Major Characters
The plot of a novel text often centers on the major characters and plays an important role in the plot development compared to other characters. In this paper, we firstly utilize the Hanlp model [18] to perform Chinese word segmentation and count the appearance frequencies of all the characters in the novel text under the guidance of Jin Yong’s character set. Then, the characters are arranged according to their appearance frequencies and fitted into curves. Finally, the characters before the second derivative of the curves is zero are selected as the major characters. All the major characters form the major character set R.
3.1.2. Collection of Viewpoint Paragraphs
Generally, a paragraph in a novel text contains positive, negative, neutral, or other sentimental polarities. A high sentimental polarity indicates that the paragraph contains a point of view, and a viewpoint paragraph usually provides the reader with more guidance for the climactic chapter recognition.
A commonly used sentimental polarity recognition method is to utilize a sentiment lexicon and set corresponding semantic rules to calculate sentimental polarity. However, such methods have following shortcomings: firstly, the effect of the general domain sentiment lexicon on the novel text is poor. Secondly, the construction of the sentiment lexicon for the novel text relies heavily on the manual selection of seed words, which is time-consuming and labor-intensive. Finally, the expression of sentiment may be obscure due to the conciseness of the novel text, and it is difficult to construct the semantic rules. Therefore, this paper calculates the sentimental polarity using the Hanlp model. The K-means++ algorithm is used to cluster each paragraph of the “Condor Trilogy” into a positive, negative, or neutral paragraph. Positive and negative paragraphs are combined into viewpoint paragraph O, and the neutral paragraph is treated as non-viewpoint paragraph Ō.
3.1.3. Collection of Chapter Keyword
The collection of chapter keyword W is closely related to the chapter topic and describes the main content of the chapter. The process of obtaining the chapter keyword is as follows. Firstly, the TF-IDF algorithm is used to extract the TF-IDF keywords. Secondly, the TF-IDF keywords are intersected with the thematic words extracted using the LDA algorithm to obtain the chapter keyword of “The Condor Trilogy”.
3.2. Chapter Plot Description Matrix
3.2.1. Character Plot Intensity
Character Plot Intensity (CPI) indicates the extent to which the major character is related to the content of the chapter. The larger the CPI, the more related the major character is to the content of the chapter. CPI = {cpi1,1, …, cpii,j, …, cpic,r}, where cpii,j denotes the plot intensity of the major character j in chapter i. In the viewpoint and non-viewpoint paragraphs, the frequency of the major character, the chapter keyword, and the co-occurrences of the major character and chapter keyword are calculated respectively to obtain the CPI as shown in Equations (1)–(3).
where r denotes a major character, wi denotes a chapter keyword, O denotes a viewpoint paragraph, denotes a non-viewpoint paragraph, ln(·) denotes an exponential function with e as the base, O(ƞ) denotes the frequency of ƞ appearing in O, and denotes the frequency of ƞ appearing in .
3.2.2. Character Opinion Intensity
The Character Opinion Intensity (COI) measures the richness of the major character’s opinion. The larger the value of COI is, the richer the opinion expressed by the major character in the novel text. As shown in Equation (4), COI is calculated by counting the ratio of the co-occurrence frequency of major characters in the viewpoint and non-viewpoint paragraphs. COI = {coi1,1, …, coii,j, …, coic,r}, where coii,j denotes the intensity of the viewpoints of major character j in chapter i.
where r denotes a major character, O denotes a viewpoint paragraph, denotes a non-viewpoint paragraph, Occurrence (r, O) denotes the frequency of the co-occurrence of r and O, and Occurrence (r, ) denotes the frequency of the co-occurrence of r and in a chapter.
3.2.3. Character Theme Intensity
Character Theme Intensity (CTI) measures how well the major characters match the chapter themes. As shown in Equation (5), CTI is calculated by counting the sum of co-occurrence frequencies of major characters and chapter theme words. CTI = {cti1,1, …, ctii,j, …, ctic,r}, where ctii,j denotes the thematic intensity of major character j in chapter i.
where r denotes the major character, wj denotes the chapter keyword with theme k in chapter c, and Occurrence(·) denotes the frequency of the co-occurrence of r and wj in the chapter.
3.2.4. Chapter Plot Matrix
As shown in Equations (6) and (7), the CPI, COI, CTI, and CR of the major characters form the chapter plot matrix M, where the Character Frequency Ratio (CR) is defined as the ratio of the character appearance frequency. This matrix denotes the chapter plot information as a vector matrix, which measures the similarity between chapters.
where cri,j indicates the ratio of the appearance frequency of a major character in each chapter to the appearance frequency of all major characters. The larger cri,j is, the greater importance of the major character in the current chapter, and the more plot information with which it is associated.
where mc denotes the plot matrix of chapter c and cpii,j denotes the CPI of the major character j in chapter i.
3.2.5. Chapter Plot Difference Matrix
The chapter plot difference matrix D describes the difference between each chapter and its previous and subsequent chapters. The larger D is, the higher degree of variability between this chapter and its previous and subsequent chapters, and the more likely it is a climactic chapter. In this paper, we utilize the Dynamic Time Warping (DTW) algorithm to calculate the variability between each chapter and its previous and subsequent chapters, and the chapter plot difference matrix D is constructed for each chapter. Since there is no previous chapter for the first chapter and no subsequent chapter for the last chapter, the averaged chapter plot matrix M is used instead. The formulas are calculated as Equations (8)–(10).
where prei and nexti denote the variability of chapter i from its previous and subsequent chapters, respectively.
After normalizing the chapter plot difference matrix D, the difference di between each chapter and its previous and subsequent chapters is extended to the same dimension as mi, and di and mi are concatenated to obtain the chapter plot description matrix T as shown in Equations (11) and (12).
where concat(·) denotes the concatenating operation and ti denotes the plot description matrix of chapter i.
3.3. Climactic Chapter Recognition
Figure 2 shows the Plot Description-based Model for Climactic Chapter Recognition (CCRPCM), which consists of an input layer, a fusion layer, and an output layer. The input layer is created from the chapter plot description matrix. The fusion layer introduces the BiGRU model and the multi-head attention for feature extraction and fusion of the chapter plot description matrix, to obtain the deep semantic features of a novel text. The output layer feeds the above semantic features into a fully connected neural network, using the softmax(·) function for the normalization process to obtain the output probability, from which the chapter with the biggest probability is selected as the climactic chapter. The calculation process is shown in Equations (13)–(16).
where W and b denote the weight matrix and bias, softmax(·) denotes the normalization function, and argmax(·) denotes the probability maximum function.
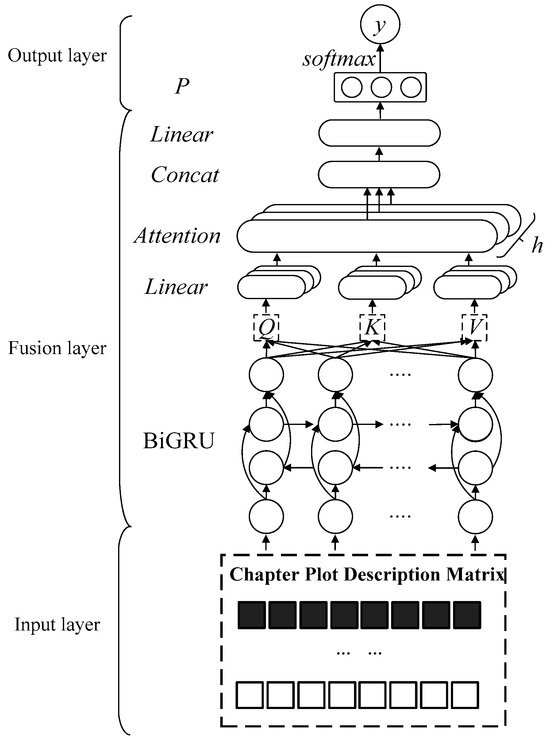
Figure 2.
Climactic chapter recognition model.
3.3.1. BiGRU
As a novel text has significant sequential features, the BiGRU model [19] is adopted as the base model for climactic chapter recognition. The Gated Recurrent Unit (GRU) model is a type of Recurrent Neural Network (RNN) that introduces a simpler structure than LSTM networks. Figure 3 shows the structure of the GRU, which consists of two key gates: the update gate and the reset gate. The update gate controls how much of the previous hidden state is preserved in the current state, while the reset gate controls how much of the previous hidden state should be ignored. These gates enable GRU to manage long-term dependencies in sequences efficiently. The calculation process of the GRU can be described in Equations (17)–(20).
where Wr, Wz, Wh, Ur, Uz, and Uh, respectively, denote the weight matrices of the GRU. The function σ denotes the sigmoid activation, and ⊙ denotes the element-wise multiplication operation. zt denotes the update gate at time step t, and rt is the reset gate at time step t. is the candidate hidden state at time step t, while ht is the hidden state at time step t.
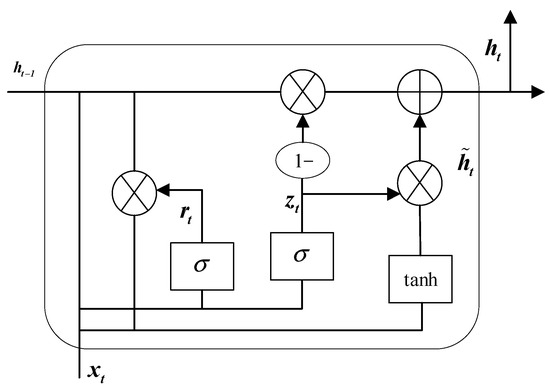
Figure 3.
The structure of the GRU.
A unidirectional GRU processes information only in the forward direction, which limits the model’s ability to capture the contextual information. To overcome this limitation, the BiGRU model extends the GRU by utilizing both forward and backward GRU layers, allowing it to capture bidirectional dependencies in the text. This bidirectional structure is well illustrated in the fusion layer of Figure 2. As shown in Equations (21)–(23), the BiGRU model makes effective use of the contextual semantic features of a novel text by concatenating the feature vectors of the forward and reverse GRU models.
where xt is the input vector at moment t, and denote the feature vectors obtained from the forward and backward GRU models, respectively, and yt is the feature vector obtained by the BiGRU model at the current moment.
3.3.2. Multi-Head Attention
As shown in Equations (24) and (25), the multi-head attention [20] concatenates multiple attentions horizontally to characterize different locations and aspects of semantic information, which helps to further improve the performance, especially the learning ability, of the proposed model CCRPCM.
where head denotes the head of attention, h denotes the number of heads, and Q, K, and V are, respectively, the Query vector, Key vector, and Value vector. , , and are the weight matrices of Query, Key, and Value for the i-th head, Wo is the weight matrix, concat(·) denotes the concatenating operation, and , , , and concat(·)Wo denote the linear layer operation.
4. Experimental Design and Analysis
4.1. Experimental Corpus
The experimental corpus includes the texts of “The Legend of the Condor Heroes”, “The Condor Heroes Return”, and “Heaven Sword and Dragon Sabre” (“The Condor Trilogy”) downloaded from the website https://github.com/weiyinfu/JinYong (accessed on 4 May 2023). The raw text is pre-processed with data cleaning, conversion of full-width characters to half-width characters, normalization of punctuation marks, conversion of complexity and simplicity, and deduplication. Forty chapters are finally selected in each novel, and this forms the experimental corpus. Since there is no annotated corpus of climactic chapters, the experimental corpus is constructed by analyzing the comment data of novel communities and combining it with the annotation results of domain experts.
Table 1 summarizes the major characters and their appearance frequencies in “The Condor Trilogy”. Table 2 shows the total number of chapters, the number of climactic chapters, and the examples of climactic chapters. Table 3 presents the total number of paragraphs, the number of viewpoint paragraphs, and the number of non-viewpoint paragraphs of “The Condor Trilogy”.

Table 1.
Part of the major characters and their frequency (U. times).
Table 2.
Number of chapters, climactic chapters, and examples of climactic chapters of “The Condor Trilogy” (U. pcs).
Table 3.
Number of paragraphs, viewpoint paragraphs, non-viewpoint paragraphs of “The Condor Trilogy” (U. pcs).
4.2. Optimal Parameters
In the comparison experiments in Section 4.4, the BernoulliNB in the sklearn package is used as the NB model, while the SVC in the sklearn with the kernel function rbf is used as the SVM mode. The grid search method is used to select the optimal parameters. In the models BiLSTM, Roberta-large, and CCRPCM, the grid search method is used to determine the optimal parameters of the climactic recognition model. Here, max_epoch is maximized to 512 and set to 10 consecutive rounds of training, and the training is stopped if there is no improvement in the model performance; batch_size is searched and selected in the grid [4, 8, 16]; lr is searched and selected in the grid [0.0001, 0.0002, 0.0004]; hidden_size is searched and selected in the grid [128, 256, 512]; dropout is searched and selected in the grid [0.1, 0.2, 0.4]; num_heads is searched and selected in the grid [4, 8, 16]; the optimizer used in this section is AdamW. Table 4 shows the denotations and values of the parameters selected in the model.
Table 4.
Parameter setting.
4.3. Result Evaluation
Recall (R), Precision (P), and the harmonic mean (F1-score, F1) are used to measure the recognition performance of the climactic chapter. The calculations are shown in Equations (26)–(28).
where True Positive (TP) denotes a correctly classified positive sample, False Positive (FP) denotes a misclassified positive sample, and False Negative (FN) denotes a misclassified negative sample. P denotes the proportion of positive samples correctly predicted by the model to the samples predicted to be positive. R denotes the proportion of positive samples correctly predicted by the model to the samples that were actually positive.
4.4. Experimental Result and Analysis
Comparison and ablation experiments are conducted to verify the effectiveness of the proposed model CCRPCM. The models used in the comparison experiments are NB [14], SVM [12], BiLSTM [21], and the pre-training model Roberta-large [22]. The ablation models include CCRPCM without the Plot Description Matrix (CCRPCM-PCM), CCRPCM without the Chapter Plot Difference Matrix (CCRPCM-PDM), CCRPCM without BiGRU (CCRPCM-BiGRU), and CCRPCM without the Multi-Attention Mechanism (CCRPCM-MultiAtt). The experimental results are shown in Table 5 (The bold font indicate the best experimental results).
Table 5.
Experimental results (U.%).
Based on the experimental corpus of “The Legend of the Condor Heroes”, CCRPCM has the best performance followed by BiLSTM, while NB is the worst. The F1 values of CCRPCM are 25.65%, 19.02%, 8.91%, and 9.58% higher than those of NB, SVM, Roberta-large, and BiLSTM respectively. Based on the experimental corpus of “The Condor Heroes Return”, CCRPCM also has the best performance followed by BiLSTM, with NB performing the worst. The F1 values of CCRPCM are 27.71%, 25.75%, 16.92%, and 12.32% higher than those of NB, SVM, Roberta-large, and BiLSTM, respectively. The result is similar based on the experimental corpus of “Heaven Sword and Dragon Sabre”, where F1 values of CCRPCM are 16.64%, 12.96%, 8.21%, and 2.73% higher than those of NB, SVM, Roberta-large, and BiLSTM, respectively. It can be concluded from the above experimental results that CCRPCM has better recognition performances than the other models, such as NB, SVM, Roberta-large, and BiLSTM. The result of BiLSTM is closer to that of Roberta-large, while NB and SVM do not perform well. The main reasons are listed as follows.
- (1)
- NB assumes that the features are independent of each other, but actually there is a high correlation between the features of the novel chapters. This leads to its poor performance. Moreover, this model requires prior probabilities in advance that generally depends on assumptions, which further increases the risk of misclassification.
- (2)
- SVM is suitable for dealing with a balanced classification problem, while the scales of the viewpoint paragraph and non-viewpoint paragraph in the experimental corpus are obviously imbalanced. However, the SVM method still performs better than NB due to two reasons: firstly, the structural risk minimization principle is used in this model, which can effectively avoid the occurrence of the “overfitting” problem, and therefore, this model has good generalization ability. Secondly, this model is very robust to the anomalies, which can effectively avoid the impact of anomalies on the recognition results.
- (3)
- BiLSTM is a typical deep learning model with strong feature-learning capability. This explains why it has a better recognition performance than traditional machine learning models, such as NB and SVM. The stacking of two layers enables this model to get rid of the limitation that it can only predict the output of the next moment based on the timing information of the previous moments. It can better combine the contextual information for feature extraction, and it is suitable for dealing with the novel text. However, the performance of this model is slightly worse than that of CCRPCM because it is committed to extracting semantic features of the novel text, but ignoring specific features for the climactic chapter recognition.
- (4)
- Roberta-large is a pre-trained language model based on the transformer structure. This model has better comprehension of the novel text by taking contextual information into account and applying the self-attention to capture the long-distance dependencies. Roberta-large performs better than BiLSTM on the experimental corpus of “The Legend of the Condor Heroes”, but not quite as well on “The Condor Heroes Return” or “Heaven Sword and Dragon Sabre”. The possible reasons include the large number of parameters, the lack of flexibility in structure, and the inflexible network.
The purpose of the ablation experiment is to verify the effectiveness of a component in the proposed model. The ablation experimental results are shown in Table 5. Based on the experimental corpus of “The Legend of the Condor Heroes”, the F1 values of CCRPCM are 16.99%, 26.33%, 28.30%, and 6.46% higher than those of CCRPCM-PCM, CCRPCM-PDM, CCRPCM-BiGRU, and CCRPCM-MultiAtt, respectively. Based on the experimental corpus of “The Condor Heroes Return”, the F1 values of CCRPCM are 15.96%, 30.10%, 34.41%, and 7.07% higher, accordingly. Based on the experimental corpus of “Heaven Sword and Dragon Sabre”, the F1 values of CCRPCM are 4.37%, 14.51%, 25.87%, and 2.75% higher. This experiment verifies that CCRPCM-PCM has the best overall performance, followed by CCRPCM-MultiAtt and CCRPCM-PDM, CCRPCM-BiGRU with the worst performance. Reasons to explain this results could be as follows:
- (1)
- BiGRU integrates the GRU model with different directions, fewer parameters, a faster training speed, and higher processing efficiency than BiLSTM. BiGRU is good at capturing the contextual semantic information of the novel text and can effectively inhibit the problems of “gradient disappearance” or “gradient explosion”. That is why CCRPCM-PCM still has basically satisfying recognition performance under the default plot description matrix.
- (2)
- It can be seen from the mechanism of the BiGRU model that it tends to weaken the long-distance information or features, which is not conducive to climactic chapter recognition. The multi-head attention differentiates various features, and it concerns the important features for climactic chapter recognition, which contributes to improving the recognition performance. Therefore, the F1 value of CCRPCM-MultiAtt is generally lower than that of CCRPCM.
- (3)
- The climactic chapter tends to change dramatically compared with its previous and subsequent chapters, which is represented by the chapter plot difference matrix. A plot description matrix is composed of a chapter plot matrix and a chapter plot difference matrix. Although a chapter plot matrix can describe the character and plot of a novel text, the performance of CCRPCM-PDM was influenced without a chapter plot difference matrix.
- (4)
- The plot description matrix can characterize the chapter and the relationships between chapters. This matrix is an essentially explicit feature representation based on the key element extraction. BiGRU, as one of the important deep learning models, has excellent feature-learning capability. It can extract the potential features of the plot description matrix, which are important to climactic chapter recognition. Therefore, the performance of CCRPCM-BiGRU is quite poor without BiGRU.
The climactic chapters recognized by CCRPCM are shown in Table 6, where the 18th chapter of “The Legend of the Condor Heroes” is “Three Test Questions”, the 23rd chapter is “Make a commotion in the Forbidden City”, the 24th chapter is “Secret Room Healing”, the 27th chapter is “In front of Xuanyuan Platform”, the 34th chapter is “Great Changes on the Island”, the 35th chapter is “Iron gun Temple”, and the 40th chapter is “Competition on Huashan Mountain”. The 13th chapter of “The Condor Heroes Return” is “Wulin Alliance Leader”, the 27th chapter is “Fight a Battle of Wits and a Contest of Strength”, the 33rd chapter is “Fengling Night Talk”, the 36th chapter is “Birthday Gift”, the 38th chapter is “Life and Death are Boundless”, and the 39th chapter is “Battle of Xiangyang”. The 20th chapter of “Heaven Sword and Dragon Sabre” is “Joining Forces with Son to Capture the Leader”, the 21st chapter is “The Six Strongest Take Charge of Resolving Disputes”, the 24th chapter is “First Lesson of Taiji: Countering Hardness with Softness”, the 27th chapter is “Hundred-Feet Tall Tower Prevent Passage”, the 29th chapter is “What Hope is There for Four Women in the Same Boat?”, the 35th chapter is “Will the Encounter While Lion-slaying Cause a Calamity?”, the 36th chapter is “Graceful Movements of Three pines in the Lush Green Forest”, and the 38th chapter is “A Gentleman is Gullible Because of His Righteous Conduct.”
Table 6.
The climactic chapters recognized by CCRPCM.
It can be seen from Table 6 that the recognized climactic chapters of “The Legend of the Condor Heroes”, “The Condor Heroes Return”, and “Heaven Sword and Dragon Sabre” are characterized by prominent conflicts and dramatic plots. Table 5 shows that the recognition performance of CCRPCM based on the experimental corpus of “Heaven Sword and Dragon Sabre” (72.54%) is significantly lower than that of “The Legend of the Condor Heroes” (77.78%) and “The Condor Heroes Return” (81.08%). The reason for the different performances based on the experimental corpus could be related to the novel writing habits. The 32nd chapter “Being Driven Mad by Unredressed Mongol Injustice” and the 39th chapter “Secret Manual and Military Treatise are Hidden Within” in “Heaven Sword and Dragon Sabre” were not recognized as the climactic chapters. These two chapters are not the parts where the key conflicts develop to the extreme point. Therefore, the plots are a little plain, which is prone to lower values of CPI, COI, and CTI, resulting in the above unrecognized problem.
The numbers of viewpoint and non-viewpoint paragraphs of the climactic chapters are shown in Table 7, Table 8 and Table 9.
Table 7.
The number of viewpoint paragraphs and non-viewpoint paragraphs of the climactic chapters based on “The Legend of the Condor Heroes”(U. pcs).
Table 8.
The number of viewpoint paragraphs and non-viewpoint paragraphs of the climactic chapters based on “The Condor Heroes Return”(U. pcs).
Table 9.
The number of viewpoint paragraphs and non-viewpoint paragraphs of the climactic chapters based on “Heaven Sword and Dragon Sabre”(U. pcs).
The major characters and their appearance frequencies in the climactic chapters are shown in Table 10, Table 11 and Table 12. The matrix heatmaps are shown in Figure 4, Figure 5 and Figure 6, where the X-axis denotes the major characters and the Y-axis denotes the climactic chapters. The color gradient reflects the frequency of appearances, where higher frequencies are closer to bright yellow, and lower frequencies are closer to blue-purple.
Table 10.
The major characters and their appearance frequencies in the climactic chapters based on “The Legend of the Condor Heroes” (U. pcs).
Table 11.
The major characters and their appearance frequencies in the climactic chapters based on “The Condor Heroes Return” (U. pcs).
Table 12.
The major characters and their appearance frequencies in the climactic chapters based on “Heaven Sword and Dragon Sabre” (U. pcs).
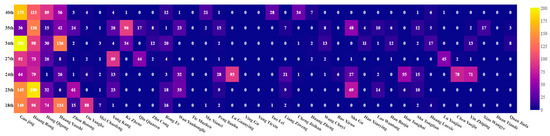
Figure 4.
The matrix heatmap of the major characters and their appearance frequencies in the climactic chapters based on “The Legend of the Condor Heroes”.
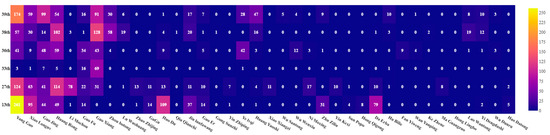
Figure 5.
The matrix heatmap of the major characters and their appearance frequencies in the climactic chapters based on “The Condor Heroes Return” (U. pcs).
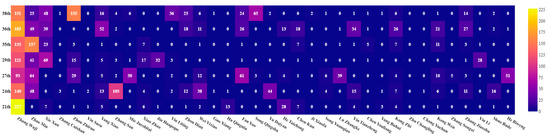
Figure 6.
The matrix heatmap of the major characters and their appearance frequencies in the climactic chapters based on “Heaven Sword and Dragon Sabre”.
Generally speaking, the climactic chapters have more viewpoint paragraphs with stronger sentiments. As shown in Table 7, Table 8 and Table 9, the number of viewpoint paragraphs in the climactic chapters of “The Legend of the Condor Heroes” is significantly greater than the number of non-viewpoint paragraphs. The number of viewpoint paragraphs in the climactic chapters of “The Condor Heroes Return” is significantly greater than the number of non-viewpoint paragraphs, except for the 33rd chapter. The number of viewpoint paragraphs in the climactic chapters of “Heaven Sword and Dragon Sabre” is greater than the number of non-viewpoint paragraphs, except for the 21st and 29th chapters. There are two chapters in “Heaven Sword and Dragon Sabre” where the number of viewpoint paragraphs is less than that of non-viewpoint paragraphs, which is more than 0 in “The Legend of the Condor Heroes” and 1 in “The Condor Heroes Return”. Due to the importance of viewpoint paragraphs, it is not difficult to understand the reason why the F1 value of “Heaven Sword and Dragon Sabre” is lower than those of the other two novels, as shown in Table 5.
More characters tend to appear in the climactic chapters. As can be seen from Table 10, Table 11 and Table 12, the character appearance frequencies in the 18th, 23rd, 24th, 27th, 34th, 35th, and 40th climactic chapters of “The Legend of the Condor Heroes” are 15, 15, 22, 19, 21, 26, and 18, respectively. The characters with higher frequencies are Guo Jing (140), Huang Rong (190), Lu Guanying (93), Guo Jing (92), Guo Jing (201), Huang Rong (136), and Guo Jing (175), respectively, where the values in parentheses are the character appearance frequencies. The character appearance frequencies in the 13th, 27th, 33rd, 36th, 38th, and 39th climactic chapters of “The Condor Heroes Return” are 19, 23, 8, 19, 20, and 21, respectively. The characters with the higher frequencies are Yang Zao (261), Yang Zao (124), Guo Xiang (69), Huang Rong (59), Guo Xiang (128), and Yang Zao (174), respectively. The character appearance frequencies in the 21st, 24th, 27th, 29th, 35th, 36th, and 39th climactic chapters of “Heaven Sword and Dragon Sabre” are 17, 22, 20, 16, 16, 18, and 24, respectively. The characters with the highest frequencies are Zhang Wuji (227), Zhang Wuji (140), Zhang Wuji (93), Zhang Wuji (121), Zhao Min (157), Zhang Wuji (183), and Zhou Zhiruo (155), respectively. It can be seen from the collection of chapter keywords and the above analysis that the major characters with higher appearance frequencies are the participants and promoters of the climactic chapters, and they play important roles in the climactic plot.
5. Conclusions
Chinese long novels have been popular because of their diverse characters and fascinating plots. As an important part of the plot, the climactic chapter is the part of the novel where the key conflict develops to the extreme point, which is most essential and attractive. How to quickly and accurately locate the climactic chapter of a Chinese long novel is quite important to the expansion of readers and improvement of its social influence. In view of this, this paper proposes a climactic-chapter-recognition method of a Chinese long novel based on the plot description. It consists of two parts; one is key element extraction, which concerns the extraction method of key elements, such as the viewpoint paragraph, non-viewpoint paragraph, chapter keyword, major character, etc. The other part is climactic chapter recognition, which tries to utilize the BiGRU model and the multi-head attention to recognize the climactic chapter on the basis of the chapter plot description matrix. Comparative experiments on the corpus of Jin Yong’s “The Condor Trilogy” show that the method proposed in this paper outperforms several existing models. In addition, an ablation experiment is designed to verify the effectiveness of the components of the proposed method. However, as experimental corpus annotation is time-consuming and labor-intensive, the corpus size is still small in this paper, which leads to the poor learning capability of deep learning models and therefore influences the performance of climactic chapter recognition.
Author Contributions
Methodology, Z.L.; Software, G.W.; Validation, Y.L.; Data curation, J.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Key Project on Interpreting CPC’s 20th National Congress Spirit of the National Social Science Fund of China, grant number 23AZD047.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available on request due to restrictions privacy.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xiao, T.J.; Liu, Y. A stylistic analysis of Jin Yong’s and Gu Long’s fictions based on text clustering and classification. J. Chin. Inf. Process. 2015, 29, 167–177. [Google Scholar]
- Yao, R.Q.; Zhang, H.; Yao, Y.H. Research on application of social network analysis on character relationships in Jin Yong’s novels. J. Libr. Data 2021, 3, 68–80. [Google Scholar]
- Zhang, X.; Liang, X.; Li, Z.Y.; Zhang, S.S.; Zhao, X.L. Identification and analysis of love relationships of protagonists in Jin Yong’s fictions. J. Chin. Inf. Process. 2019, 33, 109–119. [Google Scholar]
- Tai, Q.Q.; Rao, G.Q.; Xia, E.S.; Xu, E.D. Research on Jin Yong with text mining from the perspective of digital humanities. Digit. Humanit. 2020, 4, 115–136. [Google Scholar]
- Liu, Y.; Xiao, T.J. A stylistic analysis for Gu Long’s Kung Fu novels. J. Quant. Linguist. 2020, 27, 32–61. [Google Scholar] [CrossRef]
- Xia, E.S.; Tai, Q.Q.; Li, Q.; Li, J.T.; Rao, G.Q.; Xun, E.D. Digital humanities research of Jin Yong’s works based on quantitative linguistics. Proc. Int. J. Knowl. Lang. 2021, 12, 1–10. [Google Scholar]
- Song, Q.; Zhang, Y.; Zhang, P.Z. Research review on key techniques of topic-based news elements extraction. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 585–590. [Google Scholar]
- Li, Y.; Ning, H. Multi-feature keyword extraction method based on TF-IDF and Chinese grammar analysis. In Proceedings of the 2021 International Conference on Machine Learning and Intelligent Systems Engineering (MLISE), Chongqing, China, 9–11 July 2021; pp. 362–365. [Google Scholar]
- Wang, X.Y.; Yu, J.; Li, R. Key-elements graph constructed with evidence sentence extraction for gaokao chinese. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2020; pp. 403–414. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Kim, E.; Klinger, R. An analysis of emotion communication channels in fan-fiction: Towards emotional storytelling. In Proceedings of the Second Workshop on Storytelling, Florence, Italy, 1 August 2019; pp. 56–64. [Google Scholar]
- Zehe, A.; Becker, M.; Hettinger, L.; Hotho, A.; Reger, I.; Jannidis, F. Prediction of happy endings in German novels based on sentiment information. In Proceedings of the 3rd Workshop on Interactions between Data Mining and Natural Language, Riva del Garda, Italy, 23 September 2016; pp. 9–16. [Google Scholar]
- Mohammad, S.M.; Turney, P. NRC Emotion Lexicon. 2023. Available online: http://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm (accessed on 5 January 2024).
- Horton, T.; Taylor, K.; Yu, B.; Xiang, X. “Quite right, dear and interesting”: Seeking the sentimental in nineteenth century American fiction. In Proceedings of the 2006 Conference on Digital Humanities, Paris, France, 5–9 July 2006; pp. 81–82. [Google Scholar]
- Yu, B. An evaluation of text classification methods for literary study. Lit. Linguist. Comput. 2008, 23, 327–343. [Google Scholar] [CrossRef]
- Liang, X. An Example Analysis of Deep Learning Based Social Information Mining Applications; Science Press: Beijing, China, 2020. [Google Scholar]
- Cao, Z.W. History of Chinese Chivalry; Shanghai Bookstore Publishing House: Shanghai, China, 2014. [Google Scholar]
- Han, H.; Choi, J.D. The stem cell hypothesis: Dilemma behind multi-task learning with transformer encoders. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5555–5577. [Google Scholar]
- Kumar, A.; Vepa, J. Gated mechanism for attention based multi modal sentiment analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Washington, DC, USA, 4–8 May 2020; pp. 4477–4481. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, N.A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Guo, L.P. A NLP-Based Novel Character Attribute Extraction System. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2021. [Google Scholar]
- Xu, L.; Hu, H.; Zhang, X.W.; Li, L.; Cao, C.J.; Li, Y.D.; Xu, Y.C.; Sun, K.; Yu, D.; Yu, C.; et al. CLUE: A Chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 4762–4772. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).