

A Multimodal Recommender System Using Deep Learning Techniques Combining Review Texts and Images

 , , and
, , and 
Abstract
1. Introduction
- This study proposed CAMRec, which reflects user preferences from textual and visual perspectives and provides recommendations based on the complementarity between the two modalities.
- This study explored the impact of users’ perception of visual representations on performance in multimodal recommender systems. It offers valuable insights into how visual features reflect user preferences.
- This study conducted extensive experiments using real-world datasets from Amazon. The experimental results offer new directions for future research in the field of recommender systems.
2. Related Works
2.1. Review-Based Recommender System
2.2. Multimodal Recommender System
2.3. Multimodal Fusion Techniques
3. Methodology
3.1. Problem Definition
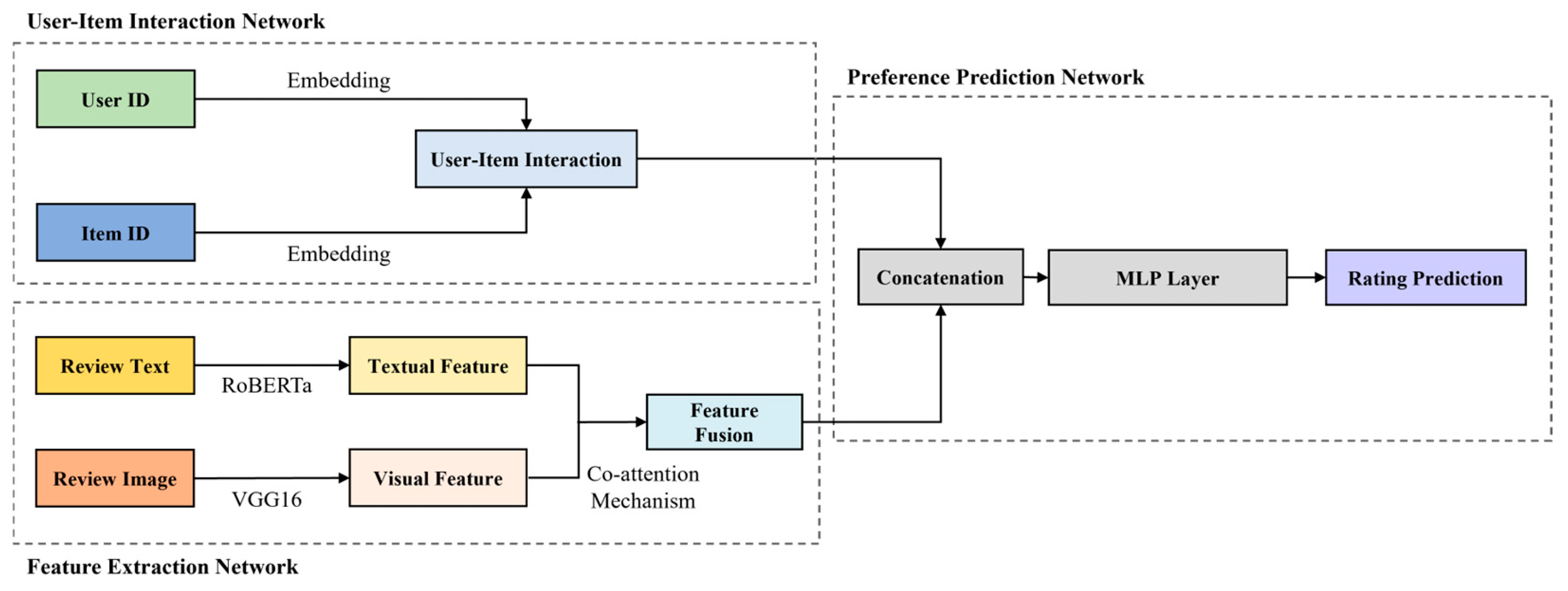
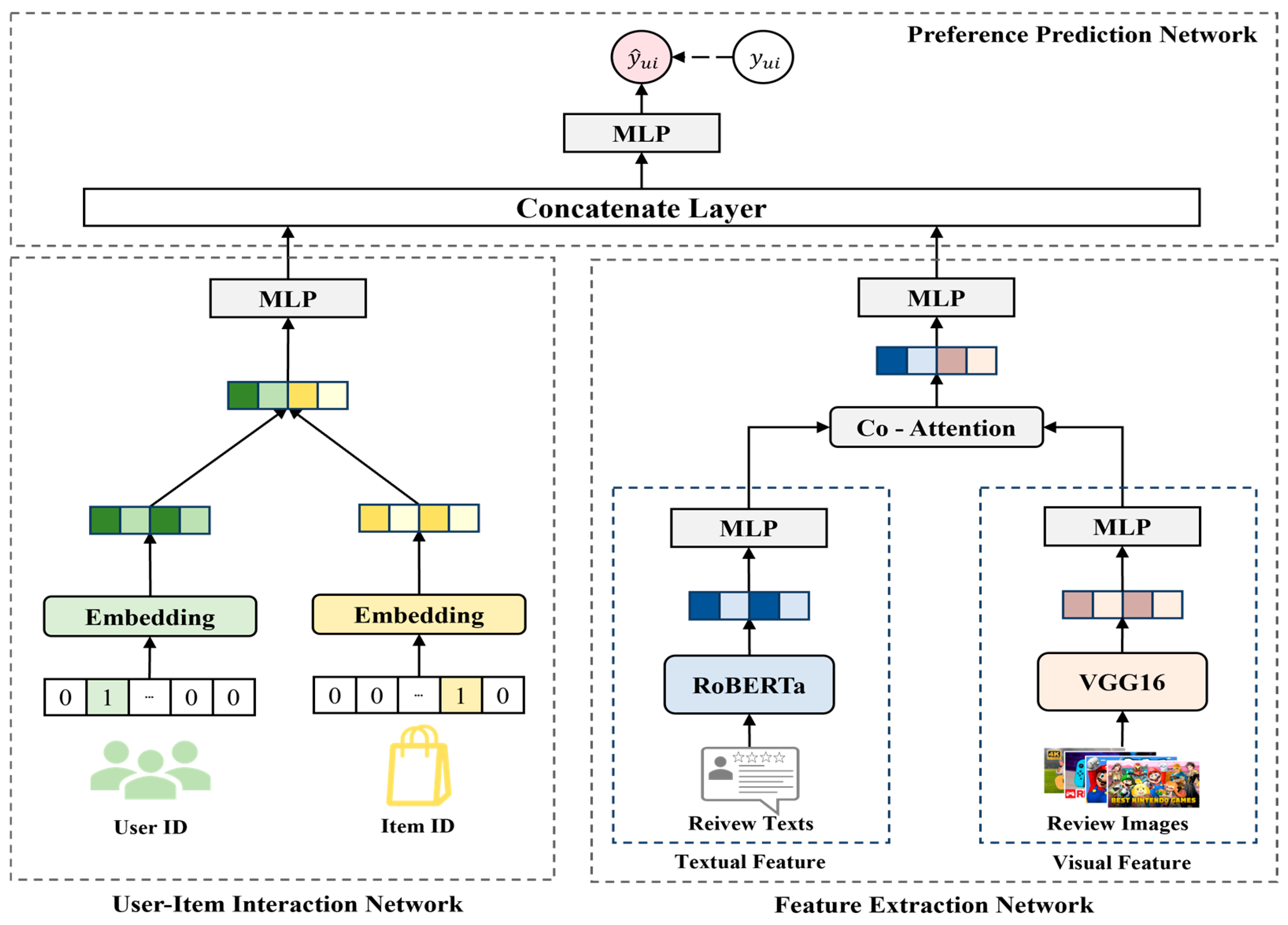
3.2. CAMRec Architecture
3.2.1. User–Item Interaction Network
3.2.2. Feature Extraction Network
3.2.3. Preference Prediction Network
4. Experiments
- RQ 1: Does the proposed CAMRec model provide better recommendation performance compared to other baseline models?
- RQ 2: How do the fused features of texts and images impact recommendation performance?
- RQ 3: Which fusion method is the most effective in fusing texts and images?
4.1. Datasets
4.2. Evaluation Metric
4.3. Baseline Models
- PMF [28]: This model predicts ratings by modeling latent factors of the user and the item using the evaluation matrix as input based on the Gaussian distribution. This model is effective on sparse, imbalanced rating data.
- NeuMF [29]: This model combines the Generalized Matrix Factorization (GMF) and MLP to measure the nonlinear relationship between the user and item latent factors.
- DeepCoNN [6]: This model uses two CNN processors for each user’s review and item’s review to extract features, which are combined with Factorization Machine (FM) to predict ratings.
- RSBM [7]: This model extracts the semantic features of review texts using CNN and self-attention mechanism, which predicts the rating based on the importance of each extracted feature.
- VBPR [18]: This model extracts visual representations from item images and incorporates them into the MF model. It can solve the cold-start problems and provide accurate recommendations using Bayesian Personalized Ranking (BPR).
- UCAM [30]: This model predicts ratings by integrating context information into the NeuMF model. In this study, we use RoBERTa and VGG-16 models to extract feature representations from the review texts and images, and then integrate them as context information into the model.
4.4. Experimental Settings
5. Experimental Results
5.1. Performance Comparison to Baseline Models (RQ 1)
5.2. Effect of Components of CAMRec (RQ 2)
5.3. Effect of Fusion Strategy (RQ 3)
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jang, D.; Li, Q.; Lee, C.; Kim, J. Attention-based multi attribute matrix factorization for enhanced recommendation performance. Inf. Syst. 2024, 121, 102334. [Google Scholar] [CrossRef]
- Zhu, Z.; Yan, M.; Deng, X.; Gao, M. Rating prediction of recommended item based on review deep learning and rating probability matrix factorization. Electron. Commer. Res. Appl. 2022, 54, 101160. [Google Scholar] [CrossRef]
- Park, J.; Li, X.; Li, Q.; Kim, J. Impact on recommendation performance of online review helpfulness and consistency. Data Technol. Appl. 2023, 57, 199–221. [Google Scholar] [CrossRef]
- Li, Q.; Li, X.; Lee, B.; Kim, J. A hybrid CNN-based review helpfulness filtering model for improving e-commerce recommendation Service. Appl. Sci. 2021, 11, 8613. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Y.; Peng, Q.; Wu, F.; Gan, L.; Pan, L.; Jiao, P. Hybrid neural recommendation with joint deep representation learning of ratings and reviews. Neurocomputing 2020, 374, 77–85. [Google Scholar] [CrossRef]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Cao, R.; Zhang, X.; Wang, H. A review semantics based model for rating prediction. IEEE Access 2019, 8, 4714–4723. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Chen, Y.-L.; Chang, P.-Y. A deep multi-embedding model for mobile application recommendation. Decis. Support Syst. 2023, 173, 114011. [Google Scholar] [CrossRef]
- Xu, C.; Guan, Z.; Zhao, W.; Wu, Q.; Yan, M.; Chen, L.; Miao, Q. Recommendation by users’ multimodal preferences for smart city applications. IEEE Trans. Ind. Inform. 2020, 17, 4197–4205. [Google Scholar] [CrossRef]
- Ren, G.; Diao, L.; Guo, F.; Hong, T. A co-attention based multi-modal fusion network for review helpfulness prediction. Inf. Process. Manag. 2024, 61, 103573. [Google Scholar] [CrossRef]
- Xiao, S.; Chen, G.; Zhang, C.; Li, X. Complementary or substitutive? A novel deep learning method to leverage text-image interactions for multimodal review helpfulness prediction. Expert Syst. Appl. 2022, 208, 118138. [Google Scholar] [CrossRef]
- Liu, M.; Liu, L.; Cao, J.; Du, Q. Co-attention network with label embedding for text classification. Neurocomputing 2022, 471, 61–69. [Google Scholar] [CrossRef]
- Yang, S.; Li, Q.; Jang, D.; Kim, J. Deep learning mechanism and big data in hospitality and tourism: Developing personalized restaurant recommendation model to customer decision-making. Int. J. Hosp. Manag. 2024, 121, 103803. [Google Scholar] [CrossRef]
- Takács, G.; Pilászy, I.; Németh, B.; Tikk, D. Scalable collaborative filtering approaches for large recommender systems. J. Mach. Learn. Res. 2009, 10, 623–656. [Google Scholar]
- Ma, Y.; Chen, G.; Wei, Q. Finding users preferences from large-scale online reviews for personalized recommendation. Electron. Commer. Res. 2017, 17, 3–29. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Liu, P.; Zhang, L.; Gulla, J.A. Dynamic attention-based explainable recommendation with textual and visual fusion. Inf. Process. Manag. 2020, 57, 102099. [Google Scholar] [CrossRef]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Chen, X.; Chen, H.; Xu, H.; Zhang, Y.; Cao, Y.; Qin, Z.; Zha, H. Personalized fashion recommendation with visual explanations based on multimodal attention network: Towards visually explainable recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 765–774. [Google Scholar]
- Liu, F.; Chen, H.; Cheng, Z.; Liu, A.; Nie, L.; Kankanhalli, M. Disentangled multimodal representation learning for recommendation. IEEE Trans. Multimed. 2022, 25, 7149–7159. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, X.; Zhao, Z.; Xu, J.; Li, Z. Image–text sentiment analysis via deep multimodal attentive fusion. Knowl.-Based Syst. 2019, 167, 26–37. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, J.; Zhao, W.; Ran, C. DMRFNet: Deep multimodal reasoning and fusion for visual question answering and explanation generation. Inf. Fusion 2021, 72, 70–79. [Google Scholar] [CrossRef]
- Ren, G.; Diao, L.; Kim, J. DMFN: A disentangled multi-level fusion network for review helpfulness prediction. Expert Syst. Appl. 2023, 228, 120344. [Google Scholar] [CrossRef]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. Adv. Neural Inf. Process. Syst. 2016, 29, 289–297. [Google Scholar]
- Laenen, K.; Moens, M.-F. A comparative study of outfit recommendation methods with a focus on attention-based fusion. Inf. Process. Manag. 2020, 57, 102316. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Unger, M.; Tuzhilin, A.; Livne, A. Context-aware recommendations based on deep learning frameworks. ACM Trans. Manag. Inf. Syst. 2020, 11, 1–15. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Feature | Cell Phones and Accessories | Electronics |
|---|---|---|
| User | 148,405 | 262,488 |
| Item | 60,665 | 102,241 |
| Review and Rating | 179,249 | 344,013 |
| Sparsity (%) | 99.998% | 99.999% |
| Model | Cell Phones and Accessories | Electronics | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| PMF | 1.839 | 2.093 | 1.795 | 2.183 |
| NeuMF | 1.543 | 1.675 | 1.299 | 1.529 |
| DeepCoNN | 0.731 | 0.971 | 0.657 | 0.896 |
| RSBM | 0.566 | 0.830 | 0.525 | 0.783 |
| VBPR | 1.490 | 1.637 | 1.258 | 1.475 |
| UCAM | 0.516 | 0.804 | 0.463 | 0.790 |
| CAMRec | 0.460 | 0.725 | 0.417 | 0.701 |
| Model | Cell Phones and Accessories | Electronics | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| CAM-R | 1.846 | 2.220 | 1.252 | 1.487 |
| CAM-RT | 0.504 | 0.764 | 0.479 | 0.735 |
| CAM-RI | 1.334 | 1.512 | 1.174 | 1.389 |
| CAMRec | 0.460 | 0.725 | 0.417 | 0.701 |
| Method | Cell Phones and Accessories | Electronics | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| Addition | 0.515 | 0.763 | 0.470 | 0.707 |
| Average | 0.553 | 0.797 | 0.473 | 0.711 |
| Multiplication | 0.530 | 0.799 | 0.486 | 0.728 |
| Concatenation | 0.509 | 0.755 | 0.469 | 0.707 |
| Co-attention | 0.460 | 0.725 | 0.417 | 0.701 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, E.; Li, X.; Kwon, A.; Park, S.; Li, Q.; Kim, J. A Multimodal Recommender System Using Deep Learning Techniques Combining Review Texts and Images. Appl. Sci. 2024, 14, 9206. https://doi.org/10.3390/app14209206
Jeong E, Li X, Kwon A, Park S, Li Q, Kim J. A Multimodal Recommender System Using Deep Learning Techniques Combining Review Texts and Images. Applied Sciences. 2024; 14(20):9206. https://doi.org/10.3390/app14209206
Chicago/Turabian StyleJeong, Euiju, Xinzhe Li, Angela (Eunyoung) Kwon, Seonu Park, Qinglong Li, and Jaekyeong Kim. 2024. "A Multimodal Recommender System Using Deep Learning Techniques Combining Review Texts and Images" Applied Sciences 14, no. 20: 9206. https://doi.org/10.3390/app14209206
APA StyleJeong, E., Li, X., Kwon, A., Park, S., Li, Q., & Kim, J. (2024). A Multimodal Recommender System Using Deep Learning Techniques Combining Review Texts and Images. Applied Sciences, 14(20), 9206. https://doi.org/10.3390/app14209206