

A Knowledge-Driven Approach for Automatic Semantic Aspect Term Extraction Using the Semantic Power of Linked Open Data

Abstract
1. Introduction
- (1)
- Identifying aspect terms presents challenges, especially when dealing with multiple words. It is imperative to conduct a comprehensive analysis, particularly for multiple-word aspect terms not presented in the training dataset. For instance, if the term “views of city” is absent from the training data, it may not be recognized as an aspect, despite the presence of the term “views” alone.
- (2)
- Relying solely on the training dataset for aspect extraction proves insufficient, particularly when certain aspects or semantic nuances are not represented. This dependency on the training data can lead to a biased understanding of aspects and may fail to provide a comprehensive comprehension of the domain. For example, the dish “foie gras terrine with figs”, categorized under “food”, may be absent from the training dataset, highlighting the limitations of this approach.
- (3)
- Within the training dataset, a notable challenge arises from numerous synonymous aspect terms, including both single-word and multiple-word aspect terms. It is essential to resolve these synonymous terms to enable more precise aspect terms and improve the semantic understanding of these aspects.
1.1. Contribution of this Paper
- (1)
- In addressing the first issue, this research introduces a novel algorithm leveraging syntactic dependency and sentiment lexicons to capture and analyze multiple aspect terms of a sentence proficiently. The proposed approach significantly improves the performance of ATE in both single-word and multiple-word aspect terms scenarios.
- (2)
- To tackle the second and third challenges, this research leverages the N-gram model [45] to capture complex text patterns and relationships, facilitating classification and accurate analysis of multiple-word aspect terms. Furthermore, knowledge-based methods, including the Linked Open Data (LOD) [46,47], with an emphasis on the DBpedia [48] and the Thesaurus lexicon [49], are employed to resolve the synonymous aspect terms and aspect categorization.
1.2. Structure of the Paper
2. Related Work
- (1)
- Supervised aspect extraction utilizes annotated datasets to teach machine learning algorithms to automatically recognize and extract aspect terms from customer reviews related to products or services [12,13,14,15,16,17,18]. Xue et al. [12] proposed a Multi-Task Neural Network (MTNN) framework for ATE, integrating Bidirectional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Networks (CNN) to improve multitask learning outcomes using restaurant review data. Yu et al. [13] introduced the Global Inference (GI) approach for ATE applied to MTNN. Their method integrates various syntactic elements to explicitly capture intra-aspect and inter-aspect relationships. Agerri et al. [14] introduced a language-agnostic system for aspect extraction that combines local, surface-level attributes with Semantic Distributional Features based on Clustering (SDFC) to aspect identification. Luo et al. [15] present an innovative framework for ATE. This framework utilizes a Bidirectional Dependency Tree Network (BiDTree) to capture tree-structured relationships within sentences. The embeddings learned from the BiDTree are subsequently fused with a Conditional Random Field (CRF) to leverage sequential information. This BiDTreeCRF approach enables the model to concurrently learn syntactic and sequential features, resulting in enhanced performance of the ATE. Akhtar et al. [16] present a Bi-LSTM paired with a self-attention mechanism for ATE. This strategy employs Bi-LSTMs to capture sequential information within sentences, and the self-attention mechanism enables the model to concentrate on the most pertinent segments of the input for ATE. Ning Liu and Bo Shen [17] introduced a new Seq2Seq learning framework for ATE using the Information-Augmented Neural Network (IANN), which utilizes the foundation of a neural network. This model addresses the issue of the limited capacity of static word embedding used in ATE, which are insufficient for capturing the evolving meaning of words. Yinghao P. and Jin Z. [18] proposed a new extraction model called BiLSTM-BGAT-GCN, which is used to identify aspect terms, opinion terms, and their corresponding sentiment orientations in customer review.
- (2)
- Unsupervised aspect extraction involves automatically identifying and extracting aspects from customer reviews without relying on pre-labeled training data. Heng Yan et al. [19] proposed a model for Chinese-oriented aspect-based sentiment analysis called LCF-ATEPC. This model utilizes the BERT model to improve the performance of ATE. Additionally, the methodologies employed in this task encompass the following techniques [20,21,22,23,24,25,26,27,28,29,30,31,32,33,34]:
- (a)
- Frequency-based ATE approaches utilize the distribution of word or phrase frequencies within a text to discern significant aspects based on their frequent occurrence [20,21,22]. Minqing Hu and Bing Liu [20] introduced a technique for aspect extraction from customer reviews, employing the frequency distribution of aspects within the reviews. Anwer et al. [21] presented their method for ATE from customer reviews, which exploits frequency distribution to identify recurring aspects discussed by customers. Toqir A. and Yu C. [22] introduced a two-fold rule-based model for aspect extraction called TF-RBM, which relies on rules derived from sequential patterns extracted from customer reviews. Moreover, this study has implemented frequency and similarity-based techniques to enhance the aspect extraction accuracy of the proposed model.
- (b)
- Syntax-based ATE approaches utilize the grammatical structure of sentences to identify aspect terms, often employing part-of-speech (POS) tagging, dependency parsing, and predefined syntactic patterns [23,24,25,26,27]. Zhao et al. [23] introduced a novel approach for ATE from product reviews, which utilizes generalized syntactic patterns and similarity measures to improve ATE performance. Maharani et al. [24] introduce a new approach to ATE based on unstructured reviews. They suggest a rule-based system that utilizes syntactic patterns derived from feature observations within the review text. This method is supported by a comprehensive analysis of the diverse patterns identified in the data. Shafie et al. [25] assessed the effectiveness of different dependency relations in combination with various POS tagging patterns for candidate ATE from customer reviews. Dragoni et al. [26] introduce an opinion monitoring service that utilizes dependency parsing for ATE and integrates a visualization tool to assist in data monitoring. Jie et al. [27] presents an adaptive semantic relative distance method that relies on dependent syntactic analysis. It utilizes adaptive semantic relative distance to identify the suitable local context for each text, hence enhancing the precision of sentiment analysis.
- (c)
- Topic modeling is an unsupervised statistical technique used to reveal latent thematic structures within a set of documents. One of the most widely used and well-established algorithms for topic modeling is Latent Dirichlet Allocation (LDA) [50]. LDA is a statistical model that represents documents as combinations of a predetermined number of underlying topics. Each topic is defined by a probability distribution over the vocabulary, indicating the likelihood of each word appearing within that topic [51]. LDA has been applied to ATE in the realm of ABSA, as discussed in several studies [28,29,30,31,32,33,34]. Titov and McDonald [28] introduced Multi-grain Latent Dirichlet Allocation (MG-LDA), an extension of LDA, for joint topic modeling and ATE from online customer reviews. MG-LDA captures aspects at various levels of granularity, allowing the extraction of both fine-grained (local topics) and coarse-grained (global topics) aspects along with their associated textual evidence within reviews. Brody and Elhadad [29] utilized LDA for ATE from restaurant customer reviews, augmenting their work with a knowledge lexicon to improve the identification of named entities within the reviews. Yao et al. [30] proposed a novel framework for named entity recognition (NER) in news articles, employing LDA to identify latent topics within the text and integrating a knowledge lexicon derived from Wikipedia to enhance entity extraction. This approach was tested on news datasets from the New York Times and Tech Crunch, demonstrating its efficacy in extracting news-related entities. Shams and Baraani-Dastjerd [31] introduced a novel method to improve the quality of automatic ATE by integrating domain knowledge through word co-occurrence relationships. This method, known as Enriched Latent Dirichlet Allocation (ELDA), seeks to capture more nuanced aspects by incorporating co-occurrence information into the standard LDA model. Annisa et al. [32] proposed an ATE approach for analyzing hotel reviews in Mandalika, Indonesia, utilizing LDA. Ozyurt and Akcayol [33] propose an innovative approach for ATE focusing on Turkish restaurant reviews. Their method utilizes Sentence Segment Latent Dirichlet Allocation (SS-LDA), an extension of the traditional LDA model, to tackle the challenge of limited data availability in the ATE task. Venugopalan et al. [34] tackle the limitations of LDA in handling overlapping topics by integrating BERT. This approach harnesses BERT’s ability to capture semantic relationships between words, enhancing ATE performance by discerning between thematically similar aspects.
- (3)
- Hybrid ATE Methods: The last category of ATE methodologies comprises hybrid approaches. These methods combine various techniques, algorithms, or resources to enhance ATE accuracy. This can involve synergistically integrating supervised, unsupervised, or other methods to address their individual limitations. The primary goal of these hybrid approaches is to achieve superior performance in aspect term extraction compared to using a single approach in isolation [35,36,37,38,39,40,41]. In their work, Wu et al. [35] introduce a novel unsupervised approach for ATE that combines linguistic conjunction rules with pruning and a deep learning model employing a Gated Recurrent Unit (GRU) network. Chauhan et al. [36] propose a two-stage unsupervised approach for ATE. This model harnesses both symbolic and neural techniques by integrating linguistic rules with an attention-based Bi-LSTM architecture. This integration aims to enhance the overall ATE performance. Musheng C. et al. [37] introduce a novel end-to-end framework for ABSA. It leverages a task-sharing layer to facilitate interaction between aspect term extraction and sentiment classification. Furthermore, the framework employs a multi-head attention mechanism to capture the relationships between different aspect items, addressing the issue of sentiment inconsistency within aspects observed in previous end-to-end models. Zhigang Jin et al. [38] introduced a model called SpanGCN, which is a Span-based dependency-enhanced Graph Convolutional Network. This model combines the Latent dependency Graph Convolutional Network (LGCN) with span enumeration to tackle the ABSA task. In this research, BERT and the Graph Convolutional Network (GCN) are employed to capture contextual semantic and dependency relationships. Fan Zhang et al. [39] presented a new model called the Syntactic Dependency Graph Convolutional Network (SD-GCN). This model uses GCN to implement syntactic dependencies and yield enhanced aspect features for ATE. Yusong M. and Shumin S. [40] introduced a novel model named Dependency-Type Weighted Graph Convolution Network (DTW-GCN) for the purpose of combining dependency-type messages with word embedding in the context of ABSA. Busst M. M. A. et al. [41] presented Ensemble BiLSTM, a novel approach for aspect extraction. The Ensemble BiLSTM model utilizes the syntactic, semantic, and contextual properties of unstructured texts found in BERT word embeddings to extract aspect terms. Additionally, it incorporates the sequential properties of aspect term categories by employing an ensemble of BiLSTM model.
3. Methodology

| Algorithm 1: Slang and Abbreviation Processing |
| Input: refers to a finite set of segmented words. Output: refers to a finite set of new segmented words resulting from the correction of slang and abbreviations. Notations used: Let be a finite set of updated slang and abbreviations verified by DBpedia. function to correct slang and abbreviations using DBpedia. function to correct slang and abbreviations using the S&A dictionary. Procedure: foreach //some cannot be found in if ( S&A dictionary) then else end if end foreach return End Procedure |
3.1. Preprocessing Module
- (1)
- Word segmentation: The Stanza toolkit extracts lexical units, such as words, symbols, and semantically significant elements.
- (2)
- Word correction: This work investigates the spelling error correction of words using the pyspellchecker library [54] and a dictionary named WordCoreection. For instance, pyspellchecker can correct “survice” to “service”, while WordCoreection handles cases like “chuwan” being replaced with “chawan”.
- (3)
- Slang and abbreviation processing: This stage aims to correct slang and abbreviations using LOD. Additionally, a Slang and Abbreviations (S&A) dictionary is utilized to correct slang and abbreviations missing in the LOD. For example, “veggie” is replaced with “vegetable”, “NYC” with “New York City”, and “rito” with “burrito”. Algorithm 1 describes this process.
- (4)
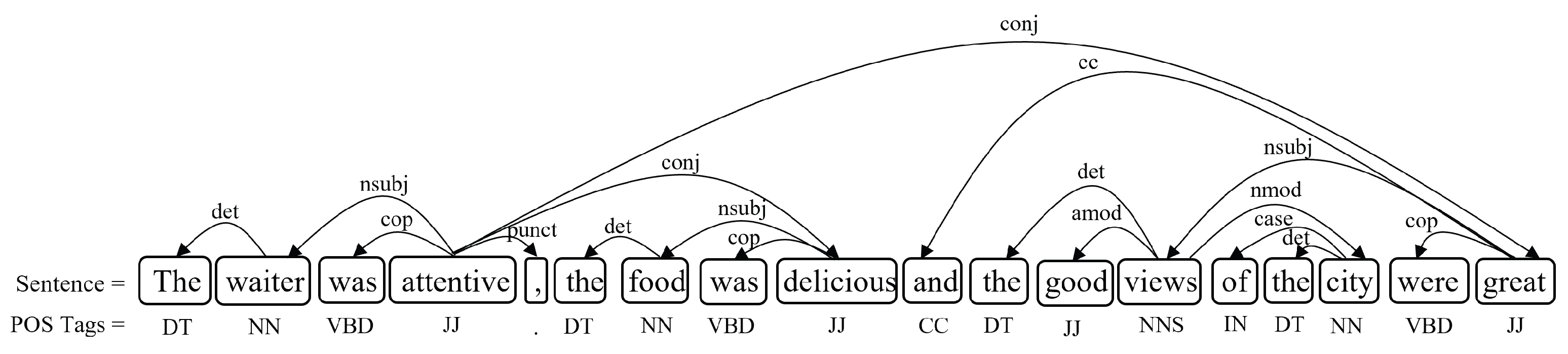
- Part of Speech (POS) tagging assigns a POS tag to each word in a sentence, forming a combination of the word and its corresponding POS tag. For example: “The (Determiner: DT)”, “waiter (Noun: NN)”, “was (Past tense verb: VBD)”, “attentive (Adjective: JJ)”, “, (End of sentence punctuation: .)”, “the (Determiner: DT)”, “food (Noun: NN)”, “was (Past tense verb: VBD)”, “delicious (Adjective: JJ)”, “and (Coordinating conjunction: CC)”, “the (Determiner: DT)”, “good (Adjective: JJ)”, “views (Plural noun: NNS)”, “of (Preposition or subordinating conjunction: IN)”, “the (Determiner: DT)”, “city (Noun: NN)”, “were (Past tense verb: VBD)”, and “great (Adjective: JJ)”.
- (5)
- Dependency parsing is a process that involves identifying the relationships between words in a sentence to analyze its grammatical structure. This process utilizes dependency grammar (DG) [55], a linguistic framework for analyzing grammatical structures. It consists of two main components. The “head” is a linguistic element that governs the syntax of other words, while the “dependent” is a word that has a semantic or syntactic connection with the head. The meaning or grammatical function of a word depends on its head, and this relationship is depicted by labeled arrows known as dependencies. These dependencies include subject, compound, object, modifier, and others, as illustrated in Figure 2.
- (6)
- Stop word removal aims to remove common words or symbols from by using the Stop Word dictionary. Examples of stop words include “the”, “is”, and “a”, which are very frequent in written language and would not change the essential meaning of the sentence in ATE. The results of this process will be updated in to eliminate common words or symbols.
3.2. Multiple Aspect Terms Extraction Module
- (1)
- Noun extraction involves extracting nouns or aspects via the function, as defined in the following definition:
- (2)
- In the single-word and multiple-word aspect terms extraction stage, related words from sets V and are associated. In this process, a tool like TextBlob [56] is utilized to identify basic compound-named entities using the function. The definition is given as follows:
| Algorithm 2: Multiple-word aspect terms extraction |
| Input: is a finite set of tuples resulting from the dependency grammar. Output: is a finite set of final aspect terms extracted from complex multiple-word aspect terms. Notations used: Let be a finite set of compound words aggregated from V and using the TextBlob function. Let be a finite set of some prepositions, such as “of” and “with”. Let be a finite set of some conjunction, such as “and”. Let be a finite set of noun POS tags. Procedure: , foreach if ( == “amod”) then if then end if else end if end foreach foreach if ( then end if end foreach foreach if then end if if then end if end foreach return End Procedure |
3.3. Semantic Aspect Categorization Extraction
- (1)
- Aspect vectorization refers to the process of transforming a set of multiple aspect terms within the into a collection of the Aspect Vectors (). The set is defined as follows:
- (2)
- Analysis of Aspect Term Types: This stage involves identifying the types associated with each aspect term extracted in . To accomplish this, each element of aspect term is examined to ascertain whether it represents a single-aspect term or comprises multiple-word aspect terms. In the case of a single-word aspect term, such as {“waiter”} or {“food”,} SPARQL queries are utilized to interrogate the properties “dbo:type” or “rdf:type” within LOD resources, thereby determining the types associated with these entities for extended aspect terms. When dealing with multiple-word terms, as exemplified by {“bread”, “and”, “butter”, “pudding”, “with”, “blueberries”}, extracted from the intricate multiple-word aspect term “bread and butter pudding with blueberries”, determining the type of this term directly from LOD is not feasible. Only fragments of it can be retrieved from LOD. Hence, a combination of the N-gram model and LOD is employed to ascertain the type of these multiple-word aspect terms. This process unfolds in three steps: The initial step entails determining the N-gram size of each , which represents a multiple-word term. This determination is achieved by utilizing Equations (3) and (4) [45] from the N-gram model, as illustrated in the sample outcomes presented in Table 1.

{kind=link}
{kind=link}
| N-Gram Size | Sequence Examples |
|---|---|
| 1-gram | [bread], [and], [butter], [pudding], [with], [blueberries] |
| 2-gram | [bread and], [and butter], [butter pudding], [pudding with], [with blueberries] |
| 3-gram | [bread and butter], [and butter pudding], [butter pudding with], [pudding with blueberries] |
| 4-gram | [bread and butter pudding], [and butter pudding with], [butter pudding with blueberries] |
| 5-gram | [bread and butter pudding with], [and butter pudding with blueberries] |
| 6-gram | [bread and butter pudding with blueberries] |
| N-Gram Size | Sequence Examples | Types of Entities |
|---|---|---|
| 1-gram | [bread] | [food], [mouna], … |
| 2-gram | [bread and] | [⌀] |
| 3-gram | [bread and butter] | [⌀] |
| 4-gram | [bread and butter pudding] | [pudding], [food] |
| 5-gram | [bread and butter pudding with] | [⌀] |
| 6-gram | [bread and butter pudding with blueberries] | [⌀] |
- (3)
- Semantic Aspect Expansion involves two steps. First, each aspect in the training dataset is identified, and their corresponding aspect types are determined. These aspect types are then aggregated and integrated into the aspect corpus. The last step entails expanding the aspect terms utilized in the training dataset by discovering synonymous aspect terms. To accomplish this, the “dbo:wikiPageRedirects” property of LOD and a thesaurus dictionary are utilized via SPARQL to search for synonymous aspect terms. This process is exemplified in the instances illustrated in Table 3.
4. Datasets and Evaluation Metrics
4.1. Datasets
4.2. Evaluation Metrics
5. Experimental Results
6. Time Complexity Analysis
7. Exploring Aspect Terms Misprediction
- (1)
- False Positives and False Negatives: Instances where the model incorrectly predicts the presence or absence of an aspect term.
- (2)
- POS Tag Errors: Instances where the POS tagging of aspect terms leads to mispredictions.
7.1. False Positives and False Negatives
7.2. POS Tag Errors
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fleisher, C.S.; Bensoussan, B.E. Strategic and Competitive Analysis: Methods and Techniques for Analyzing Business Competition; Prentice Hall: Hoboken, NJ, USA, 2003; Volume 457. [Google Scholar]
- Choi, S.; Fredj, K. Price competition and store competition: Store brands vs. national brand. Eur. J. Oper. Res. 2013, 225, 166–178. [Google Scholar] [CrossRef]
- Salinca, A. Business reviews classification using sentiment analysis. In Proceedings of the 2015 17th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 21–24 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 247–250. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Studies in Natural Language Processing; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Vajjala, S.; Majumder, B.; Gupta, A.; Surana, H. Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Toh, Z.; Wang, W. Dlirec: Aspect term extraction and term polarity classification system. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 235–240. [Google Scholar]
- Shelke, P.P.; Wagh, K.P. Review on aspect based sentiment analysis on social data. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 331–336. [Google Scholar]
- Nguyen, M.H.; Nguyen, T.M.; Van Thin, D.; Nguyen, N.L.T. A corpus for aspect-based sentiment analysis in Vietnamese. In Proceedings of the 2019 11th International Conference on Knowledge and Systems Engineering (KSE), Da Nang, Vietnam, 24–26 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Haq, B.; Daudpota, S.M.; Imran, A.S.; Kastrati, Z.; Noor, W. A Semi-Supervised Approach for Aspect Category Detection and Aspect Term Extraction from Opinionated Text. Comput. Mater. Contin. 2023, 77, 115–137. [Google Scholar] [CrossRef]
- Mishra, P.; Panda, S.K. Dependency Structure-Based Rules Using Root Node Technique for Explicit Aspect Extraction From Online Reviews. IEEE Access 2023, 11, 65117–65137. [Google Scholar] [CrossRef]
- Xue, W.; Zhou, W.; Li, T.; Wang, Q. MTNA: A neural multi-task model for aspect category classification and aspect term extraction on restaurant reviews. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 1 December 2017; pp. 151–156. [Google Scholar]
- Yu, J.; Jiang, J.; Xia, R. Global inference for aspect and opinion terms co-extraction based on multi-task neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 168–177. [Google Scholar] [CrossRef]
- Agerri, R.; Rigau, G. Language independent sequence labelling for opinion target extraction. Artif. Intell. 2019, 268, 85–95. [Google Scholar] [CrossRef]
- Luo, H.; Li, T.; Liu, B.; Wang, B.; Unger, H. Improving aspect term extraction with bidirectional dependency tree representation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1201–1212. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Garg, T.; Ekbal, A. Multi-task learning for aspect term extraction and aspect sentiment classification. Neurocomputing 2020, 398, 247–256. [Google Scholar] [CrossRef]
- Liu, N.; Shen, B. Aspect term extraction via information-augmented neural network. Complex Intell. Syst. 2023, 9, 537–563. [Google Scholar] [CrossRef]
- Piao, Y.; Zhang, J.X. Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism. Appl. Sci. 2024, 14, 3524. [Google Scholar] [CrossRef]
- Yang, H.; Zeng, B.; Yang, J.; Song, Y.; Xu, R. A multi-task learning model for chinese-oriented aspect polarity classification and aspect term extraction. Neurocomputing 2021, 419, 344–356. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining Opinion Features in Customer Reviews; AAAI: Washington, DC, USA, 2004; Volume 4, pp. 755–760. [Google Scholar]
- Anwer, N.; Rashid, A.; Hassan, S. Feature based opinion mining of online free format customer reviews using frequency distribution and Bayesian statistics. In Proceedings of the 6th International Conference on Networked Computing and Advanced Information Management, Seoul, Republic of Korea, 16–18 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 57–62. [Google Scholar]
- Rana, T.A.; Cheah, Y.N. A two-fold rule-based model for aspect extraction. Expert Syst. Appl. 2017, 89, 273–285. [Google Scholar] [CrossRef]
- Zhao, Y.; Qin, B.; Hu, S.; Liu, T. Generalizing syntactic structures for product attribute candidate extraction. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Angeles, CA, USA, 2–4 June 2010; pp. 377–380. [Google Scholar]
- Maharani, W.; Widyantoro, D.H.; Khodra, M.L. Aspect extraction in customer reviews using syntactic pattern. Procedia Comput. Sci. 2015, 59, 244–253. [Google Scholar] [CrossRef]
- Shafie, A.S.; Sharef, N.M.; Murad, M.A.A.; Azman, A. Aspect extraction performance with pos tag pattern of dependency relation in aspect-based sentiment analysis. In Proceedings of the 2018 Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Kota Kinabalu, Malaysia, 26–28 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Dragoni, M.; Federici, M.; Rexha, A. An unsupervised aspect extraction strategy for monitoring real-time reviews stream. Inf. Process. Manag. 2019, 56, 1103–1118. [Google Scholar] [CrossRef]
- Huang, J.; Cui, Y.; Wang, S. Adaptive Local Context and Syntactic Feature Modeling for Aspect-Based Sentiment Analysis. Appl. Sci. 2023, 13, 603. [Google Scholar] [CrossRef]
- Titov, I.; McDonald, R. Modeling online reviews with multi-grain topic models. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 111–120. [Google Scholar]
- Brody, S.; Elhadad, N. An unsupervised aspect-sentiment model for online reviews. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 804–812. [Google Scholar]
- Yao, L.; Zhang, Y.; Wei, B.; Li, L.; Wu, F.; Zhang, P.; Bian, Y. Concept over time: The combination of probabilistic topic model with wikipedia knowledge. Expert Syst. Appl. 2016, 60, 27–38. [Google Scholar] [CrossRef]
- Shams, M.; Baraani-Dastjerdi, A. Enriched LDA (ELDA): Combination of latent Dirichlet allocation with word co-occurrence analysis for aspect extraction. Expert Syst. Appl. 2017, 80, 136–146. [Google Scholar] [CrossRef]
- Annisa, R.; Surjandari, I. Opinion mining on Mandalika hotel reviews using latent dirichlet allocation. Procedia Comput. Sci. 2019, 161, 739–746. [Google Scholar] [CrossRef]
- Ozyurt, B.; Akcayol, M.A. A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA. Expert Syst. Appl. 2021, 168, 114231. [Google Scholar] [CrossRef]
- Venugopalan, M.; Gupta, D. An enhanced guided LDA model augmented with BERT based semantic strength for aspect term extraction in sentiment analysis. Knowl.-Based Syst. 2022, 246, 108668. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Wu, S.; Yuan, Z.; Huang, Y. A hybrid unsupervised method for aspect term and opinion target extraction. Knowl.-Based Syst. 2018, 148, 66–73. [Google Scholar] [CrossRef]
- Chauhan, G.S.; Meena, Y.K.; Gopalani, D.; Nahta, R. A two-step hybrid unsupervised model with attention mechanism for aspect extraction. Expert Syst. Appl. 2020, 161, 113673. [Google Scholar] [CrossRef]
- Chen, M.; Hua, Q.; Mao, Y.; Wu, J. An Interactive Learning Network That Maintains Sentiment Consistency in End-to-End Aspect-Based Sentiment Analysis. Appl. Sci. 2023, 13, 9327. [Google Scholar] [CrossRef]
- Jin, Z.; Tao, M.; Wu, X.; Zhang, H. Span-based dependency-enhanced graph convolutional network for aspect sentiment triplet extraction. Neurocomputing 2024, 564, 126966. [Google Scholar] [CrossRef]
- Zhang, F.; Zheng, W.; Yang, Y. Graph Convolutional Network with Syntactic Dependency for Aspect-Based Sentiment Analysis. Int. J. Comput. Intell. Syst. 2024, 17, 37. [Google Scholar] [CrossRef]
- Mu, Y.; Shi, S. Dependency-Type Weighted Graph Convolutional Network on End-to-End Aspect-Based Sentiment Analysis. In International Conference on Intelligent Information Processing; Springer: Berlin/Heidelberg, Germany, 2024; pp. 46–57. [Google Scholar]
- Busst, M.M.A.; Anbananthen, K.S.M.; Kannan, S.; Krishnan, J.; Subbiah, S. Ensemble BiLSTM: A Novel Approach for Aspect Extraction From Online Text. IEEE Access 2024, 12, 3528–3539. [Google Scholar] [CrossRef]
- Zhao, A.; Yu, Y. Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl.-Based Syst. 2021, 227, 107220. [Google Scholar] [CrossRef]
- Fu, Y.; Chen, X.; Miao, D.; Qin, X.; Lu, P.; Li, X. Label-semantics enhanced multi-layer heterogeneous graph convolutional network for Aspect Sentiment Quadruplet Extraction. Expert Syst. Appl. 2024, 255, 124523. [Google Scholar] [CrossRef]
- Alqaryouti, O.; Siyam, N.; Abdel Monem, A.; Shaalan, K. Aspect-based sentiment analysis using smart government review data. Appl. Comput. Inform. 2024, 20, 142–161. [Google Scholar] [CrossRef]
- Cavnar, W.B.; Trenkle, J.M. N-gram-based text categorization. In Proceedings of the SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 11–13 April 1994; Volume 161175, p. 14. [Google Scholar]
- Auer, S.; Bryl, V.; Tramp, S. Linked Open Data—Creating Knowledge Out of Interlinked Data: Results of the LOD2 Project; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Bauer, F.; Kaltenböck, M. Linked Open Data: The Essentials; Edition Mono/Monochrom: Vienna, Austria, 2011; Volume 710. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Boyd, M. Thesaurus Synonyms API. 2016. Available online: https://api-ninjas.com/api/thesaurus/ (accessed on 8 February 2024).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Qi, P.; Manning, C.D.; Langlotz, C.P. Biomedical and clinical English model packages for the Stanza Python NLP library. J. Am. Med. Inform. Assoc. 2021, 28, 1892–1899. [Google Scholar] [CrossRef] [PubMed]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 18 July 2006; pp. 69–72. [Google Scholar]
- Barrus, T. Pyspellchecker. 2020. Available online: https://pypi.org/project/pyspellchecker/ (accessed on 12 August 2023).
- Nivre, J. Dependency grammar and dependency parsing. MSI Rep. 2005, 5133, 1–32. [Google Scholar]
- Loria, S. textblob Documentation. Release 0.15 2018, 2, 269. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Lrec, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 2200–2204. [Google Scholar]
- Han, H.; Zhang, Y.; Zhang, J.; Yang, J.; Zou, X. Improving the performance of lexicon-based review sentiment analysis method by reducing additional introduced sentiment bias. PloS ONE 2018, 13, e0202523. [Google Scholar] [CrossRef] [PubMed]
- Agirre, E.; Bos, J.; Diab, M.; Manandhar, S.; Marton, Y.; Yuret, D. *SEM 2012: The First Joint Conference on Lexical and Computational Semantics—Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (semEval 2012), Montreal, Canada, 7–8 June 2021; Omnipress, Inc.: Madison, WI, USA, 2012. [Google Scholar]
- Kirange, D.; Deshmukh, R.R.; Kirange, M. Aspect based sentiment analysis semeval-2014 task 4. Asian J. Comput. Sci. Inf. Technol. (AJCSIT) 2014, 4, 72–75. [Google Scholar]
- Papageorgiou, H.; Androutsopoulos, I.; Galanis, D.; Pontiki, M.; Manandhar, S. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the ProWorkshop on Semantic Evaluation (SemEval-2016), Association for Computational Linguistics, San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Schwaiger, J.M.; Lang, M.; Ritter, C.; Johannsen, F. Assessing the accuracy of sentiment analysis of social media posts at small and medium-sized enterprises in Southern Germany. In Proceedings of the Twenty-Fourth European Conference on Information Systems (ECIS), Istanbul, Turkey, 12–15 June 2016. [Google Scholar]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. Dbpedia-a crystallization point for the web of data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
| Aspect | Synonymous Aspect Terms |
|---|---|
| waiter | waitress, bartender, waitperson, barkeeper, sommelier, steward, stewardess, headwaiter, … |
| food | provisions, bread, meat, meal, fare, foodstuffs table, supplies, victuals, grub, chow, … |
| views of city | views, view |
| bread and butter pudding with blueberries | whitepots, whitepot, bread and butter pudding |
| Year | Data for Training | Data for Testing |
|---|---|---|
| 2014 | 3041 sentences | 800 sentences |
| 2015 | 1315 sentences | 685 sentences |
| 2016 | 2000 sentences | 676 sentences |
| Dataset | Precision | Recall | F-Measure |
|---|---|---|---|
| SemEval 2014 | 0.82 | 0.80 | 0.80 |
| SemEval 2015 | 0.78 | 0.75 | 0.76 |
| SemEval 2016 | 0.79 | 0.76 | 0.77 |
| Research Study | Methodology | Model/Methods | SemEval 2014 (F1) | SemEval 2015 (F1) | SemEval 2016 (F1) |
|---|---|---|---|---|---|
| Xue W. et al. (2017) [12] | Supervised | MTNN+Bi-LSTM+CNN | 0.83 | 0.67 | 0.72 |
| Yu J. et al. (2018) [13] | Supervised | MTNN+GI | 0.84 | 0.71 | - |
| Agerri R. et al. (2019) [14] | Supervised | SDFC | 0.84 | 0.71 | 0.74 |
| Luo H. et al. (2019) [15] | Supervised | BiDTreeCRF | 0.85 | 0.71 | 0.74 |
| Akhtar M. S. et al. (2020) [16] | Supervised | Bi-LSTM | 0.83 | - | - |
| Wu. Chuhan et al. (2018) [35] | Hybrid | Rules+GRU | 0.76 | 0.63 | 0.64 |
| Chauhan et al. (2020) [36] | Hybrid | Rules+Bi-LSTM | - | - | 0.79 |
| Dragoni M. et al. (2019) [26] | Unsupervised | Syntax | - | 0.60 | 0.67 |
| Venugopalan et al. (2022) [34] | Unsupervised | LDA+BERT | 0.81 | 0.74 | 0.75 |
| Busst M. M. A. et al. (2024) [41] | Unsupervised | BERT | 0.82 | 0.69 | - |
| Proposed approach | Unsupervised | LOD | 0.80 | 0.76 | 0.77 |
| Algorithm | Theoretical | Actual/Min |
|---|---|---|
| Slang and Abbreviation Processing | O(n) | 0.08 |
| Multiple-Word Aspect Terms Extraction | O(n) | 0.05 |
| Case | Review Sentence | Labeled Aspect Term | Predicted Aspect Term | Misprediction Type |
|---|---|---|---|---|
| 1 | one of my favorite places in brooklyn. | Null | brooklyn | (1) |
| 2 | I trust the people at go sushi, it never disappoints. | people | people, sushi | (1) |
| 3 | I highly recommend Mioposto. | mioposto | Null | (1) |
| 4 | the best Chuwam Mushi I have ever had. | chuwam mushi | chawan mushi | (1) |
| 5 | the menu is interesting and quite reasonably priced. | menu, priced | menu | (2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suwanpipob, W.; Arch-Int, N.; Wunnasri, W. A Knowledge-Driven Approach for Automatic Semantic Aspect Term Extraction Using the Semantic Power of Linked Open Data. Appl. Sci. 2024, 14, 5866. https://doi.org/10.3390/app14135866
Suwanpipob W, Arch-Int N, Wunnasri W. A Knowledge-Driven Approach for Automatic Semantic Aspect Term Extraction Using the Semantic Power of Linked Open Data. Applied Sciences. 2024; 14(13):5866. https://doi.org/10.3390/app14135866
Chicago/Turabian StyleSuwanpipob, Worapoj, Ngamnij Arch-Int, and Warunya Wunnasri. 2024. "A Knowledge-Driven Approach for Automatic Semantic Aspect Term Extraction Using the Semantic Power of Linked Open Data" Applied Sciences 14, no. 13: 5866. https://doi.org/10.3390/app14135866
APA StyleSuwanpipob, W., Arch-Int, N., & Wunnasri, W. (2024). A Knowledge-Driven Approach for Automatic Semantic Aspect Term Extraction Using the Semantic Power of Linked Open Data. Applied Sciences, 14(13), 5866. https://doi.org/10.3390/app14135866