
An Enhanced Aircraft Carrier Runway Detection Method Based on Image Dehazing


Abstract
1. Introduction
- A lightweight dehazing network that combines CNNs with Transformers structure is introduced. An effective complementary attention module and a novel Transformer of linear computation complexity are designed to enhance the network’s capability in image restoration;
- By analyzing the positions of pixels obtained from the runway detection algorithm in two-dimensional space, adjusting the landing process of CUAVs by combining sensor data, performing multiple spatial transformations, and localization the spatial straight-line expressions of runway lines, a runway line localization method is proposed;
- A system framework is designed to address the issue of CUAVs experiencing difficulty in safely and reliably landing in hazed conditions at sea. In the Airsim simulation environment, we conduct extensive experiments. The result shows our system can effectively restore image content details and yield runway lines through localization with a deviation from ground truth of less than 2°.
2. Related Work
2.1. Image Dehazing

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citation | Method | Category | Characteristics |
|---|---|---|---|
| [16] | Dark Channel Prior (DCP) | Prior-based | Based on assumptions and prior knowledge derived from statistical analysis of a large number of degraded images’ physical properties. It requires multiple iterations of calculations, can only handle images under specific hypothetical conditions, and has high computational complexity with limited satisfactory results. |
| [17] | Color-lines regularity and an augmented Markov random field model | ||
| [19] | Color attenuation prior | ||
| [18] | Rank-one Prior (RP) | ||
| [20] | estimating transmission matrix t by CNN | CNN | With a sufficient amount of synthetic image pairs, these can achieve superior dehazing results over traditional methods. However, due to the limited receptive field of CNN, which only captures spatially local features, it is challenging to obtain long-range dependencies of pixels. |
| [21] | predicting A and t by CNN | ||
| [22] | end-to-end neural network | ||
| [23] | end-to-end neural network | ||
| [24] | CNN and conventional Transformer fusion | Transformer | Compared to traditional CNN algorithms, this method achieves better image restoration metrics and generalization ability through multi-head self-attention computation. However, traditional Transformer based image dehazing methods are computationally intensive and a higher risk of overlocalization. |
| [10] | Swin Transformer | ||
| [25] | Image Processing Transformer (IPT) |
2.2. Runway Detection
| Method | Method | Category | Characteristics |
|---|---|---|---|
| [6] | DeepLanes | classification-based | It get an advantage result of a complicated network structure. However, the prior position setting curbs its application in practical scenarios, and due to the complex network, the method is time-consuming. |
| [7] | EELane | Object detection-based | By labeling regression bounding boxes or feature points for each lane segment, lanes can be efficiently detected by coordinate regression. However, due to the inverse perspective transformation (IPM) process during post-processing, its robustness is conditioned. |
| [8] | VPGNet | ||
| [9] | STLNet | ||
| [28] | CNN-based regression approach | segmentation-based | These methods typically operate on regions of individual pixels in the entire image, leveraging the paradigm of semantic segmentation to delineate runway lines within the image. But segmentation paradigm is inherently too strict, and the emphasis is on obtaining accurate classification per pixel rather than specifying the shape. |
| [29] | color-based segmentation approach | ||
| [4] | Spatial CNN (SCNN) | ||
| [30] | Recurrent Feature-Shift Aggregator (RESA) | ||
| [31] | CLRNet | row-based | These methods use anchor point detection set along a specific direction of the image (e.g., row direction), thus achieving good runway line detection results and real-time detection speed. However, these methods are highly dependent on image quality, and their detection performance significantly degrades when the images are hazy. |
| [32] | LaneFormer | ||
| [5] | UFLD |
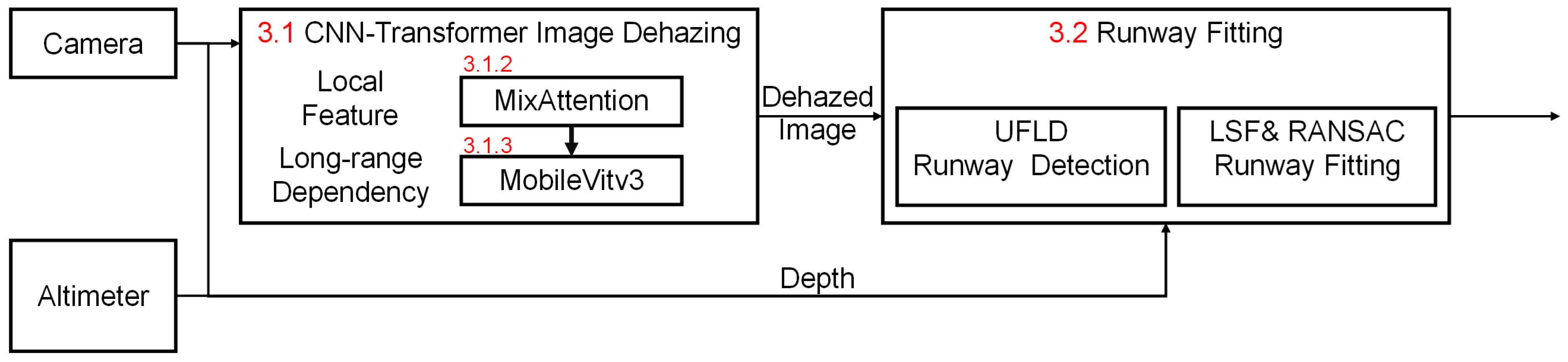
3. Materials and Methods
3.1. Dehaze Implementation
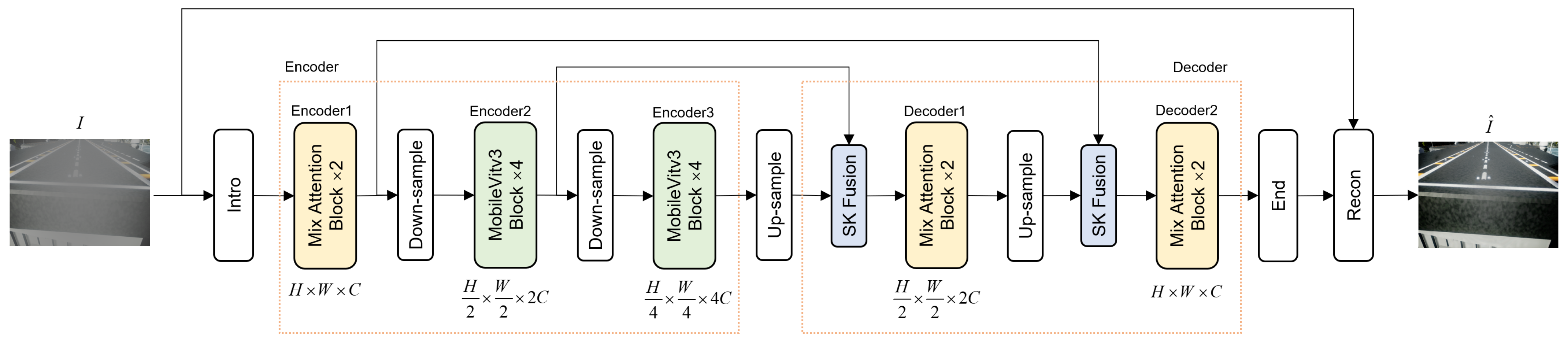
3.1.1. Network Overall
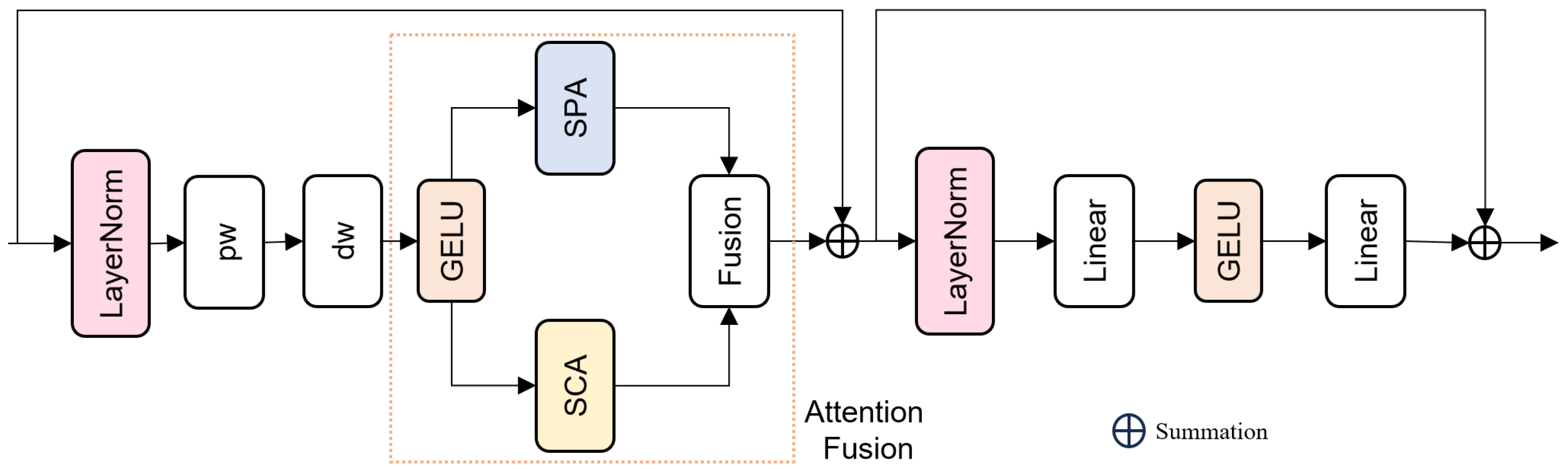
3.1.2. MixAttention Module
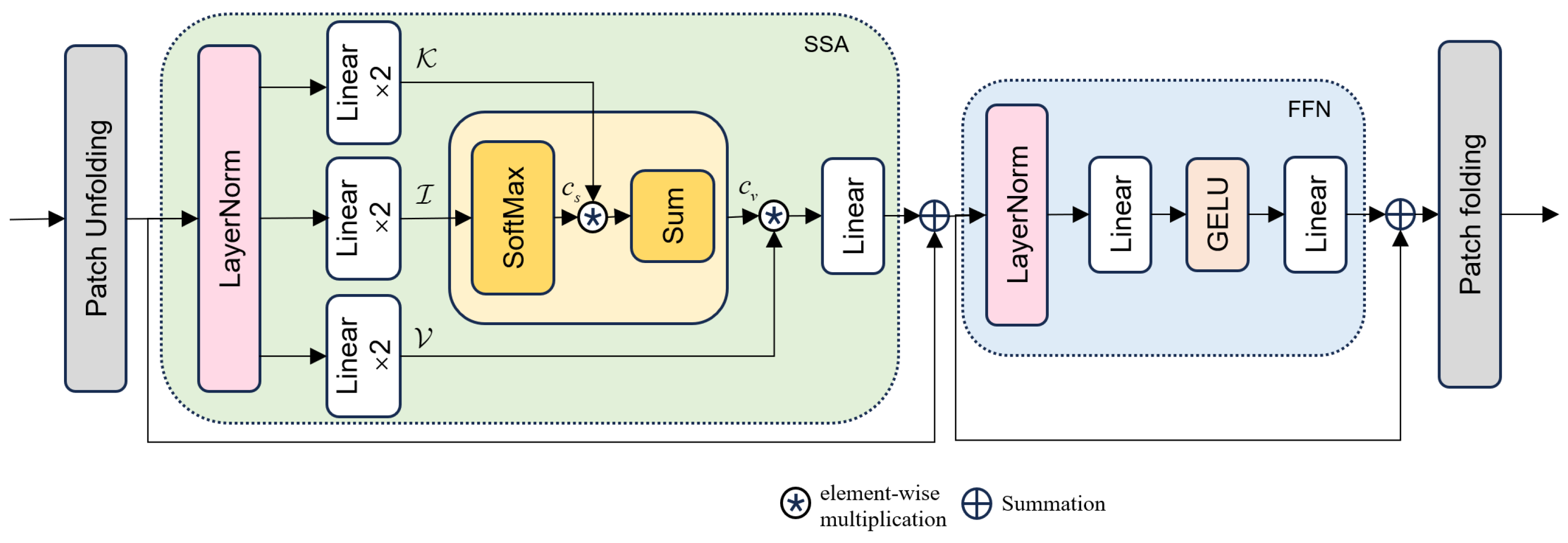
3.1.3. Mobilevitv3 Module
3.2. Runway Localization
3.3. Dataset
4. Experiment Results and Discussions
4.1. Dehazing Experiment
4.1.1. Parameter Settings
4.1.2. Performance Evaluation
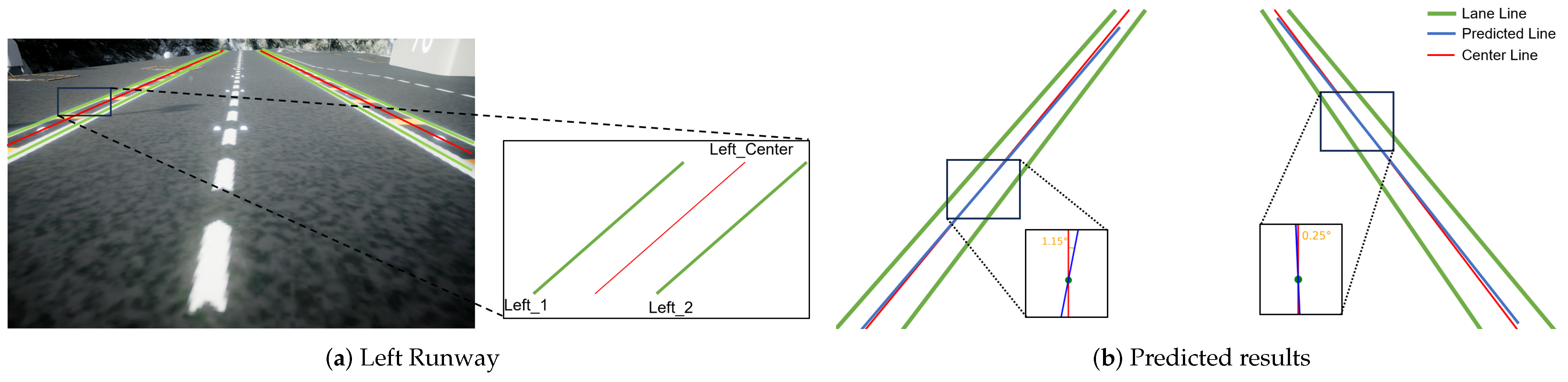
4.2. Runway Localization Analysis
4.2.1. Dehazed Function
4.2.2. Localization Details
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, N.; Weng, X.; Cao, Y.; Wu, L. Monocular-Vision-Based Precise Runway Detection Applied to State Estimation for Carrier-Based UAV Landing. Sensors 2022, 22, 8385. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Teoh, E.K.; Shen, D. Lane detection and tracking using B-Snake. Image Vis. Comput. 2004, 22, 269–280. [Google Scholar] [CrossRef]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 7–12. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 276–291. [Google Scholar]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. Deeplanes: End-to-end lane position estimation using deep neural networksa. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 38–45. [Google Scholar]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An empirical evaluation of deep learning on highway driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- Lee, S.; Kim, J.; Shin Yoon, J.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.H.; Seok Hong, H.; Han, S.H.; So Kweon, I. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1947–1955. [Google Scholar]
- Huang, Y.; Chen, S.; Chen, Y.; Jian, Z.; Zheng, N. Spatial-temproal based lane detection using deep learning. In Proceedings of the Artificial Intelligence Applications and Innovations: 14th IFIP WG 12.5 International Conference, AIAI 2018, Rhodes, Greece, 25–27 May 2018; Proceedings 14. Springer: Berlin/Heidelberg, Germany, 2018; pp. 143–154. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Xiong, Q.; Chu, D.; Xu, B. MixDehazeNet: Mix Structure Block For Image Dehazing Network. arXiv 2023, arXiv:2305.17654. [Google Scholar]
- Gui, J.; Cong, X.; Cao, Y.; Ren, W.; Zhang, J.; Zhang, J.; Cao, J.; Tao, D. A comprehensive survey and taxonomy on single image dehazing based on deep learning. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef]
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 820–827. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. Acm Trans. Graph. (TOG) 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Liu, J.; Liu, W.; Sun, J.; Zeng, T. Rank-one prior: Toward real-time scene recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14802–14810. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Chougule, S.; Koznek, N.; Ismail, A.; Adam, G.; Narayan, V.; Schulze, M. Reliable multilane detection and classification by utilizing CNN as a regression network. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 740–752. [Google Scholar]
- Chiu, K.Y.; Lin, S.F. Lane detection using color-based segmentation. In Proceedings of the IEEE Proceedings. Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 706–711. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3547–3554. [Google Scholar]
- Zheng, T.; Huang, Y.; Liu, Y.; Tang, W.; Yang, Z.; Cai, D.; He, X. Clrnet: Cross layer refinement network for lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 898–907. [Google Scholar]
- Han, J.; Deng, X.; Cai, X.; Yang, Z.; Xu, H.; Xu, C.; Liang, X. Laneformer: Object-aware row-column transformers for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence; 2022; Volume 36, pp. 799–807. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. arXiv 2017, arXiv:1705.05065. [Google Scholar] [CrossRef]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half instance normalization network for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repuiblic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1375–1383. [Google Scholar]
- Dong, J.; Pan, J. Physics-based feature dehazing networks. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 188–204. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 286–291. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repuiblic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]


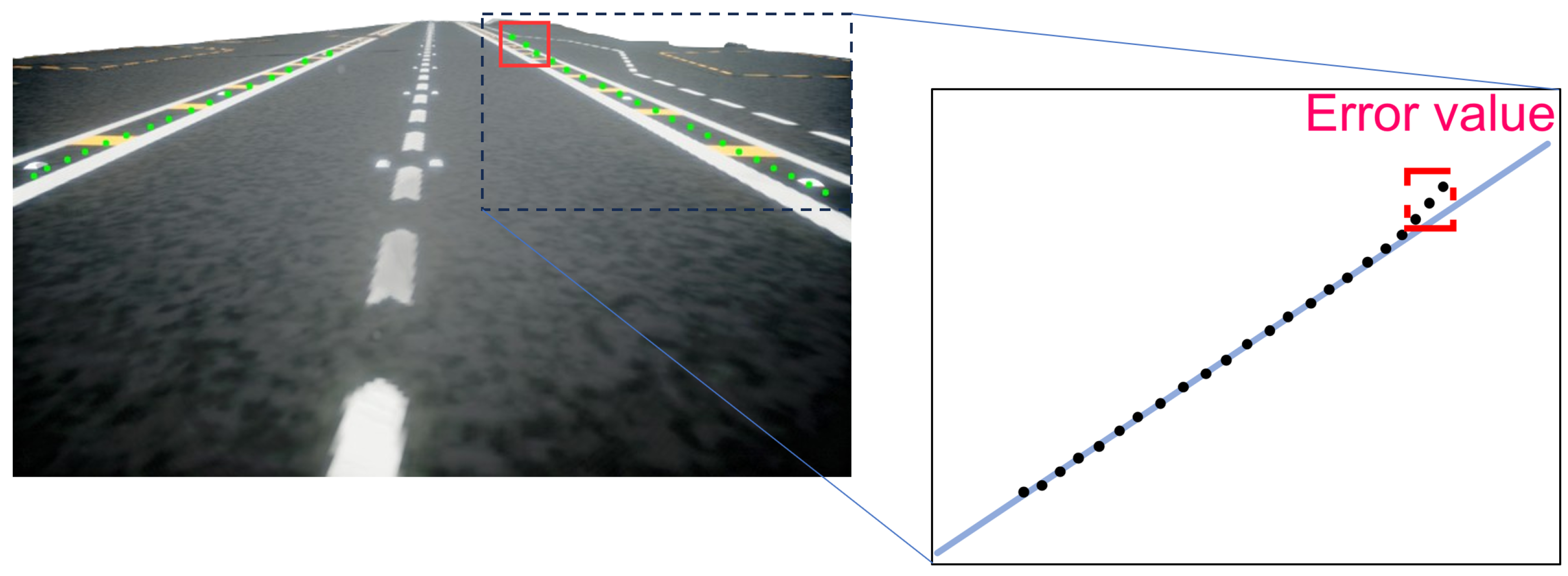
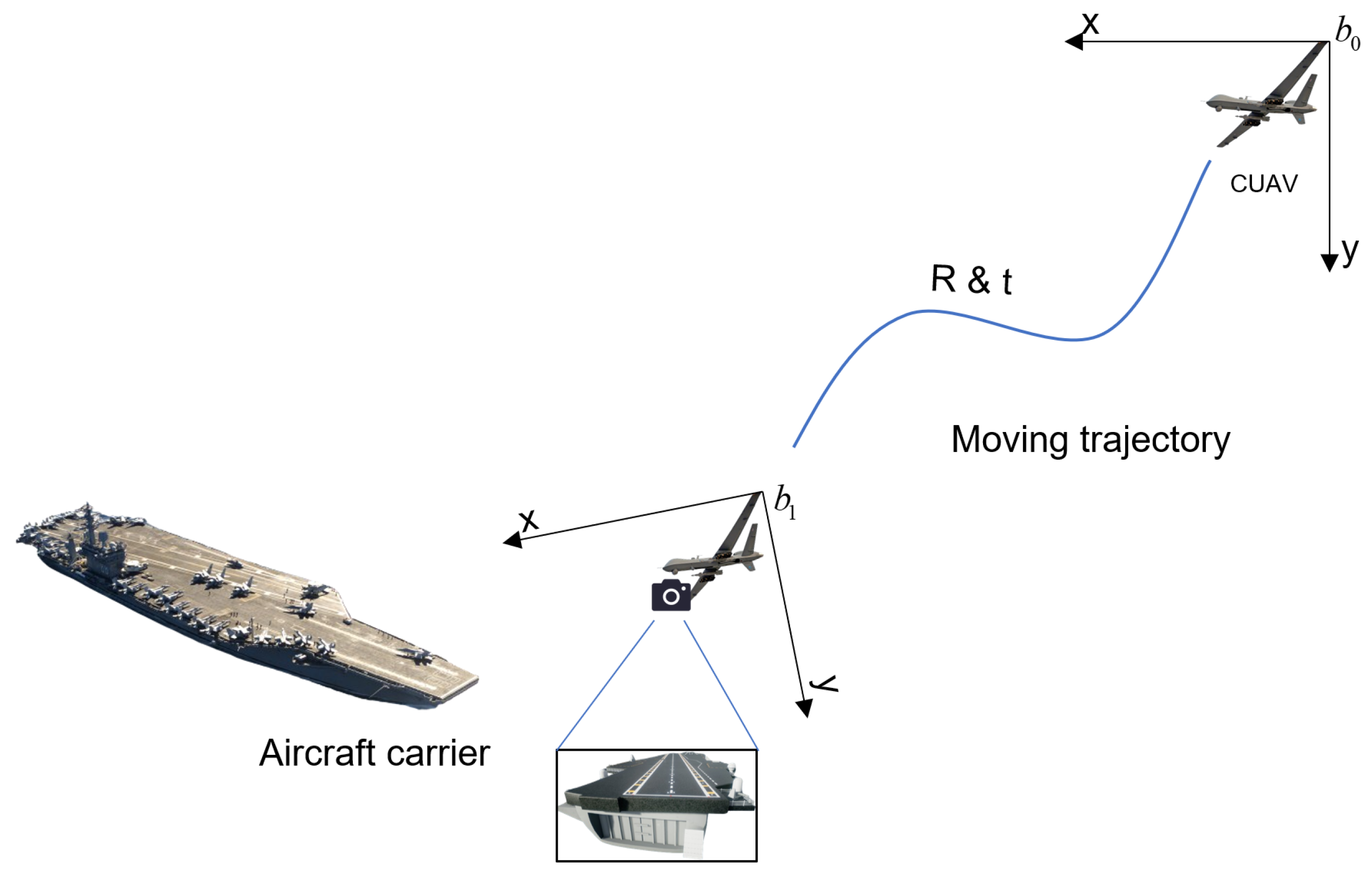


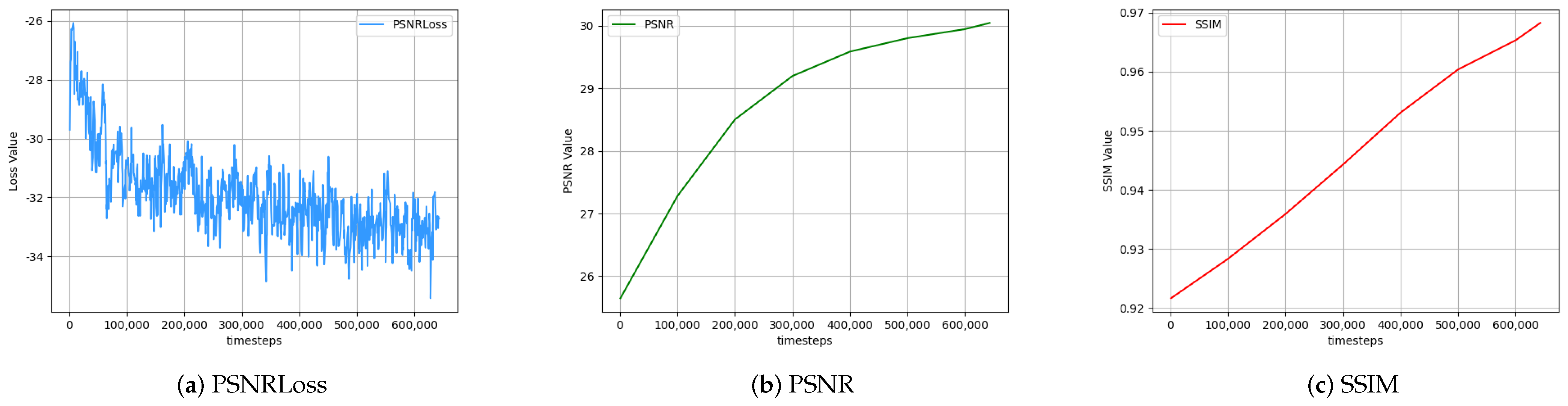


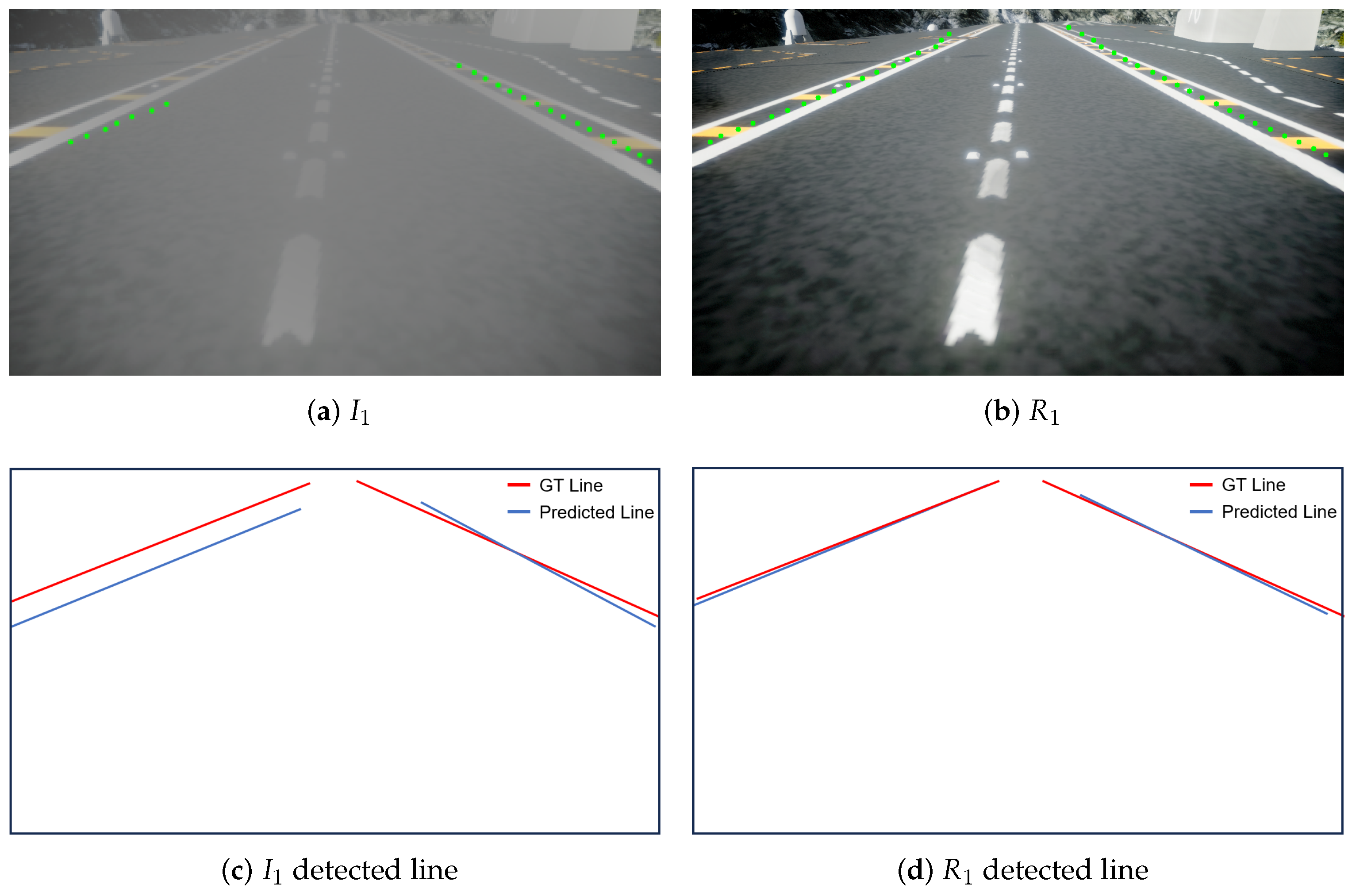
| Parameters | Value |
|---|---|
| Intrinsic parameters | |
| Radial distortion | |
| Tangential distortion | |
| FOV | 70° |
| Resolution | 1280 × 720 |
| Methods | PSNR | SSIM | Param (M) | MACs (G) | Latency-512 × 512 (ms) |
|---|---|---|---|---|---|
| hazed | 13.98 | 0.635 | - | - | - |
| DehazeNet [20] | 20.15 | 0.863 | 0.009 | 0.581 | 1.34 |
| GridDehazeNet [36] | 26.26 | 0.948 | 0.956 | 21.49 | 12.65 |
| GCANet [37] | 24.33 | 0.921 | 0.702 | 18.41 | 3.69 |
| PFDN [38] | 28.97 | 0.961 | 11.27 | 50.20 | 7.31 |
| DehazeFormer [10] | 29.11 | 0.963 | 0.686 | 6.66 | 11.24 |
| ours | 30.18 | 0.972 | 0.484 | 4.91 | 8.63 |
| Baseline | MixAttention↑ | Mobilevitv3↑ | Data Augmentation↑ | PSNR | SSIM |
|---|---|---|---|---|---|
| √ | × | × | √ | 29.02 | 0.962 |
| √ | √ | × | √ | 29.54 | 0.967 |
| √ | √ | √ | √ | 30.18 | 0.972 |
| √ | √ | √ | × | 30.10 | 0.969 |
| Method | Direction | k | b | h | ||
|---|---|---|---|---|---|---|
| UFLD [5] | Left | −0.01243 | 45.047335 | 6.0641224 | 8.5456° | 9.258812 |
| Right | −0.085547 | 26.223431 | 6.0570601 | 3.9949° | 5.333762 | |
| Lanedet [39] | Left | −0.292449 | 22.275809 | 6.0754075 | 7.0437° | 13.51271 |
| Right | −0.066909 | 30.247141 | 6.0607728 | 5.0566° | 9.357472 | |
| SAD [40] | Left | −0.269742 | 26.614948 | 6.0958085 | 5.8380° | 9.173575 |
| Right | −0.107914 | 25.097884 | 6.0965721 | 2.7254° | 4.208215 | |
| ours (UFLD + dehazed) | Left | −0.139172 | 37.652321 | 6.0611483 | 1.3347° | 1.863798 |
| Right | −0.15732 | 20.937649 | 6.0613821 | 0.0559° | 0.047980 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, Y.; Zhao, Y.; Yuan, C.; Mao, R.; Lyu, P. An Enhanced Aircraft Carrier Runway Detection Method Based on Image Dehazing. Appl. Sci. 2024, 14, 5464. https://doi.org/10.3390/app14135464
Li C, Wang Y, Zhao Y, Yuan C, Mao R, Lyu P. An Enhanced Aircraft Carrier Runway Detection Method Based on Image Dehazing. Applied Sciences. 2024; 14(13):5464. https://doi.org/10.3390/app14135464
Chicago/Turabian StyleLi, Chenliang, Yunyang Wang, Yan Zhao, Cheng Yuan, Ruien Mao, and Pin Lyu. 2024. "An Enhanced Aircraft Carrier Runway Detection Method Based on Image Dehazing" Applied Sciences 14, no. 13: 5464. https://doi.org/10.3390/app14135464
APA StyleLi, C., Wang, Y., Zhao, Y., Yuan, C., Mao, R., & Lyu, P. (2024). An Enhanced Aircraft Carrier Runway Detection Method Based on Image Dehazing. Applied Sciences, 14(13), 5464. https://doi.org/10.3390/app14135464