Abstract
The order-preserving multiple pattern matching problem is to find all substrings of T whose relative orders are the same for any pattern in a set of patterns. Various sequential algorithms have been studied for the order-preserving multiple pattern matching problems. In this paper, we propose two parallel algorithms, each of which uses Aho–Corasick automata and fingerprint tables, respectively. We also present experimental results of comparing the execution times of each parallel algorithm on various types of time-series data.
1. Introduction
Two strings from an integer alphabet are order-isomorphic if the relative orders of characters are the same. For example, given two strings and , they are order-isomorphic because their relative orders of characters are the same as . Given text and pattern , finding all substrings of T, which are order-isomorphic to P, is called the order-preserving pattern matching (OPPM for short) problem [1,2,3,4,5]. Given text and a set of patterns , the order-preserving multiple pattern matching (OPMPM for short) problem is to find all substrings of T that are order-isomorphic to any in [1,2,3,4,5]. The order-preserving pattern matching problem and order-preserving multiple pattern matching problem can be used to analyze various time-series data such as stock price indices, music melodies, and biomedical data [1,2,3,4,5].
Most existing OPMPM algorithms are performed in two phases: a preprocessing phase and a search phase. Let m, , and M denote the shortest pattern length, the longest pattern length, and the sum of the lengths of all patterns in , respectively. Kim et al. [1] proposed an algorithm that performs the preprocessing phase in time and the search phase in time using Aho–Corasick automata [6]. Han et al. [7] proposed two algorithms for the order-preserving multiple pattern matching problem. In the first algorithm, the preprocessing and search phases run in time and time, on average, and in the second algorithm, the preprocessing and search phases run in time and time, on average. Park et al. [8] proposed an algorithm that improved the space complexity of the first algorithm proposed in [7] from to using fingerprint tables. Park et al. [9] parallelized the second algorithm proposed in [7]. The preprocessing phase runs in time using threads and the search phase runs in time, on average, using threads in [9].
In this paper, we present two parallel algorithms for the OPMPM problem. First, we parallelize the algorithm proposed in [1]. The preprocessing phase of the first algorithm runs in time using threads and the search phase runs in time using threads. Second, we parallelize the algorithm proposed in [8]. The preprocessing phase of the second algorithm runs in time using threads and the search phase runs in time using threads. Then, we present experimental results that compare the execution times of each parallel algorithm for various types of time-series data. The experimental results showed that for randomly generated strings, when 100,000, , and , the execution time of the first parallel algorithm was approximately 2.12 times faster than the sequential algorithm, and the second parallel algorithm was approximately 1.6 times faster than the sequential algorithm. For all time-series data used in our experiments, the execution time of our second parallel algorithm was comparable to that of a fast parallel algorithm proposed in [9].
2. Related Works
Given string x, the length of x is denoted by and the i-th character of x is denoted by . The substring from to is denoted by . is called a prefix of x and is called a suffix of x for . For convenience, we assume that all the characters in the string are different. Given two strings , if is satisfied, and x and y are order-isomorphic and denoted by [1,4,10].
Let be the string constructed by sorting all the characters of x in ascending order. Then, the position table of x is defined as follows:

Table 1.
Prefix table and position table of .
In [7], an OPMPM algorithm was proposed using fingerprints of q-grams. The fingerprint converts a q-gram (a string of length q) into an integer within the range of using the factorial number system [11,12]. The fingerprints are used to find candidate substrings of text T that may be order-isomorphic to pattern P. Given a q-gram x, fingerprint is defined as follows [3,7]:
For example, if q-gram , .
In [1], the Aho–Corasick automaton [6] is used to solve the order-preserving multiple pattern matching problem. In the preprocessing phase, the Aho–Corasick automaton is created in time using a set of prefix tables of patterns. In each Step of the search phase, the state for is computed and is searched in the automaton using the transition function, the failure function, and the output function of the automaton. Figure 1 shows the Aho–Corasick automaton when , , and .
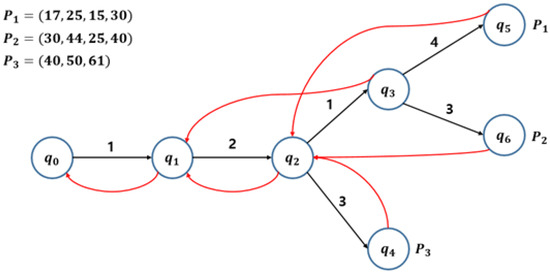
Figure 1.
Example of the Aho–Corasick automaton for OPMPM.
Let be the prefix of length m for each pattern and let . Park et al. [8] proposed an OPMPM algorithm that generates the position table for each and the fingerprint table that stores the rightmost q-gram’s fingerprint of in the preprocessing phase, to find candidate patterns that may be order-isomorphic to substrings of T. In the search phase, all substrings of T, which are order-isomorphic to any , are searched using and .
3. Parallel Algorithms for the OPMPM Problem
In this section, we propose two parallel algorithms for the OPMPM problem. The first algorithm uses the Aho–Corasick automaton, while the second algorithm utilizes the position tables and fingerprint tables.
3.1. Parallel OPMPM Algorithm Using the Aho–Corasick Automaton
Our parallel algorithm for the OPMPM problem using the Aho–Corasick automaton consists of the following steps: In the preprocessing phase, we create prefix tables using threads in time. That is, the prefix table of each pattern is calculated in parallel by assigning threads for each pattern . In the prefix table of pattern , each thread linearly searches to calculate . See Algorithm 1. Thus, a set of prefix tables for all patterns can be calculated in time using threads. To create an automaton using , the existing algorithm [1] method is employed.
| Algorithm 1 Preprocessing phase (parallel calculation of prefix tables for a pattern set). |
| Input: A set of strings Output: A set of prefix tables 1 parallel for to k do 2 parallel for to do 3 4 for to do 5 if then 6 |
In the search phase, T is divided into b blocks and each block is searched in parallel using b threads (Figure 2). Thread searches each block of T for the location of the substring that is order-isomorphic to using the automaton created in the preprocessing phase. See Algorithm 2. Since the substring of T that is order-isomorphic to can occur across two adjacent blocks, all threads except the last one set the block size to (Figure 2). Since the insertion, deletion, and rank calculation operations in the order-statistics tree require time during the search phase, they are conducted in time. If we set , the search phase can be conducted in time. Thus, this parallel algorithm can be solved as an OPMPM problem in time using threads.
| Algorithm 2 Search phase. |
| Input: Aho–Corasick automaton, string T Output: Positions i of substrings of T which is order-isomorphic to 1 , OST , int r 2 parallel for to b do 3 for to do 4 if then 5 break 6 .insert 7 .rank 8 while 9 .delete 10 11 .rank 12 13 if and then 14 print |
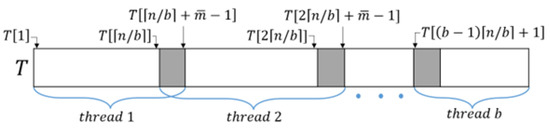
Figure 2.
Search phase of the parallel OPMPM algorithm using the Aho–Corasick automaton.
3.2. Parallel OPMPM Algorithm Using the Fingerprint Table
The algorithm that solves the OPMPM problem using a fingerprint table in parallel is as follows: In the preprocessing phase, position table and fingerprint table are created in parallel for each pattern of . The calculation is performed in parallel using threads. Each thread linearly searches to calculate the order r of . By the definition of , it satisfies , and the position tables for all patterns can be calculated in parallel in time using threads. is created in parallel using q threads (Algorithm 3). Each thread calculates the fingerprint of in parallel. Here, atomic operations are used to prevent multiple threads from accessing concurrently (Line 8 in Algorithm 3). Thus, the fingerprint table can be calculated in time using threads, and the preprocessing phase is conducted in time using threads.
In the search phase, all substrings of T are checked in parallel using threads (Algorithm 4). Each thread first calculates . and each of are sequentially compared, and if they are the same, it is verified whether and are order-isomorphic using (from Lines 2 to 5 in Algorithm 4) [13]. If , then is printed. In the worst case, it verifies whether all substrings of T are order-isomorphic to all patterns. Thus, the search phase can be performed in time using threads. This parallel algorithm can be solved as an OPMPM problem in time using threads.
| Algorithm 3 Parallel calculation of the fingerprint table. |
| Input: A set of strings , int m, int q Output: 1 parallel for to k do 2 parallel for to q do 3 4 5 for to do 6 if then 7 8 atomicAdd |
| Algorithm 4 The search phase of the algorithm using a fingerprint table. |
| Input: A string , int m Output: Positions i of substrings of T which is order-isomorphic to 1 parallel for to do 2 for to k do 3 if then 4 if then 5 print |
4. Experimental Results
The experiment was conducted on the following environment: Windows 10 (64-bit) operating system, AMD Ryzen9 3950X CPU, 64 GB RAM, NVIDIA GeForce RTX 3080 Ti GPU, C++ and CUDA programming language, and Visual Studio 2019 (CUDA SDK 11.0).
The algorithms experimented with in the present paper are denoted as follows: The OPMPM algorithm using the Aho–Corasick automaton proposed in [1] is denoted by , and the OPMPM algorithm using the fingerprint table proposed in [8] is denoted by . The parallel OPMPM algorithm proposed in [9] is denoted by , the parallel OPMPM algorithm using the Aho–Corasick automaton proposed in this paper is denoted by , and the parallel OPMPM algorithm using the fingerprint table is denoted by , respectively.
The data used in the experiment are randomly generated strings and two types of time-series data: the Dow Jones Index and electrocardiogram data.
- Randomly generated strings: Texts and patterns consisting of were randomly generated. Text T was generated by increasing length n from 10,000 by 10,000 to 100,000. A set of patterns P was generated by increasing the number of patterns k from 100 by 100 to 1000 and increasing the pattern length m from 5 by 1 to 15.
- Dow Jones Index: Texts and patterns were extracted at random for each experiment from the daily closing price of the Dow Jones Industrial Average between 2 May 1885 and 12 April 2019 [14]. The text length n was increased from 1000 by 1000 to 10,000. The number of patterns k and their length m were set to the same values used for the randomly generated strings.
- Electrocardiogram data: The electrocardiogram (ECG) data used in the experiment were obtained from the MIT-BIH ECG biosignal database provided by Physionet [15]. An electrocardiogram records the electrical impulses from the heart. Texts were randomly extracted from the total records, while patterns were extracted evenly from abnormal symptom data and normal data. It should be noted that the texts and patterns were extracted from electrocardiogram data of different individuals. The text length n and the number of patterns k were set equal to those of the randomly generated strings, and the pattern length m increased from 10 by 1 to 15 during the generation process.
The parameter setup of the algorithm and measurement of execution time were conducted as follows: In and , q was set to 5. In each of the parallel algorithms, employed 1000 threads, and and employed n threads. The execution time of each algorithm was the mean of 100 execution times, which was measured in milliseconds (ms) and rounded to three decimal places. The execution time of parallel algorithms includes the execution time of the cudaMemcpy() function that copies data between host memory and device (GPU) memory.
Experiment (1). Comparison of execution times of and , and and for randomly generated strings: Figure 3 shows the execution times of and for randomly generated strings according to n when and . When n = 10,000, was slower than due to the additional execution time required by the cudaMemcpy() function in . Most of the execution time for was spent on the cudaMemcpy() function. However, for 20,000, performed faster than . When 100,000, , and , the execution time of was around 41.22 ms and that of was around 19.49 ms, indicating that was approximately 2.12 times faster than . The execution time of increased as n increased due to the limitation of the number of available GPU cores. Figure 4 shows the execution times of and for randomly generated strings according to k when 100,000 and . In this case, was faster than in all cases.
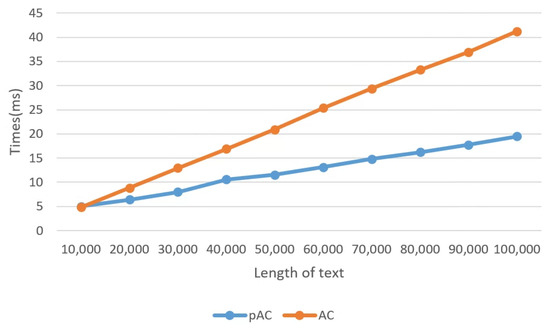
Figure 3.
Comparison of execution times of and varying n for randomly generated strings when and .
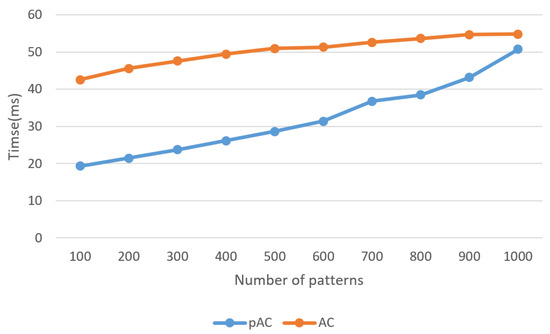
Figure 4.
Comparison of execution times of and varying k for randomly generated strings when 100,000 and .
Figure 5 shows the execution times of and for randomly generated strings according to n when and . was faster than in all cases. For instance, when 100,000, , and , the execution time of was around 8.6 ms, while that of was around 5.39 ms, indicating that was approximately 1.6 times faster than . However, as with , the execution time of also increased as n increased due to the limitation of the number of available GPU cores. Figure 6 shows the execution times of and for randomly generated strings according to k when 100,000 and . In this case, as in the previous case, was faster than in all cases.
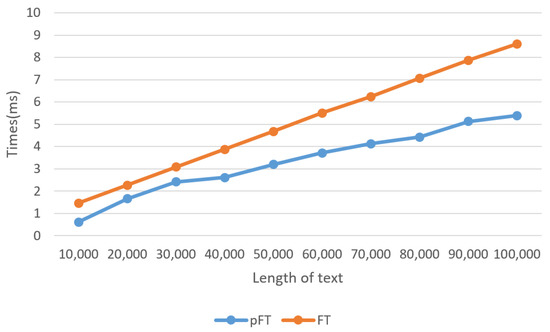
Figure 5.
Comparison of execution times of and according to n for randomly generated strings when and .
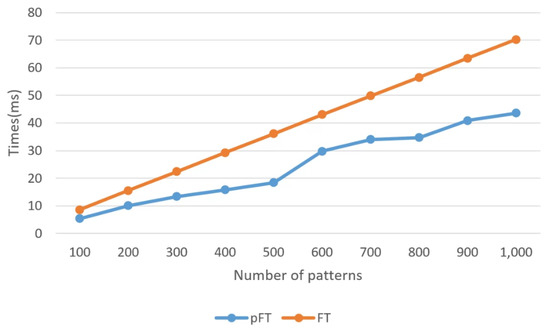
Figure 6.
Comparison of execution times of and according to k for randomly generated strings when 100,000 and .
Experiment (2). Comparison of execution times of , , and for randomly generated strings: Table 2 presents the execution times of , , and for randomly generated strings with varying parameter settings. In all cases, and performed faster than , and and exhibited comparable execution times. When 100,000, , and , the execution times of and were approximately 1.98 and 2.03 times faster, respectively, than those of pAC.
Table 2.
Comparison of execution times of , , and for random strings.
Table 2a presents the execution times of , , and according to m when 100,000 and . As the length of patterns m increased, the creation time of the Aho–Corasick automaton increased, leading to an increase in the total execution time of . The length of patterns m did not significantly affect the execution times of and . Table 2b presents the execution times of , , and according to k when 100,000 and . The execution times of all algorithms increased as k increased.
Experiment (3). Comparison of execution times of , , and for Dow Jones Index data: Table 3 presents the execution times of , , and according to the parameters for Dow Jones Index data. In all conditions, and performed faster than , and and exhibited comparable execution times. When 10,000, , and , the execution times of and were around 5.61 times and 5.71 times faster than that of . Overall, it showed a similar trend to that of Experiment 2.
Table 3.
Comparison of execution times of , , and for Dow Jones Index data.
Experiment (4). Comparison of execution times of , , and for ECG data: Table 4 presents the execution times of , , and according to the parameters for electrocardiogram data. In all cases, and performed faster than , and and exhibited comparable execution times. When 100,000, , and , the execution times of and were around 2.13 times and 2.16 times faster than that of . Overall, it showed a similar result to that of Experiments 2 and 3.
Table 4.
Comparison of execution times of , , and for ECG data.
5. Conclusions
In this paper, a parallel OPMPM algorithm using the Aho–Corasick automaton and a parallel OPMPM algorithm using a fingerprint table were proposed. In addition, comparison experiments were conducted for randomly generated strings, Dow Jones Index data, and electrocardiogram data to evaluate the performance of the proposed parallel algorithms. The experimental results showed that the execution times of the algorithms had a similar trend regardless of the data type when data-related parameters such as the length of the text, lengths of the patterns, and the number of patterns, as well as algorithm-related parameters such as the q-gram length, were kept the same. This suggests that the performance of the algorithms is dependent on these parameters rather than the specific characteristics of the data type. The performance of the verification of order-isomorphism may vary depending on the order representation method of strings used [16]. Therefore, further studies are necessary to compare the execution times and number of verifications required for different-order representation methods.
Author Contributions
S.P. and J.P. designed and analyzed the algorithms. S.P. implemented and experimented with the algorithms, and wrote the draft of the paper. Y.K. and J.S.S. reviewed and revised the paper. J.S.S. analyzed the algorithm, provided algorithmic support, and was the project manager. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. RS-2022-00155915, Artificial Intelligence Convergence Innovation Human Resources Development (Inha University)), and by INHA UNIVERSITY Research Grant.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare they have no conflicts of interest.
References
- Kim, J.; Eades, P.; Fleischer, R.; Hong, S.H.; Iliopoulos, C.S.; Park, K.; Puglisi, S.J.; Tokuyama, T. Order-preserving matching. Theor. Comput. Sci. 2014, 525, 68–79. [Google Scholar] [CrossRef]
- Kim, J.; Amir, A.; Na, J.C.; Park, K.; Sim, J.S. On representations of ternary order relations in numeric strings. Math. Comput. Sci. 2017, 11, 127–136. [Google Scholar] [CrossRef]
- Cho, S.; Na, J.C.; Park, K.; Sim, J.S. A fast algorithm for order-preserving pattern matching. Inf. Process. Lett. 2015, 115, 397–402. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, Y.; Sim, J.S. An improved order-preserving pattern matching algorithm using fingerprints. Mathematics 2022, 10, 1954. [Google Scholar] [CrossRef]
- Na, J.C.; Lee, I. A simple heuristic for order-preserving matching. IEICE Trans. Inf. Syst. 2019, 102, 502–504. [Google Scholar] [CrossRef]
- Aho, A.V.; Corasick, M.J. Efficient string matching: An aid to bibliographic search. Commun. ACM 1975, 18, 333–340. [Google Scholar] [CrossRef]
- Han, M.; Kang, M.; Cho, S.; Gu, G.; Sim, J.S.; Park, K. Fast multiple order-preserving matching algorithms. In Proceedings of the International Workshop on Combinatorial Algorithms, Verona, Italy, 5–7 October 2015; pp. 248–259. [Google Scholar]
- Park, J.; Kim, Y.; Sim, J.S. A space-efficient hashing-based algorithm for order-preserving multiple pattern matching problem. KIISE Trans. Comput. Pract. 2018, 24, 399–404. [Google Scholar] [CrossRef]
- Park, K.B.; Kim, Y.; Sim, J.S. Parallel implementation of the order-preserving multiple pattern matching algorithm using the Karp-Rabin algorithm. J. KIISE 2021, 48, 249–256. [Google Scholar] [CrossRef]
- Kubica, M.; Kulczyński, T.; Radoszewski, J.; Rytter, W.; Waleń, T. A linear time algorithm for consecutive permutation pattern matching. Inf. Process. Lett. 2013, 113, 430–433. [Google Scholar] [CrossRef]
- Knuth, D. The Art of Computer Programming, Seminumerical Algorithms; Addison-Wesley: Boston, MA, USA, 1997; Volume 2. [Google Scholar]
- Mareš, M.; Straka, M. Linear-time ranking of permutations. In Proceedings of the Algorithms–ESA 2007: 15th Annual European Symposium, Eilat, Israel, 8–10 October 2007; pp. 187–193. [Google Scholar]
- Chhabra, T.; Tarhio, J. A filtration method for order-preserving matching. Inf. Process. Lett. 2016, 116, 71–74. [Google Scholar] [CrossRef]
- Williamson, S. Daily Closing Values of the DJA in the United States, 1885 to Present, Measuring Worth. Available online: https://www.measuringworth.com/datasets/DJA/index.php (accessed on 17 December 2021).
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. Physiobank, physiotoolkit, and physionet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. Available online: http://circ.ahajournals.org/content/101/23/e215 (accessed on 20 September 2022). [CrossRef] [PubMed]
- Park, S.; Kim, Y.; Sim, J.S. Comparison of order-isomophism verification times of two strings according to their representations. In Proceedings of the Korean Institute of Next Generation Computing Spring Conference, Gwangju, Republic of Korea, 1–13 May 2021; Korean Institute of Next Generation Computing: Seoul, Republic of Korea, 2021; pp. 350–353. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).