Abstract
Background: Alzheimer’s disease (AD) leads to severe cognitive impairment and functional decline in patients, and its exact cause remains unknown. Early diagnosis of AD is imperative to enable timely interventions that can slow the progression of the disease. This research tackles the complexity and uncertainty of AD by employing a multimodal approach that integrates medical imaging and demographic data. Methods: To scale this system to larger environments, such as hospital settings, and to ensure the sustainability, security, and privacy of sensitive data, this research employs both deep learning and federated learning frameworks. MRI images are pre-processed and fed into a convolutional neural network (CNN), which generates a prediction file. This prediction file is then combined with demographic data and distributed among clients for local training. Training is conducted both locally and globally using a belief rule base (BRB), which effectively integrates various data sources into a comprehensive diagnostic model. Results: The aggregated data values from local training are collected on a central server. Various aggregation methods are evaluated to assess the performance of the federated learning model, with results indicating that FedAvg outperforms other methods, achieving a global accuracy of 99.9%. Conclusions: The BRB effectively manages the uncertainty associated with AD data, providing a robust framework for integrating and analyzing diverse information. This research not only advances AD diagnostics by integrating multimodal data but also underscores the potential of federated learning for scalable, privacy-preserving healthcare solutions.
1. Introduction
In this age, 50 million people are globally suffering because of the impact of Alzheimer’s disease, and by 2050, it is predicted that this number will increase three-fold [1]. It is difficult to understand the actual causes of Alzheimer’s; however, studies show that genetics, environment, and lifestyle can have a profound impact [2]. In addition, this disease directly impacts cognitive functions and gradually impairs the ability of the patient to perform daily activities. With time, the patient may become prone to memory loss and abnormalities in speech and encounter confusion with the time and place they are in. Early-onset signs and symptoms of this disease can begin before the age of 65, while late-onset typically begins after 65 [3]. As a result, it is necessary to diagnose Alzheimer’s early so that the quality of life can be improved, adequate treatment can be acquired, and the progression of the disease can be slowed down, allowing the patient to seek psychological support to cope with the emotional impact of the disease. To achieve this purpose, an Alzheimer’s diagnosis system needs to be developed. Since the actual cause of Alzheimer’s is not clear and remains uncertain, the system should be able to deal with information not only limited to MRI scans but also about the person’s age, lifestyle, and environment. This will, in turn, tackle the complexity of the disease. In this research, a multidisciplinary approach where machine learning, the belief rule base system [4], and federated learning [5,6] are employed. The machine learning model, namely the convolutional neural network, is customized so that it can achieve optimal accuracy when training the MRI image dataset of patients [7]. Furthermore, to overcome the uncertainty in identifying the exact stage of the disease, a trained belief rule-based model is developed by using evidential reasoning and particle swarm optimization [8]. Particle swarm optimization is used because it excels in finding optimal or near-optimal accuracy in complex, multi-dimensional search spaces. However, focusing solely on these models will not suffice for large-scale early diagnosis of Alzheimer’s. Implementing such a system in hospitals requires a broader approach, particularly addressing data sensitivity issues. Many hospitals are reluctant to share data due to privacy concerns. This is where federated learning—a form of decentralized system—becomes crucial. Federated learning enables the development of a large-scale diagnostic system without compromising data privacy, as it allows hospitals to collaboratively train models without sharing raw data [9]. This approach not only values the issue of patient data sensitivity but also leverages diverse datasets to improve diagnostic accuracy, making it a viable solution for widespread implementation in healthcare facilities.
This research intends to develop an Alzheimer’s disease diagnostic system wherein deep learning (convolutional neural network), knowledge representation (belief rule base system) [10], and federated learning technologies will be integrated. This is done to address the challenges with data uncertainty, diagnostic accuracy, privacy preservation of patient data, and reduced resource utilization.
1.1. Research Objectives
To address the research aims, the following research objectives have been formulated:
- Systematically clean and curate datasets, including medical images and demographic data, for accurate Alzheimer’s disease (AD) diagnosis.
- Design a convolutional neural network (CNN) architecture tailored for processing and classifying Alzheimer’s medical imaging data.
- Combine image data with demographic information to improve diagnostic accuracy.
- Develop an Optimized trained belief rule base (BRB) to handle data uncertainties.
- Incorporate the belief rule base (BRB) system in the federated learning framework.
- Compare and evaluate the different (i.e., FedAvg, FedProx, and genetic algorithm) aggregators used in the federated learning model.
1.2. Research Questions
- How to develop a pre-processing pipeline combining medical images and demographic data for enhanced Alzheimer’s disease diagnosis?
- How to design a CNN architecture optimized for Alzheimer’s medical imaging data classification?
- How to integrate image and demographic data to improve diagnostic accuracy?
- How to establish a federated learning framework with a belief rule base to handle data uncertainties?
- How does advanced federated learning for medical applications improve privacy-preserving diagnostic frameworks?
- How can multimodal data handling and uncertainty management in machine learning for medical diagnostics improve accuracy and overcome uncertainty?
2. Related Work
Machine learning is transforming the healthcare system, offering new advancements and solutions. Alzheimer’s disease (AD), affecting millions worldwide, remains a critical area where these technologies are making a significant impact. It is essential to detect AD in its stages to slow down its progression through proper care and treatment. Consequently, there has been a rise in the use of artificial intelligence (AI) techniques [1,3] due to their capacity to analyze datasets and recognize complex patterns. This section will delve into research on AI-driven Alzheimer’s diagnosis focusing particularly on learning methods such as convolutional neural networks (CNNs) and the application of federated learning in this field. Several studies have provided insights into classifying Alzheimer’s disease using data types machine learning approaches and federated learning techniques [5].
2.1. Machine Learning to Classify AD Using MRI Images
The XAI framework in this study uses the mapping of occlusion sensitivity, emphasizing white matter hyperintensities (WMHs) in the image data [11]. The deep learning classifier, namely EfficientNet-B0, achieves an accuracy of 80.0%. This work [12] integrates image data with the XAI frameworks of Saliency Map and Layer-wise Relevance Propagation, analyzing MRI, 3D PET, biological markers, and assessments. This study will make use of a DL 3D CNN AD classifier. This research [12] incorporates image data and XAI frameworks such as Saliency Map and Layer-wise Relevance Propagation (LRP), analyzing MRI, 3D PET, biological markers, and assessments. A DL 3D CNN AD classifier is employed for this study. This study [13] involves image data and XAI frameworks utilizing decision trees (DTs). Significant features include demographic data, cognitive factors, and brain metabolism data. Classifiers include Bernoulli naive Bayes (NB), SVM, kNN, random forest (RF), AdaBoost, and gradient boosting (GBoost), achieving an accuracy of 91.0%. Significant features, including demographic data, cognitive factors, and brain metabolism data, are highlighted in this study [13], which utilizes decision trees (DTs) as the XAI framework. The classifiers, Bernoulli naive Bayes (NB), SVM, kNN, random forest (RF), AdaBoost, and gradient boosting (GBoost) collectively achieve an accuracy of 91.0%. In this research, demographic data, cognitive factors, and MRI image data are combined [13]. The data are passed through a decision tree (DT) as the XAI framework. Other classifiers, such as Bernoulli naive Bayes (NB), SVM, kNN, random forest (RF), AdaBoost, and gradient boosting (GBoost) collectively achieve an accuracy of 91.0%. In [14], an XAI framework was employed wherein a 3D ultrametric contour map is deployed alongside a 3D class activation map and 3D GRadCAM, all to analyze the image data. As we understand, there are significant features which can be accurately classified after using the 3D CNN deep learning model. Overall, and accuracy of 76.6% was achieved. This work employed sensitivity analysis and occlusion as XAI frameworks in the analysis of 3D image data. The accuracy of the DL 3D CNN classifier is 77.0% [15]. The paper by [16] classifies healthy controls versus Alzheimer’s disease subjects based on numeric data. LIME and SHAP are used as XAI frameworks, while some of the features identified include whole brain volume, years of education, and socio-economic status. Classifiers used include support vector machine (SVM), k-nearest neighbors (kNN), and multilayer perceptron. For the classification of HC versus AD, this study [17] leverages XAI frameworks such as HAM and PCR, focusing on salient AD-related features like cerebral cortex and hippocampus atrophy. The DL CNN classifier achieves an impressive accuracy of 95.4%. In [17], healthy controls (HCs) were compared to Alzheimer’s disease (AD) classification using XAI frameworks (i.e., HAM and PCR). These frameworks focus on features such as the cerebral cortex and hippocampus atrophy through the deep learning (DL) convolutional neural network (CNN), achieving an impressive accuracy of 95.4%. This study [18] focuses on classifying healthy controls (HCs), individuals with mild cognitive impairment (MCI), and Alzheimer’s disease (AD) using brain image data. It employs the XAI framework GNNExplainer to interpret predictions made by a deep learning graph neural network (GNN). Key features include brain region volume, cortical surface area, and cortical thickness. The GNN classifier achieves an accuracy of 53.5 ± 4.5%, providing insights into the important brain features associated with these conditions. Marwa et al. [19] utilized a deep neural network (DNN) pipeline on a dataset of 6400 MRI images to effectively identify various stages of Alzheimer’s disease, achieving a remarkable accuracy of 99.68%. Ghazal et al. [20] developed a classification model using transfer learning to categorize Alzheimer’s disease into Mild Demented, Moderate Demented, Non-Demented, and Very Mild Demented stages, employing AlexNet and obtaining a simulation accuracy of 91.7%. AlSaeed et al. [21] proposed a CNN-based model, ResNet50, for automatic feature extraction from MRI images to detect Alzheimer’s disease. Their model, tested against Softmax, SVM, and RF models, showed superior performance with an accuracy ranging from 85.7% to 99% on the MRI ADNI dataset. Hamdi et al. [22] introduced a CAD system based on a CNN model for Alzheimer’s detection using the MRI ADNI dataset, achieving 96% accuracy. Helaly et al. [23] employed both CNN and VGG-19 transfer learning models to classify Alzheimer’s stages with the ADNI dataset, with VGG-19 achieving an accuracy of 97%. Mohammed et al. [24] utilized AlexNet, ResNet-50, and hybrid models combining AlexNet+SVM and ResNet-50+SVM to diagnose Alzheimer’s using the OASIS dataset, with AlexNet+SVM achieving the highest accuracy of 94.8%. Pradhan et al. [25] compared VGG-19 and DenseNet architectures for Alzheimer’s classification, finding VGG-19 to perform better. Salehi et al. [26] implemented a CNN model to diagnose Alzheimer’s early using the MRI ADNI dataset, achieving a 99% accuracy. Suganthe, Ravi Chandaran et al. [27] employed deep CNN and VGG-16-based CNN models for Alzheimer’s detection using the ADNI dataset, both showing excellent accuracy. Hussain et al. [28] proposed a 12-layer CNN model for Alzheimer’s classification using the OASIS dataset, achieving 97.75% accuracy, outperforming other existing CNN models on this dataset. Basaia et al. [29] applied a CNN model to the ADNI dataset for Alzheimer’s detection, achieving high performance with both ADNI and combined ADNI+non-ADNI datasets. Ji et al. [30] proposed an ensemble learning approach using deep learning for early Alzheimer’s diagnosis with the MRI ADNI dataset, achieving up to 97.65% accuracy for AD/mild cognitive impairment stages. Islam et al. [31] proposed a CNN model for Alzheimer’s detection and classification, evaluated on the OASIS dataset. Their model is noted for its speed, lack of reliance on handcrafted features, and suitability for small datasets.
Table 1 briefly highlights the use of various machine learning models in the classification of Alzheimer’s disease. Overall, a deduction is made that convolutional models used by Yu et al. [17] and De et al. [12] can achieve a high accuracy when it comes to image classification tasks that involve MRI scans. Yu et al. further revealed an impressive accuracy of 95.4% in differentiating between a healthy control group and Alzheimer’s disease. Complex features, such as those found in MRI scans highlighting brain atrophy, are effectively extracted and learned by CNNs, making them ideal for medical imaging tasks. In contrast, traditional models, such as decision trees and support vector machines, are limited in handling complex tasks. Unlike CNN, the problem with a traditional model is that it requires feature engineering which can be computationally expensive, and training large amounts of data can be slow. Furthermore, CNN is open to adding features of explainability such as the use of GradCAM and Layer-wise Relevance Propagation (LRP) which can enhance the CNN’s ability in the process of decision-making by adding more transparency. Explainable AI can be a future direction for this current research. In conclusion, CNNs, according to the reviewed literature, have consistently outperformed traditional machine learning models when it comes to accuracy and scalability, particularly when applied to large and complex datasets.

Table 1.
Summary of key studies in CNN-based Alzheimer’s diagnosis.
2.2. Federated Learning-Based Solution for Building Alzheimer’s Diagnosis System
Khalil et al. [5] built a hardware acceleration approach to expedite the training and testing of their FL model. In this approach, the hardware accelerator is constructed using VHDL hardware description language and an Altera 10 GX FPGA. Simulation results indicate that the proposed methods achieved accuracies of 89% and sensitivities of 87% for early detection, outperforming other state-of-the-art algorithms in terms of training time. Moreover, the proposed algorithms exhibited a power consumption range of 35–39 mW, rendering them suitable for resource-constrained devices (see Table 2).
Table 2.
Key summary of studies in Alzheimer’s disease detection using federated learning.
Mitrovska et al. [6] employed two algorithms, namely Federated Averaging (FedAvg) and Secure Aggregation (SecAgg) which were combined, and their performance was compared with a centralized ML model training. By simulating such diverse environments, the influence of demographic factors (such as sex, age, and diagnosis) and imbalanced data distributions was investigated. These simulations made it possible to assess the effect of statistical variations on ML models trained with FL, underscoring the significance of accounting for these differences in training models for AD detection. From the end result, it was demonstrated that, when FL is combined with SecAgg, it ensures privacy, as evidenced by simulated membership inference attacks showcasing its privacy guarantees.
Trivedi et al. [32] developed a streamlined federated deep learning framework for classifying Alzheimer’s diseases, ensuring data privacy using IID datasets in a client-server setup. Evaluations with single and multiple clients under traditional and federated learning scenarios revealed AlexNet as the best pre-trained model, achieving 98.53% accuracy. The framework was then tested with IID datasets using federated learning (FL).
Altalbe et al. [33] developed a deep neural network (DNN) within a federated learning framework to detect and diagnose brain disorders. The dataset used here is from the Kay Elemetrics voice disorder database, which was divided among two clients, to built separate training models. Overfitting was reduced through three review rounds by each client. The model identified brain disorders with an accuracy of 82.82%, preserving privacy and security.
Mandawkar et al. [34] engineered a federated learning-based Tawny Flamingo deep CNN classifier to classify Alzheimer’s disease. The classifier processes clinical data from multiple distributed sources and delivers high accuracy. Tuned using the Tawny Flamingo algorithm, the model achieved accuracies of 98.252% in K-fold analysis and 97.995% in training percentage-dependent analysis for detecting Alzheimer’s disease.
Castro et al. [35] deployed an Alzheimer’s diagnosis system by using MRI brain images wherein federated learning (FL) was integrated for biometric recognition validating image authentication. This approach aimed to protect privacy and prevent data poisoning attacks. Experiments conducted on the OASIS and ADNI datasets demonstrated that the system’s performance was comparable to that of a centralized ML system without privacy measures.
Qian et al. [9] introduced FeDeFo, which stands for a federal deep forest model utilized for calculating hippocampal volume using sMRI images to classify Alzheimer’s disease. This uses a federated learning framework to train a gradient-boosting decision tree (GBDT) model leveraging local client data to ensure data privacy. Furthermore, this approach addresses data discrepancies, by incorporating a deep forest model, combined with the federated GBDT to personalize the model for each client. Experiments demonstrated that this method effectively personalized the model while protecting data privacy, providing a new method for Alzheimer’s disease classification. Table 1 presents a key summary of studies in Alzheimer’s disease detection using FL.
2.3. Addressing the Existing Research Gaps
In summary, future studies should prioritize developing FL models which are capable of integrating data from multiple sources, as this will make the model more generalized. It is also necessary to explore the use of evolutionary algorithms in FL. These algorithms will not only help to optimize model parameters but also improve the performance in areas wherein data are complex and environments are distributed. As a result, methodologies incorporating these evolutionary algorithms should be built to handle data heterogeneity and uncertainty. This will ensure that FL frameworks maintain optimal accuracy and fairness across different client datasets. In scenarios wherein data are distributed across multiple servers, applying advanced privacy-preserving techniques, such as differential privacy and multi-party computation, it is crucial to ensure the security of sensitive patient data in an FL system. In addition, FL frameworks should showcase scale-able behavior to manage large-scale deployment. Furthermore, FL systems should be deployed in a clinical setting to carry out clinical trials in the real world to test their validity and applicability. In order to provide more evidence for effectiveness in real-world healthcare settings, there is also a requirement to perform more research on the aspect of expanding hardware acceleration in FL.
Hence, this research will attempt to address most of the research gaps by introducing evolutionary algorithms and optimization techniques to enhance the performance of FL framework.
3. Methods
Figure 1 illustrates the operational framework used to develop the system in this research. From the figure, it can be deduced that this framework is a hybrid system, as it combines two distinct methodologies: deep learning framework and federated learning framework [5,6]. In the first methodology, MRI images undergo pre-processing steps such as skull stripping and bias correction to improve image quality. After pre-processing the images, the dataset is passed as an input to the convolutional neural network (CNN), for the purpose of classification of Alzheimer’s disease (AD). Thus, the CNN is trained to classify Alzheimer’s disease into three categories: Alzheimer’s Disease (AD), Mild Cognitive Impairment (MCI), and Cognitively Normal (CN). Afterwards, the results from the classification are converted into a CSV file that contains the predicted classes for each subject.
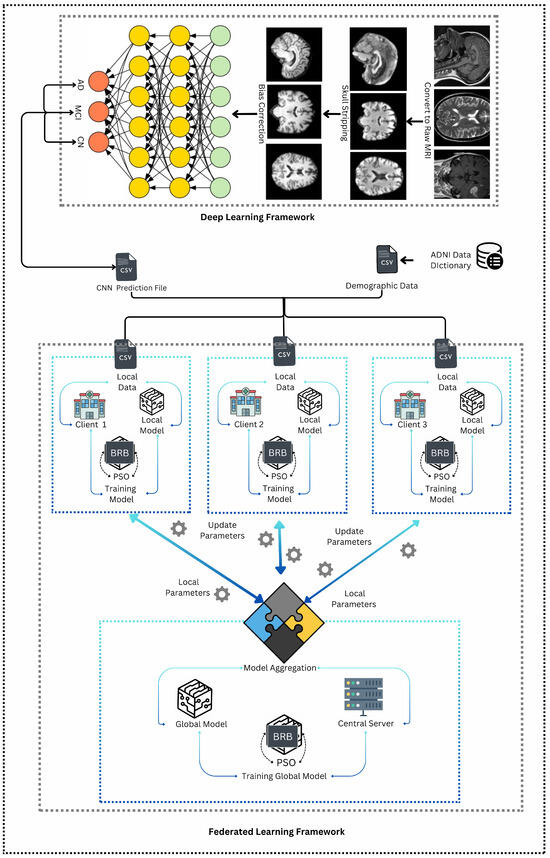
Figure 1.
Operational framework.
This CSV file is then merged with demographic data received from the ADNI dataset mentioned in Section 3.1. This results in a multi-modal dataset that integrates both clinical and demographic information. The combined dataset is subsequently split equally into three parts, each corresponding to a different client in the federated learning framework. In this second methodology, the three clients can be potentially considered as three hospitals where the local models are trained using a belief rule base (BRB) system [36]. The BRB system is enhanced with particle swarm optimization (PSO) to optimize the parameters [37]. Each client trains its BRB model locally, and the resulting parameters are then sent to a central server. At the server, these local parameters are aggregated to update the global model (which uses the same BRBs). This federated learning process is iterative, where the central server sends the updated global model parameters back to the clients. The clients then use these updated parameters to refine their local models in the next round. This iterative process continues—typically for three iterations—until the global model reaches an optimal state, effectively capturing the combined knowledge from all local models and providing a robust predictive tool for Alzheimer’s disease classification.
3.1. Description of Dataset Applied in This Research
For this research, data were obtained from the Alzheimer’s Disease Neurology Initiative (ADNI) [38]. The ADNI dataset includes a variety of modalities, making it an ideal resource for researchers aiming to utilize it for the early detection of Alzheimer’s disease. This dataset comprises both demographic information and imaging data of patients. The fMRI dataset consists of images provided in DICOM and NIFTI formats.
DICOM images resemble a series of frames, similar to those found in videos, whereas NIfTI images provide a comprehensive representation of a specific part of the human body; in this case, the brain. These images include all slices captured by scanners or other imaging methods. The NIfTI format is converted to enable access to raw MRI images.
The dataset contains a total of 5182 images, categorized into three classes: “Alzheimer’s Disease (AD)”, “Mild Cognitive Impairment (MCI)”, and “Cognitively Normal”. After pre-processing the data, the dataset was divided into training and testing sets with an 80:20 split ratio.
3.2. Steps of MRI Dataset Preprocessing
The conversion of NIfTI files into raw images involves multiple steps that differ from standard image formats such as PNG or JPG. For this process, FSL software (Version v6 2018) is utilized, installed via the Windows Subsystem for Linux (WSL) and added to the PATH environment on a Windows system. The pre-processing pipeline consists of affine registration, skull stripping, and bias correction, each executed sequentially to prepare the MRI data for further analysis.
Affine Registration:
Affine registration determines the optimal transformation that aligns points in one image with corresponding points in another. This transformation includes translation, scaling, rotation, and shearing, offering greater alignment flexibility compared to rigid or similar transformations. The process begins by selecting a reference NIfTI file from the FSL/data/standard directory. Depending on the specifications of the MRI files, the appropriate MNI152 file is chosen. For example, if the MRI files are 1 mm T1 MRIs, the MNI152_T1_1mm.nii file is selected. The reference file is then placed in the atlas folder, and the register.py file in the pre-processing folder is updated. Executing the register.py script in the terminal generates the ADNIReg folder, which contains subdirectories (AD, CN, MCI) with the transformed NIfTI files.
Skull Stripping:
MRI scans often contain extraneous details, such as the skull, eyes, nose, and other facial features, which must be removed to isolate the brain region. Skull stripping eliminates this unnecessary data, ensuring that they do not interfere with the machine learning model’s training or accuracy. The bet tool from the FSL library is used for this purpose. The resulting files are saved in a newly created ADNIBrain folder while preserving the subdirectory structure (AD, CN, MCI).
Bias Correction:
N4 bias correction is applied to address intensity inconsistencies, also known as bias fields, present in medical images. These inconsistencies, caused by scanner settings or physical structures of patients, can compromise the accuracy of image analysis. By eliminating bias fields, the clarity and reliability of the images are improved. The Advanced Normalization Tools (ANTs) library is employed for this step. Since this transformation is computationally intensive, the Python script can be modified to process images in batches by adjusting the batch size accordingly.
By implementing these pre-processing steps, the MRI data are effectively prepared for further analysis, ensuring precision and efficiency in subsequent processing stages.
3.3. Deep Learning Framework
After the MRI images undergo pre-processing, the dataset is randomly divided into 80% training and 20% testing, to integrate into the deep learning model, namely the convolutional neural network. The architecture is demonstrated as follows:
Modified Convolutional Neural Network
Based on the specified CNN model architecture for diagnosing Alzheimer’s disease from imaging data, multiple convolutional layers are incorporated to extract features from the input images. Deep learning techniques are leveraged to capture complex patterns within the data. The model starts with a sequence of convolutional layers, each followed by max pooling and batch normalization. The convolutional layers apply filters to detect features such as edges and textures in the images, with these features becoming increasingly abstract as they progress through the layers. Max pooling layers reduce the spatial dimensions of the data, which decreases the computational burden and mitigates the risk of overfitting. Batch normalization is used to stabilize the learning process by normalizing activations, making the network more robust to variations in the input data distribution. This structured combination of layers enables the model to effectively learn and generalize to new imaging data.
Dense layers with dropout are also included in the model to further refine the features extracted by the convolutional layers into meaningful patterns suitable for classification (See Table 3). Dropout randomly deactivates a fraction of the neurons during training, preventing overfitting by ensuring that the model does not become excessively reliant on any specific feature. The final output layer employs a softmax activation function to generate probabilities for each of the four classes, providing confidence scores for the potential diagnoses. The Adam optimizer and Sparse Categorical Cross-Entropy loss function are utilized to facilitate efficient and precise learning by adjusting the model weights to minimize the error between the predicted and actual class labels.
Table 3.
Modified CNN model architecture.
Overall, this CNN architecture delivers a robust and accurate approach for diagnosing Alzheimer’s disease from imaging data. By leveraging advanced deep learning techniques, the model achieves high performance and reliability.
3.4. Federated Learning Architecture
Federated learning enables the decentralized training of large-scale models without accessing user data, thus ensuring privacy. Federated learning is classified into Horizontal Federated Learning (HFL), Vertical Federated Learning (VFL), and Federated Transfer Learning (TFL). In this research, HFL is adopted, enabling multiple clients to jointly train a global model while ensuring the privacy of their local data. The steps involved in the HFL framework are described as follows:
3.4.1. Data Preparation
Figure 2 illustrates how the data preparation process, essential for implementing a federated learning (FL) framework, is carried out for diagnosing Alzheimer’s disease. This process combines demographic information with CNN-generated predictions and distributes the resulting dataset across multiple clients while ensuring data privacy is maintained.
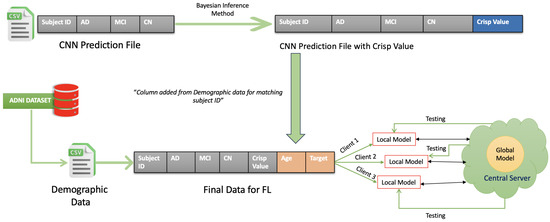
Figure 2.
Data preparation.
Step 1: Preparing and Matching Demographic Data
Initially, the demographic data such as patients’ ages and patient ID are extracted from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset. The duplicated values are excluded in the CSV file. The CNN predictions—providing the probabilities for Alzheimer’s stages such as Alzheimer’s Disease (AD), Mild Cognitive Impairment (MCI), and Cognitively Normal (CN)—are gathered into another CSV file. The demographic data are then matched to the CNN predictions by using the Subject ID.
Step 2: Calculating the Crisp Value Using the Utility Function
Once the data have been matched, a “Crisp Value” is calculated for each patient. This is performed by applying a utility function, which combines the predicted probabilities of the Alzheimer’s stages with their corresponding utility scores. The utility function is as follows:
Here, , , and are the predicted probabilities for Cognitively Normal, Mild Cognitive Impairment, and Alzheimer’s Disease, respectively. Meanwhile, , , and represent the utility values for each stage. These utility values are derived from [39], with scores ranging from 0.2 for severe Alzheimer’s to 0.7 for mild cognitive impairment.
Step 3: Horizontal Partitioning of Data Across Clients
Once the Crisp Values are calculated and the data are enriched, the dataset is horizontally partitioned. This means that the data are split into subsets with identical columns but different rows. These subsets are distributed to various clients (Client 1, Client 2, Client 3), allowing them to train their models locally. By ensuring that raw data are never exchanged between clients or with a central server, this process effectively maintains patient privacy.
By integrating CNN predictions with demographic data and applying utility-based calculations, this system improves the accuracy and nuance of Alzheimer’s diagnosis. Horizontal partitioning ensures data privacy is preserved within a federated learning setup, making this approach both practical and secure for real-world healthcare applications.
3.4.2. Local Training with BRB and PSO
Each client independently trains a local model using the belief rule base (BRB) mechanism combined with particle swarm optimization (PSO). The belief rule base (BRB) incorporates uncertainty by assigning belief degrees to different possible outcomes based on input variables such as CNN values and age. These belief degrees represent the level of confidence in each classification, allowing the model to account for uncertainty in the data. The rules in the BRB assess the likelihood of different conditions (such as CN, MCI, AD) and help manage any uncertainty arising from incomplete or noisy data. In the training process, each client in the federated learning setup independently trains a local model using the BRB mechanism. The belief rule base parameters are optimized using particle swarm optimization (PSO), which helps the model better handle data uncertainties and improve classification performance. After local training, the parameters are shared with a central server, where they are aggregated and refined to create a global model. This ensures that the model learns from data across different clients while maintaining privacy. This combination allows the model to handle uncertainties in the data effectively and optimize the parameters for better performance.
3.4.3. Belief Rule Base (BRB) Mechanism
The BRB mechanism is central to our model. It involves defining rules that map input variables to belief degrees for classification outcomes (see Figure 3). Each rule is formulated to assess the probability of a patient’s condition based on their CNN value and age. The rules and their weights are applied to determine the likely classification outcome. Table 4 presents the initial rule base used in our framework, detailing the rules, their weights, and activation weights.
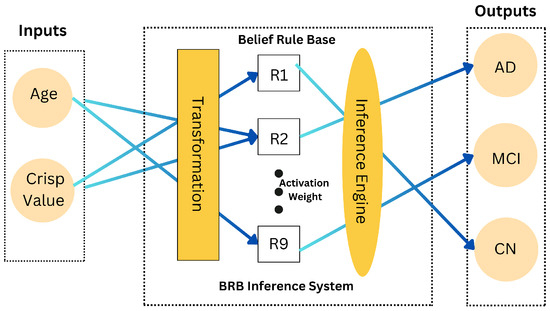
Figure 3.
Belief rule base system architecture.
Table 4.
Initial rule base.
The rules in Table 4 serve as the foundation for the BRB framework, guiding the decision-making process by evaluating the likelihood of each classification outcome (CN, MCI, AD) based on the input variables (CNN_Value, Age).
The BRB mechanism is fundamental for managing uncertainties and variability in the data. It encompasses several key components [4,36]:
Rule Structure:
Each rule in the BRB maps input variables (e.g., CNN values, age) to belief degrees for possible outcomes (CN, MCI, AD):
Belief Degrees and Rule Weights:
Belief degrees quantify the confidence in each classification outcome given a rule . These degrees must sum to 1 for each rule:
Rule weights indicate the importance of each rule and are normalized such that
where N is the total number of rules.
Attribute Weights:
Attribute weights reflect the significance of each input variable in influencing the belief degrees. They adjust the impact of each variable on the matching degree calculation.
Analytical Process of BRB:
The analytical process of the belief rule base (BRB) involves the following steps: input transformation, calculation of the matching degree, belief update, and output aggregation.
3.4.4. Local Parameter Optimization
The local model parameters are updated by minimizing the local objective function using PSO. The optimization process ensures that the model parameters converge to an optimal solution that reflects the local data characteristics [8,37]. The optimization process is defined as
where represents the optimized parameters at iteration t, and is the dataset for client i.
3.4.5. Parameter Sharing and Aggregation
After completing the local training, the clients transmit their updated BRB parameters to the central server. The gradients from each client are then aggregated to update the global model parameters .
Here, is the learning rate and N represents the number of clients. This aggregation process ensures that each client’s data influence the global model proportionally.
3.4.6. Global Model Update and PSO Optimization
The central server retrains the global model using the aggregated BRB parameters and further optimizes them using PSO. This iterative refinement of parameters helps to achieve a consistent global model across all clients. The updated global parameters are then sent back to the clients:
3.4.7. Iterative Optimization with PSO
This iterative process, which involves local training, parameter sharing, and global model updating, is repeated for five iterations to ensure faster convergence and efficient training (see Figure 4). The detailed steps of the PSO optimization process are outlined in Algorithm 1.
| Algorithm 1 Federated Learning with Particle Swarm Optimization (PSO) for Alzheimer’s Disease Diagnosis using FedAvg. |
|
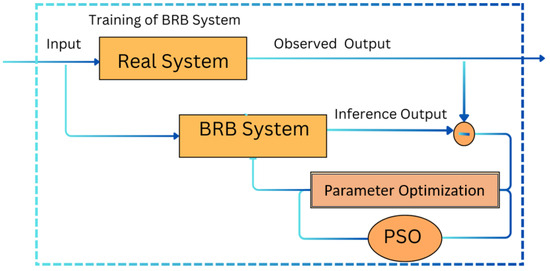
Figure 4.
Trained belief rule base system.
This framework demonstrates the integration of federated learning, the BRB mechanism, and PSO for effective Alzheimer’s disease diagnosis. The iterative process of local training, parameter sharing, and global model updating ensures efficient training and accurate diagnostic results. The detailed structure and mechanisms of the BRB ensure that the system can handle data variability and uncertainties effectively. This Algorithm 1 integrates federated learning (FL) with particle swarm optimization (PSO) to optimize a belief rule base (BRB) model aimed at diagnosing Alzheimer’s disease. The key steps are as follows:
First, the dataset, consisting of features such as “CNN_Value”, “Age”, and “Group”, is divided among three clients. Each client scales the data using a MinMaxScaler, processes it, and stores the results for use in the federated learning process.
In the BRB model, functions are defined to transform input values into belief degrees and calculate matching degrees, which are used to compute the overall belief for a diagnosis. The model’s performance is assessed using Mean Squared Error (MSE) to ensure accuracy.
During the optimization phase, each client independently applies PSO to tune the BRB parameters. The belief degrees are normalized, and the model’s accuracy is evaluated on training and testing data. After each iteration, the parameters from all clients are averaged using the FedAvg technique to create a global model.
The global model undergoes further refinement with PSO, and its performance is evaluated on the entire dataset. Finally, the algorithm outputs the optimized parameters and classification results, which can be used to diagnose Alzheimer’s disease more effectively.
4. Results
4.1. Libraries and Packages for System Implementation
The Alzheimer’s disease prediction system was developed using a comprehensive set of Python libraries, each serving specific roles in the process from data preparation to model deployment. The system started by converting MRI images from the NIFTI format to raw PNG files using libraries like Nibabel, NumPy, and PIL, enabling the images to be used as input for the convolutional neural network (CNN). The CNN, built with TensorFlow and Keras, processed these images to predict disease stages, and its outputs were structured into CSV files using Pandas. These predictions were then merged with demographic data, cleaned by removing redundant values, and a crisp value was calculated using NumPy to quantify the prediction outcomes.
The system also included a custom-built federated learning framework, which involved manual implementation of the trained belief rule-based (BRB) model and particle swarm optimization (PSO) for parameter tuning. The federated learning setup was established by creating secure connections between client nodes and a central server using libraries like Sockets, Paramiko, and Flask. This setup allowed local models to be trained independently on different datasets and then aggregated at the server to form a global model, ensuring data privacy while improving predictive accuracy. The entire process was managed and executed in Visual Studio Code, providing a robust environment for developing and refining the Alzheimer’s disease prediction system. The code constructed for the development of the Alzheimer’s Diagnostic System is available on ERROR: Failed to execute system command: GitHub.
4.2. Hyperparameter Setting
The hyperparameter settings for the Federated Averaging (FedAvg) algorithm in diagnosing Alzheimer’s disease are outlined in Table 5. Initially, the CNN prediction data combined with demographic data are divided among three clients. In each client, 80% and 20% of data are available for training and testing of the optimized BRB model. For optimization of BRB, particle swarm optimization (PSO) is used. The parameters in PSO have a swarm size of 50 and a maximum of 100 iterations, with parameter bounds ranging from 0 to 1 for each of the 38 parameters. A total of five iterations is performed in PSO.
Table 5.
Hyperparameter setting for FedAvg.
4.3. Evaluation Metrics
Mean square error (MSE) is a critical metric used to evaluate the performance of models in detecting Alzheimer’s disease. MSE measures the average of the squares of the errors, which are the differences between the predicted outcomes and the actual outcomes. It provides a quantitative assessment of the model’s prediction accuracy, particularly in medical diagnosis contexts such as Alzheimer’s disease detection.
where:
- n is the number of observations or patients in the dataset.
- represents the actual diagnostic score or label for the i-th patient.
- denotes the predicted diagnostic score or label for the i-th patient made by the model.
In the context of Alzheimer’s disease detection, might correspond to the true diagnostic status of a patient (e.g., Mild Cognitive Impairment, or Alzheimer’s Disease), and represents the model’s prediction. The MSE metric helps to quantify how closely the model’s predictions match the true diagnostic statuses.
A lower MSE value indicates that the model’s predictions are close to the actual diagnostic results, suggesting a higher level of accuracy in detecting Alzheimer’s disease. Achieving a low MSE is crucial for ensuring the reliability of the model in clinical settings, where accurate detection of Alzheimer’s disease is essential for timely intervention and treatment.
4.4. Performance of CNN for MRI Classification of Alzheimer’s
Figure 5 illustrates the loss and accuracy graph of the customised CNN used to train and test the MRI images extracted from the ADNI dataset. It is observed that the model reached an accuracy of approximately 98% and a loss of 0.01%. It can be deduced that there is little or no difference between the training and testing accuracy and loss. This means that the model is well fit.
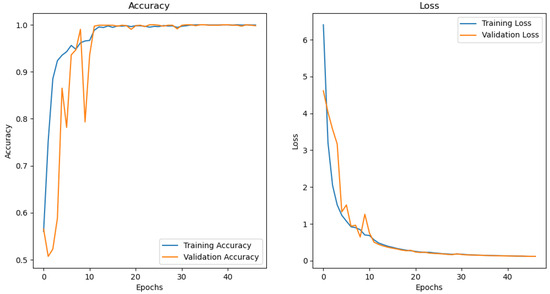
Figure 5.
CNN performance graph.
4.5. Rule Base Overview for Federated Learning Clients and Servers
The tables below represent the outcome of the rule base for the three iterations. This section is divided into two Section 4.6 and Section 4.7: one for the clients and one for the server. Section 4.6 indicates the client-side rule-base as the input rule-base which takes into account the following parameters: the CNN prediction value represented as “CNN_Value”, the age of the person represented as “Age”, and the predicted Alzheimer’s level represented as “Group”. In contrast, Section 4.7 indicates the server-side rule base as the output rule base, which takes into account the optimized values obtained after training the BRB. The optimized parameters are the likelihood of the person being diagnosed with Alzheimer’s which is distributed in three levels: Cognitively Normal “CN”, Mild Cognitive Impairment “MCI”, and Alzheimer’s Disease “AD”. To find more information about the inheritance of the rule base, refer to the initial rule base depicted in Table 4 of Section 3.4.3.
4.6. Rule Base for Local Training Model on Client Side
In this section, the client-side rule base from three different aggregators, namely FedAvg, FedProx, and Genetic Algorithm, are demonstrated in the following ables. Each table (Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12, Table 13, Table 14, Table 15, Table 16, Table 17, Table 18, Table 19, Table 20, Table 21, Table 22, Table 23, Table 24, Table 25, Table 26, Table 27, Table 28, Table 29, Table 30, Table 31 and Table 32) illustrates the type of aggregator used, the client, and the number of iterations.
Table 6.
Rule base for FedAvg aggregator client 1: first iteration.
Table 7.
Rule base for FedAvg aggregator client 2: first iteration.
Table 8.
Rule base for FedAvg aggregator client 3: first iteration.
Table 9.
Rule base for FedAvg aggregator client 1: second iteration.
Table 10.
Rule base for FedAvg aggregator client 2: second iteration.
Table 11.
Rule base for FedAvg aggregator client 3: second iteration.
Table 12.
Rule base for FedAvg aggregator client 1: third iteration.
Table 13.
Rule base for FedAvg aggregator client 2: third iteration.
Table 14.
Rule base for FedAvg aggregator client 3: third iteration.
Table 15.
FedProx aggregator client 1 rule base: first iteration.
Table 16.
FedProx aggregator client 2 rule base: first iteration.
Table 17.
FedProx aggregator client 3 rule base: first iteration.
Table 18.
FedProx aggregator client 1 rule base: second iteration.
Table 19.
FedProx aggregator client 2 rule base: second iteration.
Table 20.
FedProx aggregator client 3 rule base: second iteration.
Table 21.
FedProx aggregator client 1 rule base: third iteration.
Table 22.
FedProx aggregator client 2 rule base: third iteration.
Table 23.
FedProx aggregator client 3 rule base: third iteration.
Table 24.
Rule base for Genetic Algorithm aggregator client 1: first iteration.
Table 25.
Rule base for Genetic Algorithm aggregator client 2: first iteration.
Table 26.
Rule base for Genetic Algorithm aggregator client 3: first iteration.
Table 27.
Rule base for Genetic Algorithm aggregator client 1: second iteration.
Table 28.
Rule base for Genetic Algorithm aggregator client 2: second iteration.
Table 29.
Rule base for Genetic Algorithm aggregator client 3: second iteration.
Table 30.
Rule base for Genetic Algorithm aggregator client 1: third iteration.
Table 31.
Rule base for Genetic Algorithm aggregator client 2: third iteration.
Table 32.
Rule base for Genetic Algorithm aggregator client 3: third iteration.
4.7. Optimized Rule Base for Global Training Model on Server Side
In this section, the server-side rule base from three different aggregators, namely FedAvg, FedProx, and Genetic Algorithm, are demonstrated in the following tables. Each table (Table 33, Table 34, Table 35, Table 36, Table 37, Table 38, Table 39, Table 40 and Table 41) illustrates the type of aggregator used, the client, and the number of iterations.
Table 33.
Optimized server for FedAvg aggregator rule base: first iteration.
Table 34.
Final optimized server for FedAvg aggregator rule base: second iteration.
Table 35.
Optimized server for FedAvg aggregator rule base: third iteration.
Table 36.
Optimized server for FedProx aggregator rule base: first iteration.
Table 37.
Optimized server for FedProx aggregator rule base: second iteration.
Table 38.
Optimized server for FedProx aggregator rule base: third iteration.
Table 39.
Optimized server for Genetic Algorithm aggregator rule base: first iteration.
Table 40.
Optimized server for Genetic Algorithm aggregator rule base: second iteration.
Table 41.
Optimized server for Genetic Algorithm aggregator rule base: third iteration.
4.8. Graphical Representation of Accuracy and Loss for the Clients and Servers
In this section, some illustrations display the accuracy and loss data, for clients and servers using aggregation methods like FedAvg, Genetic Algorithm, and FedProx. These visuals present a comparison of performance measures, by depicting how local accuracy/loss changes throughout the iterations.
- Figure 6: The graph visualizes the Global Accuracy derived using the FedAvg aggregator in the three iterations. The x-axis represents the number of iterations, and the y-axis shows the accuracy achieved during global training.
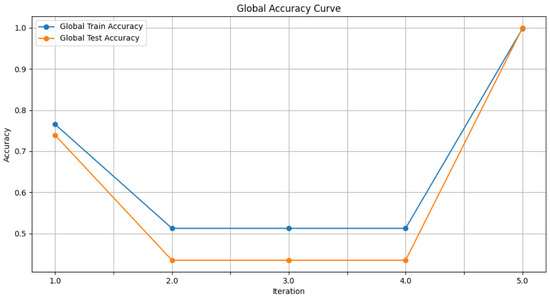 Figure 6. Global accuracy from FedAvg aggregator.
Figure 6. Global accuracy from FedAvg aggregator. - Figure 7: This plot dictates the Local Client Accuracy from the FedAvg aggregator for each client across the three iterations. The accuracy for each client is plotted independently, demonstrating the performance consistency or variability among the clients.
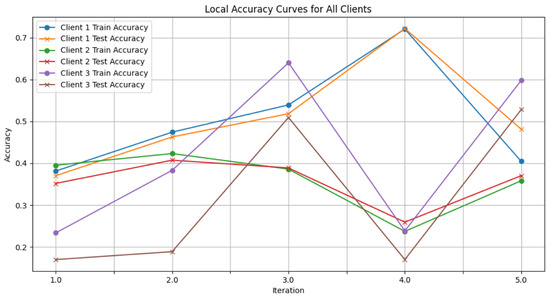 Figure 7. Local client accuracy from FedAvg aggregator.
Figure 7. Local client accuracy from FedAvg aggregator. - Figure 8: This figure presents the Global Accuracy achieved using the Genetic Algorithm aggregator. The plot distinguishes the training versus testing accuracy over the three iterations, illustrating the effectiveness of the Genetic Algorithm in global optimization.
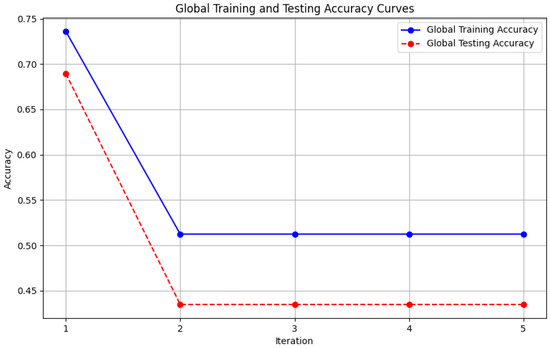 Figure 8. Global accuracy from Genetic Algorithm aggregator.
Figure 8. Global accuracy from Genetic Algorithm aggregator. - Figure 9: Similar to Figure 7, this plot shows the Local Accuracy for each client when using the Genetic Algorithm aggregator. The fluctuation in accuracy among clients across iterations is depicted.
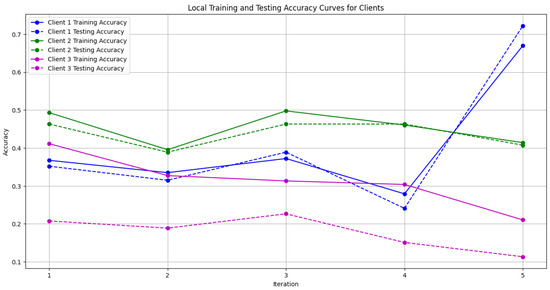 Figure 9. Local accuracy from Genetic Algorithm aggregator.
Figure 9. Local accuracy from Genetic Algorithm aggregator. - Figure 10: This plot depicts the Global Loss during training and testing using the Genetic Algorithm aggregator. The y-axis represents the loss, and the x-axis shows the iterations. A reduction in loss over iterations indicates better convergence.
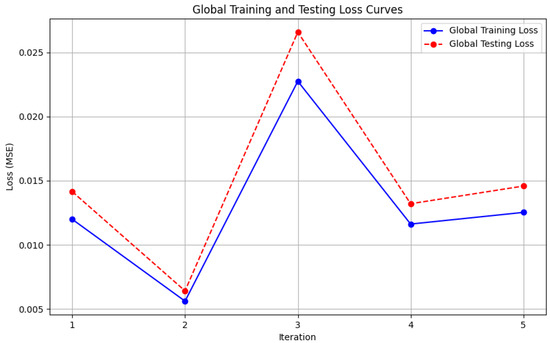 Figure 10. Global loss from Genetic Algorithm aggregator.
Figure 10. Global loss from Genetic Algorithm aggregator. - Figure 11: This figure shows the Local Loss for each client under the Genetic Algorithm aggregator. The figure aids in visualizing how individual clients are optimizing their loss functions.
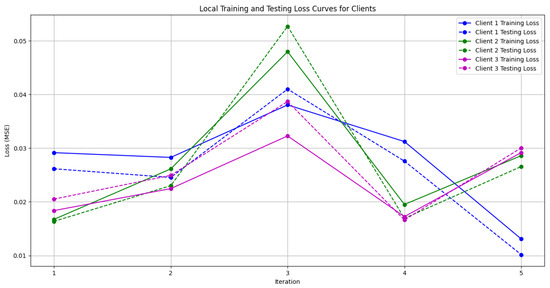 Figure 11. Local loss from Genetic Algorithm aggregator.
Figure 11. Local loss from Genetic Algorithm aggregator. - Figure 12: This plot shows the Global Accuracy achieved using the FedProx aggregator. It illustrates the effectiveness of FedProx in improving the global model accuracy across iterations.
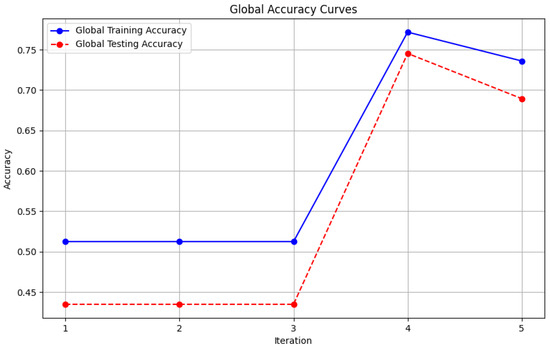 Figure 12. Global loss from FedProx aggregator.
Figure 12. Global loss from FedProx aggregator. - Figure 13: Finally, this plot presents the Local Accuracy for each client when using the FedProx aggregator. The comparison among clients is essential to understanding the federated learning model’s performance across distributed data sources.
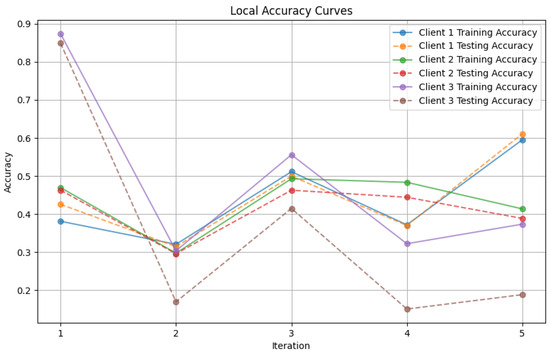 Figure 13. Local loss from FedProx aggregator.
Figure 13. Local loss from FedProx aggregator.
These plots offer an analysis of the precision and error measurements when using approaches, in federated learning aiding in determining the best method suited to a specific situation.
4.9. Interpretation of Model Performance of Aggregators Used in Federated Learning
This study investigates how aggregation techniques, namely FedAvg, FedProx, and Genetic Algorithm, work within a federated learning (FL) setup to detect Alzheimer’s disease by analyzing images and demographic data. The findings detailed in Table 42 shed light on how each method performs on an overall scale.
Table 42.
Model performance after last iteration.
4.9.1. FedAvg Aggregator
The FedAvg aggregator, which averages the model parameters from each client, demonstrated remarkable performance. At the global level, it achieved a nearly flawless testing accuracy of 0.99999 and a minimal mean squared error (MSE) of 0.00465. This impressive performance can be attributed to several factors inherent to the FedAvg algorithm:
- Robust Aggregation of Model Updates: The FedAvg method involves averaging the model parameters from clients to reduce the impact of data differences, among them. By blending these updates, the overall model can effectively adapt to datasets resulting in improved performance.
- Effective Handling of Data Heterogeneity: In federated learning setups, there is often a challenge, with IID (Independent and Identically Distributed) data, where various clients possess distinct data distributions. To address this, FedAvg tackles the problem by combining updates from all clients, allowing for a representation of data patterns and minimizing the chances of tailoring to any one client’s specific data.
- Generalization Across Multiple Clients: The variety of data from clients helps the overall model perform effectively in situations. This is shown by the testing accuracy of the model, which is close to 1.0, proving its excellent performance, with different types of data inputs.
Despite its performance, there are clear differences, in accuracy levels across different clients. For instance, client 3 only managed to achieve a testing accuracy of 0.52830, underscoring the difficulties FedAvg may face in adapting to client nuances. This disparity indicates that, while FedAvg excels in building a model, it might struggle to account for the distinct traits present in individual client datasets. Moreover, from Table 43, it can be deduced that the average time required to run PSO is 7,721.84 s. Now, if the number of iteration alongside rules increases, the time required to run BRBs will also increase. So, this raises an issue of time complexity which will not be applicable for real-time applications which support large-scale datasets with large rule sets.
Table 43.
PSO time analysis across iterations for FedAvg aggregator.
4.9.2. FedProx Aggregator
FedProx, a modified version of FedAvg that incorporates a term to address data differences efficiently, also exhibited impressive results. It reached a testing accuracy of 0.68944 with an MSE of 0.00687. The inclusion of the term in FedProx contributes to enhancing the training process in scenarios with diverse data.
The consistent performance outcomes among clients using FedProx imply that its regularization features offer benefits in maintaining performance stability across varying data distributions. For example, client 1 achieved a testing accuracy of 0.61111, notably surpassing the results seen with FedAvg, suggesting that FedProx might excel in managing types of data disparities.
4.9.3. Genetic Algorithm Aggregator
The Genetic Algorithm (GA) aggregator, which evolves model parameters based on a fitness function, demonstrated potential in adapting to client-specific data. For example, client 1 achieved a testing accuracy of 0.29629 with an MSE of 0.032451. However, the global accuracy was lower, with a testing accuracy of 0.43478 and an MSE of 0.00904.
The lower global accuracy implies that, while GA is adept at fine-tuning models for individual clients, it may require more extensive fine-tuning or a larger population size to reach the same level of generalization as FedAvg. Nonetheless, the adaptability of GA highlights its potential for scenarios wherein client data vary significantly, suggesting that, with further refinement, GA could become a more robust aggregator in FL settings.
4.10. Comparison with State-of-the-Art Methods
In times, there have been advancements in methods to improve the accuracy and reliability of diagnosing Alzheimer’s disease (see Table 44). These cutting-edge techniques leverage sophisticated machine learning models. However, our proposed method shows progress in accuracy and maintaining privacy setting, a benchmark in this field.
Table 44.
Comparison with state-of-the-art methods (X indicates that the issue was not addressed).
For example, Umme [1] and colleagues utilized DementiaNet with transfer learning to achieve a 97% accuracy on an MRI dataset with 6400 images. While this technique enhances performance on medical imaging tasks using trained models, it falls short in addressing data privacy concerns and uncertainties. Similarly, Raees et al. [40] combined support vector machines (SVMs) with deep neural networks (DNNs) to analyze data from 111 individuals in an MCI dataset achieving a 90% accuracy rate. While effective for datasets, this approach may require modifications to generalize to larger and more complex datasets. Buvaneswari et al. [41] experimented with SegNet and ResNet 101 on the ADNI dataset obtaining an accuracy of 96%. This method makes use of learning for feature extraction and segmentation, proving particularly effective for datasets like ADNI. However, there are still challenges when it comes to maintaining data privacy and handling uncertainties in the predictions. In a study by Saratxaga et al. [42] (2021), they created a model using ResNet 18 and BrainNet utilizing datasets from Kaggle. They found varying levels of accuracy ranging from 80% to 90% depending on the dataset used. While their method shows promise, the fluctuations in accuracy indicate a need for improvements to ensure consistency across datasets. Another study by Hu et al. [43] (2021) employed a convolutional neural network (CNN) trained on ADNI and NIFD datasets achieving an accuracy of 92%. CNNs are known for their effectiveness in image classification tasks as they can automatically learn features from raw image data. However, similar to other approaches, this method lacks mechanisms for safeguarding data privacy during the training process. Khalil et al. [5] (2023) investigated the use of hardware acceleration with VHDL and FPGA for diagnosing Alzheimer’s disease using simulation data. Despite reaching an accuracy of 89%, with a sensitivity rate of 87% and low power consumption (35–39 mW), this technique primarily emphasizes hardware efficiency rather than enhancing diagnostic accuracy or addressing concerns regarding data privacy. In their work, Mitrovska et al. [6] (2024) introduced a federated learning framework integrated with aggregation (SecAgg) and demographic simulations. The researchers focus on the importance of ensuring privacy in their work and analyze variations although they do not provide accuracy metrics. This underscores the increasing awareness of privacy in handling data. This also suggests that their method may need further refinement to achieve precise diagnostic results. In their study, Trivedi et al. [32] and colleagues applied federated deep learning using AlexNet on a distributed dataset achieving an accuracy rate of 98.53%. Their research stands out for its emphasis on safeguarding data privacy and demonstrating reliability across both multiple client settings. While this approach marks progress in learning, there is still room for enhancing the management of data distributions and addressing uncertainties. Altalbe et al. [33] developed a network within a federated learning framework for analyzing Kay Elemetrics voice disorder data reaching an accuracy level of 82.82%. Their strategy concentrates on mitigating overfitting and upholding privacy standards for medical applications. However, there is potential for enhancing accuracy, particularly when dealing with more varied datasets. Mandawkar et al. [34] utilized the Tawny Flamingo Deep CNN model on datasets achieving accuracies of 98.252% through Kfold validation and 97.995% during training sessions. Their methodology showcases the effectiveness of adjustments in attaining precision results; however, it falls short in addressing privacy concerns or uncertainties. Castro et al. [35] merged federated learning with biometric authentication and tested this on the OASIS and ADNI datasets. They found accuracy levels focused primarily on safeguarding privacy and preventing data manipulation, both essential aspects in federated learning settings.This strategy highlights the balance between security and performance, although there is room for enhancements in accuracy to improve its practical utility. On a similar note, Qian et al. [9] introduced FeDeFo, a combination of deep forest with federated learning applied to sMRI images. Their approach prioritizes model development while ensuring data privacy even though specific accuracy metrics were not disclosed. This indicates an emphasis on privacy protection and customized modeling, suggesting advancements in accuracy down the line.
In contrast, our research proposes a hybrid deep and federated learning methodology implemented on the ADNI and NIfTI files dataset. This approach achieved a 99.9% accuracy rate, significantly surpassing existing methods’ reported accuracies. Moreover, our model prioritizes data privacy and effectively manages uncertainties, offering a solution to the challenges associated with diagnosing Alzheimer’s disease. By combining the strengths of learning with the benefits of federated learning, our model not only establishes a new standard for diagnostic precision, but also addresses crucial concerns regarding data privacy and uncertainty management. This makes it a robust and dependable tool for world applications.
5. Conclusions and Future Research Directions
In this study, a method is proposed for diagnosing Alzheimer’s disease, addressing challenges such as data variability, privacy concerns, and uncertainty in datasets. CNNs analyze MRI scans, while federated learning ensures patient data privacy, and the BRB system manages diagnostic uncertainty. Experiments evaluating FedAvg, FedProx, and Genetic Algorithm aggregation methods revealed that FedAvg achieved near-perfect accuracy (99.99%) and minimal mean squared error (MSE), demonstrating strong generalization across datasets but limited performance for client-specific variations. FedProx delivered consistent results by effectively addressing client-specific data differences through regularization, while the Genetic Algorithm showed adaptability to diverse data distributions, requiring additional fine-tuning but highlighting its potential for optimizing client-specific parameters.
The proposed framework applies convolutional neural networks (CNNs) in Alzheimer’s disease classification. This heavily relies on access to labeled datasets. Even with the use of techniques like data augmentation and transfer learning, there is still a challenge in ensuring the model’s adaptability to unseen data.
In order to overcome this limitation, the FL framework was employed. This framework is beneficial in sensitive domains such as healthcare. Because it ensures that patient data remain localized on client devices, FL also minimizes the risk of privacy breaches. In the FL approach, these advantages are further enhanced by optimizing the model’s performance across heterogeneous client datasets to enable robust training under uncertainty without compromising data privacy.
However, it is important to recognize the limitations of this research. The implementation of federated learning (FL) which plays a role in safeguarding data privacy, has brought about challenges concerning communication model convergence. In scenarios wherein datasets vary widely, maintaining model performance across nodes has proven to be quite challenging. Despite the utilization of strategies like model averaging and communication-efficient algorithms, there is still a need for optimization within FL frameworks.
Regarding the belief rule base (BRB) system, known for its effectiveness in handling uncertainty, it poses complexity concerns, especially when combined with particle swarm optimization (PSO). This complexity could potentially hinder large-scale applications in real-time situations that require decision-making.
Several avenues for exploration are proposed for future to improve the efficiency and applicability of the framework in real-life situations.
To optimize training and inference times, hardware acceleration tools should be explored to address the complexity of federated learning and belief rule-based systems. These tools can significantly reduce computational overhead, making the framework more feasible for resource-constrained environments. Enhanced data security measures, such as privacy-preserving techniques and homomorphic encryption, should also be integrated to safeguard patient information beyond the privacy provided by federated learning.
Testing the scalability of the framework with diverse datasets is essential, along with extending its application to other neurodegenerative diseases or medical conditions requiring privacy and uncertainty management. This would highlight the framework’s adaptability and robustness across various healthcare contexts.
Practical considerations for large-scale deployment, including resource requirements, must be addressed. Collaborations with healthcare providers and regulatory agencies will be essential to ensure the system meets high diagnostic standards and integrates seamlessly into existing healthcare processes.
Future research should focus on incorporating additional data modalities, such as genetic information, lifestyle factors, and longitudinal data, to improve the precision of the diagnosis of Alzheimer’s disease. Expanding data sources could improve the model’s ability to detect patterns and relationships, enabling more precise and comprehensive diagnoses. Trials in real-world settings will be crucial to validate the framework’s efficacy, with collaboration from healthcare institutions to deploy and monitor its performance while gathering feedback from experts. Moreover, future work should explore cross-dataset performance evaluation to enhance generalization and extend the framework’s applicability across broader medical domains.
Author Contributions
Conceptualization, N.B. and K.A.; methodology, N.B. and K.A.; software, N.B. and K.A.; validation, N.B., T.M., R.U.I. and K.A.; formal analysis, N.B. and K.A.; data curation, N.B., T.M., R.U.I. and K.A.; writing—original draft preparation, N.B.; writing—review and editing, N.B., T.M., R.U.I. and K.A.; visualization, N.B. and T.M.; supervision, K.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
All necessary informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data used to support the findings of this study are available upon reasonable request to the corresponding author.
Acknowledgments
All praise and glory to Almighty Allah for giving me the endurance to pursue this research and complete my academic journey. We extend my deepest gratitude to my thesis supervisor, Karl Andersson, for his invaluable guidance, mentorship, and insightful feedback. His support was crucial to the success of this research. We would also like to express my sincere appreciation to the members of the GENIAL committee for their constructive critiques and suggestions that greatly enhanced the quality of this work. My gratitude goes to Jean-Philippe Georges, Program Coordinator, for always managing our requirements and addressing our challenges, Ah-Lian Kor from Leeds Beckett University, for always looking after us and supporting our academic journey, and Karan Mitra from Luleå University of Technology. Lastly, we wish to acknowledge my family and friends for their unwavering love, prayers, and encouragement, which have been my greatest source of strength throughout this journey. This work is dedicated to them.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Umme Habiba, S.; Debnath, T.; Islam, M.K.; Nahar, L.; Shahadat Hossain, M.; Basnin, N.; Andersson, K. Transfer Learning-Assisted DementiaNet: A Four Layer Deep CNN for Accurate Alzheimer’s Disease Detection from MRI Images. In Proceedings of the International Conference on Brain Informatics, Hoboken, NJ, USA, 1–3 August 2023; Springer: Cham, Switzerland, 2023; pp. 383–394. [Google Scholar]
- Mahmud, T.; Aziz, M.T.; Uddin, M.K.; Barua, K.; Rahman, T.; Sharmen, N.; Shamim Kaiser, M.; Sazzad Hossain, M.; Hossain, M.S.; Andersson, K. Ensemble Learning Approaches for Alzheimer’s Disease Classification in Brain Imaging Data. In Proceedings of the International Conference on Trends in Electronics and Health Informatics, Dhaka, Bangladesh, 20–21 December 2023; Springer: Cham, Switzerland, 2023; pp. 133–147. [Google Scholar]
- Mahmud, T.; Barua, K.; Barua, A.; Das, S.; Basnin, N.; Hossain, M.S.; Andersson, K.; Kaiser, M.S.; Sharmen, N. Exploring Deep Transfer Learning Ensemble for Improved Diagnosis and Classification of Alzheimer’s Disease. In Proceedings of the International Conference on Brain Informatics, Hoboken, NJ, USA, 1–3 August 2023; Springer: Cham, Switzerland, 2023; pp. 109–120. [Google Scholar]
- Hossain, M.S.; Rahaman, S.; Mustafa, R.; Andersson, K. A belief rule-based expert system to assess suspicion of acute coronary syndrome (ACS) under uncertainty. Soft Comput. 2018, 22, 7571–7586. [Google Scholar] [CrossRef]
- Khalil, K.; Khan Mamun, M.M.R.; Sherif, A.; Elsersy, M.S.; Imam, A.A.A.; Mahmoud, M.; Alsabaan, M. A federated learning model based on hardware acceleration for the early detection of alzheimer’s disease. Sensors 2023, 23, 8272. [Google Scholar] [CrossRef] [PubMed]
- Mitrovska, A.; Safari, P.; Ritter, K.; Shariati, B.; Fischer, J.K. Secure federated learning for Alzheimer’s disease detection. Front. Aging Neurosci. 2024, 16, 1324032. [Google Scholar] [CrossRef]
- Mahmud, T.; Barua, K.; Habiba, S.U.; Sharmen, N.; Hossain, M.S.; Andersson, K. An Explainable AI Paradigm for Alzheimer’s Diagnosis Using Deep Transfer Learning. Diagnostics 2024, 14, 345. [Google Scholar] [CrossRef] [PubMed]
- Beheshti, Z.; Shamsuddin, S.M.H.; Beheshti, E.; Yuhaniz, S.S. Enhancement of artificial neural network learning using centripetal accelerated particle swarm optimization for medical diseases diagnosis. Soft Comput. 2014, 18, 2253–2270. [Google Scholar] [CrossRef]
- Qian, C.; Xiong, H.; Li, J. FeDeFo: A Personalized Federated Deep Forest Framework for Alzheimer’s Disease Diagnosis. In Proceedings of the 35th International Conference on Software Engineering and Knowledge Engineering, San Francisco, CA, USA, 1–10 July 2023. [Google Scholar]
- Hossain, M.S.; Ahmed, F.; Andersson, K. A belief rule based expert system to assess tuberculosis under uncertainty. J. Med. Syst. 2017, 41, 43. [Google Scholar] [CrossRef]
- Bordin, V.; Coluzzi, D.; Rivolta, M.W.; Baselli, G. Explainable AI points to white matter hyperintensities for Alzheimer’s disease identification: A preliminary study. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; IEEE: New York, NY, YSA, 2022; pp. 484–487. [Google Scholar]
- De Santi, L.A.; Pasini, E.; Santarelli, M.F.; Genovesi, D.; Positano, V. An Explainable Convolutional Neural Network for the Early Diagnosis of Alzheimer’s Disease from 18F-FDG PET. J. Digit. Imaging 2023, 36, 189–203. [Google Scholar] [CrossRef] [PubMed]
- García-Gutierrez, F.; Díaz-Álvarez, J.; Matias-Guiu, J.A.; Pytel, V.; Matías-Guiu, J.; Cabrera-Martín, M.N.; Ayala, J.L. GA-MADRID: Design and validation of a machine learning tool for the diagnosis of Alzheimer’s disease and frontotemporal dementia using genetic algorithms. Med. Biol. Eng. Comput. 2022, 60, 2737–2756. [Google Scholar] [CrossRef]
- Yang, C.; Rangarajan, A.; Ranka, S. Visual explanations from deep 3D convolutional neural networks for Alzheimer’s disease classification. In Proceedings of the AMIA Annual Symposium Proceedings, San Francisco, CA, USA, 3–7 November 2018; American Medical Informatics Association: Bethesda, MD, USA, 2018; Volume 2018, p. 1571. [Google Scholar]
- Rieke, J.; Eitel, F.; Weygandt, M.; Haynes, J.D.; Ritter, K. Visualizing convolutional networks for MRI-based diagnosis of Alzheimer’s disease. In Proceedings of the Understanding and Interpreting Machine Learning in Medical Image Computing Applications: First International Workshops, MLCN 2018, DLF 2018, and iMIMIC 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16–20 September 2018; Proceedings 1. Springer: Cham, Switzerland, 2018; pp. 24–31. [Google Scholar]
- Loveleen, G.; Mohan, B.; Shikhar, B.S.; Nz, J.; Shorfuzzaman, M.; Masud, M. Explanation-driven hci model to examine the mini-mental state for alzheimer’s disease. Acm Trans. Multimed. Comput. Commun. Appl. 2023, 20, 1–16. [Google Scholar] [CrossRef]
- Yu, L.; Xiang, W.; Fang, J.; Chen, Y.P.P.; Zhu, R. A novel explainable neural network for Alzheimer’s disease diagnosis. Pattern Recognit. 2022, 131, 108876. [Google Scholar] [CrossRef]
- Kim, M.; Kim, J.; Qu, J.; Huang, H.; Long, Q.; Sohn, K.A.; Kim, D.; Shen, L. Interpretable temporal graph neural network for prognostic prediction of Alzheimer’s disease using longitudinal neuroimaging data. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; IEEE: New York, NY, YSA, 2021; pp. 1381–1384. [Google Scholar]
- Marwa, E.G.; Moustafa, H.E.D.; Khalifa, F.; Khater, H.; AbdElhalim, E. An MRI-based deep learning approach for accurate detection of Alzheimer’s disease. Alex. Eng. J. 2023, 63, 211–221. [Google Scholar]
- Ghazal, T.M.; Abbas, S.; Munir, S.; Khan, M.; Ahmad, M.; Issa, G.F.; Zahra, S.B.; Khan, M.A.; Hasan, M.K. Alzheimer Disease Detection Empowered with Transfer Learning. Comput. Mater. Contin. 2022, 70, 5005–5019. [Google Scholar] [CrossRef]
- AlSaeed, D.; Omar, S.F. Brain MRI analysis for Alzheimer’s disease diagnosis using CNN-based feature extraction and machine learning. Sensors 2022, 22, 2911. [Google Scholar] [CrossRef] [PubMed]
- Hamdi, M.; Bourouis, S.; Rastislav, K.; Mohmed, F. Evaluation of neuro images for the diagnosis of Alzheimer’s disease using deep learning neural network. Front. Public Health 2022, 10, 834032. [Google Scholar]
- Helaly, H.A.; Badawy, M.; Haikal, A.Y. Deep learning approach for early detection of Alzheimer’s disease. Cogn. Comput. 2021, 14, 1711–1727. [Google Scholar] [CrossRef]
- Mohammed, B.A.; Senan, E.M.; Rassem, T.H.; Makbol, N.M.; Alanazi, A.A.; Al-Mekhlafi, Z.G.; Almurayziq, T.S.; Ghaleb, F.A. Multi-method analysis of medical records and MRI images for early diagnosis of dementia and Alzheimer’s disease based on deep learning and hybrid methods. Electronics 2021, 10, 2860. [Google Scholar] [CrossRef]
- Pradhan, A.; Gige, J.; Eliazer, M. Detection of Alzheimer’s disease (AD) in MRI images using deep learning. Int. J. Eng. Res. Technol. 2021, 10. [Google Scholar]
- Salehi, A.W.; Baglat, P.; Sharma, B.B.; Gupta, G.; Upadhya, A. A CNN model: Earlier diagnosis and classification of Alzheimer disease using MRI. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; IEEE: New York, NY, YSA, 2020; pp. 156–161. [Google Scholar]
- Suganthe, R.C.; Latha, R.S.; Geetha, M.; Sreekanth, G.R. Diagnosis of Alzheimer’s disease from brain magnetic resonance imaging images using deep learning algorithms. Adv. Electr. Comput. Eng. 2020, 20, 57–64. [Google Scholar] [CrossRef]
- Hussain, E.; Hasan, M.; Hassan, S.Z.; Azmi, T.H.; Rahman, M.A.; Parvez, M.Z. Deep learning based binary classification for alzheimer’s disease detection using brain mri images. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; IEEE: New York, NY, YSA, 2020; pp. 1115–1120. [Google Scholar]
- Basaia, S.; Agosta, F.; Wagner, L.; Canu, E.; Magnani, G.; Santangelo, R.; Filippi, M.; The Alzheimer’s Disease Neuroimaging Initiative. Automated classification of Alzheimer’s disease and mild cognitive impairment using a single MRI and deep neural networks. Neuroimage Clin. 2019, 21, 101645. [Google Scholar] [CrossRef]
- Ji, H.; Liu, Z.; Yan, W.Q.; Klette, R. Early diagnosis of Alzheimer’s disease using deep learning. In Proceedings of the 2nd International Conference on Control and Computer Vision, Jeju, Republic of Korea, 15–18 June 2019; pp. 87–91. [Google Scholar]
- Islam, J.; Zhang, Y. A novel deep learning based multi-class classification method for Alzheimer’s disease detection using brain MRI data. In Proceedings of the Brain Informatics: International Conference, BI 2017, Beijing, China, 16–18 November 2017; Proceedings. Springer: Cham, Switzerland, 2017; pp. 213–222. [Google Scholar]
- Trivedi, N.K.; Jain, S.; Agarwal, S. Identifying and Categorizing Alzheimer’s Disease with Lightweight Federated Learning Using Identically Distributed Images. In Proceedings of the 2024 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 14–15 March 2024; IEEE: New York, NY, YSA, 2024; pp. 1–5. [Google Scholar]
- Altalbe, A.; Javed, A.R. Privacy Preserved Brain Disorder Diagnosis Using Federated Learning. Comput. Syst. Sci. Eng. 2023, 47, 2187–2200. [Google Scholar] [CrossRef]
- Mandawkar, U.; Diwan, T. Alzheimer disease classification using tawny flamingo based deep convolutional neural networks via federated learning. Imaging Sci. J. 2022, 70, 459–472. [Google Scholar] [CrossRef]
- Castro, F.; Impedovo, D.; Pirlo, G. A Federated Learning System with Biometric Medical Image Authentication for Alzheimer’s Diagnosis. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM), Rome, Italy, 24–26 February 2024; pp. 951–960. [Google Scholar]
- Biswas, M.; Chowdhury, S.U.; Nahar, N.; Hossain, M.S.; Andersson, K. A belief rule base expert system for staging non-small cell lung cancer under uncertainty. In Proceedings of the 2019 IEEE International Conference on Biomedical Engineering, Computer and Information Technology for Health (BECITHCON), Dhaka, Bangladesh, 28–30 November 2019; IEEE: New York, NY, YSA, 2019; pp. 47–52. [Google Scholar]
- Mandal, A.K.; Sarma, P.K.D. Usage of particle swarm optimization in digital images selection for monkeypox virus prediction and diagnosis. Malays. J. Comput. Sci. 2024, 37, 124–139. [Google Scholar]
- Alzheimer’s Disease Neuroimaging Initiative (ADNI). Available online: https://adni.loni.usc.edu. (accessed on 25 February 2024).
- Wimo, A.; Jonsson, L.; Gustavsson, A.; McDaid, D.; Ersek, K.; Georges, J.; Gulácsi, L.; Karpati, K.; Kenigsberg, P.; Valtonen, H. Utility score changes in Alzheimer’s disease. Value Health 2009, 12, 295–305. [Google Scholar]
- Raees, P.M.; Thomas, V. Automated detection of Alzheimer’s Disease using Deep Learning in MRI. J. Phys. Conf. Ser. 2021, 1921, 012024. [Google Scholar] [CrossRef]
- Buvaneswari, P.; Gayathri, R. Deep learning-based segmentation in classification of Alzheimer’s disease. Arab. J. Sci. Eng. 2021, 46, 5373–5383. [Google Scholar] [CrossRef]
- Saratxaga, C.L.; Moya, I.; Picón, A.; Acosta, M.; Moreno-Fernandez-de Leceta, A.; Garrote, E.; Bereciartua-Perez, A. MRI deep learning-based solution for Alzheimer’s disease prediction. J. Pers. Med. 2021, 11, 902. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Qing, Z.; Liu, R.; Zhang, X.; Lv, P.; Wang, M.; Wang, Y.; He, K.; Gao, Y.; Zhang, B. Deep learning-based classification and voxel-based visualization of frontotemporal dementia and Alzheimer’s disease. Front. Neurosci. 2021, 14, 626154. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).