
A Comprehensive CNN Model for Age-Related Macular Degeneration Classification Using OCT: Integrating Inception Modules, SE Blocks, and ConvMixer

 , , , , and
, , , , and
Abstract
1. Introduction
- An innovative method is presented, merging the benefits of reducing parameter count using depthwise separable convolutions with the multi-scale parallel design of the Inception module. This combined technique, known as the modified Inception module, effectively minimizes the number of trainable parameters, thus reducing computational costs.
- Incorporating a depthwise separable convolutions layer into the Squeeze-and-Excitation block within DSEB creates a sturdier configuration. The resultant DSEB architecture adeptly assigns significance to low-level features and integrates them with high-level ones, optimizing the utilization of low-level features while marginally affecting the computational load. Consequently, the suggested design bolsters both training efficacy and network efficiency. Empirical findings affirm that integrating this structure within the proposed architecture enhances classification accuracy.
- ConvMixer offers robust capabilities for extracting features, enabling the model to grasp intricate patterns and formations within the input images. This method excels in extracting features abundant in spatial details. Operating directly on input patches and employing standard convolutions solely for mixing steps, it significantly boosts classification accuracy. Moreover, the integration of depthwise separable convolution layers and a modified Inception module into the ConvMixer architecture curtails computational expenses, rendering the proposed architecture more straightforward and less computationally burdensome.
- Comprehensive experimental studies were conducted on a private AMD dataset consisting of 2316 images to analyze the classification performance of the PM. F1 score of 97.86%, recall of 97.77%, precision of 97.95%, and an accuracy of 97.98% were achieved with the PM. In addition, as a result of the experimental studies carried out on the public (Noor) AMD dataset, 100% results were obtained in all evaluation metrics. Comparisons with different DL models have shown the superior performance of the PM.
2. Related Works
3. Proposed Model (PM)
3.1. Depthwise Squeeze-and-Excitation Block (DSEB)
3.2. Modified Inception Module (MIM)
3.3. ConvMixer Architecture
4. Experimental Studies
4.1. AMD Datasets
4.2. Experimental Setup
4.3. Evaluation Metrics
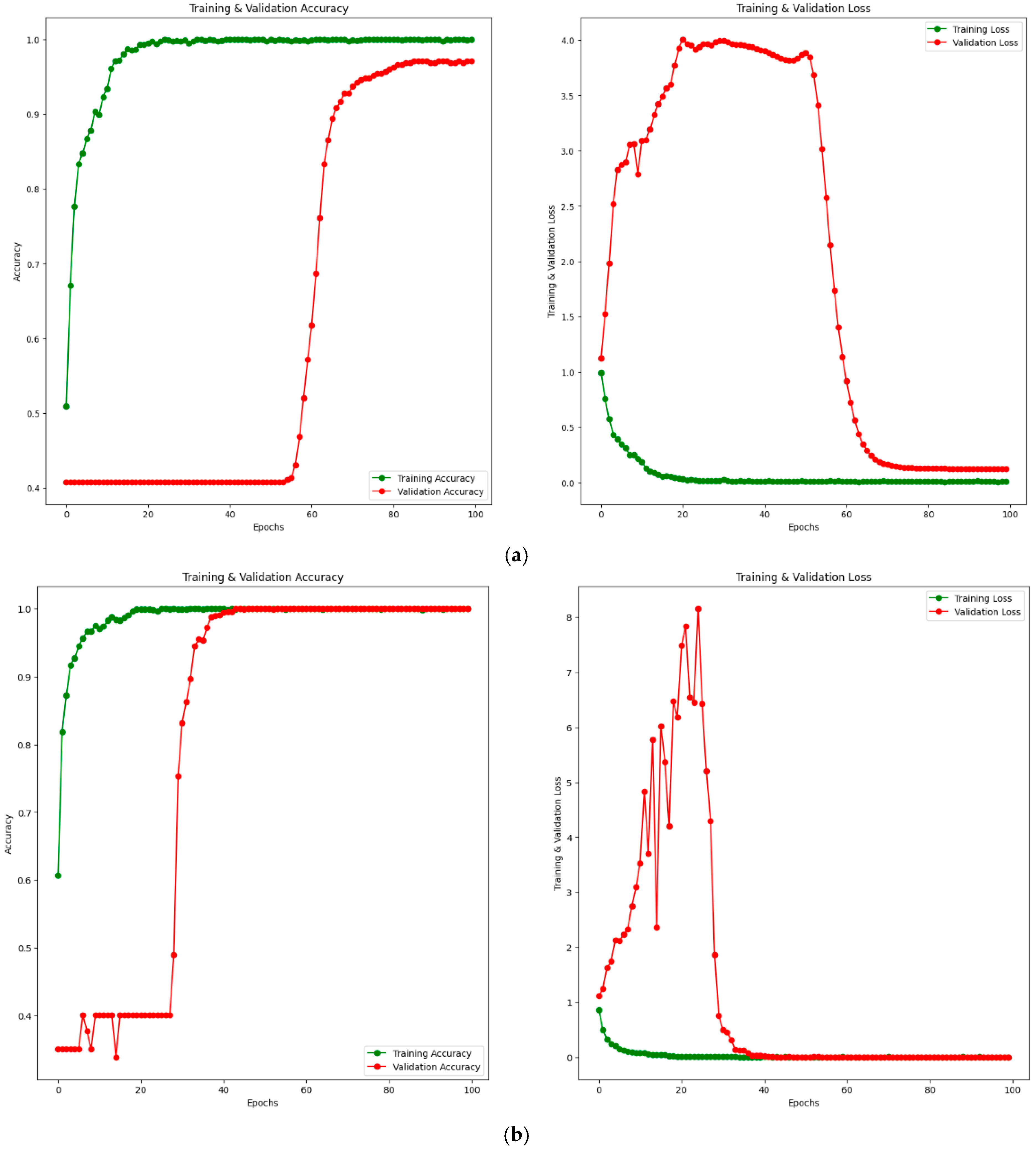
4.4. Experimental Results
4.5. Discussion
4.6. Ablation Study
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Umer, M.J.; Sharif, M.; Raza, M.; Kadry, S. A Deep Feature Fusion and Selection-Based Retinal Eye Disease Detection from OCT Images. Expert Syst. 2023, 40, e13232. [Google Scholar] [CrossRef]
- Nowak, J.Z. Age-Related Macular Degeneration (AMD): Pathogenesis and Therapy. Pharmacol. Rep. 2006, 58, 353–363. [Google Scholar] [PubMed]
- Mitchell, P.; Liew, G.; Gopinath, B.; Wong, T.Y. Age-Related Macular Degeneration. Lancet 2018, 392, 1147–1159. [Google Scholar] [CrossRef] [PubMed]
- Fleckenstein, M.; Keenan, T.D.L.; Guymer, R.H.; Chakravarthy, U.; Schmitz-Valckenberg, S.; Klaver, C.C.; Wong, W.T.; Chew, E.Y. Age-Related Macular Degeneration. Nat. Rev. Dis. Primers 2021, 7, 31. [Google Scholar] [CrossRef]
- Yang, K.; Liang, Y.B.; Gao, L.Q.; Peng, Y.; Shen, R.; Duan, X.R.; Friedman, D.S.; Sun, L.P.; Mitchell, P.; Wang, N.L.; et al. Prevalence of Age-Related Macular Degeneration in a Rural Chinese Population: The Handan Eye Study. Ophthalmology 2011, 118, 1395–1401. [Google Scholar] [CrossRef] [PubMed]
- Wong, W.L.; Su, X.; Li, X.; Cheung, C.M.G.; Klein, R.; Cheng, C.Y.; Wong, T.Y. Global Prevalence of Age-Related Macular Degeneration and Disease Burden Projection for 2020 and 2040: A Systematic Review and Meta-Analysis. Lancet Glob. Health 2014, 2, e106–e116. [Google Scholar] [CrossRef]
- Ricci, F.; Bandello, F.; Navarra, P.; Staurenghi, G.; Stumpp, M.; Zarbin, M. Neovascular Age-Related Macular Degeneration: Therapeutic Management and New-Upcoming Approaches. Int. J. Mol. Sci. 2020, 21, 8242. [Google Scholar] [CrossRef] [PubMed]
- Schultz, N.M.; Bhardwaj, S.; Barclay, C.; Gaspar, L.; Schwartz, J. Global Burden of Dry Age-Related Macular Degeneration: A Targeted Literature Review. Clin. Ther. 2021, 43, 1792–1818. [Google Scholar] [CrossRef] [PubMed]
- Stahl, A. Diagnostik Und Therapie Der Altersabhängigen Makuladegeneration. Dtsch. Arztebl. Int. 2020, 117, 513–520. [Google Scholar] [CrossRef]
- Gheorghe, A.; Mahdi, L.; Musat, O. Age-Related Macular Degeneration. Rom. J. Ophthalmol. 2015, 59, 74–77. [Google Scholar] [PubMed]
- Davis, M.D.; Gangnon, R.E.; Lee, L.-Y.; Hubbard, L.D.; Klein, B.E.K.; Klein, R.; Ferris, F.L.; Bressler, S.B.; Milton, R.C. The Age-Related Eye Disease Study Severity Scale for Age-Related Macular Degeneration: AREDS Report No. 17. Arch. Ophthalmol. 2005, 123, 1484–1498. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Zhou, Q.; Zou, Y. Automatic Detection of Age-Related Macular Degeneration Based on Deep Learning and Local Outlier Factor Algorithm. Diagnostics 2022, 12, 532. [Google Scholar] [CrossRef] [PubMed]
- Heo, T.Y.; Kim, K.M.; Min, H.K.; Gu, S.M.; Kim, J.H.; Yun, J.; Min, J.K. Development of a Deep-Learning-Based Artificial Intelligence Tool for Differential Diagnosis between Dry and Neovascular Age-Related Macular Degeneration. Diagnostics 2020, 10, 261. [Google Scholar] [CrossRef] [PubMed]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully Automated Detection of Diabetic Macular Edema and Dry Age-Related Macular Degeneration from Optical Coherence Tomography Images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed]
- Podoleanu, A.G. Optical Coherence Tomography. J. Microsc. 2012, 247, 209–219. [Google Scholar] [CrossRef]
- Liew, A.; Agaian, S.; Benbelkacem, S. Distinctions between Choroidal Neovascularization and Age Macular Degeneration in Ocular Disease Predictions via Multi-Size Kernels ξCho-Weighted Median Patterns. Diagnostics 2023, 13, 729. [Google Scholar] [CrossRef] [PubMed]
- Ferris, F.L.; Wilkinson, C.P.; Bird, A.; Chakravarthy, U.; Chew, E.; Csaky, K.; Sadda, S.R. Clinical Classification of Age-Related Macular Degeneration. Ophthalmology 2013, 120, 844–851. [Google Scholar] [CrossRef]
- Shelton, R.L.; Shrestha, S.; Park, J.; Applegate, B.E. Optical Coherence Tomography. Biomed. Technol. Devices Second Ed. 2013, 254, 247–266. [Google Scholar] [CrossRef]
- Darooei, R.; Nazari, M.; Kafieh, R.; Rabbani, H. Optimal Deep Learning Architecture for Automated Segmentation of Cysts in OCT Images Using X-Let Transforms. Diagnostics 2023, 13, 1994. [Google Scholar] [CrossRef] [PubMed]
- Muntean, G.A.; Marginean, A.; Groza, A.; Damian, I.; Roman, S.A.; Hapca, M.C.; Muntean, M.V.; Nicoară, S.D. The Predictive Capabilities of Artificial Intelligence-Based OCT Analysis for Age-Related Macular Degeneration Progression—A Systematic Review. Diagnostics 2023, 13, 2464. [Google Scholar] [CrossRef] [PubMed]
- Thomas, A.; Sunija, A.P.; Manoj, R.; Ramachandran, R.; Ramachandran, S.; Varun, P.G.; Palanisamy, P. RPE Layer Detection and Baseline Estimation Using Statistical Methods and Randomization for Classification of AMD from Retinal OCT. Comput. Methods Programs Biomed. 2021, 200, 105822. [Google Scholar] [CrossRef]
- Adamis, A.P.; Brittain, C.J.; Dandekar, A.; Hopkins, J.J. Building on the Success of Anti-Vascular Endothelial Growth Factor Therapy: A Vision for the next Decade. Eye 2020, 34, 1966–1972. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Lung Chong, K.K.; Li, Z. Applications of AI to Age-Related Macular Degeneration: A Case Study and a Brief Review. In Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shijiazhuang, China, 22–24 July 2022; 2022; pp. 586–589. [Google Scholar]
- Serener, A.; Serte, S. Dry and Wet Age-Related Macular Degeneration Classification Using OCT Images and Deep Learning. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics and Biomedical Engineering and Computer Science, EBBT, Istanbul, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Sotoudeh-Paima, S.; Jodeiri, A.; Hajizadeh, F.; Soltanian-Zadeh, H. Multi-Scale Convolutional Neural Network for Automated AMD Classification Using Retinal OCT Images. Comput. Biol. Med. 2022, 144, 105368. [Google Scholar] [CrossRef]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef] [PubMed]
- Thomas, A.; Harikrishnan, P.M.; Ramachandran; Ramachandran, S.; Manoj, R.; Palanisamy, P.; Gopi, V.P. A Novel Multiscale and Multipath Convolutional Neural Network Based Age-Related Macular Degeneration Detection Using OCT Images. Comput. Methods Programs Biomed. 2021, 209, 106294. [Google Scholar] [CrossRef]
- Celebi, A.R.C.; Bulut, E.; Sezer, A. Artificial Intelligence Based Detection of Age-Related Macular Degeneration Using Optical Coherence Tomography with Unique Image Preprocessing. Eur. J. Ophthalmol. 2023, 33, 65–73. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Wu, B.; Lu, D.; Xie, J.; Chen, Y.; Yang, Z.; Dai, W. Two-Step Hierarchical Neural Network for Classification of Dry Age-Related Macular Degeneration Using Optical Coherence Tomography Images. Front. Med. 2023, 10, 1221453. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Xie, X.; Terry, L.; Wood, A.; White, N.; Margrain, T.H.; North, R. V Age-Related Macular Degeneration Detection and Stage Classification Using Choroidal OCT Images. In Image Analysis and Recognition; Campilho, A., Karray, F., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 707–715. [Google Scholar]
- Lee, C.S.; Baughman, D.M.; Lee, A.Y. Deep Learning Is Effective for the Classification of OCT Images of Normal versus Age-Related Macular Degeneration. Ophthalmol. Retin. 2017, 1, 322–327. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y.; Seo, J.G.; Ramasubramanian, B.; Selvaperumal, S.; Kim, D.W. The Possibility of the Combination of OCT and Fundus Images for Improving the Diagnostic Accuracy of Deep Learning for Age-Related Macular Degeneration: A Preliminary Experiment. Med. Biol. Eng. Comput. 2019, 57, 677–687. [Google Scholar] [CrossRef]
- Hwang, D.-K.; Hsu, C.-C.; Chang, K.-J.; Chao, D.; Sun, C.-H.; Jheng, Y.-C.; Yarmishyn, A.A.; Wu, J.-C.; Tsai, C.-Y.; Wang, M.-L.; et al. Artificial Intelligence-Based Decision-Making for Age-Related Macular Degeneration. Theranostics 2019, 9, 232–245. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Wang, W.; Yang, J.; Zhao, J.; Ding, D.; He, F.; Chen, D.; Yang, Z.; Li, X.; Yu, W.; et al. Automated Diagnoses of Age-Related Macular Degeneration and Polypoidal Choroidal Vasculopathy Using Bi-Modal Deep Convolutional Neural Networks. Br. J. Ophthalmol. 2021, 105, 561–566. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xue, Y.; Wu, X.; Zhong, Y.; Rao, H.; Luo, H.; Weng, Z. Deep Learning-Based System for Disease Screening and Pathologic Region Detection From Optical Coherence Tomography Images. Transl. Vis. Sci. Technol. 2023, 12, 29. [Google Scholar] [CrossRef]
- Kadry, S.; Rajinikanth, V.; González Crespo, R.; Verdú, E. Automated Detection of Age-Related Macular Degeneration Using a Pre-Trained Deep-Learning Scheme. J. Supercomput. 2022, 78, 7321–7340. [Google Scholar] [CrossRef]
- Das, V.; Dandapat, S.; Bora, P.K. Multi-Scale Deep Feature Fusion for Automated Classification of Macular Pathologies from OCT Images. Biomed. Signal Process. Control 2019, 54, 101605. [Google Scholar] [CrossRef]
- Das, V.; Prabhakararao, E.; Dandapat, S.; Bora, P.K. B-Scan Attentive CNN for the Classification of Retinal Optical Coherence Tomography Volumes. IEEE Signal Process. Lett. 2020, 27, 1025–1029. [Google Scholar] [CrossRef]
- Rasti, R.; Rabbani, H.; Mehridehnavi, A.; Hajizadeh, F. Macular OCT Classification Using a Multi-Scale Convolutional Neural Network Ensemble. IEEE Trans. Med. Imaging 2018, 37, 1024–1034. [Google Scholar] [CrossRef]
- Farsiu, S.; Chiu, S.J.; O’Connell, R.V.; Folgar, F.A.; Yuan, E.; Izatt, J.A.; Toth, C.A. Quantitative Classification of Eyes with and without Intermediate Age-Related Macular Degeneration Using Optical Coherence Tomography. Ophthalmology 2014, 121, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Trockman, A.; Kolter, J.Z. Patches Are All You Need? arXiv 2022, arXiv:2201.09792. [Google Scholar]
- Asker, M.E. Hyperspectral Image Classification Method Based on Squeeze-and-Excitation Networks, Depthwise Separable Convolution and Multibranch Feature Fusion. Earth Sci. Inform. 2023, 16, 1427–1448. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Tuncer, A. Cost-Optimized Hybrid Convolutional Neural Networks for Detection of Plant Leaf Diseases. J. Ambient Intell. Humaniz. Comput. 2021, 12, 8625–8636. [Google Scholar] [CrossRef]
- Ozcelik, S.T.A.; Uyanık, H.; Deniz, E.; Sengur, A. Automated Hypertension Detection Using ConvMixer and Spectrogram Techniques with Ballistocardiograph Signals. Diagnostics 2023, 13, 182. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 9–15 June 2019; pp. 10691–10700. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Sabi, S.; Gopi, V.P.; Raj, J.R.A. Detection of Age-Related Macular Degeneration from Oct Images Using Double Scale Cnn Architecture. Biomed. Eng. Appl. Basis Commun. 2021, 33, 2150029. [Google Scholar] [CrossRef]
- Mishra, S.S.; Mandal, B.; Puhan, N.B. MacularNet: Towards Fully Automated Attention-Based Deep CNN for Macular Disease Classification. SN Comput. Sci. 2022, 3, e0261285. [Google Scholar] [CrossRef]
- Xu, L.; Wang, L.; Cheng, S.; Li, Y. MHANet: A Hybrid Attention Mechanism for Retinal Diseases Classification. PLoS ONE 2021, 16, 1–20. [Google Scholar] [CrossRef]
- Fang, L.; Wang, C.; Li, S.; Rabbani, H.; Chen, X.; Liu, Z. Attention to Lesion: Lesion-Aware Convolutional Neural Network for Retinal Optical Coherence Tomography Image Classification. IEEE Trans. Med. Imaging 2019, 38, 1959–1970. [Google Scholar] [CrossRef] [PubMed]
- Sahoo, M.; Mitra, M.; Pal, S. Improved Detection of Dry Age-Related Macular Degeneration from Optical Coherence Tomography Images Using Adaptive Window Based Feature Extraction and Weighted Ensemble Based Classification Approach. Photodiagnosis Photodyn. Ther. 2023, 42, 103629. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Datasets | Models | Results | Notes |
|---|---|---|---|---|
| Thomas et al. [21] | 2130 images, 30 cases (2 classes: 15 dry AMD and 15 normal) | The speckle elimination relies on an adaptive denoising technique using contrast enhancement. To identify the retinal pigment epithelium layer, a method involving pixel grouping and iterative elimination is employed, utilizing knowledge about typical layer intensities and positions. | Acc: 96.66% | The primary focus of this study revolves around AMD classification employing a statistical method. By estimating drusen height through the retinal pigment epithelium layer and baseline, the severity of the disease becomes comprehensible. A step-by-step process, involving despeckling, retinal pigment epithelium and baseline estimation, drusen height detection, and classification, is implemented. Nevertheless, its efficacy diminishes when dealing with images where the majority of noisy pixels in columns exceed the intensity of the retinal pigment epithelium and are positioned below it. |
| Serener et al. [24] | UCSD [26] (Training: 26,315 normal, 8616 dry AMD, 11,348 DME, and 37,205 wet AMD Testing: 250 normal, 250 DME, 250 wet AMD, and 250 dry AMD) | Two pre-trained CNNs, ResNet18 and AlexNet, were used to classify OCT images associated with wet and dry AMD. | Dry AMD: ResNet18 (AUC: 94%, Acc: 99.5%) Dry AMD: AlexNet (AUC: 81%, Acc: 93.8%) Wet AMD: ResNet18 (AUC: 63%, Acc: 98.8%) Wet AMD: AlexNet (AUC: 61%, Acc: 96.5%) | In both instances (wet AMD and dry AMD), the ResNet18 outperformed the AlexNet. In addition, using pre-trained AlexNet and ResNet18 resulted in a large number of learnable parameters. |
| Paima et al. [25] | UCSD dataset [26] and Noor Eye Hospital OCT dataset (5667 normal, 3742 drusen, and 3240 CNV) | Multi-scale CNN with a feature pyramid network-based feature fusion strategy | Noor Eye Hospital OCT dataset (87.8% Acc for FPN-EfficientNetB0, 90.9% Acc for FPN-DenseNet121, 90.1% Acc for FPN-ResNet50, and 92.0% Acc for FPN-VGG16) UCSD dataset (93.9% Acc for FPN-VGG16, 5-fold cross-validation) | Within this research, the multi-scale CNN framework served as the backbone structure alongside CNN framework like VGG16, ResNet50, DenseNet121, and EfficientNetB0. Upon merging these architectures with the FPN framework, the most superior classification results were achieved using FPN-VGG16. |
| Authors | Datasets | Models | Results | Notes |
|---|---|---|---|---|
| Kermany et al. [26] | UCSD dataset (4 classes: 51,140 normal, 8616 dry AMD, 37,205 wet AMD, and 11,349 DME) | An algorithm for transfer learning founded on the InceptionV3 model | Acc: 96.53% | This research showcased the effective capabilities of the transfer learning model, removing the necessity for an exceedingly specialized DL model and a dataset comprising millions of images. The classification process employed pre-trained InceptionV3 networks. However, their extensive number of learnable parameters and network complexity render them unsuitable for real-time applications. |
| Thomas et al. [27] | Dataset 1: (2 classes: 15 dry AMD and 15 normal) Dataset 2: (3 classes: 50 normal, 50 DME, and 48 dry AMD) Dataset 3: 2 classes: 115 normal and 269 AMD) Dataset 4: UCSD [26] | Multipath CNN with six convolutional layers and RF classifier | Acc = 96.66% for dataset 1, Acc = 98.97% for dataset 2, Acc = 99.74% for dataset 3, Acc = 99.78% for dataset 4 (Using OCT alone) | They introduced a CNN design that aims to aid AMD detection by analyzing OCT images. This CNN model consists of six convolutional layers using a multi-scale approach that enables the extraction of various local structures at various filter sizes. They achieved successful results using an RF classifier. |
| Celebi et al. [28] | Private dataset (266 normal, 156 wet AMD, 145 dry AMD, and 159 drusen), UCSD dataset | Capsule Network | Acc = 96.39% for private dataset, Acc = 98.07% for UCSD dataset (Using OCT alone) | The objective of the research is to enhance the precision of detecting early stages of AMD using a proposed Capsule Network trained on spectral domain OCT images with reduced speckle noise. This improvement is achieved through optimized augmentation techniques involving Bayesian non-local mean filters. |
| Hu et al. [29] | Private dataset 3401 OCT images (1167 drusen, 811 geographic atrophy, 711 nascent geographic atrophy, and 712 normal) | Hierarchical classification (EfficientNetV2, DenseNet169, Xception, and Normalizer-Free ResNet50) | The best F1S (92.08% Normalizer-Free ResNet50) Makro-F1s = 91.32% for four models (5-fold cross-validation) | This research introduces a hierarchical classification model. Within this model, the primary function of the base models is to extract features, which are subsequently employed to categorize images into their respective classes at varying hierarchical levels. Four CNNs—Normalizer-Free ResNet50, Xception, DenseNet169, and EfficientNetV2—were assessed as classification models for dry AMD. The most favorable outcomes were achieved using Normalizer-Free ResNet50 among these models. |
| Authors | Datasets | Models | Results | Notes |
|---|---|---|---|---|
| Deng et al. [30] | Private dataset (Total 21 participants = 7 wet AMD, 7 normal, and 7 dry AMD, a total of 420 images, 20 images from each participant) | Texture features were extracted through the utilization of Gabor filters and non-linear energy transformation techniques, subsequently utilized to train a range of machine learning models, encompassing SVM, NN, and RF. | SVM: (normal Acc: 95.3%, dry AMD Acc: 93.1%, wet AMD Acc: 94.7%) NN: (normal Acc: 80.3%, dry AMD Acc: 73.1%, wet AMD Acc: 81.0%) RF: (normal Acc: 95.4%, dry AMD Acc: 80.0%, wet AMD Acc: 90.8%) | The proposed approach employs machine learning to identify AMD and differentiate between its various stages by utilizing choroidal images acquired through OCT. Texture characteristics are derived through Gabor filter banks and non-linear energy transformation. Subsequently, feature descriptors based on histograms are applied to train RF, SVM, and NN. These models were then evaluated on a dataset of choroid OCT images, featuring 21 participants. |
| Lee et al. [31] | Private OCT images dataset (48,312 AMD and 52,690 normal) | Modified VGG16 | (Image Level) AUC = 92.78%, Acc = 87.63% (Macula Level) AUC = 93.83%, Acc = 88.98% (Patient Level) AUC = 97.45%, Acc = 93.45% | Employing a modified VGG16 model, the researchers attained significant classification accuracy. They acquired an area under the ROC curve of 92.78% for image-level analysis, 93.83% for macula-level assessment, and 97.45% for patient-level distinction, effectively discerning between normal and AMD images. |
| Yoo et al. [32] | 83 cases (3 classes: 18 dry AMD, 38 wet AMD, 27 normal) | Feature extraction: VGG19 Classifier: RF | AUC = 90.6%, Acc = 82.6% (Using OCT alone) | They suggested VGG19 as a feature extractor, pre-trained on ImageNet photos, and a multiclass RF classifier to identify AMD images. On a limited dataset that included both OCT and matched fundus pictures, the total accuracy using OCT alone was 82.60%. |
| Hwang et al. [33] | Private dataset: 200 cases (4 classes: 968 dry AMD, 968 inactive wet AMD, 968 active wet AMD, 968 normal) | Pre-trained VGG16, ResNet50, InceptionV3 | Acc = 90.73%(ResNet50) Acc = 92.67% (Inception V3) Acc = 91.40% (VGG16) | Among the three pre-trained models, InceptionV3 was found to be more successful. |
| Authors | Datasets | Models | Results | Notes |
|---|---|---|---|---|
| Xu et al. [34] | OCT images dataset (821 cases (4 classes: 367 wet AMD, 62 dry AMD, 195 normal, 197 PCV)) Fundus images dataset (1099 cases (4 classes: 496 wet AMD, 107 dry AMD, 195 normal, 301 PCV)) | ResNet50 and RF | Acc = 87.4%, Se = 88.8%, Sp = 95.6% (Using fundus and OCT) | They evaluated the effectiveness of a bi-modality deep CNN architecture in classifying AMD and PCV using OCT images and color fundus images. Each image was pre-labeled as PCV, dry or wet AMD, or normal. ResNet50 models served as the base, and alternative machine learning models such as RF classifiers were established for comparative analysis. |
| Chen et al. [35] | 37,138 OCT images from 775 cases (2 classes: with or without lesions) | Ensemble model (AlexNet, VGG16, Inception V3, ResNet50, DenseNet) | Ensemble model Acc = 98.5%, Se = 98.7%, Sp = 98.4%, F1S = 97.7% (Using OCT alone) | They applied ensemble learning to screen retinal diseases and detect lesions using OCT images. The ensemble learning achieved better results than individual models. |
| Kadry et al. [36] | Private dataset (800 OCT and 800 fundus retinal images) (2 classes: AMD and non-AMD) | The handcrafted features, like the discrete wavelet transform, pyramid histogram of oriented gradients, and local binary pattern, are taken out from the test images and combined with VGG16’s DL features. | OCT: Acc: 97.50% and fundus retinal images: Acc: 97.08% | VGG16 was used to classify retinal images into non-AMD/AMD classes by combining deep and handcrafted features. In addition, basic handcrafted features were extracted from retinal test images through the discrete wavelet transform, local binary pattern methods, and pyramid histogram of oriented gradients which were combined with deep features to improve performance. The proposed combined deep and handcrafted feature technique using different binary classifiers achieved >97% accuracy for OCT and FRI images. |
| Kadry et al. [36] | Private dataset (800 OCT and 800 fundus retinal images) (2 classes: AMD and non-AMD) | Pre-trained VGG19, ResNet50, AlexNet, VGG16 | Acc: VGG16: 86.66%, VGG19: 85.20%, AlexNet: 86.45% and ResNet50: 86.25% | They performed classification on 800 OCT and 800 fundus images from the Challenge AMD database and the OCT Image Database covering two classes: AMD and non-AMD. They used VGG19, ResNet50, AlexNet, and VGG16 for this task. The best accuracy was found with VGG16. |
| Authors | Datasets | Models | Results | Notes |
|---|---|---|---|---|
| Das et al. [37] | UCSD dataset (4 classes: 51,140 normal, 8616 dry AMD, 37,205 wet AMD, and 11,349 DME) | Multi-scale deep feature fusion framework, aimed at enhancing classification efficiency | Acc: 99.6% Se: 99.6% Sp: 99.87% | Combining features from multiple scales enables the encompassment of variations spanning these scales, supplying supplementary details to the classifier. This approach eliminates the need for manually adjusting parameters to enhance accuracy. Nevertheless, the utilization of multiple CNNs amplifies the time needed for inference and the computational intricacy. Furthermore, to counter the class imbalance within the datasets, the loss function applied class-weighted categorical cross-entropy consistently during the learning phase. |
| Das et al. [38] | Noor Eye Hospital [39] and Duke [40] dataset | B-scan attentive CNN | 94.9% Acc, 95% AUC for Noor Eye Hospital and 97.12% Acc, 97% AUC for Duke | An innovative B-scan attentive CNN is presented, mirroring the diagnostic approach of ophthalmologists. This method concentrates on clinically relevant B-scans for classification. Initially, a CNN-based feature extraction module is employed to derive spatial feature representations from the B-scans. Subsequently, a personal attention module combines these features based on their clinical significance to acquire a distinctive high-level feature vector, ensuring a dependable diagnosis. |
| Rasti et al. [39] | Noor Eye Hospital [39] dataset | A new model based on a multi-scale convolutional mixture of expert ensemble model to identify DME, dry AMD, and normal. | F1S: 99.34%, Recall: 99.36%, Precision: 99.39%, AUC: 99.8% | The methodology’s mathematical model was integrated with a fresh cost function that incorporates an extra cross-correlation penalty term. Achieving the best accuracy relies on manually adjusting the loss function. The utilization of multiple CNNs raises both computational complexity and inference time. |
| Proposed Model | Private dataset (2316 OCT images: 3 classes (653 dry AMD, 920 normal, and 743 wet AMD)) Public dataset: Noor Eye Hospital | A combination of the modified Inception modules, Depthwise Squeeze-and-Excitation Blocks, and ConvMixer | Private dataset: (F1S: 97.86% and Acc: 97.98%) Public Noor dataset: (Acc: 100% and F1s: 100%) | This study suggested a new CNN-based DL method for AMD diagnosis using the complexity of AMD and OCT images. The proposed model combines modified Inception modules, Depthwise Squeeze-and-Excitation Blocks, and ConvMixer architecture, offering computational efficiency while improving classification accuracy. |
| Layer | Input | Kernel_size/Filter | Number of Parameters |
|---|---|---|---|
| Input_Image | 224 × 224 × 3 | - | - |
| Conv1 | Input_Image | 1 × 1/64 | 256 |
| Conv2 | Input_Image | 3 × 3/64 | 1792 |
| Conv3 | Conv2 | 1 × 1/64 | 4160 |
| Conv4 | Input_Image | 5 × 5/64 | 4864 |
| Conv5 | Conv4 | 1 × 1/64 | 4160 |
| Max_pooling | Input_Image | 3 × 3/64 | 0 |
| Conv6 | Max_pooling | 1 × 1/64 | 256 |
| Total number of parameters | 15,488 | ||
| Layer | Input | Kernel_size/Filter | Number of Parameters |
|---|---|---|---|
| Input_Image | 224 × 224 × 3 | - | - |
| Conv1 | Input_Image | 1 × 1/64 | 256 |
| DConv1 | Input_Image | 3 × 3/64 | 30 |
| PConv1 | DConv1 | 1 × 1/64 | 256 |
| DConv2 | Input_Image | 5 × 5/64 | 78 |
| PConv2 | DConv2 | 1 × 1/64 | 256 |
| Max_pooling | Input_Image | 3 × 3/64 | 0 |
| Conv 6 | Max_pooling | 1 × 1/64 | 256 |
| Total number of parameters | 1132 | ||
| Model | Acc (%) | Pr (%) | Re (%) | F1s (%) | Parameters |
|---|---|---|---|---|---|
| VGG16 | 93.66 | 93.16 | 93.03 | 93.09 | 14,718,275 |
| ResNet50 | 91.07 | 90.43 | 89.89 | 90.16 | 23,602,051 |
| ResNet101 | 90.78 | 90.15 | 89.67 | 89.91 | 42,672,515 |
| InceptionV3 | 95.68 | 95.49 | 94.53 | 95.01 | 21,817,123 |
| DenseNet121 | 95.68 | 95.18 | 95.43 | 95.30 | 7,044,675 |
| DenseNet201 | 95.97 | 95.74 | 95.51 | 95.62 | 18,335,427 |
| EfficientNetB0 | 77.23 | 76.16 | 75.03 | 75.59 | 4,058,534 |
| EfficientNetB7 | 84.15 | 82.27 | 81.48 | 81.87 | 64,115,610 |
| MobileNet | 79.25 | 78.10 | 77.63 | 77.86 | 3,236,035 |
| ConvNeXtTiny | 59.37 | 65.16 | 56.35 | 60.44 | 27,825,507 |
| PM | 97.98 * | 97.95 * | 97.77 * | 97.86 * | 1,650,020 * |
| Model | Acc (%) | Pr (%) | Re (%) | F1s (%) | Parameters |
|---|---|---|---|---|---|
| VGG16 | 97.69 | 97.70 | 97.81 | 97.75 | 14,718,275 |
| ResNet50 | 98.92 | 99.06 | 98.82 | 98.94 | 23,602,051 |
| ResNet101 | 98.92 | 98.98 | 98.97 | 98.97 | 42,672,515 |
| InceptionV3 | 99.23 | 99.26 | 99.31 | 99.28 | 21,817,123 |
| DenseNet121 | 99.85 | 99.86 | 99.86 | 99.86 | 7,044,675 |
| DenseNet201 | 99.69 | 99.72 | 99.65 | 99.68 | 18,335,427 |
| EfficientNetB0 | 91.52 | 91.17 | 91.48 | 91.32 | 4,058,534 |
| EfficientNetB7 | 90.29 | 90.61 | 89.56 | 90.08 | 64,115,610 |
| MobileNet | 91.22 | 90.73 | 91.13 | 90.93 | 3,236,035 |
| ConvNeXtTiny | 62.86 | 68.65 | 59.84 | 63.94 | 27,825,507 |
| PM | 100 * | 100 * | 100 * | 100 * | 1,650,020 * |
| Study | Model | Acc (%) | Pr (%) | Re (%) | F1s (%) | Parameters |
|---|---|---|---|---|---|---|
| Paima et al. [25] | FPN and VGG16 | 92.00 | - | 91.80 | - | - |
| FPN and ResNet50 | 90.10 | - | 89.80 | - | ||
| FPN and DenseNet121 | 90.90 | - | 90.50 | - | - | |
| FPN and EfficientNetB0 | 87.80 | - | 86.60 | - | - | |
| Thomas et al. [27] | Multipath CNN with six convolutional layers and RF classifier | 98.97 | 99.00 | 99.00 | 99.00 | 6,024,512 |
| Thomas et al. [27] | Multipath CNN with six convolutional layers and SVM classifier | 94.89 | 94.90 | 94.90 | 94.90 | 6,024,512 |
| Thomas et al. [27] | Multipath CNN with six convolutional layers and multilayer perceptron classifier | 96.93 | 97.00 | 96.90 | 96.90 | 6,024,512 |
| Das et al. [38] | B-scan attentive CNN | 94.9 | - | 93.26 | - | - |
| Rasti et al. [39] | Multi-scale convolutional mixture of expert ensemble model | - | 99.39 | 99.36 | 99.34 | - |
| Sabi et al. [53] | Double-Scale CNN | 94.89 | - | - | - | - |
| Sahoo et al. [57] | Adaptive window-based feature extraction and weighted ensemble-based classification approach | 96.94 | 95.83 | 97.87 | 96.84 | - |
| Xu et al. [55] | Multi-branch hybrid attention network | 99.76 | 99.70 | 99.79 | 99.74 | - |
| Mishra et al. [54] | MacularNet | 99.79 | 99.80 | 99.79 | 99.79 | Approximately 19 million |
| Fang et al. [56] | Lesion-aware CNN | - | 99.39 | 99.33 | 99.36 | - |
| PM | Combination of the modified Inception modules, Depthwise Squeeze-and-Excitation Blocks, and ConvMixer architecture | 100 * | 100 * | 100 * | 100 * | 1,650,020 * |
| Model | MIM | DSEB | CM | Private Dataset | Public (Noor) Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Pr (%) | Re (%) | F1s (%) | Acc (%) | Pr (%) | Re (%) | F1s (%) | ||||
| Model 1 | X | - | - | 61.67 | 58.34 | 57.80 | 58.07 | 82.13 | 82.08 | 82.84 | 82.46 |
| Model 2 | - | X | - | 63.69 | 61.24 | 59.35 | 60.28 | 82.28 | 81.61 | 82.19 | 81.90 |
| Model 3 | - | - | X | 95.10 | 95.16 | 94.68 | 94.92 | 99.54 | 99.55 | 99.50 | 99.52 |
| Model 4 | - | X | X | 95.68 | 95.55 | 95.36 | 95.45 | 99.69 | 99.71 | 99.59 | 99.65 |
| Model 5 | X | - | X | 96.54 | 95.95 | 96.51 | 96.23 | 99.85 | 99.86 | 99.79 | 99.82 |
| Model 6 | X | X | - | 66.28 | 61.37 | 61.62 | 61.49 | 92.91 | 92.82 | 92.90 | 92.86 |
| Model 7 | X | X | X | 97.98 * | 97.95 * | 97.77 * | 97.86 * | 100 * | 100 * | 100 * | 100 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yusufoğlu, E.; Fırat, H.; Üzen, H.; Özçelik, S.T.A.; Çiçek, İ.B.; Şengür, A.; Atila, O.; Guldemir, N.H. A Comprehensive CNN Model for Age-Related Macular Degeneration Classification Using OCT: Integrating Inception Modules, SE Blocks, and ConvMixer. Diagnostics 2024, 14, 2836. https://doi.org/10.3390/diagnostics14242836
Yusufoğlu E, Fırat H, Üzen H, Özçelik STA, Çiçek İB, Şengür A, Atila O, Guldemir NH. A Comprehensive CNN Model for Age-Related Macular Degeneration Classification Using OCT: Integrating Inception Modules, SE Blocks, and ConvMixer. Diagnostics. 2024; 14(24):2836. https://doi.org/10.3390/diagnostics14242836
Chicago/Turabian StyleYusufoğlu, Elif, Hüseyin Fırat, Hüseyin Üzen, Salih Taha Alperen Özçelik, İpek Balıkçı Çiçek, Abdulkadir Şengür, Orhan Atila, and Numan Halit Guldemir. 2024. "A Comprehensive CNN Model for Age-Related Macular Degeneration Classification Using OCT: Integrating Inception Modules, SE Blocks, and ConvMixer" Diagnostics 14, no. 24: 2836. https://doi.org/10.3390/diagnostics14242836
APA StyleYusufoğlu, E., Fırat, H., Üzen, H., Özçelik, S. T. A., Çiçek, İ. B., Şengür, A., Atila, O., & Guldemir, N. H. (2024). A Comprehensive CNN Model for Age-Related Macular Degeneration Classification Using OCT: Integrating Inception Modules, SE Blocks, and ConvMixer. Diagnostics, 14(24), 2836. https://doi.org/10.3390/diagnostics14242836