Abstract
Rotating machinery plays a critical role in industrial systems, and effective anomaly detection and assessment are indispensable for ensuring operational safety and reliability. However, the performance of existing methods is often constrained by the difficulty in acquiring fault samples—such samples are typically scarce during the initial operational phase of equipment. To address this challenge, this paper proposes a novel anomaly detection and evaluation framework based on Data-Accumulation-Aware Generative Adversarial Networks (DAA-GANs) and similarity estimation. The core innovation of this framework lies in its adaptability across different data accumulation stages. During the early operational phase dominated by normal samples, only normal data is used to train the DAA-GAN to establish a baseline detector. As fault data gradually accumulates, the detection threshold undergoes adaptive adjustment through collaborative optimization of normal and abnormal samples, thereby enhancing the detector’s generalization capability. Upon amassing annotated fault samples of varying severity, the framework assesses anomaly severity by analyzing the similarity between test outputs of unknown samples and known fault samples. The framework is validated through two case studies: a fault simulation model for a torque-splitting transmission system and the publicly available Case Western Reserve University (CWRU) bearing dataset. In the simulation case, the detection accuracy reaches 100% for the gear tooth breakage levels. On the CWRU dataset, the proposed method achieves an overall average detection accuracy of 99.83% across three operating speeds (1730/1750/1772 rpm), and the similarity-based assessment provides consistent severity identification. These results demonstrate that the proposed framework can support reliable anomaly detection and severity assessments under progressive data accumulation.
1. Introduction
In modern large-scale industrial installations such as machinery and power plants, rotating machinery constitutes an indispensable universal component within mechanical equipment. The success of industrial enterprises likewise hinges upon the secure operation of their equipment systems. Within mechanical engineering, should mechanical equipment suffer a malfunction, minor faults will diminish the equipment’s operational functionality, directly impacting production; severe faults, however, may precipitate catastrophic incidents. Equipment health monitoring and fault diagnosis constitute vital components of preventive maintenance systems, playing a significant role in extending the operational lifespan of machinery, reducing maintenance costs, and enhancing operational safety.
The operational status of rotating machinery directly influences critical performance parameters of large-scale equipment, including machining precision, operational reliability, and service life. Research into health monitoring, fault diagnosis, and predictive methodologies for rotating machinery forms the foundation for ensuring the safe and stable operation of mechanical equipment [1,2]. In recent years, deep learning has achieved remarkable success in numerous data prediction and classification tasks. Leveraging extensive historical data stored within systems and operating without requiring precise physical models, data-driven fault diagnosis methods have gained widespread application in intelligent factories and the health monitoring and fault diagnosis of mechanical equipment [3].
Deep learning has become an effective paradigm for feature extraction, alleviating the limitations of shallow learning in capturing highly nonlinear patterns from large-scale data. Nevertheless, the robust performance of deep learning-based fault diagnosis still hinges on the availability of sufficient, high-quality training data. In rotating machinery, fault events (e.g., catastrophic failures or abrupt malfunctions) are typically scarce, whereas normal-condition data are abundant [4], making class imbalance a pervasive challenge. To mitigate this issue, Viola et al [5] employed time–frequency transformations to obtain two-dimensional representations of vibration signals and used deep convolutional GANs to generate both normal and faulty samples. Zhou et al [6] proposed a globally optimized generative adversarial network to learn fault-feature generation under imbalanced conditions. Xie and Zhang [7] introduced a deep convolutional generative adversarial network (DCGAN) to address sample imbalance; after balancing the dataset via DCGAN-based sample generation, statistical features from time-domain and frequency-domain signals were extracted to train an SVM classifier for bearing fault classification, showing improved performance over conventional resampling strategies (e.g., random oversampling/undersampling and synthetic undersampling) under highly imbalanced settings. Beyond sample-count imbalance, real industrial datasets often present additional constraints such as heterogeneous sampling rates and limited fault coverage. For example, Huang et al. [8] developed a deep learning model tailored to multirate industrial measurements and reported that reliable diagnosis can still be achieved under severe imbalance in practice. Zareapoor et al. [9] further proposed an oversampling adversarial network that explicitly generates minority-class samples to enhance diagnosis performance for class-imbalanced conditions. In another industrial application, Yan et al. [10] combined a VAE with adversarial generation to synthesize informative fault patterns for chiller fault diagnosis when fault data are limited. However, most data-augmentation-oriented solutions still assume the presence of at least a small number of fault samples for model calibration and validation. In practical deployments—especially during early-life or newly commissioned stages—fault data may be entirely unavailable, which motivates lifecycle-aware methods that can perform stable and accurate detection under extreme imbalance (including normal-only training) and progressively adapt as fault data accumulate.
Recent studies have emphasized robustness under variable working conditions and model interpretability. For instance, Spirto et al. [11] proposed a VKF-MOT-SDP-CNN pipeline to enhance gear fault detection under variable operating conditions, and Chen et al. [12] developed an interpretable wavelet Kolmogorov–Arnold Convolutional LSTM for spatio-temporal feature extraction and intelligent fault diagnosis. These advances further motivate the development of lifecycle-aware and explainable anomaly detection frameworks for rotating machinery.
Anomaly detection (AD), also known as outlier detection (OD) or novelty detection (ND), refers to the identification of data points that deviate significantly from the majority of the dataset [13]. Consequently, anomaly detection can address more extreme instances of data imbalance.
Currently, mechanical equipment anomaly detection methods are primarily categorized into three types: boundary-based approaches, probability density estimation-based approaches, and deep learning-based approaches [14]. Boundary-based anomaly detection methods establish boundaries for training datasets to determine the classification of unknown objects, thereby enabling anomaly detection. The core principle of probability density estimation-based anomaly detection is that outliers can be identified in low-density regions, whereas normal values reside in high-density regions.
Maliuk, A.S. et al. [15] proposed a bearing fault detection method based on Gaussian Mixture Models (GMM). This approach utilizes GMM window sequences oriented towards fault frequencies for signal feature extraction, employing a weighted K-nearest neighbor algorithm for fault classification. The aforementioned approaches separate feature extraction from model construction. Numerous classical methods exist for feature extraction, including time-frequency feature extraction [16], wavelet decomposition [17], and empirical mode decomposition [18]. With advances in modern industrial technology, the widespread application of various sensors has led to a substantial increase in data volumes for detection objects. Traditional methods struggle to identify outliers within large datasets [19], whereas deep learning has demonstrated excellent performance in handling big data [20]. Zhang et al. [21] employed a deep generative model based on Variational Autoencoders (VAE) for bearing anomaly detection, effectively leveraging sparse labeled information within datasets with favorable outcomes. Lee et al. [22] utilized stacked Convolutional Neural Networks (CNNs) to extract features from vibration sensor signal patterns, then trained a stacked bidirectional Long Short-Term Memory (LSTM) network on these features, ultimately achieving anomaly prediction through a regression layer. Ahmad et al. [23] proposed an autoencoder-based method for rotating machinery condition monitoring, directly extracting features from raw vibration signals without manual feature design. Experimental results demonstrated superior performance compared to manually engineered features.
Generative adversarial network (GAN) models have garnered increasing attention from researchers in recent years. First proposed by Goodfellow et al. [24], they were initially applied to image generation. Given a deterministic dataset, GAN models learn to generate new data that share the same statistical distribution as the original dataset. To address anomaly detection requirements for fault-free data, Schlegl et al. [25] introduced the first GAN framework for anomaly detection, AnoGAN. Donahue et al. [26] introduced the BiGAN architecture to anomaly detection, aiming to overcome limitations of AnoGAN. GANomaly [27] enhanced the loss function to improve model stability. Ou et al. [12] leveraged the memory properties of LSTM networks and GAN models to achieve robust results in bearing signal anomaly detection across varying signal-to-noise ratios. Jiang et al. [28] trained a triple encoder–decoder-encoder network generator to learn features meticulously extracted from normal samples. Hu et al. [29] proposed a Wasserstein Generative Digital Twin (WGDT) model capable of stably and efficiently simulating the distribution of healthy physical samples, ensuring high fidelity between virtually generated and physical samples.
Although GANs have achieved preliminary breakthroughs in anomaly detection, model training is prone to collapse, and detection accuracy remains insufficient for identifying anomalies across different device stages. Consequently, it is imperative to design distinct detection and evaluation methodologies tailored to various operational phases of equipment. Such frameworks should enable health monitoring during early stages without reliance on fault data, leverage mature monitoring models during intermediate and late stages, and facilitate assessment of anomaly severity.
Inspired by the aforementioned research, this paper constructs an anomaly detection and evaluation framework based on Data Accumulation-Aware Generative Adversarial Networks (DAA-GAN). This framework adapts to the varying stages of anomaly data accumulation in equipment, employing distinct detection and evaluation methodologies for each phase. In the first stage, the equipment operates normally with no fault data available. Models are trained solely on normal data to learn its distribution, aligning closely with practical applications. During the second stage, when minor faults emerge and limited anomaly data becomes available, error reduction is achieved by adjusting decision thresholds and evaluation outcomes. In the third stage, with substantial fault data accumulation, the probability distributions of anomaly scores across different fault categories and severity levels are statistically analyzed. Pearson correlation coefficients are calculated to identify and classify faults, while similarity features are employed to assess anomaly severity. Experimental results demonstrate the stability and efficacy of the DAA-GAN approach.
This approach enables phased detection of anomalies in machine operation under conditions of extreme sample data imbalance. Different detection and evaluation methods can be applied according to the stage of accumulated equipment anomaly data. It facilitates health monitoring during the initial phase without any fault data, while leveraging mature detection models to assess anomaly severity in the middle and later stages. Fault diagnosis: Following equipment failure or abnormality detection, the proposed framework can rapidly identify the fault category and assess its severity based on anomaly-score distributions, thereby providing quantitative decision support for maintenance personnel to restore operation. It is worth nothing that determining underlying root causes (e.g., crack initiation mechanisms or specific defect formation causes) typically requires additional physics-based investigation and operational context, which is beyond the scope of this paper and is left for future integration.
Key highlights of this work are as follows:
(1) DAA-GAN enables phased equipment detection, employing distinct detection and evaluation methods according to the accumulation stage of anomaly data. It facilitates health monitoring during the initial phase without fault data, while utilizing mature detection models to assess anomaly severity in the middle and later stages.
(2) The proposed method demonstrates high detection rates for mechanical equipment conditions and effectively distinguishes between fault severity levels. Experimental results confirm our approach maintains stable high performance, ensuring excellent anomaly detection accuracy even under imbalanced data conditions.
(3) The framework was validated using a split-torque transmission system dataset and open datasets, enabling a stepwise approach to anomaly detection, threshold optimization, and optimal assessment.
2. Anomaly Detection and Assessment Framework
This section details the proposed anomaly detection and evaluation framework alongside its Data-Accumulation-Aware Generative Adversarial Network (DAA-GAN) model. Unlike traditional GAN-based approaches such as AnoGAN and GANomaly, which focus solely on single-stage unsupervised anomaly detection, our approach integrates DAA-GAN with the phased evolution of data during device operation. It learns the normal distribution using only healthy samples, performs threshold adaptation optimization upon the emergence of a small number of fault samples, and introduces similarity assessments to determine fault severity as fault samples gradually accumulate. This design better accommodates the characteristics of evolving device states and progressively accumulating data in real-world engineering scenarios.
2.1. Theoretical Background
Generative adversarial networks (GANs) and their variants have been widely adopted for representation learning and anomaly detection. In this work, we build upon the GAN-based anomaly detection paradigm and employ a DAA-GAN model to learn normal-condition representations and produce anomaly scores for input samples. These anomaly scores are subsequently utilized in a staged framework: Stage I performs unsupervised detection using only normal data; Stage II updates the decision threshold when limited labeled faults become available; and Stage III conducts severity assessment by comparing anomaly-score distributions via similarity measures.
For conciseness and readability, the standard GAN objective and the commonly used GANomaly-style background formulation are summarized in Appendix A, while the main text focuses on the proposed staged design and implementation details that are specific to this study.
2.2. A Comprehensive Framework for Anomaly Detection and Estimation
In practice, fault data of rotating machinery are progressively accumulated during the equipment lifecycle: the system starts with only normal data, then a small number of fault samples appear, and finally multiple fault categories and severities are observed. To explicitly reflect this process, this paper proposes a three-stage, da-ta-accumulation-aware framework built upon DAA-GAN. The framework contains three key modules: (i) a DAA-GAN-based anomaly detector trained with only normal samples, (ii) an adaptive threshold update strategy using limited fault samples, and (iii) a multi-index similarity fusion strategy for anomaly severity assessment based on anomaly-score probability density distributions.
Stage I (no-fault stage): only normal data are available. DAA-GAN is trained using normal samples to learn the normal latent patterns and data distribution, providing an unsupervised anomaly detector.
Stage II (few-fault stage): a small amount of fault data becomes available. The decision threshold is updated on a validation set by selecting the threshold that minimizes the total error (FAR+MAR), which improves the robustness of detection under early-fault and imbalanced conditions.
Stage III (many-fault stage): sufficient fault samples with labeled severities are accumulated. The anomaly-score distributions of the test samples are compared with reference fault distributions using multiple similarity measures (KL/JS divergences and correlation coefficients). After directional alignment and normalization, these similarity scores are fused to identify the most similar fault type/severity.
Notably, the proposed DAA-GAN structure focuses on robust unsupervised representation learning for anomaly detection, while the stage-dependent threshold adaptation and similarity fusion strategies enable the framework to operate effectively when fault data evolve from ‘none’ to ‘few’ and to ‘many’. The specific framework diagram is shown in Figure 1 below.

Figure 1.
The overall framework.
2.3. Anomaly Detection Based on DAA-GAN
This section proposes a deep learning model based on Data Accumulation-Aware Generative Adversarial Networks (DAA-GAN) for rolling bearing anomaly detection under varying operating conditions and imbalanced datasets. For the generator, two encoders learn representations of the latent features and the regenerated features, respectively, from the raw data. The decoder attempts to simultaneously reconstruct. The entire process is as follows:
DAA-GAN adopts the GANomaly-style encoder–decoder–encoder backbone as the core unsupervised anomaly detector and is integrated into the proposed data-accumulation-aware framework. In this study, the network provides a unified anomaly-score generation mechanism across lifecycle stages, while the stage-dependent strategies (adaptive threshold update and similarity-based assessment) constitute the main extensions that enable practical deployment under progressively accumulated fault data.
(1) is composed of the convolutional layer, the BatchNorm layer, and the leaky ReLU activation layer.
reduces the dimension of F to the hidden feature Z, where h is the dimension of the hidden vector Z. b is the number of training samples.
(2) is composed of the convolutional transposition layer, the leaky ReLU activation layer, and the BatchNorm layer. re-decodes Z into .
(3) The last encoder has the same structure but with different parameters, and the output has the same dimension as Z.
The generator learns both the properties of the original feature set F and the patterns of the latent vector Z simultaneously. Meanwhile, discriminator D employs the standard discriminator network introduced in DCGAN to distinguish between real and generated input data. Once the overall network architecture is defined, the next step is to define the loss function used for training.
During the training phase, only the normal dataset is considered, the model acquires normal patterns exclusively. However, in the testing phase, one must discern faulty samples by generating higher anomaly scores. This implies that and will decode Z and encode . Consequently, and will inevitably diverge from the original F and Z, aiding in fault identification. Given that this generator utilizes a triple-subnet structure involving encoding, decoding, and encoding, its final loss function comprises three components: fraud loss, apparent loss, and latent loss.
Fraud Loss: Fraud loss is designed to compel the discriminator to misclassify the generated samples from the generator as real samples. The fraud loss is calculated using the output of the discriminator, with the formula as follows:
where is the binary cross-entropy loss function and is the probability that a sample is predicted to be true. To trick the discriminator and prompt the generator to produce fake samples that are as true as possible, define .
Apparent loss: It is not enough for the generator to learn the latent patterns under normal conditions and reconstruct the generated samples as realistically as possible, so the characterization loss is defined by measuring the Manhattan distance between the real and generated samples with the following formula:
Latent loss: It represents the distance between the potential feature representation of the real sample and the potential feature of the generated sample. This loss can help learn the potential representations in both real and fake examples with the following formula:
In summary, the loss function of the generator is
where , and are used to adjust the weights of , and in the generator loss function. For the discriminator, the feature matching loss proposed by Salimans et al. [30]. Adversarial learning is performed to reduce the instability of GAN training.
During training, the Kinga et al. [31] optimizer is used to update Equations (7) and (8) using backward propagation.
2.4. Adaptive Threshold Update for DAA-GAN
In the testing phase, differences in latent features are used to score anomalies for a given sample. The anomaly score is defined as
Since this anomaly detector is trained solely on normal data, it captures only normal latent patterns and data distributions. The anomaly score will be close to 0 for normal samples and will be significantly higher for faulty samples, making it easy to detect anomalies by comparing the values . The distribution is then assessed based on the model’s output after processing the faulty samples.
This paper is given a time series dataset , where represents the number of samples recorded by sensors at time t. The model is trained using a subset of the dataset , where b is the number of training samples. The corresponding validation set is , where v and u represent the number of normal and abnormal samples, n is the number of total samples, . For an imbalanced dataset, the size of normal samples should be much larger than that of abnormal samples, , During the training phase, a GAN-based model is trained using . The objective of the training process is to minimize the output of each . After training, is fed into the trained model . The trained generator encodes and decodes the faulty and normal samples accordingly. Since the trained network only learns the distribution pattern of normal data, inputting an abnormal sample would result in a significant deviation from the output of a normal input . This deviation ultimately determines the presence of an abnormal sample. The DAA-GAN framework is shown in Figure 2.
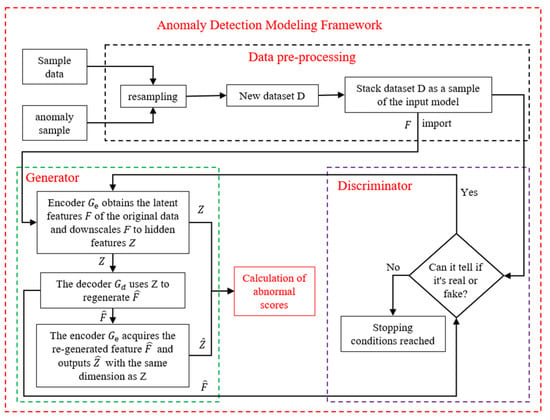
Figure 2.
The framework of DAA-GAN.
To assess the effectiveness of the proposed method, this paper employs common evaluation metrics for anomaly detection, as depicted in Figure 3, along with an introduction to anomaly detection. Specifically, this paper considers the following key metrics:
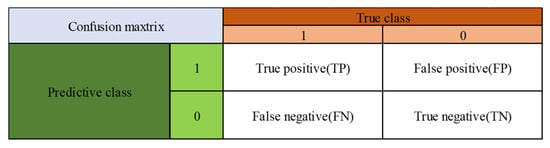
Figure 3.
Confusion matrix.
TP is the number of positive samples correctly predicted as positive. FN is the number of positive samples incorrectly predicted as negative. FP is the number of negative samples incorrectly predicted as positive. TN is the number of negative samples correctly predicted as negative. These metrics collectively form the confusion matrix, illustrated in Figure 3. The evaluation indices include Accuracy, Precision, Recall, F1-score (F1), False Alarm Rate (FAR), Missing Alarm Rate (MAR), etc. Their calculations are depicted in Equations (10) and (11).
2.5. Similarity Estimation for Anomaly Assessment
From the anomaly detection stage in the previous step, the anomaly scores of different samples can be obtained, first by calculating the probability distribution of the anomaly scores of different samples, and then by obtaining the probability density distribution graph of the anomaly scores and adopting different similarity analyses to analyses the probability density distributions for similarity analysis, so as to complete the anomaly estimation of the faults, and the specific anomaly estimation framework is shown in the following Figure 4.
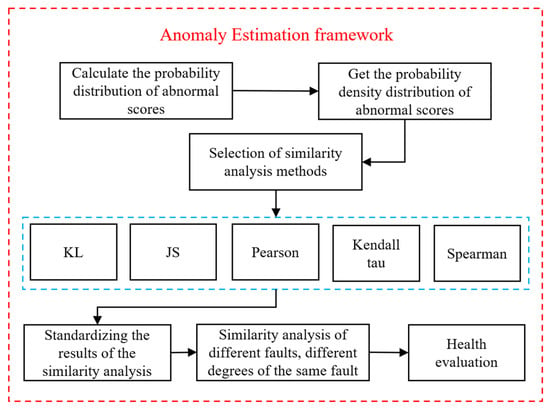
Figure 4.
Anomaly estimation framework.
In data science, a similarity metric is a measure of how data samples are related or close to each other. On the other hand, a similarity measure is a way of telling how many of the data objects are different. Also, when similar data samples are grouped into a cluster, these terms are often used for clustering. All other data samples are grouped into different samples. It is also used for classification (e.g., KNN) where data objects are labeled based on the similarity of features. Another example is when discussing outliers that differ from other data samples, such as anomaly detection.
The similarity metric is usually expressed as a numerical value: it is higher when the data samples are more similar. Generally, 0 or 1 is used to indicate the highest degree of similarity; for example, in the KL and JS methods, as the values converge to 0, they become more similar, whereas in Pearson et al.’s methods, as the values converge to 1, they become more similar. Several major methods of similarity analysis are described below.
(1) Kullback–Leibler Divergence
Kullback–Leibler divergence is also known as the KL distance or relative entropy. KL scatter is a way of describing the difference between two probability distributions, P and Q. It is a measure of the degree to which a given distribution deviates from the true distribution, so it can be used to measure the extent to which a given arbitrary distribution deviates from the true distribution. If the two distributions match exactly, then KL (p||q) = 0; otherwise it should take a value between 0 and ∞ (inf). The smaller the KL scatter, the better the match between the true and myopic distributions.
(2) Jensen–Shannon Distance
The Jensen–Shannon distance calculates the distance between two probability distributions, p and q. It uses the Kullback–Leibler dispersion (relative entropy) formula to calculate the distance. The value domain of JS dispersion ranges from [0, 1] to 0 for the same and 1 for the opposite.
(3) Pearson Correlation Coefficient
Pearson’s linear correlation coefficient is the most used linear correlation coefficient. The most applicable form of data is linear data, which is continuous and conforms to the normal distribution, and the difference between data cannot be too large. There are m objects and n columns of indicators, which can form the data matrix ; now we study the correlation between column a, , and column b, . Let the correlation coefficients of columns a and b be .
(4) Kendall Correlation Coefficient
The Kendall tau correlation coefficient is also a rank correlation coefficient, although it is calculated for categorical variables and applies to both variables. Based on the analysis of the data matrix mentioned in the Pearson correlation coefficient, the Kendall tau coefficient is based on the counts of (i, j) homoscedastic pairs (where i < j), homoscedastic means that and have the same sign. The Kendall tau equations include an adjustment term for the knot value in the normalized constant, often called tau-b. For column a, , and column b, , of the matrix, the Kendall tau coefficients are defined as
The value of the correlation coefficient ranges from −1 to +1. A value of −1 means that one column order is the inverse of the other, and a value of +1 means that the two column orders are the same. A value of 0 indicates that there is no relationship between the columns.
(5) Spearman’s Rank Correlation Coefficient
Spearman’s rank correlation coefficient is applied to two columns of variables with a hierarchical variable nature of data with a linear relationship, which can well deal with the same values and outliers in the sequence. Based on the data matrix mentioned in the Pearson correlation coefficient for analysis, the Spearman equivalent is applied to the Pearson linear correlation coefficient for the order of columns and . For the correlation between column a, , and column b, , in the matrix, let the correlation coefficient for columns a, and b be .
where d is the difference between the ranks of the two columns and m is the length of each column.
The raw outputs of different similarity measures have different ranges and, more importantly, different directions. For KL/JS divergences, smaller values indicate higher similarity, whereas for correlation coefficients (Pearson/Kendall/Spearman), larger values indicate higher similarity. To ensure the physical meaning of the fused score is consistent, a two-step processing is adopted before fusion: (i) directional alignment, which converts all measures into similarity scores where a larger value always means ‘more similar’; and (ii) normalization, which scales the aligned similarity scores to a comparable range (0–1) prior to fusion.
(6) Directional alignment
Directional alignment is performed as follows. For divergence-type measures (KL/JS), let be the divergence between a test distribution and the -th reference distribution. We first apply Min-Max scaling across the candidate reference set and then invert it to obtain a similarity score:
(7) is the set of divergences over all candidate references, and is a small constant to avoid division by zero. Correlation-type measures (Pearson/Kendall/Spearman). For correlation coefficients , we map them into [0, 1] by
After this alignment, all similarity scores are further normalized using Equation (21) when necessary.
(8) Normalization
Where is an aligned similarity score (after directional alignment), is the normalized score in , and are the maximum and minimum values in the candidate reference set, and is a small constant to avoid division by zero:
(9) Fusion of multi-index similarity scores
After directional alignment and normalization, the similarity scores from the five methods are fused to obtain an overall similarity for fault assessment. In this study, a weighted average is adopted (equal weights by default). After the standardization of the analysis results, the five similarity indicators need to be fused, and the fused indicators are compared to come to the fault assessment. The specific fusion formula is:
where is the fused similarity score, is the number of similarity measures, is the weight of the -th measure, and is the aligned-and-normalized similarity score of the -th measure for the -th reference. Where is the fused similarity metric, is the number of similarity analysis methods, is the known (reference) data, is the test data, and is the analysis result of a single similarity analysis method. The pseudocode for Algorithm 1 is shown below.
| Algorithm 1. Multi-index similarity fusion for Stage III |
| Input: anomaly-score sequence of a test sample and reference anomaly-score sequences for each fault class/severity k. |
| Output: as the identified fault type/severity. |
| Step 1: Estimate the probability density distributions and (e.g., by kernel density estimation or histogram normalization). |
| Step 2: Compute raw metrics for each |
| Step 3 (Directional alignment): Convert divergences to similarities using and convert correlations using |
| Step 4 (Optional normalization): Apply Equation (21) to normalize each aligned similarity vector across k. |
| Step 5 (Fusion): Fuse the aligned-and-normalized similarities by |
| Step 6 (Decision): Output . as the identified fault type/severity. |
Numerical example (illustrative). Suppose three references yield . Then and the aligned similarities are . If Pearson , then . After normalization and equal-weight fusion, the reference with the largest is selected as the closest fault severity.
3. Validation
3.1. A Simulation Case of the Split-Torque Transmission System
The split-torque transmission system represents a typical multi-path gear transmission configuration that is widely employed in helicopter gearboxes, naval propulsion systems, and other high-power-density rotating machinery drive chains. Compared to conventional single-path transmissions, split-torque transmissions distribute and combine input power through multiple parallel paths, offering advantages such as high power density, high transmission efficiency, and excellent redundancy. However, the presence of multiple meshing pairs and multi-path couplings also complicates fault mechanisms and vibration responses, posing challenges for fault detection and severity assessment. To systematically evaluate the performance of the proposed phased anomaly detection and assessment framework under controlled conditions, this paper first constructs a simulation case using a torque-splitting gear transmission system, whose structural schematic is shown in Figure 5. Subsequently, Section 3.1.1 presents the fault simulation model for this system.
Figure 5.
A split-torque transmission system.
3.1.1. Split-Torque Transmission System and Its Simulation Model
A split-torque transmission system is illustrated in Figure 5. The system adopts a two-stage transmission architecture. In the input stage, an input pinion simultaneously meshes with two identical large spur gears, thereby splitting the input power into two parallel paths. In the output stage, two identical pinions on the duplex shafts simultaneously mesh with the output large spur gear, recombining the transmitted torque at the output. In this configuration, the two duplex gear shafts constitute the two power branches of the split-torque system.
When the potential energy method is used to compute gear meshing stiffness, the gear tooth is commonly idealized as a two-dimensional cantilever beam with a variable cross-section, as shown in Figure 6.
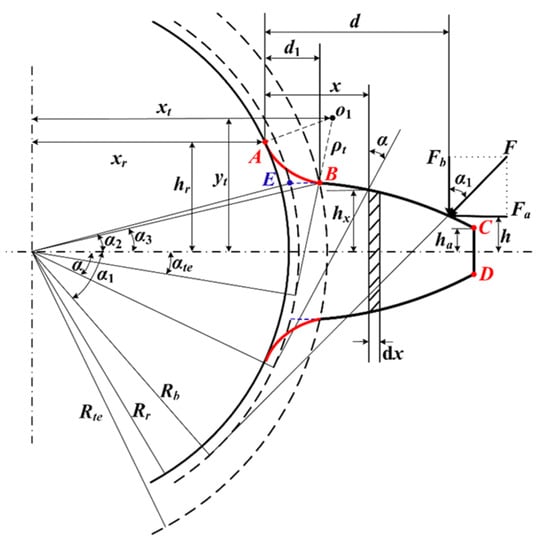
Figure 6.
Variable cross-section cantilever-beam model of an involute spur-gear tooth (used to derive tooth stiffness and the time-varying meshing stiffness in the dynamic simulation).
Figure 6 presents the beam-based formulation for evaluating tooth bending stiffness, which is subsequently incorporated into the time-varying meshing stiffness of the gear-pair model. Variations in meshing stiffness provide the primary mechanism by which tooth-root crack growth or tooth breakage alters the simulated vibration response. The resulting time-domain response signals serve as inputs to the proposed staged framework: DAA-GAN generates anomaly-score sequences for Stage I–II detection, and the anomaly-score probability density distributions form the basis for similarity-based severity assessment in Stage III.
The gear-tooth profile is composed of three segments: AB represents the root filet (transition arc), BC denotes the involute flank, and CD corresponds to the addendum-circle arc. Point E is the intersection between the involute and the base circle. Point is the center of the transition arc with coordinates (xt, yt); Point A marks the start of the transition arc on the root circle with coordinates (xr, hr); and point B is the end of the transition arc. The parameter denotes the equivalent cantilever length, defined as the distance from the meshing point to the tooth root. The load is the force acting normal to the meshing surface, and is the angle between and the vertical direction (i.e., the tooth-thickness direction). The quantities , , and denote the distances from the tooth profile to the neutral axis at the meshing point, at position , and at the addendum circle, respectively. Moreover, , , and denote the radii of the root circle, base circle, and the transition-arc endpoint circle at point B, respectively.
As tooth-root cracks propagate to a critical extent, local tooth fracture may occur, which is referred to as a broken-tooth fault. When the fracture develops along the face-width direction, the stiffness components of an intact tooth—namely the bending stiffness, shear stiffness, axial compressive stiffness, Hertzian contact stiffness, and gear-body stiffness—indicate that each sub-stiffness term is linearly proportional to the tooth face width . Accordingly, the meshing stiffness of a fractured tooth can be obtained by replacing the intact face width with the remaining effective face width in the corresponding stiffness expressions. The meshing stiffness of the fractured tooth is therefore calculated as follows:
where is the elastic contact deformation of the contact surface during gear meshing, the corresponding Hertzian contact stiffness; is the bending stiffness of the gear tooth in the broken tooth state; is the axial compression stiffness of the gear tooth; is the shear stiffness of the gear tooth in the broken tooth state; is the stiffness of the gear wheel body; is the bending stiffness of the gear tooth; is the axial compression stiffness of the gear tooth; is the shear stiffness of the gear tooth; is the stiffness of the gear wheel body.
Specific parameters for these gears are provided in Table 1. Gear 1 is the input, with an input speed of 7050 revolutions per minute. The drive train is rated at 500 kW. kbx and kby denote the stiffness coefficients of the bearing in the X-axis and Y-axis directions, respectively. The parameters of the Split-torque transmission are shown in Table 1.

Table 1.
Split-torque transmission system parameters.
Mark the split-torque transmission system orientation as shown in Figure 7 to divide the drive train into front and rear (FWD, AFT) branches. Mark the input small spur gear, the input large spur gear (FWD, AFT), the output small spur gear (FWD, AFT), and the output large spur gear in the system as gears 1 to 6 in that order.
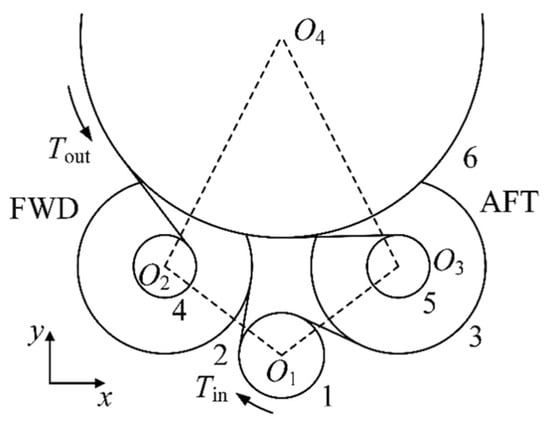
Figure 7.
Schematic diagram of a split-torque transmission system.
A generalized coordinate system of the transmission system is established with the rotary center O2 of gear 2 pointing to the rotary center O3 of gear 3 as the x-axis positive direction, and the rotary center O1 of gear 1 pointing to the rotary center O4 of gear 6 as the y-axis positive direction. Each gear contains x, y, and θ degrees of freedom. For any two of these gear pairs (gear i and gear j) that mesh with each other, an expression for their gear mesh force can be written as follows:
where is the time-varying meshing stiffness of the gears; is the counterclockwise angle from the y-axis positive to the positive direction of the meshing line (gear i pointing to gear j). is the dynamic transfer error, which is expressed as:
According to Newton’s second theorem, the dynamic equation of the meshing pair consisting of gear i and gear j can be written as:
After obtaining the kinetic equations of each gear meshing pair, the kinetic equations of each meshing pair are assembled and converted into matrix form to obtain the kinetic equations of the whole torsion split transmission system as follows:
where the total stiffness matrix, K = Km + Kc + Kxy, is the sum of the gear meshing stiffness matrix, the coupling stiffness matrix between gears, and the support stiffness matrix of the bearings; C is the damping matrix; M is the mass matrix; F is the external load matrix; and x is the vector of degrees of freedom of the system:
3.1.2. Anomaly Detection and Threshold Optimization
Normal and abnormal data were collected in experiments conducted at different rotational speeds for gears in a split torque transmission system. To differentiate between the two, different data samples were processed through the model, resulting in different evaluation scores. Depending on whether the score was high or low, it was determined whether the data was normal or abnormal. The result of the threshold selection determined this distinction, as shown in Figure 8. Figure 8 shows the Split-torque transmission system’s relationship between the error (FAR, MAR) and the threshold.
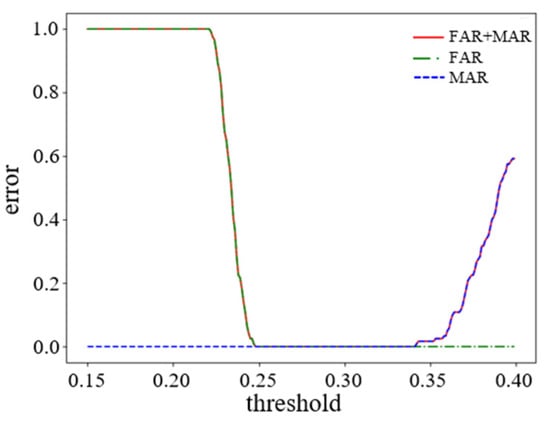
Figure 8.
Relationship between torque transmission system error and threshold.
3.1.3. Anomaly Evaluation
In the split-torque simulation case, we consider fracture-related fault scenarios and organize them into severity-level classes for evaluation. Particularly, each fault mode is parameterized into 10 severity levels (Level 1 to Level 10), and 120 samples are generated for each level. The physical definitions of the 10 severity levels for fracture-related faults (and their corresponding stiffness-degradation interpretation) are provided in Appendix B Table A1. Specifically, the broken-tooth severity is implemented by replacing the tooth face width with in the stiffness expressions (Table A1(a)), while the tooth-root crack severity is parameterized by the crack depth in the cantilever-beam model (Table A1(b)).
Each sample used in the simulation study is a fixed-length time-domain vibration-response segment generated by numerically integrating the split-torque dynamic model under the specified operating conditions. The simulated vibration response is recorded at a constant sampling rate of Hz and then segmented into non-overlapping windows of points (i.e., a window duration of s), which are used as the input samples for subsequent modeling and evaluation. For each severity level, 120 samples are obtained in a reproducible manner by conducting repeated simulations with different initial phases and independent noise realizations to reflect variability, and extracting multiple non-overlapping windows from the steady-state portion of the simulated response so that exactly 120 segments are collected per level. Unless otherwise stated, the model is trained using normal-condition samples only, whereas validation and testing are performed on disjoint (non-overlapping) sample sets containing both normal and faulty conditions to compute FAR/MAR and the corresponding detection accuracy.
In the following, the broken tooth fault is mainly analyzed. In Figure 9 and Figure 10, the samples of different faults are colored differently, the color is from purple to red, the degree of the fault is deepening, the abnormality scores of the model output are increasing, and the corresponding density distributions are also different. Comparing Figure 9 and Figure 10, the anomaly scores of cracked faults in both Gear 1 and Gear 2 tend to increase with the increase in fault grade. However, the probability density curves for the 10 fault classes in Gear 1 are more discriminating than those in Gear 2. This difference may be because the vibration shocks in Gear 2 are weaker and the vibration shocks transmitted to Gear 1 have very little loss in the transmission path and are therefore less distinguishable.
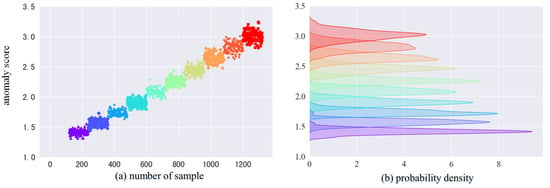
Figure 9.
Gear 1 broken fault anomaly score and probability density.
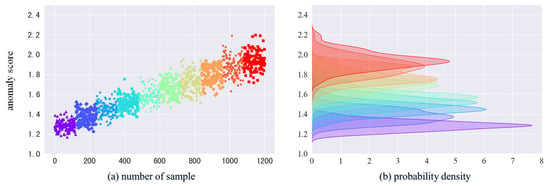
Figure 10.
Gear 2 broken fault anomaly score and probability density.
To support the detection-performance statement quantitatively, fracture-fault detection is formulated as a binary decision based on the DAA-GAN anomaly score . Specifically, normal-condition samples are treated as the negative class, whereas fracture-related fault samples (across the 10 severity levels) are treated as the positive class. A test sample is classified as faulty if , where the threshold is selected in Stage II by analyzing the FAR–MAR trade-off on disjoint validation sets that contain both normal and fault samples (Figure 8). For clarity of presentation, we further report a normalized anomaly score , such that the decision threshold becomes (i.e., indicates a fault). Note that Figure 9 and Figure 10 visualize the anomaly-score distributions of the ten fault severity levels; the detection conclusion is not inferred from the plots alone, but is validated by the confusion-matrix statistics on the held-out test set. Accordingly, detection accuracy is computed as:
where , , , and denote true positives, true negatives, false positives, and false negatives, respectively. In addition, the false alarm rate and miss alarm rate are defined as and .
Under the adopted protocol, the final detection performance is evaluated on a held-out test set that contains both normal-condition samples (negative class) and fracture-related fault samples (positive class). The training, validation, and test sets are disjoint and non-overlapping, ensuring that no signal segments are shared across splits and thus avoiding information leakage. After obtaining the anomaly score for each test sample, we apply the decision rule using with , and assign the predicted label as:
The confusion-matrix entries are then computed by sample-wise counting on the test set: is the number of normal samples satisfying , is the number of normal samples satisfying , is the number of fracture-fault samples satisfying , and is the number of fracture-fault samples satisfying . Therefore, FAR and MAR directly quantify the misclassification counts on the negative and positive classes, respectively.
In the simulated fracture-fault experiments, the held-out test set contains 120 normal-condition samples and 2400 fracture-fault samples (Gear 1 and Gear 2, Levels 1–10; 120 samples per level, i.e., ). Under the selected threshold, all 120 normal test samples satisfy , yielding and ; meanwhile, all 2400 fracture-fault test samples satisfy , yielding and . Therefore, , , and , which supports the reported 100% detection accuracy under the adopted evaluation protocol.
The following five similarity analysis methods were used to correlate the different failure cases of Gear 1 and Gear 2. Plots (a), (b), (c), (d), and (e) in Figure 11 and Figure 12 represent the results of five similarity analysis methods, namely KL distance, JS distance, Pearson’s correlation coefficient, Kendall’s tau correlation coefficient and Spearman’s correlation coefficient, for the different breakage failure classes (G1–G10) of Gear 1 and Gear 2, respectively. From the results, there is a good differentiation between the different degrees of failure. The KL distance analysis method gives better results for the type of fracture failure. Overall, Gear 1 shows higher discrimination at each failure level, while Gear 2 shows lower discrimination at neighboring failure levels.

Figure 11.
Gear 1 broken fault correlation analysis results.
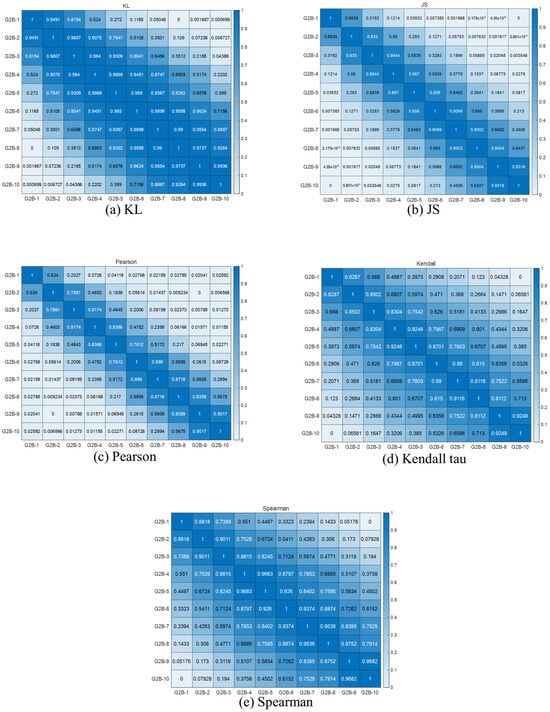
Figure 12.
Gear 2 broken fault correlation analysis results.
Taking gear 1 as an example, the test data G1test is utilized for evaluation using the DAA-GAN model. Firstly, the anomaly score is computed for the test data, followed by obtaining the probability density plot of the anomaly scores, as depicted in Figure 13.
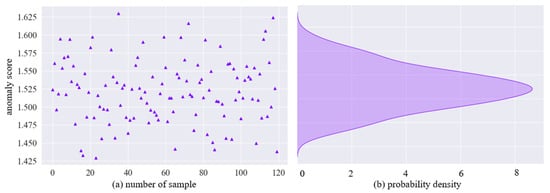
Figure 13.
Test data anomaly score and probability density.
Subsequently, similarity analysis is conducted between the test data and known data, and the results of this analysis are normalized. Figure 14 illustrates the standardized results of the similarity analysis. During the assessment phase, the standardized similarity metrics between the test data and known data are integrated. The evaluation reveals that the test data most closely resembles the fault condition represented by G1B-2, as detailed in Table 2. From Table 2, it is evident that the test data exhibits the highest similarity with G1B-2, suggesting the fault condition of the test data corresponds to G1B-2.
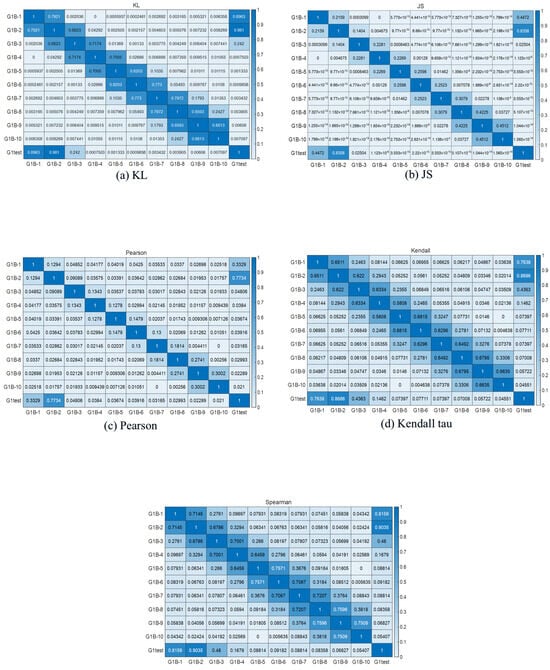
Figure 14.
Test data correlation analysis results.
Table 2.
Overall similarity results between test samples and reference samples for each fault level.
3.2. Validation with Popular Open Datasets
3.2.1. CWRU Dataset
Rolling bearing vibration data were acquired from the Case Western Reserve University (CWRU) Bearing Data Center [32], which is widely used as a benchmark dataset for bearing fault diagnosis and anomaly detection [33]. In this work, we use the drive-end accelerometer signals sampled at 48 kHz under three operating speeds (1730, 1750, and 1772 rpm). The dataset includes normal condition and three fault types: inner race (IR), rolling element (Ball), and outer race (OR) faults. Fault diameters are 0.007, 0.014, and 0.021 inch, and OR faults are located at 3, 6, and 12 o’clock positions. Figure 15 shows the CWRU test bed, and Table 3 summarizes the key settings and the subset configuration adopted in this study.

Figure 15.
Testing bed of CWRU.
Table 3.
CRWU dataset description.
Within the proposed framework, the CWRU drive-end vibration signals are segmented into fixed-length time-domain windows and fed into DAA-GAN for unsupervised anomaly detection; as labeled fault data accumulate, the anomaly-score probability density distributions are further utilized for similarity-based severity assessment in Stage III.
3.2.2. Anomaly Detection and Threshold Optimization
In the experiments conducted on the CWRU drive end rolling bearing under various speeds, both normal and abnormal samples were collected.
To distinguish between the two, different data samples were processed through the model, resulting in distinct evaluation scores. Based on the scores being either high or low, the determination of whether the data is normal or abnormal is made. The results of threshold selection, which determine this distinction, are depicted in Figure 16.
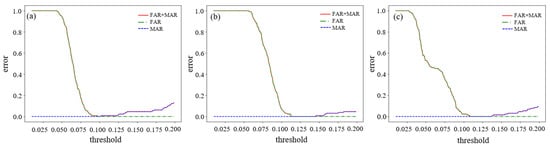
Figure 16.
Error threshold relationships on the CWRU dataset: (a) condition 1; (b) condition 2; (c) condition 3.
3.2.3. Anomaly Evaluation
Figure 16 shows the change in error for RPM1730, RPM1750, and RPM1772 operating conditions, represented by plots (a), (b), and (c), respectively, as the threshold is varied. The horizontal axis represents the threshold value, while the vertical axis represents the error. The green dotted and blue dashed lines show the curves of FAR and MAR relative to the threshold, respectively, and the red solid line shows the sum of the errors of the two ratios.
In the initial stage, when the equipment is operating normally and only normal data samples are available, continuous adjustment of the threshold leads to a gradual decrease in the false alarm rate, approaching zero.
In the second stage, as equipment failures occur to a limited extent, the threshold value continues to increase, causing the leakage alarm rate to rise. The threshold value within the range of low total error is used to assess the abnormal scores of the test set’s outputs, with values exceeding this threshold classified as abnormal.
In the third stage, as the number of faults increases and a substantial amount of fault data is collected, fault categories are determined based on the probability distributions of different anomaly scores. The results of the anomaly scores and density plots are illustrated in Figure 17, Figure 18 and Figure 19.
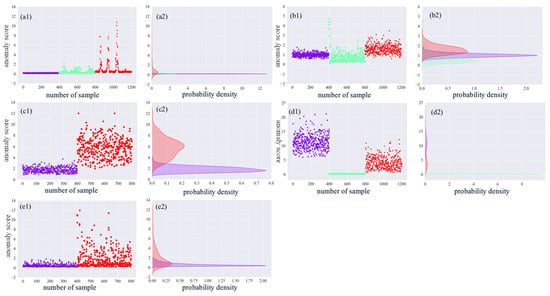
Figure 17.
RPM 1730 anomaly score and probability density: (a1) anomaly scores for case A; (a2) probability density of anomaly scores for case A; (b1) anomaly scores for case B; (b2) probability density of anomaly scores for case B; (c1) anomaly scores for case C; (c2) probability density of anomaly scores for case C; (d1) anomaly scores for case D; (d2) probability density of anomaly scores for case D; (e1) anomaly scores for case E; (e2) probability density of anomaly scores for case E.
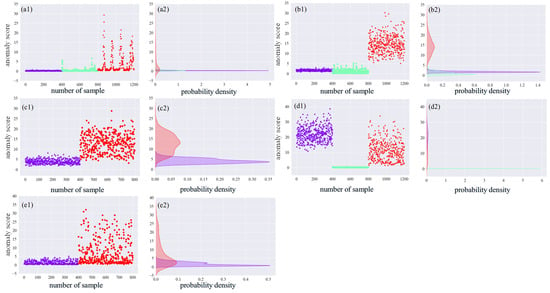
Figure 18.
RPM 1750 anomaly score and probability density: (a1) anomaly scores for case A; (a2) probability density of anomaly scores for case A; (b1) anomaly scores for case B; (b2) probability density of anomaly scores for case B; (c1) anomaly scores for case C; (c2) probability density of anomaly scores for case C; (d1) anomaly scores for case D; (d2) probability density of anomaly scores for case D; (e1) anomaly scores for case E; (e2) probability density of anomaly scores for case E.
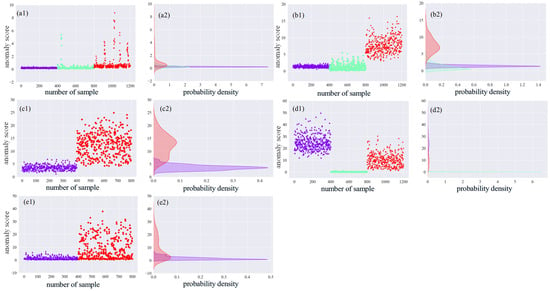
Figure 19.
RPM 1772 anomaly score and probability density: (a1) anomaly scores for case A; (a2) probability density of anomaly scores for case A; (b1) anomaly scores for case B; (b2) probability density of anomaly scores for case B; (c1) anomaly scores for case C; (c2) probability density of anomaly scores for case C; (d1) anomaly scores for case D; (d2) probability density of anomaly scores for case D; (e1) anomaly scores for case E; (e2) probability density of anomaly scores for case E.
In each of the graphs in Figure 17, Figure 18 and Figure 19, the labels (a1), (a2), (b1), and (b2) represent the anomaly scores and probability densities of rolling body faults and inner ring faults for various operating conditions. Meanwhile, the labels (c1), (c2), (d1), (d2), and (e1), (e2) represent the anomaly scores and probability densities of outer ring faults, each corresponding to different fault placements. Additionally, each fault type has a distinct fault diameter. To distinguish them, this paper uses purple to indicate 0.007-inch faults, light green to indicate 0.014-inch faults, and red again to indicate 0.021-inch faults.
In the (a1), (b1), (c1), (d1), and (e1) plots of Figure 17, Figure 18 and Figure 19, the horizontal coordinates represent the total number of tests set samples, while the vertical coordinates represent the sample anomaly scores. The red dashed line represents the threshold value. In the (a2), (b2), (c2), (d2), and (e2) plots of Figure 17, Figure 18 and Figure 19, density plots for different faults are presented. The horizontal axis represents the probability, and the vertical axis represents the anomaly score. The probability density plots in Figure 17, Figure 18 and Figure 19 demonstrate that different fault sizes within the same fault type are well distinguished. However, some distinct faults are modeled with probability densities that appear more similar, leading to challenges in differentiation.
The graphs show variations in probability density distributions among different fault categories. For instance, in the (a1) plots of Figure 17, Figure 18 and Figure 19, the anomaly scores for 0.007 inches, 0.014 inches, and 0.021 inches of rolling body faults exhibit an increasing trend. On the other hand, inner ring faults are differentiated based on fault levels and exhibit distinct density distributions. For outer ring faults at 3 o’clock and 12 o’clock directions within the loaded area, deeper degrees of failure result in higher overall anomaly scores. However, for the 6 o’clock direction orthogonal to the loaded area, anomalies at 0.014 inches yield smaller output fractions. Notably, the distributions for 0.007 inches and 0.021 inches of outer ring faults differ significantly. The accuracy of anomaly detection is summarized in Table 4.
Table 4.
Detection accuracy on the CWRU dataset (Mean ± Std across three speeds).
As indicated in Table 4, most anomalies can be successfully detected across operating conditions, with an overall average detection accuracy of 99.83% on the CWRU dataset. To improve the rigor of result reporting, Table 4 also reports the mean and standard deviation (Std) across the three operating speeds (1730/1750/1772 rpm). The main performance degradation is observed for the Ball fault with 0.014-inch diameter (minimum accuracy 0.955 at 1772 rpm), while the remaining fault categories achieve near-perfect accuracy with low variance.
In this paper, five similarity analysis methods are used to analyze the similarity between different fault-type distribution patterns observed under various operating conditions. This helps determine the degree of resemblance between the new faults and existing fault categories. It also calculates the accuracy of fault classification, facilitating fault identification. Firstly, five correlation analysis methods are used to analyze the three types of faults at 1730 RPM, and the results are shown in Figure 20, Figure 21 and Figure 22. In plots (a), (b), (c), (d), and (e) of Figure 20, Figure 21 and Figure 22, which represent the results of the five methods of similarity analysis, namely KL distance, JS distance, Pearson correlation coefficient, Kendall tau correlation coefficient, and Spearman correlation coefficient, respectively. For rolling body defects, as shown in Figure 20, the JS method gives the best results, while for inner ring defects, as shown in Figure 21, the Spearman method gives better results, and for outer ring 6 o’clock defects, as shown in Figure 22, the Pearson method gives better results.
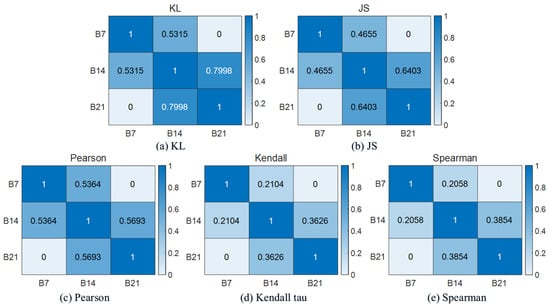
Figure 20.
RPM1730 Ball correlation analysis results.
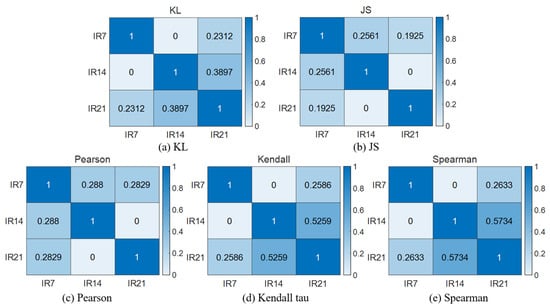
Figure 21.
RPM1730 IR correlation analysis results.
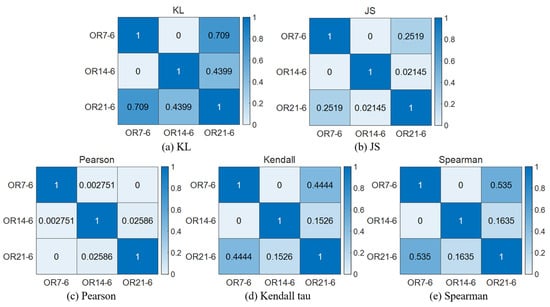
Figure 22.
RPM1730 OR6 correlation analysis results.
In the context of the RPM1730 operating condition, with the fault type being a 6 o’clock position defect on the rolling element, test data “test” was analyzed using the DAA-GAN model. Initially, the anomaly scores were calculated, leading to the generation of a probability density graph of the anomaly scores, as represented in Figure 23, which illustrates the anomaly scores and the probability density graph of the test data. Subsequently, the test data was subjected to a similarity analysis with known data, and the results of this analysis were normalized. Figure 24 showcases the results of the similarity analysis after normalization. In the evaluation phase, the normalized similarity indices between the test data and the known data were fused to assess the fault condition most like that of the test data. The assessment results, as documented in Table 5, indicate a higher similarity of the test data with OR7-6. Based on this analysis, it can be inferred that the fault condition of the test data corresponds to OR7-6.

Figure 23.
Test data anomaly score and probability density.
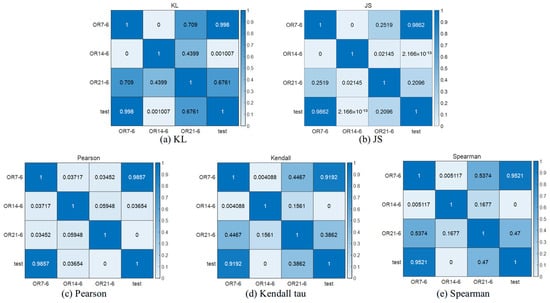
Figure 24.
Test data correlation analysis results.
Table 5.
Comprehensive similarity evaluation results.
3.2.4. Comparison with Related Methods on the CWRU Dataset
Since the CWRU dataset has been widely used in bearing diagnostics, we further compare the proposed DAA-GAN framework with representative methods reported in the recent literature. Table 6 summarizes the published results. Note that CWRU performance is sensitive to data preprocessing, class definition and data splitting strategy; therefore, the comparison is indicative rather than strictly identical.
Table 6.
Comparison with representative methods on the CWRU dataset (indicative).
Recent benchmark studies have also reported that overly optimistic splits may lead to inflated CWRU results; rigorous, leakage-free evaluation remains important for reproducibility [36]. In this paper, we therefore report mean and standard deviation across operating speeds (Table 4) and will further extend benchmarking under stricter split protocols in future work. More importantly, beyond pursuing high accuracy, this study aims to provide a data-accumulation-aware diagnostic framework that remains effective when fault data are unavailable: it enables anomaly detection using normal-condition data only in the initial stage, and progressively improves detection performance as fault data accumulate over the equipment lifecycle.
4. Conclusions
This paper proposes a data-accumulation-aware anomaly detection and severity assessment framework for rotating machinery based on DAA-GAN. By explicitly considering the progressive accumulation of fault data during the equipment lifecycle, the framework integrates unsupervised anomaly detection, adaptive threshold updating, and similarity-based severity evaluation. The main findings and contributions are summarized as follows:
(1) High detection accuracy: The proposed method achieves 100% detection accuracy for the simulated gear tooth breakage levels and an overall average detection accuracy of 99.83% on the CWRU bearing dataset across three operating speeds (1730/1750/1772 rpm). These results demonstrate the effectiveness of DAA-GAN for learning normal patterns and detecting deviations.
(2) Robust performance under imbalanced data: With only a small number of fault samples available (Stage II), the adaptive threshold update strategy selects a decision threshold by minimizing FAR+MAR on a validation set, which improves detection robustness and reduces the sensitivity to operating-condition variation.
(3) Lifecycle-aware staged assessment: When sufficient labeled fault samples are accumulated (Stage III), the proposed multi-index similarity fusion strategy compares anomaly-score distributions between test samples and reference faults, enabling consistent fault type/severity assessment rather than only binary anomaly detection.
Limitations and future work: (i) The current validation method focuses on two case studies and single-sensor vibration signals. More datasets and real industrial deployments are needed to fully verify generalization. (ii) The similarity fusion strategy currently adopts fixed (default equal) weights. Learning adaptive weights or uncertainty-aware fusion is a promising direction. (iii) To further improve reproducibility, future work will conduct more extensive ablation studies and benchmarking under stricter, leakage-free data splits and multiple random seeds and explore online incremental updating for long-term deployment.
Author Contributions
Conceptualization, L.H. and P.L.; methodology, X.M. and L.H.; software(version number: Matlab R2022b and Python3.10), L.T. and X.M.; validation, L.T. and X.M.; formal analysis, J.Z.; investigation, L.T. and X.M.;, resources, Y.Y.; data curation, J.Z. and Y.Y.; writing—original draft preparation, X.M. and L.T.; writing—review and editing, L.H. and P.L.; supervision, P.L.; project administration, L.H.; funding acquisition, L.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China, grant number 2022YFF0608704, and by the Research Start-up Fund for High-level Talents of Shandong Xiehe University, grant number SDXHQD2025004.
Data Availability Statement
The data that support the findings of the simulation case in Section 3.1 are available from the corresponding author upon reasonable request; The data that support the findings of the CWRU dataset case in Section 3.2 are available in [31].
Conflicts of Interest
Author Jiyu Zeng was employed by the company Yingtan Huadian New Energy Co., LTD. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A. Standard GAN Objective and Background Formulation
Recently, GANs have gained increasing attention from researchers. It was first proposed by Goodfellow in 2014 as an unsupervised learning model. It allows two neural networks to learn through mutual competition. The original GAN model is shown in Appendix A Figure A1a, which consists mainly of a generator network G and a discriminator network D.
The core idea of GAN is to generate new data that is like real data by adversarial training of two neural networks. These two networks are the generator network and the discriminator network. The goal of the Generator Network is to generate data that is as realistic as possible to deceive the discriminator network. It receives a random noise as input, and passes it through the neural network to output data like real data. The task of the Discriminator is to distinguish whether the input data comes from the real data set or is fake data generated by the Generator.

Figure A1.
The framework of: (a) GAN and (b) GANomaly.
The generator G of the GAN model takes a random number Z as input, intending to generate samples that are as consistent as possible with the distribution of real data X. The discriminator D takes the original sample X as input, intending to deceive the discriminator D as much as possible. The generator and discriminator compete against each other and adjust their respective parameters. The goal is to make the discriminator D unable to distinguish between the output and the real sample X. Given the prior distribution of the input Z if represents the distribution of real data, the optimization objective of the discriminator is to maximize Equation (A1):
The optimization objective of discriminator training is to minimize Equation (A2):
The optimization objective of the discriminator training is to minimize the equation, where D(x) represents the probability of the original sample X being judged as a real sample by the discriminator, and D(G(Z)) represents the probability of the generated sample G(Z) being judged as a real sample by the discriminator.
GAN is based on the idea of zero-sum games in game theory. For the generator model G, its goal is to learn the data distribution of real samples and generate new samples with similar data distribution. For the discriminator model D, its goal is to determine whether the input sample is a generated sample or a real sample. During model training, the generator hopes to generate data that is infinitely close to real sample data, while the discriminator’s objective is to distinguish all generated samples from real samples. The two models compete and gradually optimize. The optimization objective of GAN can be expressed as a min-max process, and the objective function is given by the following Equation (A3):
where X and Z represent the real sampled data and random noise, respectively, and represent their corresponding data distributions. The symbol E represents the expected operation. G and D are trained adversarial and can be seen as a binary max-min game process. The goal of the discriminator is to maximize the recognition accuracy of real and generated samples, while the goal of the generator is to minimize the difference between real and generated samples to deceive the discriminator. The ultimate state of optimization is to achieve Nash equilibrium between the generator and the discriminator. That is, the probability distribution of the generated samples is almost the same as that of the real samples. At the same time, the output of the discriminator judging real and fake is very close to 0.5, which means that the discriminator cannot distinguish between real and fake samples well among all input data.
Akcay et al. [27] proposed the GANomaly model based on the original GAN framework. As shown in Appendix A Figure A1b, the network structure consists of three sub-networks. The first sub-network is a traditional bowl-shaped autoencoder used to reconstruct normal input data. Specifically, the Decoder is almost the same as the generator network of DCGAN [37], which maps from a low-dimensional vector to a high-dimensional sample, while the Encoder maps from a high-dimensional sample to a low-dimensional vector.
The second sub-network is E, which compresses and reconstructs samples into low-dimensional vectors. Although the structure of E is the same as that of the encoder network, their parameters are different. By comparing the difference between the original data and the reconstructed data in a higher-level abstract space, a new method is used to infer anomalies, which greatly improves the ability to resist noise interference and learns a more robust anomaly detection model. The third sub-network D has the same structure as the encoder network of the first sub-network and is used to distinguish between original and generated data.
In traditional GANs, although the generator G and discriminator D employ multi-layer neural network architectures, they are prone to issues such as training instability, pattern collapse, and insufficient feature learning under fully unsupervised training. This is particularly pronounced in scenarios with extreme class imbalance, where normal samples vastly outnumber fault samples. GANomaly improves upon this by employing error reconstruction for anomaly detection, yet it remains primarily suited to single-stage unsupervised detection. It lacks the capacity to model the gradual accumulation of data from ‘solely normal’ to ‘multi-level faults’ during equipment operation, and struggles to accommodate subsequent threshold adaptation and fault severity assessment. Therefore, it is necessary to design a novel data-accumulation-aware generative adversarial network (DAA-GAN) tailored to the data accumulation process, thereby better supporting anomaly detection and assessment throughout the entire lifecycle of rotating machinery.
Appendix B. Definition of Severity Levels for Fracture-Related Faults in the Split-Torque Simulation
(1) For the faulty gears considered in this study, the baseline (healthy) face width is mm (see the gear-parameter table in the manuscript).
(2) In the tooth-stiffness expressions derived from the cantilever-beam model (Figure 6), the stiffness contributions are proportional to the tooth face width . Therefore, for a broken-tooth fault occurring along the face-width direction, we implement severity by replacing with the remaining effective face width (i.e., ) in all stiffness components used to compute the meshing stiffness .
(3) For the tooth-root crack fault, severity is parameterized by the crack depth (mm) in the tooth-root region. To provide a scale-consistent and fully reproducible definition based on known gear parameters, we set the maximum crack depth as (with mm in the manuscript), and define the normalized crack ratio .
Definition:
Definition:
For broken-tooth faults, at each severity level we set the effective face width in the tooth-stiffness computation as (Table A1(a)). Since the bending, shear, axial-compression, and contact stiffness terms derived from the cantilever-beam formulation are proportional to the face width, this substitution directly yields the level-dependent meshing stiffness .
For tooth-root crack faults, at each severity level we impose a crack depth (Table A1(b)) in the tooth-root region and recompute the cross-sectional properties (e.g., area and second moment of inertia) used in the compliance integrals of the cantilever-beam model, thereby producing a monotonic reduction in meshing stiffness with increasing . The regenerated time-domain responses are then used to produce the anomaly-score sequences for the 10-level severity assessment.
Table A1.
(a) Broken-tooth severity levels (fracture along face-width direction). (b) Tooth-root crack severity levels (crack depth).
Table A1.
(a) Broken-tooth severity levels (fracture along face-width direction). (b) Tooth-root crack severity levels (crack depth).
| (a) | |||||
|---|---|---|---|---|---|
| Severity Level | Damage Ratio (–) | Remaining Face Width (mm) | Removed Width (mm) | ||
| Level 1 | 0.10 | 27.0 | 3.0 | ||
| Level 2 | 0.20 | 24.0 | 6.0 | ||
| Level 3 | 0.30 | 21.0 | 9.0 | ||
| Level 4 | 0.40 | 18.0 | 12.0 | ||
| Level 5 | 0.50 | 15.0 | 15.0 | ||
| Level 6 | 0.60 | 12.0 | 18.0 | ||
| Level 7 | 0.70 | 9.0 | 21.0 | ||
| Level 8 | 0.80 | 6.0 | 24.0 | ||
| Level 9 | 0.85 | 4.5 | 25.5 | ||
| Level 10 | 0.90 | 3.0 | 27.0 | ||
| (b) | |||||
| Severity Level | Crack Depth (mm) | Normalized Crack Ratio (–) | |||
| Level 1 | 0.5625 | 0.10 | |||
| Level 2 | 1.1250 | 0.20 | |||
| Level 3 | 1.6875 | 0.30 | |||
| Level 4 | 2.2500 | 0.40 | |||
| Level 5 | 2.8125 | 0.50 | |||
| Level 6 | 3.3750 | 0.60 | |||
| Level 7 | 3.9375 | 0.70 | |||
| Level 8 | 4.5000 | 0.80 | |||
| Level 9 | 5.0625 | 0.90 | |||
| Level 10 | 5.6250 | 1.00 | |||
References
- Deng, W.; Li, Z.; Li, X.; Chen, H.; Zhao, H. Compound Fault Diagnosis Using Optimized MCKD and Sparse Representation for Rolling Bearings. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Ma, J.; Shang, J.; Zhao, X.; Zhong, P. Bayes-DCGRU with bayesian optimization for rolling bearing fault diagnosis. Appl. Intell. 2022, 52, 11172–11183. [Google Scholar] [CrossRef]
- Shao, H.; Xia, M.; Wan, J.; de Silva, C.W. Modified Stacked Autoencoder Using Adaptive Morlet Wavelet for Intelligent Fault Diagnosis of Rotating Machinery. IEEE/ASME Trans. Mechatron. 2022, 27, 24–33. [Google Scholar] [CrossRef]
- Zhou, P.; Hu, X.; Li, P.; Wu, X. Online feature selection for high-dimensional class-imbalanced data. Knowl.-Based Syst. 2017, 136, 187–199. [Google Scholar] [CrossRef]
- Viola, J.; Chen, Y.; Wang, J. FaultFace: Deep convolutional generative adversarial network (DCGAN) based ball-bearing failure detection method. Inf. Sci. 2021, 542, 195–211. [Google Scholar] [CrossRef]
- Zhou, F.; Yang, S.; Fujita, H.; Chen, D.; Wen, C. Deep learning fault diagnosis method based on global optimization GAN for unbalanced data. Knowl.-Based Syst. 2020, 187, 104837. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, T. Imbalanced learning for fault diagnosis problem of rotating machinery based on generative adversarial networks. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 3248–3253. [Google Scholar]
- Huang, K.; Wu, S.; Li, F.; Yang, C.; Gui, W. Fault Diagnosis of Hydraulic Systems Based on Deep Learning Model with Multirate Data Samples. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6789–6801. [Google Scholar] [CrossRef]
- Zareapoor, M.; Shamsolmoali, P.; Yang, J. Oversampling adversarial network for class-imbalanced fault diagnosis. Mech. Syst. Signal Process. 2021, 149, 107175. [Google Scholar] [CrossRef]
- Yan, K.; Su, J.; Huang, J.; Mo, Y. Chiller Fault Diagnosis Based on VAE-Enabled Generative Adversarial Networks. IEEE Trans. Autom. Sci. Eng. 2022, 19, 387–395. [Google Scholar] [CrossRef]
- Spirto, M.; Nicolella, A.; Melluso, F.; Malfi, P.; Cosenza, C.; Savino, S.; Niola, V. Enhancing SDP-CNN for Gear Fault Detection Under Variable Working Conditions via Multi-Order Tracking Filtering. J. Dyn. Monit. Diagn. 2025, 4, 226–238. [Google Scholar] [CrossRef]
- Chen, J.; Li, T.; He, J.; Liu, T. An interpretable wavelet Kolmogorov–Arnold convolutional LSTM for spatial-temporal feature extraction and intelligent fault diagnosis. J. Dyn. Monit. Diagn. 2025, 4, 183–193. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Ou, X.; Wen, G.; Huang, X.; Su, Y.; Chen, X.; Lin, H. A deep sequence multi-distribution adversarial model for bearing abnormal condition detection. Measurement 2021, 182, 109529. [Google Scholar] [CrossRef]
- Maliuk, A.S.; Prosvirin, A.E.; Ahmad, Z.; Kim, C.H.; Kim, J.-M. Novel bearing fault diagnosis using gaussian mixture model-based fault band selection. Sensors 2021, 21, 6579. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Yang, B.; Zhang, X.; Wang, S.; Chen, X. Time-frequency atoms-driven support vector machine method for bearings incipient fault diagnosis. Mech. Syst. Signal Process. 2016, 75, 345–370. [Google Scholar] [CrossRef]
- Bendjama, H. Bearing fault diagnosis based on optimal Morlet wavelet filter and Teager-Kaiser energy operator. J. Braz. Soc. Mech. Sci. Eng. 2022, 44, 392. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Guo, Y. Unknown fault feature extraction of rolling bearings under variable speed conditions based on statistical complexity measures. Mech. Syst. Signal Process. 2022, 172, 108964. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar] [CrossRef]
- Hou, Y.; Ma, J.; Wang, J.; Li, T.; Chen, Z. Enhanced generative adversarial networks for bearing imbalanced fault diagnosis of rotating machinery. Appl. Intell. 2023, 53, 25201–25215. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Semi-supervised learning of bearing anomaly detection via deep variational autoencoders. arXiv 2019, arXiv:1912.01096. [Google Scholar] [CrossRef]
- Lee, K.; Kim, J.K.; Kim, J.; Hur, K.; Kim, H. Stacked convolutional bidirectional LSTM recurrent neural network for bearing anomaly detection in rotating machinery diagnostics. In Proceedings of the 2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju, Republic of Korea, 23–27 July 2018; pp. 98–101. [Google Scholar]
- Ahmad, S.; Styp-Rekowski, K.; Nedelkoski, S.; Kao, O. Autoencoder-based condition monitoring and anomaly detection method for rotating machines. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 4093–4102. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; pp. 146–157. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Akçay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Computer Vision—ACCV, Perth, Australia, 2–6 December 2018; Springer: Cham, The Netherlands, 2018; pp. 622–637. [Google Scholar]
- Jiang, W.; Hong, Y.; Zhou, B.; He, X.; Cheng, C. A GAN-based anomaly detection approach for imbalanced industrial time series. IEEE Access 2019, 7, 143608–143619. [Google Scholar] [CrossRef]
- Hu, W.; Wang, T.; Chu, F. A Wasserstein generative digital twin model in health monitoring of rotating machines. Comput. Ind. 2023, 145, 103807. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. ArXiv 2016, arXiv:1606.03498. [Google Scholar]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Volume 5. [Google Scholar]
- Case Western Reserve University Bearing Data Center Website. Available online: https://engineering.case.edu/bearingdatacenter/welcome (accessed on 1 January 2025).
- Neupane, D.; Seok, J. Bearing fault detection and diagnosis using case western reserve university dataset with deep learning approaches: A review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Yan, H.; Si, X.; Liang, J.; Duan, J.; Shi, T. Unsupervised Learning for Machinery Adaptive Fault Detection Using Wide-Deep Convolutional Autoencoder with Kernelized Attention Mechanism. Sensors 2024, 24, 8053. [Google Scholar] [CrossRef]
- Dai, Z.; Jiang, L.; Li, F.; Chen, Y. A Multi-Scale Self-Supervision Approach for Bearing Anomaly Detection Using Sensor Data Under Multiple Operating Conditions. Sensors 2025, 25, 1185. [Google Scholar] [CrossRef]
- Rosa, R.K.; Braga, D.; Silva, D. Benchmarking deep learning models for bearing fault diagnosis using the cwru dataset: A mul-ti-label approach. arXiv 2024, arXiv:2407.14625. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.