Abstract
In this work, we present a new distribution, which is a slash extension of the distribution of the sum of two independent Lindley random variables. This new distribution is developed using the slash methodology, resulting in a distribution with more flexible kurtosis, i.e., the ability to model atypical data. We study the density function of the new model and some of its properties, such as the cumulative distribution function, moments, and its asymmetry and kurtosis coefficients. The parameters are estimated by the maximum likelihood method with the EM algorithm. Finally, we apply the proposed model to two real datasets with high kurtosis, showing that it provides a better fit than two distributions known in the literature.
MSC:
62E15; 62E20; 62F10; 62P99
1. Introduction
The slash distribution is a distribution with heavier tails than the normal distribution, and its representation is the quotient between two independent random variables, one normal and the other a power of the uniform distribution. We say that X has a slash distribution if its representation is given by
where , , Y is independent of U and ; its representation can be seen in Johnson et al. [1]. Properties of this family are discussed by Rogers and Tukey [2] and Mosteller and Tukey [3]. The maximum likelihood estimators for location and scale are discussed in Kafadar [4]. Wang and Genton [5] offer a multivariate version and a multivariate skew version of the slash distribution. Gómez et al. [6] extend the slash distribution using the family of univariate and multivariate elliptical distributions. This methodology for increasing the weight of tails has also been used in distributions with positive support; for example, by Olmos et al. ([7,8]) in the half-normal and generalized half-normal distributions, Astorga et al. [9] in the power Muth distribution, and Rivera et al. [10] in the Rayleigh distribution.
A distribution with positive support is the Lindley model (see Lindley [11]); we say that a random variable X has a Lindley (L) distribution if its probability density function (pdf) is given by
where is the shape parameter. We denote this . The L distribution has been used in various areas. Researchers who have carried out these studies include Ghitany ([12,13]), Gómez-Déniz [14], Krishna and Kumar [15], Bakouch et al. [16], Gui [17], Oluyede and Yang [18], Shanker et al. [19], and Abouammoh et al. [20]. Gui [17] made an extension of the L distribution using the slash methodology described in (1); by considering that they obtain the L slash distribution (LSD). The L distribution and its generalizations have also been studied by Tomy [21].
Chesneau et al. [22] introduced a distribution constructed as the sum of two independent random variables, i.e., if and are independent and identically distributed as , then a new random variable is defined as . We say Y has a 2SL distribution with shape parameter and its pdf is given by:
where is the shape parameter. We denote this by . The derivation of the pdf of Y is based on the convolution product, and is detailed in Section 2.1 of Chesneau et al. [22].
The principal object of this paper is to increase the weight of the tail of the 2SL distribution, using the slash methodology given in (1) and considering . In this way we obtain a distribution with a heavier right tail than the 2SL distribution, for modelling atypical data.
The article is organized as follows: in Section 2 we describe the new distribution and its properties. In Section 3, we carry out inferences by the moments and maximum likelihood (ML) methods using the EM algorithm, and perform a simulation study. In Section 4, we present two applications to real datasets, comparing them with the 2SL and LSD distributions. In Section 5, we provide some conclusions.
2. Density and Properties
In this section, we provide the representation, pdf and basic properties of the new distribution.
2.1. Stochastic Representation
A random variable X follows a slash 2SL (S2SL) distribution with parameters and q if X is obtained as
where X and Y are independent, , , , and . We denote this as .
Proposition 1.
Let . Then, the density function of X is given by
where and is the lower incomplete gamma function.
Proof.
Using the stochastic representation given in (2) and the random vectors transformation method, we obtain
Then, , , . Marginalizing with respect to the random variable W, we have that
By substituting the variable and evaluating the integrals, the result is obtained. □
The 2SL distribution is an alternative to the L distribution, and the construction of the S2SL distribution aims to increase the right tail of the 2SL distribution. On the other hand, one of the representations of the S2SL distribution facilitates parameter estimation using the EM algorithm, thereby transforming it into an alternative distribution to other heavy-tailed distributions.
Figure 1 shows the density of the S2SL and 2SL distributions for and different values of parameter q. It can be seen that as parameter q diminishes, the density function of the S2SL distribution presents greater kurtosis.
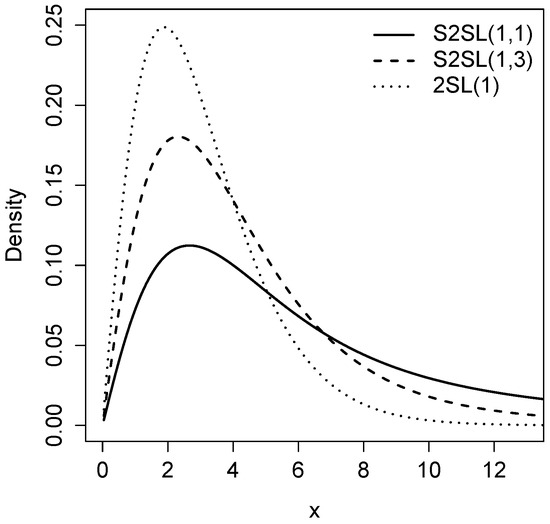
Figure 1.
Graphical comparison of the pdf between the 2SL and S2SL distributions for a fixed beta () and different values of q.
2.2. Properties
Proposition 2.
Let . Then the cumulative distribution function (cdf) of X is given by
Proof.
Using the definition of cdf and integrating by parts, the result is obtained. □
Figure 2 presents a graphical comparison of the cdf of the S2SL model (with ) for different values of q, compared to the 2SL distribution.
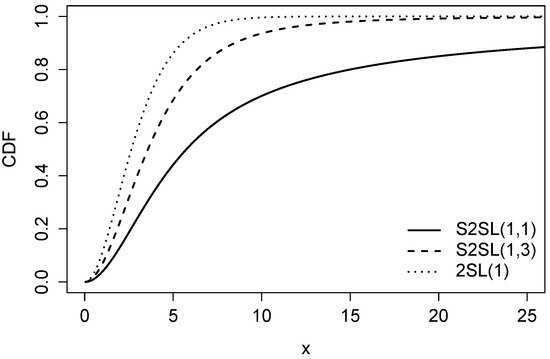
Figure 2.
Graphical comparison of the cdf between the 2SL and S2SL distributions for a fixed beta () and different values of q.
The survival and hazard functions are defined as and , respectively. These are two important functions in survival analysis because they represent the probability that an observation does not present the event of interest as a function of time, and the approximate probability of presenting the event of interest at the immediately following instant. For the S2SL distribution, these functions are presented in the following proposition.
Proposition 3.
Let ; then, the survival and hazard functions are given by
Proof.
Using the definitions of the survival and hazard functions,
and replacing and , the result is obtained. □
Figure 3, shows the survival function (left) and hazard function (right) and different values of q, compared with the 2SL distribution.
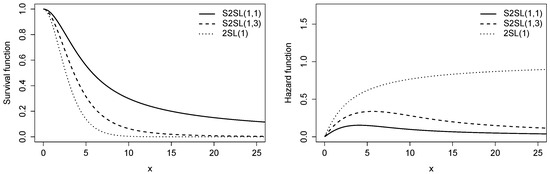
Figure 3.
Plots of the survival function (left) and the hazard function (right) for the S2SL distribution with and different values of q, compared to the 2SL distribution.
Table 1 shows for different values of x in the mentioned distribution.

Table 1.
Comparison of the tails of the 2SL and S2SL distributions.
The size of the right tail of a distribution is crucial when the chosen model aims to capture values far from the beginning of the distribution’s support, such as outliers. The concept of heavy tails is fundamental in actuarial statistical applications. In this context, distributions such as Pareto, Lognormal, and Weibull, among others, have been widely used to model losses in automobile insurance and catastrophic insurance. It is well-established that any probability distribution defined by its cdf on the real line is classified as heavy right-tailed (see Rolski et al. [23]) if . An important topic in extreme value theory is regular variation (see Bingham [24]), a concept formalized in the following definition.
Definition 1.
A distribution function is called regular varying at infinity with index si
where the parameter is called the tail index.
The following proposition states that the survival function of the S2SL distribution exhibits regular variation.
Proposition 4.
The survival function of the random variable is a survival function with regularly varying tails.
Proof.
Applying the above definition and using L’Hospital’s rule we have that
Since , the result is obtained when calculating the limit. □
A direct consequence of the above proposition is that the S2SL distribution is heavy right-tailed (see Rolski et al. [23]).
Proposition 5 shows that the S2SL distribution is the product of a scale mixture between the 2SL and Beta distributions.
Proposition 5.
Let and . Then, .
Proof.
The marginal density function of X is given by
Finally, substituting the variable , the result is obtained. □
Proposition 6.
Let . If , then , where denotes convergence in the distribution.
Proof.
Let and given in (2). First, we study the convergence in the probability of . We have that, and . Thus, we obtain
where if . Therefore, , where denotes convergence in probability. Finally, applying Slutsky’s theorem for , we have that . □
2.3. Moments
Proposition 7.
Let , then the r-th moment of X is given by
Proof.
Using the stochastic representation given in (2), we have that
where , and , are the r-th moments of and Y, respectively, where and . □
Corollary 1.
If with β and , the first four moments and variance of X are
The asymmetry and kurtosis coefficients are defined as and , respectively, where represents the standardized variable. These coefficients are of great importance, since the first allows us to quantify the degree of asymmetry of a variable, while the kurtosis coefficient can be used to detect the presence of heavy tails in the underlying distribution. The following proposition presents these coefficients for the S2SL distribution.
Proposition 8.
Let ; then, the asymmetry and kurtosis coefficients of the random variable Y are given by
where .
Proof.
Using the definitions of the standardized asymmetry and kurtosis coefficients,
where , , and are given by Corollary 1. The result is obtained by substituting the corresponding terms. □
Figure 4 shows that when the values of parameter q are low, the asymmetry and kurtosis coefficients increase.
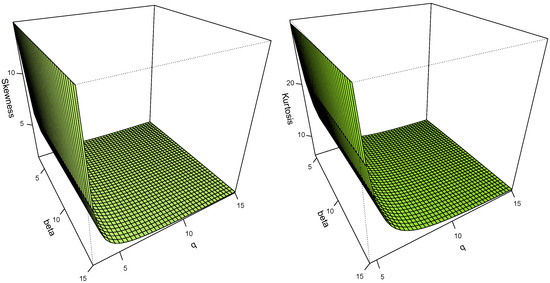
Figure 4.
Graphs of the asymmetry and kurtosis coefficients of the S2SL () model.
3. Inference
In this section, we carry out parameter estimation of the S2SL distribution using the moments and ML methods with the EM algorithm, and perform a simulation study.
3.1. Moments Estimators
Proposition 9.
3.2. ML Estimators
Let , be a random sample of size n of a random variable X with distribution, then the log-likelihood function for can be expressed as
Deriving partially the log-likelihood function for and q and equalling to zero, we obtain the following equations:
where , , and (see Milgram [25]) where is related with the generalized integral-exponential function when .
The solutions to Equations (9) and (10) can be obtained using digital methods like the Newton–Raphson algorithm. One alternative for obtaining the ML estimators is to maximize Equation (8) using the optim function of the R software [26] version 4.0.5. However, in order to obtain a more robust estimation procedure, in the next subsection we will explore the use of the EM algorithm for this particular problem.
3.3. EM Algorithm
The EM algorithm (see Dempster et al. [27]) is a widely used tool for estimating ML in scenarios with unobserved or latent data. In this context, the S2SL distribution can also be expressed by the following stochastic approach.
where and , for represent the unobserved variables. The data observed are given by , where . The vectors , and are the latent variables and the vector are the complete data. The joint distribution of is given by
Thus the complete log-likelihood function for can be expressed as
where c is a constant that does not depend on the parameters vector. Thus the expected , given by the observed data, is
where and . Note that
where , is the cdf of the gamma model. Furthermore, we define and ; this denotes the gamma distribution with shape parameter a and rate b truncated in the interval .
Therefore, using properties of conditional expectations, we have that ; according to (12), this expectation is simple to compute, and we obtain similarly. The results are as follows:
where is the normalization constant, defined as
Thus, the EM algorithm for estimating the vector is as follows:
- Step M1: update as,
- Step M2: update as the solution of the following non-linear equation
Steps E, M1, and M2 are repeated until convergence is reached, defined when the difference between the estimations of two consecutive iterations is less than a previously fixed value. Note that Step M1 has an explicit solution, while can be solved using, for example, the uniroot function in R.
3.4. Simulation Study
In this section, we present a simulation study to evaluate the performance of the EM algorithm in estimating the parameters of the S2SL distribution. A total of 1000 replicas were generated for four sample sizes: and 500, using fixed values for parameters and q. The initial values to start the EM algorithm are and . Based on the stochastic representation given in Equation (11), random numbers can be generated from the S2SL model, leading to Algorithm 1.
| Algorithm 1 For simulating values from the distribution |
|
Table 2 shows the estimated mean for each parameter (Mean), together with their standard errors (SE), the root mean squared error (RMSE), and the coverage percentage (CP) of the ML estimators, based on a 95% confidence interval. It may be concluded from the results that the ML estimators are consistent. As the sample size increases, the estimation means draw progressively closer to the true value of the parameter. As might be expected, the values of the SE and the RMSE diminish and stabilize as the sample size increases, suggesting that the standard errors of the estimators are calculated correctly. The R codes are available in Appendix A.
Table 2.
Simulation study for the parameters of and q in the S2SL model.
4. Applications
In this section, we analyse two real datasets to evaluate the performance of the S2SL distribution in modelling data with high kurtosis. A comparison is made between the S2SL, 2SL, and LSD distributions, using the Akaike information criterion (AIC) presented in Akaike [28], and the Bayesian information criterion (BIC) proposed in Schwarz [29]. Below, we present the pdf of the LSD distribution (see Gui [17]):
4.1. Application 1: Patients with Acute Bone Cancer
The dataset contains the survival times (in days) of 73 patients diagnosed with acute bone cancer. The data were originally presented by Mansour et al. [30] and subsequently analysed by Klakattawi [31] and Alanzi et al. [32]. The dataset is available in the R software package [26] “ComRiskModel” with the “data_acutebcancer” database.
Table 3 presents the descriptive statistics of the data: sample mean, standard deviation, sample asymmetry and kurtosis coefficients. Figure 5 shows a boxplot for the patients with acute bone cancer dataset, which is seen to present atypical observations and high kurtosis ().
Table 3.
Descriptive statistics for the application to bone cancer patients.
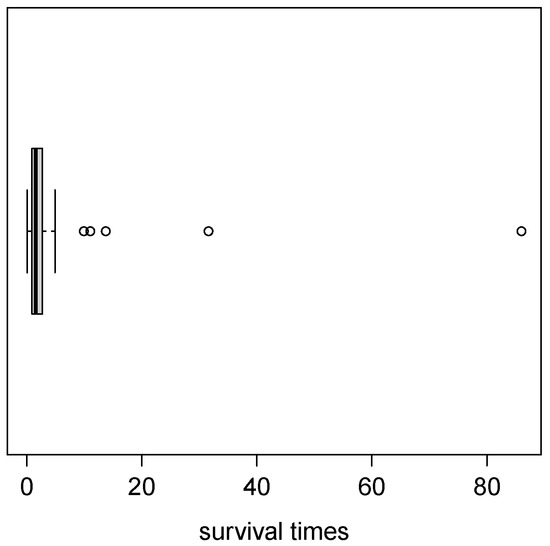
Figure 5.
Boxplot for the bone cancer dataset.
The moments estimators for the parameters of the S2SL model are and . These estimators were used as initial values to calculate the ML estimators. Table 4 shows the ML estimations with their standard errors and the AIC and BIC criteria. The S2SL distribution shows a better fit to the bone cancer patients dataset than the 2SL and LSD distributions, as the AIC and BIC values are smaller.
Table 4.
Estimations for the 2SL, LSD and S2SL distributions.
Figure 6 shows that the theoretical quantiles of the proposed S2SL model present a more exact fit to the quantiles of the survival data in the sample, when compared with the 2SL and LSD distributions. This supports the above finding, since according to the AIC and BIC selection criteria, the S2SL model presents a better fit to these dataset.
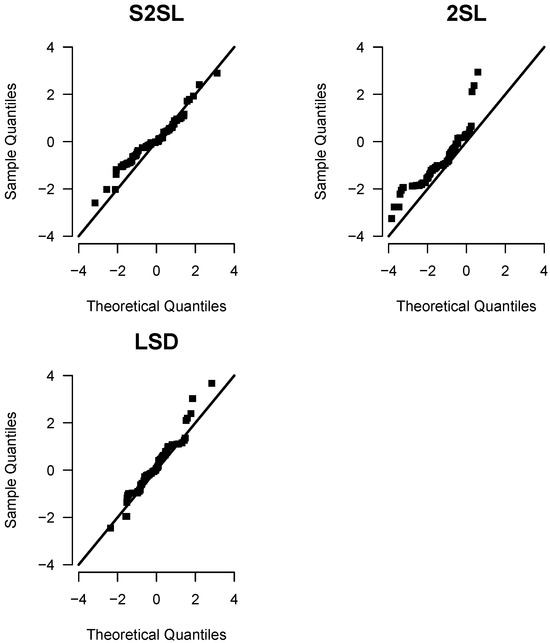
Figure 6.
QQ-plot for the S2SL, 2SL, and LSD distributions for the bone cancer patients dataset.
4.2. Application 2: Air Transceiver Repair Times
The second application is to a set of 46 repair times for an air communications transceiver, measured in hours. The complete dataset was taken from Jorgensen [33]. Table 5 shows the descriptive statistics for the repair times, which present high kurtosis. Figure 7 shows the boxplot of the dataset, in which the existence of outliers can also be appreciated.
Table 5.
Descriptive statistics for the application to repair times.
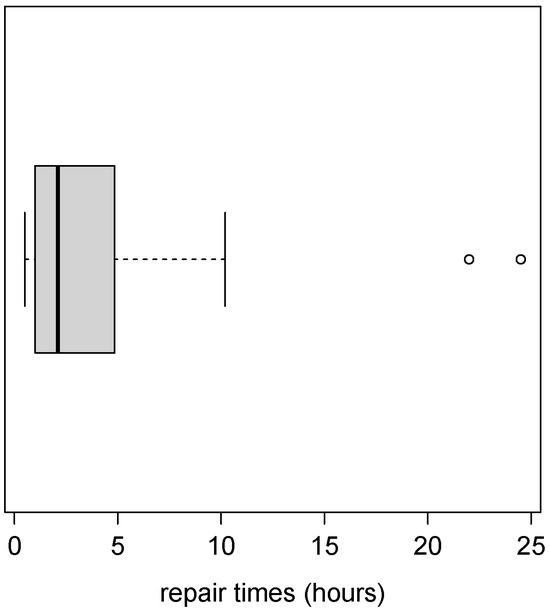
Figure 7.
Boxplot for repair times dataset.
The moments estimators used as starting points for estimation by ML of the S2SL distribution are and . Table 6 shows the ML estimates for the parameters, with their respective SE, and the values of the AIC and BIC criteria for each distribution compared. Figure 8 presents the QQ-plots for the 2SL, LSD and S2SL distributions. All these summaries and graphs enable us to conclude that the S2SL distribution provides the best fit to the repair times data.
Table 6.
ML estimates for the 2SL, LSD and S2SL distributions.
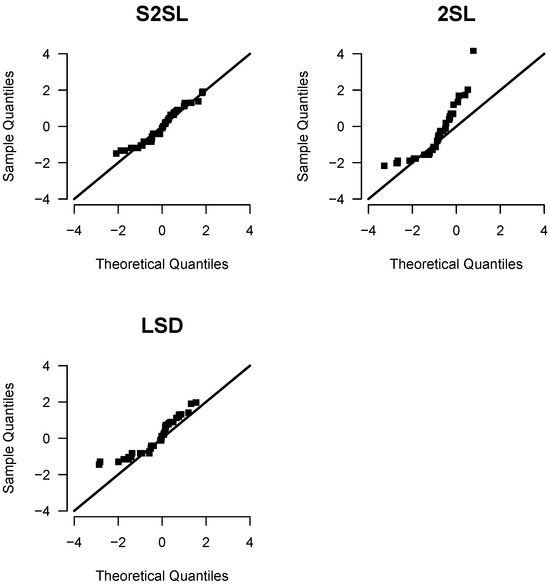
Figure 8.
QQ-plot for the S2SL, 2SL and LSD distributions for the repair times data.
5. Conclusions
In this work, we present the S2SL distribution, an extension of the 2SL distribution in which the slash methodology is used to increase its flexibility for modelling data with heavy tails and outlying observations. Some properties of this new distribution are obtained, and its parameters are estimated by the ML method using the EM algorithm. Below, we highlight some of the most important characteristics of the S2SL distribution:
- The S2SL distribution has two different stochastic representations, given in Equation (2) and Proposition 5.
- The expressions of the pdf, cdf, and hazard function are obtained, all of which have a closed form and are represented by the lower incomplete gamma function.
- When the coefficients of asymmetry and kurtosis are analysed, the S2SL model is shown to be more flexible than the 2SL model. Furthermore, as shown in Table 1, the distribution tails become heavier as parameter q diminishes.
- Implementation of the EM algorithm allows ML estimators for the model parameters to be obtained more efficiently.
- The simulation study shows that as the sample size is increased, the ML estimators draw progressively closer to the true values of the parameters, suggesting that the estimators are consistent and stable.
- In the applications to real data, the S2LS distribution is seen to provide a better fit to the data when compared with the 2SL and LSD distributions, reflected in lower values in the AIC and BIC criteria.
In future work, we will consider exploring Bayesian inference for model parameters using the Bayesian bootstrap algorithm described by Lyddon et al. [34], as it represents a relevant complementary approach to the methodology presented in this study.
Author Contributions
Conceptualization, H.A.M. and H.W.G.; methodology, D.I.G. and H.W.G.; software, J.S.C. and D.I.G.; validation, J.S.C., D.I.G. and O.V.; formal analysis, H.A.M. and H.W.G.; investigation, J.S.C.; writing—original draft preparation, H.A.M.; writing—review and editing, D.I.G., O.V. and H.W.G.; funding acquisition, D.I.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The dataset for Application 1 is available in the R software package [26]. Specific details can be found in the text. The dataset for Application 2 was taken from Jorgensen [33].
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Codes in R to reproduce the results.
- Density functionrm(list=ls(all=TRUE))x <- seq(0.04,15,0.006)library(expint)pdf_S2SL <- function(x,beta,q){G4 <- gamma(q+4)-gammainc(q+4,beta*x)G3 <- gamma(q+3)-gammainc(q+3,beta*x)G2 <- gamma(q+2)-gammainc(q+2,beta*x)((q*x^(-(q+1)))/(6*beta^q*(1+beta)^2))*(G4+6*beta*G3+6*beta^2*G2)}resultado1 <- pdf_S2SL(x,1,1)resultado2 <- pdf_S2SL(x,1,3)resultado3 <- pdf_S2SL(x,1,5)plot(x,resultado1,type="l",lty=1,lwd=2,xlab="x",ylab="Density",xlim=c(0,13),ylim=c(0,0.25),cex.lab=1.35,cex.axis=1.35)lines(x,resultado2,lty=2,lwd=2)lines(x,resultado3,lty=3,lwd=2)
- Hazard functionhazard_S2SL <- function(x, beta, q) {library(expint)x <- seq(0.04, 15, 0.006)G44 <- gamma(q+4)-gammainc(beta*x,q+4)G33 <- gamma(q+3)-gammainc(beta*x,q+3)G22 <- gamma(q+2)-gammainc(beta*x,q+2)G4 <- gamma(4)-gammainc(beta*x,4)G3 <- gamma(3)-gammainc(beta*x,3)G2 <- gamma(2)-gammainc(beta*x,2)numerator <- q*x^(-(q+1))*(G44+6*beta*(G33+beta*G22))denominator <- 6*beta^(q)*(1+beta)^2-x^(-q)*((beta*x)^q*(G4+6*beta*(beta*G2+G3))-6*beta*(beta*G22+G33)-G44)hazard <- numerator/denominatorreturn(hazard)}
- Asymmetry and kurtosis coefficientrm(list=ls(all=TRUE))library(plot3D)library(latex2exp)beta <- seq(3.1,15,length=40)q <- seq(3.1,15,length=40)beta2 <- seq(4.1,15,length=40)q2 <- seq(4.1,15,length=40)Skewness_S2SL <- function(beta,q){m1 <- (2*q*(beta+2))/(beta*(q-1)*(1+beta))m2 <- (2*q*(3*beta^2+12*beta+10))/(beta^2*(q-2)*(1+beta)^2)m3 <- (24*q*(beta^2+5*beta+5))/(beta^3*(q-3)*(1+beta)^2)(m3-3*m1*m2+2*m1^3)/((m2-m1^2)^(3/2))}Kurtosis_S2SL <- function(beta2,q2){m1 <- (2*q2*(beta2+2))/(beta2*(q2-1)*(1+beta2))m2 <- (2*q2*(3*beta2^2+12*beta2+10))/(beta2^2*(q2-2)*(1+beta2)^2)m3 <- (24*q2*(beta2^2+5*beta2+5))/(beta2^3*(q2-3)*(1+beta2)^2)m4 <- (120*q2*(beta2^2+6*beta2+7))/(beta2^4*(q2-4)*(1+beta2)^2)(m4-4*m1*m3+6*m1^2*m2-3*m1^4)/((m2-m1^2)^2)}Resultado_Skewness <- outer(beta,q,Vectorize(Skewness_S2SL))Resultado_Kurtosis <- outer(beta2,q2,Vectorize(Kurtosis_S2SL))persp(beta,q,Resultado_Skewness,theta=55,phi=20,col="#CAFF70",xlab=TeX(’$\\beta$’),ylab=TeX(’$q$’),zlab="Skewness",ticktype="detailed",nticks=4,shade=0.3,cex.lab=1.2,cex.axis=1.2,cex.main=1.2,cex.sub=1.2)persp(beta2,q2,Resultado_Kurtosis,theta=55,phi=20,col="#FFD700",xlab=TeX(’$\\beta$’),ylab=TeX(’$q$’),zlab="Kurtosis",ticktype="detailed",nticks=4,shade=0.3,cex.lab=1.2,cex.axis=1.2,cex.main=1.2,cex.sub=1.2)
- Simulation study for the S2SL distributionrm(list=ls(all=TRUE))library(knitr)library(pracma)set.seed(1234)replicas=1000b_true=4q_true=0.5muestra<-c(50,100,200,500)resultados<-list()for(J in muestra){cat("Processing sample size:",J,"\n")flush.console()bias.rep<-c()se.rep<-c()CP.rep<-c()est.rep<-c()for(j in 1:replicas){if(j%%100==0){cat("Replica:",j,"for sample size:",J,"\n")flush.console()}Z1<-rbinom(J,1,1/(1+b_true))Z2<-rbinom(J,1,1/(1+b_true))U<-rbeta(J,q_true,1)shape_Y<-2+Z1+Z2rate_Y<-b_true*Ux<-rgamma(J,shape=shape_Y,rate=rate_Y)beta_last=1q_last=1dif=1max.iter=10000i<-1n<-length(x)while(i<=max.iter&dif>0.0001){u<-numeric(n)k<-numeric(n)for(j in 1:n){g2<-gamma(2+q_last)g3<-gamma(3+q_last)g4<-gamma(4+q_last)G2<-pgamma(x[j]*beta_last,q_last+2)G3<-pgamma(x[j]*beta_last,q_last+3)G4<-pgamma(x[j]*beta_last,q_last+4)G5<-pgamma(x[j]*beta_last,q_last+5)Sumf<-g2*G2+(g3*G3)/beta_last+((g4*G4)/(6*(beta_last)^2))u[j]<-(1/(x[j]*beta_last*Sumf))*(g2*G3*(2+q_last)+((g3*(3+q_last)*G4)/beta_last)+((g4*(4+q_last)*G5)/(6*beta_last^2)))int1<-integrate(function(w) log(w)*w^(q_last+1)*exp(-w),0,x[j]*beta_last)$valueint2<-integrate(function(w) log(w)*w^(q_last+2)*exp(-w),0,x[j]*beta_last)$valueint3<-integrate(function(w) log(w)*w^(q_last+3)*exp(-w),0,x[j]*beta_last)$valuek[j]<--log(x[j]*beta_last)+int1/Sumf+int2/(beta_last*Sumf)+int3/(6*((beta_last)^2)*Sumf)}q_new<--n/sum(k)solve_beta<-function(beta_val){(4*n/beta_val)-(2*n)/(1+beta_val)-sum(x*u)}result<-uniroot(solve_beta,interval=c(0.01,100))beta_new<-result$rootdif<-max(abs(c(beta_new,q_new)-c(beta_last,q_last)))beta_last<-beta_newq_last<-q_newi<-i+1}param<-cbind(beta_last,q_last)loglike<-function(theta,x,t.param=TRUE){beta=theta[1]q=theta[2]if(t.param){beta=exp(theta[1]);q=exp(theta[2])}ll=log(q)-(q+1)*log(x)-log(6)-q*log(beta)-2*log1p(beta)+log(exp(pgamma(beta*x,shape=q+4,log.p=TRUE)+lgamma(q+4))+6*beta*(exp(pgamma(beta*x,shape=q+3,log.p=TRUE)+lgamma(q+3))+beta*exp(pgamma(beta*x,shape=q+2,log.p=TRUE)+lgamma(q+2))))-sum(ll)}H<-hessian(loglike,x0=param,x=x,t.param=FALSE)var.est<-diag(solve(H))if(min(var.est)>0){bias.rep<-rbind(bias.rep,param-c(b_true,q_true))se.rep<-rbind(se.rep,sqrt(var.est))est.rep<-rbind(est.rep,param)lim.inf<-param-1.96*sqrt(var.est)lim.sup<-param+1.96*sqrt(var.est)cp.aux<-as.numeric(c(b_true,q_true)>lim.inf&c(b_true,q_true)<lim.sup)CP.rep<-rbind(CP.rep,cp.aux)}}est_mean<-round(apply(est.rep,2,mean),3)se_prom<-round(apply(se.rep,2,mean),3)rmse<-round(sqrt(apply(bias.rep^2,2,mean)),3)cp_prom<-round(apply(CP.rep,2,mean),3)resultados[[as.character(J)]]<-cbind(est_mean,se_prom,rmse,cp_prom)}tabla_resultados<-as.matrix(do.call(cbind,resultados))tabla_latex<-kable(tabla_resultados,format="latex",booktabs=TRUE,digits=3)print(tabla_latex)
References
- Jonhson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Wiley: New York, NY, USA, 1995; Volume 1. [Google Scholar]
- Rogers, W.H.; Tukey, J.W. Understanding some long-tailed symmetrical distributions. Stat. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Mosteller, F.; Tukey, J.W. Data Analysis and Regression; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Kafadar, K. A biweight approach to the one-sample problem. J. Am. Statist. Assoc. 1982, 77, 416–424. [Google Scholar] [CrossRef]
- Wang, J.; Genton, M.G. The multivariate skew-slash distribution. J. Stat. Plan. Inference 2006, 136, 209–220. [Google Scholar] [CrossRef]
- Gómez, H.W.; Quintana, F.A.; Torres, F.J. A New Family of Slash-Distributions with Elliptical Contours. Stat. Probab. Lett. 2007, 77, 717–725, Erratum in Erratum in Stat. Probab. Lett. 2008, 78, 2273–2274. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the half-normal distribution. Stat. Pap. 2012, 53, 875–886. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Bolfarine, H.; Gómez, H.W. An extension of the generalized half-normal distribution. Stat. Pap. 2014, 55, 967–981. [Google Scholar] [CrossRef]
- Astorga, J.M.; Reyes, J.; Santoro, K.I.; Venegas, O.; Gómez, H.W. A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function. Mathematics 2020, 8, 1537. [Google Scholar] [CrossRef]
- Rivera, P.A.; Barranco-Chamorro, I.; Gallardo, D.I.; Gómez, H.W. Scale Mixture of Rayleigh Distribution. Mathematics 2020, 8, 1842. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its applications. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Ghitany, M.; Al-Mutairi, D.; Balakrishnan, N.; Al-Enezi, I. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Calderin-Ojeda, E. The discrete Lindley distribution: Properties and application. J. Stat. Comput. Simul. 2011, 81, 1405–1416. [Google Scholar] [CrossRef]
- Krishna, H.; Kumar, K. Reliability estimation in Lindley distribution with progressively type II right censored sample. Math. Comput. Simul. 2011, 82, 281–294. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Al-Zaharani, B.; Al-Shomrani, A.; Marchi, V.; Louzada, F. An extended Lindley distribution. J. Korean Stat. Soc. 2012, 41, 75–85. [Google Scholar] [CrossRef]
- Gui, W. Statistical properties and applications of the Lindley slash distribution. J. Appl. Statist. Sci. 2012, 20, 283–298. [Google Scholar]
- Oluyede, B.O.; Yang, T. A new class of generalized Lindley distribution with applications. J. Stat. Comput. Simul. 2014, 85, 2072–2100. [Google Scholar] [CrossRef]
- Shanker, R.; Hagos, F.; Sujatha, S. On modeling of Lifetimes data using exponential and Lindley distributions. Biom. Biostat. Int. J. 2015, 2, 140–147. [Google Scholar] [CrossRef]
- Abouammoh, A.M.; Alshangiti, A.M.; Ragab, I.E. A new generalized Lindley distribution. J. Stat. Comput. Simul. 2015, 85, 3662–3678. [Google Scholar] [CrossRef]
- Tomy, L. A retrospective study on Lindley distribution. Biom. Biostat. Int. J. 2018, 7, 163–169. [Google Scholar] [CrossRef][Green Version]
- Chesneau, C.; Tomy, L.; Gillariose, J. On a Sum and Difference of two Lindley Distributions: Theory and Applications. REVSTAT 2020, 18, 673–695. [Google Scholar]
- Rolski, T.; Schmidli, H.; Schmidt, V.; Teugel, J. Stochastic Processes for Insurance and Finance; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Bingham, N. Regular Variation; Cambridge University Press: Cambridge, UK, 1987. [Google Scholar]
- Milgram, M.S. The generalized integro-exponential function. Math. Comput. 1985, 44, 443–458. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.r-project.org/ (accessed on 16 October 2024).
- Dempster, A.P.; Laird, N.M.; Rubim, D.B. Maximum likelihood from incomplete data via the EM algorithm (with discussion). J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Automat. Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Mansour, M.; Yousof, H.M.; Shehata, W.A.; Ibrahim, M. A new two parameters Burr XII distribution: Properties, copula, different estimation methods and modeling acute bone cancer data. J. Nonlinear Sci. Appl. 2020, 13, 223–238. [Google Scholar] [CrossRef]
- Klakattawi, H.S. Survival analysis of cancer patients using a new extended Weibull distribution. PLoS ONE 2022, 17, e0264229. [Google Scholar] [CrossRef]
- Alanzi, A.R.; Imran, M.; Tahir, M.H.; Chesneau, C.; Jamal, F.; Shakoor, S.; Sami, W. Simulation analysis, properties and applications on a new Burr XII model based on the Bell-X functionalities. AIMS Math. 2023, 8, 6970–7004. [Google Scholar] [CrossRef]
- Jorgensen, B. Statistical Properties of the Generalized Inverse Gaussian Distribution; Lecture Notes in Statistics; Springer: New York, NY, USA, 1982. [Google Scholar]
- Lyddon, S.P.; Holmes, C.C.; Walker, S.G. General bayesian updating and the loss-likelihood bootstrap. Biometrika 2019, 106, 465–478. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).