A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems



Abstract
1. Introduction
2. Related Work
3. Employed Dataset
4. Discussion on the Input Features
5. Architecture of the CNN
Training of the CNN
6. Performance Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Ageing & Life Course Unit. In WHO Global Report on Falls Prevention in Older Age; World Health Organization: Geneva, Switzerland, 2008. [Google Scholar]
- Fleming, J.; Brayne, C. Inability to get up after falling, subsequent time on floor, and summoning help: Prospective cohort study in people over 90. BMJ 2008, 337, 1279–1282. [Google Scholar] [CrossRef] [PubMed]
- Wild, D.; Nayak, U.S.; Isaacs, B. How dangerous are falls in old people at home? Br. Med. J. (Clin. Res. Ed.) 1981, 282, 266–268. [Google Scholar] [CrossRef] [PubMed]
- Van De Ven, P.; O’Brien, H.; Nelson, J.; Clifford, A. Unobtrusive monitoring and identification of fall accidents. Med. Eng. Phys. 2015, 37, 499–504. [Google Scholar] [CrossRef] [PubMed]
- Florence, C.S.; Bergen, G.; Atherly, A.; Burns, E.; Stevens, J.; Drake, C. Medical Costs of Fatal and Nonfatal Falls in Older Adults. J. Am. Geriatr. Soc. 2018, 66, 693–698. [Google Scholar] [CrossRef] [PubMed]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Igual, R.; Medrano, C.; Plaza, I. Challenges, issues and trends in fall detection systems. Biomed. Eng. Online 2013, 12, 66. [Google Scholar] [CrossRef]
- Chaccour, K.; Darazi, R.; El Hassani, A.H.; Andres, E. From Fall Detection to Fall Prevention: A Generic Classification of Fall-Related Systems. IEEE Sens. J. 2017, 17, 812–822. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, H.; Wang, Y.; Ma, J. Anti-Fall: A Non-intrusive and Real-time Fall Detector Leveraging CSI from Commodity WiFi Devices. In Proceedings of the International Conference on Smart Homes and Health Telematics (ICOST’2015), Geneva, Switzerland, 10–12 June 2015; Volume 9102, pp. 181–193. [Google Scholar]
- Casilari, E.; Luque, R.; Morón, M. Analysis of android device-based solutions for fall detection. Sensors 2015, 15, 17827–17894. [Google Scholar] [CrossRef]
- Aziz, O.; Musngi, M.; Park, E.J.; Mori, G.; Robinovitch, S.N. A comparison of accuracy of fall detection algorithms (threshold-based vs. machine learning) using waist-mounted tri-axial accelerometer signals from a comprehensive set of falls and non-fall trials. Med. Biol. Eng. Comput. 2017, 55, 45–55. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ordóñez, F.; Roggen, D.; Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, convolutional, and recurrent models for human activity recognition using wearable. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (AAAI), New York, NY, USA, 9–15 July 2016; pp. 1533–1540. [Google Scholar]
- He, J.; Zhang, Z.; Wang, X.; Yang, S. A low power fall sensing technology based on fd-cnn. IEEE Sens. J. 2019, 19, 5110–5118. [Google Scholar] [CrossRef]
- Sucerquia, A.; López, J.D.; Vargas-bonilla, J.F. SisFall: A Fall and Movement Dataset. Sensors 2017, 17, 198. [Google Scholar] [CrossRef] [PubMed]
- SisFall Dataset (SISTEMIC Research Group, University of Antioquia, Colombia). Available online: http://sistemic.udea.edu.co/en/investigacion/proyectos/english-falls/ (accessed on 12 February 2020).
- Casilari-Pérez, E.; García-Lagos, F. A comprehensive study on the use of artificial neural networks in wearable fall detection systems. Expert Syst. Appl. 2019, 138, 112811. [Google Scholar] [CrossRef]
- Pierleoni, P.; Belli, A.; Palma, L.; Pellegrini, M.; Pernini, L.; Valenti, S. A High Reliability Wearable Device for Elderly Fall Detection. IEEE Sens. J. 2015, 15, 4544–4553. [Google Scholar] [CrossRef]
- Tomkun, J.; Nguyen, B. Design of a Fall Detection and Prevention System for the Elderly. Master’s Thesis, McMaster University, Hamilton, ON, Canada, 2010. [Google Scholar]
- Ge, W.; Shuwan, X. Portable Preimpact Fall Detector with Inertial Sensors. IEEE Trans. Neural Syst. Rehabil. Eng. 2008, 16, 178–183. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.K.; Robinovitch, S.N.; Park, E.J. Inertial Sensing-Based Pre-Impact Detection of Falls Involving Near-Fall Scenarios. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 258–266. [Google Scholar] [CrossRef]
- Felisberto, F.; Fdez-Riverola, F.; Pereira, A. A ubiquitous and low-cost solution for movement monitoring and accident detection based on sensor fusion. Sensors 2014, 14, 8961–8983. [Google Scholar] [CrossRef]
- Mao, A.; Ma, X.; He, Y.; Luo, J. Highly portable, sensor-based system for human fall monitoring. Sensors 2017, 17, 2096. [Google Scholar] [CrossRef]
- Chang, S.-Y.; Lai, C.-F.; Chao, H.-C.J.; Park, J.H.; Huang, Y.-M. An environmental-adaptive fall detection system on mobile device. J. Med. Syst. 2011, 35, 1299–1312. [Google Scholar] [CrossRef]
- Dai, J.; Bai, X.; Yang, Z.; Shen, Z.; Xuan, D. Mobile phone-based pervasive fall detection. Pers. Ubiquitous Comput. 2010, 14, 633–643. [Google Scholar] [CrossRef]
- Nyan, M.N.; Tay, F.E.H.; Tan, A.W.Y.; Seah, K.H.W. Distinguishing fall activities from normal activities by angular rate characteristics and high-speed camera characterization. Med. Eng. Phys. 2006, 28, 842–849. [Google Scholar] [CrossRef] [PubMed]
- Kepski, M.; Kwolek, B.; Austvoll, I. Fuzzy inference-based reliable fall detection using kinect and accelerometer. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2012; Volume 7267 LNAI, pp. 266–273. ISBN 9783642293467. [Google Scholar]
- Ando, B.; Baglio, S.; Lombardo, C.O.; Marletta, V. A multisensor data-fusion approach for ADL and fall classification. IEEE Trans. Instrum. Meas. 2016, 65, 1960–1967. [Google Scholar] [CrossRef]
- Astriani, M.S.; Heryadi, Y.; Kusuma, G.P.; Abdurachman, E. Human fall detection using accelerometer and gyroscope sensors in unconstrained smartphone positions. Int. J. Recent Technol. Eng. 2019, 8, 69–75. [Google Scholar]
- Baek, W.S.; Kim, D.M.; Bashir, F.; Pyun, J.Y. Real life applicable fall detection system based on wireless body area network. In Proceedings of the 2013 IEEE 10th Consumer Communications and Networking Conference (CCNC 2013), Las Vegas, NV, USA, 11–14 January 2013; pp. 62–67. [Google Scholar]
- Bourke, A.K.; O’Donovan, K.J.; Olaighin, G. The identification of vertical velocity profiles using an inertial sensor to investigate pre-impact detection of falls. Med. Eng. Phys. 2008, 30, 937–946. [Google Scholar] [CrossRef]
- Bourke, A.K.; Lyons, G.M. A threshold-based fall-detection algorithm using a bi-axial gyroscope sensor. Med. Eng. Phys. 2008, 30, 84–90. [Google Scholar] [CrossRef]
- Boutellaa, E.; Kerdjidj, O.; Ghanem, K. Covariance matrix based fall detection from multiple wearable sensors. J. Biomed. Inform. 2019, 94, 103189. [Google Scholar] [CrossRef]
- Chen, G.C.; Huang, C.N.; Chiang, C.Y.; Hsieh, C.J.; Chan, C.T. A reliable fall detection system based on wearable sensor and signal magnitude area for elderly residents. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; Volume 6159 LNCS, pp. 267–270. ISBN 3642137776. [Google Scholar]
- Chernbumroong, S.; Cang, S.; Yu, H. Genetic algorithm-based classifiers fusion for multisensor activity recognition of elderly people. IEEE J. Biomed. Health Inform. 2015, 19, 282–289. [Google Scholar] [CrossRef]
- Choi, Y.; Ralhan, A.S.; Ko, S. A study on machine learning algorithms for fall detection and movement classification. In Proceedings of the 2011 International Conference on Information Science and Applications (ICISA 2011), Jeju Island, South Korea, 26–29 April 2011. [Google Scholar]
- Dau, H.A.; Salim, F.D.; Song, A.; Hedin, L.; Hamilton, M. Phone based fall detection by genetic programming. In Proceedings of the 13th International Conference on Mobile and Ubiquitous Multimedia (MUM), Melbourne, Australia, 25–27 November 2014; pp. 256–257. [Google Scholar]
- De Cillis, F.; De Simio, F.; Guido, F.; Incalzi, R.A.; Setola, R. Fall-detection solution for mobile platforms using accelerometer and gyroscope data. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Milan, Italy, 25–29 August 2015; Institute of Electrical and Electronics Engineers Inc.: Milan, Italy, 2015; pp. 3727–3730. [Google Scholar]
- Dinh, T.A.; Chew, M.T. Application of a commodity smartphone for fall detection. In Proceedings of the 6th International Conference on Automation, Robotics and Applications (ICARA 2015), Queenstown, New Zealand, 17–19 February 2015; IEEE: Queenstown, New Zealand, 2015; pp. 495–500. [Google Scholar]
- Dinh, A.; Teng, D.; Chen, L.; Shi, Y.; McCrosky, C.; Basran, J.; Del Bello-Hass, V. Implementation of a physical activity monitoring system for the elderly people with built-in vital sign and fall detection. In Proceedings of the 6th International Conference on Information Technology: New Generations (ITNG 2009), Las Vegas, NV, USA, 27–29 April 2009; pp. 1226–1231. [Google Scholar]
- Dinh, A.; Shi, Y.; Teng, D.; Ralhan, A.; Chen, L.; Dal Bello-Haas, V.; Basran, J.; Ko, S.-B.; McCrowsky, C. A fall and near-fall assessment and evaluation system. Open Biomed. Eng. J. 2009, 3, 1–7. [Google Scholar] [CrossRef]
- Dzeng, R.J.; Fang, Y.C.; Chen, I.C. A feasibility study of using smartphone built-in accelerometers to detect fall portents. Autom. Constr. 2014, 38, 74–86. [Google Scholar] [CrossRef]
- Figueiredo, I.N.; Leal, C.; Pinto, L.; Bolito, J.; Lemos, A. Exploring smartphone sensors for fall detection. mUX J. Mob. User Exp. 2016, 5, 2. [Google Scholar] [CrossRef]
- Guo, H.W.; Hsieh, Y.T.; Huang, Y.S.; Chien, J.C.; Haraikawa, K.; Shieh, J.S. A threshold-based algorithm of fall detection using a wearable device with tri-axial accelerometer and gyroscope. In Proceedings of the International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS 2015), Okinawa, Japan, 28–30 November 2015; IEEE: Okinawa, Japan, 2015; pp. 54–57. [Google Scholar]
- Hakim, A.; Huq, M.S.; Shanta, S.; Ibrahim, B.S.K.K. Smartphone Based Data Mining for Fall Detection: Analysis and Design. Procedia Comput. Sci. 2017, 105, 46–51. [Google Scholar] [CrossRef]
- He, J.; Hu, C.; Wang, X. A Smart Device Enabled System for Autonomous Fall Detection and Alert. Int. J. Distrib. Sens. Networks 2016, 12, 2308183. [Google Scholar] [CrossRef]
- He, Y.; Li, Y. Physical Activity Recognition Utilizing the Built-In Kinematic Sensors of a Smartphone. Int. J. Distrib. Sens. Networks 2013, 9, 481580. [Google Scholar] [CrossRef]
- Huynh, Q.T.; Nguyen, U.D.; Irazabal, L.B.; Ghassemian, N.; Tran, B.Q. Optimization of an Accelerometer and Gyroscope-Based Fall Detection Algorithm. J. Sensors 2015, 2015, 1–8. [Google Scholar] [CrossRef]
- Hwang, J.Y.; Kang, J.M.; Jang, Y.W.; Kim, H.C. Development of novel algorithm and real-time monitoring ambulatory system using Bluetooth module for fall detection in the elderly. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology, San Francisco, CA, USA, 1–5 September 2004; pp. 2204–2207. [Google Scholar]
- Lai, C.F.; Chen, M.; Pan, J.S.; Youn, C.H.; Chao, H.C. A collaborative computing framework of cloud network and WBSN applied to fall detection and 3-D motion reconstruction. IEEE J. Biomed. Health Inform. 2014, 18, 457–466. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Stankovic, J.A.; Hanson, M.A.; Barth, A.T.; Lach, J.; Zhou, G. Accurate, fast fall detection using gyroscopes and accelerometer-derived posture information. In Proceedings of the 6th International Workshop on Wearable and Implantable Body Sensor Networks (BSN 2009), Berkeley, CA, USA, 3–5 June 2009; pp. 138–143. [Google Scholar]
- Majumder, A.J.A.; Zerin, I.; Uddin, M.; Ahamed, S.I.; Smith, R.O. SmartPrediction: A real-time smartphone-based fall risk prediction and prevention system. In Proceedings of the 2013 Research in Adaptive and Convergent Systems (RACS 2013), Montreal, QC, Canada, 1–4 October 2013; ACM: Montreal, QC, Canada, 2013; pp. 434–439. [Google Scholar]
- Majumder, A.J.A.; Rahman, F.; Zerin, I.; Ebel, W., Jr.; Ahamed, S.I. iPrevention: Towards a novel real-time smartphone-based fall prevention system. In Proceedings of the 28th Annual ACM Symposium on Applied Computing (SAC 2013), Coimbra, Portugal, 18–22 March 2013; ACM: Coimbra, Portugal, 2013; pp. 513–518. [Google Scholar]
- Martínez-Villaseñor, L.; Ponce, H.; Espinosa-Loera, R.A. Multimodal Database for Human Activity Recognition and Fall Detection. In Proceedings of the 12th International Conference on Ubiquitous Computing and Ambient Intelligence (UCAmI 2018), Punta Cana, Dominican Republic, 4–7 December 2018; Volume 2. [Google Scholar]
- Nari, M.I.; Suprapto, S.S.; Kusumah, I.H.; Adiprawita, W. A simple design of wearable device for fall detection with accelerometer and gyroscope. In Proceedings of the 2016 International Symposium on Electronics and Smart Devices (ISESD 2016), Bandung, Indonesia, 29–30 November 2017; pp. 88–91. [Google Scholar]
- Ntanasis, P.; Pippa, E.; Özdemir, A.T.; Barshan, B.; Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare (MobiHealth 2016), Milan, Italy, 14–16 November 2016; Springer: Milan, Italy, 2016; pp. 225–232. [Google Scholar]
- Nyan, M.N.; Tay, F.E.H.; Murugasu, E. A wearable system for pre-impact fall detection. J. Biomech. 2008, 41, 3475–3481. [Google Scholar] [CrossRef] [PubMed]
- Ojetola, O.; Gaura, E.I.; Brusey, J. Fall Detection with Wearable Sensors—Safe (Smart Fall Detection). In Proceedings of the 7th International Conference on Intelligent Environments, Nottingham, UK, 25–28 July 2011; pp. 318–321. [Google Scholar]
- Özdemir, A.T. An analysis on sensor locations of the human body for wearable fall detection devices: Principles and practice. Sensors 2016, 16, 1161. [Google Scholar] [CrossRef] [PubMed]
- Park, C.; Suh, J.W.; Cha, E.J.; Bae, H.D. Pedestrian navigation system with fall detection and energy expenditure calculation. In Proceedings of the IEEE Instrumentation and Measurement Technology Conference, Binjiang, China, 10–12 May 2011; pp. 841–844. [Google Scholar]
- De Quadros, T.; Lazzaretti, A.E.; Schneider, F.K. A Movement Decomposition and Machine Learning-Based Fall Detection System Using Wrist Wearable Device. IEEE Sens. J. 2018, 18, 5082–5089. [Google Scholar] [CrossRef]
- Rakhecha, S.; Hsu, K. Reliable and secure body fall detection algorithm in a wireless mesh network. In Proceedings of the 8th International Conference on Body Area Networks (BODYNETS 2013), Boston, MA, USA, 30 September–2 October 2013; ICST: Boston, MA, USA, 2013; pp. 420–426. [Google Scholar]
- Rungnapakan, T.; Chintakovid, T.; Wuttidittachotti, P. Fall detection using accelerometer, gyroscope & impact force calculation on android smartphones. In Proceedings of the 4th International Conference on Human-Computer Interaction and User Experience in Indonesia (CHIuXiD ’18), Yogyakarta, Indonesia, 23–29 March 2018; Association for Computing Machinery: Yogyakarta, Indonesia, 2018; pp. 49–53. [Google Scholar]
- Santiago, J.; Cotto, E.; Jaimes, L.G.; Vergara-Laurens, I. Fall detection system for the elderly. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; Institute of Electrical and Electronics Engineers Inc.: Las Vegas, NV, USA, 2017. [Google Scholar]
- Sorvala, A.; Alasaarela, E.; Sorvoja, H.; Myllyla, R. A two-threshold fall detection algorithm for reducing false alarms. In Proceedings of the 2012 6th International Symposium on Medical Information and Communication Technology (ISMICT 2012), La Jolla, CA, USA, 25–29 March 2012. [Google Scholar]
- Tamura, T.; Yoshimura, T.; Sekine, M.; Uchida, M.; Tanaka, O. A Wearable Airbag to Prevent Fall Injuries. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 910–914. [Google Scholar] [CrossRef]
- Wibisono, W.; Arifin, D.N.; Pratomo, B.A.; Ahmad, T.; Ijtihadie, R.M. Falls Detection and Notification System Using Tri-axial Accelerometer and Gyroscope Sensors of a Smartphone. In Proceedings of the 2013 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taipei, Taiwan, 6–8 December 2013; IEEE: Taipei, Taiwan, 2013; pp. 382–385. [Google Scholar]
- Yang, B.-S.; Lee, Y.-T.; Lin, C.-W. On Developing a Real-Time Fall Detecting and Protecting System Using Mobile Device. In Proceedings of the International Conference on Fall Prevention and Protection (ICFPP 2013), Tokyo, Japan, 23–25 October 2013; pp. 151–156. [Google Scholar]
- Zhao, G.; Mei, Z.; Liang, D.; Ivanov, K.; Guo, Y.; Wang, Y.; Wang, L. Exploration and Implementation of a Pre-Impact Fall Recognition Method Based on an Inertial Body Sensor Network. Sensors 2012, 12, 15338–15355. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Mehmood, N.; Nadeem, A.; Mehmood, A.; Rizwan, K. Fall detection system for the elderly based on the classification of shimmer sensor prototype data. Healthc. Inform. Res. 2017, 23, 147–158. [Google Scholar] [CrossRef] [PubMed]
- Chelli, A.; Patzold, M. A Machine Learning Approach for Fall Detection and Daily Living Activity Recognition. IEEE Access 2019, 7, 38670–38687. [Google Scholar] [CrossRef]
- Ghazal, M.; Khalil, Y.A.; Dehbozorgi, F.J.; Alhalabi, M.T. An integrated caregiver-focused mHealth framework for elderly care. In Proceedings of the 2015 IEEE 11th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Abu Dhabi, UAE, 19–21 October 2015; IEEE: Abu Dhabi, UAE, 2015; pp. 238–245. [Google Scholar]
- Nukala, B.T.; Shibuya, N.; Rodriguez, A.I.; Tsay, J.; Nguyen, T.Q.; Zupancic, S.; Lie, D.Y.C. A real-time robust fall detection system using a wireless gait analysis sensor and an Artificial Neural Network. In Proceedings of the 2014 IEEE Healthcare Innovation Conference (HIC), Seattle, WA, USA, 8–10 October 2014; IEEE: Seattle, WA, USA, 2014; pp. 219–222. [Google Scholar]
- Özdemir, A.T.; Barshan, B. Detecting Falls with Wearable Sensors Using Machine Learning Techniques. Sensors 2014, 14, 10691–10708. [Google Scholar] [CrossRef]
- Rashidpour, M.; Abdali-Mohammadi, F.; Fathi, A. Fall detection using adaptive neuro-fuzzy inference system. Int. J. Multimed. Ubiquitous Eng. 2016, 11, 91–106. [Google Scholar]
- Wang, S.; Zhang, X. An approach for fall detection of older population based on multi-sensor data fusion. In Proceedings of the 2015 12th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang, South Korea, 28–30 October 2015; IEEE: Goyang, South Korea, 2015; pp. 320–323. [Google Scholar]
- Yang, S.-H.; Zhang, W.; Wang, Y.; Tomizuka, M. Fall-prediction algorithm using a neural network for safety enhancement of elderly. In Proceedings of the 2013 CACS International Automatic Control Conference (CACS), Nantou, Taiwan, 2–4 December 2013; IEEE: Nantou, Taiwan, 2013; pp. 245–249. [Google Scholar]
- Yodpijit, N.; Sittiwanchai, T.; Jongprasithporn, M. The development of Artificial Neural Networks (ANN) for falls detection. In Proceedings of the 2017 3rd International Conference on Control, Automation and Robotics (ICCAR), Nagoya, Japan, 24–26 April 2017; IEEE: Nagoya, Japan, 2017; pp. 547–550. [Google Scholar]
- Bianchi, F.; Redmond, S.J.; Narayanan, M.R.; Cerutti, S.; Lovell, N.H. Barometric pressure and triaxial accelerometry-based falls event detection. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 619–627. [Google Scholar] [CrossRef]
- Perry, J.T.; Kellog, S.; Vaidya, S.M.; Youn, J.-H.; Ali, H.; Sharif, H. Survey and evaluation of real-time fall detection approaches. In Proceedings of the 6th International Symposium on High-Capacity Optical Networks and Enabling Technologies (HONET 2009), Alexandria, Egypt, 28–30 December 2009; IEEE: Alexandria, Egypt, 2009; pp. 158–164. [Google Scholar]
- Becker, C.; Schwickert, L.; Mellone, S.; Bagalà, F.; Chiari, L.; Helbostad, J.L.; Zijlstra, W.; Aminian, K.; Bourke, A.; Todd, C.; et al. Proposal for a multiphase fall model based on real-world fall recordings with body-fixed sens. Z. Gerontol. Geriatr. 2012, 45, 707–715. [Google Scholar] [CrossRef]
- Viet, V.Q.; Lee, G.; Choi, D. Fall Detection Based on Movement and Smart Phone Technology. In Proceedings of the EEE RIVF International Conference on Computing and Communication Technologies, Research, Innovation, and Vision for the Future (RIVF 2012), Ho Chi Minh City, Vietnam, 27 February–1 March 2012; IEEE: Ho Chi Minh City, Vietnam, 2012; pp. 1–4. [Google Scholar]
- Tsinganos, P.; Skodras, A. On the Comparison of Wearable Sensor Data Fusion to a Single Sensor Machine Learning Technique in Fall Detection. Sensors 2018, 18, 592. [Google Scholar] [CrossRef]
- Abbate, S.; Avvenuti, M.; Corsini, P.; Light, J.; Vecchio, A. Monitoring of Human Movements for Fall Detection and Activities Recognition in Elderly Care Using Wireless Sensor Network: A survey. Wireless Sensor Networks: Application-Centric Design; Tan, Y.K., Merrett, G., Eds.; InTech, 2010. Available online: https://www.intechopen.com/books/wireless-sensor-networks-application-centric-design/monitoring-of-human-movements-for-fall-detection-and-activities-recognition-in-elderly-care-using-wi (accessed on 1 April 2020). [CrossRef]
- Lorincz, K.; Chen, B.; Challen, G.W.; Chowdhury, A.R.; Patel, S.; Bonato, P.; Welsh, M. Mercury: A Wearable Sensor Network Platform for High-Fidelity Motion Analysis. In Proceedings of the 7th International Conference on Embedded Networked Sensor Systems (SenSys 2009), Berkeley, CA, USA, 4–6 November 2009. [Google Scholar]
- Nguyen Gia, T.; Sarker, V.K.; Tcarenko, I.; Rahmani, A.M.; Westerlund, T.; Liljeberg, P.; Tenhunen, H. Energy efficient wearable sensor node for IoT-based fall detection systems. Microprocess. Microsyst. 2018, 56, 34–46. [Google Scholar] [CrossRef]
- Kangas, M.; Vikman, I.; Nyberg, L.; Korpelainen, R.; Lindblom, J.; Jämsä, T. Comparison of real-life accidental falls in older people with experimental falls in middle-aged test subjects. Gait Posture 2012, 35, 500–505. [Google Scholar] [CrossRef]
- Klenk, J.; Becker, C.; Lieken, F.; Nicolai, S.; Maetzler, W.; Alt, W.; Zijlstra, W.; Hausdorff, J.M.; Van Lummel, R.C.; Chiari, L. Comparison of acceleration signals of simulated and real-world backward falls. Med. Eng. Phys. 2011, 33, 368–373. [Google Scholar] [CrossRef] [PubMed]
- Jämsä, T.; Kangas, M.; Vikman, I.; Nyberg, L.; Korpelainen, R. Fall detection in the older people: From laboratory to real-life. Proc. Est. Acad. Sci. 2014, 63, 341–345. [Google Scholar] [CrossRef]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. Analysis of public datasets for wearable fall detection systems. Sensors 2017, 17, 1513. [Google Scholar] [CrossRef] [PubMed]
- Frank, K.; Vera Nadales, M.J.; Robertson, P.; Pfeifer, T. Bayesian recognition of motion related activities with inertial sensors. In Proceedings of the 12th ACM International Conference on Ubiquitous Computing (ACM), Copenhagen, Denmark, 26–29 September 2010; pp. 445–446. [Google Scholar]
- Ojetola, O.; Gaura, E.; Brusey, J. Data Set for Fall Events and Daily Activities from Inertial Sensors. In Proceedings of the 6th ACM Multimedia Systems Conference (MMSys’15), Portland, OR, USA, 18–20 March 2015; pp. 243–248. [Google Scholar]
- Vavoulas, G.; Pediaditis, M.; Spanakis, E.G.; Tsiknakis, M. The MobiFall dataset: An initial evaluation of fall detection algorithms using smartphones. In Proceedings of the IEEE 13th International Conference on Bioinformatics and Bioengineering (BIBE 2013), Chania, Greece, 10–13 November 2013; pp. 1–4. [Google Scholar]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M. The Mobiact dataset: Recognition of Activities of Daily living using Smartphones. In Proceedings of the International Conference on Information and Communication Technologies for Ageing Well and e-Health (ICT4AWE), Rome, Italy, 21–22 April 2016. [Google Scholar]
- Gasparrini, S.; Cippitelli, E.; Spinsante, S.; Gambi, E. A depth-based fall detection system using a Kinect® sensor. Sensors 2014, 14, 2756–2775. [Google Scholar] [CrossRef]
- Vilarinho, T.; Farshchian, B.; Bajer, D.G.; Dahl, O.H.; Egge, I.; Hegdal, S.S.; Lones, A.; Slettevold, J.N.; Weggersen, S.M. A Combined Smartphone and Smartwatch Fall Detection System. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing (CIT/IUCC/DASC/PICOM), Liverpool, UK, 26–28 October 2015; pp. 1443–1448. [Google Scholar]
- Medrano, C.; Igual, R.; Plaza, I.; Castro, M. Detecting falls as novelties in acceleration patterns acquired with smartphones. PLoS ONE 2014, 9, e94811. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. Analysis of a Smartphone-Based Architecture with Multiple Mobility Sensors for Fall Detection. PLoS ONE 2016, 11, e01680. [Google Scholar] [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A new dataset for human activity recognition using acceleration data from smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef]
- Wertner, A.; Czech, P.; Pammer-Schindler, V. An Open Labelled Dataset for Mobile Phone Sensing Based Fall Detection. In Proceedings of the 12th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MOBIQUITOUS 2015), Coimbra, Portugal, 22–24 July 2015; pp. 277–278. [Google Scholar]
- Nguyen, L.P.; Saleh, M.; Le Bouquin Jeannès, R. An Efficient Design of a Machine Learning-Based Elderly Fall Detector. In Proceedings of the International Conference on IoT Technologies for HealthCare (HealthyIoT 2017), Angers, France, 24–25 October 2017; Springer: Angers, France, 2017; pp. 34–41. [Google Scholar]
- Hsieh, C.-Y.; Liu, K.-C.; Huang, C.-N.; Chu, W.-C.; Chan, C.-T. Novel Hierarchical Fall Detection Algorithm Using a Multiphase Fall Model. Sensors 2017, 17, 307. [Google Scholar] [CrossRef]
- Yu, X. Approaches and principles of fall detection for elderly and patient. In Proceedings of the 10th International Conference on e-health Networking, Applications and Services (HealthCom 2008), Singapore, 7–9 July 2008; pp. 42–47. [Google Scholar]
- Igual, R.; Medrano, C.; Plaza, I. A comparison of public datasets for acceleration-based fall detection. Med. Eng. Phys. 2015, 37, 870–878. [Google Scholar] [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P.; Tisato, F. Falls as anomalies? An experimental evaluation using smartphone accelerometer data. J. Ambient Intell. Humaniz. Comput. 2017, 8, 87–99. [Google Scholar] [CrossRef]
- Davis, T.; Sigmon, K. MATLAB Primer, Seventh Edition. Available online: http://www.mathworks.com/products/matlab/ (accessed on 25 July 2019).
- Carletti, V.; Greco, A.; Saggese, A.; Vento, M. A Smartphone-Based System for Detecting Falls Using Anomaly Detection. In Proceedings of the 19th International Conference on Image Analysis and Processing (ICIAP 2017), Catania, Italy, 11–15 September 2017; pp. 490–499. [Google Scholar]
- Mastorakis, G. Human Fall Detection Methodologies: From Machine Learning Using Acted Data to Fall Modelling Using Myoskeletal Simulation. Ph.D. Thesis, Kingston University, London, UK, 2018. [Google Scholar]
- Putra, I.P.E.S.; Brusey, J.; Gaura, E.; Vesilo, R. An Event-Triggered Machine Learning Approach for Accelerometer-Based Fall Detection. Sensors 2017, 18, 20. [Google Scholar] [CrossRef] [PubMed]
- Mauldin, T.R.; Canby, M.E.; Metsis, V.; Ngu, A.H.H.; Rivera, C.C. SmartFall: A Smartwatch-Based Fall Detection System Using Deep Learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef] [PubMed]
- Lipsitz, L.A.; Tchalla, A.E.; Iloputaife, I.; Gagnon, M.; Dole, K.; Su, Z.Z.; Klickstein, L. Evaluation of an Automated Falls Detection Device in Nursing Home Residents. J. Am. Geriatr. Soc. 2016, 64, 365–368. [Google Scholar] [CrossRef] [PubMed]
- Thilo, F.J.S.; Hürlimann, B.; Hahn, S.; Bilger, S.; Schols, J.M.G.A.; Halfens, R.J.G. Involvement of older people in the development of fall detection systems: A scoping review. BMC Geriatr. 2016, 16, 1–9. [Google Scholar] [CrossRef]
- Hawley-Hague, H.; Boulton, E.; Hall, A.; Pfeiffer, K.; Todd, C. Older adults’ perceptions of technologies aimed at falls prevention, detection or monitoring: A systematic review. Int. J. Med. Inform. 2014, 83, 416–426. [Google Scholar] [CrossRef]
- Godfrey, A. Wearables for independent living in older adults: Gait and falls. Maturitas 2017, 100, 16–26. [Google Scholar] [CrossRef]
- Thilo, F.J.S.; Hahn, S.; Halfens, R.J.G.; Schols, J.M.G.A. Usability of a wearable fall detection prototype from the perspective of older people - a real field testing approach. J. Clin. Nurs. 2019, 28, 310–320. [Google Scholar] [CrossRef]
- Medrano, C.; Plaza, I.; Igual, R.; Sánchez, Á.; Castro, M. The Effect of Personalization on Smartphone-Based Fall Detectors. Sensors 2016, 16, 117. [Google Scholar] [CrossRef]




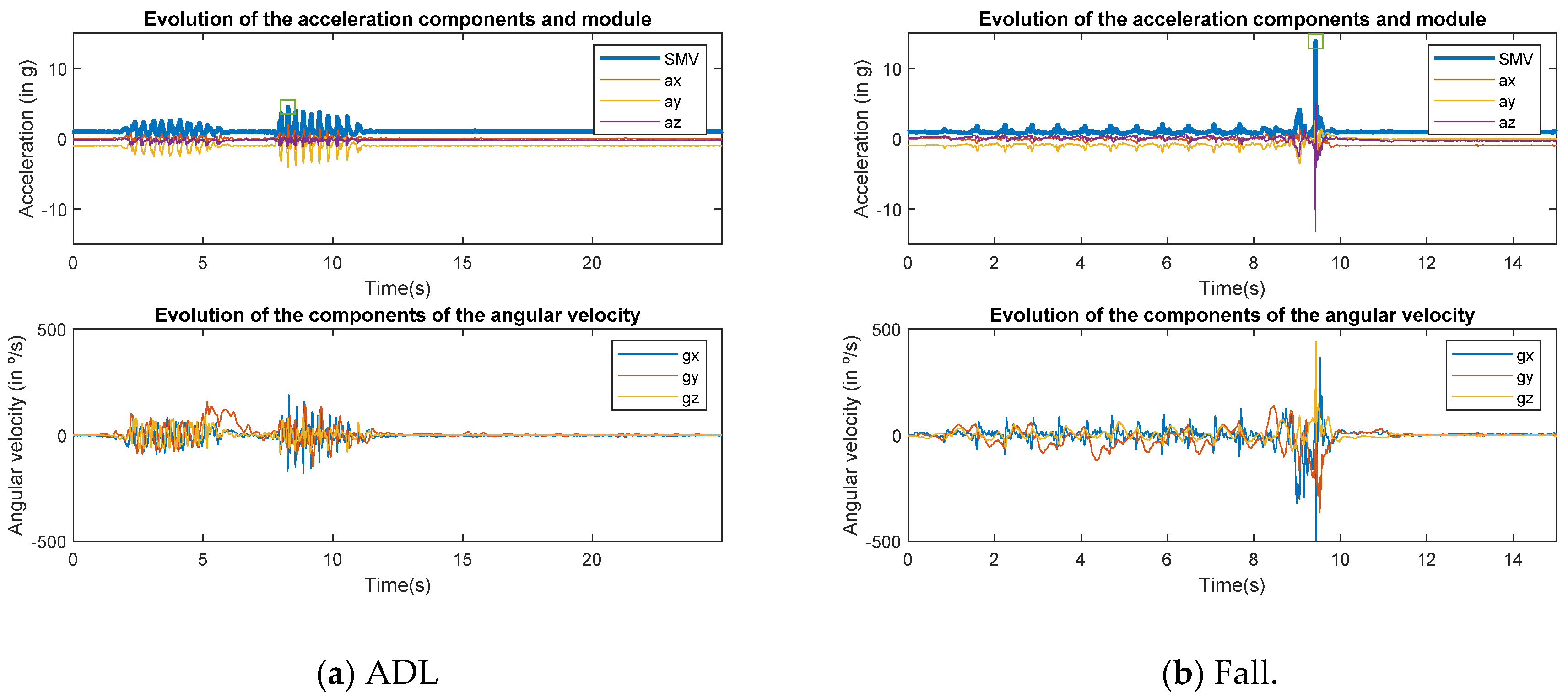{kind=link}
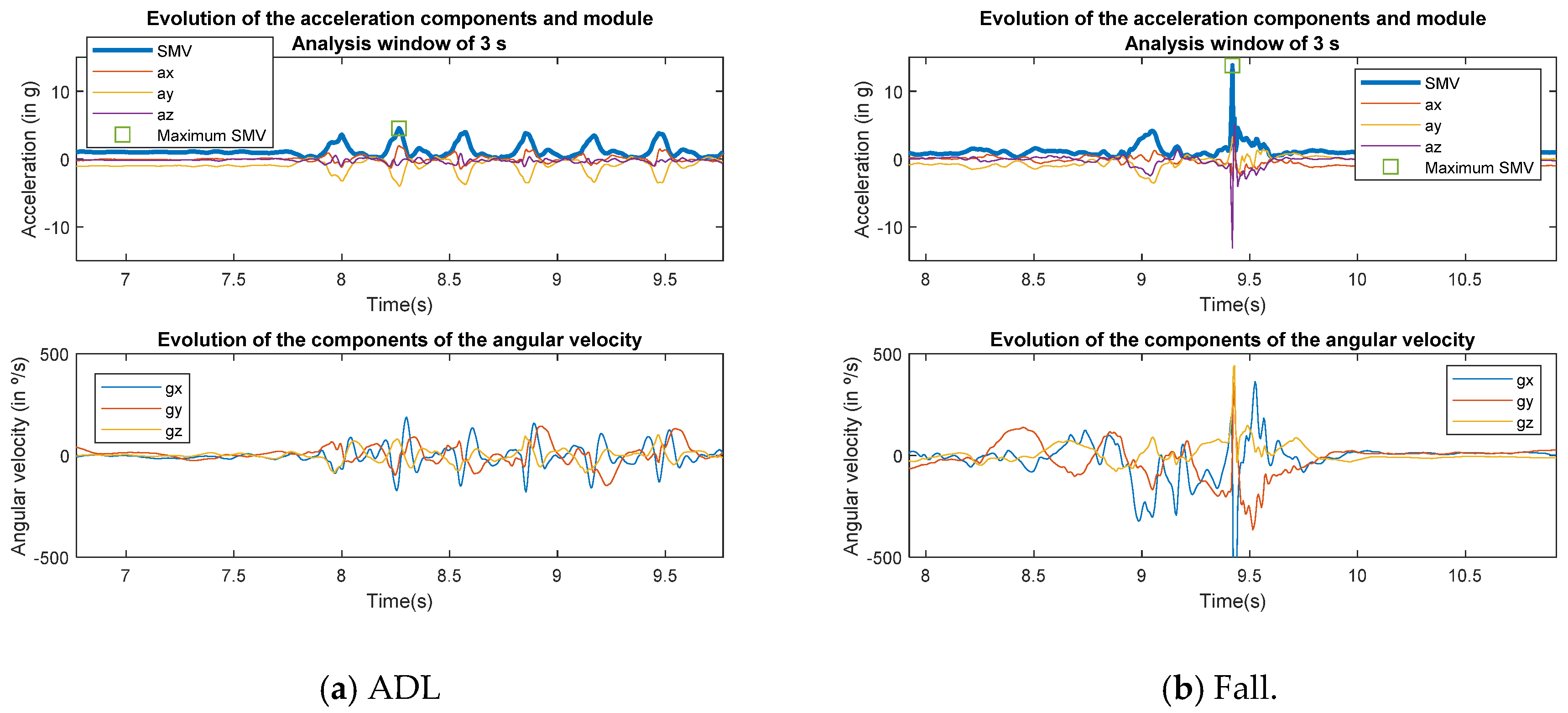{kind=link}
{kind=link}
| Authors | Ref. | Method | Sensitivity | Specificity | No. Subjects |
|---|---|---|---|---|---|
| Andò et al. (2016) | [29] | Threshold-based | 0.55%–0.90% | 100% | 10 |
| Astriani et al. (2018) | [30] | Threshold-based | 95.82% (Accuracy) | n.i. | |
| Baek et al. (2013) | [31] | Threshold-based | 81.6% | 100% | 5 |
| Bourke, O’Donovan et al. (2008) | [32] | Threshold-based | 100% | 100% | 5 |
| Bourke, Lyons et al. (2008) | [33] | Threshold-based | 100% | 100% | 10 |
| Boutellaa et al. (2019) | [34] | k-NN | Acc: 96.37%–96.85% (DLR Dataset) Acc: 88.76%–92.24% (Cogent Dataset) | 19 42 | |
| Chen et al. (2010) | [35] | Threshold-based | n.i. | n.i. | 3 |
| Chernbumroong et al. (2015) | [36] | Fusion of RBF, SVM, MLP | Accuracy: 96.93%–97.29% (Acc.) | 12 | |
| Choi et al. (2011) | [37] | NB | 97.73% | 100% | n.i. |
| Dau et al. (2014) | [38] | Genetic Programming | 79–97% | 76–97% | 1 |
| De Cillis et al. (2015) | [39] | Threshold-based | 100% | 100% | 16 |
| Dinh, Chew et al. (2015) | [40] | Threshold-based | 30–90% | 100% | n.i. |
| Dinh, Teng et al. (2009) | [41] | NB, SVM, RDRL | 92.3%–97.3% (Accuracy) | n.i. | |
| Dinh, Shi et al. (2009) | [42] | NB, SVM, RBF, C4.5 | 92.8%–97.3% (Accuracy) | 1 | |
| Dzeng et al. (2014) | [43] | Threshold-based | 4%–88% (Accuracy) | 4 | |
| Figueiredo et al. (2016) | [44] | Threshold-based | 100% | 93% | 2 |
| Guo et al. (2016) | [45] | Threshold-based | n.i. | Up to 100% | 6 |
| Hakim et al. (2017) | [46] | k-NN, SVM, DT, Discriminant Analysis | 74.3%–99% (Accuracy) | 8 | |
| He, Hu et al. (2016) | [47] | kNN, NB, DT (J48), Bayes Net, MLP, Bagging, Ripper | 91.1%–93.8% | 97.6%–99.1% | 15 |
| He, Li et al. (2013) | [48] | Threshold-based DT (Fisher’s discriminant ratio and J3 Criteria were used for feature selection) | 97.63% (accuracy) | 10 | |
| Huynh et al. (2015) | [49] | Threshold-based | 96.55% | 89.50% | 36 |
| Hwang et al. (2004) | [50] | Threshold-based | 95.55% | 100% | 3 |
| Lai et al. (2014) | [51] | K-Means and Bayesian inference | 75%–95% | n.i. | 10 |
| Li et al. (2009) | [52] | Threshold-based | n.i. | n.i. | 3 |
| Majumder, Zerin et al. (2013) | [53] | DT | 71%–98% (Accuracy) | 15 | |
| Majumder, Rahman et al. (2013) | [54] | DT | 28%–98% (Accuracy) | 5 | |
| Martínez-Villaseñor et al. (2018) | [55] | LDA, DT, NB, SVM, RF, K-NN | 15.25%–69.18% (Accuracy) | 4 | |
| Nari et al. (2016) | [56] | Threshold-based | 90% | 86.7% | 1 |
| Ntanasis et al. (2017) | [57] | DT(J-48), k-NN, RF, Random Committee, SVM | 84.13%–99.64% | 92.37%–99.82% | 14 (Erciyes Dataset) |
| Nyan et al. (2008) | [58] | Threshold-based | 95.2% | 100% | 21 |
| Ojetola et al. (2011) | [59] | DT (C.45) | 62.5%–100% | n.i. | 8 |
| Özdemir et al. (2016) | [60] | k-NN, BDM, SVM, LSM, DTW, ANN | 92.40–99.91% (Accuracy) | 14 (Erciyes Dataset) | |
| Park et al. (2011) | [61] | Threshold-based | n.i. | n.i. | 3 |
| Quadros et al. (2018) | [62] | Threshold-based, DT, k-NN, LDA, LR, SVM | 97.9%–100% | 93.8%–97.9% | 22 |
| Rakhecha et al. (2013) | [63] | Threshold-based | 86%–94% | 73%–88% | n.i. |
| Rungnapakan et al. (2018) | [64] | Threshold-based | 79%–100% | 96.67%–100% | 6 |
| Santiago et al. (2017) | [65] | Threshold-based | 83%–92%(Accuracy) | n.i. | |
| Sorvala et al. (2012) | [66] | Threshold-based | 95.6% | 99.6% | 2 |
| Tamura et al. (2009) | [67] | Threshold-based | 93% (Accu.) | 16 | |
| Wibisono et al. (2013) | [68] | Threshold-based | 85%–100% | n.i. | n.i. |
| Yang et al. (2013) | [69] | Threshold-based | n.i. | 6.67%–100% | 12 |
| Zhao et al. (2012) | [70] | Threshold-based | n.i. | n.i. | 8 |
| Authors (Date) | Ref. | Sensitivity | Specificity | Input: Raw Data/Derived Features |
|---|---|---|---|---|
| Ahmed et al. (2017) | [71] | 67.9%–77.8% (Accuracy) | Raw data | |
| Chelli and Patzold (2019) | [72] | 96.8%−99.11% | 100% | 328 derived features |
| Chernbumroong et al. (2015) | [36] | 96.93%–97.29% (Acc), | 202 derived features | |
| Ghazal et al. (2015) | [73] | 73.31% | 93.33%, | Derived features |
| He et al. (2019) | [15] | 100% | 99.74% | Raw data |
| Martínez Villaseñor et al. (2018) | [55] | 64.03%–68.66% (Accuracy) | 33 derived features | |
| Nukala et al. (2014) | [74] | 96%–98% | 96.5%–98.1% | 6 derived features |
| Özdemir and Barshan (2014) | [75] | 97.47% | 93.44% | 78 derived features |
| Özdemir and Turan (2016) | [60] | 94.20%–96.27% (Accuracy) | 78 derived features | |
| Rashidpour et al. (2016) | [76] | 100% | 100% | Raw data |
| Wang and Zhang (2015) | [77] | 95%–100% | 100% | 3 derived features |
| Yang et al. (2013) | [78] | 70% | 92.26% | Raw data |
| Yodpijit et al. (2017) | [79] | 99.37% | 99.23% | Raw data |
| Name or Origin of the Dataset and Reference | No. of Types of Emulated ADLs/Falls | No. of Samples (ADLs/falls) | No. of Subjects (F/M) | Positions of the Sensing Motes | Sensors in the Motes |
|---|---|---|---|---|---|
| DLR [92] | 15/1 | 1017 (961/56) | 19 (8/11) | Waist (belt) | A, G, M |
| Cogent Labs [93] | 8/6 | 1968 (1520/448) | 42(6/36) | Chest and Thigh | A, G |
| MobiFall [94] | 9/4 | 630 (342/288) | 24 (7/17) | Trouser pocket | A, G, O |
| MobiAct [95] | 9/4 | 2526 (879/647) | 57 (15/42) | Trouser pocket | A, G, O |
| TST [96] | 4/4 | 264 (132/132) | 11 (n.i.) | Right wrist and Waist | A |
| SINTEF ICT [97] | 7/12 | 117 (45/72) | 2 (n.i.) | Waist and Wrist | A |
| tFall [98] | Real Life conditions/8 | 10,909 (9883/1026) | 10 (3/7) | Pocket, Hand bag | A |
| SisFall [16] | 19/15 | 4505 (2707/1798) | 38 (19/19) | Waist | A, G |
| UR Fall Detection [99] | 5/3 | 70 (40/30) | 5 (0/5) | Near pelvis (waist) | A |
| Erciyes University | 16/20 | 3302(1476/1826) | 17 (7/10) | Chest, Head, Ankle, Thigh, Wrist, Waist | A, G, O |
| UMAFall [100] | 8/3 | 531 (322/209) | 17 (7/10) | Ankle, Chest, Thigh, Waist Wrist | A, G, M |
| UniMiB SHAR [101] | 9/8 | 7013 (5314/1699) | 30 (24/6) | Left or right trouser pocket | A |
| Graz University of Technology [102] | 10/4 | 492 (74/418) | 10 (n. i.) | Waist (belt bag) | A, O |
| Parameter | Value |
|---|---|
| Number of convolutional layers | 4 |
| Number of max pooling layers | 3 |
| Activation functions | ReLU for convolutiona layers, Softmax for output layer |
| Type of output layer | Fully connected |
| Max Pooling Window | 1 × 5 |
| Number of filters in each layer | 16 (1st layer)-32 (2nd)-64 (3rd)-128 (4th) |
| Size of the filters (for all layers) | 1 × 5 |
| Pool size of the max-pooling layer (Max Pooling Window. MPW = 5) | 1 × 5 |
| Mini batch size | 64 training instances |
| Training Method | Stochastic Gradient Descent with Momentum |
|---|---|
| Learning rate | 0.0001 |
| Validation patience | 2 |
| Iterations per epoch | 42 |
| Maximum number of training epochs | 5 |
| Size of zero-padding | 2 samples |
| Metric | Result |
|---|---|
| Accuracy | 0.949 |
| Sensitivity | 0.911 |
| Specificity | 0.974 |
| Metric | MPW = 5 | MPW = 3 |
|---|---|---|
| Accuracy | 0.949 | 0.970 |
| Sensitivity | 0.911 | 0.948 |
| Specificity | 0.974 | 0.985 |
| Duration of the Observation Window Around the Peak (TW) | |||||
|---|---|---|---|---|---|
| Metric | 1 s | 3 s | 5 s | 6 s | 8 s |
| Accuracy | 0.956 | 0.970 | 0.975 | 0.973 | 0.973 |
| Sensitivity | 0.910 | 0.948 | 0.956 | 0.957 | 0.955 |
| Specificity | 0.987 | 0.985 | 0.987 | 0.984 | 0.985 |
| Dimension (in Samples) of the Filters | ||||
|---|---|---|---|---|
| Metric | 1 × 5 | 1 × 10 | 1 × 20 | 1 × 30 1 |
| Accuracy | 0.975 | 0.976 | 0.975 | 0.979 |
| Sensitivity | 0.956 | 0.954 | 0.958 | 0.957 |
| Specificity | 0.987 | 0.990 | 0.987 | 0.993 |
| Number of Convolutional Layers | |||
|---|---|---|---|
| Metric | 2 | 3 | 4 |
| Accuracy | 0.970 | 0.978 | 0.979 |
| Sensitivity | 0.945 | 0.960 | 0.957 |
| Specificity | 0.987 | 0.990 | 0.993 |
| Number of Filters in Each Layer | |||
|---|---|---|---|
| Metric | 16-32-64 | 4-4-4 | 64-64-64 |
| Accuracy | 0.978 | 0.923 | 0.977 |
| Sensitivity | 0.960 | 0.880 | 0.957 |
| Specificity | 0.990 | 0.952 | 0.991 |
| Metric | Results without ReLU Layers | Results without ReLU Layers |
|---|---|---|
| Accuracy | 0.978 | 0.938 |
| Sensitivity | 0.960 | 0.902 |
| Specificity | 0.990 | 0.961 |
| Mini-Batch Size | |||
|---|---|---|---|
| Metric | 64 | 32 | 16 |
| Accuracy | 0.978 | 0.981 | 0.982 |
| Sensitivity | 0.960 | 0.964 | 0.968 |
| Specificity | 0.990 | 0.992 | 0.991 |
| Employed Signals | ||
|---|---|---|
| Metric | Accelerometer and Gyroscope | Only Accelerometer |
| Accuracy | 0.981 | 0.994 |
| Sensitivity | 0.964 | 0.988 |
| Specificity | 0.992 | 0.997 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casilari, E.; Álvarez-Marco, M.; García-Lagos, F. A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems. Symmetry 2020, 12, 649. https://doi.org/10.3390/sym12040649
Casilari E, Álvarez-Marco M, García-Lagos F. A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems. Symmetry. 2020; 12(4):649. https://doi.org/10.3390/sym12040649
Chicago/Turabian StyleCasilari, Eduardo, Moisés Álvarez-Marco, and Francisco García-Lagos. 2020. "A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems" Symmetry 12, no. 4: 649. https://doi.org/10.3390/sym12040649
APA StyleCasilari, E., Álvarez-Marco, M., & García-Lagos, F. (2020). A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems. Symmetry, 12(4), 649. https://doi.org/10.3390/sym12040649