
Investigating Tropical Cyclone Rapid Intensification with an Advanced Artificial Intelligence System and Gridded Reanalysis Data


Abstract
1. Introduction
2. Data
3. Methods
3.1. Summary of SHIPS Data Preprocessing [27]
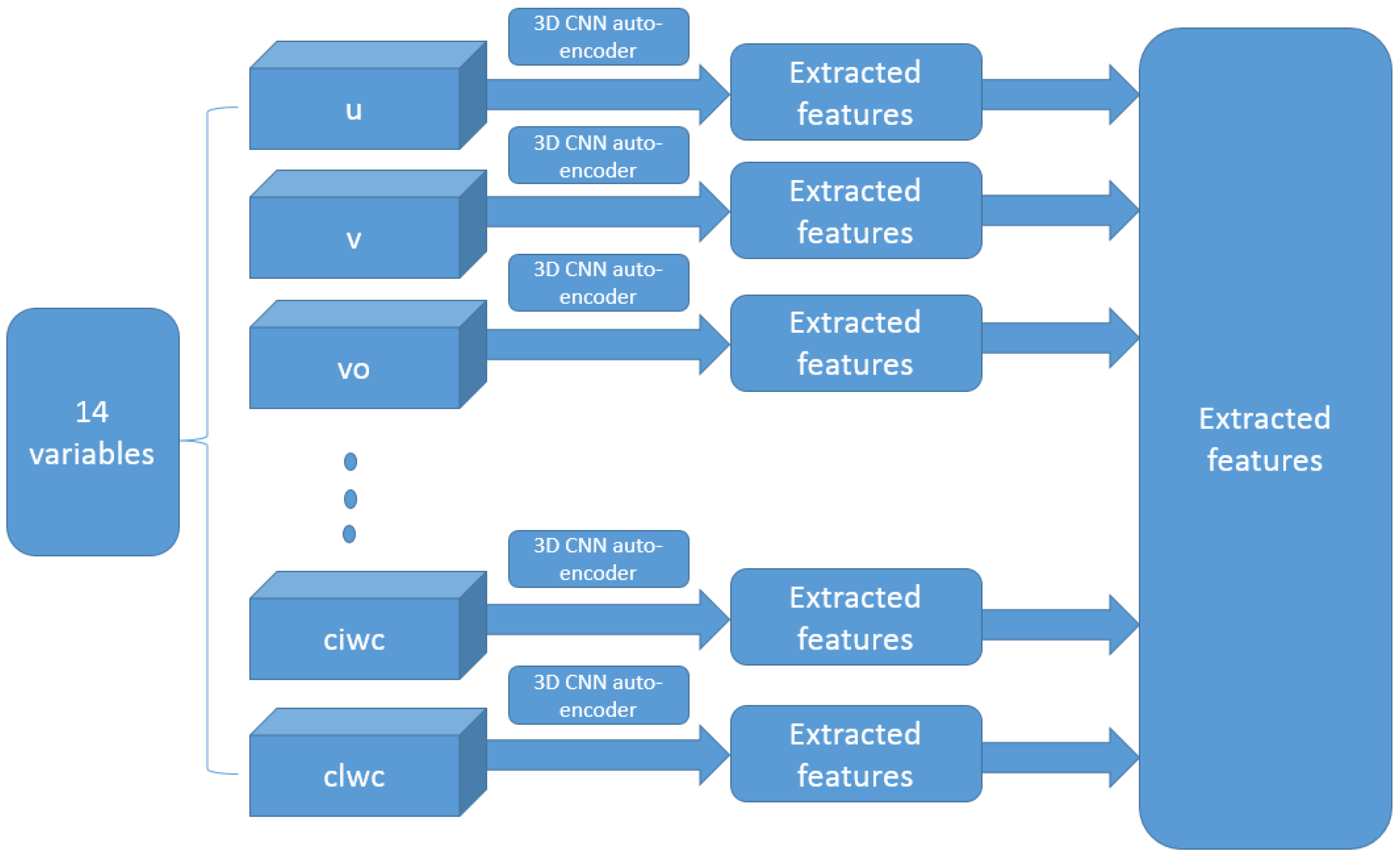
3.2. ERA-Interim Data Preprocessing Strategy
3.3. Review of CNN, a Deep Learning Technique
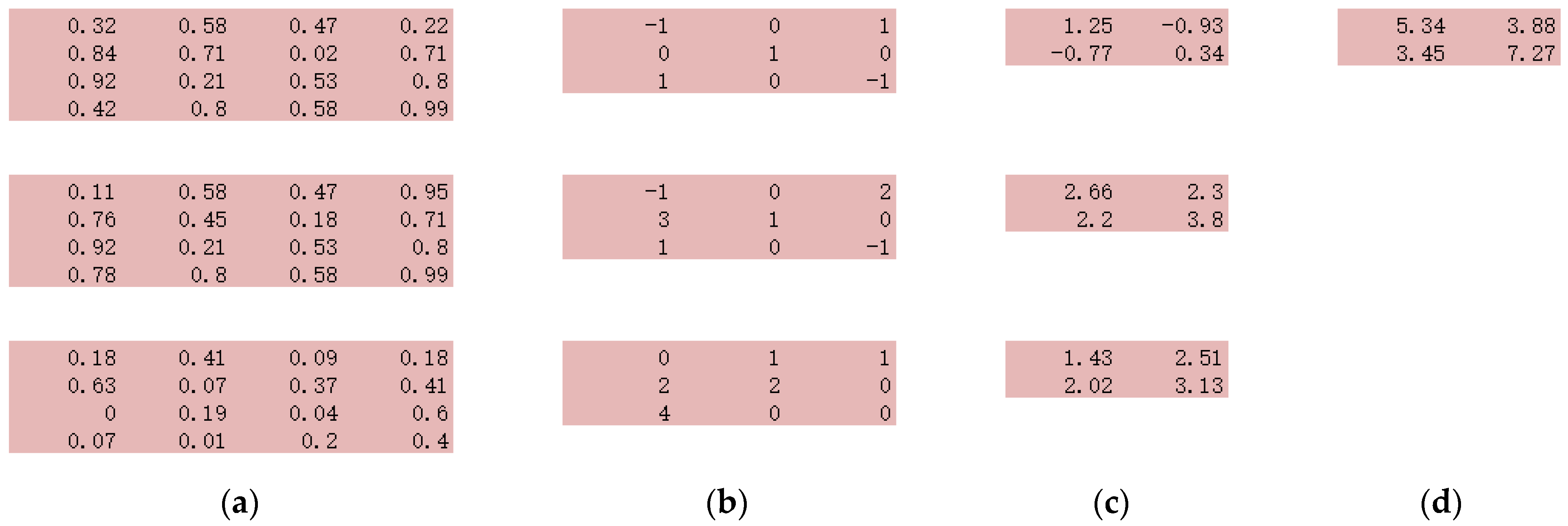
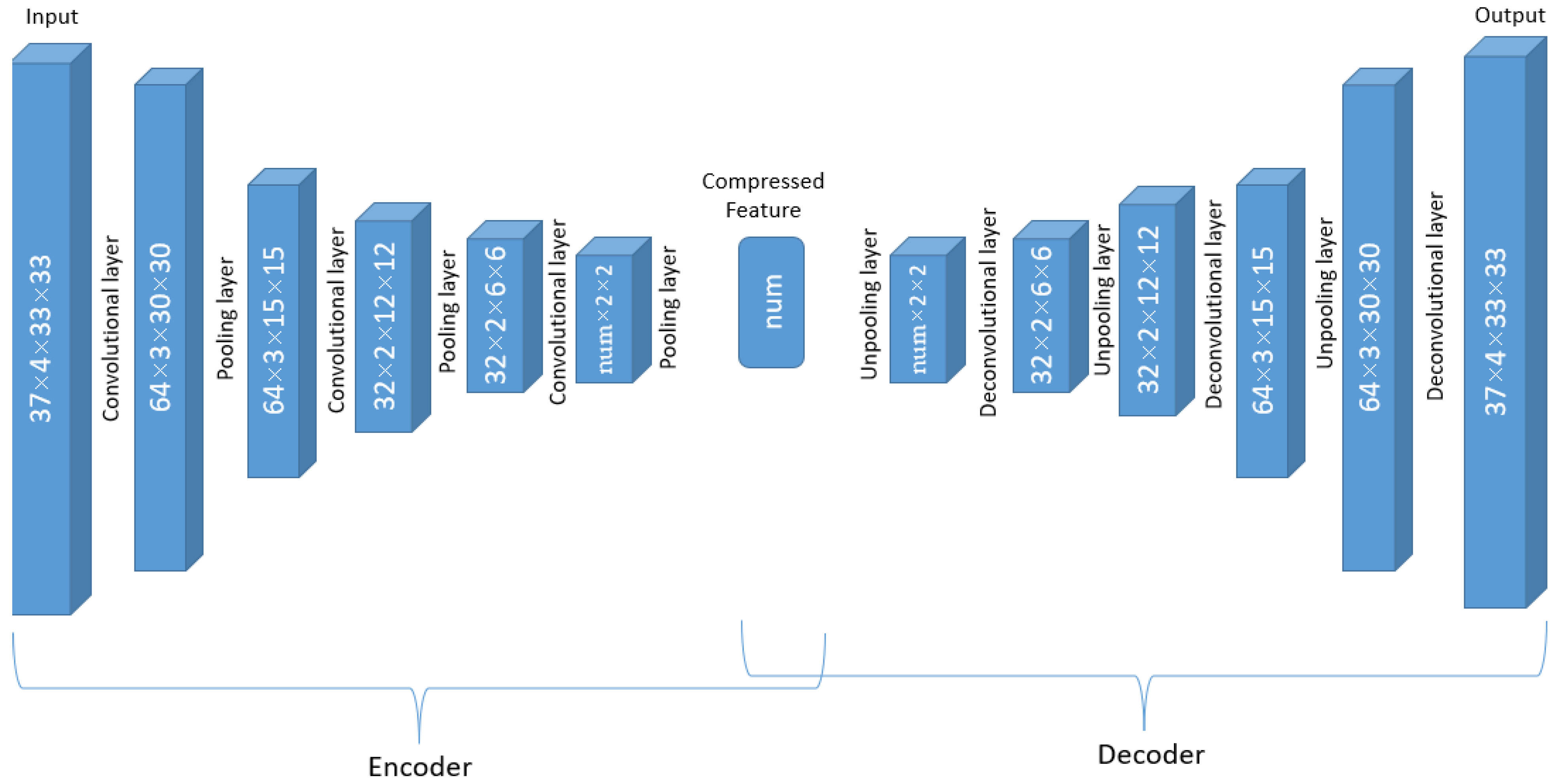
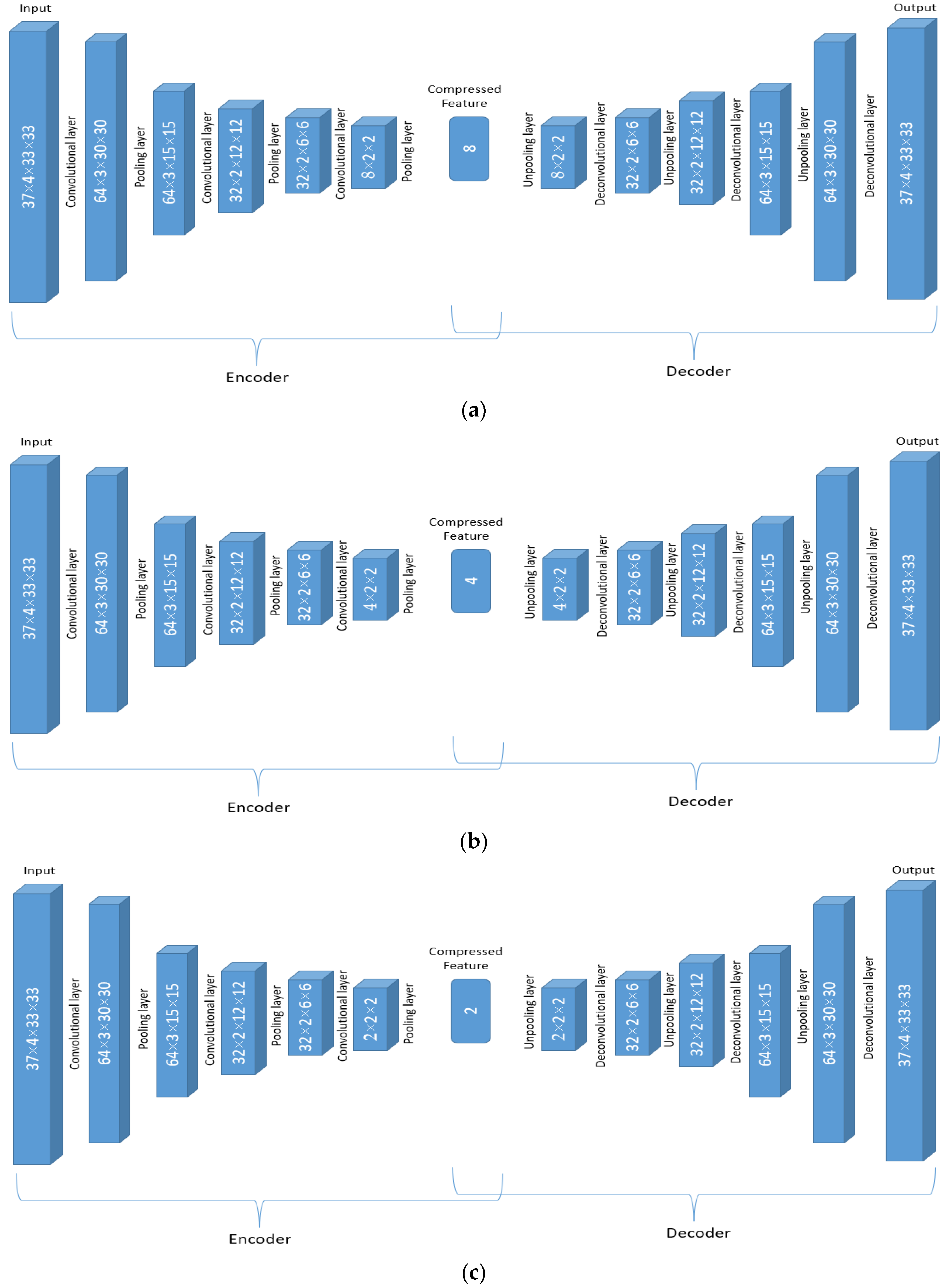
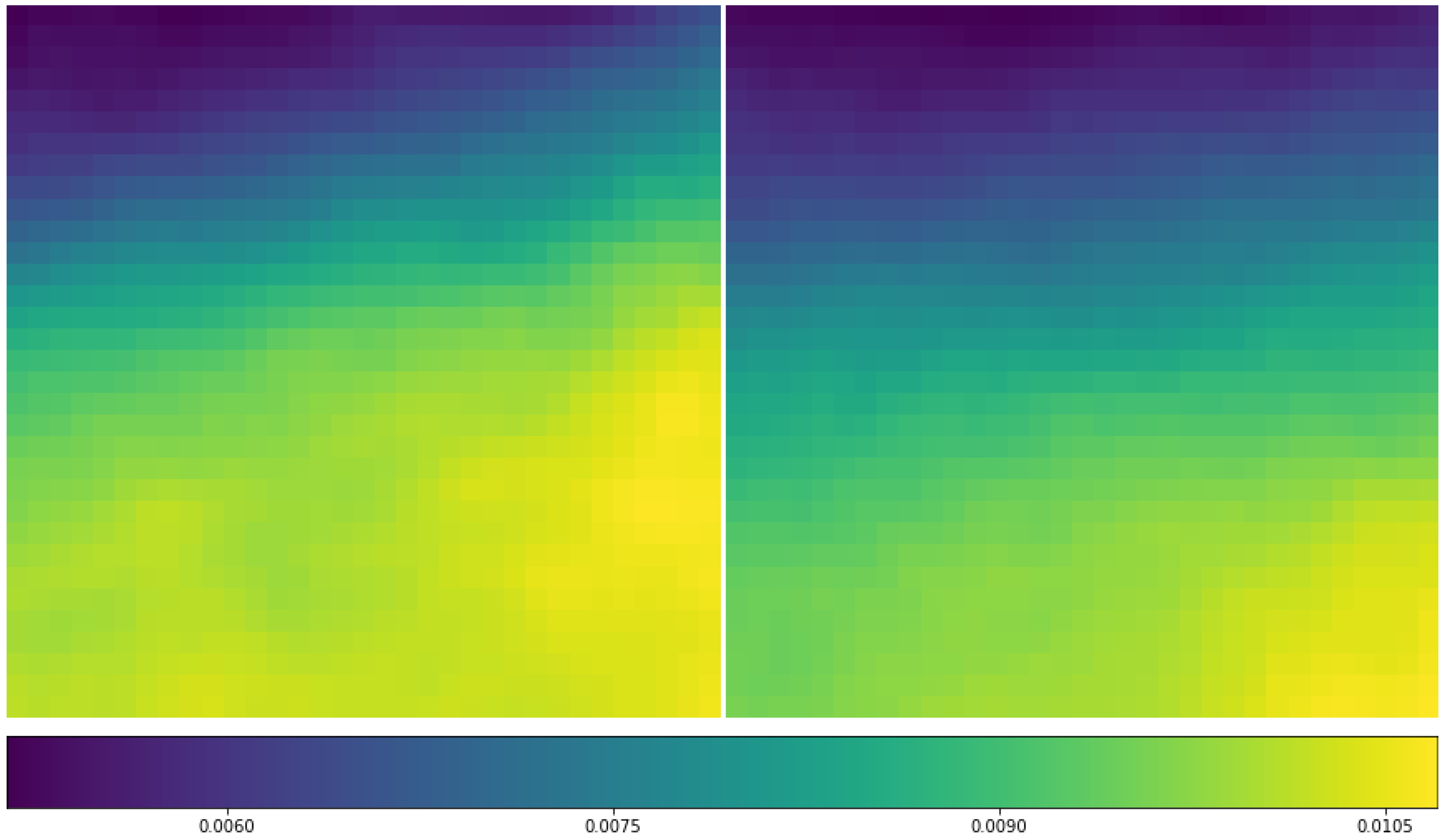
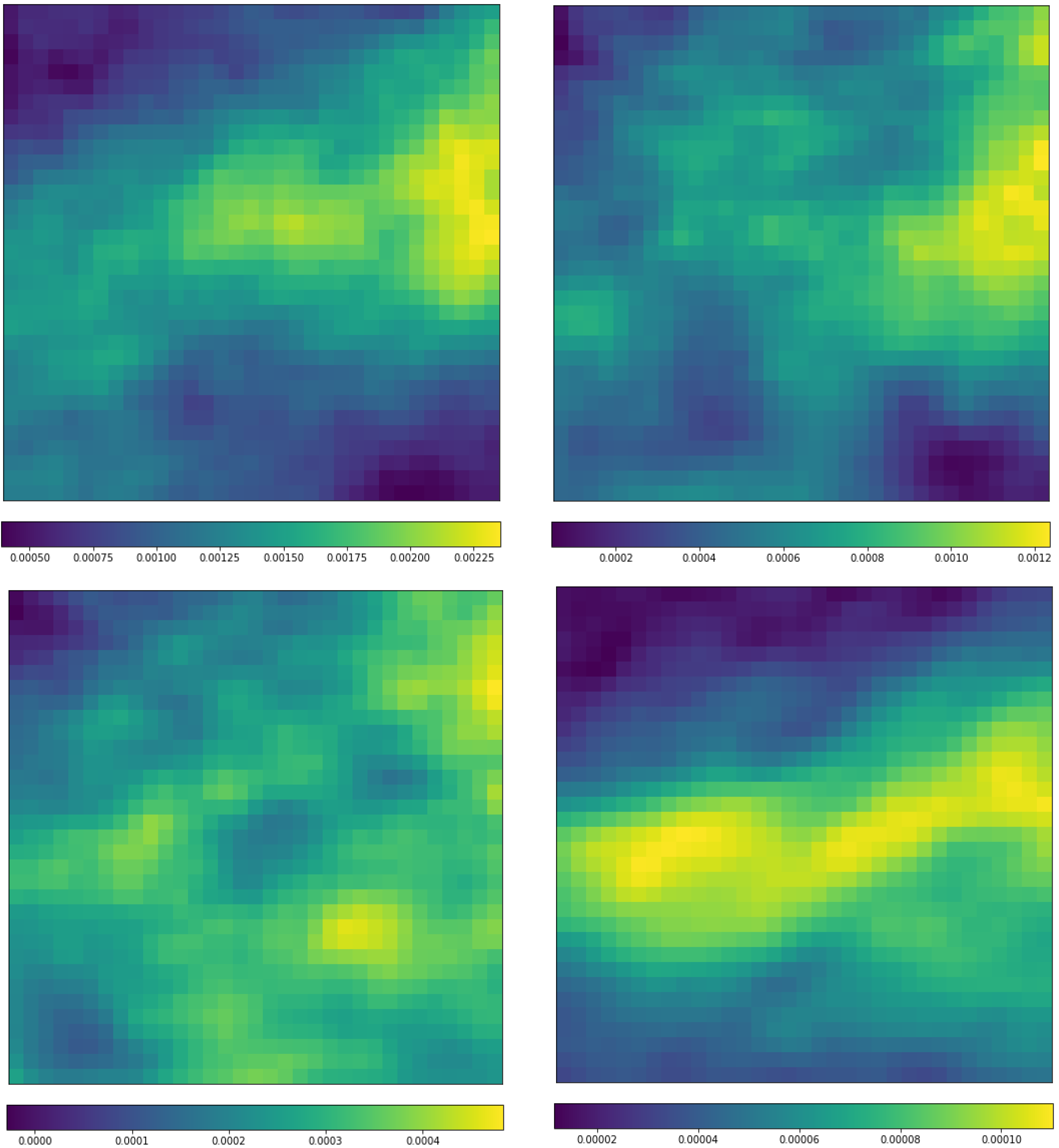
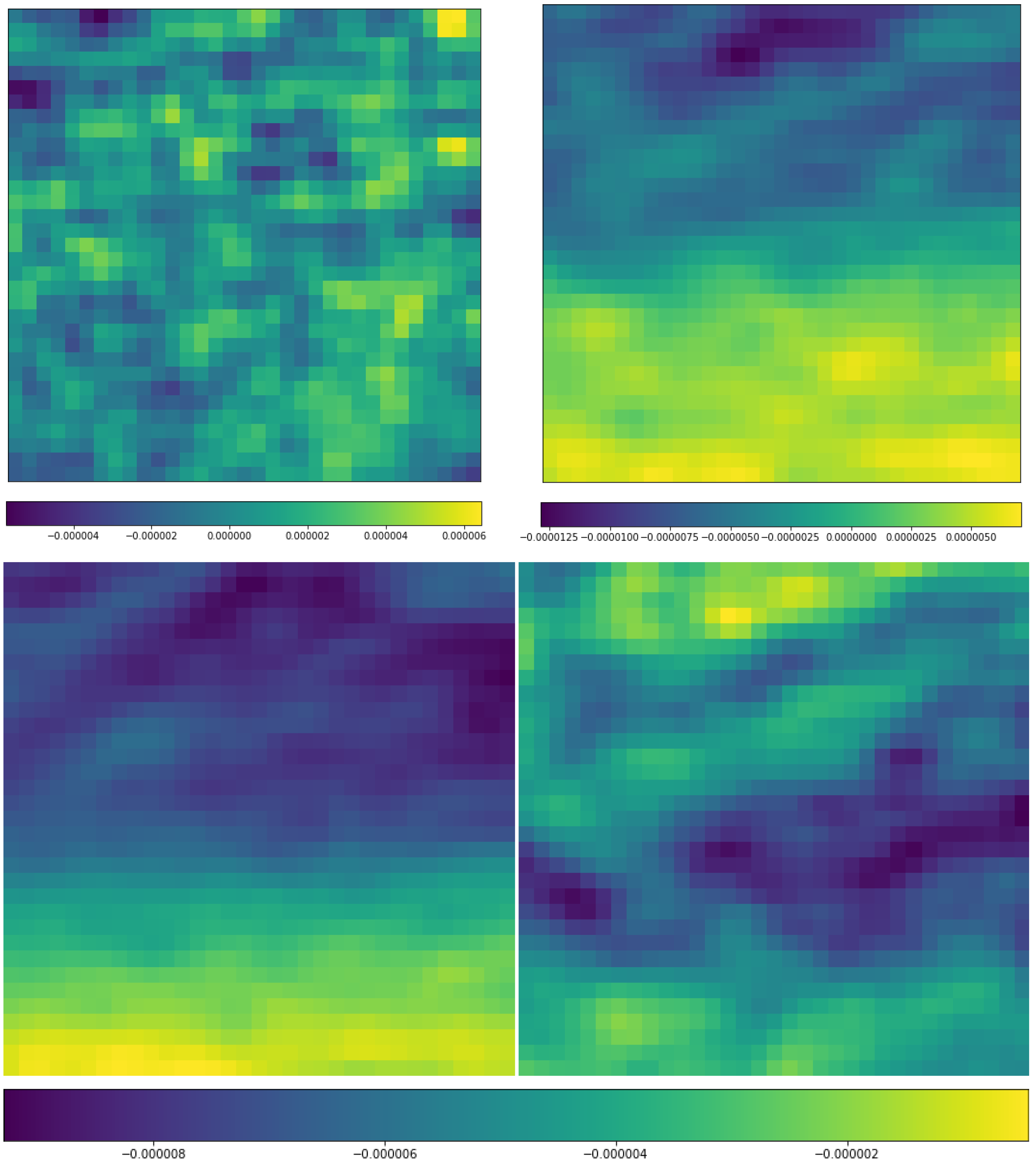
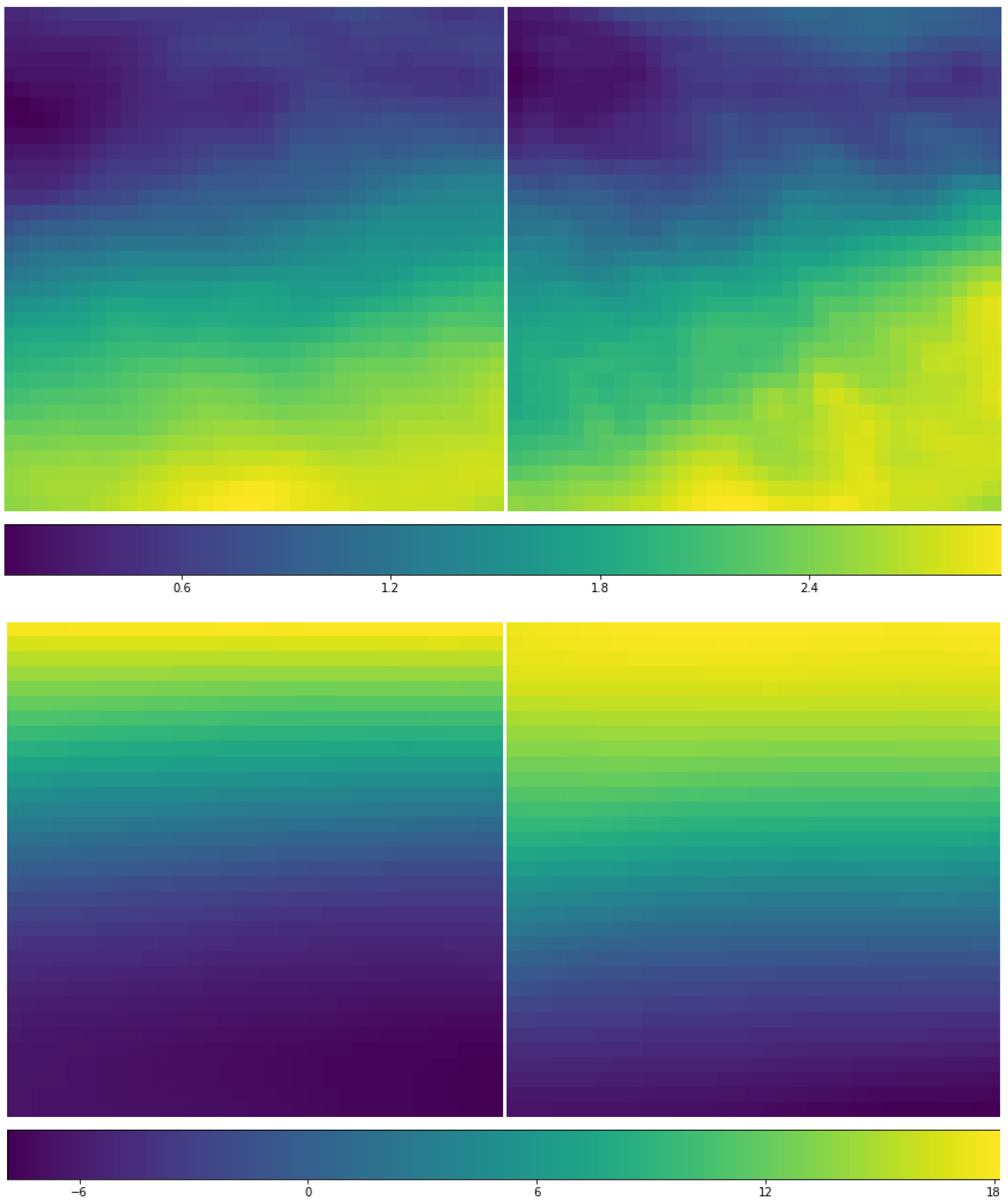
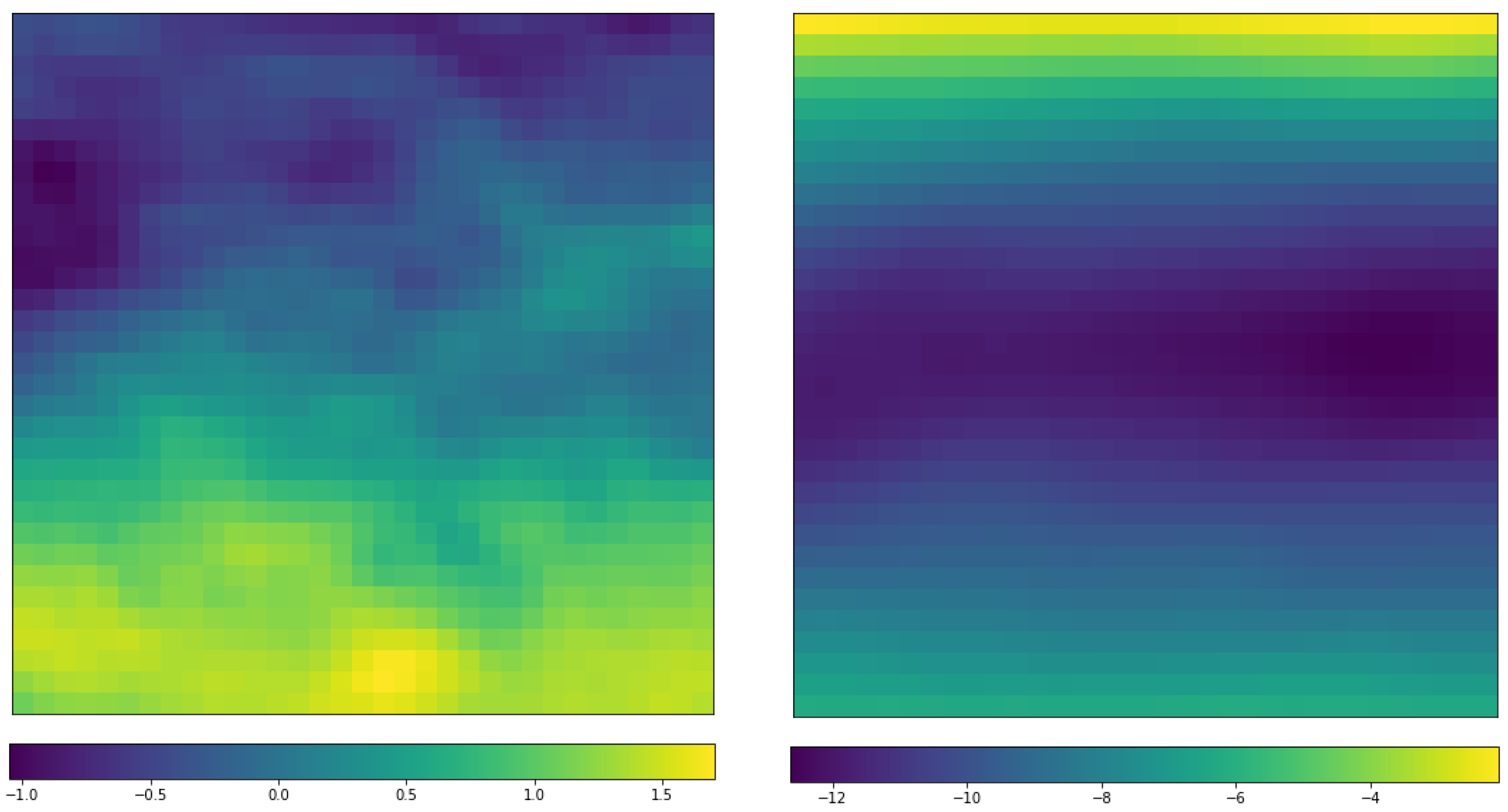
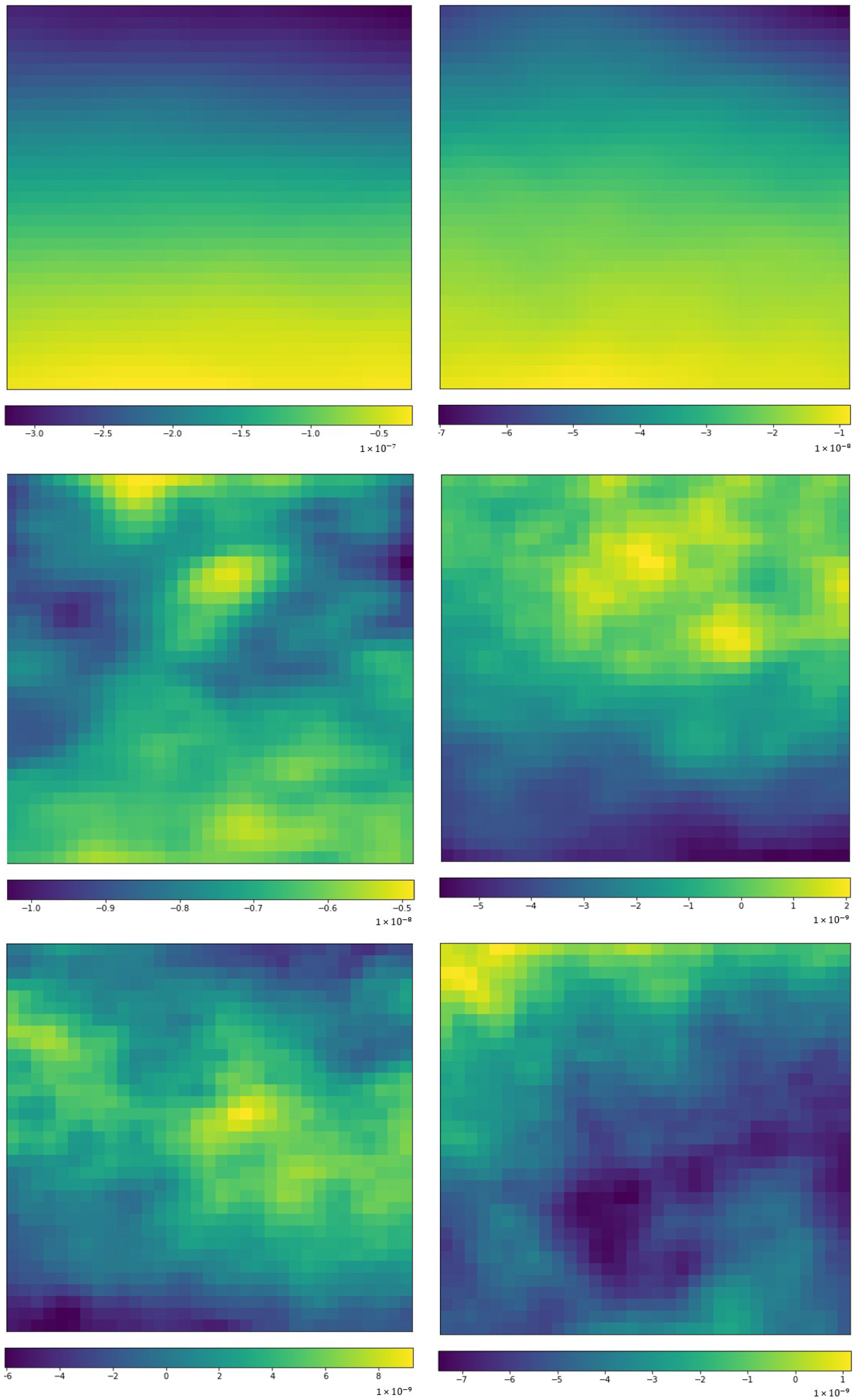
3.4. Implementation Details of CNN for the ERA-Interim Filtering (Readers Familiar with CNN Procedure Could Read the Figures on Major Structures Only without Going through the Technical Details of CNN)
4. Results
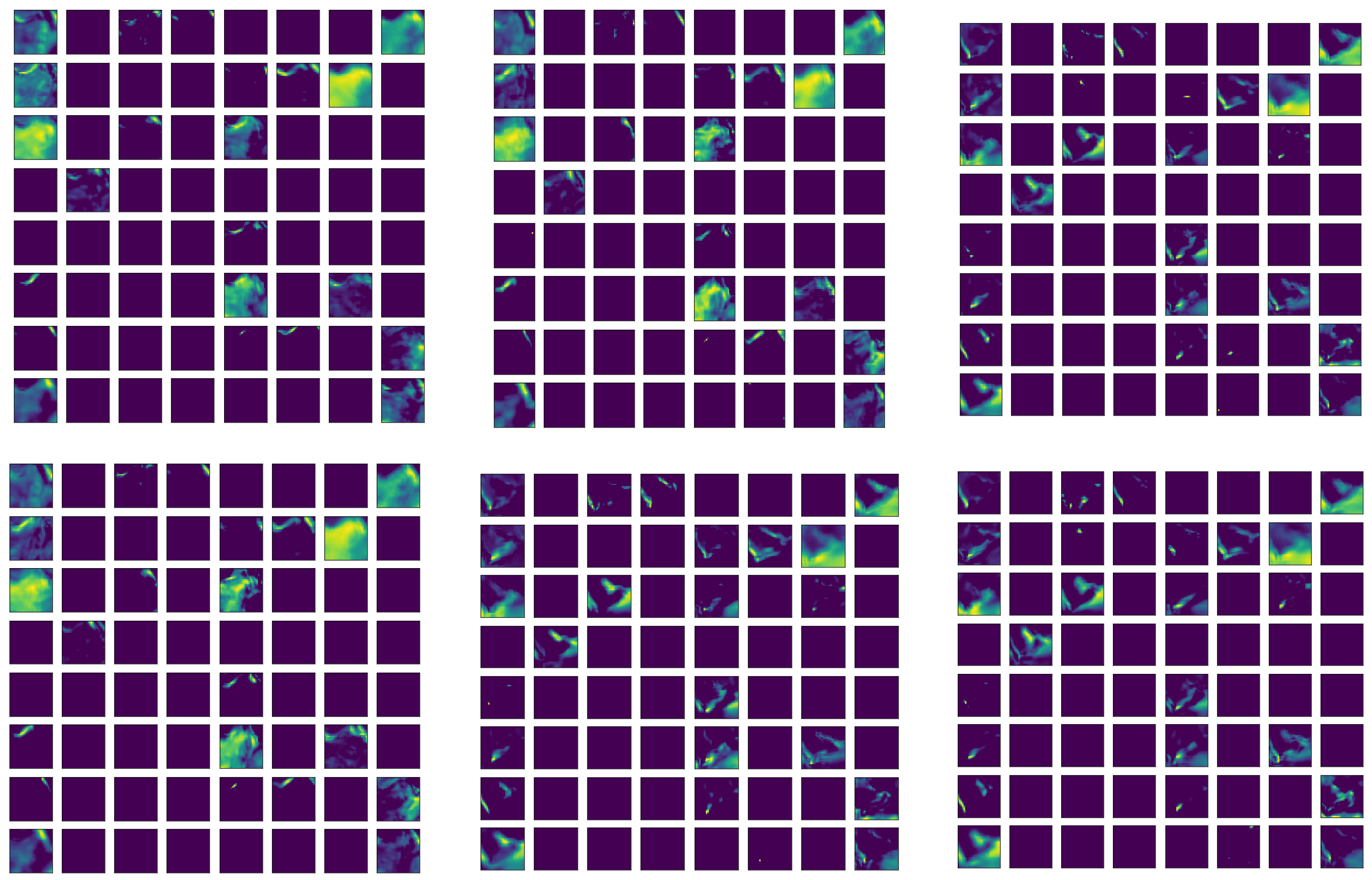
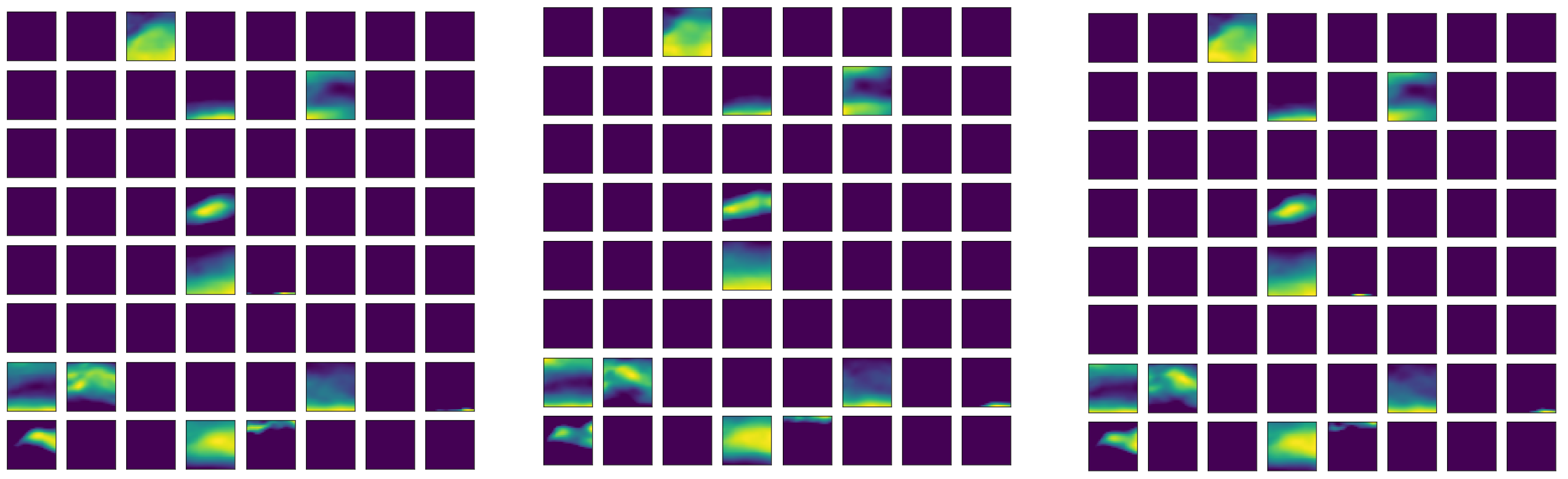
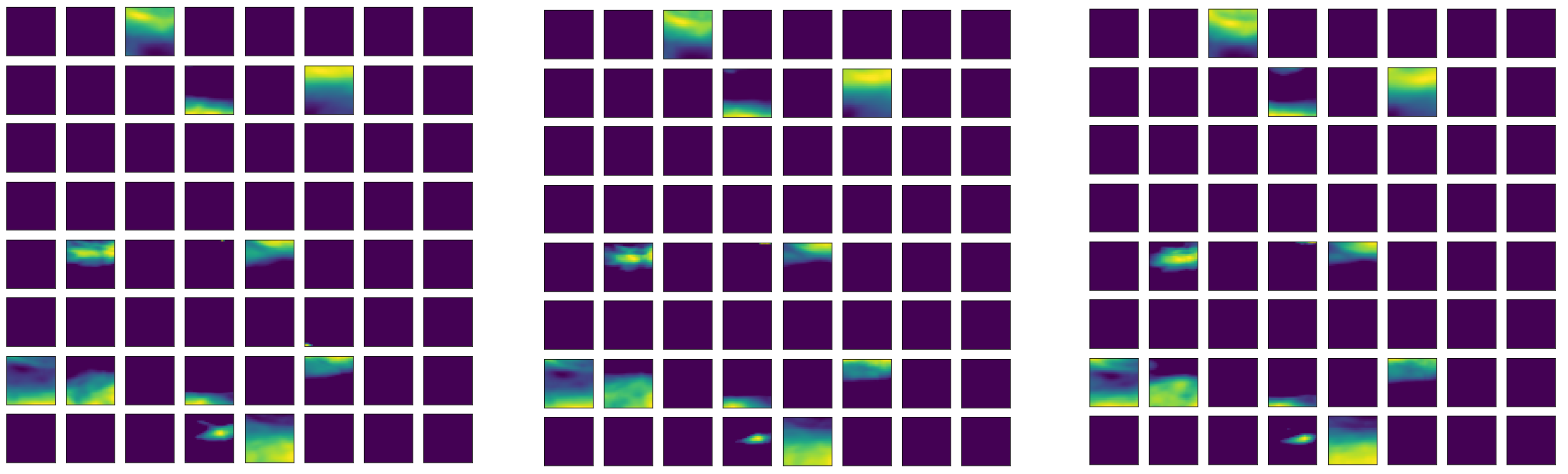
4.1. Hyperparameters Tuning for the Autoencoder Structure
4.2. Hyperparameters Tuning for GMM-SMOTE and XGBoost
4.3. Model Results on Test Data
4.4. Performance Comparison
4.5. Feature Importance
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

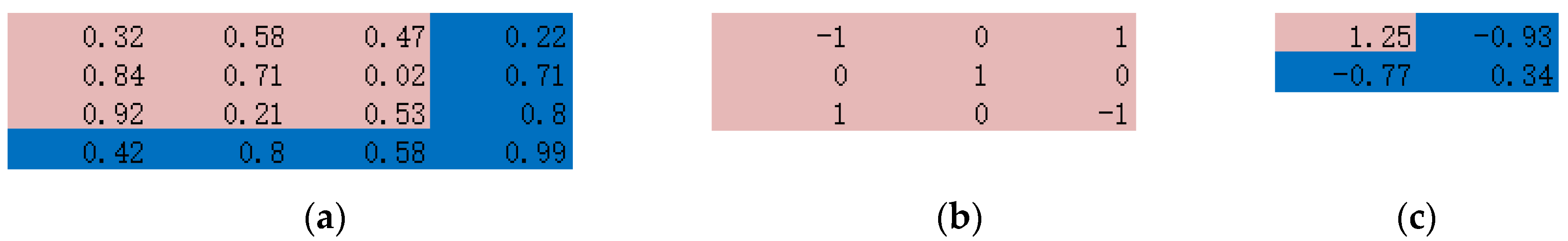{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IS | Variable | Ranking | IS | Variable | Ranking | IS | Variable | Ranking |
|---|---|---|---|---|---|---|---|---|
| 0.02 | BD12 | 1 | 0.009 | vo6 | 41 | 0.007 | Z850 | 81 |
| 0.018 | VMAX | 2 | 0.009 | MTPW_1 | 42 | 0.007 | SHTD | 82 |
| 0.015 | SHRD | 3 | 0.009 | u2 | 43 | 0.007 | NOHC | 83 |
| 0.014 | DTL | 4 | 0.009 | r4 | 44 | 0.007 | OAGE | 84 |
| 0.014 | IRM1_5 | 5 | 0.009 | pv7 | 45 | 0.006 | XD18 | 85 |
| 0.013 | o31 | 6 | 0.009 | pv6 | 46 | 0.006 | IR00_3 | 86 |
| 0.013 | G150 | 7 | 0.009 | PSLV_1 | 47 | 0.006 | IRM1_16 | 87 |
| 0.013 | q7 | 8 | 0.009 | TADV | 48 | 0.006 | PSLV_4 | 88 |
| 0.013 | u3 | 9 | 0.009 | v8 | 49 | 0.006 | NTFR | 89 |
| 0.013 | q4 | 10 | 0.009 | HIST_2 | 50 | 0.006 | HIST_9 | 90 |
| 0.013 | G200 | 11 | 0.009 | VMPI | 51 | 0.006 | ND20 | 91 |
| 0.013 | vo3 | 12 | 0.009 | V300 | 52 | 0.006 | IR00_14 | 92 |
| 0.012 | REFC | 13 | 0.009 | SHRS | 53 | 0.006 | IRM3_17 | 93 |
| 0.012 | vo5 | 14 | 0.009 | VVAC | 54 | 0.006 | EPSS | 94 |
| 0.012 | vo8 | 15 | 0.009 | MTPW_19 | 55 | 0.006 | clwc2 | 95 |
| 0.012 | PEFC | 16 | 0.009 | v5 | 56 | 0.006 | D200 | 96 |
| 0.012 | d3 | 17 | 0.008 | t1 | 57 | 0.006 | V850 | 97 |
| 0.012 | CFLX | 18 | 0.008 | RD26 | 58 | 0.006 | PC00 | 98 |
| 0.012 | PSLV_3 | 19 | 0.008 | SDDC | 59 | 0.006 | r8 | 99 |
| 0.011 | T150 | 20 | 0.008 | q6 | 60 | 0.005 | u5 | 100 |
| 0.011 | jd | 21 | 0.008 | O500 | 61 | 0.005 | NDFR | 101 |
| 0.011 | R000 | 22 | 0.008 | v7 | 62 | 0.005 | PCM1 | 102 |
| 0.011 | TWXC | 23 | 0.008 | IRM3_11 | 63 | 0.005 | NSST | 103 |
| 0.011 | u8 | 24 | 0.008 | E000 | 64 | 0.005 | PENV | 104 |
| 0.011 | PW08 | 25 | 0.008 | PW14 | 65 | 0.005 | TGRD | 105 |
| 0.011 | q3 | 26 | 0.008 | z2 | 66 | 0.005 | IRM3_14 | 106 |
| 0.011 | XDTX | 27 | 0.008 | G250 | 67 | 0.005 | IR00_20 | 107 |
| 0.011 | CD26 | 28 | 0.008 | pv1 | 68 | 0.005 | T250 | 108 |
| 0.011 | q8 | 29 | 0.008 | cc1 | 69 | 0.005 | RHMD | 109 |
| 0.011 | pv3 | 30 | 0.008 | XDML | 70 | 0.005 | IRM1_14 | 110 |
| 0.011 | v4 | 31 | 0.008 | pv8 | 71 | 0.005 | IRM1_17 | 111 |
| 0.011 | r1 | 32 | 0.007 | vo1 | 72 | 0.005 | cc2 | 112 |
| 0.01 | u1 | 33 | 0.007 | ciwc1 | 73 | 0.003 | NDTX | 113 |
| 0.01 | q5 | 34 | 0.007 | v3 | 74 | 0.003 | r7 | 114 |
| 0.01 | IR00_12 | 35 | 0.007 | SHTS | 75 | 0.003 | TLAT | 115 |
| 0.01 | vo4 | 36 | 0.007 | v6 | 76 | 0.002 | PCM3 | 116 |
| 0.01 | HE07 | 37 | 0.007 | ciwc2 | 77 | 0.002 | HIST_16 | 117 |
| 0.01 | u6 | 38 | 0.007 | w1 | 78 | 0.0006 | r2 | 118 |
| 0.01 | q2 | 39 | 0.007 | IRM3_19 | 79 | 0 | r3 | 119 |
| 0.009 | r6 | 40 | 0.007 | IR00_17 | 80 | 0 | r5 | 120 |
References
- DeMaria, M.; Knaff, J.A.; Sampson, C.R. Evaluation of Long-Term Trends in Operational Tropical Cyclone Intensity Forecasts. Meteor. Atmos. Phys. 2007, 97, 19–28. [Google Scholar] [CrossRef]
- Rappaport, E.N.; Franklin, J.L.; Avila, L.A.; Baig, S.R.; Beven, J.L.; Blake, E.S.; Burr, C.A.; Jiing, J.-G.; Juckins, C.A.; Knabb, R.D.; et al. Advances and Challenges at the National Hurricane Center. Weather Forecast. 2009, 24, 395–419. [Google Scholar] [CrossRef]
- DeMaria, M.; Sampson, C.R.; Knaff, J.; Musgrave, K.D. Is Tropical Cyclone Intensity Guidance Improving? Bull. Amer. Meteor. Soc. 2014, 95, 387–398. [Google Scholar] [CrossRef]
- Cangialosi, J.P.; Blake, E.; DeMaria, M.; Penny, A.; Latto, A.; Rappaport, E.; Tallapragada, V. Recent Progress in Tropical Cyclone Intensity Forecasting at the National Hurricane Center. Weather Forecast. 2020, 35, 1913–1922. [Google Scholar] [CrossRef]
- Kaplan, J.; DeMaria, M. Large-scale characteristics of rapidly intensifying tropical cyclones in the North Atlantic basin. Weather Forecast. 2003, 18, 1093–1108. [Google Scholar] [CrossRef]
- Kaplan, J.; Rozoff, C.M.; DeMaria, M.; Sampson, C.R.; Kossin, J.; Velden, C.S.; Cione, J.J.; Dunion, J.P.; Knaff, J.; Zhang, J.; et al. Evaluating environmental impacts on tropical cyclone rapid intensification predictability utilizing statistical models. Weather Forecast. 2015, 30, 1374–1396. [Google Scholar] [CrossRef]
- DeMaria, M.; Franklin, J.L.; Onderlinde, M.J.; Kaplan, J. Operational Forecasting of Tropical Cyclone Rapid Intensification at the National Hurricane Center. Atmosphere 2021, 12, 683. [Google Scholar] [CrossRef]
- Schumacher, A.B.; DeMaria, M.; Knaff, J.A. Objective Estimation of the 24-h Probability of Tropical Cyclone Formation. Weather Forecast. 2009, 24, 456–471. Available online: https://journals.ametsoc.org/view/journals/wefo/24/2/2008waf200710 (accessed on 6 October 2022). [CrossRef]
- DeMaria, M. A Simplified Dynamical System for Tropical Cyclone Intensity Prediction. Mon. Weather Rev. 2009, 137, 68–82. Available online: https://journals.ametsoc.org/view/journals/mwre/137/1/2008mwr2513.1 (accessed on 6 October 2022). [CrossRef]
- DeMaria, M.; Kaplan, J. A statistical hurricane intensity prediction scheme (SHIPS) for the Atlantic basin. Weather Forecast. 1994, 9, 209–220. [Google Scholar] [CrossRef]
- DeMaria, M.; Kaplan, J. An Updated Statistical Hurricane Intensity Prediction Scheme (SHIPS) for the Atlantic and Eastern North Pacific Basins Mark. Weather Forecast. 1999, 14, 326–337. [Google Scholar] [CrossRef]
- DeMaria, M.; Mainelli, M.; Shay, L.K.; Knaff, J.A.; Kaplan, J. Further Improvements to the Statistical Hurricane Intensity Prediction Scheme (SHIPS). Weather Forecast. 2005, 20, 531–543. [Google Scholar] [CrossRef]
- Wei, Y. An Advanced Artificial Intelligence System for Investigating the Tropical Cyclone Rapid Intensification. Ph.D. Thesis, George Mason University, Fairfax, VA, USA, 2020. [Google Scholar]
- Dee, D.P.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.A.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2021, 137, 553–597. [Google Scholar] [CrossRef]
- Wang, Y.; Rao, Y.; Tan, Z.-M.; Schönemann, D. A statistical analysis of the effects of vertical wind shear on tropical cyclone intensity change over the western North Pacific. Mon. Weather Rev. 2015, 143, 3434–3453. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, C.; Peng, S.; Chen, S.; Wang, S. A Horizontal Index for the Influence of Upper-Level Environmental Flow on Tropical Cyclone Intensity. Weather Forecast. 2016, 31, 237–253. [Google Scholar] [CrossRef]
- Wang, Z. What is the key feature of convection leading up to tropical cyclone formation? J. Atmos. Sci. 2018, 75, 1609–1629. [Google Scholar] [CrossRef]
- Astier, N.; Plu, M.; Claud, C. Associations between tropical cyclone activity in the Southwest Indian Ocean and El Niño Southern Oscillation. Atmos. Sci. Lett. 2015, 16, 506–511. [Google Scholar] [CrossRef]
- Ferrara, M.; Groff, F.; Moon, Z.; Keshavamurthy, K.; Robeson, S.M.; Kieu, C. Large-scale control of the lower stratosphere on variability of tropical cyclone intensity. Geophys. Res. Lett. 2017, 44, 4313–4323. [Google Scholar] [CrossRef]
- Yang, R.; Tang, J.; Kafatos, M. Improved associated conditions in rapid intensifications of tropical cyclones. Geophys. Res. Lett. 2007, 34, L20807. [Google Scholar] [CrossRef]
- Yang, R.; Sun, D.; Tang, J. A “sufficient” condition combination for rapid intensifications of tropical cyclones. Geophys. Res. Lett. 2008, 35, L20802. [Google Scholar] [CrossRef]
- Su, H.; Wu, L.; Jiang, J.H.; Pai, R.; Liu, A.; Zhai, A.J.; Tavallali, P.; DeMaria, M. Applying satellite observations of tropical cyclone internal structures to rapid intensification forecast with machine learning. Geophys. Res. Lett. 2020, 47, e2020GL089102. [Google Scholar] [CrossRef]
- Mercer, A.E.; Grimes, A.D.; Wood, K.M. Application of Unsupervised Learning Techniques to Identify Atlantic Tropical Cyclone Rapid Intensification Environments. J. Appl. Meteorol. Climatol. 2021, 60, 119–138. Available online: https://journals.ametsoc.org/view/journals/apme/60/1/jamc-d-20-0105.1.xml (accessed on 23 March 2021). [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Wei, Y.; Yang, R. An Advanced Artificial Intelligence System for Investigating Tropical Cyclone Rapid Intensification with the SHIPS Database. Atmosphere 2021, 12, 484. [Google Scholar] [CrossRef]
- Wei, Y.; Yang, R.; Kinser, J.; Griva, I.; Gkountouna, O. An Advanced Artificial Intelligence System for Identifying the Near-Core Impact Features to Tropical Cyclone Rapid Intensification from the ERA-Interim Data. Atmosphere 2022, 13, 643. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- SHIPS. A Link to the 2018 Version of the SHIPS Developmental Data. 2018. Available online: http://rammb.cira.colostate.edu/research/tropical_cyclones/ships/docs/AL/lsdiaga_1982_2017_sat_ts.dat (accessed on 3 February 2020).
- SHIPS. A Link to the 2018 Version of the SHIPS Developmental Data Variables. 2018. Available online: http://rammb.cira.colostate.edu/research/tropical_cyclones/ships/docs/ships_predictor_file_2018.doc (accessed on 3 February 2020).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Liu, Y.; Racah, E.; Correa, J.; Khosrowshahi, A.; Lavers, D.; Kunkel, K.; Wehner, M.; Collins, W. Application of Deep Convolutional Neural Networks for Detecting Extreme Weather in Climate Datasets. arXiv 2016, arXiv:1605.01156. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wei, Y.; Sartore, L.; Abernethy, J.; Miller, D.; Toppin, K.; Hyman, M. Deep Learning for Data Imputation and Calibration Weighting. In JSM Proceedings, Statistical Computing Section; American Statistical Association: Alexandria, VA, USA, 2018; pp. 1121–1131. [Google Scholar]
- Gogna, A.; Majumdar, A. Discriminative Autoencoder for Feature Extraction: Application to Character Recognition. Neural Process. Lett. 2019, 49, 1723–1735. [Google Scholar] [CrossRef]
- Racah, E.; Beckham, C.; Maharaj, T.; Pal, C. Semi-Supervised Detection of Extreme Weather Events in Large Climate Datasets. arXiv 2016, arXiv:1612.02095. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional neural networks. In Proceedings of the 13th European Conference Computer Vision and Pattern Recognition, Zurich, Switzerland, 6–12 September 2014; pp. 6–12. [Google Scholar]
- Trevor, H.; Robert, T.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Yang, R. A Systematic Classification Investigation of Rapid Intensification of Atlantic Tropical Cyclones with the SHIPS Database. Weather Forecast. 2016, 31, 495–513. [Google Scholar] [CrossRef]
- Randel, W.J.; Stolarski, R.S.; Cunnold, D.M.; Logan, J.A.; Newchurch, M.J.; Zawodny, J.M. Trends in the vertical distribution of ozone. Science 1999, 285, 1689–1692. [Google Scholar] [CrossRef]
- Wu, Y.; Zou, X. Numerical test of a simple approach for using TOMS total ozone data in hurricane environment. Q. J. R. Meteorol. Soc. 2008, 134, 1397–1408. [Google Scholar] [CrossRef]
- Zou, X.; Wu, Y. On the relationship between total ozone mapping spectrometer ozone and hurricanes. J. Geophys. Res. 2005, 110, D06109. [Google Scholar] [CrossRef]
- Lin, L.; Zou, X. Associations of Hurricane Intensity Changes to Satellite Total Column Ozone Structural Changes within Hurricanes. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–7. [Google Scholar] [CrossRef]














| Variables | Name | IS | Feature Number | Removed Features |
|---|---|---|---|---|
| q | Specific humidity | 0.065 | 5 | q3, q8; q7 |
| r | Relative humidity | 0.064 | 7 | r4 |
| u | Horizontal wind | 0.067 | 8 | |
| v | Meridional wind | 0.062 | 7 | v7 |
| pv | Potential vorticity | 0.056 | 6 | pv7, pv8 |
| vo | Relative vorticity | 0.051 | 5 | vo1, vo6, vo7 |
| w | Vertical wind | 0.043 | 5 | w3, w4; w1 |
| d | Divergence | 0.042 | 3 | d1, d4, d6; d2, d3 |
| t | Temperature | 0.024 | 4 | t1, t2, t5, t6 |
| z | Geopotential | 0.020 | 3 | z2, z3, z5, z7, z8 |
| o3 | mass mixing ratio | 0.020 | 3 | o31, o32, o33, o34, o36 |
| clwc | Cloud liquid water content | 0.013 | 2 | clwc2, clwc4, clwc5, clwc6, clwc7, clwc8 |
| cc | Fraction of cloud cover | 0.017 | 1 | cc2, cc4, cc5, cc6, cc7; cc3, cc8 |
| ciwc | Cloud ice water content | 0.011 | 1 | ciwc2, ciwc3, ciwc4, ciwc5, ciwc6, ciwc7, ciwc8 |
| Hyperparameter | Component | Explanation | Min | Max | MB | MA |
|---|---|---|---|---|---|---|
| n_cluster | GMM-SMOTE | The maximum number of clusters in the Gaussian Mixture Model | 1 | 10 | 1 | 3 |
| m_neighbors | GMM-SMOTE | The number of nearest neighbors used to determine if a minority sample is in danger | 3 | 10 | 10 | 10 |
| k_neighbors | GMM-SMOTE | The number of nearest neighbors used to construct synthetic samples | 3 | 14 | 5 | 9 |
| shrinkage | XGBoost | Shrinkage ratio for each feature | 0 | 0.3 | 0.1 | 0.19 |
| n_estimator | XGBoost | The number of CART to grow | 100 | 2000 | 100 | 2000 |
| subsample | XGBoost | Subsample ratio of the training instances | 0.5 | 1 | 1 | 0.5 |
| colsample | XGBoost | Subsample ratio of columns for creating each classifier | 0.5 | 1 | 1 | 1 |
| reg_alpha | XGBoost | L1 regularization term on weights | 0 | 20 | 0 | 0.5 |
| reg_lambda | XGBoost | L2 regularization term on weights | 0.5 | 20 | 1 | 20 |
| gamma | XGBoost | Minimum loss reduction required to make a further partition on a leaf node of the CART | 0 | 10 | 0 | 0 |
| min_child_weight | XGBoost | Minimum sum of instance weight in a split | 0.5 | 5 | 1 | 0.5 |
| max_depth | XGBoost | Max depth of each CART model in XGBoost | 3 | 10 | 3 | 3 |
| decision threshold | XGBoost | Decision threshold on the XGBoost classifier output | 0 | 1 | 0.5 | 0.2 |
| Predicted RI | Predicted Non-RI | Actual | |
|---|---|---|---|
| Actual RI | 48 (29) | 47 (66) | 95 |
| Actual non-RI | 37 (31) | 1465 (1471) | 1502 |
| Total Predicted | 85 (60) | 1512 (1537) |
| Model | Kappa | PSS | POD | FAR |
|---|---|---|---|---|
| MB | 0.344 | 0.285 | 0.305 | 0.517 |
| MA | 0.506 | 0.481 | 0.505 | 0.435 |
| Improvement | 47.10% | 68.80% | 65.60% | −15.90% |
| Model | Kappa | PSS | POD | FAR |
|---|---|---|---|---|
| COR-SHIPS | 0.354 | 0.368 | 0.411 | 0.621 |
| LLE-SHIPS | 0.454 | 0.399 | 0.421 | 0.563 |
| TCNET | 0.506 | 0.481 | 0.505 | 0.435 |
| Y16 | 0.275 | NA | 0.34 | 0.711 |
| KRD15 | NA | 0.225 | 0.275 | 0.825 |
| vs. COR-SHIPS | 42.9% | 30.7% | 22.9% | −30.0% |
| vs. Y16 | 84.0% | NA | 48.5% | −38.8% |
| vs. KRD15 | NA | 114.0% | 83.6% | −47.3% |
| Variable | IS | Description |
|---|---|---|
| BD12 | 0.019747 | The past 12-h intensity change |
| VMAX | 0.0176 | Maximum Surface Wind |
| SHRD | 0.01481 | 850–200 hPa shear magnitude |
| DTL | 0.014381 | The distance to nearest major land |
| IRM1_5 | 0.013737 | Predictors from GOES data (not time dependent) for r = 100–300 km but at 1.5 h before initial time |
| o31 | 0.013308 | 1st variable in o3 |
| G150 | 0.013093 | Temperature perturbation at 150 hPa due to the symmetric vortex calculated from the gradient thermal wind. Averaged from r = 200 to 800 km centered on input lat/lon (not always the model/analysis vortex position) |
| q7 | 0.013093 | 7th variable in q |
| u3 | 0.012878 | 3rd variable in u |
| q4 | 0.012878 | 4th variable in q |
| Variables | Summed IS | Feature Number | IS Rank | Average IS | Average IS Rank |
|---|---|---|---|---|---|
| q | 0.0759 | 7 | 1 | 0.0108 | 3 |
| vo | 0.0635 | 6 | 2 | 0.0106 | 4 |
| u | 0.0585 | 6 | 3 | 0.0098 | 5 |
| v | 0.0509 | 6 | 4 | 0.0085 | 7 |
| pv | 0.0441 | 5 | 5 | 0.0088 | 6 |
| r | 0.0387 | 8 | 6 | 0.0048 | 14 |
| ciwc | 0.0144 | 2 | 7 | 0.0072 | 10 |
| o3 | 0.0133 | 1 | 8 | 0.0133 | 1 |
| cc | 0.0120 | 2 | 9 | 0.0060 | 12 |
| d | 0.0118 | 1 | 10 | 0.0118 | 2 |
| t | 0.0082 | 1 | 11 | 0.0082 | 8 |
| z | 0.0077 | 1 | 12 | 0.0077 | 9 |
| w | 0.0071 | 1 | 13 | 0.0071 | 11 |
| clwc | 0.0058 | 1 | 14 | 0.0058 | 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Y.; Yang, R.; Sun, D. Investigating Tropical Cyclone Rapid Intensification with an Advanced Artificial Intelligence System and Gridded Reanalysis Data. Atmosphere 2023, 14, 195. https://doi.org/10.3390/atmos14020195
Wei Y, Yang R, Sun D. Investigating Tropical Cyclone Rapid Intensification with an Advanced Artificial Intelligence System and Gridded Reanalysis Data. Atmosphere. 2023; 14(2):195. https://doi.org/10.3390/atmos14020195
Chicago/Turabian StyleWei, Yijun, Ruixin Yang, and Donglian Sun. 2023. "Investigating Tropical Cyclone Rapid Intensification with an Advanced Artificial Intelligence System and Gridded Reanalysis Data" Atmosphere 14, no. 2: 195. https://doi.org/10.3390/atmos14020195
APA StyleWei, Y., Yang, R., & Sun, D. (2023). Investigating Tropical Cyclone Rapid Intensification with an Advanced Artificial Intelligence System and Gridded Reanalysis Data. Atmosphere, 14(2), 195. https://doi.org/10.3390/atmos14020195