
The Segmented Colour Feature Extreme Learning Machine: Applications in Agricultural Robotics


Abstract
:1. Introduction
2. Materials and Methods
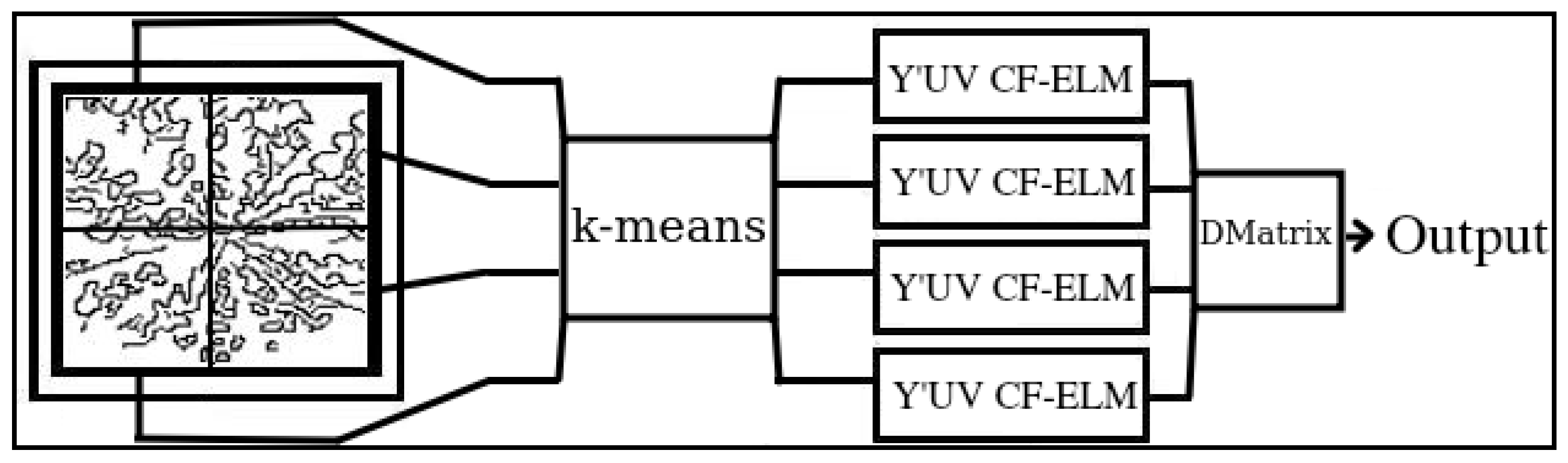
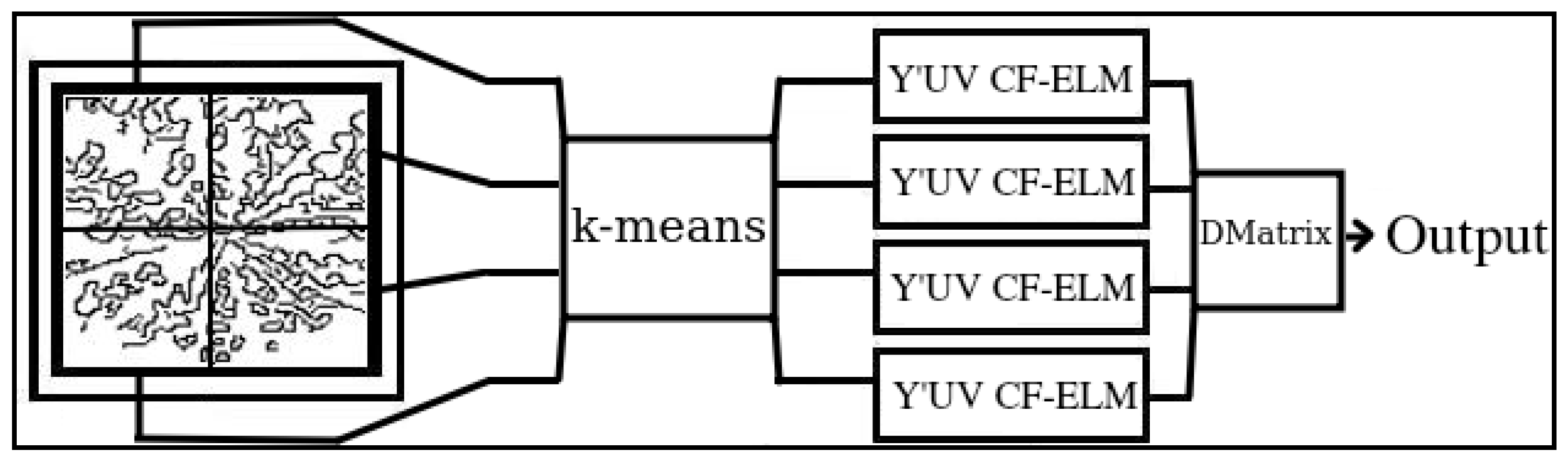
2.1. Extreme Learning Machine (ELM) and Colour Feature Variant (CF-ELM)
2.2. Equal K-Means
| Algorithm 1 Equal K-means |
| Require: Require:
|
2.3. Decision Matrix
| Algorithm 2 Decision Matrix - Square Matrix: First pass |
| Require: Require:
|
2.4. Hardware/Implementation Specifics
2.5. Training/Testing Algorithms
| Algorithm 3 SCF-ELM Training |
Require:
|
| Algorithm 4 SCF-ELM Testing - for the image |
| Require: Require: ← train() Require: D ← decision_matrix()
|
2.6. Benchmarking Details
2.7. Data Sets
- Bull Thistle: The Cirsium Vulgare (or Bull Thistle) and surrounding landscape were cropped to eliminate background. These images were photograph using a Fujifilm 10 megapixel hand held camera, at a fixed distance of 2m and nadir geometry. Bull thistle can cause injury to livestock and competes with pasture growing in the area, this has become a problem in eastern areas of Australia [36]. Samples from this dataset are on display in Figure 3.
- Horehound: The Marrubium vulgare (or Horehound) and surrounding landscape were cropped to eliminate background. These images were photograph using a Cannon EOS 6D 20 megapixel hand held camera, at a fixed distance of 2m and nadir geometry. Horehound is unpalatable for livestock and competes with pasture growing in the area, this weed has also become a problem in eastern areas of Australia [36]. Samples from this dataset are on display in Figure 4.
- Vehicle detection: The vehicle detection dataset contains cropped images of an all terrain vehicle (ATV) on farm land and surrounding landscape. The ATV was photographed using a Fujifilm 10 megapixel hand held camera at a fixed distance of 5 m and at oblique angles and random orientations to simulate a drone fly over. ATV accidents are a major cause of injury and/or death in farm related incidents [37]. A collection of samples from the dataset are available in Figure 5.
- Cattle detection: The cattle detection dataset contains cropped images of Poll Herefords in and of a farming landscape. The images were cropped from multiple stationary surveillance cameras that were position at different creek beds waiting for animals to come to drink. These images were captured in AVI video format using a Scoutguard SG860C camera with 640 by 480 pixels at 16 frames per second for 1 min. Image frames were extracted into JPEG format at 1 frame per second, cropped to surround the cattle. The purpose of this dataset is determine if the algorithms could be used in the tracking and counting of cattle. A sample of the image set is displayed in Figure 6.
3. Results
3.1. Dataset Test Results
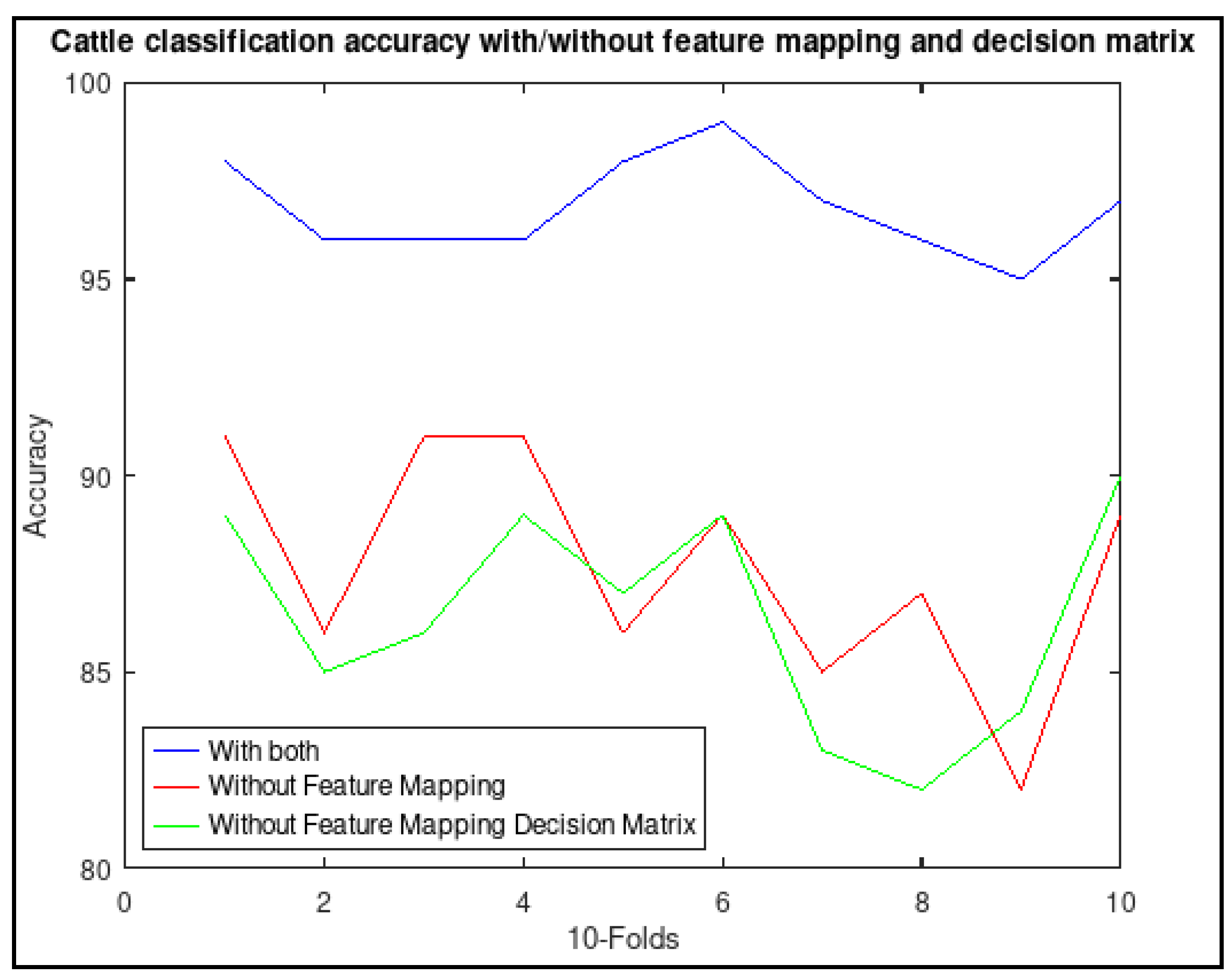
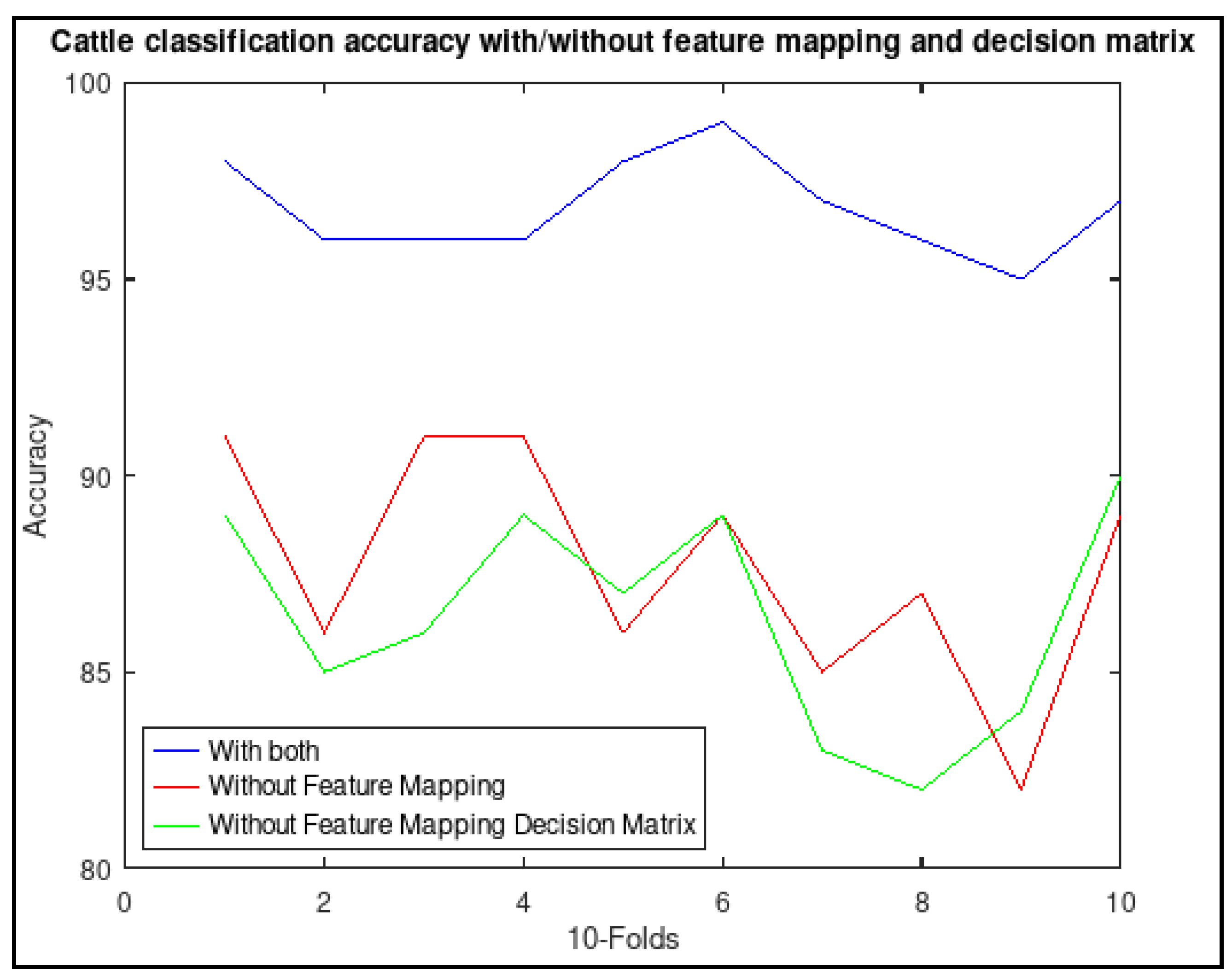
3.2. Benefits of Feature Mapping and Decision Matrix
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| ANN | Artificial Neural Network |
| ATV | All Terrain Vehicle |
| CF-ELM | Colour Feature Extreme Learning Machine |
| CNN | Convolutional Neural Network |
| CIW-ELM | Computed Input Weights Extreme Learning Machine |
| C-SVC | C-Support Vector Machine |
| DCT | Discrete Cosine Transform |
| ELM | Extreme Learning Machine |
| EN-ELM | Ensemble Extreme Learning Machine |
| LSVM | Linear Support Vector Machine |
| MEC-ELM | Multiple Expert Colour Feature Extreme Learning Machine |
| SCF-ELM | Segemented Colour Feature Extreme Learning Machine |
| SVM | Support Vector Machine |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| YCrCb | Light intensity, chrominance red and blue. |
| Y’UV | Light intensity, chrominance red and blue. |
References
- Gonzalez-Gonzalez, M.G.; Blasco, J.; Cubero, S.; Chueca, P. Automated Detection of Tetranychus urticae Koch in Citrus Leaves Based on Colour and VIS/NIR Hyperspectral Imaging. Agronomy 2021, 11, 1002. [Google Scholar] [CrossRef]
- Rahman, M.; Robson, A.; Salgadoe, S.; Walsh, K.; Bristow, M. Exploring the Potential of High Resolution Satellite Imagery for Yield Prediction of Avocado and Mango Crops. Proceedings 2019, 36, 154. [Google Scholar] [CrossRef] [Green Version]
- Daga, A.P.; Garibaldi, L. GA-Adaptive Template Matching for Offline Shape Motion Tracking Based on Edge Detection: IAS Estimation from the SURVISHNO 2019 Challenge Video for Machine Diagnostics Purposes. Algorithms 2020, 13, 33. [Google Scholar] [CrossRef] [Green Version]
- Palumbo, M.; Pace, B.; Cefola, M.; Montesano, F.F.; Serio, F.; Colelli, G.; Attolico, G. Self-Configuring CVS to Discriminate Rocket Leaves According to Cultivation Practices and to Correctly Attribute Visual Quality Level. Agronomy 2021, 11, 1353. [Google Scholar] [CrossRef]
- Bishop, J.; Falzon, G.; Trotter, M.; Kwan, P.; Meek, P. Livestock Vocalisation Classification in Farm Soundscapes. Comput. Electron. Agric. 2019, 162, 531–542. [Google Scholar] [CrossRef]
- Hsu, D.; Muthukumar, V.; Xu, J. On the proliferation of support vectors in high dimensions. arXiv 2020, arXiv:math.ST/2009.10670. [Google Scholar]
- Zhang, M.; Luo, H.; Song, W.; Mei, H.; Su, C. Spectral-Spatial Offset Graph Convolutional Networks for Hyperspectral Image Classification. Remote Sens. 2021, 13, 4342. [Google Scholar] [CrossRef]
- Chand, A.A.; Prasad, K.A.; Mar, E.; Dakai, S.; Mamun, K.A.; Islam, F.R.; Mehta, U.; Kumar, N.M. Design and Analysis of Photovoltaic Powered Battery-Operated Computer Vision-Based Multi-Purpose Smart Farming Robot. Agronomy 2021, 11, 530. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Wang, X.; An, S.; Xu, Y.; Hou, H.; Chen, F.; Yang, Y.; Zhang, S.; Liu, R. A Back Propagation Neural Network Model Optimized by Mind Evolutionary Algorithm for Estimating Cd, Cr, and Pb Concentrations in Soils Using Vis-NIR Diffuse Reflectance Spectroscopy. Appl. Sci. 2020, 10, 51. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Zhou, H.; Huang, G.B. Extreme Learning Machine based fast object recognition. Int. Conf. Inf. Fusion (FUSION) 2012, 15, 1490–1496. [Google Scholar]
- Sadgrove, E.J.; Falzon, G.; Miron, D.; Lamb, D. Fast object detection in pastoral landscapes using a Colour Feature Extreme Learning Machine. Comput. Electron. Agric. 2017, 139, 204–212. [Google Scholar] [CrossRef]
- Tapson, J.; de Chazal, P.; van Schaik, A. Explicit Computation of Input Weights in Extreme Learning Machines. In International Conference on Extreme Learning Machines; Algorithms and Theories; Springer: Cham, Switzerland, 2015; Volume 1, pp. 41–49. [Google Scholar]
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 6. [Google Scholar] [CrossRef] [Green Version]
- Sadgrove, E.J.; Falzon, G.; Miron, D.; Lamb, D. Real-time object detection in agricultural/remote environments using the multiple-expert colour feature extreme learning machine (MEC-ELM). Comput. Ind. 2018, 98, 183–191. [Google Scholar] [CrossRef]
- Urban, G.; Geras, K.; Kahou, S.E.; Aslan, O.; Wang, S.; Caruana, R.; Mohamed, A.; Philipose, M.; Richardson, M. Do Deep Convolutional Nets Really Need to be Deep (Or Even Convolutional)? arXiv 2016, arXiv:1603.05691. [Google Scholar]
- Rod, Z.P.; Adams, R.; Bolouri, H. Dimensionality Reduction of Face Images Using Discrete Cosine Transforms for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- Cambria, E.; Huang, G.B.; Kasun, L.L.C.; Zhou, H.; Vong, C.M.; Lin, J.; Yin, J.; Cai, Z.; Liu, Q.; Li, K.; et al. Extreme Learning Machines [Trends & Controversies]. IEEE Intell. Syst. 2013, 28, 30–59. [Google Scholar]
- Ertuğrul, Ö.F.; Kaya, Y. A detailed analysis on extreme learning machine and novel approaches based on ELM. Am. J. Comput. Sci. Eng. 2014, 1, 43–50. [Google Scholar]
- da Gomes, G.S.S.; Ludermir, T.B.; Lima, L.M.M.R. Comparison of new activation functions in neural network for forecasting financial time series. Neural Comput. Appl. 2011, 20, 417–439. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef] [Green Version]
- Barata, J.C.A.; Hussein, M.S. The Moore–Penrose Pseudoinverse: A Tutorial Review of the Theory. Braz. J. Phys. 2011, 42, 146–165. [Google Scholar] [CrossRef] [Green Version]
- Kanungo, T.; Mount, D.; Netanyahu, N.; Piatko, C.; Silverman, R.; Wu, A. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Liberti, L.; Lavor, C.; Maculan, N.; Mucherino, A. Euclidean Distance Geometry and Applications. SIAM Rev. 2012, 56, 3–69. [Google Scholar] [CrossRef]
- Wang, J.; Su, X. An improved K-Means clustering algorithm. In Proceedings of the 2011 IEEE 3rd International Conference on Communication Software and Networks, Xi’an, China, 27–29 May 2011; pp. 44–46. [Google Scholar] [CrossRef]
- Malinen, M.I.; Fränti, P. Balanced K-Means for Clustering. In Structural, Syntactic, and Statistical Pattern Recognition; Fränti, P., Brown, G., Loog, M., Escolano, F., Pelillo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 32–41. [Google Scholar]
- Hashemi, A.; Dowlatshahi, M.; Nezamabadi-pour, H. Ensemble of feature selection algorithms: A multi-criteria decision-making approach. Int. J. Mach. Learn. Cybern. 2021, 1–21. [Google Scholar] [CrossRef]
- Netlib.org. The LAPACKE C Interface to LAPACK. Available online: https://www.netlib.org/lapack/lapacke.html (accessed on 24 May 2019).
- Liu, N.; Wang, H. Ensemble Based Extreme Learning Machine. IEEE Signal Process. Lett. 2010, 17, 754–757. [Google Scholar] [CrossRef]
- Studio Encoding Parameters of Digital Television for Standard 4:3 and Wide-Screen 16:9 Aspect Ratios; Technical Report; International Telecommunications Union, Electronic Publication: Geneva, Switzerland, 2015.
- Al-Tairi, Z.H.; Rahmat, R.W.; Saripan, M.I.; Sulaiman, P.S. Skin Segmentation Using YUV and RGB Colour Spaces. J. Inf. Process. Syst. 2014, 10, 283–299. [Google Scholar] [CrossRef] [Green Version]
- Harase, S. Comparison of Sobol’ sequences in financial applications. Monte Carlo Methods Appl. 2019, 25, 61–74. [Google Scholar] [CrossRef]
- Kim, Y.; Street, W.N.; Russell, G.J.; Menczer, F. Customer Targeting: A Neural Network Approach Guided by Genetic Algorithms. Manag. Sci. 2005, 51, 264–276. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of Machine Learning Research, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics; Teh, Y.W., Titterington, M., Eds.; PMLR: Chia Laguna Resort, Sardinia, Italy, 2010; Volume 9, pp. 249–256. [Google Scholar]
- Grace, B.S.; Whalley, R.D.B.; Sheppard, A.W.; Sindel, B.M. Managing Saffron Thistle in pastures with strategic grazing. Rangel. J. 2002, 24, 313–325. [Google Scholar] [CrossRef]
- Wood, A.; Duijff, J.W.; Christey, G.R. Quad bike injuries in Waikato, New Zealand: An institutional review from 2007–2011. ANZ J. Surg. 2013, 83, 206–210. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D. SVM and ELM: Who Wins? Object Recognition with Deep Convolutional Features from ImageNet. In Theory, Algorithms and Applications; ELM; Springer: Berlin/Heidelberg, Germany, 2015; Volume 1, pp. 249–263. [Google Scholar]
- Zhou, G.; Li, C.; Cheng, P. Conference: Geoscience and Remote Sensing Symposium, Proceedings of the Unmanned Aerial Vehicle (UAV) Real-time Video Registration for Forest Fire Monitoring; IEEE International: Seoul, Korea, 2005; Volume 3. [Google Scholar]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | All Images | Training | Testing | Resolution |
|---|---|---|---|---|
| Bull Thistle | 1000 | 450 | 50 | 100,100 |
| Horehound | 1000 | 225 | 25 | 100,100 |
| Cattle | 1000 | 450 | 50 | 100,100 |
| ATV | 1000 | 450 | 50 | 100,100 |
| Dataset | Classifier | Train Time(s) | Time/Image(s) | TPR | FPR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
| Bull Thistle | SCF-ELM | 9.94 | 0.0111 | 94.00 | 12.80 | 88.01 | 90.60 |
| LSVM | 2.91 | 0.0057 | 68.4 | 21.60 | 76.00 | 73.40 | |
| C-SVC | 1939.60 | 0.0069 | 89.60 | 27.60 | 76.45 | 81.00 | |
| EN-ELM | 64.19 | 0.0048 | 53.27 | 15.93 | 76.98 | 68.67 | |
| CF-ELM | 1.56 | 0.0029 | 86.40 | 16.00 | 84.38 | 85.20 | |
| CIW-ELM | 4.51 | 0.0019 | 71.52 | 54.24 | 56.87 | 58.64 | |
| ELM | 1.08 | 0.0019 | 80.58 | 55.11 | 59.39 | 62.74 |
| Dataset | Classifier | Train Time(s) | Time/Image(s) | TPR | FPR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
| Cattle | SCF-ELM | 9.92 | 0.0110 | 95.20 | 5.40 | 94.63 | 94.90 |
| LSVM | 1.51 | 0.0036 | 88.00 | 11.60 | 88.35 | 88.20 | |
| C-SVC | 1749.16 | 0.0064 | 90.00 | 2.80 | 96.98 | 93.60 | |
| EN-ELM | 63.89 | 0.0046 | 74.00 | 10.93 | 87.13 | 81.54 | |
| CF-ELM | 1.55 | 0.0029 | 78.10 | 15.80 | 83.17 | 81.15 | |
| CIW-ELM | 4.43 | 0.0019 | 80.40 | 30.32 | 72.62 | 75.04 | |
| ELM | 1.08 | 0.0019 | 76.05 | 28.31 | 72.87 | 73.87 |
| Dataset | Classifier | Train Time(s) | Time/Image(s) | TPR | FPR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
| ATV | SCF-ELM | 9.93 | 0.0110 | 99.8 | 1.00 | 99.01 | 99.40 |
| LSVM | 0.52 | 0.0014 | 99.60 | 1.20 | 98.71 | 99.20 | |
| C-SVC | 591.27 | 0.0048 | 100.00 | 4.00 | 96.51 | 98.00 | |
| EN-ELM | 64.34 | 0.0047 | 86.35 | 5.73 | 93.78 | 90.31 | |
| CF-ELM | 1.56 | 0.0029 | 85.92 | 7.88 | 91.60 | 89.02 | |
| CIW-ELM | 4.399858 | 0.0019 | 76.88 | 3.16 | 96.05 | 86.86 | |
| ELM | 1.09 | 0.0019 | 81.16 | 13.56 | 85.68 | 83.80 |
| Dataset | Classifier | Train Time(s) | Time/Image(s) | TPR | FPR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
| Horehound | SCF-ELM | 9.93 | 0.0111 | 97.20 | 18.20 | 84.23 | 89.50 |
| LSVM | 3.13 | 0.0061 | 68.40 | 21.60 | 76.00 | 73.40 | |
| C-SVC | 2037.52 | 0.0073 | 89.60 | 27.60 | 76.45 | 81.00 | |
| EN-ELM | 60.26 | 0.0048 | 66.67 | 53.90 | 55.30 | 56.38 | |
| CF-ELM | 1.56 | 0.0029 | 90.27 | 25.69 | 77.85 | 82.29 | |
| CIW-ELM | 4.51 | 0.0019 | 70.92 | 51.77 | 57.80 | 59.57 | |
| ELM | 1.08 | 0.0019 | 73.05 | 55.32 | 56.91 | 58.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadgrove, E.J.; Falzon, G.; Miron, D.; Lamb, D.W. The Segmented Colour Feature Extreme Learning Machine: Applications in Agricultural Robotics. Agronomy 2021, 11, 2290. https://doi.org/10.3390/agronomy11112290
Sadgrove EJ, Falzon G, Miron D, Lamb DW. The Segmented Colour Feature Extreme Learning Machine: Applications in Agricultural Robotics. Agronomy. 2021; 11(11):2290. https://doi.org/10.3390/agronomy11112290
Chicago/Turabian StyleSadgrove, Edmund J., Greg Falzon, David Miron, and David W. Lamb. 2021. "The Segmented Colour Feature Extreme Learning Machine: Applications in Agricultural Robotics" Agronomy 11, no. 11: 2290. https://doi.org/10.3390/agronomy11112290
APA StyleSadgrove, E. J., Falzon, G., Miron, D., & Lamb, D. W. (2021). The Segmented Colour Feature Extreme Learning Machine: Applications in Agricultural Robotics. Agronomy, 11(11), 2290. https://doi.org/10.3390/agronomy11112290