Abstract
This paper studies the synthesis of controllers for cyber-physical systems (CPSs) that are required to carry out complex time-sensitive tasks in the presence of an adversary. The time-sensitive task is specified as a formula in the metric interval temporal logic (MITL). CPSs that operate in adversarial environments have typically been abstracted as stochastic games (SGs); however, because traditional SG models do not incorporate a notion of time, they cannot be used in a setting where the objective is time-sensitive. To address this, we introduce durational stochastic games (DSGs). DSGs generalize SGs to incorporate a notion of time and model the adversary’s abilities to tamper with the control input (actuator attack) and manipulate the timing information that is perceived by the CPS (timing attack). We define notions of spatial, temporal, and spatio-temporal robustness to quantify the amounts by which system trajectories under the synthesized policy can be perturbed in space and time without affecting satisfaction of the MITL objective. In the case of an actuator attack, we design computational procedures to synthesize controllers that will satisfy the MITL task along with a guarantee of its robustness. In the presence of a timing attack, we relax the robustness constraint to develop a value iteration-based procedure to compute the CPS policy as a finite-state controller to maximize the probability of satisfying the MITL task. A numerical evaluation of our approach is presented on a signalized traffic network to illustrate our results.
1. Introduction
Cyber-physical systems (CPSs) are playing increasingly important roles in multiple applications, including autonomous vehicles, robotics, and advanced manufacturing [1]. In many of these applications, the CPS is expected to satisfy complex, time-critical objectives in dynamic environments with autonomy. An example is a scenario where a drone has to periodically surveil a target region in its environment. One way to specify requirements on the CPS behavior is through a temporal logic framework [2] such as metric interval temporal logic (MITL) or signal temporal logic (STL). The verification of satisfaction of the temporal logic objective can then be achieved by applying principles from model checking [2,3] to a finite transition system that abstracts the CPS [4,5,6,7]. Solution techniques to verify such an objective usually return a ‘yes/no’ output, which indicates if the behavior of the CPS will satisfy the desired task and if it is possible to synthesize a control policy to satisfy this objective.
However, such binary-valued verification results may not be adequate when an adversary can inject inputs that affect the behavior of the CPS. Small perturbations can result in significantly large changes in the output of a CPS and can lead to violations of the desired task. The authors of [8,9] defined a notion of robustness degree to quantify the extent to which a CPS could tolerate deviations from its nominal behavior without resulting in violation of the desired specification.
For time-critical CPSs, an adversary could launch attacks on clocks of the system (by timing attack) and the inputs to the system (by actuator attack). In the latter case, stochastic games (SGs) have been used to model the interaction between the CPS and the adversary [10]. However, SGs do not include information about the time taken for a transition between two states. To bridge this gap, we introduce durational stochastic games (DSGs). In addition to transition probabilities between states under given actions of the CPS and adversary, a DSG encodes the time taken for the transition as a probability mass function. Although DSGs present a modeling formalism for time-critical objectives, they introduce an additional attack surface that can be exploited by an adversary.
In this paper, we synthesize controllers to satisfy an MITL specification that can be represented by a deterministic timed Büchi automaton with a desired robustness guarantee. The robustness guarantee quantifies how sensitive the synthesized policy (that satisfies the MITL task) will be to disturbances and adversarial inputs. The adversary is assumed to have the following abilities: it can tamper with the input to the defender through an actuator attack [11], and it can affect the time index observed by the CPS by effecting a timing attack [12]. An actuator attack could steer the DSG away from a target set of states, while a timing attack will prevent it from satisfying the objective within the specified time interval.
To address perturbations originating from different attack surfaces (timing information and system inputs), we develop three notions of robustness, namely spatial, temporal, and spatio-temporal robustness. Spatial robustness is defined over discrete timed words and quantifies the maximum perturbation that can be tolerated by timed words so that the desired tasks can still be satisfied in the absence of timing attacks. The temporal robustness characterizes the maximum timing perturbation that can be tolerated by a CPS such that the given MITL objective will not be violated. We introduce a notion of spatio-temporal robustness that unifies the concepts of spatial and temporal robustness. Using these three notions of robustness, we develop algorithms to estimate them and compute controllers for CPSs to guarantee that the given MITL objective can be satisfied with the desired robustness guarantee. This paper makes the following contributions:
- We introduce durational stochastic games (DSGs) to model the interaction between the CPS that has to satisfy a time-critical objective and an adversary who can initiate actuator and timing attacks.
- We define notions of spatial, temporal, and spatio-temporal robustness, which quantify the robustness of system trajectories to spatial, temporal, and spatio-temporal perturbations, respectively, and present computational procedures to estimate them. We design an algorithm to compute a policy for the CPS (defender) with a robustness guarantee when the adversary is limited to effecting only actuator attacks.
- We demonstrate that the defender cannot correctly estimate the spatio-temporal robustness when the adversary can initiate both actuator and timing attacks. We relax the robustness constraints in such cases and present a value iteration-based procedure to compute the defender’s policy, represented as a finite-state controller, to maximize the probability of satisfying the MITL objective.
- We evaluate our approach on a signalized traffic network. We compare our approach with two baselines and show that it outperforms both baselines.
The remainder of this paper is organized as follows. Section 2 discusses related work. Section 3 provides background on MITL and deterministic timed Büchi automata. We define the DSG and notions of robustness in Section 4 and formally state the problem of interest. Section 5 and Section 6 present our results when the adversary is limited to initiating only actuator attacks and when it can effect both actuator and timing attacks, respectively. The experimental results are presented in Section 7. Section 8 concludes the paper.
2. Related Work
For a single agent, semi-Markov decision processes (SMDPs) [13] can be used to model Markovian dynamics, where the time taken for transitions between states is a random variable. SMDPs have been used in production scheduling [14] and the optimization of queues [15].
Stochastic games (SGs) generalize MDPs when there is more than one agent taking an action [16]. SGs have been widely adopted to model strategic interactions between CPSs and adversaries. For example, a zero-sum SG was formulated in [17] to allocate resources to protect power systems against malicious attacks. Two SGs were developed in [18] to detect intrusions to achieve secret and reliable communications. The satisfaction of complex objectives modeled by linear temporal logic (LTL) formulae for zero-sum two-player SGs was presented in [10], where the authors synthesized controllers to maximize the probability of satisfying the LTL formula. However, this approach will not apply when the system has to satisfy a time-critical specification and the adversary can launch a timing attack.
Timed automata (TA) [3] finitely attach many clock constraints to each state. A transition between any two states will be influenced by the satisfaction of the clock constraints in the respective states. There has been significant work performed in the formulation of timed temporal logic frameworks, a detailed survey of which is presented in [19]. Metric interval temporal logic (MITL) [20] is one such fragment that allows for the specification of formulae that explicitly depend on time. Moreover, an MITL formula can be represented as a TA [20,21] that will have a feasible path in it if and only if the MITL formula is true.
Control synthesis under metric temporal logic constraints was studied for motion planning applications in [6,7,22,23]. The authors of [22] considered a vehicle routing problem to meet MTL specifications by solving a mixed integer linear program. Timed automaton-based control synthesis under a subclass of MITL specifications was studied in [6,7]. Cooperative task planning of a multi-agent system under MITL specifications was studied in [24]. In comparison, we consider the actions of an adversarial player, whose objective is opposite to that of the defender. This leads to a modeling of the interaction between the adversary and defender as an SG. Moreover, the previous works have limited their focus to a certain fragment of the MITL, whereas this paper offers a generalized treatment to arbitrary MITL formulae.
Finite-state controllers (FSCs) were used to simplify the policy iteration procedure for POMDPs in [25]. The satisfaction of an LTL formula of a POMDP was presented in [26]. This was extended to the case with an adversary who also only had partial observation of the environment and whose goal was to prevent the defender from satisfying the LTL formula in [27,28]. These treatments, however, did not account for the presence of timing constraints on the satisfaction of a temporal logic formula.
Control synthesis for control systems under disturbances with robustness guarantees has been extensively studied [29,30,31,32]. Such robustness guarantees can be categorized as a notion of spatial robustness. Robust satisfaction of temporal logic tasks have been studied for signal monitoring and property verification. A notion of robustness degree for continuous signals was defined in [8] by computing a distance between the given timed behavior and the set of behaviors that satisfy a property expressed in temporal logic. Our notion of spatial robustness is defined over discrete timed words using the Levenshtein distance, which distinguishes our approach from [8]. The robustness degree between two LTL formulae was introduced in [33]. The authors of [34] adopted a different approach and used the weighted edit distance to quantify a measure of robustness. The notion of temporal robustness was also investigated in [9]. There are three differences between our definition of temporal robustness and that found in [9]. First, the temporal robustness in [9] is defined for a specific trace. In our framework, as the DSG is not deterministic, there could be multiple traces that satisfy the MITL objective under the defender and adversary policies. Therefore, we define temporal robustness with respect to the policies of the defender and adversary and the MITL specification. Second, the temporal robustness of a real-valued signal is computed as the maximum amount of time units by which we can shift on the rising/falling edge of a ‘characteristic function’ in [9]. In comparison, we work with discrete timed words. Finally, our work considers the presence of an adversary, while [9] assumes a single agent. Robust control under signal temporal logic (STL) formulae has been studied based on notions of space robustness [35,36] and temporal robustness [37,38]. These works did not consider the presence of an adversary.
A preliminary version of this paper [39] synthesized policies to satisfy MITL objectives under actuator and timing attacks without robustness guarantees. In this paper, we define three robustness degrees and develop algorithms to compute these quantities. We show that any defender policy that provides a positive robustness degree is an almost-sure satisfaction policy, which is stronger than the quantitative satisfaction policies synthesized in [39].
3. MITL and Timed Automata
We introduce the syntax and semantics of metric interval temporal logic and its equivalent representation as a timed automaton. We use and to denote the sets of real numbers, non-negative reals, positive integers, and non-negative rationals, respectively. Vectors are represented by bold symbols. The comparison between vectors and is element-wise, and denotes the i-th element of . Given a set of atomic propositions , a metric interval temporal logic (MITL) formula is inductively defined as
where is an atomic proposition and I is a non-singular time interval with integer end-points. MITL admits derived operators such as ‘constrained eventually’ () and ‘constrained always’ (). Throughout this paper, we assume that I is bounded. We further rewrite the given MITL formula in the negation normal form so that negations only appear in front of atomic propositions. We augment the atomic proposition set so that any atomic proposition and its negation are both included in .
We focus on the pointwise MITL semantics [40]. A timed word is an infinite sequence , where ; is the time index with . We denote as a word over and as a time sequence. With , we define: and
We interpret MITL formulae over timed words as follows.
Definition 1
(MITL Semantics). Given a timed word ρ and an MITL formula φ, the satisfaction of φ at position j, denoted as , is inductively defined as follows:
- 1.
- if and only if (iff) is true;
- 2.
- iff ;
- 3.
- iff does not satisfy φ;
- 4.
- iff and ;
- 5.
- iff such that , and holds for all .
We denote if . The satisfaction of an MITL formula can be equivalently associated with accepting words of a timed Büchi automaton (TBA) [20]. Let be a finite set of clocks. Define a set of clock constraints over C as where , are clocks, and is a non-negative rational number. In this paper, we focus on a subclass of MITL formulae that can be equivalently represented as deterministic timed Büchi automaton, which are defined as follows.
Definition 2
(Deterministic Timed Büchi Automaton [3]). A deterministic timed Büchi automaton (DTBA) is a tuple , where Q is a finite set of states, is an alphabet over atomic propositions in is the initial state, is the set of transitions, and is the set of accepting states. A transition if enables the transition from q to when a subset of atomic propositions and clock constraints evaluate to true. The clocks in are reset to zero after the transition.
We present the DTBA representing MITL formula as an example in Figure 1. In this figure, the states Q and transitions E are represented by circles and arrows, respectively. Here, the initial state is . The set of accepting states is . Consider the transition from initial state to state . The transition can take place if atomic proposition is evaluated to be true and clock constraint defined on clock c satisfies . Furthermore, the clock c is reset to zero after the transition.
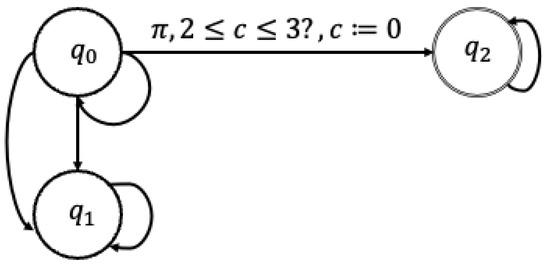
Figure 1.
The deterministic timed Büchi automaton (DTBA) representing a metric interval temporal logic formula . The states and transitions of the DTBA are represented by circles and arrows, respectively. The initial state of this DTBA is and the accepting state is . The formula can be satisfied if the DTBA reaches state .
Given the set of clocks C, is the valuation of C, where . Let be the valuation of clock . We say if for all . Given , we let . A configuration of is a pair , where is a state of . Suppose a transition is taken after time units. Then, the DTBA is transited from configuration to such that , for all and for all . We denote the transition between these configurations as . A run of is a sequence of such transitions between configurations . A feasible run on is accepting iff it intersects with F infinitely often.
4. Problem Setup and Formulation
In this section, we propose durational stochastic games that generalize stochastic games and present the defender and adversary models in terms of the information available to them. We then define three robustness degrees and state the problem of interest.
4.1. Environment, Defender, and Adversary Models
We introduce durational stochastic games as a generalization of stochastic games [10]. Different from SGs, DSGs model (i) the timing information for transitions between states and (ii) an attack surface resulting from the timing information.
An SG is defined as follows:
Definition 3
(Stochastic game). A (labeled) stochastic game is a tuple , where S is a finite set of states, is a finite set of actions of the defender, is a finite set of actions of an adversary, and is a transition function where is the probability of a transition from state s to state when the defender takes action and the adversary takes action . is a set of atomic propositions. is a labeling function mapping each state to a subset of propositions in .
The SG in Definition 3 cannot be used to verify satisfaction of an MITL objective as it does not include a notion of time. We define durational stochastic games to bridge this gap. DSGs incorporate a notion of time taken for a transition between states and also models the ability of an adversary to modify this timing information.
Definition 4
(Durational stochastic game). A (labeled) durational stochastic game (DSG) is a tuple . is a finite set of states, is the initial state, and , are finite sets of actions. and are information sets of the defender and adversary, respectively, where is the Kleene operator. encodes , the transition probability from state to when the controller and adversary take actions and . is a probability mass function. denotes the probability that a transition from to under actions and takes time units, where is a finite set of time units that each transition of DSG can possibly take to complete. is a set of atomic propositions. is a labeling function that maps each state to atomic propositions in that are true in that state, and is a finite set of clocks.
The set of admissible actions that can be taken by the defender (adversary) in a state is denoted as (). A path on is a sequence of states such that , and for some , , and for all . Consider the DSG with , , and presented in Figure 2 as an example. We have that is a finite path. We denote the set of finite (infinite) paths by (). Given a path w, is the sequence of atomic propositions corresponding to states in w. The sequence of state-time tuples in w is obtained as , where , .

Figure 2.
This figure presents an example of a DSG consisting of 4 states, denoted as . The transition probabilities and probability mass function for some transitions are given in the figure. The labeling function L for state is given as .
For the defender, a deterministic policy is a map from the set of finite paths to its actions. A randomized policy maps the set of finite paths to a probability distribution over its actions. A policy is memoryless if it only depends on the the most recent state.
Consider a path w in . At a state s, the information set of the defender is , where is the time perceived by the defender when it reaches s along w. For example, given the finite path for the DSG presented in Figure 2, information set . For the adversary, , where is the time observed by the adversary at s, and is the defender’s policy. Information sets of the defender and adversary are given by and .
We assume that the initial time is 0, and this is known to both agents. The adversary having knowledge of the policy committed to by the defender introduces an asymmetry between the information sets of the two agents. We note that although the adversary is aware of the defender’s randomized policy, it does not know the exact action . This is also known as the Stackelberg setting in game theory. We assume a concurrent Stackelberg setting in that both the defender and adversary take their actions at each state simultaneously.
The solution concept to a Stackelberg game is a Stackelberg equilibrium, which is defined as follows.
Definition 5
(Stackelberg equilibrium [16]). A tuple is a Stackelberg equilibrium if , where and are the expected utilities of the defender and adversary under policies μ and , respectively, and .
If contains multiple adversary policies, the defender will arbitrarily pick one. During an actuator attack, the adversary can manipulate state transitions in as its actions will influence the transition probabilities . The adversary could also exploit the attack surface that will be introduced as a consequence of including timing information. We term this a timing attack. In this paper, we consider the worst-case scenario and assume that the adversary knows the correct time index at each time k. However, it can manipulate the timing information perceived by the defender through . Thus, the time index perceived by the defender need not be the same as that known to the adversary, .
The adversary launches actuator and timing attacks through attack policies. An actuator attack policy specifies the action taken by the adversary given the set of finite paths. A timing attack policy takes as its input the correct clock valuation and yields a probability distribution over clock valuations. This models the ability of the adversary to manipulate clock valuations. For an intelligent adversary, it should launch the timing attack such that the resulting sequence of clock valuations is monotone when the clocks are not reset. The reason is such non-monotone clock valuations informs the defender of the presence of a timing attack; thus, the defender can simply ignore the perceived clock valuations.
4.2. Definitions of Robustness Degree
In this subsection, we define three robustness degrees defined with respect to policies on the DSG .
4.2.1. Spatial Robustness
The spatial robustness, denoted as , represents the minimum distance between any accepting (resp. non-accepting) path on the DSG induced by policies and and the language of the MITL specification without regard to the timing information. We define the spatial robustness using the Levenshtein distance, which is used to measure the distance between strings [41].
Definition 6
(Levenshtein distance [41]). The Levenshtein distance between sequences of symbols and , denoted , is the minimum number of edit operations (insertions, substitutions, or deletions) that can be applied to so that can be converted to .
Consider timed words and that differ at position 1, where . Then, , as can be converted to by substituting with . Relying on the Levenshtein distance in Definition 6, we define the spatial robustness for policies and on a DSG with respect to the MITL formula as:
In Equation (1), is the set of paths enabled on under policies and , and contains the set of paths on that satisfy . We note that as , any path synthesized under policies and that satisfies will result in . If, for some , , then .
4.2.2. Temporal Robustness
The temporal robustness captures the maximum time units by which any accepting path synthesized under policies and can be temporally perturbed so that the MITL formula is not violated.
Given an accepting run w and , we let We define the left temporal robustness and right temporal robustness as:
The left (right) temporal robustness () indicates that an accepting run w induced by and can be perturbed up to k time units to the left (right) without violating . These definitions also ensure that any perturbation smaller than or will not violate . The temporal robustness is then:
where is a symbol indicating that policies and can lead to non-accepting runs.
4.2.3. Spatio-Temporal Robustness
We define the spatio-temporal robustness to unify notions of spatial and temporal robustness as:
where is an indicator function that equals to 1 if and otherwise. In other words, the spatio-temporal robustness captures the maximum time units by which any accepting run can be perturbed without violating the MITL specification , given a desired spatial robustness , under policies and . Note that when the spatio-temporal robustness is , we have that policies and lead to non-accepting runs.
4.2.4. Robust MITL Semantics
Given the spatio-temporal robustness in Equation (5), we can use a real-valued function to reason about the satisfaction of such that .
Definition 7
(Robust MITL Semantics). Let ρ be a timed word. We define a real-valued function such that the satisfaction of an MITL formula φ at position j by a timed word ρ, written , can be recursively defined as:
- 1.
- ;
- 2.
- ;
- 3.
- ;
- 4.
- .
where and .
4.3. Problem Statement
Before formally stating the problem of interest, we prove a result which shows that a defender’s policy that provides positive spatio-temporal robustness satisfies the MITL objective with probability one.
Proposition 1.
Given an MITL objective φ and policies μ and , the spatio-temporal robustness implies almost-sure satisfaction of φ under the agent policies when there is no timing attack.
Proof.
The proof of this result is deferred to Appendix B. □
Given Proposition 1, we formally state our problem:
Problem 1
(Robust policy synthesis for defender). Given a DSG and an MITL formula φ, compute an almost-sure defender policy. That is, compute μ such that , where .
5. Solution: Only Actuator Attack
We present a solution to robust policy synthesis for the defender as described in Problem 1, assuming that the adversary only launches an actuator attack. We construct a product DSG from DSG and DTBA . We present procedures to evaluate the spatio-temporal robustness and compute an optimal policy for the defender on .
5.1. Product DSG
In the following, we provide the definition of product DSG.
Definition 8
(Product durational stochastic game). A PDSG constructed from a DSG , DTBA , and clock valuation set V is a tuple . is a finite set of states, is the initial state, and , are finite sets of actions. , are information sets of the defender and adversary. encodes , the probability of a transition from state to when the defender and adversary take actions and . The probability
if and only if , zero otherwise. is a finite set of accepting states.
The following result shows that the transition probability of is well defined.
Proposition 2.
The function satisfies and
Proof.
The proof is presented in Appendix B. □
We write to represent a state in PDSG . We denote the clock valuation of by . In the sequel, we compute a set of states called generalized accepting maximal end components (GAMECs) of . Any state in GAMECs satisfies that the successor state also belongs to GAMECs under any policy committed by the defender, regardless of the actions taken by the adversary. Therefore, for a path that stays within GAMECs, it is guaranteed that the path corresponds to a run that intersects with F infinitely many times, and thus, the path satisfies specification . We can thus translate the problem of satisfying to the problem of reaching GAMECs under any adversary action. The set can be computed using the procedure Compute_GAMEC() in Algorithm 1. The idea is that at each state, we prune the defender’s admissible action set by retaining only those actions that ensure state transitions in will remain within GAMECs under any adversary action.
| Algorithm 1 Computing the set of GAMECs . |
|
The procedure Compute_GAMEC() presented in Algorithm 1 takes the product DSG as its input and returns set . The algorithm iteratively updates by removing a set of states R. R includes any state that is in some strongly connected component (SCC) and has an empty admissible defender action set (Line 13). R also includes states from which can be steered to R under some adversary action (Line 20). Lines 35–37 verify accepting conditions defined by the DTBA. The termination of Algorithm 1 is given by the following proposition.
Proposition 3.
Algorithm 1 terminates in a finite number of iterations.
Proof.
The proof of this proposition is given in Appendix B. □
5.2. Evaluating Spatial Robustness
From Equation (1), evaluating the spatial robustness is equivalent to computing the Levenshtein distance between paths on the DSG synthesized under policies and and . This is equivalent to computing the Levenshtein distance between two automata, where the first automaton is the PDSG induced by policies and . The second automaton is , the DTBA representing . We adopt the approach proposed in [42] to compute the Levenshtein distance between and .
We first construct a DSG from the original DSG . Given policies and , we retain only those transitions such that , for some , , and , and we remove all other transitions. We augment the alphabet of DTBA as , where is a symbol that will be used to indicate deletion and insertion operations. The alphabet of is also augmented to include . The PDSG in Definition 8 can be constructed from and . Given and , we construct . Following [42], we construct a weighted transducer to capture the cost associated to each edit operation (assumed ). We assign a cost to each transition from state to in . In particular, if is not the same as the label of the transition from to in . We can then apply a shortest path algorithm on from the initial state to the union of the GAMECs of to compute the minimum Levenshtein distance. The correctness of this approach follows from [42] [Theorem 2].
The computational complexity of calculating the spatial robustness for any given policies and is , where and are the sizes of and , respectively [42].
5.3. Evaluating Temporal Robustness
In this subsection, we present a procedure to evaluate the temporal robustness. We introduce some notation. For a time interval I, we use and to represent its lower and upper bounds. The upper bound of the clock valuation set is denoted as . The indicator function takes value 1 if is in GAMEC and 0 otherwise. A state is said to be a neighboring state of if for some and such that and . Given the policies of the defender and adversary, we define
The procedure Temporal() presented in Algorithm 2 computes the left and right temporal robustness with respect to the MITL objective . The left and right temporal robustness of can be computed by searching over a directed graph representation of the product DSG. The algorithm determines the temporal robustness of following the robust MITL semantics (Definition 7) by simple algebraic computations over the temporal robustness of all atomic propositions in .
| Algorithm 2 Evaluate temporal robustness. |
|
We detail the workings of Algorithm 2, which is a recursive procedure that is used to compute the temporal robustness. It takes an MITL formula , current state , time duration , and indicator function as its inputs. If , then Algorithm 2 computes the minimum left temporal robustness (Line 5) and right temporal robustness (Line 6), respectively. The minimum of these quantities is returned as the temporal robustness. From the robust MITL semantics, Algorithm 2 returns the minimum (maximum) temporal robustness when is a conjunction (disjunction). When , the robustness is computed following Lines 16–27. Here, . Because we focus on the worst-case robustness, we compute the minimum value over times and neighboring states in Line 18. We establish the correctness of Algorithm 2 as follows.
Theorem 1.
Given a PDSG with initial state , MITL formula φ, and policies μ and τ, suppose Algorithm 2 returns . Then, any run on the PDSG synthesized under policies μ and τ can be temporally perturbed by without violating φ.
Proof.
The proof is presented in Appendix B. □
The complexity of Algorithm 2 is , where is the size of the closure of formula and is the number of nonzero elements in matrix .
5.4. Evaluating Spatio-Temporal Robustness
We use the results of the previous two subsections to compute the spatio-temporal robustness using the procedure Robust() presented in Algorithm 3. From Equation (5), when the spatial robustness is above , Algorithm 3 returns the temporal robustness. Otherwise, it returns the negative value of the temporal robustness. The complexity of Algorithm 3 is . Table 1 summarizes the computational complexities of evaluating the spatial and temporal robustness.
| Algorithm 3 Evaluate spatio-temporal robustness. |
|

Table 1.
Computational complexities of evaluating the spatial and temporal robustness when policies are given. is the size of product DSG induced by policies and . is the size of the timed Büchi automaton of MITL specification . denotes the size of the closure of , and is the number of nonzero elements in matrix . The complexity of Algorithm 3 is .
5.5. Control Policy Synthesis
In this subsection, we compute a control policy that solves the robust policy synthesis for the defender in Problem 1 when there is no timing attack. From Proposition 1, solving the robust policy synthesis for the defender in Problem 1 is equivalent to finding a defender policy so that the spatio-temporal robustness exceeds a desired threshold. This procedure is named as Policy_Synthesis() and is presented in Algorithm 4. We initialize a policy , (Line 4). We also define sets of states and that will indicate states/transitions that lead to violations of temporal and spatial robustness. We then compute the best response to as and evaluate the spatio-temporal robustness . If , we then synthesize the policy returned in Line 6. If , then the spatial robustness exceeds but the temporal robustness is below . In this case, we eliminate defender actions that steer the PDSG into states in with the positive probability thereby causing a violation of the temporal robustness constraint. If (Line 17), then the spatial robustness constraint is violated. In this case, we eliminate defender actions that steer the system into states in . If no state in GAMEC is reachable from the initial state of the product DSG , then the procedure Policy_Synthesis() presented in Algorithm 4 reports failure, indicating that no solution is found for robust policy synthesis for defender in Problem 1, and terminates. We establish the converge of Algorithm 4 as follows.
| Algorithm 4 Robust control policy synthesis for defender. |
|
Theorem 2.
Algorithm 4 terminates within a finite number of iterations.
Proof.
The proof of this theorem is presented in Appendix B. □
In the worst case, we have that Algorithm 4 updates with at most number of iterations. Thus, the complexity of Algorithm 4 is . We further present the optimality of the policy found by Algorithm 4 in the following theorem:
Theorem 3.
If Algorithm 4 returns a defender’s policy, denoted as , then the problem of robust policy synthesis for the defender in Problem 1 is feasible. Moreover, the defender’s policy is an optimal solution to Problem 1.
Proof.
The proof is presented in Appendix B. □
The soundness of Algorithm 4 is given below:
Corollary 1.
Algorithm 4 is sound but not complete. That is, any control policy returned by Algorithm 4 guarantees probability one of satisfying the given MITL specification, but we cannot conclude that there exists no solution to the problem if Algorithm 4 returns no solution.
6. Solution: Actuator and Timing Attacks
In this section, we present a solution under both actuator attack and timing attacks.
Compared with the case where there is no timing attack, we make the following observations. The evaluation of spatial robustness remains unchanged when the adversary can initiate both actuator and timing attacks. Second, the evaluation of temporal robustness can become inaccurate during a timing attack. This is because timing information perceived by the defender can be arbitrarily manipulated by the adversary. As a result, the defender will not be able to evaluate the temporal robustness and hence the spatio-temporal robustness during a timing attack. Finally, as the defender cannot accurately evaluate the temporal robustness, Proposition 1 will not hold during a timing attack. In the following, we relax the problem of robust synthesis for the defender in Problem 1 and try to compute a defender policy such that the probability of satisfying the is maximized in the presence of actuator and timing attacks. The reason the defender can evaluate the probability of satisfying is that it knows the transition probability and probability mass function . Thus, it can determine the expected probability and time of reaching each state, given the policies of the defender and adversary. The relaxed problem is:
Problem 2
(Policy synthesis for defender). Given a DSG and an MITL objective φ, compute a defender’s policy such that the probability of satisfying φ is maximized and adversary policy is the best response to control policy μ. That is, , where .
Because the timing information perceived by the defender has been manipulated by the adversary, the defender has limited knowledge of the current time. Even in this case, it can still detect unreasonable time sequences, e.g., a time sequence that is not monotonic. To recover from the deficit of timing information, we represent the defender’s policy using a finite-state controller, which enables the defender to track the estimated time.
Definition 9
(Finite-state controller [25]). A finite-state controller (FSC) is a tuple , where is a finite set of internal states, is a set of estimates of clock valuations, and the set indicates if a timing attack has been detected (1) or not (0). is the initial internal state. μ is the defender policy, given by:
where and denote the control policies that will be executed when hypothesis or holds, respectively.
For an FSC as given in Definition 9, hypothesis represents the scenario where no timing attack is detected by the defender, while represents the scenario where a timing attack is detected. In the FSC, the defender’s policy specifies the probability of reaching the next internal state by taking an action given the current state of DSG, detection result of the timing attack, and state of DTBA.
To capture the state evolutions of DSG, DTBA, and FSC, we construct a global DSG.
Definition 10
(Global DSG (GDSG)). A GDSG is a tuple , where is a finite set of states and is the initial state. and are finite sets of actions and and are the information sets of the defender and adversary, respectively. is a transition function where is the probability of a transition from state to when the defender and adversary take actions and , respectively. The transition probability is given by
is the set of accepting states.
Consider the global DSG. Let be the probability of satisfying . Then, can be computed from Proposition 4. A proof is presented in [39].
Proposition 4.
Let be the probability of satisfying φ. Then,
Moreover, the value vector is unique.
We use the procedure Control_Synthesis() presented in Algorithm 5 to compute the policy . Guarantees on its termination is presented in [39]. We finally remark on the complexity of Algorithm 5. We first make the following relaxation to Line 5 of Algorithm 5 so that is updated if the following holds:
Then, Algorithm 5 converges to some satisfying within iterations, where parameter is the smallest value of for Furthermore, Line 8 of Algorithm 5 can be solved using a linear program in polynomial time, denoted as f. Combining these arguments, the complexity of Algorithm 5 is .
| Algorithm 5 Computing an optimal control policy. |
|
7. Case Study
In this section, we present a numerical case study on a signalized traffic network. The case study was implemented using MATLAB on a Macbook Pro with a 2.6 GHz Intel Core i5 CPU and 8 GB of RAM.
7.1. Signalized Traffic Network Model
We consider a signalized traffic network [43] consisting of five intersections and twelve links under the remote control of a transportation management center (TMC). A representation of the signalized traffic network is shown in Figure 3.
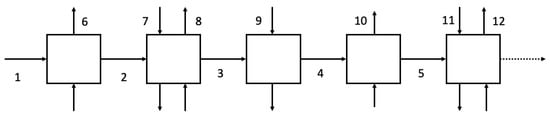
Figure 3.
Representation of a signalized traffic network consisting of five intersections and twelve links.
We briefly explain how a DSG from Definition 4 can model the network. Each DSG state models the total number of vehicles on a link in the network. Transitions between the states in the DSG models the flow of vehicles. Because the vehicle capacity of a link is finite, the number of states in the DSG will be finite.
The defender’s action set represents that the TMC can actuate a link by issuing a ‘green signal’ on outgoing intersections of that link. Conversely, the TMC can block a link by issuing a ‘red signal’.
The TMC is assumed to control the traffic network over an unreliable wireless channel. Thus, an intelligent adversary can launch man-in-the-middle attacks to tamper with the traffic signal issued by the TMC or manipulate observations of the TMC. In particular, the adversary can initiate an actuator attack to change the traffic signal and a timing attack to manipulate the time-stamped measurement (number of vehicles at each link along with the time index) perceived by the TMC.
The TMC is given one of the following objectives: (i) number of vehicles at link 4 is eventually below 10 before deadline : ; (ii) number of vehicles at links 3 and 4 are eventually below 10 before : ; or (iii) number of vehicles at links 3, 4, and 5 are eventually below 10 before : . Spatial and temporal robustness thresholds are set to and . We compare our approach with two baselines. In Baseline 1, the TMC periodically issues green signals. In Baseline 2, the TMC always issues green signals for links and 5 to greedily minimize the number of vehicles on these links.
7.2. Numerical Results
In the following, we present the numerical results using our proposed approach and the two baselines.
We first report the results when the adversary only launches an actuator attack and the TMC is given specification . We compute a control policy using Algorithm 4. A sample sequence of traffic signals is presented in Table 2. Using Proposition 1 and Corollary 1, the MITL specification is satisfied with probability one.
Table 2.
Sample sequence of traffic lights realized at each intersection for the MITL specification . The letters ‘R’ and ‘G’ represent ‘red’ and ‘green’ signals, respectively.
We then consider an adversary that launches both actuator and timing attacks. Suppose that the TMC is equipped with an FSC with five states. We show the results of our approach using Algorithm 5 in Figure 4. In this example, is violated as the number of vehicles on link 5 exceeds the threshold of 10. We also give the probabilities of satisfying each MITL specification using Algorithm 5. Specifications , , and are satisfied with the probabilities , , and , respectively.
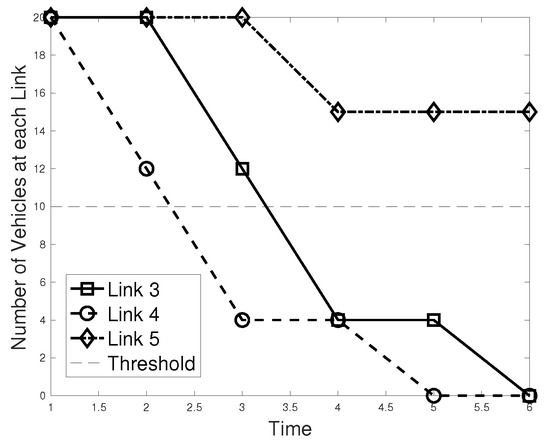
Figure 4.
A sample of the number of vehicles on links 3, 4, and 5 over time using our proposed approach. In this realization, the number of links on link 5 is above the threshold.
We assume that the TMC commits to deterministic policies in both baselines. In Baseline 1, the adversary launches actuator attacks when the TMC issues a green signal and does not attack when it issues a red signal. In Baseline 2, the adversary always launches an actuator attack. In both baselines, the adversary launches a timing attack at each time instant to delay the TMC’s observation. As a consequence, both baselines have zero probability of satisfying , or .
The DSG in our experiments had 232 states. For , the GAMEC of the product DSG had 400 states. For and , the GAMEC had 160 and 80, states respectively. The computation time of Algorithm 4 for was 264 s. Algorithm 5 took 720 s.
8. Conclusions and Future Work
In this paper, we proposed methods to synthesize controllers for cyber-physical systems to satisfy metric interval temporal logic (MITL) tasks in the presence of an adversary while additionally providing robustness guarantees. We considered the fragment of MITL formulae that can be represented by deterministic timed Büchi automata. The adversary could initiate actuator and timing attacks. We modeled the interaction between the defender and adversary using a durational stochastic game (DSG). We introduced three notions of robustness degree—spatial robustness, temporal robustness, and spatio-temporal robustness—and presented procedures to estimate these quantities, given the defender and adversary’s policies and current state of the DSG. We further presented a computational procedure to synthesize the defender’s policy that provided a robustness guarantee when the adversary could only initiate an actuator attack. A value iteration-based procedure was given to compute a defender’s policy to maximize the probability of satisfying the MITL goal. A case study using a signalized traffic network illustrated our approach.
DSGs can be adopted to model interactions between a defender and adversary across various application domains with time-sensitive constraints. Examples include the time-sensitive motion planning of drones, product scheduling of industrial control systems, and time-sensitive message transmissions in wireless communications in the presence of adversaries. For future work, we will generalize our definition of the DSG to broaden its applications. We will generalize DSGs to address partial observations by the CPS and adversary. We will additionally investigate the scenarios where the adversary is nonrational and may not perform its best response to the strategies committed by defender.
Author Contributions
Conceptualization, L.N., B.R., A.C. and R.P.; methodology, L.N., B.R., A.C. and R.P.; software, L.N. and B.R.; validation, B.R.; formal analysis, L.N., B.R. and A.C.; writing—original draft, L.N. and B.R.; writing—review and editing, A.C. and R.P.; supervision, R.P.; project administration, R.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Office of Naval Research grant N00014-20-1-2636, National Science Foundation grants CNS 2153136 and CNS 1941670, and Air Force Office of Scientific Research grants FA9550-20-1-0074 and FA9550-22-1-0054.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Summary of Notations
This appendix summarizes the notations used in this paper, as presented in Table A1.
Table A1.
This table provides a list of the notation and symbols used in this paper.
Table A1.
This table provides a list of the notation and symbols used in this paper.
| Variable Notation | Interpretation |
|---|---|
| MITL formula | |
| Timed word | |
| Deterministic timed Büchi automaton (DTBA) | |
| Clock valuation | |
| Run of DTBA | |
| Durational stochastic game (DSG) | |
| Defender’s policy | |
| Actuator attack policy by the adversary | |
| Timing attack policy by the adversary | |
| Spatial robustness | |
| Temporal robustness | |
| Spatio-temporal robustness | |
| Product durational stochastic game | |
| Finite-state controller (FSC) | |
| Global durational stochastic game (GDSG) | |
| Set of generalized accepting maximal end components (GAMECs) |
Appendix B. Proofs of Technical Results
In this appendix, we present the proofs of all of the technical results.
Proof of Proposition 1.
From Equation (4), is non-negative. If , then , and hence, . This implies that , i.e., all runs obtained under policies and are accepting. This gives , or almost-sure satisfaction of under the respective agent policies. □
Proof of Proposition 2.
The statement that for all transitions in follows from the fact that and . We have that iff , or , or both. Moreover, we have that iff and . Let , which is an indicator function that takes value 1 if its argument is true and 0 otherwise. Then, Equation (7) can be rewritten as:
This follows from the substitution from Equation (6) and product DSG in Definition 8. The result follows by and . □
Proof of Proposition 3.
We proceed by showing that each loop in Algorithm 1 is executed a finite number of times. The PDSG has a finite number of states and actions as the DSG has a finite number of states and actions, the DTBA has a finite number of states, and the clock valuation set V is bounded due to the boundedness of time interval I. Therefore, the for-loops in Line 7, 10, 11, and 27 are executed for a finite number of times. The while-loop in Line 18 is executed a finite number of times as is a finite set. Moreover, there are a finite number of states that will be added to R (Line 14), and this will be carried out finitely many times. The overall complexity is , where and are the number of vertices and edges in . □
Proof of Theorem 1.
We leverage the recursive robust MITL semantics to prove the theorem and consider the following cases:
Case 1— : In this case, the temporal robustness is computed by Lines 4–7 of Algorithm 2: . This means that there must exist a state that is reachable from under policies and such that . Without loss of generality, we assume that . As , we have , i.e., is the time index of state . Therefore, a shift to the left by will not affect the satisfaction of as holds true independent of time. If the accepting run is temporally perturbed by more than time units, the clock valuation becomes negative. This contradicts our assumption that clock valuations take positive values.
Case 2— : Consider Lines 8–11 of Algorithm 2. Suppose . Let From Line 11, it follows that . As , we can apply Case 1 to and . Therefore, if we shift the run synthesized under policies and by time units to the left, will still be satisfied. Moreover, as , will also be satisfied. Hence, will still be satisfied if we shift the run synthesized under policies and by at most time units.
Case 3 — : Consider Lines 12–15. Suppose . Let From Case 1, we can shift any accepting run starting from by at most time units without violating . Then by semantics of the disjunction operator, is also satisfied when the accepting run is shifted by at most time units.
Case 4 — : In this case, the temporal robustness is computed by Lines 16–27. We consider the case that . Let .
If , is satisfied at state , and hence, is satisfied at . Therefore, is in GAMEC. From the definition of GAMEC, we have that and its neighboring states are in GAMEC (the defender does not take any action that steers the PDSG outside GAMEC), and hence, . Thus, Algorithm 2 will execute Lines 19–20. We have that , where and are the upper and lower bounds of I. As , Line 23 will be executed. indicates that can be obtained from Lines 4–7. This gives , and hence, . We remark that this only indicates that we cannot shift the accepting run to the left temporally without violating . Shifting the run to the right might not lead to violation of . However, as the temporal robustness is defined as the minimum of the left and right temporal robustness, the algorithm returns .
If , from the semantics of time constrained until operator , is satisfied up to time and is satisfied immediately after time t; thus, is satisfied. Therefore, we will eventually reach some accepting state so that for some . In this case, , where is given in Line 20 and is given in Lines 22–26 of Algorithm 2. Suppose . From Line 27, we must have . From Line 20, . Thus, we can shift any accepting run by at most time units to the left without violating if . After the perturbation, is satisfied at time and is satisfied immediately after . The case where can be obtained analogously. Suppose . From Lines 22–26, . Since , can be obtained from Lines 4–7. Recall that we consider a bounded clock valuation set. Let . Then models the maximum distance between the time index at which is satisfied and the upper bound of I. From Case 1, we have that perturbing an accepting run by at most time units will not violate as the run obtained after perturbation satisfies at the boundary of I.
Case 5 — and in Cases 2-4 are MITL formulae: In this case, we can apply the previous analyses using the recursive definition of MITL formula. □
Proof of Theorem 2.
We prove the theorem in the following way. At each iteration within the while loop (starting at Line 5), Algorithm 4 executes one of the three cases of the if-else statement (Lines 7, 9, or 17), with each case corresponding to the satisfaction of the spatio-temporal robustness constraint, violation of the temporal robustness constraint, or violation of the spatial robustness constraint. We denote the execution of Line 7 as Scenario I, Line 9 as Scenario II, and Line 17 as Scenario III. We will show that Algorithm 4 reaches Scenario I at most once and reaches Scenarios II and III finitely many times. If Algorithm 4 reaches Scenario I, it terminates (Line 8). For Scenarios II and III, we will show that there exists an index k such that if Algorithm 4 reaches Scenario II or III at iteration k, then Scenario I will be executed at iteration and hence terminates, or Lines 26–29 will be executed and the process will terminate at iteration k.
Scenario I — executing Line 7: Suppose Algorithm 4 reaches Scenario I at iteration k. In this case, the control policy satisfies the spatio-temporal robustness constraints. By Line 8 we have that Scenario I is reached exactly once and hence Algorithm 4 terminates.
Scenario II — executing Line 9: Suppose Algorithm 4 reaches Scenario II at iteration k. In this case, the policy satisfies the spatial robustness constraint but violates the temporal robustness constraint. Let be the state that results in temporal robustness constraint violation and let be a neighboring state of . We decompose our discussion into the following cases:
- 1.
- Suppose . In this case, state is included in set . If adding to makes states in GAMEC not reachable from , then Algorithm 4 executes Lines 26–29 and terminates by reporting failure.
- 2.
- Suppose . However, the remaining control actions cannot make GAMEC reachable from the initial state . In this case, Algorithm 4 will execute Lines 26–29 and terminates.
- 3.
- Suppose , and GAMEC is reachable from . We further assume that all actions that are admissible by the policy generated at Line 25 result in a robustness greater than or equal to . As a consequence, the remaining control actions in must steer the system into some neighboring state of such that . Therefore, Algorithm 4 will execute Scenario I at iteration and thus terminates.
- 4.
- Suppose and GAMEC is reachable from the initial state . Now assume that there exists some action such that it is admissible by the policy generated at Line 25 and results in the robustness below for some neighboring state of . In this case, this will be removed according to Line 12 at iteration . As there are only finitely many states and control actions, this case will converge to one of the cases discussed in (1), (2), or (3) in a finite number of iterations.
Scenario III — executing Line 17: Suppose Algorithm 4 reaches Scenario III at iteration k. In this case, the control policy violates the spatial robustness constraint. We use to denote the state that violates the spatial robustness constraint and use to denote the neighboring state of . We analyze Scenario III by dividing our discussion into the following cases:
- 1.
- Suppose . From Line 18, is included in set . If adding to makes states in GAMEC not reachable from , then Algorithm 4 executes Lines 26–29 and terminates by reporting failure.
- 2.
- Suppose and GAMEC is not reachable from the for all . In this case, Algorithm 4 will execute Lines 26–29 and terminate.
- 3.
- Suppose , and GAMEC is reachable from . Assume that all actions that are admissible by the policy generated at Line 25 result in robustness . In this case, the game must be steered to a neighboring state of such that . Then, Algorithm 4 will execute Scenario I at iteration and terminate.
- 4.
- Suppose , and GAMEC is reachable from . Now assume that the policy generated at Line 25 results in robustness below for some neighboring state of . In this case, the control action will be removed according to Lines 12 and 20 at iteration . As there are only finitely many states and control actions, this case will converge to one of the cases discussed in (1), (2), or (3) in a finite number of iterations.
From the preceding discussion, the control action set will converge to a set that will never lead Algorithm 4 to Scenarios II or III. In the worst case, when there will be at most actions being removed due to Scenarios II and III, leading Algorithm 4 to Line 28, where it terminates by reporting failure.
Therefore, Algorithm 4 converges to a set that will never cause violations of the robustness constraints, and the game can be driven to GAMEC in a finite number of iterations. If no such set exists, it terminates by reporting failure. If , then Algorithm 4 returns a policy over . □
Proof of Theorem 3.
Suppose Algorithm 4 returns a policy . From Theorem 2, is defined over (otherwise, should not be returned by Algorithm 4 as no admissible defender action is available). From Lines 10 to 16 in Algorithm 4, the defender’s policy will not result in a temporal robustness below . From Lines 17 to 23, guarantees a positive spatio-temporal robustness. Therefore, if is returned by Algorithm 4, we must have a spatio-temporal robustness , where are the best responses of the adversary. Thus, is a feasible solution for robust policy synthesis for the defender in Problem 1. From Proposition 1, the probability of satisfying the MITL formula equals 1, which is the maximum value that can be achieved for any control policy; therefore, is an optimal policy. □
References
- Baheti, R.; Gill, H. Cyber-physical systems. Impact Control. Technol. 2011, 12, 161–166. [Google Scholar] [CrossRef]
- Baier, C.; Katoen, J.P.; Larsen, K.G. Principles of Model Checking; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Alur, R.; Dill, D.L. A theory of timed automata. Theor. Comput. Sci. 1994, 126, 183–235. [Google Scholar] [CrossRef]
- Kress-Gazit, H.; Fainekos, G.E.; Pappas, G.J. Temporal-logic-based reactive mission and motion planning. IEEE Trans. Robot. 2009, 25, 1370–1381. [Google Scholar] [CrossRef]
- Ding, X.; Smith, S.L.; Belta, C.; Rus, D. Optimal control of Markov decision processes with linear temporal logic constraints. IEEE Trans. Autom. Control. 2014, 59, 1244–1257. [Google Scholar] [CrossRef]
- Zhou, Y.; Maity, D.; Baras, J.S. Timed automata approach for motion planning using metric interval temporal logic. In Proceedings of the European Control Conference, Aalborg, Denmark, 29 June–1 July 2016; pp. 690–695. [Google Scholar] [CrossRef]
- Fu, J.; Topcu, U. Computational methods for stochastic control with metric interval temporal logic specifications. In Proceedings of the Conference on Decision and Control, Osaka, Japan, 15–18 December 2015; pp. 7440–7447. [Google Scholar] [CrossRef]
- Fainekos, G.E.; Pappas, G.J. Robustness of temporal logic specifications for continuous-time signals. Theor. Comput. Sci. 2009, 410, 4262–4291. [Google Scholar] [CrossRef]
- Donzé, A.; Maler, O. Robust satisfaction of temporal logic over real-valued signals. In Proceedings of the International Conference on Formal Modeling and Analysis of Timed Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–106. [Google Scholar] [CrossRef]
- Niu, L.; Clark, A. Optimal Secure Control with Linear Temporal Logic Constraints. IEEE Trans. Autom. Control. 2020, 65. [Google Scholar] [CrossRef]
- Zhu, M.; Martinez, S. Stackelberg-game analysis of correlated attacks in cyber-physical systems. In Proceedings of the American Control Conference, San Francisco, CA, USA, 29 June–1 July 2011; pp. 4063–4068. [Google Scholar] [CrossRef]
- Wang, J.; Tu, W.; Hui, L.C.; Yiu, S.M.; Wang, E.K. Detecting time synchronization attacks in cyber-physical systems with machine learning techniques. In Proceedings of the International Conference on Distributed Computing Systems, Atlanta, GA, USA, 5–8 June 2017; pp. 2246–2251. [Google Scholar] [CrossRef]
- Jewell, W.S. Markov-renewal programming: Formulation, finite return models. Oper. Res. 1963, 11, 938. [Google Scholar] [CrossRef]
- Ross, S.M. Introduction to Stochastic Dynamic Programming; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Stidham, S.; Weber, R. A survey of Markov decision models for control of networks of queues. Queueing Syst. 1993, 13, 291–314. [Google Scholar] [CrossRef]
- Leitmann, G. On generalized Stackelberg strategies. J. Optim. Theory Appl. 1978, 26, 637–643. [Google Scholar] [CrossRef]
- Wei, L.; Sarwat, A.I.; Saad, W.; Biswas, S. Stochastic games for power grid protection against coordinated cyber-physical attacks. IEEE Trans. Smart Grid 2016, 9, 684–694. [Google Scholar] [CrossRef]
- Garnaev, A.; Baykal-Gursoy, M.; Poor, H.V. A game theoretic analysis of secret and reliable communication with active and passive adversarial modes. IEEE Trans. Wirel. Commun. 2015, 15, 2155–2163. [Google Scholar] [CrossRef]
- Bouyer, P.; Laroussinie, F.; Markey, N.; Ouaknine, J.; Worrell, J. Timed temporal logics. In Models, Algorithms, Logics and Tools; Springer: Berlin/Heidelberg, Germany, 2017; pp. 211–230. [Google Scholar] [CrossRef]
- Alur, R.; Feder, T.; Henzinger, T.A. The benefits of relaxing punctuality. J. ACM 1996, 43, 116–146. [Google Scholar] [CrossRef]
- Maler, O.; Nickovic, D.; Pnueli, A. From MITL to timed automata. In Proceedings of the International Conference on Formal Modeling and Analysis of Timed Systems; Springer: Berlin/Heidelberg, Germany, 2006; pp. 274–289. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Vehicle routing problem with metric temporal logic specifications. In Proceedings of the Conference on Decision and Control, Cancun, Mexico, 9–11 December 2008; pp. 3953–3958. [Google Scholar] [CrossRef]
- Liu, J.; Prabhakar, P. Switching control of dynamical systems from metric temporal logic specifications. In Proceedings of the International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 5333–5338. [Google Scholar] [CrossRef]
- Nikou, A.; Tumova, J.; Dimarogonas, D.V. Cooperative task planning of multi-agent systems under timed temporal specifications. In Proceedings of the American Control Conference, Boston, MA, USA, 6–8 July 2016; pp. 7104–7109. [Google Scholar] [CrossRef]
- Hansen, E.A. Solving POMDPs by searching in policy space. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 211–219. [Google Scholar]
- Sharan, R.; Burdick, J. Finite state control of POMDPs with LTL specifications. In Proceedings of the American Control Conference, Portland, OR, USA, 4–6 June 2014; p. 501. [Google Scholar] [CrossRef]
- Ramasubramanian, B.; Clark, A.; Bushnell, L.; Poovendran, R. Secure control under partial observability with temporal logic constraints. In Proceedings of the American Control Conference, Philadelphia, PA, USA, 10–12 July 2019; pp. 1181–1188. [Google Scholar] [CrossRef]
- Ramasubramanian, B.; Niu, L.; Clark, A.; Bushnell, L.; Poovendran, R. Secure control in partially observable environments to satisfy LTL specifications. IEEE Trans. Autom. Control 2021, 66, 5665–5679. [Google Scholar] [CrossRef]
- Zhao, G.; Li, H.; Hou, T. Input–output dynamical stability analysis for cyber-physical systems via logical networks. IET Control Theory Appl. 2020, 14, 2566–2572. [Google Scholar] [CrossRef]
- Zhao, G.; Li, H. Robustness analysis of logical networks and its application in infinite systems. J. Frankl. Inst. 2020, 357, 2882–2891. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H infinity, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Angeli, D. A Lyapunov approach to incremental stability properties. IEEE Trans. Autom. Control 2002, 47, 410–421. [Google Scholar] [CrossRef]
- Rizk, A.; Batt, G.; Fages, F.; Soliman, S. A general computational method for robustness analysis with applications to synthetic gene networks. Bioinformatics 2009, 25, i169–i178. [Google Scholar] [CrossRef]
- Jakšić, S.; Bartocci, E.; Grosu, R.; Nguyen, T.; Ničković, D. Quantitative monitoring of STL with edit distance. Form. Methods Syst. Des. 2018, 53, 83–112. [Google Scholar] [CrossRef]
- Aksaray, D.; Jones, A.; Kong, Z.; Schwager, M.; Belta, C. Q-learning for robust satisfaction of signal temporal logic specifications. In Proceedings of the Conference on Decision and Control, Las Vegas, NV, USA, 12–14 December 2016; pp. 6565–6570. [Google Scholar] [CrossRef]
- Lindemann, L.; Dimarogonas, D.V. Robust control for signal temporal logic specifications using discrete average space robustness. Automatica 2019, 101, 377–387. [Google Scholar] [CrossRef]
- Rodionova, A.; Lindemann, L.; Morari, M.; Pappas, G. Temporal robustness of temporal logic specifications: Analysis and control design. ACM Trans. Embed. Comput. Syst. 2022, 22, 1–44. [Google Scholar] [CrossRef]
- Rodionova, A.; Lindemann, L.; Morari, M.; Pappas, G.J. Combined left and right temporal robustness for control under STL specifications. IEEE Control Syst. Lett. 2022, 7, 619–624. [Google Scholar] [CrossRef]
- Niu, L.; Ramasubramanian, B.; Clark, A.; Bushnell, L.; Poovendran, R. Control Synthesis for Cyber-Physical Systems to Satisfy Metric Interval Temporal Logic Objectives under Timing and Actuator Attacks. In Proceedings of the International Conference on Cyber-Physical Systems, Sydney, Australia, 21–25 April 2020; pp. 162–173. [Google Scholar] [CrossRef]
- Ouaknine, J.; Worrell, J. Some recent results in metric temporal logic. In Proceedings of the International Conference on Formal Modeling and Analysis of Timed Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–13. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. In Proceedings of the Soviet Physics Doklady; The American Institute of Physics: New York, NY, USA, 1966; Volume 10, pp. 707–710. [Google Scholar]
- Mohri, M. Edit-distance of weighted automata: General definitions and algorithms. Int. J. Found. Comput. Sci. 2003, 14, 957–982. [Google Scholar] [CrossRef]
- Coogan, S.; Gol, E.A.; Arcak, M.; Belta, C. Traffic network control from temporal logic specifications. IEEE Trans. Control Netw. Syst. 2015, 3, 162–172. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).