Abstract
Trajectory prediction constitutes a key technology for intelligent systems to forecast future movements of dynamic agents, yet it faces significant challenges due to the uncertainty of motion behavior. We propose iDMa, a stochastic trajectory prediction framework that pioneers the integration of diffusion model with Mamba architecture to achieve high-precision and high-efficiency trajectory generation. Our approach introduces two key innovations: (1) a dual-parameter learning mechanism that optimizes noise estimation of mean and variance space, unlike conventional diffusion methods that employ fixed variance during the denoising process, so as to constrain the feasible domain more accurately; (2) a hybrid denoising backbone network that incorporates Transformer encoders and Mamba blocks. Compared to existing state-of-the-art methods, iDMa reduces the average displacement error (ADE) by 4.76% (0.20 vs. 0.21) on the ETH-UCY dataset and 1.85% (7.95 vs. 8.10) on the SDD dataset.
1. Introduction
Trajectory prediction is a critical task for understanding target motion intent, with wide applications in pedestrian [1,2], vehicle [3,4] and drone [5] tracking scenarios. The accurate prediction of target future motion paths remains challenging, primarily due to the high uncertainty of movement intentions, which gives rise to multiple plausible trajectories, and the dynamic interaction between targets and their environment, which further amplifies trajectory randomness.
Over the past few decades, trajectory prediction methods have evolved from traditional statistical models [6,7,8] to deep learning-based approaches. Recurrent neural networks [9,10,11] excel at temporal dependency modeling but ignore spatial interactions, and while subsequent studies introduced attention mechanisms [12,13,14,15] to enhance spatial relationship capture, this improvement came with higher model complexity and computational overhead; graph-based methods [16,17,18,19,20,21,22] capture social interactions yet have limitations in capturing temporal dynamics. Generative models such as GANs [23,24,25,26,27] and VAEs [28,29,30] have made progress in multi-modality modeling, with GAN-based methods capable of generating diverse trajectories but suffering from unstable training processes, and VAE-based methods featuring more stable training while often struggling to ensure prediction accuracy for complex trajectories such as those with sharp curvature or highly nonlinear shapes.
In recent years, denoising diffusion probabilistic models (DDPMs) have offered a new direction for time series prediction due to their stable training process and powerful ability to generate samples. Studies like [31,32] are pioneers to introduce diffusion models into time series prediction tasks. Early works like MID [33], LED [34] and MLD [35] have applied diffusion models to trajectory prediction, but still struggle with high computational cost and limited ability to model dynamic interactions. Furthermore, the single-parameter mean estimation approach adopted by these methods struggles to characterize multimodal distribution patterns effectively. In scenarios with high uncertainty, they persistently generate deterministic mean trajectories, which can result in misjudgments for downstream decision-making tasks. To address these challenges, we propose a novel framework named Improved Diffusion Mamba (iDMa), which employs an enhanced diffusion modeling strategy. In particular, we introduce a dual-parameter learning mechanism that incorporates a variance branch, enabling explicit modeling of multimodal distributions and reliable uncertainty calibration. Moreover, the proposed framework integrates an advanced Mamba architecture as the backbone of the denoising model, further enhancing prediction performance.
Specifically, the proposed iDMa framework introduces an innovative dual-parameter learning mechanism in the Markov chain process. Unlike standard diffusion models that only predict the mean, this framework learns both mean and variance parameters at the same time during denoising. The variance learning strategy dynamically modulates the output variance based on the multimodal properties of observed trajectories. It elevates variance when multiple plausible future paths exist and maintains low variance for highly deterministic trajectories, thereby balancing multimodal coverage and prediction accuracy. For uncertainty calibration, the learned variance exhibits a positive correlation with actual prediction errors. Low variance corresponds to high-confidence scenarios while high variance signals ambiguous scenarios and quantifies elevated prediction risk. This design endows the iDMa framework with built-in uncertainty awareness, enabling it to self-assess prediction reliability. This capability is critical for stochastic trajectory prediction tasks, as it addresses core challenges related to multimodality and uncertainty quantification that standard diffusion models fail to resolve. To reduce model parameters while keeping good performance, and considering the selection mechanism in Mamba, we design a hybrid denoising backbone network called T-Mamba. By integrating a Transformer encoder with Mamba [36] block, the model significantly enhances its capability to model the noise distribution of trajectory data. Theoretical analysis demonstrates that the framework can stably converge to the optimal solution. Experiments on the ETH-UCY [37,38] and Stanford Drone (SDD) [39] datasets confirm that iDMa performs much better than existing top methods in short-term trajectory prediction tasks. All experimental data used is based on 2D trajectories taken from image sequences. This paper’s main contributions are as follows:
- 1.
- Our iDMa framework introduces a new dual-parameter learning method during the diffusion process that fundamentally extends conventional diffusion models through simultaneous mean-variance optimization. This paradigm shift enables (1) probabilistically tighter trajectory bounds via KL-optimal noise matching, and (2) physically plausible prediction spaces through variance-constrained sampling;
- 2.
- We design a hybrid denoising network for the denoising process that combines Transformer encoders with Mamba blocks, specifically engineered to capture both the fine-grained local details within the data and the broader, global connections between all points in a trajectory. The two components work together to create a more powerful representation of the path data.
2. Related Works
2.1. Stochastic Trajectory Prediction
Stochastic trajectory prediction aims to forecast an agent’s future motion trajectory based on its historical movement. Most current methods use an encoder–decoder framework. The encoder gathers multi-source information such as the target’s own history, interactive behaviors with neighbors even scene map [40]. For temporal modeling, models like RNNs [41], LSTMs [10], GRUs [42], and Transformers [13,43] are commonly used. As for social modeling, specialized networks like SGCN [18], STAR [16], Trajectron++ [9], and GroupNet [19] have been developed. Finally, the decoder integrates these encoded features to generate final trajectory predictions. However, this common framework has the following clear limitations in dealing with complex trajectory distributions: (1) The training process can be unstable [23,24], and (2) the generated samples may lack diversity [29,30]. In contrast, methods based on diffusion models can generate more diverse and realistic paths through a step-by-step noise removal process, while exhibiting better stability during training. This demonstrates the great potential of diffusion models for trajectory prediction.
2.2. Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models (DDPMs) [44,45,46] are inspired by the particle diffusion process in non-equilibrium thermodynamics. The core idea is to gradually add noise to the original data until it converges to a noise-dominated distribution, and then use a reparameterized Markov chain to reconstruct the data. By learning to remove the noise, the model captures underlying structural dependencies, enabling the generation of highly realistic and diverse samples. Methods such as MID [33], LED [34], and SingularTrajectory [47] follow the basic DDPM [45] framework to refine the initially uncertain feasible region into a deterministic trajectory distribution. However, these methods use a fixed variance strategy during denoising, overlooking its importance. Research [48] indicates that properly adjusting the variance, especially in the early stages of denoising, is crucial for accurate data reconstruction. Therefore, we propose a new dual-parameter training mechanism that dynamically adapts the variance throughout the denoising process, which is integrated into our framework to improve the quality of the generated trajectories.
2.3. Mamba in Trajectory Prediction
Mamba [36] is recognized for its ability to handle long-range dependencies, which relies on a structured State Space Model (SSM) [49] mechanism that offers excellent memory and computational efficiency, thereby improving both its practicality and performance. Hippo [50] represents a key contribution to SSMs, establishing their effectiveness in long-sequence modeling tasks. Subsequent research [51] further refined the underlying mechanisms of SSMs by introducing a selective mechanism, leading to significant performance improvements. In time series tasks, Mamba-based approaches [52,53] have shown clear advantages, providing a theoretical basis for the stochastic trajectory prediction method studied in this paper.
For trajectory prediction tasks, Mamba-based methods [54,55] focus more on modeling the long-range dependencies of individual trajectories, lacking an explicit mechanism to model global correlations between multiple trajectories. In complex scenes, using Mamba alone will make it difficult to accurately capture group social interaction patterns, resulting in predicted trajectories that violate social common sense. In contrast, the self-attention mechanism of Transformer can directly calculate the dependency weights between any two agents, thereby explicitly modeling the correlation between trajectories of different individuals. This feature provides indispensable global social constraints for the denoising process of DDPM [45], ensuring that the generated trajectories conform to group behavior logic. On the other hand, in terms of functionality, when the Transformer-based MID [33] method extracts trajectory spatiotemporal features, it is prone to introducing redundant social interaction noise. Although the attention stacking strategy it adopts can mitigate this defect, the resulting computational burden has become a new problem to be solved. To address the above issues, this paper adopts a Transformer-Mamba fusion strategy and proposes a T-Mamba block. First, the attention mechanism of Transformer is leveraged to capture social interactions among agents and local temporal dependencies of individual agents. Then, Mamba adaptively captures the long-range dependencies of trajectory sequences to filter out local noise, enhance temporal consistency, and reduce computational overhead, thus achieving complementary advantages between the two.
Notably, Mamba has not been fully explored in the field of pedestrian stochastic trajectory prediction. This paper integrates the diffusion model architecture with Mamba for stochastic trajectory prediction tasks, and systematic experiments demonstrate that the proposed method effectively improves prediction accuracy while maintaining computational efficiency.
3. Method
3.1. Architecture
Trajectory prediction refers to the task of inferring an object’s future trajectory given its observed historical trajectory within a known time window. Mathematically, given a set of target objects to be predicted, let the 2D coordinates of target i at time t be denoted as For the observation period , the historical trajectory of target i is represented as , while the collective historical trajectories of N targets are denoted as . Correspondingly, for the future period , the future trajectory of target i is expressed as , and the future trajectories of all N targets are represented as . For notational simplicity, we hereafter use and to denote the historical and future trajectories, respectively.
This paper proposes an iDMa framework for stochastic trajectory prediction, which conceptualizes the ambiguous future motion area as isotropic Gaussian noise and refines it step-by-step through a denoising process to generate deterministic trajectory distribution. The overall architecture is illustrated in Figure 1a. Within this framework, the model takes observed historical trajectory and target’s motion states as inputs, generating multiple trajectory samples during inference. The output samples are guaranteed to include at least one sample that closely approximates the ground-truth (GT) future trajectory. The following sections provide detailed mathematical formulations of the forward noise diffusion process and the reverse denoising inference procedure in our framework.
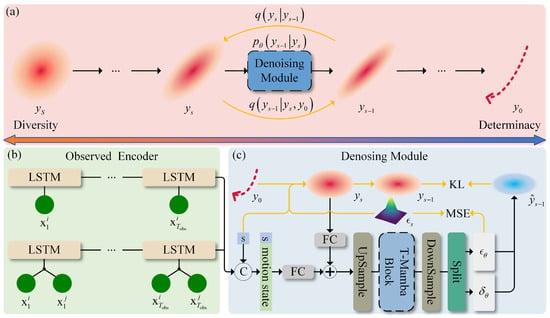
Figure 1.
The iDMa framework. (a) Overall architecture; (b) Encoder: Target’s trajectory feature learning; (c) Decoder: Denoising at step s (training and inference). Yellow arrows indicate training-phase-only operations.
We formally describe the noise diffusion and denoising processes in the iDMa framework as follows. To model the uncertainty in future motion patterns, we formulate a progressive noise injection mechanism through a forward diffusion process q. This process gradually corrupts the GT future trajectory by adding isotropic Gaussian noise according to a linear noise schedule [45], generating a sequence of latent variables . The diffusion process can be formally expressed as
Leveraging the additive property of Gaussian distributions, we can derive a closed-form sampling equation for any step of the diffusion process:
where , . Based on Bayesian theorem, we can derive the posterior distribution of the reverse process. Let denote the posterior distribution of the latent variable at the previous step given the noisy motion region and the desired trajectory . This posterior follows a Gaussian distribution, with its mean and variance expressed as
The derived posterior mean and variance establish a theoretical foundation for the denoising process, enabling the reparameterization of the posterior distribution through neural networks to progressively recover the desired motion trajectory from noise.
The mitigation of future motion uncertainty is conceptualized as the inverse process within diffusion models. Provided with an initial uncertain motion region and objective historical motion state information , the intended motion trajectory generation process is formally characterized as a Markov chain:
where denotes the initial noise distribution and represents the learnable parameters of the diffusion model. During the denoising process, the mean and variance of the predicted noise distribution at each step are derived via reparameterization, utilizing the noise and the control variable generated by the deep learning backbone network, as follows:
3.2. Training Objective
To train an iDMa model for accurate modeling of future trajectory, we optimize the model parameters by minimizing the divergence between the latent distribution in the denoising process and the true posterior distribution. Specifically, we adopt a variational inference strategy to maximize the following evidence lower bound (ELBO):
where represents the KL divergence between two Gaussian distributions. serves as a reconstruction loss, preserving the fidelity of generated trajectories, while regularizes the denoising process by aligning its distribution with the true posterior. Notably, when the diffusion step S is sufficiently large, converges to an isotropic Gaussian, making negligible (i.e., approaching 0). This simplifies optimization by allowing the model to omit this term during training.
Given the critical influence of the variance term in the initial stage of the diffusion process on the quality of generated samples [48], we propose a mixed-loss training strategy that introduces a learnable variance control vector to guide the Gaussian transition in the denoising process. The training objective is formulated as
where is optimized via the L2 norm of the noise distribution, aligning with the conventional training objective [33,45]. Furthermore, we introduce a small manually tuned weighting coefficient to ensure that effectively guides without compromising its primary role. This design preserves the simplicity of the original noise prediction framework while explicitly modeling the variance term to improve the model’s generative performance in pivotal diffusion stage. The complete training algorithm is detailed in Algorithm 1.
| Algorithm 1 The Algorithm for Training |
| Input: and ; Output: , ; 1: Compute Encoded vector ; 2: repeat 3: ; 4: ; 5: ; 6: ; 7: Compute according to Equation (7); 8: Take gradient descent step on . 9: until convered |
3.3. Inference Phase
The inference phase utilizes the trained noise predictor and the control variable, and performs S iterative Gaussian transition on an initial pure Gaussian noise distribution following the reparameterization in Equation (5), ultimately generating the predicted future trajectory. This phase is described in Algorithm 2. Below, we will elaborate on the deep learning model architecture employed for this generative framework, encompassing critical aspects such as network design, conditional fusion mechanisms, and other implementation details.
| Algorithm 2 The Algorithm for Inference |
| Input: ; Output: ; 1: Compute Encoded vector ; 2: for do 3: ; 4: for do 5: if then 6: ; 7: else 8: ; 9: end if 10: ; 11: ; 12: end for, return ; 13: end for, return . |
3.4. Denoising Module
We design a dedicated denoising module for the iDMa architecture tailored to the characteristics of trajectory data, as illustrated in Figure 1b,c. The module follows an encoder–decoder structure. Specifically, the encoder inherits partial encoding components from Trajectron++ [9], adopts hierarchical bidirectional LSTM modules to extract the temporal motion characteristics of the target and its social interaction features with neighboring entities from the input historical trajectory and then concatenates these two types of features to form a latent feature representation that simultaneously encodes temporal dynamics and social correlations. The decoder consists of the proposed T-Mamba block (see Figure 2), which integrates the Transformer encoder and Mamba block. This design addresses the limitations of standard Transformer, where MLP components exhibit limited spatial relationship modeling capabilities between sequence elements. It also reduces the computational cost associated with stacked attention layers, while achieving stronger performance in capturing key positional dependencies in trajectory sequences.
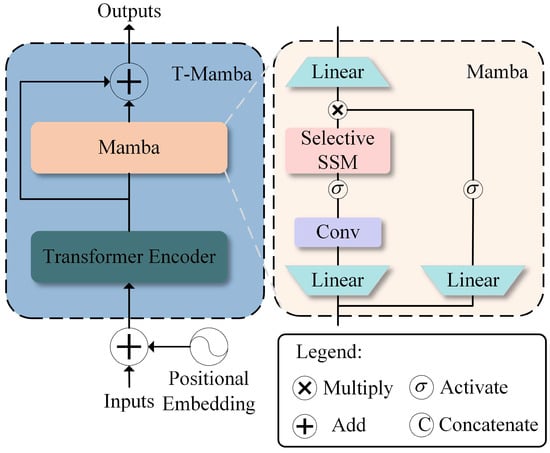
Figure 2.
T-Mamba block.
The decoder takes three inputs: the current diffusion timestep s, the observed motion features , and the noisy motion region at s. We first compute the timestep embedding and concatenate it with the motion features, forming a conditional vector . The region and the conditional vector are then passed through a fully-connected (FC) layer with upsampling. Their outputs are summed to form a fused feature representation , which is fed into the T-Mamba block to learn complex spatiotemporal dependencies. Specifically, the input sequence is initially processed by a Transformer encoder for local context modeling:
where PE denotes sinusoidal positional encoding, enhancing the model’s awareness of sequential order. Then, a Mamba block is applied to capture long-range dependencies efficiently via a discretized state-space model:
where , , , are learnable parameters and denotes the hidden state. To combine the global perception of the Transformer with the efficient sequence modeling of Mamba, we apply a residual connection between the Transformer output and the Mamba output:
Finally, the output of T-Mamba block undergoes dimensionality reduction through multiple FC layers, yielding the noise estimate and the variance control vector for the current timestep. They guide the Gaussian transition process and the computation of the training loss.
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
The proposed method is evaluated on the ETH-UCY [37,38] and SDD [39] datasets, following the standards of existing studies [29,33,35,47], predicting future trajectory for the next 12 frames based on the trajectory of the past 8 frames. The ETH [38] and UCY [37] datasets are classic benchmarks for pedestrian trajectory prediction, containing five distinct scenes: ETH, HOTEL, UNIV, ZARA1, and ZARA2. These sub-datasets provide trajectories annotated with real-world coordinates, and we follow the standard leave-one-out evaluation strategy for assessment. The SDD dataset is a large-scale dataset collected from a bird’s-eye view, in which the trajectory coordinates of various targets such as pedestrians and bicycles are annotated in pixel coordinates.
4.1.2. Evaluation Metrics
We employ widely used Average Displacement Error (ADE) and Final Displacement Error (FDE) as evaluation metrics [9,23,24,47,56,57]. ADE calculates the mean Euclidean distance between the predicted trajectory and the GT trajectory at all timesteps, reflecting the overall prediction accuracy. FDE measures the Euclidean distance between the predicted final position and the GT final position, evaluating the model’s long-term forecasting capability. These metrics provide a comprehensive assessment of the model’s trajectory prediction performance. Their mathematical formulations are given below:
4.1.3. Implementation Details
The proposed denoising module includes an upsampling block, T-Mamba block with a dimension of 512, and two downsampling blocks with dimensions halved at each stage. The T-Mamba block consists of single-layer Transformer encoder with 4 attention heads, and a Mamba layer featuring a state space dimension of 16 and convolutional kernel size of 4. During training, the model is trained for 150 epochs with an initial learning rate of 0.001 and a decay rate of 0.9. The weight factor for the loss function is set to 0.001. During inference, each prediction case generates random trajectories. All experiments are conducted on a single RTX 4070 GPU.
4.2. Ablation Studies
We conduct ablation studies on ETH-UCY and SDD to evaluate the effectiveness of the key components in our proposed method. As shown in Table 1, we focus on analyzing two main designs: (1) variance control in the diffusion model, and (2) the role of T-Mamba block. The experimental results reveal three key patterns: First, when the T-Mamba block is disabled, incorporating variance learning still leads to the improvement in prediction performance across both datasets. Second, in the scenario where variance learning is turned off, integrating the T-Mamba block yields even more significant enhancements in model performance on the two datasets, while also reducing the number of parameters and inference time. Third, when both the variance learning module and the T-Mamba block are activated simultaneously, the model attains its optimal performance with the fewest parameters and fastest inference, outperforming the baseline configurations on both ETH-UCY and SDD.

Table 1.
The results of ablation studies for iDMa on ETH-UCY and SDD datasets using ADE/FDE, where ETH-UCY is measured in meters and SDD in pixels. Bold fonts represent the best, lower is better.
To clarify the contribution of each component, we compare ablation studies with MID in the ZARA2 scene (see Figure 3). From the analysis of visual comparison results, we find that the variance variable can indeed constrain the predicted trajectory points within a reasonable range during the late-stage denoising process of the model. Additionally, the T-Mamba block iteratively captures the noise distribution in the high-dimensional space during denoising.

Figure 3.
Visualization of ablation experiments. (a) Standard Transformer denoising process; (b) only variance component; (c) only T-Mamba component; (d) Combination of variance and T-Mamba components.
Figure 4 clearly illustrates how T-Mamba denoising block shifts high-dimensional features from being noise-dominated to trajectory-semantics-dominated. In the initial state, the pure noise distribution shows a disordered mapping of color patches. As the denoising steps proceed, the high-dimensional mapping gradually exhibits consistent trends in time and increasingly approximates the high-dimensional mapping of real trajectory. These findings strongly validate the importance of variance control in the diffusion process and confirm Mamba’s effectiveness in capturing critical latent space features.
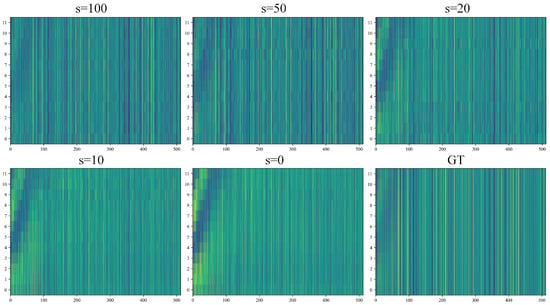
Figure 4.
Visualization of noisy trajectory at different denoising timestamps in the high-dimensional state space, with brighter colors indicating larger values and the color variation represents the hidden-layer confidence of the model. Horizontal axis: high-dimensional representation of target coordinates at time t; Vertical axis: predicted duration.
Moreover, we investigated the impact of the number of denoising steps on model performance and computational efficiency. As shown in Table 2, the prediction performance and inference time of the Transformer-Only (TF-O, 3 layers), Mamba-Only (M-O, 3 layers), and our proposed T-Mamba baselines are compared across different denoising steps on the ETH-UCY and SDD datasets. A clear trend emerges from the results: as the number of steps increases, the prediction accuracy of all three models gradually improves and eventually converges. However, this improvement in accuracy is accompanied by a near-linear increase in inference time, indicating that gains in prediction performance come at the cost of substantially higher computational overhead. Compared to these two baselines, under the setting of S = 100, the hybrid architecture proposed in this paper achieves an improvement of 3.4% in ADE and 7.7% in FDE on the SDD dataset. Considering the trade-off between computational cost and performance, we set the timesteps to 100.
Table 2.
Prediction performance and inference time comparison of Transformer-Only, Mamba-Only, and T-Mamba across different denoising steps on ETH-UCY and SDD datasets.
4.3. Quantitative Evaluation
As illustrated in Table 3, our method achieves notable improvement on the ETH-UCY dataset, reducing the ADE index from 0.21 to 0.20, which corresponds to a relative improvement of 4.76%. On the more challenging SDD dataset, our method also exhibits competitive performance, lowering the ADE from 8.10 to 7.95, representing a relative gain of 1.85%. Given the complexity of the dataset and the performance saturation observed in existing research, this progress holds practical importance. The consistent performance gains across diverse datasets demonstrate the robustness and generalization capability of the proposed method.
Table 3.
Comparison with baseline models on ETH-UCY and SDD dataset using ADE/FDE, where ETH-UCY is measured in meters and SDD in pixels. AVG is the average over five tested scenes of ETH-UCY. Bold/underlined fonts represent the best/second-best result.
4.4. Qualitative Evaluation
For a more intuitive evaluation of model performance, we conduct a visual comparison on the ETH-UCY dataset, comparing our method with several existing approaches: NPSN [62], EigenTrajectory [56], and SingularTrajectory [47]. As shown in Figure 5, the historical trajectories, GT future trajectories, and predicted trajectories are represented by green curves, red curves, and blue dashed lines, respectively. Notably, the blue dashed lines correspond to the optimal predicted trajectories selected from 20 generated samples, which exhibit the closest alignment with the GT trajectories. To highlight the performance differences more clearly, we select a representative sample from each scene for zoomed-in qualitative analysis.

Figure 5.
Visualization comparison on ETH/UCY. We compare the best-of-20 predictions by our method against NPSN, EigenTrajectory, and SingularTrajectory. (green curves: Observed trajectories; red curves: GT future trajectories; sky-blue dashed lines: Best-of-20 predictions).
The visual results demonstrate that the trajectories predicted by our method are more consistent with GT trajectories in both overall trend and local fine-grained details. More importantly, under challenging scenes, such as the densely crowded and complex interaction scene in the zoomed-in UNIV sample, our method maintains high prediction accuracy and outperforms the compared benchmarks significantly. This advantage stems from our model’s unique design of a diffusion model framework with dual-parameter learning, combined with a denoising module that fuses T-Mamba, which effectively addresses the limitations of existing methods. In contrast, our dual-parameter learning enables adaptive quantification of motion randomness by explicitly modeling the central tendency (mean) of trajectory distributions and trajectory boundary convergence (variance). This characteristic compensates for the deficiency of NPSN’s static sampling by dynamically responding to real-time interaction changes, while preserving subtle motion fluctuations through variance modeling to alleviate the loss of fine-grained details in EigenTrajectory. Meanwhile, the T-Mamba denoising module fully leverages Transformer’s strength in capturing local spatiotemporal dependencies and utilizes Mamba’s efficient selective state update mechanism to capture global temporal dynamic interaction cues. This synergy not only resolves SingularTrajectory’s trade-off dilemma between generalization and specificity but also ensures the model retains global consistency while responding to local interaction dynamics, thereby generating more realistic and accurate trajectories.
5. Discussion
The proposed iDMa framework exclusively takes the target’s location information as input and dispenses with pixel-level data such as maps. This characteristic endows the method with broad applicability in trajectory prediction tasks across diverse scenarios, transcending the limitation to pedestrian targets alone. Despite its favorable performance in relevant tasks, the framework still exhibits certain inherent constraints. Firstly, the iterative denoising process demands substantial computational resources, which poses a significant obstacle to real-time deployment in practical applications. Secondly, the model encounters difficulties in accurately characterizing complex trajectories, especially those involving abrupt curvatures or sharp turns, indicating inadequacies in capturing highly nonlinear motion patterns. Additionally, it is worth noting that its performance degrades markedly in highly interactive and crowded scenes. The mutual interference between multiple moving targets elevates motion complexity, and the absence of pixel-level environmental information impairs the model’s ability to infer target collision avoidance behaviors. Additionally, the model is sensitive to such key hyperparameters as diffusion steps and loss weights. Reducing diffusion steps accelerates inference but drastically compromises prediction accuracy, while tuning loss weights leads to performance fluctuations across datasets.
6. Conclusions
In this paper, we propose a novel stochastic trajectory prediction framework based on diffusion model. The framework integrates a dual-parameter learning mechanism for mean and variance, thereby enhancing the accuracy of noise estimation. Additionally, a hybrid denoising backbone is designed by combining Transformer and Mamba architectures, which not only reduces parameter overhead effectively but also strengthens the model’s capability to capture complex noise distributions. Experimental results validate that the iDMa framework achieves superior performance in trajectory prediction tasks, generating predictions with high accuracy and motion consistency while maintaining remarkable computational efficiency. Looking ahead, we will focus on optimizing real-time inference performance and further improving the models ability to predict highly nonlinear motion patterns, so as to expand its practical application scenarios.
Author Contributions
Conceptualization, Y.W. and F.F.; methodology, Y.W.; software, Y.W.; validation, Y.W., F.F. and J.F.; formal analysis, Y.W.; investigation, Y.W.; resources, Z.R.; data curation, Y.G.; writing—original draft preparation, Y.W. and J.F.; writing—review and editing, Y.W., F.F. and M.F.; visualization, Y.W. and Z.R.; supervision, L.D.; project administration, M.F.; funding acquisition, M.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by grants from Zhongshan Institute of Changchun University of Science and Technology (NO.CXTD2023005) and the Science and Technology Development Plan Project of Jilin Provincial Department of Science and Technology (No.YDZJ202301ZYTS411).
Data Availability Statement
All data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bera, A.; Kim, S.; Randhavane, T.; Pratapa, S.; Manocha, D. GLMP-realtime Pedestrian Path Prediction Using Global and Local Movement Patterns. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5528–5535. [Google Scholar] [CrossRef]
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; Arras, K.O. Human Motion Trajectory Prediction: A Survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Attention Based Vehicle Trajectory Prediction. IEEE Trans. Intell. Veh. 2021, 6, 175–185. [Google Scholar] [CrossRef]
- Zhou, W.; Jiang, K.; Cao, Z.; Deng, N.; Yang, D. Integrating Deep Reinforcement Learning with Optimal Trajectory Planner for Automated Driving. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Floreano, D.; Wood, R.J. Science, Technology and the Future of Small Autonomous Drones. Nature 2015, 521, 460–466. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.C.; Huang, D.A.; Lee, N.; Kitani, K.M. Forecasting Interactive Dynamics of Pedestrians with Fictitious Play. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Piscataway, NJ, USA, 2017; pp. 4636–4644. [Google Scholar] [CrossRef]
- Pfeiffer, M.; Paolo, G.; Sommer, H.; Nieto, J.; Siegwart, R.; Cadena, C. A Data-Driven Model for Interaction-Aware Pedestrian Motion Prediction in Object Cluttered Environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5921–5928. [Google Scholar]
- Schöller, C.; Aravantinos, V.; Lay, F.; Knoll, A. What the Constant Velocity Model Can Teach Us about Pedestrian Motion Prediction. IEEE Robot. Autom. Lett. 2020, 5, 1696–1703. [Google Scholar] [CrossRef]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-feasible Trajectory Forecasting with Heterogeneous Data. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 683–700. [Google Scholar]
- Ahmadi, A.M.S.; Semnani, S.H. Human Trajectory Prediction Using LSTM with Attention Mechanism. arXiv 2023, arXiv:2309.00331. [Google Scholar] [CrossRef]
- Slaughter, I.; Charla, J.L.; Siderius, M.; Lipor, J. Vessel Trajectory Prediction with Recurrent Neural Networks: An Evaluation of Datasets, Features, and Architectures. J. Ocean Eng. Sci. 2025, 10, 229–238. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Yuan, Y.; Weng, X.; Ou, Y.; Kitani, K. AgentFormer: Agent-aware Transformers for Socio-Temporal Multi-Agent Forecasting. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9793–9803. [Google Scholar] [CrossRef]
- Peng, X.; Shen, Y.; Wang, H.; Nie, B.; Wang, Y.; Wu, Z. SoMoFormer: Social-aware Motion Transformer for Multi-Person Motion Prediction. arXiv 2022, arXiv:2208.09224. [Google Scholar] [CrossRef]
- Liu, M.; Cheng, H.; Chen, L.; Broszio, H.; Li, J.; Zhao, R.; Sester, M.; Yang, M.Y. LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 2039–2049. [Google Scholar] [CrossRef]
- Yu, C.; Ma, X.; Ren, J.; Zhao, H.; Yi, S. Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 507–523. [Google Scholar] [CrossRef]
- Bae, I.; Park, J.H.; Jeon, H.G. Learning Pedestrian Group Representations for Multi-Modal Trajectory Prediction. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 270–289. [Google Scholar]
- Shi, L.; Wang, L.; Long, C.; Zhou, S.; Zhou, M.; Niu, Z.; Hua, G. SGCN:Sparse Graph Convolution Network for Pedestrian Trajectory Prediction. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8990–8999. [Google Scholar] [CrossRef]
- Xu, C.; Li, M.; Ni, Z.; Zhang, Y.; Chen, S. GroupNet: Multiscale Hypergraph Neural Networks for Trajectory Prediction with Relational Reasoning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6488–6497. [Google Scholar] [CrossRef]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE Computer Society: Piscataway, NJ, USA, 2020; pp. 14412–14420. [Google Scholar] [CrossRef]
- Zhang, K.; Feng, X.; Wu, L.; He, Z. Trajectory Prediction for Autonomous Driving Using Spatial-Temporal Graph Attention Transformer. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22343–22353. [Google Scholar] [CrossRef]
- Yang, R.; Wang, W.; Gui, P. Predicting Pedestrian Trajectories in Architectural Spaces: A Graph Neural Network Approach. In Proceedings of the 29th Annual Conference for Computer-Aided Architectural Design Research, Singapore, 20–26 April 2024; pp. 251–260. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2255–2264. [Google Scholar] [CrossRef]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, H.; Savarese, S. SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar] [CrossRef]
- Labaca-Castro, R. Generative Adversarial Nets. In Machine Learning Under Malware Attack; Springer Fachmedien: Wiesbaden, Germany, 2023; pp. 73–76. [Google Scholar] [CrossRef]
- Lao, L.; Du, D.; Chen, P. Predicting Pedestrian Trajectories with Deep Adversarial Networks Considering Motion and Spatial Information. Algorithms 2023, 16, 566. [Google Scholar] [CrossRef]
- Yang, B.; He, C.; Wang, P.; Chan, C.Y.; Liu, X.; Chen, Y. TPPO: A Novel Trajectory Predictor With Pseudo Oracle. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 2846–2859. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2022, arXiv:1312.6114. [Google Scholar] [PubMed]
- Xu, P.; Hayet, J.B.; Karamouzas, I. SocialVAE: Human Trajectory Prediction Using Timewise Latents. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 511–528. [Google Scholar] [CrossRef]
- Xiang, W.; YIN, H.; Wang, H.; Jin, X. SocialCVAE: Predicting Pedestrian Trajectory via Interaction Conditioned Latents. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 6216–6224. [Google Scholar] [CrossRef]
- Rasul, K.; Seward, C.; Schuster, I.; Vollgraf, R. Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting. arXiv 2021, arXiv:2101.12072. [Google Scholar] [CrossRef]
- Tashiro, Y.; Song, J.; Song, Y.; Ermon, S. CSDI: Conditional Score-Based Diffusion Models for Probabilistic Time Series Imputation. arXiv 2021, arXiv:2107.03502. [Google Scholar] [CrossRef]
- Gu, T.; Chen, G.; Li, J.; Lin, C.; Rao, Y.; Zhou, J.; Lu, J. Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17092–17101. [Google Scholar] [CrossRef]
- Mao, W.; Xu, C.; Zhu, Q.; Chen, S.; Wang, Y. Leapfrog Diffusion Model for Stochastic Trajectory Prediction. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5517–5526. [Google Scholar] [CrossRef]
- Wu, W.; Deng, X. Motion Latent Diffusion for Stochastic Trajectory Prediction. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 6665–6669. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time Sequence Modeling with Selective State Spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Lerner, A.; Chrysanthou, Y.; Lischinski, D. Crowds by Example. Comput. Graph. Forum 2007, 26, 655–664. [Google Scholar] [CrossRef]
- Pellegrini, S.; Ess, A.; Van Gool, L. Improving Data Association by Joint Modeling of Pedestrian Trajectories and Groupings. In Computer Vision—ECCV 2010, Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6311, pp. 452–465. [Google Scholar] [CrossRef]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Understanding in Crowded Scenes. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
- Mangalam, K.; An, Y.; Girase, H.; Malik, J. From Goals, Waypoints & Paths to Long Term Human Trajectory Forecasting. arXiv 2020, arXiv:2012.01526. [Google Scholar] [CrossRef]
- Pool, E. Context-Based Cyclist Path Prediction: Crafted and Learned Models for Intelligent Vehicles. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Archana, M.; Viji, R.; Ganapathy, S. A CNN-GRU Based Hybrid Approach for Pedestrian Trajectory Prediction. In Proceedings of the 2024 10th International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 12–14 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1611–1616. [Google Scholar] [CrossRef]
- Shi, L.; Wang, L.; Zhou, S.; Hua, G. Trajectory Unified Transformer for Pedestrian Trajectory Prediction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 9641–9650. [Google Scholar] [CrossRef]
- Sohl-Dickstein, J.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. arXiv 2015, arXiv:1503.03585. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the 34th International Conference on Neural Information Processing Systems (Nips ’20), Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. arXiv 2020, arXiv:2010.02502. [Google Scholar] [CrossRef]
- Bae, I.; Park, Y.J.; Jeon, H.G. SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 17890–17901. [Google Scholar] [CrossRef]
- Nichol, A.; Dhariwal, P. Improved Denoising Diffusion Probabilistic Models. arXiv 2021, arXiv:2102.09672. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Re, C. HiPPO: Recurrent Memory with Optimal Polynomial Projections. Adv. Neural Inf. Process. Syst. 2020, 33, 1474–1487. [Google Scholar] [CrossRef]
- Ali, A.; Zimerman, I.; Wolf, L. The Hidden Attention of Mamba Models. arXiv 2024, arXiv:2403.01590. [Google Scholar] [CrossRef]
- Ahamed, M.A.; Cheng, Q. TimeMachine: A Time Series Is Worth 4 Mambas for Long-Term Forecasting. arXiv 2024, arXiv:2403.09898. [Google Scholar] [CrossRef]
- Wang, Z.; Kong, F.; Feng, S.; Wang, M.; Yang, X.; Zhao, H.; Wang, D.; Zhang, Y. Is Mamba Effective for Time Series Forecasting? Neurocomputing 2025, 619, 129178. [Google Scholar] [CrossRef]
- Huang, Y.; Cheng, Y.; Wang, K. Trajectory Mamba: Efficient Attention-Mamba Forecasting Model Based on Selective SSM. arXiv 2024, arXiv:2503.10898. [Google Scholar]
- Yuan, D.; Xue, J.; Su, J.; Xu, W.; Zhou, H. ST-Mamba: Spatial-Temporal Mamba for Traffic Flow Estimation Recovery using Limited Data. In Proceedings of the 2024 IEEE/CIC International Conference on Communications in China (ICCC), Hangzhou, China, 7–9 August 2024; pp. 1928–1933. [Google Scholar] [CrossRef]
- Bae, I.; Oh, J.; Jeon, H.G. EigenTrajectory: Low-rank Descriptors for Multi-Modal Trajectory Forecasting. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE Computer Society: Piscataway, NJ, USA, 2023; pp. 9983–9995. [Google Scholar] [CrossRef]
- Chai, Y.; Sapp, B.; Bansal, M.; Anguelov, D. MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction. In Proceedings of the Conference on Robot Learning; Kaelbling, L.P., Kragic, D., Sugiura, K., Eds.; Proceedings of Machine Learning Research; PMLR: Cambridge, MA, USA, 2020; Volume 100, pp. 86–99. [Google Scholar]
- Hu, Y.; Chen, S.; Zhang, Y.; Gu, X. Collaborative Motion Prediction via Neural Motion Message Passing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6318–6327. [Google Scholar] [CrossRef]
- Ruan, K.; Di, X. InfoSTGCAN: An Information-Maximizing Spatial-Temporal Graph Convolutional Attention Network for Heterogeneous Human Trajectory Prediction. Computers 2024, 13, 151. [Google Scholar] [CrossRef]
- Maeda, T.; Ukita, N. Fast Inference and Update of Probabilistic Density Estimation on Trajectory Prediction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 9761–9771. [Google Scholar] [CrossRef]
- Yang, B.; Fan, F.; Ni, R.; Wang, H.; Jafaripournimchahi, A.; Hu, H. A Multi-Task Learning Network with a Collision-Aware Graph Transformer for Traffic-Agents Trajectory Prediction. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6677–6690. [Google Scholar] [CrossRef]
- Bae, I.; Park, J.H.; Jeon, H.G. Non-Probability Sampling Network for Stochastic Human Trajectory Prediction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 18–24 June 2022; pp. 6467–6477. [Google Scholar] [CrossRef]
- Chen, J.; Cao, J.; Lin, D.; Kitani, K.; Pang, J. Mgf: Mixed Gaussian Flow for Diverse Trajectory Prediction. Adv. Neural Inf. Process. Syst. 2024, 37, 57539–57563. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.