Abstract
Recent advances in deep learning have witnessed the wide application of convolutional neural networks (CNNs), Transformer models, and Mamba models in optical remote sensing image (ORSI) analysis, particularly for salient object detection (SOD) tasks in disaster warning, urban planning, and military surveillance. Although existing methods improve detection accuracy by optimizing feature extraction and attention mechanisms, they still face limitations when dealing with the inherent challenges of ORSI. These challenges mainly manifest as complex backgrounds, extreme scale variations, and topological irregularities, which severely affect detection performance. However, the deeper underlying issue lies in how to effectively align and integrate local detail features with global semantic information. To tackle these issues, we propose the Trans-Mamba Hybrid Network with Semantic Feature Alignment (TSFANet), a novel architecture that exploits intrinsic correlations between semantic information and detail features. Our network comprises three key components: (1) a Trans-Mamba Semantic-Detail Dual-Stream Collaborative Module (TSDSM) that combines CNNs-Transformer and CNNs-Mamba in a hybrid dual-branch encoder to capture both global context and multi-scale local features; (2) an Adaptive Semantic Correlation Refinement Module (ASCRM) that leverages semantic-detail feature correlations for guided feature optimization; and 3) a Semantic-Guided Adjacent Feature Fusion Module (SGAFF) that aligns and refines multi-scale semantic features. Extensive experiments on three public RSI-SOD datasets demonstrate that our method consistently outperforms 30 state-of-the-art approaches, effectively accomplishing the task of salient object detection in remote sensing imagery.
1. Introduction
Remote sensing image salient object detection (RSI-SOD) aims to identify and extract visually prominent regions and objects from complex remote sensing scenes [1,2,3,4]. By analyzing image features such as texture, edges, and color patterns, SOD effectively suppresses background interference while highlighting objects of interest. With the advancement of Transformer architectures [5], RSI-SOD has demonstrated remarkable success in various applications, including terrain change detection [6], disaster early warning [7], and military object surveillance [8]. Different from natural scene images (NSI) captured by conventional cameras, RSIs are acquired by aerial platforms and satellites from high altitudes, providing broader coverage and higher resolution. However, this unique imaging perspective introduces several critical challenges:
(1) Complex Backgrounds: As illustrated in Figure 1 (first row), conventional NSI-SOD models struggle with RSI-SOD detection, often failing to differentiate between background and foreground elements, leading to numerous false positives; (2) Extreme Scale Variations: The second and third rows of Figure 1 demonstrate how the NSI-SOD model BASNet [9], while effective for large-scale salient region object extraction, significantly underperforms in detecting small-scale salient objects; (3) Irregular Topological Structures: The fourth and fifth rows of Figure 1 reveal that existing models can only roughly extract salient regions from objects with complex topologies and intricate edge details, resulting in significant loss of fine-grained features.
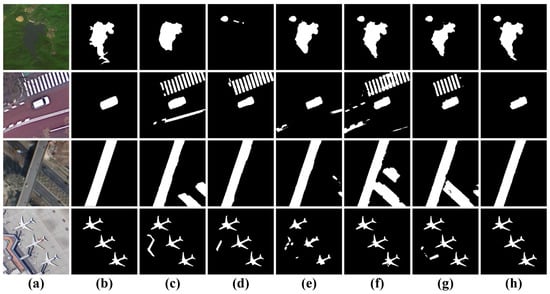
Figure 1.
Performance comparison between our method and the advanced Mamba-based, CNNs-based, Transformer-based, and hybrid CNNs-Transformer methods in classic challenging scenarios. (a) RSI. (b) GT. (c) VMamba. (d) BASNet. (e) R3Net. (f) GeleNet. (g) HFANet. (h) Ours.
Recent approaches to address these challenges can be categorized into CNNs-based, Transformer-based, Mamba-based, and hybrid architectures. The CNNs-based R3Net [10] (Figure 1e) focuses on local feature learning but struggles with global context integration. The Transformer-based GeleNet [11] (Figure 1f) excels in capturing contextual relationships but lacks precision in edge detection. The Mamba-based VMamba [12] (Figure 1c) shows improved detail extraction through sequential modeling but lacks comprehensive scene understanding. While the hybrid CNNs-Transformer model HFANet [13] (Figure 1g) combines local and global feature processing, it still suffers from false detections. The feature visualization analysis in Figure 2 reveals that current RSI-SOD models, while showing improved object region focus compared to NSI-SOD approaches, still struggle with background suppression, inconsistent multi-scale target localization, and boundary preservation. For example, the suppression of interfering backgrounds such as the runway target region in the lower right corner of the first row and the red building above the second row is still insufficient, the positioning of the large-scale building region and the small-scale car region in the third row is incorrect, and the extraction of the boundary integrity of the road region in the fourth row is insufficient.
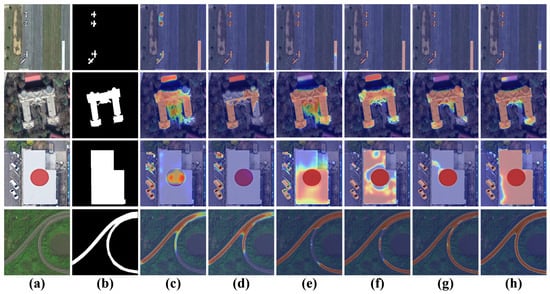
Figure 2.
Feature map visualization illustration of the object region positioning deviation of different SOD models. (a) RSI. (b) GT. (c) VMamba. (d) BASNet. (e) R3Net. (f) GeleNet. (g) HFANet. (h) Ours.
To address these limitations, we propose the Trans-Mamba Hybrid Network with Semantic Feature Alignment (TSFANet) to align and integrate local detail features with global semantic representations. By combining the strengths of Transformer-based global modeling and Mamba-based local detail extraction, our TSFANet is able to capture richer and more robust feature representations, leading to more accurate and reliable saliency prediction. This hybrid design is motivated by the complementary characteristics of both architectures, where global semantics help distinguish salient objects from cluttered backgrounds and local details refine object boundaries and small-scale structures. The primary contributions of this work are summarized as follows:
- To achieve comprehensive feature extraction, we designed the Trans-Mamba Semantic-Detail Dual-Stream Collaborative Module (TSDSM), a novel dual-stream architecture that synergistically combines CNNs-Transformer and CNNs-Mamba branches. This hybrid structure effectively leverages Transformer’s global modeling capabilities and Mamba’s local processing advantages, enabling more accurate salient detection in complex remote sensing scenes.
- For effective alignment of local details and global semantic features, we constructed the Adaptive Semantic Correlation Refinement Module (ASCRM). This module models the correlation between semantic and local features, utilizing matrix reshaping and SoftMax activation to accurately capture the spatial information of significant regions, thereby enhancing the precision of optical remote sensing salient object detection.
- To better integrate semantic features with local details, we designed the Semantic-Guided Adjacent Feature Fusion Module (SGAFF). This module extracts the overall semantic framework using a global attention mechanism and fuses it with local features to enhance the semantic information. Through the global semantic fluid information, SGAFF effectively filters out background noise, highlights target details, and improves object detection accuracy.
- Extensive experiments on three public RSI-SOD datasets demonstrate that our method consistently outperforms 26 state-of-the-art approaches. Detailed ablation studies verify that our proposed modules effectively address the challenges of complex backgrounds, scale variations, and irregular topologies in RSI-SOD tasks.
2. Related Works
2.1. State Space Models
Mamba has emerged as the most advanced state space model (SSM) variant, achieving Transformer-comparable modeling capabilities through its hardware-aware design while maintaining superior efficiency for long sequence processing. Recent developments in Mamba-based architectures can be categorized into several key research directions: Architectural Innovations: Early works focused on enhancing Mamba’s basic architecture. Matten [14] pioneered bidirectional processing with spatiotemporal attention, while MambaVision [15] introduced a restructured architecture that effectively integrates with Transformer mechanisms. nnMamba [16] advanced the field by incorporating Channel-Spatial Siamese learning with CNN integration, significantly improving long-range modeling capabilities. DualMamba [17] proposed a hybrid approach combining cross-attention modules for global modeling with residual learning for local feature extraction. Vision-Specific Adaptations: Several works have focused on adapting Mamba for vision tasks. VMamba [12] introduced the SS2D module for 2D selective scanning, enhancing contextual information collection. Weak-Mamba-UNet [18] developed a comprehensive framework combining CNN, Transformer, and Mamba-based encoders for multi-level feature processing. LocalMamba [19] proposed a dynamic, layer-wise scanning strategy for localized feature capture while maintaining global context. VIM [20] enhanced visual representation through position-aware bidirectional modeling. Task-Specific Applications: Recent research has expanded Mamba’s applications across various domains. Graph-Mamba [21] enhanced graph network modeling through input-dependent node selection. VMRNN [22] and SpikeMba [23] focused on temporal dynamics and neural information processing. CU-Mamba [24] and VMambaMorph [25] addressed medical imaging challenges through specialized architectures. MedMamba [26] developed multi-modal medical image analysis capabilities, while Pan-Mamba [27] and Vmambair [28] focused on cross-modal interaction and image restoration, respectively. Despite these advances in Mamba’s applications across various computer vision tasks, its potential in remote sensing image analysis remains largely unexplored, particularly in the context of salient object detection. Most existing Mamba-based methods for remote sensing images focus solely on semantic segmentation tasks, leaving a significant gap in RSI-SOD applications.
2.2. SOD in Natural Scene Images
Traditional Natural Scene Image Salient Object Detection (NSI-SOD) primarily relied on classical machine learning algorithms, leveraging handcrafted features such as regularization techniques [4], color variation [29], and background priors [30]. While these methods achieved initial progress, they were limited by their dependence on manually designed features and inability to extract deep semantic information. The advent of deep learning brought revolutionary advances to saliency detection. Itti et al. [1] pioneered computational visual attention with a center-surround disparity mechanism, efficiently integrating multi-scale features for salient region identification. Subsequently, CNNs-based approaches demonstrated remarkable improvements. R3Net [10] enhanced detection through recurrent networks and residual learning, alternating between low- and high-level features. AFNet [31] improved boundary accuracy by combining boundary perception with attention mechanisms, while MDF [32] strengthened feature representation through multi-level feature cascading. Amulet [33] introduced effective feature fusion strategies, and MSIN [34] enhanced feature extraction through multi-scale interaction. Edge information processing saw significant diversification. C2SNet [35] utilized boundary information as auxiliary signals, while BASNet [9] improved performance in challenging scenarios through boundary-aware mechanisms. EGNet [36] and ITSD [37] enhanced boundary prediction through edge guidance and two-stream encoding. TRACER [38] optimized feature selection through extreme attention, and PiCANet [39] employed contextual attention for dynamic feature fusion. Recent advances include PFANet’s [40] pyramid feature extraction, BBRFNet’s [41] multi-scale receptive fields, and VST’s [5] Transformer-based long-range dependency modeling. Despite these advances in NSI-SOD, optical remote sensing image saliency detection faces unique challenges due to imaging limitations, including resolution variations, illumination changes, and atmospheric interference. Direct application of existing models to remote sensing images remains problematic, highlighting the need for specialized approaches that effectively integrate multi-scale global and local features while addressing domain-specific challenges.
2.3. SOD in Optical RSIs
RSI-SOD addresses more complex remote sensing scenes compared to NSI-SOD, leading to significant methodological advances organized in four main development stages: (1) The foundational stage focused on establishing datasets and basic frameworks. Zhao et al. [42] introduced a sparsity-guided SOD method with initial RSI datasets. Li et al. [43] developed the Optical Remote Sensing for Salient Object Detection Dataset (ORSSD) and LVNet, combining nested networks with pyramid structures. Zhang et al. [44] extended this with the higher-resolution Extended Optical Remote Sensing for Salient Object Detection Dataset (EORSSD) and proposed DAFNet featuring dense attention mechanisms. Tu et al. [45] contributed the challenging Optical Remote Sensing Image Dataset with 4199 Samples (ORSI-4199) and MJRBM model. (2) CNNs-based methods then emerged to address RSI-specific challenges. EMFINet [46] combined edge awareness with multi-scale feature pyramids, while MCCNet [47] tackled complex backgrounds through multi-content completion. SARNet [48] introduced coarse-to-fine detection with semantic guidance, and ACCoNet [49] leveraged neighborhood context coordination. ICON [50] focused on boundary preservation and feature diversity enhancement. (3) Recent advances have centered on Transformer-based and hybrid architectures. GeleNet [11], the pioneering Transformer-based method, introduced direction-aware spatial attention. Subsequent works like RAGRNet [51], BSCGNet [52], and ESGNet [53] enhanced feature interaction through various graph-based and attention mechanisms. Ma et al. [54] proposed an end-to-end framework that integrates superpixel generation and region merging for remote sensing image segmentation. ASTTNet [55] and IDELNet [56] further refined Transformer-based feature extraction. (4) The latest hybrid approaches have shown promising results. HFANet [13] combined CNN and Transformer encoders for multi-scale modeling. ASNet [57] and HFCNet [58] focused on balancing global-local feature integration. PROFILE [59] and WeightNet [60] introduced sophisticated feature enhancement and noise suppression mechanisms. Ma et al. [61] introduced a deep superpixel-wise segmentation approach for remote sensing image, which leverages task-specific superpixel sampling and soft graph convolution to enhance both accuracy and computational time. FPS-U2Net [62] focuses on gradually extracting salient information from the image by aggregating multi-scale and multi-level features extracted from different stage encoders. Despite these advances, achieving optimal accuracy in complex scenarios remains challenging, particularly for regions with intricate backgrounds, scale variations, and irregular topologies. Our proposed TSFANet addresses these limitations by introducing a novel dual-encoder architecture combining CNNs-Mamba for local features and CNNs-Transformer for global representation, unified by correlation-guided multi-scale feature fusion.
3. Methodology
This section describes the proposed TSFANet. Firstly, we introduce the overall structure. Then, the details of TSDSM, ASCRM, and SGAFF are described respectively. Finally, the loss function for network training is introduced.
3.1. Overall Structure
The overall architecture of TSFANet is illustrated in Figure 3. Built upon the foundational structure of HFANet [13], TSFANet enhances the classic encoder-decoder framework to improve feature extraction and integration. The model employs a dual encoder architecture comprising CNNs-Transformer and CNNs-Mamba components. Specifically, the CNNs-Transformer module captures complex global correlations across spatial positions, while the CNNs-Mamba module integrates these global correlations with local feature details, thereby enhancing the effectiveness of feature extraction.
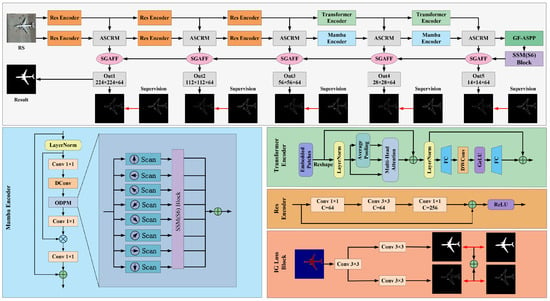
Figure 3.
The overall architecture of TSFANet, includes Res Encoder, Mamba Encoder, Transformer Encoder, Adaptive Semantic Correlation Refinement Module (ASCRM), and Semantic-Guided Adjacent Feature Fusion Module (SGAFF).
At each encoding stage, the ASCRM module leverages global features to guide attention shifts within the local feature maps, optimizing them to emphasize detailed characteristics of salient target regions. Additionally, to further enrich semantic content and support robust feature interaction and fusion, the SGAFF module is integrated. This module provides semantic cues through deep-layer features and detailed structural information through shallow-layer features, facilitating accurate small-target recognition and effective background suppression. Algorithm 1 details the implementation process of the method. For an input image , the TSDSM encoding process operates as follows: the CNNs-Transformer branch extracts global feature maps , , , , and . Concurrently, the CNNs-Mamba branch captures local features , , , , and . For each global feature and local feature () at different stages, the ASCRM module is utilized to obtain fused features . These fused features are then processed through the GF-ASPP and S6 modules, resulting in selectively enhanced detailed features . Using the SGAFF module, the fused features () and deep features () are combined to produce deep fused features () for each stage. Finally, the deep fused features are fed into convolutional module to generate the outputs ().
| Algorithm 1: Training Framework for TSFANet |
 |
3.2. Trans-Mamba Semantic-Detail Dual-Stream Collaborative
To capture the detailed features of target regions in remote sensing images (RSI), existing methods commonly integrate CNNs and Transformers to construct encoders for feature extraction. Typically, CNNs are employed for pixel-level local feature information modeling, followed by Transformers for pixel-block-level global feature information modeling. However, this encoder architecture fails to effectively leverage both local and global features simultaneously. Inspired by Ref. [17], we propose the Trans-Mamba Semantic-Detail Dual-Stream Collaborative Module (TSDSM), which integrates CNNs-Transformer and CNNs-Mamba to form a dual-path encoder. The CNNs-Transformer branch is for global feature modeling, capturing global relationships and long-range dependencies within the image while guiding the CNNs-Mamba branch in local feature modeling. Although the two branches operate independently in feature extraction, their collaboration is achieved through the Adaptive Semantic Correlation Refinement Module (ASCRM), which is applied after each encoding stage (as illustrated in Figure 3). The ASCRM module explicitly models the intrinsic correlations between the global semantic features from the CNNs-Transformer branch and the local detail features from the CNNs-Mamba branch by learning a cross-attention weight matrix. This mechanism enables information exchange and mutual guidance between the branches, allowing global semantic cues to refine local features and vice versa. The resulting fused features integrate both holistic context and local structure, forming a unified representation for subsequent decoding and prediction.
3.2.1. CNNs-Transformer
As illustrated in Figure 3, the Res encoder is utilized to extract low-level features of RSI targets, while the Transformer encoder acquires global semantic information. The Res encoder is defined as follows
where denotes a convolution operation with a kernel size of , and ⊕ represents element-wise addition. The Transformer captures global attention by constructing query (Q), key (K), and value (V) matrices from input feature image patches. However, due to its computational complexity increasing with image resolution, the Transformer is employed only in the 3rd and 4th stages. As shown in Figure 3, the Transformer encoder partitions the input image into patches through patch embedding. After normalization, it computes the Q, K, and V matrices for these patches. The multi-head attention is then applied to assign attention weights to each image patch. Finally, the feed-forward layer and convolutional layers are integrated to further extract and aggregate features, producing a sequence of token features. The computations processes are defined as follows:
where FC denotes a fully connected feed-forward layer, represents a depth-wise convolution with a kernel size of , LN represents layer normalization, PE indicates patch embedding operations, represents the multi-head attention feature map, and is the multi-head attention operation. The multi-head attention is calculated as:
where is the activation function, ⊤ denotes matrix transposition, and d is the dimensionality of input features divided by the number of multi-head attention.
3.2.2. CNNs-Mamba
As depicted in Figure 3, the CNNs-Mamba branch employs ResBlock to capture low-level features such as edges, textures, and corners of the target, thereby reducing the complexity burden on the Mamba coding module. The Mamba encoder is responsible for synthesizing the local and global information captured by the model in deeper layers. Global information guides the construction of long-range dependencies between different local features, refining the local features in key regions. As shown in Figure 3, the Mamba encoder utilizes the State Space Module (SSM) in conjunction with the Omnidirectional Sensing Module (ODPM) to perform selective scanning in various directions, achieving linear complexity and a globally effective receptive field while extracting local details by integrating global semantic information. For the input features , after layer normalization and dimensionality reduction via a convolution, spatial features of each input channel are extracted through deep convolution. Subsequently, the ODPM selectively scans in different directions to extract distinct detail features, which are adjusted using the normalized features. To prevent gradient loss during model operations, the features are added back to the input features after dimensionality restoration via convolution, supplementing the foreground information overlooked in local feature extraction.
In contrast to VMamba’s 2D selective scanning, which performs forward and backward scanning in horizontal and vertical directions, the proposed ODPM introduces additional diagonal and anti-diagonal direction scanning to address the anisotropy inherent in remote sensing images. It conducts global modeling in all directions and processes each scanning sequence independently through the SSM module. This approach selectively propagates key features while discarding background noise, enabling global modeling in specific directions. Finally, all sequences are aggregated and summed, capturing detailed features from different directions within the remote sensing image. For the input feature map , where denotes the token located at the m-th row and n-th column of the feature map, the horizontal scanning operations used by VMamba are defined as follows
where , x represents the position index of an element in the flattened feature map, ranging from 0 to , and denote the one-dimensional token sequences obtained by flattening along the horizontal scanning direction. The vertical scanning operations are defined as
where represent the one-dimensional token sequences obtained by flattening along the vertical scanning direction. The diagonal scanning operations introduced by ODPM are computed as follows:
where denote the one-dimensional token sequences obtained by flattening along the diagonal scanning direction. The anti-diagonal scanning operations are as
where represent the one-dimensional token sequences obtained by flattening along the anti-diagonal scanning direction. After completing the scanning in horizontal, vertical, diagonal, and anti-diagonal directions, the one-dimensional token sequences obtained from forward and backward scanning in each direction are input into the SSM (S6) block to learn attention features for significant targets in each direction. Subsequently, the corresponding inverse operations are applied to each direction
where represents the eight scanning directions. The final ODPM output is obtained by summing the projections from all directions as .
3.3. Adaptive Semantic Correlation Refinement
The CNNs-Transformer and CNNs-Mamba encoders extract feature information with dimensional discrepancies. While many existing methods address this issue through feature fusion, they often overlook the intrinsic correlations within the features extracted by different encoders. Inspired by Ref. [57], we recognize that such intrinsic correlations exist within the feature information extracted by different encoders. To refine local feature details by leveraging the correlation between semantic and detailed features, we propose the Adaptive Semantic Correlation Refinement Module (ASCRM).
As illustrated in Figure 4, for the input semantic feature and local feature , matrix reshaping is first applied to obtain and . By learning a weight matrix , the reshaped semantic features are projected into the semantic correlation matrix . The matrix multiplication is then utilized to compute the correlation matrix r, representing the correlation between semantic and local features. The correlation matrix r is calculated as follows:
where ⊤ denotes the transpose operation and ⊗ represents matrix multiplication. The correlation matrix r is subsequently processed using the softmax function for activation and normalization. This processing enables the weighted semantic correlation matrix to capture the spatial location information of significant regions within each feature. The corrected semantic feature and local feature are defined as follows:
where denotes the matrix reshaping operation, and represents the activation function. Subsequently, location information is generated for and through a convolution, resulting in and , respectively. Based on these mapped values, redundant information is filtered out to obtain and , calculated as follows:
where denotes the sigmoid activation function, which maps feature values to the range , and Conv represents the convolution operation. Through residual connections, is fused with , and is fused with , resulting in and :
where denotes the depthwise separable convolution, and ⊕ represents element-wise addition. For the two effective components, and , concatenation is performed followed by convolution to extract the location features of their significant regions. These features are then transformed into position information using the convolution and the sigmoid function:
where denotes channel-wise concatenation. By applying the extracted position information to the local feature , the refined local feature is obtained as follows:
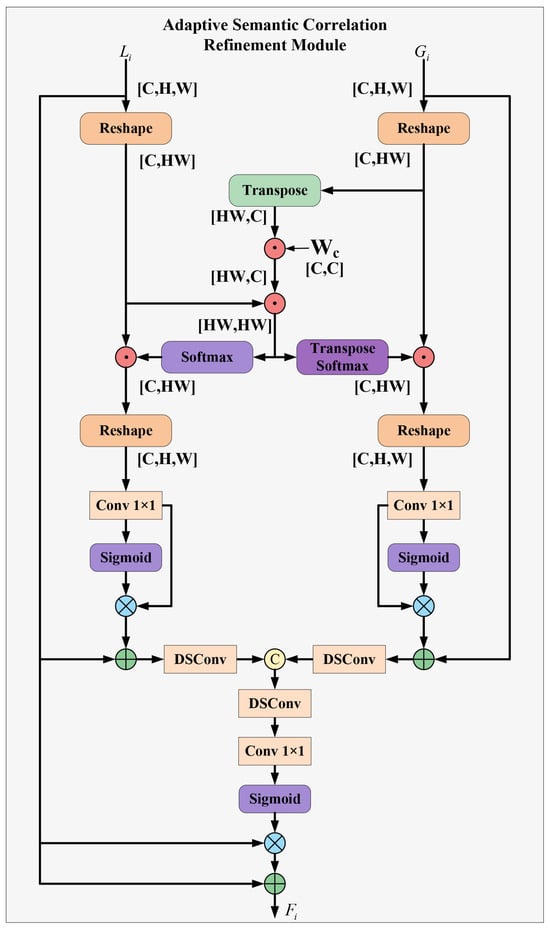
Figure 4.
Architecture of Adaptive Semantic Correlation Refinement Module.
This direct feature modulation approach provides precise collaborative semantic guidance for refining local features, thereby laying a solid foundation for the fine-grained processing of remote sensing images.
3.4. Semantic-Guided Adjacent Feature Fusion
The remote sensing image contains rich semantic information that can assist the model in accurately locating target positions. When combined with local features, this semantic information can better identify targets of varying sizes within complex backgrounds. Although many existing methods effectively learn feature information at different scales, significant semantic differences persist across layer features. Inspired by Ref. [48], we constructed the Semantic-Guided Adjacent Feature Fusion Module (SGAFF) to align and fuse features by effectively utilizing deep semantic features and details across scales.
As illustrated in Figure 5, for the deep input feature from the encoder, it is transformed into through matrix operations for computational convenience. Subsequently, the Global Attention Mechanism (GAM) is employed to capture the overall semantic framework of the feature . The overall semantic framework is calculated as follows:
where represents the activation function, and denotes the matrix transpose operation. Semantic features aid in understanding the overall context and meaning of the image but are susceptible to noise and complex backgrounds. To mitigate these issues, the semantic framework is fused with the local features extracted from the input features to obtain the global semantic fluid information . This provides detailed information beneficial for distinguishing similar objects in different regions. The is calculated as:
where represents the convolution, ⊕ denotes element-wise addition, and ⊗ represents matrix multiplication. To facilitate the fusion of features with the shallow input features from the encoder, the deep-layer input features are upsampled and reshaped into a feature tensor with dimensions :
where represents the matrix reshaping operation, and denotes the upsampling. The semantic information is projected to the corresponding positions, aggregated, and integrated into the semantic feature :
where transforms the feature matrix from to dimensions to facilitate subsequent computation and processing; ⊗ represents matrix multiplication, and ⊕ denotes element-wise addition. Since different channel dimensions contain varying feature details of the target and include background noise interference, it is essential to highlight the detailed parts of the target. To achieve this, channel dimension features are resampled to obtain attention across different channels, thereby enhancing the shallow input features through channel attention. To prevent feature information loss while filtering out background noise, semantic features are used to guide and obtain the channel attention projection . Through matrix reshaping, the channel attention feature is obtained:
where represents the softmax activation function, and ⊗ denotes matrix multiplication. The Sigmoid function is applied to the semantic feature and multiplied with the channel feature , leveraging the semantic features to further select the target’s feature information. Then, is element-wise added to the semantic feature and passed through a convolution and normalization to obtain the aggregated feature :
where ⊙ represents element-wise matrix multiplication, and denotes the batch normalization and ReLU operations.
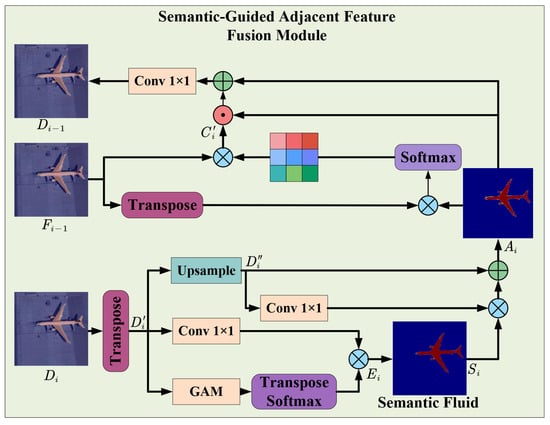
Figure 5.
Architecture of Semantic-Guided Adjacent Feature Fusion Module.
3.5. Loss Function
The proposed TSFANet extends HFANet [13] by employing the designed IG Loss and weighted Intersection over Union (wIoU) as the loss functions. As shown in Figure 3, IG Loss is calculated as follows:
where and are the predicted saliency map and predicted edge map, respectively; and are the ground truth saliency map and edge map; i represents the index of each pixel; n is the total number of pixels; and are balancing weight factors (both set to 1 in our implementation, following Ref. [13]) that control the contribution of the edge and region terms in the loss function, and is the Binary Cross Entropy (BCE) loss. The BCE loss is defined as follows:
By introducing the wIoU loss into the IG loss, is calculated as follows:
where and represent the sum and element-wise multiplication of the predicted saliency map and ground truth values at pixel j, respectively. The total loss for each stage can be expressed as
For the model training process, high-quality saliency prediction maps are generated in five stages, and the model is supervised using image labels and edge labels. To better balance the five detection stages of the model, the losses of the five stages are weighted and summed as Equation (35). In addition, we find that the hyperparameters and are all set to 1 and work best in our experiments.
4. Experiments and Analysis
4.1. Dataset Description
To comprehensively evaluate the performance of the proposed model, we conducted extensive experimental comparisons on three publicly available Remote Sensing Image Saliency Object Detection (RSI-SOD) datasets: ORSSD, EORSSD, and ORSI-4199.
- ORSSD: The first publicly available RSI-SOD dataset, ORSSD, comprises 800 optical RSI images with corresponding annotations. Of these, 600 images are designated for training, and 200 images for testing.
- EORSSD: An extended version of ORSSD, EORSSD incorporates more challenging scenarios to better assess model robustness. It includes 1400 training samples and 600 testing samples.
- ORSI-4199: The most diverse saliency detection dataset in terms of scene complexity, ORSI-4199 contains 2000 training samples and 2199 testing samples.
Following the standard protocol, the training sets of each dataset are utilized for model training, while performance evaluations are conducted on their respective test sets.
4.2. Implementation Details and Evaluation Metrics
We developed TSFANet using the PyTorch 2.0.0 framework and Python 3.8.0. Model inference is accelerated using an NVIDIA RTX 4090 GPU. To prevent overfitting and enhance the generalization performance of the model, we employed various data augmentation techniques, including random rotations, color transformations, and noise addition. For model parameter optimization, we set the initial learning rate to , the batch size to 16, and used the Adam optimizer to update the network parameters. A polynomial learning rate strategy is applied to automatically adjust the learning rate during training. The model is trained for 300 epochs. In training and testing phases, input images are resized to pixels to maintain consistency.
To comprehensively assess the performance of our method, we adopt five widely used evaluation metrics: S-measure (), F-measure (), E-measure (), mean absolute error (MAE), and the precision-recall (P-R) curve. The S-measure jointly considers region-aware and object-aware similarities to reflect both global and structural correspondence between the predicted saliency map and the ground truth. The F-measure calculates the weighted harmonic mean of precision and recall, with a stronger emphasis on precision, to evaluate the overall detection quality. The E-measure combines pixel-level precision and image-level structural information for a balanced measurement of saliency map accuracy. The MAE quantifies the average pixel-wise error between the predicted and true saliency maps, providing an intuitive indicator of prediction error. Finally, the P-R curve illustrates the model’s performance under different binarization thresholds by plotting precision versus recall, offering a comprehensive view of detection capability across varying criteria.
4.3. Comparison with State-of-the-Art Methods
To comprehensively evaluate the proposed method, TSFANet is benchmarked against state-of-the-art models on three public Remote Sensing Image Saliency Object Detection (RSI-SOD) datasets. The comparison involves a Mamba-based semantic image segmentation model (SSI) VMamba [12] and Samba [63] (with one class in the experiments), eight Natural Scene Image (NSI) models (PicaNet [39], R3Net [10], RAS [64], BASNet [9], CPDNet [65], EGNet [36], PoolNet [66], U2Net [67], and VST [5]), and sixteen Remote Sensing Image (RSI) models (CSNet [68], CoorNet [69], GeleNet [11], HVPNet [70], SAMNet [71], MCCNet [47], SUCA [72], ACCoNet [49], DNTD [73], MJRBM [45], ICON [50], EMFINet [46], HFANet [13], DPORTNet [74], PA-KRN [75], ERPNet [76], DBINet [77], DCNet [78], and DSINet [79]). To ensure experimental fairness, results for the 30 comparison methods were derived from publicly available data provided by the authors, with some reproduced using publicly available source code.
4.3.1. Quantitative Comparison
The quantitative comparison results of TSFANet and the other 30 latest methods on three RSI-SOD datasets are shown in Table 1, Table 2 and Table 3. Clearly, our method outperforms these advanced methods across each dataset. Specifically, for the simpler ORSSD dataset, TSFANet achieves three optimal results and one third-best result. Compared with the top-performing traditional CNN-based NSI-SOD model R3Net, the , , and scores are increased by 4.37%, 5.59%, and 5.79%, respectively, while the MAE is reduced by 0.93%. Although it trails behind the leading RSI-SOD model MCCNet by 0.67% on the metric, TSFANet leads by 0.18%, 0.59%, and 0.1% on the , , and MAE metrics, respectively. On the extended and more challenging EORSSD dataset, TSFANet slightly lags behind HFANet by 0.67% and 0.77% on the and indicators, respectively, but surpasses it by 0.07% and 0.1% on the and MAE indicators, respectively. On the most challenging ORSI-4199 dataset, TSFANet achieves the best results with an of 88.76%, of 86.17%, of 94.53%, and MAE of 2.77%. To visually illustrate the model’s overall performance, Figure 6 presents the precision-recall (P-R) curves and F-measure curves of the comparison methods across the three datasets. The comparison of the curves reveals that TSFANet’s P-R curve is closest to the coordinate (1, 1), demonstrating its ability to achieve high precision while maintaining high recall. Additionally, TSFANet achieves the largest area under the F-measure curve compared to all other methods. The computational complexity analysis of the various methods is presented in Table 4. It can be observed that the introduction of multiple Transformer modules leads to a large number of parameters in the baseline model HFANet, while the proposed TSFANet improves on it by discarding some of the modules with a large number of parameters, enhancing the capture of feature details and the understanding of semantic information. Although the number of parameters is the largest, the computational complexity is at a medium level, which can guarantee high performance while providing a better price–performance ratio in terms of hardware resources and practical applications. While TSFANet consistently outperforms existing methods overall, there remain certain cases, such as images containing extremely small, low-contrast, or densely clustered salient objects, where the improvement is less significant. These cases reveal that further enhancement is needed to address the detection of subtle and highly challenging targets in complex remote sensing scenes.

Table 1.
Quantitative comparisons of our method with 30 state-of-the-art methods on the ORSSD dataset. The Top-3 results in each column are highlighted in red, blue, and green. “-” denotes the authors do not provide the corresponding results.
Table 2.
Quantitative comparisons of our method with 30 state-of-the-art methods on the EORSSD dataset. The Top 3 results in each column are highlighted in red, blue, and green. “-” denotes the authors do not provide the corresponding results.
Table 3.
Quantitative comparisons of our method with 30 state-of-the-art methods on the ORSI-4199 dataset. The Top 3 results in each column are highlighted in red, blue, and green. “-” denotes the authors do not provide the corresponding results.
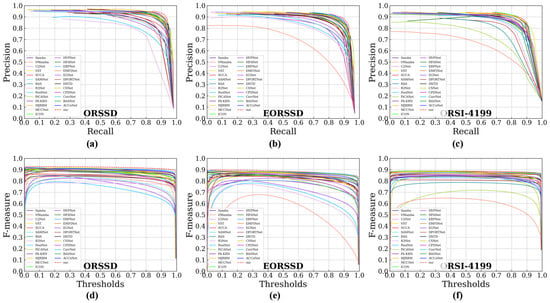
Figure 6.
The P-R and F-measure curves of different comparison methods on ORSSD, EORSSD and ORSI datasets. (a) P-R curves on ORSSD. (b) P-R curves on EORSSD. (c) P-R curves on ORSI-4199. (d) F-measure curves on ORSSD. (e) F-measure curves on EORSSD. (f) F-measure curves on ORSI-4199.
Table 4.
Computational complexity of different methods. The best results are marked in bold.
4.3.2. Qualitative Comparison
Qualitative evaluations across different RSI scenarios highlight the advantages of our proposed method under complex conditions. The visualization results are presented in Figure 7. Typical scenarios for analysis and comparison include (1) Objects in complex cluttered backgrounds; (2) Small-scale salient objects; (3) Topologically irregular objects. By comparing the prediction results generated by each test image, ground truth labels, and different models, it is evident that our TSFANet more closely aligns with real-world scenarios than other methods. Specifically, the advantages of saliency detection in different scenarios are as follows:

Figure 7.
Visualization comparison of different RSI-SOD models on typical challenging scenarios. (a1–c1,a2–c2): Objects in complex cluttered backgrounds; (d1–f1,d2–f2): Small-scale salient objects; (g1–i1,g2–i2): Topologically irregular objects. The compared methods include CNNs-based methods (Mamba-based semantic image segmentation model (SSI) VMamba [12] and Samba [63], NSI models (PicaNet [39], R3Net [10], RAS [64], BASNet [9], CPDNet [65], EGNet [36], PoolNet [66], U2Net [67], and VST [5]), and RSI models (CSNet [68], CoorNet [69], GeleNet [11], HVPNet [70], SAMNet [71], MCCNet [47], SUCA [72], ACCoNet [49], DNTD [73], MJRBM [45], ICON [50], EMFINet [46], HFANet [13], DPORTNet [74], PA-KRN [75], ERPNet [76]), DBINet [77], DCNet [78], and DSINet [79]).
(1) Objects in Complex Cluttered Backgrounds: As shown in Figure 7a–c, human activities introduce abundant clutter information similar to the target in RSI, making it difficult for some models to achieve high-precision detection. For example, in Figure 7a, only EMFINet, SUCA, CorrNet, ACCoNet, ERPNet, MCCNet, and DBSINet effectively filter out the interference from the terminal building, which has a similar color to the target airplane on the right. In Figure 7b, BASNet, R3Net, ENFNet, RAS, EMFINet, EGNet, GeleNet, and CPD learn some non-significant object features, leading to the recognition of the right guiding surface as part of the target. In Figure 7c, due to the excessive similarity between the salient target and background features, most models fail to completely extract the road target, with only Smamba, GeleNet, VIT, HFANet, DBNet, DCNet, and DSINet extracting the road region relatively comprehensively. In contrast, our method filters redundant information by effectively extracting and fusing local features with global semantic information, enhancing edge details after identifying the foreground position.
(2) Small-Scale Salient Objects: As shown in Figure 7d–f, the large imaging range and high spatial resolution of RSI often contain numerous small-scale targets, making it challenging for some models to accurately locate and finely extract these targets. For example, in Figure 7d,e, VMamba, R3Net, and BASNet suffer from severe localization deficiencies, resulting in the loss of six ships and four airplanes. While Samba, PA-KRN, and HFANet achieve more comprehensive salient target extraction than other methods, they still lack edge details and encounter false alarms and misclassifications, such as in the road extraction scenario shown in Figure 7f. Dual coding models DBNet, DCNet and DSINet all show good ability of small-scale target location, but due to different information integration abilities of the models, the determination of target boundary still needs to be improved. The comparison results indicate that our model provides more accurate and detailed extraction of small-scale targets, underscoring the effectiveness of integrating local and global feature information for saliency detection in such scenarios.
(3) Topologically Irregular Objects: As shown in Figure 7g–i, the diversity and complexity of natural terrain in RSI lead to objects like mountains, rivers, and landmark buildings often having irregular topology and complex edge features. In Figure 7g, due to the complexity of the mall structure designed for aesthetics, except for BASNet and DPORTNet, which do not fully capture the entire mall, other models exhibit varying degrees of loss in mall edge details. In Figure 7h, the staircases on different floors of the building lead to severe misjudgments by models such as VMamba, Samba, R3Net, RAS, PoolNet, GeleNet, VIT, SUCA, and DNTD, mistakenly identifying them as part of the main target. In Figure 7i, due to the detailed lake area and background complexity, as well as irregular topology, the detection results of each model are suboptimal. Although EGNet, GeleNet, and DSINet achieve more accurate detections, there are still some false alarms. In comparison, our model excels in addressing topologically irregular targets.
In summary, our method demonstrates excellent detection accuracy in scenarios with cluttered backgrounds, multi-scale targets, and topologically irregular objects. Despite the strong qualitative performance, we observe that TSFANet can still miss very subtle objects or confuse background clutter with salient regions under extreme conditions, such as heavy shadow, severe occlusion, or ambiguous object boundaries. To address these limitations, future research will explore more robust feature fusion strategies and adaptive attention mechanisms tailored to complex and diverse remote sensing environments.
4.4. Ablation Study
As the baseline model HFANet has achieved better results on two datasets, ORSSD and EORSSD, it provides a more adequate basis for comparison to validate the new method. However, ORSI-4199 is a more challenging dataset, especially in dealing with complex backgrounds and extreme scale variations, and Baseline’s performance on this dataset still needs to be greatly improved. Therefore, we used only the ORSI-4199 dataset in our ablation experiments to better assess the performance and improvement of the model when dealing with more difficult tasks. Based on the quantitative results in Table 5, the evaluation metrics progressively improve with the sequential incorporation of different modules. Additionally, Figure 8 presents visualization results for the sequential integration of these modules.
Table 5.
Ablation experiments on the ORSI-4199 dataset. TSDSM, ASCRM, and SGAFF denote Trans-Mamba Semantic-Detail Dual-Stream Collaborative Encoder Module, Adaptive Semantic Correlation Refinement Attention Module and Semantic-Guided Adjacent Feature Fusion Module, respectively. The best results are marked in bold.

Figure 8.
Comparison of ablation study visualization results. (a) RSI. (b) GT. (c) Baseline. (d) Baseline + TSDSM. (e) Baseline + TSDSM + ASCRM. (f) Baseline + TSDSM + ASCRM + SGAFF.
4.4.1. Effect of TSDSM
We constructed a hybrid feature encoder structure combining CNN-Transformer and CNN-Mamba architectures to analyze the effectiveness of different encoder combinations.
As shown in Table 6, various encoder architectures and their pairwise combinations were evaluated, including TSDSM using CNN, Transformer, and Mamba. The TSDSM hybrid coding structure achieved the highest evaluation scores, with and reaching 0.8617 and 0.9453, respectively. Figure 9 visualizes the feature maps obtained by each encoder structure. The CNN coding structure alone accurately captures the salient target features but lacks global semantic information, leading to significant attention to background interference. The Transformer encoder effectively captures global information but struggles with detailed feature processing. The Mamba encoder offers better global understanding through state space modeling but is insufficient for the RSI-SOD task. Combining CNNs with Transformer or Mamba reduces background interference but either lacks edge completeness or misclassifies regions. In contrast, the TSDSM structure effectively captures both global contextual and fine-grained local features, leading to superior performance.
Table 6.
Comparative experiments of different encoder structures on ORSI-4199 datasets. The best results are marked in bold.

Figure 9.
Feature visualization comparison of different encoder structures. (a) RSI. (b) GT. (c) CNNs. (d) Transformer. (e) Mamba. (f) CNNs + Transformer. (g) CNNs + Mamba. (h) TSDSM.
4.4.2. Effect of ASCRM
ASCRM is designed to guide the fusion of global semantic features from the CNN-Transformer encoder and local detailed features from the CNN-Mamba encoder by leveraging global-local feature relationships, enabling precise salient region localization and extraction. Ablation experiments were performed by replacing ASCRM in TSFANet with alternative structures numbered No. 1–No. 10 in Figure 10.
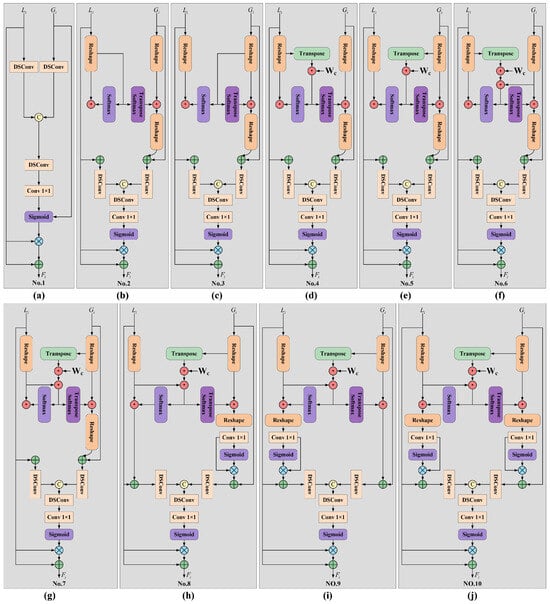
Figure 10.
The Framework of various ASCRM ablation experiment modules. (a) Baseline module without semantic correlation; (b) Module with single-branch semantic guidance; (c) Module with additional convolution layer; (d) Module with alternative activation function; (e) Module using channel attention only; (f) Module using spatial attention only; (g) Module with modified correlation calculation; (h) Module with different normalization strategy; (i) Module combining multiple attention mechanisms; (j) The proposed ASCRM module.
As shown in Table 7, the No.10 (ASCRM) structure achieved the highest quantitative evaluation scores. This is attributed to ASCRM’s learnable weight matrix, which effectively establishes relationships between global and local features, guiding their optimization and fusion for accurate salient region extraction. Figure 11 illustrates the feature visualization results of the ASCRM ablation experiments. Structures No.1 to No.9 exhibit various limitations, such as insufficient global understanding, low confidence in detailed features, and incomplete edge extraction. In contrast, No. 10 (ASCRM) demonstrates the best detection effect, effectively focusing on salient target regions and extracting fine-grained edge features. To further validate ASCRM’s effectiveness, it was compared with advanced attention mechanisms, including AAM [39], BAM [80], CAM [81], CBAM [82], CoT-Attention [83], ECA-Attention [84], NLAM [10], RSAM [85], and Self-Attention [86]. As shown in Table 8, ASCRM achieves higher scores across all evaluation metrics. Figure 12 provides heatmaps of various attention mechanisms, where blue indicates lower model attention and red indicates higher attention. ASCRM effectively guides the model to focus on salient regions, enabling precise extraction of fine-grained edge features for targets like vehicles, airplanes, and buildings.
Table 7.
Comparative of different ASCRM ablation modules on ORSI-4199 datasets. The best results are marked in bold.

Figure 11.
Feature visualization comparison of different ASCRM ablation modules. (a) RSI. (b) GT. (c) NO.1. (d) NO.2. (e) NO.3. (f) NO.4. (g) NO.5. (h) NO.6. (i) NO.7. (j) NO.8. (k) NO.9. (l) NO.10.
Table 8.
Comparative experiments of different attention modules on ORSI-4199 datasets. The best results are marked in bold.
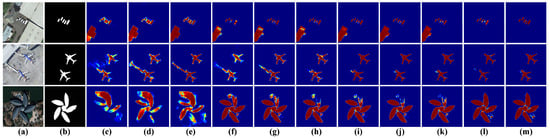
Figure 12.
Feature visualization comparison of different attention moudles. (a) RSI. (b) GT. (c) + Baseline. (d) + AAM. (e) + BAM. (f) + CAM. (g) + CBAM. (h) + CoT-Attention. (i) + ECA-Attention. (j) + NLAM. (k) + RSAM. (l) + Self-Attention. (m) + ASCRM.
4.4.3. Effect of SGAFF
To effectively integrate different levels of feature information, we constructed the Semantic-Guided Adjacent Feature Fusion (SGAFF) module to align and fuse detailed features between different scales. As shown in Table 9, SGAFF outperforms existing feature fusion methods, including element-wise summation, element-wise multiplication, feature channel concatenation, and AFAM [13], achieving the best evaluation scores. Figure 13 presents feature visualization analysis comparing SGAFF with other fusion methods. Element-wise summation introduces redundant information and biases towards common regions, while element-wise multiplication enhances commonly attended regions but excludes salient areas lacking sufficient features. Channel concatenation alleviates some defects but remains limited by feature richness and confidence. AFAM improves channel concatenation by incorporating deformable convolution and residual connections but is constrained by fused feature semantics. In contrast, SGAFF effectively learns and sorts semantic information in the deep network and supplements shallow local information, resulting in optimized feature fusion between different levels.
Table 9.
Comparative experiments of different feature fusion modules on ORSI-4199 datasets. The best results are marked in bold.

Figure 13.
Results of different feature fusion methods. (a) RSI. (b) GT. (c) Baseline. (d) + Element-wise Summation. (e) + Element-wise Multiplication. (f) + Channel Concatenation. (g) + SGAFF.
4.4.4. Effect of the Loss Function
To evaluate the effectiveness of the IG Loss + IoU Loss hybrid function, we compared various loss functions and their combinations, including F-measure Loss, BCE Loss, CT Loss, IG Loss, and their combinations with IoU Loss.
Table 10 shows that F-measure Loss performs poorly in metrics other than , as it focuses solely on optimizing the -measure metric. CT Loss assigns higher weights to boundary pixels using fixed or adaptive thresholds but lacks consistent mutual supervision between edge and salient region predictions, resulting in only slight performance improvements over F-measure Loss. BCE Loss, which calculates cross-entropy supervision between each pixel and the label, achieved a sub-optimal evaluation score with , , , and MAE reaching 0.8748, 0.8543, 0.8797, and 0.0361, respectively. IG Loss adaptively adjusts edge and salient region prediction losses using learnable parameters during training, improving over the second-best results by 0.07%, 0.44%, 1.15%, and 0.53%, respectively. When combined with IoU Loss, IG Loss + IoU Loss achieves the best results on the ORSI-4199 dataset, further validating the effectiveness of the hybrid loss function.
Table 10.
Comparative experiments of different loss functions on ORSI-4199 datasets. The best results are marked in bold.
5. Conclusions
This study addresses the SOD task within the RSI domain by introducing TSFANet, which comprises three core components: TSDSM, ASCRM, and SGAFF. To enhance the model’s ability to extract salient region features, TSDSM integrates CNNs-Mamba and CNNs-Transformer dual encoders. The CNNs-Mamba encoder effectively captures local features, while the CNNs-Transformer encoder models global semantic information. ASCRM leverages the correlation consistency between local detail features and global semantic features to guide and optimize the fusion of semantic information and detailed features. Addressing significant semantic differences in cross-layer features, SGAFF is designed to align and fuse deep semantic features with multi-scale details, ensuring comprehensive feature integration. Through extensive evaluations against 26 state-of-the-art methods on multiple public RSI-SOD datasets, our method has demonstrated superior performance in various rating indicators and prediction quality metrics. Additionally, ablation experiments have validated the specific contributions of each component within TSFANet, underscoring the effectiveness of the integrated modules in improving SOD performance. The successful implementation of TSFANet highlights its potential for advancing salient object detection in complex remote sensing environments.
Author Contributions
Conceptualization, J.L. and Z.W.; methodology, J.L. and C.Z.; software, Z.W. and N.X.; validation, N.X. and C.Z.; formal analysis, J.L. and Z.W.; investigation, Z.W.; resources, Z.W. and C.Z.; data curation, J.L.; original draft preparation, J.L.; review and editing, Z.W. and C.Z.; visualization, Z.W.; supervision, Z.W. and C.Z.; project administration, Z.W. and N.X.; funding acquisition, Z.W. and N.X. All authors have read and agreed on the published version of the manuscript.
Funding
This work was supported in part by the Youth Talent Support Program of Shaanxi Science and Technology Association under Grant 23JK0701, in part by the Xi’an Science and Technology Planning Projects under Grant 20240103, and in part by the China Postdoctoral Science Foundation under Grant 2024M754225.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Borji, A. What is a salient object? A dataset and a baseline model for salient object detection. IEEE Trans. Image Process. 2014, 24, 742–756. [Google Scholar] [CrossRef]
- Li, C.; Yuan, Y.; Cai, W.; Xia, Y.; Dagan Feng, D. Robust saliency detection via regularized random walks ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2710–2717. [Google Scholar]
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Reversion correction and regularized random walk ranking for saliency detection. IEEE Trans. Image Process. 2017, 27, 1311–1322. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual Saliency Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 4702–4712. [Google Scholar]
- Lv, Z.; Huang, H.; Li, X.; Zhao, M.; Benediktsson, J.A.; Sun, W.; Falco, N. Land cover change detection with heterogeneous remote sensing images: Review, progress, and perspective. Proc. IEEE 2022, 110, 1976–1991. [Google Scholar] [CrossRef]
- Sarkar, A.; Chowdhury, T.; Murphy, R.R.; Gangopadhyay, A.; Rahnemoonfar, M. Sam-vqa: Supervised attention-based visual question answering model for post-disaster damage assessment on remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702716. [Google Scholar] [CrossRef]
- Han, Y.; Liao, J.; Lu, T.; Pu, T.; Peng, Z. KCPNet: Knowledge-driven context perception networks for ship detection in infrared imagery. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5000219. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 7479–7489. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3Net: Recurrent residual refinement network for saliency detection. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient object detection in optical remote sensing images driven by transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Wang, Q.; Liu, Y.; Xiong, Z.; Yuan, Y. Hybrid feature aligned network for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624915. [Google Scholar] [CrossRef]
- Gao, Y.; Huang, J.; Sun, X.; Jie, Z.; Zhong, Y.; Ma, L. Matten: Video Generation with Mamba-Attention. arXiv 2024, arXiv:2405.03025. [Google Scholar]
- Hatamizadeh, A.; Kautz, J. MambaVision: A Hybrid Mamba-Transformer Vision Backbone. arXiv 2024, arXiv:2407.08083. [Google Scholar]
- Gong, H.; Kang, L.; Wang, Y.; Wan, X.; Li, H. nnmamba: 3D biomedical image segmentation, classification and landmark detection with state space model. arXiv 2024, arXiv:2402.03526. [Google Scholar]
- Sheng, J.; Zhou, J.; Wang, J.; Ye, P.; Fan, J. DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification. arXiv 2024, arXiv:2406.07050. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, C. Weak-Mamba-UNet: Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation. arXiv 2024, arXiv:2402.10887. [Google Scholar]
- Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; Xu, C. LocalMamba: Visual state space model with windowed selective scan. arXiv 2024, arXiv:2403.09338. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Wang, C.; Tsepa, O.; Ma, J.; Wang, B. Graph-mamba: Towards long-range graph sequence modeling with selective state spaces. arXiv 2024, arXiv:2402.00789. [Google Scholar]
- Tang, Y.; Dong, P.; Tang, Z.; Chu, X.; Liang, J. VMRNN: Integrating Vision Mamba and LSTM for Efficient and Accurate Spatiotemporal Forecasting. arXiv 2024, arXiv:2403.16536. [Google Scholar]
- Li, W.; Hong, X.; Fan, X. Spikemba: Multi-modal spiking saliency mamba for temporal video grounding. arXiv 2024, arXiv:2404.01174. [Google Scholar]
- Deng, R.; Gu, T. CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration. arXiv 2024, arXiv:2404.11778. [Google Scholar]
- Wang, Z.; Zheng, J.Q.; Ma, C.; Guo, T. Vmambamorph: A visual mamba-based framework with cross-scan module for deformable 3D image registration. arXiv 2024, arXiv:2404.05105. [Google Scholar]
- Yue, Y.; Li, Z. Medmamba: Vision mamba for medical image classification. arXiv 2024, arXiv:2403.03849. [Google Scholar]
- He, X.; Cao, K.; Yan, K.; Li, R.; Xie, C.; Zhang, J.; Zhou, M. Pan-Mamba: Effective pan-sharpening with State Space Model. arXiv 2024, arXiv:2402.12192. [Google Scholar] [CrossRef]
- Shi, Y.; Xia, B.; Jin, X.; Wang, X.; Zhao, T.; Xia, X.; Xiao, X.; Yang, W. Vmambair: Visual state space model for image restoration. arXiv 2024, arXiv:2403.11423. [Google Scholar] [CrossRef]
- Kim, J.; Han, D.; Tai, Y.W.; Kim, J. Salient region detection via high-dimensional color transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 883–890. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Zhang, Z.; Li, S.; Li, H. C2SNet: Contour-to-Saliency Network for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 3076–3088. [Google Scholar]
- Zhao, J.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 Octorber–2 November 2019; pp. 8779–8788. [Google Scholar]
- Zhou, H.; Xie, X.; Lai, J.H.; Chen, Z.; Yang, L. Interactive two-stream decoder for accurate and fast saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9138–9147. [Google Scholar]
- Lee, M.S.; Shin, W.; Han, S.W. TRACER: Extreme attention guided salient object tracing network. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Online, 22 February–1 March 2022. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Ma, M.; Xia, C.; Xie, C.; Chen, X.; Li, J. Boosting broader receptive fields for salient object detection. IEEE Trans. Image Process. 2023, 32, 1026–1038. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, J.; Shi, J.; Jiang, Z. Sparsity-guided saliency detection for remote sensing images. J. Appl. Remote Sens. 2015, 9, 095055. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. ORSI salient object detection via multiscale joint region and boundary model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607913. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-aware multiscale feature integration network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605315. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-content complementation network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614513. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Liu, B.; Wang, Z. Semantic-guided attention refinement network for salient object detection in optical remote sensing images. Remote Sens. 2021, 13, 2163. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Lin, D.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef] [PubMed]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Zhao, J.; Jia, Y.; Ma, L.; Yu, L. Recurrent adaptive graph reasoning network with region and boundary interaction for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5630720. [Google Scholar] [CrossRef]
- Feng, D.; Chen, H.; Liu, S.; Liao, Z.; Shen, X.; Xie, Y.; Zhu, J. Boundary-semantic collaborative guidance network with dual-stream feedback mechanism for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4706317. [Google Scholar] [CrossRef]
- Gong, A.; Nie, J.; Niu, C.; Yu, Y.; Li, J.; Guo, L. Edge and skeleton guidance network for salient object detection in optical remote sensing images. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7109–7120. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Xiang, D.; Yin, Q.; Zhou, Y. Fast task-specific region merging for SAR image segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222316. [Google Scholar] [CrossRef]
- Gao, L.; Liu, B.; Fu, P.; Xu, M. Adaptive spatial tokenization transformer for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602915. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, B.; Lu, J.; Yan, H. Towards integrity and detail with ensemble learning for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5624615. [Google Scholar] [CrossRef]
- Yan, R.; Yan, L.; Geng, G.; Cao, Y.; Zhou, P.; Meng, Y. ASNet: Adaptive semantic network based on transformer-CNN for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608716. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, M.; Xiao, T.; Tang, H.; Hu, Y.; Nie, L. Heterogeneous feature collaboration network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5635114. [Google Scholar] [CrossRef]
- Han, P.; Zhao, B.; Li, X. Progressive feature interleaved fusion network for remote-sensing image salient object detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5500414. [Google Scholar] [CrossRef]
- Di, L.; Zhang, B.; Wang, Y. Multi-scale and multi-dimensional weighted network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5625114. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Yin, Q.; Xiang, D.; Zhou, Y. Fast SAR image segmentation with deep task-specific superpixel sampling and soft graph convolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5214116. [Google Scholar] [CrossRef]
- Fang, W.; Fu, Y.; Sheng, V.S. FPS-U2Net: Combining U2Net and Multi-level Aggregation Architecture for Fire Point Segmentation in Remote Sensing Images. Comput. Geosci. 2024, 189, 105628. [Google Scholar] [CrossRef]
- Zhu, Q.; Cai, Y.; Fang, Y.; Yang, Y.; Chen, C.; Fan, L.; Nguyen, A. Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model. arXiv 2024, arXiv:2404.01705. [Google Scholar] [CrossRef]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-net: Going deeper with nested u-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Cheng, M.M.; Gao, S.H.; Borji, A.; Tan, Y.Q.; Lin, Z.; Wang, M. A highly efficient model to study the semantics of salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8006–8021. [Google Scholar] [CrossRef]
- Giglietto, F.; Righetti, N.; Rossi, L.; Marino, G. COORNET: An Integrated Approach to Surface Problematic Content, Malicious Actors, and Coordinated Networks. Aoir Sel. Pap. Internet Res. 2021, 21, 13–16. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good visual guidance makes a better extractor: Hierarchical visual prefix for multimodal entity and relation extraction. arXiv 2022, arXiv:2205.03521. [Google Scholar]
- Liu, Y.; Zhang, X.Y.; Bian, J.W.; Zhang, L.; Cheng, M.M. Samnet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef]
- Li, J.; Pan, Z.; Liu, Q.; Wang, Z. Stacked U-shape network with channel-wise attention for salient object detection. IEEE Trans. Multimed. 2020, 23, 1397–1409. [Google Scholar] [CrossRef]
- Fang, C.; Tian, H.; Zhang, D.; Zhang, Q.; Han, J.; Han, J. Densely nested top-down flows for salient object detection. Sci. China Inf. Sci. 2022, 65, 182103. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, D.; Liu, N.; Xu, S.; Han, J. Disentangled capsule routing for fast part-object relational saliency. IEEE Trans. Image Process. 2022, 31, 6719–6732. [Google Scholar] [CrossRef]
- Xu, B.; Liang, H.; Liang, R.; Chen, P. Locate globally, segment locally: A progressive architecture with knowledge review network for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3004–3012. [Google Scholar]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 539–552. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Fu, Y.; Sheng, V.S. Dual Backbone Interaction Network For Burned Area Segmentation in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6008805. [Google Scholar] [CrossRef]
- Fu, Y.; Fang, W.; Sheng, V.S. Burned Area Segmentation in Optical Remote Sensing Images Driven by U-shaped Multi-stage Masked Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10770–10780. [Google Scholar] [CrossRef]
- Ge, Y.; Liang, T.; Ren, J.; Chen, J.; Bi, H. Enhanced salient object detection in remote sensing images via dual-stream semantic interactive network. Vis. Comput. 2024, 44, 5153–5169. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. arXiv 2021, arXiv:2107.12292. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Pan, J.; Canton Ferrer, C.; McGuinness, K.; O’Connor, N.E.; Torres, J.; Sayrol, E.; Giro-i Nieto, X. SalGAN: Visual Saliency Prediction with Generative Adversarial Networks. arXiv 2018, arXiv:1701.01081. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).