

Deep Learning-Based Spatiotemporal Fusion Architecture of Landsat 8 and Sentinel-2 Data for 10 m Series Imagery




Abstract
1. Introduction
- We have devised a multiscale mechanism that incorporates the concept of dilated convolution to more effectively extract feature information from coarse images across multiple scales. We have also designed an attention mechanism to effectively extract feature information from fine images, maximizing feature utilization.
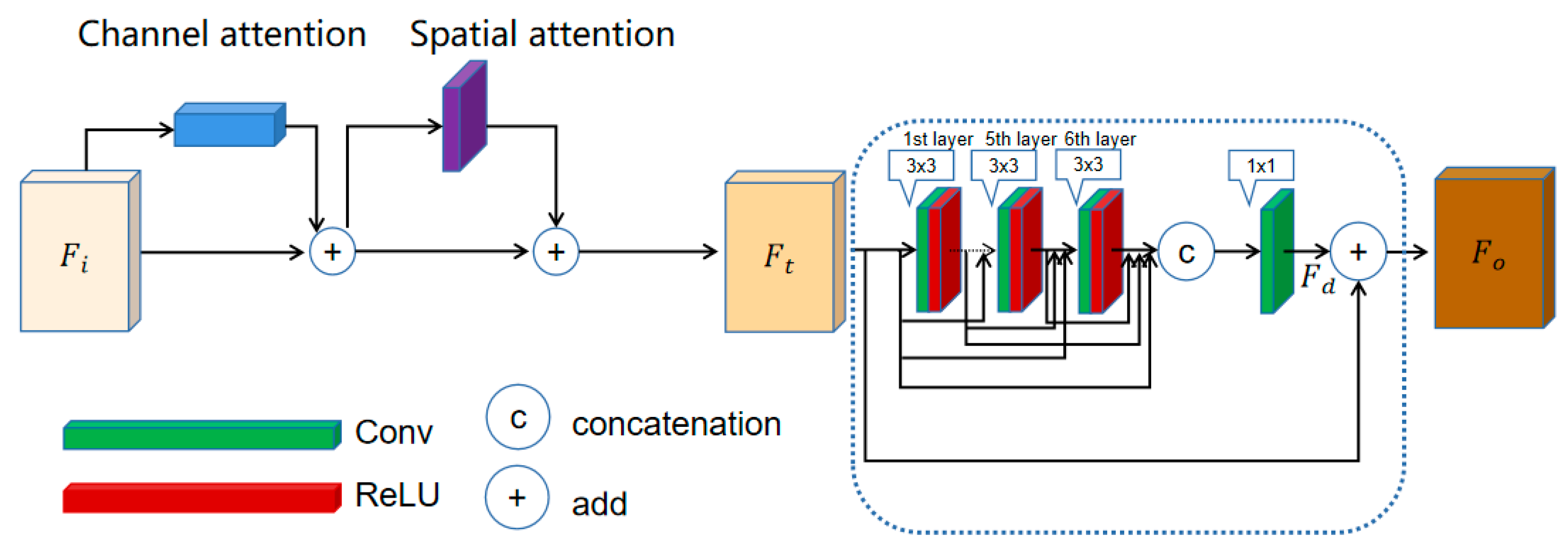
- We have designed a channel and spatial attention-coupled residual dense block (CSARDB) module, which combines the convolutional block attention module (CBAM) [43] and the residual dense block (RDB) [44]. This network architecture proceeds by initially extracting image features using the attention module, followed by their injection into the residual module. Simultaneously, the presence of skip connections within the residual module permits the extraction of additional features. Such a collaborative network configuration fortifies the precision of both spatial and spectral information encapsulated within the generated predictions.
- We present a fusion architecture, referred to as MARSTFN, which incorporates the principles of the multiscale mechanism, the attention mechanism, and the residual network. This innovative design skillfully merges Landsat 8 and Sentinel-2 data to produce high-resolution data outputs.
2. Materials and Methods
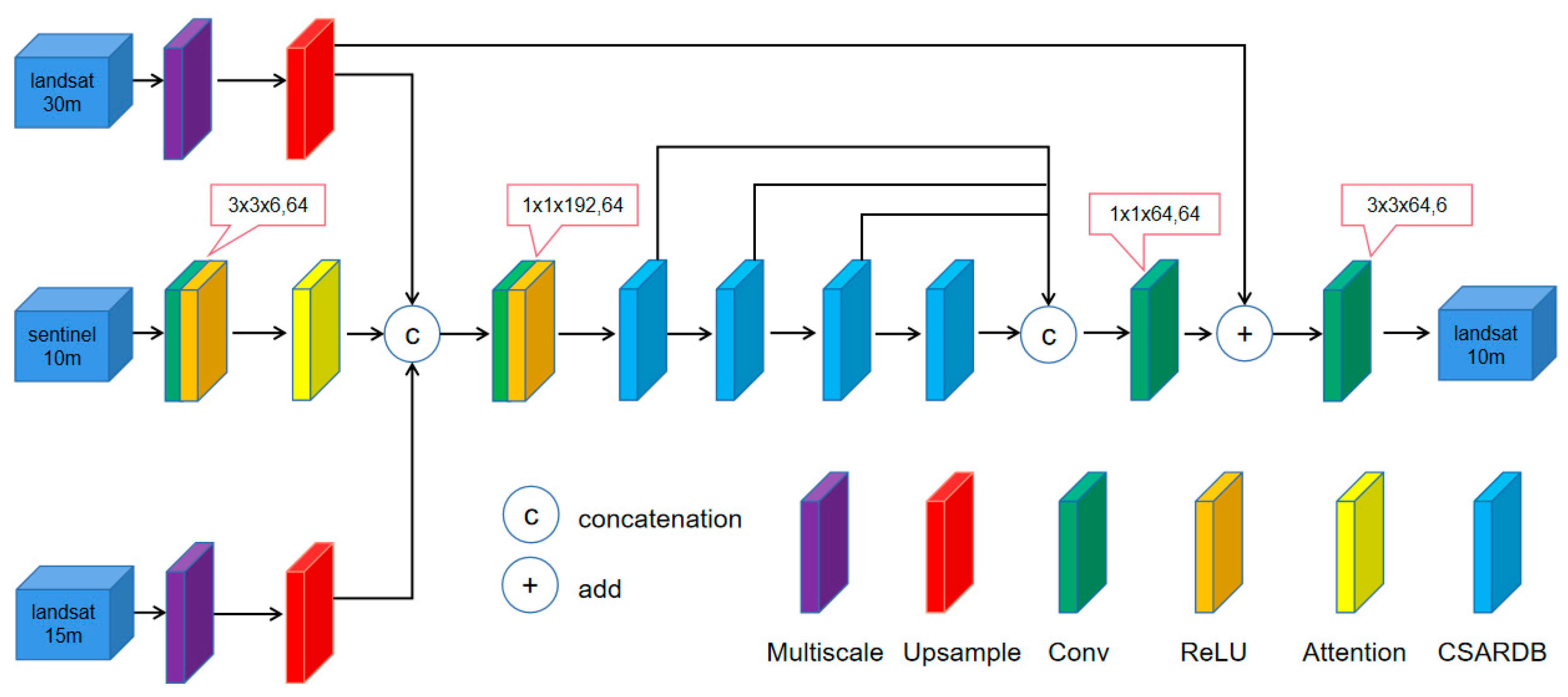
2.1. Network Architecture
2.1.1. MARSTFN Architecture
2.1.2. Multiscale Mechanism
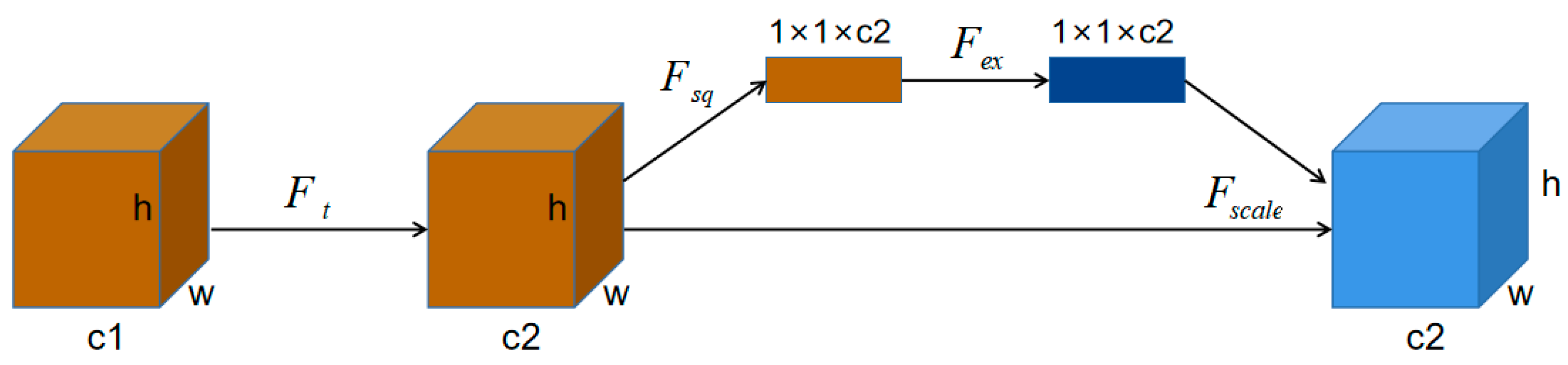
2.1.3. Attention Mechanism
2.1.4. Channel and Spatial Attention-Coupled Residual Dense Block (CSARDB) Module
2.2. Loss Function
3. Experiment Results
3.1. Datasets and Network Training
3.2. Evaluation Indicators
3.3. Parameter Setting
3.4. Results
3.4.1. Evaluation of the Methods on the Hailar Dataset
3.4.2. Evaluation of the Methods on the Dezhou Dataset
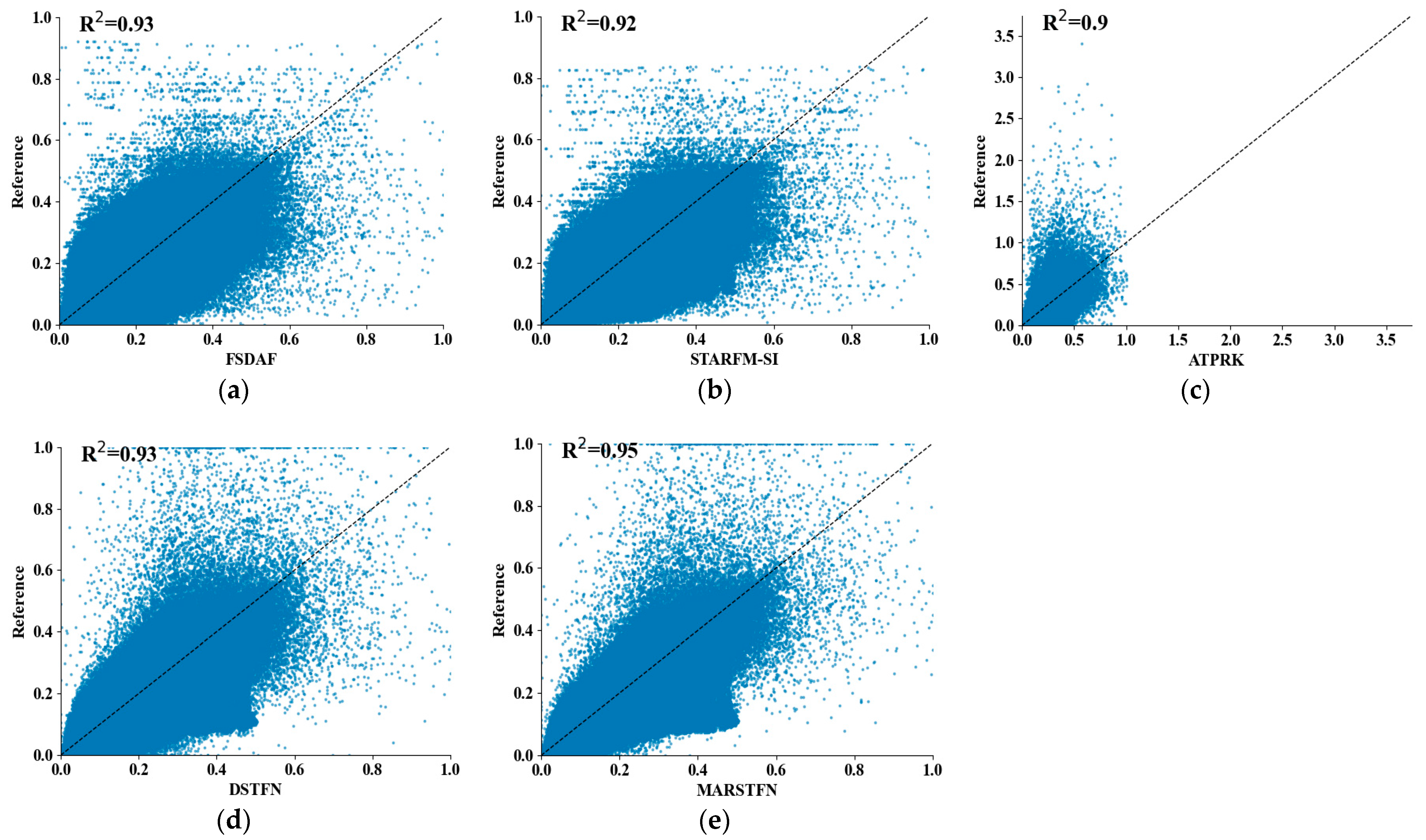
3.4.3. Quantitative Evaluation
4. Discussion
4.1. Generalized Analysis
4.2. Ablation Experiments
5. Conclusions
- We introduced a novel spatiotemporal fusion (STF) architecture, namely MARSTFN, which combines a multiscale mechanism, an attention mechanism, and a residual network to effectively extract spatial and spectral information from the images.
- Through comprehensive experiments on two datasets, we demonstrated that MARSTFN outperforms other existing methods in terms of image detail preservation, as well as overall prediction accuracy.
- Our proposed STF architecture addresses the limitations of existing methods in capturing both spatial and spectral information, particularly in areas with significant spectral variations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gutman, G.; Byrnes, R.A.; Masek, J.; Covington, S.; Justice, C.; Franks, S.; Headley, R. Towards monitoring land-cover and land-use changes at a global scale: The Global Land Survey 2005. Photogramm. Eng. Remote Sens. 2008, 74, 6–10. [Google Scholar]
- Woodcock, C.E.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E. Free Access to Landsat Imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef] [PubMed]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Justice, C.O.; Vermote, E.; Townshend, J.R.; Defries, R.; Roy, D.P.; Hall, D.K.; Salomonson, V.V.; Privette, J.L.; Riggs, G.; Strahler, A. The Moderate Resolution Imaging Spectroradiometer (MODIS): Land remote sensing for global change research. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1228–1249. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, B.; Xu, Y.; Cao, K.; Guo, C.; Meng, D. Spatial and temporal image fusion via regularized spatial unmixing. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1362–1366. [Google Scholar]
- Kim, D.-H.; Sexton, J.O.; Noojipady, P.; Huang, C.; Anand, A.; Channan, S.; Feng, M.; Townshend, J.R. Global, Landsat-based forest-cover change from 1990 to 2000. Remote Sens. Environ. 2014, 155, 178–193. [Google Scholar] [CrossRef]
- Senf, C.; Pflugmacher, D.; Heurich, M.; Krueger, T. A Bayesian hierarchical model for estimating spatial and temporal variation in vegetation phenology from Landsat time series. Remote Sens. Environ. 2017, 194, 155–160. [Google Scholar] [CrossRef]
- Fu, P.; Weng, Q. A time series analysis of urbanization induced land use and land cover change and its impact on land surface temperature with Landsat imagery. Remote Sens. Environ. 2016, 175, 205–214. [Google Scholar] [CrossRef]
- Claverie, M.; Masek, J.G.; Ju, J.; Dungan, J.L. Harmonized Landsat-8 Sentinel-2 (HLS) Product User’s Guide; National Aeronautics and Space Administration (NASA): Washington, DC, USA, 2017.
- Skakun, S.; Kussul, N.; Shelestov, A.; Kussul, O. Flood hazard and flood risk assessment using a time series of satellite images: A case study in Namibia. Risk Anal. 2014, 34, 1521–1537. [Google Scholar] [CrossRef]
- Melaas, E.K.; Friedl, M.A.; Zhu, Z. Detecting interannual variation in deciduous broadleaf forest phenology using Landsat TM/ETM+ data. Remote Sens. Environ. 2013, 132, 176–185. [Google Scholar] [CrossRef]
- White, J.C.; Wulder, M.A.; Hermosilla, T.; Coops, N.C.; Hobart, G.W. A nationwide annual characterization of 25 years of forest disturbance and recovery for Canada using Landsat time series. Remote Sens. Environ. 2017, 194, 303–321. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Gao, F.; Zhang, X. Mapping crop phenology in near real-time using satellite remote sensing: Challenges and opportunities. J. Remote Sens. 2021, 2021, 8379391. [Google Scholar] [CrossRef]
- Soltanikazemi, M.; Minaei, S.; Shafizadeh-Moghadam, H.; Mahdavian, A. Field-scale estimation of sugarcane leaf nitrogen content using vegetation indices and spectral bands of Sentinel-2: Application of random forest and support vector regression. Comput. Electron. Agric. 2022, 200, 107130. [Google Scholar] [CrossRef]
- Putri, A.F.S.; Widyatmanti, W.; Umarhadi, D.A. Sentinel-1 and Sentinel-2 data fusion to distinguish building damage level of the 2018 Lombok Earthquake. Remote Sens. Appl. Soc. Environ. 2022, 26, 100724. [Google Scholar]
- Ju, J.; Roy, D.P. The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Shen, H.; Wu, J.; Cheng, Q.; Aihemaiti, M.; Zhang, C.; Li, Z. A spatiotemporal fusion based cloud removal method for remote sensing images with land cover changes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 862–874. [Google Scholar] [CrossRef]
- Pan, L.; Xia, H.; Yang, J.; Niu, W.; Wang, R.; Song, H.; Guo, Y.; Qin, Y. Mapping cropping intensity in Huaihe basin using phenology algorithm, all Sentinel-2 and Landsat images in Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102376. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Wu, J.; Cheng, Q.; Li, H.; Li, S.; Guan, X.; Shen, H. Spatiotemporal fusion with only two remote sensing images as input. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6206–6219. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, H.; Shen, H.; Wu, P.; Zhang, L. A spatial and temporal nonlocal filter-based data fusion method. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4476–4488. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. A Bayesian data fusion approach to spatio-temporal fusion of remotely sensed images. Remote Sens. 2017, 9, 1310. [Google Scholar] [CrossRef]
- Wang, Q.; Blackburn, G.A.; Onojeghuo, A.O.; Dash, J.; Zhou, L.; Zhang, Y.; Atkinson, P.M. Fusion of Landsat 8 OLI and Sentinel-2 MSI data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3885–3899. [Google Scholar] [CrossRef]
- Wei, J.; Wang, L.; Liu, P.; Chen, X.; Li, W.; Zomaya, A.Y. Spatiotemporal fusion of MODIS and Landsat-7 reflectance images via compressed sensing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7126–7139. [Google Scholar] [CrossRef]
- Wang, Z.; Fang, S.; Zhang, J. Spatiotemporal Fusion Model of Remote Sensing Images Combining Single-Band and Multi-Band Prediction. Remote Sens. 2023, 15, 4936. [Google Scholar] [CrossRef]
- Chen, G.; Lu, H.; Di, D.; Li, L.; Emam, M.; Jing, W. StfMLP: Spatiotemporal Fusion Multilayer Perceptron for Remote-Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 20, 5000105. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Mishra, B.; Shahi, T.B. Deep learning-based framework for spatiotemporal data fusion: An instance of landsat 8 and sentinel 2 NDVI. J. Appl. Remote Sens. 2021, 15, 034520. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of Landsat-8 and Sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Ao, Z.; Sun, Y.; Xin, Q. Constructing 10-m NDVI time series from Landsat 8 and Sentinel 2 images using convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1461–1465. [Google Scholar] [CrossRef]
- Chen, J.; Wang, L.; Feng, R.; Liu, P.; Han, W.; Chen, X. CycleGAN-STF: Spatiotemporal fusion via CycleGAN-based image generation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5851–5865. [Google Scholar] [CrossRef]
- Wu, J.; Lin, L.; Li, T.; Cheng, Q.; Zhang, C.; Shen, H. Fusing Landsat 8 and Sentinel-2 data for 10-m dense time-series imagery using a degradation-term constrained deep network. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102738. [Google Scholar] [CrossRef]
- Liang, J.; Ren, C.; Li, Y.; Yue, W.; Wei, Z.; Song, X.; Zhang, X.; Yin, A.; Lin, X. Using Enhanced Gap-Filling and Whittaker Smoothing to Reconstruct High Spatiotemporal Resolution NDVI Time Series Based on Landsat 8, Sentinel-2, and MODIS Imagery. ISPRS Int. J. Geo-Inf. 2023, 12, 214. [Google Scholar] [CrossRef]
- Liu, H.; Yang, G.; Deng, F.; Qian, Y.; Fan, Y. MCBAM-GAN: The Gan Spatiotemporal Fusion Model Based on Multiscale and CBAM for Remote Sensing Images. Remote Sens. 2023, 15, 1583. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.K.; Roy, D.P.; Yan, L.; Li, Z.; Huang, H.; Vermote, E.; Skakun, S.; Roger, J.-C. Characterization of Sentinel-2A and Landsat-8 top of atmosphere, surface, and nadir BRDF adjusted reflectance and NDVI differences. Remote Sens. Environ. 2018, 215, 482–494. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Carli, M. Modified image visual quality metrics for contrast change and mean shift accounting. In Proceedings of the 2011 11th International Conference The Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Polyana, Ukraine, 23–25 February 2011; pp. 305–311. [Google Scholar]
- Tan, Z.; Yue, P.; Di, L.; Tang, J. Deriving high spatiotemporal remote sensing images using deep convolutional network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landsat 8 | Sentinel-2 | ||||
|---|---|---|---|---|---|
| Band | Wavelength (nm) | Resolution | Band | Wavelength (nm) | Resolution |
| 1 (coastal) | 430–450 | 30 | 1 (coastal) | 433–453 | 60 |
| 2 (blue) | 450–515 | 30 | 2 (blue) | 458–523 | 10 |
| 3 (green) | 525–600 | 30 | 3 (green) | 543–578 | 10 |
| 4 (red) | 630–680 | 30 | 4 (red) | 650–680 | 10 |
| 5 (NIR) | 845–885 | 30 | 8A (NIR) | 855–875 | 10 |
| 6 (SWIR 1) | 1560–1660 | 30 | 11 (SWIR) | 1565–1655 | 20 |
| 7 (SWIR 2) | 2100–2300 | 30 | 12 (SWIR) | 2100–2280 | 20 |
| Evaluation | Method | ||||
|---|---|---|---|---|---|
| FSDAF | STARFM-SI | ATPRK | DSTFN | MARSTFN | |
| PSNR | 29.9821 | 30.2142 | 30.9168 | 32.3470 | 32.4808 |
| 29.5619 | 29.6318 | 28.9653 | 30.3120 | 31.2037 | |
| 29.2083 | 29.1779 | 29.4909 | 30.4400 | 31.3767 | |
| 29.5278 | 29.1653 | 29.5383 | 29.1339 | 29.6070 | |
| 33.4398 | 33.4254 | 32.2749 | 33.6752 | 34.3020 | |
| 30.3845 | 30.2776 | 29.6360 | 30.6992 | 31.3778 | |
| Average | 30.3507 | 30.3154 | 30.1370 | 31.1012 | 31.7247 |
| SSIM | 0.9505 | 0.9510 | 0.9577 | 0.9580 | 0.9597 |
| 0.9605 | 0.9590 | 0.9613 | 0.9612 | 0.9652 | |
| 0.9454 | 0.9441 | 0.9449 | 0.9444 | 0.9521 | |
| 0.9150 | 0.9132 | 0.9236 | 0.9240 | 0.9294 | |
| 0.9561 | 0.9594 | 0.9636 | 0.9640 | 0.9656 | |
| 0.9359 | 0.9426 | 0.9420 | 0.9437 | 0.9490 | |
| Average | 0.9439 | 0.9449 | 0.9489 | 0.9492 | 0.9535 |
| RMSE | 0.0310 | 0.0302 | 0.0282 | 0.0235 | 0.0231 |
| 0.0338 | 0.0339 | 0.0328 | 0.0290 | 0.0261 | |
| 0.0326 | 0.0324 | 0.0351 | 0.0298 | 0.0269 | |
| 0.0328 | 0.0342 | 0.0372 | 0.0343 | 0.0325 | |
| 0.0205 | 0.0205 | 0.0236 | 0.0195 | 0.0183 | |
| 0.0290 | 0.0294 | 0.0319 | 0.0278 | 0.0259 | |
| Average | 0.0300 | 0.0301 | 0.0315 | 0.0273 | 0.0255 |
| Evaluation | Method | ||||
|---|---|---|---|---|---|
| FSDAF | STARFM-SI | ATPRK | DSTFN | MARSTFN | |
| PSNR | 31.9103 | 32.4065 | 31.5480 | 34.2633 | 34.6670 |
| 31.9498 | 32.4436 | 32.9046 | 34.6958 | 35.6082 | |
| 31.3712 | 31.6537 | 29.9532 | 32.1945 | 32.9657 | |
| 27.9400 | 28.4388 | 26.7805 | 28.9720 | 29.7145 | |
| 28.6961 | 28.6151 | 27.4919 | 28.9879 | 29.6476 | |
| Average | 30.3735 | 30.7115 | 29.7356 | 31.8227 | 32.5206 |
| SSIM | 0.9719 | 0.9705 | 0.9627 | 0.9700 | 0.9731 |
| 0.9732 | 0.9685 | 0.9705 | 0.9730 | 0.9743 | |
| 0.9636 | 0.9658 | 0.9630 | 0.9661 | 0.9680 | |
| 0.8697 | 0.8814 | 0.8760 | 0.8923 | 0.8978 | |
| 0.9031 | 0.9111 | 0.9028 | 0.9057 | 0.9146 | |
| Average | 0.9363 | 0.9395 | 0.9350 | 0.9414 | 0.9456 |
| RMSE | 0.0252 | 0.0238 | 0.0265 | 0.0192 | 0.0182 |
| 0.0250 | 0.0236 | 0.0224 | 0.0183 | 0.0164 | |
| 0.0267 | 0.0259 | 0.0314 | 0.0242 | 0.0222 | |
| 0.0378 | 0.0352 | 0.0446 | 0.0341 | 0.0314 | |
| 0.0357 | 0.0360 | 0.0408 | 0.0341 | 0.0317 | |
| Average | 0.0301 | 0.0289 | 0.0331 | 0.0260 | 0.0240 |
| Data | Index | ARNet | MRNet | MANet | MARSTFN |
|---|---|---|---|---|---|
| Hailar | SSIM | 0.9492 | 0.9514 | 0.9502 | 0.9535 |
| RMSE | 0.0271 | 0.0267 | 0.0265 | 0.0259 | |
| Dezhou | SSIM | 0.9415 | 0.9413 | 0.9422 | 0.9456 |
| RMSE | 0.0254 | 0.0248 | 0.0245 | 0.0240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Q.; Xie, R.; Wu, J.; Ye, F. Deep Learning-Based Spatiotemporal Fusion Architecture of Landsat 8 and Sentinel-2 Data for 10 m Series Imagery. Remote Sens. 2024, 16, 1033. https://doi.org/10.3390/rs16061033
Cheng Q, Xie R, Wu J, Ye F. Deep Learning-Based Spatiotemporal Fusion Architecture of Landsat 8 and Sentinel-2 Data for 10 m Series Imagery. Remote Sensing. 2024; 16(6):1033. https://doi.org/10.3390/rs16061033
Chicago/Turabian StyleCheng, Qing, Ruixiang Xie, Jingan Wu, and Fan Ye. 2024. "Deep Learning-Based Spatiotemporal Fusion Architecture of Landsat 8 and Sentinel-2 Data for 10 m Series Imagery" Remote Sensing 16, no. 6: 1033. https://doi.org/10.3390/rs16061033
APA StyleCheng, Q., Xie, R., Wu, J., & Ye, F. (2024). Deep Learning-Based Spatiotemporal Fusion Architecture of Landsat 8 and Sentinel-2 Data for 10 m Series Imagery. Remote Sensing, 16(6), 1033. https://doi.org/10.3390/rs16061033