






Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation


Abstract
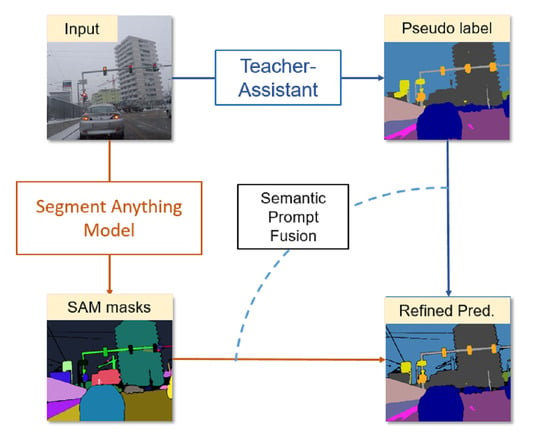
1. Introduction
- (1)
- We propose a simple, but effective semantic filling and prompt method for SAM masks, which utilizes the output of existing semantic segmentation models to provide SAM with class information and explore methods to address the scale of the SAM segmentation results;
- (2)
- To the best of our knowledge, we are the first to incorporate SAM into an unsupervised domain adaptation framework, which includes the SAM-teacher, teacher-assistant, and student models, achieving knowledge distillation in the case of completely inconsistent structures and output spaces between SAM and the main segmentation model, effectively improving its adaptability in adverse scenarios;
- (3)
- Our method is applicable to different UDA frameworks and SAM variants, providing useful references for the application of large models in local professional fields.
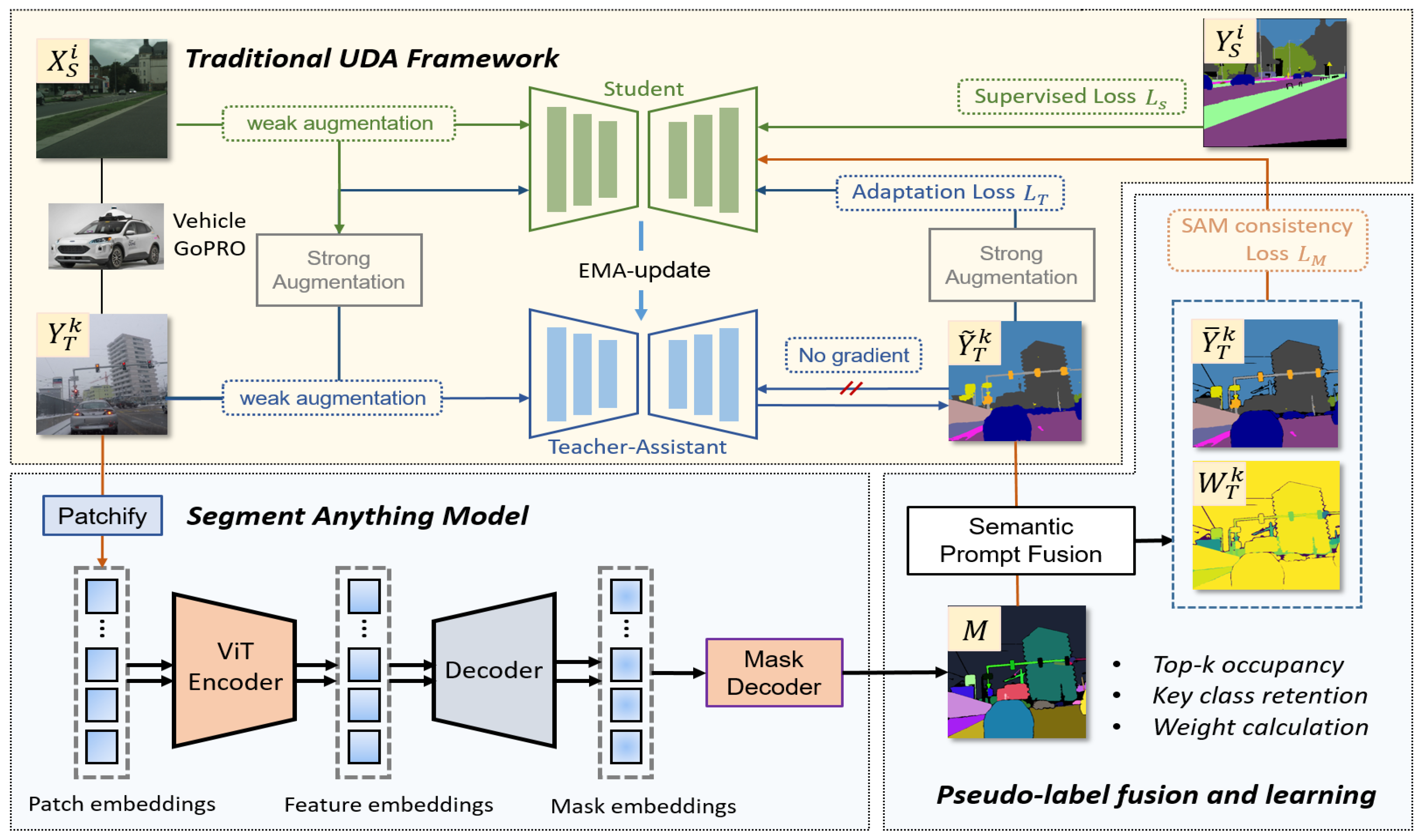
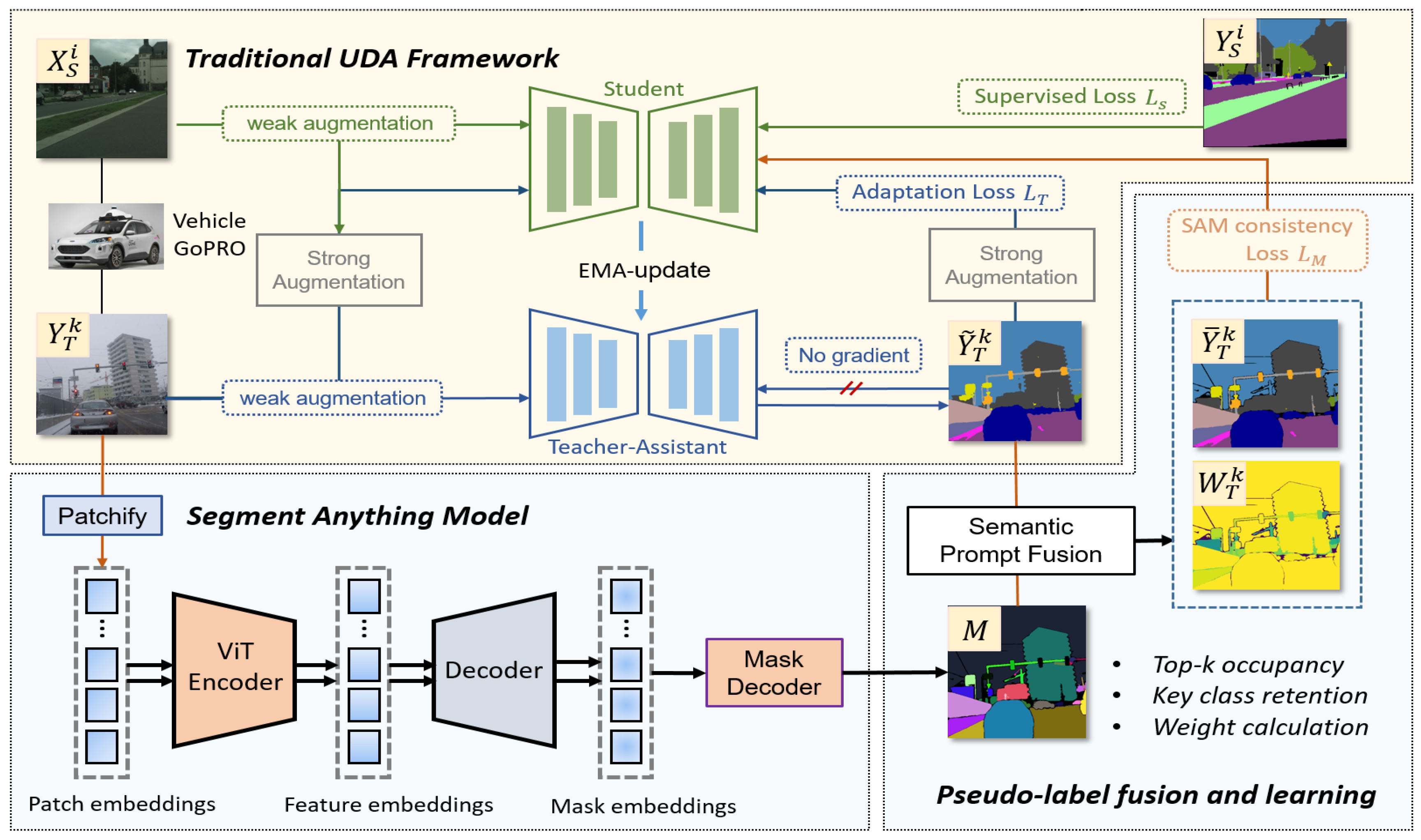
2. Method
2.1. Unsupervised Domain Adaptation (UDA)
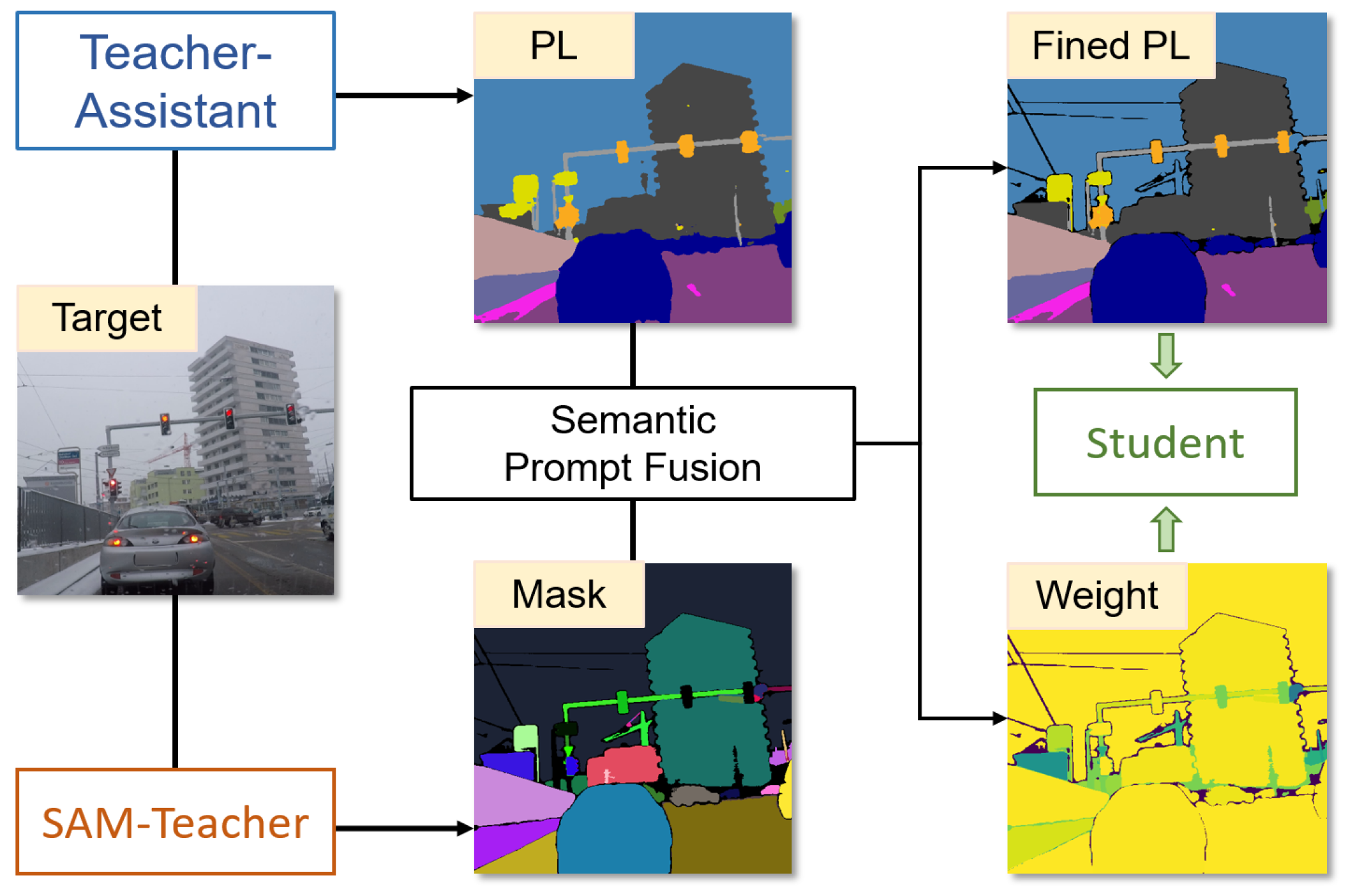
2.2. Semantic Prompt Fusion and Learning
3. Results
3.1. Implementation Details
3.1.1. Adverse Condition Semantic Segmentation Dataset
3.1.2. SAM-EDA Parameters
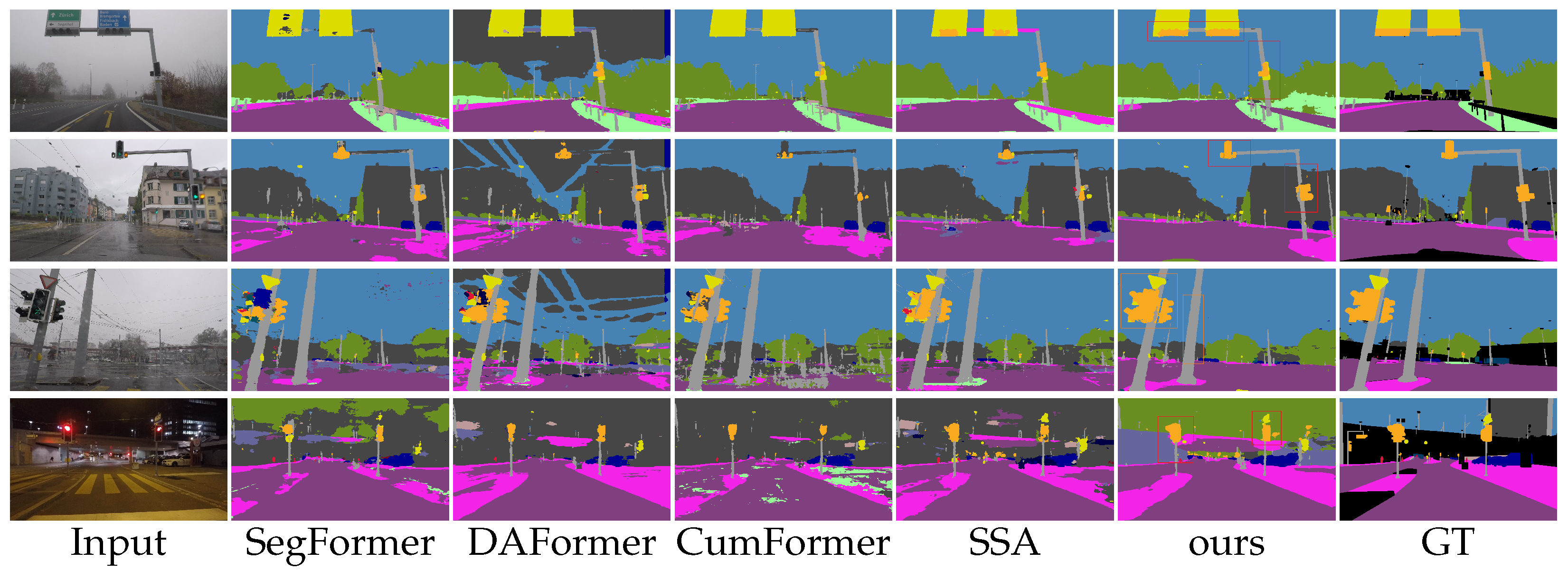
3.2. Performance Comparison
4. Discussion
4.1. SAM-EDA for Different UDA Methods
4.2. Influence of Different Pseudo-Label Fusion Methods
4.3. SAM-EDA for SAM Variants
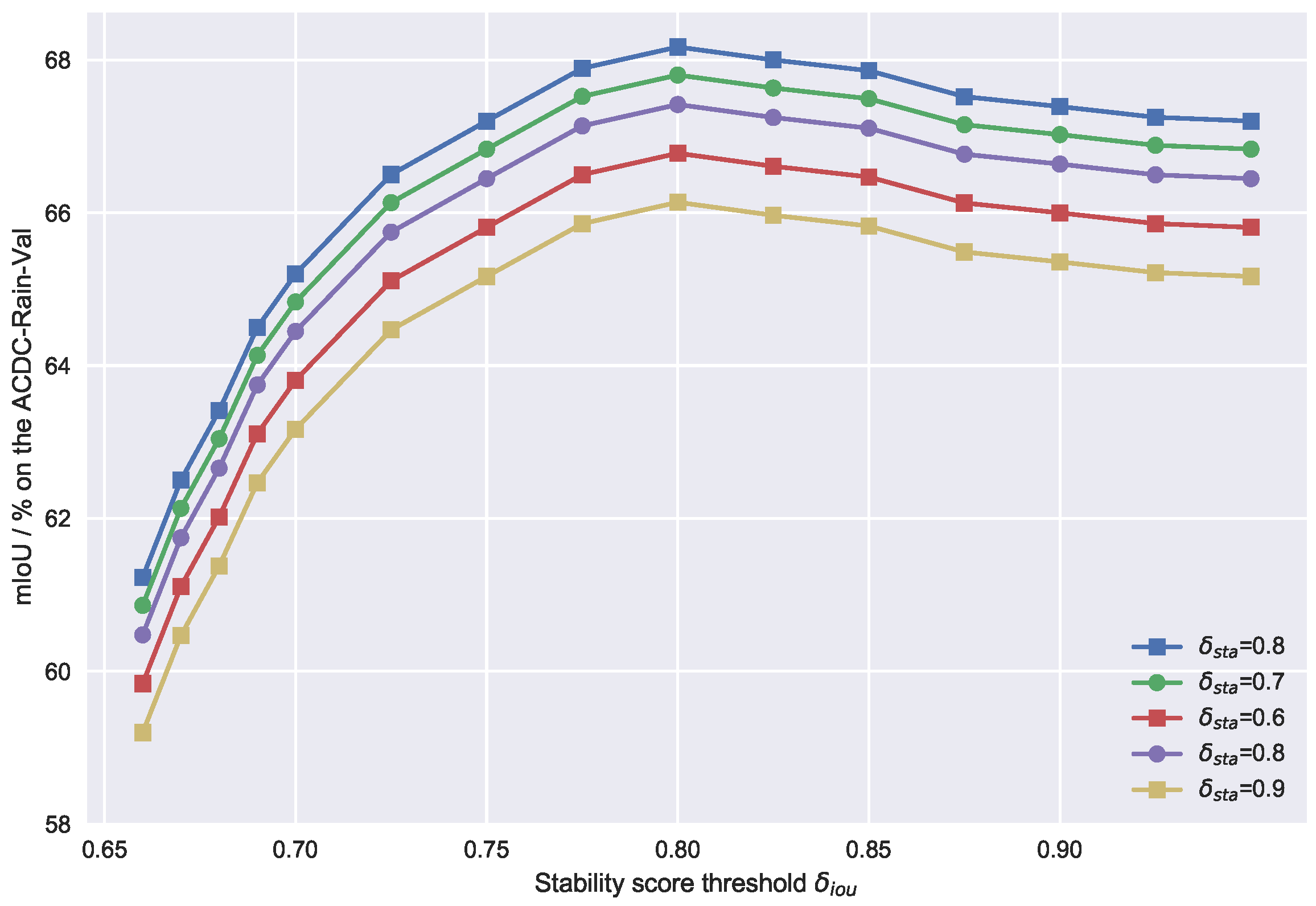
4.4. Influence of SAM’s Hyper-Parameters
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Šarić, J.; Oršić, M.; Šegvić, S. Panoptic SwiftNet: Pyramidal Fusion for Real-Time Panoptic Segmentation. Remote Sens. 2023, 15, 1968. [Google Scholar] [CrossRef]
- Lv, K.; Zhang, Y.; Yu, Y.; Zhang, Z.; Li, L. Visual Localization and Target Perception Based on Panoptic Segmentation. Remote Sens. 2022, 14, 3983. [Google Scholar] [CrossRef]
- Dai, Y.; Li, C.; Su, X.; Liu, H.; Li, J. Multi-Scale Depthwise Separable Convolution for Semantic Segmentation in Street–Road Scenes. Remote Sens. 2023, 15, 2649. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, Y.; Jiang, Z.; Pei, Y.; Zheng, B.; Zheng, L.; Fu, Z. Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sens. 2023, 15, 2800. [Google Scholar] [CrossRef]
- Sun, Q.; Chao, J.; Lin, W.; Xu, Z.; Chen, W.; He, N. Learn to Few-Shot Segment Remote Sensing Images from Irrelevant Data. Remote Sens. 2023, 15, 4937. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yang, W.; Wang, S.J.; Khanna, P.; Li, X. Pattern Recognition Techniques for Non Verbal Human Behavior (NVHB). Pattern Recognit. Lett. 2019, 125, 684–686. [Google Scholar] [CrossRef]
- Chen, G.; Hua, M.; Liu, W.; Wang, J.; Song, S.; Liu, C.; Yang, L.; Liao, S.; Xia, X. Planning and tracking control of full drive-by-wire electric vehicles in unstructured scenario. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2023, 09544070231195233. [Google Scholar] [CrossRef]
- Liu, W.; Hua, M.; Deng, Z.; Meng, Z.; Huang, Y.; Hu, C.; Song, S.; Gao, L.; Liu, C.; Shuai, B.; et al. A Systematic Survey of Control Techniques and Applications in Connected and Automated Vehicles. IEEE Internet Things J. 2023, 10, 21892–21916. [Google Scholar] [CrossRef]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Veh. 2023, 8, 4069–4080. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.; Hassani, A.; Orlov, N.; Shi, H. OneFormer: One Transformer to Rule Universal Image Segmentation. arXiv 2022, arXiv:2211.06220. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10765–10775. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- Ma, X.; Wang, Z.; Zhan, Y.; Zheng, Y.; Wang, Z.; Dai, D.; Lin, C.W. Both style and fog matter: Cumulative domain adaptation for semantic foggy scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18922–18931. [Google Scholar]
- Tang, L.; Xiao, H.; Li, B. Can SAM Segment Anything? When SAM Meets Camouflaged Object Detection. arXiv 2023, arXiv:2304.04709. [Google Scholar]
- Wang, X.; Wang, W.; Cao, Y.; Shen, C.; Huang, T. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6830–6839. [Google Scholar]
- Shan, X.; Zhang, C. Robustness of Segment Anything Model (SAM) for Autonomous Driving in Adverse Weather Conditions. arXiv 2023, arXiv:2306.13290. [Google Scholar]
- Yao, L.; Zuo, H.; Zheng, G.; Fu, C.; Pan, J. SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation. arXiv 2023, arXiv:2307.01024. [Google Scholar]
- Chen, J.; Yang, Z.; Zhang, L. Semantic Segment Anything. 2023. Available online: https://github.com/fudan-zvg/Semantic-Segment-Anything (accessed on 5 May 2023).
- Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.H.; Lee, S.; Hong, C.S. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv 2023, arXiv:2306.14289. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Hecker, S.; Van Gool, L. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. In Proceedings of the of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 687–704. [Google Scholar]
- Lin, H.; Li, Y.; Fu, X.; Ding, X.; Huang, Y.; Paisley, J. Rain o’er me: Synthesizing real rain to derain with data distillation. IEEE Trans. Image Process. 2020, 29, 7668–7680. [Google Scholar] [CrossRef]
- Dai, D.; Gool, L.V. Dark Model Adaptation: Semantic Image Segmentation from Daytime to Nighttime. arXiv 2018, arXiv:1810.02575. [Google Scholar]
- Lee, S.; Son, T.; Kwak, S. Fifo: Learning fog-invariant features for foggy scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18911–18921. [Google Scholar]
- Li, M.; Xie, B.; Li, S.; Liu, C.H.; Cheng, X. VBLC: Visibility Boosting and Logit-Constraint Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions. arXiv 2022, arXiv:2211.12256. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Gool, L. Guided Curriculum Model Adaptation and Uncertainty-Aware Evaluation for Semantic Nighttime Image Segmentation. arXiv 2019, arXiv:1901.05946. [Google Scholar]
- Wang, Z.; Zhang, Y.; Ma, X.; Yu, Y.; Zhang, Z.; Jiang, Z.; Cheng, B. Semantic Segmentation of Foggy Scenes Based on Progressive Domain Gap Decoupling. TechRxiv 2023. [Google Scholar] [CrossRef]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1379–1389. [Google Scholar]
- Chen, T.; Mai, Z.; Li, R.; Chao, W.l. Segment anything model (sam) enhanced pseudo labels for weakly supervised semantic segmentation. arXiv 2023, arXiv:2305.05803. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Pub/Year | Backbone | Fog | Rain | Snow | Night | Speed/FPS | GPU/GB | ||||
| ACDC-f | FD | FDD | ACDC-r | Rain-CS | ACDC-s | ACDC-n | DZ | |||||
| DAFormer [19] | CVPR 2022 | SegFormer [7] | 63.41 | 47.32 | 39.63 | 48.27 | 75.34 | 49.19 | 46.13 | 43.80 | 6–10 | Train: 16 GB Test: 8 GB |
| CuDA-Net [20] | CVPR 2022 | DeepLabv2 [13] | 68.59 | 53.50 | 48.20 | 48.52 | 69.47 | 47.20 | - | - | ||
| FIFO [33] | CVPR 2022 | Refinelw-101 [14] | 70.36 | 50.70 | 48.90 | - | - | - | - | - | ||
| CumFormer [36] | TechRXiv 2023 | SegFormer | 74.92 | 56.25 | 51.91 | 57.14 | 79.34 | 62.42 | 44.75 | 43.20 | ||
| VBLC [34] | AAAI 2023 | SegFormer | - | - | - | - | 79.80 | - | - | 44.41 | ||
| GCMA [35] | ICCV 2019 | DeepLabv2 | - | - | - | - | - | - | - | 42.01 | ||
| SegFormer (cs) | NeurIPS 2021 | - | 64.74 | 46.06 | 33.15 | 40.62 | 68.31 | 42.03 | 26.61 | 23.43 | 6–10 | - |
| SSA + SAM + SegFormer | arXiv 2023 Github 2023 | ViT-B [28] | 60.57 | 39.02 | 25.33 | 43.17 | 67.51 | 42.93 | 24.97 | 22.36 | <0.1 | Train: 8–48 GB Test: 16–24 GB |
| ViT-L [28] | 66.78 | 48.02 | 31.33 | 52.94 | 68.69 | 51.47 | 27.69 | 26.73 | ||||
| ViT-H [28] | 68.16 | 50.89 | 33.72 | 54.39 | 70.27 | 53.32 | 29.60 | 28.92 | ||||
| OneFormer (cs) [15] | arXiv 2022 | - | 72.31 | 51.33 | 44.31 | 56.72 | 74.96 | 55.13 | 32.41 | 26.74 | 4–5 | - |
| SSA + SAM + OneFormer | arXiv2023 GitHub2023 | ViT-B | 69.13 | 46.97 | 41.96 | 58.77 | 73.03 | 57.14 | 36.78 | 28.96 | <0.1 | Train: 8–48 GB Test: 16–24 GB |
| ViT-L | 75.94 | 53.14 | 46.78 | 64.25 | 75.62 | 64.21 | 40.14 | 34.25 | ||||
| ViT-H | 77.87 | 55.61 | 48.41 | 69.25 | 76.31 | 66.22 | 41.22 | 37.43 | ||||
| SAM-EDA(Ours) | - | ViT-B | 68.10 | 50.74 | 43.66 | 54.20 | 71.01 | 55.47 | 33.62 | 27.63 | 6.7 | Train: 8–48 GB Test: 8 GB |
| ViT-L | 75.30 | 55.49 | 46.98 | 64.68 | 73.41 | 58.12 | 41.30 | 35.45 | ||||
| ViT-H | 78.25 | 56.37 | 51.25 | 69.38 | 76.63 | 68.17 | 43.15 | 42.63 | ||||
| UDA Method | w/o SAM-EDA | w/SAM-EDA | Diff. |
|---|---|---|---|
| DACS [37] | 61.08 | 64.28 | +3.20 |
| ProDA [18] | 65.17 | 68.74 | +3.57 |
| DAFormer [19] | 67.93 | 71.61 | +3.68 |
| CuDA-Net [20] | 68.56 | 72.37 | +3.81 |
| CumFormer [36] | 74.92 | 77.89 | +2.97 |
| Method/Datasets | ACDC-F | Dark-Z | Mean | Gain
(mIoU) | |||
|---|---|---|---|---|---|---|---|
| Fog | Rain | Snow | Night | ||||
| DAFormer [19] | 63.41 | 48.27 | 49.19 | 46.13 | 43.80 | 50.16 | +0.00 |
| IoU [38] | 55.19 | 41.58 | 42.17 | 39.48 | 27.66 | 41.22 | −8.94 |
| SSA (SegFormer) [25] | 68.16 | 54.39 | 53.32 | 29.60 | 28.92 | 46.88 | −3.28 |
| SAM-EDA w/o Weight | 74.02 | 65.17 | 62.74 | 38.74 | 39.91 | 56.12 | +5.96 |
| SAM-EDA w/Weight | 78.25 | 69.38 | 68.17 | 43.15 | 42.63 | 60.32 | +10.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhang, Y.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Li, L. Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation. Remote Sens. 2024, 16, 758. https://doi.org/10.3390/rs16050758
Wang Z, Zhang Y, Zhang Z, Jiang Z, Yu Y, Li L, Li L. Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation. Remote Sensing. 2024; 16(5):758. https://doi.org/10.3390/rs16050758
Chicago/Turabian StyleWang, Ziquan, Yongsheng Zhang, Zhenchao Zhang, Zhipeng Jiang, Ying Yu, Li Li, and Lei Li. 2024. "Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation" Remote Sensing 16, no. 5: 758. https://doi.org/10.3390/rs16050758
APA StyleWang, Z., Zhang, Y., Zhang, Z., Jiang, Z., Yu, Y., Li, L., & Li, L. (2024). Exploring Semantic Prompts in the Segment Anything Model for Domain Adaptation. Remote Sensing, 16(5), 758. https://doi.org/10.3390/rs16050758