

Supraglacial Lake Evolution over Northeast Greenland Using Deep Learning Methods


Abstract
:
1. Introduction
2. Materials and Methods
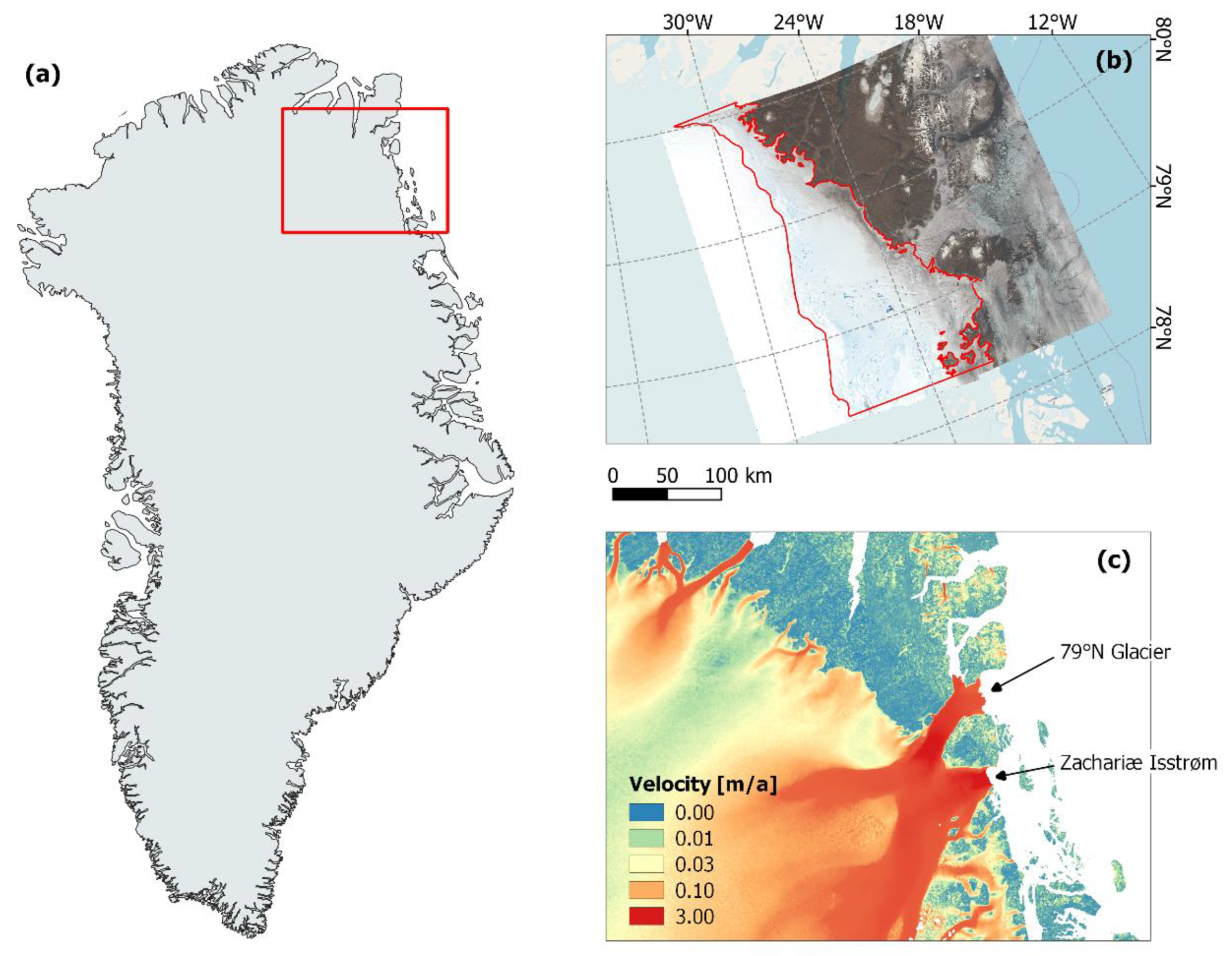
2.1. Area of Interest
2.2. Sentinel-2 Data
2.3. Data Selection and Preprocessing
2.4. Preparation of Training and Testing Data
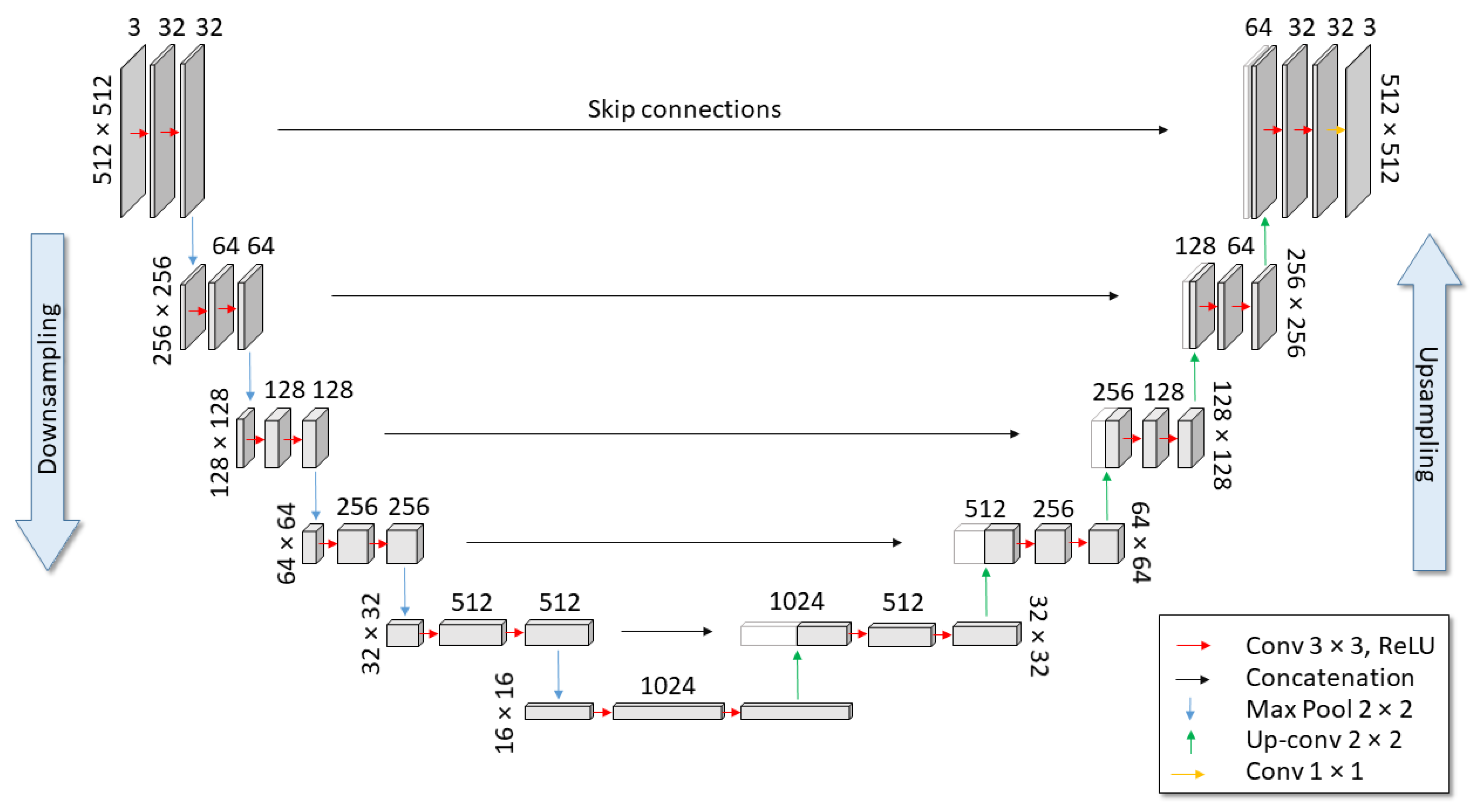
2.5. Deep Learning Architecture
2.6. Model Development and Hyperparameter Tuning
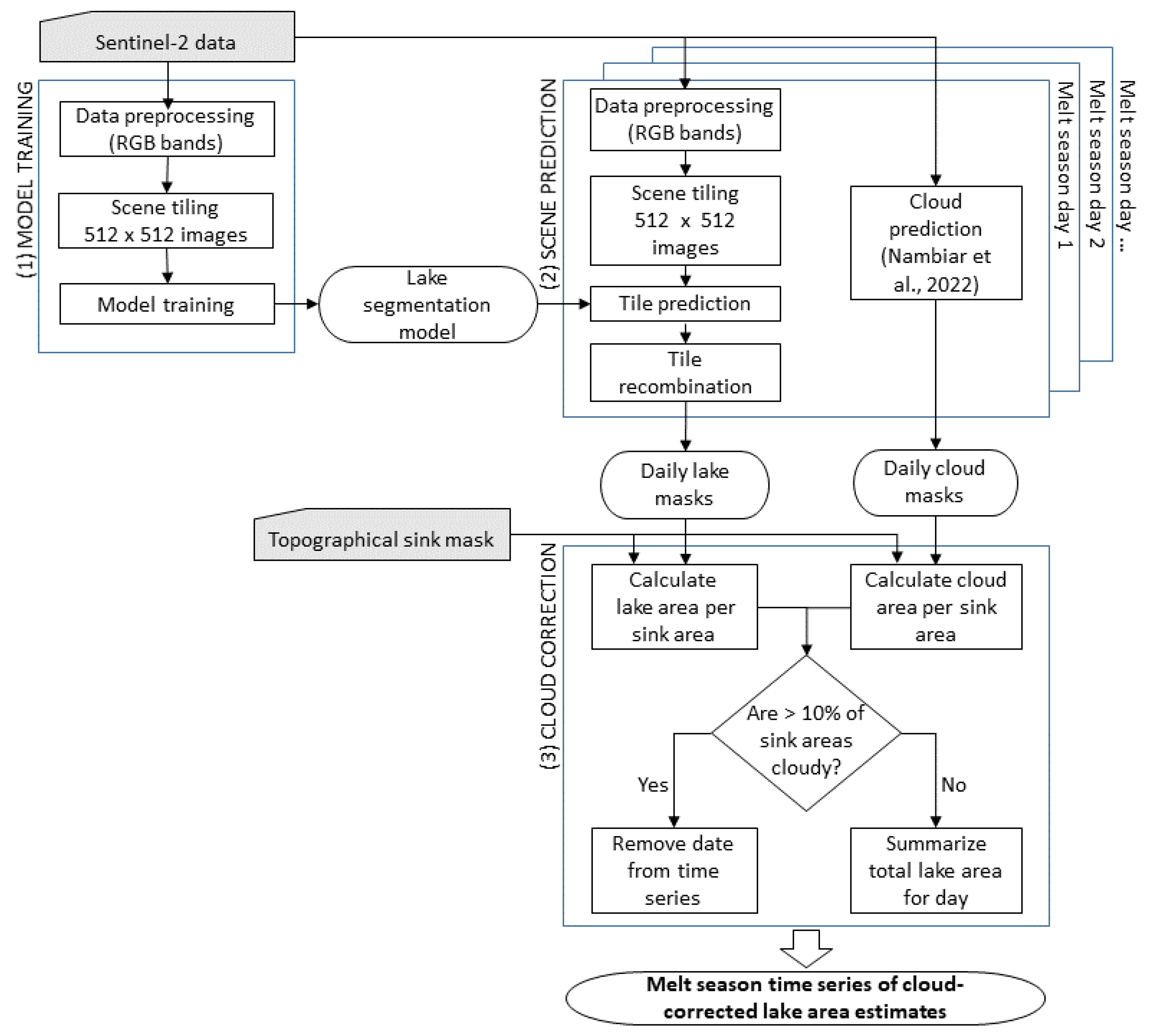
2.7. Post-Processing and Time Series Evaluation
3. Results
3.1. Model Selection and Application to Testing Dataset
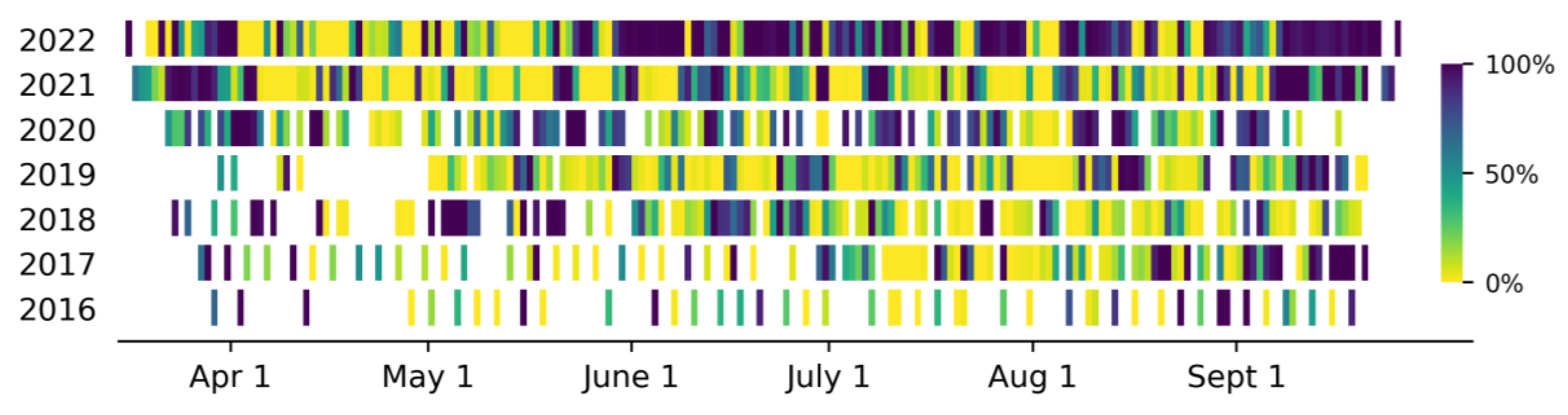
3.2. Influence of Cloudy Days on Time Series Results
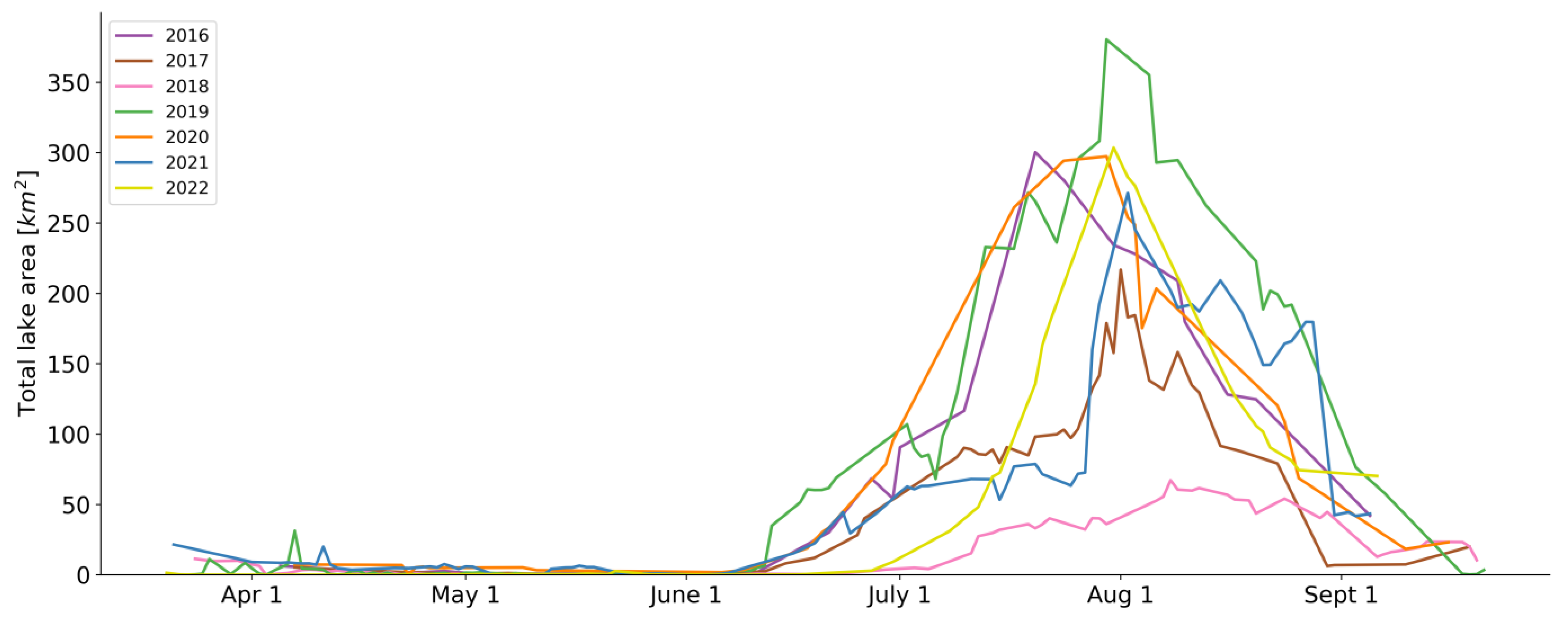
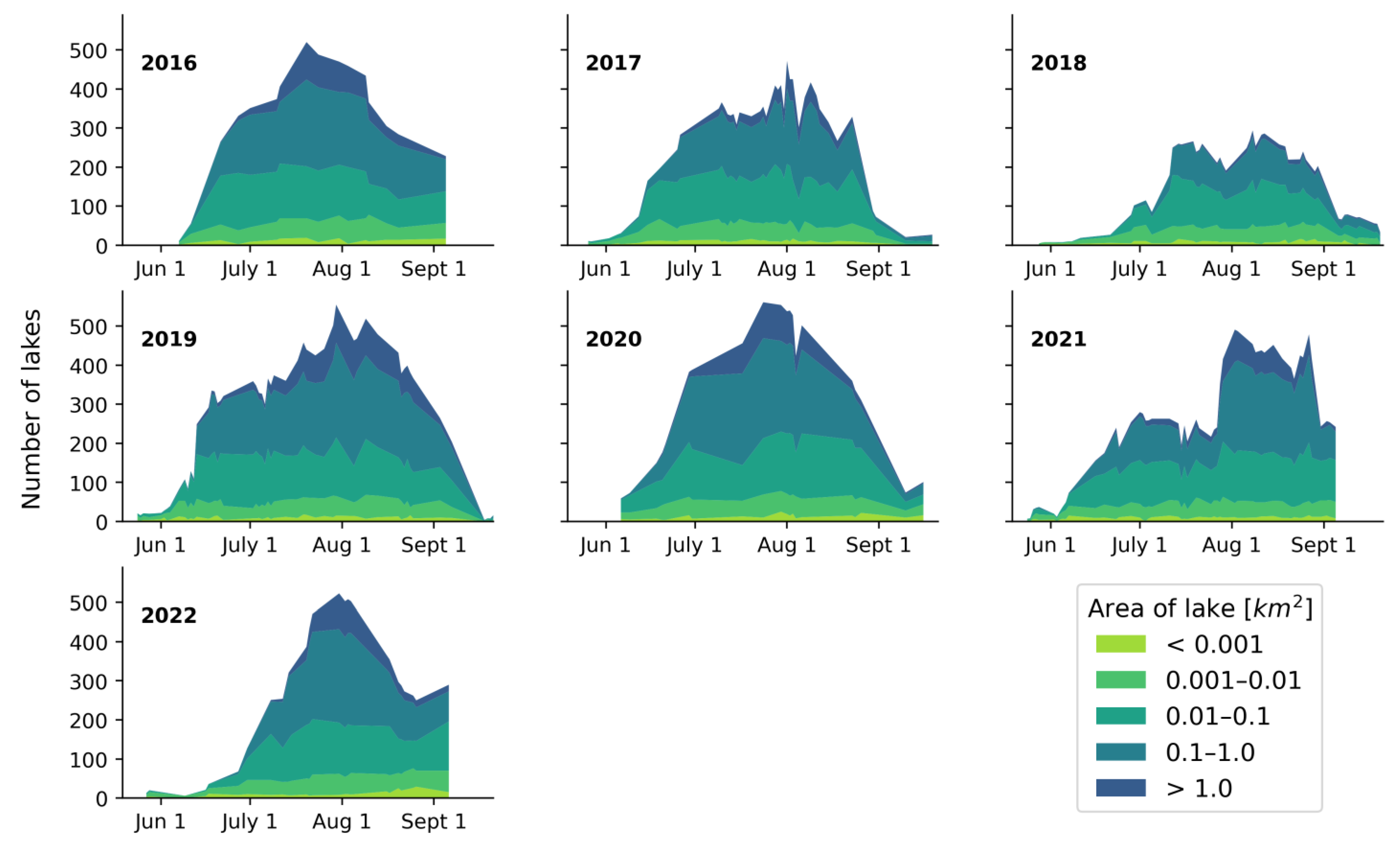
3.3. Seasonal Trends and Interannual Comparison of Supraglacial Lake Area
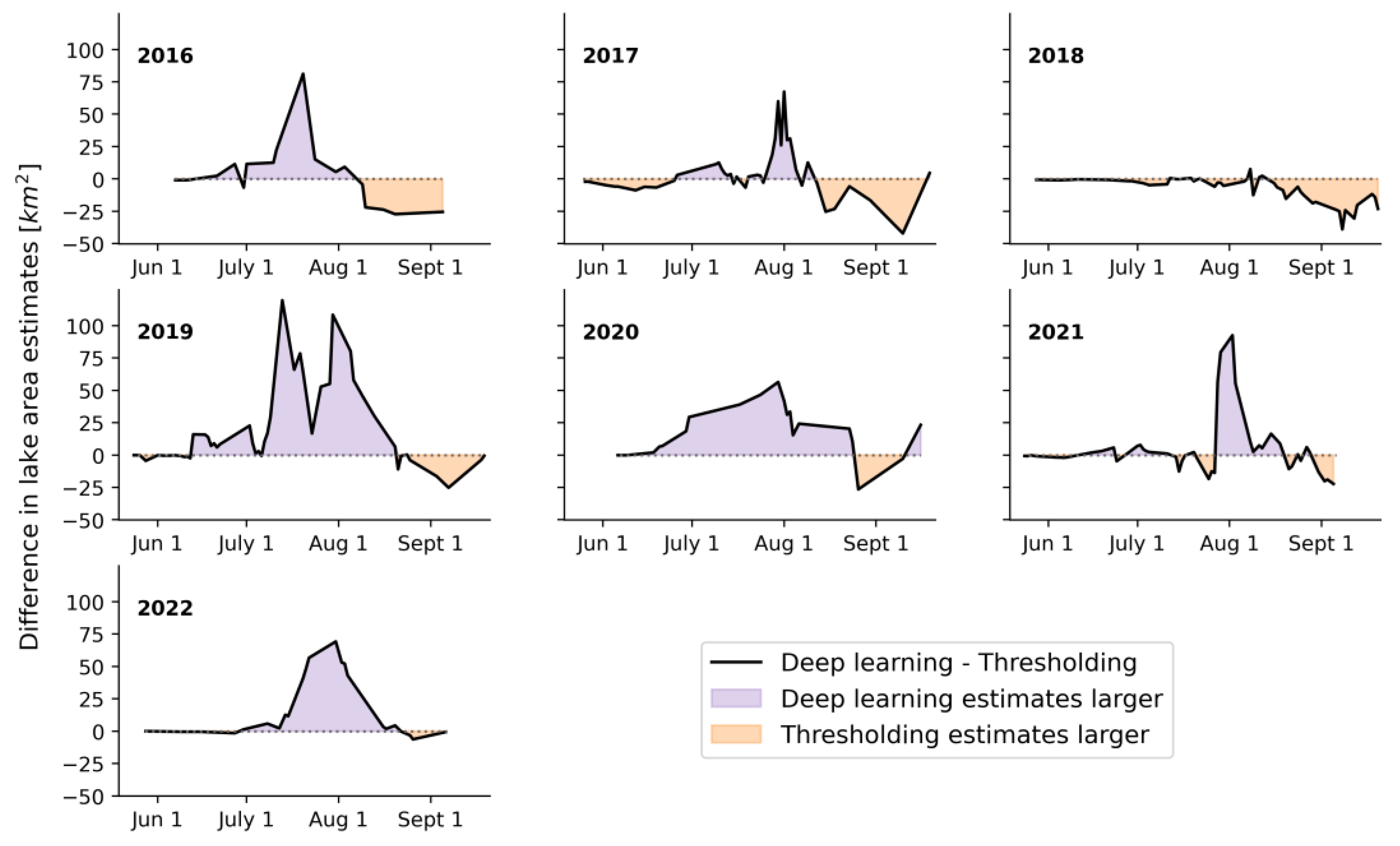
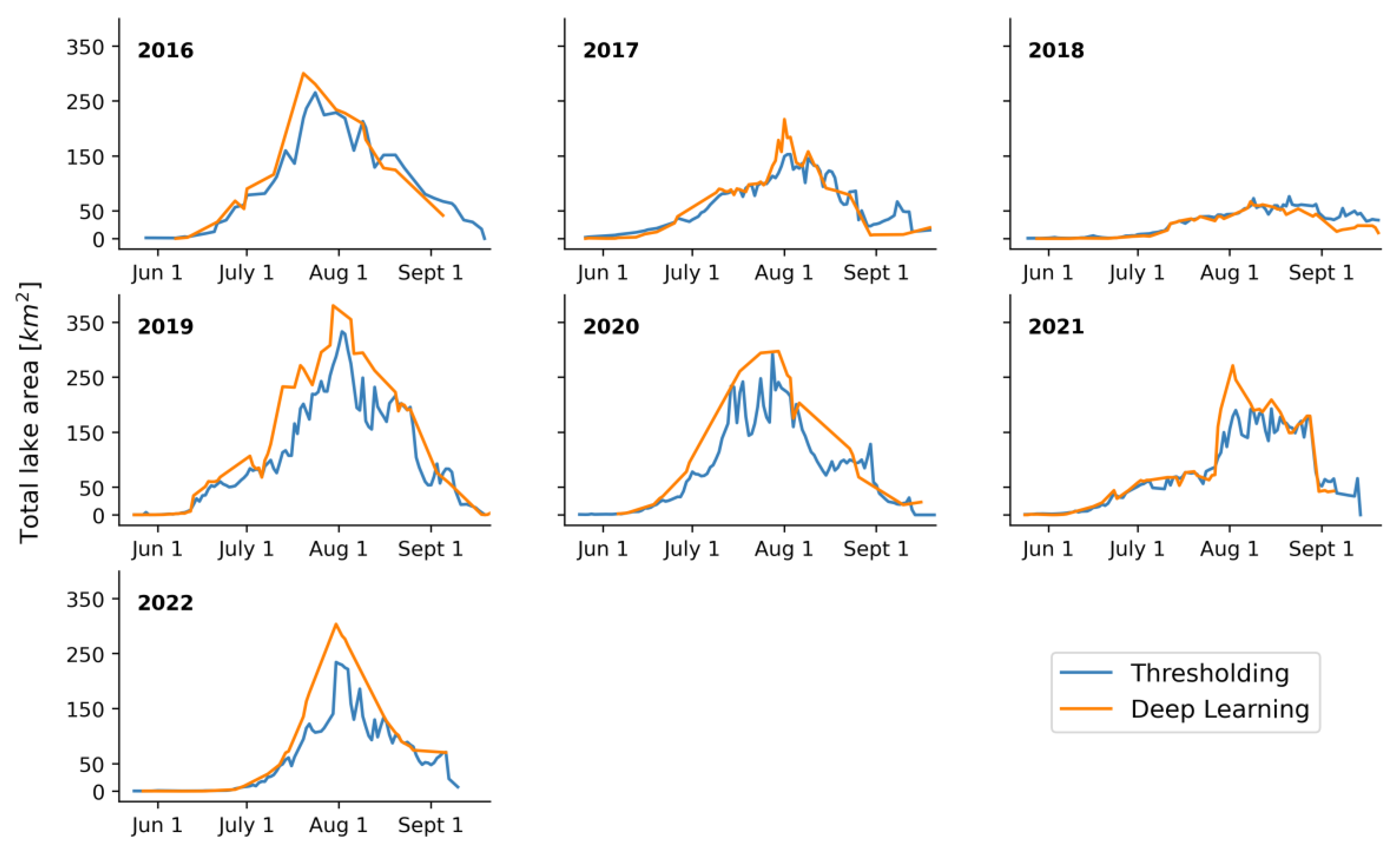
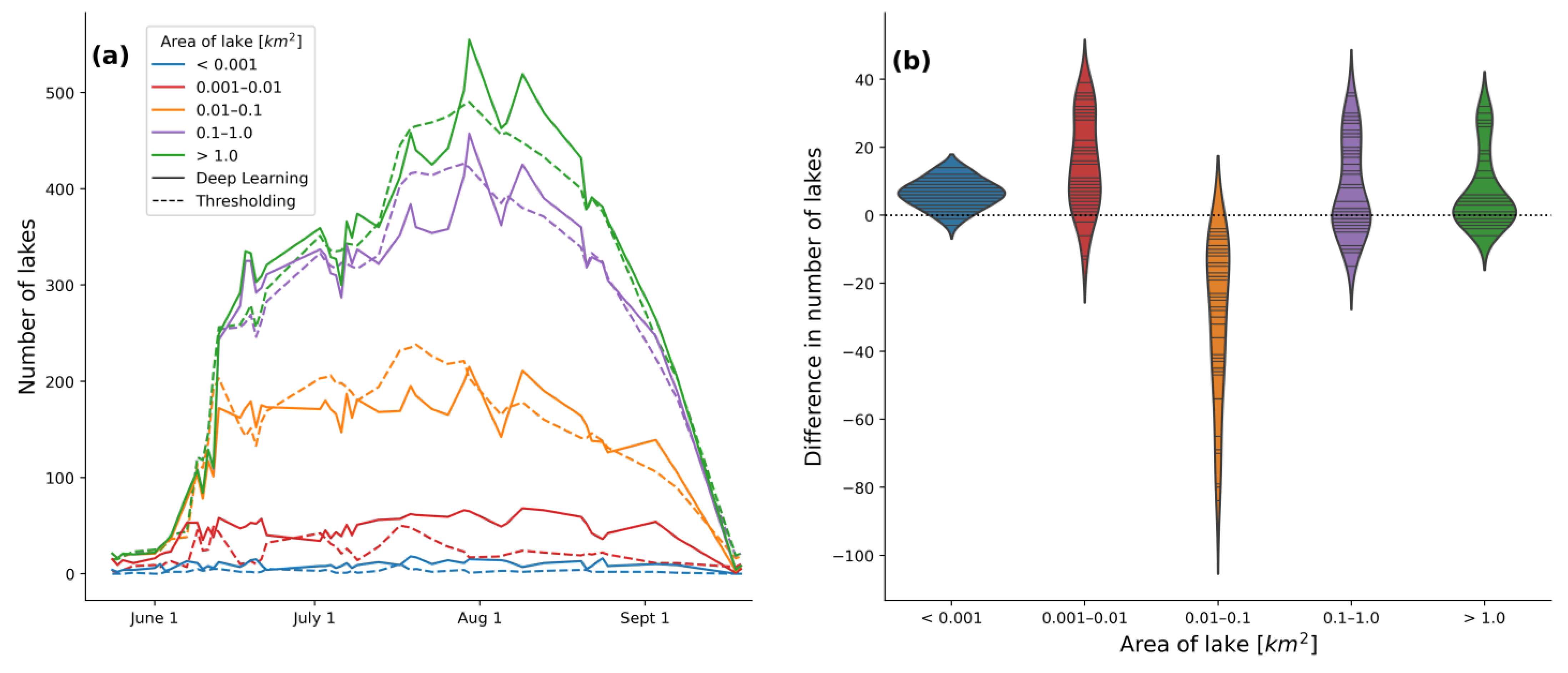
3.4. Comparison between Methods: Thresholding vs. Deep Learning
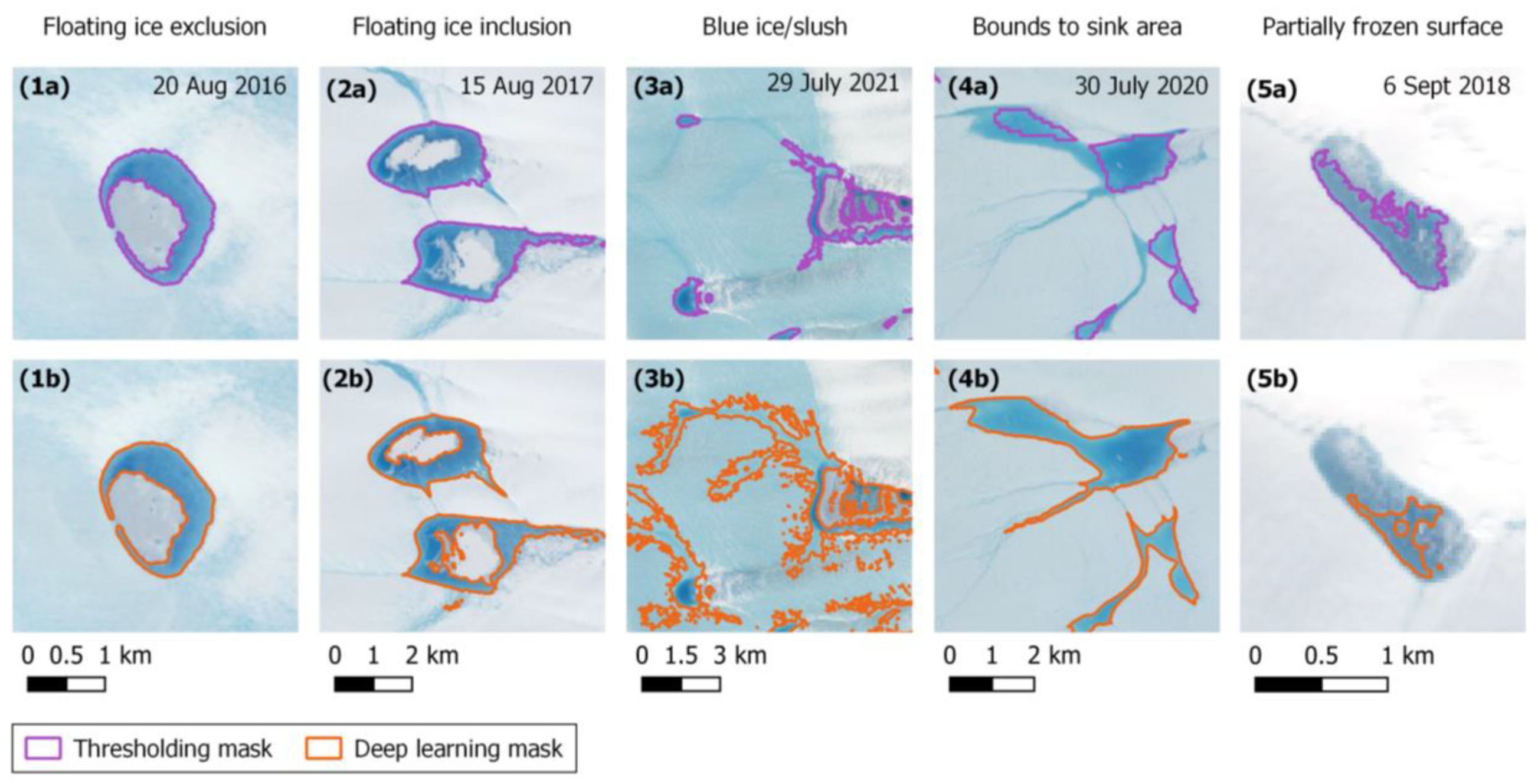
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentinel-2 Scene | Number of Tiles Used |
|---|---|
| S2A_MSIL1C_20160802T155912_N0204_R097_T26XNN_20160802T155907 | 172 |
| S2A_MSIL1C_20170715T154911_N0205_R054_T27XVH_20170715T154905 | 165 |
| S2A_MSIL1C_20200717T150921_N0209_R025_T27XVH_20200717T170914 | 156 |
| S2A_MSIL1C_20210801T150911_N0301_R025_T27XVJ_20210801T171130 | 67 |
| S2B_MSIL1C_20190826T153819_N0208_R011_T26XNP_20190826T191152 | 56 |
| S2B_MSIL1C_20190826T153819_N0208_R011_T27XVH_20190826T191152 | 64 |
| S2B_MSIL1C_20210801T155819_N0301_R097_T26XNP_20210801T175737 | 47 |
| S2B_MSIL1C_20210802T152809_N0301_R111_T27XVH_20210802T173148 | 73 |
| S2A_MSIL1C_20160803T152912_N0204_R111_T27XVH_20160803T152910 | 100 |
| S2B_MSIL1C_20190713T155829_N0208_R097_T27XVH_20190713T193729 | 38 |
| S2B_MSIL1C_20220820T153809_N0400_R011_T27XVH_20220831T150550 | 3 |
References
- Oppenheimer, M.; Glavovic, B.C.; Hinkel, J.; van de Wal, R.; Magnan, A.K.; Abd-Elgawad, A.; Cai, R.; Cifuentes-Jara, M.; DeConto, R.M.; Ghosh, T.; et al. Sea level rise and implications for low-lying islands, coasts and communities. In IPCC Special Report on the Ocean and Cryosphere in a Changing Climate; Pörtner, H.-O., Roberts, D.C., Masson-Delmotte, V., Zhai, P., Tignor, M., Poloczanska, E., Mintenbeck, K., Alegría, A., Nicolai, M., Okem, A., et al., Eds.; Cambridge University Press: Cambridge, UK, 2022; pp. 321–446. ISBN 9781009157964. [Google Scholar]
- Turton, J.; Hochreuther, P.; Reimann, N.; Blau, M. The distribution and evolution of supraglacial lakes on the 79° N Glacier (northeast Greenland) and interannual climatic controls. Cryosphere Discuss. 2021, 15, 3877–3896. [Google Scholar] [CrossRef]
- Lüthje, M.; Pedersen, L.T.; Reeh, N.; Greuell, W. Modelling the evolution of supraglacial lakes on the west Greenland ice-sheet margin. J. Glaciol. 2006, 52, 608–618. [Google Scholar] [CrossRef]
- Tedesco, M.; Steiner, N. In-situ multispectral and bathymetric measurements over a supraglacial lake in western Greenland using a remotely controlled watercraft. Cryosphere 2011, 5, 445–452. [Google Scholar] [CrossRef]
- Bartholomew, I.; Nienow, P.; Sole, A.; Mair, D.; Cowton, T.; Palmer, S.; Wadham, J. Supraglacial forcing of subglacial drainage in the ablation zone of the Greenland ice sheet. Geophys. Res. Lett. 2011, 38, L08502. [Google Scholar] [CrossRef]
- Doyle, S.H.; Hubbard, A.L.; Dow, C.F.; Jones, G.A.; Fitzpatrick, A.; Gusmeroli, A.; Kulessa, B.; Lindback, K.; Pettersson, R.; Box, J.E. Ice tectonic deformation during the rapid in situ drainage of a supraglacial lake on the Greenland Ice Sheet. Cryosphere 2013, 7, 129–140. [Google Scholar] [CrossRef]
- Zwally, H.J.; Abdalati, W.; Herring, T.; Larson, K.; Saba, J.; Steffen, K. Surface melt-induced acceleration of Greenland ice-sheet flow. Science 2002, 297, 218–222. [Google Scholar] [CrossRef] [PubMed]
- Das, S.B.; Joughin, I.; Behn, M.D.; Howat, I.M.; King, M.A.; Lizarralde, D.; Bhatia, M.P. Fracture Propagation to the Base of the Greenland Ice Sheet During Supraglacial Lake Drainage. Science 2008, 320, 778–781. [Google Scholar] [CrossRef]
- Danielson, B.; Sharp, M. Development and application of a time-lapse photograph analysis method to investigate the link between tidewater glacier flow variations and supraglacial lake drainage events. J. Glaciol. 2013, 59, 287–302. [Google Scholar] [CrossRef]
- Chudley, T.R.; Christoffersen, P.; Doyle, S.H.; Bougamont, M.; Schoonman, C.M.; Hubbard, B.; James, M.R. Supraglacial lake drainage at a fast-flowing Greenlandic outlet glacier. Proc. Natl. Acad. Sci. USA 2019, 116, 25468–25477. [Google Scholar] [CrossRef]
- Neckel, N.; Zeising, O.; Steinhage, D.; Helm, V.; Humbert, A. Seasonal Observations at 79° N Glacier (Greenland) From Remote Sensing and in situ Measurements. Front. Earth Sci. 2020, 8, 142. [Google Scholar] [CrossRef]
- Wessels, R.L.; Kargel, J.S.; Kieffer, H.H. ASTER measurement of supraglacial lakes in the Mount Everest region of the Himalaya. Ann. Glaciol. 2002, 34, 399–408. [Google Scholar] [CrossRef]
- Box, J.E.; Ski, K. Remote sounding of Greenland supraglacial melt lakes: Implications for subglacial hydraulics. J. Glaciol. 2007, 53, 257–265. [Google Scholar] [CrossRef]
- Banwell, A.F.; Caballero, M.; Arnold, N.S.; Glasser, N.F.; Cathles, L.M.; MacAyeal, D.R. Supraglacial lakes on the Larsen B ice shelf, Antarctica, and at Paakitsoq, West Greenland: A comparative study. Ann. Glaciol. 2014, 55, 1–8. [Google Scholar] [CrossRef]
- Pope, A.; Scambos, T.A.; Moussavi, M.; Tedesco, M.; Willis, M.; Shean, D.; Grigsby, S. Estimating supraglacial lake depth in West Greenland using Landsat 8 and comparison with other multispectral methods. Cryosphere 2016, 10, 15–27. [Google Scholar] [CrossRef]
- Hochreuther, P.; Neckel, N.; Reimann, N.; Humbert, A.; Braun, M. Fully automated detection of supraglacial lake area for northeast greenland using sentinel-2 time-series. Remote Sens. 2021, 13, 205. [Google Scholar] [CrossRef]
- Everett, A.; Murray, T.; Selmes, N.; Rutt, I.C.; Luckman, A.; James, T.D.; Clason, C.; O’Leary, M.; Karunarathna, H.; Moloney, V.; et al. Annual down-glacier drainage of lakes and water-filled crevasses at Helheim Glacier, southeast Greenland. J. Geophys. Res. Earth Surf. 2016, 121, 1819–1833. [Google Scholar] [CrossRef]
- Williamson, A.G.; Arnold, N.S.; Banwell, A.F.; Willis, I.C. A Fully Automated Supraglacial lake area and volume Tracking (“FAST”) algorithm: Development and application using MODIS imagery of West Greenland. Remote Sens. Environ. 2017, 196, 113–133. [Google Scholar] [CrossRef]
- Stokes, C.R.; Sanderson, J.E.; Miles, B.W.J.; Jamieson, S.S.R.; Leeson, A.A. Widespread distribution of supraglacial lakes around the margin of the East Antarctic Ice Sheet. Sci. Rep. 2019, 9, 13823. [Google Scholar] [CrossRef]
- Yang, K.; Smith, L.C. Supraglacial Streams on the Greenland Ice Sheet Delineated from Combined Spectral–Shape Information in High-Resolution Satellite Imagery. IEEE Geosci. Remote Sens. Lett. 2013, 10, 801–805. [Google Scholar] [CrossRef]
- Miles, K.E.; Willis, I.C.; Benedek, C.L.; Williamson, A.G.; Tedesco, M. Toward Monitoring Surface and Subsurface Lakes on the Greenland Ice Sheet Using Sentinel-1 SAR and Landsat-8 OLI Imagery. Front. Earth Sci. 2017, 5, 58. [Google Scholar] [CrossRef]
- Williamson, A.G.; Banwell, A.F.; Willis, I.C.; Arnold, N.S. Dual-satellite (Sentinel-2 and Landsat 8) remote sensing of supraglacial lakes in Greenland. Cryosphere 2018, 12, 3045–3065. [Google Scholar] [CrossRef]
- Arthur, J.F.; Stokes, C.R.; Jamieson, S.S.; Carr, J.R.; Leeson, A.A. Distribution and seasonal evolution of supraglacial lakes on Shackleton Ice Shelf, East Antarctica. Cryosphere 2020, 14, 4103–4120. [Google Scholar] [CrossRef]
- Carrivick, J.L.; Quincey, D.J. Progressive increase in number and volume of ice-marginal lakes on the western margin of the Greenland Ice Sheet. Glob. Planet. Change 2014, 116, 156–163. [Google Scholar] [CrossRef]
- Shugar, D.H.; Burr, A.; Haritashya, U.K.; Kargel, J.S.; Watson, C.S.; Kennedy, M.C.; Bevington, A.R.; Betts, R.A.; Harrison, S.; Strattman, K. Rapid worldwide growth of glacial lakes since 1990. Nat. Clim. Change 2020, 10, 939–945. [Google Scholar] [CrossRef]
- Moussavi, M.; Pope, A.; Halberstadt, A.; Trusel, L.D.; Cioffi, L.; Abdalati, W. Antarctic Supraglacial Lake Detection Using Landsat 8 and Sentinel-2 Imagery: Towards Continental Generation of Lake Volumes. Remote Sens. 2020, 12, 134. [Google Scholar] [CrossRef]
- Schröder, L.; Neckel, N.; Zindler, R.; Humbert, A. Perennial Supraglacial Lakes in Northeast Greenland Observed by Polarimetric SAR. Remote Sens. 2020, 12, 2798. [Google Scholar] [CrossRef]
- Benedek, C.L.; Willis, I.C. Winter drainage of surface lakes on the Greenland Ice Sheet from Sentinel-1 SAR imagery. Cryosphere 2021, 15, 1587–1606. [Google Scholar] [CrossRef]
- Li, W.; Lhermitte, S.; López-Dekker, P. The potential of synthetic aperture radar interferometry for assessing meltwater lake dynamics on Antarctic ice shelves. Cryosphere 2021, 15, 5309–5322. [Google Scholar] [CrossRef]
- Halberstadt, A.R.W.; Gleason, C.J.; Moussavi, M.S.; Pope, A.; Trusel, L.D.; DeConto, R.M. Antarctic Supraglacial Lake Identification Using Landsat-8 Image Classification. Remote Sens. 2020, 12, 1327. [Google Scholar] [CrossRef]
- Wangchuk, S.; Bolch, T. Mapping of glacial lakes using Sentinel-1 and Sentinel-2 data and a random forest classifier: Strengths and challenges. Sci. Remote Sens. 2020, 2, 100008. [Google Scholar] [CrossRef]
- Yuan, J.; Chi, Z.; Cheng, X.; Zhang, T.; Li, T.; Chen, Z. Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network. Water 2020, 12, 891. [Google Scholar] [CrossRef]
- Dirscherl, M.; Dietz, A.J.; Kneisel, C.; Kuenzer, C. Automated Mapping of Antarctic Supraglacial Lakes Using a Machine Learning Approach. Remote Sens. 2020, 12, 1203. [Google Scholar] [CrossRef]
- Hu, J.; Huang, H.; Chi, Z.; Cheng, X.; Wei, Z.; Chen, P.; Xu, X.; Qi, S.; Xu, Y.; Zheng, Y. Distribution and Evolution of Supraglacial Lakes in Greenland during the 2016–2018 Melt Seasons. Remote Sens. 2021, 14, 55. [Google Scholar] [CrossRef]
- Dell, R.L.; Banwell, A.F.; Willis, I.C.; Arnold, N.S.; Halberstadt, A.R.W.; Chudley, T.R.; Pritchard, H.D. Supervised classification of slush and ponded water on Antarctic ice shelves using Landsat 8 imagery. J. Glaciol. 2022, 68, 401–414. [Google Scholar] [CrossRef]
- Qayyum, N.; Ghuffar, S.; Ahmad, H.; Yousaf, A.; Shahid, I. Glacial Lakes Mapping Using Multi Satellite PlanetScope Imagery and Deep Learning. ISPRS Int. J. Geo-Inf. 2020, 9, 560. [Google Scholar] [CrossRef]
- Wu, R.; Liu, G.; Zhang, R.; Wang, X.; Li, Y.; Zhang, B.; Cai, J.; Xiang, W. A Deep Learning Method for Mapping Glacial Lakes from the Combined Use of Synthetic-Aperture Radar and Optical Satellite Images. Remote Sens. 2020, 12, 4020. [Google Scholar] [CrossRef]
- Dirscherl, M.; Dietz, A.J.; Kneisel, C.; Kuenzer, C. A Novel Method for Automated Supraglacial Lake Mapping in Antarctica Using Sentinel-1 SAR Imagery and Deep Learning. Remote Sens. 2021, 13, 197. [Google Scholar] [CrossRef]
- Dirscherl, M.C.; Dietz, A.J.; Kuenzer, C. Seasonal evolution of Antarctic supraglacial lakes in 2015-2021 and links to environmental controls. Cryosphere 2021, 15, 5206–5226. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for Sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–13 September 2017; Bruzzone, L., Bovolo, F., Eds.; SPIE: Bellingham, WA, USA, 2017; p. 3, ISBN 9781510613188. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Nambiar, K.G.; Morgenshtern, V.I.; Hochreuther, P.; Seehaus, T.; Braun, M.H. A Self-Trained Model for Cloud, Shadow and Snow Detection in Sentinel-2 Images of Snow- and Ice-Covered Regions. Remote Sens. 2022, 14, 1825. [Google Scholar] [CrossRef]
- Mouginot, J.; Rignot, E.; Scheuchl, B.; Fenty, I.; Khazendar, A.; Morlighem, M.; Buzzi, A.; Paden, J. Fast retreat of Zachariæ Isstrøm, northeast Greenland. Science 2015, 350, 1357–1361. [Google Scholar] [CrossRef] [PubMed]
- Rignot, E.; Mouginot, J. Ice flow in Greenland for the International Polar Year 2008–2009. Geophys. Res. Lett. 2012, 39, L11501. [Google Scholar] [CrossRef]
- Khan, S.A.; Choi, Y.; Morlighem, M.; Rignot, E.; Helm, V.; Humbert, A.; Mouginot, J.; Millan, R.; Kjær, K.H.; Bjørk, A.A. Extensive inland thinning and speed-up of Northeast Greenland Ice Stream. Nature 2022, 611, 727–732. [Google Scholar] [CrossRef] [PubMed]
- Gudmundsson, G.H. Transmission of basal variability to a glacier surface. J. Geophys. Res. 2003, 108. [Google Scholar] [CrossRef]
- Lampkin, D.J.; Vanderberg, J. A preliminary investigation of the influence of basal and surface topography on supraglacial lake distribution near Jakobshavn Isbrae, western Greenland. Hydrol. Process. 2011, 25, 3347–3355. [Google Scholar] [CrossRef]
- Howat, I.M.; Negrete, A.; Smith, B.E. The Greenland Ice Mapping Project (GIMP) land classification and surface elevation data sets. Cryosphere 2014, 8, 1509–1518. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Maas, A.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; p. 3. [Google Scholar]

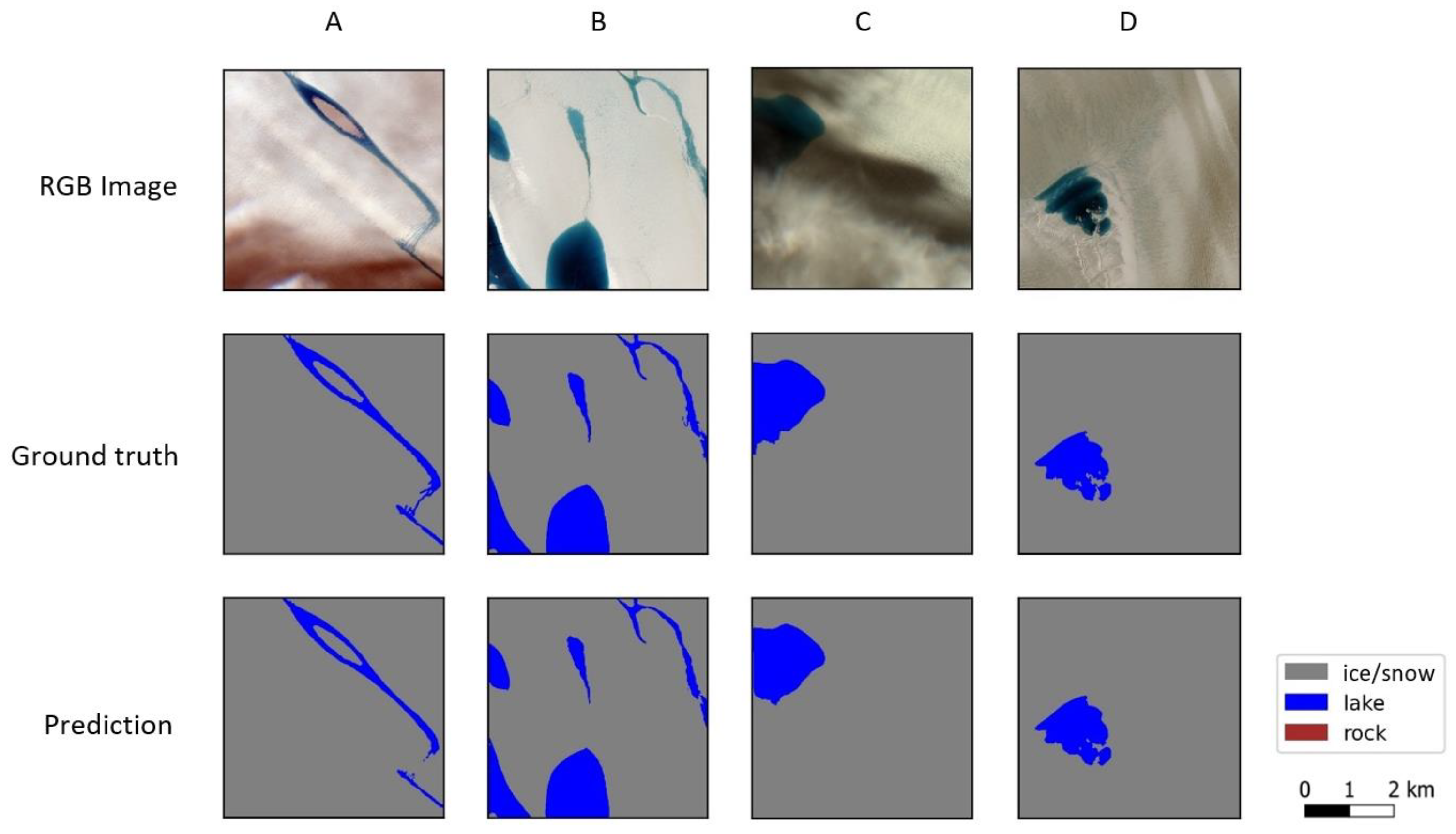

| Class | Precision | Recall | F1-Score | Accuracy | Kappa Coefficient |
|---|---|---|---|---|---|
| Ice/snow | 1.00 | 1.00 | 1.00 | 0.99 | 0.93 |
| Lake | 0.90 | 0.91 | 0.90 | ||
| Rock | 0.98 | 0.92 | 0.95 |
| 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|
| Number of cloudy days (out of total images *) | 20/52 | 27/100 | 42/137 | 51/176 | 68/110 | 73/168 | 114/179 |
| Percentage of cloudy days | 38.5% | 27.0% | 30.7% | 32.4% | 61.8% | 43.5% | 63.7% |
| 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|
| Date of maximum number of lakes | 20 July | 1 August | 8 August | 30 July | 24 July | 2 August | 3 August |
| Maximum number of lakes | 424 | 472 | 294 | 555 | 561 | 491 | 508 |
| Average lake area on peak date (km2) | 1.24 ± 3.52 | 0.57 ± 1.25 | 0.23 ± 0.48 | 1.06 ± 2.94 | 0.57 ± 1.33 | 0.70 ± 1.61 | 0.80 ± 2.65 |
| 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|
| Peak lake area from thresholding method (km2) | 265.39 | 153.26 | 76.66 | 333.19 | 292.91 | 192.83 | 234.30 |
| Peak lake area from deep learning method (km2) | 300.33 | 184.47 | 67.27 | 380.47 | 297.47 | 271.41 | 303.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lutz, K.; Bahrami, Z.; Braun, M. Supraglacial Lake Evolution over Northeast Greenland Using Deep Learning Methods. Remote Sens. 2023, 15, 4360. https://doi.org/10.3390/rs15174360
Lutz K, Bahrami Z, Braun M. Supraglacial Lake Evolution over Northeast Greenland Using Deep Learning Methods. Remote Sensing. 2023; 15(17):4360. https://doi.org/10.3390/rs15174360
Chicago/Turabian StyleLutz, Katrina, Zahra Bahrami, and Matthias Braun. 2023. "Supraglacial Lake Evolution over Northeast Greenland Using Deep Learning Methods" Remote Sensing 15, no. 17: 4360. https://doi.org/10.3390/rs15174360
APA StyleLutz, K., Bahrami, Z., & Braun, M. (2023). Supraglacial Lake Evolution over Northeast Greenland Using Deep Learning Methods. Remote Sensing, 15(17), 4360. https://doi.org/10.3390/rs15174360