1. Introduction
To address the issue of the uneven spatial distribution of water resources, as there are more water resources in the southern regions of China and less in the northern regions, the Chinese government has planned and implemented the South-to-North Water Diversion Middle Route Project. The South-to-North Water Diversion Middle Route Project is one of the world’s major water conservancy projects. Its objective is to address the water scarcity issue in Northern China by diverting the abundant water resources from the southern regions of the country to the water-deficient areas in the north. The South-to-North Water Diversion Middle Route Project in China has a total length of 1432 km. The project encounters complex and variable geological conditions, especially in the multiple sections along the channel that have expansive soil foundations [
1]. Due to its characteristics of desiccation-induced consolidation and water-induced expansion, expansive soil is prone to the induction of deformation disasters in channel slopes during prolonged cycles of consolidation and expansion [
2]. Therefore, the effective detection of soil moisture is crucial for ensuring the safe operation of this project. Soil moisture is one of the key factors influencing the stability of expansive soil channel slopes. By monitoring soil moisture, real-time information about soil water content can be obtained. This provides the support of scientific data for a comprehensive assessment of the risk of deformation disaster in the expansive soil channel slopes. The early detection of potential slope instability issues and the implementation of appropriate maintenance and repair measures can be facilitated to ensure the safety of the project [
3]. Therefore, conducting research on soil moisture inversion methods holds significant importance for the high-quality development of the South-to-North Water Diversion Middle Route Project and for the regional economies involved.
Traditional soil moisture monitoring methods mainly include soil drying method, neutron moisture meter method, and tensiometer method, etc. They are all based on point measurement, which is high in accuracy but has a large workload, a long time period, and more demanding requirements, and cannot obtain data quickly. Conventional optical remote sensing (e.g., TM, SPOT, etc.), with fewer bands and low spectral resolution, is suitable for soil moisture monitoring over large areas, and has a large error for regional or plot-level soil moisture monitoring. In recent years, in order to obtain soil moisture in real-time, people have developed soil moisture sensors, but a single sensor can only realize the soil moisture monitoring of its buried location, and if you want to realize regional soil moisture monitoring, you need to bury a large number of sensors, which will cost a lot of manpower, material, and financial resources. In order to realize the soil moisture monitoring of the channel slopes in the deep excavated expansive soil section of the China South-to-North Water Diversion Project, through the on-site research, we found that in order to grasp the deformation status of the channel slopes in real-time, the project managers have installed a large number of GNSS observation stations in the risk areas of the channel slopes, and a huge amount of GNSS observation data can be acquired every day. At the same time, by reviewing the literature, we found that the monitoring of soil moisture can be realized by using GNSS-R technology. Based on the above, we fused the GNSS-R technique and deep learning method to carry out the soil moisture inversion study on the channel slope of the deep excavated square canal section of the South-to-North Water Diversion Central Route Project in China. GNSS-R technology utilizes the multipath reflection component of the signal-to-noise ratio (SNR) from GNSS satellites to retrieve near-surface physical parameters. In comparison with traditional soil moisture measurement methods, rapidly evolving remote sensing techniques offer numerous irreplaceable advantages for monitoring soil moisture. The use of GNSS-R involves the microwave frequency band (L-band), which exhibits strong penetration capabilities, reduced atmospheric attenuation, and excellent vegetation penetration. Consequently, it is considered an ideal frequency for soil moisture inversion at present [
4]. Currently, GNSS-R technology has been widely extended to various application areas, including soil moisture [
5], sea surface wind measurement [
6], oil spill detection [
7], and sea ice monitoring [
8], among others.
Currently, European and American countries have conducted extensive fundamental research and experimentation on soil moisture detection techniques based on GNSS-R. In 2002, NASA included GPS dual-frequency radar measurements in the SMEX02 (Soil Moisture Experiment 2002) trial, which demonstrated the spatial and temporal correlations between the reflected signal strength and soil moisture [
9]. In 2003, the UK-DMC satellite, which was equipped with GNSS-R instruments, successfully obtained physical parameters of the Earth’s surface, such as sea surface roughness [
10]. Additionally, high-precision elevation measurements can be derived from GPS reflection signals over calm sea areas [
11]. During the period of 2013–2015, the Polytechnic University of Catalonia in Spain conducted multiple ground-based and airborne GNSS-R experiments to carry out soil moisture measurements. These experiments involved both direct and reflected GNSS signal measurements while considering polarization. The researchers also took the instrument parameters that could affect the calculation of reflection coefficients into account [
12,
13,
14,
15,
16]. With the emergence of unmanned aerial vehicles (UAVs) as a new remote sensing platform, there have been studies on soil moisture inversion with GNSS-R by using UAVs. In the field of direct and reflected signal interferometry with GNSS, Larson et al. proposed the GPS-MR (GPS–multipath reflectometry) soil moisture measurement technique. They utilized GPS signal-to-noise ratio (SNR) data from the Crustal Deformation Monitoring Network for this purpose [
17]. Rodriguez-Alvarez et al. proposed the interference pattern technique (IPT) for soil moisture measurement. They used a custom-designed receiver and a vertically polarized antenna for this technique [
18]. In China, research on GNSS-R technology started relatively later. In 2016, Han Moutian et al. derived a model for soil moisture inversion by using GNSS interferometric signal amplitudes based on the interference effect and the GNSS receiver signal-to-noise ratio estimation method. They also conducted a simulation verification of the proposed model [
19]. In 2016, Yang Lei et al. and Zou Wenbo et al. conducted research on soil moisture measurement by using signals reflected from GEO satellites. They proposed empirical or analytical soil moisture inversion models based on their studies [
20,
21]. In 2018, Wu Jizhong et al. addressed the parameter estimation problem for obtaining soil moisture content by using GPS-IR (GPS–interferometric reflectometry). They proposed an improved method for estimating reflection signal parameters and studied the process of establishing soil moisture inversion models [
22]. With the development of computer technology, scholars began to use deep learning techniques for soil moisture inversion. In 2019, Sun Bo et al. proposed a GA-SVM (genetic algorithm–support vector machine)-assisted method for soil moisture inversion and demonstrated through experiments that this method effectively improved the accuracy of soil moisture inversion [
23]. In the same year, Zhang Nan et al. proposed a method for eliminating the micro-Doppler effect in GEO satellites for soil moisture inversion [
24]. Zhang Xiaoyu et al. used GA-BP neural network to invert snow depth, effectively eliminating the jump phenomenon in the inversion process, reducing the error and improving the inversion accuracy [
25]. In 2020, Zhu Chonghao et al. used the GABP neural network model to assess landslide risk in Sichuan Province as an example, and the results were better than BP neural network, which improved the efficiency of landslide risk assessment [
26]. In 2021, Yang Lianbing et al. used a BP neural network optimized by a genetic algorithm to invert soil salinity, and the inversion results were better than the traditional BP neural network [
27]. In the same year, Zhao Jianhui et al. used feature selection and GA-BP neural network to invert soil moisture, which provided a new idea for multi-source remote sensing surface soil moisture inversion in farmland [
28]. In 2022, Schiajer performed soil moisture inversion using three neural networks, GABP, GRNN, and ELM, all of which achieved better inversion results [
29]. In the same year, new mathematics study findings have been reported by researchers at Akdeniz University by comparing different ANN (Ffbp Grnn F) algorithms and multiple linear regression for daily streamflow prediction in Kocasu River, Turkey [
30].
However, single-site single-satellite GNSS-R is unable to accurately monitor short-term variations in soil moisture, and the limited observation information obtained with a single satellite can result in significant differences in data quality [
31]. To enhance the accuracy of the results, this study proposes a novel technique for multi-satellite and multi-frequency data fusion. This technique automatically selects satellites with a high correlation among the amplitude, phase, and soil moisture. It employs an adaptive fusion algorithm based on least squares to combine data from multiple satellites in the same frequency band. Furthermore, an entropy-based method is applied to fuse data from different frequency bands. By utilizing the fused data for GNSS-R technology, this study mitigates signal gaps and improves the quality of observational data, thereby enhancing the estimation accuracy of soil moisture. The data fusion approach helps fill in missing information and reduces the variability in the observations, leading to more reliable and precise estimations of soil moisture. In order to validate the feasibility of the proposed method, this study employed the deep excavation of expansive soil channels in the South-to-North Water Diversion Project as the study area. By using deep learning techniques, models were established to correlate the phase, amplitude, and other relevant features with soil moisture. The results demonstrated that the soil moisture estimations obtained with the fused data from the proposed multi-satellite multi-frequency fusion technique outperformed those obtained from single-satellite single-frequency data inversion in terms of accuracy. This confirmed the effectiveness of the data fusion approach in improving the accuracy of soil moisture estimation when applied to the study area of the deep excavation of expansive soil channels in the South-to-North Water Diversion Project. In this paper, we use multi-satellite and multi-band data fusion techniques to process the GNSS-R observation data in order to obtain more comprehensive observation information, and use deep learning techniques to establish high-precision inversion models, which provide a new technical route for soil moisture inversion of deep excavated expansive soil channel slopes in the South-to-North Water Diversion Middle Route Project.
2. Basic Principles and Methods of GNSS-R Soil Moisture Inversion
2.1. GNSS-R Fundamentals
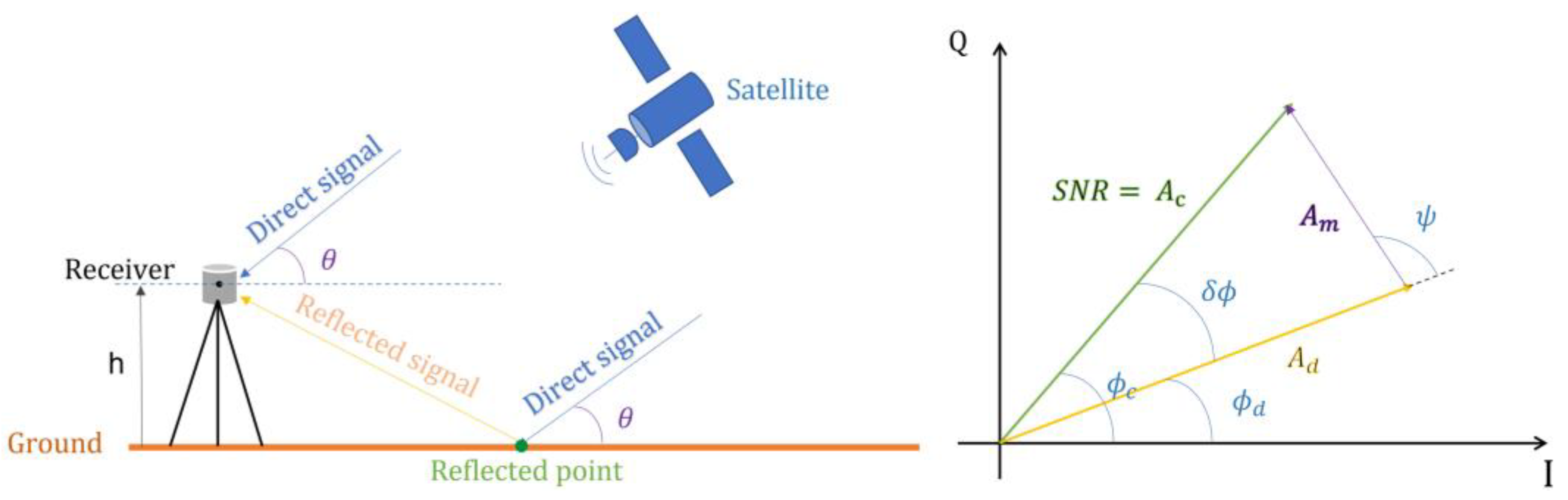
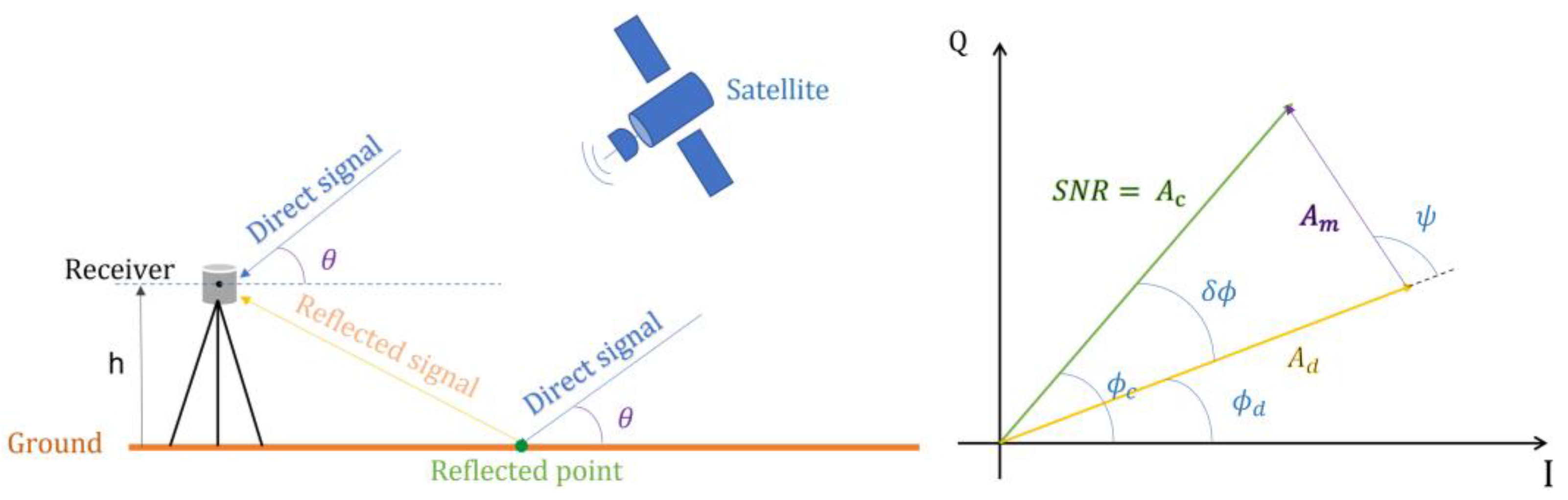
The GNSS-R reflectometry technique involves a dual-base radar that allows one to obtain surface roughness features and geophysical parameters, i.e., by using GNSS to measure the delay (time delay or phase delay) between the direct signal and the signal reflected from the surface mirror; then, based on the geometric positional relationships between GNSS satellites, receivers, and mirror reflection points, the surface features can be inverted [
32]. When using geodetic receivers, the environmental noise level remains constant, so the signal-to-noise ratio directly corresponds to the strength of the GNSS signal that is received.
Figure 1 depicts the direct and reflected signals received by the GNSS antenna, where the direct signal exhibits much higher intensity than that of the reflected signal. As shown in
Figure 1, the interference between the direct signal and the reflected signal (or multipath signal) results in an overlay effect, causing oscillations, particularly at low satellite elevations. In most environments, the amplitude of the reflected signal is much smaller than that of the direct signal. Therefore, the signal-to-noise ratio is controlled by the direct signal, and the desired multipath effects can be extracted by separating this oscillation pattern.
The relationship between the
SNR multipath amplitude and
is established by identifying the effect of the gain pattern of the receiving antenna on the recorded signal strength, and at any moment, the
and satellite altitude
θ can be expressed by Equation (1) [
33]:
where
represent the amplitudes of the direct signal and multipath signal, respectively, which indicate the contributions of the multipath signal to the SNR.
denotes the phase difference between the two signals.
is expressed as the composite signal amplitude of the two signals, i.e., the signal-to-noise ratio (SNR).
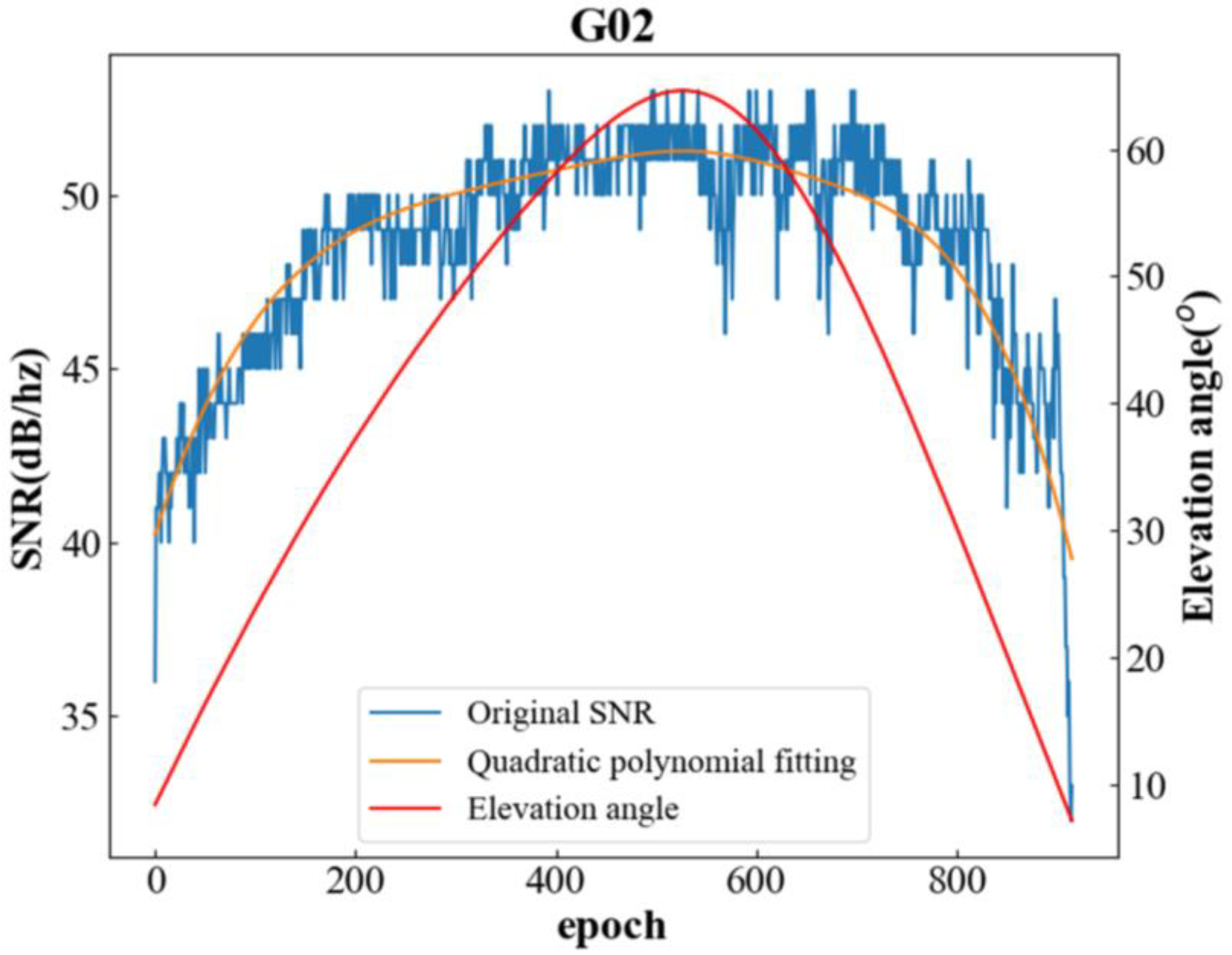
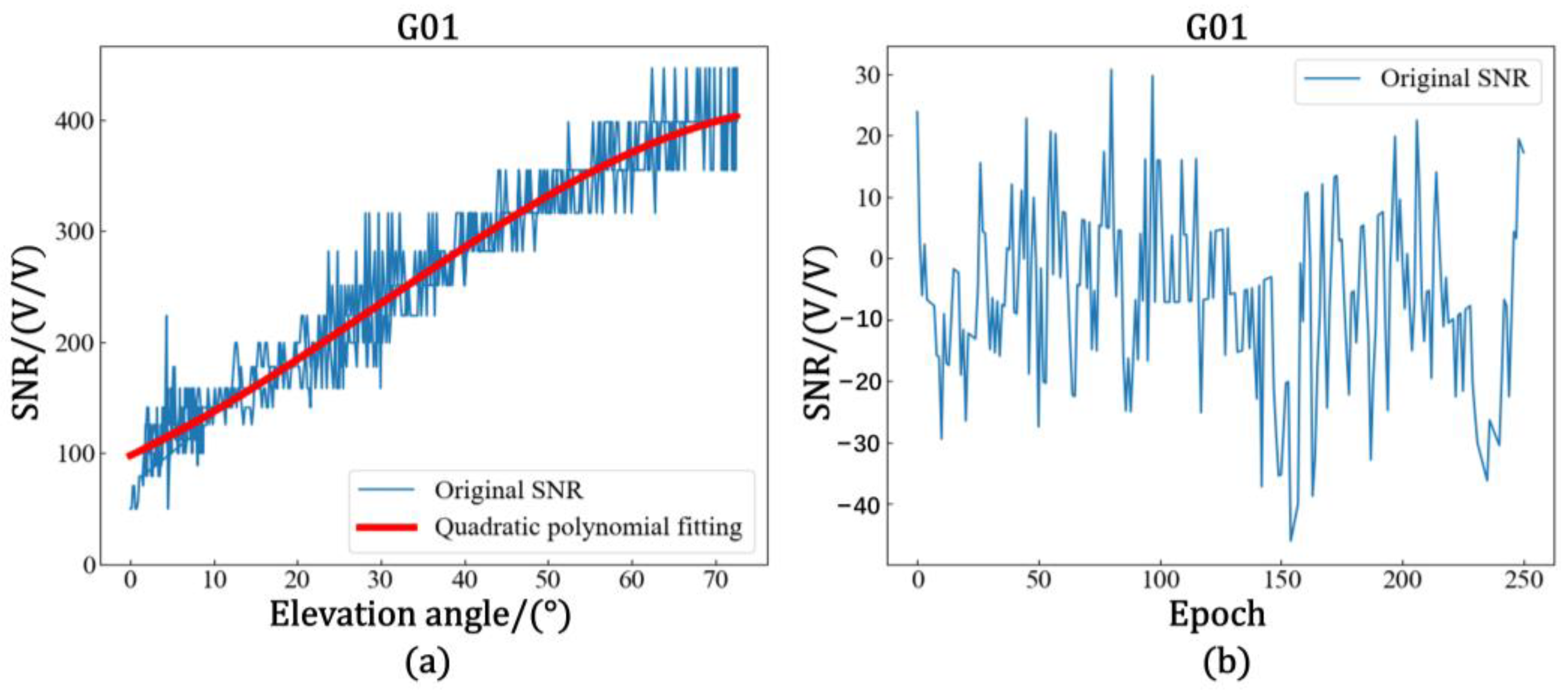
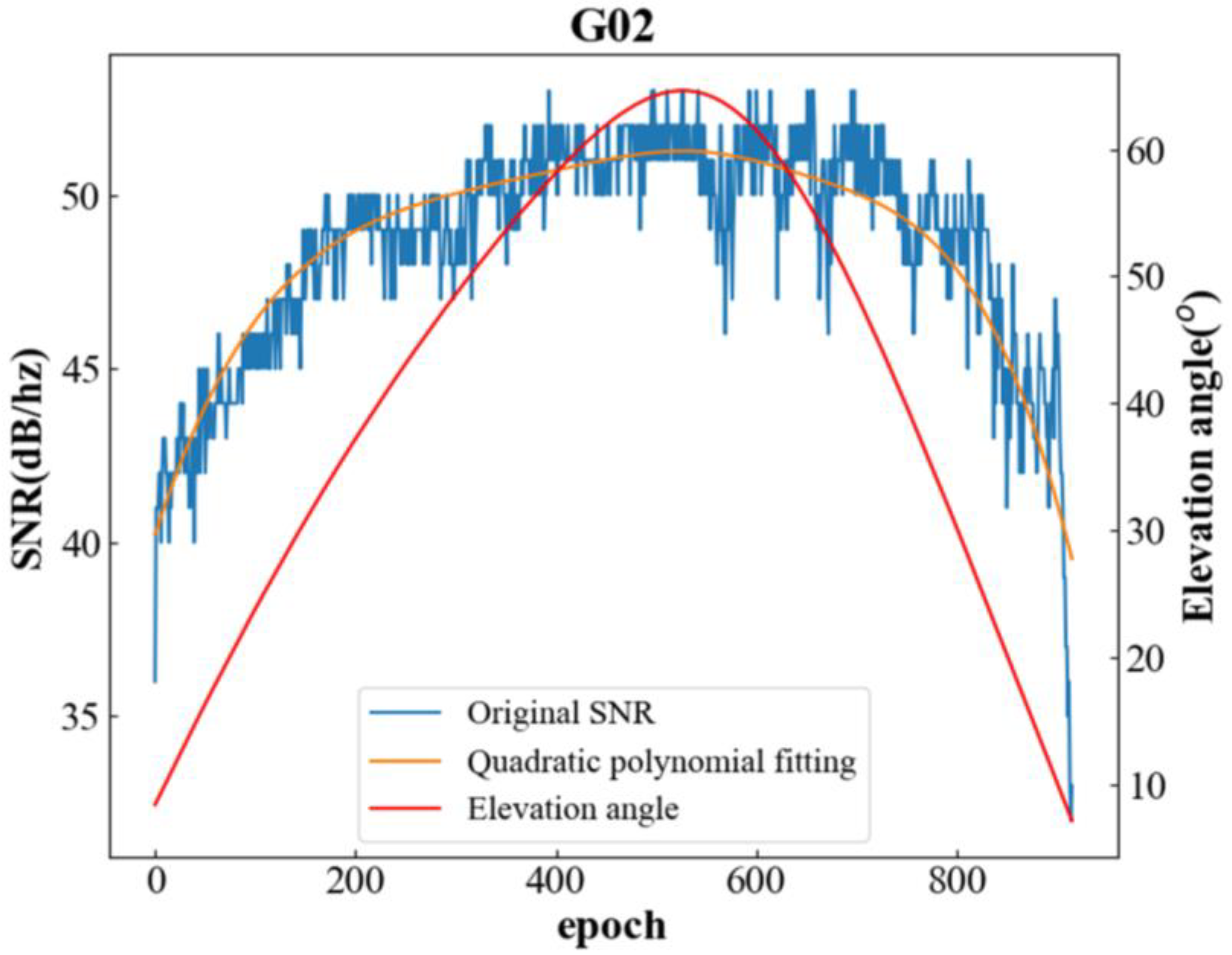
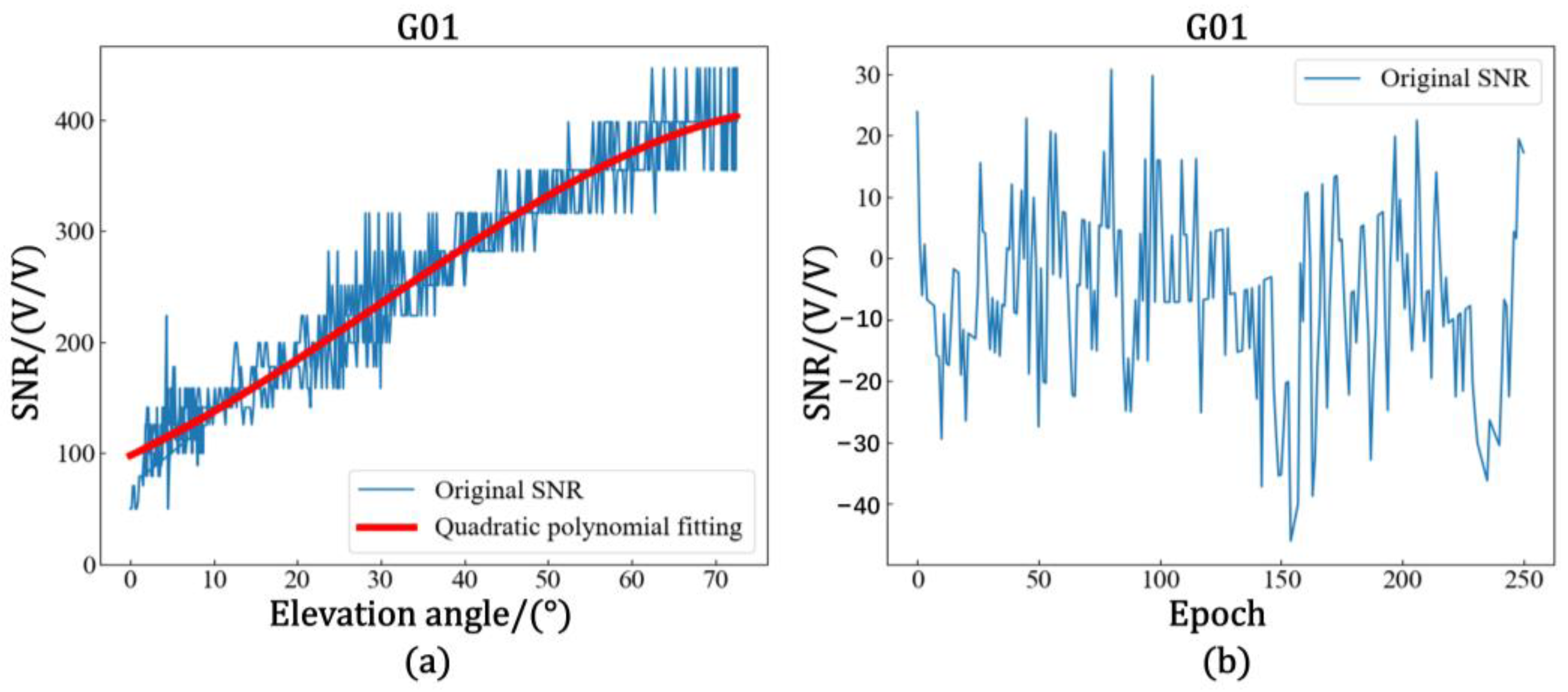
Figure 2 shows the trend of SNR variation and altitude angle variation in the L1 band of the G02 satellite on 1 January 2021 at station GP01.
As seen in Equation (1) and
Figure 2, the change in the amplitude of the direct signal or multipath signal with respect to the phase leads to a corresponding change in the SNR amplitude, and the effect of the antenna gain pattern indicates that
. Thus, the overall amplitude of the SNR is mainly driven by the direct signal [
34], while the multipath signal produces a small-amplitude, high-frequency oscillation in the direct signal and, thus, affects the SNR. This oscillation is more pronounced at lower satellite azimuth angles [
35].
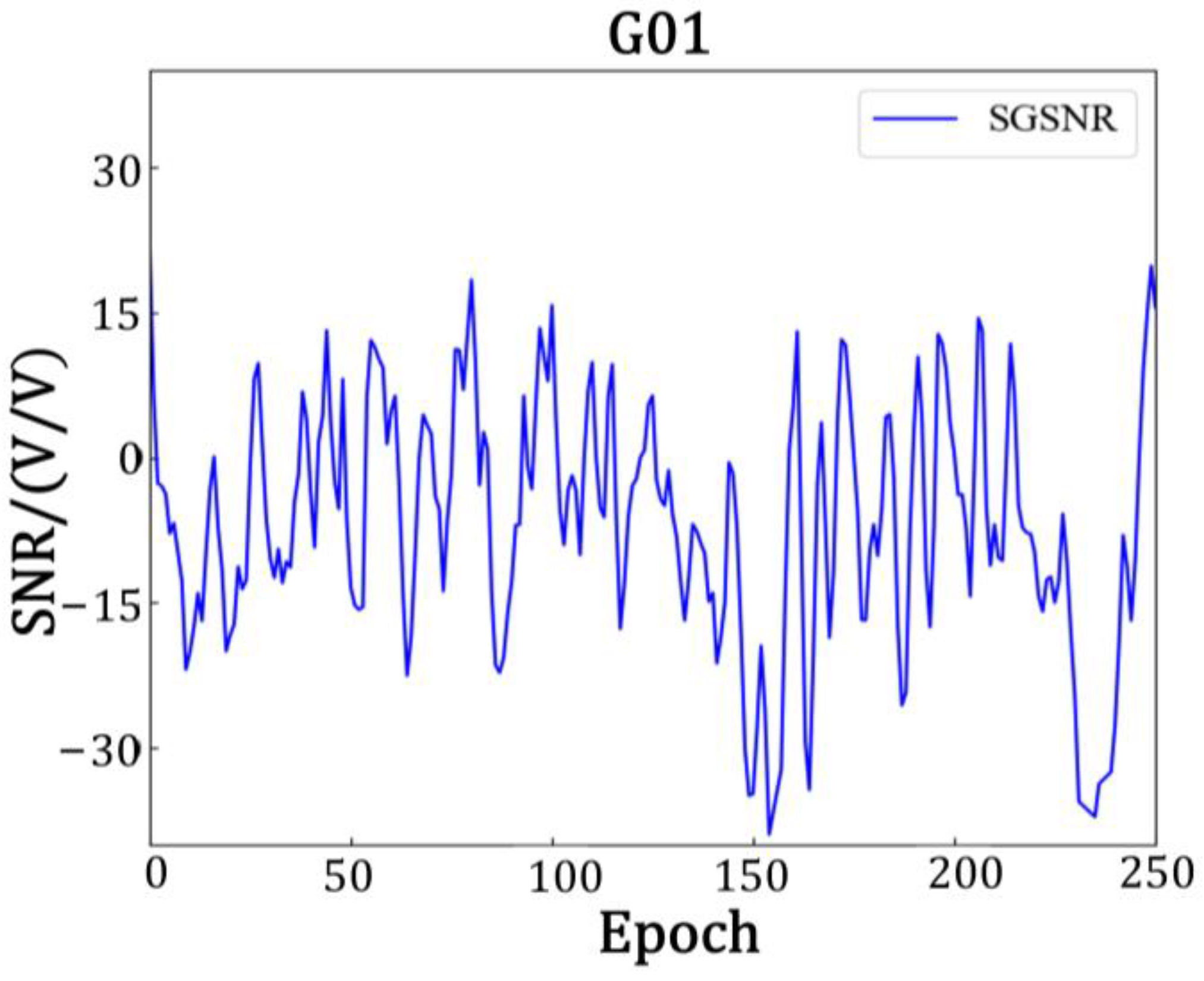
To determine the multipath amplitude of the SNR, it is necessary to separate the contribution of the multipath signal to the SNR from the amplitude of the direct signal
. This can be achieved by fitting a low-order polynomial to the SNR time series to estimate the direct signal and subtracting it from the original SNR data. The residual sequence,
, represents the multipath component and can be expressed with Equation (2):
In the equation, represents the amplitude, denotes the carrier wavelength, represents the phase, and h is the distance from the phase center of the receiving antenna to the reflecting surface, which is also known as the effective antenna height.
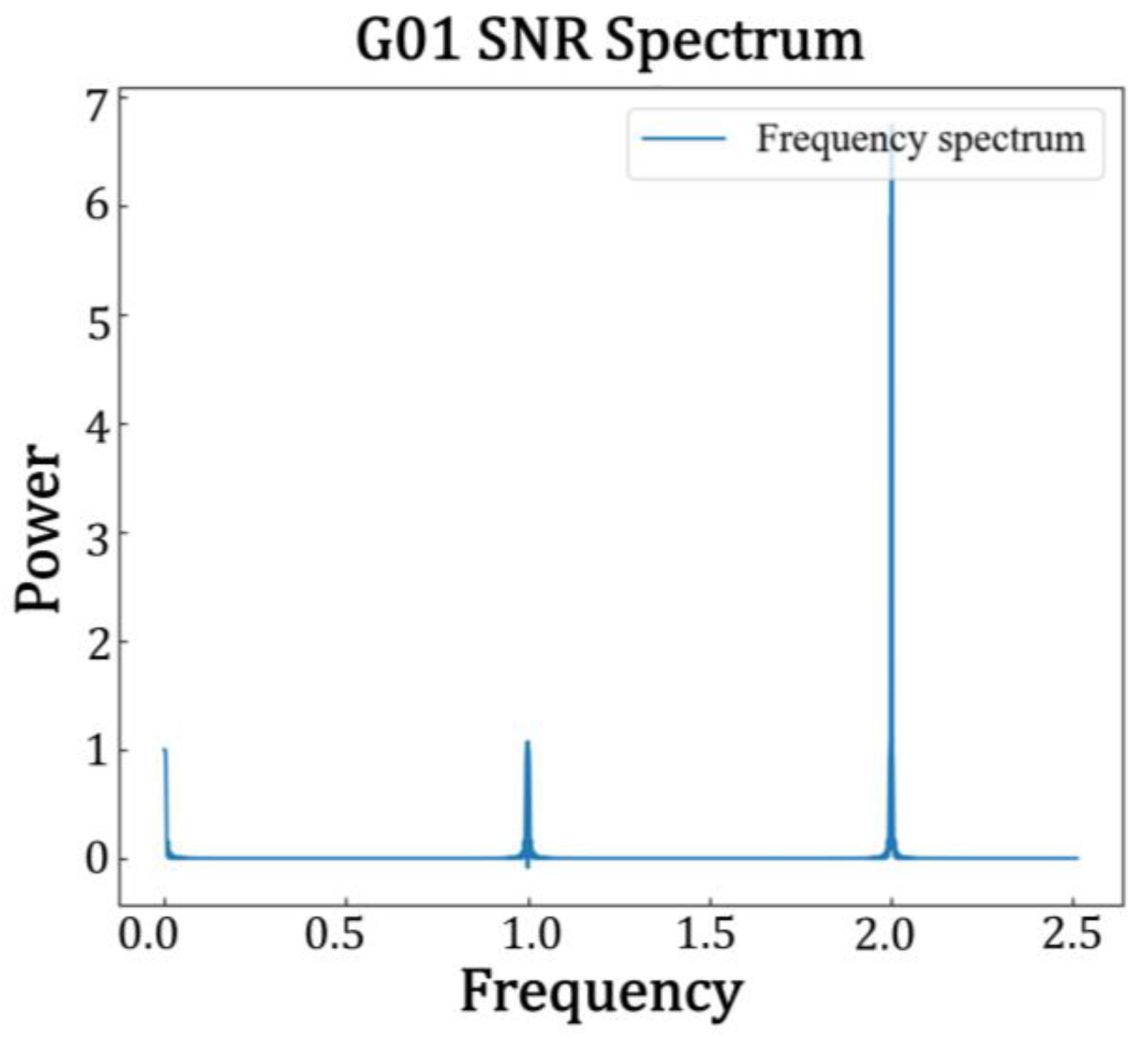
Due to the inability to obtain a complete periodic segment of the SNR’s residual sequence in
Figure 2, it is generally challenging to address it with a fast Fourier transform. However, the Lomb–Scargle algorithm can effectively extract weak periodic signals from non-uniform sequences [
36]. Therefore, Lomb–Scargle spectral analysis is applied to the SNR’s residual sequence to obtain the highest frequency, leading to the determination of the most effective vertical reflection height, h. During the fitting process for obtaining
and
, the effective antenna height, h, is often treated as a fixed constant. However, in practical measurements, variations in satellite trajectories and environmental conditions around the receiver station can cause changes in h. In long-term observation sequences, the median of the effective antenna height is closest to the vertical distance from the receiver antenna to the reflecting surface. Therefore, this study adopts the median value of the effective antenna height in the long-term observation sequence as a fixed value for h in the fitting of the feature parameters. The SNR reflection component exhibits periodic oscillations with the satellite elevation angle, approximating a cosine function. Therefore, a nonlinear least squares algorithm is employed to perform cosine fitting on the resampled data to obtain the reflection signal’s amplitude parameter
and phase parameter
. Finally, the soil moisture is inverted by using the amplitude parameter
and phase parameter
.
2.2. Data Fusion Methods
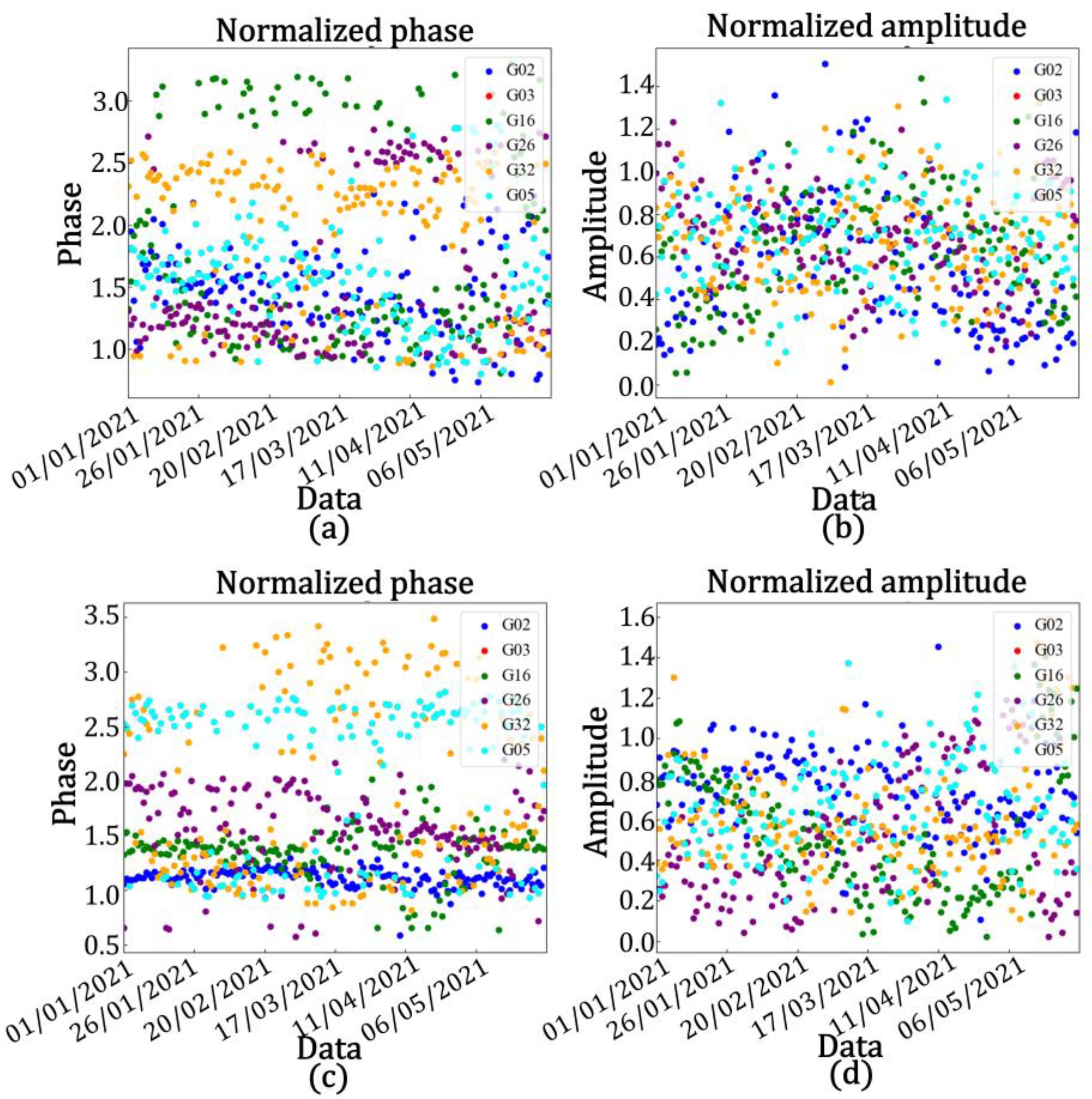
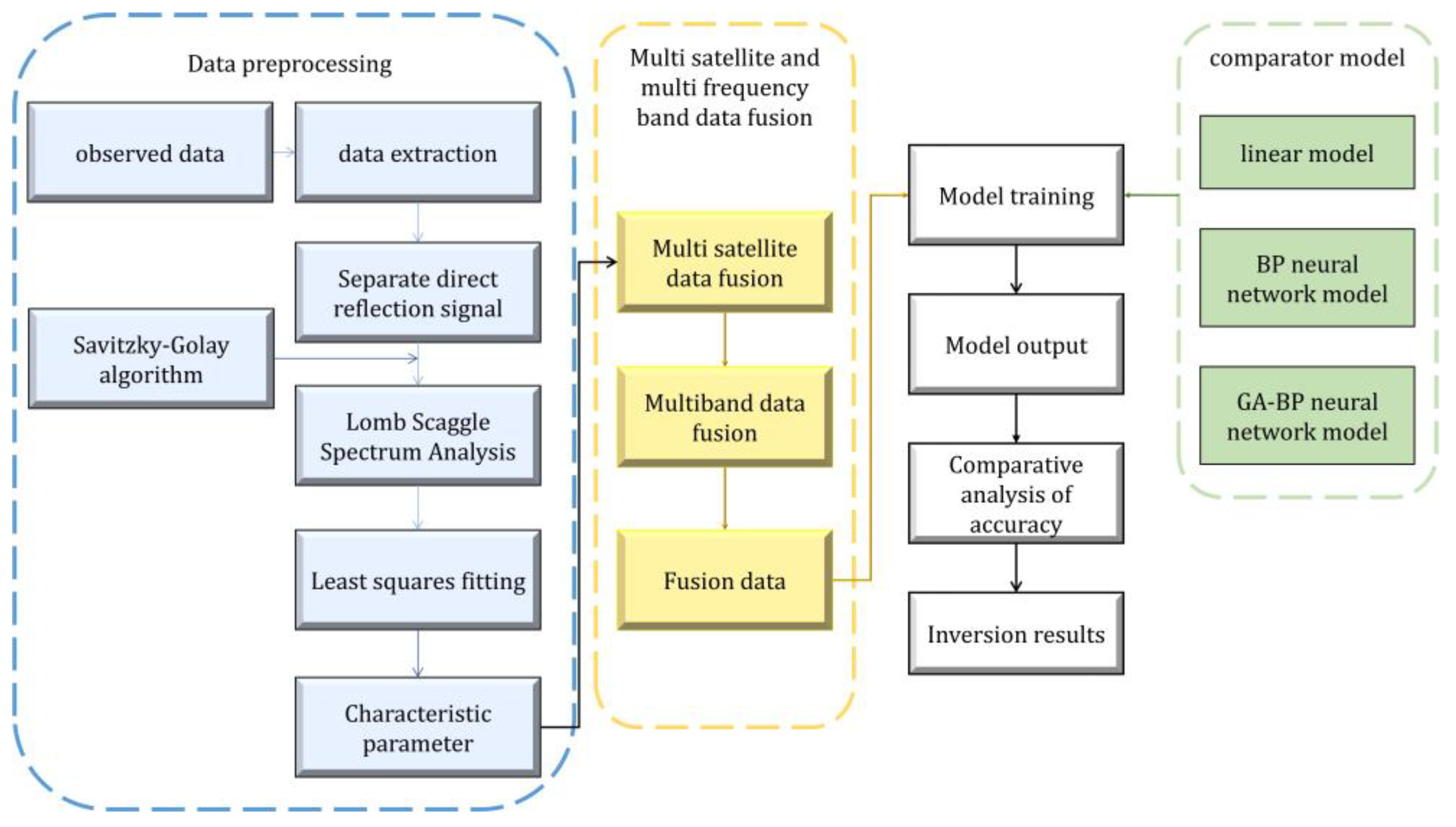
This study proposes a novel data fusion method that utilizes multiple data processing algorithms for data preprocessing to enhance the inversion process. The method automatically selects satellites with a high correlation among the amplitude, phase, and soil moisture. An adaptive fusion algorithm based on least squares is then applied to merge data from multiple satellites in the same frequency band. Furthermore, an entropy-based fusion method is employed to merge amplitude and phase data from different frequency bands. By using this method, signal gaps are reduced, and the limitations of the limited observation information from a single satellite and varying data quality are addressed, resulting in improved data quality and enhanced accuracy in soil moisture inversion.
Before performing data fusion, to reduce the significant differences in amplitude caused by different satellites, the amplitude sequence is first arranged in ascending order. The average value of the top 20% of the sequence is selected as the baseline for normalization, as shown in Equation (3):
For the phase, the initial phase of each satellite signal arriving at the ground is different. In order to clearly derive the phase variation caused by humidity changes for the comparison of the phase characteristics of different satellites, etc., the phase time series of each satellite track needs to be zeroed, i.e., the minimum value is set to zero. When zeroing according to Equation (4), first, the average of the lowest 20% of observations for each track (satellite) is calculated, and then this average is subtracted from the phase time series.
In the above equation, represents the average of the top 20% of the largest values in the amplitude sequence, and represents the average of the bottom 20% of the smallest values in the phase sequence. By applying the aforementioned processing, noise and errors caused by vegetation, terrain, and other factors can be removed from the time series, which is beneficial for soil moisture inversion. This step helps enhance the accuracy of soil moisture retrieval by mitigating the impacts of various sources of interference.
After normalizing the data, the same frequency band data from multiple satellites are fused by using an adaptive fusion algorithm based on the least squares method. The adaptive fusion algorithm based on the least squares method aims to minimize the total variance with respect to the true value by adjusting the weights of each datum, thus achieving more accurate fusion results. For the SNR observations provided by multiple satellites, the phase and amplitude values of each satellite are obtained after processing. These phase and amplitude data are then fused to obtain a more precise estimation. In this algorithm, the least squares method is used to solve for the optimal weighting coefficients that minimize the sum of squared errors between the fused result and the true value. Specifically, assuming that there are n satellites providing observations, and after processing, the phase data
, …,
is obtained, along with their corresponding weight coefficients
, …,
, the objective is to solve the optimal weight coefficients that bring the weighted result closest to the true value y. Then, the problem can be transformed into the following problem of minimizing an objective function:
Equation (5) is derived so that the derivative is zero to solve for the optimal weight coefficients
, …,
. The optimal weighting factor can be expressed as Equation (6):
where
X = [
, …,
], y is the true value, and
w = [
, …,
] is the weight coefficient. Specifically, for the
ith weighting factor,
The optimal weighting coefficients are calculated according to Equation (7), and they are used to weigh the observations to obtain a more accurate estimate.
Finally, the entropy method is used to fuse data from different frequency bands acquired by GNSS receivers for fusion in order to obtain higher-quality observation data and improve the inversion accuracy. Data fusion with the entropy method involves multivariate data fusion based on the principle of information entropy. The core idea is that a greater information entropy indicates a greater uncertainty of the index and a smaller weight; a smaller information entropy indicates a lower uncertainty of the index and a larger weight. The observed values of each indicator are quantified according to certain rules, and then the information entropy and weight of each indicator are calculated; the final fusion result is calculated through the information entropy principle and the weighted average principle. Specifically, the entropy value method is calculated as follows:
- (1)
The normalized values of each column in the data are calculated and scaled to a range of [0, 1]; the formula is shown in Equation (8):
In Equation (8), x represents the original data, denotes the minimum value of the data, and corresponds to the maximum value of the data.
- (2)
The weight of the
ith sample under the
jth indicator is calculated for that indicator; the formula is shown in Equation (9):
- (3)
The entropy value is calculated for each column of data; the definition of entropy is used to compute the entropy value for each column of data. Entropy represents the uncertainty or information content of the data, and the formula for calculating the entropy value is shown in Equation (10):
- (4)
The weights of each datum are calculated; the formula for calculating the weight
for the
jth indicator is shown in Equation (11):
- (5)
The formula for performing data fusion is shown in Equation (12):
The fusion algorithm automatically selects satellites with high correlation between amplitude–phase data and soil moisture, fuses data from multiple satellites in multiple segments, reduces signal loss, improves the quality of observation data, and obtains high-precision inversion models.
2.3. Soil Moisture Inversion Based on Deep Learning
2.3.1. BP Neural Network
The artificial neural network algorithm, as the name suggests, is an algorithmic network composed of artificial neurons that mimics the way neural transmission occurs in the human brain. It possesses strong capabilities for nonlinear mapping, self-organization, adaptation, memory, and prediction, making it well suited for solving complex logical operations and nonlinear problems [
37]. Neural networks can be used for tasks such as classification, clustering, and prediction. They require a sufficient amount of historical data, and by training on this data, a network can learn the underlying knowledge within the data. The BP neural network, which is a widely used and a classical artificial neural network, possesses the aforementioned capabilities, along with characteristics such as strong plasticity, simplicity, and powerful learning abilities. Today, it is used in extensive applications across various fields [
38].
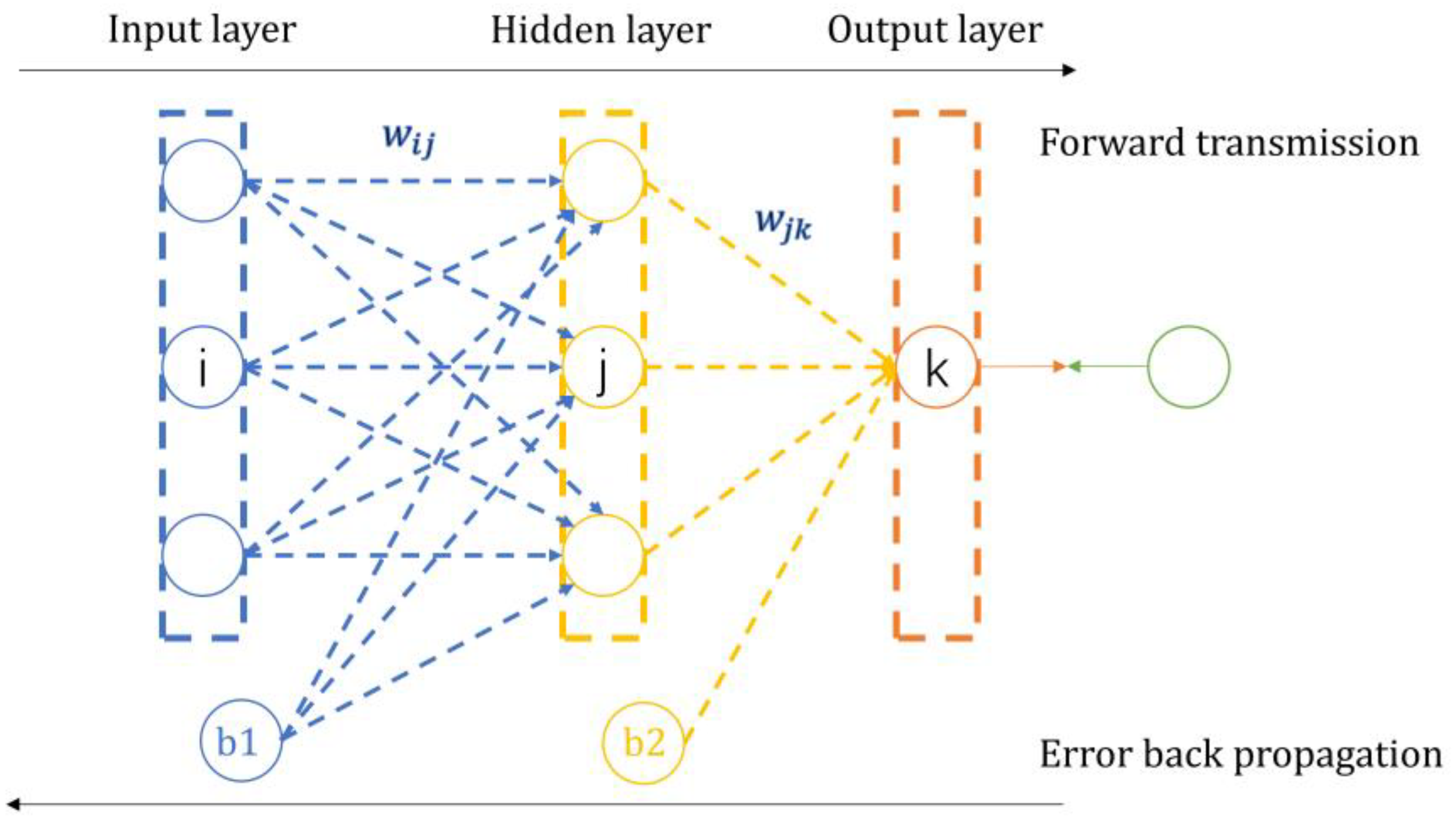
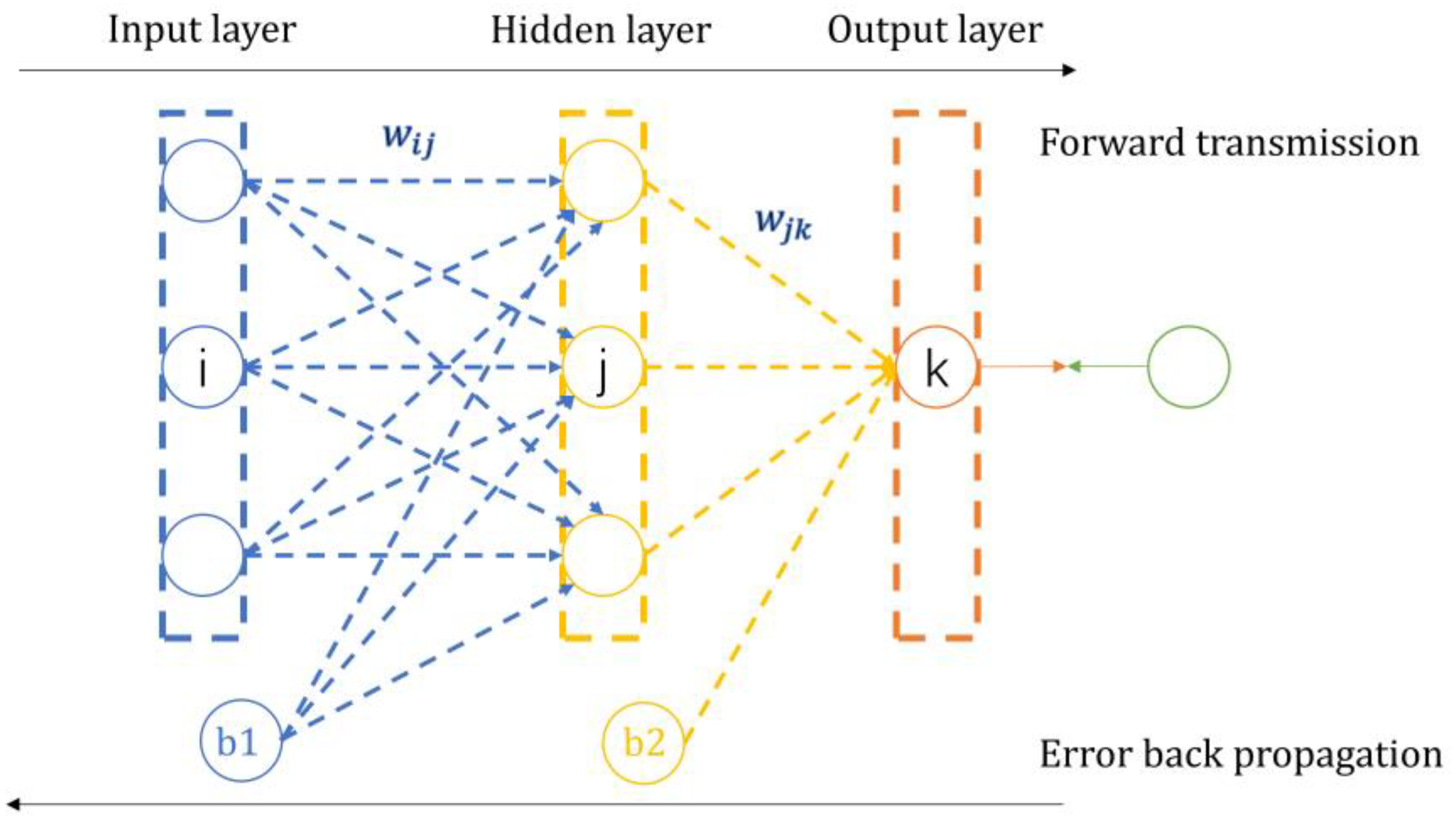
The BP neural network is the fundamental form of a neural network, and its output is obtained through forward propagation, while the error is propagated back through the network by using a backpropagation method. A BP neural network emulates the activation and propagation processes of human neurons. Considering a three-layer neural network as an example, a BP neural network consists of three layers: the input layer, the hidden layer, and the output layer. The input layer receives data, and the output layer outputs data. Each neuron in the previous layer is connected to neurons in the next layer, collecting information from the previous layer and transmitting it to the next layer through activation. The structure of a BP neural network is depicted in
Figure 3.
Here, i is the number of input layer neurons, j is the number of hidden layer neurons, k is the number of output layer neurons, w is the weight, and b is the “bias”. Each circle is a neuron.
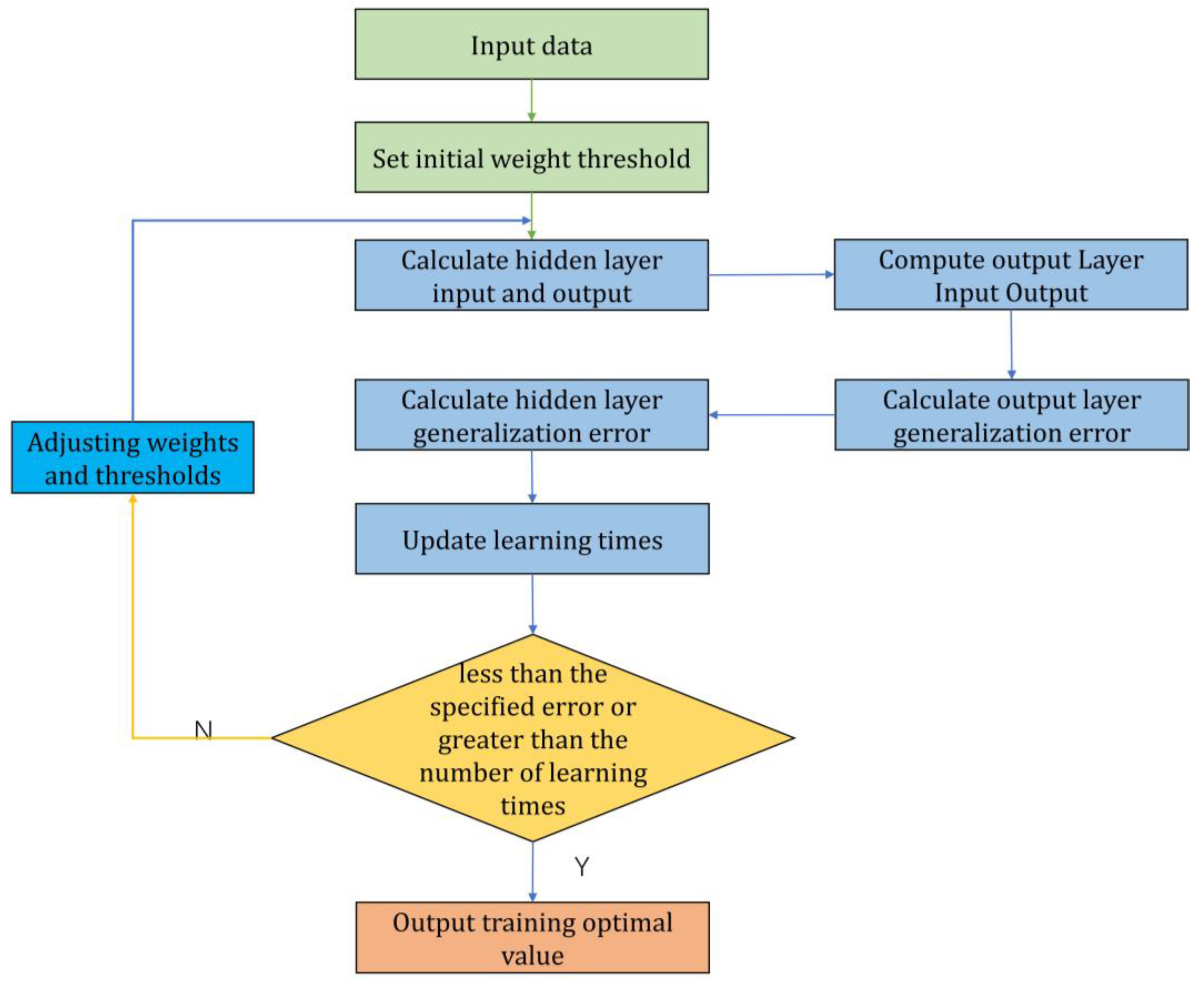
The BP algorithm includes the following two processes: (1) Forward propagation of information, where the feature signal is passed forward along the input layer and passed to the output layer nodes through the hidden layer’s neurons. The output nodes do not directly output the signal but need to undergo a series of nonlinear changes. The obtained output signal is analyzed for error with the target output signal, and if the error is too large, it is transferred to the error backpropagation process. (2) In the backward propagation of error, the error obtained from the forward propagation of the signal is reversed from the output layer to the entire neural network; the error is divided equally among the nodes in each layer when it passes through the hidden layer and the input layer, and the network weights are updated so that the error decreases layer by layer along the reversed neural network and so on until the forward propagation of the signal reaches the desired output. The threshold and weights corresponding to the actual output are determined at this time, and the training of the neural network can be stopped. Specifically, assuming a three-layer BP neural network with M input layer nodes, N hidden layer nodes, and O output layer nodes and by using a sigmoid function as the activation function, the main steps of BP neural network training are as follows.
- (1)
The input variables
are computed for the
ith node of the hidden layer of the neural network; the equation is shown in Equation (13):
where the meaning of the variable
denotes the input parameter of the
jth node of the input layer,
j = 1, …, M; the meaning of the variable
denotes the neural network’s weight parameter between the
ith node of the hidden layer and the
jth node of the input layer; the meaning of the variable
denotes the threshold parameter of the ith node of the hidden layer.
- (2)
The output variable
is computed for the
ith node of the hidden layer of the neural network; the equation is shown in Equation (14):
where
is the excitation function of the hidden layer. A sigmoid function expressed by Equation (15) is used in this study:
- (3)
The input variable
is calculated for the
kth node of the output layer of the neural network; the equation is shown in Equation (16):
where the meaning of the variable
denotes the weight parameter between the
kth node of the output layer and the
ith node of the hidden layer,
i = 1, …, q; the variable
denotes the threshold parameter of the
kth node of the output layer,
k = 1, …, L;
- (4)
The output variable
is computed for the
kth node of the output layer of the neural network; the equation is shown in Equation (17):
- (5)
The error
E is calculated with Equation (18):
where
is the desired output.
- (6)
The weight is updated with Equation (19):
where
is the learning rate.
- (7)
The threshold is updated with Equation (20):
- (8)
It is determined whether the iteration of the algorithm is finished, and if not, one returns to step (2).
A flowchart of the BP neural network is shown in
Figure 4.
2.3.2. GA-BP Neural Network
While BP neural networks have strong learning capabilities and robustness, they can suffer from some limitations. Because their search mechanism is that of gradient descent, without prior knowledge, the initial values and weights of the network are random, making them prone to being trapped in local minima instead of finding the global minimum. Consequently, a network may fail to obtain the optimal solution, and its learning and memory can be unstable. If training samples are added, the pre-trained network needs to be retrained from the beginning without leveraging the previous knowledge of weights and thresholds. This increases the learning burden and reduces the learning efficiency [
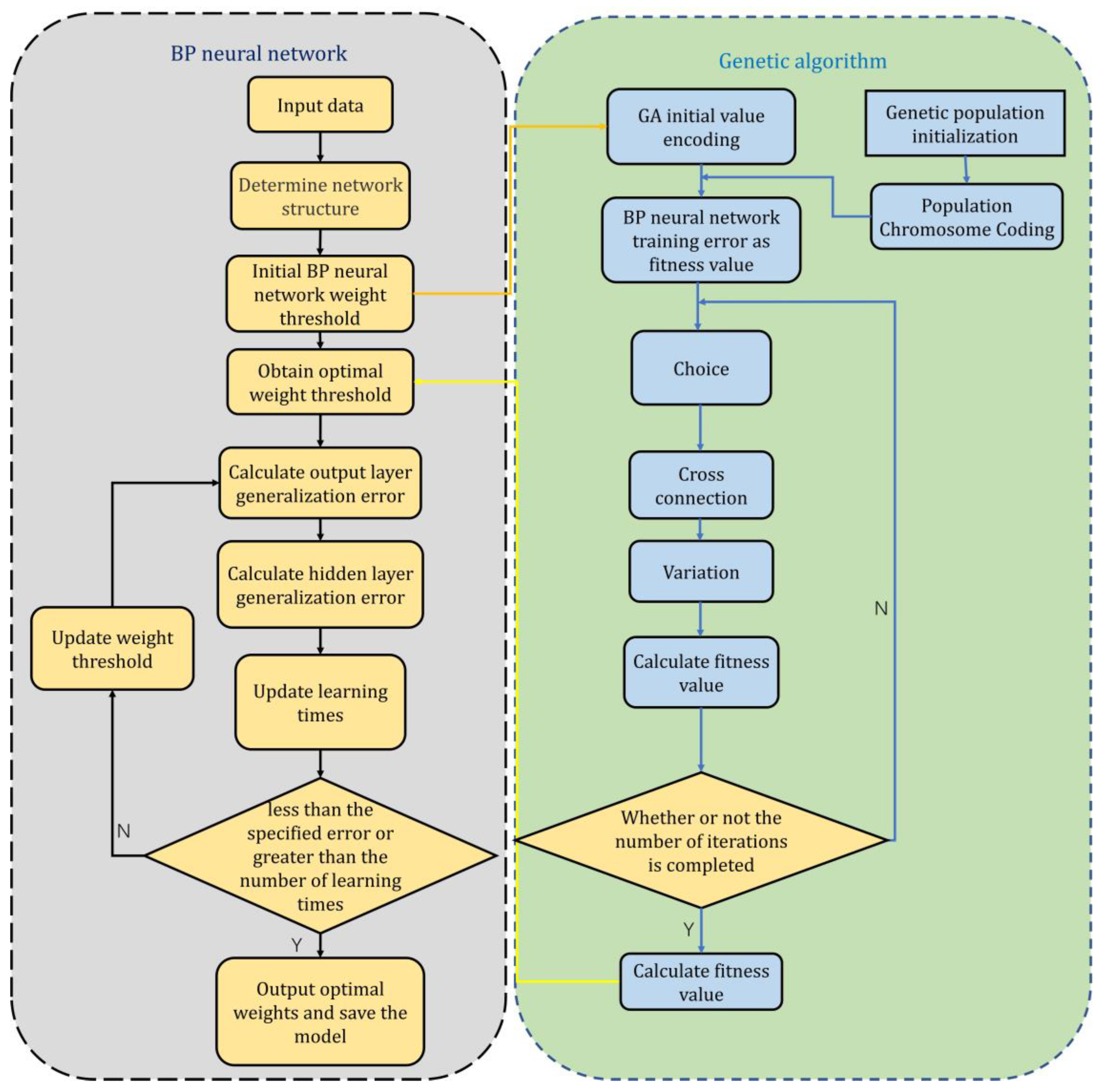
39]. To address these issues, the genetic algorithm (GA) can be used to optimize a BP neural network. By incorporating the GA, it is possible to quickly obtain the optimal neural network parameters, accelerate the learning process, and enhance the progress of network inversion.
Genetic algorithms are used to construct a fitness function based on the objective function of a problem, evaluate and perform genetic operations, select a population consisting of multiple solutions (each solution corresponds to a chromosome), and reproduce it over multiple generations to obtain the individual with the best fitness value as the optimal solution to the problem [
40]. The specific steps are as follows:
- (1)
Chromosome encoding: A real-number encoding strategy is used to implement the encoding of the chromosomes of the genetic algorithm. The S-order real matrix is set to [−1, 1], based on which the parameters, such as the connection weights between nodes in each layer of the BP neural network and node thresholds in the hidden layer and output layer, are encoded and solved for optimality [
41]. Compared with binary coding, real-number coding does not require decoding at a later stage, the coding length is shorter, and the accuracy of the parameter search is high [
42].
- (2)
Initializing the population: The initial population of W = (; ; …; ) is randomly generated, and the number of individuals in the population is set to P. Individuals , ; ; …; are generated with a linear interpolation function for one chromosome of the algorithm.
- (3)
Calculation of the population individuals’ fitness values: The sum of the squared training errors is used for the calculation of the population individuals’ fitness values.
- (4)
Selection: By using the roulette wheel method, the selection probability can be calculated with Equation (21):
where
is the fitness function, and p is the population size.
- (5)
Crossover: The crossover operation of gene
at position j and the crossover operation of gene
at position j are performed according to Equation (22):
where
b is a random number in the range of [0, 1].
- (6)
Mutation: The
jth gene of the
ith individual undergoes population variation, and the operation of which can be described by Equations (23) and (24):
where
and
are the maximum and minimum values of gene
, respectively;
is the maximum number of evolutions;
is the current iteration number;
is a random number in the range of [0,1];
is a random number.
- (7)
Obtaining new populations: Steps (4) to (6) are repeated until the optimal solution is output.
A flowchart of GA-BP neural network training is shown in
Figure 5.
5. Discussion
In this study, five metrics—the root mean square error (RMSE), model goodness of fit (R2), correlation (r), mean absolute error (MAE): and mean squared error (MSE)—were used to evaluate the models’ accuracy.
Root mean square error (
RMSE): The square root of the ratio of the square of the deviation of the observed value from the true value to the number of observations
N. This reflects the extent to which the measured data deviate from the true value. The formula is shown in Equation (27):
where
is the predicted value of soil moisture, and
is the true value of soil moisture.
Model goodness of fit (
R2): The percentage of the variance in the dependent variable y that can be explained by the independent variable x. The formula is shown in Equation (28)–(31):
Correlation (
): This measures the correlation between the predicted and actual values. The formula is shown in Equation (32):
Mean absolute error (
MAE): This is the average of the absolute error between the predicted value and the actual value. The formula is shown in Equation (33):
Mean Squared Error (
MSE): This is a commonly used measure of the difference between the predicted values of a model and the actual observed values to assess how well the model fits on the given data. The formula is shown in Equation (34):
Table 7 shows the results for the root mean square error
(RMSE), model goodness of fit (
R2), correlation (
), mean absolute error (
MAE), and mean squared error (
MSE) between the predicted and true values of soil moisture for the linear model.
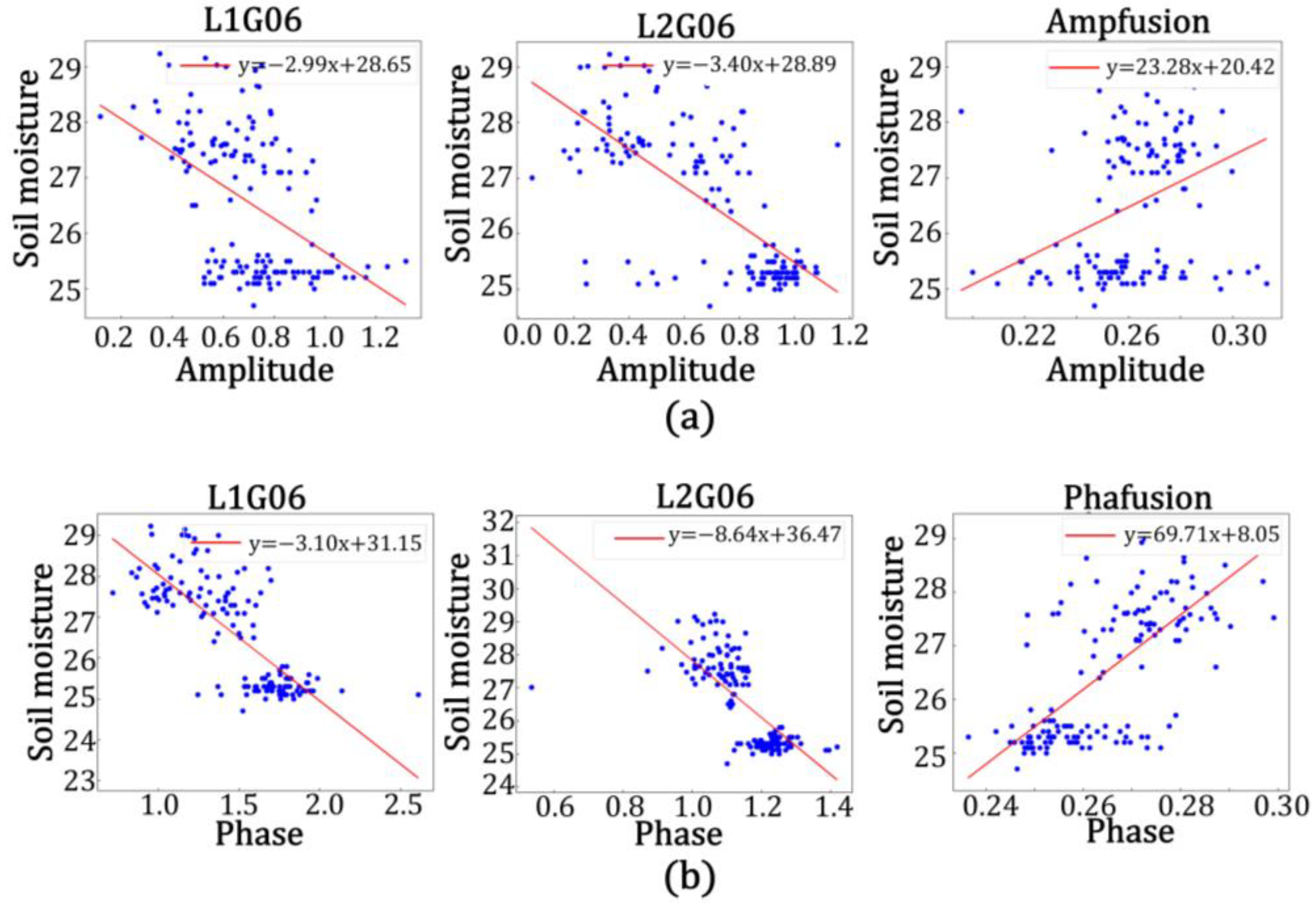
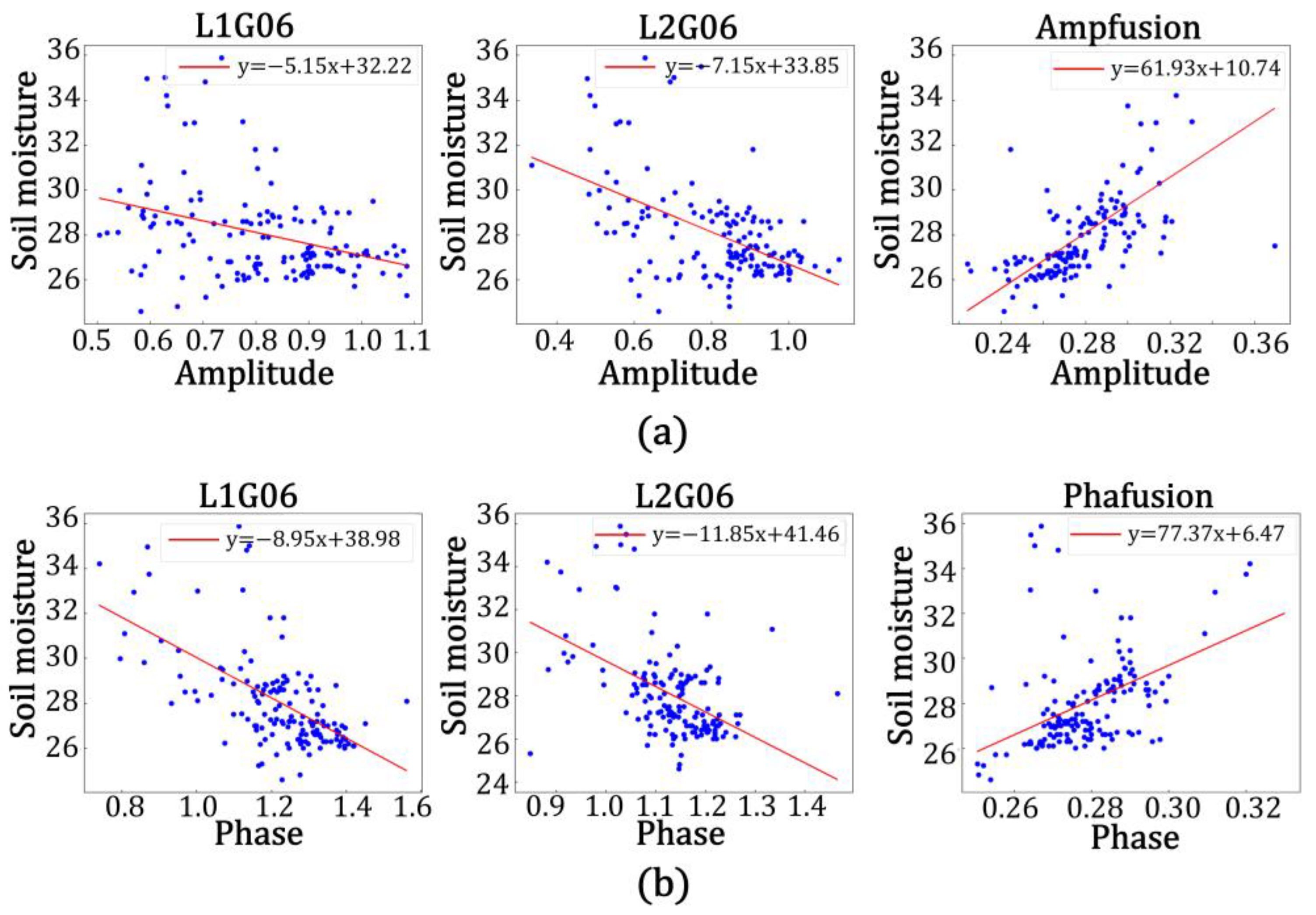
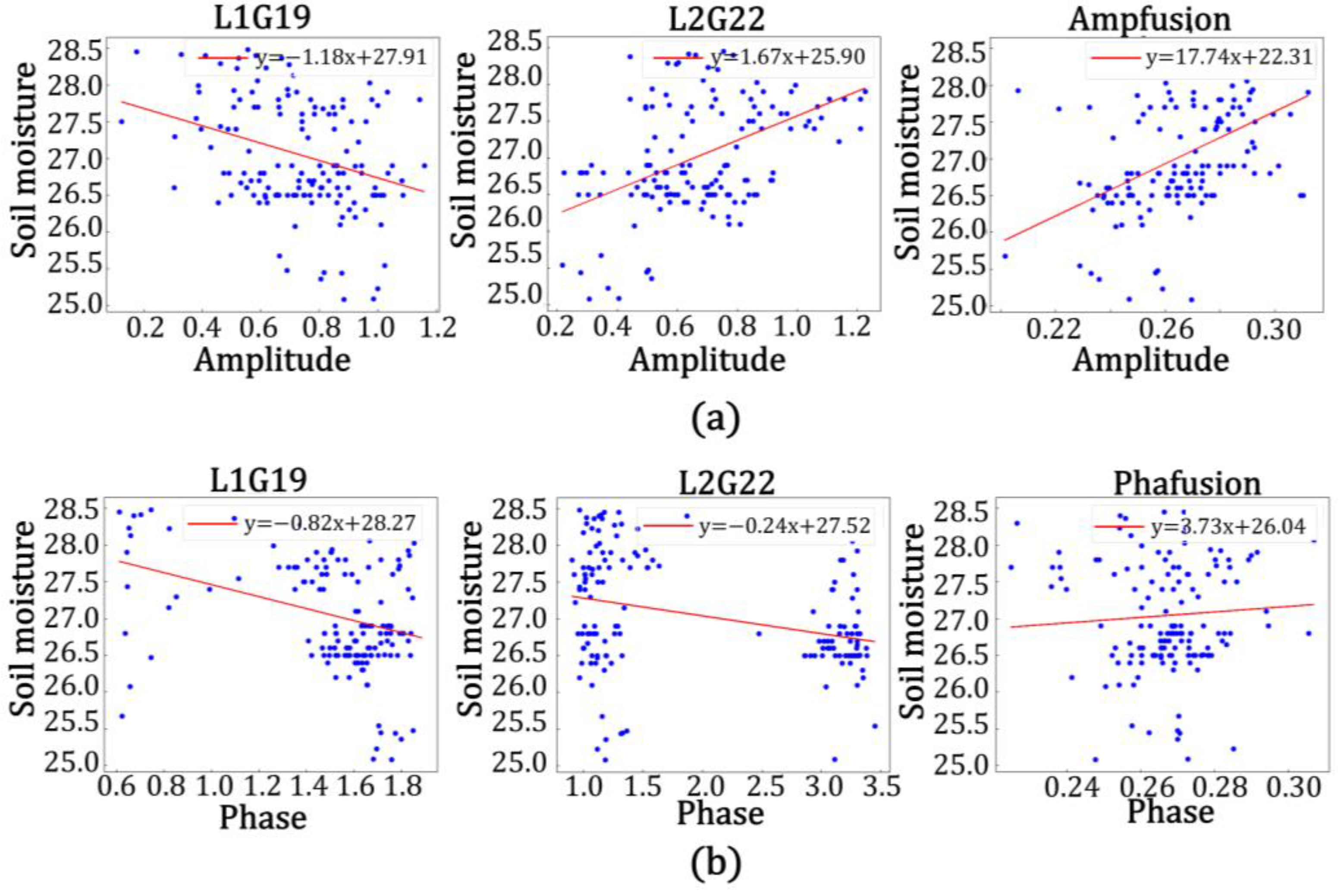
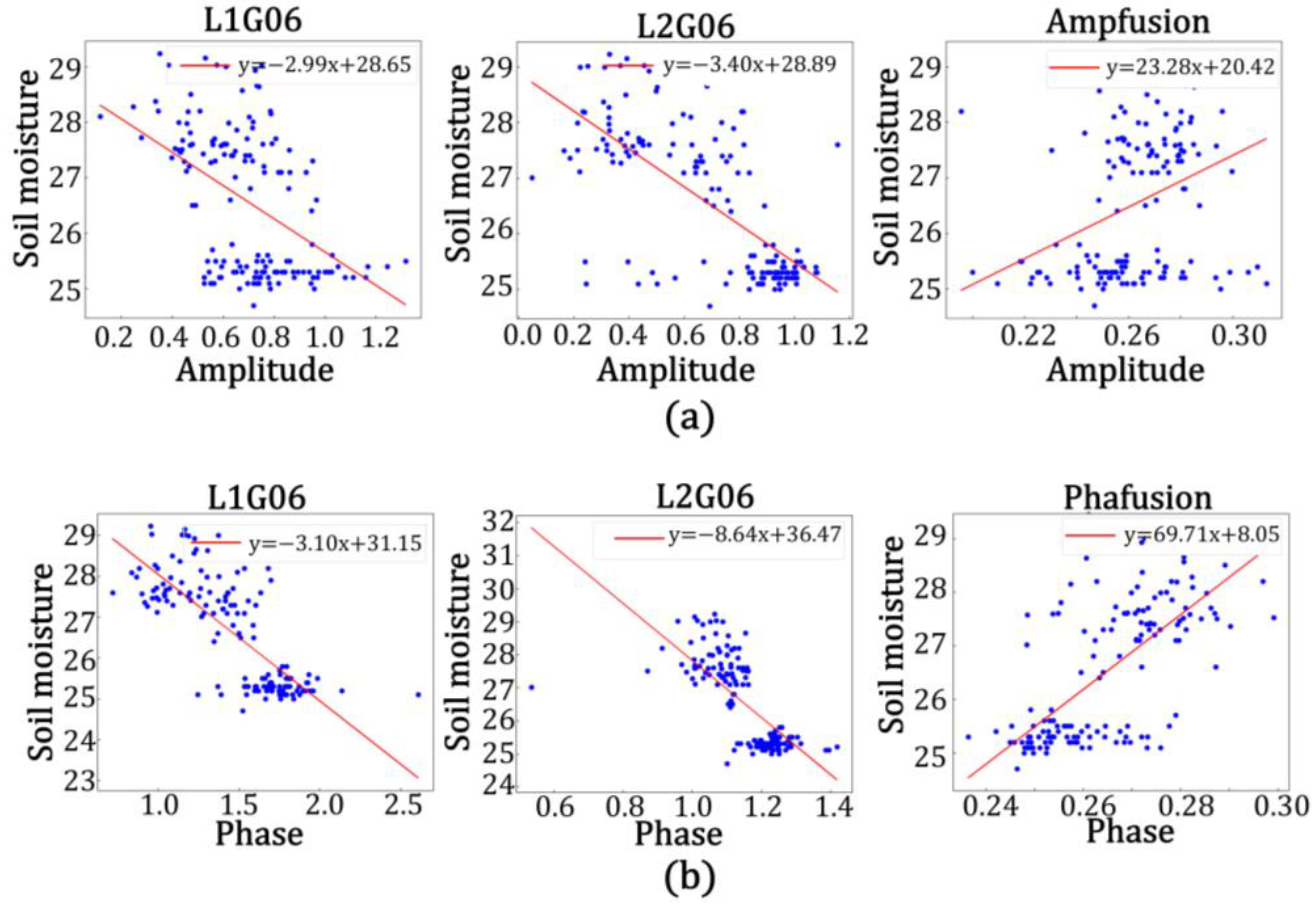
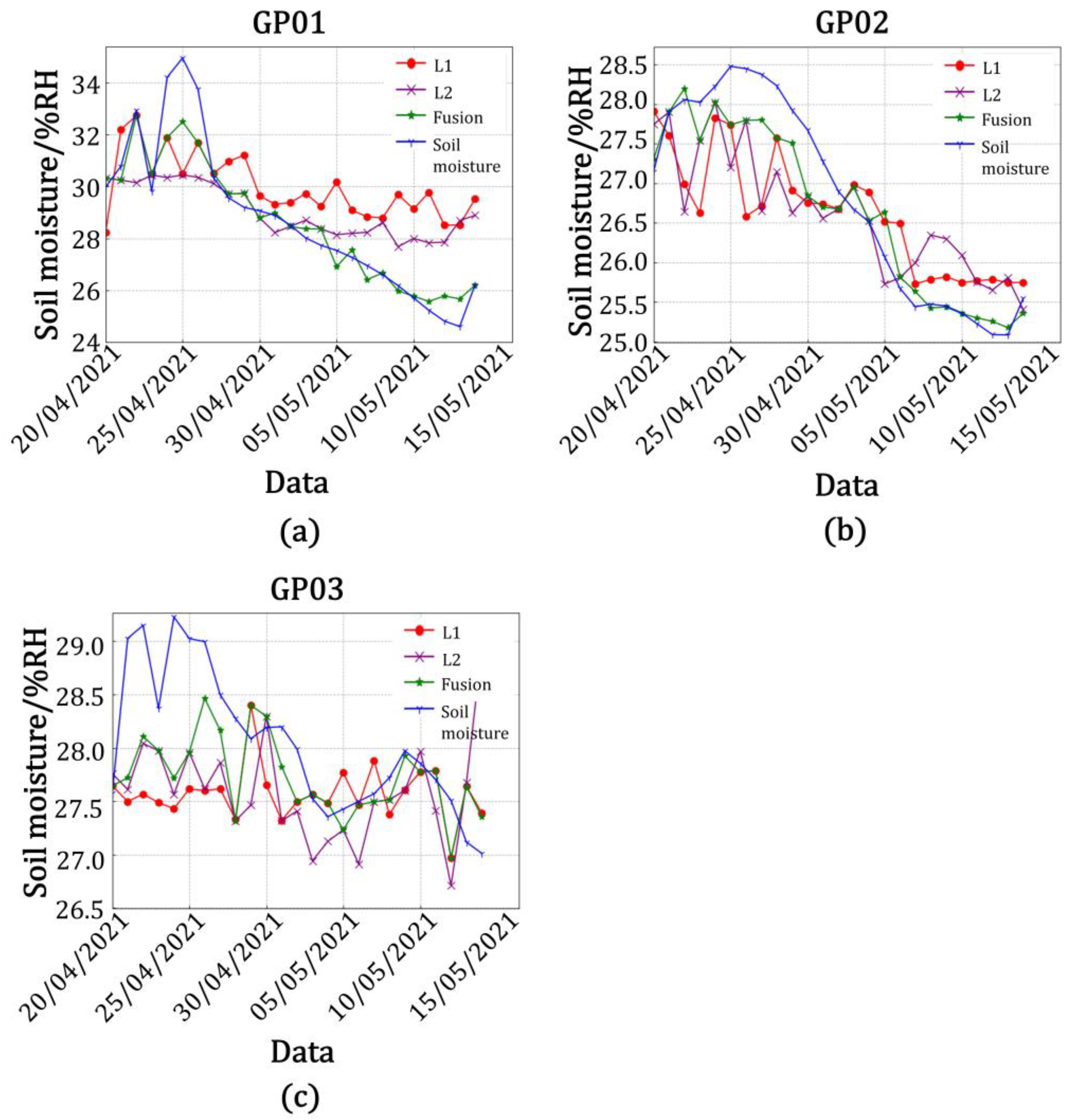
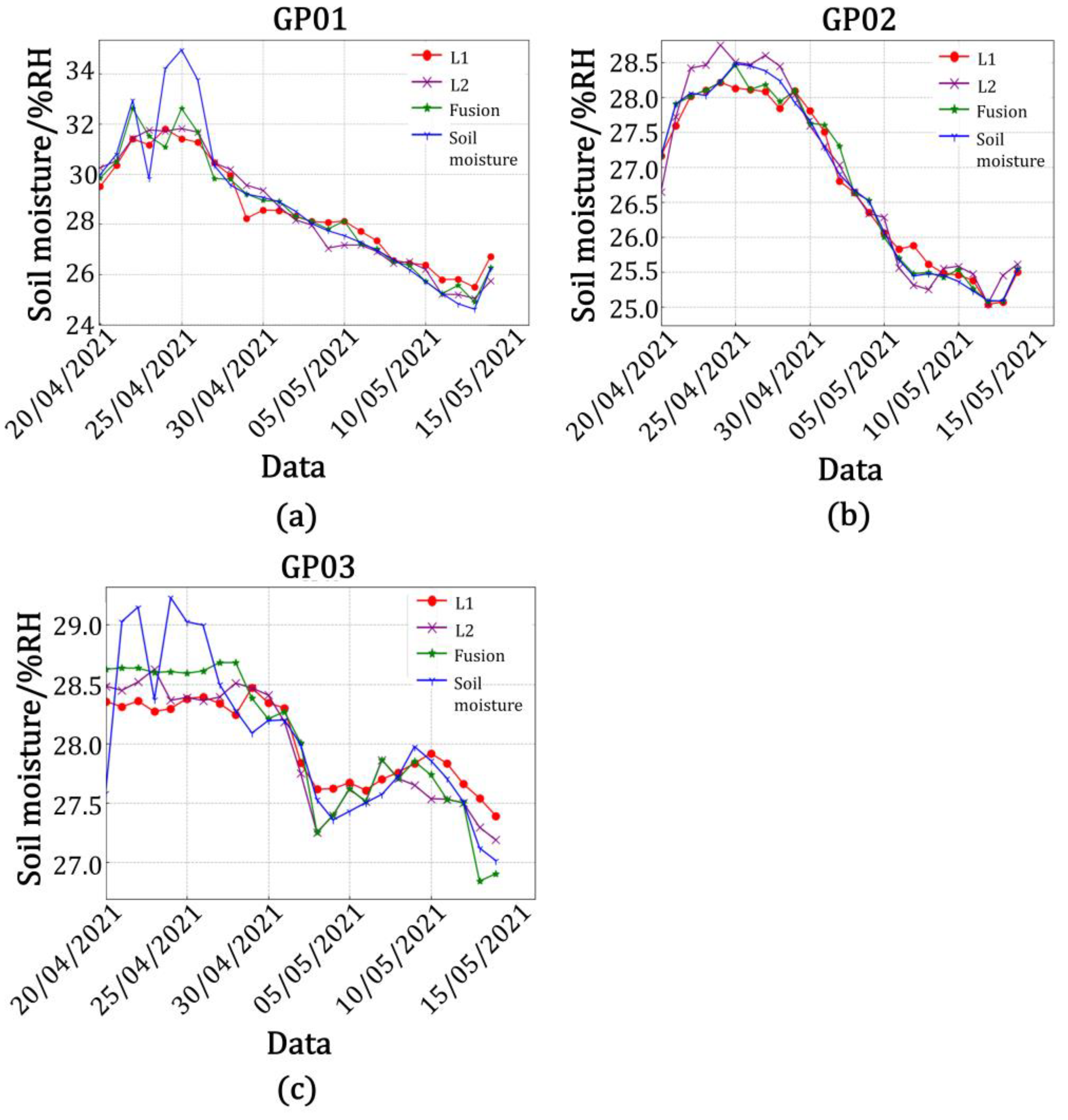
As shown in
Figure 19 and
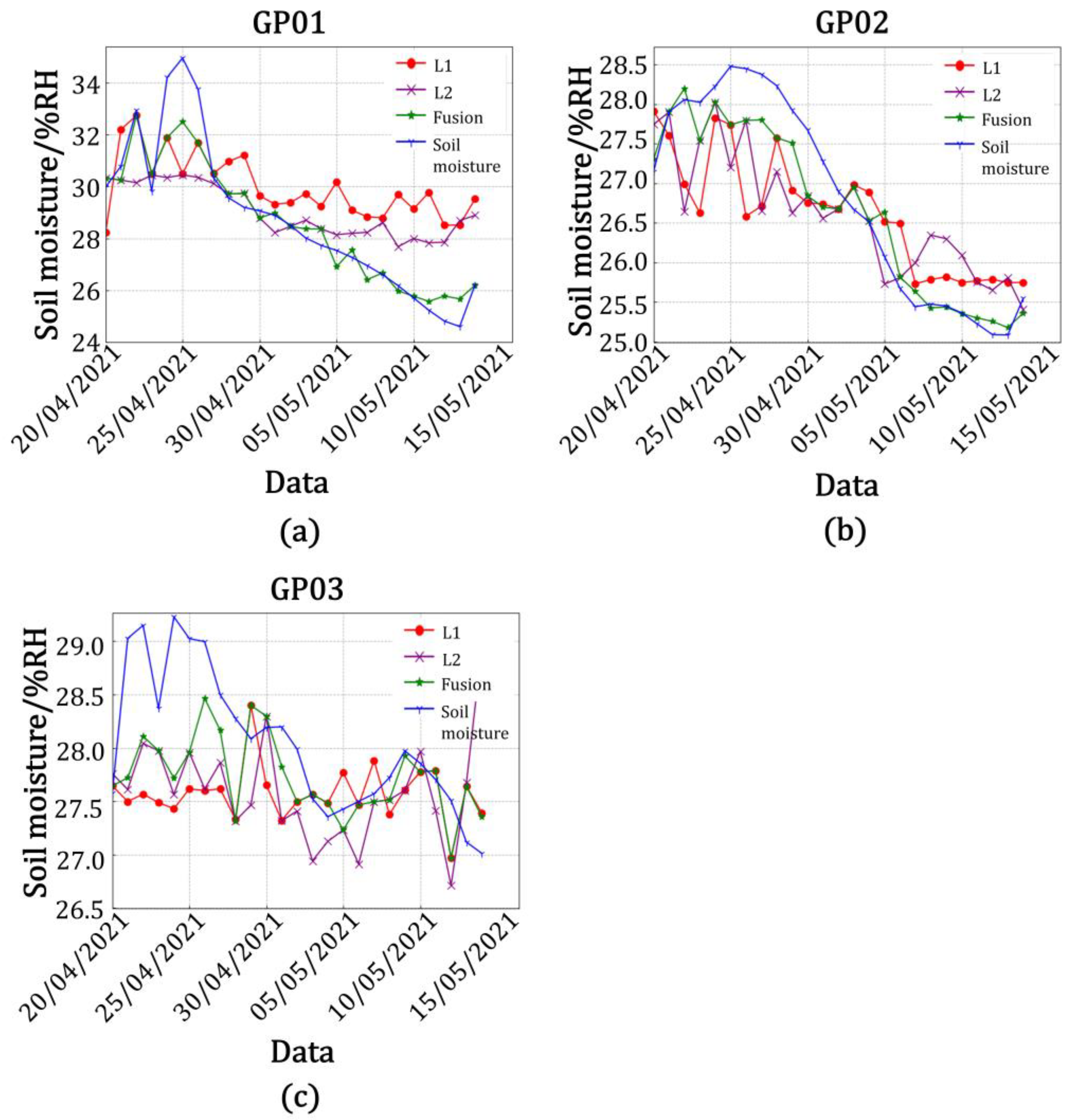
Table 7, the accuracy of the model built by using the data from the L2 band was higher than that when using the L1 band in the model of amplitude and soil moisture at station GP01, with the correlation between the predicted and true values of L2 band being 76.0%, the root mean square error being 2.144, the goodness of fit being 0.578, the mean square error being 4.597, and the mean absolute error being 1.608. The correlation between the predicted and true values of the fused data was 87.7%, the root mean square error was 1.927, the goodness of fit was 0.769, the mean square error being 3.713, and the mean absolute error was 1.365. It was calculated that the correlation between the predicted and true values of the fused data improved by 12.7%, the root mean square error decreased by 0.217, the goodness of fit improved by 0.191, the mean square error decreased by 0.884, and the mean absolute error decreased by 0.243 in comparison with the single-satellite data on the L2 band. In the model, the accuracy of the model built with data from the L2 band was higher than that built with data from the L1 band. The correlation between the predicted and true values of the L2 band was 88.9%, the root mean square error was 1.921, the goodness of fit was 0.790, the mean square error being 3.690, the mean absolute error was 1.560, and the correlation between the predicted and true values of fused data was 98.4%; the root mean square error was 1.028, the goodness of fit was 0.968, the mean square error being 1.057, and the mean absolute error was 0.790. It was calculated that the correlation between the predicted and true values of the fused data was improved by 9.5%, the root mean square error was reduced by 0.893, the goodness of fit was improved by 0.178, the mean square error decreased by 2.633, and the mean absolute error was reduced by 0.770 in comparison with the single-satellite data in the L2 band. Similarly, it could be calculated that the correlation between the predicted and true values of the fused data in the amplitude and soil moisture model for station GP02 was improved by 7.6%, the root mean square error was reduced by 0.476, the fit was improved by 0.251, the mean square error decreased by 0.719, and the mean absolute error was reduced by 0.449 in comparison with the single-satellite data for the L2 band. In the phase and soil moisture model for station GP02, the correlation between the predicted and true values of the fused data improved by 7.6%, the root mean square error decreased by 0.472, the fit improved by 0.127, the mean square error decreased by 0.969, and the mean absolute error decreased by 0.458 in comparison with the single-satellite data for the L2 band. In the amplitude and soil moisture model for station GP03, the correlation between the predicted and true values of the fused data improved by 9.3%, the root mean square error decreased by 0.636, the fit improved by 0.151, the mean square error decreased by 0.940, and the mean absolute error decreased by 0.463 in comparison with the single-satellite data for the L1 frequency band. In the phase and soil moisture model for station GP03, the correlation between the predicted and true values of the fused data improved by 6.5%, the root mean square error decreased by 0.18, the fit improved by 0.087, the mean square error decreased by 0.240, and the mean absolute error decreased by 0.162 in comparison with the single-satellite data for the L1 band.
Table 8 shows the results for the root mean square error (
RMSE), model goodness of fit (
R2), correlation (
r), mean absolute error (
MAE), and mean squared error (
MSE) between the predicted and true values of soil moisture from the BP neural network model.
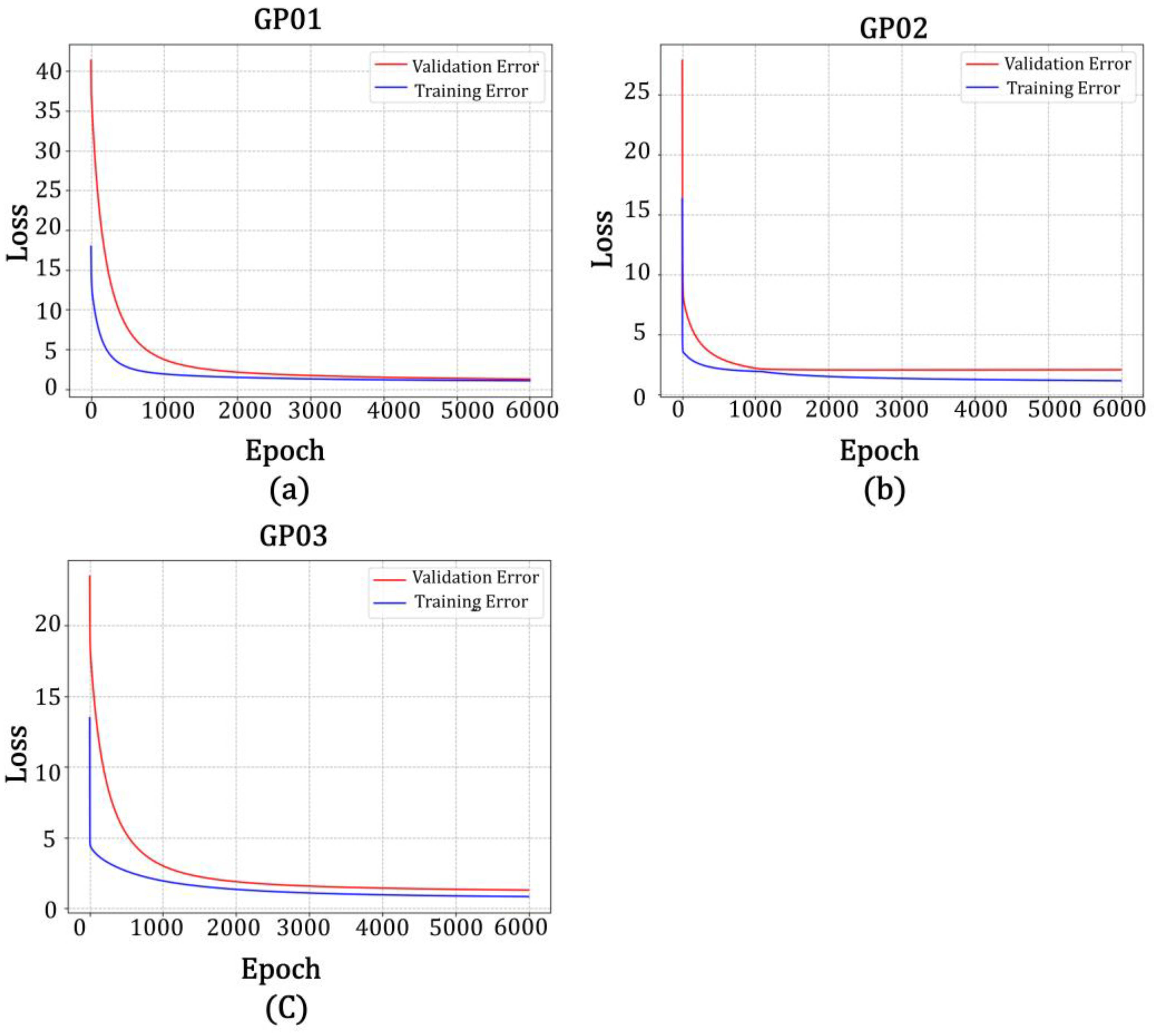
As shown in
Figure 20 and
Table 8, the accuracy of the model built by using the data from the L2 band in the BP neural network model of station GP01 was higher than the accuracy of that built with the data from the L1 band. The correlation between the predicted and true values for the L2 band was 84.2%, the root mean square error was 2.114, the goodness of fit was 0.447, the mean square error was 4.469, and the mean absolute error was 1.615. The correlation between the predicted and true values for the fused data was 96.4%, the root mean square error was 0.907, the goodness of fit was 0.898, the mean square error was 0.823, and the mean absolute error was 0.602. It was calculated that the correlation between the predicted and true values of the fused data was improved by 12.2%, the root mean square error was reduced by 1.207, the goodness of fit was improved by 0.122, the mean square error was decreased by 3.646, and the mean absolute error was reduced by 1.013 in comparison with the single-satellite data in the L2 band. In the BP neural network model for station GP02, the accuracy of the model built with the data from the L2 band was higher than that of the model built with data from the L1 band. The correlation between the predicted and true values for the L2 band was 81.1%, the root mean square error was 0.787, the goodness of fit was 0.594, the mean square error was 0.619, and the mean absolute error was 0.651. The correlation between the predicted and true values for the fused data was 96.5%, the root mean square error was 0.392, the goodness of fit was 0.899, the mean square error was 0.154, and the mean absolute error was 0.298. It was calculated that the correlation between the predicted and true values of the fused data was improved by 15.4%, the root mean square error was reduced by 0.395, the goodness of fit was improved by 0.305, the mean square error was decreased by 0.465, and the mean absolute error was reduced by 0.353 in comparison with the single-satellite data for the L2 band. In the BP neural network model for station GP03, the accuracy of the model built with the data from the L1 band was higher than that of the model built with data from the L2 band. The correlation between the predicted and true values of the L1 band was 70.1%, the root mean square error was 0.826, the goodness of fit was 0.671, the mean square error was 0.682, and the mean absolute error was 0.635. The correlation between the predicted and true values for the fused data was 75.9%, the root mean square error was 0.599, the goodness of fit was 0.720, the mean square error was 0.359, and the mean absolute error was 0.432. Compared with the single-satellite data for the L1 band, the correlation between the predicted and true values of the fused data was improved by 5.8%, the root mean square error was reduced by 0.227, the goodness of fit was improved by 0.058, the mean square error was decreased by 0.323, and the mean absolute error was reduced by 0.203.
Table 9 shows the results for the root mean square error (
RMSE), model goodness of fit (
R2), correlation (
r), mean absolute error (
MAE), and mean squared error (
MSE) between the predicted and true values of soil moisture for the GA-BP neural network model.
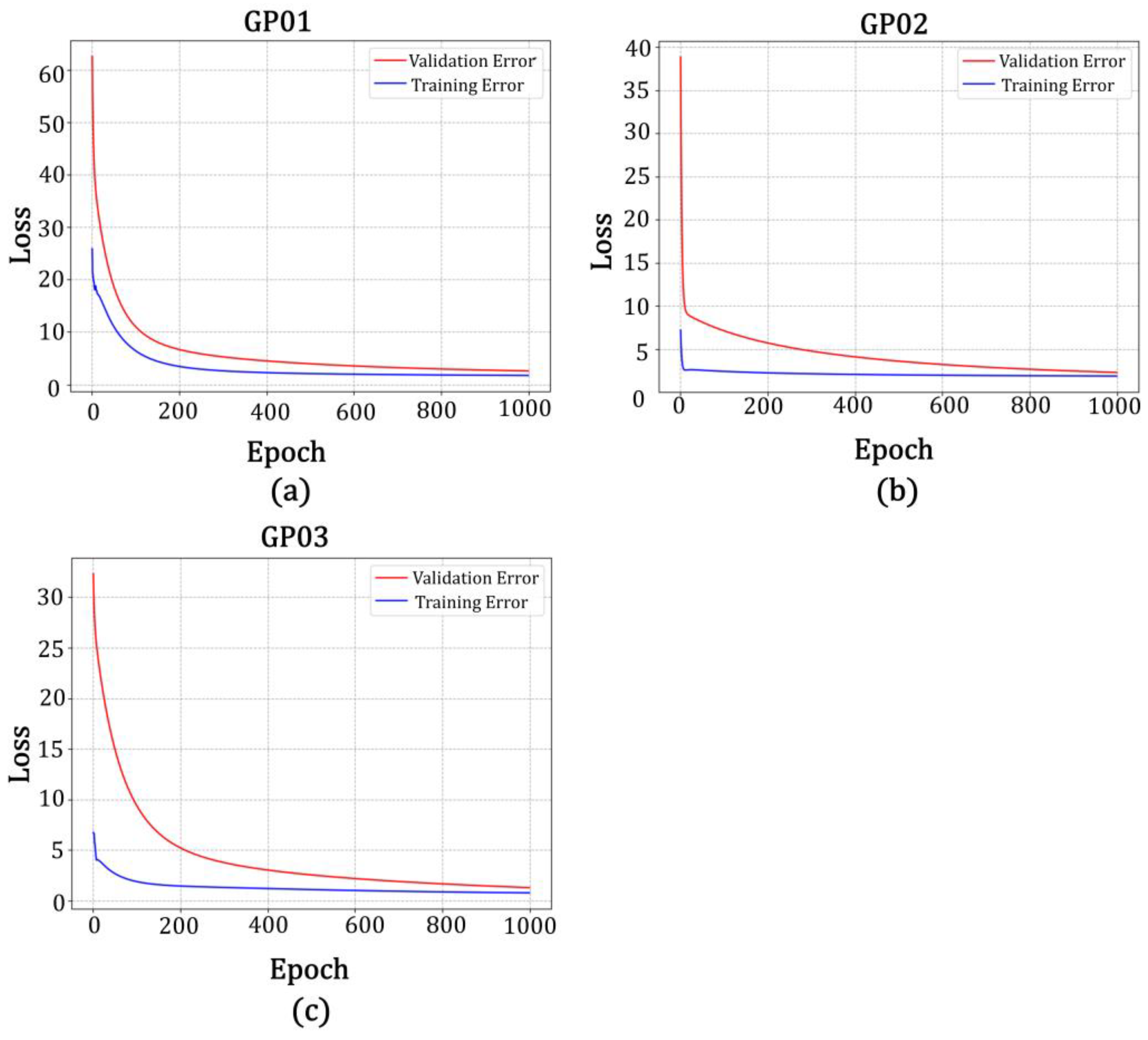
As shown in
Figure 21 and
Table 9, the accuracy of the model built with the data from the L2 band in the GA-BP neural network model for station GP01 was higher than that of the model built with data from the L1 band. The correlation between the predicted and true values for the L2 band was 89.1%, the root mean square error was 1.078, the goodness of fit was 0.856, the mean square error was 1.162, and the mean absolute error was 0.688, and the correlation between the predicted and true values of the fused data was 95.4%. The correlation between the predicted and true values of the fused data was 95.4%, the root mean square error was 0.983, the goodness of fit was 0.880, the mean square error was 0.966, and the mean absolute error was 0.533. It was calculated that the correlation between the predicted and true values of the fused data improved by 6.3%, the root mean square error decreased by 1.207, the goodness of fit improved by 0.024, the mean square error was decreased by 0.196, and the mean absolute error decreased by 0.155 in comparison with the single-satellite data for the L2 band. In the GA-BP neural network model for station GP02, the accuracy of the model built with the data from the L2 band was higher than that of the model built with the data from the L1 band. The correlation between the predicted and true values for the L2 band was 88.5%, the root mean square error was 0.199, the goodness of fit was 0.874, the mean square error was 0.040, and the mean absolute error was 0.151. The correlation between the predicted and true values of the fused data was 94.2%, the root mean square error was 0.154, the goodness of fit was 0.885, the mean square error was 0.024, and the mean absolute error was 0.096. It was calculated that the correlation between the predicted and true values of the fused data was improved by 5.3%, the root mean square error was reduced by 0.045, the goodness of fit was improved by 0.011, the mean square error was decreased by 0.016, and the mean absolute error was reduced by 0.055 in comparison with the single-satellite data for the L2 band. In the GA-BP neural network model for station GP03, the accuracy of the model built with the data from the L1 band was higher than that of the model built with the data from the L2 band. The correlation between the predicted and true values for the L1 band was 82.2%, the root mean square error was 0.409, the goodness of fit was 0.590, the mean square error was 0.167, and the mean absolute error was 0.308. The correlation between the predicted and true values of the fused data was 84.8%, the root mean square error was 0.342, the goodness of fit was 0.713, the mean square error was 0.117, and the mean absolute error was 0.250. It was calculated that the correlation between the predicted and true values of the fused data was improved by 2.6%, the root mean square error was reduced by 0.067, the goodness of fit was improved by 0.123, the mean square error was decreased by 0.050, and the mean absolute error was reduced by 0.058 in comparison with the single-satellite data for the L1 band.
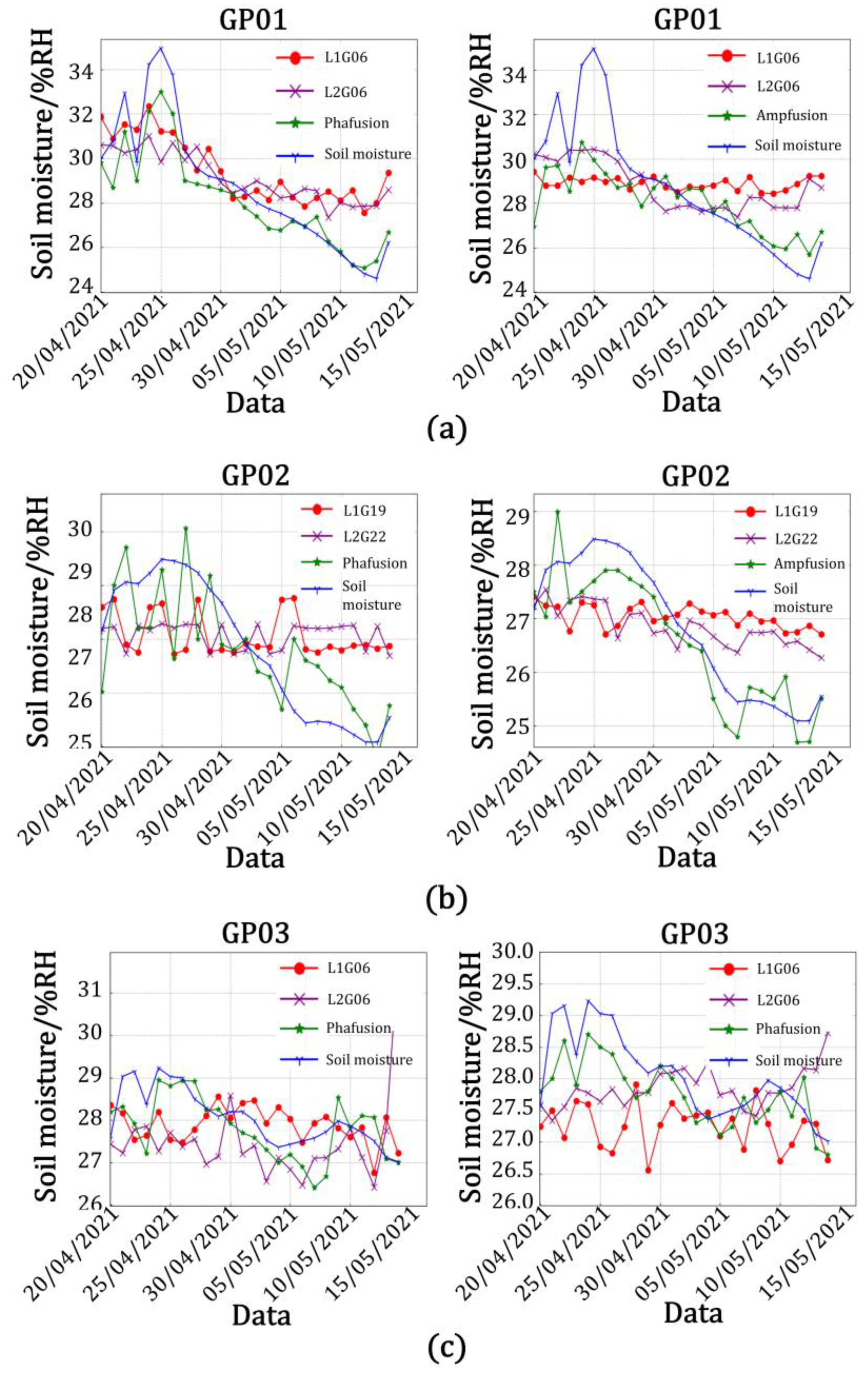
We analyzed the soil moisture inversion error, calculated the absolute soil moisture inversion error (the difference between the inversion error and the true value), and analyzed the interval distribution pattern.
Table 10 shows the maximum, median, and minimum true values of soil moisture, the predicted values of soil moisture for each inversion model, and the absolute errors between the predicted values and the true values.
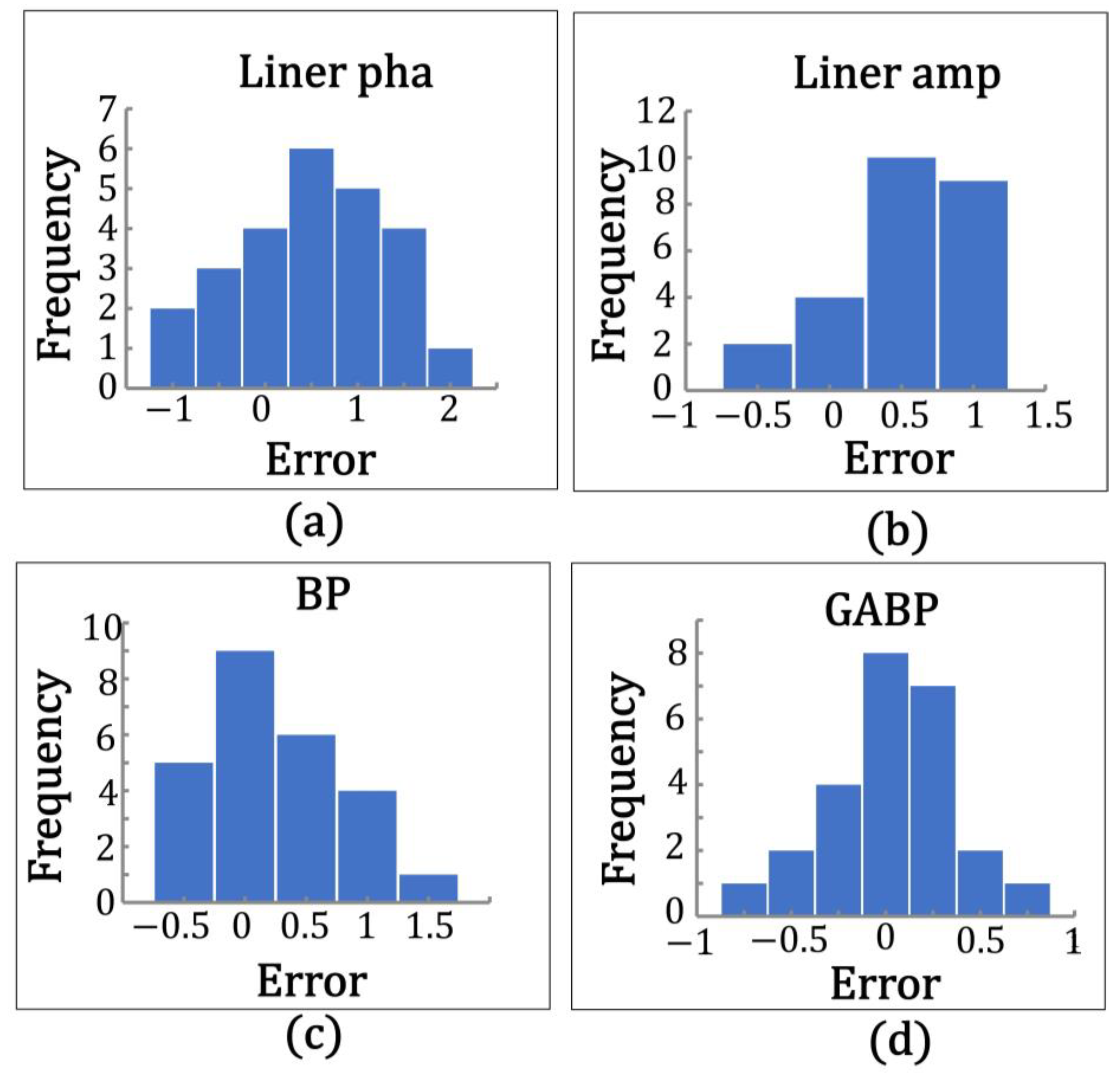
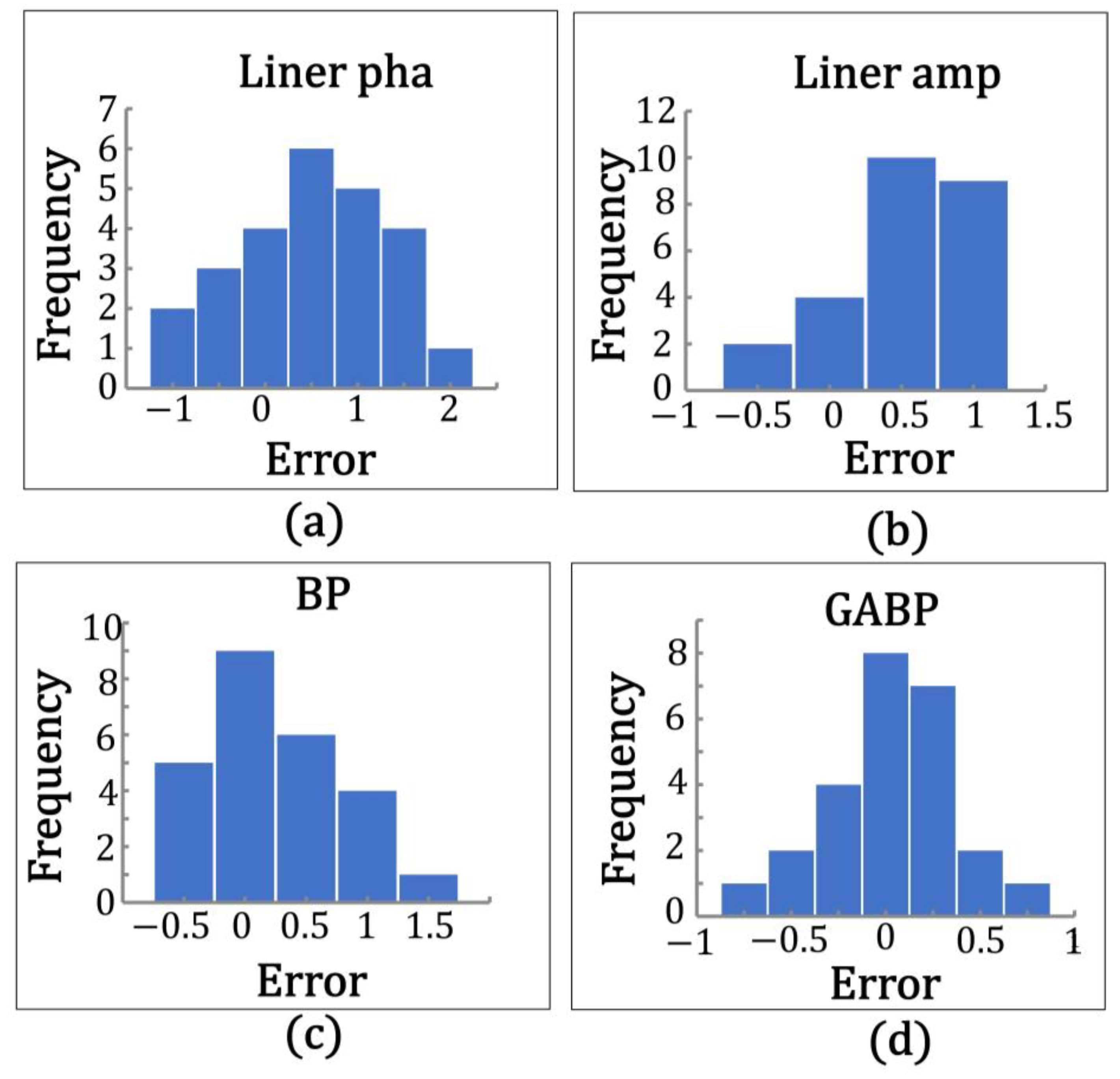
Figure 22 shows a statistical histogram of the frequency of absolute errors in soil moisture accounted for by the three model inversions at station GP02. As shown in the figure, the absolute error distribution of the linear model is between 0.5 and 1.5, the BP neural network model has an absolute error distribution of −0.5 to 0.5, the GABP neural network model has an absolute error distribution of −0.25 to 0.25, and overall, the three models conform to a normal distribution.
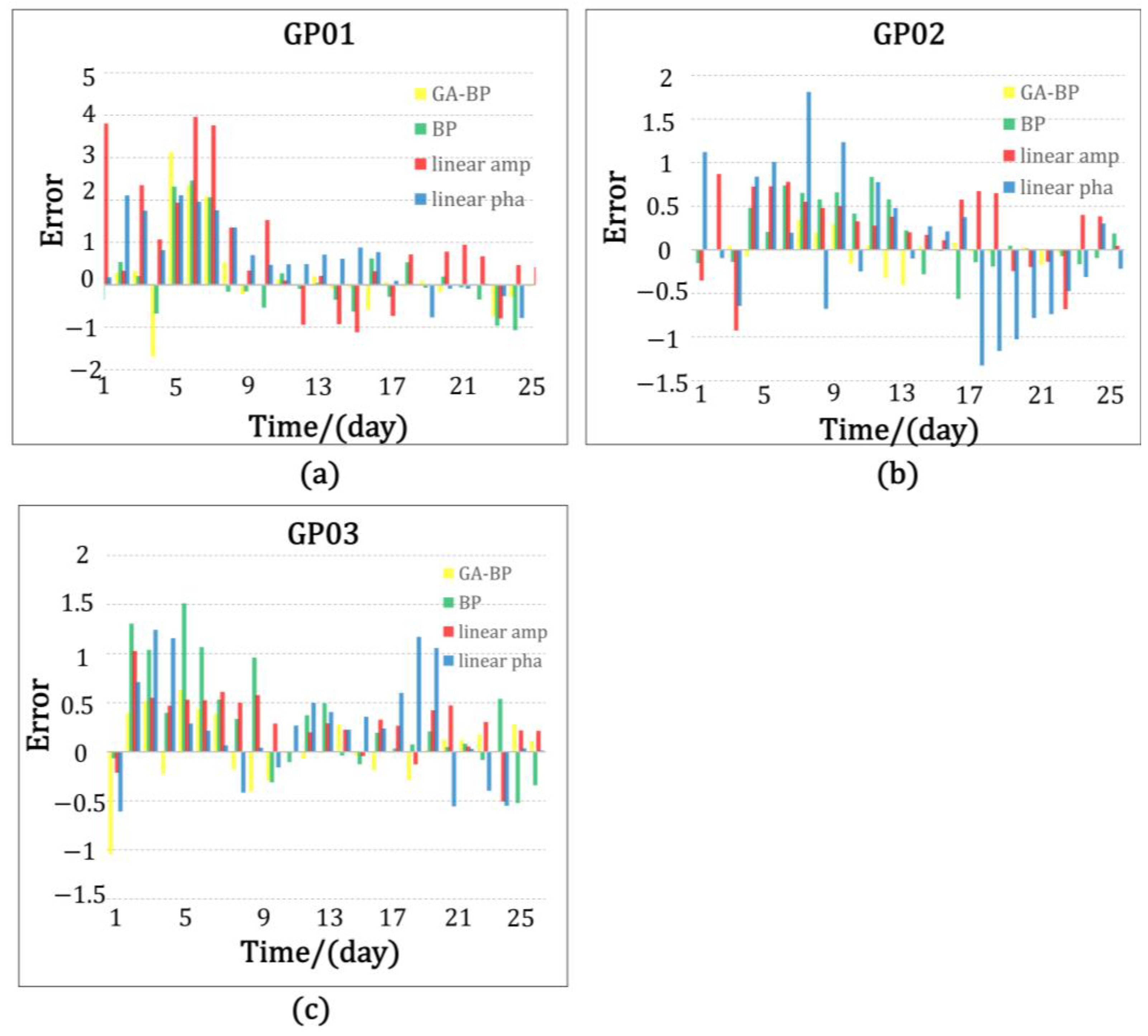
From the above experimental results, it can be seen that the accuracy of the linear model, BP neural network model, and GA-BP neural network model built by fusing multi-satellite multi-band data by using the technique proposed in this study was higher than that of the model built from single-satellite data, which fully proved the feasibility and effectiveness of the method proposed in the study. The values predicted with the GA-BP neural network model were closer to the true values received by the sensors.
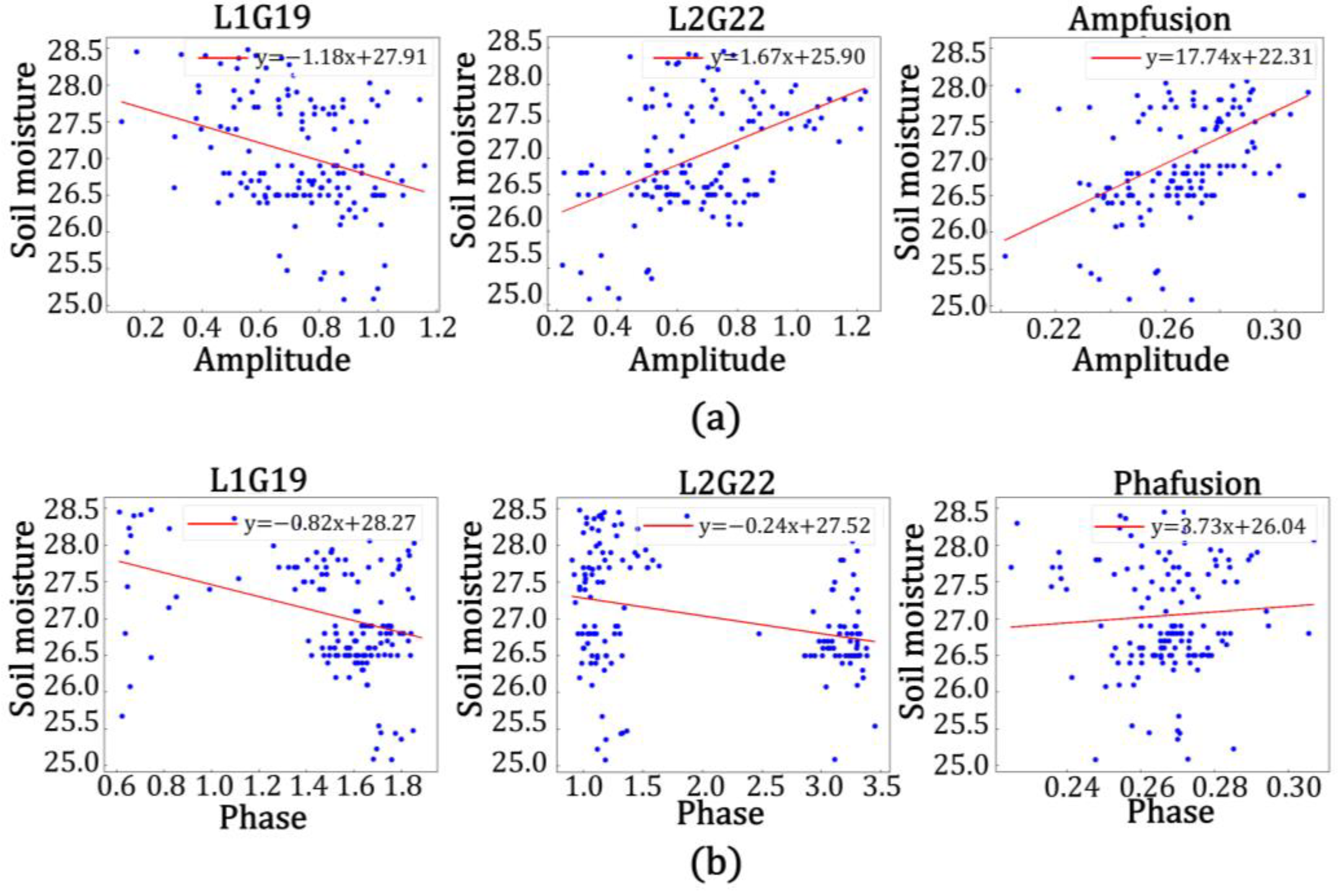
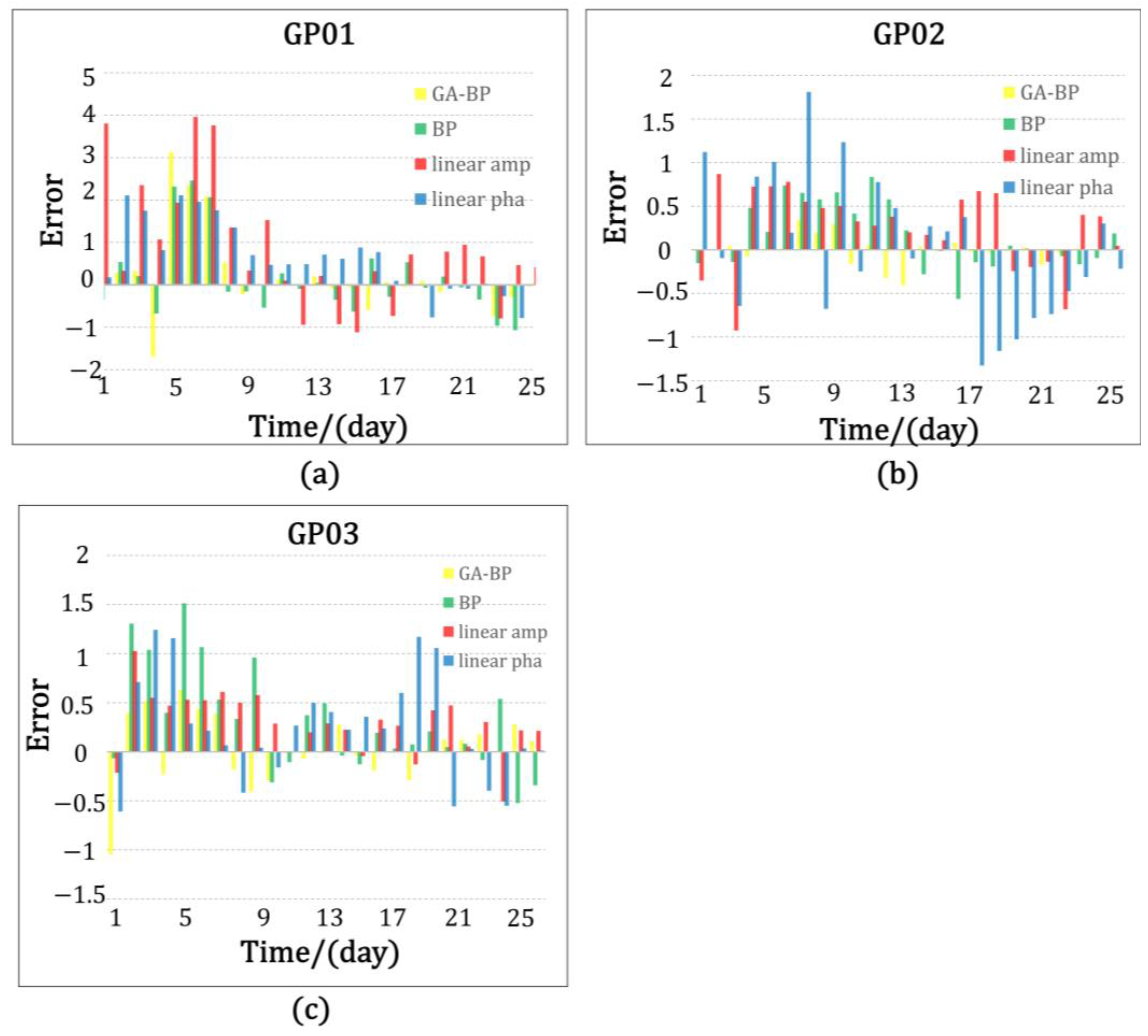
Figure 23 shows the plot of soil moisture values and error in the true values for the inversion of the three models, where yellow is the predicted value and error in the true values for the GA-BP neural network model, green is the predicted value and error in the true values for the BP neural network model, red is the predicted value and error in the true values for the linear model built with the amplitude of the characteristic elements, and blue is the predicted value and error in the true values for the linear model built with the phase of the characteristic elements.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}