1. Introduction
Remote sensing object detection is a prominent and consequential application within the realm of remote sensing image processing [
1]. It aims to accurately identify and locate specific target instances within an image. Within this domain, remote sensing small object detection holds particular importance as it focuses on detecting objects in remote sensing images that occupy a very small area or consist of only a few pixels. Detecting small objects is considerably more challenging than detecting larger objects, resulting in lower accuracy rates [
2]. In recent years, small object detection based on convolutional neural networks (CNNs) has rapidly developed with the rapid growth of deep learning [
3]. Small object detection often faces challenges such as limited information on small objects, scarcity of positive samples, and imbalanced classification. To tackle this challenge, researchers and experts have put forth diverse deep neural network methodologies, encompassing CNNs, GANs, RNNs, and transformers, to tackle the detection of small objects, encompassing remote sensing small objects. To improve the detection of small objects, Liu W et al., proposed the YOLOV5-Tassel network, which introduced the SimAM module in front of each detection head to extract the features of interest [
4]. Li J. et al., suggested using GAN models to generate high-resolution images of small objects, narrowing the gap between small and large objects, and improving the detection capability of tiny objects [
5]. Xu W et al. integrated contextual information into the Swin Transformer and designed an advanced framework called the foreground-enhanced attention Swin Transformer (FEA-Swin) [
6]. Although the accuracy of detecting small objects has improved, the speed has been somewhat compromised. Zhu X. et al., proposed the YOLOv5-THP model, which is based on YOLOv5 and adds a transformer model with an attention mechanism to the detection head [
7]. While this enhances the network’s performance in detecting small objects, it also brings a significant computing burden.
In the field of remote sensing, detecting small objects remains challenging due to large image scales, complex and varied backgrounds, and unique shooting perspectives. Cheng et al. propose a model training regularization method that enhances the performance of detection of small or tiny objects in remote sensing by exploiting and incorporating global contextual cues and image-level contextual information [
8]. Liu J. et al., added a dilated convolution module to the FPN and designed a relationship connection attention module to automatically select and refine features, combining global and local attention to achieve the detection task of small objects in remote sensing [
9]. Cheng et al., proposed an end-to-end cross-scale feature fusion (CSFF) framework based on the feature pyramid network (FPN), which inserted squeeze-and-excitation (SE) modules at the top layer to achieve better detection of tiny objects in optical remote sensing images [
10]. Dong et al., proposed a CNN method based on balanced multi-scale fusion (BMF-CNN), which fused high- and low-level semantic information to improve the detection performance of tiny objects in remote sensing [
11]. Liang X. et al., proposed a single-shot detector (FS-SSD) based on feature fusion and scaling to better adapt to the detection of tiny or small objects in remote sensing. FS-SSD added a scaling branch in the deconvolution module and used two feature pyramids generated by the deconvolution module and feature fusion module together for prediction, improving the accuracy of object detection [
12]. Xu et al., designed a transformer-guided multi-interaction network (TransMIN) using local–global feature interaction (LGFI) and cross-view feature interaction (CVFI) modules to enhance the performance of small object detection in remote sensing. However, this improvement unavoidably introduces a computational burden [
13]. Li et al., proposed a transformer that aggregates multi-scale global spatial positions to enhance small object detection performance but it also comes with a computational burden [
14]. To reduce the computational cost of the transformer, Xu et al., improved the lightweight Swin transformer and designed a Local Perception Swin transformer (LPSW) backbone network to enhance small-scale detection accuracy [
15]. Gong et al., designed an SPH-YOLOv5 model based on Swin Transformer Prediction Heads (SPHs) to balance the accuracy and speed of small object detection in remote sensing [
16]. Although many experts and scholars are studying the balance between detection accuracy and inference speed, achieving an elegant balance remains a challenging problem [
17,
18,
19,
20,
21].
Considerable advancements have been achieved in the utilization of transformers [
6,
7,
13,
14,
15,
16] for small object detection within the remote sensing domain. The exceptional performance of the Contextual Transformer (CoT) [
22] in harnessing spatial contextual information, thereby offering a fresh outlook on transformer design, merits significant attention. In the domain of remote sensing, small target pixels are characterized by a scarcity of spatial information but a profusion of channel-based data. Consequently, the amalgamation and modeling of spatial and channel information assume paramount importance. Furthermore, transformers impose notable demands on computational resources and network capacity, presenting a challenge in striking an optimal balance between detection accuracy and processing speed for small object detection in the remote sensing discipline. Meanwhile, Bar M et al. demonstrated that the background is critical for human recognition of objects [
18]. Empirical research in computer vision has also shown that both traditional methods [
19] and deep learning-based methods [
12] can enhance algorithm performance by properly modeling spatial context. Moreover, He K. et al., have proven that residual structures are advantageous for improving network performance [
17,
20]. Finally, we note that the classification and regression tasks of object detection focus on the salient features and boundary features of the target, respectively [
23]. Therefore, a decoupled detection head incorporating residual structure as well as channel and spatial context knowledge should have a positive impact on the detection of small or tiny objects.
We propose a new detection framework, YOLO-DCTI, for detecting small or tiny objects in remote sensing images. By introducing a global residual structure and a local fusion structure into the contextual transformer (CoT), and designing an improved decoupled contextual transformer detection head structure (DCTI) based on CoT, we have achieved improved detection performance for small or tiny objects on the powerful single-stage benchmark network YOLOv7. The main contributions of this paper can be summarized as follows:
- (1)
We have developed the CoT-I module, an extension of the original CoT framework, which integrates global residual structures and local fusion modules. This integration facilitates the extraction of spatial context background features and the fusion of channel features, thereby enabling the network to learn deeper-level characteristics. In comparison to the conventional CoT approach, the inclusion of global residual structures empowers the network to capture more profound features, while the incorporation of local fusion structures seamlessly combines background context features with channel features.
- (2)
We introduce an efficient decoupled detection head structure DCTI, leveraging the CoT-I framework, to mitigate the limited exploration and utilization of salient region features and boundary-adjoining features arising from the interdependence of classification and regression tasks within most object detection heads. This decoupled design allows the classification task to emphasize salient region features, while the regression task focuses on boundary-surrounding features. Concurrently, CoT-I effectively exploits and harnesses the feature relationships between spatial context and channels, facilitating the detection of small objects in remote sensing and yielding substantial improvements in detection accuracy.
- (3)
Despite the escalation in model parameters and the consequential inference latency resulting from the adoption of our proposed DCTI structure, the integration of global residual connections and local fusion strategies yields a notable enhancement in inference accuracy without incurring any detrimental impact on the inference speed. Comparative evaluation against the baseline YOLO v7 model showcases a substantial improvement in the inference accuracy specifically for diminutive targets, mAP@0.5:0.95 surging from 61.8 to 65.2. Additionally, our model achieves a reduction of 0.3ms in the inference speed per image with dimensions of 640 × 640.
3. Proposed Method
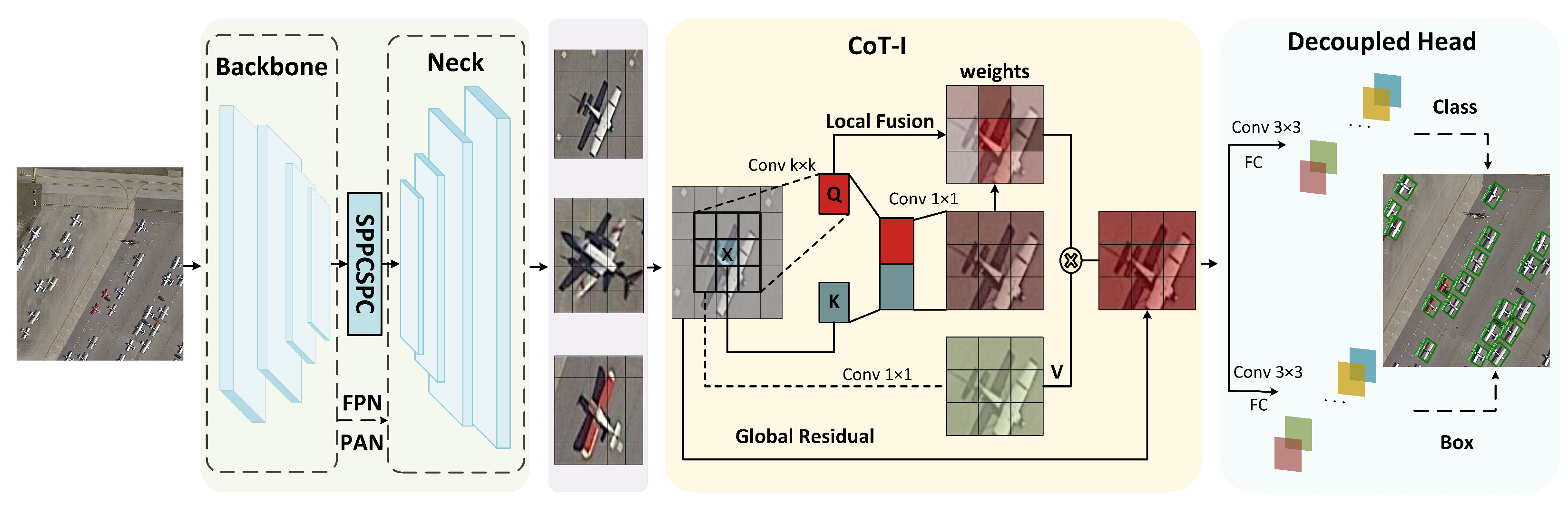
We present an improved decoupled contextual transformer (YOLO-DCTI) for the detection of tiny or small objects in the domain of remote sensing. Our proposed framework is built upon the foundation of YOLOv7. The comprehensive architecture of our framework is depicted in
Figure 1. Our contributions begin with the feature
obtained after the backbone, FPN, and PAN stages. In this section, we first give a brief overview of the widely adopted Contextual Transformer (CoT) framework in object detection. Subsequently, we introduce an enhanced variant named CoT-I, which incorporates a global residual structure and a local fusion structure into the CoT module. The global residual mechanism integrates input information with self-attention features, while the local fusion mechanism combines spatial contextual information with channel-based information. Ultimately, we integrate the CoT-I module into a decoupled detection head named DCTI, enabling the establishment of global interdependencies between the classification and regression tasks through the utilization of self-attention mechanisms. This integration facilitates the comprehensive exploration and exploitation of a wider spectrum of channel features and spatial contextual features.
3.1. Contextual Transformer
In this section, we present the formulation of the Contextual Transformer (CoT) framework, illustrated in
Figure 2 (left). The input
X, obtained from the Feature Pyramid Network (FPN), undergoes three transformation matrices:
. These matrices yield
. Specifically,
is an identity matrix,
represents spatial convolution using a
kernel, and
signifies spatial convolution with a 1 × 1 kernel. The output
Y is mathematically expressed as:
In the above equation, the function denotes concatenation along the channel dimension C, while and correspond to 1 × 1 convolutions in the spatial domain. The symbol × represents matrix multiplication. For brevity, we omit the transformation of the channel dimension C and the batch normalization (BN) operation during the 1 × 1 convolutions.
It is evident that the learned key matrix
K captures significant information from neighboring pixels within the spatial domain, incorporating essential static spatial context information. Subsequently,
Q and
K are concatenated along the channel dimension, followed by the application of two 1 × 1 convolutions:
with an activation function and
without an activation function. Matrix multiplication is then performed with
V, resulting in a matrix
T enriched with dynamic contextual information, which can be used as follows:
This resultant matrix T is subsequently fused with the static contextual information K to derive the final output Y. Notably, Y incorporates both dynamic contextual information and static contextual information. CoT demonstrates exceptional performance in leveraging contextual information; however, it partially overlooks the joint contribution of channel information and contextual information.
3.2. Improved Contextual Transformer (CoT-I)
First of all, the ResNet [
20] and Densenet [
17] models prove the effectiveness of the residual structure in the model, which helps optimize the deeper layer of the architecture. We add a residual structure from the input to the output, called the global residual structure.
Secondly, we note that the intermediate matrix
T captures relatively persistent global dependencies along the channel dimension, whereas the static contextual information
K contains abundant spatial contextual information. The interrelation between them is more closely intertwined compared to the dynamic contextual information. Hence, we integrate the intermediate matrix
T with the static contextual information
K to achieve a more comprehensive representation of spatial and channel features. This fusion can be mathematically expressed as follows:
where + represents through attention mechanism to complete the fusion of static
K and intermediate vector
T.
The global residual mechanism plays a pivotal role in facilitating the fusion of input information and self-attention features. By incorporating a global residual structure, the method adeptly amalgamates and consolidates information from diverse hierarchical levels of input, thereby engendering a more comprehensive and all-encompassing feature representation. This ensemble effectively captures long-range dependencies and augments the overall discriminative capacity of the model.
The local fusion mechanism concentrates on integrating spatial context information with channel-based information. Through the integration of these two distinct information sources, the method proficiently models the intricate interplay between neighboring pixels and harnesses the wealth of channel-based information inherent in remote sensing data. This fusion framework empowers the model to capture intricate details and contextual cues with greater precision, thereby engendering superior performance in the detection of small objects.
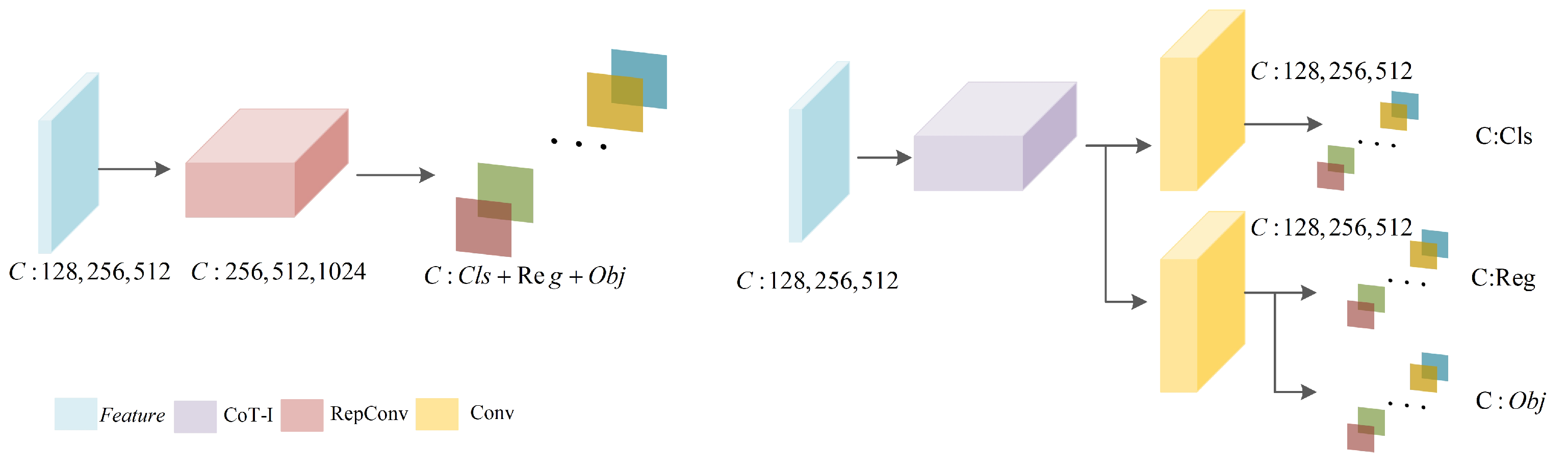
3.3. Improved Decoupled Contextual Transformer Detection Head (DCTI)
Our DCTI structure starts with features
obtained after the backbone, FPN, and PAN stages.
X has three different dimensions of features; (
H,
W, and
C) are (20, 20, 128), (40, 40, 256), and (80, 80, 512), respectively. For the purpose of enhancing the lucidity of the presentation, we solely exemplify the variations in channel C, as depicted in
Figure 3. The coupled detection head depicted (left) leverages 1 × 1 convolutions and the RepConv module to enhance feature information along the channel dimension. Despite its simplicity, this approach is remarkably effective. However, in the context of object detection tasks, it becomes evident that the classification task primarily emphasizes salient feature information, while the regression task is more concerned with capturing boundary feature information related to the targets. Employing a shared Repconv module for both tasks inevitably introduces conflicts between them.
Moreover, we observe the exceptional capability of CoT-I in capturing global information for effective modeling. In comparison to 1 × 1 convolutions, CoT-I exhibits superior feature exploration in both the classification and regression tasks.
Consequently, we propose the DCTI, building upon the CoT-I framework, as illustrated (right). Initially, CoT-I assimilates the feature information derived from the feature pyramid and computes an intermediate variable
T, which encompasses abundant spatial information, employing Equation (
1). Subsequently, a local fusion strategy is employed to merge the spatial and channel information, yielding the dynamic feature K1 through the utilization of Equation (
3). Finally, employing a global residual strategy, the input from the feature pyramid is combined with the dynamic feature to produce the output Y. The decoupled detection head further individually models Y to obtain category information and bounding box information.
4. Results
To evaluate the performance of the YOLOv7-DCTI algorithm for remote sensing small object detection, training, and testing were conducted on the Dota-small dataset [
49]. Furthermore, to assess the algorithm’s overall performance, this experiment included training and testing on the VISDrone dataset [
50] and NWPU VHR-10 datasets [
51]. A comparison was made between seven different networks, namely Faster RCNN, SSD, YOLO v5s, YOLO v5l, YOLO v5m, YOLO v7-tiny, and YOLOv7, using the aforementioned three datasets. To ensure fairness among the YOLO series, a batch size of 16 was utilized during the training process and pre-trained weights were not employed. The data augmentation strategy [
52,
53] remained consistent with other training conditions. During testing, the NMS [
54] threshold was uniformly set to 0.65 and the batch size was uniformly set to 32.
4.1. Datasets
4.1.1. Dota-Small
In recent years, several remote sensing datasets have been developed. This paper focuses on the extraction of small or tiny objects from the DoTAv1.0 dataset, which consists of 2000 aerial images of 2000 cities and over 190,000 fully labeled objects, each of which comprises eight positional parameters (x1, y1, x2, y2, x3, y3, x4, and y4). In this study, we have selected a dataset that includes five categories of small objects, namely small vehicles, large vehicles, planes, storage tanks, and ships. However, due to the large image size in the DoTAv1.0 dataset, direct training is not feasible. Therefore, we have cropped the images to a size of 1024 × 1024, resulting in a total of 8624 images. These images were subsequently divided into three sets according to the train:val:test ratio, with a split of 8:2:2. Among these, 5176 images were used for training, while 1724 images were allocated to validation and testing. The five types of objects included in the dataset are small vehicle, large vehicle, plane, storage tank, and ship, as illustrated in
Figure 4. We have set three sets of anchors with the following dimensions: (10,10, 13,22, 24,12), (23,24, 28,37, 45,25), and (49,50, 91,88, 186,188).
4.1.2. VisDrone
VisDrone is a widely recognized and highly demanding aerial photography dataset that is extensively used in UAV (Unmanned Aerial Vehicle) applications. It features a meticulous manual annotation process that has accurately labeled and classified 342,391 objects into 10 distinct categories. However, the official evaluation portal for the test-challenge set is unavailable, so we have utilized the test-dev set for evaluating our proposed method.
Figure 5,
Figure 6 and
Figure 7 showcases a selection of unprocessed images extracted from the VisDrone dataset. In our experiments, we have employed three sets of anchor dimensions: (3,4, 4,8, 8,7), (7,14, 14,9, 13,20), and (25,13, 27,27, 51,40).
4.1.3. NWPU VHR-10
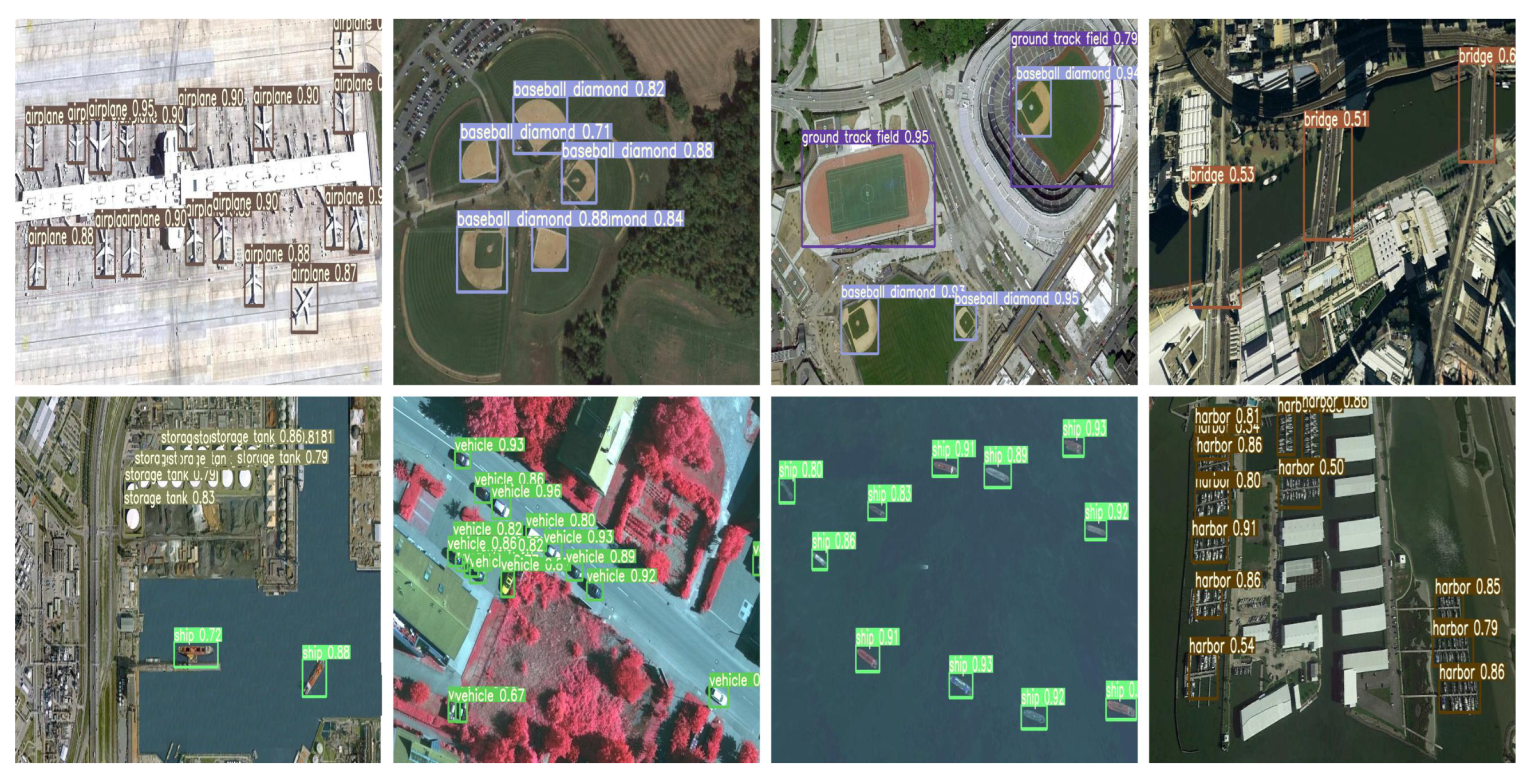
To assess the generalization capability of our proposed method, we conducted experiments on the NWPU VHR-10 dataset. This dataset is specifically designed for geospatial object detection and comprises ten different object categories, namely airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle. In our study, we randomly divided the dataset into three sets: 60% of the images were allocated to the training set, 20% to the validation set, and the remaining 20% to the testing set.
Figure 8 showcases a selection of unprocessed images from the NWPU VHR-10 dataset. For our experiments, we employed three sets of anchor dimensions: (24,23, 30,30, 32,46), (47,32, 52,51, 74,61), and (88,96, 205,104, 150,194).
4.2. Experimental Environment and Settings
The experiment was conducted using a 64-bit Windows 10 operating system. The GPU utilized was NVIDIA GeForce RTX3090 and the deep learning framework employed was Torch v1.10.0. To evaluate the performance of object detection methods, this paper adopts the common indicators of object detection. this paper employs several metrics, including accuracy, recall, average precision, mean average precision, and average inference time per image (ms). The accuracy rate measures the proportion of correctly predicted samples out of the total tested samples. The recall rate indicates the proportion of positive samples that are accurately predicted. AP is calculated as the area under the precision–recall curve. mAP represents the average of AP values across all categories. Specifically, mAP@0.5:0.95 refers to the average mAP value computed at ten IoU thresholds (0.50, 0.55,…, 0.95). On the other hand, mAP@0.5 denotes the mAP value computed at an IOU threshold greater than 0.5.
4.3. Experimental Results and Analysis
Experiments were conducted on three publicly available datasets, namely VISDrone, NWPU VHR-10, and Dota-small, to assess the efficacy of the proposed method. The experimental evaluation was carried out in four distinct stages: (1) Validation of the method’s feasibility on the Dota-small dataset, including a comparative analysis against other object detection techniques to showcase its effectiveness. (2) Examination of the method’s generalization capability using the VISDrone dataset. (3) Further validation of the method’s performance on the NWPU VHR-10 dataset. (4) Evaluation of the performance of our model, encompassing inference speed, model parameters, and detection accuracy, and conducting a comparative analysis with existing models. (5) Execution of ablation experiments to scrutinize the effectiveness of each step within the proposed method and assess the optimal parameter configuration.
4.3.1. Experiments on Dota-Small Dataset
To validate the proposed model, we trained it for 200 epochs on the Dota-small dataset. To ensure fairness, we used a batch size of 24 during the training process and did not use pre-trained weights. We kept the data augmentation strategy [
52,
53] and other training conditions consistent. During testing, the NMS [
54] threshold was uniformly set to 0.65 and the batch size was uniformly set to 32. In our experimental analysis, we conducted a comparative evaluation of the YOLOv7-DCTI algorithm with mainstream object detection algorithms using the Dota-small dataset generated specifically for this study. The outcomes of these experiments are documented in
Table 1, encompassing five distinct categories: small vehicles, large vehicles, planes, storage tanks, and ships. The AP@0.5 values provided in the table indicate the average recognition accuracy achieved by each algorithm for individual categories. Additionally, the columns denoted as mAP@0.5 and mAP@0.5:0.95 represent the average recognition accuracy across all categories.
The Dota-small dataset contains predominantly small or tiny objects with limited information and is characterized by complex and variable image backgrounds. Distinguishing these objects from the background presents significant challenges, as some objects may be partially occluded, further complicating detection. In comparison to other mainstream object detection algorithms, the enhanced network proposed in this study demonstrates a notable accuracy advantage in detecting small or tiny objects.
Our proposed method achieves the highest accuracy rate of 65.2% for small or tiny objects in the Dota-small dataset, surpassing YOLOv7 by 3.4%. In comparison to these four object detection algorithms, Faster R-CNN, SSD, YOLOv5l, and YOLOv7-tiny, the mean average precision (mAP) at the intersection over union (IoU) threshold range of 0.5 to 0.95 showed improvements of 19.3%, 45.2%, 4.5%, and 12.1%, respectively.
Although the detection speed of YOLOv7 and YOLOv5 is similar to that of our proposed method, their mAP scores are lower. In scenarios where the differentiation among the YOLO series detection heads is minimal, the proposed method achieves higher mAP at the IoU range of 0.5 to 0.95, while maintaining similar detection speeds. This demonstrates that the proposed method effectively compensates for the differences in detection heads and offers greater advantages.
The introduction of a Contextual Transformer (CoT) in the decoupled head unavoidably leads to a slight sacrifice in reasoning speed. However, the global residual structure and local fusion structure do not experience any decrease in speed. As a result, the detection speed of the proposed structure remains largely unaffected even with increasing complexity, achieving a favorable balance between inference speed and detection accuracy.
As illustrated in
Figure 7, YOLO-DCTI demonstrates superior performance in accurately detecting objects with unclear features or small sizes, even in complex backgrounds. It exhibits no omissions or false detections, unlike YOLOv7, which is prone to such errors. The proposed YOLO-DCTI algorithm in this paper excels at identifying small or tiny objects in challenging scenarios, yielding relatively high prediction probabilities. In contrast, YOLOv7 may struggle to accurately recognize small or tiny objects, resulting in lower recognition probabilities compared to YOLO-DCTI.
Figure 8 depicts the detection outcomes obtained through the utilization of the YOLO-DCTI methodology. On the whole, the performance is laudable; nonetheless, certain instances of missed detections persist in densely populated target scenes exhibiting analogous configurations. This phenomenon can be ascribed to the intricacy involved in discerning like attributes within such highly congested environments. As a result, this specific issue accentuates the imperativeness of conducting more extensive and meticulous investigations in future research endeavors.
4.3.2. Experiments on VisDrone Dataset
Table 2 presents the experimental results, demonstrating the strong performance of the proposed method on the VisDrone dataset. YOLO-DCTI achieves a noteworthy improvement of 0.2% in mAP@0.5:0.95 compared to the original method while maintaining a comparable detection speed. Notably, YOLOv5x achieves a mAP@0.5 of 48.1% on this dataset, while YOLOv7 achieves a mAP@0.5 of 49.2%. However, it is important to note that both networks employ coupled detection heads, which are unable to effectively address the inherent discrepancy between classification and regression tasks, resulting in slightly lower detection accuracy compared to our proposed method. As shown in
Figure 9, the effectiveness of our method is reflected in its effective detection of small and dense objects (e.g., people and cars).
4.3.3. Experiments on NWPU VHR-10 Dataset
Based on the results presented in
Table 3, the proposed method exhibits robust performance on the NWPU VHR-10 dataset. Notably, our model achieves impressive AP@0.5 scores for the ten object categories: 99.6%, 93.0%, 96.8%, 99.5%, 90.9%, 95.0%, 99.2%, 91.5%, 98.9%, and 90.3%. Moreover, our model achieves a mAP@0.5 score of 95.5%.
Figure 10 presents the detection results of the YOLO-DCTI model on the NWPU VHR-10 dataset, showcasing its efficacy in detecting targets of diverse scales.
To visually illustrate the effectiveness of the method,
Figure 11 shows the detection results and grad-cam map of YOLO-DCTI on the NWPU VHR-10 dataset. These numbers provide convincing evidence of our model’s ability to accurately identify object locations and assign appropriate attention to them. Overall, the experimental results highlight the robust performance of the proposed method in object detection tasks, thus indicating its potential in various real-world applications.
4.3.4. Comparison Experiment on Inference Speed and Model Parameters
To elucidate the equilibrium achieved by our YOLO-DCTI model concerning inference speed and detection performance, we conducted a comprehensive comparative analysis of various models using the Dota-small dataset, as presented in
Table 4. This analysis incorporates essential metrics such as mAP@0.5:0.95, inference speed, and model parameters. The evaluation employed test images with a resolution of 640 × 640 and the inference speed was quantified in milliseconds (ms). Our model showcased a total of 37.67 M parameters, closely akin to the 39.46 M parameters of Faster RCNN. However, our model gained a notable advantage due to the absence of candidate box generation operations, leading to commendable inference speed. While our inference speed aligns with YOLOv5l and YOLOv7, the distinctive structural design of DCTI fortifies its capacity to effectively capture features of small targets. Although our approach may not outperform others in terms of model parameters and inference speed, it successfully achieves a favorable equilibrium between inference speed and detection accuracy.
4.3.5. Ablation Experiment
The Dota-small dataset was used to conduct an ablation experiment aiming to investigate the impact of different structures on the final detection results. The obtained test results are presented in
Table 5.
After incorporating CoT in the decoupled head, the mAP@0.5:0.95 value increased by 0.4%. CoT helps in identifying small or tiny objects by exploiting spatial context and global channel information. The addition of global residual structure and local fusion to CoT led to an improvement in mAP@0.5:0.95 by 1.0%. CoT-I further fuses spatial context and channel features, enabling the network to learn more about small object information, thereby enhancing detection performance. After incorporating the CoT-I structure in YOLOV7, mAP@0.5:0.95 increased by 1.5%, providing further evidence that CoT-I can enhance detection accuracy.
We conducted a comparative analysis of the model’s performance regarding speed and parameters, as presented in
Table 6. The results demonstrate that the incorporation of decoupled heads and CoT introduced a speed latency of 0.1 ms and 0.2 ms, respectively, in comparison to the baseline, along with an augmentation of 0.4 M and 2.86 M parameters. However, it is noteworthy that the inclusion of Global-Residual and Local-Fusion did not impose any discernible burden on the inference speed and parameter requirements.
We analyzed the kernel sizes utilized in CoT-I and present our findings in
Table 7. In Equation (
1), the kernel size, denoted as
, is specifically referred to as k = 3, 5, and 7. Our analysis reveals that the model achieves the highest inference speed when employing a kernel size of k = 3. On the other hand, adopting a kernel size of k = 5 results in improved detection accuracy, albeit with a certain trade-off in terms of inference speed. Notably, when utilizing a kernel size of k = 7, both the model’s detection accuracy and inference speed significantly decrease. These observations suggest that expanding the perception range does not necessarily lead to performance enhancement.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}