1. Introduction
High-spatial-resolution satellite sequence data can be used to observe changes on Earth. However, it is difficult to obtain satellite data with both high temporal resolution and high spatial resolution. For example, the Landsat-8 Operational Land Imager (OLI) [
1] sensor has a ground resolution of 30 m, but it takes at least 16 days for it to obtain a repeatable image of the same location. In contrast, the Moderate-resolution Imaging Spectroradiometer (MODIS) obtains an image every half a day but with a coarse 500 m ground resolution. Some new satellites have high-resolution capabilities. For instance, Sentinel-2 provides 10 m ground resolution with a five-day revisiting period; these values are 16 m and 4 days, respectively, for Gaofen-1. However, adverse weather conditions make these satellite images far less available, as would be expected. Thus, spatiotemporal fusion algorithms have been designed to combine images from different sources in order to obtain data with both high temporal resolution and high spatial resolution.
In the past twenty years, more than one hundred spatiotemporal fusion algorithms have been proposed [
2]. In recent years, many spatiotemporal fusion algorithms based on convolutional neural networks (CNNs) have emerged to challenge the classic algorithms represented by the spatial and temporal adaptive reflectance fusion model (STARFM) [
3] and flexible spatiotemporal data fusion (FSDAF) [
4]. Various models, including deep convolutional spatiotemporal fusion networks (DCSTFN) [
5]; enhanced deep convolutional spatiotemporal fusion networks (EDCSTFN) [
6]; spatiotemporal adaptive reflectance fusion models using generative adversarial networks (GASTFN) [
7]; and spatial, sensor, and temporal spatiotemporal fusion (SSTSTF) have been proposed. These models contributed to building a common framework for spationtemporal fusion algorithms that employs the use of two streams and the stepwise modeling of spatial, sensor, and temporal differences. In recent works [
8,
9,
10,
11,
12,
13,
14,
15], multiscale learning, spatial channel attention mechanisms, and edge reservation have been introduced into CNNs for the extraction and integration of features.
Most CNN-based algorithms use large amounts of time-series training data, while traditional algorithms perform better using one-pair training. Time series data allow an algorithm to learn the trends seen in changes in features over the course of seasons. Traditional algorithms lack the ability to learn big data and therefore are not good at anticipating temporal trends. A few algorithms, such as enhanced STARFM [
16], attempt to make interpolations in the time dimension with two pairs of sequences. However, it is time-consuming to collect long time series data. Data preparation takes up to one or two years after a satellite is launched, resulting in the inability to synthesize data during this period. Considering the limited lifetime of satellites and the emergence of new satellites, there is still a need for research on one-pair spatiotemporal fusion.
Whether end-to-end CNNs can be used for one-pair spatiotemporal fusion is not known yet. This question may be partially addressed by paying attention to the sizes of the individual images used for this purpose. In the datasets most commonly used to train CNNs [
17], each image is
and
, respectively. Although a standard Landsat scene has
pixels before it is geometrically corrected, the scene’s reduced size may not be adequate for the process of training a CNN. It is a known fact that CNNs require multiple pairs of images in their training process. If a single pair of images is sufficiently large, can a CNN be used for one-pair spatiotemporal fusion? This is the question we want to explore.
As far as land cover changes are concerned, it is not clear whether change detection can be performed on fused images of land cover successfully. Some works have shown that the images predicted by spatiotemporal fusion can be applied for some interpretation and inversion tasks. For example, the authors of [
18] found that by mapping planting patterns and paddies to the spatiotemporally fused images obtained from a phenology-based fusion method, the accuracy of rice recognition can exceed 90%. In [
19], the land surface temperature was quantitatively predicted with spatiotemporally fused images, with the results showing that the average deviation was within about 2.5 K; furthermore, the
scores were greater than 0.96. Although room exists for further improvements, these values are approaching those necessary for practical use. As an important downstream task, change detection has not been investigated in terms of its relationship to spatiotemporal fusion; therefore, this will be investigated in this work.
The exploration of the accuracy of and potential for change detection with the use of spatiotemporal fusion constitutes the research goal of this article. In addition to collecting the three existing commonly used spatiotemporal fusion datasets [
3,
17], this paper produces a new dataset, which we partly use for mosaicking purposes [
20]. Each image in the new dataset has 5792 columns and 5488 rows, which is much larger than the images in the commonly used datasets; therefore, this new dataset may benefit the performance achieved by CNN-based one-pair spatiotemporal fusion methods. A time series dataset [
21] for super-resolution tests is also harnessed for fusion. Fourteen representative algorithms are tested on these five datasets. Compared with the existing studies, our work shows the performance boundary and limitations of the spatiotemporal fusion algorithms in a comprehensive way, allowing some new conclusions to be drawn.
The contributions of this paper can be summarized as follows:
A new dataset is designed for one-pair spatiotemporal fusion with CNN-based models.
A comprehensive comparison involving 14 fusion algorithms and 5 datasets is given to illustrate the differences in the performance of spatiotemporal fusion algorithms with regard to various sensors and image sizes.
The feasibility of the use of spatiotemporal fusion for change detection is investigated.
The rest of this paper is organized as follows.
Section 2 provides a survey of the existing fusion algorithms.
Section 3 presents the datasets, methods, and metrics used to compare the performance of these algorithms, and our new dataset is proposed.
Section 4 gives the experimental results via a comparison of our results with fourteen state-of-the-art methods on five datasets. In
Section 5, the reconstructed results are tested for change detection. The performance threshold, stability, and potential of each algorithm are discussed in
Section 6.
Section 7 gives the conclusions.
2. Background and Related Work
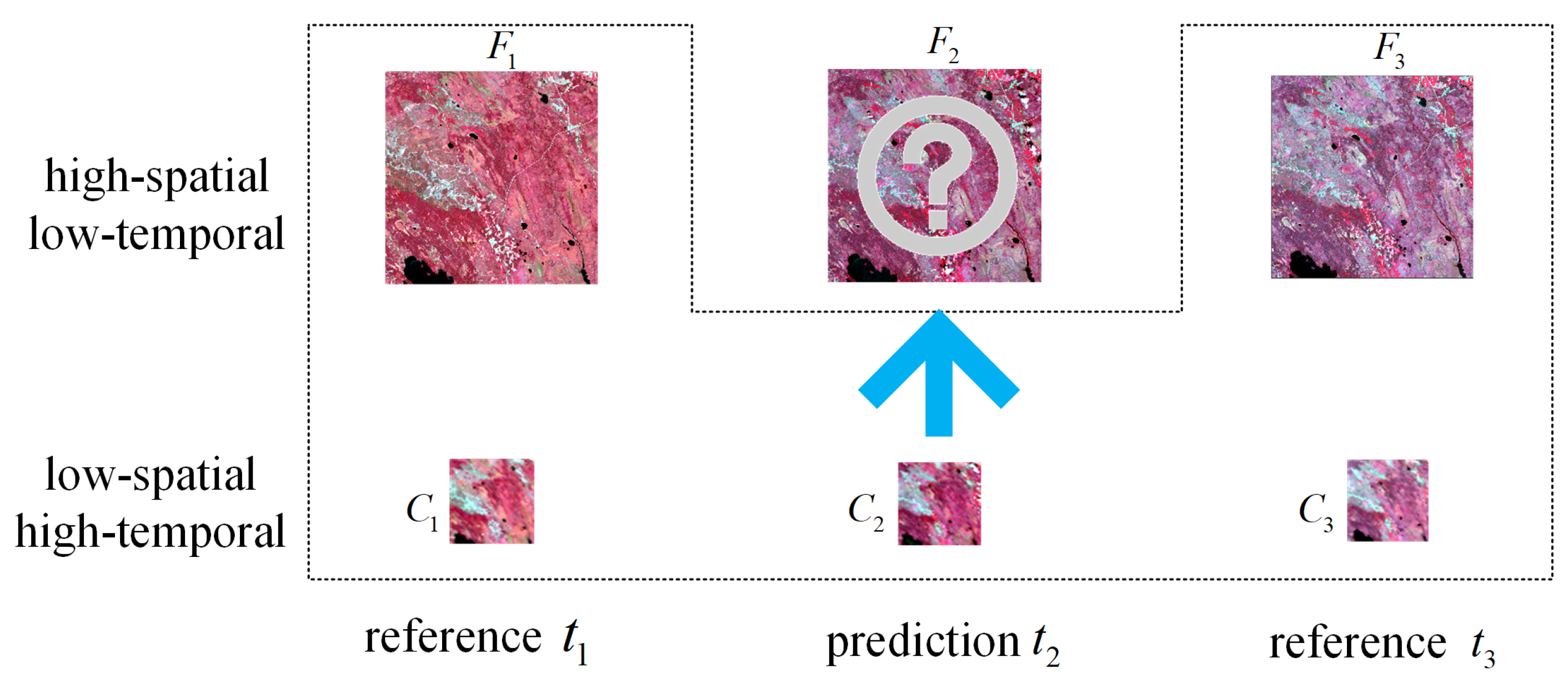
Spatiotemporal fusion consists of two types of remote sensing images, as shown in
Figure 1. One type has high temporal and low spatial resolutions (hereinafter referred to as low-resolution or coarse-resolution images). The other type has high spatial and low temporal resolution (hereinafter referred to as high-resolution or fine-resolution images). The spatiotemporal fusion is to predict the missing high-resolution image on the prediction date
by utilizing the low-resolution image at
and at least one pair of high- and low-resolution images for reference at
(where
).
Existing spatiotemporal fusion methods can be categorized as weight-based, unmixing-based, learning-based, and hybrid methods. Weight-function-based methods apply a linear model to multi-source observations of pure coarse-resolution pixels, and further utilize a weighting strategy to enhance predictions for mixed pixels. These methods exploit the spatial dependence of spectrally similar pixels to reduce the uncertainty and block artifacts in fusion results. The fusion is performed locally, which leads to fast and linear processing speeds. Besides the classic STARFM algorithm [
3], enhanced STARFM [
16], linear injection [
22], and Fit-FC [
23] are also typical weight-based methods. However, strategies that relies solely only on pixel similarity fail to maintain structure and detail, so that complex regions require higher coarse image resolution.
Following the framework proposed by Zhukov et al. [
24], unmixing-based methods [
25,
26,
27,
28] employ spatial unmixing techniques for fusion, which estimate the high-resolution endmembers by unmixing the coarse-resolution pixels using the class scores explained by the reference image. Due to the wide spectrum and large resolution ratio, the unmixing-based methods may be prone to errors in abundance estimation, spectral variations, and nonlinear mixing.
Learning-based methods take advantage of recent advances in machine learning [
29] to model the relationship between inputs and outputs, which include dictionary learning, extreme learning machine, random forest, Bayesian framework, and convolutional neural networks. The dictionary-pair-based algorithms [
30,
31,
32,
33] use sparse representation to establish connections between high- and low-resolution images. Deep neural networks have replaced them for learning large volumes of data more efficiently. Using complex network structures, neural network learning has the potential to map spatial, temporal, and sensor relationships between images from different sources, as have been proposed for spatiotemporal fusion [
6,
20,
34,
35,
36,
37]. These methods have significant modeling advantages, but suffer from the quality and size of the training data. Low-quality data will train worse nonlinear relationships than dictionary learning. The fusion effect of inadequate training may also be inferior to that of traditional weight or unmixed based models. Therefore, neural network methods are not easily used for the spatiotemporal fusion of one pair.
Hybrid methods combine the advantages of diverse categories to pursue better performance. The flexible spatiotemporal data fusion (FSDAF) algorithm is an important representative that harnesses weight and unmixing for spatiotemporal fusion. Its revisions, such as SFSDAF [
38], FSDAF 2.0 [
39], and EFSDAF [
40], can also be categorized into this type. Other hybrid studies [
28,
41] integrated weight and unmixing strategies, too. Our previous work [
42] is also a hybrid type, which integrates the results of FSDAF and Fit-FC to enhance performance.
A typical spatiotemporal fusion uses three images, but a few studies have attempted to reduce the number of input images to two. Fung et al. [
43] utilized the optimization concept in the Hopfield neural network for spatiotemporal image fusion and proposed a new algorithm named the Hopfield neural network Spatio-temporal data fusion model (HNN-SPOT). The algorithm uses a fine-resolution image taken on an arbitrary date and a coarse image taken on the forecast date to derive a synthesized fine-resolution image of the forecast date. Subsequently, Wu et al. [
44] also achieved data fusion only using the other two images as input. They proposed an efficient fusion strategy that degenerates the high-resolution images of the reference date to obtain simulated low-resolution images, which can be combined with any spatiotemporal fusion model to accomplish the fusion with simplified input. On the three spatiotemporal fusion algorithms of STARFM, STNLFFM, and FSDAF, experiments were carried out on the datasets of MODIS, Landsat, and Sentinel-2 land surface reflectance product, and the results suggest that the fusion performance with only two input images is comparable to or even superior than that of three input images. Tan et al. [
36] proposed the GAN-based spatiotemporal fusion model (GAN-STFM) with a conditional generative adversarial network to reduce the number of model inputs free of the time restriction on reference image selection. Liu et al. [
45] presented a GAN survey for remote sensing fusion.
Some algorithms focus on improving the fusion speed of spatiotemporal fusion. Li et al. [
46] proposed an extremely fast spatiotemporal fusion method with local normalization to extract spatial information from the prior high-spatial-resolution images and embeds that information into the low-spatial-resolution images in order to predict the missing high-spatial-resolution images. Gao et al. [
47] proposed an enhanced FSDAF (cuFSDAF) with GPUs of different computing capabilities to process datasets of arbitrary size.
It is well-known that the performance of spatiotemporal fusion algorithms is unstable. Therefore, several studies have analyzed the impact of factors such as time interval, registration error, number of bands, and clouds. The experiment conducted by Shao et al. [
48] originating from an enhanced super-resolution convolutional neural network demonstrated that the number of input auxiliary images and the temporal interval (i.e., the difference between image acquisition dates) between the auxiliary images and the target image both influence the performance of the fusion network. Tang and Wang [
49] analyzed the influence of geometric registration errors on spatiotemporal fusion. Subsequently, Wang et al. [
50] studied the effect of registration errors on patch-based spatiotemporal fusion methods. Experimental results show that the patch-based fusion model SPSTFM is more robust and accurate than pixel-based fusion models (such as STARFM and Fit-FC), and for each method, the effect of the registration error is greater for heterogeneous regions than for homogeneous regions. Tan et al. [
6] proposed an enhanced deep convolutional spatiotemporal fusion network (EDCSTFN) and found that multiband deep learning models slightly outperform single-band deep learning models. Luo et al. [
51] proposed a generic and fully automated method (STAIR) for spatiotemporal fusion to impute the missing-value pixels due to cloud cover or sensor mechanical issues in satellite images using an adaptive-average correction process to generate cloud- or gap-free data.
Spatiotemporal fusion has the potential to construct results whose resolution exceeds that of high-resolution reference images. Chen and Xu [
52] proposed a unified spatial–temporal–spectral blending model to improve the utilization of accessible satellite data. First, an improved adaptive intensity–hue–saturation approach was used to enhance the spatial resolution of Landsat Enhanced Thematic Mapper Plus (ETM+) data; then, STARFM was used to fuse the MODIS and enhanced Landsat ETM+ data to generate the final synthetic data. Wei et al. [
53] fused 8-m multispectral images with 16-m wide-field-view images to reduce the revisiting time of the 8-m multispectral images to 4 days from the original 49 days. The fused results are further improved to 2 m using the panchromatic band.
The data used for spatiotemporal fusion are largely either the Landsat series or MODIS data, but spatiotemporal fusion for other satellites is also being explored, too. For example, Rao et al. [
54] conducted spatiotemporal fusion of the LISS sensor (23.5 m with a 24-day revisiting period) and the AWiFS sensor (56 m and a revisiting period of 5 days) on the Indian satellite Resourcesat-2 to obtain synthetic data with a ground resolution of 23.5 m and a revisiting period of 5 days. Similar studies were performed between Sentinel-3 and Sentinel-2 [
23], SPOT5 and MODIS [
55], Landsat Thematic Mapper (TM) and Envisat Medium Resolution Imaging Spectrometer (MERIS) [
56], Planet and Worldview [
57], and the multispectral sensors within Gaofen-1 [
53].
Although the performance of spatiotemporal fusion algorithms is far from perfect, they have been put to practice. For example, Ding et al. [
18] used the fusion results to extract rice fields. Xin et al. [
58] used the fusion results to improve the near-real-time monitoring of forest disturbances. Zhang et al. [
59] utilized the NDVI data obtained via spatiotemporal fusion to establish a grassland biomass estimation model for monitoring seasonal vegetable changes. In terms of water applications, Guo et al. [
60] proposed a spatiotemporal fusion model to monitor marine ecology through chlorophyll-a inversion. In addition to conventional remote sensing applications, spatiotemporal fusion is also applied to synthesize surface brightness temperature data [
19,
61]. Shi et al. [
62] proposed a comprehensive FSDAF (CFSDAF) method to observe the land surface temperature in urban areas with high spatial and temporal resolutions.
3. Preparation for Comparison
3.1. Datasets
Most spatiotemporal fusion studies were conducted between the Landsat series and MODIS Terra. Both are in sun-synchronous orbits at an altitude of 705 km and captured between 10:00 a.m. and 10:30 a.m. local time. The spectral response curves of commonly used data sources are shown in
Figure 2. The mean absolute deviations between MODIS and Landsat-5, Landsat-7, and Landsat-8 are 0.1704, 0.1524, and 0.3301, respectively.
Four Landsat datasets have been prepared for the experiment and comparisons. All Landsat images are the product of surface reflectance obtained after atmospheric correction. The pixel values are then magnified by a factor of 10,000 and quantized with 16-bit integers so that they fall within the theoretical range of 0 to 10,000. Besides the Landsat-7 and Landsat-8 sources, we also tested a time-series FY4ASRcolor dataset from the FY4A Meteorological Satellite. The FY4ASRcolor images are from two separate cameras of the same satellite. The summaries of all the datasets are given in
Table 1 and will be detailed as follows.
3.1.1. L7STARFM
L7STARFM contains three pairs of Landsat-7 ETM+ and MODIS images that were captured on 24 May 2001; 11 July 2001; and 12 August 2001, respectively. All images consist of green, red, and near-infrared bands that are derived from the surface reflectance products. The image sizes are 1200 × 1200. The ground resolution of Landsat-7 images is 30 m, while it is 500 m for MODIS. The data were first used in STARFM [
3] and have been tested in numerous works for traditional one-pair algorithms including weight-based, unmixing-based, and dictionary-learning-based methods, which have no complex architectures for training; therefore, the dataset is named L7STARFM. The dataset is available at
https://github.com/isstncu/l8jx (accessed on 20 July 2023).
3.1.2. CIA
The CIA dataset [
17] is widely used to benchmark spatiotemporal fusion algorithms. Seventeen cloud-free Landsat7 ETM+ to MODIS image pairs were captured between October 2001 and May 2002, a time when crop phenology has significant temporal dynamics. Geographically, the area covered by the CIA dataset is the Coleambally Irrigation Area (CIA) in southern New South Wales, Australia (34.0034
E, 145.0675
S). Each image spans 43 km from north to south and 51 km from east to west. The total area is 2193 km
and consists of 1720 columns and 2040 rows at a ground resolution of 25 m. Each image consists of six bands. The dataset is available at
https://data.csiro.au/collection/csiro:5846v1 (accessed on 20 July 2023).
In the test, the blue, green, red, and near-infrared (NIR) bands of CIA images are used, and the image size is reduced to 1408 columns and 1824 rows by removing the blank areas outside the valid image scope. The blank areas are cropped because the algorithms do not account for invalid data during processing, which may result in significant errors in training and reconstruction. The neural-network-based algorithms require a large amount of data for training. Therefore, the training data come from the 10 images in 2002, while the validation dataset comprises 5 images from 2001. Other algorithms can perform one-pair spatiotemporal fusion, in which the reference times are 5 January 2002; 13 February 2002; 11 April 2002; 18 April 2002; and 18 April 2002, respectively, and the prediction times are 4 December 2001; 2 November 2001; 17 October 2001; 9 November 2001; and 25 November 2001, respectively.
Other algorithms can perform one-pair spatiotemporal fusion, in which the reference time is 5 January 2002, 13 February 2002, 11 April 2002, 18 April 2002, and 18 April 2002, respectively, and the prediction time is 4 December 2001, 2 November 2001, 17 October 2001, 9 November 2001, and 25 November 2001, respectively.
3.1.3. LGC
The Lower Gwydir Catchment (LGC) study site [
17] is located in northern New South Wales, Australia (149.2815
E, 29.0855
S). Fourteen cloud-free Landsat Thematic Mapper (TM) and MODIS image pairs across the LGC were taken from April 2004 to April 2005. The LGC dataset spans the Gwidir river with a width of 80 km from north to south and 68 km from east to west and an total area of 5440 km
. The images have 3200 columns and 2720 rows with a ground resolution of 25 m. LGC experienced severe flooding in mid-December 2004, resulting in approximately 44% of the area being submerged. Due to the different spatial and temporal changes caused by flood events, the LGC dataset can be considered a dynamically changing site. The dataset is available at
https://data.csiro.au/collection/csiro:5847v1 (accessed on 20 July 2023).
Similar to the CIA dataset, the blue, green, red, and NIR bands of the LGC dataset are extracted after removing the outer blank areas within the images, so 3184 columns and 2704 rows remain. When used for neural network evaluation, the nine images from 2004 are used for training, while the four images from 2001 are to be reconstructed. The dates to be reconstructed are set as follows: 3 April 2005; 2 March 2005; 13 January 2005; and 29 January 2005. Other algorithms use one-pair fusion, where the corresponding reference images are 2 May 2004; 26 November 2004; 28 December 2004; and 28 December 2004.
3.1.4. L8JX
The L8JX dataset is designed by us to test the availability of neural networks for one-pair spatiotemporal fusion. Landsat-8 OLI images were captured in December 2017, October 2018, and November 2017, respectively. The corresponding low-resolution images are the synthesized 8-day MODIS MOD09A1 products. Each image has the blue, green, red, and NIR bands. According to the grid rule of Landsat satellites, these images cover Jiangxi Province in China. The path numbers are 121, and the row numbers are 41, 42, and 43, respectively. The dataset is given the name L8JX for abbreviation, which has 9 pairs of images.
Due to the tilt of the orbit, there are black borders around the image content. In order to remove the useless space in the images, additional processing was carried. The original Landsat-8 images were rotated counterclockwise by approximately 13 degrees, and then the common areas without black borders were extracted. The entire dataset was then divided into three scenes that are geographically connected through small overlapping areas, which can be used as the ground truth to benchmark spatiotemporal fusion or mosaicking algorithms. Each image in L8JX has 5792 columns and 5488 rows. The 8-day MODIS images were rotated, and the blank areas were also removed at the same time. The dataset is available at
https://github.com/isstncu/l8jx (accessed on 20 July 2023).
3.1.5. FY4ASRcolor
The FY4ASRcolor dataset [
21] is proposed for testing the super resolution of low-resolution remote sensing images. The FY4ASRcolor dataset spans the blue (450–490 nm), red–green (550–750 nm), and visible near-infrared (VNIR, 750–900 nm) bands. The ground resolutions are 1 km for the high-resolution part and 4 km for the low-resolution part. Images in the dataset were captured on 16 September 2021. Each image in L8JX has 10,992 columns and 4368 rows. All the bands are in a 16-bit data format with 12-bit quantization, meaning that each digital number ranges from 0 to 4095. The dataset is available at
https://github.com/isstncu/fy4a (accessed on 20 July 2023).
FY4ASRcolor can be used to test spatiotemporal fusion because it comprises time-series data. The images in FY4ASRcolor are all captured by the Advanced Geostationary Radiation Imager (AGRI) camera with full disc scanning covering China (region of China, REGC) with a 5-min time interval for regional scanning. Because of the continuous change in solar angle, the radiation values can change dramatically over large time intervals. Since the daily radiative variation is repetitive, the spatiotemporal fusion of FY4ASRcolor can be used to assess the feasibility of learning the variation pattern throughout a year.
The FY4ASRcolor dataset gives another chance of spatiotemporal fusion within homogeneous platforms instead of heterogenous platforms. The high- and low-resolution images in FY4ASRcolor are acquired by separately mounted sensors of the same type. Different from MODIS and Landsat, each pair of images in the FY4ASRcolor dataset was taken simultaneously using the same sensor response. The sensor difference in FY4ASRcolor is much smaller compared to the L7STARFM, CIA, LGC, and L8JX datasets, as the average absolute error is 29.63. Usually, the sensor difference is hardly modeled, as it is stochastic and scene-dependent. The minimal sensor difference in the FY4ASRcolor dataset makes it ideal for conducting spatiotemporal fusion studies, as it eliminates the fatal sensor discrepancy issue in fusing MODIS and Landsat. A similar work was carried out by us for the spatiotemporal–spectral fusion of the Gaofen-1 images [
53]. However, there is only a 2-fold difference in spatial resolution.
3.2. Methods
Fourteen spatiotemporal fusion algorithms covering three categories are collected for evaluation. These algorithms include STARFM [
3], Fit-FC [
3], VIPSTF [
63], FSDAF [
4], SFSDAF [
38], SPSTFM [
30], EBSCDL [
31], CSSF [
33], BiaSTF [
34], DMNet [
35], EDCSTFN [
6], GANSTFM [
36], MOST [
20], and SSTSTF [
37].
STARFM, Fit-FC, and VIPSTF-SW are weight-based methods. STARFM is a classic and widely used spatiotemporal fusion approach. Fit-FC addresses the problem of discontinuities caused by clouds or shadows in spatiotemporal fusion. VIPSTF is a flexible framework with two versions, VIPSTF-SW and VIPSTF-SU, where the weight-based version (VIPSTF-SW) will be used and abbreviated as VIPSTF. VIPSTF produced the concept of a virtual image pair (VIP), which makes use of the observed image pairs to reduce the uncertainty of estimating the increment from fine-resolution images.
FSDAF and SFSDAF are hybrid methods. FSDAF is a spatiotemporal fusion framework that is compatible with both slow and abrupt changes in land surface reflectance and automatically predicts both gradual and land cover changes through an error analysis in the fusion process. SFSDAF is an enhanced FSDAF framework that aims to reconstruct heterogeneous regions undergoing land cover changes. It utilizes sub-pixel class fraction change information to make inferences.
SPSTFM, EBSCDL, and CSSF are dictionary-learning-based methods. SPSTFM trains two dictionaries generated from coarse- and fine-resolution difference image patches at the given time to build the coupled dictionaries for reconstruction. EBSCDL fixed the dictionary perturbations in SPSTFM using the error-bound-regularized method, which leads to a semi-coupled dictionary pair to address the differences between the coarse- and fine-resolution images. Compressed sensing for spatiotemporal fusion is addressed in CSSF, which explicitly describes the downsampling process and solves it using the dual semi-coupled dictionary pairs.
In the comparison methods, STARFM, BiaSTF, DMNet, EDCSTFN, GANSTFM, MOST, and SSTSTF are coded with Python. The PyTorch framework is used for deep learning. Fit-FC, VIPSTF, SFSDAF, SPSTFM, EBSCDL, and CSSF are coded with MATLAB. FSDAF is coded with Interactive Data Language (IDL). All hyperparameters are set according to the original articles. The experimental conditions are presented in
Table 2.
BiaSTF, DMNet, EDCSTFN, GANSTF, MOST, and SSTSTF use convolutional neural networks for fusion. BiaSTF models the sensor differences as a bias, which is modeled with convolutional neural networks to alleviate the spectral and spatial distortions in reconstructed images. DMNet introduces multiscale mechanisms and dilated convolutions to capture more abundant details while reducing the number of trainable parameters. EDCSTFN is an enhanced deep convolutional spatiotemporal fusion network with convolutional neural networks used to extract details of high-resolution images and residuals between all known images. GANSTF introduces the conditional generative adversarial network and switchable normalization technique into the spatiotemporal fusion problem, where the low-resolution images at the given time are not needed. MOST cascades enhanced deep neural networks and trains the spatial and sensor differences separately to fuse images quickly and effectively. SSTSTF proposes a step-by-step modeling framework, and three models have been designed based on deep neural networks to explicitly model the spatial difference, sensor difference, and temporal difference separately. In the training stage, BiaSTF, DMNet, MOST, and SSTSTF can be trained with only one pair, while EDCSTFN and GANSTF need two or more pairs to learn temporal changes. Training parameters are given in
Table 3 for CNN-based algorithms, where the average training time is also given by training the first band of the L8JX dataset twice.
3.3. Metrics
Metrics are also used to assess the performance of the synthesized images. Root mean square error (RMSE) measures the radiometric discrepancy. Spectral angle mapper (SAM), relative average spectral error (RASE) [
64], relative dimensionless global error in synthesis (ERGAS) [
65], and Q4 [
66] measure the color consistency. Three metrics are used to measure the structural similarity, including the classic structural similarity (SSIM), the normalized difference Robert’s edge (ndEdge) for edge similarity, and the normalized difference local binary pattern (ndLBP) for textural similarity. To help readers understand the digital trends, the negative SSIM (nSSIM) and negative Q4 (nQ4) are used instead of the standard definitions.
To establish the metrics, the LandSat images taken at a specific time are used as the ground truth. To evaluate the spectral consistency with SAM, RASE, ERGAS, and nQ4, the NIR, red, and green bands are used, but not the blue band. The ideal results are 0 for all the metrics.
RMSE is calculated as
where
x and
y are two single-band images sharing the same pixel quantity
N, and
i is a pixel location.
For a reference image
x and an evaluation image
y, the spectral angle SAM metric between
y and
x is calculated using the normalized correlated coefficient as follows:
where
is the inner product between
x and
y.
For a reference image
x and an evaluation image
y, the RASE metric for
y to reference
x is calculated as
where RMSE is the root mean square error between two images (calculated using pixels in all bands),
N is the number of pixel locations (product of the width and height), and
C is the number of bands.
The ERGAS metric is calculated as
where
C is the number of total bands in an image,
is the
band of image
x,
is the
band of image
y, and
is the mean value of
.
r is the resolution ratio between high- and low-resolution images which is initially defined for pansharpening. For example,
r is set to 2 to evaluate the LandSat-7 fusion between the 15m panchromatic band and the 30 m multispectral bands. For hyperspectral visualization,
r is set to 1.
Q4 is defined by
where two quaternion variables are defined as
where
,
, and
are basic notations of a quaternion.
For a color image x, is 0, and , , and correspond in turn to pixel values of the three bands. This forms a column vector of quaternions. Analogously, is 0, and , , and correspond in turn to pixel values of the three bands of the image y. and are the mean values of quaternion vectors and , respectively.
For a quaternion notation
, the modulus
is calculated using
where
is the conjugate of
z and defined by
The covariance between quaternion vectors
and
is
Instead of the standard Q4 index, the negative Q4 (nQ4) is used, which is defined as
nSSIM is calculated using
where
x and
y are two single-band images,
and
denote the mean values,
and
denote the standard deviations, and
is the covariance between
x and
y.
and
are small constants to avoid zeros.
Robert’s edge (Edge) is used to measure the edge features of fused images by detecting local discontinuities. For an image
x, the edge discontinuity at the coordinate
is defined as
where
is the pixel value at the location
.
A Robert’s edge image is generated after the point-by-point calculation for the image
x, which can be defined as
. By denoting the Robert’s edge images for the fused image and the ground truth image as
and
, respectively, the normalized difference Edge index (
) between them is calculated as
It should be noted that the ndEdge’s calculation involves only 10% of locations with higher Edge values which are determined from
. For a multiband image, after finding the ndEdge of each band, the average of these values yields a total ndEdge.
The local binary pattern (LBP) is an operator that describes the local texture characteristics of an image. In a window, the center pixel is adjacent to 8 pixels. The adjacent locations are marked as 1 if their gray values are larger than that of the center pixel, and 0 otherwise. By concatenating the eight comparison results, an 8-bit binary digit is obtained ranging from 0 to 255, which we call the LBP code of the center pixel. The point-by-point calculation for each point gives an LBP image.
By denoting the LBP images for the fused image and the ground truth image as
and
, respectively, the normalized difference LBP index (
) between them is calculated as
Similar to the calculation of multiband ndEdge, after finding the ndLBP for each band of a multiband image, the average of these values is the total ndLBP.
In order to present the radiometric error with a percentage indicator, the relative uncertainty is evaluated, which is defined as
The mean relative uncertainty of a single-channel image is the mean value of relative uncertainty across all pixel locations. The best uncertainty is given to represent the optimal performance that the state-of-the-art algorithms can reach.
The mean value (mean) and correlated coefficient (CC) are also calculated. The mean value is an indicator for data range, and CC illustrates the similarity between the reference images and the target images.
6. Discussion
The motivation of this work is to address the questions raised in the first section, which are the upper performance boundaries, the stability of the algorithms, and the possibility of using CNN for one-pair fusion. Answers to these questions can be inferred from the comparison of the experimental results.
6.1. Performance Analysis
When the digital scores are concerned in the popular CIA dataset, the RMSE performance of the current algorithms is not significantly improved by comparing them with the STARFM algorithm that was proposed in 2006. When considering uncertainty, the relative uncertainties for the first image of the CIA dataset obtained by STARFM are 2.87%, 2.25%, 4.45%, 2.54%, 7.78%, 4.43%, 9.32%, 20.70%, 4.98%, 2.22%, 4.24%, 8.05%, 0.00%, 0.00%, 0.00%, 0.00%, 0.76%, 1.99%, 2.91%, and 6.46% higher than the best scores, respectively. For the fourth image of the CIA dataset, STARFM even achieves the best scores for all bands.
However, when considering the structural quality, the results obtained using STARFM are not as good as state-of-the-art methods because it tends to predict blurry images with a large number of speckles in smooth regions, which can be observed in
Figure 3 and
Figure 4. The neural-network-based algorithms produce acceptable images only when they are given sufficient training data. In this case, the results by SSTSTF show admirable spectral color and structural details. In summary, although the digital evaluation shows small improvement, the existing spatiotemporal fusion algorithms have made significant advancements in fusion quality. These algorithms have been able to remove speckles and adapt to abrupt changes or heterogeneous regions.
The best uncertainties show that the reconstruction accuracy of the NIR bands is generally higher than that of the red, green, and blue bands. In the L8JX and LGC datasets, the best uncertainties of NIR are all below 12%. The uncertainty scores over 20% are only observed in the CIA dataset.
More conclusions can be drawn from
Table 20. It can be seen that the average uncertainty scores of LGC and L8JX are both less than 15%, indicating that the current spatiotemporal fusion methods are practically feasible. However, the best performance of LGC and L8JX are produced with CNN-based algorithms. When the training data are insufficient to effectively train the CNNs (e.g., L7STARFM), the least error of some in the red band is 35.4%, which is too large to be accepted. Therefore, the scale of the training data is possibly the most important factor that determines the outcome of the fusion, followed by the algorithms.
It is observed that among the four bands, the red band is the most difficult to reconstruct. The reason may be attributed to the rich structure and high temporal sensitivity of the red band. Surface reflectance is generally used in spatiotemporal fusion, where the amplitude of the red band is negatively correlated with vegetation density. Limited by scale, a typical fusion scene can include woodland, farmland, and grassland, resulting in rich structures in the red band. The red spectrum of vegetation varies greatly with the changing of the seasons, resulting in a significant shift in the red band. In contrast, the blue band has a small intensity and less detail, and the green band is less sensitive to seasonal variations than the red band. Although the NIR band is also susceptible to temporal variations, it is spatially smooth.
6.2. Threshold of Uncertainty for Practical Use
When the popular uncertainty metric is used to assess the feasibility of spatiotemporal fusion to practical applications, a threshold helps to judge the fusion quality conveniently. The radiometric standards of the ground processing systems can be referenced. In terms of radiometric calibration targets, the uncertainty is uniformly set to 5% for the multispectral sensors of MODIS, Landsat-5 TM, Landsat-7 ETM+, and Landsat-8 OLI in terms of the blue, green, red, and NIR bands. As for the actual uncertainty, it is within 2% for MODIS [
69], 5% for Landsat-5 TM [
70], 5% for Landsat-7 ETM+ [
71], and 4% for Landsat-8 OLI [
71].
Compared to radiometric calibration, the fusion problem is more similar to the cross-calibration problem, which has been widely investigated. Based on the radiometric values of MODIS as the baseline, the differences are 4% for Landsat-5 TM [
72], 7% for Landsat-7 ETM+ [
73], and 4% for Landsat-8 OLI [
72]. In these studies, MODIS is commonly adopted as the calibration reference in the reflective solar spectral range due to its exceptional radiometric accuracy.
A simple criterion is needed to evaluate the practicality of fusion tasks. Due to the unavailability of high-resolution images at the target time, the error in spatiotemporal fusion is usually greater than that of cross-calibration. Consequently, it seems not practical to set the uncertainty threshold to 5% for spatiotemporal fusion.
As a result, this paper suggests a 10% uncertainty as the common threshold to determine the uniform availability of fusion results. Scores show that the best fusion results can reach to about 10%. Furthermore, several practices have proved the feasibility of the fusion results in its present form. The ideal threshold may vary depending on the type of downstream tasks. Quantitative applications such as surface temperature may pursue small uncertainty. Interpretive tasks, such as classification and segmentation, are less sensitive to uncertainty if the structures are rich.
6.3. Stability
An algorithm is considered stable in this paper when it consistently outperforms other algorithms. As the quality of fusion is influenced by image content and time intervals, it is unrealistic to expect an algorithm to perform equally well in all scenarios. Instead, certain algorithms may outperform others in specific scenarios, allowing us to choose the most suitable algorithm accordingly.
Table 21 shows that CNN-based algorithms achieved the best performance for three out of the five datasets. The weight-based algorithms rank first for CIA and L7STARFM. Although the hybrid algorithms failed to win first place, they performed much more stably, ranking second in four competitions. To conclude, hybrid algorithms handle all cases steadily in spite of their training scales. However, when the training data are sufficient, neural networks can work stably.
When considering the stability of each algorithm, things are much different. The conclusion can be drawn from the results of the datasets where neural networks have advantages. In LGC, GANSTFM ranked first and SSTSTF ranked second. In L8JX, SSTSTF ranked first and DMNet ranked second. In FY4A, GANSTFM and MOST both ranked first. This shows that GANSTFM and SSTSTF are superior in performance and stability compared to other neural-network-based algorithms.
The remaining two datasets can be analyzed for other types of algorithms. In CIA, Fit-FC ranked first and FSDAF ranked second. In L7STARFM, Fit-FC ranked first and VIPSTF ranked second. This shows that Fit-FC is more stable among the weight-based algorithms that were tested.
6.4. CNN for One-Pair Spatiotemporal Fusion
It can be concluded from
Table 21 that the performance of CNN-based spatiotemporal fusion algorithms is greatly affected by the size of the single input image. An image has to be cropped into patches before being fed into the networks, so a larger single image size yields a higher number of patches from the same moment. The algorithms can only show better performance with sufficient training, such as with many groups of small reference images for offline training as in CIA and LGC or a group of large reference images for online one-pair fusion as in L8JX and FY4ASRcolor.
The data scales are similar between CIA and L8JX, but there is a significant difference in the ranks of CNN-based methods. By comparing their results, it can be concluded that the quality of CNN-based algorithms is more influenced by the image size. Larger image sizes train algorithms better for modeling spatial differences and recognizing land covers. A larger number of image pairs can lead to better training for modeling time differences. If spatiotemporal fusion is understood as an aggregation of various categories, such as in the unmixing-based methods, the accurate extraction of ground features with an encoder forms the foundation for learning temporal differences.
Therefore, we can conclude that CNN-based algorithms can perform one-pair spatiotemporal fusion only when the image size is sufficiently large. If this condition is not satisfied, hybrid algorithms are alternative choices. On the other hand, when there are large images with long time series, CNN-based algorithms can further improve performance by learning temporal differences. When the amount of data becomes even larger, neural networks can possibly be constructed with a transformer or a diffusion model.
The results of weight-based methods are independent of image size. The unmixing-based or unmixing-involved hybrid methods are extremely slow when clustering large images, so the images of L8JX have to be divided into four blocks and fused separately. CNN-based methods perform the best on both LGC, L8JX, and FY4ASRcolor, which is consistent with their large image size. In particular, in the FY4ASRcolor dataset, which has the largest image size, neural-network-based algorithms achieve the optimal values for all bands. Therefore, the ability of neural networks to learn from big data makes them more promising than other types of algorithms.
6.5. Similarity and Content for Fusion
To further clarify the key factors influencing fusion quality,
Table 22 and
Table 23 are presented, which illustrate the relationship between the average results of Fit-FC and FSDAF and the input image pairs. These two algorithms were chosen because they suffer less performance loss from small image sizes. NIR is not used because its amplitudes are not in line with other bands.
Table 22 and
Table 23 demonstrate that the time interval between the reference time and the predicted time has the first-place influence on the reconstruction results. The smallest error occurs for the 16-day interval of LGC. The second smallest error occurs for the 32-day interval of LGC. The third smallest error occurs for the CIA’s 32-day interval. The maximum error occurs for the CIA’s 176-day interval, which is the actual maximum interval when considering a cycle of four seasons. The errors of the 32-day interval are significantly larger than those of the 16-day interval, but the average uncertainty remains less than 15%. The small time interval indicates that the similarity between the reference image and the target image is the main factor influencing the reconstruction performance. This finding has been validated in all five datasets.
Besides the time interval, the correlation coefficient is another available indicator that is useful when the time intervals are the same. For the CIA dataset, the correlation coefficient of the first image pair is significantly higher than that of the other four images, and its uncertainty is the lowest. The same conclusion can be found in the third image of LGC, the first image of L8JX, and the second image of L7STARFM. By comparing the results of images 1 and 4 of LGC in
Table 23, which have the same 32-day interval, we can expect better performance from higher correlated coefficients.
In terms of heterogeneity, CIA is considered a homogeneous region and LGC is a heterogeneous region. It is evident from
Table 22 and
Table 23 that Fit-FC performs better on CIA while FSDAF wins LGC. This conclusion is consistent with their motivations. To conclude, FSDAF focuses on heterogeneous or changing land covers, while Fit-FC works well for homogeneous areas. Similar conclusions have been drawn in [
42].
6.6. Ranking the Algorithms and Metrics
Ranks could be given for each class of spatiotemporal algorithms. Among the neural-network-based methods, SSTSTF achieves the highest scores on both the CIA dataset and the L8JX dataset. Among the weight-based methods, Fit-FC performs the best as it outperforms the other weight-based algorithms on datasets, with the exception of L8JX. Among the dictionary-based algorithms, CSSF is the best for LGC, L7, and FY4ASRCOLOR. Among the hybrid methods, FSDAF consistently outperforms SFSDAF.
As far as the metrics are concerned, RMSE and SSIM are classical and accurate, which evaluate the radiometric and structural errors, respectively. Among the spectral criteria, ERGAS shows the best stability. In the change detection experiment, the IOU and F1-score show similar results with admirable stability.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}