
Development of AI- and Robotics-Assisted Automated Pavement-Crack-Evaluation System

 ,
,  ,
,  and
and
Abstract
1. Introduction
- Developing a robotics platform that will collect visual data automatically;
- Presenting a novel deep learning model to implement the platform on the robot’s onboard computer to detect cracks from the RGB images in real-time;
- Presenting a crack quantification algorithm for finding out crack length, width, and area;
- Finally, presenting a visualization of the crack severity map.
2. Literature Review
2.1. Robotic System for Crack Inspection
2.1.1. Traditional Methods
2.1.2. Learning-Based Methods
3. Architecture of the AMSEL Robot
3.1. Mechanical Unit
3.1.1. Chassis Module
3.1.2. Reconfigurable Sensory Frame
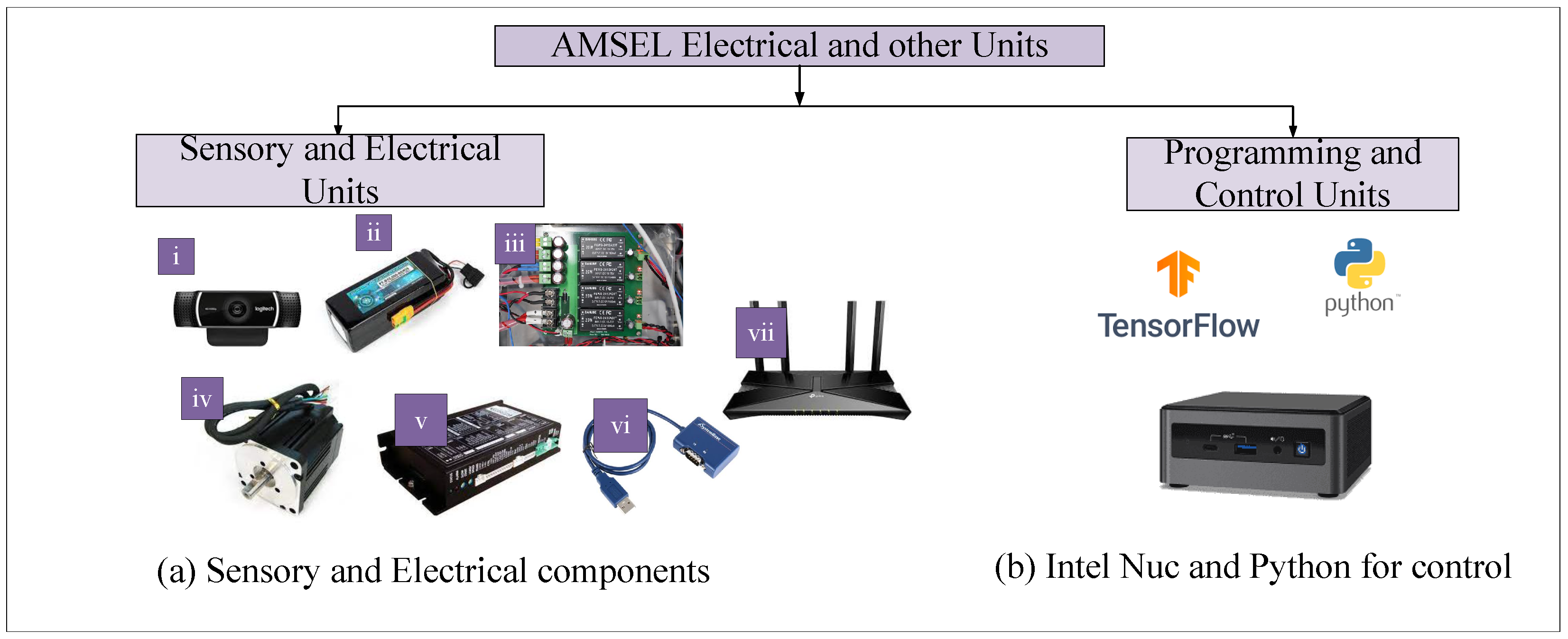
3.2. Electrical and Functional Unit
3.2.1. Electrical Units
- Vision System: A Logitech c922 Pro HD Stream Webcam is been utilized as the vision system of the AMSEL robotic platform (Figure 3a (i)).
- Power source: In the AMSEL robot, a Polytronics Lithium-Polymer (Li-Po) battery is used as the power source. The model number of the utilized battery is PT-B16-Fx30 (Figure 3a (ii)).
- Power supply board: A custom-designed power supply board is utilized to split the power from the Li-Po battery among the other electronic devices used in the robotic platform (Figure 3a (iii)).
- DC motors: For navigating the robot, four DC motors are used in the AMSEL robot (Figure 3a (iv)). The DC motors used in this robot are 200W Brushless DC (BLDC) motors. The model number of these motors is TM90-D0231.
- BLDC motor controller: For driving and controlling the motors in the AMSEL robot, four BLDC motor controllers are used (Figure 3a (v)). The model number of the utilized controller is TMC-MD02.
- Serial communication adapter: The AMSEL robotic platform uses multiple serial communication adapters for converting the RS485 communication to USB communication, as the system’s main controller uses USB communication protocol (Figure 3a (vi)).
- Router: A Tplink Archer Ax73 outer is used in the AMSEL robot for communicating with the host PC in the ground station (Figure 3a (vii)).
3.2.2. Control Unit
4. Crack Detection and Quantification from Image
4.1. Proposed Architecture for Crack Segmentation
4.1.1. Encoder Module
4.1.2. Context Embedded Channel Attention Module
4.1.3. Decoder with Global Attention Module
4.2. Dataset Description and Training of the Model
4.2.1. Dataset
4.2.2. Implementation Details
4.3. Crack Severity Analysis
4.3.1. Counting the Cracks
4.3.2. Extracting Morphological Features
| Algorithm 1: Algorithm for length and width calculation |
 |
5. AMSEL Robot Working Method
5.1. Manual Navigation and Pavement Inspection
5.2. Automated Navigation and Pavement Inspection
| Algorithm 2: Algorithm for automated navigation and inspection |
 |
6. Results and Discussion
6.1. Performance of the Deep Learning Model
6.2. Comparison with Other State-of-the-Art Methods
6.3. Pavement Assessment in Manual Mode
6.4. Pavement Assessment in Automated Mode
7. Drawbacks of the Proposed System
- The proposed DL model named RCDNet cannot detect cracks with widths less than 1 mm from a 30 cm height.
- When the sunshine is extreme and there is a dark shadow in the outdoor environment, the RCDNet may predict a shadow line as a crack.
- The RCDNet fails if the depth between the edges of the crack is very small, such that it does not look like a crack but rather a scratch on the pavement.
- The robotic vehicle occasionally encounters a slight deviation from the linear path during automated navigation, which poses challenges in reestablishing its initial pose upon returning to the starting position.
- The camera’s frame size was slightly larger than the gap between the two consecutive lanes, causing a small overlap in the captured images.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, R.B. Development of korean highway capacity manual. In Highway Capacity and Level of Service; Routledge: London, UK, 2021; pp. 233–238. [Google Scholar]
- Chen, C.; Seo, H.; Jun, C.; Zhao, Y. A potential crack region method to detect crack using image processing of multiple thresholding. Signal Image Video Process. 2022, 16, 1673–1681. [Google Scholar] [CrossRef]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement crack detection using otsu thresholding for image segmentation. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018. [Google Scholar]
- Nigam, R.; Singh, S.K. Crack detection in a beam using wavelet transform and photographic measurements. Structures 2020, 25, 436–447. [Google Scholar] [CrossRef]
- Zoubir, H.; Rguig, M.; Aroussi, M.E.; Chehri, A.; Saadane, R. Concrete Bridge Crack Image Classification Using Histograms of Oriented Gradients, Uniform Local Binary Patterns, and Kernel Principal Component Analysis. Electronics 2022, 11, 3357. [Google Scholar] [CrossRef]
- Gehri, N.; Mata-Falcón, J.; Kaufmann, W. Automated crack detection and measurement based on digital image correlation. Constr. Build. Mater. 2020, 256, 119383. [Google Scholar] [CrossRef]
- Medina, R.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E.; Segarra, M.J. Crack Detection in Concrete Tunnels Using a Gabor Filter Invariant to Rotation. Sensors 2017, 17, 1670. [Google Scholar] [CrossRef]
- Nguyen, H.-N.; Kam, T.-Y.; Cheng, P.-Y. An Automatic Approach for Accurate Edge Detection of Concrete Crack Utilizing 2D Geometric Features of Crack. J. Signal Process. Syst. 2013, 77, 221–240. [Google Scholar] [CrossRef]
- Chun, P.; Izumi, S.; Yamane, T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput.-Aided Civ. Infrastruct. Eng. 2020, 36, 61–72. [Google Scholar] [CrossRef]
- Vedrtnam, A.; Kumar, S.; Barluenga, G.; Chaturvedi, S. Early crack detection using modified spectral clustering method assisted with FE analysis for distress anticipation in cement-based composites. Sci. Rep. 2021, 11, 1–19. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.-M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Li, Y.; Han, Z.; Xu, H.; Liu, L.; Li, X.; Zhang, K. YOLOv3-Lite: A Lightweight Crack Detection Network for Aircraft Structure Based on Depthwise Separable Convolutions. Appl. Sci. 2019, 9, 3781. [Google Scholar] [CrossRef]
- Li, L.; Zheng, S.; Wang, C.; Zhao, S.; Chai, X.; Peng, L.; Tong, Q.; Wang, J. Crack Detection Method of Sleeper Based on Cascade Convolutional Neural Network. J. Adv. Transp. 2022, 2022, 1–14. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civil Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Polovnikov, V.; Alekseev, D.; Vinogradov, I.; Lashkia, G.V. DAUNet: Deep Augmented Neural Network for Pavement Crack Segmentation. IEEE Access 2021, 9, 125714–125723. [Google Scholar] [CrossRef]
- Yong, P.; Wang, N. RIIAnet: A Real-Time Segmentation Network Integrated with Multi-Type Features of Different Depths for Pavement Cracks. Appl. Sci. 2022, 12, 7066. [Google Scholar] [CrossRef]
- Yu, S.N.; Jang, J.-H.; Han, C.-S. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Autom. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Lei, B.; Ren, Y.; Wang, N.; Huo, L.; Song, G. Design of a new low-cost unmanned aerial vehicle and vision-based concrete crack inspection method. Struct. Heal. Monit. 2020, 19, 1871–1883. [Google Scholar] [CrossRef]
- Oyekola, P.; Mohamed, A.; Pumwa, J. Robotic model for unmanned crack and corrosion inspection. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 862–867. [Google Scholar] [CrossRef]
- Li, H.; Song, D.; Liu, Y.; Li, B. Automatic Pavement Crack Detection by Multi-Scale Image Fusion. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2025–2036. [Google Scholar] [CrossRef]
- La, H.M.; Dinh, T.H.; Pham, N.H.; Ha, Q.P.; Pham, A.Q. Automated robotic monitoring and inspection of steel structures and bridges. Robotica 2018, 37, 947–967. [Google Scholar] [CrossRef]
- La, H.M.; Gucunski, N.; Dana, K.; Kee, S.-H. Development of an autonomous bridge deck inspection robotic system. J. Field Robot. 2017, 34, 1489–1504. [Google Scholar] [CrossRef]
- Kolvenbach, H.; Valsecchi, G.; Grandia, R.; Ruiz, A.; Jenelten, F.; Hutter, M. Tactile inspection of concrete deterioration in sewers with legged robots. In Proceedings of the 12th Conference on Field and Service Robotics (FSR 2019), Tokyo, Japan, 29–31 August 2019. [Google Scholar]
- Le, D.V.K.; Chen, Z.; Rajkumar, R. Multi-sensors in-line inspection robot for pipe flaws detection. IET Sci. Meas. Technol. 2020, 14, 71–82. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, X.; Cervone, G.; Yang, L. Detection of Asphalt Pavement Potholes and Cracks Based on the Unmanned Aerial Vehicle Multispectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3701–3712. [Google Scholar] [CrossRef]
- Montero, R.; Menendez, E.; Victores, J.G.; Balaguer, C. Intelligent robotic system for autonomous crack detection and caracterization in concrete tunnels. In Proceedings of the 2017 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Coimbra, Portugal, 26–28 April 2017. [Google Scholar]
- Yang, L.; Li, B.; Li, W.; Brand, H.; Jiang, B.; Xiao, J. Concrete defects inspection and 3D mapping using CityFlyer quadrotor robot. IEEE/CAA J. Autom. Sin. 2020, 7, 991–1002. [Google Scholar] [CrossRef]
- Gui, Z.; Li, H. Automated Defect Detection and Visualization for the Robotic Airport Runway Inspection. IEEE Access 2020, 8, 76100–76107. [Google Scholar] [CrossRef]
- Ramalingam, B.; Hayat, A.A.; Elara, M.R.; Gómez, B.F.; Yi, L.; Pathmakumar, T.; Rayguru, M.M.; Subramanian, S. Deep Learning Based Pavement Inspection Using Self-Reconfigurable Robot. Sensors 2021, 21, 2595. [Google Scholar] [CrossRef]
- He, Z.; Jiang, S.; Zhang, J.; Wu, G. Automatic damage detection using anchor-free method and unmanned surface vessel. Autom. Constr. 2021, 133, 104017. [Google Scholar] [CrossRef]
- Yang, L.; Li, B.; Feng, J.; Yang, G.; Chang, Y.; Jiang, B.; Xiao, J. Automated wall-climbing robot for concrete construction inspection. J. Field Robot. 2022, 40, 110–129. [Google Scholar] [CrossRef]
- Yuan, C.; Xiong, B.; Li, X.; Sang, X.; Kong, Q. A novel intelligent inspection robot with deep stereo vision for three-dimensional concrete damage detection and quantification. Struct. Health Monit. 2021, 21, 788–802. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; MICCAI 2015; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Gurita, A.; Mocanu, I.G. Image Segmentation Using encoder–decoder with Deformable Convolutions. Sensors 2021, 21, 1570. [Google Scholar] [CrossRef] [PubMed]
- Caputo, G.; Lombardi, L. Attention mechanisms in computer vision systems. In Proceedings of the Conference on Computer Architectures for Machine Perception, Como, Italy, 18–20 September 1995. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researchers | Inspected Structure | Robot Platform | Deep Learning | Remarks |
|---|---|---|---|---|
| Yu et al. [19] | Concrete Tunnel | Mobile robot | No | Images were collected by the robotic system. An image-processing algorithm was utilized in an external computer for detecting cracks and crack information. |
| Oyekola et al. [21] | Concrete Tank | Mobile robot | No | Images were collected by the robotic system. A threshold-based algorithm was used in another computer for detecting the cracks. |
| Li et al. [22] | Concrete pavement | Guimi robot co ltd. | No | Detected crack using an unsupervised learning algorithm named MFCD. Detection was not performed in the onboard computer |
| La et al. [23] | Steel bridge | Wall climbing robot | No | Images were collected and passed to the ground station in real-time. Cracks were detected using the Hessian-matrix algorithm. |
| La et al. [24] | Bridge deck | Seekur robot | No | Combined visual sensor and NDE sensors for crack inspection. Presented stitched images after crack detection and a delamination map. |
| Hendrik et al. [25] | Concrete sewers | ANYmal (legged robot) | Yes (Machine learning) | Tactile sensory system were used to collect time-series signals from the footstep of ANYmal, and Support Vector Machine (SVM) was used to classify types of cracks. |
| Le et al. [26] | Concrete pipe | Mobile robot | Yes (Machine Learning) | Data from the camera and other sensors were fused to classify using SVM for detecting cracks. |
| Pan et al. [27] | Asphalt pavement | UAV | Yes (Machine learning) | Collected images using the UAV and the cracks were detected using Random Forest (RF), SVM, and Artificial Neural Network (ANN) models. |
| Montero et al. [28] | Concrete Tunnel | Mobile robot | Yes | Collected RGB images using a camera and ultrasound data by an ultrasonic sensor. A CNN model was used for detecting cracks from the images, and a traditional method was used for estimating crack depth from the ultrasonic data. |
| Li et al. [29] | Concrete Bridge | Flying robot | Yes | A deep learning model named Adanet was developed for detecting cracks. Crack location and severity information was provided as well. |
| Gui et al. [30] | Airport pavement | ARIR robot | Yes | Both surface and subsurface data were collected by a camera and a GPR interfaced into the robotic system. An intensity-based algorithm and voting-based CNN were applied for processing image and GPR data. |
| Ramalingam et al. [31] | Concrete pavement | Panthera robot | Yes | A SegNet-based model was developed to detect cracks and garbage using the onboard computer. A Mobile Mapping System was also utilized to localize the cracks. |
| He et al. [32] | Concrete Bridge | USV | Yes | A USV with an onboard computer was applied to detect cracks in the bottom of a concrete bridge using a model named cenWholeNet. |
| Yang et al. [33] | Concrete wall | Climbing robot | Yes | A network named InspectionNet was used for detecting the cracks from the RGB-D camera on the onboard computer of a robotic system. A map-fusion module was also proposed to highlight the cracks. |
| Yuan et al. [34] | Reinforced concrete | Mobile robot | Yes | This robotic system used a stereo camera for collecting pictures and utilized a Mask RCNN model on the onboard computer to detect cracks. A 3D point cloud was reconstructed from the actual size of the cracks. |
| Parameter | Dimension | Unit |
|---|---|---|
| AMSEL Height | 21 | cm |
| AMSEL Width | 48.5 | cm |
| AMSEL Length (with sensor frame) | 91 | cm |
| AMSEL Length (without sensor frame) | 74 | cm |
| Sensor frame height | 35.3 | cm |
| Sensor frame length | 17 | cm |
| Sensor frame width | 36 | cm |
| Wheel numbers | 4 | - |
| Wheel radius | 13.25 | cm |
| Continuous driving time | >4 | h |
| Power source | Lipo battery | 22 V |
| Sensor | RGB camera, vibration sensor | - |
| Accuracy (%) | Dice Coefficient (%) | IoU (%) | Dice Loss (%) | |
|---|---|---|---|---|
| Train set | 96.35 | 97.40 | 97.35 | 0.0180 |
| Test set | 96.29 | 97.33 | 96.90 | 0.0214 |
| Network | Accuracy (%) | Dice Coefficient (%) | IoU (%) | Number of Parameters (M) |
|---|---|---|---|---|
| FCN | 93.20 | 93.16 | 92.93 | 134.27 |
| SegNet | 95.60 | 95.83 | 94.44 | 29.44 |
| U-Net | 96.33 | 98.40 | 97.92 | 13.40 |
| RCDNet | 96.29 | 97.33 | 96.90 | 0.91 |
| Measurements (M) | Severity | Limit |
|---|---|---|
| Area (mm) | Fair | M < 0.4% |
| Poor | 0.4% ≤ M < 1% | |
| Severe | M > 1% |
| Picture | Number of Cracks | Manual Length | Manual Maximum Width | No of Cracks after Prediction | Digital Length | Digital Maximum Width | Area | Density | Severity |
|---|---|---|---|---|---|---|---|---|---|
| 1.jpg | 1 | 227 mm | 10 mm | 1 | 227.45 mm | 8.93 mm | 1039.75 mm | 1.44%. | Severe |
| 2.jpg | 2 | 72 mm, 187 mm | 3 mm, 7 mm | 2 | 72.04 mm, 178.75 mm | 2.82 mm, 7.52 mm | 484.675 mm | 0.67%. | Poor |
| 3.jpg | 1 | 302 mm | 17 mm | 1 | 295.91 mm | 15.97 mm | 2123.575 mm | 2.94%. | Severe |
| 4.jpg | 1 | 150 mm | 5 mm | 1 | 157.67 mm | 5.11 mm | 318.66 mm | 0.44%. | Poor |
| 5.jpg | Web crack | - | - | Web crack | - | - | 4330.93 mm | 6%. | Severe |
| 6.jpg | 1 | 240 mm | 5 mm | 1 | 232.56 mm | 5.64 mm | 344.98 mm | 0.47%. | Poor |
| 7.jpg | 1 | 325 mm | 8 mm | 1 | 312.24 mm | 7.82 mm | 545.32 mm | 0.83%. | Poor |
| 8.jpg | Web crack | - | - | Web crack | - mm | - | 599.83 mm | 0.88%. | Poor |
| 9.jpg | 1 | 302 mm | 9 mm | 1 | 302 mm | 8 mm | 1227.775 mm | 1.70%. | Severe |
| 10.jpg | 1 | 200 mm | 3 mm | 1 | 192.28 mm | 2.82 mm | 200.33 mm | 0.32%. | Fair |
| Picture | Number of Cracks | Manual Length | Manual Maximum Width | No of Cracks after Prediction | Digital Length | Digital Maximum Width | Area | Density | Severity |
|---|---|---|---|---|---|---|---|---|---|
| 11.jpg | 1 | 232 mm | 8 mm | 1 | 224.87 mm | 7.52 mm | 1144.09 mm | 1.59%. | Severe |
| 12.jpg | 1 | 307 mm | 10 mm | 1 | 300.86 mm | 10.81 mm | 1912.665 mm | 2.65%. | Severe |
| 13.jpg | Web crack | - | - | Web crack | - | - | 2747.5 mm | 3.81%. | Severe |
| 14.jpg | Web crack | - | - | Web crack | - | - | 3699.37 mm | 5.12%. | Severe |
| 15.jpg | 1 | 351 mm | 17 mm | 1 | 341.33 mm | 15.81 mm | 1713.26 mm | 2.37%. | Severe |
| 16.jpg | 1 | 240 mm | 9 mm | 1 | 225.67 mm | 18.33 mm | 1712.32 mm | 2.37%. | Severe |
| 17.jpg | 2 | 312 mm, 255 mm | 9 mm,6 mm | 2 | 305.15 mm, 238.87 mm | 8 mm, 6.11 mm | 2575.13 mm | 3.56%. | Severe |
| 18.jpg | 1 | 323 mm | 10 mm | 1 | 306.92 mm | 10.81 mm | 1841.572 mm | 2.55%. | Severe |
| 19.jpg | 2 | 268 mm, 98 mm | 8 mm,18 mm | 2 | 253 mm, 63.92 mm | 8.46 mm, 17.86 mm | 1487.54 mm | 2.06%. | Severe |
| 20.jpg | 1 | 230 mm | 9 mm | 1 | 224.43 mm | 10 mm | 1179.81 mm | 1.63%. | Severe |
| Number of Cracks | Maximum Area | Minimum Area | Total Area | Total Density |
|---|---|---|---|---|
| 43 | 3841.995 mm, Loc. (x = 0 m, y = 0.25 m) | 38.305 mm, Loc. (x = 2 m, y = 3 m) | 22,617.69 mm | 0.38% |
| Number of Cracks | Maximum Area | Minimum Area | Total Area | Total Density |
|---|---|---|---|---|
| 18 | 1741.35 mm, Loc. (x = 0.5 m, y = 0.25 m) | 308.2025 mm, Loc. (x = 0.75 m, y = 0.5 m) | 15,231.88 mm | 0.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.-M.; Harseno, R.W.; Kee, S.-H.; Nahid, A.-A. Development of AI- and Robotics-Assisted Automated Pavement-Crack-Evaluation System. Remote Sens. 2023, 15, 3573. https://doi.org/10.3390/rs15143573
Khan MA-M, Harseno RW, Kee S-H, Nahid A-A. Development of AI- and Robotics-Assisted Automated Pavement-Crack-Evaluation System. Remote Sensing. 2023; 15(14):3573. https://doi.org/10.3390/rs15143573
Chicago/Turabian StyleKhan, Md. Al-Masrur, Regidestyoko Wasistha Harseno, Seong-Hoon Kee, and Abdullah-Al Nahid. 2023. "Development of AI- and Robotics-Assisted Automated Pavement-Crack-Evaluation System" Remote Sensing 15, no. 14: 3573. https://doi.org/10.3390/rs15143573
APA StyleKhan, M. A.-M., Harseno, R. W., Kee, S.-H., & Nahid, A.-A. (2023). Development of AI- and Robotics-Assisted Automated Pavement-Crack-Evaluation System. Remote Sensing, 15(14), 3573. https://doi.org/10.3390/rs15143573