
Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review




Abstract
1. Introduction
- It presents a scientometric analysis of a few selected papers on image-based crack detection algorithms using data mining techniques to find out the current research trends, important research terms, influential publications, journals, and collaboration patterns of this research field.
- It presents a critical analysis of the papers related to image-based crack detection methods.
- Finally, it provides a summary of prominent image processing techniques and classifier algorithms for detecting cracks.
2. Literature Review
3. Research Methodology
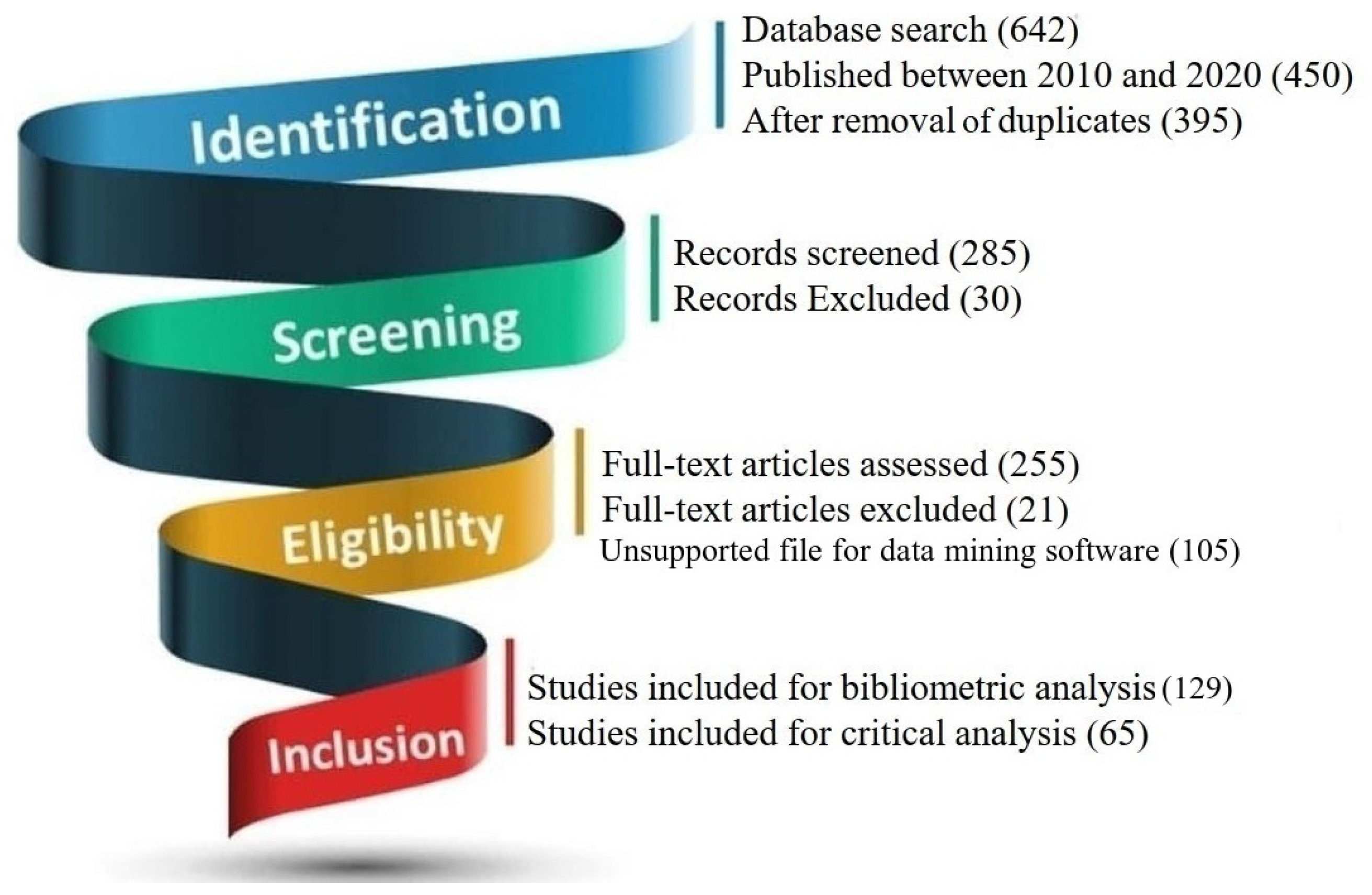
- Phase 1: The authors searched for the papers in four different online digital libraries in November 2020 including Web of Science (WOS), Sciencedirect, IEEE Xplore, and Willey online library using the search string “crack detection” AND (“bridge” OR “road” OR “concrete”) AND (“vision” OR “image”). In this way, the authors were able to download 642 papers initially. However, they limited the search string to a time span of ten years (2010 to 2020) for discussing the latest technologies. After removing the duplicate records, the authors identified a total of 395 papers at the end of Phase 1.
- Phase 2: In this stage, the authors screened 285 papers among the 395 papers extracted in Phase 1 by title and abstract which were published in the peer-reviewed journals. To avoid the inclusion of irrelevant articles in a systematic fashion, the authors developed some exclusion criteria and discarded the papers if (a) the research focus of any particular article is on non-image-based crack detection algorithms, (b) the paper discusses crack detection on reinforced plastic, beam, or steel structures, (c) the article is a review article instead of an original study. By employing the exclusion criteria, a total of 30 articles were excluded in this phase.
- Phase 3: In this stage, the remaining 255 papers were assessed by investigating the full text of the articles. The authors excluded an article from the systematic review if the article (a) was not closely related to the research focus of this study, (b) did not have a novel as well as efficient contribution to the research domain of image-based crack detection algorithms, (c) did not provide detailed information about the design or the implementation of the proposed idea. As a consequence, 21 papers were excluded. So, the number of extracted papers becomes 234. After that, an additional 105 papers were also excluded from these 234 papers for bibliometric analysis as they were not supported by the data mining software utilized in this work.
- Phase 4: After completing all the previous phases, 129 papers were finally included in this systematic review for scientometric analysis, and of the 234 papers, 65 DL-based papers were selected for critical analysis.
4. Bibliometric Analysis
4.1. Overview of the Publications
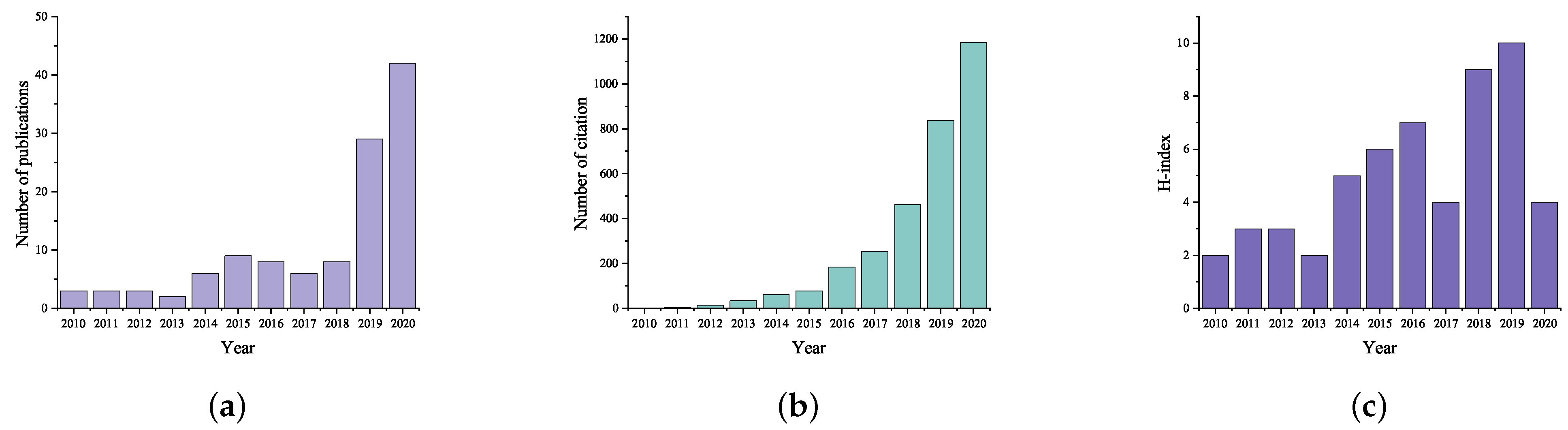
4.1.1. Annual Analysis of the Publications
4.1.2. The Most Cited Publications

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Journal | Corresponding Author | Country of Corresponding Author | Publication Year | Citation | Average Citation per Year |
|---|---|---|---|---|---|---|
| [35] | Computer-aided Civil and Infrastructure Engineering | Young-Jin Cha | Canada | 2017 | 575 | 143.50 |
| [38] | Pattern Recognition Letters | Qin Zou | China | 2012 | 242 | 26.89 |
| [43] | Machine Vision and Applications | Tomoyuki Yamaguchi | Japan | 2010 | 176 | 16 |
| [39] | Computer-aided Civil and Infrastructure Engineering | Shirley Dyke | USA | 2015 | 142 | 23.67 |
| [44] | IEEE Transactions On Intelligent Transportation Systems | Henrique Oliveira | Portugal | 2013 | 139 | 17.38 |
| [45] | Computer-aided Civil and Infrastructure Engineering | Takafumi Nishikawa | Japan | 2012 | 136 | 15.11 |
| [40] | IEEE Transactions on Automation Science And Engineering | Kristin J. Dana | USA | 2016 | 118 | 23.60 |
| [46] | Sensors | David F. Llorca | Spain | 2011 | 115 | 11.50 |
| [47] | Computer-aided Civil and Infrastructure Engineering | Eduardo Zalama | Spain | 2014 | 102 | 14.57 |
| [48] | Machine Vision And Applications | Yusuke Fujita | Japan | 2011 | 101 | 10.10 |
| [36] | Automation In Construction | Cao Vu Dung | Japan | 2019 | 80 | 40 |
| [37] | Construction And Building Materials | Sattar Dorafshan | USA | 2018 | 80 | 26.67 |
| [10] | Optik | Ahmed Mahgoub Ahmed Talab | China | 2016 | 57 | 11.40 |
| [41] | Image And Vision Computing | Qin Zou | China | 2011 | 56 | 5.60 |
| [42] | Journal Of Computing In Civil Engineering | Matthew M. Torok | Japan | 2014 | 52 | 7.43 |
4.2. Influential Journals, Authors, and Countries
4.2.1. The Most Productive Journals
4.2.2. The Most Productive Authors
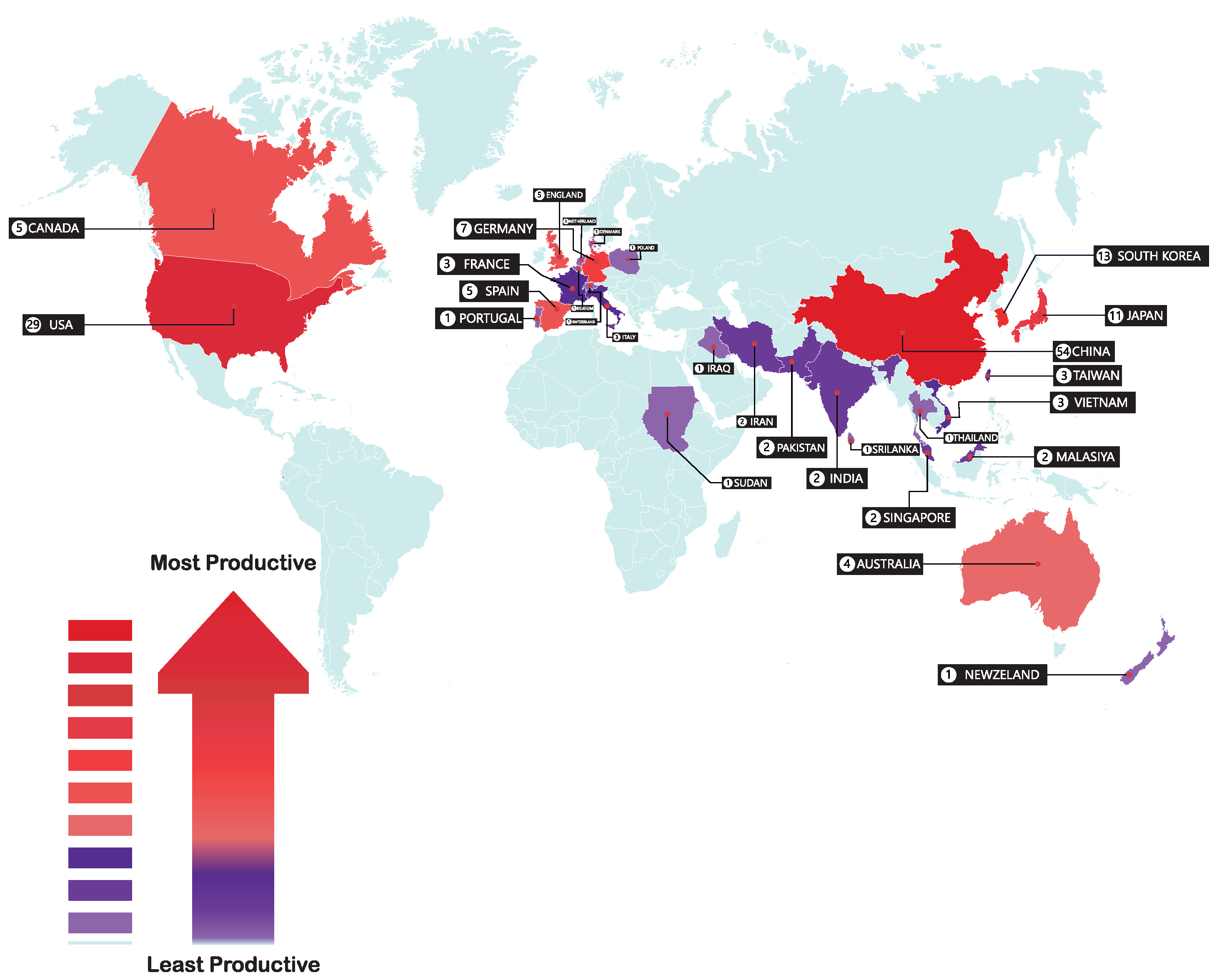
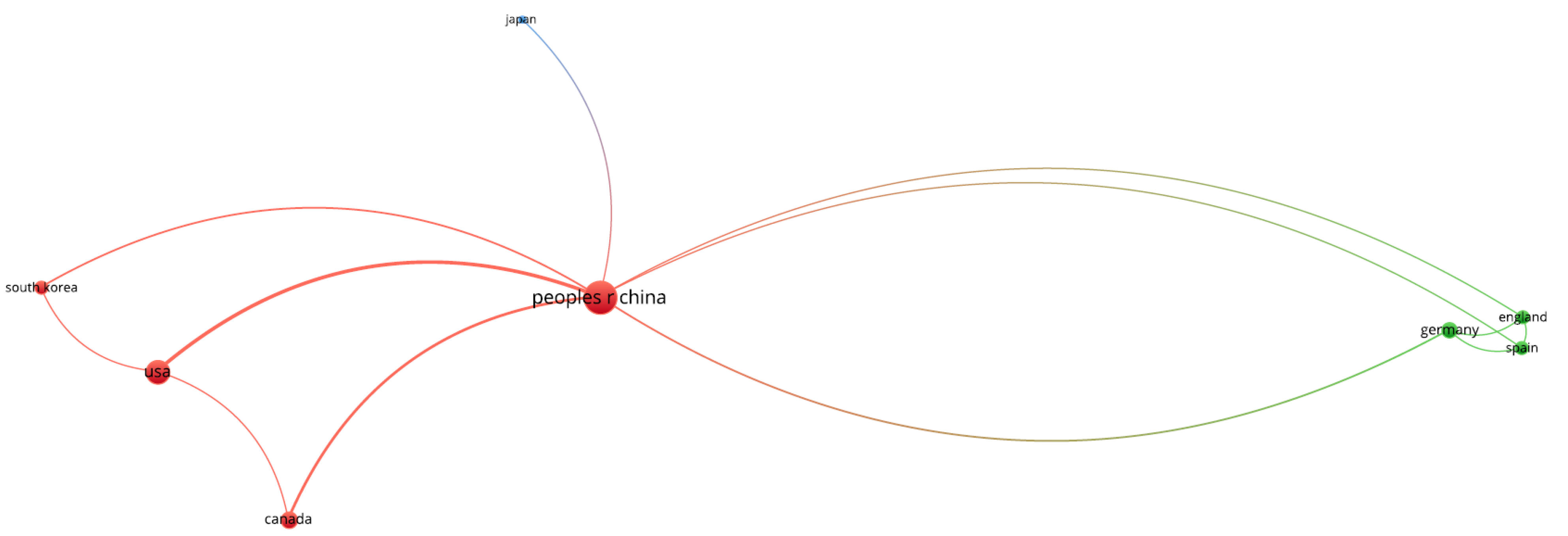
4.2.3. The Most Productive Countries
4.3. Science Mapping Analysis
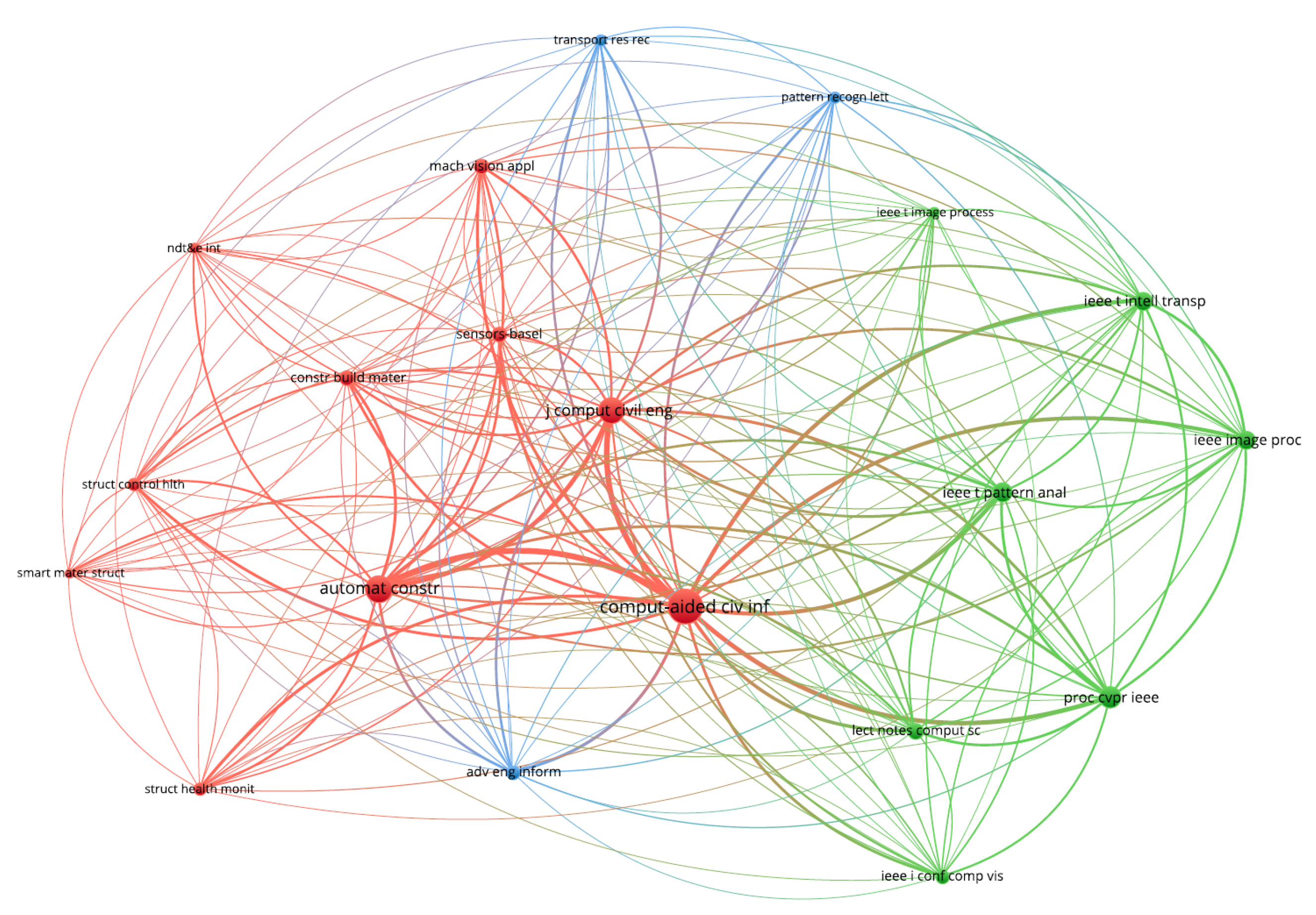
4.3.1. Co-Citation Analysis
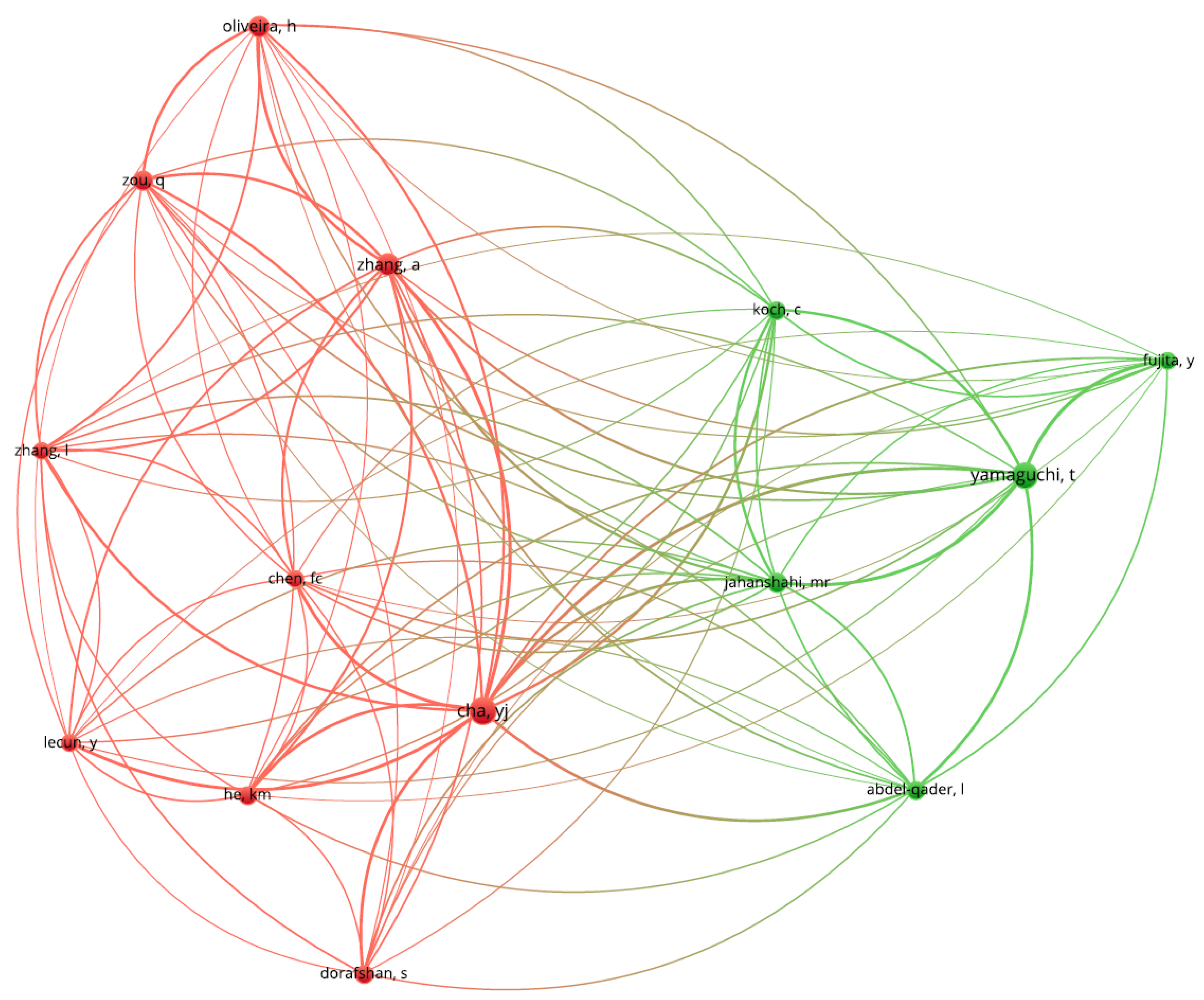
4.3.2. Co-Authorship Analysis
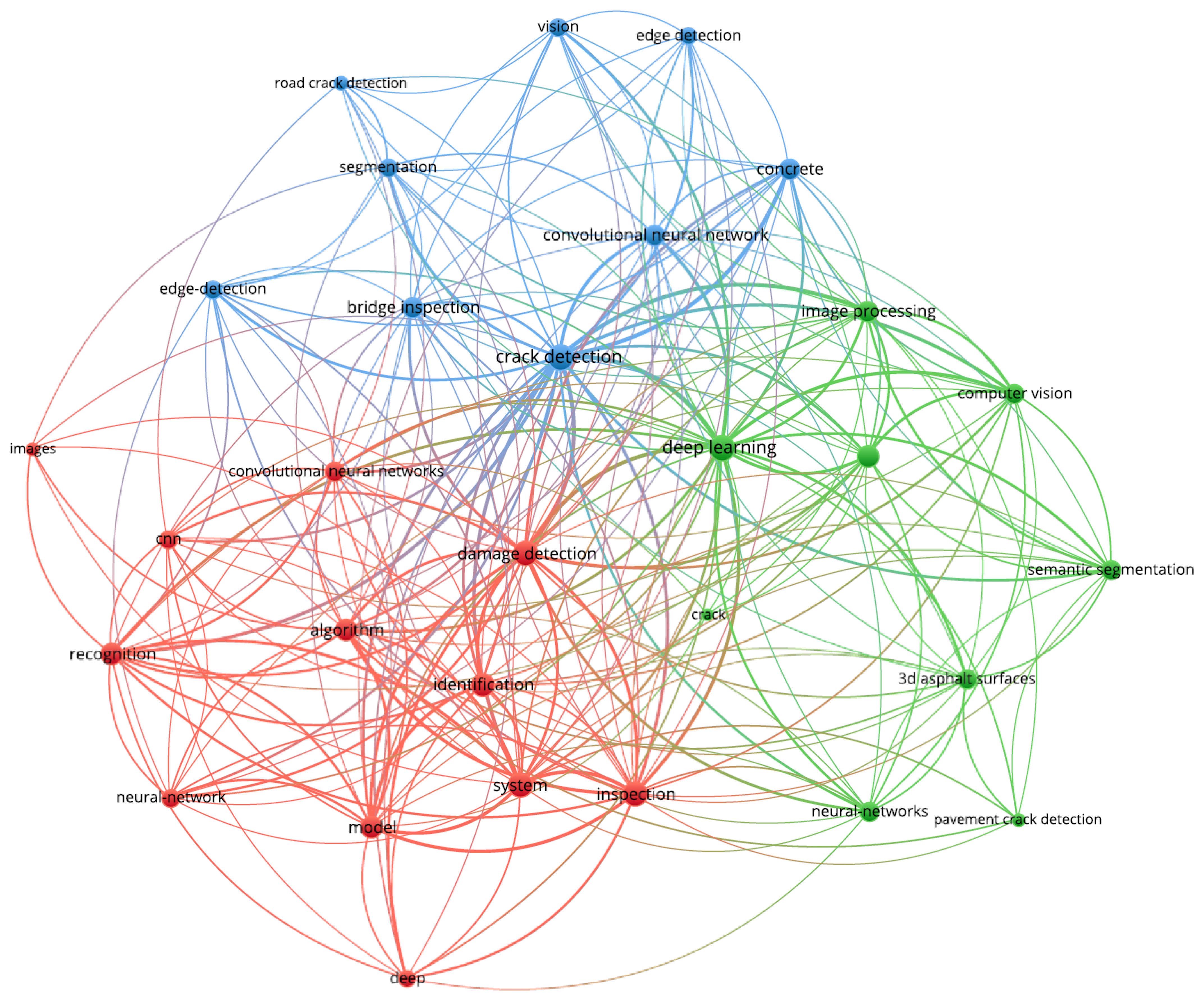
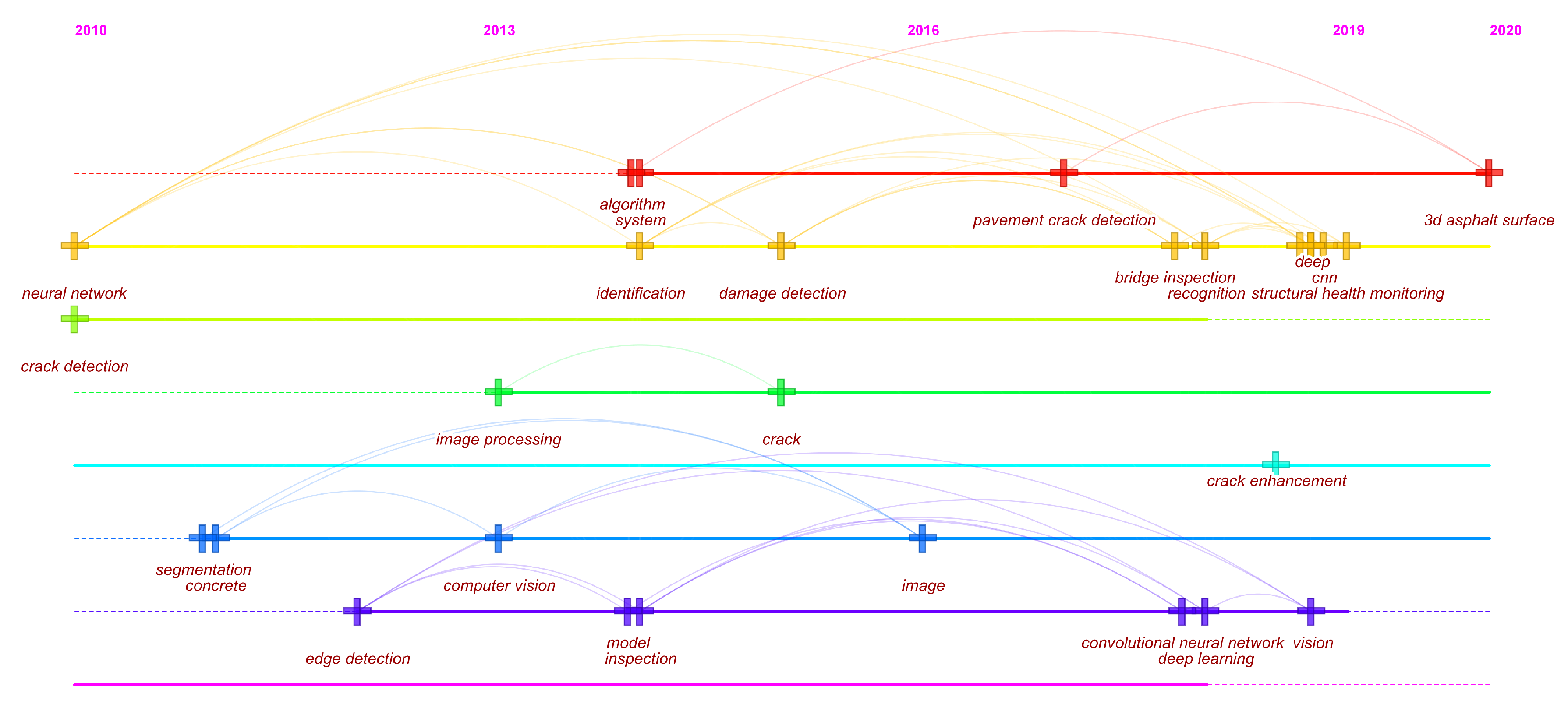
4.3.3. Co-Occurrence and Timeline View Analysis
5. Critical Analysis
- Q1. Which DL method is used in an article?
- Q2. Which backbone is used by the DL method?
- Q3. Which DL library is used by an article?
- Q4. Which datasets are used by an article?
- Q5. Which concrete surface is taken into consideration by an article?
- Q6. Which loss function is used in an article?
- Q7. Which optimizer is used in an article?
- Q8. Which annotation tool is used by an article?
- Q9. What performances are achieved by an article?
5.1. Classification
5.2. Detection
5.3. Segmentation
| Ref | Method | Backbone | Framework | Dataset | Surface | Loss Function | Optimizer | Annotation Tool | Performance (%) |
|---|---|---|---|---|---|---|---|---|---|
| [69] | CedNet | DenseNet-121 | Caffe | Own collection | Building | - | - | Manually | Accuracy = 98.90%, Precision = 93.58%, Recall = 93.18%, F1-score = 87.23%, IoU = 98.82% |
| [70] | CrackU-Net | U-Net | Tensorflow | Own collection | Road | - | Adam | - | Accuracy = 99.01%, Precision = 98.56%, Recall = 97.98%, F1-score = 98.42%% |
| [71] | ARF-crack | DeepCrack | - | DeepCrack, CFD, Crack500, GAPS384 | Pavement | - | - | - | Average precision = 76.45%, 76.9%, 48.9% |
| [72] | SCHNet | VGG19 | Tensorflow | SDNET2018 | Bridge deck | Cross-entropy | - | LabelMe | mIoU = 85.31% |
| [73] | FRCNN, Mask RCNN | Inception ResNet-V2 | Tensorflow | Own collection | Bridge | - | - | LabelImg | Average precision = 66%, 78% |
| [74] | Multiscale Adversarial NN | - | Pytorch | METU | concrete structures | Customized Loss function | Adam | LEAR | Accuracy = 98.176%, MIoU = 88.936%, F1 = 88.789% |
| [75] | U-HDN | U-Net | Pytorch | CFD, AgileRN | Road | Customized loss function | - | - | Precision = 94.5%, 92.1%, Recall = 93.6%, 93.1% |
| [76] | ConnCrack | VGG16 | - | CFD | pavement | CwGAN loss | - | - | Precision = 96.79%, Recall = 87.75%, F1-score = 91.96% |
| [77] | CrackPix | VGG16 | Pytorch | Own collection | concrete structures | - | - | Image Labeler tool of MATLAB | Precision = 91.24%, F1-score = 91.70% |
| [78] | DeepLabV3+ | - | Tensorflow | Own collection | Pavement | Regression Loss | - | LabelMe | mIoU = 83.42% |
| [79] | DSS framework | GAN | Pytorch | Roadcrack | Road | - | Adam | - | F1-score = 82% |
| [80] | U-Net | ResNet-34 | Pytorch, Fastai | CFD, Crack500 | Pavement | Dice coefficient loss | Adamw | - | F1-score = 96%, 73% |
| [81] | Customized model | ResNet-40 | Tensorflow | CrackDataset | Pavement | - | - | - | Precision = 98.74%, Recall = 98.05%, F1-score = 98.39% |
| [36] | FCN | VGG16 | Keras | CCIC | Concrete structures | Binary cross-entropy | RMSprop | LIBLABEL | AP = 90% |
| [82] | FCN | ResNet-152 | Tensorflow | Own collection | Roads | Cross-entropy | SGD | LEAR | Recall = 71.98%, Precision = 77.68% |
| [83] | UNet, DeepCrack | VGG13, VGG16 | Tensorflow | CrackTree200 | pavement | - | Adam | Manually | Recall = 83.1%, 80.0%, Precision = 77.5%, 76.2% |
| [84] | PCSN-512 | VGG16 | Keras, Tensorflow | Own collection | Bridge, pavement | Categorical cross-entropy | Adadelta | Manually | mAP83%, |
| [85] | U-Net | - | - | Own collection | Concrete structures | Focal loss function | Adam | Manually | Precision = 96%, Recall = 81%, F1-score = 88% |
| [86] | VGG16 | - | Caffe | CCD1500 | Concrete structures | Cross-entropy | - | - | Precision = 88.9%, Recall = 81%, F1-socre = 88% |
| [87] | Ensemble CNN | - | Tensorflow | CFD, AgileRN | Pavement | Cross-entropy | - | - | Precision = 95.52%, 93.02% Recall = 95.2%, 91.6% |
| [88] | Pyramid Residual Network | - | - | Own collection | Road | - | Adam | - | Precision = 90.64%, Recall = 94.92%, F1-score = 92.73% |
| [89] | CrackSegNet | VGG16 | Keras | Own collection | Tunnel | Binary cross-entropy | BP | Manually with photoshop | PA = 98.88%, Precision = 66.49%, F1-score = 63.09% |
| [90] | ResNet-18 | - | Pytorch | CCIC, GAPS | Concrete and asphalt structures | Customized loss function | SGD | - | Accuracy = 97.95%, 94.3% |
| [92] | Cascaded Mask RCNN | ResNet | Pytorch | Own collection | stay cables | Multitask loss function | - | Manually | IoU = 74.3% Accuracy = 99.6%, Precision = 82.1%, Recall = 88.32% |
| [93] | RFCN | - | Tensorflow | Own collection | Roads, Bridge | Customized loss function | - | LabelMe | pA = 80.44%, mIoU = 80.15% |
| [94] | FCN | VGG16 | - | METU | Concrete structures | - | - | - | precision = 91.3%, Recall = 94.1%, F1-score = 92.7% |
| [95] | U-Net+Ternary classifier | - | Pytorch | Own collection | Tunnel | Binary cross-entropy | Adam | Manually | Recall = 92%, Precision = 47%, F1-score = 61% |
| [96] | Customized CNN | - | Pytorch | Own collection | Bridge | - | - | - | F1-score = 84%, Accuracy = 99.55%, Precision = 78.49% |
| [97] | NB-FCN | VGG19 | Tensorflow | Own collection | Bridge | Customized Loss function | SGD | LabelMe | Accuracy = 97.96%, Precision = 81.73%, Recall = 78.97% |
| [98] | FCN | VGGNet | MXNet | Own collection | Bridge | 2D cross-entropy | Adam | - | AP = 96.7% |
| [99] | CrackNet | - | C++ | PaveVision 3D | Asphalt surface | Cross-entropy | SGD | - | Precision = 90.13%, Recall = 87.63%, F1-score = 88.86% |
| [100] | CrackNet-R | RNN | - | PaveVision3D | Asphalt surface | - | - | - | Precision = 88.89%, Recall = 95%, F1-score = 91.84% |
| [101] | FCN | VGG19 | Tensorflow | Own collection | Concrete structures | Cross-entropy | Adam | Manually | Accuracy = 97.96%, Precision = 81.73%, Recall = 78.8 = 97% |
| [102] | SegNet | VGG16 | MATLAB R 2018A | CFD, TRIMMD | Concrete structures | - | - | - | Precision = 82%, 79%, Recall = 82.83%, 85.38% |
| [103] | FCN | - | Tensorflow | Crack500 | Pavement | Softmax loss function | - | - | map = 77% |
| [104] | CrackNet-V | VGG | - | PaveVision3D | Asphalt pavement | Cross-entropy | SGD | manually | Precision = 84.31%, Recall = 90.12%, F1-score = 87.12% |
| [105] | U-Net | - | Pytorch | CrackTree200, ALE, CrackForest | Road | Focal loss | - | Recall = 90.11%, 93.99%, 76.23% | |
| [106] | SDDNet | Customized CNN | - | Own collection | Concrete structures | mIoU loss | Adam | Affinity photo | IoU = 84.6% |
| [107] | DenseNet | - | Pytorch | CFD, AgileRN | Pavement | Cross-entropy | SGD | GAN technology | Accuracy = 95.91% |
| [108] | CracSeg | - | Tensorflow | CrackDataset | Pavement | Cross-entropy | Adam | - | Precision = 98%, Recall = 97.85%, F1-score = 97.92% |
| [109] | TDB-Net | FCN | Tensorflow | Own collection | Bridge deck | Binary cross-entropy | SGD | Manually | Accuracy = 98% |
| [110] | FPHBN | VGG | Caffe | Crack500 | Pavement | - | - | Manually | Average Intersection Over Union (AIU) = 48% |
| [111] | Ci-Net | LeNet-5 | - | CrackForest, TITS | Crack structures | - | Adam | - | Precision = 84%, Recall = 82%, IoU = 72.7% |
| [112] | CrackUNet | U-Net | Keras | CrackForest | Concrete structures | GDL | SGD | LabelMe | Precision = 92.84%, Recall = 92.84%, F1-score = 95.44% |
6. Findings and Future Research Scope
6.1. Findings of the Study
- –
- The publication rate in the earlier years (2010–2013) was too low; less than five papers were published each year. After 2013, the number of published articles per year begins to accelerate and fluctuates in the range of six to nine during the years 2014–2019. However, the number of published articles increases dramatically in 2019 (29 papers were published). In 2020, the publication rate also follows an upward trajectory (42 papers were published).
- –
- Ying Chen, Zhong Qu, Weigang Zou, Wei Li, Qingquan Li, Young-zin Cha, Choi Wooram, Oral Buyukozturk, Qingquan Li, and Mao Qin ZOu are the influential authors in this research field.
- –
- Computer-aided Civil Infrastructure and Engineering, Sensors, Journal of Computing in Civil Engineering, Automation in Construction, and Construction and Building Materials are the most cited journals.
- –
- –
- The highly influential countries are China, the USA, Germany, and Japan.
- –
- The important research terms are crack detection, deep learning, damage detection, image processing, system algorithm, inspection, model, identification, and concrete.
- –
- Deep learning techniques for detecting cracks are classified into three categories including classification, detection, and segmentation.
- –
- Among the techniques, crack segmentation is widely adopted by researchers.
- –
- CNN, Faster-RCNN, FCN, and U-net are the most used DL methods for performing crack classification, detection, and segmentation tasks, respectively.
- –
- VGG-16 is the most utilized backbone among the DL methods.
- –
- Most of the works performed their DL tasks on Tensorflow and PyTorch frameworks.
- –
- LabelMe, LEAR, LIBLABEL, and LabelImg are the most widely adopted annotation tools.
- –
- SGD and the Adam optimizer are utilized for optimizing the DL model by most of the researchers.
- –
- –
- –
6.2. Future Research Direction
- –
- It is our understanding that the segmentation of concrete cracks using DL techniques is going to be an engrossing research topic in this field. Researchers can focus on developing and modifying benchmark DL methods for segmenting concrete cracks with better accuracy. The design and integration of attention mechanisms, the ASPP module, SSE module, SCSE module, and other modules can be a promising research topic for researchers, as several research papers showed that usage of the modules can increase accuracy.
- –
- –
- Refs. [62,63,64,72] highlighted the presence of noise, such as shadow problems, shadings, contaminated backgrounds, road markings, rough surfaces, and variations in illumination, as challenging scenarios for detecting the cracks and provided solutions. However, more research should be carried out to develop robust models to tackle these issues. As a result, this can be pointed out as a huge research scope for new researchers.
- –
- Another important perspective is to take class imbalance problems into consideration, as in [50]. As only a few pixels in an image contain crack information, DL models are very likely to face the class imbalance problem, which may hamper the classification accuracy. As a result, it also should be a research concern for future researchers.
- –
- Though a few research works [49,53,81,101] already focused on this, there is still plenty to be researched in developing algorithms to extract the geometric information of cracks from the segmented images. As a consequence, the researchers will be able to monitor the length, width, area, and severity level of the cracks.
- –
- Collecting data for research is always a laborious task for researchers. New researchers in this field can reduce their efforts by putting their focus on collecting data using drones and vehicles, as in [66,82]. It could be more effective if the researchers follow the research direction of [5] and develop a robotic vehicle for both collecting data and detecting cracks in real time.
- –
- As the DL model is data-hungry method and it needs plenty of labeled images to be trained, researchers need to put a huge amount of effort into collecting images and labelling them. For solving these issues, ref. [79] comes up with an interesting solution, producing train images using a GAN simulator from only one sample image. Refs. [74,107] showed methods for labelling the images automatically by developing semi-supervised techniques using adversarial networks. New researchers can devote their efforts in this direction, as it could create a revolution in the research of DL for crack detection by providing plenty of labeled data within a shorter time and with less labor.
7. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Peng, T.; Kavya, T.S.; Jang, Y.-M.; Kim, B.-W. Concrete Crack Detection using Relative Standard Deviation for Image Thresholding. Int. J. Eng. Res. Technol. 2020, 13, 2720. [Google Scholar] [CrossRef]
- Ho, S.K.; White, R.M.; Lucas, J. A vision system for automated crack detection in welds. Meas. Sci. Technol. 1990, 1, 287–294. [Google Scholar] [CrossRef]
- Moon, H.; Jung, H.K.; Lee, C.W.; Park, G. Camera image processing for automated crack detection of pressed panel products. Act. Passiv. Smart Struct. Integr. Syst. 2017, 10164, 1016409. [Google Scholar]
- Runnemalm, A.; Broberg, P. Surface crack detection using infrared thermography and ultraviolet excitation. In Proceedings of the 2014 International Conference on Quantitative InfraRed Thermography, Bordeaux, France, 7–11 July 2014. [Google Scholar]
- La, H.M.; Gucunski, N.; Kee, S.-H.; Nguyen, L.V. Data analysis and visualization for the bridge deck inspection and evaluation robotic system. Vis. Eng. 2015, 3, 6. [Google Scholar] [CrossRef]
- Su, T.-C. Assessment of Cracking Widths in a Concrete Wall Based on TIR Radiances of Cracking. Sensors 2020, 20, 4980. [Google Scholar] [CrossRef]
- Nigam, R.; Singh, S.K. Crack detection in a beam using wavelet transform and photographic measurements. Structures 2020, 25, 436–447. [Google Scholar] [CrossRef]
- Gehri, N.; Mata-Falcón, J.; Kaufmann, W. Automated crack detection and measurement based on digital image correlation. Constr. Build. Mater. 2020, 256, 119383. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Nakamura, S.; Hashimoto, S. An efficient crack detection method using percolation-based image processing. In Proceedings of the 2008 3rd IEEE Conference on Industrial Electronics and Applications, Singapore, 3–5 June 2008. [Google Scholar]
- Talab, A.M.; Huang, Z.; Xi, F.; HaiMing, L. Detection crack in image using Otsu method and multiple filtering in image processing techniques. Optik 2016, 127, 1030–1033. [Google Scholar] [CrossRef]
- Yun, H.-B.; Mokhtari, S.; Wu, L. Crack Recognition and Segmentation Using Morphological Image-Processing Techniques for Flexible Pavements. Transp. Res. Rec. J. Transp. Res. Board 2015, 2523, 115–124. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Hutchinson, T.C. Image-Based Framework for Concrete Surface Crack Monitoring and Quantification. Adv. Civ. Eng. 2010, 2010, 215295. [Google Scholar] [CrossRef]
- Tong, X.; Guo, J.; Ling, Y.; Yin, Z. A new image-based method for concrete bridge bottom crack detection. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2011. [Google Scholar]
- Mathavan, S.; Vaheesan, K.; Kumar, A.; Chandrakumar, C.; Kamal, K.; Rahman, M.; Stonecliffe-Jones, M. Detection of pavement cracks using tiled fuzzy Hough transform. J. Electron. Imaging 2017, 26, 1. [Google Scholar] [CrossRef]
- Sari, Y.; Prakoso, P.B.; Baskara, A.R. Road Crack Detection using Support Vector Machine (SVM) and OTSU Algorithm. In Proceedings of the 2019 6th International Conference on Electric Vehicular Technology (ICEVT), Bali, Indonesia, 18–21 November 2019. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Yusof, N.A.; Osman, M.K.; Hussain, Z.; Noor, M.H.; Ibrahim, A.; Tahir, N.M.; Abidin, N.Z. Automated Asphalt Pavement Crack Detection and Classification using Deep Convolution Neural Network. In Proceedings of the 2019 9th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 29 November–1 December 2019. [Google Scholar]
- Zhang, Q.; Barri, K.; Babanajad, S.K.; Alavi, A.H. Real-Time Detection of Cracks on Concrete Bridge Decks Using Deep Learning in the Frequency Domain. Engineering 2020, 7, 1786–1796. [Google Scholar] [CrossRef]
- Vijayan, S.; Geethalakshmi, D.S.N. A Survey on Crack Detection Using Image Proces Techniques and Deep Learning Algorithms. Int. J. Pure Appl. Math. 2018, 118, 215–220. [Google Scholar]
- McCann, D.M.; Forde, M.C. Review of NDT methods in the assessment of concrete and masonry structures. NDT E Int. 2001, 34, 71–84. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Kelly, J.S.; Masri, S.F.; Sukhatme, G.S. A survey and evaluation of promising approaches for automatic image-based defect detection of bridge structures. Struct. Infrastruct. Eng. 2009, 5, 455–486. [Google Scholar] [CrossRef]
- Yao, Y.; Tung, S.-T.E.; Glisic, B. Crack detection and characterization techniques-An overview. Struct. Control Health Monit. 2014, 21, 1387–1413. [Google Scholar] [CrossRef]
- Zakeri, H.; Nejad, F.M.; Fahimifar, A. Image Based Techniques for Crack Detection, Classification and Quantification in Asphalt Pavement: A Review. Arch. Comput. Methods Eng. 2016, 24, 935–977. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Milovanović, B.; Pečur, I.B. Review of Active IR Thermography for Detection and Characterization of Defects in Reinforced Concrete. J. Imaging 2016, 2, 11. [Google Scholar] [CrossRef]
- Gopalakrishnan, K. Deep Learning in Data-Driven Pavement Image Analysis and Automated Distress Detection: A Review. Data 2018, 3, 28. [Google Scholar] [CrossRef]
- Sharma, R.; Potnis, D.A.; Chourasia, V. Review of Image Based Concrete Crack Detection. In Proceedings of the 2021 International Conference on Advances in Technology, Management & Education (ICATME), Bhopal, India, 8–9 January 2021. [Google Scholar]
- Hsieh, Y.-A.; Tsai, Y.J. Machine Learning for Crack Detection: Review and Model Performance Comparison. J. Comput. Civ. Eng. 2020, 34, 04020038. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef]
- Hussain, A.; Akhtar, S. Review of Non-Destructive Tests for Evaluation of Historic Masonry and Concrete Structures. Arab. J. Sci. Eng. 2017, 42, 925–940. [Google Scholar] [CrossRef]
- Popovics, J.S.; Rose, J.L. A survey of developments in ultrasonic NDE of concrete. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 1997, 30, 258. [Google Scholar] [CrossRef]
- Bhat, S.; Naik, S.; Gaonkar, M.; Sawant, P.; Aswale, S.; Shetgaonkar, P. A Survey On Road Crack Detection Techniques. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020. [Google Scholar]
- van Eck, N.J.; Waltman, L. VOSviewer Manual; University Leiden: Leiden, The Netherlands, 2020. [Google Scholar]
- Chen, C. Visualizing and Exploring Scientific Literature with CiteSpace. In Proceedings of the 2018 Conference on Human Information Interaction & Retrieval, New Brunswick, NJ, USA, 11–15 March 2018. [Google Scholar]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J. Vision-Based Automated Crack Detection for Bridge Inspection. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Torok, M.M.; Golparvar-Fard, M.; Kochersberger, K.B. Image-Based Automated 3D Crack Detection for Post-disaster Building Assessment. J. Comput. Civ. Eng. 2014, 28. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2009, 21, 797–809. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic Road Crack Detection and Characterization. IEEE Trans. Intell. Transp. Syst. 2013, 14, 155–168. [Google Scholar] [CrossRef]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete Crack Detection by Multiple Sequential Image Filtering. Comput.-Aided Civ. Infrastruct. Eng. 2011, 27, 29–47. [Google Scholar] [CrossRef]
- Gavilán, M.; Balcones, D.; Marcos, O.; Llorca, D.F.; Sotelo, M.A.; Parra, I.; Ocaña, M.; Aliseda, P.; Yarza, P.; Amírola, A. Adaptive Road Crack Detection System by Pavement Classification. Sensors 2011, 11, 9628–9657. [Google Scholar] [CrossRef]
- Zalama, E.; Gómez-García-Bermejo, J.; Medina, R.; Llamas, J. Road Crack Detection Using Visual Features Extracted by Gabor Filters. Comput.-Aided Civ. Infrastruct. Eng. 2013, 29, 342–358. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2010, 22, 245–254. [Google Scholar] [CrossRef]
- Tran, T.S.; Tran, V.P.; Lee, H.J.; Flores, J.M.; Le, V.P. A two-step sequential automated crack detection and severity classification process for asphalt pavements. Int. J. Pavement Eng. 2020, 23, 2019–2033. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, G.; Ding, Y.; Wu, B.; Lu, G. A vision-based active learning convolutional neural network model for concrete surface crack detection. Adv. Struct. Eng. 2020, 23, 2952–2964. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, G.; Han, Y.; Lin, H.; Wu, Y. Application of Internet of Things Technology and Convolutional Neural Network Model in Bridge Crack Detection. IEEE Access 2018, 6, 39442–39451. [Google Scholar] [CrossRef]
- Dung, C.V.; Sekiya, H.; Hirano, S.; Okatani, T.; Miki, C. A vision-based method for crack detection in gusset plate welded joints of steel bridges using deep convolutional neural networks. Autom. Constr. 2019, 102, 217–229. [Google Scholar] [CrossRef]
- Flah, M.; Suleiman, A.R.; Nehdi, M.L. Classification and quantification of cracks in concrete structures using deep learning image-based techniques. Cem. Concr. Compos. 2020, 114, 103781. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, W.; Chen, J.; Lin, W. Deep convolution neural network-based transfer learning method for civil infrastructure crack detection. Autom. Constr. 2020, 116, 103199. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. Image-Based Concrete Crack Detection Using Convolutional Neural Network and Exhaustive Search Technique. Adv. Civ. Eng. 2019, 2019, 6520620. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee, V.C.-S. Imaging-based crack detection on concrete surfaces using You Only Look Once network. Struct. Health Monit. 2020, 20, 147592172093848. [Google Scholar] [CrossRef]
- Li, H.; Xu, H.; Tian, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Bridge Crack Detection Based on SSENets. Appl. Sci. 2020, 10, 4230. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Park, S.E.; Eem, S.-H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Majidifard, H.; Adu-Gyamfi, Y.; Buttlar, W.G. Deep machine learning approach to develop a new asphalt pavement condition index. Constr. Build. Mater. 2020, 247, 118513. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 35, 373–388. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Zhai, J.; Xu, Z.; Chen, Y. Detection of sealed and unsealed cracks with complex backgrounds using deep convolutional neural network. Autom. Constr. 2019, 107, 102946. [Google Scholar] [CrossRef]
- Ma, D.; Fang, H.; Xue, B.; Wang, F.; Msekh, M.A.; Chan, C.L. Intelligent Detection Model Based on a Fully Convolutional Neural Network for Pavement Cracks. Comput. Model. Eng. Sci. 2020, 123, 1267–1291. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef]
- Cao, M.-T.; Tran, Q.-V.; Nguyen, N.-M.; Chang, K.-T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inform. 2020, 46, 101182. [Google Scholar] [CrossRef]
- Li, C.; Xu, P.; Niu, L.; Chen, Y.; Sheng, L.; Liu, M. Tunnel crack detection using coarse-to-fine region localization and edge detection. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1308. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. Automatic Crack Detection and Measurement of Concrete Structure Using Convolutional Encoder-Decoder Network. IEEE Access 2020, 8, 134602–134618. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control. Health Monit. 2020, 27. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. ARF-Crack: Rotation invariant deep fully convolutional network for pixel-level crack detection. Mach. Vis. Appl. 2020, 31, 47. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, G.; Zhang, L. A spatial-channel hierarchical deep learning network for pixel-level automated crack detection. Autom. Constr. 2020, 119, 103357. [Google Scholar] [CrossRef]
- Kalfarisi, R.; Wu, Z.Y.; Soh, K. Crack Detection and Segmentation Using Deep Learning with 3D Reality Mesh Model for Quantitative Assessment and Integrated Visualization. J. Comput. Civ. Eng. 2020, 34, 04020010. [Google Scholar] [CrossRef]
- Shim, S.; Kim, J.; Cho, G.-C.; Lee, S.-W. Multiscale and Adversarial Learning-Based Semi-Supervised Semantic Segmentation Approach for Crack Detection in Concrete Structures. IEEE Access 2020, 8, 170939–170950. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Wei, J.; Loprencipe, G.; Chen, X.; Mascio, P.D. Automatic Crack Detection on Road Pavements Using Encoder-Decoder Architecture. Materials 2020, 13, 2960. [Google Scholar] [CrossRef] [PubMed]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust Pixel-Level Crack Detection Using Deep Fully Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Wei, T.; Cao, D.; Zheng, C.; Yang, Q. A simulation-based few samples learning method for surface defect segmentation. Neurocomputing 2020, 412, 461–476. [Google Scholar] [CrossRef]
- Lau, S.L.; Chong, E.K.; Yang, X.; Wang, X. Automated Pavement Crack Segmentation Using U-Net-Based Convolutional Neural Network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Jia, D.; Zhu, H. Automatic Pavement Crack Detection and Classification Using Multiscale Feature Attention Network. IEEE Access 2019, 7, 171001–171012. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Chen, H.; Lin, H.; Yao, M. Improving the Efficiency of Encoder-Decoder Architecture for Pixel-Level Crack Detection. IEEE Access 2019, 7, 186657–186670. [Google Scholar] [CrossRef]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.-Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef]
- Feng, H.; Xu, G.; Guo, Y. Multi-scale classification network for road crack detection. IET Intell. Transp. Syst. 2018, 13, 398–405. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K. Increasing the robustness of material-specific deep learning models for crack detection across different materials. Eng. Struct. 2020, 206, 110157. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.-M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Hou, S.; Dong, B.; Wang, H.; Wu, G. Inspection of surface defects on stay cables using a robot and transfer learning. Autom. Constr. 2020, 119, 103382. [Google Scholar] [CrossRef]
- Zheng, M.; Lei, Z.; Zhang, K. Intelligent detection of building cracks based on deep learning. Image Vis. Comput. 2020, 103, 103987. [Google Scholar] [CrossRef]
- Islam, M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]
- Han, J.H.; Moon, Y.S.; Lee, C.H.; Kim, I.S. Crack Detection Method for Tunnel Lining Surfaces using Ternary Classifier. KSII Trans. Internet Inf. Syst. 2020, 14. [Google Scholar]
- Li, Y.; Zhao, W.; Zhang, X.; Zhou, Q. A Two-Stage Crack Detection Method for Concrete Bridges Using Convolutional Neural Networks. IEICE Trans. Inf. Syst. 2018, E101.D, 3249–3252. [Google Scholar] [CrossRef]
- Li, G.; Liu, Q.; Zhao, S.; Qiao, W.; Ren, X. Automatic crack recognition for concrete bridges using a fully convolutional neural network and naive Bayes data fusion based on a visual detection system. Meas. Sci. Technol. 2020, 31, 075403. [Google Scholar] [CrossRef]
- Wang, D.; Dong, Y.; Pan, Y.; Ma, R. Machine Vision-Based Monitoring Methodology for the Fatigue Cracks in U-Rib-to-Deck Weld Seams. IEEE Access 2020, 8, 94204–94219. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.; Li, J.Q.; Yang, E.; Qiu, S. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces with a Recurrent Neural Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 34, 213–229. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zhang, X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Xiang, X.; Zhang, Y.; Saddik, A.E. Pavement crack detection network based on pyramid structure and attention mechanism. IET Image Process. 2020, 14, 1580–1586. [Google Scholar] [CrossRef]
- Fei, Y.; Wang, K.C.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images Through Deep-Learning- Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2020, 21, 273–284. [Google Scholar] [CrossRef]
- Wu, S.; Fang, J.; Zheng, X.; Li, X. Sample and Structure-Guided Network for Road Crack Detection. IEEE Access 2019, 7, 130032–130043. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.-J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Li, G.; Wan, J.; He, S.; Liu, Q.; Ma, B. Semi-Supervised Semantic Segmentation Using Adversarial Learning for Pavement Crack Detection. IEEE Access 2020, 8, 51446–51459. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Zhu, J.; Song, J. Weakly supervised network based intelligent identification of cracks in asphalt concrete bridge deck. Alex. Eng. J. 2020, 59, 1307–1317. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Ye, X.-W.; Jin, T.; Chen, P.-Y. Structural crack detection using deep learning–based fully convolutional networks. Adv. Struct. Eng. 2019, 22, 3412–3419. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, J.; Zhu, B. A research on an improved UNET-based concrete crack detection algorithm. Struct. Health Monit. 2020, 20, 1864–1879. [Google Scholar] [CrossRef]









| Ref | Year of Publication | Name of the Journal/Conference | Major Contributions | Limitations |
|---|---|---|---|---|
| [20] | 2001 | NDT & E International |
|
|
| [21] | 2009 | Structure and Infrastructure Engineering |
|
|
| [22] | 2014 | Structural Control and Health Monitoring |
|
|
| [29] | 2016 | Advanced Engineering Informatics |
|
|
| [23] | 2016 | Computational Methods in Engineering |
|
|
| [24] | 2016 | Alexandria Engineering Journal |
|
|
| [25] | 2016 | Journal of Imaging |
|
|
| [30] | 2017 | Arabic Journal of Science & Engineering |
|
|
| [31] | 2017 | ISPRS Journal of Photogrammetry and Remote Sensing |
|
|
| [26] | 2018 | Data |
|
|
| [19] | 2018 | International Journal of Pure and Applied Mathematics |
|
|
| [27] | 2020 | Easychair Preprint |
|
|
| [32] | 2020 | 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-EITTE) |
|
|
| [28] | 2020 | American Society of Civil Engineers |
|
|
| Journal Name | Total Publications | Total Citations | Average Citations | Impact Factor | 5 Years Impact Factor | Publisher | H-Index |
|---|---|---|---|---|---|---|---|
| Computer-aided Civil Infrastructure and Engineering | 11 | 1100 | 122.22 | 8.552 | 6.212 | Willey | 8 |
| Sensors | 10 | 193 | 21.44 | 3.275 | 3.427 | MDPI | 6 |
| Journal of Computing in Civil Engineering | 9 | 136 | 19.43 | 2.979 | 2.943 | ASCE-AMER SOC Civil Engineers | 6 |
| Automation in Construction | 8 | 143 | 71.50 | 5.669 | 6.121 | Elsevier | 4 |
| Construction and Building Materials | 7 | 128 | 21.33 | 4.419 | 5.0396 | Elsevier | 4 |
| IEEE Access | 7 | 15 | 7.50 | 3.745 | 4.076 | IEEE | 2 |
| Applied Sciences Basel | 5 | 20 | 10.00 | 2.474 | 2.458 | MDPI | 2 |
| Structural Health Monitoring an International Journal | 4 | 12 | 2.00 | 4.87 | 4.922 | SAGE | 2 |
| Advances in Civil Engineering | 3 | 23 | 11.50 | 1.176 | - | Hindawi | 2 |
| Machine Vision and Applications | 3 | 277 | 27.70 | 1.605 | 2 | Springer | 2 |
| Journal Name | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | C | P | C | P | C | P | C | P | C | P | C | P | C | P | C | P | C | P | C | P | C | |
| Computer-aided Civil Infrastructure and Engineering | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 12 | 2 | 17 | 1 | 7 | 0 | 39 | 1 | 67 | 1 | 196 | 3 | 331 | 2 | 429 |
| Sensors | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 2 | 0 | 3 | 0 | 9 | 0 | 20 | 1 | 22 | 3 | 28 | 3 | 36 | 2 | 71 |
| Journal of Computing in Civil Engineering | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 4 | 3 | 13 | 0 | 12 | 0 | 23 | 2 | 34 | 3 | 49 |
| Automation in Construction | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 25 | 3 | 116 |
| Construction and Building Materials | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 3 | 0 | 5 | 0 | 0 | 2 | 6 | 1 | 35 | 2 | 79 |
| IEEE Access | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 3 | 2 | 3 | 13 |
| Applied Sciences Basel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 8 | 2 | 12 |
| Structural Health Monitoring an International Journal | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 3 | 0 | 0 | 0 | 0 | 3 | 7 |
| Advances in Civil Engineering | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 5 | 1 | 18 |
| Machine Vision And Applications | 1 | 0 | 1 | 3 | 0 | 7 | 0 | 10 | 0 | 16 | 0 | 15 | 0 | 32 | 0 | 34 | 0 | 47 | 0 | 50 | 1 | 63 |
| Author’s Name | Total Publications | Total Citations | Average Citations | As 1st Author | H-Index | Country | |
|---|---|---|---|---|---|---|---|
| Based on Publications | Ying Chen | 5 | 49 | 12.25 | 0 | 3 | China |
| Zhong Qu | 5 | 44 | 8.80 | 5 | 3 | China | |
| Weigang Zou | 4 | 18 | 9.00 | 0 | 3 | China | |
| Wei Li | 4 | 9 | 4.50 | 1 | 2 | China | |
| Qingquan Li | 3 | 338 | 37.56 | 1 | 3 | China | |
| Based on Citations | Young-zin Cha | 1 | 575 | 143.75 | 1 | 1 | Canada |
| Choi Wooram | 1 | 575 | 143.75 | 0 | 1 | Canada | |
| Oral Buyukozturk | 1 | 575 | 143.75 | 1 | 1 | Canada | |
| Qingquan Li | 3 | 338 | 37.56 | 0 | 3 | China | |
| Mao Qin ZOu | 2 | 298 | 33.11 | 1 | 2 | China |
| Country | TP | TC | AC | ≥30 | ≥20 | ≥10 | ≥5 | H-Index |
|---|---|---|---|---|---|---|---|---|
| China | 54 | 722 | 60.57 | 5 | 9 | 5 | 3 | 14 |
| USA | 29 | 1450 | 161.11 | 8 | 3 | 21 | 24 | 11 |
| South Korea | 13 | 104 | 52 | 6 | 1 | 5 | 1 | 7 |
| Japan | 11 | 551 | 55.10 | 2 | 1 | 1 | 2 | 6 |
| Germany | 7 | 21 | 4.89 | 0 | 0 | 1 | 2 | 3 |
| Canada | 5 | 584 | 23.14 | 3 | 1 | 0 | 1 | 5 |
| Spain | 5 | 252 | 12.10 | 2 | 2 | 1 | 0 | 5 |
| England | 5 | 21 | 5.33 | 0 | 0 | 2 | 1 | 4 |
| Australia | 4 | 16 | 3.56 | 0 | 0 | 1 | 1 | 3 |
| Vietnam | 3 | 90 | 13.13 | 1 | 1 | 0 | 1 | 3 |
| Cited Source | Citation | Total Link Strength |
|---|---|---|
| Computer-aided Civil Infrastructure and Engineering (compute-aided civ inf) | 363 | 5201 |
| Automation in Construction (automat constr) | 183 | 3053 |
| Journal of Computer in Civil Engineering (j comput civil eng) | 178 | 2943 |
| Proceeding CVPR IEEE (proc cvpr ieee) | 112 | 1905 |
| IEEE Transactions on Pattern Analysis and Machine Intelligence (ieee t pattern anal) | 98 | 1541 |
| IEEE Transactions on Intelligent Transportation Systems (ieee t intell transp) | 78 | 1364 |
| Lecture Notes in Computer Science (lect notes comput sc) | 63 | 1105 |
| Construction and Building Materials (constr build mater) | 72 | 1010 |
| Machine Vision and Applications (mach vision appl) | 63 | 933 |
| Sensors (sensors-basel) | 70 | 924 |
| Advanced Engineering Informatics (adv eng inform) | 48 | 881 |
| IEEE Conference on Computer Vision and Pattern Recognition (ieee i conf comp vis) | 39 | 806 |
| Structural Health Monitoring (struct health monit) | 36 | 707 |
| Structural Control and Health Monitoring (struct control hlth) | 44 | 677 |
| Pattern Recognition Letters (patetrn recogn lett) | 45 | 623 |
| Transportation Research Record (transport res rec) | 39 | 602 |
| NDT & E International (ndt & e int) | 34 | 463 |
| IEEE Transactions on Image Processing (ieee t image process) | 30 | 432 |
| Smart Materials and Structures (smart mater struct) | 30 | 360 |
| Cited Author | Citation | Total Link Strength |
|---|---|---|
| Young-Jin Cha | 363 | 5201 |
| Tomoyuki Yamaguchi | 77 | 387 |
| Qinayun Zhang | 52 | 372 |
| Mohammad R. Jahanshahi | 44 | 314 |
| Qiang Zou | 44 | 255 |
| Christian Koch | 37 | 254 |
| Abed Abdel Qader | 39 | 253 |
| Fu-Chen Chen | 31 | 250 |
| Lei Zhang | 33 | 245 |
| KM Liew | 35 | 240 |
| Yann LeCun | 33 | 220 |
| Henrique Oilveira | 49 | 219 |
| Yusuke Fujita | 32 | 208 |
| Sattar Dorafshan | 38 | 202 |
| Country | Documents | Total Link Strength |
|---|---|---|
| China | 54 | 18 |
| USA | 29 | 9 |
| Canada | 5 | 5 |
| Germany | 7 | 4 |
| England | 5 | 3 |
| South Korea | 13 | 3 |
| Spain | 5 | 3 |
| Japan | 11 | 1 |
| Cluster Color | Observed Keywords | No. of Keywords |
|---|---|---|
| Red | damage detection, algorithm, identification, model, system, inspection, deep, convolutional neural network, neural-network, recognition, CNN, images | 12 |
| Green | deep learning, crack, neural-networks, pavement crack detection, 3d asphalt surfaces, semantic segmentation, structural health monitoring, computer vision, image processing | 9 |
| Blue | crack detection, concrete, edge detection, vision, bridge inspection, segmentation, edge-detection, road crack detection | 9 |
| Keyword | Frequency | Links | Link Strength |
|---|---|---|---|
| crack detection | 45 | 9 | 61 |
| deep learning | 25 | 9 | 44 |
| damage detection | 21 | 9 | 46 |
| image processing | 18 | 7 | 19 |
| system | 17 | 9 | 37 |
| algorithm | 16 | 7 | 27 |
| inspection | 14 | 9 | 39 |
| model | 12 | 7 | 33 |
| identification | 12 | 9 | 27 |
| concrete | 12 | 7 | 21 |
| Periods | Keywords |
|---|---|
| 2010–2013 | neural network, crack detection, segmentation, concrete, edge detection, computer vision, image processing |
| 2013–2016 | algorithm, system, identification, damage detection, crack, image, model, inspection |
| 2016–2019 | pavement crack detection, bridge inspection, recognition, deep, cnn, crack enhancement, convolutional neural network, deep learning, vision |
| 2019–2020 | structural health monitoring, 3d asphalt surfaces |
| Ref | Method | Backbone | Framework | Dataset | Surface | Loss Function | Optimizer | Performance (%) |
|---|---|---|---|---|---|---|---|---|
| [49] | Mask RCNN | ResNet-101 | Keras, Tensorflow | Own collection | Asphalt pavement | - | Adam | Accuracy = 92.10%, Precision = 96.32%, Recall = 94.67% |
| [50] | CNN | AlexNet | MATLAB | Own collection | Concrete structure | Cross entropy | - | Accurac y = 97.22%, Precision = 90.53%, Recall = 83.37%, F1-score = 84.63% |
| [51] | CNN | - | MATLAB 2016A | Own collection | Bridge deck | - | Back propagation | Accuracy = 90% |
| [52] | CNN | VGG16 | - | Metropoliton expressway Co. Ltd. | Bridge deck | Binary cross-entropy | Stochastic Gradient Descent (SGD) | Accuracy = 97% |
| [35] | CNN | MatConvNet | - | Own collection from University of Manitoba | Concrete structures | Softmax loss function | SGD | Accuracy = 98% |
| [53] | CNN | - | - | CCIC | Concrete structures | Binary cross-entropy | Natural Gradient Descent (NGD) | Accuracy = 96.17% |
| [37] | DCNN | AlexNet | MATLAB 2018A | Simulated panels from SMASH Lab | Bridge deck | - | - | Accuracy = 97% |
| [54] | CNN | VGG16 | Keras | FHWA, LTPP | Pavement | - | Adam | Accuracy = 90%, Cohen’s Kappa score = 74.2% |
| [55] | DCNN | VGG16 | Keras | CCIC, SDNET, BCD | Concrete structures | - | - | Accuracy = 99.15%, 92.59%, 98.97% |
| [56] | CNN | AlexNet | Caffe | Own collection | Concrete structures | Softmax loss function | SGD | Accuracy = 99.06% |
| Ref | Method | Backbone | Framework | Dataset | Surface | Loss Function | Optimizer | Annotation Tool | Performance (%) |
|---|---|---|---|---|---|---|---|---|---|
| [57] | YOLO v2 | VGG16 | MATLAB 2019A | Own collection | Concrete bridges | SDGM | SGD | Labeler app in MATLAB | map = 77% |
| [58] | SSENets | VGG16 | Pytorch | Bridge crack dataset of Xu et al. [59] | Bridge deck | - | SGD | - | Accuracy = 97.77%, Precision = 95.45%, Recall = 97.67% |
| [60] | NB-CNN | Customized CNN | - | Own collection | Nuclear power plant | - | - | Manually | Hit rate = 98.3%, AUC = 79.2% |
| [61] | YOLO V3-tiny | Customized CNN | - | Own collection | Concrete structures | - | - | YOLO V3-tiny | Accuracy = 94%, Precision = 98% |
| [62] | YOLO v2 + U-Net | - | - | Own collection | Pavement | - | GEP | Python based software | F1-score = 84%, Precision = 93%, Recall = 77% |
| [63] | Faster R-CNN | ZF-net | MATLAB 2018B | Own collection | Bridge | Momentum loss function | SGD | Labeler app in MATLAB | mAP = 79%, F1 = 67% |
| [64] | CrackDN | Customized CNN | Tensorflow | Own collection | Pavement | Multitask loss function | - | - | Accuracy = 85% |
| [65] | FCN | ResNet-101 | Caffe | CCIC, CIDB | Pavement | Binary cross-entropy | SGD | Manually | Accuracy = 91.4%, 86.4% |
| [66] | CNN | AlexNet | MATLAB | Own collection | Concrete structures | - | - | - | Average precision = 86.73%, Average recall = 88.68% |
| [67] | Faster R-CNN, SSD | - | - | BCD | Road | - | - | - | mAP = 27.66%, 19.45% |
| [68] | Faster R-CNN | ZF-Net | Caffe | Own collection | Tunnel | Regression loss | SGD | Manually | mAP = 93.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.-M.; Kee, S.-H.; Pathan, A.-S.K.; Nahid, A.-A. Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review. Remote Sens. 2023, 15, 2400. https://doi.org/10.3390/rs15092400
Khan MA-M, Kee S-H, Pathan A-SK, Nahid A-A. Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review. Remote Sensing. 2023; 15(9):2400. https://doi.org/10.3390/rs15092400
Chicago/Turabian StyleKhan, Md. Al-Masrur, Seong-Hoon Kee, Al-Sakib Khan Pathan, and Abdullah-Al Nahid. 2023. "Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review" Remote Sensing 15, no. 9: 2400. https://doi.org/10.3390/rs15092400
APA StyleKhan, M. A.-M., Kee, S.-H., Pathan, A.-S. K., & Nahid, A.-A. (2023). Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review. Remote Sensing, 15(9), 2400. https://doi.org/10.3390/rs15092400