
BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection


Abstract
1. Introduction
- Proposing BoxPaste, an easy but powerful data augmentation strategy for SAR ship detection.
- Developing a principle to design a SAR image detector and proposing a modified detector SAR-FCOS.
- Combining the two previous contributions to achieve a great detection performance on the SSDD dataset employing ResNet-50 [22] as the backbone.
2. Related Works
2.1. Traditional Methods
2.2. Deep Learning-Based Methods
2.3. Data Augmentation for Object Detection and Instance Segmentation
3. Methods
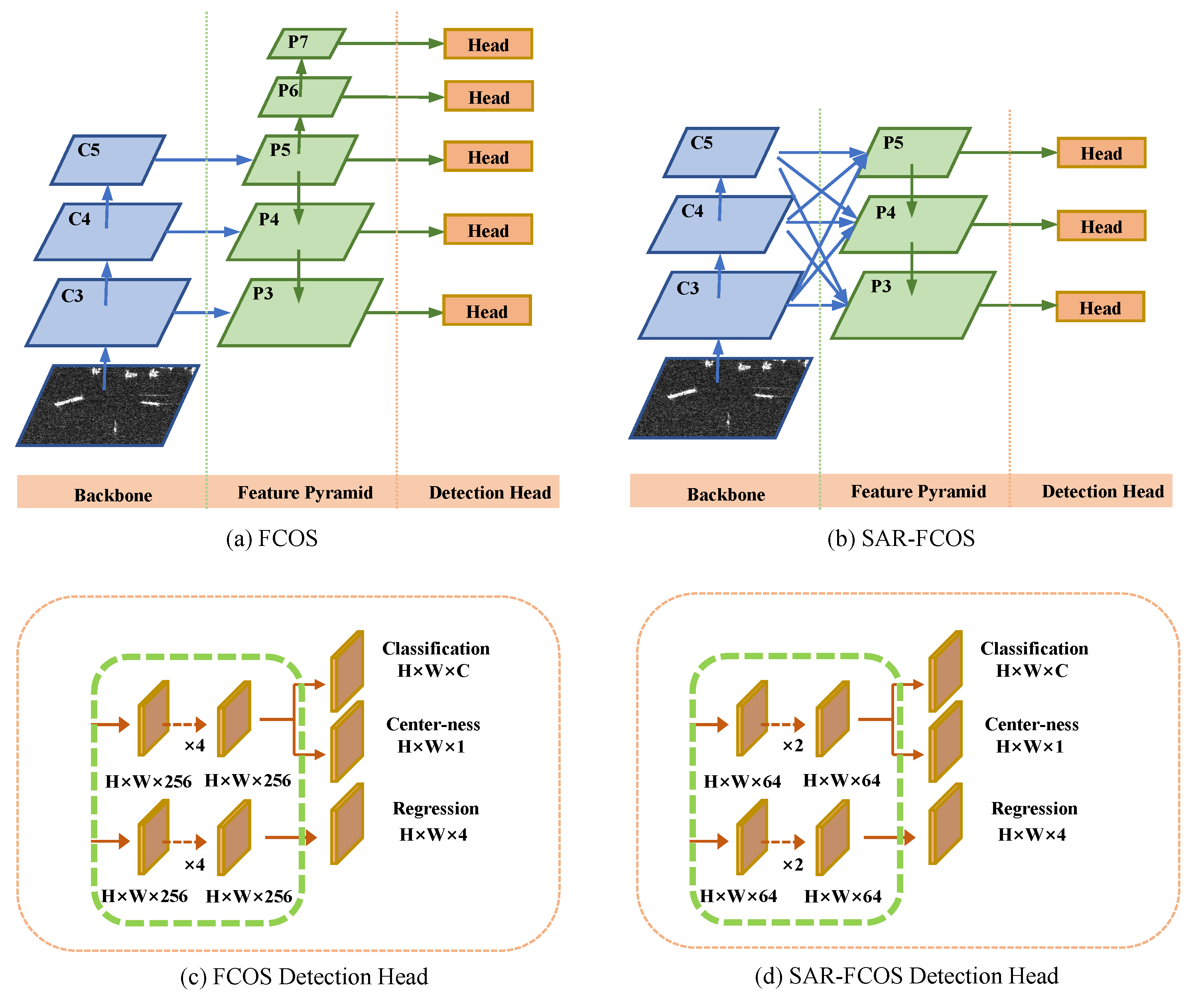
3.1. Revisiting FCOS
3.2. SAR-FCOS
3.2.1. Light FPN
3.2.2. Light Detection Head
3.3. BoxPaste
3.3.1. Revisiting CopyPaste
3.3.2. BoxPaste
4. Experiment
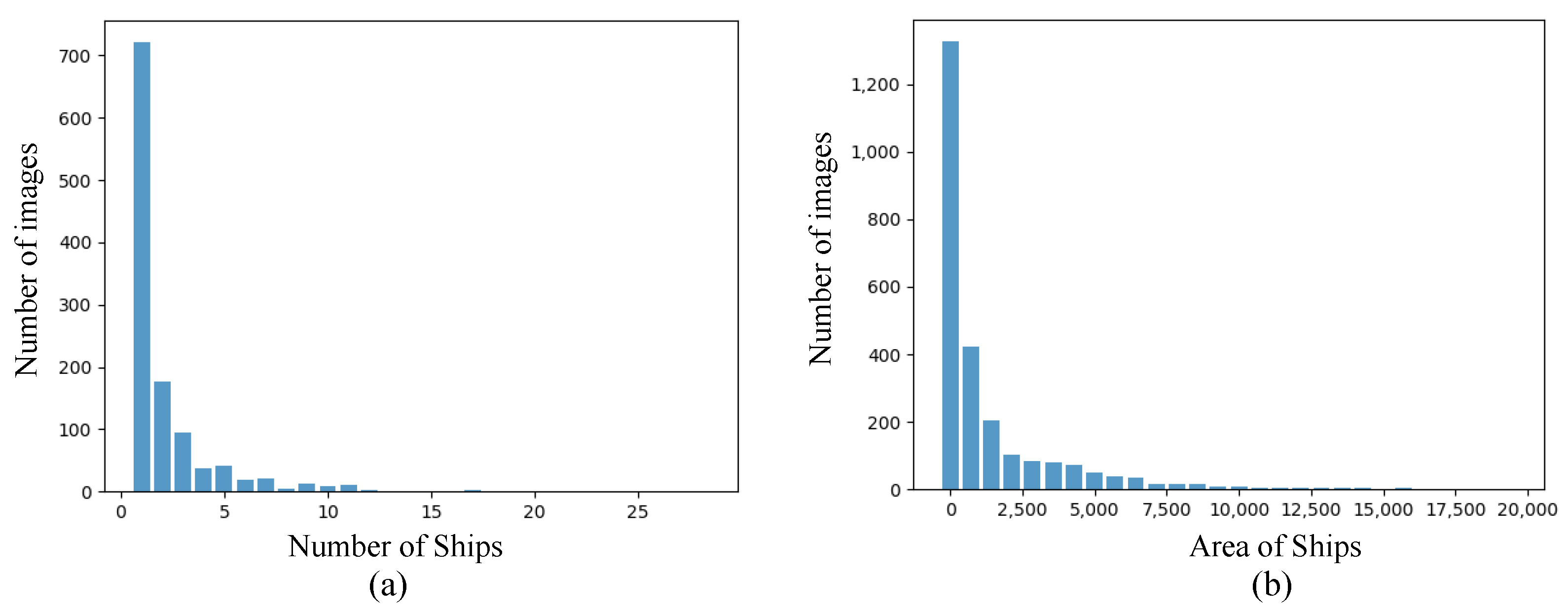
4.1. Dataset and Training Details
4.2. Ablation Study
4.2.1. Experiments on SAR-FCOS
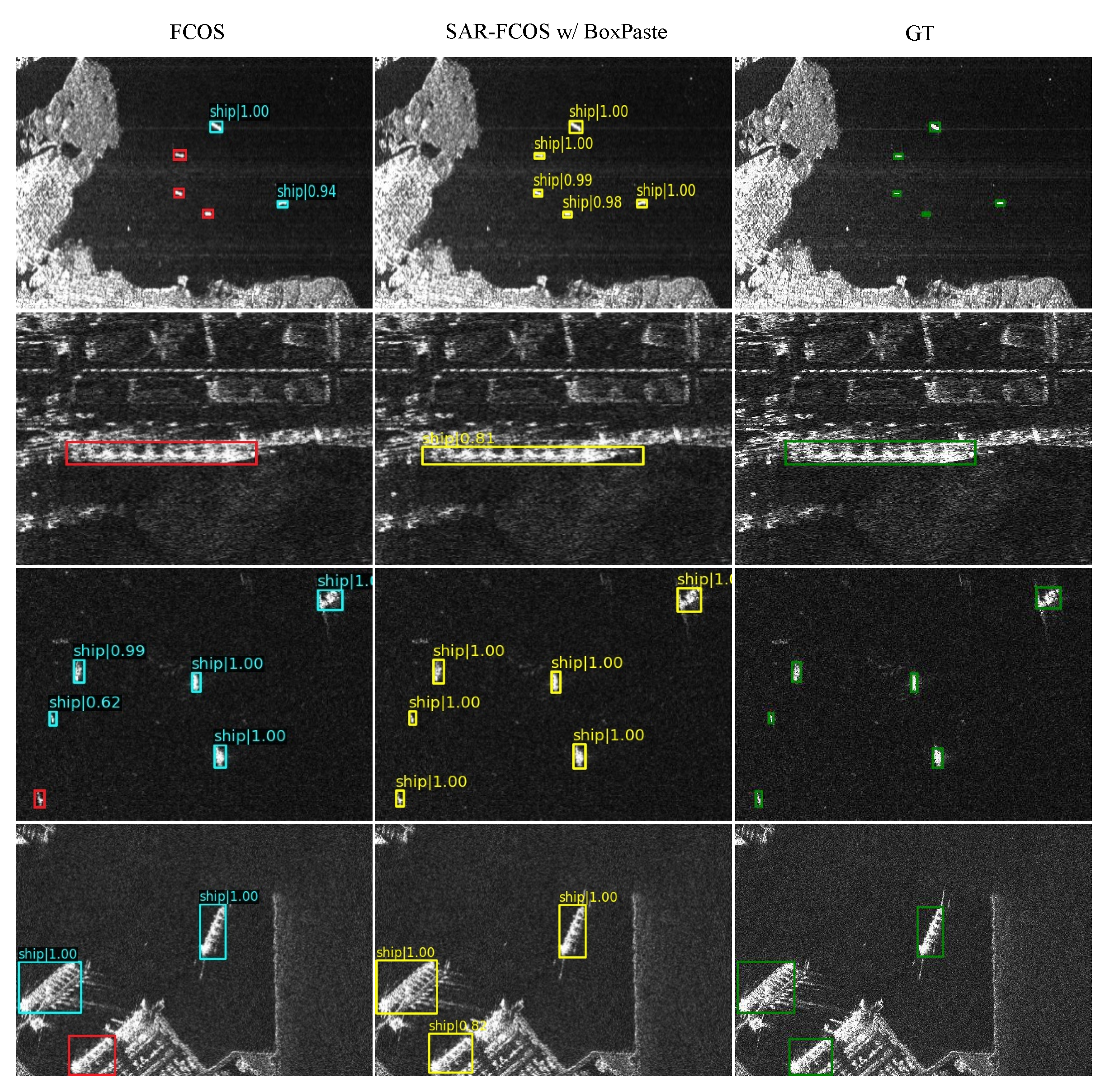
4.2.2. Ablation Study on BoxPaste
4.2.3. Comparing BoxPaste to CopyPaste
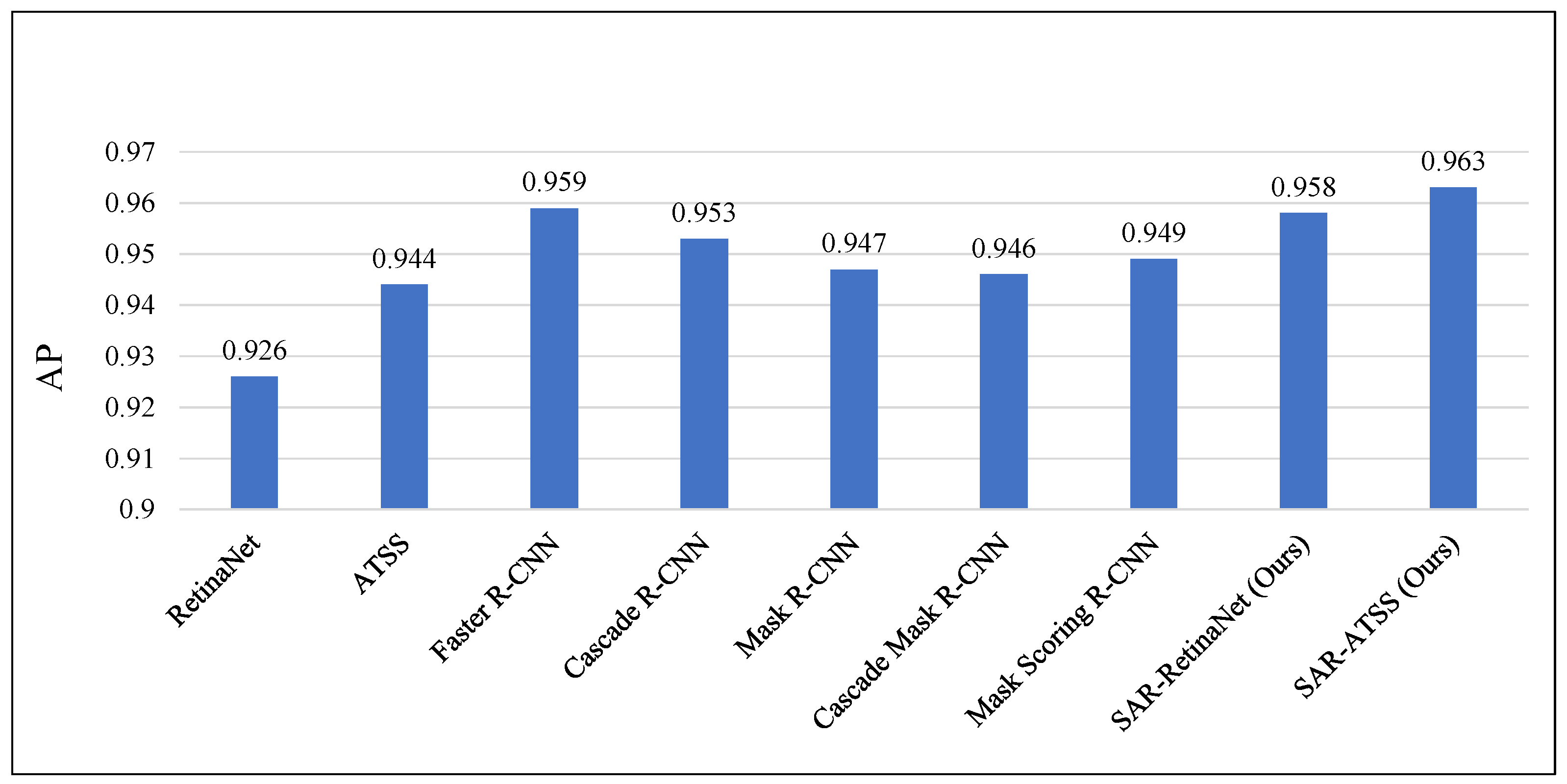
4.3. Wide Applicability
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, H.J.; Huang, L.F.; Chen, Z. Multi-frame ship detection and tracking in an infrared image sequence. Pattern Recognit. 1990, 23, 785–798. [Google Scholar] [CrossRef]
- Mingbo, Z.; Jianwu, Z.; Jianguo, H. Imaging simulation of sea surface with full polarization SAR. In Proceedings of the 2015 IEEE 5th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Singapore, 1–4 September 2015; pp. 815–817. [Google Scholar]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; van Schie, B. Ship Surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1092–1103. [Google Scholar] [CrossRef]
- Eldhuset, K. An automatic ship and ship wake detection system for spaceborne SAR images in coastal regions. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1010–1019. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Ouchi, K.; Tamaki, S.; Yaguchi, H.; Iehara, M. Ship detection based on coherence images derived from cross correlation of multilook SAR images. IEEE Geosci. Remote Sens. Lett. 2004, 1, 184–187. [Google Scholar] [CrossRef]
- Ai, J.; Qi, X.; Yu, W.; Deng, Y.; Liu, F.; Shi, L. A new CFAR ship detection algorithm based on 2-D joint log-normal distribution in SAR images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 806–810. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, S.; Zhang, H.; Wu, F.; Zhang, B. Ship detection for high-resolution SAR images based on feature analysis. IEEE Geosci. Remote Sens. Lett. 2013, 11, 119–123. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A bilateral CFAR algorithm for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1536–1540. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Su, Y. Inshore ship detection via saliency and context information in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. OTA: Optimal Transport Assignment for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise separable convolution neural network for high-speed SAR ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Ge, Z.; Jie, Z.; Huang, X.; Li, C.; Yoshie, O. Delving deep into the imbalance of positive proposals in two-stage object detection. Neurocomputing 2021, 425, 107–116. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–862. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and robust ship detection for high-resolution SAR imagery based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M.; Su, H.; Zhang, J. Efficient low-cost ship detection for SAR imagery based on simplified U-net. IEEE Access 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A CenterNet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- Gao, F.; He, Y.; Wang, J.; Hussain, A.; Zhou, H. Anchor-free convolutional network with dense attention feature aggregation for ship detection in SAR images. Remote Sens. 2020, 12, 2619. [Google Scholar] [CrossRef]
- Dvornik, N.; Mairal, J.; Schmid, C. Modeling visual context is key to augmenting object detection datasets. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 364–380. [Google Scholar]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1301–1310. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-Frst AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NHead | CHead | FPN | AP (%) | Recall (%) | FPS | |
|---|---|---|---|---|---|---|
| FCOS (baseline) | 4 | 256 | P3–P7 | 90.8 | 91.1 | 53.1 |
| Light Head | 2 | 256 | P3–P7 | 90.4 | 90.5 | 66.3 |
| 2 | 128 | P3–P7 | 91.1 | 91.5 | 96.3 | |
| 2 | 64 | P3–P7 | 92.4 | 92.4 | 101.2 | |
| 2 | 32 | P3–P7 | 89.2 | 89.4 | 102.8 | |
| Light FPN | 2 | 64 | P3–P5 | 92.3 | 91.9 | 119.9 |
| 2 | 64 | P3–P4 | 90.1 | 90.3 | 127.6 | |
| Light Head + ASFF [42] | 2 | 64 | P3–P5 | 93.0 | 94.4 | 110.1 |
| Scale Jit. Range | Total Epochs | BoxPaste | AP (%) | Recall (%) | FPS | |
|---|---|---|---|---|---|---|
| SAR-FCOS | - | 12 | - | 93.0 | 94.4 | 110.1 |
| - | 12 | ✓ | 94.1 | 95.1 | ||
| [0.5, 1.5] | 12 | ✓ | 94.5 | 95.2 | ||
| [0.1, 2] | 12 | ✓ | 94.6 | 95.5 | ||
| [0.1, 2] | 24 | ✓ | 95.2 | 96.5 | ||
| [0.1, 2] | 36 | ✓ | 95.5 | 96.6 | ||
| [0.1, 2] | 48 | ✓ | 95.0 | 96.1 |
| AP (%) | Recall (%) | |
|---|---|---|
| BoxPaste+BBox-SSDD | 95.5 | 96.6 |
| CopyPaste+PSeg-SSDD | 95.8 | 97.0 |
| RetinaNet | ATSS | |||||
|---|---|---|---|---|---|---|
| Baseline | +Light | +BoxPaste | Baseline | +Light | +BoxPaste | |
| AP (%) | 92.6 | 93.3 | 95.8 | 94.4 | 94.9 | 96.3 |
| Recall (%) | 94.1 | 94.2 | 96.5 | 95.5 | 95.5 | 97.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suo, Z.; Zhao, Y.; Chen, S.; Hu, Y. BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection. Remote Sens. 2022, 14, 5761. https://doi.org/10.3390/rs14225761
Suo Z, Zhao Y, Chen S, Hu Y. BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection. Remote Sensing. 2022; 14(22):5761. https://doi.org/10.3390/rs14225761
Chicago/Turabian StyleSuo, Zhiling, Yongbo Zhao, Sheng Chen, and Yili Hu. 2022. "BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection" Remote Sensing 14, no. 22: 5761. https://doi.org/10.3390/rs14225761
APA StyleSuo, Z., Zhao, Y., Chen, S., & Hu, Y. (2022). BoxPaste: An Effective Data Augmentation Method for SAR Ship Detection. Remote Sensing, 14(22), 5761. https://doi.org/10.3390/rs14225761