
Enhancing Reproducibility and Replicability in Remote Sensing Deep Learning Research and Practice

Abstract
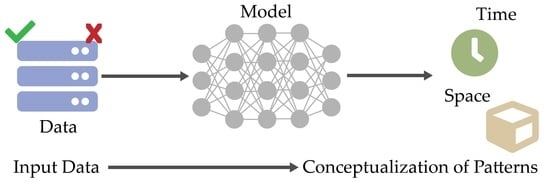
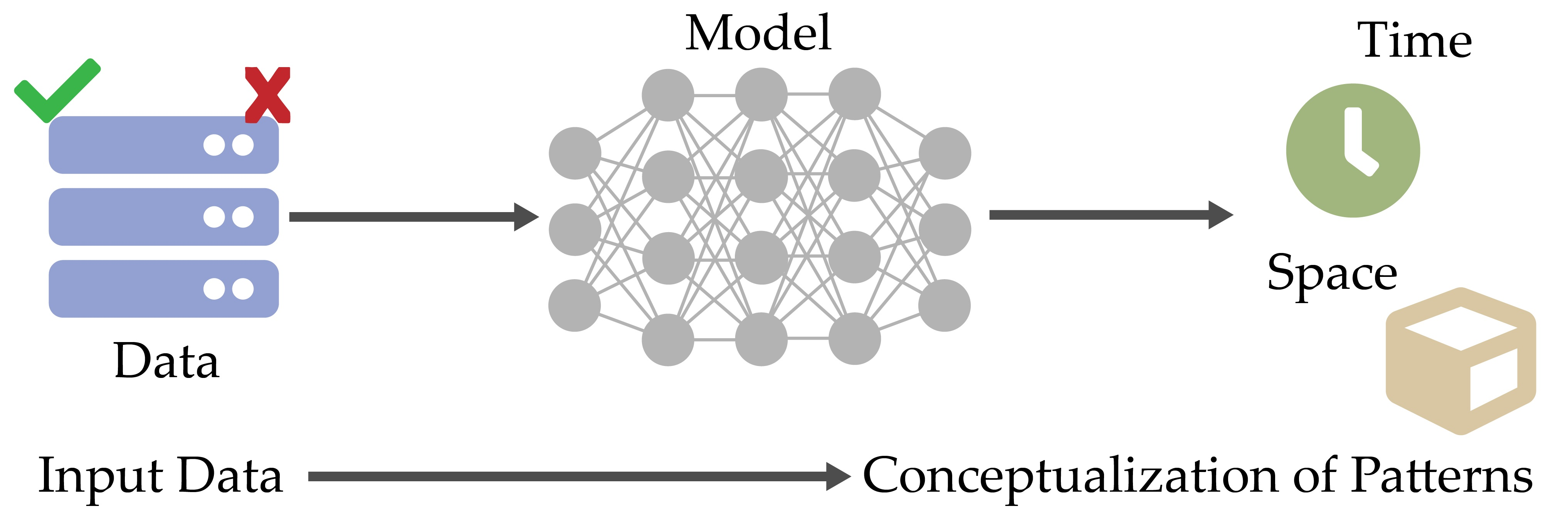
1. Introduction
2. Issues and Needs
3. Recommendations and Best Practices
- Where appropriate and available, data originator, sensor and platform, and product level information should be indicated along with collection date(s) and data identifiers. Pre-processing operations and pipelines should be documented including georeferencing and orthorectification, coordinate transformations, resampling methods, spatial and spectral enhancements, pan sharpening, and contrast enhancements.
- Whenever possible, code should be made publicly available using an academic or code repository. The code should be well commented and explained, and version numbers of used software, development environments, code libraries, and/or dependencies should be provided. If it is not possible to make code available, then it is of increased importance to clearly document the methods, data, processing, and algorithm architecture in associated research articles and/or other documentation.
- Algorithms should be well explained and documented in articles and reports. This should include the base algorithm or architectures used, original citations for the method, and descriptions of any augmentations to the base architecture (e.g., adding batch normalization, using a different activation function, modifying the number of convolutional blocks, or changing the number of learned kernels). Readers should be able to use the described methods to augment the base architecture to reproduce the augmented algorithm used in the study or project.
- Random seeds can be set to enhance reproducibility. However, needs and methods vary between frameworks, as described by Alahmari et al. [37]. Users should consult documentation to determine how to appropriately set random seeds to obtain deterministic models or reproducible results. However, this may not be possible in all software or framework environments. As an alternative, researchers could run multiple, randomly initialized models, and report the variability in the final model results, which may be especially useful when comparing algorithms, methods, or feature spaces. However, this may not be possible given the computational costs of running multiple model iterations.
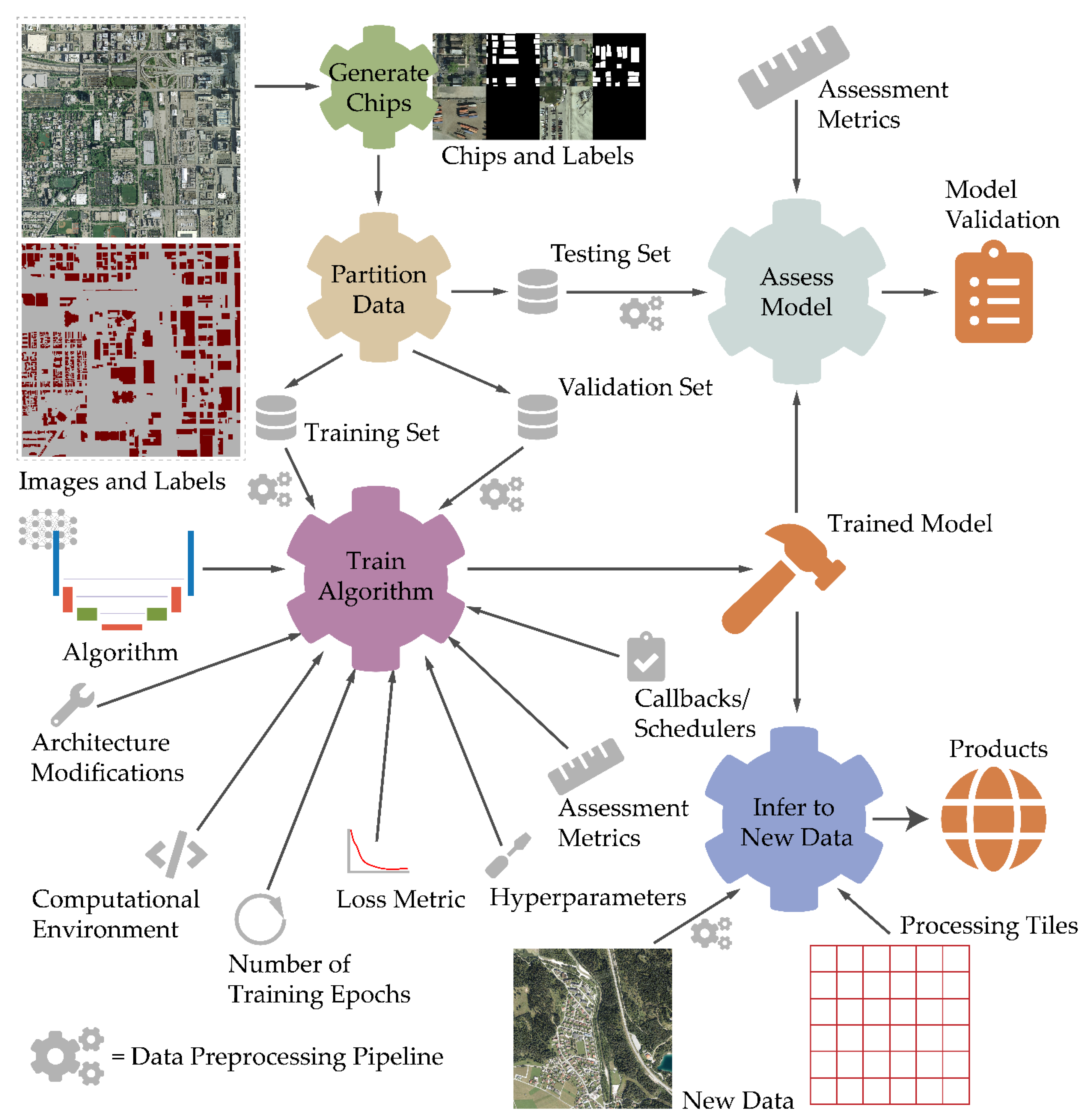
- The entire training process should be clearly described, including input chip size, number of training samples, number of validation samples, batch size, epochs, callbacks and/or schedulers used, optimization algorithm used and associated parameters (e.g., learning rate), and loss metric implemented.
- Training, validation, and testing data should be provided if possible. The number of available chips and how chips and associated labels were generated from larger image extents should be clearly documented. The methods used to partition the available chips into training, validation, and testing sets should be well explained. The geographic extent of the dataset(s) and source data should be well described and referenced. Any processing applied, such as rescaling pixel values or applying normalization, requires explanation. Other researchers and analyst should be able to reproduce the experimental workflow to obtain the same values and tensors used in the original analysis. If it is not possible to make the training data available, it is still important to clearly document the workflow used since others may need to implement the same methods in order to apply the algorithm to new data.
- Studies must be carefully designed so as not to introduce data leakage, which can severely impact replicability and even invalidate model assessment results [46]. Researchers should pay special attention to data partitioning methods, issues of temporal and spatial autocorrelation between samples in the data partitions, and not incorporating testing data into preprocessing and feature selection workflows.
- If transfer learning is used to initialize the model weights, the source of the weights should be explained, such as the image dataset used. Moreover, it is necessary to explain what weights in the model were updated during the training process and which were not. If some weights were only updated during a subset of training epochs, such as those associated with the CNN backbone used to develop feature maps, this should also be explained and documented.
- All data augmentations or transformations applied to increase the size of the training dataset and potentially reduce overfitting need to be explained including what transformations were used (e.g., blur, sharpen, brighten, contrast shifts, flip, rotate, etc.) and the probabilities of applying them. For increased transparency, augmented data can be written to files and provided with the original chips.
- Methods used to validate and assess models should be explained such that they can be reproduced. When evaluating models, it is also important that researchers adhere to defendable methods for assessing model performance and the accuracy of products, such as those suggested by Maxwell et al. [22,23].
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Fracastoro, G.; Magli, E.; Poggi, G.; Scarpa, G.; Valsesia, D.; Verdoliva, L. Deep Learning Methods For Synthetic Aperture Radar Image Despeckling: An Overview Of Trends And Perspectives. IEEE Geosci. Remote Sens. Mag. 2021, 9, 29–51. [Google Scholar] [CrossRef]
- Geng, Z.; Yan, H.; Zhang, J.; Zhu, D. Deep-Learning for Radar: A Survey. IEEE Access 2021, 9, 141800–141818. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A Hyper-Light Deep Learning Network for High-Accurate and High-Speed Ship Detection from Synthetic Aperture Radar Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Li, N.; Kähler, O.; Pfeifer, N. A Comparison of Deep Learning Methods for Airborne Lidar Point Clouds Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6467–6486. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep Learning on Point Clouds and Its Application: A Survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [PubMed]
- Behrens, T.; Schmidt, K.; MacMillan, R.A.; Viscarra Rossel, R.A. Multi-Scale Digital Soil Mapping with Deep Learning. Sci. Rep. 2018, 8, 15244. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sens. 2020, 12, 547. [Google Scholar] [CrossRef]
- Van der Meij, W.M.; Meijles, E.W.; Marcos, D.; Harkema, T.T.; Candel, J.H.; Maas, G.J. Comparing Geomorphological Maps Made Manually and by Deep Learning. Earth Surf. Process. Landf. 2022, 47, 1089–1107. [Google Scholar] [CrossRef]
- Yu, Y.; Rashidi, M.; Samali, B.; Mohammadi, M.; Nguyen, T.N.; Zhou, X. Crack Detection of Concrete Structures Using Deep Convolutional Neural Networks Optimized by Enhanced Chicken Swarm Algorithm. Struct. Health Monit. 2022, 21, 2244–2263. [Google Scholar] [CrossRef]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-Based Concrete Crack Detection Using a Hybrid Framework Considering Noise Effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 2: Recommendations and Best Practices. Remote Sens. 2021, 13, 2591. [Google Scholar] [CrossRef]
- National Academies of Sciences, Engineering and Medicine. Reproducibility and Replicability in Science; National Academies of Sciences, Engineering and Medicine: Washington, DC, USA, 2019. [Google Scholar]
- Small, C. Grand Challenges in Remote Sensing Image Analysis and Classification. Front. Remote Sens. 2021, 1, 605220. [Google Scholar] [CrossRef]
- Kedron, P.; Li, W.; Fotheringham, S.; Goodchild, M. Reproducibility and Replicability: Opportunities and Challenges for Geospatial Research. Int. J. Geogr. Inf. Sci. 2021, 35, 427–445. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Fotheringham, A.S.; Kedron, P.; Li, W. Introduction: Forum on Reproducibility and Replicability in Geography. Ann. Am. Assoc. Geogr. 2021, 111, 1271–1274. [Google Scholar] [CrossRef]
- Marrone, S.; Olivieri, S.; Piantadosi, G.; Sansone, C. Reproducibility of Deep CNN for Biomedical Image Processing Across Frameworks and Architectures. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Renard, F.; Guedria, S.; Palma, N.D.; Vuillerme, N. Variability and Reproducibility in Deep Learning for Medical Image Segmentation. Sci. Rep. 2020, 10, 13724. [Google Scholar] [CrossRef]
- Sethi, R.J.; Gil, Y. Reproducibility in Computer Vision: Towards Open Publication of Image Analysis Experiments as Semantic Workflows. In Proceedings of the 2016 IEEE 12th International Conference on e-Science (e-Science), Baltimore, MD, USA, 23–27 October 2016; pp. 343–348. [Google Scholar]
- Liu, C.; Gao, C.; Xia, X.; Lo, D.; Grundy, J.; Yang, X. On the Replicability and Reproducibility of Deep Learning in Software Engineering. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–46. [Google Scholar] [CrossRef]
- Warner, T.A.; Foody, G.M.; Nellis, M.D. The SAGE Handbook of Remote Sensing; Sage Publications: New York, NY, USA, 2009. [Google Scholar]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Jensen, J.R. Digital Image Processing: A Remote Sensing Perspective; Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Alahmari, S.S.; Goldgof, D.B.; Mouton, P.R.; Hall, L.O. Challenges for the Repeatability of Deep Learning Models. IEEE Access 2020, 8, 211860–211868. [Google Scholar] [CrossRef]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. Batch Normalization: An Empirical Study of Their Impact to Deep Learning. Multimed Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding Batch Normalization. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 11 September 2022).
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 11 September 2022).
- PyTorch. Available online: https://pytorch.org/ (accessed on 11 September 2022).
- CUDA Deep Neural Network. Available online: https://developer.nvidia.com/cudnn (accessed on 11 September 2022).
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A.L. Loss Odyssey in Medical Image Segmentation. Med. Image Anal. 2021, 71, 102035. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Kapoor, S.; Narayanan, A. Leakage and the Reproducibility Crisis in ML-Based Science. arXiv 2022, arXiv:2207.07048. [Google Scholar]
- ImageNet. Available online: https://image-net.org/index (accessed on 11 September 2022).
- COCO—Common Objects in Context. Available online: https://cocodataset.org/#home (accessed on 11 September 2022).
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Welcome to Python.Org. Available online: https://www.python.org/ (accessed on 11 September 2022).
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef]
- PyTorch Lightning. Available online: https://www.pytorchlightning.ai/ (accessed on 11 September 2022).
- Contributors, P.-I. Ignite Your Networks!—PyTorch-Ignite v0.4.10 Documentation. Available online: https://pytorch.org/ignite/ (accessed on 11 September 2022).
- 2D, 3D & 4D GIS Mapping Software|ArcGIS Pro. Available online: https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview (accessed on 11 September 2022).
- Arcgis.Learn Module. Available online: https://developers.arcgis.com/python/api-reference/arcgis.learn.toc.html (accessed on 11 September 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T.; Berkeley, U. Fully Convolutional Networks for Semantic Segmentation. arXiv 2014, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:180202611. [Google Scholar]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key Issues in Rigorous Accuracy Assessment of Land Cover Products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Baur, C.; Albarqouni, S.; Navab, N. Semi-Supervised Deep Learning for Fully Convolutional Networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017, Quebec City, QC, Canada, 10–14 September 2017; Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D.L., Duchesne, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 311–319. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Semi-Supervised Deep Learning with Memory. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 268–283. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. An Overview of Deep Semi-Supervised Learning. arXiv 2020, arXiv:2006.05278. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Jin, Y.; Han, D.; Ko, H. TrSeg: Transformer for Semantic Segmentation. Pattern Recognit. Lett. 2021, 148, 29–35. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. arXiv 2021, arXiv:2105.05633. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Chen, B.; Wen, M.; Shi, Y.; Lin, D.; Rajbahadur, G.K.; Jiang, Z.M. Towards Training Reproducible Deep Learning Models. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022; pp. 2202–2214. [Google Scholar]
- Hartley, M.; Olsson, T.S.G. DtoolAI: Reproducibility for Deep Learning. Patterns 2020, 1, 100073. [Google Scholar] [CrossRef] [PubMed]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1–Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Wu, Y.; Liu, L.; Bae, J.; Chow, K.-H.; Iyengar, A.; Pu, C.; Wei, W.; Yu, L.; Zhang, Q. Demystifying Learning Rate Policies for High Accuracy Training of Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1971–1980. [Google Scholar]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2020. ahead-of-print. [Google Scholar] [CrossRef]
- Angelov, P.; Soares, E. Towards Explainable Deep Neural Networks (XDNN). Neural Netw. 2020, 130, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Wang, X.; Liu, X.; Liu, Q.; Song, J.; Sebe, N.; Kim, B. Explainable Deep Learning for Efficient and Robust Pattern Recognition: A Survey of Recent Developments. Pattern Recognit. 2021, 120, 108102. [Google Scholar] [CrossRef]
- Choo, J.; Liu, S. Visual Analytics for Explainable Deep Learning. IEEE Comput. Graph. Appl. 2018, 38, 84–92. [Google Scholar] [CrossRef]
- Musgrave, K.; Belongie, S.; Lim, S.-N. A Metric Learning Reality Check. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 681–699. [Google Scholar]
- Ivie, P.; Thain, D. Reproducibility in Scientific Computing. ACM Comput. Surv. 2018, 51, 63. [Google Scholar] [CrossRef]
- Tullis, J.A.; Kar, B. Where Is the Provenance? Ethical Replicability and Reproducibility in GIScience and Its Critical Applications. Ann. Am. Assoc. Geogr. 2021, 111, 1318–1328. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Burgess, A.; Tullis, J.A.; Magill, A.B. Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows. ISPRS Int. J. Geo-Inf. 2020, 9, 119. [Google Scholar] [CrossRef]
- Baker, M. Reproducibility Crisis. Nature 2016, 533, 353–366. [Google Scholar]


{kind=link}
{kind=link}
| Topic | Title | Citation | Year |
|---|---|---|---|
| Selecting a Loss Metric | “Loss odyssey in medical image segmentation” | Ma et al. [72] | 2021 |
| Learning Rate, Schedulers, and Hyperparameters | “Cyclical learning rates for training neural networks” | Smith [73] | 2017 |
| “A disciplined approach to neural network hyper-parameters: Part 1–learning rate, batch size, momentum, and weight decay” | Smith [74] | 2018 | |
| “Demystifying learning rate policies for high accuracy training of deep neural networks” | Wu et al. [75] | 2019 | |
| Data Leakage | “Leakage and the reproducibility crisis in ML-based science” | Kapoor and Narayannan [46] | 2022 |
| Accuracy Assessment Best Practices | “Classification assessment methods” | Tharwat [76] | 2020 |
| “Accuracy assessment in convolutional neural network-based deep learning remote sensing studies—Part 1: literature review” | Maxwell et al. [22] | 2021 | |
| “Accuracy assessment in convolutional neural network-based deep learning remote sensing studies—Part 2: recommendations and best practices” | Maxwell et al. [23] | 2021 | |
| Combating Overfitting | “Batch normalization: Accelerating deep network training by reducing internal covariate shift” | Ioffe and Szegedy [40] | 2015 |
| “Understanding batch normalization” | Bjorck et al. [39] | 2018 | |
| “A survey on image data augmentation for deep learning” | Shorten and Khoshgoftaar [45] | ||
| “Dropout vs. batch normalization: an empirical study of their impact to deep learning” | Garbin et al. [38] | 2020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Bester, M.S.; Ramezan, C.A. Enhancing Reproducibility and Replicability in Remote Sensing Deep Learning Research and Practice. Remote Sens. 2022, 14, 5760. https://doi.org/10.3390/rs14225760
Maxwell AE, Bester MS, Ramezan CA. Enhancing Reproducibility and Replicability in Remote Sensing Deep Learning Research and Practice. Remote Sensing. 2022; 14(22):5760. https://doi.org/10.3390/rs14225760
Chicago/Turabian StyleMaxwell, Aaron E., Michelle S. Bester, and Christopher A. Ramezan. 2022. "Enhancing Reproducibility and Replicability in Remote Sensing Deep Learning Research and Practice" Remote Sensing 14, no. 22: 5760. https://doi.org/10.3390/rs14225760
APA StyleMaxwell, A. E., Bester, M. S., & Ramezan, C. A. (2022). Enhancing Reproducibility and Replicability in Remote Sensing Deep Learning Research and Practice. Remote Sensing, 14(22), 5760. https://doi.org/10.3390/rs14225760