Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine


Abstract
1. Introduction
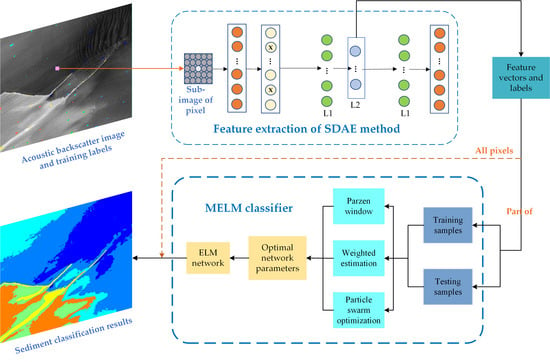
2. The Proposed Sediment Classification Technique
2.1. Overall Framework
2.2. SDAE Method for Feature Extraction
2.3. ELM and Its Modified Model
2.3.1. Basic ELM Model
2.3.2. MELM Model
Theory of RELM Model
RELM Model and PSO Combined into MELM Classifier
2.4. Evaluation Indexes of the Classification Model
3. Results and Analysis
3.1. Data Description and Parameter Settings
3.2. Results of Feature Extraction
3.3. Results of Classifiers Design
4. Discussion
4.1. Comparison of Feature Extraction
4.2. Comparison between Classifiers
4.3. Ablation Study between ELM Families
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cuff, A.; Anderson, J.T.; Devillers, R. Comparing surficial sediments maps interpreted by experts with dual-frequency acoustic backscatter on the Scotian shelf, Canada. Cont. Shelf Res. 2015, 110, 149–161. [Google Scholar] [CrossRef]
- Hamouda, A.Z.; Abdel-Salam, K.M. Estuarine habitat assessment for construction of a submarine transmission line. Surv. Geophys. 2010, 31, 449–463. [Google Scholar] [CrossRef]
- Silberberger, M.J.; Renaud, P.E.; Buhl-Mortensen, L.; Ellingsen, I.H.; Reiss, H. Spatial patterns in sub-Arctic benthos: Multiscale analysis reveals structural differences between community components. Ecol. Monogr. 2019, 89, e01325. [Google Scholar] [CrossRef]
- Innangi, S.; Di Martino, G.; Romagnoli, C.; Tonielli, R. Seabed classification around Lampione islet, Pelagie Islands Marine Protected area, Sicily Channel, Mediterranean Sea. J. Maps. 2019, 15, 153–164. [Google Scholar] [CrossRef]
- Luo, X.; Qin, X.; Wu, Z.; Yang, F.; Wang, M.; Shang, J. Sediment classification of small-size seabed acoustic images using convolutional neural networks. IEEE Access. 2019, 7, 98331–98339. [Google Scholar] [CrossRef]
- Zhou, P.; Chen, G.; Wang, M.; Liu, X.; Chen, S.; Sun, R. Side-Scan Sonar Image Fusion Based on Sum-Modified Laplacian Energy Filtering and Improved Dual-Channel Impulse Neural Network. Appl. Sci. 2020, 10, 1028. [Google Scholar] [CrossRef]
- Preston, J. Automated acoustic seabed classification of multibeam images of Stanton Banks. Appl. Acoust. 2009, 70, 1277–1287. [Google Scholar] [CrossRef]
- Diesing, M.; Green, S.L.; Stephens, D.; Lark, R.M.; Stewart, H.A.; Dove, D. Mapping seabed sediments: Comparison of manual, geostatistical, object-based image analysis and machine learning approaches. Cont. Shelf Res. 2014, 84, 107–119. [Google Scholar] [CrossRef]
- Mohamed, H.; Nadaoka, K.; Nakamura, T. Towards Benthic Habitat 3D Mapping Using Machine Learning Algorithms and Structures from Motion Photogrammetry. Remote Sens. 2020, 12, 127. [Google Scholar] [CrossRef]
- Tegowski, J.; Trzcinska, K.; Kasprzak, M.; Nowak, J. Statistical and spectral features of corrugated seafloor shaped by the Hans glacier in Svalbard. Remote Sens. 2016, 8, 744. [Google Scholar] [CrossRef]
- Huang, Z.; Siwabessy, J.; Nichol, S.; Anderson, T.; Brooke, B. Predictive mapping of seabed cover types using angular response curves of multibeam backscatter data: Testing different feature analysis approaches. Cont. Shelf Res. 2013, 61, 12–22. [Google Scholar] [CrossRef]
- Ji, X.; Yang, B.; Tang, Q. Seabed sediment classification using multibeam backscatter data based on the selecting optimal random forest model. Appl. Acoust. 2020, 167, 107387. [Google Scholar] [CrossRef]
- Berthold, T.; Leichter, A.; Rosenhahn, B.; Berkhahn, V.; Valerius, J. Seabed sediment classification of side-scan sonar data using convolutional neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Zhou, P.; Han, J.; Cheng, G.; Zhang, B. Learning Compact and Discriminative Stacked Autoencoder for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4823–4833. [Google Scholar] [CrossRef]
- Kan, X.; Zhang, Y.; Zhu, L.; Xiao, L.; Wang, J.; Tian, W.; Tan, H. Snow cover mapping for mountainous areas by fusion of MODIS L1B and geographic data based on stacked denoising auto-encoders. CMC Comput. Mat. Contin. 2018, 57, 49–68. [Google Scholar] [CrossRef]
- Hao, S.; Wang, W.; Ye, Y.; Nie, T.; Bruzzone, L. Two-Stream Deep Architecture for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2349–2361. [Google Scholar] [CrossRef]
- Tian, S.; Wang, C.; Zhang, H.; Bhanu, B. SAR object classification using the DAE with a modified triplet restriction. IET Radar Sonar Navig. 2019, 13, 1081–1091. [Google Scholar] [CrossRef]
- Cooper, K.M.; Bolam, S.G.; Downie, A.L.; Barry, J. Biological-based habitat classification approaches promote cost-efficient monitoring: An example using seabed assemblages. J. Appl. Ecol. 2019, 56, 1085–1098. [Google Scholar] [CrossRef]
- Chakraborty, B.; Kaustubha, R.; Hegde, A.; Pereira, A. Acoustic seafloor sediment classification using self-organizing feature maps. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2722–2725. [Google Scholar] [CrossRef]
- Li, D.; Tang, C.; Xia, C.; Zhang, H. Acoustic mapping and classification of benthic habitat using unsupervised learning in artificial reef water. Estuar. Coast. Shelf Sci. 2017, 185, 11–21. [Google Scholar] [CrossRef]
- Karmakar, M.; Maiti, S.; Singh, A.; Ojha, M.; Maity, B.S. Mapping of rock types using a joint approach by combining the multivariate statistics, self-organizing map and Bayesian neural networks: An example from IODP 323 site. Mar. Geophys. Res. 2018, 39, 407–419. [Google Scholar] [CrossRef]
- Yegireddi, S.; Thomas, N. Segmentation and classification of shallow subbottom acoustic data, using image processing and neural networks. Mar. Geophys. Res. 2014, 35, 149–156. [Google Scholar] [CrossRef]
- McLaren, K.; McIntyre, K.; Prospere, K. Using the random forest algorithm to integrate hydroacoustic data with satellite images to improve the mapping of shallow nearshore benthic features in a marine protected area in Jamaica. GISci. Remote Sens. 2019, 56, 1065–1092. [Google Scholar] [CrossRef]
- Choubin, B.; Darabi, H.; Rahmati, O.; Sajedi-Hosseini, F.; Klove, B. River suspended sediment modelling using the CART model: A comparative study of machine learning techniques. Sci. Total Environ. 2018, 615, 272–281. [Google Scholar] [CrossRef] [PubMed]
- Trzcinska, K.; Janowski, L.; Nowak, J.; Nowak, J.; Rucinska-Zjadacz, M.; Kruss, A.; von Deimling, J.S.; Pocwiardowski, P.; Tegowski, J. Spectral features of dual-frequency multibeam echosounder data for benthic habitat mapping. Mar. Geol. 2020, 427, 106239. [Google Scholar] [CrossRef]
- Ojha, M.; Maiti, S. Sediment classification using neural networks: An example from the site-U1344A of IODP Expedition 323 in the Bering Sea. Deep Sea Res. Part II Top. Stud. Oceanogr. 2013, 125, 202–213. [Google Scholar] [CrossRef]
- Tang, Q.; Lei, N.; Li, J.; Wu, Y.; Zhou, X. Seabed mixed sediment classification with multi-beam echo sounder backscatter data in Jiaozhou Bay. Mar. Geores. Geotechnol. 2015, 33, 1–11. [Google Scholar] [CrossRef]
- Wang, M.; Wu, Z.; Yang, F.; Ma, Y.; Wang, X.; Zhao, D. Multifeature extraction and seafloor classification combining LiDAR and MBES data around Yuanzhi Island in the South China Sea. Sensors 2018, 18, 3828. [Google Scholar] [CrossRef]
- Deo, R.C.; Samui, P.; Kim, D. Estimation of monthly evaporative loss using relevance vector machine, extreme learning machine and multivariate adaptive regression spline models. Stoch. Environ. Res. Risk Assess. 2016, 30, 1769–1784. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J. A robust combination approach for short-term wind speed forecasting and analysis–Combination of the ARIMA (Autoregressive Integrated Moving Average), ELM (Extreme Learning Machine), SVM (Support Vector Machine) and LSSVM (Least Square SVM) forecasts using a GPR (Gaussian Process Regression) model. Energy. 2015, 93, 41–56. [Google Scholar]
- Song, Y.; He, B.; Liu, P.; Yan, T. Side scan sonar image segmentation and synthesis based on extreme learning machine. Appl. Acoust. 2019, 146, 56–65. [Google Scholar] [CrossRef]
- Ren, G.; Sun, Y.; Li, M.; Ning, J.; Zhang, Z. Cognitive spectroscopy for evaluating Chinese black tea grades (Camellia sinensis): Near-infrared spectroscopy and evolutionary algorithms. J. Sci. Food Agric. 2020, 100, 3950–3959. [Google Scholar] [CrossRef] [PubMed]
- Man, Z.; Lee, K.; Wang, D.; Cao, Z.; Khoo, S.Y. Robust single-hidden layer feedforward network-based pattern classifier. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1974–1986. [Google Scholar] [PubMed]
- He, Y.; Ashfaq, R.A.R.; Huang, J.; Wang, X. Imbalanced ELM Based on Normal Density Estimation for Binary-Class Classification. In Proceedings of the 20th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Auckland, New Zealand, 19–22 April 2016; pp. 48–60. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, Y. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Shao, L.; Cai, Z.; Liu, L.; Lu, K. Performance evaluation of deep feature learning for RGB-D image/video classification. Inf. Sci. 2017, 385, 266–283. [Google Scholar] [CrossRef]
- Belciug, S.; Gorunescu, F. Learning a single-hidden layer feedforward neural network using a rank correlation-based strategy with application to high dimensional gene expression and proteomic spectra datasets in cancer detection. J. Biomed. Inform. 2018, 83, 159–166. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, H.; Wang, Y. A modified extreme learning machine with sigmoidal activation functions. Neural Comput. Appl. 2013, 22, 541–550. [Google Scholar] [CrossRef]
- Fonseca, L.; Hung, E.M.; Neto, A.A.; Magrani, F. Waterfall notch-filtering for restoration of acoustic backscatter records from Admiralty Bay, Antarctica. Mar. Geophys. Res. 2018, 39, 139–149. [Google Scholar] [CrossRef]
- Cheng, K.; Gao, S.; Dong, W.; Yang, X.; Wang, Q.; Yu, H. Boosting label weighted extreme learning machine for classifying multi-label imbalanced data. Neurocomputing. 2020, 403, 360–370. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, D.; Fan, L.; Jia, Y. Study on Icing Prediction of Power Transmission Lines Based on Ensemble Empirical Mode Decomposition and Feature Selection Optimized Extreme Learning Machine. Energies 2019, 12, 2163. [Google Scholar] [CrossRef]
- Rashno, A.; Nazari, B.; Sadri, S.; Saraee, M. Effective pixel classification of Mars images based on ant colony optimization feature selection and extreme learning machine. Neurocomputing 2017, 226, 66–79. [Google Scholar] [CrossRef]
- Lee, Y.; Han, D.; Ahn, M.H.; Im, J.; Lee, S. Retrieval of total precipitable water from Himawari-8 AHI data: A comparison of random forest, extreme gradient boosting, and deep neural network. Remote Sens. 2019, 11, 1741. [Google Scholar] [CrossRef]
- Foster, D.S.; Baldwin, W.E.; Barnhardt, W.A.; Schwab, W.C.; Ackerman, S.D.; Andrews, B.D.; Pendleton, E.A. Shallow Geology, Sea-Floor Texture, and Physiographic Zones of Buzzards Bay, Massachusetts; Open-File Report 2014–1220; U.S. Geological Survey: Reston, VA, USA, 2016. [CrossRef]
- Zajac, R.N.; Stefaniak, L.M.; Babb, I.; Conroy, C.W.; Penna, S.; Chadi, D.; Auster, P.J. An integrated seafloor habitat map to inform marine spatial planning and management: A case study from Long Island Sound (Northwest Atlantic). In Seafloor Geomorphology as Benthic Habitat, 2nd ed.; Peter, T.H., Elaine, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 199–217. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objective Indexes | Mathematical Formulation |
|---|---|
| Overall Accuracy | |
| Category Accuracy | |
| Kappa Coefficient | , |
| RMSE of label prediction |
| Image Size | Class | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|---|
| Z1 area 1 | 492 × 505 | Train sample | 534 | 506 | 599 | 606 | 183 | 369 |
| Test sample | 811 | 571 | 634 | 677 | 270 | 240 | ||
| Z2 area 2 | 717 × 634 | Train sample | 419 | 368 | 342 | 325 | 442 | 383 |
| Test sample | 463 | 405 | 370 | 283 | 428 | 333 |
| CA1 | CA2 | CA3 | CA4 | CA5 | CA6 | OA | Kappa | RMSE | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Z1 area | Gabor | 64.7% | 60.7% | 90.0% | 92.7% | 78.7% | 97.7% | 78.7% | 0.733 | 0.4360 |
| CNN | 100% | 70.0% | 100% | 96.9% | 56.9% | 93.1% | 85.2% | 0.812 | 0.3832 | |
| SAE | 98.1% | 77.1% | 85.3% | 77.1% | 73.8% | 94.6% | 84.4% | 0.806 | 0.3256 | |
| SDAE | 99.7% | 76.6% | 99.3% | 88.8% | 71.9% | 96.8% | 89.3% | 0.868 | 0.3110 | |
| Z2 area | Gabor | 100% | 77.4% | 93.1% | 100% | 100% | 87.1% | 91.9% | 0.902 | 0.2888 |
| CNN | 100% | 75.7% | 94.3% | 99.6% | 100% | 95.9% | 93.0% | 0.915 | 0.2765 | |
| SAE | 100% | 84.8% | 86.6% | 100% | 99.8% | 86.7% | 92.8% | 0.913 | 0.2637 | |
| SDAE | 100% | 95.4% | 81.0% | 97.6% | 100% | 100% | 95.4% | 0.944 | 0.2601 |
| CA1 | CA2 | CA3 | CA4 | CA5 | CA6 | OA | Kappa | RMSE | |
|---|---|---|---|---|---|---|---|---|---|
| RF | 89.6% | 82.8% | 99.8% | 87.7% | 64.7% | 95.7% | 87.0% | 0.840 | 0.4505 |
| SVM | 94.4% | 73.7% | 96.8% | 95.7% | 74.2% | 63.5% | 85.5% | 0.822 | 0.4585 |
| GA-SVM | 95.4% | 72.1% | 100% | 95.8% | 71.4% | 81.3% | 87.3% | 0.843 | 0.4135 |
| PSO-SVM | 95.5% | 71.7% | 100% | 94.6% | 72.6% | 78.0% | 86.9% | 0.839 | 0.4292 |
| ELM | 91.0% | 73.0% | 99.4% | 84.6% | 88.2% | 95.6% | 86.8% | 0.836 | 0.4521 |
| RELM | 86.3% | 75.7% | 98.8% | 85.7% | 95.5% | 93.2% | 87.3% | 0.842 | 0.4376 |
| GA-RELM | 97.4% | 77.4% | 90.4% | 82.6% | 84.4% | 99.0% | 87.5% | 0.845 | 0.4293 |
| Our MELM | 99.7% | 76.6% | 99.3% | 88.8% | 71.9% | 96.8% | 89.3% | 0.868 | 0.3110 |
| CA1 | CA2 | CA3 | CA4 | CA5 | CA6 | OA | Kappa | RMSE | |
|---|---|---|---|---|---|---|---|---|---|
| RF | 100% | 75.7% | 98.0% | 100% | 99.3% | 81.5% | 90.7% | 0.888 | 0.3290 |
| SVM | 100% | 73.5% | 90.3% | 100% | 99.1% | 69.4% | 86.4% | 0.836 | 0.3826 |
| GA-SVM | 100% | 75.8% | 95.3% | 100% | 97.5% | 73.5% | 88.3% | 0.859 | 0.3497 |
| PSO-SVM | 100% | 75.8% | 95.0% | 100% | 98.4% | 73.2% | 88.4% | 0.860 | 0.3322 |
| ELM | 100% | 78.8% | 94.9% | 100% | 100% | 89.8% | 93.1% | 0.916 | 0.2878 |
| RELM | 100% | 77.4% | 97.3% | 99.6% | 99.3% | 94.5% | 93.5% | 0.922 | 0.2837 |
| GA-RELM | 100% | 79.4% | 97.1% | 100% | 100% | 90.6% | 93.6% | 0.923 | 0.2615 |
| Our MELM | 100% | 95.4% | 81.0% | 97.6% | 100% | 100% | 95.4% | 0.944 | 0.2601 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, P.; Chen, G.; Wang, M.; Chen, J.; Li, Y. Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine. Remote Sens. 2020, 12, 3762. https://doi.org/10.3390/rs12223762
Zhou P, Chen G, Wang M, Chen J, Li Y. Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine. Remote Sensing. 2020; 12(22):3762. https://doi.org/10.3390/rs12223762
Chicago/Turabian StyleZhou, Ping, Gang Chen, Mingwei Wang, Jifa Chen, and Yizhe Li. 2020. "Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine" Remote Sensing 12, no. 22: 3762. https://doi.org/10.3390/rs12223762
APA StyleZhou, P., Chen, G., Wang, M., Chen, J., & Li, Y. (2020). Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine. Remote Sensing, 12(22), 3762. https://doi.org/10.3390/rs12223762