


An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM




Abstract
1. Introduction
1.1. Motivation
1.2. Background
1.3. Novelty and Our Contribution
- The definition of the phases to study the time series that define energy consumption in buildings;
- The definition of the analysis process of the dependency relations between the variables, especially the temporal ones;
- The definition of the analysis process of the dimensions in the dataset to determine the fusion and extraction of characteristics.
- The utilization of this approach for the definition of forecast models based on time series.
2. Theoretical Framework
2.1. The Energy Consumption Forecasting Problem
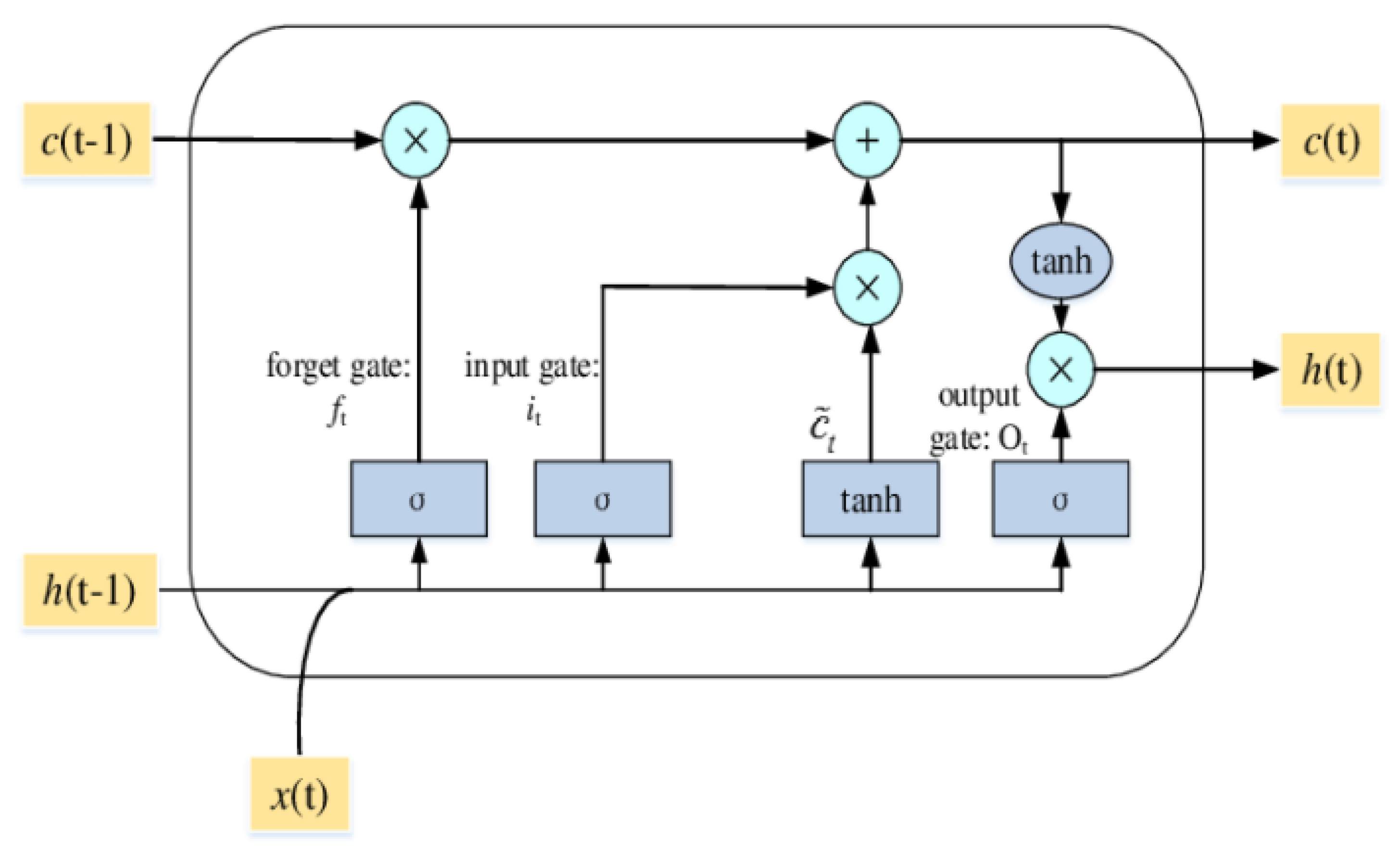
2.2. Long Short-Term Memory (LSTM) Technique
3. Analysis of the Energy Consumption Forecasting Problem
3.1. Analysis of the Variables (Feature Engineering Process)
- Date: represents the date each sample is taken, with the format: YYYY: MM: DD.
- Month: represents the month in which each sample is taken (integer).
- Day: represents the day of the week (Sunday–Monday) on which each sample is taken (string).
- Time: represents the time of day at which the sample is taken, with the format hh: mm (time).
- Hour and Minute: represent the hour and minute of the sample collection, respectively (integer).
- Skyspark: represents the total energy consumption for each observation, in kilowatts (kW). This will be the target or dependent variable.
- AV.Controller, Coffee.Maker, Copier, Office Computer, Lamp, Laptop, Microwave, Monitor, Phone.Charger, Printer, Projector, Toaster.Oven, TV, Video.Conference.Camera, Water.Boiler, Conference.Podium, Auto.Door.Opener, Treadmill, Refrigerator, Central-Monitoring-Station, TVs, etc. represent the energy consumption of each device in each observation (kilowatts (kW)). These will be our descriptive or independent variables.
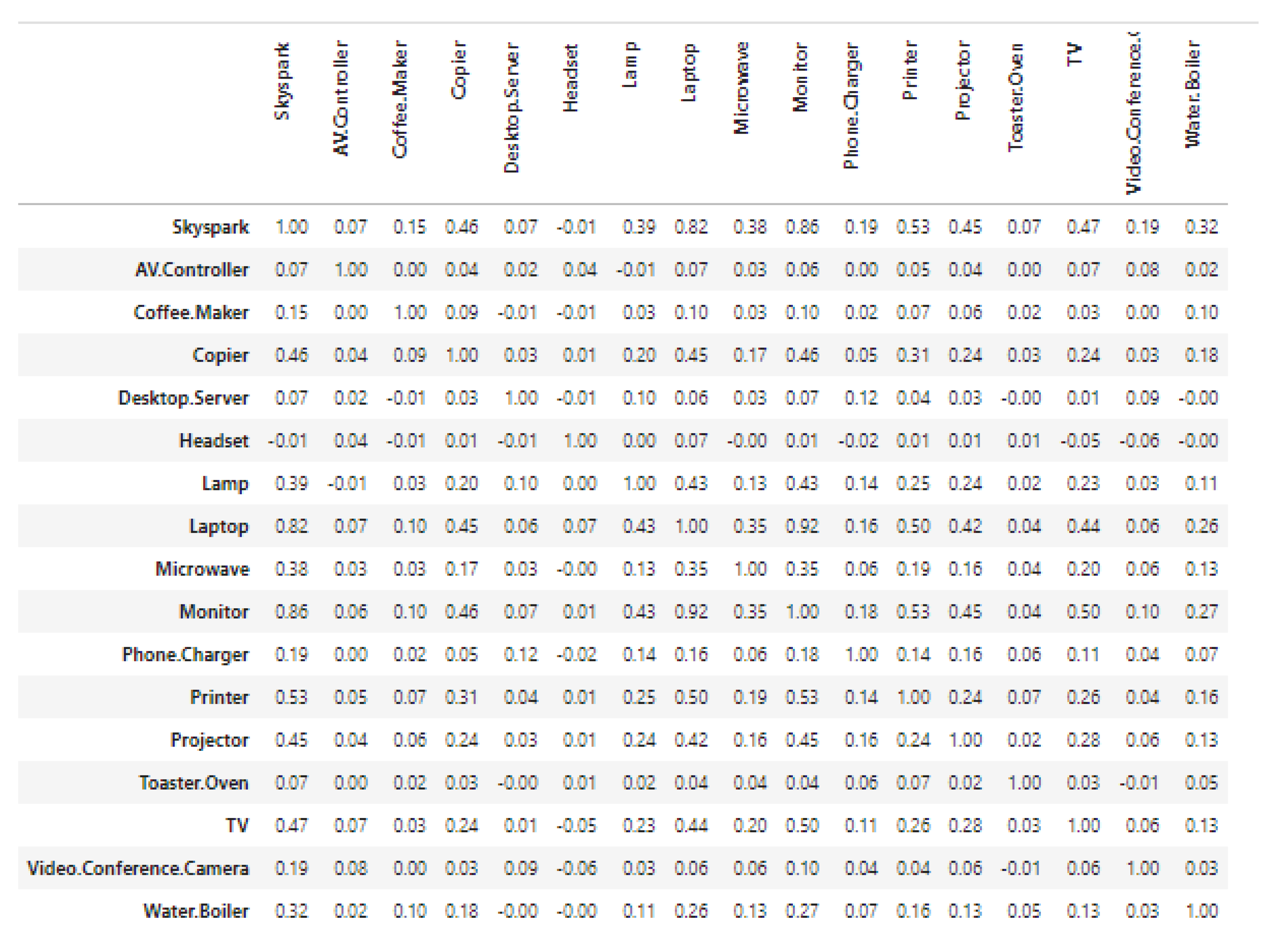
3.1.1. Analysis Using Pearson’s Correlation
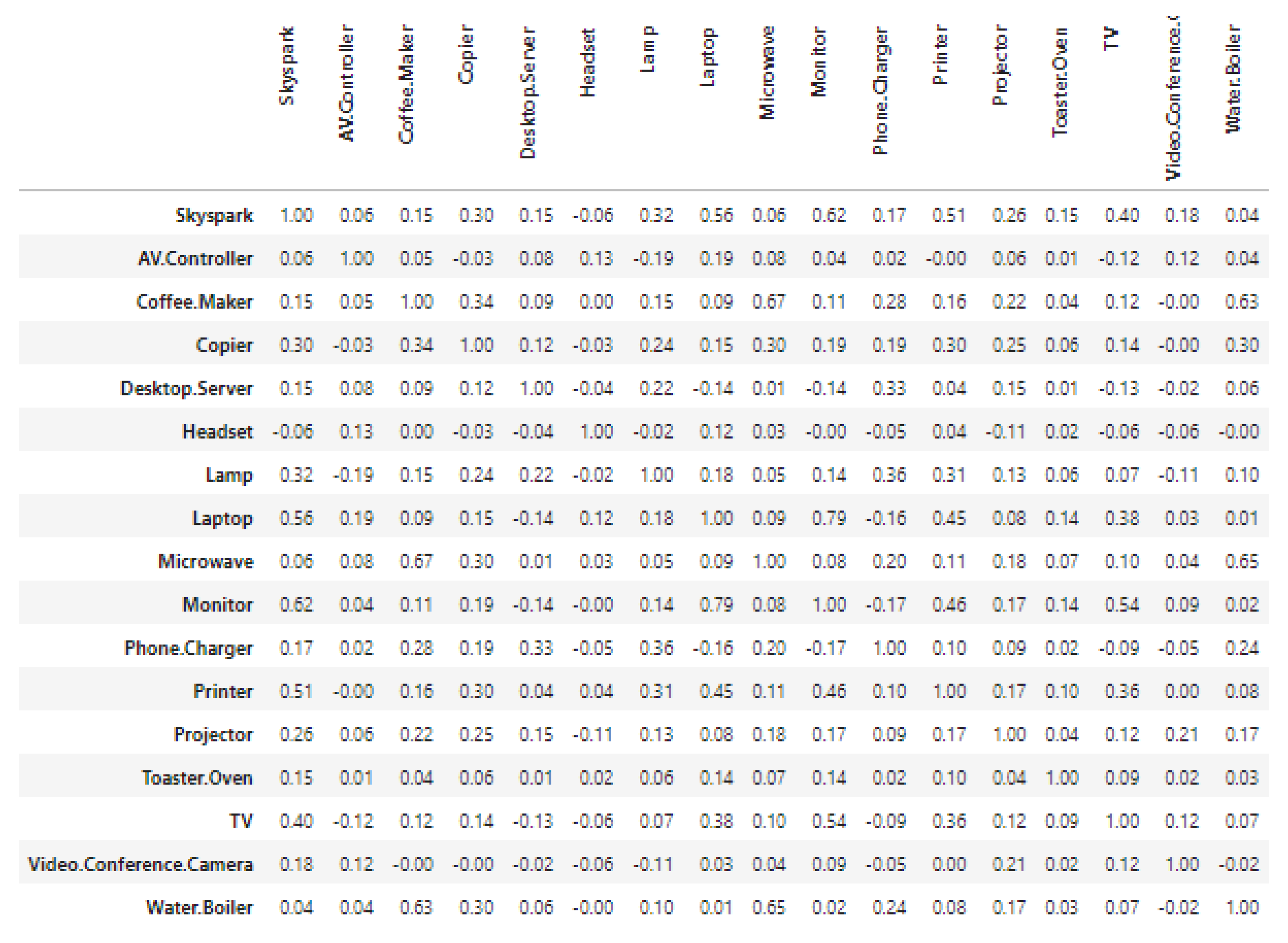
3.1.2. Analysis Using Spearman’s Correlation
3.1.3. Analysis Using Multiple Linear Regression
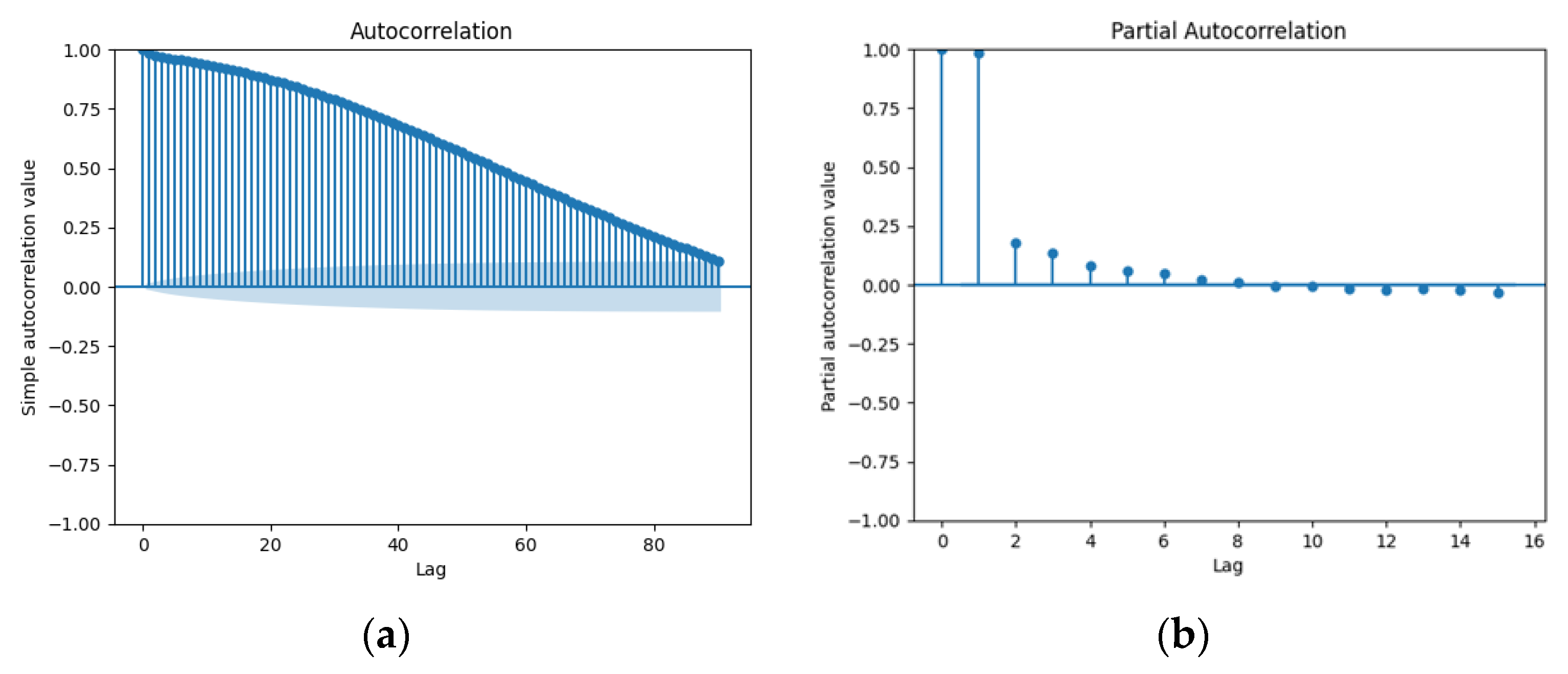
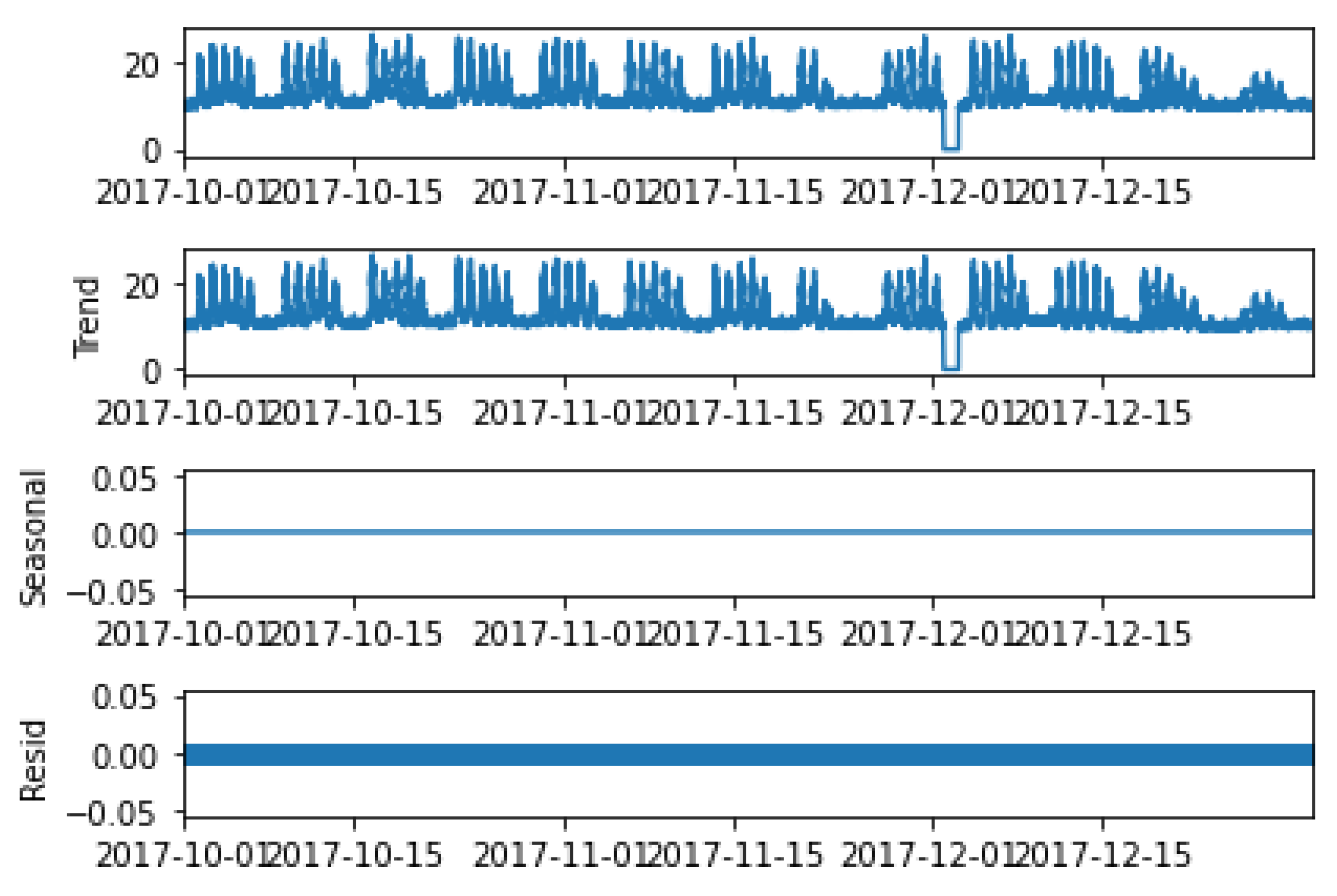
3.1.4. Autocorrelation Analysis
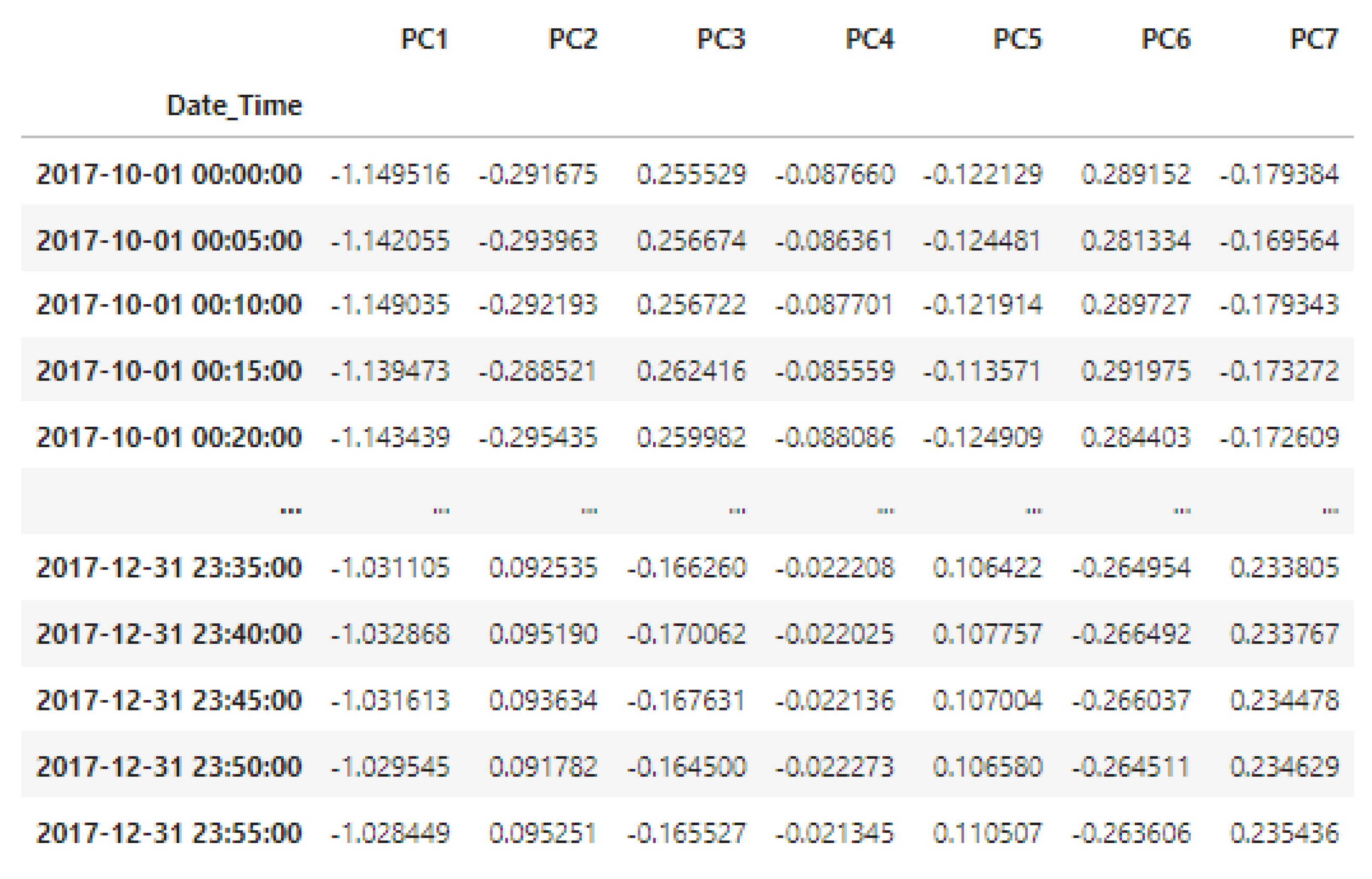
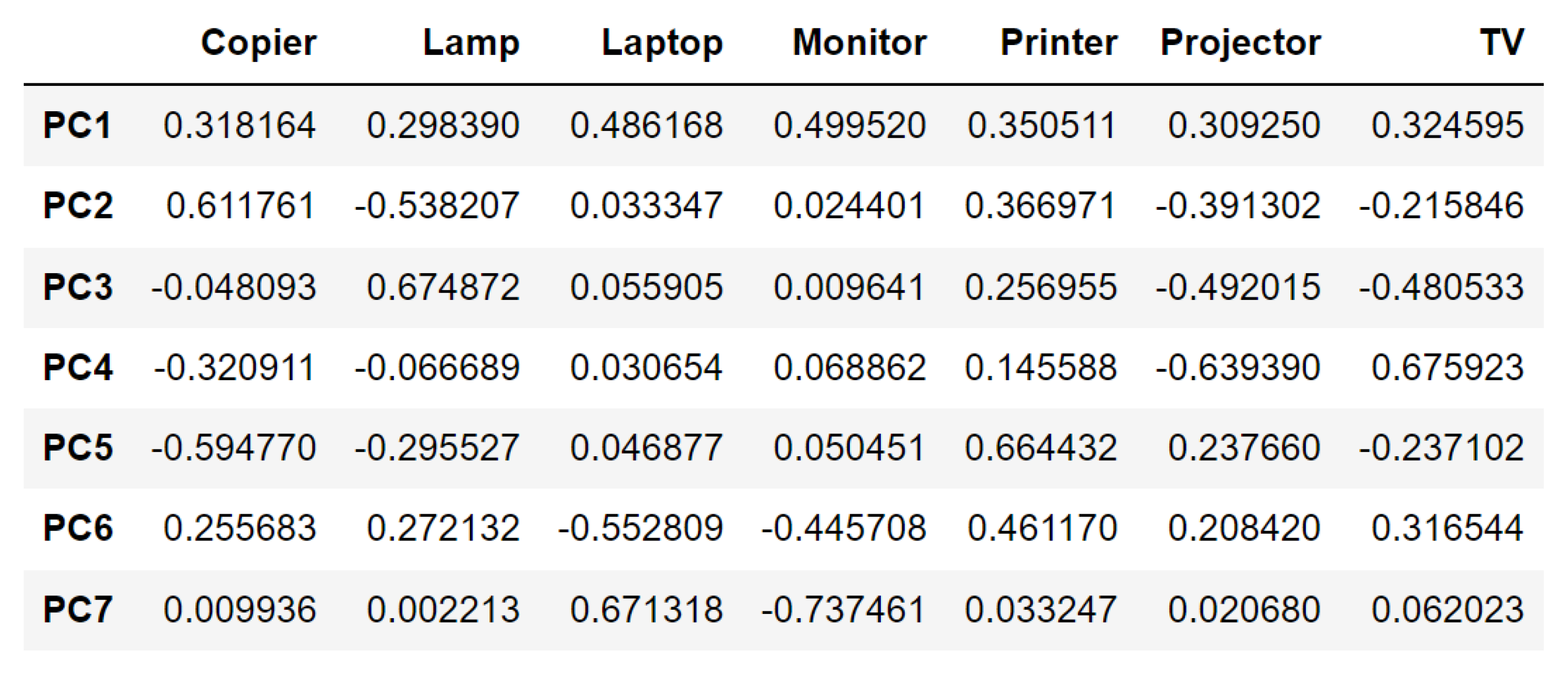
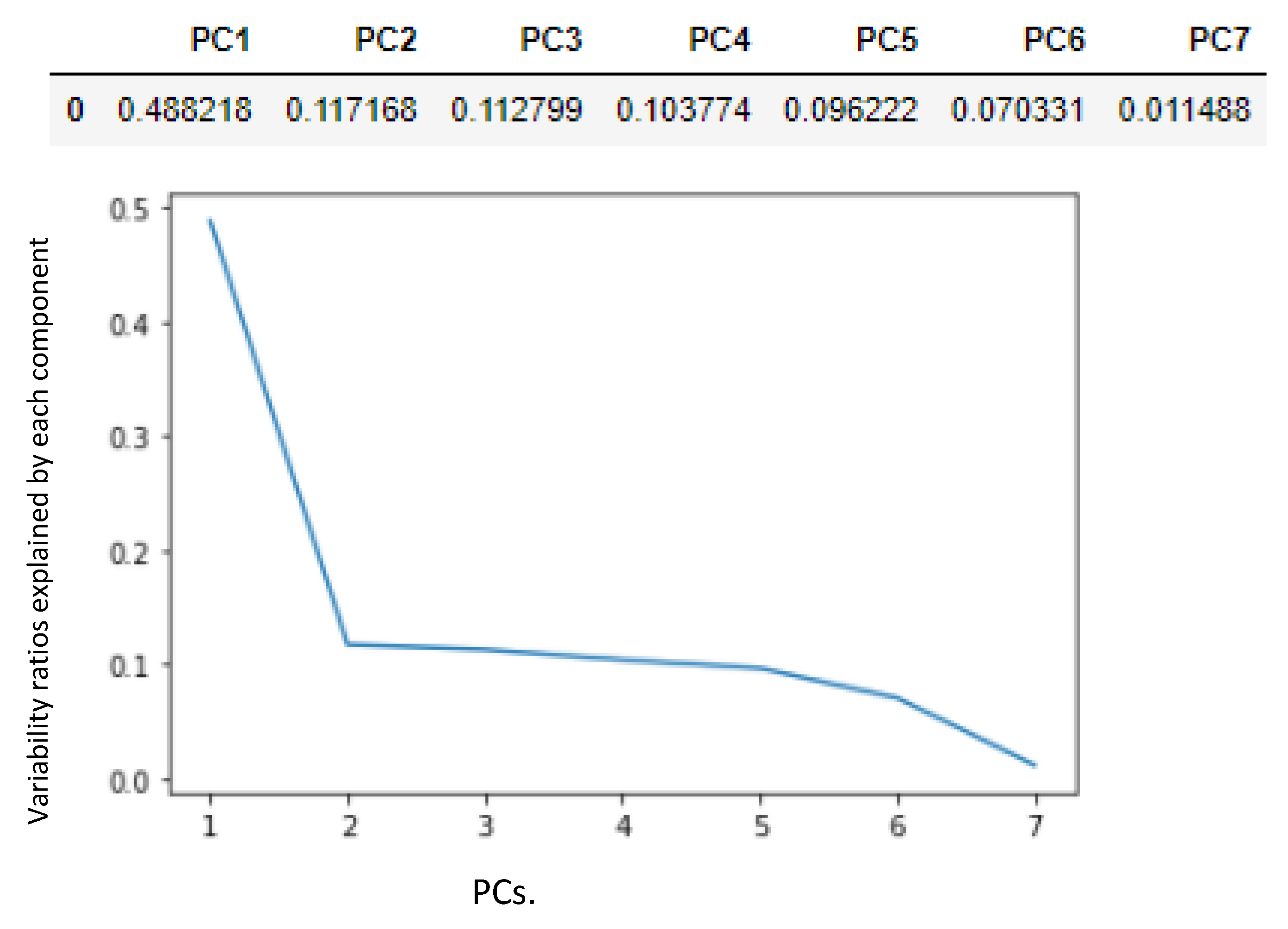
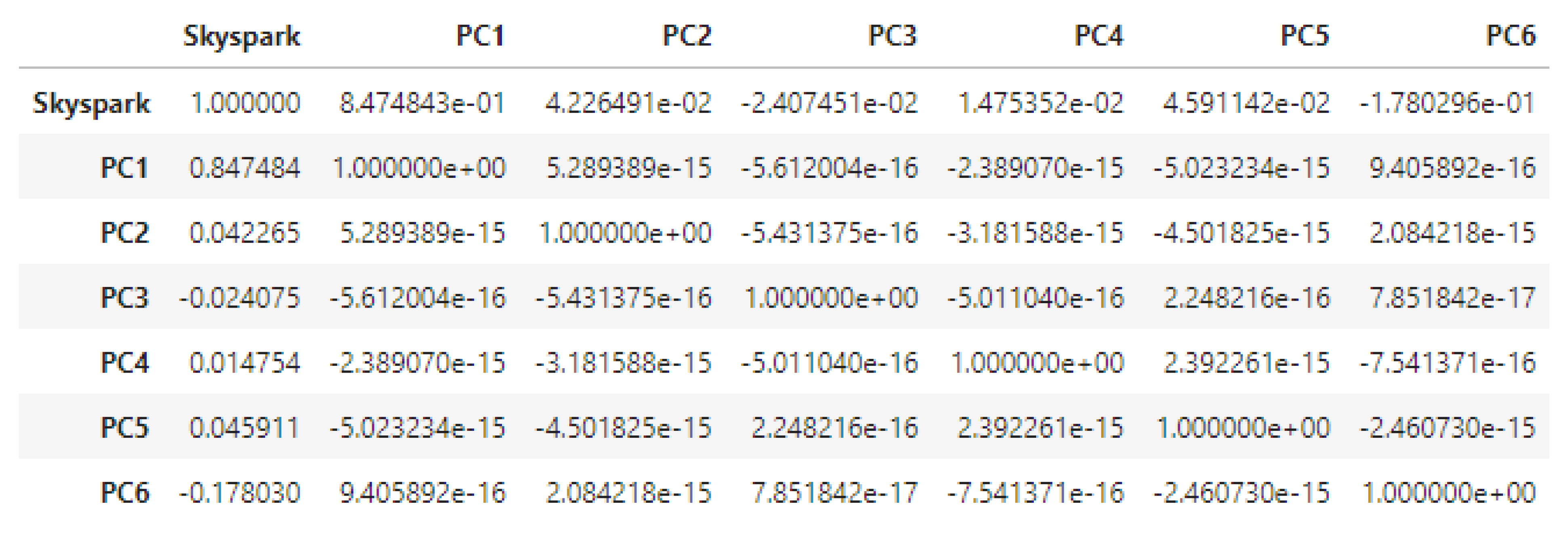
3.1.5. Principal Component Analysis (PCA)
3.1.6. Analysis Using ARIMA Models
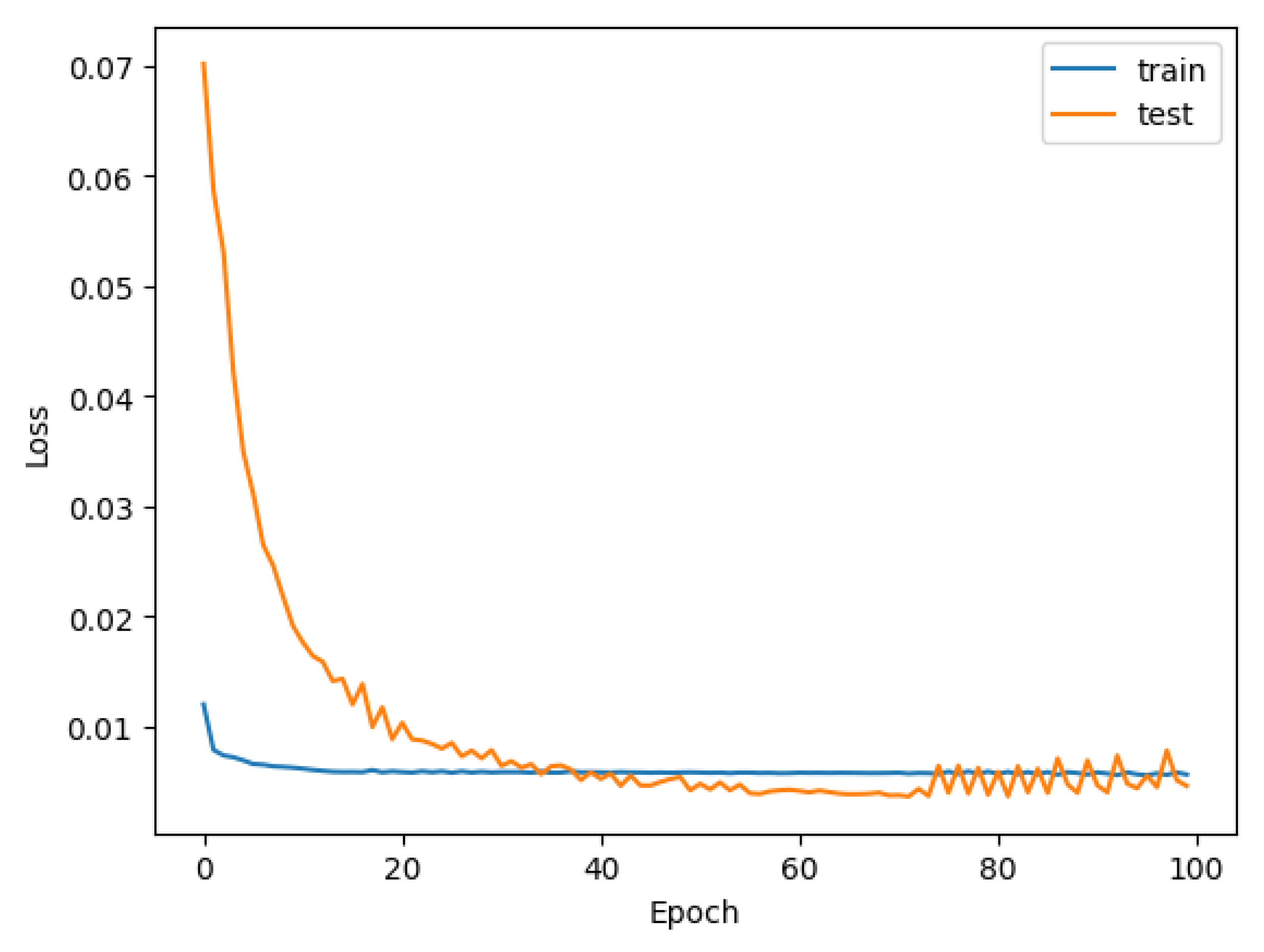
3.2. Generation and Evaluation of the Forecasting Models Using LSTM
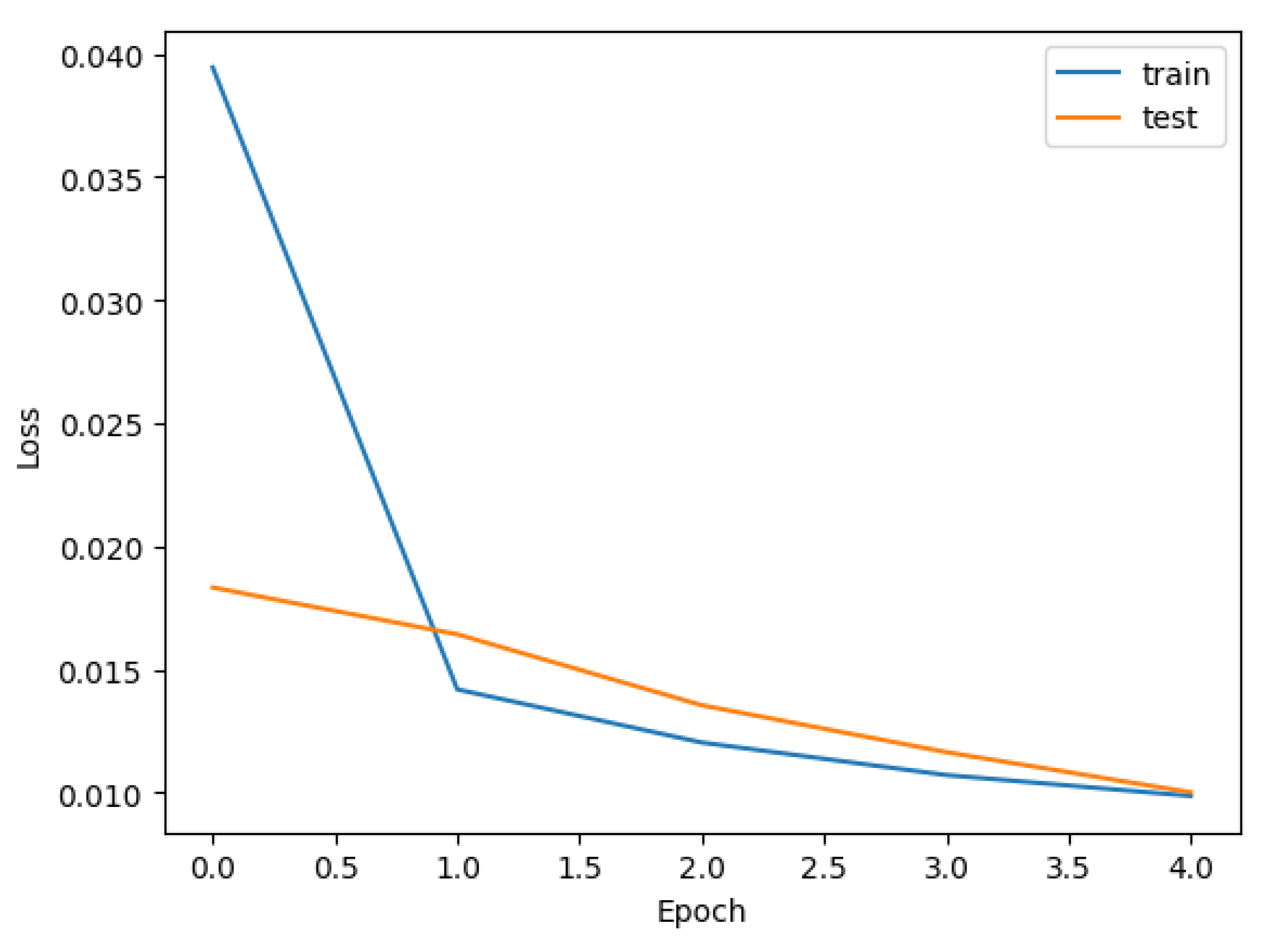
3.2.1. Group 1: PC1 and Skyspark
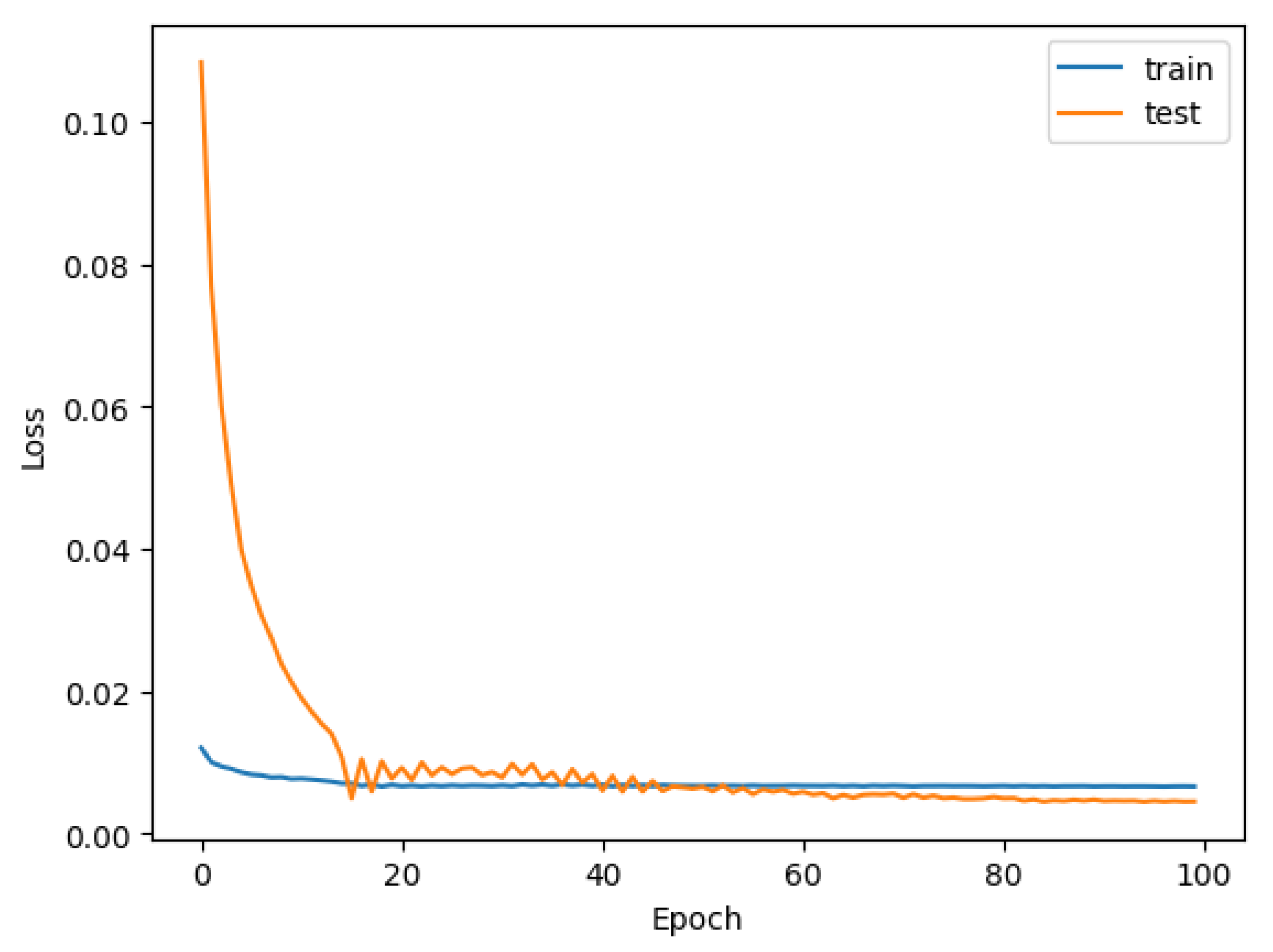
3.2.2. Model Group 2: PC1, PC2 and Skyspark
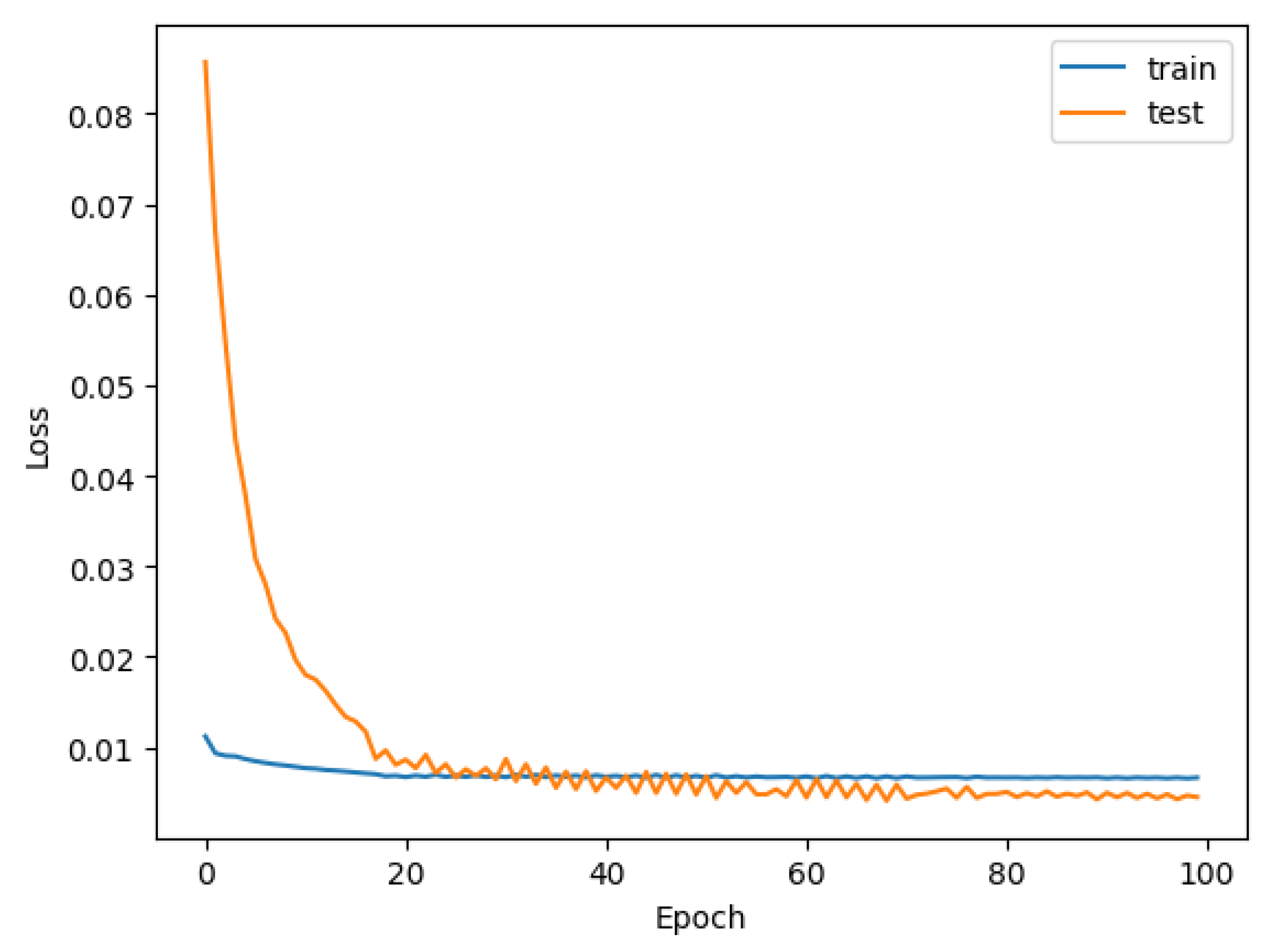
3.2.3. Model Group 3: Original Variables and Skyspark
3.3. Comparison of the Forecasting Models of Each Group
4. Comparison of LSTM with Other Techniques
- −
- Studies the temporal relationship between the variable to be predicted and the rest of the variables;
- −
- Performs a feature reduction analysis using PCA.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aguilar, J.; Garces-Jimenez, A.; R-Moreno, M.D.; García, R. A systematic literature review on the use of artificial intelligence in energy self-management in smart buildings. Renew. Sustain. Energy Rev. 2021, 151, 111530. [Google Scholar] [CrossRef]
- Minoli, D.; Sohraby, K.; Occhiogrosso, B. IoT considerations, requirements, and architectures for smart buildings—Energy optimization and next-generation building management systems. IEEE Internet Things J. 2017, 4, 269–283. [Google Scholar] [CrossRef]
- Rodriguez-Mier, P.; Mucientes, M.; Bugarín, A. Feature Selection and Evolutionary Rule Learning for Big Data in Smart Building Energy Management. Cogn. Comput. 2019, 11, 418–433. [Google Scholar] [CrossRef]
- García, D.; Goméz, M.; Noguera, F.V. A Comparative Study of Time Series Forecasting Methods for Short Term Electric Energy Consumption Prediction in Smart Buildings. Energies 2019, 12, 1934. [Google Scholar]
- Alduailij, M.; Petri, I.; Rana, O.; Alduailij, M.; Aldawood, A. Forecasting peak energy demand for smart buildings. J. Supercomput. 2021, 77, 6356–6380. [Google Scholar] [CrossRef]
- Hernández, M.; Hernández-Callejo, L.; Solís, M.; Zorita-Lamadrid, A.; Duque-Perez, O.; Gonzalez-Morales, L.; Santos-García, F. Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings. Appl. Sci. 2021, 11, 7886. [Google Scholar] [CrossRef]
- Hernández, M.; Hernández-Callejo, L.; García, F.; Duque-Perez, O.; Zorita-Lamadrid, A. A Review of Energy Consumption Forecasting in Smart Buildings: Methods, Input Variables, Forecasting Horizon and Metrics. Appl. Sci. 2020, 10, 8323. [Google Scholar] [CrossRef]
- Moreno, M.; Dufour, L.; Skarmeta, A. Big data: The key to energy efficiency in smart buildings. Soft Comput. 2016, 20, 1749–1762. [Google Scholar] [CrossRef]
- Nabavi, S.; Motlagh, N.; Zaidan, M.; Aslani, A.; Zakeri, B. Deep Learning in Energy Modeling: Application in Smart Buildings with Distributed Energy Generation. IEEE Access 2021, 9, 125439–125461. [Google Scholar] [CrossRef]
- Somu, N.; Raman, G.; Ramamritham, K. A hybrid model for building energy consumption forecasting using long short term memory networks. Appl. Energy 2020, 261, 114131. [Google Scholar] [CrossRef]
- Le, T.; Vo, M.; Kieu, T.; Hwang, E.; Rho, S.; Baik, W. Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building. Sensors 2020, 20, 2668. [Google Scholar] [CrossRef] [PubMed]
- Hadri, S.; Naitmalek, Y.; Najib, M.; Bakhouya, M.; Fakhri, Y.; Elaroussi, M. A Comparative Study of Predictive Approaches for Load Forecasting in Smart Buildings. Procedia Comput. Sci. 2019, 160, 173–180. [Google Scholar] [CrossRef]
- González-Vidal, A.; Jiménez, F.; Gómez-Skarmeta, A.F. A methodology for energy multivariate time series forecasting in smart buildings based on feature selection. Energy Build. 2019, 196, 71–82. [Google Scholar] [CrossRef]
- González-Vidal, A.; Ramallo-González, A.; Terroso-Sáenz, F.; Skarmeta, A. Data driven modeling for energy consumption prediction in smart buildings. In Proceedings of the IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 4562–4569. [Google Scholar]
- Sülo, S.; Keskin, G.; Dogan, T.; Brown, T. Energy Efficient Smart Buildings: LSTM Neural Networks for Time Series Prediction. In Proceedings of the International Conference on Deep Learning and Machine Learning in Emerging Applications, Istanbul, Turkey, 26–28 August 2019; pp. 18–22. [Google Scholar]
- Aliberti, A.; Bottaccioli, L.; Macii, E.; di Cataldo, S.; Acquaviva, A.; Patti, E. A Non-Linear Autoregressive Model for Indoor Air-Temperature Predictions in Smart Buildings. Electronics 2019, 8, 979. [Google Scholar] [CrossRef]
- Alawadi, S.; Mera, D.; Fernández-Delgado, M. A comparison of Machine Learning algorithms for forecasting indoor temperature in smart buildings. Energy Syst. 2020, 13, 689–705. [Google Scholar] [CrossRef]
- Siddiqui, A.; Sibal, A. Energy Disaggregation in Smart Home Appliances: A Deep Learning Approach. Energy, 2021; in press. [Google Scholar]
- Bhatt, D.; Hariharasudan, A.; Lis, M.; Grabowska, M. Forecasting of Energy Demands for Smart Home Applications. Energies 2021, 14, 1045. [Google Scholar] [CrossRef]
- Escobar, L.M.; Aguilar, J.; Garcés-Jiménez, A.; de Mesa, J.A.G.; Gomez-Pulido, J.M. Advanced Fuzzy-Logic-Based Context-Driven Control for HVAC Management Systems in Buildings. IEEE Access 2020, 8, 16111–16126. [Google Scholar] [CrossRef]
- Bourhnane, S.; Abid, M.; Lghoul, R.; Zine-Dine, K.; Elkamoun, N.; Benhaddou, D. Machine Learning for energy consumption prediction and scheduling in smart buildings. SN Appl. Sci. 2020, 2, 297. [Google Scholar] [CrossRef]
- Hadri, S.; Najib, M.; Bakhouya, M.; Fakhri, Y.; el Arroussi, M. Performance Evaluation of Forecasting Strategies for Electricity Consumption in Buildings. Energies 2021, 14, 5831. [Google Scholar] [CrossRef]
- Khan, A.-N.; Iqbal, N.; Rizwan, A.; Ahmad, R.; Kim, D. An Ensemble Energy Consumption Forecasting Model Based on Spatial-Temporal Clustering Analysis in Residential Buildings. Energies 2021, 14, 3020. [Google Scholar] [CrossRef]
- Keytingan, M.; Shapi, M.; Ramli, N.; Awalin, L. Energy consumption prediction by using machine learning for smart building: Case study in Malaysia. Dev. Built Environ. 2021, 5, 100037. [Google Scholar]
- Son, N.; Yang, S.; Na, J. Deep Neural Network and Long Short-Term Memory for Electric Power Load Forecasting. Appl. Sci. 2020, 10, 6489. [Google Scholar] [CrossRef]
- Moon, J.; Park, S.; Rho, S.; Hwang, E. Robust building energy consumption forecasting using an online learning approach with R ranger. J. Build. Eng. 2022, 47, 103851. [Google Scholar] [CrossRef]
- Pinto, T.; Praça, I.; Vale, Z.; Silva, J. Ensemble learning for electricity consumption forecasting in office buildings. Neurocomputing 2021, 423, 747–755. [Google Scholar] [CrossRef]
- Somu, N.; Raman, G.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Amidi, S. Recurrent Neural Networks Cheatsheet. Available online: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks (accessed on 15 April 2021).
- Yuan, X.; Li, L.; Wang, Y. Nonlinear Dynamic Soft Sensor Modeling with Supervised Long Short-Term Memory Network. IEEE Trans. Ind. Inform. 2021, 16, 3168–3176. [Google Scholar]
- Doherty, K. Trenbath, Raw_Data, CO, USA: Mendeley Data. 2019. Available online: https://data.mendeley.com/datasets/g392vt7db9/1 (accessed on 15 April 2021).
- Aguilar, J.; Terán, O. Modelo del proceso de Influencia de los Medios de Comunicación Social en la Opinión Pública. Educere 2018, 22, 179–191. [Google Scholar]
- Brownlee, J. Multivariate Time Series Forecasting with LSTMs in Keras. Available online: https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/ (accessed on 15 April 2021).
- Quintero, Y.; Ardila, D.; Camargo, E.; Rivas, F.; Aguilar, J. Machine learning models for the prediction of the SEIRD variables for the COVID-19 pandemic based on a deep dependence analysis of variables. Comput. Biol. Med. 2021, 134, 104500. [Google Scholar] [CrossRef]
- Cavaleiro, J.; Neves, M.; Hewlins, M.; Jackson, A. The photo-oxidation of meso-tetraphenylporphyrins. J. Chem. Soc. 1990, 7, 1937–1943, Perkin Transactions 1. [Google Scholar] [CrossRef]
- Jiménez, M.; Aguilar, J.; Monsalve-Pulido, J.; Montoya, E. An automatic approach of audio feature engineering for the extraction, analysis and selection of descriptors. Int. J. Multimed. Info. Retr. 2021, 10, 33–42. [Google Scholar] [CrossRef]
- Aguilar, J.; Salazar, C.; Velasco, H.; Monsalve-Pulido, J.; Montoya, E. Comparison and Evaluation of Different Methods for the Feature Extraction from Educational Contents. Computation 2020, 8, 30. [Google Scholar] [CrossRef]
- Aguilar, J. A Fuzzy Cognitive Map Based on the Random Neural Model. Lect. Notes Comput. Sci. 2001, 2070, 333–338. [Google Scholar]
- Sánchez, H.; Aguilar, J.; Terán, O.; de Mesa, J.G. Modeling the process of shaping the public opinion through Multilevel Fuzzy Cognitive Maps. Appl. Soft Comput. 2019, 85, 105756. [Google Scholar] [CrossRef]
- Papaioannou, T.; Stamoulis, G. Teaming and competition for demand-side management in office buildings. In Proceedings of the IEEE International Conference on Smart Grid Communications (SmartGridComm), Dresden, Germany, 23–26 October 2017; pp. 332–337. [Google Scholar]
- Power Consumption Data of a Hotel Building. Available online: https://ieee-dataport.org/documents/power-consumption-data-hotel-building (accessed on 15 April 2021).
- Zhang, L.; Wen, J. A systematic feature selection procedure for short-term data-driven building energy forecasting model development. Energy Build. 2019, 183, 428–442. [Google Scholar] [CrossRef]
- Pipattanasomporn, M.; Chitalia, G.; Songsiri, J.; Aswakul, C.; Pora, W.; Suwankawin, S.; Audomvongseree, K.; Hoonchareon, N. CU-BEMS, smart building electricity consumption and indoor environmental sensor datasets. Sci. Data 2020, 7, 241. [Google Scholar] [CrossRef]
- Long-Term Energy. Consumption & Outdoor Air Temperature for 11 Commercial Buildings. Available online: https://trynthink.github.io/buildingsdatasets/show.html?title_id=long-term-energy-consumption-outdoor-air-temperature-for-11-commercial-buildings (accessed on 15 April 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | R2 | p-Value |
|---|---|---|
| AV.Controller | 0.019 | 2.99 × 1099 |
| Coffee.Maker | 0.020 | 3.62 × 10106 |
| Copier | 0.230 | 0.00 |
| Desktop.Server | 0.031 | 8.48 × 10174 |
| Headset | 0.031 | 1.69 × 10173 |
| Lamp | 0.205 | 0.00 |
| Laptop | 0.848 | 0.00 |
| Microwave | 0.132 | 0.00 |
| Monitor | 0.867 | 0.00 |
| Phone.Charger | 0.063 | 0.00 |
| Printer | 0.297 | 0.00 |
| Projector | 0.214 | 0.00 |
| Toaster.Oven | 0.010 | 2.90 × 1050 |
| TV | 0.262 | 0.00 |
| Video.Conference.Camera | 0.036 | 8.81 × 10199 |
| Water.Boiler | 0.086 | 0.00 |
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 |
|---|---|---|---|---|---|---|
| 3.4175 | 0.8202 | 0.7896 | 0.7264 | 0.6735 | 0.4923 | 0.0804 |
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 |
|---|---|---|---|---|---|---|
| 0.4882 | 0.6053 | 0.7181 | 0.8219 | 0.9181 | 0.9885 | 1.0 |
| Model | p | q |
|---|---|---|
| Skyspark | 5 | 1 |
| PC1 | 5 | 0 |
| PC2 | 5 | 1 |
| Group | No. of Neurons | No. of Epochs | RMSE | MAPE | R2 |
|---|---|---|---|---|---|
| 1 | 100 | 100 | 0.07 | 0.10 | 0.74 |
| 2 | 50 | 100 | 0.07 | 0.11 | 0.72 |
| 3 | 50 | 100 | 0.07 | 0.12 | 0.74 |
| Dataset | Technique | RMSE | MAPE | R2 |
|---|---|---|---|---|
| [40] | Gradient boosting | 0.0249 | 75.7002 | 0.9937 |
| Random forest | 0.0244 | 75.4282 | 0.9928 | |
| LSTM | 0.0101 | 75.3260 | 0.9920 | |
| L-BFGS | 0.0220 | 76.7360 | 0.9939 | |
| CNN | 0.0229 | 75.7002 | 0.9936 | |
| [41] | Gradient boosting | 0.0331 | 21.6070 | 0.9750 |
| Random forest | 0.0351 | 21.5721 | 0.9600 | |
| LSTM | 0.0310 | 19.4190 | 0.9710 | |
| L-BFGS | 0.0320 | 19.4860 | 0.9570 | |
| CNN | 0.0663 | 21.6816 | 0.9019 | |
| [42] | Gradient boosting | 0.0395 | 17.1182 | 0.9309 |
| Random forest | 0.0457 | 17.4153 | 0.9336 | |
| LSTM | 0.0417 | 15.0250 | 0.9497 | |
| L-BFGS | 0.0487 | 15.1240 | 0.9393 | |
| CNN | 0.0608 | 17.0162 | 0.9401 | |
| [43] | Gradient boosting | 0.0645 | 17.5819 | 0.9352 |
| Random forest | 0.0914 | 18.0262 | 0.8930 | |
| LSTM | 0.0625 | 17.3260 | 0.9147 | |
| L-BFGS | 0.0910 | 22.7140 | 0.9126 | |
| CNN | 0.1318 | 19.8812 | 0.8966 | |
| [44] | Gradient boosting | 0.1415 | 21.7193 | 0.6254 |
| Random forest | 0.1177 | 21.9066 | 0.6694 | |
| LSTM | 0.1351 | 21.0200 | 0.7300 | |
| L-BFGS | 0.1313 | 21.0180 | 0.7430 | |
| CNN | 0.0973 | 21.0040 | 0.7671 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Durand, D.; Aguilar, J.; R-Moreno, M.D. An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM. Sustainability 2022, 14, 13358. https://doi.org/10.3390/su142013358
Durand D, Aguilar J, R-Moreno MD. An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM. Sustainability. 2022; 14(20):13358. https://doi.org/10.3390/su142013358
Chicago/Turabian StyleDurand, Daniela, Jose Aguilar, and Maria D. R-Moreno. 2022. "An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM" Sustainability 14, no. 20: 13358. https://doi.org/10.3390/su142013358
APA StyleDurand, D., Aguilar, J., & R-Moreno, M. D. (2022). An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM. Sustainability, 14(20), 13358. https://doi.org/10.3390/su142013358